基因组重测序
人类基因组重测序分析

医学检测
肺癌 结直肠癌 消化道癌 乳腺癌
科学与技术
软件 实验技术 发表论文 硬件平台
市场与支持
产品文件 市场与活动 进展与动态
加入我们
社会招聘 校园招聘
关于我们
公司简介 办公环境 团队介绍 荣誉资质 联系我们 医学检验所
版权所有:北京诺禾致源生物信息科技有限公司
[6] https:///wiki/Regulatory_sequence 阅读原文 >>
[7] Sudmant P H, Rausch T, Gardner E J, et al. An integrated map of structural variation in 2,504 human genomes.[J]. Nature, 2015, 526 (7571):75-81. 阅读原文 >>
升级亮点
基于健康中国人群的千人测序数据,测序深度 > 30× 参考 ACMG 等,推出针对复杂疾病变异位点有害性的分类标准 应用 ENCODE 数据库最新内容,并结合国际通用数据库、自建数 据库以及保守性预测软件进行分析 应用 DGV、DECIPHER、CNVD 等多个数据库进行有害性 CNV/SV 筛选和 de novo CNV/SV 分析
6 可视化的结果展示
诺禾致源疾病基因组信息分析团队,会为客户提供不断更新的变异注释、项目特异性分析和灵活易用的“变异-基因-疾病”可视化结 果,让科学研究更轻松。
图6 疾病与基因关联性展示图
参考文献
[1] Nagasaki M, Yasuda J, Katsuoka F, et al. Rare variant discovery by deep whole-genome sequencing of 1,070 Japanese individuals.[J]. Nature Communications, 2015, 6. 阅读原文 >>
重测序ppt20120406

反转(Inversion)
成对reads比对到基因组上应该是一条正向,一条 反向互补。但结果两条reads都正向或反向互补比 对到参考基因组上
移码突变
• 在正常的DNA分子中,碱基缺失或增加非3 的倍数,造成这位置之后的一系列编码发
生移位错误的改变,这种现象称为移码突
变。
移码突变
多态性分布与差异分析
碱基平均测序深度
1 2 3 4 5 10 15
基因组未覆盖率
3.68E-01 1.35E-01 4.98E-02 1.83E-02 6.74E-03 4.54E-05 3.06E-07
基因组覆盖率
63.21% 86.47% 95.02% 98.17% 99.33% 100% 100%
测序深度与覆盖度
9
10
0
0
0x0200 the read fails platform/vendor quality checks
转为二进制后,以上各位代表含义均为0无据
比对
深度、覆盖度 SNP检测 SV检测
统计与注释
通过深度、质量值等筛选 得到可靠结果
重测序分析流程图
SAMtools
三、基因组重测序的发展
• 2008年4月17日的 Nature 杂志上,美国的科学家 发表了首个利用新一代 高通量测序技术得到的 人类全基因组, 这个基 因组正是“ DNA之父” James D.Watson的 。
2013/1/13
三、基因组重测序的发展
大豆重测序
水稻重测序
第一部分 基因组重测序概况 第二部分 重测序分析原理及内容
颠换
参考基因组上的碱基为G,但实际在物种中测得的为A,该位 点突变类型为颠换,且为纯合。
动植物全基因组重测序简介

全基因组重测序是对已知基因组序列的物种进行不同个体的基因组测序,并在此基础上对个体或群体进行差异性分析。
基于全基因组重测序技术,人们可以快速进行资源普查筛选,寻找到大量遗传变异,实现遗传进化分析及重要性状候选基因的预测。
随着测序成本降低和拥有参考基因组序列物种增多,全基因组重测序成为动植物育种和群体进化研究迅速有效的方法。
简化基因组测序技术是对与限制性核酸内切酶识别位点相关的DNA进行高通量测序。
RAD-seq(Restriction-site Associated DNA Sequence)和GBS (Genotyping-by-Sequencing)技术是目前应用最为广泛的简化基因组技术,可大幅降低基因组的复杂度,操作简便,同时不受参考基因组的限制,可快速鉴定出高密度的SNP位点,从而实现遗传进化分析及重要性状候选基因的预测。
简化基因组技术尤其适合于大样本量的研究,可以为利用全基因组重测序技术做深度信息挖掘奠定坚实的基础。
全基因组重测序和简化基因组测序技术可广泛应用于变异检测、遗传图谱构建、功能基因挖掘、群体进化等研究,具有重大的科研和产业价值。
产品脉络图。
基因组重测序mutmap分析

在MutMap中,一个突变体与其野生型品系杂交后自交,在F2群体中可以明确观察到表型差异的分离情况。
这一方法尤其适用于作物物种,可以使遗传杂交次数最小化,而可得到突变表型的F2子代是必须的。
我们将MutMap应用于一个日本骨干水稻栽品种的7个突变体,鉴定出来包含了淡绿色叶片和半矮生突变表型
相关突变位点的唯一基因组区域。这些结果显示MutMap可以加速水稻和其它作物的遗传改良。
MutMap:即突变位点图谱,针对有参考基因组的突变体物种,通过目标性状差异构建两个极端的子代DNA池,检测功能性突变位点。诺禾致源已做过多种动、植物突变检测项目。
主要的农艺性状是由多基因控制的,而单个基因仅引起较小的表型效应,故而对其鉴定和克隆非常困难。
我们在此介绍MutMap,该方法基于对一个分离群体中呈现有用表型植株的DNA混合后而进行的全基因组重测序。
单个性状定位主要针对有参考基因组的物种,通过混合分组分析(BSA)的手段,利用二代高通量测序得到数据与参考序列比对开发分子标记,进行标记与性状的共分离分析,检测变异并进行性状相关区域的基因结构及功能的注释,分析基因控制目标性状的机制。单个性状定位主要分为以下3个产品:MutMap、QTL-seq以及功能基因挖掘。
日本水稻骨干栽培种Hitomebore(一目惣),EMS处理得1200个M1系,自交3-4代,得M3-M4。
F2群体,群体大于200子代,
野生型与突变型分离比为3:1,被选用于MutMap分析。
选择20个突变性状的F2子代进行DNA提取,混合后全基因组重测序(10X以上),
测序常用名词解释整理
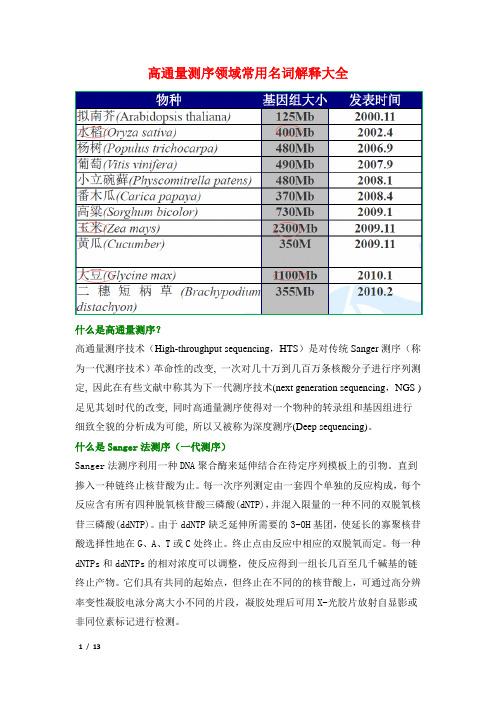
高通量测序领域常用名词解释大全什么是高通量测序?高通量测序技术(High-throughput sequencing,HTS)是对传统Sanger测序(称为一代测序技术)革命性的改变, 一次对几十万到几百万条核酸分子进行序列测定, 因此在有些文献中称其为下一代测序技术(next generation sequencing,NGS )足见其划时代的改变, 同时高通量测序使得对一个物种的转录组和基因组进行细致全貌的分析成为可能, 所以又被称为深度测序(Deep sequencing)。
什么是Sanger法测序(一代测序)Sanger法测序利用一种DNA聚合酶来延伸结合在待定序列模板上的引物。
直到掺入一种链终止核苷酸为止。
每一次序列测定由一套四个单独的反应构成,每个反应含有所有四种脱氧核苷酸三磷酸(dNTP),并混入限量的一种不同的双脱氧核苷三磷酸(ddNTP)。
由于ddNTP缺乏延伸所需要的3-OH基团,使延长的寡聚核苷酸选择性地在G、A、T或C处终止。
终止点由反应中相应的双脱氧而定。
每一种dNTPs和ddNTPs的相对浓度可以调整,使反应得到一组长几百至几千碱基的链终止产物。
它们具有共同的起始点,但终止在不同的的核苷酸上,可通过高分辨率变性凝胶电泳分离大小不同的片段,凝胶处理后可用X-光胶片放射自显影或非同位素标记进行检测。
什么是基因组重测序(Genome Re-sequencing)全基因组重测序是对基因组序列已知的个体进行基因组测序,并在个体或群体水平上进行差异性分析的方法。
随着基因组测序成本的不断降低,人类疾病的致病突变研究由外显子区域扩大到全基因组范围。
通过构建不同长度的插入片段文库和短序列、双末端测序相结合的策略进行高通量测序,实现在全基因组水平上检测疾病关联的常见、低频、甚至是罕见的突变位点,以及结构变异等,具有重大的科研和产业价值。
什么是de novo测序de novo测序也称为从头测序:其不需要任何现有的序列资料就可以对某个物种进行测序,利用生物信息学分析手段对序列进行拼接,组装,从而获得该物种的基因组图谱。
高通量基因组测序中 测序深度,覆盖度

高通量基因组测序中,什么是测序深度和覆盖度?1G=1024M测序深度是指测序得到的总碱基数与待测基因组大小的比值。
假设一个基因大小为2M,测序深度为10X,那么获得的总数据量为20M。
(测序深度=总数据量20M/基因组大小2M=10X)覆盖度是指测序获得的序列占整个基因组的比例。
由于基因组中的高GC、重复序列等复杂结构的存在,测序最终拼接组装获得的序列往往无法覆盖有所的区域,这部分没有获得的区域就称为Gap。
例如一个细菌基因组测序,覆盖度是98%,那么还有2%的序列区域是没有通过测序获得的。
序的个体,通过序列比对,可以找到大量的单核苷酸多态性位点(SNP),插入缺失位点(InDel,Insertion/Deletion)、结构变异位点(SV,技术路线提取基因组DNA,利用Covaris进行随机打断,电泳回收所需长度的DNA片段(0.2~5Kb),加上接头, 进行cluster制备(Solexa)或E-PCR (SOLiD),最后利用Paired-End(Solexa)或者Mate-Pair(SOLiD)的方法对插入片段进行重测序。
图1-1,以SOLiD为例,说明整个实验方案。
高效策略,外显子测序相对于基因组重测序成本较低,对研究已知基因的SNP、Indel 等具有较大的优势。
外显子(expressed region)是真核生物基因的一部分,它在剪接(Splicing)后仍会被保存下来,并可在蛋白质生物合成过程中被表达为蛋白质。
外显子是最后出现在成熟RNA中的基因序列,又称表达序列。
既存在于最初的转录产物中,也存在于成熟的RNA分子中的核苷酸序列。
在人类基因中大约有180,000外显子,占人类基因组的1%,约30MB。
全基因组重测序数据分析

全基1. 简通过变(d 的功况,dise 比较实验(1)(2)基因组重测序简介(Introduc 过高通量测序识deletioin, du 功能性进行综合杂合性缺失ease (cance 较基因组学,群验设计与样本Case-Contr)家庭成员组序数据分析ction)识别发现de plication 以及合分析;我们(LOH )以及r )genome 中群体遗传学综ol 对照组设计组设计:父母novo 的som 及copy numb 们将分析基因及进化选择与中的mutation 综合层面上深计 ;-子女组(4人matic 和germ ber variation 因功能(包括与mutation 之n 产生对应的深入探索疾病基人、3人组或m line 突变,)以及SNP miRNA ),重之间的关系;以的易感机制和基因组和癌症多人);结构变异-SN 的座位;针对重组率(Rec 以及这些关系功能。
我们将症基因组。
NV ,包括重排对重排突变和combination )系将怎样使得将在基因组学排突SNP)情在学以及初级数据分析1.数据量产出:总碱基数量、Total Mapping Reads、Uniquely Mapping Reads统计,测序深度分析。
2.一致性序列组装:与参考基因组序列(Reference genome sequence)的比对分析,利用贝叶斯统计模型检测出每个碱基位点的最大可能性基因型,并组装出该个体基因组的一致序列。
3.SNP检测及在基因组中的分布:提取全基因组中所有多态性位点,结合质量值、测序深度、重复性等因素作进一步的过滤筛选,最终得到可信度高的SNP数据集。
并根据参考基因组信息对检测到的变异进行注释。
4.InDel检测及在基因组的分布: 在进行mapping的过程中,进行容gap的比对并检测可信的short InDel。
在检测过程中,gap的长度为1~5个碱基。
对于每个InDel的检测,至少需要3个Paired-End序列的支持。
重测序

全基因组重测序项目简介全基因组重测序是对已有参考序列(Reference Sequence)的物种的不同个体进行基因组测序,并以此为基础进行个体或群体水平的差异性分析。
通过这种方法,可以寻找出大量的单核苷酸多态性位点(SNP),插入缺失位点(InDel,Insertion Deletion),结构变异位点(SV,Structure Variation),拷贝数变异(Copy Number Variation,CNV)等变异信息,从而获得生物群体的遗传特征。
这对在群体水平上研究物种的进化历史、环境适应性、自然选择等方面具有重大意义。
利用全基因组重测序有助于快速发现与动植物重要性状相关的遗传变异,缩短分子育种的实验周期;有助于发现人类疾病相关的重要变异基因,加快生物医药研发的速度等,这对人类疾病及动植物育种研究等方面具有重大的指导意义。
技术流程提取基因组DNA后,采用物理方法随机打断,选择性回收所需长度的DNA片段(0.2~5Kb),并在两端连接接头以构建测序文库,进行桥式PCR(Bridge Amplification)制备Cluster,最后利用Paired-End的方法对插入片段进行重测序。
生物信息分析1.数据量产出总碱基数量、Totally mapped reads、Uniquely mapped reads统计,测序深度分析。
2.一致性序列组装与参考基因组序列(Reference genome sequence)的比对分析,利用贝叶斯统计模型检测出每个碱基位点的最大可能性基因型,并组装出该个体基因组的一致序列。
3.SNP检测及在基因组中的分布提取全基因组中所有多态性位点,结合质量值、测序深度、重复性等因素作进一步的过滤筛选,最终得到可信度高的SNP数据集。
并根据参考基因组序列对检测到的变异进行注释。
4.InDel检测及在基因组的分布在进行mapping的过程中,进行容Gap的比对并检测可信的Short InDel。
生物信息学名词解释

什么是高通量测序?高通量测序技术(High-throughput sequencing,HTS)是对传统Sanger测序(称为一代测序技术)革命性的改变, 一次对几十万到几百万条核酸分子进行序列测定, 因此在有些文献中称其为下一代测序技术(next generation sequencing,NGS )足见其划时代的改变, 同时高通量测序使得对一个物种的转录组和基因组进行细致全貌的分析成为可能, 所以又被称为深度测序(Deep sequencing)。
什么是Sanger法测序(一代测序)Sanger法测序利用一种DNA聚合酶来延伸结合在待定序列模板上的引物。
直到掺入一种链终止核苷酸为止。
每一次序列测定由一套四个单独的反应构成,每个反应含有所有四种脱氧核苷酸三磷酸(dNTP),并混入限量的一种不同的双脱氧核苷三磷酸(ddNTP)。
由于ddNTP缺乏延伸所需要的3-OH基团,使延长的寡聚核苷酸选择性地在G、A、T或C处终止。
终止点由反应中相应的双脱氧而定。
每一种dNTPs和ddNTPs的相对浓度可以调整,使反应得到一组长几百至几千碱基的链终止产物。
它们具有共同的起始点,但终止在不同的的核苷酸上,可通过高分辨率变性凝胶电泳分离大小不同的片段,凝胶处理后可用X-光胶片放射自显影或非同位素标记进行检测。
什么是基因组重测序(Genome Re-sequencing)全基因组重测序是对基因组序列已知的个体进行基因组测序,并在个体或群体水平上进行差异性分析的方法。
随着基因组测序成本的不断降低,人类疾病的致病突变研究由外显子区域扩大到全基因组范围。
通过构建不同长度的插入片段文库和短序列、双末端测序相结合的策略进行高通量测序,实现在全基因组水平上检测疾病关联的常见、低频、甚至是罕见的突变位点,以及结构变异等,具有重大的科研和产业价值。
什么是de novo测序de novo测序也称为从头测序:其不需要任何现有的序列资料就可以对某个物种进行测序,利用生物信息(bioinformation)学分析手段对序列进行拼接,组装,从而获得该物种的基因组图谱。
基因组测序术语解释

DNA关键词:WG-BSA (全基因组重测序 BSA)对已有参考基因组序列的物种的所有作图群体( F1、 F2、 RIL、 DH 和 BC1等),对亲本进行个体重测序,对某个极端性状材料混池测序,检测 SNP,获得与性状紧密关联的分子标记和精细定位区域,是目前最高效的基因定位方法。
通过选取某个极端性状,利用高效率低成本的混池测序技术,勿需开发分子标记进行遗传图的构建,快速定位与性状相关的候选 QTL。
MP-Reseq (多混池全基因组重测序)针对特有的优良地方品种中的不同品种/品系,通过群体内 pooling 建库的方法,进行全基因组重测序,采用生物信息学方法全基因组范围内扫描变异位点,能快速的定位不同混池样品基因组中明显经过人工或自然选择的区域,检测与性状相关的基因区域及其功能基因。
全基因组个体重测序基于全基因组重测序的变异图谱通过测序手段结合生物信息分析研究同一物种不同个体之间的变异情况,获得大量的变异信息,如 SNP、 Indel、 SV 等。
主要可以快速地获得大量的分子标记以及不同个体在基因组水平上的差异。
全基因组关联分析-GWAS通过重测序对动植物重要种质资源进行全基因组基因型鉴定,与关注的表型数据进行全基因组关联分析,找出与关注表型相关的SNP位点,定位数量性状基因,与数量性状相关的基因紧密连锁的SNP标记,后续可用于分子标记辅助育种,助力育种进程。
全基因组重测序-遗传进化通过对来自全国各地、具有代表性的 XX 份 XX 材料进行全基因组重测序,检测 SNP、 Indel、 SV,并利用获得的 SNP 与 SV 数据进行群体多样性分析,包括连锁不平衡分析、群体进化分析、群体结构分析、群体主成分分析等。
全基因组重测序-遗传图谱基于全基因组重测序技术对已有参考基因组序列的物种进行个体或群体的全基因组测序,利用高性能计算平台和生物信息学方法,检测单核苷酸多态性位点( SNP),并计算多态性标记间的遗传连锁距离,绘制高密度的遗传图谱。
高通量基因组测序中测序深度覆盖度

1G=1024M测序深度是指测序得到的总碱基数与待测基因组大小的比值.假设一个基因大小为2M,测序深度为10X,那么获得的总数据量为20M.测序深度=总数据量20M/基因组大小2M=10X覆盖度是指测序获得的序列占整个基因组的比例.由于基因组中的高GC、重复序列等复杂结构的存在,测序最终拼接组装获得的序列往往无法覆盖有所的区域,这部分没有获得的区域就称为Gap.例如一个细菌基因组测序,覆盖度是98%,那么还有2%的序列区域是没有通过测序获得的.核苷酸多态性位点SNP,插入缺失位点InDel,Insertion/Deletion、结构变异位点SV,StructureVariation位点.SBC可以协助客户,通过手段,分析不同间的结构差异,同时完成注释.技术路线提取基因组DNA,利用Covaris进行随机打断,电泳回收所需长度的DNA片段0.2~5Kb,加上接头,进行cluster制备Solexa或E-PCRSOLiD,最后利用Paired-EndSolexa或者Mate-PairSOLiD的方法对插入片段进行重测序.图1-1,以SOLiD为例,说明整个实验方案.2、外显子测序也称目标组捕获,是指利用序列捕获技术将全基因组外显子区域DNA捕捉并富集后进行高通量测序的基因组分析方法.是一种选择基因组的的高效策略,外显子测序相对于基因组重测序成本较低,对研究已知基因的SNP、Indel等具有较大的优势.外显子expressedregion是真核生物基因的一部分,它在剪接Splicing后仍会被保存下来,并可在蛋白质生物合成过程中被表达为蛋白质.外显子是最后出现在成熟RNA中的基因序列,又称表达序列.既存在于最初的产物中,也存在于成熟的RNA分子中的核苷酸序列.在人类基因中大约有180,000,占人类基因组的1%,约30MB.。
基因组和蛋白质组大数据分析挑战与方法总结

基因组和蛋白质组大数据分析挑战与方法总结大数据分析已经成为了生物学研究中不可或缺的一部分,特别是在基因组学和蛋白质组学领域。
随着高通量测序和高通量质谱分析技术的进步,生物学家们可以生成大量的基因组和蛋白质组数据。
然而,处理和分析这些大数据并从中提取有用的信息是一项艰巨的任务。
本文将讨论基因组和蛋白质组大数据分析中的挑战,并总结一些常用的方法。
一、挑战1.数据存储和管理:基因组和蛋白质组的大数据通常需要巨大的存储空间,并且需要经常访问和更新。
因此,在进行大数据分析之前,生物学家们需要建立高效的数据存储和管理系统,以确保数据的可靠性和安全性。
此外,大数据的存储和管理也需要考虑数据的备份和恢复机制,以防止数据丢失。
2.高维数据分析:基因组和蛋白质组数据通常包含大量的变量,这使得数据分析变得复杂和困难。
如何处理这些高维数据,并从中提取有意义的信息是一个具有挑战性的任务。
特别是在蛋白质组学中,蛋白质的复杂性和功能多样性增加了数据分析的难度。
3.数据清洗和预处理:生物学实验产生的大数据通常存在噪声和错误。
因此,在进行数据分析之前,生物学家们需要进行数据清洗和预处理,以排除这些异常值和错误数据。
数据清洗和预处理的过程需要运用统计学和机器学习的方法,以提高数据质量和准确性。
4.数据整合和交叉分析:基因组和蛋白质组数据通常来自于不同的实验和技术平台,这些数据需要进行整合和交叉分析,以寻找它们之间的关联和相互作用。
数据整合和交叉分析需要使用多种统计学和网络分析的方法,以揭示不同基因和蛋白质之间的功能和关系。
二、方法总结1.基因组数据分析方法:(1)基因表达分析:基因表达谱揭示了不同条件下基因的表达水平,常用的方法有基因芯片和RNA测序。
生物学家可以通过这些方法研究基因表达的调控机制和生物过程中的基因功能。
(2)基因组重测序:基因组重测序可以帮助研究人员探究生物体的基因组结构、突变和遗传变异等。
重测序方法如全基因组测序和基因组DNA甲基化测序提供了宝贵的信息,有助于了解基因组的功能和变异。
全基因组重测序

基因间区 基因内(无转录本信息) 内含子 基因上游区域(5K以内) 基因下游区域(5K以内) 基因的5’UTR内 基因的3’UTR内 剪切受体突变(exon前2bp内) 剪切供体突变(exon后2bp内) 起始密码子丢失 移码突变(非3的整数倍插入或删除) 密码子删除(3的整数倍) 整个外显子被删除 密码子插入(3的整数倍)
以个体间核苷酸序列变异为基础的遗传标记 是 DNA 水平遗传多态性的直接反映 能直接反映生物个体或种群间基因组DNA间的差异
1. 直接以DNA的形式表现,不受组织、发育阶段、季节、环境等 因素的限制,不存在表达与否等问题,表现稳定
2. 数量极多,遍布整个基因组 3. 多态性高,自然界存在许多等位变异 4. 许多标记表现为共显性的特点,能区别显性纯合体和杂合体,
chrposrefr01r02chr0473cgcchr0801gtgchr0892gcgchr0963grgchr01013ccychr01231cycchr02387gtgsmallindel?指的是在基因组的某个位置上所发生的小片段序列的插入或者删除其长度通常在50bp以下?单端reads能够跨越而不影响序列比对的indelindel功能intergenic基因间区intragenic基因内无转录本信息intron内含子upstream基因上游区域5k以内downstream基因下游区域5k以内utr5prime基因的5utr内utr3prime基因的3utr内splicesiteacceptor剪切受体突变exon前2bp内splicesitedonor剪切供体突变exon后2bp内startlost起始密码子丢失frameshift移码突变非3的整数倍插入或删除codondeletion密码子删除3的整数倍exondeleted整个外显子被删除codoninsertion密码子插入3的整数倍codonchangepluscodondeletion非密码子边界上的3的整数倍的删除codonchangepluscodoninsertion非密码子边界上的3的整数倍的插入stopgained终止密码子获得stoplost终止密码子丢失other由于gff文件中基因信息不完整错误而无法得到准确的判断?移码突变
全基因组重测序数据分析详细说明

全基因组重测序数据分析1. 简介(Introduction)通过高通量测序识别发现de novo的somatic和germ line 突变,结构变异-SNV,包括重排突变(deletioin, duplication 以及copy number variation)以及SNP的座位;针对重排突变和SNP的功能性进行综合分析;我们将分析基因功能(包括miRNA),重组率(Recombination)情况,杂合性缺失(LOH)以及进化选择与mutation之间的关系;以及这些关系将怎样使得在disease(cancer)genome中的mutation 产生对应的易感机制和功能。
我们将在基因组学以及比较基因组学,群体遗传学综合层面上深入探索疾病基因组和癌症基因组。
实验设计与样本(1)Case-Control 对照组设计;(2)家庭成员组设计:父母-子女组(4人、3人组或多人);初级数据分析1.数据量产出:总碱基数量、Total Mapping Reads、Uniquely Mapping Reads统计,测序深度分析。
2.一致性序列组装:与参考基因组序列(Reference genome sequence)的比对分析,利用贝叶斯统计模型检测出每个碱基位点的最大可能性基因型,并组装出该个体基因组的一致序列。
3.SNP检测及在基因组中的分布:提取全基因组中所有多态性位点,结合质量值、测序深度、重复性等因素作进一步的过滤筛选,最终得到可信度高的SNP数据集。
并根据参考基因组信息对检测到的变异进行注释。
4.InDel检测及在基因组的分布: 在进行mapping的过程中,进行容gap的比对并检测可信的short InDel。
在检测过程中,gap的长度为1~5个碱基。
对于每个InDel的检测,至少需要3个Paired-End序列的支持。
5.Structure Variation检测及在基因组中的分布: 能够检测到的结构变异类型主要有:插入、缺失、复制、倒位、易位等。
全基因组重测序数据分析报告

全基因组重测序数据分析1. 简介(Introduction)通过高通量测序识别发现de novo的somatic和germ line 突变,结构变异-SNV,包括重排突变(deletioin, duplication 以及copy number variation)以及SNP的座位;针对重排突变和SNP的功能性进行综合分析;我们将分析基因功能(包括miRNA),重组率(Recombination)情况,杂合性缺失(LOH)以及进化选择与mutation之间的关系;以及这些关系将怎样使得在disease(cancer)genome中的mutation产生对应的易感机制和功能。
我们将在基因组学以及比较基因组学,群体遗传学综合层面上深入探索疾病基因组和癌症基因组。
实验设计与样本(1)Case-Control 对照组设计;(2)家庭成员组设计:父母-子女组(4人、3人组或多人);初级数据分析1.数据量产出:总碱基数量、Total Mapping Reads、Uniquely Mapping Reads统计,测序深度分析。
2.一致性序列组装:与参考基因组序列(Reference genome sequence)的比对分析,利用贝叶斯统计模型检测出每个碱基位点的最大可能性基因型,并组装出该个体基因组的一致序列。
3.SNP检测及在基因组中的分布:提取全基因组中所有多态性位点,结合质量值、测序深度、重复性等因素作进一步的过滤筛选,最终得到可信度高的SNP数据集。
并根据参考基因组信息对检测到的变异进行注释。
4.InDel检测及在基因组的分布: 在进行mapping的过程中,进行容gap的比对并检测可信的short InDel。
在检测过程中,gap的长度为1~5个碱基。
对于每个InDel的检测,至少需要3个Paired-End序列的支持。
5.Structure Variation检测及在基因组中的分布: 能够检测到的结构变异类型主要有:插入、缺失、复制、倒位、易位等。
几种常见的基因测序技术的优缺点及应用

随着人类基因组计划的完成,人类对自身遗传信息的了解和掌握有了前所未有的进步。
与此同时,分子水平的基因检测技术平台不断发展和完善,使得基因检测技术得到了迅猛发展,基因检测效率不断提高。
从最初第一代以Sanger 测序为代表的直接检测技术和以连锁分析为代表的间接测序技术,到2005 年,以Illumina 公司的Solexa 技术和ABI 公司的SOLiD技术为标志的新一代测序(next-generation sequencing,NGS) 的相继出现,测序效率明显提升,时间明显缩短,费用明显降低,基因检测手段有了革命性的变化。
其技术正向着大规模、工业化的方向发展,极大地提高了基因检测的检出率,并扩展了疾病在基因水平的研究范围。
2009 年3 月,约翰霍普金斯大学的研究人员在《Science》杂志上发表了通过NGS外显子测序技术,发现了一个新的遗传性胰腺癌的致病基因PALB2,标志着NGS 测序技术成功应用于致病基因的鉴定研究。
同年,《Nature》发表了采用NGS 技术发现罕见弗里曼谢尔登综合征MYH3 致病基因突变和《Nat Genet》发表了遗传疾病米勒综合征致病基因。
此后,通过NGS 技术,与遗传相关的致病基因不断被发现,NGS 技术已成为里程碑式的进步。
2010 年,《Science》杂志将这一技术评选为当年“十大科学进展”。
近两年,基因检测成为临床诊断和科学研究的热点,得到了突飞猛进和日新月异的发展,越来越多的临床和科研成果不断涌现出来。
同时,基因检测已经从单一的遗传疾病专业范畴扩展到复杂疾病和个体化应用更加广阔的领域,其临床检测范围包括高危疾病的新生儿筛查、遗传疾病的诊断和基因携带的检测以及基因药物检测用于指导个体化用药剂量、选择和药物反应等诸多方面的研究。
目前,基因检测在临床诊断和医学研究的应用正越来越受到医生的普遍重视和引起研究人员的极大的兴趣。
本文介绍了几种DNA 水平基因检测常见的方法,比较其优缺点和在临床诊断和科学研究中的应用,对指导研究生和临床医生课外学习,推进临床科研工作和提升科研教学水平有着指导意义。
基因相关名词解释

基因相关名词解释名词解释⼀、⽣物学名称解释1. 什么是⾼通量测序技术?⾼通量测序技术(High-throughput sequencing,HTS)是对传统Sanger测序(称为⼀代测序技术)⾰命性的改变, ⼀次对⼏⼗万到⼏百万条核酸分⼦进⾏序列测定, 因此在有些⽂献中称其为下⼀代测序技术(next generation sequencing,NGS )⾜见其划时代的改变, 同时⾼通量测序使得对⼀个物种的转录组和基因组进⾏细致全貌的分析成为可能, 所以⼜被称为深度测序(Deep sequencing)。
2. 什么是Sanger法测序(⼀代测序)?Sanger法测序利⽤⼀种DNA聚合酶来延伸结合在待定序列模板上的引物。
直到掺⼊⼀种链终⽌核苷酸为⽌。
每⼀次序列测定由⼀套四个单独的反应构成,每个反应含有所有四种脱氧核苷酸三磷酸(dNTP),并混⼊限量的⼀种不同的双脱氧核苷三磷酸(ddNTP)。
由于ddNTP缺乏延伸所需要的3-OH基团,使延长的寡聚核苷酸选择性地在G、A、T或C处终⽌。
终⽌点由反应中相应的双脱氧⽽定。
每⼀种dNTPs和ddNTPs的相对浓度可以调整,使反应得到⼀组长⼏百⾄⼏千碱基的链终⽌产物。
它们具有共同的起始点,但终⽌在不同的的核苷酸上,可通过⾼分辨率变性凝胶电泳分离⼤⼩不同的⽚段,凝胶处理后可⽤X-光胶⽚放射⾃显影或⾮同位素标记进⾏检测。
3. 什么是SNP、SNV(单核苷酸位点变异)?单核苷酸多态性(single nucleotide polymorphism,SNP)和单核苷酸位点变异(single nucleotide variants, SNV)。
个体间基因组DNA序列同⼀位置单个核苷酸变异(替代、插⼊或缺失)所引起的多态性。
不同物种、个体基因组DNA序列同⼀位置上的单个核苷酸存在差别的现象。
有这种差别的基因座、DNA序列等可作为基因组作图的标志。
⼈基因组上平均约每1000个核苷酸即可能出现1个单核苷酸多态性的变化,其中有些单核苷酸多态性可能与疾病有关,但可能⼤多数与疾病⽆关。
测序常用名词解释整理
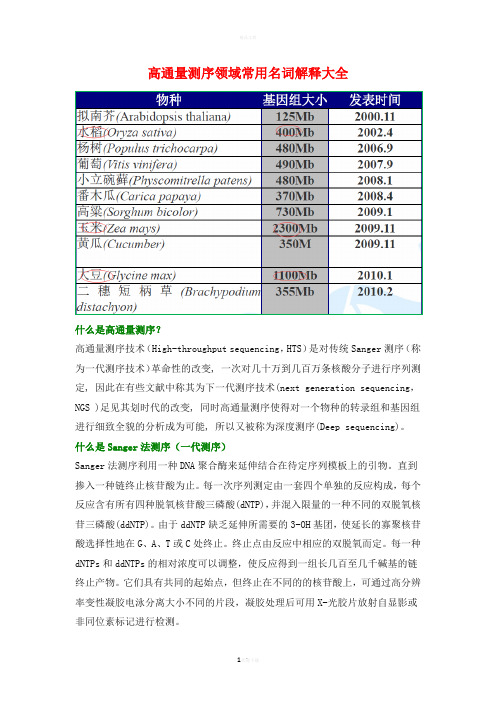
高通量测序领域常用名词解释大全什么是高通量测序?高通量测序技术(High-throughput sequencing,HTS)是对传统Sanger测序(称为一代测序技术)革命性的改变, 一次对几十万到几百万条核酸分子进行序列测定, 因此在有些文献中称其为下一代测序技术(next generation sequencing,NGS )足见其划时代的改变, 同时高通量测序使得对一个物种的转录组和基因组进行细致全貌的分析成为可能, 所以又被称为深度测序(Deep sequencing)。
什么是Sanger法测序(一代测序)Sanger法测序利用一种DNA聚合酶来延伸结合在待定序列模板上的引物。
直到掺入一种链终止核苷酸为止。
每一次序列测定由一套四个单独的反应构成,每个反应含有所有四种脱氧核苷酸三磷酸(dNTP),并混入限量的一种不同的双脱氧核苷三磷酸(ddNTP)。
由于ddNTP缺乏延伸所需要的3-OH基团,使延长的寡聚核苷酸选择性地在G、A、T或C处终止。
终止点由反应中相应的双脱氧而定。
每一种dNTPs和ddNTPs的相对浓度可以调整,使反应得到一组长几百至几千碱基的链终止产物。
它们具有共同的起始点,但终止在不同的的核苷酸上,可通过高分辨率变性凝胶电泳分离大小不同的片段,凝胶处理后可用X-光胶片放射自显影或非同位素标记进行检测。
什么是基因组重测序(Genome Re-sequencing)全基因组重测序是对基因组序列已知的个体进行基因组测序,并在个体或群体水平上进行差异性分析的方法。
随着基因组测序成本的不断降低,人类疾病的致病突变研究由外显子区域扩大到全基因组范围。
通过构建不同长度的插入片段文库和短序列、双末端测序相结合的策略进行高通量测序,实现在全基因组水平上检测疾病关联的常见、低频、甚至是罕见的突变位点,以及结构变异等,具有重大的科研和产业价值。
什么是de novo测序de novo测序也称为从头测序:其不需要任何现有的序列资料就可以对某个物种进行测序,利用生物信息学分析手段对序列进行拼接,组装,从而获得该物种的基因组图谱。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基因组重测序
背景介绍 全基因组重测序,是对基因组序列已知的个体进行基因组测序,并在个体或群体水平上进行差异性分析的方法。
与已知序列比对,寻找单核苷酸多态性位点(SNP )、插入缺失位点(InDel ,Insertion/Deletion )、结构变异位点(SV ,Structure Variation )位点及拷贝数变化(CNV) 。
可以寻找到大量基因差异,实现遗传进化分析及重要性状候选基因的预测。
涉
及临床医药研究、群体遗传学研究、关联分析、进化分析等众多应用领域。
随着测序成本的大幅度降低以及测序效率的数量级提升,
全基因组重测序已经成为研究人类疾病及动植物分子育种最为快速有效的方法之一。
利用illumina Hiseq 2000
平台,将不同插入片段文库和双末端测序相结合,可以高效地挖掘基因序列差异和结构变异等信息,
为客户进行疾病研究、分子育种等提供准确依据。
重测序的两个条件:(1)该物种基因组序列已知;(2)所测序群体之间遗传性差异不大( >99% 相似度 )
在已经完成的全基因组测序及其基因功能注释的基础上,采用全基因组鸟枪法(WGS )对DNA 插入片段进行双末端测序。
技术路线
生物信息学分析
送样要求
1.样品总量:每次样品制备需要大于5ug 的样品。
为保证实验质量及延续性,请一次性提供至少20ug的样品。
如需多次制备样品,按照制备次数计算样品总量。
2.样品纯度:OD值260/280应在1.8~2.0 之间;无蛋白质、RNA或肉眼可见杂质污染。
3.样品浓度:不低于50 ng/μL。
4.样品质量:基因组完整、无降解,电泳结果基因组DNA主带应在λ‐Hind III digest 最大条带23 Kb以上且主带清晰,无弥散。
5.样品保存:限选择干粉、酒精、TE buffer或超纯水一种,请在样品信息单中注明。
6.样品运输:样品请置于1.5 ml管中,做好标记,使用封口膜封好;基因组DNA如果用乙醇沉淀,可以常温运输;否则建议使用干冰或冰袋运输,并选择较快的运输方式。
提供结果
根据客户需求,提供不同深度的信息分析结果。