非关系型数据库大作业
非关系型数据库(NoSQL)技术考试

非关系型数据库(NoSQL)技术考试(答案见尾页)一、选择题1. 什么是非关系型数据库(NoSQL)?A. 一种基于关系的数据库技术B. 一种不基于关系的数据库技术C. 一种只能存储结构化数据的数据库技术D. 一种只能存储半结构化数据的数据库技术2. NoSQL数据库与传统的关系型数据库的主要区别是什么?A. 数据存储方式B. 数据模式C. 查询语言D. 事务处理3. 在NoSQL数据库中,哪种数据模型是最常用的?A. 关系模型B. 键值对模型C. 文档模型D. 列模型4. 在NoSQL数据库中,哪种类型的键值对存储是最高效的?A. 单键值存储B. 多键值存储C. 哈希键值存储D. 字符串键值存储5. 什么是NoSQL数据库中的列族存储?A. 一种将数据分组成多个列的存储方式B. 一种将数据分组成多个行的存储方式C. 一种将数据按行分组的存储方式D. 一种将数据按列分组的存储方式6. 在NoSQL数据库中,哪种类型的数据库适合处理大规模数据集?A. 关系型数据库B. 键值对数据库C. 文档数据库D. 列族数据库7. NoSQL数据库与传统关系型数据库在数据一致性和可用性方面的权衡是如何实现的?A. 通过增加冗余数据来提高可用性B. 通过减少冗余数据来提高一致性C. 通过使用分布式事务来保证数据一致性D. 通过使用副本集来保证数据可用性和一致性8. 在NoSQL数据库中,哪种类型的数据库适合需要高并发读写的场景?A. 关系型数据库B. 键值对数据库C. 文档数据库D. 列族数据库9. 什么是NoSQL数据库中的分布式缓存?A. 一种内存中的缓存技术,用于提高数据访问速度B. 一种分布式的、可扩展的数据存储技术,用于提高数据访问速度C. 一种分布式的内存数据库技术,用于提高数据访问速度D. 一种分布式的、可扩展的缓存技术,用于提高数据访问速度10. 什么是非关系型数据库(NoSQL)?A. 一种基于关系的数据库技术B. 一种不基于关系的数据库技术C. 一种只能存储结构化数据的数据库技术D. 一种只能存储非结构化数据的数据库技术11. NoSQL数据库与传统的关系型数据库的主要区别是什么?B. 查询语言C. 一致性模型D. 扩展性12. 在NoSQL数据库中,哪种类型的数据库最适合处理大量非结构化数据?A. 文档型数据库B. 键值对数据库C. 列式数据库D. 图形数据库13. 什么是NoSQL数据库中的图形数据库?A. 一种基于关系的数据库技术B. 一种不基于关系的数据库技术,用于存储和查询复杂的关系数据C. 一种只支持图结构的数据库D. 一种不支持事务的数据库14. 在NoSQL数据库中,哪种类型的数据库通常用于实时数据分析?A. 文档型数据库B. 键值对数据库C. 列式数据库D. 图形数据库15. NoSQL数据库的扩展性是指什么?A. 数据库可以自动扩展其存储容量B. 数据库可以通过添加更多的服务器来提高性能C. 数据库可以通过读写分离来提高性能D. 数据库可以通过复制数据来实现高可用性16. 在NoSQL数据库中,哪种类型的数据库通常用于存储时间序列数据?A. 文档型数据库B. 键值对数据库C. 列式数据库17. 什么是非关系型数据库(NoSQL)?A. 一种关系型数据库技术B. 一种面向文档的数据库技术C. 一种基于键值存储的数据库技术D. 一种支持高并发读写的数据库技术18. NoSQL数据库与传统的关系型数据库的主要区别是什么?A. 数据模型B. 查询语言C. 一致性模型D. 扩展性19. 以下哪个选项是NoSQL数据库中的常用数据操作?A. 插入B. 更新C. 删除D. 查询20. 在NoSQL数据库中,哪种类型的数据库具有水平扩展的特性?A. 关系型数据库B. 文档型数据库C. 键值型数据库D. 列族型数据库21. NoSQL数据库中的列族型数据库(如Cassandra)通常用于哪种场景?A. 高并发读写B. 高可用性C. 大量小文件存储D. 实时数据分析22. 在NoSQL数据库中,哪种类型的数据库适用于需要复杂查询的场景?B. 文档型数据库C. 键值型数据库D. 列族型数据库23. NoSQL数据库中的键值型数据库(如Redis)通常用于哪种场景?A. 缓存B. 数据库缓存C. 高可用性D. 实时数据分析24. 在NoSQL数据库中,哪种类型的数据库具有高度的数据一致性和完整性?A. 关系型数据库B. 文档型数据库C. 键值型数据库D. 列族型数据库25. 什么是非关系型数据库(NoSQL)?A. 一种关系型数据库技术B. 一种面向文档的数据库技术C. 一种面向列的数据库技术D. 一种关系型数据库的非关系型变种26. NoSQL数据库有哪些特点?A. 高可扩展性B. 高可用性C. 灵活的数据模型D. 严格的模式设计27. 在NoSQL数据库中,哪种数据模型是最常用的?A. 关系模型B. 文档模型C. 列模型28. NoSQL数据库与传统关系型数据库的主要区别是什么?A. 数据模型B. 事务处理C. 查询语言D. 数据一致性模型29. 在NoSQL数据库中,哪种类型的数据库通常用于存储大量非结构化数据?A. 键值存储B. 文档存储C. 列存储D. 图存储30. NoSQL数据库中的键值存储有何特点?A. 键值对结构,允许快速查找和存储B. 提供复杂的查询功能C. 支持事务处理D. 适用于高并发读写场景31. 列存储有何特点?A. 数据按列进行存储,适合大规模数据的存储和分布式处理B. 提供高性能的读写操作C. 适用于需要高效数据压缩和编码的场景D. 支持复杂的数据查询和聚合操作32. 图存储有何特点?A. 数据以图的形式存储,适合处理复杂的关系数据B. 适用于社交网络、推荐系统等场景C. 提供高效的路径查询和连接操作D. 支持高并发的读写和实时更新33. 在NoSQL数据库中,哪种数据库通常用于需要高可用性和可扩展性的场景?B. 文档存储C. 列存储D. 图存储34. 什么是非关系型数据库(NoSQL)?A. 是一种关系型数据库技术B. 提供分布式数据存储C. 支持结构化数据查询D. 采用面向列的存储方式35. NoSQL数据库与传统的关系型数据库的主要区别是什么?A. 数据模型B. 查询语言C. 一致性模型D. 扩展性36. 在NoSQL数据库中,哪种数据模型被广泛使用?A. 关系模型B. 键值对模型C. 文档模型D. 图模型37. NoSQL数据库中的数据一致性是如何保证的?A. 通过事务B. 使用分布式锁C. 通过副本集D. 通过分片38. 以下哪个不是NoSQL数据库的特点?A. 高可扩展性B. 高可用性C. 灵活的数据模型D. 严格的数据模式39. 在NoSQL数据库中,哪种类型的数据库具有固定的表结构?A. 列族数据库B. 文档数据库C. 关系数据库D. 集合数据库40. 在NoSQL数据库中,哪种类型的数据库支持高并发读写?A. 列族数据库B. 文档数据库C. 关系数据库D. 集合数据库41. 以下哪个不是NoSQL数据库的优势?A. 灵活的数据模型B. 高可用性C. 严格的数据模式D. 高扩展性42. 在NoSQL数据库中,哪种类型的数据库支持水平扩展?A. 列族数据库B. 文档数据库C. 关系数据库D. 集合数据库二、问答题1. 什么是非关系型数据库(NoSQL)?2. NoSQL数据库有哪些类型?3. NoSQL数据库与传统关系型数据库的主要区别是什么?4. NoSQL数据库的优势是什么?5. 如何选择合适的NoSQL数据库?6. 在NoSQL数据库中,如何实现数据的一致性?7. NoSQL数据库在大数据和实时分析方面的优势如何体现?8. 如何在NoSQL数据库中进行数据备份和恢复?参考答案选择题:1. B2. A3. C4. D5. A6. D7. D8. D9. D 10. B11. ABCD 12. A 13. C 14. D 15. B 16. C 17. B 18. D 19. ABCD 20. D 21. ACD 22. A 23. AB 24. A 25. C 26. ABC 27. C 28. D 29. B 30. A 31. AC 32. ABCD 33. D 34. B 35. D 36. C 37. C 38. D 39. C 40. A 41. C 42. A问答题:1. 什么是非关系型数据库(NoSQL)?非关系型数据库(NoSQL)是一类不同于传统的关系型数据库的存储数据的方法。
mongo练习题

mongo练习题一、基础知识篇1. MongoDB是什么类型的数据库?2. MongoDB中的文档是什么?3. MongoDB中的集合与关系型数据库中的表有什么区别?4. 请简述MongoDB的主要特点。
5. MongoDB支持哪些数据类型?6. 如何在MongoDB中创建一个数据库?7. 如何在MongoDB中创建一个集合?8. 请列举MongoDB的几种索引类型。
二、数据操作篇1. 如何向MongoDB集合中插入一条文档?2. 如何查询MongoDB集合中的所有文档?3. 如何根据指定条件查询MongoDB集合中的文档?4. 如何更新MongoDB集合中的文档?5. 如何删除MongoDB集合中的文档?6. 请写出使用MongoDB进行分页查询的语句。
7. 如何在MongoDB中使用聚合管道进行数据分析?8. 请举例说明MongoDB中的投影操作。
三、安全管理篇1. 如何在MongoDB中创建用户?2. 如何为MongoDB用户设置权限?3. 请简述MongoDB中的角色权限管理。
4. 如何备份MongoDB数据库?5. 如何恢复MongoDB数据库?6. 请列举几种MongoDB的安全性能优化措施。
四、性能优化篇1. 如何查看MongoDB的索引信息?2. 如何创建复合索引?3. 请简述MongoDB索引的使用原则。
4. 如何分析MongoDB的查询性能?5. 如何优化MongoDB的写入性能?6. 请举例说明MongoDB中的数据归档操作。
五、高可用与复制篇1. 请简述MongoDB副本集的概念。
2. 如何搭建一个MongoDB副本集?3. 副本集中的主节点和从节点有哪些区别?4. 请列举几种MongoDB副本集的故障转移场景。
5. 如何配置MongoDB的分片集群?6. 请简述MongoDB分片集群的数据分布策略。
六、综合应用篇1. 如何使用Python操作MongoDB?2. 请设计一个基于MongoDB的用户登录注册系统。
非关系型数据库的特点与应用

非关系型数据库的特点与应用随着互联网的快速发展和大数据的涌现,传统的关系型数据库在面对海量数据的存储和处理时显得力不从心。
为了满足高并发访问和灵活的数据模型需求,非关系型数据库应运而生。
非关系型数据库(NoSQL)是一种将数据存储为键-值对或其他非结构化格式的数据库,它的出现扩展了传统关系型数据库的应用领域,提供了高性能、高可扩展性和灵活性等特点。
一、非关系型数据库的特点1.高可扩展性:非关系型数据库采用分布式架构,能够在集群环境下轻松扩展,实现横向伸缩。
这使得非关系型数据库在应对高并发访问的情况下具有较好的性能表现。
2.灵活的数据模型:非关系型数据库采用非结构化或半结构化的数据存储方式,能够灵活地存储和处理各种类型的数据,包括文档、键-值对、列族和图等。
这使得非关系型数据库能够适应各种不同的应用场景。
3.高性能:由于非关系型数据库不需要遵循严格的数据完整性和一致性要求,相比于传统的关系型数据库,非关系型数据库的读写性能更高。
此外,非关系型数据库在大数据量的情况下具有更短的查询响应时间。
4.数据分片存储:非关系型数据库基于分布式架构,可以将数据分片存储在多个节点上,提高数据的可用性和冗余度,降低单点故障的风险。
5.低成本:非关系型数据库的硬件和维护成本相对较低,不需要额外的数据库管理员来管理数据库的结构和模式。
同时,非关系型数据库能够利用廉价的、通用的硬件来构建高可用的分布式系统。
二、非关系型数据库的应用1.大数据存储和分析:随着数据量的不断增长,传统的关系型数据库往往无法胜任大数据存储和分析的任务。
非关系型数据库在这方面具有天然的优势,能够方便地存储和处理海量的非结构化或半结构化数据,提供快速的查询和分析能力。
2.实时数据处理:非关系型数据库的分布式架构和高性能特点使得它非常适合处理实时大数据流。
例如,对于电商网站来说,非关系型数据库可以用来实时跟踪和分析用户的浏览行为,从而做出个性化推荐和营销策略。
非关系型数据库的查询处理与优化方法

非关系型数据库的查询处理与优化方法随着互联网的快速发展和大数据的持续增长,数据库的查询处理成为了一个重要的研究方向。
在传统的关系型数据库中,查询处理的性能问题逐渐凸显出来,尤其是面对大规模数据和高并发访问的情况。
为了解决这个问题,非关系型数据库(NoSQL)被广泛应用。
本文将介绍非关系型数据库的查询处理和优化方法。
一、非关系型数据库的查询处理方法1. 索引索引在非关系型数据库中同样起着重要的作用。
通过创建合适的索引,可以大大提高查询的效率。
一些常见的索引类型包括哈希索引、B树索引和位图索引等。
哈希索引适用于等值查询,通过哈希函数将键映射到存储位置;B树索引适用于范围查询,通过维护有序的B树数据结构实现快速查找;位图索引适用于具有大量重复值的列,通过位图标志的方式高效地进行查询。
2. 分布式查询非关系型数据库通常采用分布式架构,数据分布在多个节点上。
查询处理涉及到跨节点的数据访问和计算,在设计查询时需要考虑数据的分布和负载均衡。
常见的分布式查询方法包括并行查询、分片查询和全局统计等。
并行查询利用多个节点同时处理查询,提高了查询的并发度;分片查询将数据划分为若干片段,分布在不同的节点上进行查询,减少了单个节点的查询负载;全局统计则用于从全局数据中获取统计信息,辅助查询优化。
3. 缓存非关系型数据库通常具有高速的读取能力,通过缓存机制可以减少重复查询和加快查询响应时间。
缓存可以采用内存缓存或分布式缓存,将频繁访问的数据存储在缓存中,减少对数据库的访问压力。
在设计查询时,可以使用缓存机制预先计算和存储一些常用的查询结果,提高查询的响应速度。
二、非关系型数据库的查询优化方法1. 数据模型设计在非关系型数据库中,数据模型的设计对查询性能有着直接的影响。
根据具体的业务需求,选择合适的数据模型,避免冗余和复杂的关系结构,能够提高查询的效率。
一般来说,数据模型的设计应该尽量符合横向扩展的原则,充分利用分布式数据库的优势。
数据库大作业(全·参考答案)

《数据库原理与应用》综合设计任务书前言《数据库原理与应用》课程的重点知识模块包括:1)数据库设计、2)用SQL实现建库、建表、查询、更新、和创建视图、3)存储过程和触发器设计。
针对这三个应用能力,用一个案例作为背景,布置三次大作业。
在校大学生都能理解“图书管理系统”的应用场合和业务流程。
因此,以图书管理系统作为案例来布置作业,可以降低业务分析难度,让学生将主要精力放在知识消化与技术应用上。
本文档包括四个部分。
第一部分描述系统的需求,第二部分提出E-R模型设计和关系模型设计的任务;第三部分提出在SQL Server中,用SQL语句来建库、建表、查询、更新数据、创建视图的任务;第四部分,根据应用需求、安全需求和数据完整性要求,提出设计存储过程和触发器的任务。
每个任务之前,都给出了完成任务所需要掌握的关键知识点,学生可以在对这些知识点进行复习的基础上完成任务,每个任务是一次大作业。
第一部分案例的需求描述本部分描述“图书管理系统”的需求,学生通过阅读本部分内容,了解系统的功能要求、运行环境,对系统所需的数据有总体认识,作为三次作业的基础。
1.2 需求分析1)功能需求图1-1:功能需求示意图教师信息管理:用于教师基本资料的增删改查。
图书信息管理:用于图书基本信息的增删改查,分类统计图书册数和价值。
借书登记:记录借书时间、所借图书、借书人、办理人。
还书登记:记录还书时间、所还图书、还书人、办理人。
催还:查询借阅逾期的借书信息,给借书人发电子邮件,给借书人的部门打电话。
2)运行环境要求图1-2:运行环境拓扑图系统采用C/S模式,有两台PC和一台服务器,联成一个局域网。
PC上安装图书管理软件的客户端,服务器上安装DBMS,服务器也可由两台PC中的一台来代替。
第二部分作业1——E-R模型与关系模型设计(满分8分)本部分的任务是:在需求分析的基础上,进行E-R图设计,然后将E-R模型转换为关系模型。
任务:1)根据需求描述,绘制E-R图。
非关系型数据库的应用与技巧

非关系型数据库的应用与技巧随着信息时代的发展,海量数据的存储和处理成为了当代社会的一个重要挑战。
对于传统的关系型数据库而言,其在处理大规模数据时存在诸多限制和瓶颈。
为了解决这些问题,非关系型数据库逐渐崭露头角,并在各个领域得到广泛应用。
本文将会介绍非关系型数据库的应用场景及相应的技巧,帮助读者更好地了解和使用非关系型数据库。
一、应用场景1. 大规模数据存储:非关系型数据库以其分布式、可扩展的特性,成为海量数据存储的首选解决方案。
在需要处理大量数据的场景中,使用非关系型数据库可以轻松应对数据爆炸的挑战。
例如,电商平台可使用非关系型数据库存储和管理用户、商品、订单等大批量数据。
2. 高并发读写:非关系型数据库具有良好的读写性能,在高并发的情况下表现出色。
这使得非关系型数据库在互联网、物联网等领域中应用广泛。
以社交网络为例,用户之间的消息互通需要承受海量的并发读写请求,非关系型数据库能够快速响应并保持高效稳定运行。
3. 实时数据处理:非关系型数据库具备支持实时数据处理的能力,这对于需要快速分析、反馈数据结果的场景来说非常重要。
例如,智能城市中的交通管控系统需要实时地采集和分析各类数据,通过非关系型数据库可以实现快速的数据处理和决策支持。
4. 复杂数据结构:相比于关系型数据库固定的表结构,非关系型数据库更灵活地处理复杂的数据结构,如树形结构、图形结构等。
特别是在存储文档型数据时,非关系型数据库能够大大简化数据模型设计的复杂性,提高开发效率。
此外,非关系型数据库还常用于存储日志、传感器数据等非结构化或半结构化的数据。
二、技巧与实践1. 数据模型设计:非关系型数据库具有灵活的数据模型,但要充分利用其特性,合理的数据模型设计非常重要。
在设计数据模型时,需要根据具体应用场景和需求,选择最适合的非关系型数据库类型,如文档型、列式存储、图形数据库等。
同时,注意避免数据冗余,合理划分数据集合,以及添加适当的索引等,以提高数据库的读写性能。
数据库大作业总结

数据库大作业总结在数据库大作业中,我学到了很多关于数据库设计和实现的知识和技巧。
这次大作业要求我们创建一个完整的数据库系统,包括数据库设计、表结构的创建、数据的插入和查询等。
首先,我学会了如何进行数据库设计。
在设计数据库时,我们需要考虑到数据库的目标和需求,确定数据库的主题和范围。
然后,我们需要分析数据库中的实体和关系,将其转化为实体关系模型(ER模型)。
在ER模型的基础上,我们可以继续进行表结构的设计,确定每个表的字段和数据类型。
在完成数据库设计之后,我学会了如何使用SQL语句创建表结构和插入数据。
SQL语句是数据库管理系统与用户之间进行交互的语言。
通过使用SQL语句,我们可以创建表格、定义字段以及插入数据。
我学会了创建主键和外键,以及如何利用索引来提高查询效率。
接下来,我学会了如何编写SQL查询语句。
通过使用SELECT语句,我们可以从数据库中检索所需的数据。
我学会了使用WHERE子句来过滤数据,使用ORDER BY子句来排序数据,以及使用JOIN语句来连接多个表。
这些查询语句可以帮助我们根据特定条件来获取所需的数据。
在数据库大作业中,我还学会了如何进行数据库的备份和恢复。
数据库的备份是为了防止数据丢失或损坏,可以通过创建数据库的镜像或者将数据导出为文件的方式来进行备份。
而数据库的恢复则是在数据库出现故障或数据丢失时,将备份的数据重新导入到数据库中。
总的来说,通过这次数据库大作业,我对数据库的设计和实现有了更深入的理解。
我学会了如何进行数据库设计,如何创建表结构和插入数据,以及如何编写SQL查询语句。
这些知识和技巧对于我未来的工作和学习都非常有帮助。
《非关系型数据库开发》课程设计,使用mongodb和redis

《非关系型数据库开发》课程设计,使用mongodb和
redis
课程设计题目:非关系型数据库开发
使用技术:MongoDB 和 Redis
一、课程设计目标
本课程设计旨在让学生掌握非关系型数据库的基本原理和开发技术,了解MongoDB和Redis的特性及使用方法,通过实际项目开发,培养学生的数据库设计和应用能力。
二、课程设计内容
1. MongoDB和Redis的基本概念和原理;
2. MongoDB和Redis的安装与配置;
3. MongoDB和Redis的数据模型设计;
4. MongoDB和Redis的数据操作;
5. MongoDB和Redis的查询优化;
6. MongoDB和Redis的集群部署;
7. 综合项目:基于MongoDB和Redis的在线购物系统。
三、课程设计步骤
1. 准备阶段:了解MongoDB和Redis的基本概念和原理,熟悉它们的安装和配置过程;
2. 设计阶段:根据项目需求,进行数据模型设计,包括数据结构、索引、聚合等;
3. 开发阶段:实现数据操作,包括插入、查询、更新、删除等,同时进行查询优化和集群部署;
4. 测试阶段:对系统进行测试,确保数据操作的正确性和系统的稳定性;
5. 总结阶段:总结项目经验,撰写课程设计报告。
四、课程设计要求
1. 掌握MongoDB和Redis的基本概念和原理;
2. 熟练使用MongoDB和Redis的数据模型设计和数据操作;
3. 能够进行查询优化和集群部署;
4. 完成一个基于MongoDB和Redis的在线购物系统的设计和实现;
5. 提交课程设计报告,包括数据模型设计、数据操作实现、查询优化、集群部署等方面的内容。
非关系型数据库的数据模型与应用场景分析

非关系型数据库的数据模型与应用场景分析近年来,非关系型数据库(NoSQL)的使用逐渐增多,并在大数据领域取得了广泛的应用。
非关系型数据库的数据模型不同于传统的关系型数据库,它的灵活性和可扩展性使得它适用于存储和处理各种类型和规模的数据。
本文将从数据模型和应用场景两个方面对非关系型数据库进行分析。
首先,非关系型数据库的数据模型有多种类型,其中最常见的包括键值对(Key-Value)、文档型(Document)、列族型(Column Family)和图型(Graph)。
每种数据模型都有自己的特点和适用场景。
键值对模型是最简单的数据模型,它将数据存储为由键和值组成的对。
键值对模型适合存储和获取简单的数据,例如用户信息和配置信息。
它的查询速度快,但不支持复杂的查询操作。
文档型模型是建立在键值对模型基础上的,它将数据存储为类似于JSON格式的文档。
文档型模型适合存储和处理半结构化和无结构化的数据,例如文章、日志和社交媒体数据。
它支持复杂的查询操作,可以根据文档的属性进行索引和过滤。
列族型模型将数据存储为列的集合,每个列族包含多个列。
列族型模型适合存储和查询结构化的数据,例如时间序列数据和日志数据。
它的查询性能非常高,能够快速地读取和写入大量的列。
图型模型是用来处理网络和关系数据的,它将数据存储为节点和边的集合。
图型模型适合存储和分析具有复杂关系的数据,例如社交网络和知识图谱。
它具有高效的图遍历能力,能够快速地查找和分析节点之间的关系。
除了以上几种数据模型,还有一些混合型的非关系型数据库,它们将多种数据模型结合起来,可以同时满足多种应用需求。
接下来,我们将分析非关系型数据库的几个应用场景。
首先是大规模数据存储和分析。
非关系型数据库能够轻松处理大规模数据的存储和查询,而且支持分布式架构,可以通过数据分片和负载均衡实现数据的并行处理。
这使得非关系型数据库成为大数据领域的首选。
其次是实时数据处理和推荐系统。
非关系型数据库通过快速的读写操作和高效的索引机制,可以实现实时的数据处理和推荐算法。
MySQL之五——非关系型数据库(nosql)介绍

MySQL之五——⾮关系型数据库(nosql)介绍⾮关系型数据库也叫Nosql数据库,全称是not noly sql。
2009年初,Johan Oskarsson举办了⼀场关于开源分布式数据库的讨论,Eric Evans在这次讨论中提出了NoSQL⼀词,⽤于指代那些⾮关系型的,分布式的,且⼀般不保证遵循ACID原则的数据存储系统。
Eric Evans使⽤NoSQL这个词,并不是因为字⾯上的“没有SQL”的意思,他只是觉得很多经典的关系型数据库名字都叫“**SQL”,所以为了表⽰跟这些关系型数据库在定位上的截然不同,就是⽤了“NoSQL“⼀词。
⾮关系型数据库提出另⼀种理念,例如,以键值对存储,且结构不固定,每⼀个元组可以有不⼀样的字段,每个元组可以根据需要增加⼀些⾃⼰的键值对,这样就不会局限于固定的结构,可以减少⼀些时间和空间的开销。
使⽤这种⽅式,⽤户可以根据需要去添加⾃⼰需要的字段,这样,为了获取⽤户的不同信息,不需要像关系型数据库中,要对多表进⾏关联查询。
仅需要根据id取出相应的value 就可以完成查询。
♂ 关系型数据库与⾮关系型数据库的区别:关系型数据库通过外键关联来建⽴表与表之间的关系,⾮关系型数据库通常指数据以对象的形式存储在数据库中,⽽对象之间的关系通过每个对象⾃⾝的属性来决定。
♂ nosql数据库的特点:模式⾃由不需要定义表结构,数据表中的每条记录都可能有不同的属性和格式。
逆规范化不遵循范式要求,去掉完整性约束,减少表之间的依赖弹性可扩展可在系统运⾏的过程中,动态的删除和增加节点。
多副本异步复制数据快速写⼊⼀个节点,其余节点通过读取写⼊的⽇志来实现异步复制。
弱事务不能完全满⾜事务的ACID特性,但是可以保证事务的最终⼀致性。
♂ 什么时候⽤nosql数据库:数据库表schema经常变化数据库表字段是复杂数据类型⾼并发数据库请求海量数据的分布式存储Mongodb➡ Mongodb简介MongoDB.inc 公司研发的⼀款nosql类型的⽂档型数据库。
数据库大作业1

数据库技术与应用课程设计报告教务管理系统学院:软件学院专业名称:班级:计科三班设计题目:教务管理系统学生姓名:时间:2021 /6/23 分数:目录第一章引言 (3)课程设计目的 (3)工程背景 (3)第二章教务管理系统需求分析 (3)2.1 需求分析概述 (3)角色职责描述 (4)2.2 教务管理系统的功能需求 (4)功能需求分析 (4)第三章概念设计 (5)3.1 实体之间的联系 (5)3.2.1 局部E-R图 (6)3.2.2 全局E-R图 (8)第四章逻辑构造设计 (9)4.1 关系模型的设计依据 (9)4.2 实体间联系转化的关系模式 (9)第五章物理构造设计 (11) (11)5.2 数据库初始化代码 (13)第一章引言利用一种SQL server作为设计平台,理解并应用课程中关于数据库设计的相关理论,能按照数据库设计步骤完成完整的数据库设计,包括需求分析、概念设计、逻辑设计、物理设计。
同时能够正确应用各个阶段的典型工具进展表示本工程作为?数据库?课程的实习工程提出,希望通过教务管理系统的分析与设计,切实领会系统分析、系统设计和实施各个阶段的要点;掌握根本的信息系统的开发方法以及体会信息管理系统设计,教务管理系统第二章教务管理系统需求分析2.1 需求分析概述本系统为教务管理系统,教务管理系统中主要有四类用户,即学生用户,教师用户,教务管理员和系统管理员。
对应这些用户,其处理要求的主要的功能就是进展一系列的查询和各类数据的管维护。
表2-1 角色职责2.2 教务管理系统的功能需求1〕系统管理:实现系统管理人员对系统的管理,包括添加删除用户,更改密码,数据备份,数据复原,注销等功能。
2〕教务管理:实现教务管理人员对系统的管理,包括课程安排,成绩审核,学生成绩管理,学生学籍管理等功能。
3〕根本信息:实现显示学生和教师以及课程、班级、系别的根本信息〔包括学生根本信息,教师根本信息,课程根本信息等〕。
非关系型数据库考试

非关系型数据库考试(答案见尾页)一、选择题1. 什么是非关系型数据库?A. 一种基于关系的数据库B. 一种非关联的数据存储系统C. 一种基于键值对的非关系型数据存储D. 一种分布式数据库2. 非关系型数据库与传统的关系型数据库的主要区别是什么?A. 数据结构的不同B. 数据操作的性能差异C. 数据一致性的要求D. 存储引擎的不同3. 在非关系型数据库中,通常使用哪种数据结构来存储数据?A. 数组B. 链表C. 树D. 图4. 非关系型数据库的优势包括哪些?A. 高可扩展性B. 高性能C. 高可用性D. 灵活的数据模型5. 下列哪个是非关系型数据库中的常用数据类型?A. 整数B. 浮点数C. 字符串D. 布尔值6. 在非关系型数据库中,如何实现数据的完整性?A. 使用事务B. 设置约束C. 使用触发器D. 使用视图7. 非关系型数据库与关系型数据库在范式应用上的主要区别是什么?A. 非关系型数据库不遵守ACID原则B. 非关系型数据库只遵守ACID原则的一部分(通常是ACID中的A和C)C. 非关系型数据库遵守关系型数据库的所有范式D. 非关系型数据库完全不遵守任何范式8. 在非关系型数据库中,如何进行数据备份和恢复?A. 使用SQL语句进行备份B. 使用图形化工具进行备份C. 使用内置的备份函数进行备份D. 使用第三方备份工具进行备份9. 非关系型数据库在哪些场景下适用?A. 大规模数据存储B. 高并发读写C. 实时数据分析D. 事务处理10. 在非关系型数据库中,如何实现数据的一致性和事务的原子性、一致性、隔离性、持久性(ACID)?A. 使用分布式事务B. 使用最终一致性C. 使用分布式锁D. 使用多副本技术11. 非关系型数据库(NoSQL)与传统的关系型数据库(RDBMS)的主要区别是什么?A. 数据模型B. 事务处理C. 查询语言D. 存储结构12. 在非关系型数据库中,哪种数据模型被广泛使用?A. 关系模型B. 键值对模型C. 文档模型D. 图模型13. 非关系型数据库的优势包括哪些?A. 灵活的数据模型B. 高可扩展性C. 快速的读写速度D. 严格的模式设计14. 以下哪个是非关系型数据库的典型应用场景?A. 大规模数据仓库B. 实时数据分析C. 企业资源规划(ERP)D. 电子商务15. 在非关系型数据库中,通常使用哪种一致性模型?A. 强一致性B. 弱一致性C. 最终一致性D. 有状态一致性16. 非关系型数据库的支持水平扩展与垂直扩展的主要区别是什么?A. 水平扩展通过添加更多节点实现,而垂直扩展通过升级硬件实现。
MongoDB非关系型数据库操作练习题参考答案

MongoDB非关系型数据库操作练习题参考答案MongoDB是一种被广泛使用的非关系型数据库,具有高性能、可伸缩性和灵活的数据模型等特点。
在进行MongoDB数据库操作时,掌握相应的技巧和方法是非常重要的。
以下是MongoDB非关系型数据库操作练习题的参考答案,供您参考。
一、数据库连接和基本操作1. 连接MongoDB数据库使用connect()方法可以连接到MongoDB数据库:```pythonfrom pymongo import MongoClientclient = MongoClient('mongodb://localhost:27017/')```2. 创建数据库使用create_database()方法可以创建一个新的数据库:```pythondb = client['mydatabase']```3. 创建集合使用create_collection()方法可以创建一个新的集合:```pythoncollection = db['mycollection']```4. 插入文档使用insert_one()方法可以向集合中插入一条文档:```pythondocument = {"name": "John", "age": 30}collection.insert_one(document)```二、查询和过滤数据1. 查询所有文档使用find()方法可以查询集合中的所有文档:```pythondocuments = collection.find()for document in documents:print(document)```2. 查询指定条件的文档使用find()方法可以根据指定的条件查询文档:```pythonquery = {"age": {"$gte": 25}}documents = collection.find(query)for document in documents:print(document)```3. 查询单个文档使用find_one()方法可以查询满足条件的第一条文档:```pythonquery = {"age": 30}document = collection.find_one(query)print(document)```三、更新和删除数据1. 更新文档使用update_one()方法可以更新满足条件的第一个文档:```pythonfilter = {"name": "John"}update = {"$set": {"age": 35}}collection.update_one(filter, update)```2. 删除文档使用delete_one()方法可以删除满足条件的第一个文档:```pythonfilter = {"name": "John"}collection.delete_one(filter)```四、索引和排序1. 创建索引使用create_index()方法可以创建集合的索引:```pythoncollection.create_index("name")```2. 根据字段排序使用sort()方法可以根据指定字段对文档进行排序:```pythondocuments = collection.find().sort("age", 1) # 升序for document in documents:print(document)```五、聚合操作1. 聚合函数使用聚合函数可以对文档进行统计和计算操作:```python# 统计集合中文档的数量count = collection.count_documents({})print(count)# 计算集合中指定字段的总和sum_result = collection.aggregate([{"$group": {"_id": None, "total_age": {"$sum": "$age"}}}])for result in sum_result:print(result)```2. 数据分组使用聚合函数可以对文档进行分组操作:```pythonresult = collection.aggregate([{"$group": {"_id": "$name", "total_age": {"$sum": "$age"}}}])for document in result:print(document)```六、事务处理MongoDB支持事务处理,可以保证数据的一致性和完整性。
数据库设计中的非关系型数据库规范

数据库设计中的非关系型数据库规范随着大数据时代的到来,传统的关系型数据库已经无法满足日益增长的数据存储和处理需求。
与传统的关系型数据库相比,非关系型数据库以其高度可扩展性、灵活性和高性能而受到广泛关注和应用。
在进行非关系型数据库的设计时,以下是我们应该考虑的规范和最佳实践。
1. 数据模型选择非关系型数据库可以有多种数据模型,例如文档型、键值对型、图形型等。
在进行数据库设计时,必须选择适合项目需求的数据模型。
文档型数据库如MongoDB适合存储半结构化数据,键值对数据库如Redis适合缓存和快速数据访问,图形型数据库如Neo4j适合处理复杂的关系网络。
正确选择数据模型可以提高系统的性能和开发效率。
2. 数据结构设计在非关系型数据库中,数据的结构不需要像关系型数据库那样预先定义表结构。
然而,为了保证数据的一致性和查询性能,我们仍然需要进行一定的数据结构设计。
在设计数据结构时,应该考虑数据的层次性、关联性以及查询的需求。
合理定义数据的层次结构和索引可以加快数据的访问速度,并提升系统的性能。
3. 数据库分区与分片非关系型数据库具有分布式特性,可以水平扩展以应对高并发和海量数据存储的需求。
在设计数据库时,应该考虑数据的分区和分片策略。
数据分区是将数据划分到不同的节点上,而数据分片是将数据划分到不同的存储单元上。
合理的分区和分片策略可以提高系统的负载均衡和可用性。
4. 数据备份与恢复数据备份和恢复是数据库设计中必不可少的一环。
在非关系型数据库中,数据备份可以采用多种方式,例如全量备份、增量备份和延迟备份等。
在设计数据库时,应该考虑数据备份的频率、备份的存储位置以及备份的恢复方法。
合理的备份和恢复策略可以为系统的可靠性提供保障。
5. 安全性和权限控制非关系型数据库也需要考虑数据的安全性和权限控制。
在设计数据库时,应该合理设置用户和角色的权限,限制对敏感数据的访问。
同时,还应该采用加密技术来保护数据的传输和存储安全。
解析和设计非关系型数据库的最佳实践

解析和设计非关系型数据库的最佳实践随着大数据时代的到来,非关系型数据库作为一种新型的数据库存储方式,受到了越来越多企业的青睐。
相比传统的关系型数据库,非关系型数据库具有分布式、横向扩展、高容量、高性能等优势,适合用于处理大规模高并发的数据。
在设计和实现非关系型数据库时,有一些最佳实践值得我们借鉴和遵循。
1.数据建模在设计非关系型数据库时,和关系型数据库不同的是,不需要通过建立表之间的关系来存储数据。
非关系型数据库通常采用文档、键值对、列簇等方式来存储数据,因此在数据建模时需要考虑数据的结构和层次关系。
在存储数据时,要充分考虑到查询和检索的需求,合理设计数据结构,避免冗余数据和不必要的复杂性。
2.数据存储非关系型数据库通常采用分布式存储方式,数据存储在多个节点上,通过副本和分片来保证数据的高可用性和容错性。
在设计数据存储时,要考虑数据的分布和复制策略,确保数据的安全性和一致性。
同时,要考虑数据的读写性能,在数据分片和负载均衡上进行合理设计,提高系统的并发能力和响应速度。
3.数据操作非关系型数据库通常以键值对方式进行数据操作,支持基本的增删改查操作。
在进行数据操作时,要注意事务的一致性和原子性,保证数据的完整性和可靠性。
同时,要注意数据的并发访问和锁机制,避免数据的竞争和死锁现象,提高系统的并发能力和性能表现。
4.数据备份数据备份是保证数据安全的重要手段,在设计非关系型数据库时,要考虑数据备份和恢复的策略。
通常可以采用数据复制、快照、增量备份等方式来保证数据的安全性和可靠性。
同时,要定期进行数据备份和检查,确保数据的完整性和一致性,提高系统的可用性和容错性。
5.数据扩展非关系型数据库具有横向扩展的特点,可以通过增加节点和分片来扩展系统的容量和性能。
在设计数据库时,要考虑数据的扩展性和可伸缩性,避免单点故障和性能瓶颈。
同时,要考虑系统的负载均衡和分布式计算,提高系统的并发能力和响应速度。
总之,在设计和实现非关系型数据库时,要充分考虑数据的结构、存储、操作、备份和扩展等方面,遵循最佳实践,确保数据的安全性、可靠性和高性能。
非关系数据库NoSQL-章节配套习题

非关系数据库NoSQL-章节配套习题非关系数据库NoSQL-章节配套习题1.【单选题】1分| NOSQL 数据库的四大分类是指( )A 键值存储数据库,列存储数据库,文档型数据库,关系型数据库B 列存储数据库,文档型数据库,关系型数据库,分布式数据库C 键值存储数据库,列存储数据库,文档型数据库,图数据库D 列存储数据库,文档型数据库,关系型数据库,图数据库2.【单选题】1分| NewSQL具备而NoSQL不具备的特性是()。
A 海量数据存储特性B 可扩展和高性能特性C ACID和SQL特性D 分布式数据管理特性3.【单选题】1分| 适合于存储大量复杂、互连接的数据类型,比如人际交往、推荐系统和知识图谱的NoSQL数据库有()。
A MongoDBB Neo4jC RedisD HBase4.【单选题】1分| CAP理论是NoSQL数据库的基础,只能三者选二,以下哪些属于不CAP特性()。
A 容灾性B 分区容错性C 一致性D 可用性5.【单选题】1分| v以下哪些不是NoSQL数据库的特点()。
A NoSQL数据满足最终一致性B 灵活的数据模式C NoSQL集群的可扩展性强,可动态添加和删除节点D NoSQL数据库需要满足ACID事务特性6.【单选题】1分| 大数据时代,数据的存储与管理有新的要求,催生了NoSQL的出现,下面哪个不是新要求()。
A 数据管理系统具有很高的扩展性,适应海量数据的迅速增长B 满足完整性的约束条件C 满足用户的高并发读写D 要适应多变的数据结构7.【单选题】1分| HBase、MongoDB分别属于那种类型的NoSQL数据库()?A 键值数据库、图形数据库B 文档数据库、文档数据库C 列族数据库、文档数据库D 文档数据库、列族数据库8.【单选题】1分| 在分布式系统中,N1和N2节点上存有相同的数据,当用户A对N1节点的数据进行修改时,正常情况下,N2节点会同步N1节点的数据,但是当出现分区容错时,即N1与N2节点由于某种原因数据无法同步,这时,用户B需要从N2节点获取数据,如果系统返回原来的旧数据给用户B,这个系统满足()的CAP条件。
非关系型数据库的原理与应用说明书

非关系型数据库的原理与应用说明书一、背景介绍随着互联网技术的飞速发展,数据量的爆炸性增长对传统关系型数据库提出了巨大的挑战。
为了应对大规模数据的存储和处理需求,非关系型数据库应运而生。
本说明书旨在介绍非关系型数据库的原理与应用,帮助读者更好地理解和应用非关系型数据库。
二、非关系型数据库的原理1. 数据模型非关系型数据库采用不同于传统关系数据库的数据模型。
常见的非关系型数据库数据模型包括键值存储、列存储、文档存储和图形存储等。
这些不同的数据模型适用于不同的应用场景,能够提供更高效的数据存储和访问方式。
2. 分布式架构非关系型数据库采用分布式架构,将数据分布在多台服务器上。
通过使用分片和副本机制,可以实现数据的水平扩展和容灾恢复。
这使得非关系型数据库能够应对大规模数据的处理需求,并且具备较高的可用性和可伸缩性。
3. CAP定理CAP定理是非关系型数据库设计的基础原则。
根据CAP定理,分布式系统无法同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition tolerance)这三个特性。
非关系型数据库根据实际需求,在一致性、可用性和分区容忍性之间进行权衡,选择适合的数据模型和架构。
三、非关系型数据库的应用1. 大数据存储与分析在大数据时代,非关系型数据库成为了海量数据存储与分析的首选。
它们能够高效地存储和处理PB级别的数据,支持实时数据访问和快速查询,为用户提供更好的数据分析和挖掘能力。
2. 实时应用程序非关系型数据库适用于实时应用程序,如社交网络、在线游戏等。
它们能够实现高并发的读写操作,并具备较低的延迟。
通过灵活的数据模型和分布式架构,非关系型数据库能够满足实时应用程序对性能和可伸缩性的要求。
3. 日志存储与监控非关系型数据库能够高效地存储和查询日志数据,并且支持实时的监控和分析。
在日志存储和监控领域,非关系型数据库提供了高性能、高可用性和高可扩展性的解决方案。
非关系数据库课后习题第一章
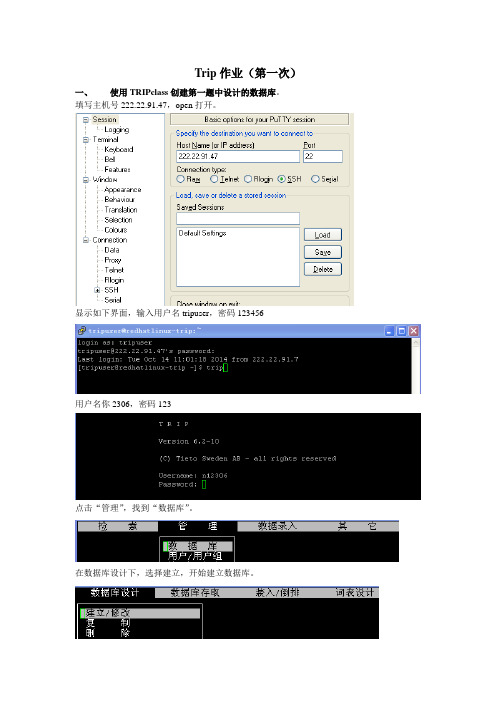
Trip作业(第一次)
一、使用TRIPclass创建第一题中设计的数据库。
填写主机号222.22.91.47,open打开。
显示如下界面,输入用户名tripuser,密码123456
用户名你2306,密码123
点击“管理”,找到“数据库”。
在数据库设计下,选择建立,开始建立数据库。
建立一个名为zjbase的数据库,显示三个物理文件:存储原始数据的文件(BAF)、检索词索引文件(BIF)、从每个检索词分解出来的单/二/三连符索引文件(VIF)。
ENTER之后保存,该空数据库建立成功。
二、使用CCL命令,删除上题中创建的数据库。
(CCL命令没有删除操作)
三、使用GUI方式重新创建第一题中设计的数据库。
输入用户名tripuser,如下:
双击左侧222.22.91.47的图标,如下输入用户名和密码:
双击New Database,创建名为zjbase的数据库:
数据库建立成功:。
非关系型数据库大作业

非关系型数据库大作业-标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII实验三HBase环境搭建、sehll操作及Java API编程实验步骤:1.搭建Zookeeper和HBase1.ntp时间同步服务器搭建与使用安装ntp服务端(master)# apt-get install ntp启动ntp服务# /etc/init.d/ntp start修改配置文件# vim /etc/ntp.conf修改内容如下:重启ntp服务# /etc/init.d/ntp restart1.2安装ntp客户端(slaver1、slaver2)使用ntpdate命令,如果不存在这个命令,则先安装apt-get install ntp同步服务器时间# /usr/sbin/ntpdate 10.49.85.172设置定时同步# vim /etc/crontab1.3 ulimit 和 nproc设置(集群均配置)HBase是数据库,会在同一时间使用很多的文件句柄。
大多数Ubuntu系统使用的默认值1024是不能满足的,所以你需要修改你的最大文件句柄限制。
可以设置到10k. 你还需要修改 hbase 用户的 nproc,如果过低会造成OutOfMemoryError异常。
需要澄清的,这两个设置是针对操作系统的,不是Hbase本身的。
有一个常见的错误是Hbase运行的用户,和设置最大值的用户不是一个用户。
在Hbase启动的时候,第一行日志会现在ulimit信息,所以你最好检查一下。
1)修改limits.conf文件# vim /etc/security/limits.conf添加如下内容:2)修改common-session文件# vim /etc/pam.d/common-session添加如下内容:重启系统1.4 Zookeeper集群环境安装过程详解1)解压zookeepertar zxvf zookeeper-3.4.5.tar.gz2)修改zoo.cfg配置文件进入到zookeeper的conf目录下将zoo_sample.cfg文件拷贝一份,命名为为zoo.cfgvim zoo.cfg修改内容如下:配置文件中"server.id=host:port:port"中的第一个port是从机器(follower)连接到主机器(leader)的端口号,第二个port是进行leadership选举的端口号。
了解非关系型数据库和NoSQL解决方案

了解非关系型数据库和NoSQL解决方案非关系型数据库(Non-Relational Database)是一种与传统的关系型数据库(Relational Database)相对的数据库管理系统。
在关系型数据库中,数据以表格的形式存储,具有固定的结构和严格的数据模式。
而非关系型数据库则以键值对、文档、列族等不同的数据模型来存储数据,具有更灵活的数据结构和数据模式。
非关系型数据库的出现是为了应对互联网时代海量数据的存储和查询需求。
在传统关系型数据库中,随着数据量的增长,查询效率逐渐下降,因为关系型数据库使用的是SQL语言进行查询,需要对结构化数据进行复杂的连接操作。
非关系型数据库则采用了更简单的查询语言和更高效的数据存储方式,能够提供更高的查询性能和可伸缩性。
NoSQL(Not Only SQL)是一种非关系型数据库的统称,其主要特点是高度可扩展性、分布式架构、灵活的数据模型和复杂查询的高性能。
这些特点使得NoSQL成为了处理大数据和实时数据的理想解决方案。
下面将详细介绍非关系型数据库和NoSQL解决方案。
一、非关系型数据库的特点1.高度可扩展性:非关系型数据库采用分布式架构,可以方便地水平扩展,从而适应数据量的快速增长。
2.灵活的数据模型:非关系型数据库支持多种数据模型,例如键值对、文档、列族、图等,可以根据应用的需求选择合适的数据模型,灵活性更高。
3.高性能:非关系型数据库通常采用了更高效的数据存储方式,如内存存储、索引存储等,能够提供更高的查询性能。
4.处理大数据:非关系型数据库能够处理海量的数据,并具有良好的可伸缩性和高并发性能。
5.多样化的查询方式:非关系型数据库提供了不同的查询方式,如键值查询、全文检索、图查询等,能够满足不同应用的查询需求。
二、NoSQL解决方案1.键值存储(Key-Value Store):键值存储是最简单的非关系型数据库模型,数据以键值对的形式进行存储。
这种数据模型适用于需要快速查找的场景,如用户缓存、会话管理等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验三HBase环境搭建、sehll操作及Java API编程实验步骤:
1.搭建Zookeeper和HBase
1.ntp时间同步服务器搭建与使用
安装ntp服务端(master)
# apt-get installntp
启动ntp服务
# /etc/init.d/ntp start
修改配置文件
# vim /etc/ntp.conf
修改内容如下:
重启ntp服务
# /etc/init.d/ntp restart
1.2安装ntp客户端(slaver1、slaver2)
使用ntpdate命令,如果不存在这个命令,则先安装apt-get install ntp
同步服务器时间
# /usr/sbin/ntpdate 10.49.85.172
设置定时同步
# vim /etc/crontab
1.3 ulimit和nproc设置(集群均配置)
HBase是数据库,会在同一时间使用很多的文件句柄。
大多数Ubuntu系统使用的默认值1024是不能满足的,所以你需要修改你的最大文件句柄限制。
可以设置到10k. 你还需要修改hbase用户的nproc,如果过低会造成OutOfMemoryError 异常。
需要澄清的,这两个设置是针对操作系统的,不是Hbase本身的。
有一个常见的错误是Hbase运行的用户,和设置最大值的用户不是一个用户。
在Hbase 启动的时候,第一行日志会现在ulimit信息,所以你最好检查一下。
1)修改limits.conf文件
# vim /etc/security/limits.conf
添加如下内容:
2)修改common-session文件
# vim /etc/pam.d/common-session
添加如下内容:
重启系统
1.4 Zookeeper集群环境安装过程详解
1)解压zookeeper
tarzxvf zookeeper-3.4.5.tar.gz
2)修改zoo.cfg配置文件
进入到zookeeper的conf目录下将zoo_sample.cfg文件拷贝一份,命名为为zoo.cfg vimzoo.cfg
修改内容如下:
配置文件中"server.id=host:port:port"中的第一个port是从机器(follower)连接到主机器(leader)的端口号,第二个port是进行leadership选举的端口号。
接下来在dataDir所指定的目录下创建一个文件名为myid的文件,文件中的内容只有一行,为本主机对应的id值,也就是上图中server.id中的id。
例如:在服务器1中的myid的内容应该写入1,在服务器2中的myid的内容应该写入2,在服务器3中的myid的内容应该写入3。
3)同时创建log目录
# mkdir log
4)修改环境变量
# vim /etc/profile
# source /etc/profile
# scp -r /root/zookeeper-3.4.5/ cc-slaver1:/root/
# scp -r /root/zookeeper-3.4..5/ cc-slaver2:/root/
在对应slaver节点同时修改profile文件,添加
export ZOOKEEPER_HOME=/root/zookeeper-3.4.5
export CLASSPATH=.:${ZOOKEEPER_HOME}/lib:$CLASSPATH
export PATH=${ZOOKEEPER_HOME}/bin:${ZOOKEEPER_HOME}/conf:$PATH
同时:
在slaver1节点中
# pwd
/soft/zookeeper
# mkdir data
# echo "2" >myid
在slaver2节点中
# pwd
/soft/zookeeper
# mkdir data
# echo "3" >myid
1.5 启动zookeeper集群
在ZooKeeper集群的每个结点上,执行启动ZooKeeper服务的脚本:
# zkServer.sh start
如下图所示:
其中,QuorumPeerMain是zookeeper进程,启动正常。
出现错误可以通过
# tail -f /soft/zookeeper/zookeeper.out
如上依次启动了所有机器上的Zookeeper之后可以通过ZooKeeper的脚本来查看启动状态,包括集群中各个结点的角色(或是Leader,或是Follower),如下所示,是在ZooKeeper集群中的每个结点上查询的结果:
通过上面状态查询结果可见,cc-slaver1是集群的Leader,其余的两个结点是Follower。
另外,可以通过客户端脚本,连接到ZooKeeper集群上。
对于客户端来说,ZooKeeper是一个整体(ensemble),连接到ZooKeeper集群实际上感觉在独享整个集群的服务,所以,你可以在任何一个结点上建立到服务集群的连接,例如:# zkCli.sh -server cc-slaver2:2181
1.6 停止zookeeper进程
在ZooKeeper集群的每个结点上,执行停止ZooKeeper服务的脚本:
# zkServer.sh stop
至此,Zookeeper集群安装完成。
1.7HBase的安装和配置
# tar -zxvf hbase-1.2.4.tar.gz
1)配置conf/hbase-env.sh
修改内容如下:
一个分布式运行的Hbase依赖一个zookeeper集群。
所有的节点和客户端都必须能够访问zookeeper。
默认的情况下Hbase会管理一个zookeep集群,即Hbase 默认自带一个zookeep集群。
这个集群会随着Hbase的启动而启动。
而在实际的商业项目中通常自己管理一个zookeeper集群更便于优化配置提高集群工作效率,但需要配置Hbase。
需要修改conf/hbase-env.sh里面的HBASE_MANAGES_ZK 来切换。
这个值默认是true的,作用是让Hbase启动的时候同时也启动zookeeper.在本实验中,我们采用独立运行zookeeper集群的方式,故将其属性值改为false。
2)配置conf/hbase-site.xml
写入:cc-slaver1、cc-slaver2
在这里列出了你希望运行的全部HRegionServer,一行写一个host (就像Hadoop 里面的slaver 一样). 列在这里的server会随着集群的启动而启动,集群的停止而停止。
4)hadoop配置文件拷入
# cp ~/hadoop-2.6.5/etc/hadoop/hdfs-site.xml ~/hbase-1.2.4/conf
# cp ~/hadoop-2.6.5/etc/hadoop/core-site.xml ~/hbase-1.2.4/conf
5)分发hbase
# scp -r /root/hbase-1.2.4 cc-slaver1:/root
# scp -r /root/hbase-1.2.4 cc-slaver2:/root
配置环境变量
# vim /etc/profile
在末尾添加如下内容
6)运行和测试
在master上执行:
(1)# start-all.sh
(2)# zkServer.sh start(各个节点均执行)
(3)# start-hbase.sh (涵盖web管理界面的启动)
使用jps查看进程
通过浏览器查看60010,60030端口查看
http://10.49.85.172:60010/
浏览器主节点信息
7)多节点启动HMaster
# hbase-daemon.sh start master
在其他子节点同时启动HMaster
可以做等待备份作用;
2.使用HBase shell命令进行表的创建,增加删除修改操作。
Hbase 脚本
启动:hbase shell
创建表
在member表中添加几条数据
修改表数据
删除数据
3使用Java API进行表的创建,增加删除修改操作。
向表中添加数据:
更新表updateTable:
删除所有列deleteAllColumn:
删除列deleteColumn:
删除表deleteTable:
删除所有表getAllTables:
获取结果getResult:
获取某一列的值getResultByColumn:
查询某列的多版本getResultByVersion:
遍历查询getResultByScann:
具体代码如下:。