基于Python的图片文字识别
python paddleocr用法

python paddleocr用法
PaddleOCR 是一个基于PaddlePaddle深度学习平台的开源OCR工具库,用于实现文字识别任务。
以下是PaddleOCR 的基本用法:
1. 安装PaddleOCR 库:
pip install paddlepaddle paddleocr
2. 导入PaddleOCR:
from paddleocr import PaddleOCR
3. 初始化OCR 模型:
ocr = PaddleOCR()
4. 运行OCR 识别任务:
- 识别图片文件:
result = ocr.ocr('your_image.jpg')
- 识别图片数据:
result = ocr.ocr(image_data)
其中,`image_data` 可以是numpy 数组、PIL.Image.Image 对象、OpenCV 格式图片等。
5. 获取OCR 结果:
`result` 是一个二维列表,每个元素是一个包含识别结果的字典。
可以通过遍历`result` 来获取识别的文本内容和其对应的坐标。
for line in result:
line_text = ' '.join([word_info['text'] for word_info in line])
print(line_text)
对于每个识别的单词,可以通过`word_info` 字典获取其文本、置信度和坐标等信息。
以上是PaddleOCR 的基本用法,你可以根据具体需求进行参数配置、自定义模型和后处理等操作。
更详细的用法可以参考PaddleOCR 的官方文档。
pytesseract库用法-概述说明以及解释

pytesseract库用法-概述说明以及解释1.引言1.1 概述随着人工智能技术的快速发展,文字识别成为自动化处理的重要一环。
而Python作为一种广泛应用的编程语言,其中的pytesseract库成为了文字识别的常用工具之一。
pytesseract库是基于Google的开源OCR引擎Tesseract的Python封装。
它能够实现将图像中的文字提取出来并转化为可编辑的文本,为文本数据的后续处理提供了便利。
与传统的文字识别方法相比,pytesseract库具有几个明显的优势。
首先,作为一个开源工具,它可以在多个平台上轻松部署和使用。
其次,pytesseract库不需要额外的训练步骤,即可准确地识别各种字体的文本。
此外,它还支持多种语言的文字识别,使得在处理多语言文字的场景下更加便利。
在本文中,我们将介绍pytesseract库的基本使用方法和一些常见的应用场景。
首先,我们将详细讲解pytesseract库的安装步骤,并介绍一些可能遇到的问题及其解决方法。
然后,我们将通过一个简单的示例演示如何使用pytesseract库实现图像文字的提取和识别。
最后,我们将进一步探讨pytesseract库的性能优化和提升方法,以及一些注意事项和应用上的建议。
通过本文的学习,读者将能够掌握pytesseract库的基本用法,了解如何利用该库进行文字识别,并能够根据实际需求进行相应的定制和调整。
同时,本文还将帮助读者更好地理解文字识别的原理和技术,并为其在其他项目中应用文字识别提供一些参考和借鉴。
文章结构部分的内容可以对整篇文章的组织和布局进行介绍。
以下是一个可能的内容:1.2 文章结构本文将按照以下结构进行展开:1. 引言在引言部分,我们将介绍pytesseract库的背景和作用。
首先,我们会简要概述pytesseract库的用途和功能,并介绍该库与OCR(Optical Character Recognition,光学字符识别)技术的关系。
easyocr用法

easyocr用法EasyOCR是一款基于Python的OCR(Optical Character Recognition)工具,它可以识别多种语言的文字,包括中文、英文、日文、韩文等。
EasyOCR的使用非常简单,只需要几行代码就可以实现文字识别功能。
需要安装EasyOCR。
可以使用pip命令进行安装,如下所示:```pip install easyocr```安装完成后,就可以开始使用EasyOCR了。
下面是一个简单的示例代码:```import easyocrreader = easyocr.Reader(['ch_sim', 'en'])result = reader.readtext('example.jpg')print(result)```这段代码的作用是读取一张名为example.jpg的图片,并识别其中的文字。
其中,['ch_sim', 'en']表示要识别的语言类型,这里包括中文和英文。
如果需要识别其他语言,可以在列表中添加相应的语言代码。
运行上述代码后,会输出一个包含识别结果的列表。
每个识别结果都是一个元组,包含四个元素:识别出的文字、文字的位置、置信度和语言类型。
例如,下面是一个识别结果的示例:```('Hello, world!', [(10, 10), (100, 10), (100, 50), (10, 50)], 0.99, 'en') ```这个结果表示识别出了一段英文文字“Hello, world!”,它的位置是一个矩形,左上角坐标为(10, 10),右下角坐标为(100, 50),置信度为0.99,语言类型为英文。
除了识别图片中的文字,EasyOCR还支持识别文本文件中的文字。
下面是一个读取文本文件并识别其中文字的示例代码:```import easyocrreader = easyocr.Reader(['ch_sim', 'en'])with open('example.txt', 'r') as f:text = f.read()result = reader.readtext(text)print(result)```这段代码的作用是读取一个名为example.txt的文本文件,并识别其中的文字。
基于Python的图像识别算法研究与实现

基于Python的图像识别算法研究与实现一、引言随着人工智能技术的不断发展,图像识别技术在各个领域得到了广泛的应用。
而Python作为一种简洁、易学、功能强大的编程语言,被广泛应用于图像识别算法的研究与实现中。
本文将探讨基于Python的图像识别算法研究与实现的相关内容。
二、图像识别算法概述图像识别算法是指通过对图像进行分析和处理,从中提取出有用信息的一种技术。
常见的图像识别算法包括但不限于:卷积神经网络(CNN)、循环神经网络(RNN)、支持向量机(SVM)等。
这些算法在不同场景下有着各自的优势和适用性。
三、Python在图像识别中的应用Python作为一种开发效率高、生态丰富的编程语言,在图像识别领域也有着得天独厚的优势。
通过使用Python编写图像识别算法,可以快速实现从数据处理到模型训练再到结果预测的全流程。
同时,Python拥有丰富的第三方库支持,如TensorFlow、Keras、OpenCV等,为图像识别算法的实现提供了强大的工具支持。
四、基于Python的图像识别算法研究1. 数据准备在进行图像识别算法研究之前,首先需要准备好相应的数据集。
数据集的选择对于算法的性能和效果至关重要。
可以选择公开数据集,也可以自行采集和标注数据。
2. 模型选择针对不同的图像识别任务,需要选择合适的模型架构。
比如对于物体检测任务可以选择Faster R-CNN或YOLO等模型,对于人脸识别任务可以选择FaceNet或VGGFace等模型。
3. 模型训练利用Python编写代码,加载数据集并进行模型训练。
通过调整超参数、优化损失函数等方式,不断优化模型性能。
4. 模型评估在训练完成后,需要对模型进行评估以验证其准确性和泛化能力。
可以使用交叉验证、混淆矩阵等方法进行评估。
5. 模型部署将训练好的模型部署到实际应用中,实现对新数据的预测和识别。
可以将模型封装成API接口或嵌入到移动应用中。
五、基于Python的图像识别算法实现1. 图像预处理在进行图像识别之前,通常需要对图像进行预处理操作,如缩放、裁剪、灰度化等。
paddleocr python推理

PaddleOCR是一个由PaddlePaddle开发的OCR(光学字符识别)工具包,可以用来进行文字识别等任务。
以下是一个用PaddleOCR进行文字识别的Python代码示例:首先,确保你已经正确安装了PaddleOCR。
如果没有安装,你可以通过pip来安装:```pythonpip install paddlepaddle paddleocr```以下是一个基本的OCR文字识别(OCR)推理例子:```pythonfrom paddleocr import PaddleOCR, draw_ocr# 使用预训练的模型进行OCR识别ocr = PaddleOCR(use_gpu=False)# 对图片进行OCR识别,得到文本列表results = ocr.ocr('test.jpg', use_gpu=False)# 打印结果for line in results:line_text = ' '.join([word_info[-1] for word_info in line])print(line_text)```在这个例子中,`ocr()` 函数对指定的图片进行OCR识别,返回一个包含每行文本的列表,每个列表元素是一个包含文本块信息的元组。
每个文本块信息包括`word_info`,其中`word_info[-1]` 是该文本块识别的文本内容。
注意,这个例子使用的是预训练的模型,它可能不能完全适用于你的特定场景。
如果你需要更好的性能,你可能需要自己训练一个模型。
PaddleOCR提供了详细的训练和优化教程。
此外,`use_gpu=False` 表示我们不使用GPU进行推理。
如果你的机器上有可用的GPU,并且你希望使用GPU进行推理来提高速度,你可以将`use_gpu` 设置为`True`。
python ocr识别公式

python ocr识别公式OCR(Optical Character Recognition)是一种将图片或扫描文档中的文本内容转换成可编辑格式的技术。
在Python中,有几种OCR库可以用于识别公式,如Tesseract、Pytesseract和OCRopus等。
下面将介绍这些库以及一些相关的参考内容。
1. Tesseract:Tesseract是一个开源的OCR引擎,由Google开发和维护。
它可以识别多种语言,并且能够处理包括公式在内的复杂文档。
在Python中,可以使用pytesseract库来调用Tesseract引擎。
相关参考内容:- 《pytesseract官方文档》,可以在终端使用命令`pytesseract -h`来获取帮助信息。
- 《如何在Python中使用Tesseract库进行OCR识别?》,介绍了如何安装和使用pytesseract库,并提供了示例代码。
2. Pytesseract:Pytesseract是一个Python封装的Tesseract库,它简化了与Tesseract引擎的交互。
它提供了一个简单的接口,使得可以很容易地将图片或扫描文档中的文本提取出来。
相关参考内容:- 《pytesseract库的Github仓库》,提供了详细的教程和用法示例。
- 《如何在Python中使用pytesseract库进行OCR识别?》,介绍了pytesseract的安装和使用方法,并提供了示例代码。
3. OCRopus:OCRopus是一个由Google开发的OCR引擎。
它基于统计学习方法,能够处理包括公式在内的复杂文本。
OCRopus还提供了一些辅助工具,如布局分析、格式转换等功能。
相关参考内容:- 《OCRopus官方文档》,提供了详细的使用说明和API参考。
- 《Python-OCRopus库的Github仓库》,包含了使用OCRopus进行OCR识别的示例代码。
4. MathOCR:MathOCR是一个专门用于数学公式识别的OCR引擎。
python 文字识别训练集

python 文字识别训练集Python 文字识别训练集随着人工智能技术的不断发展,文字识别成为了一个热门领域。
在这个领域中,Python 作为一种高效且易学的编程语言,一直以其强大的功能和丰富的库而备受青睐。
本文将介绍使用 Python 进行文字识别训练集的方法和技巧。
我们需要明确什么是文字识别训练集。
文字识别训练集是用于训练文字识别模型的数据集,其中包含了各种不同字体、大小、颜色和倾斜程度的文字图像。
这些图像需要经过预处理和标注,以便模型能够准确地识别其中的文字。
在 Python 中,我们可以使用多个库来进行文字识别训练集的处理。
其中最常用的库包括 TensorFlow、Keras 和 OpenCV。
这些库提供了丰富的函数和工具,可以帮助我们对图像进行处理和分析。
我们需要加载训练集的图像。
在 Python 中,我们可以使用 OpenCV 库来读取图像文件,并将其转换为适合模型训练的数组格式。
通过使用 OpenCV 的函数,我们可以加载图像、调整图像大小、转换图像颜色空间等。
接下来,我们需要对图像进行预处理。
预处理主要包括图像增强、去噪和归一化等操作。
通过增强图像的对比度和亮度,我们可以使文字更加清晰可见。
通过去除图像中的噪声,我们可以提高文字识别的准确性。
通过归一化图像的尺寸和颜色空间,我们可以使不同样本具有相同的特征,从而提高模型的泛化能力。
在预处理完成后,我们需要对图像进行标注。
标注是将图像中的文字位置和内容与相应的标签对应起来的过程。
在 Python 中,我们可以使用 OpenCV 或 TensorFlow 的图像处理函数来实现标注。
通过标注,我们可以为模型提供准确的训练目标,从而提高模型的识别能力。
在标注完成后,我们可以开始训练文字识别模型。
在 Python 中,我们可以使用 TensorFlow 或 Keras 来构建和训练模型。
这些库提供了丰富的函数和工具,可以帮助我们定义模型的结构、选择合适的损失函数和优化算法,并进行模型的训练和评估。
Python如何基于Tesseract实现识别文字功能

Python如何基于Tesseract实现识别⽂字功能机器视觉从Google的⽆⼈驾驶汽车到可以识别假钞的⾃动售卖机,机器视觉⼀直都是⼀个应⽤⼴泛且具有深远的影响和雄伟的愿景的领域。
这⾥我们将重点介绍机器视觉的⼀个分⽀:⽂字识别。
介绍如何⽤⼀些Python库来识别和使⽤在线图⽚中的⽂字。
我们可以很轻松的阅读图⽚⾥的⽂字,但是机器阅读这些图⽚就会⾮常困难,利⽤这种⼈类⽤户可以正常读取但是⼤多数存贮器没法读取的图⽚,这时验证码(CAPTCHA)就出现了。
验证码读取的难易程序也⼤不相同。
将图像翻译成⽂字⼀般被称为光学⽂字识别(Optical Character Recognition,OCR)。
可以实现OCR的底层库并不多,⽬前很多库都是使⽤共同的⼏个底层OCR库,或者是在上⾯进⾏定制。
OCR库概述在读取和处理图像、图像相差的机器学习以及创建图像等任务中,Python⼀直都是⾮常出⾊的语⾔。
虽然有很多库可以进⾏图像处理,但是这⾥我们只介绍Tesseract库。
TesseractTesseract是⼀个OCR库,⽬前由Google赞助。
Tesseract是⽬前公认最优秀、最精确的开源OCR系统。
除了极⾼的精确度,Tesseract也具有很⾼的灵活性。
它可以通过训练识别出任何字体,也可以识别出任何Unicode字符。
安装Tesseract:Windows系统下载可执⾏安装⽂件安装即可。
安装pytesseractTesseract是⼀个Python的命令⾏⼯具,不是通过import语句导⼊的库。
安装之后,要⽤tesseract命令在Python的外⾯运⾏,但我们可以通过pip安装⽀持Python版本的Tesseract库:pip install pytesseract处理规范的⽂字你要处理的⼤多数⽂字都是⽐较⼲净、格式规范的。
格式霍英东的⽂字通常具有以下特点:使⽤统⼀的标准字体(不包含⼿写体、草书或者⼗分“花哨”的字体),复印或者拍照但是字体清晰、没有多余的痕迹或者污点。
pyocr 用法

`pyocr` 是一个Python 库,用于与光学字符识别(OCR) 引擎进行交互,从图像中提取文字。
以下是一个简单的介绍和用法示例:首先,确保你已经安装了`pyocr` 库。
你可以使用`pip` 命令来安装它:```bashpip install pyocr```接下来,确保你已经安装了一个OCR 引擎(例如Tesseract),`pyocr` 支持多个OCR 引擎,但默认使用Tesseract。
以下是一个示例,展示了如何使用`pyocr` 库来进行OCR 文字提取:```pythonimport pyocrfrom PIL import Image# 获取OCR 引擎tools = pyocr.get_available_tools()if len(tools) == 0:print("未找到可用的OCR 引擎")exit(1)# 选择第一个OCR 引擎tool = tools[0]# 打印当前选择的OCR 引擎的名称print("使用的OCR 引擎:", tool.get_name())# 选择要识别的图像文件image_file = 'example_image.png'# 使用PIL 打开图像image = Image.open(image_file)# 使用OCR 引擎进行文字识别text = tool.image_to_string(image,lang='eng', # 识别语言,这里示例为英文builder=pyocr.builders.TextBuilder())# 打印识别结果print("识别结果:")print(text)```在上述示例中,我们首先导入了`pyocr` 库和必要的依赖,然后获取了可用的OCR 引擎。
接着,我们选择第一个可用的引擎,并打印其名称。
然后,指定要识别的图像文件,使用PIL 库打开图像,最后使用选择的OCR 引擎进行文字识别。
python-使用百度AipOcr实现表格文字图片识别

python-使⽤百度AipOcr实现表格⽂字图⽚识别代码运⾏环境:win10 python3.7需要aip库,使⽤pip install baidu-aip即可(1)⽬的通过百度AipOcr库,来实现识别图⽚中的表格,并输出问表格⽂件。
(2)实现1# encoding: utf-82import os3import sys4import requests5import time6import tkinter as tk7from tkinter import filedialog8from aip import AipOcr910# 定义常量11 APP_ID = 'xxxxxx'12 API_KEY = 'xxxxxxxxxxxxxxxxxxxxxx'13 SECRET_KEY = 'xxxxxxxxxxxxxxxxxxxxxxxxx'14# 初始化AipFace对象15 client = AipOcr(APP_ID, API_KEY, SECRET_KEY)1617# 读取图⽚18def get_file_content(filePath):19 with open(filePath, 'rb') as fp:20return fp.read()212223#⽂件下载函数24def file_download(url, file_path):25 r = requests.get(url)26 with open(file_path, 'wb') as f:27 f.write(r.content)282930if__name__ == "__main__":31 root = ()32 root.withdraw()33 data_dir = filedialog.askdirectory(title='请选择图⽚⽂件夹') + '/'34 result_dir = filedialog.askdirectory(title='请选择输出⽂件夹') + '/'35 num = 036for name in os.listdir(data_dir):37print ('{0} : {1} 正在处理:'.format(num+1, name.split('.')[0]))38 image = get_file_content(os.path.join(data_dir, name))39 res = client.tableRecognitionAsync(image)40# print ("res:", res)41if'error_code'in res.keys():42print ('Error! error_code: ', res['error_code'])43 sys.exit()44 req_id = res['result'][0]['request_id'] #获取识别ID号4546for count in range(1, 20): #OCR识别也需要⼀定时间,设定10秒内每隔1秒查询⼀次47 res = client.getTableRecognitionResult(req_id) #通过ID获取表格⽂件XLS地址48print(res['result']['ret_msg'])49if res['result']['ret_msg'] == '已完成':50break#云端处理完毕,成功获取表格⽂件下载地址,跳出循环51else:52 time.sleep(1)5354 url = res['result']['result_data']55 xls_name = name.split('.')[0] + '.xls'56 file_download(url, os.path.join(result_dir, xls_name))57 num += 158print ('{0} : {1} 下载完成。
python中easyocr用法

python中easyocr用法EasyOCR 是一个基于深度学习的开源 OCR(光学字符识别)库,用于识别图像中的文本。
以下是 EasyOCR 的基本使用方法:1. 首先,确保已经安装了 EasyOCR 库。
可以通过以下命令使用 pip 进行安装:```pythonpip install easyocr```2. 导入 EasyOCR 模块:```pythonimport easyocr```3. 创建一个 EasyOCR 的实例,并指定所需的语言(默认为英文):```pythonreader = easyocr.Reader(['ch_sim', 'en'])```在上述示例中,指定了 `'ch_sim'` 表示使用中文简体语言模型,`'en'` 表示使用英语语言模型。
你可以根据需要添加其他语言。
4. 调用 `readtext()` 方法对图像中的文本进行识别:```pythonresult = reader.readtext('image.jpg')```在上述示例中,`'image.jpg'` 是待识别的图像文件路径。
你可以根据实际情况指定图像文件的路径。
5. `readtext()` 方法返回一个包含检测到的文本及其位置的列表。
你可以使用循环遍历列表,并提取所需的文本信息:```pythonfor detection in result:text, bbox = detection[0], detection[1]print(f"Text: {text}, Bbox: {bbox}")```在上述示例中,`detection[0]` 是文本内容,`detection[1]` 是文本所在的边界框(bounding box)。
这是 EasyOCR 的基本用法示例。
请注意,EasyOCR 还提供了其他一些功能,如指定 GPU 使用、调整识别阈值等。
pytesseract 的用法

pytesseract 是一个Python 库,它是Tesseract OCR 引擎的Python 接口。
Tesseract 是一种开源OCR 引擎,可以识别图像中的文本,并将其转换为可编辑的文本。
下面是一个简单的示例,展示了如何使用pytesseract 识别图像中的文本:
import pytesseract
# 读取图像
image = pytesseract.image_to_string('image.png')
# 打印识别结果
print(image)
在上面的示例中,首先导入了pytesseract 库,然后使用image_to_string() 方法读取名为image.png 的图像,并将其转换为文本字符串。
最后,使用print() 函数打印识别结果。
除了image_to_string() 方法,pytesseract 还提供了其他几个方法,例如image_to_data() 和image_to_boxes(),可以分别将图像转换为数据和边界框。
需要注意的是,使用pytesseract 进行OCR 识别需要安装Tesseract OCR 引擎,并将其添加到系统的PATH 环境变量中。
另外,为了获得更好的识别效果,还需要对图像进行预处理,例如调整图像的亮度和对比度,或者使用图像增强算法。
如何使用Python进行OCR识别图片中的文字

如何使⽤Python进⾏OCR识别图⽚中的⽂字⽬录Tesseractpytesseracttesserocr朋友需要⼀个⼯具,将图⽚中的⽂字提取出来。
我帮他在⽹上找了⼀些OCR的应⽤,都不好⽤。
所以准备⾃⼰研究,写⼀个Web APP供他使⽤。
OCR1,全称Optical character recognition,或者optical character reader,中⽂译名叫做光学⽂字识别。
它是把图像⽂件中的⼿写⽂本,打印⽂本转换为机器编码⽂本的⼀种⽅法。
OCR技术⼴泛⽤于识别打印纸张中的⽂字数据 -- ⽐如护照,⽀票,银⾏声明,收据,统计表单,邮件等。
OCR的早期版本,需要对图⽚中的每个⽂字都进⾏训练,⼀次只能作⽤于⼀种字体。
⾼级的版本增加了很⼤的识别率,可以同时识别现在很多流⾏的字体,⽀持不同种类格式的图⽚⽂件。
⼀些系统可以⽣成接近于原来图⽚格式的输出,包括图⽚,排版,以及其它⾮⽂本组件,这也叫做版⾯还原。
⼯具Tesseract现在最出名,最常⽤的OCR就是⾕歌的tesseract OCR engine2。
最新的版本是Tesseract4。
Tesseract的主要开发者是Ray Smith3.Tesseract⽀持unicode(UTF-8),安装后即可识别超过100种语⾔。
Tesseract⽀持不同的输出可是:普通⽂本,hOCR(html),PDF,TSV,invisible-text-only PDF。
在master分⽀,还试验性地⽀持ALTO(XML)格式。
请记住,在⼤多数情况下,为了获得更好的OCR结果,你需要为提供给Tesseract的图⽚提升质量4.Tesseract可以通过训练来识别其它语⾔和其它字体5.另外,有很多第三⽅的Tesseract GUI应⽤。
可以直接下载使⽤6。
pytesseractPython-tesseract7(pytesseract)是Google Tesseract ORC引擎的封装。
easyocr函数

easyocr函数EasyOCR函数是一款基于Python的OCR识别工具,能够实现文本识别和图像转换,支持多种语言,例如中文、英文、法文、德文、日文等,对于需要大量处理OCR的开发者或工程师来说,是一款十分实用的软件工具。
以下是对于EasyOCR函数的相关介绍及应用。
一、EasyOCR函数的安装及使用1.安装在Python环境下,使用pip命令可在线安装:pip install easyocr2.使用基本使用流程如下:'''import easyocrreader = easyocr.Reader(['ch_sim', 'en'])result = reader.readtext('example.jpg')print(result)'''其中:(1)import easyocr:导入easyocr模块;(2)easyocr.Reader( ):创建OCR识别对象,参数为需要识别的语言;(3)reader.readtext( ):执行文本识别操作,参数为需要识别的图片路径;(4)print(result):打印识别结果。
二、EasyOCR函数的特点及优势1.多语言支持EasyOCR函数支持多种语言,可应用于多种语言文字的识别,如中文、英文、法文、德文、日文等,对于多语言处理具有重要意义。
2.高精度识别EasyOCR函数基于深度学习技术,具备高精度、高准确性的文本识别能力,可实现对于文字的准确定位及识别。
3.简单易用EasyOCR函数的使用方式简单明了,只需要安装模块、导入模块、编写脚本和调用函数即可,适用于初学者及开发者快速应用及开发。
4.开源免费EasyOCR函数是开源免费的,可以任意下载、使用及修改,使得该软件工具能够便捷的应用于开发、研究、教育等领域,具有广泛的应用前景。
三、EasyOCR函数的应用场景1.图像文字转换EasyOCR函数能够实现将图片中的文本信息转换为可编辑的文字文档,方便文字的处理和管理。
python ocr文字识别模型训练

python ocr文字识别模型训练
要训练一个OCR文字识别模型,可以按照以下步骤进行:
1. 收集和准备训练数据:收集包含不同字体、大小和风格的文字图像,然后将其标记为对应的文字标签。
2. 数据预处理:对收集的图像进行预处理,例如调整大小、灰度化、二值化、去噪等操作,以便提高模型的训练效果。
3. 特征提取:从预处理后的图像中提取有用的特征,例如边缘、角点、文本区域等,可以使用一些计算机视觉技术来实现。
4. 构建模型:选择适合OCR任务的模型架构,例如卷积神经网络(CNN)或循环神经网络(RNN),并根据需要进行修改和调整。
5. 模型训练:使用准备好的训练数据和特征,将其输入到模型中进行训练。
可以使用常见的深度学习框架,例如TensorFlow、PyTorch或Keras来实现模型训练。
6. 模型评估和调优:对训练的模型进行评估和调优,可以使用一些评估指标,例如准确率、召回率、F1分数等来评估模型的性能,并根据需要进行参数调整和模型优化。
7. 模型部署和应用:将训练好的模型部署到实际应用中,例如使用API接口或集成到其他软件中,以便对输入的图像进行文字识别。
需要注意的是,OCR文字识别是一个复杂的任务,可能需要大量的训练数据和计算资源来获得较好的识别效果。
此外,还可以考虑使用预训练模型作为基础,并进行迁移学习或微调来加速模型训练和提高识别准确率。
Python图片文字识别的实现之PaddleOCR

Python图⽚⽂字识别的实现之PaddleOCR⽬录项⽬使⽤项⽬结构环境部署1、安装Anaconda,构造虚拟环境2、依赖包下载测试代码参数补充总结前⾔什么是OCR?光学字符识别(Optical Character Recognition, OCR),是指对⽂本资料的图像⽂件进⾏分析识别处理,获取⽂字及版⾯信息的过程。
简⽽⾔之,检测图像中的⽂本资料,并且识别出⽂本的内容。
那么有哪些应⽤场景呢?其实我们⽇常⽣活中处处都有ocr的影⼦,⽐如在疫情期间⾝份证识别录⼊信息、车辆车牌号识别、⾃动驾驶等。
我们的⽣活中,机器学习已经越来越多的扮演着重要⾓⾊,也不再是神秘的东西。
OCR的技术路线是什么呢?ocr的运⾏⽅式如下图,输⼊->图像预处理->⽂字检测->⽂本识别->输出。
本⽂主要是介绍⼀个博主使⽤的⽐较好的OCR开源项⽬,在这⾥分享给⼤家——PaddleOCR。
项⽬Github地址:我会按照刚接触的状态,梳理⼀下验证使⽤该项⽬的过程。
项⽬使⽤先把项⽬从github上clone下来,慢慢分析。
项⽬结构⾸先我们看⼀下项⽬的构造。
发现项⽬有中⽂的介绍说明,这就很⽅便了,点开按照官⽅的说明开始操作。
环境部署点开README.md,,可以从⽂档教程中看到第⼀步就是教你如何安装环境。
由于内容过多,我就做个概括,⽅便⼤家直接上⼿。
1、安装Anaconda,构造虚拟环境这⾥可以参考我的另⼀篇⽂章,⾥⾯很详细:官⽅给的是python3.8的虚拟环境,我们也构造⼀个,打开Anaconda Prompt。
输⼊命令:conda create -n paddle_env python=3.8激活环境:conda activate paddle_env2、依赖包下载paddlepaddle安装pip install paddlepaddle -i https:///pypi/simplelayoutparser安装pip3 install -U https:///whl/layoutparser-0.0.0-py3-none-any.whlShapely安装,这个需要下载,下载地址:我选的是这个安装命令:pip install Shapely-1.8.0-cp38-cp38-win_amd64.whlpaddleocr安装pip install paddleocr -i https:///pypi/simple好的,环境有点多,都安装好了就开始上⼿使⽤吧。
如何利用Python识别图片中的文字详解
如何利⽤Python识别图⽚中的⽂字详解⼀、Tesseract⽂字识别是ORC的⼀部分内容,ORC的意思是光学字符识别,通俗讲就是⽂字识别。
Tesseract是⼀个⽤于⽂字识别的⼯具,我们结合Python使⽤可以很快的实现⽂字识别。
但是在此之前我们需要完成⼀个繁琐的⼯作。
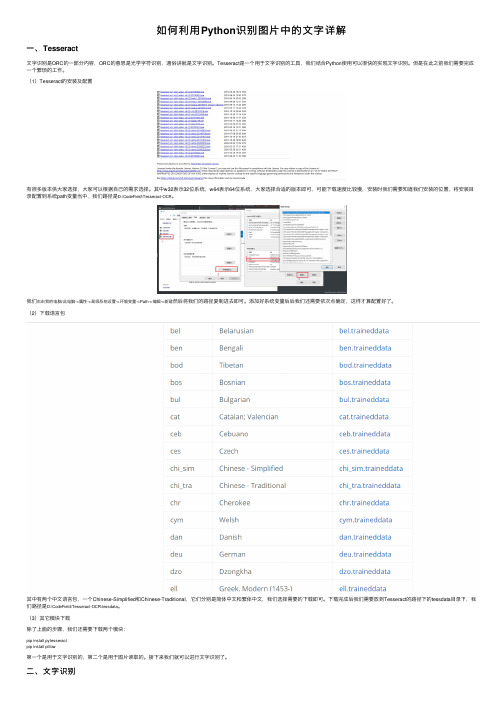
(1)Tesseract的安装及配置有很多版本供⼤家选择,⼤家可以根据⾃⼰的需求选择。
其中w32表⽰32位系统,w64表⽰64位系统,⼤家选择合适的版本即可,可能下载速度⽐较慢,安装时我们需要知道我们安装的位置,将安装⽬录配置到系统path变量当中,我们路径是D:\CodeField\Tesseract-OCR。
我们右击我的电脑/此电脑->属性->⾼级系统设置->环境变量->Path->编辑->新建然后将我们的路径复制进去即可。
添加好系统变量后后我们还需要依次点确定,这样才算配置好了。
(2)下载语⾔包其中有两个中⽂语⾔包,⼀个Chinese-Simplified和Chinese-Traditional,它们分别是简体中⽂和繁体中⽂,我们选择需要的下载即可。
下载完成后我们需要放到Tesseract的路径下的tessdata⽬录下,我们路径是D:\CodeField\Tesseract-OCR\tessdata。
(3)其它模块下载除了上⾯的步骤,我们还需要下载两个模块:pip install pytesseractpip install pillow第⼀个是⽤于⽂字识别的,第⼆个是⽤于图⽚读取的。
接下来我们就可以进⾏⽂字识别了。
⼆、⽂字识别(1)单张图⽚识别接下来的操作就要简单的多,下⾯是我们要识别的图⽚:接下来就是我们⽂字识别的代码:import pytesseractfrom PIL import Image# 读取图⽚im = Image.open('sentence.jpg')# 识别⽂字string = pytesseract.image_to_string(im)print(string)识别结果如下:Do not go gentle into that good night!因为默认是⽀持英⽂的,所以我们可以直接识别,但是当我们要识别中⽂或其它语⾔时就需要做些修改:import pytesseractfrom PIL import Image# 读取图⽚im = Image.open('sentence.png')# 识别⽂字,并指定语⾔string = pytesseract.image_to_string(im, lang='chi_sim')print(string)在识别时,我们设置lang='chi_sim',也就是把语⾔设置为简体中⽂,只有当你的tessdata⽬录下有简体中⽂包该设置才会⽣效。
python ocr文字识别模型训练

一、概述Python是一种高效的编程语言,也是人工智能领域中常用的工具之一。
在人工智能应用中,文字识别是一项重要的技术,它可以将图像中的文字转换成可编辑的文本信息。
在Python中,人们可以利用OCR (Optical Character Recognition,光学字符识别)模型来进行文字识别。
二、OCR模型的原理1. 光学字符识别(OCR)是一种通过算法和模型识别图像中的文字信息并将其转化为可编辑文本的技术。
2. OCR模型的原理是利用图像处理和机器学习算法,通过对图像中的字符进行分割、特征提取、模式识别等步骤,最终实现文字识别的功能。
3. 在Python中,人们可以使用一些开源的OCR模型框架(如Tesseract、EasyOCR等)来进行文字识别模型的训练。
三、OCR模型训练的步骤1. 数据收集:首先需要收集大量的带有文字信息的图像数据作为训练集,这些图像可以包括不同字体、不同大小、不同角度的文字图片。
2. 数据预处理:对收集到的图像数据进行预处理,包括图像去噪、灰度化、二值化、字符分割等处理,以便提高文字识别的准确度。
3. 特征提取:通过特征提取算法(如SIFT、HOG等),从处理后的图像中提取出文字的特征信息,以便机器学习模型进行训练。
4. 模型训练:选择合适的机器学习算法(如深度学习的CNN、LSTM 等),根据提取的特征数据对模型进行训练,并调整模型参数以提高识别准确度。
5. 模型评估:训练完模型后,需要对其进行评估,在测试集上测试模型的准确率、召回率等指标,以验证模型的有效性。
6. 模型优化:根据评估结果,对模型进行优化,包括调整参数、增加训练数据、改进网络结构等方式。
四、Python中的OCR模型训练工具1. Tesseract:Tesseract是一个开源的OCR引擎,在Python中可以通过pytesseract库来调用Tesseract进行文字识别模型的训练。
2. EasyOCR:EasyOCR是一个基于Pytorch实现的OCR工具,支持中文、英文等多种语言的文字识别,可以用于文字识别模型的训练和应用。
python easyocr模板训练

一、概述Python是一种功能强大的编程语言,它被广泛应用于数据分析、人工智能和图像识别等领域。
而EasyOCR是一个基于Python的开源库,它提供了简单易用的文本识别功能,可以帮助我们在图像中准确快速地识别文字信息。
在实际应用中,我们经常会遇到一些特定领域或特定类型的文本,由于其特殊性,往往需要定制化的文本识别模型。
本文将介绍如何利用Python编写EasyOCR模板进行定制化文本识别模型的训练。
二、EasyOCR模板训练的基本原理1. EasyOCR的工作原理EasyOCR利用深度学习技术,结合了卷积神经网络(CNN)和循环神经网络(RNN)的特点,对图像中的文字进行识别。
它首先使用CNN 网络进行文字检测,找出图像中的文字区域,然后利用RNN网络对文字区域中的文字进行识别。
这种端到端的识别技术,使得EasyOCR在实际应用中表现出色,准确率较高。
2. 模板训练的原理在某些特定的应用场景下,我们可能需要识别特定领域或特定类型的文本。
金融领域的票据、医疗领域的医疗单据等。
针对这些特定领域或特定类型的文本,我们可以借助EasyOCR提供的模板训练功能,定制化地训练文本识别模型。
模板训练的原理是通过提供一些样本图片和对应的标注信息,让EasyOCR学习特定领域或类型的文字特征,从而提高对这类文本的识别能力。
三、模板训练的具体步骤1. 数据准备我们需要准备一些特定领域或类型的样本图片,这些样本图片应涵盖各种不同的情况,例如不同字体、不同大小、不同角度等。
我们还需要为这些样本图片标注对应的文字信息,这些标注信息将作为训练模型的监督信号。
2. 模型初始化在数据准备好之后,我们需要初始化一个模型,这个模型将用于接受样本图片和标注信息,进行学习和训练。
3. 模型训练接下来,我们开始使用准备好的样本图片和标注信息对模型进行训练。
训练的过程是一个迭代的过程,模型会不断地通过样本数据和标注信息进行学习,调整自身的参数,从而提高对特定领域或类型文本的识别能力。
paddle ocr 例子 -回复

paddle ocr 例子-回复以下是关于[PaddleOCR例子]的一篇1500-2000字文章。
PaddleOCR是一个基于PaddlePaddle的开源OCR工具箱,用于文本识别和文字检测任务。
它提供了预训练模型和示例代码,使用户可以快速搭建和训练自己的OCR模型。
本文将介绍PaddleOCR的使用方法,并通过一个例子来演示其功能和性能。
首先,我们需要安装PaddleOCR。
PaddleOCR可以通过pip命令进行安装,如下所示:bashpip install paddlepaddle paddleocr安装完成后,我们就可以使用PaddleOCR进行文字识别和检测了。
接下来,我们将使用一个示例图片来进行文字检测和识别。
我们选择一张包含英文和中文文字的图片作为示例。
图片路径为"example.jpg",如下所示:result = ocr.ocr(image_path='example.jpg', use_gpu=False)print(result)在上述代码中,我们首先导入paddleocr模块。
然后,我们创建一个OCR 类的实例,并将其存储在ocr变量中。
接下来,我们调用ocr类的ocr方法,将图片路径传递给它,以及use_gpu参数设置为False,表示我们不使用GPU进行文字检测。
最后,我们打印出结果。
运行以上代码后,我们将获得示例图片中所有文字的检测和识别结果。
输出结果如下所示:bash[[['Hello', 0.254, [202, 61, 342, 84]], ['World!', 0.982, [763, 62, 870, 83]]]]上述输出结果表示PaddleOCR成功地检测并识别出了图片中的文字。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于Python的图片文字识别
【摘要】
在有些工程中,有时候我们需要对图片文字识别。
本文利用Python,调用OpenCV库,先对图片进行预处理,然后借助Google开源的pytesser对图片文字进行了识别。
【关键词】:OpenCV,pytesser,文字识别
一关于OCR
光学字符识别(英语:Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。
一般包括以下几个过程:图像输入、图像前处理、预识别:
1 图像输入:对于不同的图像格式,有着不同的存储格式,不同的压缩方式,目前有OpenCV、CxImage等开源项目。
2 预处理:主要包括二值化,噪声去除,倾斜较正等。
2.1二值化:
对摄像头拍摄的图片,大多数是彩色图像,彩色图像所含信息量巨大,对于图片的内容,我们可以简单的分为前景与背景,为了让计算机更快的、更好地识别文字,我们需要先对彩色图进行处理,使图片只剩下前景信息与背景信息,可以简单的定义前景信息为黑色,背景信息为白色,这就是二值化图。
2.2噪声去除:
对于不同的文档,我们对噪声的定义可以不同,根据噪声的特征进行去燥,就叫做噪声去除。
3 倾斜校正:由于一般用户,在拍照文档时,都比较随意,因此拍照出来的图片不可避免的产生倾斜,这就需要文字识别软件进行较正。
4版面分析:将文档图片分段落,分行的过程就叫做版面分析,由于实际文档的多样性,复杂性,因此,目前还没有一个固定的,最优的切割模型。
5字符切割:由于拍照条件的限制,经常造成字符粘连,断笔,因此极大限制了识别系统的性能。
6 字符识别:这一研究已经是很早的事情了,比较早有模板匹配,后来以特征提取为主,由于文字的位移,笔画的粗细,断笔,粘连,旋转等因素的影响,极大影响特征的提取的难度。
7 版面还原:人们希望识别后的文字,仍然像原文档图片那样排列着,段落不变,位置不变,顺序不变地输出到Word文档、PDF文档等,这一过程就叫做版面还原。
8 后处理、校对:根据特定的语言上下文的关系,对识别结果进行校正,就是后处理。
二利用OpenCV进行预处理
(一)关于OpenCV
OpenCV的全称是Open Source Computer Vision Library,是一个跨平台的计算机视觉库。
OpenCV可用于开发实时的图像处理、计算机视觉以及模式识别程序。
OpenCV用C++语言编写,它的主要接口也是C++语言,但是依然保留了大量的C 语言接口。
该库也有大量的Python,Java和MATLAB的接口。
另外,一个使用CUDA 的GPU接口也于2010年9月开始实现。
(二)使用OpenCV进行图片预处理
1.读入图像,并把彩色图转化为灰度图
本文需要识别的图片如下,为一张彩色图
在进行图像处理的时候,对灰度图的处理往往比彩色图简单一些,也少消耗一下资源,所以,在进行下一步工作前,我们先把图像转化为灰度图。
OpenCV 提供的读入图像接口函数为成imread,转化为灰度图的接口函数为cvtColor,并给它传入参数COLOR_BGR2GRAY,它就可以实现彩色图到灰度图的转换,转化为灰度图后图像如下。
2.对图像进行形态学开运算,并做自适应阈值处理
把图像转换为灰度图后,有时候会产生噪点,有时候文字会在有些地方断裂,这是我们不希望看到的,所以,我们利用开运算去除噪点,并是文字连续。
另外,转化为灰度图后,我们发现图片对比度不是很好,为此,我们在采用自适应阈值对图片进行阈值处理,以增强对比度,便于后文的pytesser对文字进行识别。
尽心开运算和自适应阈值处理以后,图片效果如下
三利用pytesser进行文字识别
pytesser,OCR in Python using the Tesseract engine from Google。
是谷歌OCR 开源项目的一个模块,可将图片中的文字转换成文本(主要是英文)。
本文的前面已经对图片进行了各种预处理,现在就利用pytesser来进行文字识别。
如果对图片的预处理做的很好,pytesser基本可以实现100%的文字识别。
但是pytesser 也有它的不足,它对于图片质量要求较高,除此之外,对于形态相同的数字和字母容易混淆,比如0和O。
改进的办法是利用机器学习,纠正识别错的,提高之后的识别准确率。
四总结与结论
通过对图像进行阈值变换,开运算等预处理,最后采用pytesser对图片文字信息进行了提取,由于图片的质量不同,识别成功率也有所不同。
在今后的研究中,可能有必要采取机器学习来提高识别的准确率。
参考文献:
[1] 陈胜勇,刘盛等. 基于OpenCV 的计算机视觉技术实现[M]. 北京:科学出版社,2008.
[2] 汪益民. 基于OCR的书写文字识别系统设计. 安徽农业大学 2007
[3] 沈艳. 基于CMAC神经网络的手写字体识别技术. 哈尔滨工程大学. 2011
[4] 颜伟,李巧月.基于OpenCV 的高斯平滑和自适应阈值化算法研究中国矿业大学2010
附录源程序
#图片预处理
import os
from pytesser import *
import cv2
import numpy as np
img = cv2.imread('p.jpg',0)
imgray =
cv2.cvtColor(img,cv2.COLOR_BGR2GRA Y)
#img = cv2.medianBlur(img,5)
#进行开运算处理
opening = cv2.morphologyEx(imgray, cv2.MORPH_OPEN, kernel)
#自适应阈值处理
th2 =
cv2.adaptiveThreshold(opening,255, cv2.ADAPTIVE_THRESH_MEAN_C,\
cv2.THRESH_BINARY,15,20)
#显示图片
cv2.imshow('adative',th2)
cv2.waitKey(0)
cv2.destroyAllWindows()#利用pytesser进行识别import os
import Image
import ImageEnhance import ImageFilter
import sys
from pytesser import *
im = Image.open('me.JPG') img = im.convert('L')
enhancer = ImageEnhance.Contrast(img) img = enhancer.enhance(2) img.show()
print image_to_string(img)。