OpenMP (4)
openMP入门

OpenMP 入门阅读(17)评论(1)发表时间:2009年05月06日 21:31本文地址:/blog/55032144-1241616677OpenMP是一个业界的标准,很早以前就有了,只是近一段时间才逐渐热起来。
我们可以在C/C++和Fortran使用OpenMP、很容易的引入多线程。
下图是一个典型的OpenMP程序的示意图,我们可以看到它是由串行代码和并行代码交错组成的,并行代码的区域我们把它叫做“并行区”。
主线程一旦进入并行区,就自动产生出多个线程,来并行的执行。
怎样在我们的代码中使用OpenMP呢?很简单,拿我们常用的C/C++代码来说,只需要插入如下pragma,然后我们选择不同的construct就可以完成不同的功能。
首先,我们来看一下如何创建一个并行区:增加一行代码#pragma omp parallel,然后用花括号把你需要放在并行区内的语句括起来,并行区就创建好了。
并行区里每个线程都会去执行并行区中的代码。
下面我们将看一个最简单的OpenMP代码,看看并行区是怎样工作的。
我们来看一个最简单的OpenMP程序例子:===================================#include <stdio.h>int main() {#pragma omp parallel{int i;printf("Hello World\n");for(i=0;i <6;i++)printf("Iter:%d\n",i);}printf("GoodBye World\n");}===================================我们现在用Intel编译器来编译这个小程序,当然你也可以用VS2005来编译。
我们可以看到编译器在没有加 /Qopenmp 开关的时候,会忽略掉所有openmp pragma。
openmp原子操作

openmp原子操作OpenMP(Open Multi-Processing)是一种并行编程模型,用于编写多线程并行程序。
OpenMP原子操作是指一种并行编程中的技术,用于确保对共享变量的原子性操作,以避免并发访问导致的竞态条件。
在OpenMP中,原子操作可以通过使用#pragma omp atomic指令来实现。
原子操作允许在并行代码中对共享变量执行原子操作,这意味着在执行原子操作期间,不会发生其他线程对同一变量的并发访问。
这有助于避免数据竞争和确保程序的正确性。
在OpenMP中,原子操作可以应用于一些基本的算术运算,比如加法、减法、乘法和除法,以及位操作,比如与、或、异或等。
原子操作的语法如下:c.#pragma omp atomic.x += 1;这个例子中,对变量x的自增操作是一个原子操作,即使在并行环境中也能够保证操作的原子性。
需要注意的是,原子操作虽然可以确保操作的原子性,但在高度并行化的情况下可能会导致性能下降。
因此,在使用原子操作时,需要权衡并行性和原子性之间的关系,以确保程序既能够正确运行,又能够获得良好的性能表现。
除了原子操作外,OpenMP还提供了其他一些机制来处理并发访问共享变量的问题,比如使用临界区(critical section)、使用互斥锁(mutex)、使用重复检测(test-and-set)等。
选择合适的并发控制机制取决于具体的并行算法和应用场景。
总之,OpenMP原子操作是一种重要的并行编程技术,用于确保对共享变量的原子性操作,从而避免数据竞争和确保程序的正确性。
在实际应用中,需要根据具体情况选择合适的并发控制机制,以实现既能够正确运行又能够高效利用并行计算资源的并行程序。
OpenMP简介

OpenMP提供了schedule子句来实现任务的调度。
schedule子句
schedule(type, size), 参数type是指调度的类型,可以取值为static,dynamic,guided三种值。 参数size表示每次调度的迭代数量,必须是整数。该参数是可选的。 2. 3. 动态调度 启发式调度 dynamic guided 1. 静态调度 static 采用启发式调度方法进行调度,每次分配给线程迭代次数不同,开始比较大, 动态调度依赖于运行时的状态动态确定线程所执行的迭代,也就是线程执行完 static在编译的时候就已经确定了,那些循环由哪些线程执行。 以后逐渐减小。 已经分配的任务后,会去领取还有的任务。由于线程启动和执行完的时间不确 当不使用size 时,将给每个线程分配┌N/t┐个迭代。当使用size时,将每 size 表示每次分配的迭代次数的最小值,由于每次分配的迭代次数会逐渐减少, 定,所以迭代被分配到哪个线程是无法事先知道的。 次给线程分配size次迭代。 少到 size时,将不再减少。如果不知道 size的大小,那么默认size 为1 ,即一直减少 当不使用 size 时,是将迭代逐个地分配到各个线程。当使用 size 时,逐个 到1 。具体采用哪一种启发式算法,需要参考具体的编译器和相关手册的信息。 分配 size 个迭代给各个线程。
用for语句来分摊是由系统自动进行,只要每次循环间没有时间 上的差距,那么分摊是很均匀的,使用section来划分线程是一种手 工划分线程的方式,最终并行性的好坏得依赖于程序员。
OpenMP中的线程任务调度
OpenMP中任务调度主要针对并行的for循环,当循环中每次迭代的计算量 不相等时,如果简单地给各个线程分配相同次数的迭代,则可能会造成各个线 程计算负载的不平衡,影响程序的整体性能。
openmp语言标准

openmp语言标准
OpenMP(Open Multi-Processing)是一种支持共享内存并行编程的API,由OpenMP Architecture Review Board牵头提出,并已被广泛接受,用于共享内存并行系统的多处理器程序设计的一套指导性编译处理方案(Compiler Directive)。
OpenMP支持的编程语言包括C、C++和Fortran;而支持OpenMp 的编译器包括Sun Compiler,GNU Compiler和Intel Compiler等。
OpenMp提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。
当选择忽略这些pragma,或者编译器不支持OpenMp时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。
OpenMP标准由一些具有国际影响力的软件和硬件厂商共同定义和提出,是一种在共享存储体系结构上的可移植编程模型,广泛应用于UNIX、Linux、Windows等多种平台上。
以上信息仅供参考,如有需要,建议您查阅相关网站。
openmp用法

openmp用法OpenMP是一种支持共享内存多线程编程的标准API。
它提供了一种简单而有效的方法,用于在计算机系统中利用多核和多处理器资源。
本文将逐步介绍OpenMP的用法和基本概念,从简单的并行循环到复杂的并行任务。
让我们一步一步来学习OpenMP吧。
第一步:环境设置要开始使用OpenMP,我们首先需要一个支持OpenMP的编译器。
常见的编译器如GCC、Clang和Intel编译器都支持OpenMP。
我们需要确保在编译时启用OpenMP支持。
例如,在GCC中,可以使用以下命令来编译包含OpenMP指令的程序:gcc -fopenmp program.c -o program第二步:并行循环最简单的OpenMP并行化形式是并行循环。
在循环的前面加上`#pragma omp parallel for`指令,就可以让循环被多个线程并行执行。
例如,下面的代码演示了如何使用OpenMP并行化一个简单的for循环:c#include <stdio.h>#include <omp.h>int main() {int i;#pragma omp parallel forfor (i = 0; i < 10; i++) {printf("Thread d: d\n", omp_get_thread_num(), i);}return 0;}在上面的例子中,`#pragma omp parallel for`指令会告诉编译器将for 循环并行化。
`omp_get_thread_num()`函数可以获取当前线程的编号。
第三步:数据共享与私有变量在并行编程中,多个线程可能会同时访问和修改共享的数据。
为了避免数据竞争和不一致的结果,我们需要显式地指定哪些变量是共享的,哪些变量是私有的。
我们可以使用`shared`和`private`子句来指定。
`shared`子句指定某个变量为共享变量,对所有线程可见。
OpenMP的应用与实现

OpenMP的应用与实现OpenMP的应用与实现随着计算机技术的不断发展,程序员们需要在更短的时间内开发出更高效、更快速的程序,以满足现代科学和工程领域对计算的需求。
在多核处理器和集群系统的背景下,一种新的编程技术——OpenMP,应运而生。
OpenMP为C、C++和Fortran等语言提供了一种简单而有效的方式来并行化应用程序,可显著加速程序的执行速度。
本文将介绍OpenMP的应用与实现。
一、OpenMP的基本概念OpenMP是一种可移植、可扩展的共享内存并行编程技术,被广泛用于高性能计算应用中。
它可以在现有的串行代码中添加共享内存并行性,从而提高程序的效率。
OpenMP采用指令集合作,程序员可以通过在应用程序中添加特定的OpenMP指令,来控制并行执行的细节。
这些指令将告诉编译器如何将串行代码并行化。
OpenMP的并行模型是基于线程的共享内存模型。
线程是程序执行的最小单元,可以实现不同的计算任务同时运行。
OpenMP使用共享内存模型,即多个线程可以访问同一块内存,从而实现数据的共享。
为了保证数据的安全性,OpenMP提供了同步机制,可以保证共享资源的一致性和正确性。
二、OpenMP指令OpenMP定义了一系列指令,用于控制多线程的创建、同步和运行。
下面是一些常用的OpenMP指令:1. #pragma omp parallel该指令用于创建一个并行区域。
在这个区域内所有指令都会被多个线程执行。
当线程遇到这个指令时,会创建一个线程队列,然后每个线程会执行这个指令块内的内容。
2. #pragma omp for该指令用于循环并行化。
在多核处理器或者集群系统中,循环的迭代次数可以分配给不同的线程来并行执行,从而加速程序的执行速度。
3. #pragma omp sections该指令用于将代码分成多个段,每个段可以由不同的线程执行。
4. #pragma omp critical该指令用于保证在同一时间只有一个线程可以执行指定的代码块。
OpenMP

OpenMP是一种针对共享内存的多线程编程技术,由一些具有国际影响力的大规模软件和硬件厂商共同定义的标准.它是一种编译指导语句,指导多线程、共享内存并行的应用程序编程接口(API)OpenMP是一种面向共享内存以及分布式共享内存的多处理器多线程并行编程语言,OpenMP是一种能被用于显示指导多线程、共享内存并行的应用程序编程接口.其规范由SGI发起.OpenMP具有良好的可移植性,支持多种编程语言.OpenMP能够支持多种平台,包括大多数的类UNIX以及WindowsNT系统.OpenMP最初是为了共享内存多处理的系统结构设计的并行编程方法,与通过消息传递进行并行编程的模型有很大的区别.因为这是用来处理多处理器共享一个内存设备这样的情况的.多个处理器在访问内存的时候使用的是相同的内存编址空间.SMP是一种共享内存的体系结构,同时分布式共享内存的系统也属于共享内存多处理器结构,分布式共享内存将多机的内存资源通过虚拟化的方式形成一个同意的内存空间提供给多个机子上的处理器使用,OpenMP对这样的机器也提供了一定的支持.OpenMP的编程模型以线程为基础,通过编译指导语句来显示地指导并行化,为编程人员提供了对并行化的完整控制.这里引入了一种新的语句来进行程序上的编写和设计.OpenMP的执行模型采用Fork-Join的形式,Fork-Join执行模式在开始执行的时候,只有一个叫做“主线程“的运行线程存在.主线程在运行过程中,当遇到需要进行并行计算的时候,派生出线程来执行并行人物,在并行执行的时候,主线程和派生线程共同工作,在并行代码结束后,派生线程退出或者是挂起,不再工作,控制流程回到单独的主线程中。
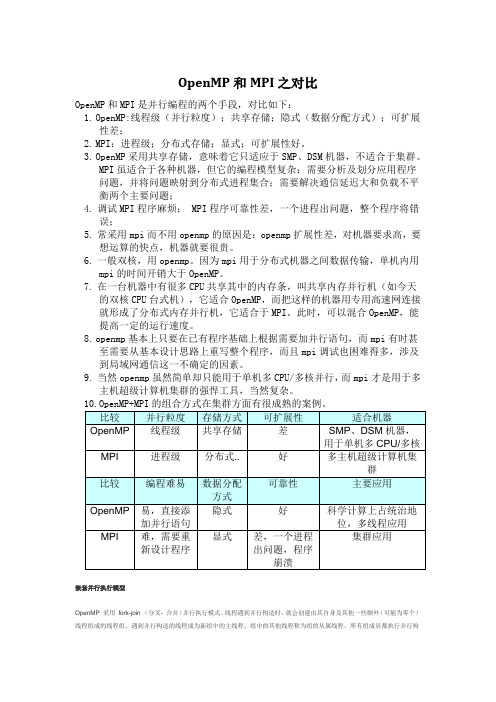
OpenMP的功能由两种形式提供:编译指导语句和运行时库函数,并通过环境变量的方式灵活控制程序的运行.OpenMP和MPI是并行编程的两个手段,对比如下:∙OpenMP:线程级(并行粒度);共享存储;隐式(数据分配方式);可扩展性差;∙MPI:进程级;分布式存储;显式;可扩展性好。
利用OpenMP给程序加速

二、OpenMP使用方法
1、搭建OpenMP编译环境
• 在VS2005以上的版本中,只需要在“项 目——属性——C/C++——语言—— OpenMP”中点选“是” • 在GCC4.2以上的版本中,只需要编译 时加上-fopenmp参数就行了
ห้องสมุดไป่ตู้
2、OpenMP一些语法
它的语法很简单,如下所示:
#pragma omp option [clause[ [, ]clause] …] { Program code1; Program code2; }
多核的简单编程——
利用OpenMP给程序加速
报告者:空气
主要内容
一、OpenMP简介 二、OpenMP使用方法 三、OpenMP效率测试
一、OpenMP简介
1、OpenMP的特点
1)、OpenMP是作为共享存储标准 而问世的 2)、它是为在多处理机上编写并行 程序而设计的一个应用编程接口 3)、它包括一套编译指导语句和一 个用来支持它的函数库
三、OpenMP效率测试
欢迎大家批评指正 谢谢!
• void main() • { • #pragma omp parallel sections num_threads(2){ • #pragma omp section • • • • } • 执行后将打印出以下结果: • section 1 ThreadId = 0 • section 2 ThreadId = 1 printf(“section 1 ThreadId = %d\n”,omp_get_thread_num()); printf(“section 2 ThreadId = %d\n”,omp_get_thread_num()); } • #pragma omp section
openmp 加速原理

openmp 加速原理标题,OpenMP 加速原理。
OpenMP(Open Multi-Processing)是一种并行编程模型,旨在简化多核处理器上的并行编程。
它通过在程序中嵌入指令来实现并行化,从而充分利用多核处理器的性能。
OpenMP 提供了一种简单、灵活的方法,使得程序员可以更轻松地将串行程序转换为并行程序,以提高程序的性能。
OpenMP 的加速原理主要基于以下几个方面:1. 并行化指令,OpenMP 提供了一系列的并行化指令,如#pragma omp parallel、#pragma omp for 等,通过在程序中插入这些指令,程序员可以指定哪些部分需要并行化执行,从而实现并行加速。
2. 线程级并行,OpenMP 通过创建多个线程来实现并行化。
在并行区域中,每个线程可以独立执行指定的任务,从而实现并行加速。
线程的创建和管理由 OpenMP 运行时库来完成,程序员无需过多关注线程的创建和销毁。
3. 工作分配,OpenMP 会自动将任务分配给不同的线程来执行,并且会根据系统的核心数和负载情况进行动态调整,以充分利用系统资源,提高程序的并行性能。
4. 数据共享,OpenMP 通过共享内存的方式来实现数据共享,不同线程可以访问同一块内存,从而实现数据的共享和协同计算,提高程序的并行效率。
总的来说,OpenMP 的加速原理主要依托于并行化指令、线程级并行、工作分配和数据共享等机制,通过这些方式来实现程序的并行加速,充分利用多核处理器的性能,提高程序的执行效率。
在实际应用中,程序员可以通过合理地使用 OpenMP 的并行化指令和机制,来加速串行程序,从而提高程序的性能和效率。
openmp手册

openmp手册OpenMP手册本文档旨在为使用OpenMP(Open Multi-Processing)编程模型的开发人员提供详细的参考指南和使用范例。
OpenMP是一套用于共享内存并行编程的API(Application Programming Interface)。
它允许程序员利用多线程并行化程序,以便在多个处理器上执行计算任务,以提高性能。
1、简介1.1 OpenMP的背景1.2 OpenMP的概述1.3 OpenMP的优势1.4 OpenMP的特性2、OpenMP基础指令2.1 并行区域(Parallel Regions)2.2 线程同步(Thread Synchronization)2.3 数据范围(Data Scoping)2.4 工作分配(Work Sharing)2.5 循环指令(Loop Directive)2.6 条件指令(Conditional Directive)2.7 函数指令(Function Directive)2.8并行性管理(Parallelism Management)3、OpenMP环境设置3.1 编译器支持3.2 编译选项3.3 运行时库3.4 环境变量4、OpenMP任务(Task)4.1 任务创建与同步4.2 任务调度4.3 任务优先级4.4 任务捕获变量5、OpenMP并行循环5.1 并行循环概述5.2 循环调度5.3 循环依赖5.4 循环优化6、OpenMP同步6.1 同步指令6.2 互斥锁6.3 条件变量6.4 同步的最佳实践7、OpenMP并行化任务图7.1 并行化任务图的概念 7.2 创建和管理任务图 7.3 数据依赖性和同步7.4 任务图调度8、OpenMP并行化内存管理 8.1 共享内存的访问模型 8.2 数据共享与私有化 8.3 内存一致性8.4 直接存储器访问模型9、OpenMP性能分析与优化9.1 性能分析工具9.2 优化技术9.3 并行编程陷阱9.4 调试OpenMP程序附件:附件一、OpenMP示例代码附件二、OpenMP编程规范附件三、OpenMP常见问题解答法律名词及注释:1、API(Application Programming Interface):应用程序编程接口,定义了软件组件之间的通信协议和接口规范。
openmp原理

openmp原理OpenMP(Open Multi-Processing)是一种并行编程模型,可简化共享内存编程中多线程编程的任务。
该编程模型利用编译器扩展语法和库等工具提供并行性,使得程序员无需显式地用锁和信号量等同步机制来管理线程。
OpenMP是一个针对共享内存多处理器(SMP)系统的编程打包标准。
OpenMP允许应用程序开发者通过为程序添加特殊的编译指示来创建线程。
这些线程可以并行运行,而不需要开发者显式地进行线程管理。
这种方法可以减少开发时间和代码复杂性,并且可以简化并行化过程。
OpenMP 的原理主要基于以下三个方面:1.编译器扩展语法OpenMP允许编译器对代码进行扩展,以便在代码中添加并行化的指令。
这些指令用于指示编译器在编译期间将计算分割成子任务,并在多线程环境中执行这些子任务。
该指令可以被嵌入到C、C++和Fortran程序中。
以下是OpenMP实现的一个简单的并行 for 循环示例:```c#include <omp.h>#include <stdio.h>int i;#pragma omp parallel for num_threads(4)for (i = 0; i < 8; i++) {printf("Thread %d is running for i=%d.\n", omp_get_thread_num(), i);}return 0;}```omp_get_thread_num()指示当前线程的编号,num_threads()指定使用 4 个线程,使 for 循环分配给这 4 个线程进行并行处理。
在运行上述代码时,将看到 4 个线程交替运行。
2.运行时库OpenMP 运行时库负责管理线程、同步和共享内存访问等操作。
它位于编译器和操作系统之间,是连接应用代码的关键。
在启动程序后,运行时库会自动创建相应数量的线程,根据代码中OpenMP指令控制线程数、同步和并行化任务等。
omp40 使用手册

omp40 使用手册OpenMP(Open Multi-Processing)是一种广泛使用的并行编程模型,用于共享内存并行系统。
OMP40是指OpenMP 4.0版本的规范,它在并行编程方面带来了许多改进和扩展。
以下是一个简短的OMP40使用手册,介绍了OMP40的主要特性和用法。
一、概述OpenMP 4.0引入了许多新功能和改进,以简化并行编程和提高性能。
它支持多线程并行编程,允许开发者在C/C++和Fortran程序中轻松实现并行化。
通过使用OpenMP指令和API,开发者可以充分利用多核处理器和分布式系统的优势。
二、主要特性动态调度:OMP40引入了多种动态调度策略,允许在运行时根据系统负载动态调整线程调度。
这些策略包括“运行时调度”(runtime scheduling)和“查询调度”(query scheduling)。
线程数控制:开发者可以使用“num_threads”指令来指定并行区域内的线程数。
此外,还可以使用环境变量“OMP_NUM_THREADS”来设置全局线程数。
任务并行:OMP40引入了任务并行,允许将代码拆分成多个独立的任务,每个任务可以由一个线程执行。
任务并行通过“task”指令实现,支持嵌套并行。
原子操作:OMP40提供了一组原子操作,允许在并行区域中进行安全的并发访问共享数据。
这些操作包括“atomic”、“atomic_add”等。
内存模型:OMP40定义了一个内存模型,用于描述并行程序中变量的可见性和顺序一致性。
这有助于开发者编写正确和高效的并行代码。
嵌套并行:OMP40支持嵌套并行,允许在一个并行区域内部创建另一个并行区域。
这有助于更好地利用多核处理器和分布式系统的资源。
动态负载均衡:OMP40引入了动态负载均衡机制,可以根据系统负载动态调整线程的执行顺序,以提高并行程序的性能。
三、使用方法使用OpenMP进行并行编程需要以下步骤:包含头文件:在C/C++程序中包含OpenMP头文件“omp.h”。
OpenMP多线程编程及性能优化_707706743

编译指导语句
运行时函数库
ቤተ መጻሕፍቲ ባይዱ
环境变量
图 6. 3 OpenMP 应用程序的组成部分 编译指导语句是 OpenMP 组成中最重要的部分,也是编写 OpenMP 程序的关键。
1.3 使用 Microsoft Visual 2005 编写 OpenMP 程 序
由于 Microsoft Visual Studio .Net 2005 已经支持 OpenMP 的编程,给 OpenMP 的初学者 带来极大的方便。Visual Studio .Net 2005 Professional 完全安装之后,即可编写 OpenMP 程 序,无需另外安装其它软件。因此,本章拟以 Visual Studio .Net 2005 环境讲解 OpenMP 的 编程。在类 Unix 环境下面,编写 OpenMP 程序与编写其它程序类似,需要加上一些有关 OpenMP 的编译选项以及链接相应的库,可以参考相应的编译器选项。从 网站上可以找到相应的信息。
OpenMP 多线程编程及性能优化
本章将以 OpenMP 为例,具体介绍多线程编程的基本技能。OpenMP 是一种针对共享内 存的多线程编程技术,由一些具有国际影响力的大规模软件和硬件厂商共同定义标准。它是 一种编译指导语句指导多线程、共享内存并行的应用程序编程接口(API)。本章介绍 OpenMP 编程的概况、编写 OpenMP 程序所需要的基本技术以及 OpenMP 程序优化的基本方法。由 于 OpenMP 同时支持 C/C++语言和 Fortran 语言,针对 OpenMP 的参考书籍非常少,而使用 C/C++来讲解 OpenMP 的参考资料也更少,因此本章将主要讲解如何用 C/C++语言来实现 OpenMP 的多线程编程。
openmp 向量加法

openmp 向量加法(实用版)目录1.OpenMP 简介2.向量加法的概念3.OpenMP 如何实现向量加法4.OpenMP 向量加法的优势5.示例代码正文1.OpenMP 简介OpenMP(Open Multi-Processing)是一种用于并行编程的应用程序接口(API),主要用于改进多线程程序的性能。
通过使用 OpenMP,程序员可以在 C、C++ 和 Fortran 等编程语言中编写并行代码,从而在多核处理器上实现更高效的计算。
2.向量加法的概念向量加法是一种基本的数学运算,用于计算两个或多个向量的和。
在计算机科学中,向量加法广泛应用于数据处理、图像处理和科学计算等领域。
3.OpenMP 如何实现向量加法OpenMP 通过提供一组并行编程库来实现向量加法。
在 C++ 语言中,可以使用 OpenMP 提供的 #pragma 指令来实现向量加法。
以下是一个简单的示例:```cpp#include <iostream>#include <vector>#include <omp.h>int main() {int n = 1000;std::vector<int> a(n), b(n);#pragma omp parallel forfor (int i = 0; i < n; i++) { a[i] = i;b[i] = i * 2;}#pragma omp parallel forfor (int i = 0; i < n; i++) { a[i] += b[i];}#pragma omp parallel forfor (int i = 0; i < n; i++) { std::cout << a[i] << " "; }std::cout << std::endl;return 0;}```在上面的示例中,我们首先使用 OpenMP 的 parallel for 指令并行化了两个 for 循环。
《2024年针对OpenMP程序的多类型资源弹性扩展研究》范文

《针对OpenMP程序的多类型资源弹性扩展研究》篇一一、引言随着计算机技术的快速发展,高性能计算已成为众多领域的研究热点。
OpenMP作为一种广泛使用的并行编程模型,能够有效地提高程序的运行效率。
然而,随着程序规模的扩大和复杂度的增加,单一资源环境已无法满足日益增长的计算需求。
因此,对OpenMP程序进行多类型资源弹性扩展研究具有重要的理论和实践意义。
本文旨在探讨OpenMP程序在多类型资源环境下的弹性扩展策略,以提高程序的运行效率和可靠性。
二、OpenMP程序与多类型资源概述OpenMP是一种支持多平台共享内存并行编程的API,能够有效地利用多核处理器进行并行计算。
而多类型资源则包括CPU、GPU、FPGA等多种计算资源。
在传统的计算环境中,主要依赖CPU进行计算,但随着技术的发展,GPU和FPGA等计算资源也逐渐被广泛应用于高性能计算领域。
三、OpenMP程序的多类型资源扩展策略(一)CPU资源扩展CPU作为传统的计算资源,其扩展策略主要在于优化任务调度和负载均衡。
通过OpenMP的并行编程模型,可以将程序划分为多个任务,并分配到多个CPU核心上执行,从而实现并行计算。
同时,还需要考虑任务间的依赖关系和通信成本,以避免资源浪费和性能瓶颈。
(二)GPU资源扩展GPU作为一种具有高度并行处理能力的计算资源,在处理大规模数据时具有显著的优势。
通过将OpenMP程序中的计算任务映射到GPU的线程上,可以充分利用GPU的并行计算能力。
同时,还需要考虑GPU内存的管理和数据的传输速度,以实现高效的计算。
(三)FPGA资源扩展FPGA作为一种可定制的硬件加速器,能够根据具体应用进行优化,具有较高的计算性能和能效比。
将OpenMP程序中的计算任务映射到FPGA上执行,可以实现高效的并行计算。
然而,由于FPGA的开发难度较大,需要针对具体应用进行定制,因此在实际应用中需要充分考虑其成本和效益。
四、多类型资源弹性扩展策略研究针对多类型资源的弹性扩展,需要综合考虑资源的类型、性能、可用性以及程序的运行需求。
OpenMP(4-30) 多核编程

简单循环并行化
两个向量相加,并将计算的结果保存到第三个向量 中,向量的维数为n。向量相加即向量的各个分量分 别相加。
for(int i=0;i<n;i++) z[i]=x[i]+y[i];
存在循环依赖性实例:
for(int i=0;i<n;i++) z[i]=z[i-1]+x[i]+y[i]
对于向量加法来说,可以使用循环并行化编译指导 语句直接对循环进行并行化 :
函数名称描述voidompinitlockomplockt初始化一个互斥锁voidompdestroylockomplockt结束一个互斥锁的使用并释放内存voidompsetlockomplockt获得一个互斥锁voidompunsetlockomplockt释放一个互斥锁intomptestlockomplockt试图获得一个互斥锁并在成功是返回真true失败是返回假false隐含的同步屏障隐含的同步屏障barrierbarrier在每一个并行区域都会有一个隐含的同步屏障barrier执行此并行区域的线程组在执行完毕本区域代码之前都需要同步并行区域的所有线程
运行时库函数
OpenMP运行时函数库原本用以设置和获取执行环境 相关的信息,它们当中也包含一系列用以同步的API。 支持运行时对并行环境的改变和优化,给编程人员 足够的灵活性来控制运行时的程序运行状况。 环境变量(OMP_NUM_THREADS )
编写OpenMP程序 编写OpenMP程序
开发工具已经增加了对OpenMP的支持,Visual Studio 2005完全支持OpemMP 。 编写OpenMP程序的必要步骤:
出的变量都是私有的。私有化是通过为每个线程创建各个 变量的独立副本来完成的。
OpenMP常用指令和库函数

2.1 OpenMP指令和库函数介绍在C/C++中,OpenMP指令(编译指导语句)使用的格式为:#pragma omp 指令[子句[子句]…]例如:#pragma omp parallel private(i, j)parallel 就是指令,private是子句。
为叙述方便把包含#pragma和OpenMP指令的一行叫做语句,如上面那行叫parallel语句。
OpenMP的常用指令:Parallel:用在一个代码段之前,表示这段代码将被多个线程并行执行For:用于for循环之前,将循环分配到多个线程中并行执行,必须保证每次循环之间无相关性。
parallel for:parallel 和for语句的结合,也是用在一个for循环之前,表示for 循环的代码将被多个线程并行执行。
Sections:用在可能会被并行执行的代码段之前parallel sections:parallel和sections两个语句的结合critical:用在一段代码临界区之前single:用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行。
Flush:用来保证线程的内存临时视图和实际内存保持一致,即各个线程看到的共享变量是一致的Barrier:用于并行区内代码的线程同步,所有线程执行到barrier时要停止,直到所有线程都执行到barrier时才继续往下执行。
Atomic:用于指定一块内存区域被制动更新Master:用于指定一段代码块由主线程执行Ordered:用于指定并行区域的循环按顺序执行Threadprivate:用于指定一个变量是线程私有的。
下面列出几个常用的库函数:omp_get_num_procs, 返回运行本线程的多处理机的处理器个数。
omp_get_num_threads, 返回当前并行区域中的活动线程个数。
omp_get_thread_num, 返回线程号omp_set_num_threads, 设置并行执行代码时的线程个数omp_init_lock, 初始化一个简单锁omp_set_lock,上锁操作omp_unset_lock,解锁操作,要和omp_set_lock函数配对使用。
OpenMP和MPI之对比
OpenMP和MPI之对比
嵌套并行执行模型
OpenMP 采用fork-join (分叉- 合并)并行执行模式。
线程遇到并行构造时,就会创建由其自身及其他一些额外(可能为零个)线程组成的线程组。
遇到并行构造的线程成为新组中的主线程。
组中的其他线程称为组的从属线程。
所有组成员都执行并行构
造内的代码。
如果某个线程完成了其在并行构造内的工作,它就会在并行构造末尾的隐式屏障处等待。
当所有组成员都到达该屏障时,这些线程就可以离开该屏障了。
主线程继续执行并行构造之后的用户代码,而从属线程则等待被召集加入到其他组。
OpenMP 并行区域之间可以互相嵌套。
如果禁用嵌套并行操作,则由遇到并行区域内并行构造的线程所创建的新组仅包含遇到并行构造的线程。
如果启用嵌套并行操作,则新组可以包含多个线程。
OpenMP 运行时库维护一个线程池,该线程池可用作并行区域中的从属线程。
当线程遇到并行构造并需要创建包含多个线程的线程组时,该线程将检查该池,从池中获取空闲线程,将其作为组的从属线程。
如果池中没有足够的空闲线程,则主线程获取的从属线程可
能会比所需的要少。
组完成执行并行区域时,从属线程就会返回到池中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
7. { $$ = $1; }8. | single_construct9. { $$ = $1; }10. | parallel_for_construct11. { $$ = $1; }12. | parallel_sections_construct13. { $$ = $1; }14. | master_construct15. { $$ = $1; }16. | critical_construct17. { $$ = $1; }18. | atomic_construct19. { $$ = $1; }20. | ordered_construct21. { $$ = $1; }22. ;从上面的代码描述可以知道OpenMP构造openmp_construct可以推导出10种构造的非终结符号,分别对应parallel构造、for构造和sections构造等等。
再进一步考察parallel构造有:1. parallel_construct:2. parallel_directive structured_block3. {4. $$ = OmpConstruct(DCPARALLEL, $1, $2);5. $$->l = $1->l;6. }7. ;这个语法规则(符号的合法序列)指出parallel构造是由parallel制导指令(parallel_directive)后面跟着C语言结构块(structured_block)而构成的。
这时候structured_block就返回到C语言的语法范畴,出现OpenMP与C的交互情况。
那么对于parallel_directive这个非终结符号的语法规则描述有:1. parallel_directive:2. PRAGMA_OMP OMP_PARALLEL parallel_clause_optseq '\n'3. { $$ = OmpDirective(DCPARALLEL, $3); }4. ;上面代码表明parallel_dirctive是由符号PRAGMA_OMP后面跟着符号OMP_PARALLEL最后跟着parallel制导指令的子句序列。
子句序列在parser.y中还有语法规则说明,但是PRAGMA_OMP和OMP_PARALLEL则不会有进一步的规则说明了,因为它们是词法分析器返回的终结符号(token标记),例如PRAGMA_OMP的规则描述在scanner.l文件中:1. [ \t]*"#"[ \t]*"pragma"[ \t]+"omp"[ \t]+ {2. count();3. on_omp_line = __has_omp = 1;4. return (PRAGMA_OMP);5. }这个规则说明出现形如“# pragma omp”的序列是OpenMP制导指令出现的标志。
其中PRAGMA_OMP的编号在Yacc在编译parser.y时输出的parser.h文件中定义的。
关于OpenMP 的语法的其他信息,可以参考相应的标准ISO/IEC 9899:1999 (OpenMP Version 2.5),例如并行构造在OpenMP标准中的语法定义是这样的:#pragma omp parallel [clause[ [, ]clause] ...] new-linestructured-block根据OpenMP v2.5规范关于OpenMP和C语言的语法,很容易将规范中的语法描述转换成Yacc的语法规则描述,从而写出正确的parser.y文件。
4.6 小结本章介绍了如何用Lex和Yacc来完成OpenMP/C代码的词法分析和语法分析。
关于词法分析的内容首先是Lex工具的使用方法,包括则正表达式的使用、Lex文件的三段代码格式与功能等内容。
然后分析了如何描述OpenMP和C代码的词法规则、如何区分公共关键字,并以OMPi的Lex文件为例详细说明了OpenMP/C词法规则的描述。
语法分析部分先是介绍了Yacc工具的使用,包括Yacc文件中三段代码的格式和功能、如何与Lex工具配合等内容。
然后分析了OpenMP/C代码的语法规则描述。
本章并没有介绍相关的语义动作,它将在第5章详细讨论。
通过本章学习并借助于Lex和Yacc的文档,读者应该能够对OMPi编译器源代码中的scanner.l和parser.y文件进行修改和增强,甚至是自行编写OpenMP/C的Lex和Yacc文件。
第5章AST的创建编译器的前端构造出源程序的中间表示,后端才能根据这个中间表示生成目标程序。
本章将讨论OpenMP编译中如何选择中间表达形式、AST的结构、相关数据结构和函数功能。
AST的建立是在语法分析的时候执行语义动作来完成的,这时涉及到AST节点类型及相应的节点创建、删除、输出等操作。
OpenMP程序AST的建立需要处理C语言的语法构造也需要处理OpenMP制导指令的语法构造。
作为中间表示,需要考虑其实现的复杂性,避免使用过多的数据类型,因此普通编程语言的AST节点的结构体往往分成语句节点、类型节点、声明节点、表达式节点四种,而对于OpenMP 代码而言需要增加一种OpenMP节点。
每种节点分成若干种类型,每个类型再分成几种子类型,从而覆盖所有的语法构造。
本章将着重讨论这五种AST节点的设计和AST的建立过程。
5.1 中间表示中间表示应该具有以下两个重要性质:易于生成、易于翻译为目标语言。
具体到不同问题还会有具体的要求。
比如在OpenMP编译原理的教学中,还需要便于将代码变换结果直观地展示出来。
下面简单地介绍两种中间表示形式,并分析为何选择AST作为中间表示形式。
5.1.1 两种中间表示形式编译器中常用的两种中间表示形式是:1. 树形结构,包括语法分析树和(抽象)语法树。
2. 线性表示形式,特别是“三地址码”。
语法树设计源代码到源代码的翻译器时,抽象语法树(Abstract Syntax Tree, AST)的数据结构是非常好的起点,因为它保留了源程序的层次化语法结构。
在一个表达式的抽象语法树中,每个内部节点代表一个运算符,该节点的子节点代表这个运算符的运算分量。
对于更一般化的程序设计语言任意一个语法构造,可以创建一个针对这个构造的运算符节点,并把这个构造的具有语义信息的组成部分作为这个运算符的运算分量。
这时候的“运算符”并不仅仅指通常意义上的数学运算,所有语句构造都需要定义相应的“运算符”,比如定义WHILE作为语句while的运算符,DOWHILE作为do{…} while…语句的运算符等等。
对于语句“do i=i+1;while (i< 100);”的抽象语法树可以表示成图 5.1-(a)所示。
图 5.1循环语句的抽象语法树及三地址码表示抽象语法树有时也简称为语法树(Syntax Tree ),与语法分析树很相似。
区别在于,抽象语法树的内部节点代表的是程序的构造,而语法分析树内部节点代表的是非终结符号。
文法中的很多非终结符号都代表程序的构造,但也有一部分是辅助符号(比如代表项、因子或其他表达式变体的非终结符号)。
抽象语法树通常不需要这些辅助符号,因此会将这些符号忽略掉。
为了区别它们,往往将语法分析树称为具体语法树(concrete syntax tree )。
三地址码三地址码是由一个基本程序步骤(比如两个值相加)组成的序列。
和树形结构不一样,它没有层次化的结构。
对于语句“do i=i+1; while (i<100);”的三地址表示的中间代码如图 5.1-(b)所示。
这是一组“三地址”指令序列,具有形如其名字的指令形式:z = x op y ,其中op 是一个二元运算符,x 和y 是两个运算分量(变量地址),z 是存放结果的地址。
三地址指令最多只执行一个运算,通常是计算、比较或分支运算。
当需要对计算过程作优化时就需要这种表示形式。
代码优化时可以将程序的三地址语句序列分割成多个不包含跳转语句的“基本块”,然后再使用各种优化技术。
5.1.2 中间表示的选择通常编程语言的编译器在创建抽象语法树的同时生成三地址码序列。
而且通常情况下这些编译器并不会创建出一棵存放了源代码所有程序构造的完整抽象语法树的数据结构,只是按照创建抽象语法树的规则“假装”构造了它,并同时生成三地址码序列。
这些编译器在分析过程中只保存将要用于语义检查和或其他目的的节点及其属性,同时也保存了语法分析的数据结构,而不会保存整棵语法树。
其目的是在构造三地址码序列时需要用到的那部分语法树的子树可用即可,一旦用完即可以释放掉。
本书选择OMPi 作为OpenMP 编译实现技术的分析对象是因为它“确实”构造了一棵完整的抽象语法树,对应了整个源代码的所有语法构造。
由于按照狭义的OpenMP 编译的定义,只需要进行源代码变换来弥补OpenMP 制导指令与C 语言之间的语义差距,而这些语义差距属于线程并发执行及相关问题,与具体的数学“计算”优化不直接相关,所以用于代码优化的三地址码表示在此处并没有优势。
综合而言,在本书讨论OpenMP 的实现技术中选择构造了完整语法树的OMPi 的原因是:(a ) (b )1: i=i+1 2: if i<100 goto 11. 本书讨论的OpenMP编译是狭义的定义,实现源代码到源代码的变换。
而使用抽象语法树作为中间表示形式便于源代码到源代码的变换,抽象语法树保留了原程序的所有层次性的语法构造,很方便地从语法树还原到源代码。
而三地址码者与源代码差别很大,从三地址码序列还原成C代码的困难较大。
2. 由于最终的可执行文件产生是依赖于后续的C编译器,因此OpenMP/C程序中的大量优化任务不在OpenMP狭义编译范畴中,因此对三地址码的需求并不迫切。
而可以将这些优化功能放在在后续的C编译器中,在那里产生三地址码的中间表示,进而完成代码优化。
3. 构造完整的抽象语法树便于教学和实践,通过输出抽象语法树可以清晰地看到源代码变换的中间过程和结果。
5.2 AST节点数据结构在使用语义动作来构建AST之前,需要先设计好AST节点的数据结构,设计的好坏将影响到AST创建和维护的难度或代码复杂度。
AST上的节点是可以表达所有的语法构造元素的,但是可以用比语法元素的类型少的节点类型(主类型),并配合上节点的子类型来表达。
比如可以将节点的主类型设计成只有以下五大类:语句、表达式、类型说明、声明、OpenMP制导。
下面先分析OMPi使用的AST节点数据结构,然后用具体例子说明如何使用这些节点来表示程序的各种语法构造。
5.2.1 语句节点编程语言中有大量的语句,这些语句在AST中使用语句节点来表示。