技术积累之linux bonding
linux bond mode=4工作原理

Linux bonding 是一种将多个网络接口绑定为一个逻辑接口的技术,以提高网络的可靠性、性能和带宽。
其中,mode=4 是IEEE 802.3ad 动态链接聚合(LACP)模式。
在mode=4 下,bonding 驱动会与交换机进行协商,以确定哪些slave 接口可以用于聚合,并建立一个聚合组。
聚合组中的每个slave 接口都会被配置为相同的速率和双工模式,并且会启用LACP 协议。
LACP 协议会在聚合组的每个slave 接口之间协商一个活动接口和一个或多个备份接口。
活动接口用于传输数据,而备份接口则处于待命状态,以便在活动接口出现故障时接替其工作。
当数据包到达聚合组时,bonding 驱动会根据其MAC 地址和聚合组中的活动接口列表,选择一个活动接口来传输该数据包。
如果活动接口出现故障,bonding 驱动会自动切换到备份接口,以确保数据的连续传输。
因此,mode=4 的工作原理主要是通过LACP 协议与交换机进行协商,建立一个聚合组,并在其中选择一个活动接口和一个或多个备份接口来传输数据。
这样可以提高网络的可靠性、性能和带宽,同时还可以实现负载均衡和容错。
Linux Bonding 模式详解

流量重新分配。接收流量负载是串行(轮转)的分配在bond的一
组速率最高的slave上。
当一个链路重连或者一个新的slave加入的时候,bond会重新
初始化ARP Replies给所有的客户端。updelay参数的值必须
点的硬件地址并且会回应一个包含绑定好的slave的硬件地址的
ARP Reply给发送的节点。用ARP协商的负载均衡的有一个问题是
每次用bond的硬件地址广播ARP报文,那么其他节点发送的数据
全部集中在一个slave上,处理ARP更新给其他所有节点的时候,
每个节点会重新学习硬件地址,导致流量重新分配。当新加入一
balance-xor or 2
XOR策略:基于所选择的传送hash策略。
本模式提供负载均衡和容错的能力。
Байду номын сангаас
broadcast or 3
广播策略:在所有的slave接口上传送所有的报文。本模式提供
容错能力。
802.3ad or 4
IEEE 802.3ad 动态链路聚合。创建共享相同的速率和双工
(ARP回应报文),并且用bond的某一个slave的硬件地址改写ARP报
文的源地址,使得本服务器对不同的设备使用不同的硬件地址。
本服务器建立的连接的接收流量也是负载均衡的。当本机发送
ARP Request时,bonding驱动通过ARP报文复制并保存节点的
IP信息。当从其他节点接收到ARP Reply,bonding驱动获取节
它的硬件地址被新选上的curr_active_slave硬件地址来替换。
linux中bonding配置步骤详解

本文介绍linux下的bonding 技术,linux 2.4.x 的内核中采用了这种技术,利用bonding 技术可以将多块网卡接口通过绑定虚拟成为一块网卡,在用户看来这个聚合起来的设备好像是一个单独的以太网接口设备,通俗点讲就是多块网卡具有相同的IP 地址而并行连接聚合成一个逻辑链路工作。
二、bond的几种算法Linux的bond支持7种工作模式,可以参考内核源码包文件:Documentation/networking/bonding.txt 。
这里逐一介绍。
模式1:mode=0 ,即:(balance-rr) Round-robin policy(平衡轮循策略)特点:传输数据包顺序是依次传输(即:第1个包走eth0,下一个包就走eth1….一直循环下去,直到最后一个传输完毕),此模式提供负载平衡和容错能力;但是我们知道如果一个连接或者会话的数据包从不同的接口发出的话,中途再经过不同的链路,在客户端很有可能会出现数据包无序到达的问题,而无序到达的数据包需要重新要求被发送,这样网络的吞吐量就会下降。
模式2:mode=1,即:(active-backup) Active-backup policy(主-备份策略)特点:只有一个设备处于活动状态,当一个宕掉另一个马上由备份转换为主设备。
mac地址是外部可见得,从外面看来,bond的MAC地址是唯一的,以避免switch(交换机)发生混乱。
此模式只提供了容错能力;由此可见此算法的优点是可以提供高网络连接的可用性,但是它的资源利用率较低,只有一个接口处于工作状态,在有N 个网络接口的情况下,资源利用率为1/N模式3:mode=2,即:(balance-xor) XOR policy(平衡策略)特点:基于指定的传输HASH策略传输数据包。
缺省的策略是:(源MAC地址XOR 目标MAC地址) % slave数量。
其他的传输策略可以通过xmit_hash_policy选项指定,此模式提供负载平衡和容错能力。
Linux网卡Bonding配置

Linux⽹卡Bonding配置⼀、bonding技术简介 bonding(绑定)是⼀种将n个物理⽹卡在系统内部抽象(绑定)成⼀个逻辑⽹卡的技术,能够提升⽹络吞吐量、实现⽹络冗余、负载等功能,有很多优势。
Linux 系统下⽀持⽹络 Bonding,也叫 channel Bonding,它允许你将 2 个或者更多的⽹卡绑定到⼀起,成为⼀个新的逻辑⽹卡,从⽽实现故障切换或者负载均衡的功能,具体情况要取决于 mode 参数的具体配置。
Linux系统bonding技术是内核层⾯实现的,它是⼀个内核模块(驱动)。
使⽤它需要系统有这个模块, 我们可以modinfo命令查看下这个模块的信息, ⼀般来说都⽀持.modinfo bondingbonding的七种⼯作模式bonding技术提供了七种⼯作模式,在使⽤的时候需要指定⼀种,每种有各⾃的优缺点.balance-rr (mode=0) 默认, 有⾼可⽤ (容错) 和负载均衡的功能, 需要交换机的配置,每块⽹卡轮询发包 (流量分发⽐较均衡).active-backup (mode=1) 只有⾼可⽤ (容错) 功能, 不需要交换机配置, 这种模式只有⼀块⽹卡⼯作, 对外只有⼀个mac地址。
缺点是端⼝利⽤率⽐较低balance-xor (mode=2) 不常⽤broadcast (mode=3) 不常⽤802.3ad (mode=4) IEEE 802.3ad 动态链路聚合,需要交换机配置,没⽤过balance-tlb (mode=5) 不常⽤balance-alb (mode=6) 有⾼可⽤ ( 容错 )和负载均衡的功能,不需要交换机配置 (流量分发到每个接⼝不是特别均衡)详细说明请参考⽹络上其他资料,了解每种模式的特点根据⾃⼰的选择就⾏, ⼀般会⽤到0、1、4、6这⼏种模式。
⼆、RHEL6 下的 Boding 配置: 在所有的 RHEL 版本下,⽬前都不⽀持在 NetworkManager 服务协作下实现 Bonding 配置.所以要么直接关闭 NetworkManager 服务,并取消其开机启动,要么在所有涉及 Bonding 的⽹卡配置⽂件中(包含ethx 或者 bondY),显式地添加⼀⾏:NM_CONTROLLED=no 要配置⽹卡 Bonding,你必须在/etc/sysconfig/network-scripts/⽬录下建⽴逻辑⽹卡的配置⽂件 ifcfg-bondX,⼀般 X 从 0 开始,依次增加.具体的⽂件内容根据参与 Bonding 的⽹卡类型的不同⼜有所差别,以最最常见的 Ethernet 为例,配置⽂件⼤致是这样的:DEVICE=bond0IPADDR=192.168.0.1NETMASK=255.255.255.0ONBOOT=yesBOOTPROTO=noneUSERCTL=noBONDING_OPTS="bonding parameters separated by spaces"NM_CONTROLLED=no BONDING_OPTS 这⼀⾏填写你需要的 Bonding 模式,⽐如 BONDING_OPTS="miimon=100 mode=1" ,下⾯也会介绍⼏种常见的配置⽅式和它代表的意义,这⾥暂时不展开说明.为了⽅便称呼,我们把Bongding 后的逻辑⽹卡 bondX 称为主⽹卡(Master),参与 Bonding 的物理⽹卡 ethY 称为⼦⽹卡(Slave). 主⽹卡配置⽂件创建完毕以后,⼦⽹卡的配置⽂件也需要做相应的改变,主要是添加 MASTER=和SLAVE=这两项参数,我们假设 2 张⼦⽹卡为 eth0 和 eth1,那么他们的配置⽂件⼤致的样⼦会是这样⼦:DEVICE=ethXBOOTPROTO=noneONBOOT=yesMASTER=bond0SLAVE=yesUSERCTL=noNM_CONTROLLED=no 像这样,分别修改 ifcfg-eth0 和 ifcfg-eth1 配置⽂件,DEVICE=ethX 中的 X ⽤相应的值代替.然后我们重启⽹络服务.service network restart这样⼦,⼦⽹卡为 eth0 和 eth1,主⽹卡为 bond0,模式为 mode 1 的⽹络 Bonding 就完成了rhel6 bonding 实例展⽰系统: rhel6⽹卡: eth2、eth3bond0:10.200.100.90负载模式: mode1(active-backup) # 这⾥的负载模式为1,也就是主备模式.1、关闭和停⽌NetworkManager服务service NetworkManager stopchkconfig NetworkManager offps: 如果有装的话关闭它,如果报错说明没有装这个,那就不⽤管2、加载bonding模块modprobe --first-time bonding3、创建基于bond0接⼝的配置⽂件[root@rhel6.6 network-scripts]# cat ifcfg-bond0DEVICE=bond0BOOTPROTO=noneIPADDR=10.200.100.90NETMASK=255.255.255.0ONBOOT=yesNM_CONTROLLED=noUSERCTL=noBONDING_OPTS="mode=1 miimon=200"4、SLAVE⽹卡的配置⽂件两种⼦⽹卡的配置⽂件如下[root@rhel6.6 network-scripts]# cat ifcfg-eth2DEVICE=eth2#HWADDR=14:58:D0:5A:0F:76NM_CONTROLLED=no#UUID=3b718bed-e8d4-4b64-afdb-455c8c3ccf91ONBOOT=yes#NM_CONTROLLED=yesBOOTPROTO=noneMASTER=bond0SLAVE=yesUSERCTL=no[root@rhel6.6 network-scripts]# cat ifcfg-eth3DEVICE=eth3#HWADDR=14:58:D0:5A:0F:77NM_CONTROLLED=no#UUID=988835c2-8bfa-4788-9e8d-e898f68458f0ONBOOT=yes#NM_CONTROLLED=yesBOOTPROTO=noneMASTER=bond0SLAVE=yesUSERCTL=no5、bonding信息查看重启⽹络服务器后bonding⽣效[root@rhel6.6 network-scripts]# ip a4: eth2: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc mq master bond0 state UP qlen 1000link/ether c4:34:6b:ac:5c:9e brd ff:ff:ff:ff:ff:ff5: eth3: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc mq master bond0 state UP qlen 1000link/infiniband a0:00:03:00:fe:80:00:00:00:00:00:00:00:02:c9:03:00:0a:6f:ba brd 00:ff:ff:ff:ff:12:40:1b:ff:ff:00:00:00:00:00:00:ff:ff:ff:ff10: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UPlink/ether c4:34:6b:ac:5c:9e brd ff:ff:ff:ff:ff:ffinet 10.200.100.90/24 brd 10.212.225.255 scope global bond0inet6 fe80::c634:6bff:feac:5c9e/64 scope linkvalid_lft forever preferred_lft forever[root@rhel6.6 network-scripts]# cat /proc/net/bonding/bond0Ethernet Channel Bonding Driver: v3.6.0 (September 26, 2009)Bonding Mode: fault-tolerance (active-backup) # bond0接⼝采⽤mode1Primary Slave: NoneCurrently Active Slave: eth2MII Status: upMII Polling Interval (ms): 200Up Delay (ms): 0Down Delay (ms): 0Slave Interface: eth2MII Status: upSpeed: 1000 MbpsDuplex: fullLink Failure Count: 0Permanent HW addr: c4:34:6b:ac:5c:9eSlave queue ID: 0Slave Interface: eth3MII Status: upSpeed: 1000 MbpsDuplex: fullLink Failure Count: 0Permanent HW addr: c4:34:6b:ac:5c:9fSlave queue ID: 0进⾏⾼可⽤测试,拔掉其中的⼀条⽹线看丢包和延时情况, 然后在插回⽹线(模拟故障恢复),再看丢包和延时的情况.三、RedHat7配置bonding系统: Red Hat Enterprise Linux Server release 7.6 (Maipo)⽹卡: eno3、eno4bonding:bond0负载模式: mode1(active-backup)服务器上两张物理⽹卡eno3和eno4, 通过绑定成⼀个逻辑⽹卡bond0,bonding模式选择mode1注: ip地址配置在bond0上, 物理⽹卡不需要配置ip地址.1、关闭和停⽌NetworkManager服务RedHat7默认安装了NetworkManager,在配置前先关掉NetworkManager服务,否则可能会对bonding或造成问题。
linux下网卡bond配置

Linux 7.x OS bond配置一、bonding技术bonding(绑定)是一种linux系统下的网卡绑定技术,可以把服务器上n个物理网卡在系统内部抽象(绑定)成一个逻辑上的网卡,能够提升网络吞吐量、实现网络冗余、负载等功能,有很多优势。
bonding技术是linux系统内核层面实现的,它是一个内核模块(驱动)。
使用它需要系统有这个模块, 我们可以modinfo命令查看下这个模块的信息, 一般来说都支持.# modinfo bondingfilename:/lib/modules/2.6.32-642.1.1.el6.x86_64/kernel/drivers/net/bonding/bonding.koauthor: Thomas Davis, tadavis@ and many othersdescription: Ethernet Channel Bonding Driver, v3.7.1version: 3.7.1license: GPLalias: rtnl-link-bondsrcversion: F6C1815876DCB3094C27C71depends:vermagic: 2.6.32-642.1.1.el6.x86_64 SMP mod_unloadmodversionsparm: max_bonds:Max number of bonded devices (int)parm: tx_queues:Max number of transmit queues (default = 16) (int)parm: num_grat_arp:Number of peer notifications to send on failover event (alias of num_unsol_na) (int)parm: num_unsol_na:Number of peer notifications to send on failover event (alias of num_grat_arp) (int)parm: miimon:Link check interval in milliseconds (int)parm: updelay:Delay before considering link up, in milliseconds (int)parm: downdelay:Delay before considering link down, in milliseconds (int)parm: use_carrier:Usenetif_carrier_ok (vs MII ioctls) in miimon; 0 for off, 1 for on (default) (int)parm: mode:Mode of operation; 0 for balance-rr, 1 for active-backup, 2 for balance-xor, 3 for broadcast, 4 for 802.3ad, 5 for balance-tlb, 6 for balance-alb (charp)parm: primary:Primary network device to use (charp)parm: primary_reselect:Reselect primary slave once it comes up; 0 for always (default), 1 for only if speed of primary is better, 2 for only on active slave failure (charp) parm: lacp_rate:LACPDUtx rate to request from 802.3ad partner; 0 for slow, 1 for fast (charp)parm: ad_select:803.ad aggregation selection logic; 0 for stable (default), 1 for bandwidth, 2 for count (charp)parm: min_links:Minimum number of available links before turning on carrier (int)parm: xmit_hash_policy:balance-xor and 802.3ad hashing method; 0 for layer 2 (default), 1 for layer 3+4, 2 for layer 2+3 (charp)parm: arp_interval:arp interval in milliseconds (int)parm: arp_ip_target:arp targets in n.n.n.n form (array of charp)parm: arp_validate:validatesrc/dst of ARP probes; 0 for none (default), 1 for active, 2 for backup, 3 for all (charp)parm: arp_all_targets:fail on any/all arp targets timeout; 0 for any (default), 1 for all (charp)parm: fail_over_mac:For active-backup, do not set all slaves to the same MAC; 0 for none (default), 1 for active, 2 for follow (charp)parm: all_slaves_active:Keep all frames received on an interface by setting active flag for all slaves; 0 for never (default), 1 for always. (int)parm: resend_igmp:Number of IGMP membership reports to send on link failure (int)parm: packets_per_slave:Packets to send per slave in balance-rr mode; 0 for a random slave, 1 packet per slave (default), >1 packets per slave. (int)parm: lp_interval:The number of seconds between instances where the bonding driver sends learning packets to each slaves peer switch. The default is 1. (uint)modinfo bondingbonding的七种工作模式:bonding技术提供了七种工作模式,在使用的时候需要指定一种,每种有各自的优缺点. 1.balance-rr (mode=0) 默认, 有高可用(容错) 和负载均衡的功能, 需要交换机的配置,每块网卡轮询发包(流量分发比较均衡).2.active-backup (mode=1) 只有高可用(容错) 功能, 不需要交换机配置, 这种模式只有一块网卡工作, 对外只有一个mac地址。
linux中bonding配置步骤详解
本文介绍linux下的bonding 技术,linux 2.4.x 的内核中采用了这种技术,利用bonding 技术可以将多块网卡接口通过绑定虚拟成为一块网卡,在用户看来这个聚合起来的设备好像是一个单独的以太网接口设备,通俗点讲就是多块网卡具有相同的IP 地址而并行连接聚合成一个逻辑链路工作。
二、bond的几种算法Linux的bond支持7种工作模式,可以参考内核源码包文件:Documentation/networking/bonding.txt 。
这里逐一介绍。
模式1:mode=0 ,即:(balance-rr) Round-robin policy(平衡轮循策略)特点:传输数据包顺序是依次传输(即:第1个包走eth0,下一个包就走eth1….一直循环下去,直到最后一个传输完毕),此模式提供负载平衡和容错能力;但是我们知道如果一个连接或者会话的数据包从不同的接口发出的话,中途再经过不同的链路,在客户端很有可能会出现数据包无序到达的问题,而无序到达的数据包需要重新要求被发送,这样网络的吞吐量就会下降。
模式2:mode=1,即:(active-backup) Active-backup policy(主-备份策略)特点:只有一个设备处于活动状态,当一个宕掉另一个马上由备份转换为主设备。
mac地址是外部可见得,从外面看来,bond的MAC地址是唯一的,以避免switch(交换机)发生混乱。
此模式只提供了容错能力;由此可见此算法的优点是可以提供高网络连接的可用性,但是它的资源利用率较低,只有一个接口处于工作状态,在有N 个网络接口的情况下,资源利用率为1/N模式3:mode=2,即:(balance-xor) XOR policy(平衡策略)特点:基于指定的传输HASH策略传输数据包。
缺省的策略是:(源MAC地址XOR 目标MAC地址) % slave数量。
其他的传输策略可以通过xmit_hash_policy选项指定,此模式提供负载平衡和容错能力。
linux双网卡绑定

一、L inux bonding研究及实现Linux Bonding本文介绍Linux(具体发行版本是CentOS5.6)下的双卡绑定的原理及实现。
Linux双网卡绑定实现是使用两块网卡虚拟成为一块网卡设备,这简单来说,就是两块网卡具有相同的IP地址而并行链接聚合成一个逻辑链路工作。
这项技术在Sun和Cisco中分别被称为Trunking和Etherchannel技术,在Linux的2.4.x及其以后的内核则称为Bonding 技术。
bonding的前提条件:网卡应该具备自己独立的BIOS芯片,并且各网卡芯片组型号相同。
同一台服务器上的网卡毫无疑问是是符合这个条件的。
Bonding原理bonding的原理:在正常情况下,网卡只接收目的硬件地址(MAC Address)是自身MAC的以太网帧,过滤别的数据帧,以减轻驱动程序的负担;但是网卡也支持另外一种被称为混杂promisc的模式,可以接收网络上所有的帧,bonding就运行在这种模式下,而且修改了驱动程序中的mac地址,将两块网卡的MAC地址改成相同,可以接收特定MAC的数据帧。
然后把相应的数据帧传送给bond驱动程序处理。
为方便理解bonding的配置及实现,顺便阐述一下Linux的网络接口及其配置文件。
在Linux 中,所有的网络通讯都发生在软件接口与物理网络设备之间。
与网络接口配置相关的文件,以及控制网络接口状态的脚本文件,全都位于 /etc/sysconfig/netwrok-scripts/目录下。
网络接口配置文件用于控制系统中的软件网络接口,并通过这些接口实现对网络设备的控制。
当系统启动时,系统通过这些接口配置文件决定启动哪些接口,以及如何对这些接口进行配置。
接口配置文件的名称通常类似于 ifcfg-<name>,其中 <name> 与配置文件所控制的设备的名称相关。
在所有的网络接口中,最常用的就是以太网接口ifcfg-eth0,它是系统中第一块网卡的配置文件。
linux bonding原理

linux bonding原理Linux bonding是一种网络连接的聚合技术,通过将多个物理网络接口绑定在一起,形成一个虚拟的网络接口,从而提供更高的带宽和冗余性。
本文将介绍Linux bonding的原理和工作方式。
让我们来了解一下什么是网络聚合。
网络聚合是一种将多个网络接口组合在一起,以提供更高带宽和更可靠的连接的技术。
通过将多个物理接口绑定在一起,网络聚合可以将它们视为一个逻辑接口,并同时使用它们来传输数据。
这不仅可以提高网络的带宽,还可以增加网络的冗余性。
在Linux系统中,网络聚合可以通过使用Linux bonding驱动程序来实现。
Linux bonding驱动程序提供了一种将多个网络接口绑定在一起的方法,以形成一个虚拟的网络接口。
这个虚拟接口可以像任何其他网络接口一样使用,并且可以通过配置不同的模式来实现不同的功能。
Linux bonding支持多种不同的模式,包括负载均衡模式、冗余模式和自适应模式等。
每种模式都有自己的特点和适用场景。
在负载均衡模式下,Linux bonding将传输的数据分配到不同的物理接口上,从而实现负载均衡。
这种模式适用于需要提高网络带宽的场景,例如服务器端口聚合或者链路聚合。
在冗余模式下,Linux bonding将所有数据都发送到所有的物理接口上,从而实现冗余性。
如果其中一个物理接口发生故障,系统可以自动切换到另一个可用的接口。
这种模式适用于对网络连接的可靠性要求较高的场景。
在自适应模式下,Linux bonding会根据网络的状况动态地调整数据的传输方式。
它可以根据网络负载和链路状态来选择最佳的物理接口进行数据传输。
这种模式适用于对网络质量要求较高的场景。
Linux bonding的原理是通过将多个物理接口绑定在一起,形成一个虚拟接口。
这个虚拟接口可以像任何其他网络接口一样使用,并且可以通过配置不同的模式来实现不同的功能。
Linux bonding驱动程序负责管理这个虚拟接口,并根据配置的模式决定如何处理传入和传出的数据。
Linux bonding源码分析

1. 目的本文档结合相关内核代码和对Linux 2.6.9内核中Bonding模块的三种主要工作模式的工作原理和流程。
在配置Bond模块时,除了资料[2],本文档也有一定的参考价值。
2. 内容本文档包含下列内容:* Bonding模块工作流程综述。
(第3节)* Bonding链路状态监控机制(mii模式、arp模式)描述。
(第4节)* Bonding模块三种主要工作模式:balance-rr、active- backup和broadcast相关代码分析。
(第5节)* Bonding模块关键数据结构和函数的代码分析。
(第5节)如果想了解bonding模块的原理和工作流程,请阅读3、4节,如果想进一步分析bonding 模块的代码,请阅读5节。
3. Bonding模块工作流程综述Bonding模块本质上是一个虚拟的网卡驱动(network device driver),只不过并没有真实的物理网卡与之对应,而是由这个虚拟网卡去“管辖”一系列的真实的物理网卡,所以它的代码结构和一般网卡驱动的代码结构非常类似,这是共性;除此之外,它还有自己的一些特性功能,例如特别的链路状态监控机制,绑定/解除绑定等。
3.1物理网卡的活动状态和链路状态在bonding模块中为每一个被绑定的物理网卡定义了两种活动状态和四种链路状态:注意,这里的链路状态和实际网卡真实的链路状态(是否故障、是否有网线连接)没有直接的关系,虽然bonding模块通过MII或者ARP侦测到实际网卡故障时也会改变自定义的链路状态值(例如从BOND_LINK_UP切换到BOND_LINK_FAIL随后切换到 BOND_LINK_DOWN状态),但是概念上应该把这两类链路状态区分开。
在本文档随后的内容中,除非特别指出,“链路状态”都指bonding模块自定义的链路状态。
活动状态:* BOND_STATE_ACTIVE:处于该状态的网卡是潜在的发送数据包的候选者* BOND_STATE_BACKUP:处于该状态的网卡在选择发送数据的网卡时被排除链路状态:* BOND_LINK_UP:上线状态(处于该状态的网卡是是潜在的发送数据包的候选者) * BOND_LINK_DOWN:故障状态* BOND_LINK_FAIL:网卡出现故障,向状态BOND_LINK_DOWN 切换中* BOND_LINK_BACK:网卡恢复,向状态BOND_LINK_UP切换中一个网卡必须活动状态为BOND_STATE_ACTIVE并且链路状态为 BOND_LINK_UP,才有可能作为发送数据包的候选者,注意,这里所说的数据包并不包含ARP请求,在使用ARP链路状态监控时,一个处于BOND_LINK_BACK状态的网卡也可能发送ARP请求。
Linux双网卡bonding举例

Linux双网卡bonding举例所谓bonding,就是将多块网卡绑定同一IP地址对外提供服务,可以实现高可用或者负载均衡。
当然,直接给两块网卡设置同一IP地址是不可能的。
通过bonding,虚拟一块网卡对外提供连接,物理网卡的被修改为相同的MAC地址。
Kernels 2.4.12及以后的版本均提供bonding模块,以前的版本可以通过patch实现。
1.确认你目前使用的网卡,检查/etc/sysconfig/network-scripts目录下以ifcfg-开头的文件,应该为eth0, eth1...2. 配置虚拟网卡bond0可以使用DHCP,也可以配置static IP,最好通过vi编辑配置文件引用[root@server1 ~]# cd /etc/sysconfig/network-scripts[root@server1 network-scripts]# cat ifcfg-bond0DEVICE=bond0BOOTPROTO=noneONBOOT=yesNETWORK=192.168.0.0NETMASK=255.255.255.0IPADDR=192.168.0.10USERCTL=noGATEWAY=192.168.0.254TYPE=Ethernet3. 修改eth0, eth1配置文件引用[root@server1 network-scripts]# ifcfg-eth0DEVICE=eth0BOOTPROTO=noneONBOOT=yesMASTER=bond0SLAVE=yesUSERCTL=yes[root@server1 network-scripts]# ifcfg-eth1DEVICE=eth1BOOTPROTO=noneONBOOT=yesMASTER=bond0SLAVE=yesUSERCTL=yes4. 将新添加的bond0设备加入modprobe.conf中,以便kernel识别。
Linux下的bonding(双网卡绑定)配置整理

Linux下的bonding(双网卡绑定)配置整理Linux下的bonding(双网卡绑定)配置整理1. 检查你的系统是否支持bonding首先,执行命令:$ rpm -qf /sbin/ifup它将会返回一行文本,以"initscripts"或"sysconfig,"开头,后面跟着一串数字。
这就是提供网络初始化脚本的包。
注意,如果查到的包是initscripts,后面配置的时候要使用initscripts的配置方式,这边的环境是initscripts方式。
如果查到的是sysconfig包,则配置会不同,详细请查看下一步,为了确定你的安装是否支持bonding,执行命令:$ grep ifenslave /sbin/ifup如果返回任何匹配记录,则表示你的initscripts或sysconfig支持bonding。
2. 修改网络适配器的配置针对现在的网络适配器配置文件进行修改,配置文件都放在/etc/sysconfig/network-scripts目录下,如下:第一个网络适配器:vi /etc/sysconfig/network-scripts/eth0DEVICE=eth0 ONBOOT=yes BOOTPROTO=none MASTER=bond0 SLA VE=yes第二个网络适配器:vi /etc/sysconfig/network-scripts/eth1DEVICE=eth1 USERCTL=no ONBOOT=yes MASTER=bond0 SLA VE=yes BOOTPROTO=non ewk_ad_begin({pid : 21});wk_ad_after(21, function(){$('.ad-hidden').hide();}, function(){$('.ad-hidden').show();});3.创建bonding的网络脚本vi /etc/sysconfig/network-scripts/bond0DEVICE=bond0IPADDR=192.168.1.66//修改为你需要的IPNETMASK=255.255.255.0 NETWORK=192.168.1.0 BROADCAST=192.168.1.255 ONBOOT= yesBOOTPROTO=none USERCTL=no4. bond驱动的选项Bonding驱动的选项是通过在加载时指定参数来设定的,通常在以下两个文件里面指定。
linux下面双网卡绑定技术

SLAVE=yes
BOOTPROTO=static
TYPE=Ethernet
(3)、ifcfg-bond0配置
DEVICE=bond0
BOOTPROTO=static
BROADCAST=192.168.44.255
IPADDR=192.168.44.202
NETMASK=255.255.255.0
ONBOOT=yes
TYPE=Ethernet
5、修改并建立bond模块文件
modprobe bonding
3、显示已经载入的bonding模块,验证上一步操作是否正常
lsmod|grep bonding
4、编辑网卡配置文件(ifcfg-eth0、ifcfg-eth1、ifcfg-bond0)如下
(1)、ifcfg-eth0配置
DEVICE=eth0
bond技术是服务器上面多块网卡同时工作,绑定同一个ip地址,当其中一块网卡坏掉之后不影响服务器的正常工作
步骤如下:
1、查看是否支持bonding技术
cat /boot/config+tab键补全|grep BONDING,如果显示有内容说明支持/etc/modprobe.d/bond.conf
添加如下内容
alias bond0 bonding
options bond0 miimon=50 mode=1
保存退出!
6、重启网卡验证
service network restart
ifconfig all
cat /proc/net/bonding/bond0
ONBOOT=yes
基于linux的bond技术

Linux网口绑定通过网口绑定(bond)技术,可以很容易实现网口冗余,负载均衡,从而达到高可用高可靠的目的。
前提约定:2个物理网口分别是:eth0,eth1绑定后的虚拟口是:bond0服务器IP是:192.168.0.100第一步,配置设定文件:/etc/sysconfig/network-scripts/ifcfg-bond0DEVICE=bond0BOOTPROTO=noneONBOOT=yesIPADDR=192.168.0.100NETMASK=255.255.255.0NETWORK=192.168.0.0BROADCAST=192.168.0.255#BROADCAST广播地址/etc/sysconfig/network-scripts/ifcfg-eth0DEVICE=eth0BOOTPROTO=noneMASTER=bond0SLAVE=yes/etc/sysconfig/network-scripts/ifcfg-eth1DEVICE=eth1BOOTPROTO=noneMASTER=bond0SLAVE=yes第二步,修改modprobe相关设定文件,并加载bonding模块:1.在这里,我们直接创建一个加载bonding的专属设定文件/etc/modprobe.d/bonding.conf[root@test ~]# vi /etc/modprobe.d/bonding.conf#追加alias bond0 bondingoptions bonding mode=0 miimon=2002.加载模块(重启系统后就不用手动再加载了)[root@test ~]# modprobe bonding3.确认模块是否加载成功:[root@test ~]# lsmod | grep bondingbonding 100065 0第三步,重启一下网络,然后确认一下状况:[root@test ~]# /etc/init.d/network restart[root@test ~]# cat /proc/net/bonding/bond0Ethernet Channel Bonding Driver: v3.5.0 (November 4, 2008) Bonding Mode: fault-tolerance (active-backup)Primary Slave: NoneCurrently Active Slave: eth0MII Status: upMII Polling Interval (ms): 200Up Delay (ms): 0Down Delay (ms): 0Slave Interface: eth0MII Status: upLink Failure Count: 0Permanent HW addr: 00:16:36:1b:bb:74Slave Interface: eth1MII Status: upLink Failure Count: 0Permanent HW addr: 00:16:36:1b:bb:80[root@test ~]# ifconfig | grep HWaddrbond0 Link encap:Ethernet HWaddr 00:16:36:1B:BB:74eth0 Link encap:Ethernet HWaddr 00:16:36:1B:BB:74eth1 Link encap:Ethernet HWaddr 00:16:36:1B:BB:74从上面的确认信息中,我们可以看到3个重要信息:1.现在的bonding模式是active-backup2.现在Active状态的网口是eth03.bond0,eth1的物理地址和处于active状态下的eth0的物理地址相同,这样是为了避免上位交换机发生混乱。
Linux网卡bond配置详解

Linux⽹卡bond配置详解⽹卡bonding模式共有0、1、2、3、4、5、6共7种mode1、5、6不需要要交换机设置mode0、2、3、4需要交换机设置1、mode=0 (round-robin)轮询策略,数据包在每个slave⽹卡上都进⾏数据传输,以逐包形式在两个物理⽹卡上转发数据。
这种模式提供了数据的负载均衡和容错能⼒。
2、mode=1 (active-backup)主备策略,只有⼀个slave被激活,只有当active的slave的接⼝down时,才会激活其它slave接⼝。
主备模式下发⽣⼀次故障切换,在新激活的slave接⼝上会发送⼀个或者多个gratuitous ARP。
主salve接⼝上以及配置在接⼝上的所有VLAN接⼝都会发送gratuitous ARP,需要在这些接⼝上配置了⾄少⼀个IP地址。
VLAN接⼝上发送的的gratuitous ARP将会附上适当的VLAN id。
本模式提供容错能⼒。
3、mode=2(XOR)基于所选择的hash策略,本模式也提供负载均衡和容错能⼒4、mode=3(broadcast)⼴播策略,向所有的slave接⼝发送数据包,本模式提供容错能⼒5、mode=4(802.3ad)动态链路聚合,根据802.3ad标准利⽤所有的slave建⽴聚合链路。
slave接⼝的出⼝取决于传输的hash策略,默认策略是简单的XOR策略,⽽hash策略则可以通xmit_hash_policy选项配置。
前提:每个slave⽹卡⽀持ethtool获取速率和双⼯状态交换机⽀持IEEE 802.3ad标准(可能需要配置启⽤)IEEE 802.3ad 是执⾏的标准⽅法。
将多个适配器聚集到单独的虚拟适配器⽅⾯与“(EtherChannel)”的功能相同,能提供更⾼的防⽌发⽣故障。
例如,eth0 和 eth1 可以聚集到称作eth3 的 IEEE 802.3ad;然后⽤ IP 地址配置接⼝ eth3。
linux 双网卡绑定(bonding)实现负载均衡或故障转移

linux 双网卡绑定(bonding)实现负载均衡或故障转移我们在这介绍的Linux双网卡绑定实现就是用法两块网卡虚拟成为一块网卡,这个聚合起来的设备看起来是一个单独的以太网接口设备,通俗点讲就是两块网卡具有相同的IP地址而并行链接聚合成一个规律链路工作。
其实这项技术在Sun和Cisco中早已存在,被称为Trunking 和Etherchannel 技术,在Linux的2.4.x的内核中也采纳这这种技术,被称为bonding。
bonding技术的最早应用是在 beowulf上,为了提高集群节点间的数据传输而设计的。
下面我们研究一下bonding 的原理,什么是bonding需要从网卡的混杂(promisc)模式说起。
我们知道,在正常状况下,网卡只接收目的硬件地址(MAC Aress)是自身Mac 的以太网帧,对于别的数据帧都滤掉,以减轻驱动程序的负担。
但是网卡也支持另外一种被称为混杂promisc的模式,可以接收网络上全部的帧,比如说mp.html' target='_blank'>tcp,就是运行在这个模式下。
bonding也运行在这个模式下,而且修改了驱动程序中的mac地址,将两块网卡的 Mac地址改成相同,可以接收特定mac的数据帧。
然后把相应的数据帧传送给bond驱动程序处理。
挺直给两块网卡设置同一IP地址是不行能的。
Kerne 2.4.12及以后的版本均供bonding模块,以前的版本可以通过实现。
一、编辑虚拟网络接口配置文件,指定网卡IP 假设eth0是对外服务的网卡,已经调试好网络;eth1是希翼与eth0同时对外提供服务的网卡。
/etc/sysconfig/network-scripts/ vi ifcfg-bond0 写入如下信息和本来 ifcfg-eth0 的配置其实差不多。
所以我建议执行如下语句,将ifcfg-eth0复制一份再改。
cp ifcfg-eth0ifcfg-bon0 复制代码将ifcfg-bon0的信息修改大致如下: DEVICE=bond0 BOOTPROTO=ic IPADDR=[IP] NETMASK=[MASK] BROADCAST=[BROADCAST] GATEWAY=[GATEWAY] ONBOOT=yes TYPE=Ethernet 二、配置真切网卡修改ifcfg-eth0如下:DEVICE=eth0 BOOTPROTO=none ONBOOT=yes MASTER=bond0第1页共2页。
Linux之网络配置以及bond介绍

Linux之⽹络配置以及bond介绍Linux之⽹络配置及bond介绍⼀、Linux系统基础⽹络配置概述Linux系统安装完成后,我们⾸要任务就是给系统配置相应的⽹络,这⾥的⽹络配置就包括:⽹络IP的配置、⽹关路由的配置、主机DNS的配置、主机名的配置以及如果安装的服务器有多个⽹⼝时我们还需要配置多个IP甚⾄会⽤到⽹⼝绑定(bond)的形式来满⾜我们的需求等等。
在linux系统下,根据配置的形式不同,总体分为两种形式:暂时的⽹络配置和永久的⽹络配置。
暂时的⽹络配置指:利⽤ifconfig等命令配置的⽹络信息,会⽴即⽣效,但重启⽹络服务和系统后,该配置会失效。
永久的⽹络配置指:通过修改系统内相关的⽹络配置⽂件,并保存后,重启⽹络服务就会永久⽣效。
⼆、暂时的⽹路配置查看系统当前的⽹络配置使⽤【ifconfig】即可,如果想要显⽰所有的⽹⼝,⽆论是否是激活的⽹⼝,使⽤【ifconfig –a】即可。
如下图:显⽰系统当前⽹⼝的配置信息,其中eth0表⽰以太⽹⽹络接⼝,lo表⽰本地回环接⼝。
下⾯介绍使⽤ifconfig临时设置⽹络配置,注意这些修改并不会保存到系统的⽹络配置⽂件中,重启⽹络服务后会恢复到之前未修改的状态。
1. 临时修改IP临时修改IP使⽤【ifconfig ⽹⼝名 ip】,如ifconfig eth0 10.82.25.90可以看到我们已将IP临时改为10.82.25.901. 修改⽹关Linux系统下查看本机路由信息,使⽤【route -n】,选项【n】表⽰以数字的⽅式显⽰,可以不加选项直接route,增加⽹关使⽤【route add default gw 10.82.25.2 dev ⽹⼝名】,删除将add改为del即可1. 修改DNSDNS在系统的【/etc/resolv.conf】路径下,修改DNS是直接修改配置⽂件,保存后会⽣效,我们直接使⽤vi去编辑该⽂件如图我们直接使⽤VI将DNS修改为10.82.1.6,保存退出即可。
Linux bonding配置指导书(CentOS5.3)

1 CentOS5.3配置指导1.1 网络规划举例来说,服务器有网卡eth0、eth1,需要将这两个进行绑定使用,绑定后虚拟网卡为bond0.1.2 内核模块加载设置在/etc/modprobe.conf 文件中,增加启用的bond口的内核模块,形式如下:alias bond0 bonding这里表示需要生效bond0口,并为其加载bonding内核模块。
1.3 增加网口配置信息修改/etc/sysconfig/network-scripts/ 目录下对应的网卡配置文件,并新增bond0口的配置,配置文件信息内容如下:[root@vm25481 network-scripts]# cat ifcfg-bond0DEVICE=bond0BOOTPROTO=staticONBOOT=yesIPADDR=192.168.254.89NETMASK=255.255.255.0GATEWAY=192.168.254.1TYPE=EthernetUSERCTL=noBONDING_OPTS="mode=2 xmit_hash_policy=1 miimon=100"[root@vm25481 network-scripts]# cat ifcfg-eth0DEVICE=eth0BOOTPROTO=noneONBOOT=yesMASTER=bond0USERCTL=noSLAVE=yes[root@vm25481 network-scripts]# cat ifcfg-eth1DEVICE=eth1BOOTPROTO=noneONBOOT=yesMASTER=bond0USERCTL=noSLAVE=yes注意:要去除物理网卡配置中mac地址的信息。
1.4 连接网线并进行交换机配置由于选用的是“mode=2 xmit_hash_policy=1”,若接到同一交换机,交换机上需做手工聚合,同时配置负载分摊模式,否则会产生MAC地址振荡,最终配置聚合配置及模式如下:[H3C-Bridge-Aggregation1]display link-aggregation load-sharing modeLink-Aggregation Load-Sharing Mode:Layer 2 traffic: destination-mac address, source-mac addressLayer 3 traffic: destination-ip address, source-ip address[H3C-Bridge-Aggregation1]1.5 配置生效确认[root@vm25481 ~]# routeKernel IP routing tableDestination Gateway Genmask Flags Metric Ref Use Iface 192.168.254.0 * 255.255.255.0 U 0 0 0 bond0 169.254.0.0 * 255.255.0.0 U 0 0 0 bond0 default 192.168.254.1 0.0.0.0 UG 0 0 0 bond02 部署过程中问题2.1 启动过程打印网卡为百兆设备启动过程中打印如下信息:bonding: bond0: Warning: failed to get speed and duplex from eth1, assumed to be100Mb/sec and Full.bnx2: eth0 NIC Link is Up, 1000 Mbps full duplex, receive & transmit flow control ONbonding: bond0: backup interface eth1 is now up上述信息是由于bond0先于物理网卡启动,因此,无法获取到相关信息,当物理网卡启动后,会通知bond来更新速率和双工信息。
linux中bonding原理

bonding•networking [1]The Linux bonding driver provides a method for aggregatingmultiple network interfaces into a single logicalbonded [2] interface.The behavior of the bonded interfaces depends upon the mode; generally speaking, modes provide either hot standby or load balancing services. Additionally, link integrity monitoring may be performed.The bonding driver originally came fromDonald Becker's [3]beowulf [4] patches for kernel 2.0.It has changed quite a bit since, andthe original tools from extreme-linux and beowulf sites will not work with this version of the driver.For new versions of the driver, updated userspace tools, andwho to ask for help, please follow the links at the end of this file. Contents• 1 Installationo 1.1 Configure and build the kernel with bondingo 1.2 Install ifenslave Control Utility• 2 Bonding Driver Options• 3 Configuring Bonding Deviceso 3.1 Configuration with sysconfig support▪ 3.1.1 Using DHCP with sysconfig▪ 3.1.2 Configuring Multiple Bonds with sysconfigo 3.2 Configuration with initscripts support▪ 3.2.1 Using DHCP with initscripts▪ 3.2.2 Configuring Multiple Bonds with initscriptso 3.3 Configuring Bonding with /etc/neto 3.4 Configuring Bonding Manually▪ 3.4.1 Configuring Multiple Bonds Manually• 4 Querying Bonding Configurationo 4.1 Bonding Configurationo 4.2 Network configuration• 5 Switch Configuration• 6 802.1q VLAN Support•7 Link Monitoringo7.1 ARP Monitor Operationo7.2 Configuring Multiple ARP Targetso7.3 MII Monitor Operation•8 Potential Sources of Troubleo8.1 Adventures in Routingo8.2 Ethernet Device Renamingo8.3 Painfully Slow Or No Failed Link Detection By Miimon•9 SNMP agentso9.1 Promiscuous mode•10 Configuring Bonding for High Availabilityo10.1 High Availability in a Single Switch Topologyo10.2 High Availability in a Multiple Switch Topology▪10.2.1 HA Bonding Mode Selection for Multiple Switch Topology▪10.2.2 HA Link Monitoring Selection for Multiple Switch Topology •11 Configuring Bonding for Maximum Throughputo11.1 Maximizing Throughput in a Single Switch Topology▪11.1.1 MT Bonding Mode Selection for Single Switch Topology▪11.1.2 MT Link Monitoring for Single Switch Topology o11.2 Maximum Throughput in a Multiple Switch Topology▪11.2.1 MT Bonding Mode Selection for Multiple Switch Topology▪11.2.2 MT Link Monitoring for Multiple Switch Topology•12 Switch Behavior Issueso12.1 Link Establishment and Failover Delayso12.2 Duplicated Incoming Packets•13 Hardware Specific Considerationso13.1 IBM BladeCentero13.2 JS20 network adapter informationo13.3 BladeCenter networking configurationo13.4 Requirements for specific modeso13.5 Link monitoring issueso13.6 Other concerns•14 Frequently Asked Questionso14.1 Is it SMP safe?o14.2 What type of cards will work with it?o14.3 How many bonding devices can I have?o14.4 How many slaves can a bonding device have?o14.5 What happens when a slave link dies?•15 Can bonding be used for High Availability?•16 Which switches/systems does it work with?o16.1 Where does a bonding device get its MAC address from?•17 Resources and Links•18 HistoryInstallationMost popular distro kernels ship with the bonding driveralready available as a module and the ifenslave user level control program installed and ready for use. If your distro does not, or you have need to compile bonding from source (e.g., configuring and installing a mainline kernel from ), you'll need to perform the following steps:Configure and build the kernel with bondingThe current version of the bonding driver is available in thedrivers/net/bonding subdirectory of the most recent kernel source (which is available on [5] ).Most users "rolling their own" will want to use the most recent kernel from .Configure kernel with "make menuconfig" (or "make xconfig" or"make config"), then select "Bonding driver support" in the "Network device support" section. It is recommended that you configure the driver as module since it is currently the only way to pass parameters to the driver or configure more than one bonding device.Build and install the new kernel and modules, then continuebelow to install ifenslave.Install ifenslave Control UtilityThe ifenslave user level control program is included in thekernel source tree, in the file Documentation/networking/ifenslave.c. It is generally recommended that you use the ifenslave that corresponds to the kernel that you are using (either from the same source tree or supplied with the distro), however, ifenslave executables from older kernels should function (but features newer than the ifenslave release are not supported). Running an ifenslavethat is newer than the kernel is not supported, and may or may not work.To install ifenslave, do the following:# gcc -Wall -O -I/usr/src/linux/include ifenslave.c -o ifenslave# cp ifenslave /sbin/ifenslaveIf your kernel source is not in "/usr/src/linux," then replace"/usr/src/linux/include" in the above with the location of your kernel source include directory.You may wish to back up any existing /sbin/ifenslave, or, fortesting or informal use, tag the ifenslave to the kernel version(e.g., name the ifenslave executable /sbin/ifenslave-2.6.10).IMPORTANT NOTE:If you omit the "-I" or specify an incorrect directory, youmay end up with an ifenslave that is incompatible with the kernelyou're trying to build it for. Some distros (e.g., Red Hat from 7.1 onwards) do not have /usr/include/linux symbolically linked to the default kernel source include directory.Bonding Driver OptionsOptions for the bonding driver are supplied as parameters tothe bonding module at load time. They may be given as command line arguments to the insmod or modprobe command, but are usually specified in either the /etc/modules.conf or /etc/modprobe.conf configuration file, or in a distro-specific configuration file (some of which are detailed in the next section).The available bonding driver parameters are listed below. If a parameter is not specified the default value is used. When initially configuring a bond, it is recommended "tail -f /var/log/messages" be run in a separate window to watch for bonding driver error messages.It is critical that either the miimon or arp_interval andarp_ip_target parameters be specified, otherwise serious networkdegradation will occur during link failures. Very few devices do not support at least miimon, so there is really no reason not to use it.Options with textual values will accept either the text nameor, for backwards compatibility, the option value. E.g.,"mode=802.3ad" and "mode=4" set the same mode.The parameters are as follows:arp_intervalSpecifies the ARP link monitoring frequency in milliseconds. If ARP monitoring is used in an etherchannel compatible mode (modes 0 and 2), the switch should be configured in a mode that evenly distributes packets across all links. If the switch is configured to distribute the packets in an XOR fashion, all replies from the ARP targets will be received on the same link which could cause the other team members to fail. ARP monitoring should not be used in conjunction with miimon. A value of 0 disables ARP monitoring.The default value is 0.arp_ip_targetSpecifies the IP addresses to use as ARP monitoring peers when arp_interval is > 0. These are the targets of the ARP request sent to determine the health of the link to the targets.Specify these values in ddd.ddd.ddd.ddd format. Multiple IP addresses must be separated by a comma. At least one IP address must be given for ARP monitoring to function. The maximum number of targets that can be specified is 16. The default value is no IP addresses.downdelaySpecifies the time, in milliseconds, to wait before disabling a slave after a link failure has been detected. This option is only valid for the miimon link monitor. The downdelay value should be a multiple of the miimon value; if not, it will be rounded down to the nearest multiple. The default value is 0.lacp_rateOption specifying the rate in which we'll ask our link partner to transmit LACPDU packets in 802.3ad mode. Possible values are:•slow or 0Request partner to transmit LACPDUs every 30 seconds.•fast or 1Request partner to transmit LACPDUs every 1 second The default is slow.max_bondsSpecifies the number of bonding devices to create for this instance of the bonding driver.E.g., if max_bonds is 3, and the bonding driver is not already loaded, then bond0, bond1and bond2 will be created. The default value is 1.miimonSpecifies the MII link monitoring frequency in milliseconds. This determines how often the link state of each slave is inspected for link failures. A value of zero disables MII link monitoring. A value of 100 is a good starting point.The use_carrier option, below, affects how the link state is determined. See the HighAvailability section for additional information. The default value is 0.modeSpecifies one of the bonding policies. The default is balance-rr (round robin).Possible values are:•balance-rr or 0Round-robin policy: Transmit packets in sequential order from the first available slave through the last. This mode provides load balancing and fault tolerance.•active-backup or 1Active-backup policy: Only one slave in the bond is active. A different slave becomes active if, and only if, the active slave fails. The bond's MAC address is externally visible on only one port (network adapter) to avoid confusing the switch.In bonding version 2.6.2 or later, when a failover occurs in active-backup mode, bonding will issue one or more gratuitous ARPs on the newly active slave. One gratutious ARP is issued for the bonding master interface and each VLAN interfaces configured above it, provided that the interface has at least one IP address configured.Gratuitous ARPs issued for VLAN interfaces are tagged with the appropriate VLAN id. This mode provides fault tolerance. The primary option, documented below, affects the behavior of this mode.•balance-xor or 2XOR policy: Transmit based on the selected transmit hash policy. The default policy is a simpleAlternate transmit policies may be selected via the xmit_hash_policy option.This mode provides load balancing and fault tolerance.•broadcast or 3Broadcast policy: transmits everything on all slave interfaces. This mode provides fault tolerance.•802.3ad or 4IEEE 802.3ad Dynamic link aggregation. Creates aggregation groups that share the same speed and duplex settings. Utilizes all slaves in the active aggregator according to the 802.3ad specification.Slave selection for outgoing traffic is done according to the transmit hash policy, which may be changed from the default simple XOR policy via the xmit_hash_policy option, documented below. Note that not all transmit policies may be 802.3ad compliant, particularly in regards to the packet mis-ordering requirements of section 43.2.4 of the 802.3ad[6] standard. Differing peer implementations will have varying tolerances for noncompliance.•Prerequisites:1.Ethtool support in the base drivers for retrieving the speed and duplexof each slave.2. A switch that supports IEEE 802.3ad Dynamic link aggregation.Most switches will require some type of configuration to enable 802.3ad mode.•balance-tlb or 5Adaptive transmit load balancing: channel bonding that does not require any special switch support. The outgoing traffic is distributed according to the current load (computed relative to the speed) on each slave. Incoming traffic is received by the current slave. If the receiving slave fails, another slave takes over the MAC address of the failed receiving slave.•Prerequisite:1.Ethtool support in the base drivers for retrieving the speed of eachslave.•balance-alb or 6Adaptive load balancing: includes balance-tlb plus receive load balancing (rlb) for IPV4 traffic, and does not require any special switch support. The receive load balancing is achieved by ARP negotiation.The bonding driver intercepts the ARP Replies sent by the local system on their way out and overwrites the source hardware address with the unique hardware address of one of the slaves in the bond such that different peers use different hardware addresses for the server.Receive traffic from connections created by the server is also balanced. When the local system sends an ARP Request the bonding driver copies and saves the peer's IP information from the ARP packet.When the ARP Reply arrives from the peer, its hardware address is retrieved and the bonding driver initiates an ARP reply to this peer assigning it to one of the slaves in the bond.A problematic outcome of using ARP negotiation for balancing is that each time that anARP request is broadcast it uses the hardware address of the bond. Hence, peers learn the hardware address of the bond and the balancing of receive traffic collapses to the current slave. This is handled by sending updates (ARP Replies) to all the peers with their individually assigned hardware address such that the traffic is redistributed. Receive traffic is also redistributed when a new slave is added to the bond and when an inactive slave is re-activated. The receive load is distributed sequentially (round robin) among the group of highest speed slaves in the bond.When a link is reconnected or a new slave joins the bond the receive traffic is redistributed among all active slaves in the bond by initiating ARP Replies with the selected mac address to each of the clients. The updelay parameter (detailed below) must be set to a value equal or greater than the switch's forwarding delay so that the ARP Replies sent to the peers will not be blocked by the switch.•Prerequisites:1.Ethtool support in the base drivers for retrieving the speed of eachslave.2.Base driver support for setting the hardware address of a device while itis open. This is required so that there will always be one slave in theteam using the bond hardware address (the curr_active_slave) whilehaving a unique hardware address for each slave in the bond. If thecurr_active_slave fails its hardware address is swapped with the newcurr_active_slave that was chosen.primaryA string (eth0, eth2, etc) specifying which slave is the primary device. The specifieddevice will always be the active slave while it is available. Only when the primary is off-line will alternate devices be used. This is useful when one slave is preferred over another, e.g., when one slave has higher throughput than another. The primary option is only valid for active-backup mode.updelaySpecifies the time, in milliseconds, to wait before enabling a slave after a link recovery has been detected. This option is only valid for the miimon link monitor. The updelay value should be a multiple of the miimon value; if not, it will be rounded down to the nearest multiple. The default value is 0.use_carrierSpecifies whether or not miimon should use MII or ETHTOOL ioctls vs. netif_carrier_ok() to determine the link status. The MII or ETHTOOL ioctls are less efficient and utilize a deprecated calling sequence within the kernel. The netif_carrier_ok() relies on the device driver to maintain its state with netif_carrier_on/off; at this writing, most, but not all, device drivers support this facility.If bonding insists that the link is up when it should not be, it may be that your network device driver does not support netif_carrier_on/off. The default state for netif_carrier is "carrier on," so if a driver does not support netif_carrier, it will appear as if the link is always up. In this case, setting use_carrier to 0 will cause bonding to revert to the MII / ETHTOOL ioctl method to determine the link state.A value of 1 enables the use of netif_carrier_ok(), a value of 0 will use the deprecatedMII / ETHTOOL ioctls. The default value is 1.xmit_hash_policySelects the transmit hash policy to use for slave selection in balance-xor and 802.3ad modes. Possible values are:•layer2Uses XOR of hardware MAC addresses to generate the hash. The formula isThis algorithm will place all traffic to a particular network peer on the same slave.This algorithm is 802.3ad compliant.•layer3+4This policy uses upper layer protocol information, when available, to generate the hash.This allows for traffic to a particular network peer to span multiple slaves, although a single connection will not span multiple slaves.The formula for unfragmented TCP and UDP packets isFor fragmented TCP or UDP packets and all other IP protocol traffic, the source and destination port information is omitted. For non-IP traffic, the formula is the same as for the layer2 transmit hash policy.This policy is intended to mimic the behavior of certain switches, notably Cisco switches with PFC2 as well as some Foundry and IBM products.This algorithm is not fully 802.3ad compliant. A single TCP or UDP conversation containing both fragmented and unfragmented packets will see packets striped across two interfaces. This may result in out of order delivery. Most traffic types will not meet this criteria, as TCP rarely fragments traffic, and most UDP traffic is not involved in extended conversations. Other implementations of 802.3ad may or may not tolerate this noncompliance.The default value is layer2. This option was added in bonding version 2.6.3. In earlier versions of bonding, this parameter does not exist, and the layer2 policy is the only policy.Configuring Bonding DevicesThere are, essentially, two methods for configuring bonding: with support from the distro's network initialization scripts, and without. Distros generally use one of two packages for the network initialization scripts: initscripts or sysconfig. Recent versions of these packages have support for bonding, while older versions do not. /etc/net has built-in support for interface bonding.We will first describe the options for configuring bonding for distros using versions of initscripts and sysconfig with full orpartial support for bonding, then provide information on enabling bonding without support from the network initialization scripts (i.e.,older versions of initscripts or sysconfig).If you're unsure whether your distro uses sysconfig or initscripts, or don't know if it's new enough, have no fear.Determining this is fairly straightforward.First, issue the command:$ rpm -qf /sbin/ifupIt will respond with a line of text starting with either "initscripts" or "sysconfig," followed by some numbers. This is thepackage that provides your network initialization scripts.Next, to determine if your installation supports bonding, issue the command:$ grep ifenslave /sbin/ifupIf this returns any matches, then your initscripts or sysconfig has support for bonding.Configuration with sysconfig supportThis section applies to distros using a version of sysconfig with bonding support, for example, SuSE Linux Enterprise Server 9.SuSE SLES 9's networking configuration system does support bonding, however, at this writing, the YaST system configurationfrontend does not provide any means to work with bonding devices. Bonding devices can be managed by hand, however, as follows.First, if they have not already been configured, configure the slave devices. On SLES 9, this is most easily done by running theyast2 sysconfig configuration utility. The goal is for to create an ifcfg-id file for each slave device. The simplest way to accomplish this is to configure the devices for DHCP [7] (this is only to get the file ifcfg-id file created; see below for some issues with DHCP). The name of the configuration file for each device will be of the form:ifcfg-id-xx:xx:xx:xx:xx:xxWhere the "xx" portion will be replaced with the digits from the device's permanent MAC address.Once the set of ifcfg-id-xx:xx:xx:xx:xx:xx files has been created, it is necessary to edit the configuration files for the slavedevices (the MAC addresses correspond to those of the slave devices).Before editing, the file will contain multiple lines, and will look something like this:BOOTPROTO='dhcp'STARTMODE='on'USERCTL='no'UNIQUE='XNzu.WeZGOGF+4wE'_nm_name='bus-pci-0001:61:01.0'Change the BOOTPROTO and STARTMODE lines to the following:BOOTPROTO='none'STARTMODE='off'Do not alter the UNIQUE or _nm_name lines. Remove any other lines (USERCTL, etc).Once the ifcfg-id-xx:xx:xx:xx:xx:xx files have been modified,it's time to create the configuration file for the bonding device itself. This file is named ifcfg-bondX, where X is the number of the bonding device to create, starting at 0. The first such file isifcfg-bond0, the second is ifcfg-bond1, and so on. The sysconfig network configuration system will correctly start multiple instances of bonding.The contents of the ifcfg-bondX file is as follows:BOOTPROTO="static"BROADCAST="10.0.2.255"IPADDR="10.0.2.10"NETMASK="255.255.0.0"NETWORK="10.0.2.0"REMOTE_IPADDR=""STARTMODE="onboot"BONDING_MASTER="yes"BONDING_MODULE_OPTS="mode=active-backup miimon=100" BONDING_SLAVE0="eth0"BONDING_SLAVE1="bus-pci-0000:06:08.1"Replace the sample BROADCAST, IPADDR, NETMASK and NETWORK values with the appropriate values for your network.The STARTMODE specifies when the device is brought online.The possible values are:onbootThe device is started at boot time. If you're not sure, this is probably what you want. manualThe device is started only when ifup is called manually. Bonding devices may be configured this way if you do not wish them to start automatically at boot for some reason.hotplugThe device is started by a hotplug event. This is not a valid choice for a bonding device.off or ignoreThe device configuration is ignored.The line BONDING_MASTER='yes' indicates that the device is a bonding master device. The only useful value is "yes."The contents of BONDING_MODULE_OPTS are supplied to the instance of the bonding module for this device. Specify the optionsfor the bonding mode, link monitoring, and so on here. Do not include the max_bonds bonding parameter; this will confuse the configuration system if you have multiple bonding devices.Finally, supply one BONDING_SLAVEn="slave device" for each slave. where "n" is an increasing value, one for each slave. The"slave device" is either an interface name, e.g., "eth0", or a device specifier for the network device. The interface name is easier to find, but the ethN names are subject to change at boot time if, e.g., a device early in the sequence has failed. The device specifiers(bus-pci-0000:06:08.1 in the example above) specify the physical network device, and will not change unless the device's bus location changes (for example, it is moved from one PCI slot to another). The example above uses one of each type for demonstration purposes; most configurations will choose one or the other for all slave devices.When all configuration files have been modified or created, networking must be restarted for the configuration changes to takeeffect. This can be accomplished via the following:# /etc/init.d/network restartNote that the network control script (/sbin/ifdown) willremove the bonding module as part of the network shutdown processing, so it is not necessary to remove the module by hand if, e.g., the module parameters have changed.Also, at this writing, YaST/YaST2 will not manage bondingdevices (they do not show bonding interfaces on its list of networkdevices). It is necessary to edit the configuration file by hand to change the bonding configuration.Additional general options and details of the ifcfg fileformat can be found in an example ifcfg template file:/etc/sysconfig/network/ifcfg.templateNote that the template does not document the various BONDING_settings described above, but does describe many of the other options.Using DHCP with sysconfigUnder sysconfig, configuring a device with BOOTPROTO='dhcp'will cause it to query DHCP for its IP address information. At this writing, this does not function for bonding devices; the scripts attempt to obtain the device address from DHCP prior to adding any of the slave devices. Without active slaves, the DHCP requests are not sent to the network.Configuring Multiple Bonds with sysconfigThe sysconfig network initialization system is capable ofhandling multiple bonding devices. All that is necessary is for each bonding instance to have an appropriately configured ifcfg-bondX file (as described above). Do not specify the "max_bonds" parameter to any instance of bonding, as this will confuse sysconfig. If you require multiple bonding devices with identical parameters, create multiple ifcfg-bondX files.Because the sysconfig scripts supply the bonding moduleoptions in the ifcfg-bondX file, it is not necessary to add them to the system /etc/modules.conf or /etc/modprobe.conf configuration file.Configuration with initscripts supportThis section applies to distros using a version of initscriptswith bonding support, for example, Red Hat Linux 9 or Red Hat Enterprise Linux version 3 or 4. On these systems, the network initialization scripts have some knowledge of bonding, and can be configured to control bonding devices.These distros will not automatically load the network adapterdriver unless the ethX device is configured with an IP address. Because of this constraint, users must manually configure anetwork-script file for all physical adapters that will be members of a bondX link. Network script files are located in the directory:/etc/sysconfig/network-scriptsThe file name must be prefixed with "ifcfg-eth" and suffixedwith the adapter's physical adapter number. For example, the script for eth0 would be named /etc/sysconfig/network-scripts/ifcfg-eth0. Place the following text in the file:DEVICE=eth0USERCTL=noONBOOT=yesMASTER=bond0SLAVE=yesBOOTPROTO=noneThe DEVICE= line will be different for every ethX device andmust correspond with the name of the file, i.e., ifcfg-eth1 must have a device line of DEVICE=eth1. The setting of the MASTER= line will also depend on the final bonding interface name chosen for your bond. As with other network devices, these typically start at 0, and go up one for each device, i.e., the first bonding instance is bond0, the second is bond1, and so on.Next, create a bond network script. The file name for thisscript will be /etc/sysconfig/network-scripts/ifcfg-bondX where X is the number of the bond. For bond0 the file is named "ifcfg-bond0",for bond1 it is named "ifcfg-bond1", and so on. Within that file, place the following text:DEVICE=bond0IPADDR=192.168.1.1NETMASK=255.255.255.0NETWORK=192.168.1.0BROADCAST=192.168.1.255。
Linux Bond的原理及其不足
Linux Bond的原理及其不足在企业及电信Linux服务器环境上,网络配置都会使用Bonding技术做网口硬件层面的冗余,防止单个网口应用的单点故障。
Linux Bond的配置很简单,当下网络上也有很多资料,这里我们就不介绍了。
我们在这篇文章中介绍Linux Bond的原理及其不足。
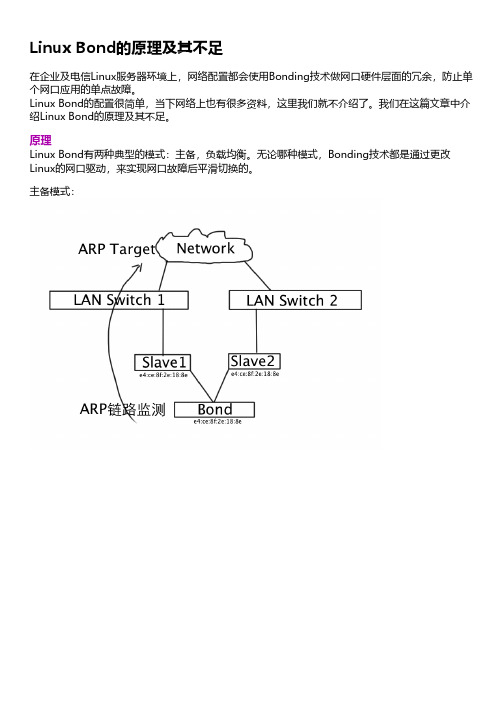
原理Linux Bond有两种典型的模式:主备,负载均衡。
无论哪种模式,Bonding技术都是通过更改Linux的网口驱动,来实现网口故障后平滑切换的。
主备模式:负载均衡模式:1. 我们先看主备模式主备模式下,Linux Bonding实现会将Bond的两个slave网口的MAC地址改为Bond的MAC地址,而Bond的MAC地址是Bond创建启动后,主用slave网口的MAC地址。
当住用网口故障后,Bond会切换到备用网口,切换过程中,上层的应用是无感知不受影响的,因为Bond在驱动层,会接管上层应用的数据包,缓存起来等备用网卡起来后再通过备用网卡发送出去。
当然,前提是切换时间很短,否则缓冲区是会溢出的,溢出后就开始丢包了。
具体的时间值本人还没有验证过。
2. 再看负载均衡模式负载均衡模式下,Linux Bonding实现可以保持两个slave网口的MAC地址不变,Bond的MAC地址是其中一个网卡的,Bond MAC地址的选择是根据Bond自己实现的一个算法来的,具体如何选择还没有研究。
当然,这里要重点说明的是,Bond负载均衡模式下,要求交换机做配置,是的两个slave网口能够互通,否则的话,丢包会很厉害,基本没法使用。
这个是因为Bond的负载均衡模式算法,会将包在两个网口之间传输以达到负载均衡。
由于负载均衡模式下,两个slave有独立的MAC地址,你可能会想,我能否给slave网口再绑定一个IP地址,用作其他用途。
这种方法是实现不了的。
负载均衡模式下,两个slave网口在操作性系统上看到是两个独立的MAC地址,但是当你指定一个MAC地址发送包的时候,实际上发生的现象,不是你期望的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
目录bonding的介绍 (3)bonding的应用 (3)bonding的参数详解 (3)bonding的模式 (5)bonding的链路监控 (6)bonding的配置 (7)单个bonding的主备模式的配置 (7)单个bonding带arp监控的主备模式 (10)多个不同模式bonding的混合配置 (11)bonding的子接口配置 (12)总结 (13)⏹bonding的介绍linux bonding 驱动提供了一个把多个网络接口设备捆绑为单个的网络接口设置来使用,用于网络负载均衡及网络冗余。
●bonding的应用1、网络负载均衡;对于bonding的网络负载均衡是我们在文件服务器中常用到的,比如把三块网卡,当做一块来用,解决一个IP地址,流量过大,服务器网络压力过大的问题。
如果在内网中,文件服务器为了管理和应用上的方便,大多是用同一个IP地址。
对于一个百M的本地网络来说,文件服务器在多个用户同时使用的情况下,网络压力是极大的,为了解决同一个IP地址,突破流量的限制,毕竟网线和网卡对数据的吞吐量是有限制的。
如果在有限的资源的情况下,实现网络负载均衡,最好的办法就是bonding 。
2、网络冗余;对于服务器来说,网络设备的稳定也是比较重要的,特别是网卡。
大多通过硬件设备的冗余来提供服务器的可靠性和安全性,比如电源。
bonding 也能为网卡提供冗余的支持。
把网个网卡绑定到一个IP地址,当一块网卡发生物理性损坏的情况下,另一块网卡也能提供正常的服务。
●. Bonding参数详解Bonding驱动的选项是通过在加载时指定参数来设定的。
可以通过insmod 或modprobe命令的命令行参数来指定,但通常在/etc /modules.conf或/etc/modprobe.conf配置文件中指定. 下面列出可用的bonding驱动参数。
如果参数没有指定,驱动会使用缺省参数。
刚开始配置bond的时候,建议在一个终端窗口中运行"tail -f /var/log/messages"来观察bonding驱动的错误信息.有些参数必须要正确的设定,比如miimon、arp_interval和arp_ip_target,否则在链接故障时会导致严重的网络性能退化。
有些选项不仅支持文本值的设定,出于兼容性的考虑,也支持数值的设定,比如,"mode=802.3ad"和"mode=4"效果是一样的。
2具体的参数列表:bonding的模式3bonding一共有7种方式:4bonding链路监控当前的bonding驱动支持两种模式,来监控slave设备的链路状态:ARP监控和MII监控。
由于bonding驱动自身的实现限制,现在我们不可能同时启用ARP和MII监控。
1、ARP监控操作ARP监控正如其名字所暗示的:它想网络上的对端系统发送ARP请求,并且通过ARP相应作为链路是否可用的标志,这可以保证网络两端的流量确实是通的。
ARP监控依赖于设备驱动来验证流量是否是通的,进一步,驱动必须保留上次接收时间,dev->last_rx,以及传输起始时间,dev->trans_start。
如果这些值不会被驱动更新,则ARP监控立刻会认为对应于该驱动的slave出现了故障,这些slave将会进入断开状态。
如果网络监控工具(比如tcpdump)显示ARP 请求和相应都正常,那有可能是你的设备驱动没有更新last_rx和trans_start。
配置多ARP目的地址尽管ARP监控可以只用一个目的地址来实现,但在高可靠性(High Availability)环境下,如果能够对多个目的地址进行监控也是很有用的。
在只有一个目的地址的情况下,如果目标本身被关闭或者遇到问题以致无法响应ARP请求,这时额外的一个目标(或更多)可以增加ARP监控的可靠性。
多个ARP目的地址之间必须以逗号分割,如下:#三个目的地址的ARP监控选项示例alias bond0 bondingoptions bond arp_interval=60 arp_ip_target=192.168.0.1,192.168.0.3,192.168.0.9如果只有一个目的地址,配置也很类似:# 只有1个目的地址的ARP监控选项示例alias bond0 bondingoptions bond0 arp_interval=60 arp_ip_target=192.168.0.10052、MII监控操作MII监控通过监控本地网络接口的载波状态来实现监控链路状态。
可以通过3种方法之一来实现:通过依赖设备驱动来维护载波状态;通过查询设备的MII寄存器;或者通过给设备发送ethtool查询。
如果模块参数use_carrier被设为1(缺省值),MII监控将会依赖于设备来获取载波状态信息(通过netif_carrier子系统)。
正如前文介绍的use_carrier参数信息,如果MII监控不能发现设备的载波消失(比如当电缆被物理拔断时),那有可能时设备不支持netif_carrier。
如果use_carrier为0,MII监控首先会查询设备(通过ioctl)的MII寄存器并检查链路状态,如果查询失败(返回载波断开不属于失败),则MII监控会发送一个ethtool ETHOOL_GLINK查询以尝试获取类似的信息,如果两种方法都失败了(设备不支持或者在处理MII寄存器和ethtool查询时发生了错误),那么MII监控将会假定链路是正常的。
⏹bonding的配置●实验环境惠普刀片服务器,操作系统为linux(东信北邮系统集成安装盘5.5版本),有四块网卡:eth0、eth1、eth2、eth3。
●单个bonding的主备模式的配置。
例如eth1和eth3捆绑成bond1,模式为主备模式1、配置/etc/sysconfig/network-scripts/ifcfg-bond0Miimon:指定MII链路监控频率,单位是毫秒(ms)。
这将决定驱动检查每个slave链路状态频率。
0表示禁止MII链路监控。
100可以作为一个很好的初始参考值。
下面的use_carrier选项将会影响如果检测链路状态。
缺省值为0。
mode:指定bonding的策略(参考bonding的7种模式)。
缺省是balance-rr(round robin)。
62、将eth1和eth3加入到bond1中,需要修改/etc/sysconfig/network-scripts下的ifcfg-eth1和ifcfg-eth3.注意:MAC地址必须正确,不能注释,否则在重启的时候会漂。
3、修改/etc/modprobe.conf,如下:4、重启主机或者重启bond模块后查看7(1)ifconfig查看结果如下,可以看到eth1和eth3的MAC地址是一样的,说明绑成功。
(2)cat /proc/net/bonding/bond1查看结果如下,可以看到模式是主备模式,链路检测时间为100ms,当前的主网卡是eth35、down掉主网口eth3后,可以看到eth1切换成主。
8单个bonding带arp监控的主备模式。
1、Bonding的配置步骤和上面一样,需要在ifcfg-bond0中添加一行arp_interval指定arp检查的时间间隔,arp_ip_target是要反向查询arp的ip地址列表,最多16个,以逗号分隔.Arp_validate制定arp的有效日期,all表示长久有效。
在配置arp_interval时,要根据实际网络的规模以及需要进行配置,否则肯能会由于arp包过多产生网络拥塞。
配置/etc/sysconfig/network-scripts/ifcfg-bond0如下:2、重启主机或者重启bond模块后,cat /proc/net/bonding/bond0如下图。
9多个不同模式bonding的混合配置例如将bond0配置成主备模式,bond1配置成广播策略模式,配置过程如下:1、配置ifcfg-bond1,mode参数为2(广播策略模式)2、配置ifcfg-bond0 ,mode参数为1(主备模式)3、重启主机或者服务后可以看到bond1的模式发生了变化:104、在同一网段的主机上ping bond1可以ping通:bonding的子接口配置例如要给bond0配置一个具有其他ip地址的子接口bond0:0,如果只是临时的地址通过命令:ifconfig bond0:0 192.0.2.1 netmask 255.255.255.0 up 就可以了如果需要永久有效的话,在/etc/sysconfig/network-scripts下新建配置文件ifcfg-bond0:0 配置如下:重启服务后可以查看到,子接口依然是有效的。
11总结linux bonding在捆绑过程中需要修改的几个配置文件:/etc/modprobe.conf和/etc/sysconfig/network-scripts/ifcfg-***。
配置完成后需要重启服务。
如果重启后没有生效,可以检查配置文件和硬件等等。
重启服务命令:service network restart重启bond模块:ifconfig bond0 downrmmod bondingifup bond012。