rfc1436.The Internet Gopher Protocol (a distributed document search and retrieval protocol)
Web前端开发技术 (第3版)储久良1

3 ftp 4 mailto
文件传输协议 电子邮件地址
5 ldap 6 news 7 file
轻型目录访问协议搜索 Usenet新闻组 当地电脑或网上分享的文件
8 gopher
Internet Gopher Protocol (Internet 查找协议)
教育部高等学校软件工程专业教学指导委员会规划教材
括代码的可维护性、组件的易用性和浏览器兼容性等。
教育部高等学校软件工程专业教学指导委员会规划教材
第1章 Web前端开发技术综述
Page: 11
Web前端开发技术-HTML5、CSS3、JavaScript
1.3 Web前端开发技术
1.3.1 HTML HTML是SGML(Standard Generalized Markup
教育部高等学校软件工程专业教学指导委员会规划教材
第1章 Web前端开发技术综述
Page: 10
1.2 Web前端开发工程师职业需求
Web前端开发技术-HTML5、CSS3、JavaScript
我国互联网行业的发展呈现迅猛的增长势头,对网站开发、 设计制作的人才需求随之大量增加。前端开发和后台开发人员的 比例为1:1,而在我国目前依旧在1:3以下,人才缺口较大。
Language,标准通用标记语言)下的一个应用(也称为一个子集) ,也是一种标准规范,它通过标记符号来标记要显示的网页中的 各个部分。而SGML是一种定义电子文档结构和描述其内容的国 际标准语言,是所有电子文档标记语言的起源。
HTML是构成Web页面(Page)的基础。 HTML文档:用来描述网页,由HTML 标记和纯文本构成文 本文件。不同于纯文本文件(不含HTML标记)。
协议类型://服务器地址(端口号)/ 路径/文件名 http://info.cern.ch/www20/0002 /kexuetansuo_1 2385/index.shtml
tcp,ip协议包括哪些

竭诚为您提供优质文档/双击可除tcp,ip协议包括哪些篇一:tcpip和osi模型分别分为几层,每层主要作用以及包括的主要协议tcp/ip协议分为4层1.网络接口层:对实际的网络媒体的管理,定义如何使用实际网络(如ethernet、serialline等)来传送数据。
主要协议:ip(internetprotocol)协议3.传输层:提供了节点间的数据传送服务,如传输控制协议(tcp)、用户数据报协议(udp)等,tcp和udp给数据包加入传输数据并把它传输到下一层中,这一层负责传送数据,并且确定数据已被送达并接收。
主要协议:传输控制协议tcp(transmissioncontrolprotocol)和用户数据报协议udp(userdatagramprotocol)。
4.应用层:应用程序间沟通的层,如简单电子邮件传输(smtp)、文件传输协议(Ftp)、网络远程访问协议(telnet)等。
主要协议:Ftp、telnet、dns、smtp、Rip、nFs、http。
osi模型分为7层1.物理层:以二进制数据形式在物理媒体上传输数据。
主要协议:eia/tia-232,eia/tia-499,V.35,V.24,Rj45,Fddi。
2.数据链路层:传输有地址的帧以及有错误检测功能。
主要协议:FrameRelay,hdlc,atm,ieee802.5/802.2。
3.网络层:为数据包选择路由。
主要协议:ip,ipx,appletalkddp。
4.传输层:提供端对端的接口。
主要协议:tcp,udp,spx。
5.会话层:解除或建立与别的接点的联系。
主要协议:Rpc,sql,nFs,asp。
6.表示层:数据的表示、压缩和加密主要协议:tiFF,giF,jpeg,,pict,ascii,mpeg,,midi。
7.应用层:文件传输,电子邮件,文件服务,虚拟终端。
主要协议:telnet,Ftp,http,snmp。
篇二:tcpip协议简介tcp/ip协议简介什么是tcp/ip?tcp协议和ip协议指两个用在internet上的网络协议(或数据传输的方法)。
OSI七层模型各层分别有哪些协议及它们的功能

OSI七层模型各层分别有哪些协议及它们的功能在互联网中实际使用的是TCP/IP参考模型。
实际存在的协议主要包括在:物理层、数据链路层、网络层、传输层和应用层。
各协议也分别对应这5个层次而已。
要找出7个层次所对应的各协议,恐怕会话层和表示层的协议难找到啊。
应用层·DHCP(动态主机分配协议)· DNS (域名解析)· FTP(File Transfer Protocol)文件传输协议· Gopher (英文原义:The Internet Gopher Protocol 中文释义:(RFC-1436)网际Gopher协议)· HTTP (Hypertext Transfer Protocol)超文本传输协议· IMAP4 (Internet Message Access Protocol 4) 即 Internet信息访问协议的第4版本· IRC (Internet Relay Chat )网络聊天协议· NNTP (Network News Transport Protocol)RFC-977)网络新闻传输协议· XMPP 可扩展消息处理现场协议· POP3 (Post Office Protocol 3)即邮局协议的第3个版本· SIP 信令控制协议· SMTP (Simple Mail Transfer Protocol)即简单邮件传输协议· SNMP (Simple Network Management Protocol,简单网络管理协议)· SSH (Secure Shell)安全外壳协议· TELNET 远程登录协议· RPC (Remote Procedure Call Protocol)(RFC-1831)远程过程调用协议· RTCP (RTP Control Protocol)RTP 控制协议· RTSP (Real Time Streaming Protocol)实时流传输协议· TLS (Transport Layer Security Protocol)安全传输层协议· SDP( Session Description Protocol)会话描述协议· SOAP (Simple Object Access Protocol)简单对象访问协议· GTP 通用数据传输平台· STUN (Simple Traversal of UDP over NATs,NAT 的UDP简单穿越)是一种网络协议· NTP (Network Time Protocol)网络校时协议传输层·TCP(Transmission Control Protocol)传输控制协议· UDP (User Datagram Protocol)用户数据报协议· DCCP (Datagram Congestion Control Protocol)数据报拥塞控制协议· SCTP(STREAM CONTROL TRANSMISSION PROTOCOL)流控制传输协议· RTP(Real-time Transport Protocol或简写RTP)实时传送协议· RSVP (Resource ReSer Vation Protocol)资源预留协议· PPTP ( Point to Point Tunneling Protocol)点对点隧道协议网络层IP(IPv4 · IPv6) Internet Protocol(网络之间互连的协议)ARP : Address Resolution Protocol即地址解析协议,实现通过IP地址得知其物理地址。
imap rfc标准

Internet Message Access Protocol (IMAP) is an email retrieval protocol. It stores email messages on a mail server and enables the recipient to view and manipulate them as though they were stored locally on their device. IMAP was developed in the late 1980s and has since become one of the most widely used email retrieval protocols.The IMAP standard is defined in RFC 3501, which was published in 2003. This document provides a detailed description of the protocol's functionality, including its data formats, commands, and responses. The standard specifies how IMAP clients and servers should communicate with each other to enable the retrieval and manipulation of email messages.One of the key features of IMAP is its support for multiple clients accessing the same mailbox simultaneously. This is achieved through the use of a "shared" storage model, where all clients see the same set of messages and folders stored on the server. This allows users to access their email from different devices without having to worry about synchronizing their messages manually.Another important aspect of IMAP is its support for message organization and management. Clients can create, delete, and rename folders, as well as move messages between folders. They can also search for specific messages based on various criteria, such as sender, subject, or date.IMAP also provides a range of features for managing individual messages. Clients can mark messages as read or unread, flag them for follow-up, and even move them to a specific folder. They can also reply to messages, forward them to others, and generate replies or forwards with attachments.Overall, the IMAP standard provides a powerful and flexible framework for managing email messages. Its support for shared storage, message organization, and advanced message management features make it a popular choice for both personal and business email users.。
srv6相关标准

SRv6(Segment Routing over IPv6)是一种基于IPv6网络的新型路由技术,它通过在IPv6数据包中添加一个24位的标签来标识不同的路径。
这种技术可以提高网络的可扩展性、灵活性和安全性。
以下是一些与SRv6相关的标准:1. RFC 8210:这是SRv6的基本规范,定义了SRv6的基本概念、操作和实现要求。
2. RFC 8365:这个文档描述了如何使用BGP-LS(Border Gateway Protocol - Link State)协议在IPv6网络中传播SRv6路由信息。
3. RFC 8402:这个文档描述了如何使用MP-BGP(Multiprotocol BGP)协议在IPv6网络中传播SRv6路由信息。
4. RFC 8415:这个文档描述了如何使用IS-IS(Intermediate System to Intermediate System)协议在IPv6网络中传播SRv6路由信息。
5. RFC 8475:这个文档描述了如何使用OSPF(Open Shortest Path First)协议在IPv6网络中传播SRv6路由信息。
6. RFC 8597:这个文档描述了如何使用BFD(Bidirectional Forwarding Detection)协议在IPv6网络中检测SRv6路径的状态。
7. RFC 8795:这个文档描述了如何使用LDP(Label Distribution Protocol)协议在IPv6网络中分发SRv6标签。
8. RFC 8879:这个文档描述了如何使用PCE(Path Computation Element)协议在IPv6网络中计算SRv6路径。
9. RFC 8915:这个文档描述了如何使用SDN(Software-Defined Networking)技术来实现SRv6网络。
10. RFC 9119:这个文档描述了如何使用SRv6技术来实现网络切片。
网络名词释义

網絡名詞釋義IP 網際協議 Internet Protocol,(RFC-791) ICMP 網際報文控製協議 Internet Control Message Protocol,(RFC-792) IGMP 網際成組多路廣播協議 Internet Group Multicast Protocol,(RFC-1112) UDP 用戶數據報協議 User Datagram Protocol,(RFC-768) TCP 傳輸控製協議 Transmission Control Protocol,(RFC-793) TELNET Telnet協議 Telnet Protocol,(RFC-854,855) FTP 文件傳輸協議 File Transfer Protocol,(RFC-959) SMTP 簡單郵件傳輸協議 Simple Mail Transfer Protocol,(RFC-821) SMTP-SIZE 可處理大信包的擴充的SMTP協議 SMTP Service Ext for Message Size,(RFC-1870) SMTP-EXT SMTP協議擴充 SMTP Service Extensions,(RFC-1869) NTPV2 網絡時間協議版本2 Network Time Protocol (Version 2),(RFC-1119) SNMP 簡單網絡管理協議 Simple Network Management Protocol,(RFC-1157) NETBIOS NetBIOS服務協議 NetBIOS Services Protocols,(RFC-1001,1002) ECHO 應答協議 Echo Protocol DISCARD 取消協議 Discard Protocol CHARGEN 字元發生器協議 Character Generator Protocol QUOTE 氣象報告協議 Quote of the Day Protocol USERS 當前用戶報告協議 Active Users Protocol DAYTIME 日期查詢協議 Daytime Protocol TIME 標準時間服務器協議 Time Server Protocol TFTP 測試用的文件傳輸協議 Trivial File Transfer Protocol TP-TCP 基於TCP的ISO傳輸層服務 ISO Transport Service on top of the TCP ETHER-MIB 乙太網管理資訊庫 Ether-MIB PPP 點對點協議 Point-to-Point Protocol PPP-HDLC HDLC分組的PPP協議 PPP in HDLC Framing IP-SMDS 基於SMDS服務的IP數據報 IP Datagram over the SMDS Service RIP 路由資訊協議 Routing Information Protocol ARP 地址解析協議 Address Resolution Protocol,(RFC-826) RARP 逆向地址解析協議 A Reverse Address Resolution Protocol,(RFC-903) POP3 電子郵局協議,版本3 Post Office Protocol,Version 3,(RFC-1725) HTTP 超文本傳輸協議 Hyper Text Transfer Protocol RPC 遠過程調用協議 Remote Procedure Call Protocol,(RFC-1831) NICNAME WhoIs協議 WhoIs Protocol,(RFC-954) DHCP 主機動態配置協議 Dynamic Host Configuration Protocol,(RFC-1541) NNTP 網絡新聞傳輸協議 Network News Transfer Protocol,(RFC-977) IARP 反向地址解析協議 Inverse Address Resolution Protocol,(RFC-1293) RAP 網際路由存取協議 Internet Route Access Protocol,(RFC-1476) IRCP 網際轉發的閑聊協議 Internet Relay Chat Protocol,(RFC-1459) RMCP 遠程郵件檢查協議 Remote Mail Checking Protocol,(RFC-1339) MTP 多路廣播傳輸協議 Multicast Transport Protocol,(RFC-1301) GOPHER 網際Gopher協議 The Internet Gopher Protocol,(RFC-1436) LISTSERV Listserv分佈協議 Listserv Distribute Protocol,(RFC-1429)Anonymous FTP 匿名FTP,當你在一個向公眾開放的服務器上下載一個文件時,一般不需向系統登記注冊,當被問到注冊名時,敲入Anonymous,而密碼則以你的郵編地址代替. Archie 在Internet各個FTP節點上查詢文件的一種程式. Browser 瀏覽器,一種可顯示或下載文件的計算機程式,如Netscape的Navigator和Microsoft的InternetExplorer. Cyberia 新興的電腦咖啡店,提供咖啡和電腦網絡服務. Dialup 利用電話線撥號上網的過程. Domain 域網絡區域等的劃分IRC Internet Relay Chat,在Internet上與其他用戶實時網上交談的系統. Ethernet 乙太網,世界上最廣泛使用的局域網類型,支援每秒10Mbits的傳輸速度,幾乎所有Internet上的局域網都是這種類型. Firewall 防火牆,Internet上用於防止外界入侵局域網的安全裝置. FTP File Transfer Protocal 文件傳輸協議,用於在Internet上傳輸文件. Gateway 網關,數據在不同系統間傳輸時,用以統一數據格式. IP Internet協議,定義了文件以一個計算機傳到另一個主機的方式,通常與另一個協議一起稱作TCP/IP. ISO 從事國際標準化的組織,批準其他組織製定的標準(例如︰IEEE和ITU-T)的國際標準化組織. ISP ISP是Internet服務的提供者,也是Internet訪問的提供者. ITU-T ITU-T是發展和批準遠程通信標準的國際標準化組織.它包括所有主要的PTT的代表. Kermit Kermit是一種流行的糾錯文件傳輸協議,主要用於BBS. MOO 下一代的MUD稱作MOO(面向對象的MUD).它們把所有的遊戲者都當作有一定能力的對象對待.在MOO中你通常可以設計你的性格. Mosaic Mosaic是第一個瀏覽器,是由美國國家超級計算機中心製作的.它真正開始了Web的流行. MUD 多用戶地牢是一個地方,經常是一個單個主機.在那個地方你能夠遇到其他人,通常殺死他們.本質上,在MUD的遊戲中,你裝扮成一個虛構的人在MUD的'房間'裡探險,聊天,拾東西,以及參與無原由的暴力.MUD通常由文本介面來訪問,而流行的MUD經常難以進入.在http://www.cisMulticast 多路廣播,是一種特殊的廣播類型,是為網上主機的用戶電話機預定的. Newsgroup Newsgroup是Internet的公告牌,有22000左右個組,幾乎覆蓋了每一個主題.決大部分的ISP(Internet提供商)和組織有一個新聞組服務器,它定期從網上別的新聞組收集新聞素材,所有新消息都是從這些素材中得來的.然後這些素材又會被傳送到另外的新聞組服務器.這些新聞NIC NIC是網絡資訊中心的縮寫.在Internet的早期,它是包含IP地址和功能變數名稱的中心站.現在有一些NIC分散在全世界. NMS 網絡管理站,監視網上所有節點如何執行命令的計算機. NNTP 網絡新聞傳輸協議,用於新聞組服務器之間交換新聞的協議,也是用於新聞瀏覽器與新聞組服務器之間的協議. NOC Internet服務商用來監視網絡錯誤的網絡操作中心. Node 節點,任何一個連到Internet上的設備(通常是指主機,但也包括網橋,路由器,網關等)都稱作節點.實際上,有IP地址的任何東西都是節點. OSI 開發系統互連,用來簡化各種型號計算機之間通訊的國際標準. Packet Packet是網絡上傳輸的一組數據.在Internet上,一個數據包由TCP/IP協議的IP部分組成.它必須包括原地址,目的地址,包的標識(這樣接收的計算機可以分辨包的種類)和一些數據. Ping Ping是一個用TCP/IP協議發送消息到主機的網絡介面,以查看它是否存在程式,這對於網絡糾錯很有用. POP3 一種電子郵件的傳輸協議.Port 這名詞用於定義進入一個單獨計算機不同類型數據的不同入口點,如23號口可能指定成遠程訪問,而21號口是FTP.現在大部分的軟件自動檢測口的號碼,埠也指在計算機上的物理輸入輸出孔. Protocol 協議本質上是兩個網絡設備都認同的相互通訊的方法.它定義了許多東西,包括它的包格式,它怎樣校驗,路由器怎樣處理它和如果一個數據包丟失將怎樣辦. PSTN 公共電話交換網,更普遍的說法是電話系統. PTT PTT指的是電話,傳真的郵寄委託給遍及全世界的公共電話系統操作者. RFC 注釋請求,一個文檔通常被IETF的工作組之一放出來,以抽取從其他有關部分來的應答和合法定義的技術.在ftp:///rfc有一個廣泛的所有FTP的有效RFC目錄. Router 路由器,互聯網工作環境的智慧部件.路由器把所有包含Internet的網絡連接起來,並在它們之間交換數據包.它也能算出將一個數據包送達目的地所需最快最便宜的路徑. Smillies 在新聞組和電子郵件中看到的標點法,它的旁邊把人類的概念加到你的消息後,如:高興 :-) 難過 :-( 驚訝 :-0. SMTP 簡單郵件傳輸協議──為了傳輸郵件的Internet協議. Spam 發送同樣的消息到多個新聞組的專用術語,讓人皺眉. UUCP Unix到Unix的複製程式,它允許一個基於Unix的主機從另一個基於Unix的主機複製文件. WAIS 廣域資訊服務器是一個資訊恢複系統,是由Apple,ThinkingMachines和Dow Jones開發的.它允許一個客戶機在多個在線數據庫上同時進行關鍵字查找. Winsock Winsock是Windows下的應用程式與網絡協議之間的標準介面.如果你想在Windows 下訪問Internet,你需要一個叫做Winsock.DLL的程式加載到你的Windows環境中.並非所有的軟件使用同樣版本的Winsock,這是最普遍出現問題的情況之一.WWW 萬維網,環球網,有時也稱作Web.這是所有Internet上基於超文本的相互連接,並可被HTTP或Web服務器訪問的HTML文檔的統稱.WWW是已經成為殺手應用程式,主宰著網絡的潮流.MAIL 電子郵件格式規範 Format of Electionic Mail Messages,(RFC-822)CONTENT 郵件內容類型域規範 Content Type Header Field,(RFC-1049)DOMAIN 功能變數名稱系統規範 Domain Name System,(RFC-1034,1035)DNS-MX 郵件路由與功能變數名稱系統規範 Mail Routing and the Domain System,(RFC-974)SMI 管理資訊結構規範 Structure of Management Information,(RFC-1155)Concise-MIB 簡明MIB規範 Concise MIB Definitions,(RFC-1212)MIB-II 管理資訊庫-2 Management Information Base-II,(RFC-1213)MIME 多用途網際郵件擴充規範 Multipurpose Internet Mail Extensions,(RFC-1521)HTML 超文本標記語言標準 Hypertext Markup Language-2.0,(RFC-1866)URL 通用資源定位符標準 Uniform Resource Locators,(RFC-1738)。
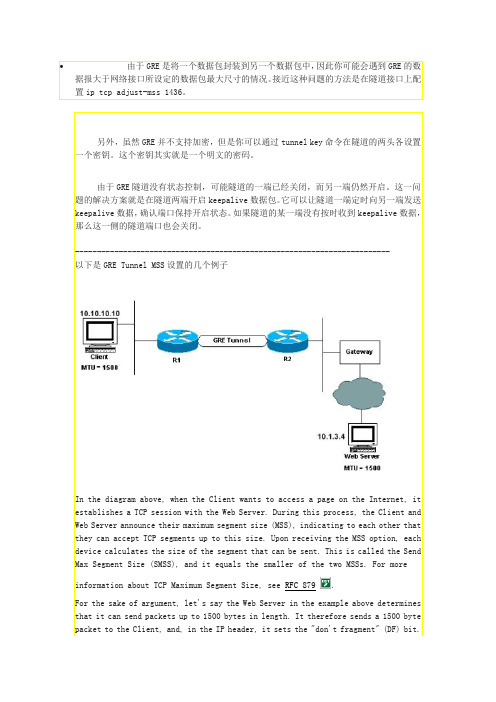
为什么GRE隧道的TCP MSS也要设置1436?
Note:Refer toImportant Information on Debug Commandsbefore you usedebugcommands.
We can view the ICMP messages sent by R2 by enabling thedebug ip icmpcommand:
url语法

url语法URL的主要部分URL通常被写成如下形式:<方案>:<方案描述部分>一个URL包含了它使用的方案名称(<方案>), 其后紧跟一个冒号,然后是一个字符串(<方案描述部分>),这部分的解释由所使用的方案来决定。
方案名称由一串字符组成。
小写字母“a”——“z”,数字,字符加号(“ ”),句点(“.”)和连字号(“-”)都可以。
为了方便起见,程序在解释URL的时候应该视方案名称中的大写字母和小写字母一样。
(例如:视“HTTP”和“http”一样)。
2.2 URL字符编码问题URL是由一串字符组成,这些字符可以是字母,数字和特殊符号。
一个URL可以用多种方法来表现,例如:纸上的字迹,或者是用字符集编码的八位字节序列。
URL的解释仅取决于所用字符的特性。
在大多数URL方案中,都是使用URL不同部分的字符序列来代表因特网协议中所使用的八位字节序列。
例如,在ftp方案中主机名,目录名和文件名就是这样的八位字节序列,它们用URL的不同部分代表。
在这些部分里,一个八位字节数可以用这样的字符来表示:该字符在US—ASCII[20]编码字符集中的编码是这个八位字节数。
另外,八位字节数可以被编成如下形式的代码:“%”后加两个十六进制数字(来自于“0123456789ABCDEF”),这两个十六进制数字代表了这八位字节数的值。
(字符“abcdef”也可以用于十六进制编码)。
如果存在下面的情况:八位字节数在US-ASCII字符集中没有相应的可显示字符,或者使用相应字符会产生不安全因素,或者相应的字符被保留用于特定的URL方案的解释,那么它们必须被编成代码。
没有相应的可显示字符:URL只能用US-ASCII字符编码集中的可显示字符表示。
US-ASCII中没有用到十六进制的八位字节80-FF,并且00-1F和7F代表了控制字符,这些字符必须进行编码。
不安全:字符不安全的原因很多。
rfc6146.Stateful NAT64 Network Address and Protocol Translation from IPv6 Clients to IPv4 Servers

Internet Engineering Task Force (IETF) M. Bagnulo Request for Comments: 6146 UC3M Category: Standards Track P. Matthews ISSN: 2070-1721 Alcatel-Lucent I. van Beijnum IMDEA Networks April 2011 Stateful NAT64: Network Address and Protocol Translationfrom IPv6 Clients to IPv4 ServersAbstractThis document describes stateful NAT64 translation, which allowsIPv6-only clients to contact IPv4 servers using unicast UDP, TCP, or ICMP. One or more public IPv4 addresses assigned to a NAT64translator are shared among several IPv6-only clients. When stateful NAT64 is used in conjunction with DNS64, no changes are usuallyrequired in the IPv6 client or the IPv4 server.Status of This MemoThis is an Internet Standards Track document.This document is a product of the Internet Engineering Task Force(IETF). It represents the consensus of the IETF community. It hasreceived public review and has been approved for publication by theInternet Engineering Steering Group (IESG). Further information onInternet Standards is available in Section 2 of RFC 5741.Information about the current status of this document, any errata,and how to provide feedback on it may be obtained at/info/rfc6146.Bagnulo, et al. Standards Track [Page 1]Copyright NoticeCopyright (c) 2011 IETF Trust and the persons identified as thedocument authors. All rights reserved.This document is subject to BCP 78 and the IETF Trust’s LegalProvisions Relating to IETF Documents(/license-info) in effect on the date ofpublication of this document. Please review these documentscarefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e ofthe Trust Legal Provisions and are provided without warranty asdescribed in the Simplified BSD License.Bagnulo, et al. Standards Track [Page 2]Table of Contents1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . . 4 1.1. Features of Stateful NAT64 . . . . . . . . . . . . . . . . 5 1.2. Overview . . . . . . . . . . . . . . . . . . . . . . . . . 6 1.2.1. Stateful NAT64 Solution Elements . . . . . . . . . . . 6 1.2.2. Stateful NAT64 Behavior Walk-Through . . . . . . . . . 81.2.3. Filtering . . . . . . . . . . . . . . . . . . . . . . 102. Terminology . . . . . . . . . . . . . . . . . . . . . . . . . 113. Stateful NAT64 Normative Specification . . . . . . . . . . . . 14 3.1. Binding Information Bases . . . . . . . . . . . . . . . . 14 3.2. Session Tables . . . . . . . . . . . . . . . . . . . . . . 15 3.3. Packet Processing Overview . . . . . . . . . . . . . . . . 17 3.4. Determining the Incoming Tuple . . . . . . . . . . . . . . 18 3.5. Filtering and Updating Binding and Session Information . . 20 3.5.1. UDP Session Handling . . . . . . . . . . . . . . . . . 21 3.5.1.1. Rules for Allocation of IPv4 TransportAddresses for UDP . . . . . . . . . . . . . . . . 23 3.5.2. TCP Session Handling . . . . . . . . . . . . . . . . . 24 3.5.2.1. State Definition . . . . . . . . . . . . . . . . . 24 3.5.2.2. State Machine for TCP Processing in the NAT64 . . 25 3.5.2.3. Rules for Allocation of IPv4 TransportAddresses for TCP . . . . . . . . . . . . . . . . 33 3.5.3. ICMP Query Session Handling . . . . . . . . . . . . . 33 3.5.4. Generation of the IPv6 Representations of IPv4Addresses . . . . . . . . . . . . . . . . . . . . . . 36 3.6. Computing the Outgoing Tuple . . . . . . . . . . . . . . . 36 3.6.1. Computing the Outgoing 5-Tuple for TCP, UDP, andfor ICMP Error Messages Containing a TCP or UDPPackets . . . . . . . . . . . . . . . . . . . . . . . 37 3.6.2. Computing the Outgoing 3-Tuple for ICMP QueryMessages and for ICMP Error Messages Containing anICMP Query . . . . . . . . . . . . . . . . . . . . . . 38 3.7. Translating the Packet . . . . . . . . . . . . . . . . . . 383.8. Handling Hairpinning . . . . . . . . . . . . . . . . . . . 394. Protocol Constants . . . . . . . . . . . . . . . . . . . . . . 395. Security Considerations . . . . . . . . . . . . . . . . . . . 40 5.1. Implications on End-to-End Security . . . . . . . . . . . 40 5.2. Filtering . . . . . . . . . . . . . . . . . . . . . . . . 40 5.3. Attacks on NAT64 . . . . . . . . . . . . . . . . . . . . . 415.4. Avoiding Hairpinning Loops . . . . . . . . . . . . . . . . 426. Contributors . . . . . . . . . . . . . . . . . . . . . . . . . 437. Acknowledgements . . . . . . . . . . . . . . . . . . . . . . . 438. References . . . . . . . . . . . . . . . . . . . . . . . . . . 43 8.1. Normative References . . . . . . . . . . . . . . . . . . . 43 8.2. Informative References . . . . . . . . . . . . . . . . . . 44 Bagnulo, et al. Standards Track [Page 3]1. IntroductionThis document specifies stateful NAT64, a mechanism for IPv4-IPv6transition and IPv4-IPv6 coexistence. Together with DNS64 [RFC6147], these two mechanisms allow an IPv6-only client to initiatecommunications to an IPv4-only server. They also enable peer-to-peer communication between an IPv4 and an IPv6 node, where thecommunication can be initiated when either end uses existing, NAT-traversal, peer-to-peer communication techniques, such as Interactive Connectivity Establishment (ICE) [RFC5245]. Stateful NAT64 alsosupports IPv4-initiated communications to a subset of the IPv6 hosts through statically configured bindings in the stateful NAT64.Stateful NAT64 is a mechanism for translating IPv6 packets to IPv4packets and vice versa. The translation is done by translating thepacket headers according to the IP/ICMP Translation Algorithm defined in [RFC6145]. The IPv4 addresses of IPv4 hosts are algorithmicallytranslated to and from IPv6 addresses by using the algorithm defined in [RFC6052] and an IPv6 prefix assigned to the stateful NAT64 forthis specific purpose. The IPv6 addresses of IPv6 hosts aretranslated to and from IPv4 addresses by installing mappings in thenormal Network Address Port Translation (NAPT) manner [RFC3022]. The current specification only defines how stateful NAT64 translatesunicast packets carrying TCP, UDP, and ICMP traffic. Multicastpackets and other protocols, including the Stream ControlTransmission Protocol (SCTP), the Datagram Congestion ControlProtocol (DCCP), and IPsec, are out of the scope of thisspecification.DNS64 is a mechanism for synthesizing AAAA resource records (RRs)from A RRs. The IPv6 address contained in the synthetic AAAA RR isalgorithmically generated from the IPv4 address and the IPv6 prefixassigned to a NAT64 device by using the same algorithm defined in[RFC6052].Together, these two mechanisms allow an IPv6-only client (i.e., ahost with a networking stack that only implements IPv6, a host with a networking stack that implements both protocols but with only IPv6connectivity, or a host running an IPv6-only application) to initiate communications to an IPv4-only server (which is analogous to theIPv6-only host above).These mechanisms are expected to play a critical role in IPv4-IPv6transition and IPv4-IPv6 coexistence. Due to IPv4 address depletion, it is likely that in the future, the new clients will be IPv6-onlyand they will want to connect to the existing IPv4-only servers. The stateful NAT64 and DNS64 mechanisms are easily deployable, since they do not require changes to either the IPv6 client or the IPv4 server. Bagnulo, et al. Standards Track [Page 4]For basic functionality, the approach only requires the deployment of the stateful NAT64 function in the devices connecting an IPv6-onlynetwork to the IPv4-only network, along with the deployment of a few DNS64-enabled name servers accessible to the IPv6-only hosts. Ananalysis of the application scenarios can be found in [RFC6144].For brevity, in the rest of the document, we will refer to thestateful NAT64 either as stateful NAT64 or simply as NAT64.1.1. Features of Stateful NAT64The features of NAT64 are:o NAT64 is compliant with the recommendations for how NATs shouldhandle UDP [RFC4787], TCP [RFC5382], and ICMP [RFC5508]. As such, NAT64 only supports Endpoint-Independent Mappings and supportsboth Endpoint-Independent and Address-Dependent Filtering.Because of the compliance with the aforementioned requirements,NAT64 is compatible with current NAT traversal techniques, such as ICE [RFC5245], and with other NAT traversal techniques.o In the absence of preexisting state in a NAT64, only IPv6 nodescan initiate sessions to IPv4 nodes. This works for roughly thesame class of applications that work through IPv4-to-IPv4 NATs.o Depending on the filtering policy used (Endpoint-Independent, orAddress-Dependent), IPv4-nodes might be able to initiate sessions to a given IPv6 node, if the NAT64 somehow has an appropriatemapping (i.e., state) for an IPv6 node, via one of the followingmechanisms:* The IPv6 node has recently initiated a session to the same oranother IPv4 node. This is also the case if the IPv6 node has used a NAT-traversal technique (such as ICE).* A statically configured mapping exists for the IPv6 node.o IPv4 address sharing: NAT64 allows multiple IPv6-only nodes toshare an IPv4 address to access the IPv4 Internet. This helpswith the forthcoming IPv4 exhaustion.o As currently defined in this NAT64 specification, only TCP, UDP,and ICMP are supported. Support for other protocols (such asother transport protocols and IPsec) is to be defined in separate documents.Bagnulo, et al. Standards Track [Page 5]1.2. OverviewThis section provides a non-normative introduction to NAT64. This is achieved by describing the NAT64 behavior involving a simple setupthat involves a single NAT64 device, a single DNS64, and a simplenetwork topology. The goal of this description is to provide thereader with a general view of NAT64. It is not the goal of thissection to describe all possible configurations nor to provide anormative specification of the NAT64 behavior. So, for the sake ofclarity, only TCP and UDP are described in this overview; the details of ICMP, fragmentation, and other aspects of translation arepurposefully avoided in this overview. The normative specificationof NAT64 is provided in Section 3.The NAT64 mechanism is implemented in a device that has (at least)two interfaces, an IPv4 interface connected to the IPv4 network, and an IPv6 interface connected to the IPv6 network. Packets generatedin the IPv6 network for a receiver located in the IPv4 network willbe routed within the IPv6 network towards the NAT64 device. TheNAT64 will translate them and forward them as IPv4 packets throughthe IPv4 network to the IPv4 receiver. The reverse takes place forpackets generated by hosts connected to the IPv4 network for an IPv6 receiver. NAT64, however, is not symmetric. In order to be able to perform IPv6-IPv4 translation, NAT64 requires state. The statecontains the binding of an IPv6 address and TCP/UDP port (hereaftercalled an IPv6 transport address) to an IPv4 address and TCP/UDP port (hereafter called an IPv4 transport address).Such binding state is either statically configured in the NAT64 or it is created when the first packet flowing from the IPv6 network to the IPv4 network is translated. After the binding state has beencreated, packets flowing in both directions on that particular floware translated. The result is that, in the general case, NAT64 only supports communications initiated by the IPv6-only node towards anIPv4-only node. Some additional mechanisms (like ICE) or staticbinding configuration can be used to provide support forcommunications initiated by an IPv4-only node to an IPv6-only node. 1.2.1. Stateful NAT64 Solution ElementsIn this section, we describe the different elements involved in theNAT64 approach.The main component of the proposed solution is the translator itself. The translator has essentially two main parts, the addresstranslation mechanism and the protocol translation mechanism. Bagnulo, et al. Standards Track [Page 6]Protocol translation from an IPv4 packet header to an IPv6 packetheader and vice versa is performed according to the IP/ICMPTranslation Algorithm [RFC6145].Address translation maps IPv6 transport addresses to IPv4 transportaddresses and vice versa. In order to create these mappings, theNAT64 has two pools of addresses: an IPv6 address pool (to represent IPv4 addresses in the IPv6 network) and an IPv4 address pool (torepresent IPv6 addresses in the IPv4 network).The IPv6 address pool is one or more IPv6 prefixes assigned to thetranslator itself. Hereafter, we will call the IPv6 address poolPref64::/n; in the case there is more than one prefix assigned to the NAT64, the comments made about Pref64::/n apply to each of them.Pref64::/n will be used by the NAT64 to construct IPv4-Converted IPv6 addresses as defined in [RFC6052]. Due to the abundance of IPv6address space, it is possible to assign one or more Pref64::/n, each of them being equal to or even bigger than the size of the whole IPv4 address space. This allows each IPv4 address to be mapped into adifferent IPv6 address by simply concatenating a Pref64::/n with the IPv4 address being mapped and a suffix. The provisioning of thePref64::/n as well as the address format are defined in [RFC6052].The IPv4 address pool is a set of IPv4 addresses, normally a prefixassigned by the local administrator. Since IPv4 address space is ascarce resource, the IPv4 address pool is small and typically notsufficient to establish permanent one-to-one mappings with IPv6addresses. So, except for the static/manually created ones, mappings using the IPv4 address pool will be created and released dynamically. Moreover, because of the IPv4 address scarcity, the usual practicefor NAT64 is likely to be the binding of IPv6 transport addressesinto IPv4 transport addresses, instead of IPv6 addresses into IPv4addresses directly, enabling a higher utilization of the limited IPv4 address pool. This implies that NAT64 performs both address and port translation.Because of the dynamic nature of the IPv6-to-IPv4 address mapping and the static nature of the IPv4-to-IPv6 address mapping, it is farsimpler to allow communications initiated from the IPv6 side towardan IPv4 node, whose address is algorithmically mapped into an IPv6address, than communications initiated from IPv4-only nodes to anIPv6 node. In that case, an IPv4 address needs to be associated with the IPv6 node’s address dynamically.Using a mechanism such as DNS64, an IPv6 client obtains an IPv6address that embeds the IPv4 address of the IPv4 server and sends apacket to that IPv6 address. The packets are intercepted by theNAT64 device, which associates an IPv4 transport address out of its Bagnulo, et al. Standards Track [Page 7]IPv4 pool to the IPv6 transport address of the initiator, creatingbinding state, so that reply packets can be translated and forwarded back to the initiator. The binding state is kept while packets areflowing. Once the flow stops, and based on a timer, the IPv4transport address is returned to the IPv4 address pool so that it can be reused for other communications.To allow an IPv6 initiator to do a DNS lookup to learn the address of the responder, DNS64 [RFC6147] is used to synthesize AAAA RRs fromthe A RRs. The IPv6 addresses contained in the synthetic AAAA RRscontain a Pref64::/n assigned to the NAT64 and the IPv4 address ofthe responder. The synthetic AAAA RRs are passed back to the IPv6initiator, which will initiate an IPv6 communication with an IPv6address associated to the IPv4 receiver. The packet will be routedto the NAT64 device, which will create the IPv6-to-IPv4 addressmapping as described before.1.2.2. Stateful NAT64 Behavior Walk-ThroughIn this section, we provide a simple example of the NAT64 behavior.We consider an IPv6 node that is located in an IPv6-only site andthat initiates a TCP connection to an IPv4-only node located in theIPv4 network.The scenario for this case is depicted in the following figure:+---------------------+ +---------------+|IPv6 network | | IPv4 || | +-------------+ | network || |--| Name server |--| || | | with DNS64 | | +----+ || +----+ | +-------------+ | | H2 | || | H1 |---| | | +----+ || +----+ | +-------+ | 192.0.2.1 ||2001:db8::1|------| NAT64 |----| || | +-------+ | || | | | |+---------------------+ +---------------+The figure above shows an IPv6 node H1 with an IPv6 address2001:db8::1 and an IPv4 node H2 with IPv4 address 192.0.2.1. H2 has as its Fully Qualified Domain Name (FQDN).A NAT64 connects the IPv6 network to the IPv4 network. This NAT64uses the Well-Known Prefix 64:ff9b::/96 defined in [RFC6052] torepresent IPv4 addresses in the IPv6 address space and a single IPv4 address 203.0.113.1 assigned to its IPv4 interface. The routing is Bagnulo, et al. Standards Track [Page 8]configured in such a way that the IPv6 packets addressed to adestination address in 64:ff9b::/96 are routed to the IPv6 interface of the NAT64 device.Also shown is a local name server with DNS64 functionality. Thelocal name server uses the Well-Known Prefix 64:ff9b::/96 to createthe IPv6 addresses in the synthetic RRs.For this example, assume the typical DNS situation where IPv6 hostshave only stub resolvers, and the local name server does therecursive lookups.The steps by which H1 establishes communication with H2 are:1. H1 performs a DNS query for h and receives thesynthetic AAAA RR from the local name server that implements the DNS64 functionality. The AAAA record contains an IPv6 addressformed by the Well-Known Prefix and the IPv4 address of H2 (i.e., 64:ff9b::192.0.2.1).2. H1 sends a TCP SYN packet to H2. The packet is sent from asource transport address of (2001:db8::1,1500) to a destinationtransport address of (64:ff9b::192.0.2.1,80), where the ports are set by H1.3. The packet is routed to the IPv6 interface of the NAT64 (sinceIPv6 routing is configured that way).4. The NAT64 receives the packet and performs the following actions: * The NAT64 selects an unused port (e.g., 2000) on its IPv4address 203.0.113.1 and creates the mapping entry(2001:db8::1,1500) <--> (203.0.113.1,2000)* The NAT64 translates the IPv6 header into an IPv4 header using the IP/ICMP Translation Algorithm [RFC6145].* The NAT64 includes (203.0.113.1,2000) as the source transport address in the packet and (192.0.2.1,80) as the destinationtransport address in the packet. Note that 192.0.2.1 isextracted directly from the destination IPv6 address of thereceived IPv6 packet that is being translated. Thedestination port 80 of the translated packet is the same asthe destination port of the received IPv6 packet.5. The NAT64 sends the translated packet out of its IPv4 interfaceand the packet arrives at H2.Bagnulo, et al. Standards Track [Page 9]6. H2 node responds by sending a TCP SYN+ACK packet with thedestination transport address (203.0.113.1,2000) and sourcetransport address (192.0.2.1,80).7. Since the IPv4 address 203.0.113.1 is assigned to the IPv4interface of the NAT64 device, the packet is routed to the NAT64 device, which will look for an existing mapping containing(203.0.113.1,2000). Since the mapping (2001:db8::1,1500) <-->(203.0.113.1,2000) exists, the NAT64 performs the followingoperations:* The NAT64 translates the IPv4 header into an IPv6 header using the IP/ICMP Translation Algorithm [RFC6145].* The NAT64 includes (2001:db8::1,1500) as the destinationtransport address in the packet and (64:ff9b::192.0.2.1,80) as the source transport address in the packet. Note that192.0.2.1 is extracted directly from the source IPv4 addressof the received IPv4 packet that is being translated. Thesource port 80 of the translated packet is the same as thesource port of the received IPv4 packet.8. The translated packet is sent out of the IPv6 interface to H1.The packet exchange between H1 and H2 continues, and packets aretranslated in the different directions as previously described.It is important to note that the translation still works if the IPv6 initiator H1 learns the IPv6 representation of H2’s IPv4 address(i.e., 64:ff9b::192.0.2.1) through some scheme other than a DNSlookup. This is because the DNS64 processing does NOT result in any state being installed in the NAT64 and because the mapping of theIPv4 address into an IPv6 address is the result of concatenating the Well-Known Prefix to the original IPv4 address.1.2.3. FilteringNAT64 may do filtering, which means that it only allows a packet inthrough an interface under certain circumstances. The NAT64 canfilter IPv6 packets based on the administrative rules to createentries in the binding and session tables. The filtering can beflexible and general, but the idea of the filtering is to provide the administrators necessary control to avoid denial-of-service (DoS)attacks that would result in exhaustion of the NAT64’s IPv4 address, port, memory, and CPU resources. Filtering techniques of incomingIPv6 packets are not specific to the NAT64 and therefore are notdescribed in this specification.Bagnulo, et al. Standards Track [Page 10]Filtering of IPv4 packets, on the other hand, is tightly coupled tothe NAT64 state and therefore is described in this specification. In this document, we consider that the NAT64 may do no filtering, or it may filter incoming IPv4 packets.NAT64 filtering of incoming IPv4 packets is consistent with therecommendations of [RFC4787] and [RFC5382]. Because of that, theNAT64 as specified in this document supports both Endpoint-Independent Filtering and Address-Dependent Filtering, both for TCPand UDP as well as filtering of ICMP packets.If a NAT64 performs Endpoint-Independent Filtering of incoming IPv4packets, then an incoming IPv4 packet is dropped unless the NAT64 has state for the destination transport address of the incoming IPv4packet.If a NAT64 performs Address-Dependent Filtering of incoming IPv4packets, then an incoming IPv4 packet is dropped unless the NAT64 has state involving the destination transport address of the IPv4incoming packet and the particular source IP address of the incoming IPv4 packet.2. TerminologyThis section provides a definitive reference for all the terms usedin this document.The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT","SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119 [RFC2119].The following additional terms are used in this document:3-Tuple: The tuple (source IP address, destination IP address, ICMP Identifier). A 3-tuple uniquely identifies an ICMP Query session. When an ICMP Query session flows through a NAT64, each session has two different 3-tuples: one with IPv4 addresses and one with IPv6 addresses.5-Tuple: The tuple (source IP address, source port, destination IPaddress, destination port, transport protocol). A 5-tupleuniquely identifies a UDP/TCP session. When a UDP/TCP sessionflows through a NAT64, each session has two different 5-tuples:one with IPv4 addresses and one with IPv6 addresses.Bagnulo, et al. Standards Track [Page 11]BIB: Binding Information Base. A table of bindings kept by a NAT64. Each NAT64 has a BIB for each translated protocol. Animplementation compliant to this document would have a BIB forTCP, one for UDP, and one for ICMP Queries. Additional BIBs would be added to support other protocols, such as SCTP.Endpoint-Independent Mapping: In NAT64, using the same mapping forall the sessions involving a given IPv6 transport address of anIPv6 host (irrespectively of the transport address of the IPv4host involved in the communication). Endpoint-Independent Mapping is important for peer-to-peer communication. See [RFC4787] forthe definition of the different types of mappings in IPv4-to-IPv4 NATs.Filtering, Endpoint-Independent: The NAT64 only filters incomingIPv4 packets destined to a transport address for which there is no state in the NAT64, regardless of the source IPv4 transportaddress. The NAT forwards any packets destined to any transportaddress for which it has state. In other words, having state for a given transport address is sufficient to allow any packets back to the internal endpoint. See [RFC4787] for the definition of the different types of filtering in IPv4-to-IPv4 NATs.Filtering, Address-Dependent: The NAT64 filters incoming IPv4packets destined to a transport address for which there is nostate (similar to the Endpoint-Independent Filtering).Additionally, the NAT64 will filter out incoming IPv4 packetscoming from a given IPv4 address X and destined for a transportaddress for which it has state if the NAT64 has not sent packetsto X previously (independently of the port used by X). In otherwords, for receiving packets from a specific IPv4 endpoint, it is necessary for the IPv6 endpoint to send packets first to thatspecific IPv4 endpoint’s IP address.Hairpinning: Having a packet do a "U-turn" inside a NAT and comeback out the same side as it arrived on. If the destination IPv6 address and its embedded IPv4 address are both assigned to theNAT64 itself, then the packet is being sent to another IPv6 hostconnected to the same NAT64. Such a packet is called a ’hairpinpacket’. A NAT64 that forwards hairpin packets back to the IPv6host is defined as supporting "hairpinning". Hairpinning support is important for peer-to-peer applications, as there are caseswhen two different hosts on the same side of a NAT can onlycommunicate using sessions that hairpin through the NAT. Hairpin packets can be either TCP or UDP. More detailed explanation ofhairpinning and examples for the UDP case can be found in[RFC4787].Bagnulo, et al. Standards Track [Page 12]ICMP Query packet: ICMP packets that are not ICMP error messages.For ICMPv6, ICMPv6 Query Messages are the ICMPv6 Informationalmessages as defined in [RFC4443]. For ICMPv4, ICMPv4 Querymessages are all ICMPv4 messages that are not ICMPv4 errormessages.Mapping or Binding: A mapping between an IPv6 transport address and a IPv4 transport address or a mapping between an (IPv6 address,ICMPv6 Identifier) pair and an (IPv4 address, ICMPv4 Identifier)pair. Used to translate the addresses and ports / ICMPIdentifiers of packets flowing between the IPv6 host and the IPv4 host. In NAT64, the IPv4 address and port / ICMPv4 Identifier is always one assigned to the NAT64 itself, while the IPv6 addressand port / ICMPv6 Identifier belongs to some IPv6 host.Session: The flow of packets between two different hosts. This may be TCP, UDP, or ICMP Queries. In NAT64, typically one host is an IPv4 host, and the other one is an IPv6 host. However, due tohairpinning, both hosts might be IPv6 hosts.Session table: A table of sessions kept by a NAT64. Each NAT64 has three session tables, one for TCP, one for UDP, and one for ICMPQueries.Stateful NAT64: A function that has per-flow state that translatesIPv6 packets to IPv4 packets and vice versa, for TCP, UDP, andICMP. The NAT64 uses binding state to perform the translationbetween IPv6 and IPv4 addresses. In this document, we also refer to stateful NAT64 simply as NAT64.Stateful NAT64 device: The device where the NAT64 function isexecuted. In this document, we also refer to stateful NAT64device simply as NAT64 device.Transport Address: The combination of an IPv6 or IPv4 address and a port. Typically written as (IP address,port), e.g.,(192.0.2.15,8001).Tuple: Refers to either a 3-tuple or a 5-tuple as defined above.For a detailed understanding of this document, the reader should also be familiar with NAT terminology [RFC4787].Bagnulo, et al. Standards Track [Page 13]。
ietf rfc 8446 标准

I. 简介在信息技术领域,标准的制定和遵循对于保障各类系统的稳定性和安全性至关重要。
其中,RFC(Request for Comments)标准是互联网工程任务组(IETF)制定的一系列文件,被广泛应用于互联网协议、技术规范和网络体系结构等方面。
RFC 8446标准是TLS(传输层安全性)协议的最新版本,本文将对该标准进行详细介绍。
II. TLS协议1. TLS概述TLS是一种安全协议,用于在互联网上传输数据。
它的主要目的是通过在通信双方之间建立安全的通道,保护数据的机密性和完整性,防止数据被窃取或篡改。
2. TLS的演进随着网络攻击技术的不断进步,TLS协议也在不断演进和升级。
RFC 8446标准就是TLS 1.3版本的规范文档,其前身是TLS 1.2,而TLS 1.0和TLS 1.1由于安全性漏洞已经被淘汰。
III. RFC 8446标准1. 发布背景RFC 8446标准于2018年8月发布,取代了TLS 1.2版本,并对之前的版本做出了一系列重大改进。
其发布旨在提高互联网数据通信的安全性和性能。
2. 主要特性RFC 8446标准在安全性和性能方面进行了多项改进,包括:- 强制使用Perfect Forward Secrecy(PFS)机制,防止密钥泄露后过去通信内容的解密。
- 精简握手流程,减少了握手时间和通信延迟,提高了通信效率。
- 支持更多的密码套件,提供更好的加密算法和安全性选项。
- 提供更好的抗攻击和防护机制,增强了通信的安全性。
- 支持0-RTT模式,进一步提高了通信速度。
IV. 对互联网的影响RFC 8446标准的发布对互联网的各个领域都有着积极的影响,具体体现在:1. 提高了通信的安全性和保密性。
RFC 8446标准的发布使得互联网数据通信的安全性得到了显著提升,能够更好地抵御各类网络攻击和数据窃取行为,有利于维护用户的隐私和利益。
2. 提升了通信的效率和性能。
RFC 8446标准的改进使得TLS协议的握手时间得到了显著缩短,通信延迟得到了一定程度的降低,为互联网数据传输提供了更加高效和快速的通道。
协议号与端口号区别

协议号与端口号区别协议号和端口号的区别网络层-数据包的包格式里面有个很重要的字段叫做协议号。
比如在传输层如果是tcp连接,那么在网络层ip包里面的协议号就将会有个值是6,如果是udp的话那个值就是17-----传输层传输层--通过接口关联(端口的字段叫做端口)---应用层,详见RFC 1700协议号是存在于IP数据报的首部的20字节的固定部分,占有8bit.该字段是指出此数据报所携带的是数据是使用何种协议,以便目的主机的IP层知道将数据部分上交给哪个处理过程。
也就是协议字段告诉IP 层应当如何交付数据。
而端口,则是运输层服务访问点TSAP,端口的作用是让应用层的各种应用进程都能将其数据通过端口向下交付给运输层,以及让运输层知道应当将其报文段中的数据向上通过端口交付给应用层的进程。
端口号存在于UDP和TCP报文的首部,而IP数据报则是将UDP或者TCP报文做为其数据部分,再加上IP数据报首部,封装成IP数据报。
而协议号则是存在这个IP数据报的首部.比方来说:端口你在网络上冲浪,别人和你聊天,你发电子邮件,必须要有共同的协议,这个协议就是TCP/IP 协议,任何网络软件的通讯都基于TCP/IP协议。
如果把互联网比作公路网,电脑就是路边的房屋,房屋要有门你才可以进出,TCP/IP协议规定,电脑可以有256乘以256扇门,即从0到65535号“门”,TCP/IP 协议把它叫作“端口”。
当你发电子邮件的时候,E-mail软件把信件送到了邮件服务器的25号端口,当你收信的时候,E-mail软件是从邮件服务器的110号端口这扇门进去取信的,你现在看到的我写的东西,是进入服务器的80端口。
新安装好的<strong class="kgb" onmouseover="isShowAds = false;isShowAds2 = false;isShowGg =true;InTextAds_GgLayer="_u4E2A_u4EBA_u7535_u8111";KeyGate_ads.ShowGgAds(this,"_u4E2A_u4 EBA_u7535_u8111",event)" style="border-top-width: 0px; padding-right: 0px; padding-left: 0px;font-weight: normal; border-left-width: 0px; border-bottom-width: 0px; padding-bottom: 0px; margin: 0px; cursor: hand; color: #0000ff; padding-top: 0px; border-right-width: 0px; text-decoration: underline" onclick="javascript:window.open("/url?sa=L&ai=BNRDFZu02R_K-Lp64sAKptpB UjISxKeiV4MADqo7g4Aew6gEQARgBIK-aqgk4AVC4o-TQ_f____8BYJ3Z34HYBaoBCjEwMDAwMTYw MDLIAQHIAoDEzgPZA2Z3S_7H1xLX&num=1&q=/homeandoffice/browseb uy/pavilion/default.asp%3Fjumpid%3Dex_cnzhpsgsem_google/Q4LTConPC&usg=AFQjCNFI8TteJWnF UdvuKn-wUxlePMFWPA");GgKwClickStat("个人电脑","/eshop","afs","1000016002");" onmouseout="isShowGg = false;InTextAds_GgLayer="_u4E2A_u4EBA_u7535_u8111"">个人电脑打开的端口号是139端口,你上网的时候,就是通过这个端口与外界联系的。
500道助理电子商务师练习题及答案

助理电子商务师练习题(单项选择题)练习题一15. 生产企业物流可细分为采购物流、厂内物流、()、退货物流和废弃物回收物流等物流活动。
(A)经营物流(B)商业物流(C)销售物流(D)配送中心物流31. 协议,或称(),是指http、FTP、Telnet 等信息传输协议。
(A)服务方式(B)服务协议(C)传输协议(D)传输文本6. 借助新闻组开展网上营销本身就是一种()。
(A)服务行为(B)传播行为(C)宣传行为(D)广告行为83. ()是通过计算机网络系统订立的,以数据电文的方式生成、存储或传递的合同。
(A)数字合同(B)数据合同(C)电子合同(D)信息合同85. 信息服务合同是指以提供信息服务为标的的合同,如信息访问、()、交易平台服务等。
(A)音乐下载(B)软件下载(C)在线支付(D)认证服务91. PIN是指()密码,与平常在自动取款机上使用的密码一样。
(A)信用卡(B)大事卡(C)借记卡(D)银行卡个人标识号(PIN=personal identification number ),用于保护智能卡免受误用的秘密标识代码。
PIN 与密码类似,只有卡的所有者才知道该PIN。
只有拥有该智能卡并知道PIN 的人才能使用该智能卡。
96. 网上订单的流程处理改善遵循的基本原则是:(),分批处理、交叉处理、删除不增值工序等。
(A)限时处理(B)订购处理(C)预订处理(D)并行处理97. ()被称为客户端持有数据,这是存储在Web客户端的小文本文件,是Web服务器跟踪在网上购物的客户操作的简单而通用的方法。
(A)CPRD (B)Cookie (C)Cookers (D)Corp练习题二7.电子支付是采用先进的技术通过()来完成信息传输的,进行款项支付。
(A)电子支票(B)数字流转(C)电子现金(D)信息传输12. 《电子商务示范法》是()于1996年通过的,这将促进协调和统一国际贸易法。
(A)国际贸易法委员会(B)国际商会(C)欧盟贸易法委员会(D)美国贸易法委员会13. 电子邮件是Internet上最频繁的应用之一,它是采用()进行传输的。
juniper交换机详细配置手册

命பைடு நூலகம்行配置指导手册
Version 1.0
目录 1 交换机基础知识 ........................................................................................................................................... 6
2 操作指导 .................................................................................................................................................... 30 2.1 通过CONSOLE线连接交换机 ............................................................................................................................... 30 2.2 SYSTEM系统参数配置 ......................................................................................................................................... 31 2.2.1 设置root密码 ............................................................................................................................................ 32 2.2.2 设置主机名 ............................................................................................................................................... 32 2.2.3 设置DNS服务器 ........................................................................................................................................ 32 2.2.4 设置日期时间 ........................................................................................................................................... 32 2.2.5 设置NTP服务器......................................................................................................................................... 33 2.2.6 开启远程Telnet登陆服务 ......................................................................................................................... 33 2.2.7 开启远程Ftp服务 ...................................................................................................................................... 33 2.2.8 开启远程ssh登陆 ...................................................................................................................................... 34 2.2.9 开启远程http登陆服务 ............................................................................................................................ 34 2.2.10 添加/删除用户........................................................................................................................................ 34 2.2.10.1 添加用户 ............................................................................................................................................................ 34 2.2.10.2 修改用户类别 .................................................................................................................................................... 35 2.2.10.3 修改用户密码 .................................................................................................................................................... 35 2.2.10.4 删除用户 ............................................................................................................................................................ 35 2.2.11 用户权限设置 ......................................................................................................................................... 35 2.3 VLAN配置 .......................................................................................................................................................... 36 2.3.1 VLAN配置步骤 .......................................................................................................................................... 37 2.3.2 VLAN配置规范要求 .................................................................................................................................. 37 2.3.3 添加VLAN .................................................................................................................................................. 37 2.3.4 修改端口VLAN .......................................................................................................................................... 39 2.3.5 删除VLAN .................................................................................................................................................. 39 2.3.6 配置VLAN网关IP ....................................................................................................................................... 40 第2页 共86页
Web前端开发技术 (第3版)储久良1
教育部高等学校软件工程专业教学指导委员会规划教材
第1章 Web前端开发技术综述
Page: 3
1.1 Web概述
Web前端开发技术-HTML5、CSS3、JavaScript
1980年Tim Berners-Lee(蒂姆·伯纳斯·李)在欧洲核子物理实 验室工作时建议建立一个以超文本系统为基础的项目来使得科学 家之间能够分享和更新他们的研究结果。他与Robert Cailliau一 起建立了一个叫做ENQUIRE的原型系统。
1989年3月,Tim Berners-Lee撰写了Information Management: A Proposal《关于信息化管理的建议》一文,文 中提及 ENQUIRE 并且描述了一个更加精巧的管理模型。
1990年11月12日他和Robert Cailliau(罗伯特·卡里奥)合作提 出了一个更加正式的关于万维网的建议。
括代码的可维护性、组件的易用性和浏览器兼容性等。
教育部高等学校软件工程专业教学指导委员会规划教材
第1章 Web前端开发技术综述
Page: 11
Web前端开发技术-HTML5、CSS3、JavaScript
1.3 Web前端开发技术
1.3.1 HTML HTML是SGML(Standard Generalized Markup
3 ftp 4 mailto
文件传输协议 电子邮件地址
5 ldap 6 news 7 file
轻型目录访问协议搜索 Usenet新闻组 当地电脑或网上分享的文件
8 gopher
Internet Gopher Protocol (Internet 查找协议)
教育部高等学校软件工程专业教学指导委员会规划教材
RFC1945中文

组织:中国互动出版网(/)RFC文档中文翻译计划(/compters/emook/aboutemook.htm)E-mail:********************译者:黄晓东(黄晓东****************)译文发布时间:2001-7-14版权:本中文翻译文档版权归中国互动出版网所有。
可以用于非商业用途自由转载,但必须保留本文档的翻译及版权信息。
Network Working Group T. Berners-Lee Request for Comments: 1945 MIT/LCS Category: Informational R. Fielding UC IrvineH. FrystykMIT/LCSMay 1996超文本传输协议 -- HTTP/1.0(Hyptertext Transfer Protocol – HTTP/1.0)关于下段备忘(Status of This Memo)本段文字为Internet团体提供信息,并没有以任何方式指定Internet标准。
本段文字没有分发限制。
IESG提示(IESG Note):IESG已在关注此协议,并期待该文档能尽快被标准跟踪文档所替代。
摘要(Abstract)HTTP(Hypertext Transfer Protocol)是应用级协议,它适应了分布式超媒体协作系统对灵活性及速度的要求。
它是一个一般的、无状态的、基于对象的协议,通过对其请求方法(request methods)进行扩展,可以被用于多种用途,比如命名服务器(name server)及分布式对象管理系统。
HTTP的一个特性是其数据表现类型允许系统的构建不再依赖于要传输的数据。
HTTP自从1990年就在WWW上被广泛使用。
该规范反映了“HTTP/1.0”的普通用法。
目录(Table of Contents)1. 介绍(Introduction) 61.1 目的(Purpose) 61.2 术语(Terminology) 61.3 概述(Overall Operation)81.4 HTTP and MIME 92. 标志转换及通用语法(Notational Conventions and Generic Grammar)9 2.1 补充反馈方式(Augmented BNF)92.2 基本规则(Basic Rules)103. 协议参数(Protocol Parameters) 123.1 HTTP版本(HTTP Version)123.2 统一资源标识(Uniform Resource Identifiers)133.2.1 一般语法(General Syntax)133.2.2 http URL 143.3 Date/Time 格式(Date/Time Formats)153.4 字符集(Character Sets)163.5 内容译码(Content Codings)163.6 介质类型(Media Types)173.6.1标准及文本缺省(Canonicalization and Text Defaults)183.6.2 多部分类型(Multipart Types) 183.7 产品标识(Product Tokens) 194. HTTP 消息(HTTP Message)194.1 消息类型(Message Types)194.2 消息标题(Message Headers)204.3 普通标题域(General Header Fields)205. 请求(Request)215.1 请求队列(Request-Line)215.1.1 方法(Method)225.1.2 请求URI(Request-URI)225.2 请求标题域(Request Header Fields)236. 回应(Response)236.1 状态行(Status-Line)246.1.1 状态代码和原因分析(Status Code and Reason Phrase)246.2 回应标题域(Response Header Fields)257. 实体(Entity)267.1 实体标题域(Entity Header Fields) 267.2 实体主体(Entity Body)267.2.1 类型(Type)277.2.2 长度(Length)278. 方法定义(Method Definitions)278.1 GET 288.2 HEAD 288.3 POST 289. 状态代码定义(Status Code Definitions) 299.1 消息1xx(Informational 1xx)299.2 成功2xx(Successful 2xx)299.3 重定向(Redirection 3xx)309.4 客户端错误(Client Error )4xx 319.5 服务器错误(Server Error )5xx 3210. 标题域定义(Header Field Definitions) 3310.1 允许(Allow) 3310.2 授权(Authorization) 3410.3 内容编码(Content-Encoding)3410.4 内容长度(Content-Length)3410.5 内容类型(Content-Type)3510.6 日期(Date)3510.7 过期(Expires)3610.8 来自(From)3710.9 从何时更改(If-Modified-Since)3710.10 最近更改(Last-Modified)3810.11 位置(Location) 3810.12 注解(Pragma)3910.13 提交方(Referer) 3910.14 服务器(Server) 4010.15 用户代理(User-Agent)4010.16 WWW-授权(WWW-Authenticate) 4011. 访问鉴别(Access Authentication)4111.1 基本授权方案(Basic Authentication Scheme)4212. 安全考虑(Security Considerations)4312.1 客户授权(Authentication of Clients) 4312.2 安全方法(Safe Methods)4312.3 服务器日志信息的弊端(Abuse of Server Log Information)4312.4 敏感信息传输(Transfer of Sensitive Information) 4412.5 基于文件及路径名的攻击(Attacks Based On File and Path Names)4413. 感谢(Acknowledgments)4514. 参考书目(References)4515. 作者地址(Authors' Addresses) 47附录(Appendices)48A. Internet介质类型消息/http(Internet Media Type message/http)48B. 容错应用(Tolerant Applications)48C. 与MIME的关系(Relationship to MIME)49C.1 转换为规范形式(Conversion to Canonical Form) 49C.2 日期格式转换(Conversion of Date Formats) 49C.3 内容编码介绍(Introduction of Content-Encoding)50C.4 无内容传输编码(No Content-Transfer-Encoding) 50C.5 多个主体的HTTP标题域(HTTP Header Fields in Multipart Body-Parts)50D. 附加特性(Additional Features) 50D.1 附加请求方法(Additional Request Methods) 51D.2 附加标题域定义(Additional Header Field Definitions)511. 介绍(Introduction)1.1 目的(Purpose)HTTP(Hypertext Transfer Protocol)是应用级协议,它适应了分布式超媒体协作系统对灵活性及速度的要求。
rfc中常用的测试协议

rfc中常用的测试协议引言在计算机网络领域中,为了确保网络协议的正确性和稳定性,测试协议起到了至关重要的作用。
RFC(Request for Comments)是一系列文件,用于描述互联网相关协议、过程和技术。
在RFC中,也包含了一些常用的测试协议,用于验证和评估网络协议的功能和性能。
本文将介绍RFC中常用的测试协议,并深入探讨其原理和应用。
二级标题1:PING协议三级标题1.1:概述PING协议是一种常用的网络测试协议,用于测试主机之间的连通性。
它基于ICMP (Internet Control Message Protocol)协议,通过发送ICMP Echo Request报文并等待目标主机的ICMP Echo Reply报文来判断目标主机是否可达。
三级标题1.2:工作原理PING协议的工作原理如下: 1. 发送方主机生成一个ICMP Echo Request报文,并将目标主机的IP地址作为目的地。
2. 发送方主机将报文发送到网络中。
3.中间路由器收到报文后,将报文转发到下一跳路由器。
4. 目标主机收到ICMP Echo Request报文后,生成一个ICMP Echo Reply报文,并将其发送回发送方主机。
5. 发送方主机收到ICMP Echo Reply报文后,通过比较报文中的标识符和序列号等字段,判断目标主机是否可达。
三级标题1.3:应用场景PING协议在网络中的应用非常广泛,常用于以下场景: - 测试主机之间的连通性,判断网络是否正常工作。
- 测试网络延迟,通过计算ICMP Echo Request报文的往返时间来评估网络质量。
- 排查网络故障,通过检查ICMP Echo Reply报文中的错误码来定位故障原因。
二级标题2:Traceroute协议三级标题2.1:概述Traceroute协议用于跟踪数据包从源主机到目标主机经过的路径。
它通过发送一系列的UDP报文,并在每个报文中设置不同的TTL(Time to Live)值来实现。
bgp的rfc标准

bgp的rfc标准
BGP(边界网关协议)是一种用于交换路由信息的外部网关协议。
BGP的RFC标准包括多个文档,这些文档定义了BGP协议的工作原理、消息格式、路由策略等方面的细节。
以下是一些与BGP相关的RFC标准:
1. RFC 4271,这个RFC定义了BGP-4协议,是BGP最重要的标
准之一。
它描述了BGP协议的基本工作原理,包括路由信息的交换、路由策略的配置等方面。
2. RFC 4456,这个RFC定义了BGP路由刷新机制,介绍了BGP
路由刷新的过程和原理。
3. RFC 4273,这个RFC定义了MP-BGP(多协议BGP)扩展,使BGP能够传递多种协议的路由信息,如IPv6、多播等。
4. RFC 4760,这个RFC定义了BGP扩展的能力,包括路由刷新、路由刷新消息的传输等。
5. RFC 4277,这个RFC介绍了BGP的安全性和稳定性,包括路
由过滤、路由策略的配置等方面。
以上列举的RFC标准只是BGP协议相关标准的一部分,BGP的标准化工作还包括其他RFC文档。
这些RFC标准共同构成了BGP协议的标准化基础,保证了不同厂商的设备能够互相兼容,从而实现了互联网的稳定和安全运行。
希望这些信息能够帮助你更好地了解BGP协议的RFC标准。
rfc中常用的测试协议

rfc中常用的测试协议摘要:1.RFC 简介2.RFC 中常用的测试协议a.网络协议测试1.网络数据包抓取和分析2.网络仿真和测试工具b.应用层协议测试1.HTTP 和HTTPS 测试2.FTP 和FTPS 测试3.SMTP 和SMTPS 测试c.安全协议测试1.TLS 和SSL 测试2.IPsec 测试d.传输协议测试1.TCP 和UDP 测试e.无线网络协议测试1.802.11 无线网络测试正文:RFC(Request for Comments)是一个用于讨论和记录互联网协议的标准文档系列。
在RFC 中,有许多常用的测试协议,这些协议用于确保互联网协议在实际应用中能够正常工作。
本文将详细介绍这些测试协议。
首先,RFC 中包含了大量的网络协议测试。
网络数据包抓取和分析是网络协议测试的基础,这对于诊断网络问题和优化网络性能至关重要。
此外,网络仿真和测试工具也是必不可少的,例如,网络模拟器(如NS-3)和测试平台(如Ixia)可以帮助工程师在实验室环境中模拟实际网络状况,从而对协议进行更严格的测试。
其次,应用层协议测试在RFC 中也占据重要地位。
HTTP 和HTTPS 是Web 应用中最常用的协议,有许多测试工具可以对它们的性能和安全性进行测试,例如,JMeter 和Locust 等负载测试工具。
此外,FTP 和FTPS、SMTP 和SMTPS 等传输协议也是常用的测试对象。
在安全协议方面,RFC 中包含了TLS 和SSL、IPsec 等协议的测试方法。
这些协议对于保护互联网数据传输的安全至关重要,因此需要进行严格的测试以确保其性能和安全性。
传输协议方面,TCP 和UDP 是互联网中最常用的传输协议,它们的测试方法也是RFC 中的重要内容。
TCP 测试关注可靠性和流量控制等方面,而UDP 测试则更注重数据传输速率和丢包率等指标。
最后,无线网络协议测试在RFC 中也有一定的比重。
例如,802.11 无线网络测试是评估无线局域网性能的关键。
开源DPI方案

2.2 数据检测流程
2.3 数据检测模块(以 skype 为例)
以 skype 为例,简述 skype 检测过程
2.3.1 skype 注册函数 ndpi_search_skype()
标题中的函数在 2.1 中检测模块初始化的时候被注册到 ndpi_detection_module_struct 中: void ndpi_search_skype(struct ndpi_detection_module_struct *ndpi_struct, struct ndpi_flow_struct *flow)
初始化检测模块完善参考数据结构
typedef struct ndpi_detection_module_struct { 包含主要的结构: 1. TCP 协议带 payload 检测函数 2. TCP 协议不带 payload 检测函数 3. UDP 协议带 payload 检测函数 4. UPD 协议不带 payload 检测函数 5. 其他的协议检测函数 }
L7 filter 是基于数据流工作的,建立在 Netfilter connstrack 功能之上。因为一个数据流 或者说一个连接的所有数据都是属于同一个应用的,所以 L7 filter 没有必要对所有的数据 包进行模式匹配,而只匹配一个流的前面几个数据包 (比如 10 个数据包)。当一个流的前 面几个数据包包含了某种应用层协议的特征码时 (比如 QQ),则这个数据流被 L7 filter 识别;当前面几个数据包的内容没有包含某种应用层协议的特征码时,则 L7 filter 放弃继 续做模式匹配,这个数据流也就没有办法被识别。
互联网正在朝着使用 SSL 来加密内容的方向发展。为了让 nDPI 支持加密连接, 我们添加了针对 SSL(包括客户端和服务端)证书解密模块。这样,我们就可以找
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Network Working Group F. Anklesaria Request for Comments: 1436 M. McCahill P. Lindner D. Johnson D. Torrey B. Alberti University of Minnesota March 1993 The Internet Gopher Protocol(a distributed document search and retrieval protocol)Status of this MemoThis memo provides information for the Internet community. It doesnot specify an Internet standard. Distribution of this memo isunlimited.AbstractThe Internet Gopher protocol is designed for distributed documentsearch and retrieval. This document describes the protocol, listssome of the implementations currently available, and has an overview of how to implement new client and server applications. Thisdocument is adapted from the basic Internet Gopher protocol document first issued by the Microcomputer Center at the University ofMinnesota in 1991.Introductiongopher n. 1. Any of various short tailed, burrowing mammals of the family Geomyidae, of North America. 2. (Amer. colloq.) Native orinhabitant of Minnesota: the Gopher State. 3. (Amer. colloq.) Onewho runs errands, does odd-jobs, fetches or delivers documents foroffice staff. 4. (computer tech.) software following a simpleprotocol for burrowing through a TCP/IP internet.The Internet Gopher protocol and software follow a client-servermodel. This protocol assumes a reliable data stream; TCP is assumed. Gopher servers should listen on port 70 (port 70 is assigned toInternet Gopher by IANA). Documents reside on many autonomousservers on the Internet. Users run client software on their desktop systems, connecting to a server and sending the server a selector (a line of text, which may be empty) via a TCP connection at a well-known port. The server responds with a block of text terminated by a period on a line by itself and closes the connection. No state isretained by the server.Anklesari, McCahill, Lindner, Johnson, Torrey & Alberti [Page 1]While documents (and services) reside on many servers, Gopher client software presents users with a hierarchy of items and directoriesmuch like a file system. The Gopher interface is designed toresemble a file system since a file system is a good model fororganizing documents and services; the user sees what amounts to one big networked information system containing primarily document items, directory items, and search items (the latter allowing searches fordocuments across subsets of the information base).Servers return either directory lists or documents. Each item in adirectory is identified by a type (the kind of object the item is),user-visible name (used to browse and select from listings), anopaque selector string (typically containing a pathname used by thedestination host to locate the desired object), a host name (whichhost to contact to obtain this item), and an IP port number (the port at which the server process listens for connections). The user onlysees the user-visible name. The client software can locate andretrieve any item by the trio of selector, hostname, and port.To use a search item, the client submits a query to a special kind of Gopher server: a search server. In this case, the client sends theselector string (if any) and the list of words to be matched. Theresponse yields "virtual directory listings" that contain itemsmatching the search criteria.Gopher servers and clients exist for all popular platforms. Because the protocol is so sparse and simple, writing servers or clients isquick and straightforward.1. IntroductionThe Internet Gopher protocol is designed primarily to act as adistributed document delivery system. While documents (and services) reside on many servers, Gopher client software presents users with a hierarchy of items and directories much like a file system. In fact, the Gopher interface is designed to resemble a file system since afile system is a good model for locating documents and services. Why model a campus-wide information system after a file system? Several reasons:(a) A hierarchical arrangement of information is familiar to many users. Hierarchical directories containing items (such asdocuments, servers, and subdirectories) are widely used inelectronic bulletin boards and other campus-wide informationsystems. People who access a campus-wide information server willexpect some sort of hierarchical organization to the informationpresented.Anklesari, McCahill, Lindner, Johnson, Torrey & Alberti [Page 2](b) A file-system style hierarchy can be expressed in a simplesyntax. The syntax used for the internet Gopher protocol iseasily understandable, and was designed to make debugging servers and clients easy. You can use Telnet to simulate an internetGopher client’s requests and observe the responses from a server. Special purpose software tools are not required. By keeping thesyntax of the pseudo-file system client/server protocol simple, we can also achieve better performance for a very common useractivity: browsing through the directory hierarchy.(c) Since Gopher originated in a University setting, one of thegoals was for departments to have the option of publishinginformation from their inexpensive desktop machines, and sincemuch of the information can be presented as simple text filesarranged in directories, a protocol modeled after a file systemhas immediate utility. Because there can be a direct mapping from the file system on the user’s desktop machine to the directorystructure published via the Gopher protocol, the problem ofwriting server software for slow desktop systems is minimized.(d) A file system metaphor is extensible. By giving a "type"attribute to items in the pseudo-file system, it is possible toaccommodate documents other than simple text documents. Complexdatabase services can be handled as a separate type of item. Afile-system metaphor does not rule out search or database-stylequeries for access to documents. A search-server type is alsodefined in this pseudo-file system. Such servers return "virtual directories" or list of documents matching user specifiedcriteria.2. The internet Gopher ModelA detailed BNF rendering of the internet Gopher syntax is availablein the appendix...but a close reading of the appendix may not benecessary to understand the internet Gopher protocol.In essence, the Gopher protocol consists of a client connecting to a server and sending the server a selector (a line of text, which maybe empty) via a TCP connection. The server responds with a block of text terminated with a period on a line by itself, and closes theconnection. No state is retained by the server between transactions with a client. The simple nature of the protocol stems from the need to implement servers and clients for the slow, smaller desktopcomputers (1 MB Macs and DOS machines), quickly, and efficiently.Below is a simple example of a client/server interaction; morecomplex interactions are dealt with later. Assume that a "well-known" Gopher server (this may be duplicated, details are discussed Anklesari, McCahill, Lindner, Johnson, Torrey & Alberti [Page 3]later) listens at a well known port for the campus (much like adomain-name server). The only configuration information the clientsoftware retains is this server’s name and port number (in thisexample that machine is and the port 70). Inthe example below the F character denotes the TAB character.Client: {Opens connection to at port 70} Server: {Accepts connection but says nothing}Client: <CR><LF> {Sends an empty line: Meaning "list what you have"}Server: {Sends a series of lines, each ending with CR LF}0About internet GopherFStuff:About F701Around University of MinnesotaFZ,5692,F701Microcomputer News & PricesFPrices/F701Courses, Schedules, F91201Student-Staff F701Departmental PublicationsFStuff:DP:F70{.....etc.....}. {Period on a line by itself}{Server closes connection}The first character on each line tells whether the line describes adocument, directory, or search service (characters ’0’, ’1’, ’7’;there are a handful more of these characters described later). Thesucceeding characters up to the tab form a user display string to be shown to the user for use in selecting this document (or directory)for retrieval. The first character of the line is really definingthe type of item described on this line. In nearly every case, theGopher client software will give the users some sort of idea aboutwhat type of item this is (by displaying an icon, a short text tag,or the like).The characters following the tab, up to the next tab form a selector string that the client software must send to the server to retrievethe document (or directory listing). The selector string should mean nothing to the client software; it should never be modified by theclient. In practice, the selector string is often a pathname orother file selector used by the server to locate the item desired.The next two tab delimited fields denote the domain-name of the host that has this document (or directory), and the port at which toconnect. If there are yet other tab delimited fields, the basicGopher client should ignore them. A CR LF denotes the end of theitem.Anklesari, McCahill, Lindner, Johnson, Torrey & Alberti [Page 4]In the example, line 1 describes a document the user will see as"About internet Gopher". To retrieve this document, the clientsoftware must send the retrieval string: "Stuff:About us" to at port 70. If the client does this, theserver will respond with the contents of the document, terminated by a period on a line by itself. A client might present the user with a view of the world something like the following list of items:About Internet GopherAround the University of Minnesota...Microcomputer News & Prices...Courses, Schedules, Calendars...Student-Staff Directories...Departmental Publications...In this case, directories are displayed with an ellipsis and filesare displayed without any. However, depending on the platform theclient is written for and the author’s taste, item types could bedenoted by other text tags or by icons. For example, the UNIXcurses-based client displays directories with a slash (/) followingthe name; Macintosh clients display directories alongside an icon of a folder.The user does not know or care that the items up for selection mayreside on many different machines anywhere on the Internet.Suppose the user selects the line "Microcomputer News & Prices...".This appears to be a directory, and so the user expects to seecontents of the directory upon request that it be fetched. Thefollowing lines illustrate the ensuing client-server interaction:Client: (Connects to at port 70) Server: (Accepts connection but says nothing)Client: Prices/ (Sends the magic string terminated by CRLF)Server: (Sends a series of lines, each ending with CR LF) 0About PricesFPrices/F700Macintosh PricesFPrices/F700IBM PricesFPrices/F700Printer & Peripheral PricesFPrices/F70 (.....etc.....). (Period on a line by itself)(Server closes connection)Anklesari, McCahill, Lindner, Johnson, Torrey & Alberti [Page 5]3. More details3.1 Locating servicesDocuments (or other services that may be viewed ultimately asdocuments, such as a student-staff phonebook) are linked to themachine they are on by the trio of selector string, machine domain-name, and IP port. It is assumed that there will be one well-knowntop-level or root server for an institution or campus. Theinformation on this server may be duplicated by one or more otherservers to avoid a single point of failure and to spread the loadover several servers. Departments that wish to put up their owndepartmental servers need to register the machine name and port with the administrators of the top-level Gopher server, much the same way as they register a machine name with the campus domain-name server.An entry which points to the departmental server will then be made at the top level server. This ensures that users will be able tonavigate their way down what amounts to a virtual hierarchical filesystem with a well known root to any campus server if they desire.Note that there is no requirement that a department registersecondary servers with the central top-level server; they may justplace a link to the secondary servers in their own primary servers.They may indeed place links to any servers they desire in their ownserver, thus creating a customized view of thethe Gopher information universe; links can of course point back at the top-level server.The virtual (networked) file system is therefore an arbitrary graphstructure and not necessarily a rooted tree. The top-level node ismerely one convenient, well-known point of entry. A set of Gopherservers linked in this manner may function as a campus-wideinformation system.Servers may of course point links at other than secondary servers.Indeed servers may point at other servers offering useful servicesanywhere on the internet. Viewed in this manner, Gopher can be seen as an Internet-wide information system.3.2 Server portability and namingIt is recommended that all registered servers have alias names(domain name system CNAME) that are used by Gopher clients to locate them. Links to these servers should use these alias names ratherthan the primary names. If information needs to be moved from onemachine to another, a simple change of domain name system alias(CNAME) allows this to occur without any reconfiguration of clientsin the field. In short, the domain name system may be used to re-map a server to a new address. There is nothing to prevent secondaryservers or services from running on otherwise named servers or ports Anklesari, McCahill, Lindner, Johnson, Torrey & Alberti [Page 6]other than 70, however these should be reachable via a primaryserver.3.3 Contacting server administratorsIt is recommended that every server administrator have a documentcalled something like: "About Bogus University’s Gopher server" asthe first item in their server’s top level directory. In thisdocument should be a short description of what the server holds, aswell as name, address, phone, and an e-mail address of the person who administers the server. This provides a way for users to get word to the administrator of a server that has inaccurate information or isnot running correctly. It is also recommended that administratorsplace the date of last update in files for which such informationmatters to the users.3.4 Modular addition of servicesThe first character of each line in a server-supplied directorylisting indicates whether the item is a file (character ’0’), adirectory (character ’1’), or a search (character ’7’). This is the base set of item types in the Gopher protocol. It is desirable forclients to be able to use different services and speak differentprotocols (simple ones such as finger; others such as CSO phonebookservice, or Telnet, or X.500 directory service) as needs dictate.CSO phonebook service is a client/server phonebook system typicallyused at Universities to publish names, e-mail addresses, and so on.The CSO phonebook software was developed at the University ofIllinois and is also sometimes refered to as ph or qi. For example, if a server-supplied directory listing marks a certain item with type character ’2’, then it means that to use this item, the client mustspeak the CSO protocol. This removes the need to be able toanticipate all future needs and hard-wire them in the basic Internet Gopher protocol; it keeps the basic protocol extremely simple. Inspite of this simplicity, the scheme has the capability to expand and change with the times by adding an agreed upon type-character for anew service. This also allows the client implementations to evolvein a modular fashion, simply by dropping in a module (or launching a new process) for some new service. The servers for the new serviceof course have to know nothing about Internet Gopher; they can justbe off-the shelf CSO, X.500, or other servers. We do not however,encourage arbitrary or machine-specific proliferation of servicetypes in the basic Gopher protocol.On the other hand, subsets of other document retrieval schemes may be mapped onto the Gopher protocol by means of "gateway-servers".Examples of such servers include Gopher-to-FTP gateways, Gopher-to-archie gateways, Gopher-to-WAIS gateways, etc. There are a number of Anklesari, McCahill, Lindner, Johnson, Torrey & Alberti [Page 7]advantages of such mechanisms. First, a relatively powerful servermachine inherits both the intelligence and work, rather than the more modest, inexpensive desktop system that typically runs clientsoftware or basic server software. Equally important, clients do not have to be modified to take advantage of a new resource.3.5 Building clientsA client simply sends the retrieval string to a server if it wants to retrieve a document or view the contents of a directory. Of course, each host may have pointers to other hosts, resulting in a "graph"(not necessarily a rooted tree) of hosts. The client software maysave (or rather "stack") the locations that it has visited in search of a document. The user could therefore back out of the currentlocation by unwinding the stack. Alternatively, a client withmultiple-window capability might just be able to display more thanone directory or document at the same time.A smart client could cache the contents of visited directories(rather than just the directory’s item descriptor), thus avoidingnetwork transactions if the information has been previouslyretrieved.If a client does not understand what a say, type ’B’ item (not a core item) is, then it may simply ignore the item in the directorylisting; the user never even has to see it. Alternatively, the item could be displayed as an unknown type.Top-level or primary servers for a campus are likely to get moretraffic than secondary servers, and it would be less tolerable forsuch primary servers to be down for any long time. So it makes sense to "clone" such important servers and construct clients that canrandomly choose between two such equivalent primary servers when they first connect (to balance server load), moving to one if the otherseems to be down. In fact, smart client implementations do thisclone server and load balancing. Alternatively, it may make sense to have the domain name system return one of a set of redundant ofserver’s IP address to load balance betwen redundant sets ofimportant servers.3.6 Building ordinary internet Gopher serversThe retrieval string sent to the server might be a path to a file or directory. It might be the name of a script, an application or even a query that generates the document or directory returned. The basic server uses the string it gets up to but not including a CR-LF or aTAB, whichever comes first.Anklesari, McCahill, Lindner, Johnson, Torrey & Alberti [Page 8]All intelligence is carried by the server implementation rather than the protocol. What you build into more exotic servers is up to you. Server implementations may grow as needs dictate and time allows.3.7 Special purpose serversThere are two special server types (beyond the normal Gopher server) also discussed below:1. A server directory listing can point at a CSO nameserver (the server returns a type character of ’2’) to allow a campusstudent-staff phonebook lookup service. This may show up on theuser’s list of choices, perhaps preceded by the icon of a phone-book. If this item is selected, the client software must resortto a pure CSO nameserver protocol when it connects to theappropriate host.2. A server can also point at a "search server" (returns a first character of ’7’). Such servers may implement campus network (or subnet) wide searching capability. The most common search servers maintain full-text indexes on the contents of text documents held by some subset of Gopher servers. Such a "full-text searchserver" responds to client requests with a list of all documentsthat contain one or more words (the search criteria). The client sends the server the selector string, a tab, and the search string (words to search for). If the selector string is empty, the client merely sends the search string. The server returns the equivalent of a directory listing for documents matching the search criteria. Spaces between words are usually implied Boolean ANDs (although in different implementations or search types, this may notnecessarily be true).The CSO addition exists for historical reasons: at time of design,the campus phone-book servers at the University of Minnesota used the CSO protocol and it seemed simplest to just engulf them. The index- server is however very much a Gopher in spirit, albeit with a slight twist in the meaning of the selector-string. Index servers are anatural place to incorperate gateways to WAIS and WHOIS services.3.7.1 Building CSO-serversA CSO Nameserver implementation for UNIX and associated documentation is available by anonymous ftp from . We do notanticipate implementing it on other machines.Anklesari, McCahill, Lindner, Johnson, Torrey & Alberti [Page 9]3.7.2 Building full-text search serversA full-text search server is a special-purpose server that knowsabout the Gopher scheme for retrieving documents. These serversmaintain a full-text index of the contents of plain text documents on Gopher servers in some specified domain. A Gopher full-text searchserver was implemented using several NeXTstations because it was easy to take advantage of the full-text index/search engine built into the NeXT system software. A search server for generic UNIX systems based on the public domain WAIS search engine, is also available andcurrently an optional part of the UNIX gopher server. In addition,at least one implementation of the gopher server incorperates agateway to WAIS servers by presenting the WAIS servers to gopherspace as full-text search servers. The gopher<->WAIS gateway servers does the work of translating from gopher protocol to WAIS so unmodifiedgopher clients can access WAIS servers via the gateway server.By using several index servers (rather than a monolithic indexserver) indexes may be searched in parallel (although the clientsoftware is not aware of this). While maintaining full-text indexes of documents distributed over many machines may seem a daunting task, the task can be broken into smaller pieces (update only a portion of the indexes, search several partial indexes in parallel) so that itis manageable. By spreading this task over several small, cheap (and fast) workstations it is possible to take advantage of fine-grainparallelism. Again, the client software is not aware of this. Client software only needs to know that it can send a search string to anindex server and will receive a list of documents that contain thewords in the search string.3.8 Item type charactersThe client software decides what items are available by looking atthe first character of each line in a directory listing. Augmenting this list can extend the protocol. A list of defined item-typecharacters follows:0 Item is a file1 Item is a directory2 Item is a CSO phone-book server3 Error4 Item is a BinHexed Macintosh file.5 Item is DOS binary archive of some sort.Client must read until the TCP connection closes. Beware.6 Item is a UNIX uuencoded file.7 Item is an Index-Search server.8 Item points to a text-based telnet session.9 Item is a binary file!Anklesari, McCahill, Lindner, Johnson, Torrey & Alberti [Page 10]Client must read until the TCP connection closes. Beware.+ Item is a redundant serverT Item points to a text-based tn3270 session.g Item is a GIF format graphics file.I Item is some kind of image file. Client decides how to display. Characters ’0’ through ’Z’ are reserved. Local experiments shoulduse other characters. Machine-specific extensions are notencouraged. Note that for type 5 or type 9 the client must beprepared to read until the connection closes. There will be noperiod at the end of the file; the contents of these files are binary and the client must decide what to do with them based perhaps on the .xxx extension.3.9 User display strings and server selector stringsUser display strings are intended to be displayed on a line on atypical screen for a user’s viewing pleasure. While many screens can accommodate 80 character lines, some space is needed to display a tag of some sort to tell the user what sort of item this is. Because of this, the user display string should be kept under 70 characters inlength. Clients may truncate to a length convenient to them.4. Simplicity is intentionalAs far as possible we desire any new features to be carried as newprotocols that will be hidden behind new document-types. Theinternet Gopher philosophy is:(a) Intelligence is held by the server. Clients have the optionof being able to access new document types (different, other types of servers) by simply recognizing the document-type character.Further intelligence to be borne by the protocol should beminimized.(b) The well-tempered server ought to send "text" (unless a filemust be transferred as raw binary). Should this text includetabs, formfeeds, frufru? Probably not, but rude servers willprobably send them anyway. Publishers of documents should begiven simple tools (filters) that will alert them if there are any funny characters in the documents they wish to publish, and givethem the opportunity to strip the questionable characters out; the publisher may well refuse.(c) The well-tempered client should do something reasonable withfunny characters received in text; filter them out, leave them in, whatever.Anklesari, McCahill, Lindner, Johnson, Torrey & Alberti [Page 11]AppendixPaul’s NQBNF (Not Quite BNF) for the Gopher Protocol.Note: This is modified BNF (as used by the Pascal people) with a few English modifiers thrown in. Stuff enclosed in ’{}’ can berepeated zero or more times. Stuff in ’[]’ denotes a set ofitems. The ’-’ operator denotes set subtraction.Directory EntityCR-LF ::= ASCII Carriage Return Character followed by Line Feedcharacter.Tab ::= ASCII Tab character.NUL ::= ASCII NUL character.UNASCII ::= ASCII - [Tab CR-LF NUL].Lastline ::= ’.’CR-LF.TextBlock ::= Block of ASCII text not containing Lastline pattern.Type ::= UNASCII.RedType ::= ’+’.User_Name ::= {UNASCII}.Selector ::= {UNASCII}.Host ::= {{UNASCII - [’.’]} ’.’} {UNASCII - [’.’]}.Note: This is a Fully Qualified Domain Name as defined in RFC 1034.(e.g., ) Hosts that have a CR-LFTAB or NUL in their name get what they deserve.Digit ::= ’0’ | ’1’ | ’2’ | ’3’ | ’4’ | ’5’ | ’6’ | ’7’ | ’8’ | ’9’ . DigitSeq ::= digit {digit}.Port ::= DigitSeq.Note: Port corresponds the the TCP Port Number, its value shouldbe in the range [0..65535]; port 70 is officially assignedto gopher.Anklesari, McCahill, Lindner, Johnson, Torrey & Alberti [Page 12]。