配置amoeba实现读写分离
Amoeba keepalived mysql高可用性方案
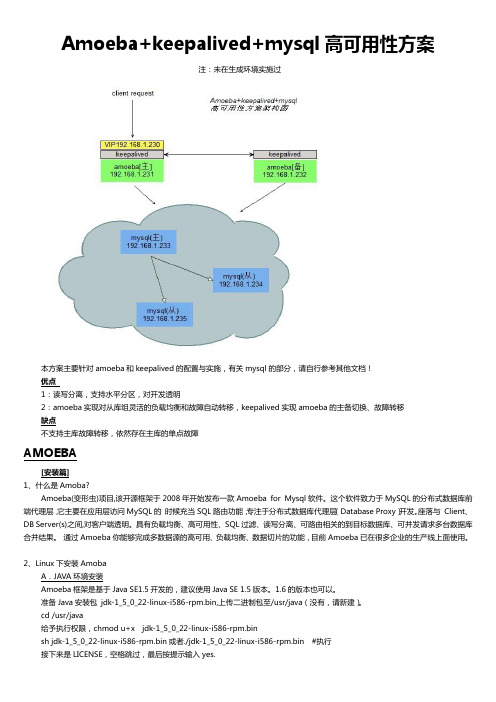
Amoeba+keepalived+mysql高可用性方案注:未在生成环境实施过本方案主要针对amoeba和keepalived的配置与实施,有关mysql的部分,请自行参考其他文档!优点1:读写分离,支持水平分区,对开发透明2:amoeba实现对从库组灵活的负载均衡和故障自动转移,keepalived实现amoeba的主备切换、故障转移缺点不支持主库故障转移,依然存在主库的单点故障AMOEBA[安装篇]1、什么是Amoba?Amoeba(变形虫)项目,该开源框架于2008年开始发布一款Amoeba for Mysql软件。
这个软件致力于MySQL的分布式数据库前端代理层,它主要在应用层访问MySQL的时候充当SQL路由功能,专注于分布式数据库代理层(Database Proxy)开发。
座落与Client、DB Server(s)之间,对客户端透明。
具有负载均衡、高可用性、SQL过滤、读写分离、可路由相关的到目标数据库、可并发请求多台数据库合并结果。
通过Amoeba你能够完成多数据源的高可用、负载均衡、数据切片的功能,目前Amoeba已在很多企业的生产线上面使用。
2、Linux下安装AmobaA.JAVA环境安装Amoeba框架是基于Java SE1.5开发的,建议使用Java SE 1.5版本。
1.6的版本也可以。
准备Java安装包jdk-1_5_0_22-linux-i586-rpm.bin,上传二进制包至/usr/java(没有,请新建)。
cd /usr/java给予执行权限,chmodu+xjdk-1_5_0_22-linux-i586-rpm.binshjdk-1_5_0_22-linux-i586-rpm.bin或者./jdk-1_5_0_22-linux-i586-rpm.bin #执行接下来是LICENSE,空格跳过,最后按提示输入yes.设置java环境变量在/etc/profile尾部加入下面的内容export JAVA_HOME=/usr/java/jdk1.5.0_22export PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarsource /etc/profile 使环境变量生效java –version 验证javajava version "1.5.0_22"Java(TM) 2 Runtime Environment, Standard Edition (build 1.5.0_22-b03)Java HotSpot(TM) Client VM (build 1.5.0_22-b03, mixed mode, sharingB 安装Amoeba去/projects/amoeba/files/下载最新版本的Amoaba2.0。
Moxa ioLogik 2500 系列智慧乙太網路遠端 I O 裝置說明说明书

ioLogik2500系列具備Click&Go Plus邏輯的智慧乙太網路遠端I/O特色與優點•具備Click&Go Plus控制邏輯的前端智慧,多達48項規則•與MX-AOPC UA伺服器進行的主動通訊•使用MX-AOPC UA日誌軟體自動補充斷線週期資料•內建4埠非網管型交換器,用於連接乙太網路裝置•用於菊鏈連接的I/O擴充連接埠,可連接多達8個ioLogik E1200裝置•三合一串列埠:RS-232、RS-422或RS-485•支援SNMP v1/v2c/v3•使用Windows或Linux版MXIO程式庫簡化I/O管理•提供寬操作溫度型號,適合-40至75°C(-40至167°F)環境認證簡介ioLogik2500智慧乙太網路遠端I/O裝置採用獨特的硬體和軟體設計,因此成為各種工業資料擷取應用的理想解決方案。
ioLogik2500的硬體設計包括4埠非網管型乙太網路交換器和2個串列埠,能夠無縫連接至各種現場裝置。
其中的一個乙太網路連接埠可用於連接8個菊鏈ioLogik E1200擴充模組,藉以提供100多個通道。
ioLogik2500做為「主機」裝置,使用Click&Go Plus邏輯控制整個I/O陣列。
最重要的是,只需要IP即可將整個I/O陣列連接至您的網路,為IP位址數量不足的工業現場提供完美的解決方案。
免程控Click&Go Plus™邏輯Click&Go Plus™控制邏輯支援多達48個規則和8個條件/動作。
此外,其圖形化使用者介面還提供3個邏輯閘和3個多層,協助您建構更強大、更有效率的IO解決方案。
您完成Click&Go Plus™邏輯規則的設定後,IOxpress易於使用的模擬功能可用於在將Click&Go Plus™規則上傳到您的線上裝置之前發現其中的潛在錯誤。
多協定資料集中器透過支援多種協定,ioLogik2500提高收集現場資料並傳送到上層系統的效率。
数据库的读写分离实现

数据库的读写分离实现数据库的读写分离是一种常见的数据库优化技术,它能够提高系统的读取和写入能力,并且有效降低数据库的负载压力。
在实际应用中,读写分离可以通过多种方式来实现,例如主从复制、数据库中间件等。
本文将介绍数据库的读写分离实现,并探讨不同实现方式的优缺点。
一、主从复制方式实现读写分离主从复制是一种常用的实现读写分离的方式,它通过将数据从主数据库同步到多个从数据库,来实现数据的读写分离。
主从复制的实现过程如下:1. 配置主数据库:在主数据库上开启二进制日志功能,并设置唯一的server_id。
2. 配置从数据库:在从数据库上设置唯一的server_id,并设置主数据库的连接信息。
3. 数据同步:主数据库将数据变更记录在二进制日志中,并将二进制日志传输给从数据库进行数据同步。
4. 读写切换:应用程序根据业务需求,将读操作发送给从数据库,将写操作发送给主数据库。
主从复制方式实现读写分离的优点是简单易懂,实现成本较低。
同时,主从复制可以提高系统的读取能力,减轻主数据库的压力。
然而,主从复制也存在一些缺点,例如主从数据同步可能存在延迟,从数据库不能实时获取最新的数据。
二、数据库中间件方式实现读写分离除了主从复制,数据库中间件也是一种常用的实现读写分离的方式。
数据库中间件是一种位于应用程序与数据库之间的中间层,它通过拦截应用程序的数据库请求,将读请求分发给从数据库,将写请求分发给主数据库。
数据库中间件的实现过程如下:1. 配置数据库中间件:在数据库中间件上配置主数据库和从数据库的连接信息。
2. 拦截请求:数据库中间件拦截应用程序的数据库请求,并根据请求的读写类型进行分发。
3. 读写分离:数据库中间件将读请求发送给从数据库,将写请求发送给主数据库。
4. 数据同步:数据库中间件监控主数据库的数据变更,并将变更同步给从数据库。
数据库中间件方式实现读写分离的优点是透明化,对应用程序无需做任何修改,能够实现动态的读写分离。
分布式作业

1.分布式数据库系统是由若干个站集合而成。
这些站又称为节点,它们在通讯网络中联接在一起,每个节点都是一个独立的数据库系统,它们都拥有各自的数据库、中央处理机、终端,以及各自的局部数据库管理系统。
因此分布式数据库系统可以看作是一系列集中式数据库系统的联合。
它们在逻辑上属于同一系统,但在物理结构上是分布式的。
产生的根本原因是:由于计算机网络通信的迅速发展,以及地理上分散的公司、团体和组织对于数据库更为广泛应用的需求,在集中式数据库系统成熟技术的基础上产生和发展了分布式数据库系统.2. 实现方案有:BigTable: BigTable内部存储数据的文件是Google SSTable格式的。
SSTable是一个持久化的、排序的、不可更改的key-value映射的数据结构。
从内部看,SSTable 是一系列的数据块。
一个BigTable集群存储了很多表,每个表包含了一个Tablet集合。
每个Tablet 包含了某个范围内的行所有相关数据。
初始状态下,一个表只有一个Tablet。
随着表中数据的增长,它被自动分割成多个Tablet。
Amobea : Amoeba(变形虫)项目,该开源框架于2008年开始发布一款Amoeba for Mysql软件。
这个软件致力于MySQL的分布式数据库前端代理层,它主要在应用层访问MySQL的时候充当SQL路由功能,专注于分布式数据库代理层(Database Proxy)开发。
Amoeba 的优点:引入Amoeba的成本很小,熟悉过程需要的时间也很少,目前Amoeba的使用文档也相对比较完善。
能够在很多场景解决单机大数据量问题、大访问量的问题。
很容易解决读写分离(Amoeba for mysql)。
3. 研究的内容:数据跟踪;分布式查询处理;分布式事务处理;复制数据的管理;安全性;分布式目录管理三1. 分布式数据查询考虑的内容有哪些?答:要考虑:查询总代价是否为最小;每个查询的时间是否为最短。
laravel mysql读写分离实现方式

laravel mysql读写分离实现方式一、前言在大型网站系统中,数据读写分离是一种常见的优化手段,可以有效提高系统的性能和可扩展性。
本文将介绍如何在 Laravel 中实现MySQL 读写分离。
二、MySQL 主从复制首先,我们需要了解 MySQL 的主从复制概念。
MySQL 可以通过设置主从配置,实现数据的同步复制。
主服务器用于写操作,从服务器用于读操作,从而实现读写分离。
三、Laravel 配置 MySQL 读写分离1. 配置主从数据库连接在 Laravel 中,我们可以通过配置文件来设置数据库连接。
在`.env` 文件中,我们需要为读库和写库分别设置连接信息。
例如,对于MySQL 数据库,我们可以设置如下:```makefileDB_CONNECTION=mysqlDB_HOST=127.0.0.1DB_PORT=3306DB_DATABASE=your_databaseDB_USERNAME=your_usernameDB_PASSWORD=your_password# Read database configurationREAD_CONNECTION_STRING=mysql:host=master_ip;port=3 306;database=your_database_read,charset=utf8mb4,collation=ut f8mb4_unicode_ci,read_default_file=/path/to/f# Write database configurationWRITE_CONNECTION_STRING=mysql:host=master_ip;port= 3306;database=your_database,charset=utf8mb4,collation=utf8m b4_unicode_ci,read_default_file=/path/to/f```其中,`f` 文件需要包含以下内容:```arduino[client]host = write_ipport = write_portsocket = /path/to/socketdefault-character-set = utf8mb4这里的 `write_ip`、`write_port`、`master_ip`、`master_port` 和`socket` 需要根据实际情况进行替换。
MySQL数据库技术与应用(慕课版)课后习题答案

第1章数据库概述1.填空题(1)Oracle(2)U 1U 2U 4U(3)体积小、安装成本低、速度快、源码开放(4)Memcached、Redis、mongoDB(5)大、中、小型网站中2.选择题(1)A(2)B(3)A(4)A(5)D3.简答题(1)常见的关系型数据库有MySQL、Oracle、SQL Server和Access数据库。
MySQL数据库主要应用在广泛地应用到互联网上的大、中、小型网站中;Oracle数据库主要应用在传统大企业、政府机构、金融机构、证券机构等;SQL Server数据库主要应用在部分电商和使用Windows 服务器平台的企业;Access数据库早期应用于小型程序系统ASP + Access、系统留言板、校友录等。
(2)关系型数据库按照结构化的方法存储数据,具备纵向扩展能力,采用结构化查询语言,强调ACID规则,强调数据的强一致性,可以控制事务原子性细粒度,并且一旦操作有误或者有需要,可以回滚事务。
非关系型数据库不需要固定的表结构,一般情况下也不存在对数据的连续操作。
不同点:关系型数据库使用表结构,非关系型的数据库格式灵活。
关系型数据库支持SQL语言,支持事务,非关系型数据库不提供SQL语言,无事务处理。
相对于关系型数据库,非关系型数据库在大数据存取上具备无法比拟的性能优势。
(3)应该注意MySQL的版本和开发人员使用的版本。
第2章环境的安装与基本配置1.填空题(1)Ubuntu CentOS Red Hat(2)RPM包二进制包源码包(3)仅主机模式NAT模式桥接模式(4)数据库语言(5)Mysqladmin、mysqldump等命令2.选择题(1)A(2)B(3)B(4)D(5)D3.简答题(1)在企业中应该使用源码编译方式安装MySQL,使用源码安装在编译安装过程可以设定参数,按照需求,进行安装,并且安装的版本,可以自己选择,灵活性比较大。
(2)VMware虚拟平台提供3种网络模式。
MySQL主从复制介绍:使用场景、原理和实践

MySQL主从复制介绍:使⽤场景、原理和实践MySQL数据库的主从复制⽅案,和使⽤scp/rsync等命令进⾏的⽂件级别复制类似,都是数据的远程传输,只不过MySQL的主从复制是其⾃带的功能,⽆需借助第三⽅⼯具,⽽且,MySQL的主从复制并不是数据库磁盘上的⽂件直接拷贝,⽽是通过逻辑的binlog⽇志复制到要同步的服务器本地,然后由本地的线程读取⽇志⾥⾯的SQL语句重新应⽤到MySQL数据库中。
1.1.1 MySQL主从复制介绍MySQL数据库⽀持单向、双向、链式级联、环状等不同业务场景的复制。
在复制过程中,⼀台服务器充当主服务器(Master),接收来⾃⽤户的内容更新,⽽⼀个或多个其他的服务器充当从服务器(Slave),接收来⾃主服务器binlog⽂件的⽇志内容,解析出SQL重新更新到从服务器,使得主从服务器数据达到⼀致。
如果设置了链式级联复制,那么,从(slave)服务器本⾝除了充当从服务器外,也会同时充当其下⾯从服务器的主服务器。
链式级复制类似A→B→C的复制形式。
1.1.2 MySQL主从复制的企业应⽤场景MySQL主从复制集群功能使得MySQL数据库⽀持⼤规模⾼并发读写称为可能,同时有效地保护了物理服务器宕机场景的数据备份。
应⽤场景1:从服务器作为主服务器的实时数据备份主从服务器架构的设置,可以⼤⼤加强MySQL数据库架构的健壮性。
例如:当主服务器出现问题时,我们可以⼈⼯或设置⾃动切换到从服务器继续提供服务,此时从服务器的数据和宕机时的主数据库⼏乎是⼀致的。
这类似NFS存储数据通过inotify+rsync同步到备份的NFS服务器,只不过MySQL的复制⽅案是其⾃带的⼯具。
利⽤MySQL的复制功能做备份时,在硬件故障、软件故障的场景下,该数据备份是有效的,但对于⼈为地执⾏drop、delete等语句删除数据的情况,从库的备份功能就没有⽤了,因为从服务器也会执⾏删除的语句。
应⽤场景2:主从服务器实时读写分离,从服务器实现负载均衡主从服务器架构可通过程序(PHP、Java等)或代理软件(mysql-proxy、Amoeba)实现对⽤户(客户端)的请求读写分离,即让从服务器仅仅处理⽤户的select查询请求,降低⽤户查询响应时间及读写同时在主服务器上带来的访问压⼒。
commvault慷孚备份还原系统安装配置手册

Commvault 安装实施文档网络科技有限公司技术部2013-5-24目录一、文档概述 (4)二、Commvault 容灾备份架构 (4)2.1、实施前用户现状 (4)2.2、容灾备份网络拓扑 (4)2.3、Commvault 容灾备份简述 (5)三、Commvault 已安装模块列表 (5)四、备份服务器的安装配置 (5)4.1、备份服务器安装 (5)4.2、备份服务器补丁安装 (18)五、Commvault Windows下客户端的安装 (20)5.1、Windows 文件系统客户端安装 (20)5.2、Windows 其余模块安装 (28)六、Unix 平台下客户端的安装 (29)6.1、Unix Oracle IDA 的安装 (29)6.2、Unix 升级补丁 (43)七、Commserver 的基本配置 (45)7.1、磁盘库配置 (45)7.2、磁带库配置 (53)7.3、CommServer存储策略配置 (53)7.3.1、创建存储策略 (53)7.3.2、创建存储策略辅助拷贝 (58)八、客户端备份设置 (61)8.1、Windows客户端文件系统备份 (61)8.2、虚拟机备份设置 (63)8.3、Unix客户端文件系统备份设置 (69)8.4、Unix客户端oracle数据库备份设置 (71)8.5、Simpana9作业计划设置 (78)8.5.1、文件系统备份计划设置 (78)8.5.2、Oracle备份计划设置(Database Backup) (79)8.5.3、Oracle备份计划设置(Archivelog Backup) (81)九、维护和管理 (84)9.1、定期查看作业摘要 (84)9.2、查看和修改计划 (87)版本历史一、文档概述本文档主要描述了在的容灾备份项目中,针对commvault 容灾备份的安装配置过程,另外对commvault 日常维护操作也进行了详细的介绍。
基于Spring Boot与MyBatis框架构建动态读写分离模型

文章编号:1007-757X(2021)02-0084-03基于Spring Boot与MyBatis框架构建动态读写分离模型张旭刚,张昕,高若寒(国电南瑞科技股份有限公司信息系统集成分公司,江苏南京210000)摘要:读写分离集群,是当前系统应对高并发、大吞吐量的一种方法,也是一种保障系统业务连续性的方法°现有实现读写分离集群的工具和方法,主要是一种静态部署,不适应资源横向扩展、动态伸缩的需求,不能够快速响应外部需求的变化°'用Spring Boot和MyBatis框架提供的技术优势,通过面向切面编程AOP,提供一种动态的低耦合的读写分离方法,数据源可以横向扩展,根据需求动态收缩,并对应用程序透明"关键词:读写分离;Spring Boot;MyBatis;AOP中图分类号:TP301文献标志码:AA Way Realizing Separation of Reading and Writing BasedonSpringBootand MyBatisZHANG Xugang,ZHANG Xin,GAO Ruohan(Information System Integration Branch!Guodian Nanrui Technology Co!Ltd!Nanjing210000!China) Abstract:The separation of reading from writing is a way in dealing with high concurrence and high throughput,also a way to enhance business continuity.The majority of main ways and tools provides a static deployment.The static deployment is lack ofscaled-outanddynamicscalability Itcannotberapidlysatisfied withouterrequirementchanges Thistopic!usingSpring Bootand MyBatisframework with AOP!providesadynamicandlow-coupling way Thedatasourcesarescaled-outanddy-namica l yscalable AnditistransparenttoapplicationprogramKey words:separation of reading and writing;Spring Boot;MyBatis;AOP0引言读写分离集群,不仅提高了系统的健壮性和可靠性,以及系统的吞吐量和性能,保障了系统业务的连续性,而且也实现了资源的最大利用率&当前的实现方法主要通过静态方式配置,主要有中间件方式,如amoeba和mysql-proxy,分业务方式,对读写操作配置u O&静态方式缺乏灵活性,无法根据系统负载、用户需求等情况,实现资源的快速动态收缩,难以满足在不停机的条件下进行数据源切换,无法保证业务的连续性&利用Spring Boot和MyBatis框架提供的优势,通过面向切面编程AOP,实现一种对应用透明、数据源可以动态收缩与切换的模型&1Spring Boot架构Spring Boot是由Pivotal团队提供,简化Spring开发的微服务框架&通过约定优于配置和起步依赖,简化复杂的依赖关系,大量减少XML配置文件,基本实现自动化位置,能够快速创建独立运行的Spring项目,并且集成了主流框架,如AOP和MyBatis&为实现动态读写分离模型,主要利用面向切面编程技术AOP、MyBtis映射.SpringBoot的类Ab-stractRoutingDataSource ThreadLocal程间的数据隔离(1)&11Spring AOPSpring AOP(Aspect-Oriented Programming,面向切面编程),是一种称为“横切”的技术,把与业务无关逻辑,但为业务模块共同调用的逻辑或功能封装起来,将其命名为"Aspect”,即方面,减少系统的重复代码,降低模块间的耦合度,便于后期的操作和维护&在论文中,主要使用AOP的前置通知,拦截MyBatis映射的SQL语句,动态选择数据源&12MyBatisMybatis是一个支持普通SQL查询、存储过程和高级映射的优秀持久层框架,在持久层映射关系的开发中,可以不用写实现类,能以代理方式自动生成实现代码,同时SQL语句写在映射XML文件中,实现了代码与SQL分离,降低耦合度&在映射XML文件中,通过id标识不同类型的SQL 语句,对查询、插入、删除和更新语句进行区分如口查询语句的id前缀为query,删除语句的id前缀为delete,通过甄别判SQL语选择的数据!的分离&作者简介:张旭冈IJC979-),男,硕士,助理工程师,研究方向:计算机应用技术。
云端操作系统详解

云端操作系统介绍2011-6-2一、JOLI OS 云操作系统介绍Joli OS操作系统下载地址Joli OS的ISO镜像文件下载地址是:Joli OSWindows下可执行文件下载地址:(安装环境需要外网连接)Joli OS可以作为Windows系统下的可执行文件进行安装,整个安装过程,您看不到原本繁琐的操作,只需单击“下一步”,同时按照相关提示输入即可。
安装完毕之后,可以为用户在系统启动时提供入口。
正在提取Joli OS欢迎界面输入用户名和密码Joli OS系统设置Joli OS安装过程中,除了上页中提到的用户名和密码的设置外,仍然需要对系统环境进行设置,包括安装路径,安装盘大小以及安装语言等。
设置安装路径,安装盘大小以及安装语言改变系统设置Joli OS安装进程安装完成之后,系统要求重启这里,默认在C:jolicloud目录下安装。
默认在C:jolicloud目录下安装自此,我们完成了Joli OS在Windows环境下的安装。
当您重启系统的时候,系统提示您有两个可供选择的操作系统可以使用,Joli OS成为选择之一。
Joli OS的硬件兼容性安装ISO镜像文件的过程可以参考《Ubuntu变种秒杀谷歌Chrome OS无惧Win8》,这里将不再赘述。
不过,无论您安装哪种Joli OS安装文件,系统安装过程中,都会提示您描述计算机您正在使用的是什么设备以及什么品牌和型号,以便于系统自动匹配相关的驱动程序,从而进一步提高系统的应用体验。
描述您的安装设备(上网本、笔记本、桌面还是其他设备)描述设备的品牌和型号作为一款商业软件,尽管下载和使用都是完全免费的,Jolicloud仍然提供了良好的硬件兼容性,所有的硬件设备,包括 wifi,蓝牙适配器,modem, SD 读卡器都被正确识别,而且能够正常工作。
Joli OS云应用体验Joli OS的特点就是用户界面友好,安装和使用都极其简单,用户的任何操作都可以通过鼠标来完成。
如何使用Amoeba

如何使⽤Amoeba For Mysql Amoeba For MysqlAmoeba For Mysql 是 Amoeba项⽬的⼦项⽬。
要使⽤Amoeba For Mysql您必须确保您已符合所有先决条件:先决条件:1. Java SE 1.5或者以上 Amoeba 框架是基于JDK1.5开发的,采⽤了JDK1.5的特性。
2. ⽀持Mysql协议版本10(mysql 4.1以后的版本)。
3. 您的⽹络环境⾄少运⾏有⼀个mysql4.1以上的服务如何快速配置:1. 配置Server(以下是双核CPU配置,调整线程数可优化性能),配置说明:配置项是否必选默认值说明port否8066Amoeba Server绑定的对外端⼝ipAddress否空Amoeba绑定的IPuser是空客户端连接到Amoeba的⽤户名password否空客户端连接到Amoeba所⽤的密码readThreadPoolSize否16负责读客户端、databa seserver 端⽹络数据包线程数clientSideThreadPoolSize否16负责读执⾏客户端请求的线程数serverSideThreadPoolSize否16负责处理服务端返回数据包的线程数Server Tag Configuration1. <server>2. <!-- proxy server绑定的端⼝ -->3. <property name="port">2066</property>4.5. <!-- proxy server绑定的IP -->6. <property name="ipAddress">127.0.0.1</property>7.8. <!-- proxy server net IO Read thread size -->9. <property name="readThreadPoolSize">100</property>10.11. <!-- proxy server client process thread size -->12. <property name="clientSideThreadPoolSize">80</property>13.14. <!-- mysql server data packet process thread size -->15. <property name="serverSideThreadPoolSize">100</property>16.17. <!-- 对外验证的⽤户名 -->18. <property name="user">root</property>19.20. <!-- 对外验证的密码 -->21. <property name="password">password</property>22. </server>3. 配置 ConnectionManager需要⾄少配置⼀个ConnectionManager,每个ConnectionManager将作为⼀个线程启动,ConnectionManager负责管理所注册在⾃⾝的Conneciton、负责他们的空闲检测,死亡检测、IO EventconnectionManagerList Tag Configuration1. <!--2. 每个ConnectionManager都将作为⼀个线程启动。
“云盘”设计方案
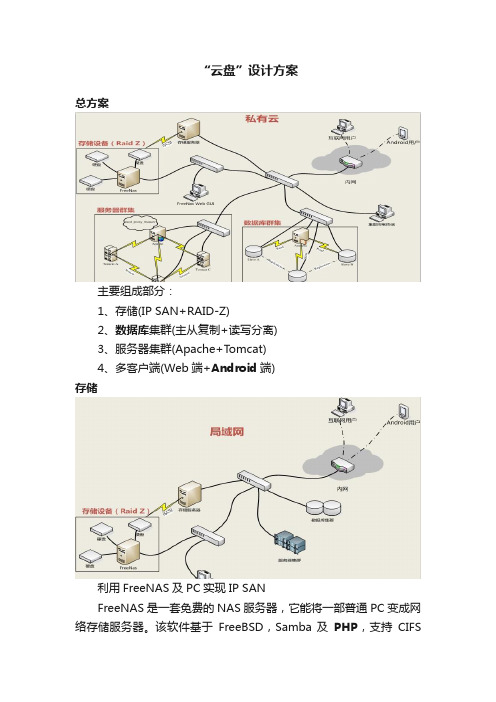
“云盘”设计方案总方案主要组成部分:1、存储(IP SAN+RAID-Z)2、数据库集群(主从复制+读写分离)3、服务器集群(Apache+T omcat)4、多客户端(Web端+Android端)存储利用FreeNAS及PC实现IP SANFreeNAS是一套免费的NAS服务器,它能将一部普通PC变成网络存储服务器。
该软件基于FreeBSD,Samba 及PHP,支持CIFS(samba), FTP, NFS protocols, Software RAID (0,1,5) 及 web 界面的设定工具。
用户可通过Windows、Macs、FTP、SSH 及网络文件系统(NFS) 来访问存储服务器;FreeNAS可被安装于硬盘或移动介质USB Flash Disk上,所占空间不足 16MB。
在FreeNas中将三块硬盘组成RAID-Z后,在服务选项中激活iSCSI服务,即可在 Windows中使用iSCSI发起程序挂载磁盘阵列。
集群数据库集群一台MySQL服务器是很难做到高可用(HA),如果没有及时做数据备份,一旦遇到故障宕机后将无法继续提供后端数据业务。
单一的数据库节点对于高并发、高负载场景呈现出各种瓶颈问题也越来越突出。
数据库集群技术通过水平扩展的方式将负载分散到多个节点上以解决一个数据库节点的不足。
本方案基于MySQL数据库主从复制及基于Amoeba For MySQL 读写分离,利用Amoeba将请求分发到不同的MySql服务器,以达到使我们项目在原有的基础上具有更快的读写速度,给用户更快的响应,更高的负载。
服务器集群Tomcat集群负载均衡有三种方式:mod_proxy、mod_proxy_blancer、mod_jk本方案采用mod_proxy_balancer,它是mod_proxy的扩展,提供负载平衡支持,通过mod_proxy_balancer.so包实现负载平衡。
采用此方式,当用户请求发布的web项目时,apache服务器会根据我们的配置,将请求分发给集群中的不同的Tomcat服务器,实现服务器的负载均衡,相对于一个服务器来说,这种集群可以响应更多的用户请求而一直保持活跃状态。
基于Amoeba中间件的分布式数据库管理系统

0 引 言
随着传 统数 据库技 术 的 日趋 成熟 , 计 算 机 网络技 术 的 飞速发 展 和应用 范 围的不 断扩充 , 数 据库 应 用 已 经普 遍 建立 于计 算 机 网络 之 上 。而传 统 的集 中式 数
a n d m o d i f y t h e i n f o r m a t i o n o f s e r v e s, r t o c o n f i g u r e t h e p ra a m e t e r s o f A m eb o a s e r v e s r nd a M y S Q L d a t a b a s e s e r v e r s , l o a d b a l n— a
e s r nd a a v o i d t e d i o u s o p e r a t i o n .At l a s t ,t h e e x p e i r me n t s h o w s t h a t i t C n a e f f e c t i v e l y c o n i f ur g e t h e p ra a me t e r s t o ma n a g e a l a r g e
( D e p a r t me n t o f C o mp u t e r S c i e n c e a n d T e c h n o l o g y , T o n g j i U n i v e r s i t y , S h a n g h a i 2 0 1 8 4, 0 C h i n a )
c i n g ,t h e s e p a r a i t o n r u l e o f r e a d nd a wr i t e,a n d d a t a s e g me n t a t i o n .Ad mi n i s t r a t o r s C n a u s e t h i s s y s t e m t o ma s t e r he t s t a t e o f s e r v —
JAVA分布式架构的演变及解决方案
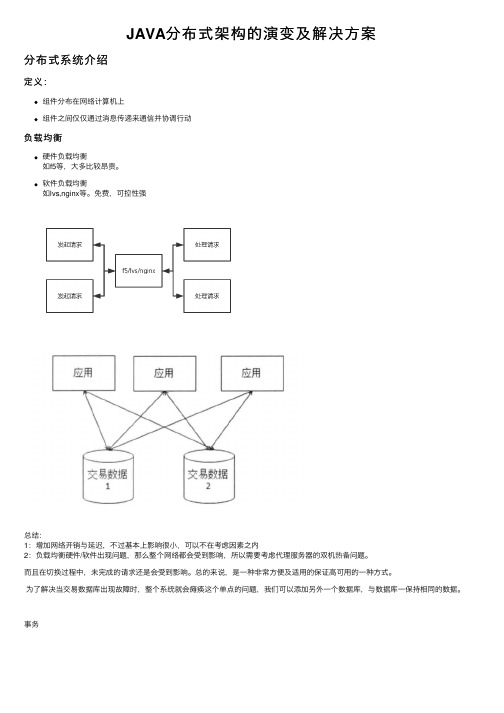
JAVA分布式架构的演变及解决⽅案分布式系统介绍定义:组件分布在⽹络计算机上组件之间仅仅通过消息传递来通信并协调⾏动负载均衡硬件负载均衡如f5等,⼤多⽐较昂贵。
软件负载均衡如lvs,nginx等。
免费,可控性强总结:1:增加⽹络开销与延迟,不过基本上影响很⼩,可以不在考虑因素之内2:负载均衡硬件/软件出现问题,那么整个⽹络都会受到影响,所以需要考虑代理服务器的双机热备问题。
⽽且在切换过程中,未完成的请求还是会受到影响。
总的来说,是⼀种⾮常⽅便及适⽤的保证⾼可⽤的⼀种⽅式。
为了解决当交易数据库出现故障时,整个系统就会瘫痪这个单点的问题,我们可以添加另外⼀个数据库,与数据库⼀保持相同的数据。
事务分布式和集群区别:⼀句话:分布式是并联⼯作的,集群是串联⼯作的。
分布式:⼀个业务分拆多个⼦业务,部署在不同的服务器上集群:同⼀个业务,部署在多个服务器上集群是个物理形态,分布式是个⼯作⽅式。
只要是⼀堆机器,就可以叫集群,他们是不是⼀起协作着⼲活,这个谁也不知道;⼀个程序或系统,只要运⾏在不同的机器上,就可以叫分布式,嗯,C/S架构也可以叫分布式。
集群⼀般是物理集中、统⼀管理的,⽽分布式系统则不强调这⼀点。
所以,集群可能运⾏着⼀个或多个分布式系统,也可能根本没有运⾏分布式系统;分布式系统可能运⾏在⼀个集群上,也可能运⾏在不属于⼀个集群的多台(2台也算多台)机器上。
1:分布式是指将不同的业务分布在不同的地⽅。
⽽集群指的是将⼏台服务器集中在⼀起,实现同⼀业务。
分布式中的每⼀个节点,都可以做集群。
⽽集群并不⼀定就是分布式的。
2:简单说,分布式是以缩短单个任务的执⾏时间来提升效率的,⽽集群则是通过提⾼单位时间内执⾏的任务数来提升效率。
例如:如果⼀个任务由10个⼦任务组成,每个⼦任务单独执⾏需1⼩时,则在⼀台服务器上执⾏该任务需10⼩时。
采⽤分布式⽅案,提供10台服务器,每台服务器只负责处理⼀个⼦任务,不考虑⼦任务间的依赖关系,执⾏完这个任务只需⼀个⼩时。
运维学习路线

运维学习路线Linux运维⼯程师是⼀个新颖岗位,现在⾮常吃⾹,⽬前从⾏业的⾓度分析,随着国内软件⾏业不断发展壮⼤,越来越多复杂系统应运⽽⽣,为了保证系统稳定运⾏,必须要有⾜够多的Linux运维⼯程师。
维护是软件⽣命周期中⾮常重要⼀个阶段,当前国内的运维⼯程师⼈才相对稀缺,故在未来⼏年,运维⼯程师肯定会成为⼀个热门职业。
Linux运维⼯程师发展前景从薪资待遇这⽅⾯来看,⼯作经验不到1年的⼈,在北上⼴⼤概是4k左右,基础相对好些的⼈,能达到5.5K左右。
有相关⼯作经验的,⼀般在7K以上。
Linux运维相关⼯作1-2年的,学习能⼒和⼯作能⼒较强的,在北上⼴能达到8-10K。
2-3年⼯作经验能达到10-15K,3年以上,待遇普遍是⽐较⾼的了,年薪20万以上。
Linux运维⼯程师发展前景从岗位的职责来看,运维岗位不像其它岗位,如研发⼯程师、测试⼯程师等,有⾮常明确的职责定位以及职业规划,⽐较有职业认同感与成就感;⽽运维⼯作可能给⼈的感觉是哪⽅⾯都要了解⼀些,但⼜都⽐以上专职⼯程师更精通。
有了以上的优势,很多⼈都开始学习Linux,毕竟向运维⼯程师这样的⾼薪⼯作已经不多了。
最近整理了⼀下我⼊⾏时的经验,当时是参考了马哥教育的培训课程学习的。
马哥教育是国内泛Linux运维技术领域⾼薪IT职业学院,是国内泛Linux运维技术领域的⾼端互联⽹IT职业教育品牌,是腾讯课堂、51CTO学员、红帽认证的培训机构,这家机构还是很靠谱的。
教程内容:Linux⼊门⾸先要分为5个阶段,各阶段从前到后技术实⼒依次增加,相应的也更加能够符合企业的⽤⼈需求。
为了让⼤家对于这5个阶段的能⼒⽔平有更清楚的认识,我们特别对能⼒进⾏了分解,按照各阶段可在企业中承担的任务进⾏标注。
图⽚不清晰的话可以看原本的⽂字版本:第⼀阶段:企业级Linux运维⼯程师1、Linux运维最佳学习⽅法”5W1H”六何分析法全⾯介绍,独家Linux快速⼊门学习技巧2、冯诺依曼体系(CPU架构、操作系统概念、发展演变、应⽤场景、业内形态)3、Linux运维基础实战⼊门,⽤户管理,权限,⽂件查找,⽂本编辑及实战讲解4、Linux运维系统管理和技能进阶,磁盘管理,软件安装,⽂件系统、内核使⽤⽅法和⾼级技巧5、Linux系统环境及⽇常管理,结合⽇常⼯作常⽤20个场景,排错思路、⾯试和⼯作中注意事项6、以实战⽅式全⽅位展⽰Bash⼋⼤特性和⾼级⽤法介绍以及⾼级企业级使⽤技巧实战演练7、Shell脚本⼯作原理、学习⽅法、配罝技巧、企业级书写规范、开发环境定制全⾯实战介绍8、职场⼈价值体系-知识、技能、成长⽬标和⽅向定位年薪30W运维⼈员必备知识体系关键技能点第⼆阶段:Linux应⽤运维⼯程师&DBA1、TCP/IP⽹络通信协议,IP地址含义、TCP有限状态机转换原理,路由协议2、利⽤Kickstart⽂件实现企业级⾃动化安装环境定制,百台并发安装实战3、Linux常见系统故障案例分析,企业级Linux运维⼯程师常犯错误Top54、全⾯讲解CDN核⼼技术理念,实现智能DNS流量分发和⽤户策略引导5、实战讲解LAMP运维架构,Apache+PHP+Mysql架构体系和⽂件存储6、介绍企业级安全体系,iptables构建安全架构以及软硬防⽕墙优劣势7、深⼊讲解运维必备Web服务开源解决⽅案Nginx及LNMP企业⾼级⽤法8、企业级DBA实战课程,Mysql企业级实战应⽤,调优及redis企业级应⽤第三阶段:企业级Linux云计算⼯程师1、全⾯讲解企业级LNMP架构及12条策略建议,实现互联⽹电⼦商务、博客、论坛等实战案例2、专业压测评估体系,从并发、响应时间、持久连接、pv、峰值、带宽,以及ab等压测⽅案实施4、讲解Linux Cluster集群,全⾯分析集群类别,讲解F5和LVS、haproxy、nginx的4-7层负载均衡5、实战带领在Centos7上实现LVS集群配罝、服务管理、调度算法修改、后端服务器上下线、服务状态监控,状态监测⽅实现NAT、DR、TUN等模型演练6、全⾯实现基于Nginx负载均衡功能,实现Nginx反代后端、Nginx负载均衡实现⽹站动静分离详解7、实战带领实现Keepalived主从架构及双主切换⽅案、报警定制、⽇志分析等8、全⾯讲解Zabbix3.X监控特性、Web服务监控、Zabbix内部监控、Zabbix特性及功能详解9、全⾯讲解Varnish缓存技术,深⼊Varnish⼯作机制、核⼼架构、及主流开源缓存技术解决⽅案10、laaS、PaaS和SaaS云平台功能及常见实现⽅式及OpenStack的功能特性及其实现的增强功能11、全⾯讲解KVM虚拟化技术,docker技术实现互联⽹容器和Docker容器云以及Kubemetes管理第四阶段:Linux⾃动化运维⼯程师&DevOps1、以⾃动化运维框架为主线,讲解Devops运维⾃动化趋和核⼼技术2、⾃动化运维⼯具Puppet、Ansible、Cobbler、Saltstack、 Fabric对⽐3、Ansible⽣产环境应⽤案例和实战操练、批量进⾏上百台服务器管理4、企业⾃动化⼯具Puppet使⽤场景,实现搭建企业运维⾃动化平台架构5、全⾯讲解Git版本控制、脚本⾃动化管理、Git分⽀合并,Git服务器搭建6、深⼊讲解基于Shell脚本企业级⾼级⽤法和常见实现Shell⾃动化管理7、python基本语法和⾃动化⼯具应⽤,及开源跳板机Jumpserver实现8、实战:基于⽣产环境持续集成案例,Jenkins+gitlab+maven+shell实现代码⾃动化上线部署,可持续集成9、⽣产环境基于⾃动化运维常见场景如⾃动化发布、灰度发布、批量上线、降级⽅案、⽆缝切换等核⼼技术第五阶段:Linux系统架构师&运维架构师1、全⾯介绍缓存技术要点,讲解数据流式化、代理式缓存、旁路式缓存、缓存算法、缓存设定策略、⼀致性哈希算法优劣势等2、全⾯讲解正向代理、反向代理机制,实战实现Nginx反向代理负载均衡,跳转规則实现动静分离、IP⽈志记录、头部信息改写、缓存模块、缓存策略、请求超时机制、健康状态监测、判定规则、状态码定义、实现后端故障及⾃动上线等能⼒3、实战带领实现千万级⼤型互联⽹Web架构核⼼技术,运⽤LVS、Haproxy、Vamish、 Nginx、tomcat、MySQL等实现⾼并发运维体系Web架构,实现分布式集群存储Fastdfs和mogileFS架构4、全⾯讲解MySQL—主多从、⼀从多主企业级⽤法,深⼊讲解MySQL读写分离、连接池及sharding技术,以及MMM、MHA、Galera-Cluster核⼼技术,MySQL读写分离Amoeba实现5、实战:分布式收集Nginx⽇志于Elk集群,并通过Kibana展⽰;实战:分布式收集 JAVA⽇志于Elk集群,并通过Kibana展⽰;实战:分布式收集Syslog⽈志于Elk集群,并通过Kibana展⽰6、结合⾃动化⼯具实现企业业务服务管理,持续化集成,实现Devops运维管理模型及架构设计。
lettuceclientconfigurationbuildercustomizer读写分离

lettuceclientconfigurationbuildercustomizer读写分离 LettuceClientConfigurationBuilderCustomizer是一个用于自定义LettuceClientConfiguration的接口,它可以让用户在建立Lettuce 连接时进行一些自定义配置。
其中读写分离是常见的一种配置需求。
读写分离是将读操作和写操作分别指向不同的 Redis 节点,以达到负载均衡和提高性能的目的。
在 Lettuce 中,可以通过使用ReadFrom 和 WriteTo 选项来实现读写分离。
我们可以通过实现LettuceClientConfigurationBuilderCustomizer 接口来设置ReadFrom 和 WriteTo 选项,示例代码如下:
```
@Configuration
public class LettuceConfig {
@Bean
public LettuceClientConfigurationBuilderCustomizer lettuceClientConfigurationBuilderCustomizer() {
return builder -> {
builder.readFrom(ReadFrom.REPLICA_PREFERRED); // 读操作优先访问从节点
builder.writeTo(WriteTo.MASTER); // 写操作只访问主节点 };
}
}
```
在上面的示例中,我们将读操作优先访问从节点,写操作只访问主节点,这样可以有效地分担主节点的负载压力,提高系统的整体性能。
mysql各种集群的优缺点

mysql各种集群的优缺点
mysql各种集群的优缺点
1.主从架构:只是有数据备份的功能;
2.主主互备+keepalived:实现数据备份加⾼可⽤;
3.主主互备,主主下⾯分别挂个从;
4.A和B主主互备,把从库都挂到B下,减少IO问题;
5.MMM架构,perl编写,基于mysql主从复制,成熟⾼可⽤集群⽅案,由⼀个管理端(monitor)和多个代理端(aget)构成
优点:监控所有Master节点及Slave节点状态,当master节点出现故障,会把vip⾃动转移到健康节点上;更重要的是当Master节点发⽣故障,会⾃动将后端Slave节点转向备⽤的Master节点继续同步复制,切换过程不需要⼈⼯⼲预;
缺点:对ip,服务器数量有要求(⾄少两台服务器,2个真实ip,3个vip);业务繁忙,数据量⼤的时候不是很稳定,会出现复制延时,切换失效等问题;所以MMM⽅案不适合应⽤于对数据安全性要求很⾼,并读写频繁的环境中。
数据量⼤的时候,会有主从数据不同步的问题;
6.MHA架构,搭建起来⽐较⿇烦,⾄少三台机器,淘宝进⾏过⼆次开发,可以⽤两台机器;
读写分离中间件:
7.mysqlproxy:通过lua脚本实现的读写分离,不太稳定,官⽹不建议⽤;
8.Amoeba:致⼒于mysql分布式数据库前端代理层,它主要在应⽤层,访问mysql的时候充当SQL路由器的功能,依据⽤户事先设置的规则,将SQL请求发送到特定的数据库上执⾏。
基于此可以实现负载均衡、、⾼可⽤性等需求。
Amoeba相当于⼀个SQL请求的,⽬的是为负载均衡、读写分离、⾼可⽤性提供机制,⽽不是完全实现它们。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
配置amoeba实现读写分离配置环境:Mater :192.168.1.229 server1 读Slave :192.168.1.181 server2 写网站主机: 192.168.1.120 测试读写一,配置mysql主从复制:请见另外一个文档。
二,配置jdk环境变量。
Amoeba框架是基于Java SE1.5开发的,建议使用Java SE 1.5版本。
目前Amoeba 经验证在JavaTM SE 1.5和Java SE 1.6能正常运行,(可能包括其他未经验证的版本)。
变量设置(在master主机上配置),此处可以设置全局环境变量设置,也可使用root 用户变量设置,同样,如果是别的用户安装的amoeba软件,则使用相应的账号来设置jdk环境变量。
全局设置如下:加入下信息:vi /etc/profileJAVA_HOME=/usr/local/jdk1.6.0_25PATH=$JAVA_HOME/bin:$PATHPATH=$PATH:$HOME/bin:/usr/local/amoeba/binCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport JAVA_HOMEexport PATHexport CLASSPATH解释如下:第一行指定了jdk的安装目录。
第二行指定了其家目录的路径。
第三行指定了amoeba的安装目录。
第四行指定了java相应的工具盒功能。
同样,如果是root用户的环境变量,则使用下面的位置的变量。
vi ~/.bash_profile加入如上得到内容即可。
完成之后,执行命令 source ~/.bash_profile 或者source /etc/profile使用如下的命令查看java手否被成功安装:[root@localhost ~]# java -versionjava version "1.6.0_25"Java(TM) SE Runtime Environment (build 1.6.0_25-b06)Java HotSpot(TM) Client VM (build 20.0-b11, mixed mode, sharing)上述显示已经成功安装1.6版本。
附注jdk的下载地址:/technetwork/java/javase/downloads/jdk-6u32-downlo ads-1594644.html三,Amoeba的安装(amoeba只需安装到一台主机上即可,默认情况下,是安装到主(master)服务器上,如果有第三台服务器,也可以将其安装到第三台服务器上。
这样,减少了mysql使用的瓶颈。
1,在安装之前,需要对mysql进行授权管理:使用下面命令对连接时使用的用户名密码及数据库,IP地址进行授权。
下面例子中授权所用户任何IP地址使用root用户访问所有的数据库。
如下命令:mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%'IDENTIFIED BY 'oppomy7gadmin' WITH GRANT OPTION;Query OK, 0 rows affected (0.20 sec)2,Amoeba软件可以从下面地址中得到。
Linux下:wget /project/amoeba/Amoeba%20for%20mysql/2.x /amoeba-mysql-binary-2.1.0-RC5.tar.gzWindows下:/projects/amoeba/3,本文中介绍的是在linux下安装的,下面开始amoeba的安装:解压amoeba 到/usr/local/tar xzf amoeba-mysql-binary-2.1.0-RC5.tar.gz -C /usr/local/amoeba4,amoeba的配置:配置Amoeba for mysql的读写分离主要涉及两个文件:① /usr/local/amoeba/conf/dbServers.xml此文件定义由Amoeba代理的数据库如何连接,比如最基础的:主机IP、端口、Amoeba 使用的用户名和密码等等。
② /usr/local/amoeba/conf/amoeba.xml5,编辑第一个配置文件:vim /usr/local/amoeba/conf/dbServers.xml内容如下:<?xml version="1.0" encoding="gbk"?><!DOCTYPE amoeba:dbServers SYSTEM "dbserver.dtd"><amoeba:dbServers xmlns:amoeba="/"><!--Each dbServer needs to be configured into a Pool,If you need to configure multiple dbServer with load balancing that can be simplified by the following configuration:add attribute with name virtual = "true" in dbServer, but the configuration does not allow the element with name factoryConfigsuch as 'multiPool' dbServer--><dbServer name="abstractServer" abstractive="true"><factoryConfigclass=".MysqlServerConnectionFactory"><property name="manager">${defaultManager}</property><property name="sendBufferSize">64</property><property name="receiveBufferSize">128</property><!-- mysql port --><property name="port">3306</property><!-- mysql schema --><property name="schema">test</property><!-- mysql user --><property name="user">root</property><!-- mysql password --><property name="password">oppomy7gadmin</property> </factoryConfig><poolConfigclass=".poolable.PoolableObjectPool"><property name="maxActive">500</property><property name="maxIdle">500</property><property name="minIdle">10</property><propertyname="minEvictableIdleTimeMillis">600000</property><propertyname="timeBetweenEvictionRunsMillis">600000</property><property name="testOnBorrow">true</property><property name="testWhileIdle">true</property></poolConfig></dbServer><dbServer name="server1" parent="abstractServer"><factoryConfig><!-- mysql ip --><property name="ipAddress">192.168.1.229</property> </factoryConfig></dbServer><dbServer name="server2" parent="abstractServer"><factoryConfig><!-- mysql ip --><propertyname="ipAddress">192.168.1.181</property></factoryConfig></dbServer><dbServer name="multiPool" virtual="true"><poolConfigclass="com.meidusa.amoeba.server.MultipleServerPool"><!-- Load balancing strategy: 1=ROUNDROBIN , 2=WEIGHTBASED , 3=HA--><property name="loadbalance">1</property><!-- Separated by commas,such as: server1,server2,server1 --><property name="poolNames">server2</property></poolConfig></dbServer></amoeba:dbServers>解释如下:更改上述中黄色区域的内容,如果没有上述内容,则添加,如果涉及到多个库,则也许添加至文档中,涉及到多个slave(文件中为server1),需要单独添加,server1为master,并指定其IP地址。