第3篇数据库表的扩展属性
关系型数据库的扩展性

SQL Databas es Don't Scale传统SQL数据库不具有可扩展性A questio n I’m often asked about Herokuis: “How do you scale the SQL databas e?” There’s a lot of thingsI can say about using caching, shardin g, and other techniq ues to take load off the databas e. But the actualansweris: we don’t. SQL databas es are fundame ntally non-scalabl e, and there is no magical pixie dust that we, or anyone, can sprinkl e on them to suddenl y make them scale.我经常向Her oku问一个问题:“你是如何进行扩展SQL数据库的?”。
当然你可以说出许多技巧来降低数据库的负载,比如利用缓存,数据分片等等。
事实上真正的回答却是:“我们做不到。
”因为从根本上讲,传统SQL数据库并不具有可扩展能力。
这个世界上也根本没有什么神奇的精灵之尘,可以让我们任何人突然使其获得扩展性的。
What Is Scaling?什么是可扩展性?To qualify as true scaling, I believe a techniq ue must fit the followi ng criteri a:必须满足以下几个标准的才是真正合格的可扩展性,我认为这都是必要条件:1. Horizon tal scale: more servers creates more capacit y.1. 水平扩展能力:更多的服务器可以提供成比例更多的容量或者更高的性能。
数据库表分区和分区扩展

数据库表分区和分区扩展数据库表分区是一种在关系数据库中将大型表拆分成更小的部分的技术。
通过将表数据分布在多个磁盘上的不同分区中,可以提高查询性能、简化维护和管理,并增加系统的可扩展性。
在本文中,将详细讨论数据库表分区和分区扩展的概念、优势和最佳实践。
1.分区概念:数据库表分区是将表的数据分布在数据库中的多个分区中的过程。
每个分区可以存储特定的数据,并且可以使用不同的分区策略进行数据的存储和访问。
分区有助于改善查询性能,减少锁竞争,并且可以更好地支持数据的增加、删除和修改操作。
2.分区类型:数据库表可以根据不同的标准进行分区,如范围分区、哈希分区、列表分区和组合分区。
-范围分区:根据某个列的范围进行分区,例如按日期、年龄或金额范围进行分区。
这种分区策略适用于以时间为基础的数据或具有连续值的列。
-哈希分区:根据某个列的哈希值进行分区,以确保数据均匀分布在多个分区上。
这种分区策略适用于没有特定范围要求的数据。
-列表分区:根据某个列的固定值列表进行分区,将符合列表值的行存储在同一个分区中。
这种分区策略适用于具有离散值的列,比如国家、地区或状态等。
-组合分区:将多个分区策略组合使用,根据不同的列和条件进行分区。
通过组合分区,可以更精确地控制数据的分布和查询优化。
3.分区优势:数据库表分区具有以下几个优势:-提高查询性能:将数据分布在多个磁盘上的不同分区中,可以并行地执行查询操作,从而提高整体查询性能。
-简化维护和管理:分区可以减少锁竞争,提高并发性能。
此外,对于大型表,备份、恢复和数据迁移等维护操作也更加高效和方便。
-增加系统的可扩展性:通过添加新的分区,可以在保持系统运行的同时扩展表的容量。
这种分区扩展方案比传统的扩展方法,如增加硬件资源或重新设计表结构,更加灵活和可行。
4.分区扩展:在进行分区扩展时,需要考虑以下几个方面:-迁移数据:将现有的表数据迁移到新的分区结构中。
可以使用数据库提供的工具或编写自定义脚本完成数据迁移。
数据库表分区和分区扩展

数据库表分区和分区扩展【原创版】目录1.数据库表分区概述2.数据库表分区的优点3.数据库表分区扩展4.结论正文1.数据库表分区概述数据库表分区是指将一个表按照一定规则划分成多个小的存储区域,这些小的存储区域称为分区。
每个分区可以独立存储数据,这样可以解决单个表数据量过大的问题。
表分区技术是数据库系统为了提高数据存储和管理效率而设计的一种技术。
2.数据库表分区的优点(1) 提高查询效率:通过将数据分散存储在不同的分区中,可以降低查询时需要扫描的数据量,从而提高查询速度。
(2) 提高存储空间利用率:分区技术可以根据数据特点进行合理的存储布局,避免数据浪费存储空间,提高存储空间利用率。
(3) 便于数据维护:分区技术可以将数据分散存储,有利于对数据进行维护和更新,提高数据维护的效率。
3.数据库表分区扩展数据库表分区扩展是指在已有分区基础上,根据业务需求增加新的分区。
分区扩展可以进一步优化数据存储和管理,提高数据库性能。
(1) 增加分区数量:根据业务需求,可以适当增加分区数量,将数据分散存储,提高查询效率。
(2) 调整分区范围:可以根据数据特点和业务需求,动态调整分区范围,使数据存储更加合理,提高存储空间利用率。
(3) 优化分区策略:可以通过优化分区策略,如按照时间、地理位置等维度进行分区,使数据查询和管理更加高效。
4.结论数据库表分区和分区扩展技术是提高数据库性能的有效手段。
合理的表分区设计可以降低查询时需要扫描的数据量,提高存储空间利用率,便于数据维护。
而分区扩展则可以进一步优化数据存储和管理,提高数据库性能。
数据库(容器)是相关数据和对象的集合数据库文件的扩展

Visual FoxPro 数据库设计
管理数据库
使用多个数据库 设置当前数据库:Set database Open database db1 Open database db2 Set database to db1 访问其它数据库中的数据表: Use db1!student browse
Visual FoxPro 数据库设计
建立表间关系……临时关系-建立方法
•利用“Set Relation to”建立临时关系 利用“ to” 举例:
use sc in 1 order in_sno use student in 2 order in_sno set relation to sno into student list sno,cno,grade,student.sname use student in 1 order in_sno use sc in 2 order in_sno set relation to sno into sc list sno,sname,o,sc.grade
Visual FoxPro 数据库设计
建立表间关系……设置参照完整性
参照完整性指相关表之间数据一致性的规则。 它建立于表间的永久关系之上。包括: 子表每一记录在父表中必须有一相应的记录; 父表主关键字修改后,子表的外部关键字必须作相应的修改; 父表记录删除时,子表相应记录也应删除。
Visual FoxPro 数据库设关系 菜单【窗口】→【数据工作期】 使用 “打开”按钮,打开两个数据表 单击左边窗口的主数据表名 按“关系”按钮 单击辅数据表 选定关键字段
Visual FoxPro 数据库设计
建立表间关系……临时关系-建立方法
利用“Set Relation to”建立临时关系 格式:SET RELATION TO[<关键字>/<数值表达式> INTO <别名> [ADDITIVE] 说明:使用本命令前必须将数据表分别在不同的工作 区中打开,并且被关联表必须按共同的关键字做索引。 ADDITIVE 表示保持以前建立的关联。 取消已建立的关系: Set relation to
表空间的扩展

表空间扩展说明17:58:05 执行SQL语句异常!insert into DC_FILE_REC(file_log_id,link_id,source_path,source_file,dcm_file_id,switch_id,exchange_id,fi)17:58:05 SQL异常信息:java.sql.SQLException: ORA-01654: unable to extend index DICDCM.IDX_FILE_REC4 by 1024 in tablespace DICDCMX17:58:05 free database connector!17:58:05 分发链路: tuoji-etsmet-c :写文件分发日志表异常: /bill2/met/bjets/data/USRMETER1H17:58:05 create database connector!用户:system 密码:manager从后台进入sql操作#sqlplus ‘/ as sysdba’输入用户名密码即可1、SQL> desc dba_segments;Name Type Nullable Default CommentsOWNER V ARCHAR2(30) Y Username of the segment ownerSEGMENT_NAME V ARCHAR2(81) Y Name, if any, of the segmentPARTITION_NAME V ARCHAR2(30) Y Partition/Subpartition Name, if any, of the segment SEGMENT_TYPE V ARCHAR2(18) Y Type of segment: "TABLE", "CLUSTER", "INDEX", "ROLLBACK","DEFERRED ROLLBACK", "TEMPORARY","SPACE HEADER", "TYPE2 UNDO"or "CACHE"TABLESPACE_NAME V ARCHAR2(30) Y Name of the tablespace containing the segment HEADER_FILE NUMBER Y ID of the file containing the segment header HEADER_BLOCK NUMBER Y ID of the block containing the segment header BYTES NUMBER Y Size, in bytes, of the segmentBLOCKS NUMBER Y Size, in Oracle blocks, of the segmentEXTENTS NUMBER Y Number of extents allocated to the segment INITIAL_EXTENT NUMBER Y Size, in bytes, of the initial extent of the segment NEXT_EXTENT NUMBER Y Size, in bytes, of the next extent to be allocated to the segmentMIN_EXTENTS NUMBER Y Minimum number of extents allowed in the segmentMAX_EXTENTS NUM BER Y Maximum number of extents allowed in the segmentPCT_INCREASE NUMBER Y Percent by which to increase the size of the next extent to be allocatedFREELISTS NUMBER Y Number of process freelists allocated in this segmentFREELIST_GROUPS NUMBER Y Number of freelist groups allocated in this segmentRELATIVE_FNO NUMBER Y Relative number of the file containing the segment headerBUFFER_POOL V ARCHAR2(7) Y The default buffer pool to be used for segments blocks2、根据segment_name查询表空间的名称SQL> select segment_name,tablespace_name from dba_segments where segment_name='DC_FILE_REC';SEGMENT_NAMETABLESPACE_NAME-------------------------------------------------------------------------------- ------------------------------DC_FILE_RECDICDCM_DEF AULT3、根据表空间的名字从表dba_data_files中查表空间的文件名:SQL> select file_name from dba_data_files where tablespace_name='DICDCM_DEFAUL T';FILE_NAME--------------------------------------------------------------------------------/oradata/ora9/dicdcm_default_1.dbf/oradata/ora9/dicdcm_default_2.dbf/oradata/ora9/dicdcm_default_3.dbf/oradata/ora9/dicdcm_default_4.dbf4、扩展指定的表空间大小SQL> alter tablespace DICDCM_DEFAUL T add datafile '/oradata/ora9/dicdcm_default_5.dbf' size 1000m;Tablespace altered5、查看所有的表空间名称SQL> select tablespace_name from dba_tablespaces;TABLESPACE_NAME------------------------------SYSTEMUNDOTBS1TEMPDRSYSINDXTOOLSUSERSDICDCM_TBS1DICDCM_TBS2DICDCM_TBS3DICDCM_TBS4DICDCM_TBS5DICDCM_TBS6DICDCM_DEFAULTDICDCM_IDXDICDCM_TEMP16 rows selected6、根据segment_name从表dba_segments中查询表空间名称SQL> select segment_name,tablespace_name from dba_segments where segment_name='IDX_FILE_REC4';SEGMENT_NAMETABLESPACE_NAME-------------------------------------------------------------------------------- ------------------------------IDX_FILE_REC4DICDCM_IDX7、根据表空间的名字从表dba_data_files中查表空间的文件名:SQL> select file_name from dba_data_files where tablespace_name='DICDCM_IDX';FILE_NAME--------------------------------------------------------------------------------/oradata/ora9/dicdcm_idx_1.dbf/oradata/ora9/dicdcm_idx_2.dbf/oradata/ora9/dicdcm_idx_3.dbf/oradata/ora9/dicdcm_idx_4.dbf8、扩展指定的表空间大小SQL> alter tablespace DICDCM_IDX add datafile'/oradata/ora9/dicdcm_idx_5.dbf' size 1024m;Tablespace altered扩展dicdcm_temp表空间的大小他的作用:用来排序、生成中间的一些结果等等。
WPS中的数据表数据源扩展

WPS中的数据表数据源扩展WPS办公套件是一款功能强大的办公软件,其中的数据表功能在数据处理和分析方面具有重要作用。
在使用WPS的数据表时,我们有时需要扩展数据源,以便更好地满足我们的需求。
本文将探讨WPS中如何进行数据表数据源的扩展。
一、什么是数据表数据源扩展数据表数据源的扩展是指在WPS中,通过增加和编辑数据源来实现数据表的扩展。
通过扩展数据源,我们可以将外部数据引入到数据表中,或者将数据表关联到其他数据源,实现更灵活和全面的数据分析。
二、数据表数据源扩展的操作步骤在WPS的数据表中进行数据源扩展需要以下步骤:1. 打开WPS数据表首先,打开WPS办公套件,在功能区中点击“数据表”图标,进入数据表编辑界面。
2. 导入外部数据源在数据表编辑界面,点击“数据”选项卡,在“导入外部数据”组中选择“来自其他工作簿”或“来自文本”,根据需要选择相应的选项。
在弹出的对话框中选择外部数据源文件,并按照步骤进行导入设置和数据映射。
3. 编辑数据表数据源通过导入外部数据源后,选择新增的数据源,点击“编辑数据源”按钮进行数据源的编辑。
在数据源编辑界面,我们可以进行数据字段的定义、筛选条件的设置、数据排序和分组等操作,根据具体需求进行相应设置。
4. 数据关联数据关联是数据表数据源扩展的重要功能之一。
在数据表编辑界面,点击“数据”选项卡的“关联数据源”按钮,选择关联的数据源文件。
通过数据关联,我们可以将多个数据源文件中的数据关联起来,实现更深入的数据分析和处理。
5. 扩展数据源在数据表编辑界面,点击“数据”选项卡的“扩展数据源”按钮,可以根据需要增加更多的数据源文件。
扩展数据源可以帮助我们获取更全面和丰富的数据,从而更好地进行数据分析和处理。
三、数据表数据源扩展的应用场景数据表数据源扩展在实际应用中有着广泛的应用场景。
以下是一些常见的应用场景:1. 多数据源集成通过数据表数据源扩展,我们可以将多个数据源文件集成到一个数据表中,从而可以更方便地进行数据分析和比较。
上机操作 十三

数据库表的扩展属性的设置
一、打开Visual FoxPro 6.0
二、创建“学生表”。
(表结构如下)
三、以“学号”字段为索引关键字,为“学生表”建立索引,索引名为“学号”,按“升序”排序,索引类型为“普通索引”。
四、创建“学生信息”数据库,并将“学生表”添加到“学生信息”数据库中。
五、
1、设置字段属性
在“表设计器”窗口中选择要设定的字段,在字段属性窗口中依次设定。
2、使用命令设置表的扩展属性。
在“命令”中输入并执行以下命令:
CREATE TABLE zg NAME zgxx (zgh c(3),xm c(10),csrq d,rzsj d,zc c(8),zp g) CREATE TABLE ck (ckh c(3),mj n(7,2),dhhm c(8) DEFAULT "86635401")ALTER table zg alter xb set DEFAULT '女'。
第3章-数据库表的扩展属性
(3) 4个课时以上(包括4个课时)的课程的 学分不得低于2个学分
(4) 课程名为空的课程记录可以被删除
(5) 必修课记录不允许被修改
3.10 数据库表的扩展属性
3.10.3 与数据库属性有关的函数
DBSETPROP( )函数
功能:为当前数据库或当前数据库中表的字段、表或视图设置 属性(常用属性参见P107) 例:要设置图书管理数据库 (tsk)中ts表的注释为“图书表” 。
=DBSETPROP(“tsk!ts”,”TABLE”,”Comment”,”图书表”)
例:设置ts表的sh字段的标题为“书号” 。 =DBSETPROP(“ts.sh”,”FIELD”,”Caption”,”书号”)
3.10 数据库表的扩展属性
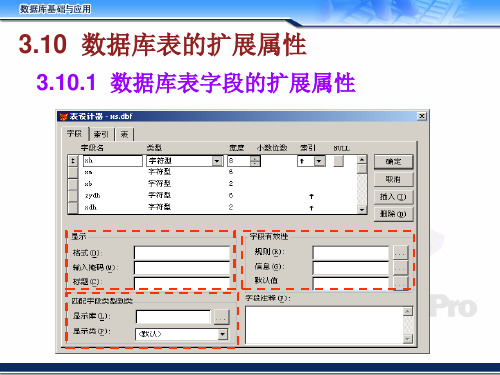
3.10.1 数据库表字段的扩展属性
3.10 数据库表的扩展属性
例:给cj表的cj字段进行如下设置:
1、cj字段在输入时只允许是三位的数字 2、设置标题为“成绩” 3、输入的成绩值必须在0-100分之间 4、设置默认值为60分 5、设置注释为:“学生各门课程的成绩”
例: 数据库表字段的默认值保存在______文件中 A.表 BB.数据库 C.项目 D.表的索引
3.10.2 数据库表的表属性
3.10 数据库表的扩展属性
练习:
3.10 数据库表的扩展属性
对GZB表设置如下规则和触发器:
(1)工龄在10年以上(包含10年)的教师,最低 工资不得低于800元 (2)当csrq字段的值是.NULL.时允许删除,否 则不允许删除 (3)只有男教师才可被修改,女教师不允许修改
3.10 数据库表的扩展属性
大数据的扩展性与可伸缩性

大数据的扩展性与可伸缩性随着互联网的迅猛发展和技术的日新月异,我们生活中产生的数据量呈爆炸式增长。
如何高效地处理和分析这些庞大的数据成为了一个重要的挑战。
在这个背景下,大数据的扩展性和可伸缩性变得尤为重要。
本文将探讨大数据的扩展性和可伸缩性的概念、重要性以及相关的技术和方法。
一、理解1. 大数据的扩展性大数据的扩展性是指系统能够处理和存储不断增长的数据量。
大数据的特点在于数据量大、速度快、种类多样,传统的数据处理方法已经无法胜任。
扩展性的实现需要考虑到数据的存储、计算和传输等各个方面。
2. 大数据的可伸缩性大数据的可伸缩性是指系统能够根据需求灵活地扩展或缩减资源,并保持稳定的性能。
可伸缩性包括水平可伸缩性和垂直可伸缩性。
水平可伸缩性是指通过增加计算节点、存储节点或网络带宽来提升系统的处理能力;垂直可伸缩性是指通过增加单个节点的计算、存储或网络资源来提升系统的处理能力。
二、大数据扩展性与可伸缩性的重要性1. 处理不断增长的数据量随着互联网的发展和物联网的兴起,数据量呈指数级增长。
传统的数据处理方法已经无法胜任,而大数据的扩展性和可伸缩性则能够满足这一需求,确保数据的有效处理和分析。
2. 提高数据处理和分析的效率大数据的扩展性和可伸缩性可以通过并行计算、分布式存储等技术来提高数据处理和分析的效率。
这样可以节省时间和资源,从而更快地获取有价值的信息。
3. 增强系统的稳定性和可靠性大数据的扩展性和可伸缩性能够使系统具备更好的稳定性和可靠性。
当系统面对意外的高负载或故障时,能够灵活地分配资源和处理任务,从而确保系统的正常运行。
三、实现大数据扩展性与可伸缩性的技术和方法1. 分布式存储与计算分布式存储系统(如Hadoop、HDFS)将数据分散存储在多个节点上,从而提高存储能力。
分布式计算框架(如MapReduce、Spark)利用集群节点的计算资源并行处理数据,提高计算能力。
2. 负载均衡负载均衡是通过将任务均匀地分配到各个计算节点上来提高系统的可伸缩性。
用VFP系统命令或SQL命令建索引库表及设置扩展属性的语句示例

一、使用命令方式设置数据库表及其字段的扩展属性举例:1. open data sjk 或者create data sjk 或者用set data to命令创建或设置当前库2. create table jsqk NAME教师基本情况表(gh c(6),xm c(8),csrq d,;gzrq d CHECK gzrq<date() ERROR "工作日期应小于当前系统日期!",;xb c(2) DEFAULT "女",zc c(10) null DEFAULT null, jl m,;CHECK year(gzrq)-year(csrq)>=18ERROR "参加工作的年龄为18岁以上!")3. (1) create table gzqk (gh c(6),xm c(8),xb c(2),zc c(10),jbgz n(8,1),;gwjt n(8,1),grsds n(8,1),yfgz n(8,1),sfgz n(8,1))(2) append from E:\vfptest\gzb(3) i) alter table gzqk SET CHECK grsds=(jbgz+gwjt-800)*0.1NOV ALIDATE&&设置gzqk表的记录有效性规则或alter table gzqk SET CHECK grsds=(jbgz+gwjt)*0.1;ERROR"个人所得税应为基本工资加岗位津贴的10%" NOV ALIDATE&&设置gzqk表的记录有效性规则及有效性信息ii) alter table gzqk alter gh SET CHECK !empty(gh) and len(allt(gh))=5;ERROR"工号不能为空且有效宽度必须为5位。
"&&设置gzqk表中gh字段的有效性规则及有效性信息iv) alter table gzqk alter jbgz SET DEFAULT400&&设置gzqk表中jbgz字段的默认值为4004. (1) alter table gzqk alter zc DROP DEFAULT&&删除gzqk表中zc字段的默认值(2) alter table gzqk alter gh DROP CHECK&&删除gzqk表中gh字段的字段的有效性规则及有效性信息(3) alter table gzqk DROP CHECK&&删除gzqk表的记录有效性规则及有效性信息5. (1) RENAME TABLE gzqk TO教师收入基本情况表&&对gzqk表进行改名操作注:i) 上述改名操作实际是修改数据库表的长表名ii)RENAME TABLE <旧名> TO <新名> 命令只用于数据库表的改名操作。
关系型数据库扩展方式

关系型数据库扩展方式一、引言关系型数据库是一种广泛应用的数据库类型,它以表格的形式存储数据,并通过关系进行数据的连接和查询。
然而,随着数据量的不断增长和业务需求的变化,传统的关系型数据库可能无法满足高并发、大容量、高可用性等要求。
因此,扩展关系型数据库成为了一种必要的选择。
本文将介绍关系型数据库的扩展方式,包括垂直扩展和水平扩展。
二、垂直扩展垂直扩展是指通过增加服务器的性能来提升关系型数据库的处理能力。
具体的扩展方式有:1. 升级硬件:可以通过增加CPU核心数、内存容量等方式提升服务器的性能。
这种方式适用于单机数据库的性能瓶颈较为明显的情况。
2. 数据库分区:将数据库按照某种规则分成多个区域,每个区域分配给不同的服务器进行处理。
这样可以减轻单一服务器的负载压力,提高整体的处理能力。
3. 垂直分库:将数据库按照业务功能进行划分,不同的业务功能存储在不同的数据库中。
这样可以减少单个数据库的数据量,提升查询性能。
三、水平扩展水平扩展是指通过增加服务器的数量来提升关系型数据库的处理能力。
具体的扩展方式有:1. 数据库复制:将一台数据库的数据复制到多台服务器上,每台服务器负责处理一部分数据。
这样可以提高读取性能,并且保证数据的冗余备份。
2. 数据库分片:将数据库按照某种规则分成多个片段,每个片段存储在不同的服务器上。
这样可以将数据分散存储,提升整体的处理能力。
3. 数据库集群:将多台服务器组成一个集群,共同处理数据库的请求。
集群可以通过主从复制、共享存储等方式实现数据的同步和共享,提高数据库的可用性和性能。
四、扩展方式的选择在选择关系型数据库的扩展方式时,需要考虑以下因素:1. 数据量:如果数据量较小,垂直扩展即可满足需求;如果数据量较大,需要考虑水平扩展。
2. 读写比例:如果读操作较多,可以考虑数据库复制或数据库集群;如果写操作较多,可以考虑数据库分片。
3. 业务需求:不同的业务需求可能对数据库的性能和可用性有不同的要求,需要根据实际情况选择合适的扩展方式。
数据库的扩展性与可伸缩性设计

数据库的扩展性与可伸缩性设计随着现代软件系统规模不断增大,数据库的扩展性和可伸缩性成为了非常重要的设计考量因素。
数据库的扩展性是指系统在面对不断增长的数据量和用户负载时,能够方便地扩展存储容量和处理能力的能力。
可伸缩性则是指系统能够根据需求自动调整资源分配,提供稳定的性能和可靠的处理能力。
本文将通过讨论数据库的扩展性与可伸缩性设计要点,来帮助开发人员在设计数据库系统时有效地考虑这些因素。
1. 数据分区与分片扩展性的一个关键设计因素是将数据进行分区和分片。
数据分区是指将数据按照规则进行划分,分散存储在不同的物理磁盘上。
这样可以提高数据的读写并发性能,并充分利用存储资源。
数据分片则是将数据按照规则拆分为多个子集合,并分散存储在不同的服务器上。
数据分片可以实现水平扩展,允许系统通过添加更多服务器节点来增加存储能力和处理能力。
在进行数据分区和分片的设计时,需要考虑数据访问模式、业务需求和系统的负载均衡等因素。
2. 数据库索引优化索引是数据库中的重要组成部分,它能够加快数据的检索速度。
在设计大规模数据库系统时,要注意索引的设计和优化。
首先,选择适当的索引数据结构,如B+树或哈希索引,以满足查询和插入操作的性能要求。
其次,需要合理地选择索引字段,避免过多的冗余和重复索引。
另外,定期维护和优化索引,以保证其高效性和一致性。
3. 读写分离读写分离是一种常见的数据库扩展性设计方案,在高并发场景下能够提高性能和可用性。
它将读操作和写操作分布在不同的服务器上,以减轻单个服务器的负载压力。
通过使用主从复制和同步机制,将写操作集中在主服务器上,而将读操作分发到多个从服务器上。
这样可以实现读操作的负载均衡和高可用性,提高系统的处理能力。
4. 缓存机制缓存是提高系统性能和可伸缩性的重要手段之一。
通过将热点数据缓存在高速存储介质中,如内存或磁盘缓存,可以加快数据的访问速度。
同时,缓存还可以减轻数据库的负载,提高数据库的响应能力。
数据库表分区和分区扩展

数据库表分区和分区扩展摘要:一、数据库表分区的概念1.数据库表分区的定义2.表分区的目的和优势二、分区扩展的方法1.横向扩展2.纵向扩展三、分区策略的选择1.基于数据量2.基于访问频率3.基于数据类型四、分区与数据库性能1.分区对查询性能的影响2.分区对数据插入、更新和删除性能的影响五、分区与数据库维护1.分区与备份和恢复2.分区与索引维护六、分区与数据库安全1.分区与数据隔离2.分区与权限控制正文:数据库表分区是一种数据库对象管理技术,通过将数据分散到多个物理存储设备上,以提高数据库性能和扩展性。
本文将详细介绍数据库表分区的概念以及分区扩展的方法,并探讨如何根据实际需求选择合适的分区策略。
此外,还将分析分区对数据库性能和维护的影响,以及如何确保数据安全。
一、数据库表分区的概念1.数据库表分区的定义数据库表分区是指将一个大表按照某种规则划分为多个小表,这些小表可以存储在不同的物理设备上。
分区可以提高数据库性能,简化管理和维护工作,同时便于进行数据备份和恢复。
2.表分区的目的和优势表分区的目的主要有两点:一是提高数据库性能,通过将数据分散到多个物理设备上,减少磁盘I/O 负载,从而提高查询速度;二是简化数据库管理和维护工作,例如在进行数据备份和恢复时,只需处理分区而非整个大表。
二、分区扩展的方法1.横向扩展横向扩展是指通过增加数据库的物理设备来提高存储容量。
这种扩展方式简单易行,但可能会导致数据分布不均,进而影响数据库性能。
因此,在进行横向扩展时,需要考虑数据分布和查询模式,以实现负载均衡。
2.纵向扩展纵向扩展是指通过增加数据库逻辑分区数量来提高存储容量。
这种扩展方式可以在不改变物理设备的情况下实现数据扩容,有利于提高数据分布均匀性。
但需要注意的是,分区数量并非越多越好,过多的分区可能会导致管理复杂度和查询性能下降。
三、分区策略的选择1.基于数据量根据数据量选择分区策略是一种常见的做法。
例如,可以将数据量较大的表进行分区,以提高查询性能。
数据库系统的可扩展性与升级方案

数据库系统的可扩展性与升级方案随着信息技术的不断发展,数据库系统的可扩展性和升级方案越来越受到关注。
在当今大数据时代,数据库系统需要能够满足日益增长的数据量和用户需求。
为了保证数据库系统的高效运行和可靠性,必须进行合理的可扩展性设计和升级方案。
可扩展性是指数据库系统在处理大规模数据时能够保持高性能和良好的扩展能力。
在设计数据库系统时,需要考虑可扩展性的方方面面,包括数据模型、存储结构、查询优化等等。
首先,一个好的数据模型是保证数据库系统可扩展性的基础。
关系型数据库系统常用的数据模型是基于表的关系模型,但在大数据背景下,NoSQL 数据库模型也变得更加重要。
NoSQL数据库模型的特点是灵活性高、适应性强,能够处理非结构化数据和高速度数据流。
因此,在设计数据库系统时,可以根据具体的业务需求选择合适的数据模型,提高数据库系统的可扩展性。
其次,存储结构的设计对数据库系统的可扩展性影响很大。
传统的关系型数据库使用B树作为索引结构,但在大规模数据情况下,这种结构的管理性能会下降。
为了提高可扩展性,可以采用分布式存储模式,将数据分散存储在多个节点上,从而实现扩展性。
此外,缓存技术也可以提高数据库的性能和可扩展性,通过将访问频率高的数据缓存在内存中,来提高数据库的响应速度。
第三,查询优化是提高数据库系统可扩展性的重要手段之一。
对于大规模数据的查询,需要进行合理的优化,减少查询时间和资源占用。
数据库系统通常会提供索引、分区等查询优化技术,可以根据具体业务需求选择适合的技术来提高可扩展性。
除了设计阶段,数据库系统的升级方案也是保证可扩展性的重要环节。
随着业务的发展和技术的更新,数据库系统可能需要进行版本升级、硬件升级或者迁移升级。
在进行升级时,需要考虑以下几点。
首先,升级前需要进行充分的测试和评估。
数据库系统的升级可能会导致数据丢失、系统崩溃等问题,因此在升级之前需要对升级方案进行全面测试,确保系统的稳定性。
其次,升级过程中需要进行数据迁移和备份。
数据库表空间管理与扩展

数据库表空间管理与扩展数据库是现代应用程序不可或缺的组成部分,它存储着海量的数据,并提供了快速的数据访问和可靠的数据保护。
数据库表空间管理是数据库管理员的核心职责之一,它涉及到对数据库空间的分配,使用和扩展。
数据库表空间是数据库中逻辑存储单元的集合,它由一个或多个数据文件组成。
每个数据文件有固定的大小,并在物理存储介质上占据一定的空间。
在数据库运行期间,数据文件会随着数据的增长而填满,此时需要进行表空间的增加和扩展。
表空间的管理需要考虑以下几个方面:1. 表空间的创建和分配:在数据库初始化或者需要新的表空间时,管理员会使用数据库管理系统提供的命令来创建一个新的表空间,并为该表空间分配必要的数据文件。
创建表空间时需要指定各种参数,如表空间的名称、大小、初始大小等。
2. 数据文件的增加和分配:数据文件是物理存储实现表空间的关键组成部分。
当数据文件不足以支持新增数据时,管理员需要考虑增加数据文件的数量和大小,并将其分配给相应的表空间。
这可以通过数据库管理系统提供的命令或者图形界面来完成。
3. 表空间的监控和维护:管理员需要定期监控表空间的使用情况,以确保表空间的容量足够支持数据库的正常运行。
如果发现某个表空间快要用完,管理员需要采取相应的扩展措施,以防止数据库的无法写入新数据。
表空间的维护也包括删除不再使用的表空间或数据文件,以释放磁盘空间。
4. 表空间的性能和优化:表空间对数据库的性能有着重要的影响。
过大的表空间容易导致资源浪费,而过小的表空间则可能影响数据库的性能和扩展能力。
管理员需要对表空间进行适当的调整和优化,如合并多个小表空间、重新分配数据文件大小等。
5. 表空间的备份和恢复:表空间中存储着重要的数据,管理员需要定期进行数据备份,以防止数据丢失。
数据库的备份策略和恢复方案需要考虑表空间的大小和内容,以确保备份的完整性和恢复的可行性。
在数据库表空间管理中,扩展表空间是一项经常需要进行的操作。
当数据库的数据越来越多时,表空间会逐渐被占满,数据库性能会受到影响。
数据库扩展性与可伸缩性的探索与实践

数据库扩展性与可伸缩性的探索与实践数据库是现代软件应用中不可或缺的一部分,对于大型企业和组织来说,保持数据库的扩展性和可伸缩性至关重要。
本文将探索数据库扩展性和可伸缩性的概念,并提供一些实践方法来实现这些目标。
首先,让我们明确数据库扩展性和可伸缩性的概念。
数据库扩展性是指数据库系统能够处理更多的数据和用户负载的能力。
可伸缩性是指数据库系统能够在需要增加或减少负载时自动调整资源以保持性能稳定的能力。
要实现数据库的扩展性和可伸缩性,下面是一些建议的实践方法:1. 数据库分片:数据库分片是将数据库水平分割成多个较小的部分,每个分片存储不同范围或类型的数据。
这种方法可以显著提高数据库的扩展性,因为每个分片都可以独立地处理一部分负载。
然而,分片带来了数据管理的复杂性,需要仔细考虑。
2. 数据库复制:通过数据库复制,可以将数据复制到多个节点上,实现读写负载的分离。
读操作可以在多个复制节点上并行处理,从而提高读取性能。
此外,如果一个节点失效,其他复制节点可以继续提供服务,提高可用性。
然而,数据库复制涉及数据复制和同步的开销,需要权衡数据一致性和性能。
3. 数据库缓存:使用数据库缓存是一种增加数据库性能和可伸缩性的方法。
数据库缓存将热数据存储在内存中,以提供快速的读取响应。
通过减少对原始数据库的访问,数据库缓存可以显著提高性能和扩展性。
然而,数据库缓存需要考虑缓存一致性和容量管理。
4. 异步处理:将一些数据库操作转化为异步处理可以提高数据库的性能和可伸缩性。
通过使用消息队列或事件驱动的架构,可以将一些需要长时间处理的操作移出关键路径,从而缩短请求响应时间。
异步处理可以减少负载密集型操作对数据库的影响,提高系统的整体性能和可伸缩性。
5. 垂直拆分和水平拆分:垂直拆分是指将数据库中的表按照功能或访问模式拆分成不同的数据库。
例如,将用户信息和订单信息拆分成不同的数据库。
这种方式可以提高数据库的扩展性和性能,并且对于某些应用特定的查询可以得到更好的性能。
用户数据管理知识:数据库的可扩展性和高可用性实践

用户数据管理知识:数据库的可扩展性和高可用性实践数据管理是当今企业中不可或缺的一部分。
随着企业数据规模的不断扩大,管理数据的复杂性和难度也随之增加。
数据库的可扩展性和高可用性是重要的数据管理方面。
在本文中,我们将探讨这两个主题,并提供一些最佳实践。
数据库的可扩展性数据库的可扩展性指的是数据库可以在需要时轻松扩展以容纳更多的数据。
对于大型企业来说,数据库的可扩展性至关重要。
在企业成长时,数据库的需求量也会增加。
为了确保数据库的可扩展性,以下是一些最佳实践:1.选择正确的数据库技术:不同的数据库技术具有不同的可扩展性。
一些数据库是纵向扩展的,这意味着它们必须通过增加CPU、内存和存储器的大小来扩展。
其他数据库是横向扩展的,这意味着它们可以添加更多的服务器以分散负载。
因此,选择正确的数据库技术可以确保数据库的可扩展性。
2.使用云存储:云存储提供无限的存储空间和可扩展性。
使用云存储可以确保数据库可以轻松地扩展,并且不必担心存储器的容量。
3.应用分割和分区:数据分割和分区可以帮助提高数据库的可扩展性。
这可以通过将数据分为多个数据结构来实现,从而减少数据访问的负载。
此外,此方法还可以提高数据处理速度。
数据库的高可用性数据库的高可用性指的是可以确保数据库在任何时间和任何情况下始终处于可用状态。
在企业活动中,数据库中的数据对业务运营是至关重要的。
如果数据库出现故障或不可用,这将对业务运营产生不良影响,甚至导致财务损失。
以下是一些最佳实践,可以确保数据库的高可用性:1.使用多台服务器:使用多台服务器可以确保数据库在某个服务器故障时仍然可以提供服务。
耐用数据库可以通过将同一个数据库运行在多个服务器上来实现高可用性。
2.应用负载均衡:可以通过将流量分配到多台服务器上以实现负载均衡。
通过负载均衡,可以确保任何服务器上的负载不会太大,从而提高数据库的可用性。
3.实现备份和恢复策略:在出现任何故障或不可用性情况下,备份和恢复策略是确保数据库恢复到正常状态的重要方法。
mysql扩展字段使用案例

mysql扩展字段使用案例扩展字段是MySQL数据库中的一种特殊类型,它允许用户在表中添加额外的自定义字段,以满足特定的数据存储需求。
扩展字段可以用于存储开放式数据,允许用户根据实际情况动态添加字段,而不需要修改表结构。
下面是一些关于MySQL扩展字段使用案例的示例:1. 商品属性表在电商网站中,商品通常具有不同的属性,如颜色、尺寸、材质等。
使用扩展字段可以方便地存储这些属性信息。
例如,可以创建一个商品属性表,其中包含商品ID和扩展字段,扩展字段用于存储商品的各种属性。
2. 用户自定义字段在某些系统中,用户可能需要自定义一些特定的字段,以满足个性化需求。
使用扩展字段,可以为每个用户创建一个自定义字段,用于存储用户的特定信息,例如用户的个人喜好、兴趣爱好等。
3. 问题答案存储在问答网站或调查问卷系统中,用户可能需要回答一系列问题。
使用扩展字段,可以动态地存储用户的答案,而不需要提前定义固定的字段。
这样可以方便地扩展问题数量和类型,满足不同场景下的需求。
4. 日志记录在日志管理系统中,使用扩展字段可以方便地存储各种日志信息,如日志类型、操作人员、操作时间等。
通过动态添加扩展字段,可以轻松记录和检索各种日志信息。
5. 动态表单在一些需要用户填写表单的应用中,使用扩展字段可以方便地存储用户提交的表单数据。
通过动态添加字段,可以适应不同类型的表单,同时保持数据的结构一致性。
6. 产品特性存储在某些产品管理系统中,产品可能具有各种特性,如尺寸、重量、功率等。
使用扩展字段可以方便地存储这些特性信息,而不需要提前定义所有可能的特性字段。
7. 资讯标签存储在新闻资讯网站或博客系统中,资讯或文章通常具有多个标签。
使用扩展字段可以方便地存储这些标签信息,而不需要预先定义所有可能的标签字段。
8. 客户关系管理在客户关系管理系统中,客户可能具有不同的属性和需求。
使用扩展字段可以方便地存储和管理客户的信息,同时适应不同客户的特定需求。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
=DBSETPROP(“tsk!ts”,”TABLE”,”Comment”,”图书表”)
例:设置ts表的sh字段的标题为“书号” 。 =DBSETPROP(“ts.sh”,”FIELD”,”Caption”,”书号”)
(2) 设置kss 字段的标题为:“课时数”,并 且每门课的课时数不得低于2个课时
(3) 4个课时以上(包括4个课时)的课程的 学分不得低于2个学分
(4) 课程名为空的课程记录可以被删除
(5) 必修课记录不允许被修改
3.10 数据库表的扩展属性
3.10.3 与数据库属性有关的函数
DBSETPROP( )函数
3.10.2 数据库表的表属性.10 数据库表的扩展属性
对GZB表设置如下规则和触发器:
(1)工龄在10年以上(包含10年)的教师,最低 工资不得低于800元 (2)当csrq字段的值是.NULL.时允许删除,否 则不允许删除 (3)只有男教师才可被修改,女教师不允许修改
3.10 数据库表的扩展属性
3.10.1 数据库表字段的扩展属性
3.10 数据库表的扩展属性
例:给cj表的cj字段进行如下设置:
1、cj字段在输入时只允许是三位的数字 2、设置标题为“成绩” 3、输入的成绩值必须在0-100分之间 4、设置默认值为60分 5、设置注释为:“学生各门课程的成绩”
例: 数据库表字段的默认值保存在______文件中 A.表 BB.数据库 C.项目 D.表的索引
3.10 数据库表的扩展属性
DBGETPROP( )函数的利用
功能:返回当前数据库的属性,或者返回当前数据库中字段、 表或视图的属性。 例: 要查看图书表(ts)中书号(sh)字段的标题、注释与默认值。
?DBGETPROP(“ts.sh”,”FIELD”,”Caption”) ?DBGETPROP(“ts.sh”,”FIELD”,”Comment”) ?DBGETPROP(“ts.sh”,”FIELD”,”DefaultValue”)
练习:
3.10 数据库表的扩展属性
CJ表中,XH(学号)字段的前两位表示年级, 设置如下规则和触发器:
(1)若08级的学生是新生,CJ(成绩)字段必须为0
(2)只有02级的学生成绩才允许被修改
(3)CJ表中所有记录不允许被删除
练习: 设置KC表的属性:
3.10 数据库表的扩展属性
(1) 设置bxk字段的默认值为:.t.