如何能让Java生成复杂Word文档(1)
java使用POI操作XWPFDocument生成Word实战(一)

java使⽤POI操作XWPFDocument⽣成Word实战(⼀)注:我使⽤的word 2016功能简介:(1)使⽤jsoup解析html得到我⽤来⽣成word的⽂本(这个你们可以忽略)(2)⽣成word、设置页边距、设置页脚(页码),设置页码(⽂本)⼀、解析htmlDocument doc = Jsoup.parseBodyFragment(contents);Element body = doc.body();Elements es = body.getAllElements();⼆、循环Elements获取我需要的html标签boolean tag = false;for (Element e : es) {//跳过第⼀个(默认会把整个对象当做第⼀个)if(!tag) {tag = true;continue;}//创建段落:⽣成word(核⼼)createXWPFParagraph(docxDocument,e);}三、⽣成段落/*** 构建段落* @param docxDocument* @param e*/public static void createXWPFParagraph(XWPFDocument docxDocument, Element e){XWPFParagraph paragraph = docxDocument.createParagraph();XWPFRun run = paragraph.createRun();run.setText(e.text());run.setTextPosition(35);//设置⾏间距if(e.tagName().equals("titlename")){paragraph.setAlignment(ParagraphAlignment.CENTER);//对齐⽅式run.setBold(true);//加粗run.setColor("000000");//设置颜⾊--⼗六进制run.setFontFamily("宋体");//字体run.setFontSize(24);//字体⼤⼩}else if(e.tagName().equals("h1")){addCustomHeadingStyle(docxDocument, "标题 1", 1);paragraph.setStyle("标题 1");run.setBold(true);run.setColor("000000");run.setFontFamily("宋体");run.setFontSize(20);}else if(e.tagName().equals("h2")){addCustomHeadingStyle(docxDocument, "标题 2", 2);paragraph.setStyle("标题 2");run.setBold(true);run.setColor("000000");run.setFontFamily("宋体");run.setFontSize(18);}else if(e.tagName().equals("h3")){addCustomHeadingStyle(docxDocument, "标题 3", 3);paragraph.setStyle("标题 3");run.setBold(true);run.setColor("000000");run.setFontFamily("宋体");run.setFontSize(16);}else if(e.tagName().equals("p")){//内容paragraph.setAlignment(ParagraphAlignment.BOTH);//对齐⽅式paragraph.setIndentationFirstLine(WordUtil.ONE_UNIT);//⾸⾏缩进:567==1厘⽶run.setBold(false);run.setColor("001A35");run.setFontFamily("宋体");run.setFontSize(14);//run.addCarriageReturn();//回车键}else if(e.tagName().equals("break")){paragraph.setPageBreak(true);//段前分页(ctrl+enter)}四、设置页边距/*** 设置页边距 (word中1厘⽶约等于567)* @param document* @param left* @param top* @param right* @param bottom*/public static void setDocumentMargin(XWPFDocument document, String left,String top, String right, String bottom) {CTSectPr sectPr = document.getDocument().getBody().addNewSectPr();CTPageMar ctpagemar = sectPr.addNewPgMar();if (StringUtils.isNotBlank(left)) {ctpagemar.setLeft(new BigInteger(left));}if (StringUtils.isNotBlank(top)) {ctpagemar.setTop(new BigInteger(top));}if (StringUtils.isNotBlank(right)) {ctpagemar.setRight(new BigInteger(right));}if (StringUtils.isNotBlank(bottom)) {ctpagemar.setBottom(new BigInteger(bottom));}}五、创建页眉/*** 创建默认页眉** @param docx XWPFDocument⽂档对象* @param text 页眉⽂本* @return返回⽂档帮助类对象,可⽤于⽅法链调⽤* @throws XmlException XML异常* @throws IOException IO异常* @throws InvalidFormatException ⾮法格式异常* @throws FileNotFoundException 找不到⽂件异常*/public static void createDefaultHeader(final XWPFDocument docx, final String text){CTP ctp = CTP.Factory.newInstance();XWPFParagraph paragraph = new XWPFParagraph(ctp, docx);ctp.addNewR().addNewT().setStringValue(text);ctp.addNewR().addNewT().setSpace(SpaceAttribute.Space.PRESERVE);CTSectPr sectPr = docx.getDocument().getBody().isSetSectPr() ? docx.getDocument().getBody().getSectPr() : docx.getDocument().getBody().addNewSectPr(); XWPFHeaderFooterPolicy policy = new XWPFHeaderFooterPolicy(docx, sectPr);XWPFHeader header = policy.createHeader(STHdrFtr.DEFAULT, new XWPFParagraph[] { paragraph });header.setXWPFDocument(docx);}}六、创建页脚/*** 创建默认的页脚(该页脚主要只居中显⽰页码)** @param docx* XWPFDocument⽂档对象* @return返回⽂档帮助类对象,可⽤于⽅法链调⽤* @throws XmlException* XML异常* @throws IOException* IO异常*/public static void createDefaultFooter(final XWPFDocument docx) {// TODO 设置页码起始值CTP pageNo = CTP.Factory.newInstance();XWPFParagraph footer = new XWPFParagraph(pageNo, docx);CTPPr begin = pageNo.addNewPPr();begin.addNewPStyle().setVal(STYLE_FOOTER);begin.addNewJc().setVal(STJc.CENTER);pageNo.addNewR().addNewFldChar().setFldCharType(STFldCharType.BEGIN);pageNo.addNewR().addNewInstrText().setStringValue("PAGE \\* MERGEFORMAT");pageNo.addNewR().addNewFldChar().setFldCharType(STFldCharType.SEPARATE);CTR end = pageNo.addNewR();CTRPr endRPr = end.addNewRPr();endRPr.addNewNoProof();endRPr.addNewLang().setVal(LANG_ZH_CN);end.addNewFldChar().setFldCharType(STFldCharType.END);CTSectPr sectPr = docx.getDocument().getBody().isSetSectPr() ? docx.getDocument().getBody().getSectPr() : docx.getDocument().getBody().addNewSectPr(); XWPFHeaderFooterPolicy policy = new XWPFHeaderFooterPolicy(docx, sectPr);policy.createFooter(STHdrFtr.DEFAULT, new XWPFParagraph[] { footer });}七、⾃定义标题样式(这个在我另⼀篇word基础中也有提及)* 增加⾃定义标题样式。
java根据模板生成word文档,兼容富文本、图片

java根据模板⽣成word⽂档,兼容富⽂本、图⽚Java⾃动⽣成带图⽚、富⽂本、表格等的word⽂档使⽤技术 freemark+jsoup ⽣成mht格式的伪word⽂档,已经应⽤项⽬中,确实是可⾏的,⽆论是富⽂本中是图⽚还是表格,都能在word中展现出来使⽤jsoup解析富⽂本框,将其中的图⽚进⾏Base64位转码,使⽤freemark替换模板的占位符,将变量以及图⽚资源放⼊模板中在输出⽂件maven地址<!--freemarker--><!--<dependency> <groupId>org.freemarker</groupId> <artifactId>freemarker</artifactId> <version>2.3.23</version></dependency><!--JavaHTMLParser--><!--<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.2</version></dependency>制作word的freemark模板1. 先将wrod的格式内容定义好,如果需要插⼊参数的地⽅以${xxx}为表⽰,例:${product}模板例⼦: 2. 将模板另存为mht格式的⽂件,打开该⽂件检查每个变量(${product})是否完整,有可能在${}中出现其他代码,需要删除。
3. 将mht⽂件变更⽂件类型,改成ftl为结尾的⽂件,引⼊到项⽬中 4. 修改ftl模板⽂件,在⽂件中加上图⽚资源占位符${imagesBase64String},${imagesXmlHrefString}具体位置如下图所⽰: 5. ftl⽂件中由⼏个关键配置需要引⼊到代码中:docSrcParent = word.filesdocSrcLocationPrex =nextPartId = 01D2C8DD.BC13AF60上⾯三个参数,在模板⽂件中可以找到,需要进⾏配置,如果配置错误,图⽚⽂件将不会显⽰下⾯这三个参数固定,切换模板也不会改变shapeidPrex = _x56fe__x7247__x0020typeid = #_x0000_t75spidPrex = _x0000_i 6. 模板引⼊之后进⾏代码编辑源码地址为:下载源码后需要进⾏调整下内容:1. 录⼊步骤5中的6个参数2. 修改freemark获取模板⽅式下⾯这种⽅式能获取模板,但是在项⽬打包之后⽆法获取jar包内的⽂件Configuration configuration=newConfiguration(Configuration.getVersion());configuration.setDefaultEncoding(StandardCharsets.UTF_8.toString());configuration.setDirectoryForTemplateLoading(newFile(templatePath));Template template=configuration.getTemplate("xxx.ftl");通过流的形式直接创建模板对象Configuration configuration=newConfiguration(Configuration.getVersion());configuration.setDefaultEncoding(StandardCharsets.UTF_8.toString());configuration.setDirectoryForTemplateLoading(newFile(templatePath));InputStream inputStream=newFileInputStream(newFile(templatePath+"/"+templateName)); InputStreamReader inputStreamReader=newInputStreamReader(inputStream,StandardCharsets.UTF_8); Template template=newTemplate(templateName,inputStreamReader,configuration);。
java生成word的几种方案

java⽣成word的⼏种⽅案1、 Jacob是Java-COM Bridge的缩写,它在Java与微软的COM组件之间构建⼀座桥梁。
使⽤Jacob⾃带的DLL动态链接库,并通过JNI的⽅式实现了在Java平台上对COM程序的调⽤。
DLL动态链接库的⽣成需要windows平台的⽀持。
2、 Apache POI包括⼀系列的API,它们可以操作基于MicroSoft OLE 2 Compound Document Format的各种格式⽂件,可以通过这些API在Java中读写Excel、Word等⽂件。
他的excel处理很强⼤,对于word还局限于读取,⽬前只能实现⼀些简单⽂件的操作,不能设置样式。
3、 Java2word是⼀个在java程序中调⽤ MS Office Word ⽂档的组件(类库)。
该组件提供了⼀组简单的接⼝,以便java程序调⽤他的服务操作Word ⽂档。
这些服务包括:打开⽂档、新建⽂档、查找⽂字、替换⽂字,插⼊⽂字、插⼊图⽚、插⼊表格,在书签处插⼊⽂字、插⼊图⽚、插⼊表格等。
填充数据到表格中读取表格数据,1.1版增强的功能:指定⽂本样式,指定表格样式。
如此,则可动态排版word⽂档。
4、 iText操作Excel还⾏。
对于复杂的⼤量的word也是噩梦。
⽤法很简单, 但是功能很少, 不能设置打印⽅向等问题。
5、 JSP输出样式基本不达标,⽽且要打印出来就更是惨不忍睹。
6、⽤XML做就很简单了。
Word从2003开始⽀持XML格式,⼤致的思路是先⽤office2003或者2007编辑好word的样式,然后另存为xml,将xml翻译为FreeMarker模板,最后⽤java来解析FreeMarker模板并输出Doc。
经测试这样⽅式⽣成的word⽂档完全符合office标准,样式、内容控制⾮常便利,打印也不会变形,⽣成的⽂档和office中编辑⽂档完全⼀样。
7、补充⼀种⽅案,可以⽤类似ueditor的在线编辑器编辑word⽂档,在将html⽂件转换为xhtml⽂件,再转换为word。
JAVA不使用POI,用PageOffice动态导出Word文档

JAVA不使用POI,用PageOffice动态导出Word文档很多情况下,软件开发者需要从数据库读取数据,然后将数据动态填充到手工预先准备好的Word模板文档里,这对于大批量生成拥有相同格式排版的正式文件非常有用,这个功能应用PageOffice的基本动态填充功能即可实现。
但若是用户想动态生成一个没有固定模版的公文时,换句话说,没有办法事先准备一个固定格式的模板时,就需要开发人员在后台用代码实现Word文档的从零到图文并茂的动态生成功能了。
这里的“零”指的是Word空白文档。
那如何实现Word文档的从无到有呢,下面我就把自己实现这一功能的过程介绍一下。
例如,我想打开一个Word文档,里面的内容为:标题(粗体、黑体、字体大小为20、居中显示)、第一段内容(内容(略)、字体倾斜、字体大小为10、中文“楷体”、英文“Times New Roman”、红色、最小行间距、左对齐、首行缩进)、第二段内容(内容(略)、字体大小为12、黑体、1.5倍行间距、左对齐、首行缩进、插入图片)、第三段内容(内容(略)、字体大小为14、华文彩云、2倍行间距、左对齐、首行缩进)第一步:请先安装PageOffice的服务器端的安装程序,之后在WEB项目下的“WebRoot/WEB-INF/lib”路径中添加pageoffice.cab和pageoffice.jar(在网站的“下载中心”中可下载相应的压缩包,解压之后直接将pageoffice.cab和pageoffice.jar文件拷贝到该目录下就可以了)文件。
第二步:修改WEB项目的配置文件,将如下代码添加到配置文件中:<!-- PageOffice Begin --><servlet><servlet-name>poserver</servlet-name><servlet-class>com.zhuozhengsoft .pageoffice.poserver.Server</servlet-class></servlet><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/poserver.do</url-pattern></servlet-mapping><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/pageoffice.cab</url-pattern></servlet-mapping><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/popdf.cab</url-pattern></servlet-mapping><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/sealsetup.exe</url-pattern></servlet-mapping><servlet><servlet-name>adminseal</servlet-name><servlet-class>com.zhuozhengsoft.pageoffice.poserver.AdminSeal </servlet-class></servlet><servlet-mapping><servlet-name>adminseal</servlet-name><url-pattern>/adminseal.do</url-pattern></servlet-mapping><servlet-mapping><servlet-name>adminseal</servlet-name><url-pattern>/loginseal.do</url-pattern></servlet-mapping><servlet-mapping><servlet-name>adminseal</servlet-name><url-pattern>/sealimage.do</url-pattern></servlet-mapping><mime-mapping><extension>mht</extension><mime-type>message/rfc822</mime-type></mime-mapping><context-param><param-name>adminseal-password</param-name><param-value>123456</param-value></context-param><!-- PageOffice End -->第三步:在WEB项目的WebRoot目录下添加文件夹存放word模板文件,在此命名为“doc”,将要打开的空白Word文件拷贝到该文件夹下,我要打开的Word文件为“test.doc”。
java 写docx xwpfdocument 大纲

java 写docx xwpfdocument 大纲一、**了解Java和XWPFC库**首先,我们需要了解Java的基本语法以及XWPFC库的使用方法。
XWPFC库是一个用于处理Microsoft Word文件的Java库,它可以生成和解析docx文件。
二、**设置开发环境**接下来,我们需要设置Java开发环境,包括安装Java开发工具包(JDK)和集成开发环境(IDE),如Eclipse或NetBeans。
此外,我们还需要安装XWPFC库的Java包装。
三、**创建大纲文档**使用XWPFC库,我们可以使用Java编写docx文件的大纲。
首先,我们需要创建一个XwpDocument对象,这是所有文档操作的起点。
然后,我们可以使用XwpParagraph和XwpList等对象来创建大纲中的段落和列表。
四、**添加内容**在创建大纲后,我们可以向其中添加内容。
这包括文本、图片、表格等。
可以使用Java的字符串操作和文件读写功能来实现这一点。
五、**保存文档**最后,我们需要将文档保存为docx文件。
可以使用XWPFC库提供的save方法来完成这一操作。
保存的文件可以以.docx为扩展名进行查看。
六、**示例代码**以下是一个简单的Java代码示例,用于创建一个包含大纲和内容的docx文件:```javaimport com.syncleus.ftglabs.xwpf.*;import com.syncleus.ftglabs.xwpf.model.*;import java.io.*;public class DocxCreator {public static void main(String[] args) {try {// 创建XwpDocument对象XwpDocument doc = new XwpDocument();// 添加标题XwpParagraph title =doc.getDocument().getParagraphs().add();title.setString("这是一个大纲");// 添加段落XwpParagraph para =doc.getDocument().getParagraphs().add();para.setString("这是第一个段落");// 保存文件doc.save("大纲.docx");} catch (Exception e) {e.printStackTrace();}}}```以上代码创建了一个简单的docx文件,包含一个标题和一个段落。
利用JavaApachePOI生成Word文档示例代码

利⽤JavaApachePOI⽣成Word⽂档⽰例代码最近公司做的项⽬需要实现导出Word⽂档的功能,⽹上关于POI⽣成Word⽂档的例⼦很少,找了半天才在官⽹⾥找到个Demo,有了Demo⼀切就好办了。
/* ====================================================================Licensed to the Apache Software Foundation (ASF) under one or morecontributor license agreements. See the NOTICE file distributed withthis work for additional information regarding copyright ownership.The ASF licenses this file to You under the Apache License, Version 2.0(the "License"); you may not use this file except in compliance withthe License. You may obtain a copy of the License at/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License.==================================================================== */package ermodel;import java.io.FileOutputStream;/*** A simple WOrdprocessingML document created by POI XWPF API** @author Yegor Kozlov*/public class SimpleDocument {public static void main(String[] args) throws Exception {XWPFDocument doc = new XWPFDocument();XWPFParagraph p1 = doc.createParagraph();p1.setAlignment(ParagraphAlignment.CENTER);p1.setBorderBottom(Borders.DOUBLE);p1.setBorderTop(Borders.DOUBLE);p1.setBorderRight(Borders.DOUBLE);p1.setBorderLeft(Borders.DOUBLE);p1.setBorderBetween(Borders.SINGLE);p1.setVerticalAlignment(TextAlignment.TOP);XWPFRun r1 = p1.createRun();r1.setBold(true);r1.setText("The quick brown fox");r1.setBold(true);r1.setFontFamily("Courier");r1.setUnderline(UnderlinePatterns.DOT_DOT_DASH);r1.setTextPosition(100);XWPFParagraph p2 = doc.createParagraph();p2.setAlignment(ParagraphAlignment.RIGHT);//BORDERSp2.setBorderBottom(Borders.DOUBLE);p2.setBorderTop(Borders.DOUBLE);p2.setBorderRight(Borders.DOUBLE);p2.setBorderLeft(Borders.DOUBLE);p2.setBorderBetween(Borders.SINGLE);XWPFRun r2 = p2.createRun();r2.setText("jumped over the lazy dog");r2.setStrike(true);r2.setFontSize(20);XWPFRun r3 = p2.createRun();r3.setText("and went away");r3.setStrike(true);r3.setFontSize(20);r3.setSubscript(VerticalAlign.SUPERSCRIPT);XWPFParagraph p3 = doc.createParagraph();p3.setWordWrap(true);p3.setPageBreak(true);//p3.setAlignment(ParagraphAlignment.DISTRIBUTE);p3.setAlignment(ParagraphAlignment.BOTH);p3.setSpacingLineRule(LineSpacingRule.EXACT);p3.setIndentationFirstLine(600);XWPFRun r4 = p3.createRun();r4.setTextPosition(20);r4.setText("To be, or not to be: that is the question: "+ "Whether 'tis nobler in the mind to suffer "+ "The slings and arrows of outrageous fortune, "+ "Or to take arms against a sea of troubles, "+ "And by opposing end them? To die: to sleep; ");r4.addBreak(BreakType.PAGE);r4.setText("No more; and by a sleep to say we end "+ "The heart-ache and the thousand natural shocks "+ "That flesh is heir to, 'tis a consummation "+ "Devoutly to be wish'd. To die, to sleep; "+ "To sleep: perchance to dream: ay, there's the rub; "+ ".......");r4.setItalic(true);//This would imply that this break shall be treated as a simple line break, and break the line after that word: XWPFRun r5 = p3.createRun();r5.setTextPosition(-10);r5.setText("For in that sleep of death what dreams may come");r5.addCarriageReturn();r5.setText("When we have shuffled off this mortal coil,"+ "Must give us pause: there's the respect"+ "That makes calamity of so long life;");r5.addBreak();r5.setText("For who would bear the whips and scorns of time,"+ "The oppressor's wrong, the proud man's contumely,");r5.addBreak(BreakClear.ALL);r5.setText("The pangs of despised love, the law's delay,"+ "The insolence of office and the spurns" + ".......");FileOutputStream out = new FileOutputStream("simple.docx");doc.write(out);out.close();}}以上就是本⽂的全部内容,希望对⼤家的学习有所帮助,也希望⼤家多多⽀持。
java 根据word模板生成word文件

java 根据word模板生成word文件Java可以使用Apache POI库来生成Word文件,并且也可以使用freemarker等模板引擎来实现根据Word模板生成Word 文件的功能。
下面是一个简单的示例代码,可以帮助您快速入门。
模板制作:offer,wps都行,我使用wps进行操作第一步制作模板CTRL+f9生成域------》鼠标右键编辑域------》选择邮件合并-----》在域代码后面加上英文${跟代码内的一致}。
这样模板就创建好了。
首先需要引入POI和freemarker的依赖:<!-- Apache POI --><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.core</artifactId><version>2.0.2</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.document< /artifactId><version>2.0.2</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.template< /artifactId><version>2.0.2</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.document.docx</artifactId><version>2.0.2</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.template.freemarker</artifactId><version>2.0.2</version></dependency>接下来是一个简单的示例代码:public class WordGenerator {public static void main(String[] args) throws IOException, TemplateException {// 读取Word模板try {= null;//wordInputStream in = new (new File("模板文件.docx"));//注册xdocreport实例并加载FreeMarker模板引擎IXDocReport r = XDocReportRegistry.getRegistry().loadReport(in, TemplateEngineKind.Freemarker);// 生成Word文件//创建xdocreport上下文对象IContext context =r.createContext();//将需要替换的数据数据添加到上下文中//其中key为word模板中的域名,value是需要替换的值User user = new User("zhangsan", 18, "福建泉州");context.put("uesrname",user.getUsername());context.put("age", user.getAge()); context.put("address",user.getAddress());out = new (newFile("D://xxx.docx"));//处理word文档并输出r.process(context, out);} catch (IOException e) {e.printStackTrace();} finally {if (in != null) {try {in.close();} catch (IOException e) {e.printStackTrace();}}if (out != null) {try {out.close();} catch (IOException e) {e.printStackTrace();}}}}}在这个示例代码中,我们读取了名为模板文件.docx的Word 模板,然后准备了一些数据,利用Freemarker模板引擎将数据填充到模板中,最后生成了一个名为xxx.docx的Word文件。
Java如何实现读取txt文件内容并生成Word文档

Java如何实现读取txt⽂件内容并⽣成Word⽂档⽬录导⼊Jar包1. Maven仓库下载导⼊2. ⼿动导⼊读取txt⽣成Word注意事项本⽂将以Java程序代码为例介绍如何读取txt⽂件中的内容,⽣成Word⽂档。
在编辑代码前,可参考如下代码环境进⾏配置:IntelliJ IDEAFree Spire.Doc for JavaTxt⽂档导⼊Jar包两种⽅法可在Java程序中导⼊jar⽂件1. Maven仓库下载导⼊在pom.xml中配置如下:<repositories><repository><id>com.e-iceblue</id><url>https:///repository/maven-public/</url></repository></repositories><dependencies><dependency><groupId>e-iceblue</groupId><artifactId>spire.doc.free</artifactId><version>3.9.0</version></dependency></dependencies>2. ⼿动导⼊需先下载jar包到本地,解压,找到lib路径下的jar⽂件。
然后在Java程序中打开“Project Structure”窗⼝,然后执⾏如下步骤导⼊:找到本地路径下的jar⽂件,添加到列表,然后导⼊:读取txt⽣成Word代码⼤致步骤如下:1. 实例化Document类的对象。
然后通过Document.addSection()⽅法和Section.addParagraph()⽅法添加节和段落。
2. 读取txt⽂件:创建InputStreamReader类的对象,构造⽅法中传递输⼊流和指定的编码表名称。
idea javadoc文档的生成方法

idea javadoc文档的生成方法【实用版3篇】目录(篇1)1.介绍 JavaDoc 文档2.JavaDoc 文档的生成方法3.使用 IDEA 自动生成 JavaDoc 文档4.手动编写 JavaDoc 文档5.结论正文(篇1)一、介绍 JavaDoc 文档JavaDoc 是 Java 开发中的一种文档编写标准,它可以描述 Java 类、方法、成员变量等的详细信息。
JavaDoc 文档通常以 HTML 格式生成,并且可以被 IDEA 等 Java 开发工具自动生成。
二、JavaDoc 文档的生成方法JavaDoc 文档的生成方法主要有两种:使用 IDEA 自动生成和手动编写。
1.使用 IDEA 自动生成 JavaDoc 文档IDEA 是一款强大的 Java 开发工具,它可以自动生成 JavaDoc 文档。
具体操作步骤如下:(1)打开 IDEA,导入 Java 项目。
(2)在项目中选择需要生成 JavaDoc 的类或方法,右键点击,选择“生成 JavaDoc”。
(3)IDEA 会自动生成 JavaDoc 文档,并将其保存在项目指定的输出目录中。
2.手动编写 JavaDoc 文档手动编写 JavaDoc 文档需要遵循一定的规范,例如使用特定的注释标签、指定文档生成工具等。
下面是一个简单的手动编写 JavaDoc 文档的示例:```java/*** 这是一个简单的 JavaDoc 注释* @author YourName* @version 1.0* @since JDK 1.8*/public class MyClass {// 类的成员变量和方法}```三、结论JavaDoc 文档是 Java 开发中重要的文档之一,它可以帮助开发者更好地理解和使用 Java 类、方法等。
使用 IDEA 可以方便地生成 JavaDoc 文档,而手动编写 JavaDoc 文档则需要遵循一定的规范。
目录(篇2)1.介绍 Javadoc2.Javadoc 的生成方法3.Javadoc 生成文档的步骤4.常见问题与解决方法5.总结正文(篇2)一、介绍 JavadocJavadoc 是 Java 开发中的一种文档生成工具,它可以从 Java 源代码中提取类、方法、成员变量等信息,并生成 HTML 格式的文档。
JAVA+根据WORD模板生成WORD+文档

/** * 把选定内容替换为设定文本 * @param selection Dispatch 选定内容 * @param newText String 替换为文本 */ public void replace(Dispatch selection,String newText) {
//设置替换文本 Dispatch.put(selection,"Text",newText); }
/* * 传入数据为 HashMap 对象,对象中的 Key 代表 word 模板中要替换的字段,Value 代表用来替换的值。 * word 模板中所有要替换的字段(即 HashMap 中的 Key)以特殊字符开头和结尾,如:$code$、$date$……, 以免执行错误的替换。 * 所有要替换为图片的字段,Key 中需包含 image 或者 Value 为图片的全路径(目前只判断文件后缀名 为:.bmp、 .jpg、.gif)。 * 要替换表格中的数据时,HashMap 中的 Key 格式为“table$R@N”,其中:R 代表从表格的第 R 行开始 替换,N 代表 word 模板中的第 N 张表格;Value 为 ArrayList 对象,ArrayList 中包含的对象统一为 String[],一条 String[] 代 表一行数据,ArrayList 中第一条记录为特殊记录,记录的是表格中要替换的列号,如:要替换第一列、第 三列、 第五列的数据,则第一条记录为 String[3] {“1”,”3”,”5”}。 */
for(int i = 0;i < count;i ++) {
Dispatch.call(selection,"MoveLeft"); } }
/** * 把选定内容或插入点向右移动 * @param selection Dispatch 要移动的内容 * @param count int 移动的距离 */ public void moveRight(Dispatch selection,int count) {
JAVA操作WORD

JAVA操作WORDJava操作Word主要有两种方式:一种是使用Apache POI库进行操作,另一种是使用XML模板进行操作。
下面将详细介绍如何通过XML模板实现Java操作Word。
1.准备工作:2. 创建Word模板:首先,创建一个空的Word文档,将其保存为XML格式,作为Word的模板。
可以在Word中添加一些标记或占位符,用于后续替换。
3.导入POI和相关依赖:在Java项目中,导入以下依赖:```xml<dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>4.1.2</version></dependency><dependency><groupId>org.apache.xmlbeans</groupId><artifactId>xmlbeans</artifactId><version>3.1.0</version></dependency>```4.读取模板文件:使用POI库读取Word模板文件,将其转换为XML格式的字符串,并保存为`template.xml`文件中。
```javaimport ermodel.XWPFDocument;import java.io.FileOutputStream;public class WordTemplateReaderpublic static void main(String[] args) throws ExceptionXWPFDocument document = new XWPFDocument(new FileInputStream("template.docx"));FileOutputStream out = new FileOutputStream("template.xml");document.write(out);out.close(;document.close(;}}```5.数据替换:读取template.xml文件,使用Java中的字符串替换功能,将模板中的占位符替换为实际的数据。
Java使用模板导出word文档

Java使⽤模板导出word⽂档Java使⽤模板导出word⽂档需要导⼊freemark的jar包1. 使⽤word模板,在需要填值的地⽅使⽤字符串代替,是因为word转换为xml⽂件时查找不到要填⼊内容的位置。
尽量不要在写字符串的时候就加上${},xml⽂件会让它和字符串分离。
⽐如:姓名| name2. 填充完之后,把word⽂件另存为xml⽂件,然后使⽤notepad 等编辑软件打开,打开之后代码很多,也很乱,根本看不懂,其实也不⽤看懂哈,搜索找到你要替换的位置的字符串,⽐如name,然后加上${},变成${name}这样,然后就可以保存了,之后把保存的⽂件名后缀替换为.ftl。
模板就ok了。
3. 有个注意事项,这⾥的值⼀定不可以为空,否则会报错,freemark有判断为空的语句,这⾥⽰例⼀个,根据个⼈需求,意思是判断name是否为空,trim之后的lenth是否⼤于0:<#if name?default("")?trim?length gt 0><w:t>${name}</w:t></#if>4. 如果在本地的话可以直接下载下来,但是想要在通过前端下载的话那就需要先将⽂件下载到本地,当作临时⽂件,然后在下载⽂件。
接下来上代码,⽰例:public void downloadCharge(String name, HttpServletRequest request, HttpServletResponse response) {Map<String, Object> map = new HashMap<>();map.put("name", name);Configuration configuration = new Configuration();configuration.setDefaultEncoding("utf-8");try { //模板存放位置InputStream inputStream = this.getClass().getResourceAsStream("/template/report/XXX.ftl");Template t = new Template(null, new InputStreamReader(inputStream));String filePath = "tempFile/";//导出⽂件名String fileName = "XXX.doc";//⽂件名和路径不分开写的话createNewFile()会报错File outFile = new File(filePath + fileName);if (!outFile.getParentFile().exists()) {outFile.getParentFile().mkdirs();}if (!outFile.exists()) {outFile.createNewFile();}Writer out = null;FileOutputStream fos = null;fos = new FileOutputStream(outFile);OutputStreamWriter oWriter = new OutputStreamWriter(fos, "UTF-8");//这个地⽅对流的编码不可或缺,使⽤main()单独调⽤时,应该可以,但是如果是web请求导出时导出后word⽂档就会打不开,并且包XML⽂件错误。
Javafreemarker生成word模板文件(如合同文件)及转pdf文件方法
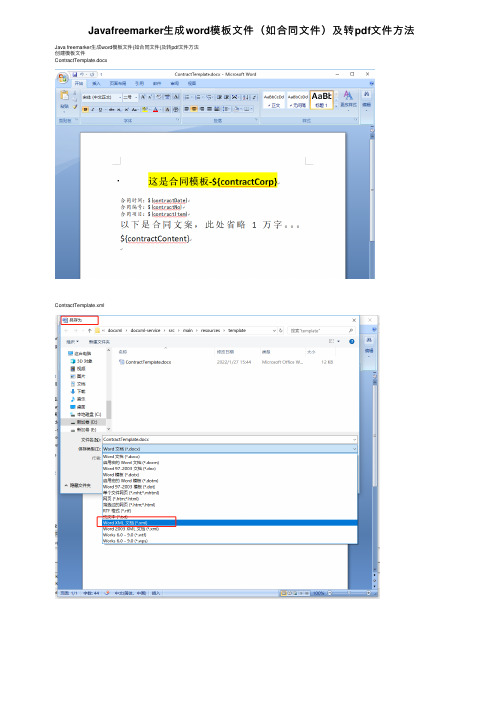
Javafreemarker⽣成word模板⽂件(如合同⽂件)及转pdf⽂件⽅法Java freemarker⽣成word模板⽂件(如合同⽂件)及转pdf⽂件⽅法创建模板⽂件ContractTemplate.docxContractTemplate.xml导⼊的Jar包compile("junit:junit")compile("org.springframework:spring-test")compile("org.springframework.boot:spring-boot-test")testCompile 'org.springframework.boot:spring-boot-starter-test'compile 'org.freemarker:freemarker:2.3.28'compile 'fakepath:aspose-words:19.5jdk'compile 'fakepath:aspose-cells:8.5.2'Java⼯具类 xml⽂档转换 Word XmlToDocx.javapackage com.test.docxml.utils;import java.io.File;import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.InputStream;import java.util.Enumeration;import java.util.zip.ZipEntry;import java.util.zip.ZipFile;import java.util.zip.ZipOutputStream;/*** xml⽂档转换 Word*/public class XmlToDocx {/**** @param documentFile 动态⽣成数据的docunment.xml⽂件* @param docxTemplate docx的模板* @param toFilePath 需要导出的⽂件路径* @throws Exception*/public static void outDocx(File documentFile, String docxTemplate, String toFilePath,String key) throws Exception { try {File docxFile = new File(docxTemplate);ZipFile zipFile = new ZipFile(docxFile);Enumeration<? extends ZipEntry> zipEntrys = zipFile.entries();FileOutputStream fileOutputStream = new FileOutputStream(toFilePath);ZipOutputStream zipout = new ZipOutputStream(fileOutputStream);int len = -1;byte[] buffer = new byte[1024];while (zipEntrys.hasMoreElements()) {ZipEntry next = zipEntrys.nextElement();InputStream is = zipFile.getInputStream(next);// 把输⼊流的⽂件传到输出流中如果是word/document.xml由我们输⼊zipout.putNextEntry(new ZipEntry(next.toString()));if ("word/document.xml".equals(next.toString())) {InputStream in = new FileInputStream(documentFile);while ((len = in.read(buffer)) != -1) {zipout.write(buffer, 0, len);}in.close();} else {while ((len = is.read(buffer)) != -1) {zipout.write(buffer, 0, len);}is.close();}}zipout.close();} catch (Exception e) {e.printStackTrace();}}}Java⼯具类 word⽂档转换 PDF WordToPdf.javapackage com.test.docxml.utils;import com.aspose.cells.*;import com.aspose.cells.License;import com.aspose.words.*;import java.io.ByteArrayInputStream;import java.io.File;import java.io.FileOutputStream;import java.io.InputStream;/*** word⽂档转换 PDF*/public class WordToPdf {/*** 获取license许可凭证* @return*/private static boolean getLicense() {boolean result = false;try {String licenseStr = "<License>\n"+ " <Data>\n"+ " <Products>\n"+ " <Product>Aspose.Total for Java</Product>\n"+ " <Product>Aspose.Words for Java</Product>\n"+ " </Products>\n"+ " <EditionType>Enterprise</EditionType>\n"+ " <SubscriptionExpiry>20991231</SubscriptionExpiry>\n"+ " <LicenseExpiry>20991231</LicenseExpiry>\n"+ " <SerialNumber>23dcc79f-44ec-4a23-be3a-03c1632404e9</SerialNumber>\n"+ " </Data>\n"+ " <Signature>0nRuwNEddXwLfXB7pw66G71MS93gW8mNzJ7vuh3Sf4VAEOBfpxtHLCotymv1PoeukxYe31K441Ivq0Pkvx1yZZG4O1KCv3Omdbs7uqzUB4xXHlOub4VsTODzDJ5MWHqlRCB1HHcGjlyT2sVGiovLt0Grvqw5+QXBuin + "</License>";InputStream license = new ByteArrayInputStream(licenseStr.getBytes("UTF-8"));License asposeLic = new License();asposeLic.setLicense(license);result = true;} catch (Exception e) {e.printStackTrace();}return result;}/*** word⽂档转换为 PDF* @param inPath 源⽂件* @param outPath ⽬标⽂件*/public static File doc2pdf(String inPath, String outPath) {//验证License,获取许可凭证if (!getLicense()) {return null;}//新建⼀个PDF⽂档File file = new File(outPath);try {//新建⼀个IO输出流FileOutputStream os = new FileOutputStream(file);//获取将要被转化的word⽂档Document doc = new Document(inPath);// 全⾯⽀持DOC, DOCX,OOXML, RTF HTML,OpenDocument,PDF, EPUB, XPS,SWF 相互转换doc.save(os, com.aspose.words.SaveFormat.PDF);os.close();} catch (Exception e) {e.printStackTrace();}return file;}public static void main(String[] args) {doc2pdf("D:/1.doc", "D:/1.pdf");}}Java单元测试类 XmlDocTest.javapackage com.test.docxml;import com.test.docxml.utils.WordToPdf;import com.test.docxml.utils.XmlToDocx;import freemarker.template.Configuration;import freemarker.template.Template;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.core.io.ClassPathResource;import org.springframework.core.io.Resource;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;import org.springframework.test.context.web.WebAppConfiguration;import java.io.File;import java.io.PrintWriter;import java.io.Writer;import java.nio.charset.Charset;import java.util.HashMap;import java.util.Locale;import java.util.Map;/*** 本地单元测试*/@RunWith(SpringJUnit4ClassRunner.class)//@RunWith(SpringRunner.class)@SpringBootTest(classes= TemplateApplication.class)@WebAppConfigurationpublic class XmlDocTest {//短租@Testpublic void testContract() throws Exception{String contractNo = "1255445544";String contractCorp = "银河宇宙⽆敌测试soft";String contractDate = "2022-01-27";String contractItem = "房地产交易中⼼";String contractContent = "稳定发展中的⽂案1万字";//doc xml模板⽂件String docXml = "ContractTemplate.xml"; //使⽤替换内容//xml中间临时⽂件String xmlTemp = "tmp-ContractTemplate.xml";//⽣成⽂件的doc⽂件String toFilePath = contractNo + ".docx";//模板⽂档String docx = "ContractTemplate.docx";//⽣成pdf⽂件String toPdfFilePath = contractNo + ".pdf";;String CONTRACT_ROOT_URL = "/template";Resource contractNormalPath = new ClassPathResource(CONTRACT_ROOT_URL + File.separator + docXml);String docTemplate = contractNormalPath.getURI().getPath().replace(docXml, docx);//设置⽂件编码(注意点1)Writer writer = new PrintWriter(new File(xmlTemp),"UTF-8");Configuration configuration = new Configuration(Configuration.VERSION_2_3_28);configuration.setEncoding(Locale.CHINESE, Charset.forName("UTF-8").name());//设置配置(注意点3)configuration.setDefaultEncoding("UTF-8");String filenametest = contractNormalPath.getURI().getPath().replace(docXml, "");System.out.println("filenametest=" + filenametest);configuration.setDirectoryForTemplateLoading(new File(filenametest));// Template template = configuration.getTemplate(ContractConstants.CONTRACT_NORMAL_URL+orderType+type+".xml"); //设置模板编码(注意点2)Template template = configuration.getTemplate(docXml,"UTF-8"); //绝对地址Map paramsMap = new HashMap();paramsMap.put("contractCorp",contractCorp);paramsMap.put("contractDate",contractDate);paramsMap.put("contractNo",contractNo);paramsMap.put("contractItem",contractItem);paramsMap.put("contractContent",contractContent);template.process(paramsMap, writer);XmlToDocx.outDocx(new File(xmlTemp), docTemplate, toFilePath, null);System.out.println("do finish");//转成pdfWordToPdf.doc2pdf(toFilePath,toPdfFilePath);}}创建成功之后的⽂件如下:。
java生成word

java⽣成word当我们使⽤Java⽣成word⽂档时,通常⾸先会想到iText和POI,这是因为我们习惯了使⽤这两种⽅法操作Excel,⾃然⽽然的也想使⽤这种⽣成word⽂档。
但是当我们需要动态⽣成word时,通常不仅要能够显⽰word中的内容,还要能够很好的保持word中的复杂样式。
这时如果再使⽤IText和POI去操作,就好⽐程序员去搬砖⼀样痛苦。
这时候,我们应该考虑使⽤FreeMarker的模板技术快速实现这个复杂的功能,让程序员在喝咖啡的过程中就把问题解决。
实现思路是这样的:先创建⼀个word⽂档,按照需求在word中填好⼀个模板,然后把对应的数据换成变量${},然后将⽂档保存为xml⽂档格式,使⽤⽂档编辑器打开这个xml格式的⽂档,去掉多余的xml符号,使⽤Freemarker读取这个⽂档然后替换掉变量,输出word⽂档即可。
具体过程如下:1.创建带有格式的word⽂档,将该需要动态展⽰的数据使⽤变量符替换。
2. 将刚刚创建的word⽂档另存为xml格式。
3.编辑这个XMl⽂档去掉多余的xml标记,如图中蓝⾊部分 4.从官⽹最新的开发包,将freemarker.jar拷贝到⾃⼰的开发项⽬中。
5.新建DocUtil类,实现根据Doc模板⽣成word⽂件的⽅法1234 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36package com.favccxx.secret.util;import java.io.BufferedWriter;import java.io.File;import java.io.FileOutputStream;import java.io.OutputStreamWriter;import java.io.Writer;import java.util.Map;import freemarker.template.Configuration;import freemarker.template.DefaultObjectWrapper;import freemarker.template.Template;import freemarker.template.TemplateExceptionHandler;public class DocUtil {privateConfiguration configure = null;publicDocUtil(){configure= new Configuration();configure.setDefaultEncoding("utf-8");}/*** 根据Doc模板⽣成word⽂件* @param dataMap Map 需要填⼊模板的数据* @param fileName ⽂件名称* @param savePath 保存路径*/publicvoid createDoc(Map<String, Object> dataMap, String downloadType, StringsavePath){try{//加载需要装填的模板Templatetemplate = null;//加载模板⽂件configure.setClassForTemplateLoading(this.getClass(),"/com/favccxx/secret/templates"); //设置对象包装器configure.setObjectWrapper(newDefaultObjectWrapper());//设置异常处理器configure.setTemplateExceptionHandler(TemplateExceptionHandler.IGNORE_HANDLER); //定义Template对象,注意模板类型名字与downloadType要⼀致template= configure.getTemplate(downloadType + ".xml");//输出⽂档FileoutFile = new File(savePath);Writerout = null;3637 38 39 40 41 42 43 44 45 46 out= new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile),"utf-8")); template.process(dataMap,out);outFile.delete();}catch(Exception e) {e.printStackTrace();}}} 6.⽤户根据⾃⼰的需要,调⽤使⽤getDataMap获取需要传递的变量,然后调⽤createDoc⽅法⽣成所需要的⽂档。
JAVA生成word文档代码加说明

import java.io.ByteArrayOutputStream;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.io.OutputStream;import java.util.Iterator;import java.util.Map;import javax.servlet.http.HttpServletResponse;import org.apache.poi.hwpf.HWPFDocument;import org.apache.poi.hwpf.model.FieldsDocumentPart;import ermodel.Field;import ermodel.Fields;import ermodel.Range;import ermodel.Table;import ermodel.TableIterator;import ermodel.TableRow;publicclass WordUtil {publicstaticvoid readwriteWord(String filePath, String downPath, Map<String, String> map, int[] num, String downFileName) { //读取word模板FileInputStream in = null;try {in = new FileInputStream(new File(filePath));} catch (FileNotFoundException e1) {e1.printStackTrace();}HWPFDocument hdt = null;try {hdt = new HWPFDocument(in);} catch (IOException e1) {e1.printStackTrace();}Fields fields = hdt.getFields();Iterator<Field> it = fields.getFields(FieldsDocumentPart.MAIN) .iterator();while (it.hasNext()) {System.out.println(it.next().getType());}//读取word表格内容try {Range range = hdt.getRange();//得到文档的读取范围TableIterator it2 = new TableIterator(range);//迭代文档中的表格int tabCount = 0;while (it2.hasNext()) {//System.out.println(" 第几个表格 "+tabCount);//System.out.println(num[tabCount] +" 行");Table tb2 = (Table) it2.next();//迭代行,默认从0开始for (int i = 0; i < tb2.numRows(); i++) {TableRow tr = tb2.getRow(i);// System.out.println(" fu "+num[tabCount] +" 行");if (num[tabCount] < i && i < 7) {tr.delete();}} //end fortabCount++;} //end while//替换word表格内容for (Map.Entry<String, String> entry : map.entrySet()) { range.replaceText("$"+ entry.getKey().trim() + "$", entry.getValue());}// System.out.println("替换后------------:"+range.text().trim());} catch (Exception e) {e.printStackTrace();}//System.out.println("--------------------------------------------------------------------------------------");ByteArrayOutputStream ostream = new ByteArrayOutputStream();String fileName = downFileName;fileName += ".doc";String pathAndName = downPath + fileName;File file = new File(pathAndName);if (file.canRead()) {file.delete();}FileOutputStream out = null;out = new FileOutputStream(pathAndName, true);} catch (FileNotFoundException e) {e.printStackTrace();}try {hdt.write(ostream);} catch (IOException e) {e.printStackTrace();}//输出字节流try {out.write(ostream.toByteArray());} catch (IOException e) {e.printStackTrace();}try {out.close();} catch (IOException e) {e.printStackTrace();}try {ostream.close();} catch (IOException e) {e.printStackTrace();}}/***实现对word读取和修改操作(输出文件流下载方式)*@param response响应,设置生成的文件类型,文件头编码方式和文件名,以及输出*@param filePathword模板路径和名称*@param map待填充的数据,从数据库读取*/publicstaticvoid readwriteWord(HttpServletResponse response, String filePath, Map<String, String> map) {//读取word模板文件//String fileDir = newFile(base.getFile(),"//.. /doc/").getCanonicalPath();//FileInputStream in = new FileInputStream(newFile(fileDir+"/laokboke.doc"));FileInputStream in;HWPFDocument hdt = null;in = new FileInputStream(new File(filePath));hdt = new HWPFDocument(in);} catch (Exception e1) {e1.printStackTrace();}Fields fields = hdt.getFields();Iterator<Field> it = fields.getFields(FieldsDocumentPart.MAIN) .iterator();while (it.hasNext()) {System.out.println(it.next().getType());}//替换读取到的word模板内容的指定字段Range range = hdt.getRange();for (Map.Entry<String, String> entry : map.entrySet()) { range.replaceText("$" + entry.getKey() + "$",entry.getValue());}//输出word内容文件流,提供下载response.reset();response.setContentType("application/x-msdownload");String fileName = "" + System.currentTimeMillis() + ".doc";response.addHeader("Content-Disposition", "attachment;filename="+ fileName);ByteArrayOutputStream ostream = new ByteArrayOutputStream();OutputStream servletOS = null;try {servletOS = response.getOutputStream();hdt.write(ostream);servletOS.write(ostream.toByteArray());servletOS.flush();servletOS.close();} catch (Exception e) {e.printStackTrace();}}}注:以上代码需要poi包, 可以下载。
java html内容生成word文件实现代码

java html内容生成word文件实现代码处理HTML标签我用的是Jsoup组件,生成word文档这方面我用的是Jacob组件。
有兴趣的朋友可以去Google搜索一下这两个组件。
大致思路如下:先利用jsoup将得到的html代码“标准化”(Jsoup.parse(String html))方法,然后利用FileWiter将此html内容写到本地的template.doc文件中,此时如果文章中包含图片的话,template.doc就会依赖你的本地图片文件路径,如果你将图片更改一个名称或者将路径更改,再打开这个template.doc,图片就会显示不出来(出现一个叉叉)。
为了解决此问题,利用jsoup组件循环遍历html文档的内容,将img元素替换成${image_自增值}的标识,取出img元素中的src属性,再以键值对的方式存储起来,例如:此时你的html内容会变成如下格式:(举个示例)保存到本地文件以后,利用MSOfficeGeneratorUtils类(工具类详见下面,基于开源组件Jacob)打开你保存的这个template.doc,调用replaceText2Image,将上面代码的图片标识替换为图片,这样就消除了本地图片路径的问题。
然后再调用copy方法,复制整篇文档,关闭template.doc文件,新建一个doc文件(createDocument),调用paste方法粘贴你刚复制的template.doc里的内容,保存。
基本上就ok了。
关于copy整个word文档的内容,也会出现一个隐式问题。
就是当复制的内容太多时,关闭word程序的时候,会谈出一个对话框,问你是否将复制的数据应用于其它的程序。
对于这个问题解决方法很简单,你可以在调用quit(退出word程序方法)之前,新建一篇文档,输入一行字,然后调用copy方法,对于复制的数据比较少时,关闭word程序时,它不会提示你的。
见如下代码//复制一个内容比较少的*.doc文档,防止在关闭word程序时提示有大量的copy内容在内存中,是否应用于其它程序对话框,msOfficeUtils.close();msOfficeUtils.quit();Jacob在sourceforge上的链接Jsoup官网MsOfficeGeneratorUtilspackage com.to ps tar.test;import java.io.File;import java.io.IOException;import java.util.List;import com.jacob.activeX.ActiveXComponent;import Thread;import .Dispatch;import .Variant;/*** 利用JACOB对Microsoft Office Word 进行相关操作** @author xiaowu* @category topstar* @version 1.0* @since 2011-12-5*/public class MSOfficeGeneratorUtils {/*** Microsoft Office Word 程序对象*/private ActiveXComponent word = null;/*** Word 活动文档对象*/private Dispatch document = null;/*** 所有 Word 文档对象*/private Dispatch documents = null;/*** select ion 代表当前活动文档窗口中的所选内容。
Java根据模板动态生成word文件

Java根据模板动态⽣成word⽂件最近项⽬中需要根据模板⽣成word⽂档,模板⽂件也是word⽂档。
当时思考⼀下想⽤POI API来做,但是觉得⽤起来相对复杂。
后来⼜找了⼀种⽅式,使⽤freemarker模板⽣成word⽂件,经过尝试觉得还是相对简单易⾏的。
使⽤freemarker模板⽣成word⽂档主要有这么⼏个步骤1、创建word模板:因为我项⽬中⽤到的模板本⾝是word,所以我就直接编辑word⽂档转成freemarker(.ftl)格式的。
2、将改word⽂件另存为xml格式,注意使⽤另存为,不是直接修改扩展名。
3、将xml⽂件的扩展名改为ftl4、编写java代码完成导出使⽤到的jar:freemarker.jar (2.3.28) ,其中Configuration对象不推荐直接new Configuration(),仔细看Configuration.class⽂件会发现,推荐的是 Configuration(Version incompatibleImprovements) 这个构造⽅法,具体这个构造⽅法⾥⾯传的就是Version版本类,⽽且版本号不能低于2.3.0闲⾔碎语不再讲,直接上代码1public static void exportDoc() {2 String picturePath = "D:/image.png";3 Map<String, Object> dataMap = new HashMap<String, Object>();4 dataMap.put("brand", "海尔");5 dataMap.put("store_name", "海尔天津");6 dataMap.put("user_name", "⼩明");78//经过编码后的图⽚路径9 String image = getWatermarkImage(picturePath);10 dataMap.put("image", image);1112//Configuration⽤于读取ftl⽂件13 Configuration configuration = new Configuration(new Version("2.3.0"));14 configuration.setDefaultEncoding("utf-8");1516 Writer out = null;17try {18//输出⽂档路径及名称19 File outFile = new File("D:/导出优惠证明.doc");20 out = new BufferedWriter(new OutputStreamWriter(new21 FileOutputStream(new File("outFile")), "utf-8"), 10240);22 } catch (UnsupportedEncodingException e) {23 e.printStackTrace();24 } catch (FileNotFoundException e) {25 e.printStackTrace();26 }27// 加载⽂档模板28 Template template = null;29try {30//指定路径,例如C:/a.ftl 注意:此处指定ftl⽂件所在⽬录的路径,⽽不是ftl⽂件的路径31 configuration.setDirectoryForTemplateLoading(new File("C:/"));32//以utf-8的编码格式读取⽂件33 template = configuration.getTemplate("导出优惠证明.ftl", "utf-8");34 } catch (IOException e) {35 e.printStackTrace();36throw new RuntimeException("⽂件模板加载失败!", e);37 }3839// 填充数据40try {41 template.process(dataMap, out);42 } catch (TemplateException e) {43 e.printStackTrace();44throw new RuntimeException("模板数据填充异常!", e);45 } catch (IOException e) {46 e.printStackTrace();47throw new RuntimeException("模板数据填充异常!", e);48 } finally {49if (null != out) {50try {51 out.close();52 } catch (IOException e) {53 e.printStackTrace();54throw new RuntimeException("⽂件输出流关闭异常!", e);55 }56 }57 }58 }View Code因为很多时候我们根据模板⽣成⽂件需要添加⽔印,也就是插⼊图⽚1/***2 * 处理图⽚3 * @param watermarkPath 图⽚路径 D:/image.png4 * @return5*/6private String getWatermarkImage(String watermarkPath) {7 InputStream in = null;8byte[] data = null;9try {10 in = new FileInputStream(watermarkPath);11 data = new byte[in.available()];12 in.read(data);13 in.close();14 } catch (Exception e) {15 e.printStackTrace();16 }17 BASE64Encoder encoder = new BASE64Encoder();18return encoder.encode(data);19 }View Code注意点:插⼊图⽚后的word转化为ftl模板⽂件(ps:⽔印图⽚可以在word上调整到⾃⼰想要的⼤⼩,然后在执⾏下⾯的步骤)1、先另存为xml2、将xml扩展名改为ftl3、打开ftl⽂件, 搜索w:binData 或者 png可以快速定位图⽚的位置,图⽚已经编码成0-Z的字符串了, 如下:5、将上述0-Z的字符串全部删掉,写上${image}(变量名随便写,跟dataMap⾥的key保持⼀致)后保存6、也是创建⼀个Map, 将数据存到map中,只不过我们要把图⽚⽤代码进⾏编码,将其也编成0-Z的字符串,代码请看上边⾄此⼀个简单的按照模板⽣成word并插⼊图⽚(⽔印)功能基本完成。
java实现的导出word文档

java实现的导出word⽂档之前没有做过类似的功能,所以第⼀次接触的时候费了我⼀天的时间来完成这个功能。
先说⼀下原理,其实就是通过修改后缀来完成的。
需要先⽤office2013做⼀个word模板,就是你想要⽣成的word的模板,保存为xml格式。
然后在线格式化⼀下,这样⽣成的代码⽐较规范,然后将后缀修改为ftl,内容为⼀下格式:、我使⽤的⽅法是通过Action跳转的⽅法来进⾏调⽤的,Action⽅法如下,[java] view plain copy print?1. public String exportProWorkOrder(){2.3. /** 取出参数**/4.5. /** 输出审批 **/6. Template t=null;7. PrintWriter wt = null;8.9. try {10. /** 查询数据 **/11. ProjectWorkOrder pwo = consultingProjectBo.findPWOMessage(18);12.13. Map<String,Object> dataMap=new HashMap<String,Object>();14.15. //getData(dataMap);16. /** 放置数据 **/17. consultingProjectBo.makeExportProWorkOrderData(pwo,dataMap);18. String fn = makeFileName(pwo);19.20. //FTL⽂件所存在的位置21. t = freeMarkerConfiguration.getTemplate("export_proworkorder.ftl"); //⽂件名22.23.24. //配置 Response 参数25. getResponse().setContentType(26. "application/msword; charset=UTF-8");27. getResponse().setHeader(28. "Content-Disposition",29. "Attachment;filename= "30. + new String(fn.toString().getBytes(31. //"UTF-8"),"UTF-8"));32. "gb2312"), "ISO8859_1"));//20151030 改为UTF-8 需要兼容性测试33. wt = getResponse().getWriter();34. t.process(dataMap, wt);34. t.process(dataMap, wt);35.36. } catch (IOException e) {37. e.printStackTrace();38. } catch (Exception e) {39. e.printStackTrace();40. } finally {41. if(wt!=null){42. wt.flush();43. wt.close();44. }45. }46. return null;47. }48.49. protected String makeFileName(ProjectWorkOrder pwo) {50. if(pwo==null){51. return "⽂件不存在";52. }53.54. String filename = "";55. if(pwo.getProjectTitle()!=null){56. filename = pwo.getProjectTitle() + "⼯程造价咨询项⽬⼯作交办单" + ".doc";57. }else{58. filename = "⼯程造价咨询项⽬⼯作交办单"+".doc";59. }60.61. return filename;62. }跳转进⼊⽅法中,期中放置数据的⽅法如下,[java] view plain copy print?1. public ProjectWorkOrder findPWOMessage(Integer projectId){2. SimpleDateFormat sdf = new SimpleDateFormat( "yyyy-MM-dd HH:mm:ss" );3. Project project = null;4. List<ProjectDepartment> list = null;5. ProjectEngineering pe = null;6. project = projectBo.findFull(projectId);7. list = projectDepartmentBo.findPDByProjectId(projectId);8. pe = projectEngineeringBo.findPEByProjectId(projectId);9. ProjectWorkOrder pwo = new ProjectWorkOrder();10. if(projectId != null){11. pwo.setProjectId(projectId);12. }13. if(project.getProject_title() != null){14. pwo.setProjectTitle(project.getProject_title());15. }16. if(project.getBegin_date() != null){17. pwo.setBeginDate(sdf.format(project.getBegin_date()));18. }19. if(project.getEnd_date() != null){20. pwo.setEndDate(sdf.format(project.getEnd_date()));21. }22. if(project.getProject_target() != null){23. pwo.setProjecTarget(project.getProject_target());24. }24. }25. if(project.getMember_id() != null){26. Member member = memberBo.getCacheMember(project.getMember_id());27. pwo.setMemberId(member.getMember_name());28. }29. if(pe.getPlan_no() != null){30. pwo.setPlanNu(pe.getPlan_no());31. }32. if(pe.getIncrement() != null){33. pwo.setInvestment(pe.getIncrement());34. }35. if(pe.getDo_item() != null){36. pwo.setDoItem(pe.getDo_item());37. }38. if(pe.getKey_point() != null){39. pwo.setKeyPoint(pe.getKey_point());40. }41. if(list != null){42. pwo.setChild(addtypePlus(list));43. }44. return pwo;45. }46. /**47. *将⼯程造价咨询项⽬⼯作交办单导出为word48. */49. @Override50. public void makeExportProWorkOrderData(ProjectWorkOrder pwo, Map<String, Object> dataMap) {51. if(pwo==null){52. return;53. }54. if(pwo.getProjectTitle() != null){55. dataMap.put("ptitle",pwo.getProjectTitle());//项⽬名称56. }else{57. dataMap.put("ptitle","⽆");58. }59. if(pwo.getProjectId() != null){60. dataMap.put("pid", pwo.getProjectId());//⼯程id61. }else{62. dataMap.put("pid", "0");63. }64. if(pwo.getBeginDate() != null){65. dataMap.put("begindate", pwo.getBeginDate());//项⽬开始时间66. }else{67. dataMap.put("begindate", "⽆");68. }69. if(pwo.getEndDate() != null){70. dataMap.put("endate", pwo.getEndDate());//结束⽇期71. }else{72. dataMap.put("endate", "⽆");73. }74. if(pwo.getProjecTarget() != null){75. dataMap.put("ptarget", pwo.getProjecTarget());//⽬标76. }else{77. dataMap.put("ptarget", "⽆");78. }79. if(pwo.getMemberId() != null){80. dataMap.put("pmemberid", pwo.getMemberId());//负责⼈81. }else{81. }else{82. dataMap.put("pmemberid", "⽆");83. }84. if(pwo.getPlanNu() != null){85. dataMap.put("plano", pwo.getPlanNu());//计划编号86. }else{87. dataMap.put("plano", "⽆");88. }if(pwo.getInvestment() != null){89. dataMap.put("investment", pwo.getInvestment());//总投资90. }else{91. dataMap.put("investment", "⽆");92. }93. if(pwo.getDoItem() != null){94. dataMap.put("doitem", pwo.getDoItem());//事项95. }else{96. dataMap.put("doitem", "⽆");97. }98. if(pwo.getKeyPoint() != null){99. dataMap.put("keypoint", pwo.getKeyPoint());//重点100. }else{101. dataMap.put("keypoint", "⽆");102. }103. if(pwo.getChild() != null){104. dataMap.put("list", pwo.getChild());//联系⼈列表105. }else{106. dataMap.put("list", "⽆");107. }108. SimpleDateFormat tempDate = new SimpleDateFormat("yyyy年MM⽉dd⽇"); 109. String datetime = tempDate.format(DateTimeUtil.getCurrDate());110. dataMap.put("datetime", datetime);111. }112. /**113. * 将单位类型数字转换为对应的字符114. */115. private List<ProjectDepartment> addtypePlus(List<ProjectDepartment> list){116. for (ProjectDepartment projectDepartment : list) {117. if(projectDepartment.getType() == 1){projectDepartment.setTypePlus("委托单位");} 118. if(projectDepartment.getType() == 2){projectDepartment.setTypePlus("建设单位");} 119. if(projectDepartment.getType() == 3){projectDepartment.setTypePlus("施⼯单位");} 120. if(projectDepartment.getType() == 4){projectDepartment.setTypePlus("监理单位");} 121. if(projectDepartment.getType() == 5){projectDepartment.setTypePlus("设计单位");} 122. if(projectDepartment.getType() == 6){projectDepartment.setTypePlus("编制单位");} 123. }124. return list;125. }配置⽂件的信息这⾥就不在多说了,同时需要修改ftl中的参数,修改⽅法如下,[html] view plain copy print?1. <w:r wsp:rsidRPr="002C3578">2. <w:rPr>3. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>4. <wx:font wx:val="宋体"/>5. <w:sz-cs w:val="21"/>6. </w:rPr>7. <w:t><![CDATA[${doitem}]]></w:t>7. <w:t><![CDATA[${doitem}]]></w:t>8. </w:r>与jsp中的⽅法基本⼀致,处理list,如果遇到循环的话,使⽤如下的⽅法,[html] view plain copy print?1. <#list list as bean><!-- Start 循环体 -->2. <w:tr wsp:rsidR="002C3578" wsp:rsidRPr="002C3578" wsp:rsidTr="002C3578">3. <w:trPr>4. <w:trHeight w:val="427"/>5. </w:trPr>6. <w:tc>7. <w:tcPr>8. <w:tcW w:w="534" w:type="dxa"/>9. <w:vmerge/>10. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>11. </w:tcPr>12. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">13. <w:pPr>14. <w:jc w:val="center"/>15. <w:rPr>16. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>17. <wx:font wx:val="宋体"/>18. <w:sz-cs w:val="21"/>19. </w:rPr>20. </w:pPr>21. </w:p>22. </w:tc>23. <w:tc>24. <w:tcPr>25. <w:tcW w:w="1596" w:type="dxa"/>26. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>27. </w:tcPr>28. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">29. <w:pPr>30. <w:spacing w:line="360" w:line-rule="auto"/>31. <w:jc w:val="center"/>32. <w:rPr>33. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>34. <wx:font wx:val="宋体"/>35. <w:sz-cs w:val="21"/>36. </w:rPr>37. </w:pPr>38. <w:r wsp:rsidRPr="002C3578">39. <w:rPr>40. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>41. <wx:font wx:val="宋体"/>42. <w:sz-cs w:val="21"/>43. </w:rPr>44. <w:t><![CDATA[${bean.typePlus}]]></w:t>45. </w:r>46. </w:p>47. </w:tc>48. <w:tc>48. <w:tc>49. <w:tcPr>50. <w:tcW w:w="2130" w:type="dxa"/>51. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>52. </w:tcPr>53. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">54. <w:pPr>55. <w:spacing w:line="360" w:line-rule="auto"/>56. <w:jc w:val="center"/>57. <w:rPr>58. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>59. <wx:font wx:val="宋体"/>60. <w:sz-cs w:val="21"/>61. </w:rPr>62. </w:pPr>63. <w:r wsp:rsidRPr="002C3578">64. <w:rPr>65. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>66. <wx:font wx:val="宋体"/>67. <w:sz-cs w:val="21"/>68. </w:rPr>69. <w:t><![CDATA[${bean.department_name}]]></w:t>70. </w:r>71. </w:p>72. </w:tc>73. <w:tc>74. <w:tcPr>75. <w:tcW w:w="2131" w:type="dxa"/>76. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>77. </w:tcPr>78. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">79. <w:pPr>80. <w:spacing w:line="360" w:line-rule="auto"/>81. <w:jc w:val="center"/>82. <w:rPr>83. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>84. <wx:font wx:val="宋体"/>85. <w:sz-cs w:val="21"/>86. </w:rPr>87. </w:pPr>88. <w:r wsp:rsidRPr="002C3578">89. <w:rPr>90. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>91. <wx:font wx:val="宋体"/>92. <w:sz-cs w:val="21"/>93. </w:rPr>94. <w:t><![CDATA[${bean.linkman}]]></w:t>95. </w:r>96. </w:p>97. </w:tc>98. <w:tc>99. <w:tcPr>100. <w:tcW w:w="2131" w:type="dxa"/>101. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>102. </w:tcPr>103. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578"> 104. <w:pPr>104. <w:pPr>105. <w:spacing w:line="360" w:line-rule="auto"/>106. <w:jc w:val="center"/>107. <w:rPr>108. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>109. <wx:font wx:val="宋体"/>110. <w:sz-cs w:val="21"/>111. </w:rPr>112. </w:pPr>113. <w:r wsp:rsidRPr="002C3578">114. <w:rPr>115. <w:rFonts w:ascii="宋体" w:h-ansi="宋体"/>116. <wx:font wx:val="宋体"/>117. <w:sz-cs w:val="21"/>118. </w:rPr>119. <w:t><![CDATA[${bean.phone}]]></w:t>120. </w:r>121. </w:p>122. </w:tc>123. </w:tr>124. </#list><!-- End 循环体 -->这样就能导出想要的word⽂档,⼀定要记住,使⽤office2013,我试着⽤WPS,但是⽣成内容让我很懵逼,全是xml代码。
Java实现用Freemarker完美导出word文档(带图片)

Java实现⽤Freemarker完美导出word⽂档(带图⽚)前⾔最近在项⽬中,因客户要求,将页⾯内容(如合同协议)导出成word,在⽹上翻了好多,感觉太乱了,不过最后还是较好解决了这个问题。
准备材料1.word原件2.编辑器(推荐Firstobject free XML editor)实现步骤1.⽤Microsoft Office Word打开word原件;2.把需要动态修改的内容替换成***,如果有图⽚,尽量选择较⼩的图⽚⼏⼗K左右,并调整好位置;3.另存为,选择保存类型Word 2003 XML ⽂档(*.xml)【这⾥说⼀下为什么⽤Microsoft Office Word打开且要保存为Word2003XML,本⼈亲测,⽤WPS找不到Word 2003XML选项,如果保存为Word XML,会有兼容问题,避免出现导出的word⽂档不能⽤Word 2003打开的问题】;4.⽤Firstobject free XML editor打开⽂件,选择Tools下的Indent【或者按快捷键F8】格式化⽂件内容。
左边是⽂档结构,右边是⽂档内容;5. 将⽂档内容中需要动态修改内容的地⽅,换成freemarker的标识。
其实就是Map<String, Object>中key,如${landName};6.在加⼊了图⽚占位的地⽅,会看到⼀⽚base64编码后的代码,把base64替换成${image},也就是Map<String, Object>中key,值必须要处理成base64;代码如:<w:binData w:name="wordml://⾃定义.png" xml:space="preserve">${image}</w:binData>注意:“>${image}<”这尖括号中间不能加任何其他的诸如空格,tab,换⾏等符号。
java生成复杂pdf的方法

java生成复杂pdf的方法摘要:1.Java 生成复杂PDF 的方法1.1.Java 的优势1.2.生成复杂PDF 的方法1.2.1.使用iText 库1.2.2.使用Apache PDFBox 库1.2.3.使用Java 内置的PDF 支持1.3.选择合适的库1.4.总结正文:Java 作为一种广泛应用的编程语言,具有跨平台、可移植性强等优势。
在生成复杂PDF 方面,Java 同样具有很好的表现。
本文将介绍几种Java 生成复杂PDF 的方法。
首先,Java 的优势在于其跨平台性,这意味着在编写代码时,可以忽略底层操作系统和硬件的差异,从而更专注于业务逻辑。
此外,Java 有着丰富的开源库,可以帮助开发者轻松实现各种功能。
在生成复杂PDF 方面,Java 有多种方法可供选择。
其中,使用iText 库、Apache PDFBox 库以及Java 内置的PDF 支持是最常见的几种方式。
iText 库是一个功能强大的Java PDF 库,可以轻松地创建、编辑和处理PDF 文件。
它提供了丰富的API,支持各种PDF 对象的创建和操作。
使用iText 库,可以方便地实现复杂PDF 的生成,例如添加图片、表格、超链接等。
同时,iText 库还支持将PDF 文件转换为其他格式,如HTML、XML 等。
Apache PDFBox 库是另一个常用的Java PDF 库,它提供了一组工具,用于处理PDF 文档。
与iText 库相比,PDFBox 库更注重底层操作,可以实现对PDF 文件的无缝解析。
通过PDFBox 库,可以提取PDF 文件中的文本、图片等元素,并对其进行操作。
这使得Apache PDFBox 库在处理复杂PDF 时具有较高的灵活性。
此外,Java 内置的PDF 支持也是一个值得关注的领域。
随着Java 7 的发布,Java 引入了PDF 支持,使得开发者可以直接在Java 代码中处理PDF 文件。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
先用office2003或者2007编辑好word的样式,然后另存为xml,将xml翻译为FreeMarker 模板,最后用java来解析FreeMarker模板并输出Doc。
经测试这样方式生成的word文档完全符合office标准,样式、内容控制非常便利,打印也不会变形,生成的文档和office中编辑文档完全一样。
AD:客户要求用程序生成标准的word文档,要能打印,而且不能变形,以前用过很多解决方案,都在客户严格要求下牺牲的无比惨烈。
POI读word文档还行,写文档实在不敢恭维,复杂的样式很难控制不提,想象一下一个20多页,嵌套很多表格和图像的word文档靠POI来写代码输出,对程序员来说比去山西挖煤还惨,况且文档格式还经常变化。
iText操作Excel还行。
对于复杂的大量的word也是噩梦。
直接通过JSP输出样式基本不达标,而且要打印出来就更是惨不忍睹。
Word从2003开始支持XML格式,用XML还做就很简单了。
大致的思路是先用office2003或者2007编辑好word的样式,然后另存为xml,将xml 翻译为FreeMarker模板,最后用java来解析FreeMarker模板并输出Doc。
经测试这样方式生成的word文档完全符合office标准,样式、内容控制非常便利,打印也不会变形,生成的文档和office中编辑文档完全一样。
看看实际效果
首先用office【版本要2003以上,以下的不支持xml格式】编辑文档的样式,图中红线的部分就是我要输出的部分:
将编辑好的文档另存为XML
再用Firstobject free XML editor将xml中我们需要填数据的地方打上FreeMarker标记
最后生成的文档样式
主要程序代码:
package com.havenliu.document;
2import java.io.BufferedWriter;
3import java.io.File;
4import java.io.FileNotFoundException;
5import java.io.FileOutputStream;
6import java.io.IOException;
7import java.io.OutputStreamWriter;
8import java.io.Writer;
9import java.util.ArrayList;
10import java.util.HashMap;
11import java.util.List;
12import java.util.Map;
13import freemarker.template.Configuration;
14import freemarker.template.Template;
15import freemarker.template.TemplateException;
16public class DocumentHandler {
17private Configuration configuration = null;
18public DocumentHandler() {
19configuration = new Configuration();
20configuration.setDefaultEncoding("utf-8");
21}
22public void createDoc() {
23//要填入模本的数据文件
24Map dataMap=new HashMap();
25getData(dataMap);
26//设置模本装置方法和路径,FreeMarker支持多种模板装载方法。
可以重servlet,classpath,数据库装载,
27//这里我们的模板是放在com.havenliu.document.template包下面
28configuration.setClassForTemplateLoading(this.getClass(),
"/com/havenliu/document/template");
29Template t=null;
30try {
31//test.ftl为要装载的模板
32t = configuration.getTemplate("test.ftl");
33} catch (IOException e) {
34 e.printStackTrace();
35}
36//输出文档路径及名称
37File outFile = new File("D:/temp/outFile.doc");
38Writer out = null;
39try {
40out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile)));
41} catch (FileNotFoundException e1) {
42e1.printStackTrace();
43}
44try {
45t.process(dataMap, out);
46} catch (TemplateException e) {
47 e.printStackTrace();
48} catch (IOException e) {
49 e.printStackTrace();
50}
51}
52/**
53* 注意dataMap里存放的数据Key值要与模板中的参数相对应54* @param dataMap
55*/
56private void getData(Map dataMap)
57{
58dataMap.put("author", "张三");
59dataMap.put("remark", "这是测试备注信息");
60List
61_table1=new ArrayList();
62Table1 t1=new Table1();
63t1.setDate("2010-10-1");
64t1.setText("制定10月开发计划内容。
");
65_table1.add(t1);
66Table1 t2=new Table1();
67t2.setDate("2010-10-2");
68t2.setText("开会讨论开发计划");
69_table1.add(t2);
70dataMap.put("table1", _table1);
71List
72_table2=new ArrayList();
73for(int i=0;i<5;i++)
74{
75Table2 _t2=new Table2();
76_t2.setDetail("测试开发计划"+i);
77_t2.setPerson("张三——"+i);
78_t2.setBegindate("2010-10-1");
79_t2.setFinishdate("2010-10-31");
80_t2.setRemark("备注信息");
81_table2.add(_t2);
82}
83dataMap.put("table2", _table2);
84}
85}。