批量生成插入数据SQL
一次插入多行数据的三种T-SQL语句

一次插入多行数据的三种T-SQL语句第一篇:一次插入多行数据的三种T-SQL语句一次插入多行数据的三种T-SQL语句一,INSERT……SELECT将从表table2中查询到的数据插入到已建立的表table1(已建立)中insert into table1(columnName1,columnName2,columnName3) selecttable2columnName1,table2columnName2,table2columnName3 from table2二,SELECT……INTO将从表table2中查询到的数据插入到表table1(未建立)中selecttable2columnName1,table2columnName2,table2columnName3 into table1from rable2 Notice:1),table1在插入时自动建立,并将table2columnName1……作为新表table1的列名2),若同时需要向表table1插入标识列,则要使用IDENTITY(数据类型,标识种子,标适增长量,)as列名。
Example:selecttable2columnName1,table2columnName2,table2columnName3, identity(int,1,1)as ID into table1from rable2三UNIONUNION用于将两个不同的数据或查询结果合成一个新的结果集insert table1(columnName1,columnName2,columnName3) select '诺基亚','N95',3280 unionselect '摩托罗拉','VE75',2680 unionselect '三星' ,'SGH-U908E',2700Notice:union不能用于插入含默认值的记录。
SQL大批量插入数据的方式(多表关联).

SQL⼤批量插⼊数据的⽅式(多表关联).前段时间,在⼯作中遇到这个需求,需要⼤批量插⼊⼏万条甚⾄⼏⼗万的数据。
因为业务特殊,多张表的相互关联,通常做法是先往主表⾥⾯插⼊⼀条数据,然后获取主表的主键ID,再往其他关联的表⾥⾯插⼊ID的关联数据。
刚开始做的时候,想到⽤事务,把⼏万条SQL拼装起来,在⼀个事务⾥⾯去执⾏,结果很壮烈,执⾏性能⾮常糟糕。
⼏千条业务数据执⾏了⼏分钟。
⽤代码分析⼯具Dottrace⼀查,发现单单操作数据库的时间占了99.9%。
(Dottrace,代码性能分析⼯具,它分dottrace Performance和dottrace Memory两个⼯具,dottrace Performance⽤来分析代码性能,⽐如函数执⾏时间,调⽤次数,消耗时间⽐率等,dottrace Memory⼀般⽤来分析内存占⽤情况。
⼤家如果有兴趣的同学可以去下载玩下,对代码优化⼯作很有帮助的。
)⾔归正传,去⽹上搜了很多资料,原来2.0有⼀个新的特性:SqlBulkCopy,效率还是很⾼的。
然后结合⾃⼰的业务需求,修改了下代码。
现在跟⼤家⼀起来学习下。
(因为也是参考前辈写的资料,所以下⾯的⽰例都⼤同⼩异)建⽴测试数据库(BulkTestDB)、主表(BulkTestMain)、从表(BulkTestDetail)--Create DataBasecreate database BulkTestDB;gouse BulkTestDB;go--Create TableCreate table BulkTestMain(Id int primary key,GuidId long,--辅助的唯⼀标识Batch long,--导⼊的批次标识Name nvarchar(32)goCreate table BulkTestDetail(Id int primary key,PId int,Lesson nvarchar(32)go数据库建⽴完毕,开始编写后台代码View Codepublic void TestMain(){using (SqlConnection connection = new SqlConnection("你的链接字符串")){connection.Open();SqlTransaction transaction = connection.BeginTransaction("Transaction1");DataTable dtTestMain= GetTableSchema("BulkTestMain");//构建BulkTestMain表结构DataTable dtTestDetail = GetTableSchema("BulkTestDetail");//构建BulkTestDetail表结构Guid Batch = Guid.NewGuid();//插⼊的批次,为后⾯查询dtTestMainTmp 做条件for (int i = 0; i < 1000000; i++)//测试100w条数据{DataRow dr= dtTestMain.NewRow();Guid newGuid = Guid.NewGuid();dr["_GuidId"] = newGuid;dr["_Batch"] = Batch;dr["_UserName"] = "测试" + i.ToString();dtTestMain.Rows.Add(dr);for(int j = 0;j<10;j++)//给从表每次插⼊10条数据{DataRow dr1 = dtTestDetail.NewRow();dr1["_GuidId"]= newGuid;dr1["_Lesson"]="课程"+j.ToString();dtTestDetail.Rows.Add(dr1);}//这样做的⽬的,让主表与从表可以临时通过GuidId关联起来}BulkToDB(dtTestMain, "BulkTestMain", connection, transaction);//先让BulkTestMain插⼊了⼤量的数据,注意这些数据是临时的,在SqlTransaction提交之前,查询时要⽤with(nolock) DataSet dtTestMainTmp = GetNewImportData(Batch.ToString());//好吧,我们来查询下,刚才⼤量插⼊的10w条数据,这⾥只需要查询标识的2列字段Dictionary<string, long> dicGuidToID = new Dictionary<string, long>();foreach (DataRow dr in dtTestMainTmp.Tables[0].Rows){dicGuidToID.Add(dr[1].ToString(), Convert.ToInt64(dr[0]));}//dicGuidToID:guid字段与插⼊的主表ID字段关联起来成字典,⽤字典是为了访问起来效率(为什么获取字典key的值效率很⾼,有兴趣的可以去研究“散列表”的概念)foreach (DataRow dr in dtTestDetail.Rows)//现在给dtTestDetail的PId字段赋值(PId字段与主表Id外键关联){dr["_PId"] = dicGuidToID[dr["_GuidId"].ToString()].ToString();}dtTestDetail.Columns.Remove("_GuidId");//移除dtTestDetail的GuidId字段,使它与数据库列匹配BulkToDB(dtTestDetail,"BulkTestDetail",connection, transaction);//给从表插⼊数据mit();connection.Close();}}///<summary>///根据批次Batch获取导进来的临时数据///</summary>///<returns></returns>public static DataSet GetNewImportData(string batch){StringBuilder strSql = new StringBuilder();strSql.Append("SELECT [Id],[GuidId]").Append(" FROM ContactInfo WITH (NOLOCK) WHERE Batch=@batch");SqlParameter[] parameters = {new SqlParameter("@Batch", SqlDbType.BigInt){Value = batch}};DataSet ds = SqlHelper.ExecuteDataset(strSql.ToString(), parameters);return ds;}public static void BulkToDB(DataTable dtSource, string TableName,SqlConnection connection, SqlTransaction transaction) {using (SqlBulkCopy sqlBulkCopy = new SqlBulkCopy(connection, SqlBulkCopyOptions.KeepIdentity, transaction)){sqlBulkCopy.DestinationTableName = TableName;//要插⼊数据的表的名称sqlBulkCopy.BatchSize = dtSource.Rows.Count;//数据的⾏数List<SqlBulkCopyColumnMapping> mpList = getMapping(TableName);//获取表映射关系foreach (SqlBulkCopyColumnMapping mp in mpList){sqlBulkCopy.ColumnMappings.Add(mp);}if (dtSource != null && dtSource.Rows.Count != 0){sqlBulkCopy.WriteToServer(dtSource);//插⼊数据}}}public static List<SqlBulkCopyColumnMapping> getMapping(string TableName){List<SqlBulkCopyColumnMapping> mpList = new List<SqlBulkCopyColumnMapping>();switch(TableName){case"BulkTestMain":{mpList.Add(new SqlBulkCopyColumnMapping("_Id", "Id"));mpList.Add(new SqlBulkCopyColumnMapping("_GuidId", "GuidId"));mpList.Add(new SqlBulkCopyColumnMapping("_Batch","Batch"));mpList.Add(new SqlBulkCopyColumnMapping("_UserName", "UserName"));}break;case"BulkTestDetail":{mpList.Add(new SqlBulkCopyColumnMapping("_Id", "Id"));mpList.Add(new SqlBulkCopyColumnMapping("_PId", "PId"));mpList.Add(new SqlBulkCopyColumnMapping("_Lesson", "Lesson"));}break;}return mpList;}private static DataTable GetTableSchema(string TableName){DataTable dataTable = new DataTable();switch(TableName){case"BulkTestMain" :{dataTable.Columns.AddRange(new DataColumn[] {new DataColumn("_Id",typeof(Int32)),new DataColumn("_GuidId",typeof(Int64)),new DataColumn("_Batch",typeof(Int64)),new DataColumn("_UserName",typeof(String))});}break;case"BulkTestDetail":{dataTable.Columns.AddRange(new DataColumn[] {new DataColumn("_Id",typeof(Int32)),new DataColumn("_PId",typeof(Int32)),new DataColumn("_GuidId",typeof(Int64)),new DataColumn("_Lesson",typeof(String))});}break;}return dataTable;}总算把代码copy完了,任务完成。
sql语句insert_into用法_概述及举例说明

sql语句insert into用法概述及举例说明1. 引言1.1 概述SQL是一种用于管理和查询关系型数据库的编程语言。
在SQL中,INSERT INTO 语句用于向表中插入新的行数据。
它是SQL语句中最常用的之一,因为它可以帮助我们往表中添加数据。
1.2 文章结构本文将介绍INSERT INTO语句的基本语法和用法,并通过举例说明来更好地理解。
首先,我们将详细讨论如何插入单行数据、插入多行数据以及使用默认值插入数据的方法。
然后,我们将通过三个具体示例对这些概念进行实际操作。
1.3 目的本文旨在帮助读者全面了解和掌握SQL语句INSERT INTO的使用方法。
通过深入探讨其基本概念和示例操作,读者能够清楚地理解如何向数据库表中插入新纪录,并能够根据实际需求合理运用相关技巧。
以上是文章“1. 引言”部分内容,请注意以普通文本格式回答,不要包含任何网址或markdown格式内容。
2. SQL语句INSERT INTO用法2.1 插入单行数据在SQL中,使用INSERT INTO语句可以向表中插入一条数据。
INSERT INTO 语句的基本语法如下:```INSERT INTO 表名(列1, 列2, 列3, ...)VALUES (值1, 值2, 值3, ...);```其中,表名代表要插入数据的目标表格名称;括号内的列1、列2、列3等代表要插入数据的目标列名称;VALUES关键字后面括号内的值1、值2、值3等为具体要插入的数值。
例如,我们有一个名为"students"的表格,它包含"id"、"name"和"age"三个列。
现在我们想向该表格中插入一条记录,id为101,姓名为张三,年龄为20。
可以使用如下SQL语句进行插入操作:```INSERT INTO students (id, name, age)VALUES (101, '张三', 20);```2.2 插入多行数据除了插入单行数据外,还可以使用INSERT INTO语句一次性插入多行数据。
PreparedStatement批量(batch)插入数据

PreparedStatement批量( batch)插入数据
JDBC操作数据库的时候,需要一次性插入大量的数据的时候,如果每次只执行一条SQL语句,效率可能会比较低。这时可以使用batch操 作,每次批量执行SQL语句,调高效率。
retuபைடு நூலகம்n true; } catch(Exception e) {
throw e; } }
this.conn.setAutoCommit(false); PreparedStatement stmt = this.conn.prepareStatement(sql); for(Emp emp : values) {
stmt.setInt(1, emp.getEmpno()); stmt.setString(2, emp.getEname()); stmt.setString(3, emp.getJob()); stmt.setDate(4, new java.sql.Date(emp.getHiredate().getTime())); stmt.setDouble(5, emp.getSal()); stmt.setDouble(6, emp.getComm()); stmt.addBatch(); } System.out.println("before executing batch..."); stmt.executeBatch(); mit(); System.out.println("after batch executed!"); this.conn.setAutoCommit(true);
public Boolean doCreateBatch(List<Emp> values) throws Exception {
sql如何向一个表中批量插入大量数据

sql如何向⼀个表中批量插⼊⼤量数据--如果是⼀个表插⼊另外⼀个表。
insert into tb1 需要的列名 select 按照前⾯写上需要的列名 from tb2--如果两表结构⼀样。
insert into tb1 * select * from tb2--也可以尝试从excel或access或TXT等⽂件导⼊。
参考如下:导⼊导出⼤全导出到excel EXEC master..xp_cmdshell 'bcp SettleDB.dbo.shanghu out c:\temp1.xls -c -q -S"GNETDATA/GNETDATA" -U"sa" -P""'/*********** 导⼊Excel SELECT * FROM OpenDataSource( 'Microsoft.Jet.OLEDB.4.0', 'Data Source="c:\test.xls";UserID=Admin;Password=;Extended properties=Excel 5.0')...xactions/*动态⽂件名 declare @fn varchar(20),@s varchar(1000) set @fn = 'c:\test.xls' set @s ='''Microsoft.Jet.OLEDB.4.0'', ''Data Source="ID=Admin;Password=;Extended properties=Excel 5.0''' set @s = 'SELECT * FROM OpenDataSource ( exec(@s) */SELECT cast(cast(科⽬编号 as numeric(10,2)) as nvarchar(255))+' ' 转换后的别名 FROM OpenDataSource( 'Microsoft.Jet.OLEDB.4.0', 'Data Source="c:\test.xls";User ID=Admin;Password=;Extended properties=Excel 5.0')...xactions/********************** EXCEL导到远程SQL insert OPENDATASOURCE( 'SQLOLEDB', 'Data Source=远程ip;UserID=sa;Password=密码' ).库名.dbo.表名 (列名1,列名2) SELECT 列名1,列名2 FROM OpenDataSource( 'Microsoft.Jet.OLEDB.4.0','Data Source="c:\test.xls";User ID=Admin;Password=;Extended properties=Excel 5.0')...xactions/** 导⼊⽂本⽂件 EXEC master..xp_cmdshell 'bcp dbname..tablename in c:\DT.txt -c -Sservername -Usa -Ppassword'/** 导出⽂本⽂件 EXEC master..xp_cmdshell 'bcp dbname..tablename out c:\DT.txt -c -Sservername -Usa -Ppassword' 或 EXEC master..xp_cmdshell 'bcp "Select * from dbname..tablename" queryout c:\DT.txt -c -Sservername -Usa -Ppassword'导出到TXT⽂本,⽤逗号分开 exec master..xp_cmdshell 'bcp "库名..表名" out "d:\tt.txt" -c -t ,-U sa -P password'BULK INSERT 库名..表名 FROM 'c:\test.txt' WITH ( FIELDTERMINATOR = ';', ROWTERMINATOR = '\n' )--/* dBase IV⽂件 select * from OPENROWSET('MICROSOFT.JET.OLEDB.4.0' ,'dBase IV;HDR=NO;IMEX=2;DATABASE=C:\','select * from [客户资料4.dbf]') --*/--/* dBase III⽂件 select * from OPENROWSET('MICROSOFT.JET.OLEDB.4.0' ,'dBase III;HDR=NO;IMEX=2;DATABASE=C:\','select * from [客户资料3.dbf]') --*/--/* FoxPro 数据库 select * from openrowset('MSDASQL', 'Driver=Microsoft Visual FoxPro Driver;SourceType=DBF;SourceDB=c:\', 'select * from [aa.DBF]') --*//**************导⼊DBF⽂件****************/ select * from openrowset('MSDASQL', 'Driver=Microsoft Visual FoxPro Driver;SourceDB=e:\VFP98\data; SourceType=DBF', 'select * from customer where country != "USA" order by country') go /***************** 导出到DBF ***************/ 如果要导出数据到已经⽣成结构(即现存的)FOXPRO表中,可以直接⽤下⾯的SQL语句insert into openrowset('MSDASQL', 'Driver=Microsoft Visual FoxPro Driver;SourceType=DBF;SourceDB=c:\', 'select * from [aa.DBF]') select * from 表说明: SourceDB=c:\ 指定foxpro表所在的⽂件夹 aa.DBF 指定foxpro表的⽂件名./*************导出到Access********************/ insert into openrowset('Microsoft.Jet.OLEDB.4.0', 'x:\A.mdb';'admin';'',A表) select * from 数据库名..B表/*************导⼊Access********************/ insert into B表 selet * from openrowset('Microsoft.Jet.OLEDB.4.0', 'x:\A.mdb';'admin';'',A表)⽂件名为参数 declare @fname varchar(20) set @fname = 'd:\test.mdb' exec('SELECT a.* FROMopendatasource(''Microsoft.Jet.OLEDB.4.0'', , topics) as a ')SELECT * FROM OpenDataSource( 'Microsoft.Jet.OLEDB.4.0', 'Data Source="f:\northwind.mdb";Jet OLEDB:DatabasePassword=123;User ID=Admin;Password=;')...产品********************* 导⼊ xml ⽂件DECLARE @idoc int DECLARE @doc varchar(1000) --sample XML document SET @doc =' <root> <Customer cid= "C1" name="Janine" city="Issaquah"> <Order oid="O1" date="1/20/1996" amount="3.5" /> <Order oid="O2" date="4/30/1997" amount="13.4">Customer was very satisfied </Order> </Customer> <Customer cid="C2" name="Ursula" city="Oelde" > <Order oid="O3" date="7/14/1999" amount="100" note="Wrap it blue white red"> <Urgency>Important</Urgency> Happy Customer. </Order><Order oid="O4" date="1/20/1996" amount="10000"/> </Customer> </root> ' -- Create an internal representation of the XML document. EXEC sp_xml_preparedocument @idoc OUTPUT, @doc-- Execute a SELECT statement using OPENXML rowset provider. SELECT * FROM OPENXML (@idoc, '/root/Customer/Order', 1) WITH (oid char(5), amount float, comment ntext 'text()') EXEC sp_xml_removedocument @idoc/**********************Excel导到Txt****************************************/ 想⽤ select * into opendatasource(...) from opendatasource(...) 实现将⼀个Excel⽂件内容导⼊到⼀个⽂本⽂件假设Excel中有两列,第⼀列为姓名,第⼆列为很⾏帐号(16位) 且银⾏帐号导出到⽂本⽂件后分两部分,前8位和后8位分开。
从excel表中生成批量SQL

从excel表中⽣成批量SQLexcel表格中有许多数据,需要将数据导⼊数据库中,⼜不能⼀个⼀个⼿⼯录⼊,可以⽣成SQL,来批量操作。
="insert into Log_loginUser (LogID, LoginId, LoginTime) values(NEWID(),'"&B2&"','"&TEXT(C2,"yyyy-mm-dd hh:mm:ss")&"')"此是时间设置:'"&TEXT(C2,"yyyy-mm-dd hh:mm:ss")&"'1.⾸先在第⼆⾏的H列,插⼊函数:=CONCATENATE("INSERT INTO `book` (`bookid`, `title`, `volume`, `author`, `urlpdf` ) VALUES ('",A2,"', '",B2,"', '3', '",C2,"', '",F2,"');"),代表从各个列中取数据到函数中。
2.在左上⽅写⼊H2:H100,表⽰在H列,从函数⾃动⽣成2⾏到100⾏,按下Ctrl+Enter,选中指定列:3.再将光标移到到上⽅ fx函数末尾,按下Ctrl+Enter,⽣成SQL语句:最后在H列最上⽅的“H”标号处,右键点击复制,就成功复制了全部SQL语句,然后将SQL语句在数据库中执⾏就OK了,成功将excel表格中数据录⼊到数据库中。
ORACLE中如何使用SQLLOAD批量添加数据

ORACLE中如何使用SQLLOAD批量添加数据在Oracle中,可以使用SQLLDR(SQL*Loader)工具来批量添加数据。
SQL*Loader是一个客户端工具,用于从文本文件中加载数据到Oracle表中。
以下是使用SQL*Loader批量添加数据的步骤:1. 创建一个控制文件(Control File):控制文件是一个文本文件,用于指导SQL*Loader加载数据。
它包含了数据文件的格式和数据应该如何被加载到Oracle表中的规则。
控制文件描述了目标表的结构、数据文件的格式和字段之间的映射关系。
一个控制文件可以对应多个数据文件。
2. 创建一个数据文件(Data File):数据文件是包含待加载数据的文本文件。
它可以是一个纯文本文件,也可以是包含字段分隔符的CSV或其他格式的文件。
数据文件的格式应该与控制文件中描述的格式匹配。
3.编写控制文件:控制文件是一个使用特定语法规则编写的文本文件。
它包含了以下几个部分:- LOAD DATA:指示SQL*Loader加载数据的开始。
-INFILE:指定数据文件的路径和名称。
-INTOTABLE:指定目标表的名称。
-FIELDSTERMINATEDBY:指定字段之间的分隔符。
-(列名1,列名2,...):指定数据文件中各个字段的映射关系。
字段的顺序和个数应该与目标表的列顺序和个数一致。
4. 运行SQL*Loader:打开终端(命令提示符或终端窗口),使用以下命令运行SQL*Loader:``````其中,`username`是Oracle用户名,`password`是密码,`database`是数据库名称,`controlfile.ctl`是控制文件的路径和名称。
5. 检查加载结果:运行完成后,SQL*Loader将输出加载的数据行数和错误行数。
如果有错误行,可以查看生成的日志文件以获得更多详细信息。
注意事项:- 在使用SQL*Loader加载数据之前,应该先创建目标表,确保表的结构与控制文件中描述的一致。
MySQL中的批量数据插入和更新方法

MySQL中的批量数据插入和更新方法MySQL是一款开源的关系型数据库管理系统,被广泛应用于各种业务领域。
在实际的应用中,数据的批量插入和更新是非常常见的操作,能够有效提高数据库的处理效率和性能。
本文将介绍MySQL中的批量数据插入和更新方法,并探讨其在实际应用中的优势和注意事项。
一、批量数据插入在日常开发中,我们经常需要将大量数据插入到数据库中,例如批量导入用户信息、日志数据等。
MySQL提供了多种批量数据插入的方法,包括使用INSERT 语句一次插入多行、使用LOAD DATA INFILE语句导入文件数据等。
1. 使用INSERT语句一次插入多行数据INSERT语句可以一次插入多行数据,通过在VALUES子句中指定多组值,可以实现批量插入。
例如:```INSERT INTO table_name (column1, column2, column3)VALUES (value1, value2, value3),(value4, value5, value6),...(valueN, valueN+1, valueN+2);```在这种方法中,可以一次插入多行数据,提高了数据库的插入效率。
但是需要注意的是,在一次插入大量数据时,可能会因为网络传输时间过长或者MySQL服务器配置不合理而导致插入超时,因此需要对数据库连接进行适当的优化。
2. 使用LOAD DATA INFILE语句导入文件数据LOAD DATA INFILE语句可以将文件中的数据导入到数据库中,是一个非常高效的批量插入数据的方法。
通过将数据存储在文件中,可以避免每条数据都进行一次插入的操作,大大提高了插入的效率。
语法如下:```LOAD DATA INFILE 'file_name'INTO TABLE table_nameFIELDS TERMINATED BY ',' -- 指定字段之间的分隔符LINES TERMINATED BY '\n' -- 指定行之间的分隔符(column1, column2, column3); -- 指定需要插入的列```需要注意的是,使用LOAD DATA INFILE导入数据时,文件必须能够被MySQL服务器访问到,可以使用绝对路径或者相对路径来指定文件名。
PLSQL批量插入单条、多条数据过程
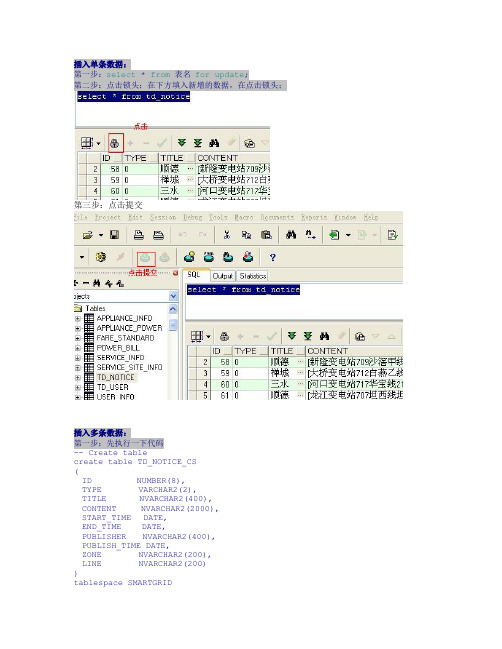
插入单条数据:第一步:select * from表名for update;第二步:点击锁头;在下方填入新增的数据,在点击锁头;第三步:点击提交插入多条数据:第一步:先执行一下代码-- Create tablecreate table TD_NOTICE_CS(ID NUMBER(8),TYPE VARCHAR2(2),TITLE NVARCHAR2(400),CONTENT NVARCHAR2(2000),START_TIME DATE,END_TIME DATE,PUBLISHER NVARCHAR2(400),PUBLISH_TIME DATE,ZONE NVARCHAR2(200),LINE NVARCHAR2(200))tablespace SMARTGRIDpctfree 10initrans 1maxtrans 255storage(initial 64Kminextents 1maxextents unlimited);第二步:执行select*from TD_NOTICE_CS for update;点击锁头,把excel数据复制黏贴进去,确定数据与字段对应没错之后,再按锁头锁住,点击提交第三步:执行以下语句:select * from TD_NOTICE_CS;查询到有你需要插入的数据之后再进行第四步;第四步:执行以下语句:insert into TD_NOTICE(ID,TYPE,TITLE,CONTENT,START_TIME,END_TIME,PUBLISHER,PUBLISH_TIME,ZONE,LINE)select ID,TYPE,TITLE,CONTENT,START_TIME,END_TIME,PUBLISHER,PUBLISH_TIME,ZONE,LINEfrom TD_NOTICE_cs执行成功后,点击“提交按钮”就可以了select max(id) from TD_NOTICEselect min(id) from TD_NOTICE_CSselect max(id) from TD_NOTICE_CSselect * from TD_NOTICE_CS for update。
MyBatis 动态批量插入sql语句方法

MyBatis 动态批量插入sql语句方法MyBatis实现动态批量插入的SQL语句可以采用foreach标签,具体方法如下:XML映射文件:xml<insert id="batchInsert">insert into USER (NAME, AGE)<foreach collection="list" item="item" separator="union all">(#{},#{item.age})</foreach></insert>Java代码:javaList<User> list = new ArrayList<>();list.add(new User("John", 20));list.add(new User("Tom", 25));list.add(new User("Jack", 30));SqlSession session = sqlSessionFactory.openSession();UserMapper mapper = session.getMapper(UserMapper.class);mapper.batchInsert(list);mit();最后生成的SQL语句为:sqlinsert into USER (NAME, AGE)values('John', 20)union allvalues('Tom', 25)union allvalues('Jack', 30)通过foreach标签,动态拼接了多条insert语句,并使用union all连接,最终实现了批量插入。
主要特点:1. 将需要批量插入的数据封装在List集合中2. 在foreach标签内,使用#{item.属性}的方式访问集合中的每条记录3. 使用separator属性,指定union all连接多条insert语句4. 将封装好的List集合,作为参数传入mapper方法,执行批量插入批量插入能有效减少数据库交互次数,提高插入效率。
在MySQL中使用批量处理和批量插入数据

在MySQL中使用批量处理和批量插入数据数据库是现代软件应用程序中常用的一种数据存储和管理工具。
无论是企业级应用程序还是个人级应用程序,数据库的设计和使用都是至关重要的。
而在数据库中,数据的插入是一个常见且频繁的操作。
在大数据量的情况下,批量处理和批量插入数据是提高数据库性能和效率的关键步骤之一。
而对于MySQL这样的关系型数据库,提供了一些特定的方法和技术来支持批量处理和插入操作。
一、什么是批量处理和批量插入数据在了解如何在MySQL中使用批量处理和批量插入数据之前,先来明确一下什么是批量处理和批量插入数据。
批量处理是将多个操作合并为一个操作进行执行的过程。
在数据库中,批量处理可以有效地减少网络传输和数据库连接的开销,提高整体的性能和效率。
常见的批量处理操作包括批量插入、批量更新和批量删除等。
批量插入数据是指一次性将多个数据记录插入到数据库表中的操作。
相比于单条插入,批量插入可以大大提高数据插入的效率。
批量插入数据的方法有很多种,可以通过使用特定的语法、命令或者工具来实现。
二、使用INSERT语句进行批量插入数据在MySQL中,使用INSERT语句可以实现数据的插入操作。
而要进行批量插入数据,可以通过INSERT语句的扩展语法来实现。
例如,假设有一个名为"employee"的表,包含着员工的信息,包括"emp_id"、"emp_name"和"emp_salary"等字段。
要批量插入多条员工记录,可以通过以下方法进行操作:```INSERT INTO employee (emp_id, emp_name, emp_salary)VALUES (1, 'John', 5000),(2, 'Mike', 6000),(3, 'Lisa', 7000),...(n, 'Tom', 8000);```在INSERT语句中,通过使用多个VALUES子句来一次性插入多条记录,这样可以大大减少插入数据的时间和开销。
c#几种数据库的大数据批量插入(SqlServer、Oracle、SQLite和MySql)

c#⼏种数据库的⼤数据批量插⼊(SqlServer、Oracle、SQLite和MySql)在之前只知道SqlServer⽀持数据批量插⼊,殊不知道Oracle、SQLite和MySql也是⽀持的,不过Oracle需要使⽤Orace.DataAccess驱动,今天就贴出⼏种数据库的批量插⼊解决⽅法。
⾸先说⼀下,IProvider⾥有⼀个⽤于实现批量插⼊的插件服务接⼝IBatcherProvider,此接⼝在前⼀篇⽂章中已经提到过了。
/// <summary>/// 提供数据批量处理的⽅法。
/// </summary>public interface IBatcherProvider : IProviderService{/// <summary>/// 将 <see cref="DataTable"/> 的数据批量插⼊到数据库中。
/// </summary>/// <param name="dataTable">要批量插⼊的 <see cref="DataTable"/>。
</param>/// <param name="batchSize">每批次写⼊的数据量。
</param>void Insert(DataTable dataTable, int batchSize = 10000);}⼀、SqlServer数据批量插⼊SqlServer的批量插⼊很简单,使⽤SqlBulkCopy就可以,以下是该类的实现:/// <summary>/// 为 System.Data.SqlClient 提供的⽤于批量操作的⽅法。
/// </summary>public sealed class MsSqlBatcher : IBatcherProvider{/// <summary>/// 获取或设置提供者服务的上下⽂。
MySQL、Oracle批量插入SQL的通用写法

MySQL、Oracle批量插⼊SQL的通⽤写法举个例⼦:现在要批量新增User对象到数据库USER表中public class User{//姓名private String name;//年龄private Integer age;//性别private Integer sex}⼤部分⼈对MySQL⽐较熟悉,可能觉得批量新增的SQL都是这样写,其实并不然。
该写法在MySQL中没问题,⽽在Oracle中,这样写就会报错。
MySQL写法:INSERT INTO USER(NAME,AGE,SEX)VALUES('val1_1', 'val1_2', 'val1_3'),('val2_1', 'val2_2', 'val2_3'),('val3_1', 'val3_2', 'val3_3');Oracle写法://多次单条插⼊INSERT INTO USER (NAME,AGE,SEX) VALUES ('val1_1', 'val1_2', 'val1_3');INSERT INTO USER (NAME,AGE,SEX) VALUES ('val2_1', 'val2_2', 'val2_3');INSERT INTO USER (NAME,AGE,SEX) VALUES ('val3_1', 'val3_2', 'val3_3');//批量插⼊INSERT ALLINTO USER (NAME,AGE,SEX) VALUES ('val1_1', 'val1_2', 'val1_3')INTO USER (NAME,AGE,SEX) VALUES ('val2_1', 'val2_2', 'val2_3')INTO USER (NAME,AGE,SEX) VALUES ('val3_1', 'val3_2', 'val3_3')SELECT1FROM DUAL;可以发现Oracle的两种写法都⽐较的⿇烦,批量插⼊也压根没有减少插⼊的列名。
MySQL批量插入和导出数据的高效方法

MySQL批量插入和导出数据的高效方法MySQL是目前最常用的开源关系型数据库管理系统之一,广泛应用于互联网、电子商务、金融等领域。
在实际开发中,经常需要进行大量数据的批量插入和导出,因此熟悉高效的批量插入和导出方法对于提升数据库操作的效率至关重要。
一、批量插入数据1. 使用INSERT INTO语句批量插入在MySQL中,最常见的插入数据的方式就是使用INSERT INTO语句。
要想实现批量插入,可以通过将多个待插入的数据值以逗号隔开,放在INSERT INTO语句的VALUES子句中。
例如,假设有一个名为users的表,有id、name和age三个字段,现在要批量插入1000条数据,可以使用以下语句:```sqlINSERT INTO users (name, age) VALUES('张三', 20),('李四', 25),...('王五', 30);```可以在一个INSERT INTO语句中一次性插入多条数据,避免了每次插入一条数据的开销,从而提高插入数据的效率。
2. 使用LOAD DATA INFILE语句批量插入除了使用INSERT INTO语句批量插入数据,还可以使用LOAD DATA INFILE语句。
这个语句可以一次性从一个文件中读取多行数据,并将其插入到MySQL表中。
首先,将待插入数据存储在一个纯文本文件中,每行数据的字段值以制表符或逗号等分隔符相隔。
然后,使用LOAD DATA INFILE语句将数据加载到表中。
例如,假设有一个名为data.txt的文件,其中的数据内容如下:```张三 20李四 25...王五 30```可以使用以下语句将数据导入到users表中:```sqlLOAD DATA INFILE '/path/to/data.txt' INTO TABLE users;```这种方式适用于需要导入大量数据的情况,相比使用INSERT INTO语句,可以显著提升插入数据的效率。
sql添加数据的语法

sql添加数据的语法全文共四篇示例,供读者参考第一篇示例:SQL语言是一种用于管理关系型数据库的标准化语言。
它支持各种操作,包括增加、删除、更新和查询数据。
在本文中,我们将重点介绍SQL中如何添加数据的语法和操作。
在SQL中,如果要向数据库中的表中插入新的数据,可以使用INSERT INTO语句。
INSERT INTO语句的基本语法如下:```sqlINSERT INTO table_name (column1, column2, column3, ...)VALUES (value1, value2, value3, ...);```在上面的语法中,table_name是要插入数据的表的名称,column1、column2、column3等是表中的列名,而value1、value2、value3等则是要插入的具体数值。
值得注意的是,插入的数值的类型必须与表中对应列的数据类型匹配,否则会引发错误。
如果我们有一个名为students的表,其中包括id、name和age 三个列,我们可以使用以下语句向表中插入一条新的学生记录:上面的示例中,我们向students表中插入了一条id为1,姓名为Alice,年龄为20的学生记录。
如果要一次性插入多条记录,也可以使用INSERT INTO语句。
我们可以插入多条学生记录:上面的示例中,我们向students表中一次性插入了三条记录,将id、name和age分别对应为2、'Bob'、22、3、'Cathy'、21和4、'David'、23。
在实际应用中,可能还需要向数据库表中插入查询结果或从其他表中获取的数据。
这时候可以使用SELECT语句结合INSERT INTO语句进行数据插入。
如果我们有一个名为teachers的表,其中包括id和name两个列,并且想向teachers表中插入students表中学生的姓名和年龄,可以使用以下语句:```sqlLOAD DATA INFILE 'file_path'INTO TABLE table_nameFIELDS TERMINATED BY ','LINES TERMINATED BY '\n';```在上面的语法中,file_path是外部数据文件的路径,table_name 是要导入数据的表的名称。
sqlite 批量sql语句

sqlite 批量sql语句《SQLite中的批量SQL语句操作》。
在SQLite数据库中,批量SQL语句操作是一种非常高效的数据处理方式。
通过批量SQL语句操作,可以大大提高数据处理的效率,特别是在需要大量数据插入、更新或删除的情况下。
下面将介绍如何在SQLite中使用批量SQL语句进行数据操作。
1. 数据插入。
在SQLite中,可以使用批量SQL语句一次性插入多条数据,而不是逐条插入。
这样可以减少数据库的I/O操作,提高数据插入的效率。
例如,可以使用如下的批量插入语句:sql.INSERT INTO table_name (column1, column2, column3) VALUES.('value1', 'value2', 'value3'),。
('value4', 'value5', 'value6'),。
('value7', 'value8', 'value9');这样就可以一次性插入多条数据,而不是使用多条单独的插入语句。
2. 数据更新。
在SQLite中,批量更新数据也是非常方便的。
可以使用如下的批量更新语句:sql.UPDATE table_name.SET column1 = 'new_value1',。
column2 = 'new_value2'。
WHERE condition;这样就可以一次性更新满足条件的多条数据,而不是逐条更新。
3. 数据删除。
类似地,批量删除数据也可以通过批量SQL语句来实现。
例如,可以使用如下的批量删除语句:sql.DELETE FROM table_name.WHERE condition;这样就可以一次性删除满足条件的多条数据,而不是逐条删除。
总之,通过批量SQL语句操作,可以在SQLite数据库中高效地进行数据处理。
Mybatis批量插入或更新数据

Mybatis批量插⼊或更新数据对于⼤量的数据,使⽤批量插⼊或修改可以提⾼效率。
原因是批量添加或修改是执⾏⼀条sql语句,传⼊多个值,可以减少与数据库的访问次数,从⽽会提⾼效率。
下⾯分别介绍Oracle和MySQL 的⽤法:1.Oracle批量插⼊数据对于集合类型的数据,在插⼊时会使⽤mybatis的<foreach>标签,那么正确的⽤法如下:<insert id="insertUserBatch">insert into user(id,name,password,addr)select user_seq.nextval,a.* from(<foreach collection="list" item="item" open="(" close=")" separator="union all">select#{},#{item.password},#{item.addr}from dual</foreach>) a</insert>以上语句是向user表循环查询数据,传递的参数是List<User>类型的集合。
需要注意是的,在使⽤时,分隔符separator必须是union all 。
2.MySQL批量插⼊数据对于集合类型的数据,在插⼊时会使⽤mybatis的<foreach>标签,那么mysql的批量插⼊数据sql如下:<insert id="insertBatch">insert into user(name,password,addr)values<foreach collection="list" item="item" separator=",">(#{},#{item.password},#{item.addr})</foreach></insert>和oracle的语句相⽐,没有指定主键,原因是主键id使⽤了⾃增。
sql批量插入的写法

sql批量插入的写法对于 SQL 批量插入,一般有几种常见的写法,具体取决于你使用的数据库管理系统。
以下是一些常见的写法:1. 使用多个 Value 值的方式:INSERT INTO table_name (column1, column2, column3)。
VALUES (value1_1, value1_2, value1_3),。
(value2_1, value2_2, value2_3),。
(value3_1, value3_2, value3_3);这种方式适用于大多数的关系型数据库,可以一次性插入多行数据。
2. 使用 SELECT 语句的方式:INSERT INTO table_name (column1, column2, column3)。
SELECT value1_1, value1_2, value1_3。
UNION ALL.SELECT value2_1, value2_2, value2_3。
UNION ALL.SELECT value3_1, value3_2, value3_3;这种方式适用于某些数据库,可以通过 SELECT 语句一次性插入多行数据。
3. 使用 INSERT ALL 语句的方式(适用于 Oracle 数据库):INSERT ALL.INTO table_name (column1, column2, column3) VALUES (value1_1, value1_2, value1_3)。
INTO table_name (column1, column2, column3) VALUES(value2_1, value2_2, value2_3)。
INTO table_name (column1, column2, column3) VALUES (value3_1, value3_2, value3_3)。
SELECT FROM dual;这种方式适用于 Oracle 数据库,可以一次性插入多行数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
)
END TRY
BEGIN CATCH
*SQLSTRING表是用来记录生成SELECT INTO 语句的
*/
IF EXISTS(SELECT NAME FROM SYS.OBJECTS WHERE NAME='SQLSTRING' AND TYPE=N'U')
DROP TABLE SQLSTRING
/*创建日志表*/
IF EXISTS(SELECT NAME FROM SYS.OBJECTS WHERE NAME='EXEC_LOG' AND TYPE=N'U')
+'['+@SourceDatabase+'].[dbo].['
+NAME
+']'
AS SQLSTRING
INTO SQLSTRING
FROM SYS.OBJECTS WHERE TYPE=N'U'
+'['+@SourceDatabase+'].[dbo].['
+NAME
+']'
AS SQLSTRING
INTO SQLSTRING
FROM SYS.OBJECTS WHERE TYPE=N'U'
/*@CMD变量是用来记录SQLSTRING表中的一行记录的,
*并给两个变量赋初使值
*/
DECLARE @SourceDatabase varchar(255)
DECLARE @DerectionDatabase varchar(255)
SET @SourceDatabase='testSoure'
SET @DerectionDatabase='testDerection'
*并给两个变量赋初使值
*/
DECLARE @SourceDatabase varchar(255)
DECLARE @DerectionDatabase varchar(255)
SET @SourceDatabase='testSoure'
SET @DerectionDatabase='testDerection'
DROP TBALE EXEC_LOG
CREATE TABLE EXEC_LOG
( CMD VARCHAR(8000),
STATUS INT,
DISCRቤተ መጻሕፍቲ ባይዱPT VARCHAR(20),
MSG VARCHAR(255)
)
/*首先检查当前数据库中是否存在SQLSTRING表,如果存在则删除
DISCRIPT,
MEG
)
VALUES
--如果目标库已经存在表结构,则执行下面语句
---------------------------------------------------------------------------------
/*创建日志表*/
IF EXISTS(SELECT NAME FROM SYS.OBJECTS WHERE NAME='EXEC_LOG' AND TYPE=N'U')
/*根据当前数据库中的所有用户生成INSERT INTO......SELECT语句*/
SELECT
'INSERT INTO ['+@DerectionDatabase+'].[dbo].['+NAME+'] '
+'('
+STUFF(
FOR XML PATH ('')
),1,1,'')
+' INTO ['+@DerectionDatabase+'].[dbo].['+NAME+']'
+' FROM '
STATUS,
DISCRIPT,
MSG
/*
*以下是根据源库生成SELECT INTO 语句,并将结果记录到SQLSTRING表中
*/
SELECT
'SELECT '
+STUFF(
(SELECT ','+NAME FROM SYS.COLUMNS
WHERE SYS.OBJECTS.object_id=SYS.COLUMNS.object_id
@MSG
)
END CATCH;
FETCH NEXT FROM INSERT_CMD INTO @CMD
END
CLOSE INSERT_CMD
DEALLOCATE INSERT_CMD
)
VALUES
(
'执行命令 '+@CMD,
@E,
(CASE @E WHEN 0 THEN '成功' else '失败' end),
*SQLSTRING表是用来记录生成SELECT INTO 语句的
*/
IF EXISTS(SELECT NAME FROM SYS.OBJECTS WHERE NAME='SQLSTRING' AND TYPE=N'U')
DROP TABLE SQLSTRING
/*定义变量@SourceDatabase源库,@DerectionDatabase目标库
(SELECT ','+NAME
FROM SYS.COLUMNS
WHERE SYS.OBJECTS.object_id=SYS.COLUMNS.object_id
(
'执行命令 '+@CMD,
@ERROR,
(CASE @@ERROR WHEN 0 THEN '成功' else '失败' end),
-------------------------------------------------------------------------------------------------------------------------
/*首先检查当前数据库中是否存在SQLSTRING表,如果存在则删除
SELECT SQLSTRING FROM SQLSTRING
OPEN INSERT_CMD
FETCH NEXT FROM INSERT_CMD INTO @CMD
WHILE (@@FETCH_STATUS=0)
BEGIN
DECLARE @E INT
DECLARE @MSG VARCHAR(255)
-------------------------------------------------------------------------------------------------------------------------
--如果目标库是一个空库,执行下面语句
--替换其中的@SourceDatabase(源) 及@DerectionDatabase(目标) 参数
SET @E=@@ERROR
SELECT @MSG=ERROR_MESSAGE()
INSERT INTO [EXEC_LOG]
(
CMD,
WHERE SYS.OBJECTS.object_id=SYS.COLUMNS.object_id
FOR XML PATH ('')
),1,1,'')
+' FROM '
BEGIN TRY
EXEC(@CMD)
INSERT INTO [EXEC_LOG].[dbo].[EXEC_LOG]
(
CMD,
STATUS,
*即一条SELECT INTO 语句
*/
DECLARE @CMD VARCHAR(8000)
/*定义游标,循环地执和SQLSTRING表中的SELECT INTO语句,
*并将执行的日志记录到EXEC_LOG表中,以供以后查询
*/
DECLARE INSERT_CMD CURSOR FOR
FOR XML PATH ('')
),1,1,'')
+')'
+' SELECT '
+STUFF(
(SELECT ','+NAME
FROM SYS.COLUMNS
DROP TBALE EXEC_LOG
CREATE TABLE EXEC_LOG
( CMD VARCHAR(8000),
STATUS INT,
DISCRIPT VARCHAR(20),
MSG VARCHAR(255)
)
/*定义变量@SourceDatabase源库,@DerectionDatabase目标库
/*删除中间生成SQLSTRING表*/