Oracle数据库强制索引
oracle 查询索引关联字段的方法

oracle 查询索引关联字段的方法在Oracle数据库中,索引是用来加速查询操作的一种数据结构。
通过使用索引,可以快速定位到包含特定值的数据行,从而提高查询的执行效率。
当需要查询索引关联字段时,可以使用以下方法。
1. 使用EXPLAIN PLAN:使用EXPLAIN PLAN可以查看查询计划,包括使用的索引和执行顺序等信息。
通过查看查询计划,可以确定是否使用了索引以及使用的索引类型。
以下是使用EXPLAIN PLAN查询索引关联字段的示例:```sqlEXPLAIN PLAN FORSELECT *FROM table_nameWHERE indexed_column = 'some_value';SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);```在执行以上语句后,可以查看查询计划中的相关信息,例如是否使用了索引、使用的索引类型等。
2. 使用索引提示:索引提示是一种指导查询优化器使用特定索引的方法。
可以使用索引提示来强制查询优化器使用特定的索引。
以下是使用索引提示查询索引关联字段的示例:```sqlSELECT /*+ INDEX(table_name index_name) */ *FROM table_nameWHERE indexed_column = 'some_value';```在以上示例中,使用了索引提示将查询优化器强制指定使用特定的索引。
3. 使用索引相关的动态视图:Oracle数据库中提供了一系列动态视图,用于查询数据库的内部信息。
以下是使用索引相关的动态视图查询索引关联字段的示例:```sqlSELECT index_name, column_nameFROM all_ind_columnsWHERE table_name = 'table_name';```在以上示例中,使用了动态视图all_ind_columns来查询指定表的索引相关的字段信息。
oracle索引的结构

oracle索引的结构Oracle索引的结构:了解索引对数据库性能的重要性引言:在数据库中,索引是一种数据结构,它可以加快数据的检索速度,提高数据库的性能。
Oracle作为一种关系型数据库管理系统,也使用索引来优化查询操作。
本文将详细介绍Oracle索引的结构以及其对数据库性能的影响。
一、什么是索引索引是一种数据结构,它类似于书籍的目录,可以帮助我们快速找到需要的数据。
在Oracle中,索引由一个或多个列组成,可以根据这些列的值快速定位到对应的行。
二、Oracle索引的结构1. B树索引B树索引是Oracle中最常见的索引类型。
它使用B树数据结构来组织索引数据,具有平衡性和高效性。
B树索引将索引数据存储在叶子节点中,并使用非叶子节点来加速查找过程。
B树索引适用于范围查询和精确查询。
2. B+树索引B+树索引是B树索引的一种变体,也是Oracle中常用的索引类型。
与B树索引不同,B+树索引将所有索引数据存储在叶子节点中,并使用非叶子节点来组织叶子节点之间的关系。
B+树索引适用于范围查询和排序操作。
3. 唯一索引唯一索引是一种特殊的索引类型,它要求索引列的值唯一,即不允许重复值。
唯一索引可以提高数据的完整性,并且可以通过快速查找来避免重复插入。
在Oracle中,唯一索引可以是B树索引或B+树索引。
4. 聚簇索引聚簇索引是一种特殊的索引类型,它将数据存储在物理上相邻的区域。
在Oracle中,表只能有一个聚簇索引,它可以加速范围查询和连接操作。
聚簇索引通常与主键约束一起使用。
三、索引对数据库性能的影响1. 提高查询速度索引可以加快查询操作的速度,尤其是在大型数据库中。
通过使用索引,数据库可以更快地定位到需要的数据,而不必扫描整个表。
2. 降低IO成本索引可以减少磁盘IO操作,提高数据库的IO性能。
当查询条件与索引列匹配时,数据库可以直接读取索引节点,而不必读取整个数据块。
3. 影响更新性能虽然索引可以提高查询性能,但对于更新操作,索引可能会带来额外的开销。
oracle索引查询语句

oracle索引查询语句Oracle索引是一种用于加快查询速度的数据结构,它能够提高数据库的性能和效率。
索引查询语句是使用索引来搜索和获取数据的查询语句。
下面列举了一些常用的Oracle索引查询语句。
1. 查询表中的所有索引```sqlSELECT index_name, table_nameFROM user_indexes;```2. 查询索引的定义和属性```sqlSELECT index_name, table_name, column_name, uniqueness FROM user_ind_columnsWHERE table_name = '表名';```3. 查询表中某个索引的使用情况```sqlSELECT index_name, table_name, statusFROM all_indexesWHERE table_name = '表名' AND index_name = '索引名';```4. 查询使用了索引的SQL语句```sqlSELECT sql_textFROM v$sqlWHERE sql_text LIKE '%索引名%';```5. 查询索引的大小和碎片情况```sqlSELECT index_name, leaf_blocks, num_rows, clustering_factor FROM user_indexesWHERE table_name = '表名';```6. 查询索引的统计信息```sqlSELECT index_name, distinct_keys, num_rows, clustering_factorFROM user_indexesWHERE table_name = '表名';``````sqlEXPLAIN PLAN FORSELECT * FROM 表名WHERE 索引列 = 值;SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);```8. 查询索引的创建时间和最后修改时间```sqlSELECT index_name, created, last_ddl_timeFROM all_indexesWHERE table_name = '表名';```9. 查询索引的统计信息和优化建议```sqlSELECT index_name, table_name, column_name, num_distinct, density, histogramFROM dba_optstat_indexesWHERE table_name = '表名';``````sqlSELECT index_name, table_name, column_name, usage, effectivenessFROM v$index_usage;```以上是一些常用的Oracle索引查询语句,可以帮助我们了解和优化索引的使用情况,提高数据库的性能和效率。
oracle索引的原理

oracle索引的原理
Oracle索引是一种数据结构,用于加快数据库查询的速度。
它通过创建一个额外的对象来存储表中某一列(或多列)的键值和指向该行的物理地址的映射关系,以提高查询效率。
Oracle索引使用B树(B-Tree)数据结构实现。
B树是一种平衡的树状结构,每个节点中存储键值和指向子节点的指针。
由于B树的特性,索引树可以高效地支持索引的快速搜索,因为它具有自平衡的性质,平均查询时间复杂度为O(logN),其中N是索引中的节点数。
当在表中创建索引时,Oracle会扫描表的每一行,并提取出索引列的键值,然后按照键值的顺序将它们插入到B树中。
为了提高查询效率,Oracle还可以使用一些技术来优化索引的性能,如压缩、分区等。
在执行查询时,Oracle会使用索引树进行搜索,以找到满足查询条件的所有行。
它首先从根节点开始搜索,根据查询条件选择相应的分支,然后逐级向下搜索,直到找到叶子节点或满足查询条件的节点。
最终,根据叶子节点中存储的指向行的物理地址,Oracle可以快速定位到满足查询条件的行。
除了提高查询速度外,索引还可以用于加速表的排序和连接操作。
通过优化索引的设计和使用,可以显着提升数据库的性能和响应时间。
需要注意的是,虽然索引可以提高查询的速度,但它也会占用
额外的存储空间,并增加数据插入、更新和删除的开销。
因此,在设计和使用索引时,需要权衡查询效率和存储空间的消耗,以达到最佳的性能优化效果。
oracle 索引语句

oracle 索引语句Oracle 索引语句是一组用来创建、修改、删除索引的 SQL 语句。
索引是数据库中的一个关键组成部分,它可以提高查询的速度,并帮助加速数据的检索。
在本文中,我们将介绍 Oracle 索引语句的相关操作,并深入了解如何使用这些语句来优化数据库性能。
### 1. 创建索引创建索引是一种常见的数据库优化技术。
一个索引是基于一个或多个列的排序数据结构,用于快速查找匹配行。
要创建索引,请使用CREATE INDEX 语句,后跟索引名称、表名和列名。
例如,以下 SQL 语句创建一个名为“idx_customers” 的索引,该索引基于“customers” 表中的“last_name” 列:```CREATE INDEX idx_customers ON customers (last_name);```### 2. 修改索引有时候,您可能需要更改现有的索引,以便优化性能或更新表结构。
要更改索引,请使用 ALTER INDEX 语句,后跟索引名称、修改选项和新值。
例如,以下 SQL 语句使用 ALTER INDEX 修改名为“idx_customers”的索引,以添加一个新列“first_name”:```ALTER INDEX idx_customers ADD (first_name);```### 3. 删除索引如果您不再需要一个索引,可以使用 DROP INDEX 语句将其删除。
但是,要小心不要删除真正需要的索引,因为这会导致查询变慢。
例如,以下 SQL 语句删除名为“idx_customers”的索引:```DROP INDEX idx_customers;```### 4. 索引分类在 Oracle 中,有多种类型的索引,每种索引都有其优点和适用范围。
以下是一些常见类型的索引:- B 树索引:这是最常用的索引类型,用于快速查找匹配值,并支持多列查询。
- 哈希索引:这种索引使用哈希表数据结构,可以快速查找匹配值。
Oracle索引详解

一.索引介绍1.1 索引的创建语法:CREATE UNIUQE | BITMAP INDEX <schema>.<index_name>ON <schema>.<table_name>(<column_name> | <expression> ASC | DESC,<column_name> | <expression> ASC | DESC,...)TABLESPACE <tablespace_name>STORAGE <storage_settings>LOGGING | NOLOGGINGCOMPUTE STATISTICSNOCOMPRESS | COMPRESS<nn>NOSORT | REVERSEPARTITION | GLOBAL PARTITION<partition_setting>相关说明1) UNIQUE | BITMAP:指定UNIQUE为唯一值索引,BITMAP为位图索引,省略为B-Tree索引。
2)<column_name> | <expression> ASC | DESC:可以对多列进行联合索引,当为expression 时即“基于函数的索引”3)TABLESPACE:指定存放索引的表空间(索引和原表不在一个表空间时效率更高)4)STORAGE:可进一步设置表空间的存储参数5)LOGGING | NOLOGGING:是否对索引产生重做日志(对大表尽量使用NOLOGGING来减少占用空间并提高效率)6)COMPUTE STATISTICS:创建新索引时收集统计信息7)NOCOMPRESS | COMPRESS<nn>:是否使用“键压缩”(使用键压缩可以删除一个键列中出现的重复值)8)NOSORT | REVERSE:NOSORT表示与表中相同的顺序创建索引,REVERSE表示相反顺序存储索引值9)PARTITION | NOPARTITION:可以在分区表和未分区表上对创建的索引进行分区1.2 索引特点:第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
oracle的索引类型

oracle的索引类型
Oracle数据库中常见的索引类型包括:1. B树索引(B-tree Index):是Oracle 默认的索引类型,适用于等值查找和范围查找。
2. 唯一索引(Unique Index):确保索引列的值在表中是唯一的。
3. 聚集索引(Cluster Index):按照表的物理存储顺序进行索引,适用于频繁进行范围查找的列。
4. 位图索引(Bitmap Index):将索引列的不同值分组为位图,并对每个位图使用压缩算法,适用于低基数列(取值范围较小)。
5. 函数索引(Function-Based Index):基于表达式或函数的结果构建的索引,适用于计算、转换或覆盖列的查询。
6. 虚拟列索引(Virtual Column Index):基于虚拟列(由表达式计算而来)构建的索引。
7. 全文索引(Full-Text Index):适用于对文本数据进行全文搜索的场景。
8. 空间索引(Spatial Index):适用于对地理位置和空间数据进行查询和分析。
9. 哈希索引(Hash Index):根据哈希函数计算的值来构建索引,适用于等值查询的索引。
10. 反向索引(Reverse Key Index):逆序存储索引键的位模式,适合于高度并发且插入操作有序的情况。
需要根据具体业务和查询需求选择合适的索引类型,以提高查询性能。
oracle数据库约束、索引,enable和disable用处

oracle数据库约束、索引,enable和disable⽤处1.数据库索引索引:索引是对数据库表中⼀列或多列的值进⾏排序的⼀种结构索引分类:主键索引(PRIMAY KEY)、唯⼀索引(UNIQUE)、常规索引(INDEX)、全⽂索引(FULLTEXT)常规索引 CREATE INDEX 索引名 ON 表名 (字段名)唯⼀索引 CREATE UNIQUE INDEX 索引名 ON 表名 (字段名)2.数据库约束约束:数据库约束时防⽌⾮法记录的规则约束分类:主键约束(Primay Key Coustraint):唯⼀性,⾮空性,⼀个表只能有主键,创建主键时会⾃动创建主键索引ALTER TABLE 表名 ADD CONSTRAINT 主键名 PRIMARY KEY (字段名)唯⼀约束(Unique Counstraint):唯⼀性,可以空,但只能有⼀个空,⼀张表可以有多个唯⼀约束,创建唯⼀约束时会⾃动创建唯⼀索引ALTER TABLE 表名 ADD CONSTRAINT 约束名 UNIQUE (字段)检查约束(Check Counstraint):对该列数据的范围、格式的限制(如:年龄、性别等)ALTER TABLE 表名 CHECK (字段约束)默认约束(Default Counstraint):该数据的默认值ALTER TABLE 表名 ALTER 字段名 SET DEFAULT '默认值'外键约束(Foreign Key Counstraint):需要建⽴两表间的关系并引⽤主表的列ALTER TABLE 表名1 ADD CONSTRAINT 外键名 FOREING KEY (表1字段) REFENCES 表名2(表2字段)3.disable与enable约束控制约束的约束,控制表的约束时禁⽌还是激活状态disable:禁⽌状态,相当于该列没有约束,使⽤disable默认为Novalidateenable:激活状态,默认新创建的约束状态是激活状态,使⽤enable默认为ValidateValidate Novalidate已有记录新增/删除记录已有记录新增/删除记录Enable Yes(表⽰需要受到约束条件限制)Yes No YesDisable Yes No No No。
oracle索引原理

oracle索引原理
Oracle索引是一种数据结构,用于加速数据库查询操作。
它们通过创建和维护一个独立的数据结构来提高查询性能。
索引的原理是基于B树(或B+树)数据结构。
B树是一种平衡的树形结构,其中每个节点(除了根节点和叶节点)包含一个指针数组和一个关键字数组。
关键字数组按顺序排列,指针数组中的每个指针分别指向关键字数组中对应关键字的子树。
当在数据库表中创建索引时,Oracle会为该索引列的每个值创建一个索引条目,并将其按照关键字的顺序插入到B树中。
这样,当执行查询时,Oracle可以使用索引来快速定位到存储在表中特定关键字值处的行。
当执行查询时,Oracle首先搜索索引树,然后根据查找条件找到索引树中符合条件的关键字值所在的位置。
通过索引树中的指针,Oracle可以轻松地定位到对应数据行的位置,从而快速返回查询结果。
另外,Oracle索引还支持唯一性约束和主键约束。
唯一性索引确保索引列的值在所有索引中是唯一的,而主键索引则是一种特殊的唯一性索引,用于定义表的主键。
然而,索引的使用也存在一些限制。
首先,索引会占用额外的存储空间。
其次,当对表进行插入、更新或删除操作时,索引也需要相应地进行更新,这可能会导致性能下降。
因此,在设
计数据库时,需要权衡索引的数量和类型,以平衡查询性能和更新性能之间的折衷。
总之,Oracle索引是一种用于加快数据库查询性能的数据结构。
通过使用B树数据结构,索引能够快速定位到符合查询条件
的数据行,提高查询效率。
然而,索引的使用需要仔细权衡,以确保在查询和更新操作之间取得最佳性能平衡。
oracle 索引原则

oracle 索引原则
Oracle索引的原则包括以下几点:
1. 唯一性原则:索引的值必须是唯一的,确保在索引字段上不存在重复值。
这可以通过在创建索引时添加UNIQUE约束来实现。
2. 精确性原则:索引应该被正确地定义和使用,以确保在查询时只返回需要的结果,并且能够准确地匹配查询条件。
使用合适的数据类型和大小限制可以提高索引的精确性。
3. 冗余性原则:索引应该避免对重复或冗余数据进行索引。
对于经常被查询的字段,可以考虑创建索引,而对于很少被查询的字段,则可以避免创建索引,以提高性能。
4. 支持性原则:索引应该能够支持常见的查询模式和条件,以提高查询性能。
合理选择索引字段和顺序,可以使索引更好地支持常用的查询操作。
5. 可管理性原则:索引应该易于管理,包括创建、修改和删除索引。
不需要的索引应该及时删除,以减少数据库的维护工作和存储空间占用。
6. 统计信息原则:索引应该基于准确和实时的统计信息进行优化。
Oracle提供了收集统计信息的机制,可以通过收集和更新统计信息来帮助数据库优化器选择最佳的查询计划。
综上所述,索引的原则是确保唯一性、精确性、避免冗余、支持常用查询模式、易于管理和基于准确统计信息进行优化。
这些原则有助于提高数据库的性能和可用性。
oracle强制索引写法

oracle强制索引写法如果你需要优化你的Oracle数据库查询,强制索引就是一个很好的选择。
因为Oracle的优化器趋向于使用统计数据来决定查询最优执行计划,这可能导致有些查询性能不佳。
此时强制索引可以让你显式地指定使用哪个索引,从而达到更好的性能。
以下是一些关于如何写Oracle强制索引的技巧:1. 使用HINTS在查询语句中使用HINTS可以指定强制使用某个索引。
例如:```SELECT /*+ index(emp emp_idx) */ emp_no, emp_name FROM emp WHERE dept_no = '10';```在这个例子中,我们明确指定了使用索引`emp_idx`来查询表`emp`中的数据。
2. 创建视图你也可以创建一个视图,并在视图中使用你想要的索引。
这样做的好处是,你可以轻松地修改查询语句而不必更改强制索引。
例如,如果你希望使用索引`emp_idx`来查询表`emp`中的数据,你可以创建一个名为`emp_view`的视图:```CREATE VIEW emp_view AS SELECT /*+ index(emp emp_idx) */emp_no, emp_name FROM emp;```现在,当你查询`emp_view`时,就会自动使用`emp_idx`索引。
例如:```SELECT * FROM emp_view WHERE dept_no = '10';```3. 为查询语句重命名表你可以为查询语句中的表重命名,并在重命名后的表上使用强制索引。
这种方法可以让你不必创建视图来使用强制索引。
例如,在查询`emp`表时,你可以为它取一个别名`e`,并强制使用索引`emp_idx`:```SELECT /*+ index(e emp_idx) */ emp_no, emp_name FROM emp e WHERE dept_no = '10';```通过这种方法,你可以把你想要使用的索引直接写在查询语句中,而不必修改表结构或创建视图。
oracle索引及使用原则

oracle索引及使用原则一、索引类型B-tree indexes 平衡二叉树,缺省的索引类型B-tree cluster indexes cluster的索引类型Hash cluster indexes cluster的hash索引类型Global and local indexes 与patitioned table相关的索引Reverse key indexes Oracle Real Application Cluster使用Bitmap indexes 位图索引,索相列的值属于一个很小的范围Function-based indexes 基于函数的索引Domain indexes二、使用索引的原则尽量在插入数据完成后建立索引,因为索引将导致插入数据变慢,特别是唯一索引在正确的表和列上建索引优化索引列顺序提高性能限制每个表的索引个数删除不需要的索引指定索引的block设置估计索引的大小设置存储参数指定索引使用的表空间建索引时使用并行使用nologing建立索引二,各种索引使用场合及建议(1)B*Tree索引。
常规索引,多用于oltp系统,快速定位行,应建立于高cardinality列(即列的唯一值除以行数为一个很大的值,存在很少的相同值)。
Create index indexname on tablename(columnname[columnname...])(2)反向索引。
B*Tree的衍生产物,应用于特殊场合,在ops环境加序列增加的列上建立,不适合做区域扫描。
Create index indexname on tablename(columnname[columnname...]) reverse(3)降序索引。
B*Tree的衍生产物,应用于有降序排列的搜索语句中,索引中储存了降序排列的索引码,提供了快速的降序搜索。
Create index indexname on tablename(columnname DESC[columnname...])(4)位图索引。
oracle where 条件强制索引写法

oracle where 条件强制索引写法在Oracle数据库中,索引是一种重要的数据结构,可以提高查询性能。
然而,有时候在编写WHERE条件时,我们可能会遇到一些特殊情况,导致无法使用索引。
在这种情况下,我们可以使用强制索引写法来确保Oracle使用正确的索引来执行查询。
首先,让我们了解一下什么是强制索引。
在Oracle数据库中,强制索引是与常规索引不同的特殊索引。
当常规索引无法满足查询条件时,我们可以使用强制索引来告诉数据库应该使用哪种索引来执行查询。
这通常通过在WHERE条件中使用特定的标识符来实现。
1. 使用EXISTS强制索引:如果查询使用了EXISTS子查询,并且需要使用特定的索引,可以使用强制索引来确保数据库使用正确的索引。
例如,假设我们有一个名为“table_name”的表,其中有一个名为“column_name”的列,我们希望使用该列上的索引来执行查询。
可以使用以下强制索引写法:```scssSELECT * FROM table_name WHERE EXISTS (SELECT 1 FROM dual WHERE column_name = 'value')```在这个例子中,我们使用了EXISTS子查询来执行查询,并在WHERE条件中指定了特定的值。
由于使用了强制索引写法,Oracle将使用“column_name”列上的索引来执行查询。
2. 使用函数强制索引:有时候,WHERE条件中的值需要经过函数处理才能使用特定的索引。
在这种情况下,可以使用函数强制索引来确保数据库使用正确的索引。
例如,假设我们有一个名为“table_name”的表,其中有一个名为“column_name”的列,该列上的值需要进行函数处理才能使用索引。
可以使用以下强制索引写法:```sqlSELECT * FROM table_name WHERE column_name = TO_NUMBER('value')```在这个例子中,我们将“value”转换为数字类型,以便使用TO_NUMBER函数强制将值绑定到特定索引上。
如何让oracle的select强制走索引
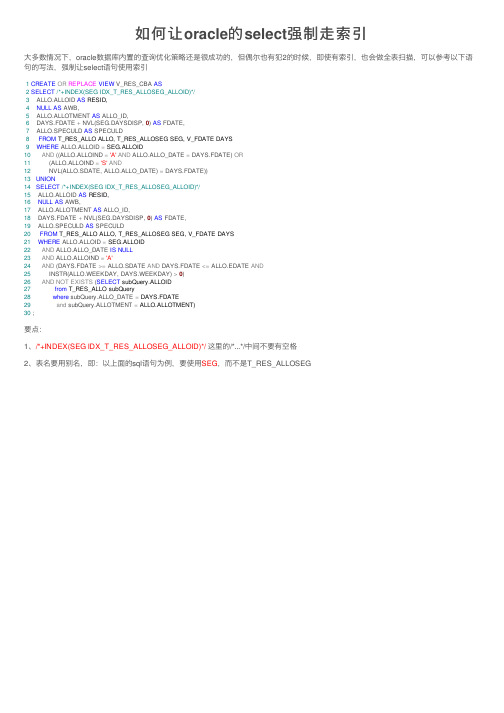
如何让oracle的select强制⾛索引⼤多数情况下,oracle数据库内置的查询优化策略还是很成功的,但偶尔也有犯2的时候,即使有索引,也会做全表扫描,可以参考以下语句的写法,强制让select语句使⽤索引1CREATE OR REPLACE VIEW V_RES_CBA AS2SELECT/*+INDEX(SEG IDX_T_RES_ALLOSEG_ALLOID)*/3 ALLO.ALLOID AS RESID,4NULL AS AWB,5 ALLO.ALLOTMENT AS ALLO_ID,6 DAYS.FDATE + NVL(SEG.DAYSDISP, 0) AS FDATE,7 ALLO.SPECULD AS SPECULD8FROM T_RES_ALLO ALLO, T_RES_ALLOSEG SEG, V_FDATE DAYS9WHERE ALLO.ALLOID = SEG.ALLOID10AND ((ALLO.ALLOIND ='A'AND ALLO.ALLO_DATE = DAYS.FDATE) OR11 (ALLO.ALLOIND ='S'AND12 NVL(ALLO.SDATE, ALLO.ALLO_DATE) = DAYS.FDATE))13UNION14SELECT/*+INDEX(SEG IDX_T_RES_ALLOSEG_ALLOID)*/15 ALLO.ALLOID AS RESID,16NULL AS AWB,17 ALLO.ALLOTMENT AS ALLO_ID,18 DAYS.FDATE + NVL(SEG.DAYSDISP, 0) AS FDATE,19 ALLO.SPECULD AS SPECULD20FROM T_RES_ALLO ALLO, T_RES_ALLOSEG SEG, V_FDATE DAYS21WHERE ALLO.ALLOID = SEG.ALLOID22AND ALLO.ALLO_DATE IS NULL23AND ALLO.ALLOIND ='A'24AND (DAYS.FDATE >= ALLO.SDATE AND DAYS.FDATE <= ALLO.EDATE AND25 INSTR(ALLO.WEEKDAY, DAYS.WEEKDAY) >0)26AND NOT EXISTS (SELECT subQuery.ALLOID27from T_RES_ALLO subQuery28where subQuery.ALLO_DATE = DAYS.FDATE29and subQuery.ALLOTMENT = ALLO.ALLOTMENT)30 ;要点:1、/*+INDEX(SEG IDX_T_RES_ALLOSEG_ALLOID)*/ 这⾥的/*...*/中间不要有空格2、表名要⽤别名,即:以上⾯的sql语句为例,要使⽤SEG,⽽不是T_RES_ALLOSEG。
oraclehint强制索引(转)
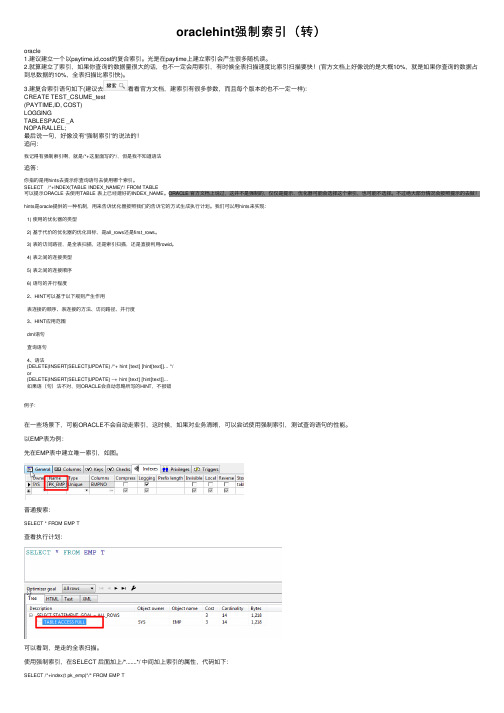
oraclehint强制索引(转)oracle1.建议建⽴⼀个以paytime,id,cost的复合索引。
光是在paytime上建⽴索引会产⽣很多随机读。
2.就算建⽴了索引,如果你查询的数据量很⼤的话,也不⼀定会⽤索引,有时候全表扫描速度⽐索引扫描要快!(官⽅⽂档上好像说的是⼤概10%,就是如果你查询的数据占到总数据的10%,全表扫描⽐索引快)。
3.建复合索引语句如下(建议去看看官⽅⽂档,建索引有很多参数,⽽且每个版本的也不⼀定⼀样):CREATE TEST_CSUME_test(PAYTIME,ID, COST)LOGGINGTABLESPACE _ANOPARALLEL;最后说⼀句,好像没有“强制索引”的说法的!追问:我记得有强制索引啊,就是/*+这⾥⾯写的*/,但是我不知道语法追答:你指的是⽤hints去提⽰你查询语句去使⽤哪个索引。
SELECT /*+INDEX(TABLE INDEX_NAME)*/ FROM TABLE可以提⽰ORACLE 去使⽤TABLE 表上已经建好的INDEX_NAME。
ORACLE 官⽅⽂档上说过,这并不是强制的,仅仅是提⽰,优化器可能会选择这个索引,也可能不选择。
不过绝⼤部分情况会按照提⽰的去做!hints是oracle提供的⼀种机制,⽤来告诉优化器按照我们的告诉它的⽅式⽣成执⾏计划。
我们可以⽤hints来实现:1) 使⽤的优化器的类型2) 基于代价的优化器的优化⽬标,是all_rows还是first_rows。
3) 表的访问路径,是全表扫描,还是索引扫描,还是直接利⽤rowid。
4) 表之间的连接类型5) 表之间的连接顺序6) 语句的并⾏程度2、HINT可以基于以下规则产⽣作⽤表连接的顺序、表连接的⽅法、访问路径、并⾏度3、HINT应⽤范围dml语句查询语句4、语法{DELETE|INSERT|SELECT|UPDATE} /*+ hint [text] [hint[text]]... */or{DELETE|INSERT|SELECT|UPDATE} --+ hint [text] [hint[text]]...如果语(句)法不对,则ORACLE会⾃动忽略所写的HINT,不报错例⼦:在⼀些场景下,可能ORACLE不会⾃动⾛索引,这时候,如果对业务清晰,可以尝试使⽤强制索引,测试查询语句的性能。
oraclelike上强制使用索引

oraclelike上强制使⽤索引当where⼦句对某⼀列使⽤函数时,除⾮利⽤这个简单的技术强制索引,否则Oracle优化器不能在查询中使⽤索引。
通常情况下,如果在WHERE⼦句中不使⽤诸如UPPER、REPLACE 或SUBSTRD等函数,就不能对指定列建⽴特定的条件。
但如果使⽤了这些函数,则会出现⼀个问题:这些函数会阻碍Oracle优化器对列使⽤索引,因⽽与采⽤索引的情况相⽐较,查询会花费更多的时间。
庆幸的是,如果在使⽤函数的这些列中包含了字符型数据,可以⽤这样⼀种⽅法修改查询语句,以达到强制性使⽤索引,更有效地运⾏查询。
这篇⽂章介绍了涉及的技术,并说明了在两种典型情况下怎样实现。
⼤⼩写混合情况在讨论由于函数修改了列的内容,如何强制使⽤索引前,让我们⾸先看看为什么Oracle优化器在这种情况下不能使⽤索引。
假定我们要搜寻包含了⼤⼩写混合的数据,如在addressbook表的name列。
因为数据是⽤户输⼊的,我们⽆法使⽤已经统⼀改为⼤写的数据。
为了找到每⼀个名为john的地址,我们使⽤包含了upper⼦句的查询语句。
如下所⽰:使⽤这种查询语句(已设置AUTOTRACE),可得到下列结果:(以下是在PL/SQL Developer中查看执⾏计划的效果:)可以看到,在这种情况下,Oracle优化器对addressbook表作了⼀次完整的扫描,⽽没有使⽤name列的索引。
这是因为索引是根据列中数据的实际值建⽴的,⽽upper函数已经将字符转换成⼤写,即修改了这些值,因此该查询不能使⽤这列的索引。
优化器不能与索引项⽐较”JOHN”,没有索引项对应于”JOHN”-只有”john” 。
值得庆幸的是,如果在这种情况下想要强制使⽤索引,有⼀种简便的⽅法:只要在where⼦句中增加⼀个或多个特定的条件,⽤于测试索引值,并减少需要扫描的⾏,但这并没有修改原来SQL 编码中的条件。
以下列查询语句为例:使⽤这种查询语句,可得到下列结果:现在,优化器为WHERE ⼦句中AND 联结的两个语句中每⼀个语句确定的范围进⾏扫描—-第⼆个语句没有引⽤函数,因⽽使⽤了索引。
oracle索引失效原因及解决方法

oracle索引失效原因及解决⽅法oracle 索引失效原因及解决⽅法2010年11⽉26⽇星期五 17:10⼀、以下的⽅法会引起索引失效1,<>2,单独的>,<,(有时会⽤到,有时不会)3,like "%_" 百分号在前.4,表没分析.5,单独引⽤复合索引⾥⾮第⼀位置的索引列.6,字符型字段为数字时在where条件⾥不添加引号.7,对索引列进⾏运算.需要建⽴函数索引.8,not in ,not exist.9,当变量采⽤的是times变量,⽽表的字段采⽤的是date变量时.或相反情况。
10, 索引失效。
11,基于cost成本分析(oracle因为⾛全表成本会更⼩):查询⼩表,或者返回值⼤概在10%以上12,有时都考虑到了但就是不⾛索引,drop了从建试试在13,B-tree索引 is null不会⾛,is not null会⾛,位图索引 is null,is not null 都会⾛14,联合索引 is not null 只要在建⽴的索引列(不分先后)都会⾛,in null时必须要和建⽴索引第⼀列⼀起使⽤,当建⽴索引第⼀位置条件是is null 时,其他建⽴索引的列可以是is null(但必须在所有列都满⾜is null的时候),或者=⼀个值;当建⽴索引的第⼀位置是=⼀个值时,其他索引列可以是任何情况(包括is null =⼀个值),以上两种情况索引都会⾛。
其他情况不会⾛。
⼆、索引失效解决⽅法1. 选⽤适合的Oracle优化器Oracle的优化器共有3种:a. RULE (基于规则)b. COST (基于成本)c. CHOOSE (选择性)。
设置缺省的优化器,可以通过对init.ora⽂件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS 。
你当然也在SQL句级或是会话(session)级对其进⾏覆盖。
oracle,执行计划的时候走索引,但是实际不走索引

oracle,执行计划的时候走索引,但是实际不走索引:索引不走执行计划o racle oracle强制走索引oracle索引失效oracle hint用法篇一:Oracle执行计划不走索引的原因总结不走索引大体有以下几个原因:你在Instance级别所用的是all_rows的方式你的表的统计信息(最可能的原因) 你的表很小,上文提到过的,Oracle的优化器认为不值得走索引。
解决方法:可以修改init.ora中的OPTIMIZER_MODE这个参数,把它改为Rule或Choose,重起数据库。
也可以使用4中所提的Hint。
不走索引的其它原因:1、建立组合索引,但查询谓词并未使用组合索引的第一列,此处有一个INDEX SKIP SCAN概念。
2、在包含有null值的table列上建立索引,当时使用select count(*) from table时不会使用索引。
3、在索引列上使用函数时不会使用索引,如果一定要使用索引只能建立函数索引。
4、当被索引的列进行隐式的类型转换时不会使用索引。
如:select * from t where indexed_column = 5,而indexed_column列建立索引但类型是字符型,这时Oracle会产生隐式的类型转换,转换后的语句类似于select * from t where to_number(indexed_column) = 5,此时不走索引的情况类似于case3。
日期转换也有类似问题,如: select * from t where trunc(date_col) = trunc(sysdate)其中date_col为索引列,这样写不会走索引,可改写成select * from t where date_col = trunc(sysdate) and date_col trunc(sysdate+1),此查询会走索引。
5、并不是所有情况使用索引都会加快查询速度,full scan table 有时会更快,尤其是当查询的数据量占整个表的比重较大时,因为full scan table采用的是多块读,当Oracle优化器没有选择使用索引时不要立即强制使用,要充分证明使用索引确实查询更快时再使用强制索引。
OracleIndex索引无效的原因与解决方法

OracleIndex索引⽆效的原因与解决⽅法索引⽆效原因最近遇到⼀个Oracle SQL语句的性能问题,修改功能之前的运⾏时间平均为0.3s,可是添加新功能后,时间达到了4~5s。
虽然⼏张表的数据量都⽐较⼤(都在百万级以上),但是也都有正确创建索引,不知道到底慢在了哪⾥,下⾯展开调查。
经过⼏次排除,把问题范围缩⼩在索引上,⾸先在确定索引本⾝没有问题的前提下,考虑索引有没有被使⽤到,那么新的问题来了,怎么知道指定索引是否被启⽤。
判断索引是否被执⾏1. 分析索引即将索引⾄于监控状态下,对索引进⾏分析。
如下对 ID_TT_SHOHOU_HIST_002 索引进⾏分析alter index ID_TT_SHOHOU_HIST_002 monitoring usage;2. 查看v$object_usage视图中记录的信息select * from v$object_usage;字段依次为:•INDEX_NAME --索引名•TABLE_NAME --表名•MONITORING --是否被监控• USED --是否被启⽤•START_MONITORING --监控开始时间•END_MONITORING --监控结束时间如上图,虽然索引已经被引⽤,但是速度依旧很慢,莫⾮是虽然启⽤了索引,但是⼜被其他的⼀些原因拖慢了速度,继续调查。
调查途中,收集到⼀些Oracle 数据库不⾛索引的原因分享给⼤家不⾛索引的原因1. 在索引列上使⽤函数时不会使⽤索引例如常见的, TO_CHAR 、 TO_DATE 、 TO_NUMBER 、 TRUNC ...等等。
此时的解决办法可以使⽤函数索引,顾名思义就是把使⽤函数后的字段整体当成索引中的字段。
如下图中的TO_CHAR(SHOHOU_DATE, 'YYYYMMDD')就是⼀个函数索引,因为⽇期字段中含有时分秒,进⾏⽇期⽐较的时候,必须转化成固定的格式。
CREATE INDEX ID_TT_SHOHOU_HIST_003ON TT_SHOHOU_HIST(DEL_FLG,TO_CHAR(SHOHOU_DATE, 'YYYYMMDD'), SHOHOU_ID)TABLESPACE SALESPA_INDEX2. 索引的列进⾏隐式的类型转换SELECT * FROM TABLE WHERE INDEX_COLUM = 5上⾯语句中的 INDEX_COLUM 字段类型为 VARCHAR2 ,这时就会发⽣隐式类型转换,类似于SELECT * FROM TABLE WHERE TO_NUMBER(INDEX_COLUM) = 53. WHERE ⼦句中使⽤不等于操作不等于操作包括: <> , != , NOT colum >= ? , NOT colum <= ?替代⽅式可以使⽤OR,colum <> 0 =====> colum > 0 or colum < 0;4. 使⽤ IS NULL 和 IS NOT NULL替代⽅式:函数索引通过 nvl(b,c) 将为空的字段转为不为空的c值,再在函数nvl(b,c)上建⽴函数索引转换前SELECT * FROM A WHERE B = NULL转换后SELECT * FROM A WHERE NVL(B,C) = C5. 组合索引组合索引:由多个列构成的索引。
oracle强制索引语法

oracle强制索引语法
Oracle强制索引语法是指在查询语句中使用FORCEINDEX关键字来强制使用某个特定的索引。
该语法可以优化查询性能,但需要谨慎使用,因为不当使用可能会影响数据库性能。
FORCE INDEX语法的基本用法是在SELECT语句中添加FORCE INDEX关键字,后跟要使用的索引的名称。
例如:
SELECT * FROM my_table FORCE INDEX (my_index);
在这个例子中,查询将强制使用名为“my_index”的索引。
此外,还可以使用FORCE INDEX来强制使用多个索引,如:
SELECT * FROM my_table FORCE INDEX (my_index1, my_index2);
在这个例子中,查询将强制使用名为“my_index1”和“my_index2”的两个索引。
需要注意的是,FORCE INDEX语法只对SELECT语句有效,对于其他类型的SQL语句(如INSERT或UPDATE),该语法无效。
在使用FORCE INDEX时需要注意以下几点:
1. 强制使用索引可能会绕过数据库优化器,导致查询性能变差。
2. 如果使用的索引不适合当前查询,将会导致查询性能变差。
3. 强制使用索引可能会导致锁定表或索引,从而影响其他查询的性能。
综上所述,Oracle强制索引语法可以提高查询性能,但需要谨慎使用。
在实际应用中,应该根据实际情况选择是否使用该语法,以达到最优的查询性能。
- 1 -。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
当where子句对某一列使用函数时,除非利用这个简单的技术强制索引,否则Oracle优化器不能在查询中使用索引。
通常情况下,如果在WHERE子句中不使用诸如UPPER、REPLACE 或SUBSTRD等函数,就不能对指定列建立特定的条件。
但如果使用了这些函数,则会出现一个问题:这些函数会阻碍Oracle优化器对列使用索引,因而与采用索引的情况相比较,查询会花费更多的时间。
庆幸的是,如果在使用函数的这些列中包含了字符型数据,可以用这样一种方法修改查询语句,以达到强制性使用索引,更有效地运行查询。
这篇文章介绍了涉及的技术,并说明了在两种典型情况下怎样实现。
大小写混合情况
在讨论由于函数修改了列的内容,如何强制使用索引前,让我们首先看看为什么Oracle优化器在这种情况下不能使用索引。
假定我们要搜寻包含了大小写混合的数据,如在表1中ADDRESS表的NAME列。
因为数据是用户输入的,我们无法使用已经统一改为大写的数据。
为了找到每一个名为john的地址,我们使用包含了UPPER子句的查询语句。
如下所示:SQL> select address from address where upper(name) like 'JOHN';
在运行这个查询语句前,如果我们运行了命令"set autotrace on", 将会得到下列结果,其中包含了执行过程:
ADDRESS
--------------------
cleveland
1 row selected.
Execution Plan
--------------------
SELECT STATEMENT
TABLE ACCESS FULL ADDRESS
可以看到,在这种情况下,Oracle优化器对ADDRESS 表作了一次完整的扫描,而没有使用NAME 列的索引。
这是因为索引是根据列中数据的实际值建立的,而UPPER 函数已经将字符转换成大写,即修改了这些值,因此该查询不能使用这列的索引。
优化器不能与索引项比较"JOHN",没有索引项对应于"JOHN"-只有"john" 。
值得庆幸的是,如果在这种情况下想要强制使用索引,有一种简便的方法:只要在WHERE 子句中增加一个或多个特定的条件,用于测试索引值,并减少需要扫描的行,但这并没有修改原来SQL 编码中的条件。
以下列查询语句为例:
SQL> select address from address where upper(name) like 'JO%' AND (name
like 'J%' or name like 'j%');
使用这种查询语句(已设置AUTOTRACE),可得到下列结果:
ADDRESS
--------------------
cleveland
1 row selected.
Execution Plan
--------------------
SELECT STATEMENT
CONCATENATION
TABLE ACCESS BY INDEX ROWID ADDRESS
INDEX RANGE SCAN ADDRESS_I
TABLE ACCESS BY INDEX ROWID ADDRESS
INDEX RANGE SCAN ADDRESS_I
现在,优化器为WHERE 子句中AND 联结的两个语句中每一个语句确定的范围进行扫描----第二个语句没有引用函数,因而使用了索引。
在两个范围扫描后,将运行结果合并。
在这个例子中,如果数据库有成百上千行,可以用下列方法扩充WHERE 子句,进一步缩小扫描范围:
select address from address where upper(name) like 'JOHN' AND (name like 'JO%'
or name like 'jo%' or name like 'Jo' or name like 'jO' );
得到的结果与以前相同,但是,其执行过程如下所示,表明有4个扫描范围。
Execution Plan
-------------------
SELECT STATEMENT
CONCATENATION
TABLE ACCESS BY INDEX ROWID ADDRESS
INDEX RANGE SCAN ADDRESS_I
TABLE ACCESS BY INDEX ROWID ADDRESS
INDEX RANGE SCAN ADDRESS_I
TABLE ACCESS BY INDEX ROWID ADDRESS
INDEX RANGE SCAN ADDRESS_I
TABLE ACCESS BY INDEX ROWID ADDRESS
INDEX RANGE SCAN ADDRESS_I
如果试图进一步提高查询速度,我们可以在特定的"name like"条件中指明3个或更多的字符。
然而,这样做会使得WHERE子句十分笨重。
因为需要大小写字符所有可能的组合-joh ,Joh,jOh,joH等等。
除此之外,指定一个或两个字符已足以加快查询的运行速度了。
现在让我们看看,当我们引用不同的函数时,怎样运用这个基本技术。
使用REPLACE的情况
正如名字不总是以大写输入一样,电话号码也会以许多格式出现:如 123-456-7890, 123 456 7890,(123)456-7890 等等。
如果在列名为 PHONE_NUMBER中搜寻上述号码时,可能需要使用函数REPLACE以保证统一的格式。
如果在PHONE_NUMBER列中只包含空格、连字符和数字,where 子句可以如下所示: WHERE replace(replace(phone_number , '-' ) , ' ' ) = '1234567890'
WHERE子句两次使用REPLACE 函数去掉了连字符和空格,保证了电话号码是简单的数字串。
然而,该函数阻止了优化器在该列使用索引。
因此,我们按如下方法修改WHERE子句,以强制执行索引。
WHERE replace(replace(phone_number, '-' ) , ' ' ) = '1234567890'
AND phone_number like '123% '
如果我们知道数据中可能包含圆括号,WHERE 子句会稍微复杂一点。
我们可以再增加REPLACE 函数(去掉圆括号、连字符和空格),按如下所示扩充增加的条件:
WHERE replace(replace(replace(replace(phone_number , ' - ' ) ,' '), '( ' )
, ' ) ' ) = '1234567890'
AND (phone number like ' 123% ' or phone_number like ' (123% ' ) '
该例强调了巧妙地选用WHERE 子句条件的重要性,而且,这些条件不会改变查询结果。
你的选择应基于完全了解该列中存在的信息类型。
在该例中,我们需要知道 PHONE_NUMBER 数据中存在几种不同的格式,这样,我们能够修改WHERE 子句而不会影响查询结果。
正确的条件
以后当你遇到包含CHARACTER 数据修改函数列的WHERE 子句时,应考虑怎样利用增加一个或两个特定的条件,迫使优化器使用索引。
适当地选择一组特定的条件能减少扫描行,并且强制使用索引不会影响查询结果----但却提高了查询的执行速度。
来源:网络编辑:联动北方技术论坛。