在eclipse中开发cassandra程序的步骤
使用Eclipse进行Java应用程序开发的入门教程

使用Eclipse进行Java应用程序开发的入门教程第一章:介绍Eclipse和Java开发环境Eclipse是一款流行的集成开发环境(IDE),可用于开发各种编程语言,包括Java。
它提供了强大的工具和功能,使Java开发变得更加高效和便捷。
1.1 Eclipse的安装首先,下载适用于Java开发的Eclipse版本。
安装过程相对简单,按照向导提示顺序执行即可完成。
确保选择Java开发工具(Java Development Tools,JDT)的安装。
1.2 JDK的安装和配置Eclipse需要Java Development Kit(JDK)才能编译和运行Java 代码。
确保已安装最新版本的JDK,并将其配置为Eclipse的默认JDK。
1.3 创建Java项目启动Eclipse后,选择"File -> New -> Java Project"来创建一个新的Java项目。
在弹出的对话框中,输入项目名称并选择所需的JDK版本。
点击"Finish"来创建项目。
第二章:Eclipse的基本功能和工作空间2.1 工作空间Eclipse使用工作空间(Workspace)来组织项目和资源文件。
在启动Eclipse时,会要求选择工作空间文件夹。
一个工作空间可以包含多个项目。
2.2 项目资源Eclipse的"Package Explorer"窗口显示项目中的所有文件和文件夹。
你可以在此窗口中创建、删除和管理项目资源。
2.3 编辑器Eclipse的编辑器是主要的编码区域,用于编写和编辑Java代码。
当你双击项目中的Java文件时,它会在编辑器中打开。
2.4 调试器Eclipse提供强大的调试功能,可帮助你发现和修复代码中的错误。
你可以设置断点、单步执行代码、查看变量的值等。
调试器是开发过程中非常有用的工具。
第三章:Java项目的创建和配置3.1 创建包和类在Eclipse的"Package Explorer"窗口中,右键点击项目,选择"New -> Package"来创建一个包。
eclipse创建maven java项目的方法与步骤

eclipse创建maven java项目的方法与步骤在Eclipse中创建Maven项目是一种相对简单的过程。
以下是创建Maven Java项目的基本步骤:前提条件:确保你的Eclipse已经安装了Maven插件。
你可以通过Eclipse Marketplace安装"Maven Integration for Eclipse"插件,或者使用Eclipse自带的"Help" -> "Eclipse Marketplace" -> "Search" 中搜索"Maven" 来安装。
创建Maven项目的步骤:1. 打开Eclipse IDE。
2. 选择菜单栏中的"File" -> "New" -> "Other"。
3. 在弹出的对话框中,展开"Maven" 文件夹,然后选择"Maven Project"。
点击"Next"。
4. 在下一个对话框中,确保"Create a simple project" 处于选中状态,然后点击"Next"。
5. 在"Group Id" 和"Artifact Id" 字段中输入你的项目的组织和项目名称。
这两个字段通常用来唯一标识一个Maven项目。
点击"Finish"。
6. Eclipse会提示你是否要切换到Maven的"Java EE Perspective",选择"Yes"。
7. 现在,Eclipse将使用Maven Archetype创建项目结构。
你可以选择不同的Archetype,比如"maven-archetype-quickstart" 用于创建一个简单的Java项目。
Cloudcomputing 理论测试题目答案(仅101题)

Cl oudcomputing 理论测试题目答案说明:1、搜索时如果找不到可先尝试去掉英文部分,只搜索中文,可能是中英文间空格问题。
2、如果碰到“下面说法错误的是()”,直接搜索选项,也仅有此类题可搜索任意选项,绿色部分为正确选项。
3、红色部分为错误选项,本人到100后就没心情继续刷了,后继者继续努力吧,据说现有300-400道题,助教打算近期再添加100多题……4、改进后上传前,你可以在此部分表明更新信息、姓名和日期,但不要抹杀前人的努力,切记!(10-本-白玉欣2012/4/20)1. 请问在Hadoop体系结构中,按照由下到上顺序,排列正确的是()mon MapReduce Pig2. 关于Datanode的描述错误的是()D.文件的副本系数由Datanode 储存3.关于MapReduce的描述错误的是()D. 一个MapReduce任务(Task)通常会把输入集切分成若干独立的数据块4. Hive查询语言和SQL的一个不同之处关于HDFS 命令错误的是()C. cp:返回到上一级目录5. 配置hbase过程中,下面那个文件没有改动。
A.hbase-default.xml6. hbase表格中行关键字对应的列值最少有几个?D.任意个7. 客户端发现域服务器崩溃之后与__交互来处理问题.B.hbasemaster8. Hive最重视的性能是可测量性,延展性,__和对于输入格式的宽松匹配性。
B. 容错性9. hbase中存储的数据类型是__。
B.byte10. INT整数型有多少个字节__。
NOT D. 8 byte11. Hive提供了基于SQL并使得熟悉SQL的用户能够查询数据的__。
A.QL12. 下面哪一个对于Hive查询语言的命令的描述是错误的__。
C.SHOW PARTITIONS page_view:列出表格page_view 的所有的分隔。
如果该表格没有被分隔,那么什么也不做。
eclipse插件开发流程

eclipse插件开发流程Eclipse插件开发流程Eclipse是一款开源的集成开发环境(IDE),它提供了丰富的插件机制,使开发者能够根据自己的需求定制和扩展IDE。
本文将介绍Eclipse插件开发的流程,帮助读者了解如何开始开发自己的插件。
1. 确定插件的功能和目标在开始插件开发之前,首先需要明确插件的功能和目标。
这包括确定插件的用途、解决的问题以及目标用户等。
明确插件的功能和目标有助于开发者更好地进行设计和实现。
2. 创建Eclipse插件项目在Eclipse中,可以通过插件开发工具(Plug-in Development Environment,简称PDE)来创建插件项目。
打开Eclipse,选择File -> New -> Project,在弹出的对话框中选择Plug-in Project,点击Next。
然后输入项目名称和选择插件的模板,点击Finish即可创建插件项目。
3. 定义插件扩展点插件扩展点是插件的核心概念,它定义了插件提供的功能和扩展的接口。
在插件项目的插件清单文件(plugin.xml)中,可以通过扩展标签来定义插件的扩展点。
根据插件的功能和目标,合理定义扩展点,使其具有良好的扩展性和灵活性。
4. 实现插件功能在插件项目中,可以创建多个插件类来实现插件的功能。
插件类通常继承自Eclipse提供的基类,并实现相应的接口。
通过重写方法和实现逻辑,可以实现插件的具体功能。
在实现插件功能的过程中,可以使用Eclipse提供的API和工具来简化开发过程。
5. 调试和测试插件在插件开发过程中,调试和测试是非常重要的环节。
Eclipse提供了强大的调试功能,可以帮助开发者定位和解决问题。
通过在Eclipse 中启动插件运行环境,可以直接调试和测试插件的功能。
在调试过程中,可以使用断点、变量监视等功能,帮助开发者更好地理解和分析插件的运行情况。
6. 打包和发布插件当插件开发完成后,可以将插件打包并发布到Eclipse插件市场或其他渠道。
用Eclipse开发和调试Android应用程序 一共10页文档

用Eclipse开发和调试Android应用程序一前面介绍了Windows环境下,基于Android SDK(2.3)和Eclipse(helios)的Android开发环境的搭建,并创建了第一个应用程序Hello Android World。
具体挺参考小生的blog:或者。
现在,我们已经可以使用Eclipse来创建和开发Android应用程序,本文将仍以Hello Android World工程来深入解析Eclipse中Android工程的结构以及调试。
写上篇的时候,刚好Android SDK Platform HoneycombPreview,revision 1(android-3.0_pre_r01-linux.zip)已经加入,却无法下载,因此我们的第一个Android应用程序是用的Android SDK Platform2.3.1,即Android 9AVD进行演示。
现在Android SDK Platform Honeycomb Preview已经放到,敢为天下先是我等求知若渴的程序员的优秀品质,因此,本次我们使用最新版本的Android SDK Platform Honeycomb Preview来进行我们本次教程。
先看看最新的Honeycomb Preview的样子吧(由于是Preview版本,启动确实不敢恭维,根据传闻,前几天之所以该版本一度无法下载安装是因为google发现这个Preview版本太烂,面子上挂不住,所以又撤掉了,呵呵):相比手机上目前使用的最高Android 2.3版本而言,Android 3.0 Honeycomb更适合平板电脑使用,是专门为Android平板电脑进行优化的系统版本。
随着SDK的发布,更加有利于开发者和厂商针对Android 3.0 Honeycomb平板电脑进行开发,包括Android平板电脑应用和匹配。
一、Android应用程序概述1.Android的嫡系组件Android有四项一等公民(或称为嫡系组件),包括:Activity(活动)、ContentProvider(内容提供程序)、BroadcastReceiver(广播接收器)与Service(服务)。
cassandra手册

cassandra手册
Cassandra 是一个开源的分布式 NoSQL 数据库管理系统,它旨在提供高度可扩展性和高性能的数据存储解决方案。
Cassandra 手册涵盖了该数据库的各种方面,包括安装、配置、数据建模、查询语言、性能优化等内容。
下面我将从多个角度来介绍 Cassandra 手册的内容。
首先,Cassandra 手册包括了安装和配置方面的内容。
这部分内容会详细介绍如何在不同操作系统上安装 Cassandra,并提供了配置文件的说明,帮助用户根据自己的需求进行定制化配置。
其次,Cassandra 手册涵盖了数据建模方面的内容。
这部分内容会介绍如何设计适合 Cassandra 数据存储的数据模型,包括表的设计、主键的选择、数据分布等方面的最佳实践。
另外,Cassandra 手册还包括了查询语言方面的内容。
这部分内容会介绍 Cassandra 的查询语言 CQL(Cassandra Query Language),包括查询操作、更新操作、事务支持等内容,帮助用户编写高效的数据查询和更新操作。
此外,Cassandra 手册还会涵盖性能优化、故障排除、安全性设置等方面的内容。
这些内容会帮助用户更好地理解和使用Cassandra 数据库,从而更好地满足其业务需求。
总的来说,Cassandra 手册是一份全面的指南,涵盖了Cassandra 数据库的各个方面,帮助用户更好地理解和使用这一强大的分布式 NoSQL 数据库管理系统。
希望我的回答能够帮助你更好地了解 Cassandra 手册的内容。
Cassandra开发入门文档第一部分

Cassandra开发⼊门⽂档第⼀部分Cassandra的特点横向可扩展性:Cassandra部署具有⼏乎⽆限的存储和处理数据的能⼒。
当需要额外的容量时,可以简单地将更多的机器添加到集群中。
当新机器加⼊集群时,Cassandra需要对现有数据进⾏重新平衡,以使扩展集群中的每个节点具有⼤致相等的份额。
⽽且,Cassandra集群的性能与集群内的节点数成正⽐。
当您继续添加实例时,读写吞吐量将保持线性增长。
⾼可⽤性:Cassandra集群中的所有节点都是没有主节点的对等节点。
如果⼀台机器变得不可⽤,Cassandra将继续向与该机器共享数据的其他节点写⼊数据,并在失败的节点重新加⼊集群时对操作进⾏排队和更新。
这意味着在⼀个典型的配置中,多个节点必须同时发⽣故障,才能在Cassandra的可⽤性中出现任何应⽤程序可见的中断。
写优化:传统的关系数据库和⽂档数据库针对读取性能进⾏了优化。
将数据写⼊关系数据库通常涉及对磁盘上的复杂数据结构进⾏就地更新,以便维护能够⾼效灵活地读取的数据结构。
从磁盘I/O的⾓度来看,更新这些数据结构是⼀项⾮常昂贵的操作,⽽磁盘I/O通常是数据库性能的限制因素。
由于写操作⽐读操作更昂贵,因此通常会避免对关系数据库进⾏任何不必要的更新,即使以额外的读操作为代价。
另⼀⽅⾯,Cassandra对写吞吐量进⾏了⾼度优化,事实上,它从不修改磁盘上的数据;它只附加到现有⽂件或创建新⽂件。
这在磁盘I/O上要容易得多,这意味着Cassandra可以提供惊⼈的⾼写吞吐量。
由于向Cassandra写⼊数据和在Cassandra中存储数据都很便宜,因此⾮规范化成本很低,是确保在各种访问场景中可以有效读取数据的好⽅法。
结构化记录:我们看到的前三个数据库特性通常出现在分布式数据存储中。
然⽽,诸如Riak和Voldemort这样的数据库纯粹是键值存储;这些数据库不知道存储在特定键中的记录的内部结构。
这意味着诸如只更新记录的⼀部分、只读取记录中的某些字段或检索在给定字段中包含特定值的记录等有⽤的功能是不可能的。
eclipse创建maven java项目的方法与步骤

eclipse创建maven java项目的方法与步骤摘要:1.安装Eclipse和Maven2.创建Maven项目3.创建Java类4.编写Java代码5.运行Java程序6.添加依赖库7.编译和部署项目正文:Eclipse是一款功能强大的Java集成开发环境(IDE),而Maven是一个项目构建工具,可以帮助我们管理Java项目的依赖、编译和部署。
以下是在Eclipse中创建Maven Java项目的详细步骤:1.安装Eclipse和Maven:首先,从官方网站下载并安装Eclipse IDE。
安装完成后,打开Eclipse。
接着,在Eclipse中安装Maven插件。
打开Eclipse的“Help”菜单,选择“Install New Software”,然后添加以下Maven插件:- Maven Integration for Eclipse- Maven Repository Manager2.创建Maven项目:在Eclipse中,创建一个Maven项目非常简单。
点击“File” >“New” > “Maven Project”,填写项目信息,如groupId、artifactId和version。
完成后,点击“Finish”。
3.创建Java类:在Maven项目中,右键点击“src/main/java”目录,选择“New” > “Class”。
填写类名、包名和父类名,点击“Finish”。
4.编写Java代码:在创建的Java类中,编写代码。
例如,编写一个简单的“HelloWorld”程序:```javapublic class HelloWorld {public static void main(String[] args) {System.out.println("Hello, World!");}}```5.运行Java程序:保存代码后,右键点击Java类,选择“Run As” > “Java Application”。
eclipse可视化工具使用方法

eclipse可视化工具使用方法一、简介Eclipse是一款开源的集成开发环境(IDE),是Java开发最常用的工具之一。
它提供了丰富的功能和插件,使开发者能够更高效地编写、调试和管理代码。
本文将介绍如何使用Eclipse的可视化工具,以及如何充分利用这些工具提升开发效率。
二、安装与配置1. 下载Eclipse在Eclipse官网上下载最新版本的Eclipse安装包,并解压到本地目录。
2. 安装Eclipse打开解压后的文件夹,运行eclipse.exe。
首次运行Eclipse时,需要选择一个工作空间,用于存储项目文件。
3. 配置Eclipse在Eclipse的菜单栏中选择“Window”->“Preferences”,可以进行各种个性化配置。
- 在“General”->“Appearance”中,可以选择主题、字体和颜色等外观设置。
- 在“Java”->“Code Style”中,可以设置代码格式化规则,使代码更易读。
- 在“Java”->“Editor”->“Content Assist”中,可以配置代码自动补全功能。
- 在“Java”->“Build Path”中,可以添加外部库和设置编译路径。
三、常用可视化工具1. 导航视图(Package Explorer)导航视图显示项目的目录结构,可以方便地浏览和管理项目文件。
在Eclipse的左侧窗口中,找到“Package Explorer”选项卡。
2. 编辑器(Editor)编辑器是Eclipse的核心功能之一,用于编辑和查看代码。
在Eclipse的右侧窗口中,找到“Editor”选项卡。
可以在编辑器中输入代码,进行语法高亮、代码折叠等操作。
3. 调试器(Debugger)调试器可以帮助开发者在代码执行过程中进行调试和排错。
在Eclipse的底部窗口中,找到“Debug”选项卡。
可以设置断点、单步执行、查看变量的值等。
Eclipse配置Tomcat的方法图解

Eclipse配置Tomcat的方法图解1.访问Tomcat的官方网站。
第二步:安装并启动Eclipse接下来,你需要安装并启动Eclipse。
4.启动Eclipse。
第三步:配置Tomcat服务器现在,你需要配置Eclipse以使用已安装的Tomcat服务器。
1.打开Eclipse。
2.点击“Window”菜单,然后选择“Preferences”选项。
4.点击“Add”按钮来添加新的服务器运行时环境。
5.在弹出的对话框中,选择“Apache”文件夹,然后选择合适的Tomcat版本(例如,Tomcat 8.5)。
6.点击“Next”按钮。
7.在下一个界面上,点击“Browse”按钮,并导航到之前安装Tomcat的目录。
选择Tomcat的安装目录,然后点击“Finish”按钮。
8.完成以上步骤后,Eclipse将显示一个新的Tomcat版本。
点击“OK”按钮以保存配置。
第四步:创建一个新的动态Web项目现在,你可以创建一个新的动态Web项目,并将其部署到已配置的Tomcat服务器上。
1.点击“File”菜单,然后选择“New” > “Dynamic Web Project”选项。
2.在弹出的对话框中,输入项目的名称和目标运行时环境(即之前配置的Tomcat版本)。
3.点击“Next”按钮。
4.在下一个界面上,选择“Generate web.xml deployment descriptor”选项。
5.点击“Finish”按钮。
第五步:部署和运行项目最后,你可以将项目部署到已配置的Tomcat服务器上并运行它。
1.在Eclipse的“Package Explorer”视图中找到你的项目,右键点击它。
2.选择“Run As” > “Run on Server”选项。
3.在弹出的对话框中,选择之前配置的Tomcat版本,并点击“Finish”按钮。
4.等待项目部署和服务器启动,然后在默认的Web浏览器中打开项目。
cassandratemplate 预编译

cassandratemplate 预编译全文共四篇示例,供读者参考第一篇示例:Cassandra是一款广泛应用于大数据存储的开源分布式数据库系统,它拥有高可用性、高扩展性和良好的性能表现。
而CassandraTemplate则是Spring Data Cassandra中的一种数据库操作模板,能够帮助开发人员更方便地与Cassandra数据库进行交互。
预编译是一种优化数据库查询的技术,可以提高查询的执行效率。
在Cassandra数据库中也可以通过预编译语句来实现相同的效果,即减少查询语句的解析和编译时间,从而提升查询的性能。
CassandraTemplate预编译功能可以帮助开发人员更好地利用预编译语句来优化数据库查询,下面我们将详细介绍CassandraTemplate预编译的使用方法及其优势。
一、CassandraTemplate预编译的基本概念CassandraTemplate预编译是指在执行数据库查询之前,提前将查询语句进行解析和编译,然后将编译好的查询语句缓存起来,从而达到减少执行时间的目的。
在Cassandra数据库中,预编译语句是一种特殊的语句,它在解析和编译时会生成一个抽象语法树,并将其存储在内存中,避免每次执行查询时都要重新解析和编译查询语句。
1. 创建预编译查询语句在使用CassandraTemplate进行数据库查询时,可以通过QueryBuilder来创建预编译查询语句。
QueryBuilder是Spring Data Cassandra提供的一个工具类,用于构建CQL查询语句。
开发人员可以通过QueryBuilder来构建预编译查询语句,并将查询结果映射为对象。
示例代码如下:```javaQueryBuilder queryBuilder =QueryBuilder.select().from("table_name").where(QueryBuilder.eq ("column_name", "value"));```在这个示例中,我们使用QueryBuilder来构建一个简单的查询语句,查询表“table_name”中满足条件“column_name=value”的数据。
在eclipse中运行cassandra
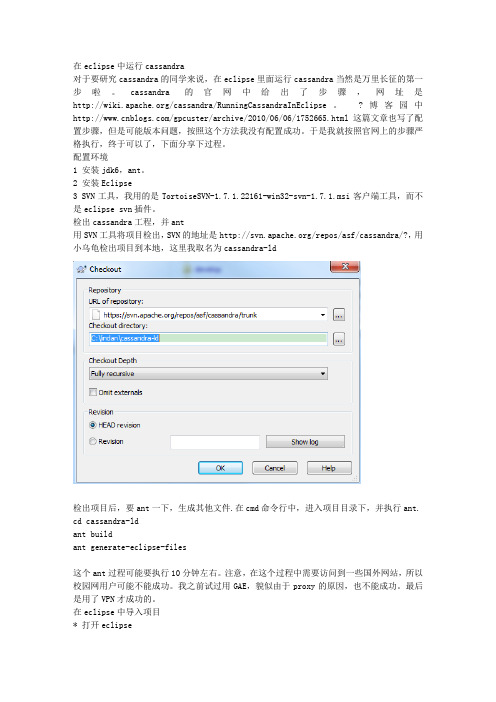
在eclipse中运行cassandra对于要研究cassandra的同学来说,在eclipse里面运行cassandra当然是万里长征的第一步啦。
cassandra的官网中给出了步骤,网址是/cassandra/RunningCassandraInEclipse。
?博客园中/gpcuster/archive/2010/06/06/1752665.html这篇文章也写了配置步骤,但是可能版本问题,按照这个方法我没有配置成功。
于是我就按照官网上的步骤严格执行,终于可以了,下面分享下过程。
配置环境1 安装jdk6,ant。
2 安装Eclipse3 SVN工具,我用的是TortoiseSVN-1.7.1.22161-win32-svn-1.7.1.msi客户端工具,而不是eclipse svn插件。
检出cassandra工程,并ant用SVN工具将项目检出,SVN的地址是/repos/asf/cassandra/?,用小乌龟检出项目到本地,这里我取名为cassandra-ld检出项目后,要ant一下,生成其他文件.在cmd命令行中,进入项目目录下,并执行ant. cd cassandra-ldant buildant generate-eclipse-files这个ant过程可能要执行10分钟左右。
注意,在这个过程中需要访问到一些国外网站,所以校园网用户可能不能成功。
我之前试过用GAE,貌似由于proxy的原因,也不能成功。
最后是用了VPN才成功的。
在eclipse中导入项目* 打开eclipse* 点击File->New->Java Project* 输入cassandra-ld作为项目名(应该与你检出的时候项目名一致)* 取消"use defalt location",选择刚才放检出项目的目录* 按next* 检查下Default Output Folder 是不是?cassandra-trunk/build/classes/main* 点击“Finish”这个时候,项目中会有些错误提示,不要紧,继续下面的操作* 关掉eclipse* 编辑项目中的.project文件,在<buildCommand></buildCommand>下加入这一段<buildCommand><name>org.eclipse.jdt.core.javabuilder</name><arguments></arguments></buildCommand>* 重启eclipse,并刷新(F5)运行cassandra* 修改conf/cassandra.yaml中的配置参数,自定义数据存储的位置:# directories where Cassandra should store data on disk.data_file_directories:- C:\lindan\cassandraData\data# commit logcommitlog_directory: C:\lindan\cassandraData\commitlog# saved cachessaved_caches_directory: C:\lindan\cassandraData\saved_caches* ?点击"run"-"run congigurations"* 选择org.apache.cassandra.thrift.CassandraDaemon作为main class.* 在VM argument 下填入下面参数-Dcassandra.config=file:C:\Users\Joaquin\workspace\cassandra-3\conf\cassandra.ya ml-Dcassandra-foreground-ea -Xmx1G-Dlog4j.configuration=file:C:\Users\Joaquin\workspace\cassandra-3\conf\log4j-ser ver.properties当然,这里的cassandra.yaml和log4j-server.properties都应该写成你自己的路径。
简述使用eclipse开发java程序的基本步骤

简述使用eclipse开发java程序的基本步骤
1.安装eclipse:从官网下载eclipse安装程序,按照提示安装。
2. 创建java项目:打开eclipse,选择“File”菜单中的“New”-“Java Project”,输入项目名称和存储路径,点击“Finish”按钮创建项目。
3. 新建java类:在项目中右键点击“src”文件夹,选择“New”-“Class”,输入类名和包名,勾选“public static void main(String[] args)”选项,点击“Finish”按钮创建类。
4. 编写java代码:在新建的类中编写java代码。
5. 运行程序:点击“Run”菜单中的“Run”按钮或按下“Ctrl+F11”快捷键运行程序。
6. 调试程序:在代码中设置断点,点击“Debug”菜单中的“Debug”按钮或按下“F11”快捷键启动调试。
7. 导出程序:点击“File”菜单中的“Export”选项,选择“Java”-“Runnable JAR file”,按照提示设置导出选项,点击“Finish”
按钮导出程序。
以上是使用eclipse开发java程序的基本步骤,可以根据实际
需求进行扩展和优化。
- 1 -。
java 连接cassandra 数据库原理

Java连接Cassandra数据库的原理主要是通过Java的数据库连接(JDBC)API来实现的。
具体来说,Java程序需要使用JDBC API来与Cassandra数据库建立连接,然后通过这个连接执行SQL查询或命令。
在连接过程中,Java程序需要提供Cassandra数据库的地址、端口、认证信息等参数,以便能够正确地连接到数据库。
一旦连接建立成功,Java程序就可以通过这个连接执行SQL查询或命令。
Cassandra数据库返回的结果会被封装成一个ResultSet对象,Java程序可以通过遍历这个对象来获取查询结果。
需要注意的是,由于Cassandra是一个NoSQL数据库,因此它不支持传统的SQL查询语言。
因此,Java程序在连接Cassandra数据库时,需要使用Cassandra特定的查询语言(CQL)来执行查询或命令。
总的来说,Java连接Cassandra数据库的原理与其他关系型数据库类似,都是通过JDBC API建立连接,然后执行SQL查询或命令。
不过,由于Cassandra是一个NoSQL数据库,因此需要使用CQL语言来执行查询或命令。
cass教程

cass教程Cassandra教程: 从入门到精通概述:Cassandra,全称为Apache Cassandra,是一个高度可扩展的分布式数据库管理系统。
它设计用于管理庞大的数据,可以在多台服务器上进行分布式部署,从而提供高可用性和容错能力。
本教程旨在为读者提供深入了解Cassandra的基本概念和操作的综合指南。
目录:1. Cassandra的基本概念1.1 分布式数据库管理系统1.2 横向扩展和可靠性1.3 Cassandra的数据模型2. Cassandra的安装和配置2.1 安装Java Development Kit (JDK)2.2 下载和安装Cassandra2.3 配置Cassandra集群3. 创建和管理数据库3.1 启动和停止Cassandra服务器 3.2 创建数据库3.3 数据库管理操作4. 数据模型和数据类型4.1 键空间(Keyspace)4.2 表(Table)4.3 列(Column)4.4 数据类型5. Cassandra查询语言(CQL)5.1 CQL简介5.2 CQL数据定义语句5.3 CQL数据操作语句6. Cassandra的读写操作6.1 读取数据6.2 写入数据6.3 批量写入数据6.4 数据一致性和写入策略7. 数据复制和一致性7.1 数据复制策略7.2 复制因子和副本7.3 数据复制的一致性问题8. Cassandra集群管理8.1 添加和移除节点8.2 节点故障和恢复8.3 数据迁移9. 性能调优和最佳实践9.1 数据建模的最佳实践9.2 查询性能优化9.3 节点调优和硬件要求10. Cassandra中的事务管理 10.1 Cassandra的事务特性 10.2 处理并发和原子性操作11. 实例和用例11.1 Cassandra在企业中的用例11.2 Cassandra在互联网应用中的应用12. Cassandra的安全性和备份12.1 Cassandra的安全机制12.2 数据备份和恢复策略结束语:本教程覆盖了Cassandra的各个方面,从基本概念到高级应用,旨在帮助读者全面了解和掌握这个分布式数据库管理系统。
快速入门使用Eclipse进行Java开发

快速入门使用Eclipse进行Java开发第一章:Eclipse简介及安装Eclipse是一种基于Java的集成开发环境(IDE),它被广泛用于Java开发项目。
Eclipse具有高度可扩展性和灵活性,可以通过插件和扩展进行功能扩展,同时也支持其他编程语言的开发。
要开始使用Eclipse进行Java开发,首先需要下载并安装Eclipse。
在Eclipse官方网站上,可以找到适用于不同操作系统的安装程序包。
安装过程相对简单:下载适合操作系统的安装程序包,双击运行程序包,按照提示完成安装即可。
第二章:创建Java项目安装完成后,可以打开Eclipse并通过以下步骤创建一个新的Java项目:1. 打开Eclipse,选择“File”菜单,然后选择“New”和“Java Project”。
2. 输入项目的名称,并选择一个默认的工作空间(如果没有特殊需求,可以使用默认的工作空间)。
3. 点击“Finish”按钮,完成项目的创建。
第三章:创建Java类在Java项目下创建Java类是进行Java开发的基本操作。
通过以下步骤可以创建一个新的Java类:1. 在项目资源管理器中,右击项目名称,选择“New”和“Class”。
2. 输入类的名称(请使用合适的命名规范)。
3. 选择“public static void main(String[] args)”选项,这样可以为新类创建一个主执行方法。
4. 点击“Finish”按钮,完成新类的创建。
第四章:为Java类编写代码创建了Java类后,可以为该类编写代码。
在Eclipse中,可以在Java类的编辑器中输入和编辑代码。
Eclipse提供了语法高亮、代码补全、代码提示等功能,让编写代码更加方便。
在Java类编辑器中输入代码时,可以使用Eclipse的自动补全功能。
例如,当输入一个类的名称时,Eclipse会自动弹出可能的选项供选择。
第五章:调试Java程序Eclipse还提供了强大的调试功能。
RAPID程序建立的基本操作

案例四:快速开发一个多媒体播放器应用
总结词
使用RAD工具,快速搭建一个多媒体播放器应用。
详细描述
通过使用RAD工具,可以快速创建一个多媒体播放器应用的基 本框架,包括音频和视频的播放和管理功能。
总结词
使用RAD工具,快速实现多媒体文件的上传和下载功能。
案例四:快速开发一个多媒体播放器应用
1 2
详细描述
RAD的历史和发展
历史
RAD最早起源于20世纪80年代的美国,当时主要用于构建企业级应用程序。随着技术的发展,RAD逐渐演变为 现在的形式,并广泛应用于各种领域。
发展
随着云计算、大数据和人工智能等技术的发展,RAD也在不断演进和改进。未来,随着技术的进步和应用需求的 不断变化,RAD将继续发展并应用于更多的领域。
通过使用RAD工具,可以快速实现多媒体文件的 上传和下载功能,包括文件的浏览、选择和下载 等操作。
总结词
使用RAD工具,快速实现多媒体文件的播放和管 理功能。
3
详细描述
通过使用RAD工具,可以快速实现多媒体文件的 播放和管理功能,包括音频和视频的播放、暂停、 停止和音量控制等操作。
案例四:快速开发一个多媒体播放器应用
基本框架,包括复杂的业务逻辑和数据管理功能。
总结词
03
使用RAD工具,快速实现企业业务流程的自动化处理
功能。
案例五:快速开发一个企业级应用
详细描述
通过使用RAD工具,可以快速实现企业业务流程的自动 化处理功能,包括业务流程的建模、执行和监控等操作。
总结词
使用RAD工具,快速实现企业数据的整合和管理功能。
02
03
总结词
使用RAD工具,快速实现数据库表的 创建和修改功能。
cass使用方法 -回复

cass使用方法-回复Cass使用方法Cass是一种基于Apache Cassandra的Java驱动程序,用于连接和与Cassandra数据库进行通信。
Cassandra是一个高性能、可扩展的分布式数据库,广泛应用于大规模的数据处理和分析场景。
Cass驱动程序提供了一个简单且强大的API,用于执行数据库操作,如创建表格、插入数据、查询和更新数据等。
本文将介绍Cass的使用方法,包括设置环境、连接到Cassandra集群、执行CRUD操作等。
第一步:设置环境在使用Cass之前,我们需要先设置Java环境和导入Cass驱动程序。
首先,确保您的系统上已安装Java JDK,并将其加入到系统路径中。
然后,下载Cass驱动程序的最新版本,可在GitHub上找到。
解压下载的文件,并将其中的jar文件添加到您的项目依赖中。
第二步:连接到Cassandra集群在连接到Cassandra之前,我们需要先了解Cassandra集群的信息和设置。
Cassandra由多个节点组成,每个节点都负责存储和处理数据的一部分。
通常,我们需要指定至少一个节点的IP地址和端口号来建立连接。
使用Cass驱动程序,可以通过Cluster类来实现连接。
以下是连接到Cassandra集群的代码示例:Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1") 设置节点的IP地址.withPort(9042) 设置节点的端口号.build();Session session = cluster.connect(); 建立连接在这个示例中,我们使用builder()方法创建一个Cluster对象,并使用addContactPoint()方法指定节点的IP地址,使用withPort()方法指定节点的端口号。
最后,使用build()方法建立与节点的连接,并通过connect()方法获取会话(Session)对象。
Cassandra使用手册lfqy

Cassandra使用手册1、安装与配置 (2)1.1 单机 (2)1.2 集群 (2)2、Cassandra数据模型 (3)2.1 column (3)2.2 super column (4)2.3 column family (4)2.4 super column family (6)3、命令行 (8)3.1 cassandra-cli (8)3.2 nodetool (9)4、简单的Java编程接口Thrift (9)4.1准备工作 (9)4.2 数据库的连接和断开连接 (9)4.3 插入 (9)4.3.1 单条数据的插入 (9)4.3.2 批量插入 (10)(1)关于Mutation (10)(2)batch_mutate (11)4.4 查询 (11)4.4.1查询相关的数据类型 (11)(1)ColumnPath (11)(2)SliceRange (12)(3)SlicePredicate (12)4.4.2查询相关的操作 (13)(1)get (13)(2)get_slice (13)4.4.3单个字段的查询 (13)4.4.4读取整条数据 (13)5、Cassandra测试 (14)6、Tips (14)7、一个Cassandra实例(在线交易系统) (14)7.1数据模型设计 (14)7.1.1 Seller (15)7.1.2 Buyer (16)7.1.3 Product (16)7.1.4 ProductCategory (17)7.1.5 Comment (18)7.2 编码实现 (18)7.2.1 修改keyspace设置 (18)7.2.2 建立eclipse项目 (19)7.3.3 向column family中batch_mutate (19)7.3.4 向super column family中batch_mutate (21)7.3.5 从Cassandra中查询数据之column family (22)7.3.6 从Cassandra中查询数据之super column family (22)参考文献 (22)这里使用的版本是Cassandra的1.1.2。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.建立java project
2.Import cassandra中的interface目录下的gen-java
3.加入lib目录下的jar文件
4.哦了
5.示例代码:
import java.io.UnsupportedEncodingException;
import java.util.Date;
import java.util.List;
import org.apache.cassandra.thrift.Cassandra;
import org.apache.cassandra.thrift.Column;
import org.apache.cassandra.thrift.ColumnOrSuperColumn;
import org.apache.cassandra.thrift.ColumnParent;
import org.apache.cassandra.thrift.ColumnPath;
import org.apache.cassandra.thrift.ConsistencyLevel;
import org.apache.cassandra.thrift.InvalidRequestException;
import org.apache.cassandra.thrift.NotFoundException;
import org.apache.cassandra.thrift.SlicePredicate;
import org.apache.cassandra.thrift.SliceRange;
import org.apache.cassandra.thrift.TimedOutException;
import org.apache.cassandra.thrift.UnavailableException;
import org.apache.thrift.TException;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.transport.TSocket;
import org.apache.thrift.transport.TTransport;
public class test {
public static final String UTF8 = "UTF8";
public static void main(String[] args) throws UnsupportedEncodingException,
InvalidRequestException, UnavailableException, TimedOutException,
TException, NotFoundException {
TTransport tr = new TSocket("10.28.0.186", 9160); TProtocol proto = new TBinaryProtocol(tr);
Cassandra.Client client = new Cassandra.Client(proto);
tr.open();
//System.out.println("dddddd");
String keyspace = "Keyspace1";
String columnFamily = "Standard1";
String keyUserID = "1";
// insert data
long timestamp = System.currentTimeMillis();
ColumnPath colPathName = new ColumnPath(columnFamily);
colPathName.setColumn("fullName".getBytes(UTF8));
client.insert(keyspace, keyUserID, colPathName, "Chris Goffinet"
.getBytes(UTF8), timestamp, ConsistencyLevel.ONE);
ColumnPath colPathAge = new ColumnPath(columnFamily);
colPathAge.setColumn("age".getBytes(UTF8));
client.insert(keyspace, keyUserID, colPathAge, "24".getBytes(UTF8),
timestamp,
ConsistencyLevel.ONE);
// read single column
System.out.println("single column:");
Column col = client.get(keyspace, keyUserID, colPathName,
ConsistencyLevel.ONE).getColumn();
System.out.println("column name: "+ new String(, UTF8));
System.out.println("column value: "+ new String(col.value, UTF8));
System.out.println("column timestamp: "+ new Date(col.timestamp));
// read entire row
SlicePredicate predicate = new SlicePredicate(); SliceRange sliceRange = new SliceRange();
sliceRange.setStart(new byte[0]);
sliceRange.setFinish(new byte[0]);
predicate.setSlice_range(sliceRange);
System.out.println("\nrow:");
ColumnParent parent = new ColumnParent(columnFamily); List<ColumnOrSuperColumn> results = client.get_slice(keyspace,
keyUserID, parent, predicate, ConsistencyLevel.ONE);
for (ColumnOrSuperColumn result : results) {
Column column = result.column;
System.out.println(new
String(, UTF8) + " -> "
+ new String(column.value, UTF8));
}
tr.close();
}
}。