R语言菜鸟联系笔记 9
R语言教程笔记

R 编程笔记2简介1.突出特点:【多领域的统计资源】目前在R 网站上约有2400个程序包,涵盖了基础统计学、社会学、经济学、生态学、空 间分析、系统发冇分析、生物信息学等诸多方而。
【免费】2.缺点:【占用内存】所有的数据处理在内存中进行,不适于处理超大规模的数据。
【运行速度稍慢】即时编译,约相当于C 语言的1/20。
3. CRAN :全称 The Comprehensive R Archive Networks由世界几十个镜像网站组成网络.提供F 载安装程序和相向软件包。
0镜像更新频率一般为天。
推荐镜像: 中国的镜像:数学所:即时更新的CRAN 源:界而下如下(版本)4.R 程序包(R packages )什么是R 程序包R 程序包是多个函数的集合,具有详细的说明和示例。
每个程序包包含R 函数、数据、帮助文件、描述 文件等window 下是zip 形式,安装时不要解压缩,R 程序包是R 功能扩展,特定的分析功能,需要用相 应的程序包实现。
例如:系统发冇分析,常用到ape 程序包,群落生态学vegan 包等。
4.2常用R 程序包ade4 adephylo ape利用欧几里得方法进行生态学数据分析 系统进化数据挖掘与比较方法系统发育与进化分析apTreeshape boot cluster ecodist FD进化树分析Bootstrap 检验聚类分析生态学数据相异性分析 功能多样性分析geiger 物种形成速率f j 进化分析Graphics lattice 栅格图绘图maptools空间对象的读取和处理R Console7PJ2S1R version Z.L1.1 (2010-05-31)Copyrlght IC) 2010 The R FouDd^t-aon £oc C OBDU S DJTSE« 3-M0OSL-07-DD 是自由恢件,不带任何担佩・在菓些条件下你可以梓我口由散布.用'llcerwe |) *或,licenced *来希阪布的库融*件.P •是个合作tt 划,利许多入为NiS 出丁贡献・•contcibut.ora I),来石合作吉的i#细用会警诉你如何在出版樹中正礎也引用卩戒口性序包・ffi'derrcO 1来着一些示范徑序,ffl* heLp (I •M 文件,戏用'lielp.atatcd '迪过时血列觅密隶薈?ft 助gf4. 用51 ■退出R ・(處来滋存的工隹空间已圧胆】> hlflLotry(|> rate<-c(2D z 22, 2今.26, 2B, 30, 32. 3" 36, 3B Z 40, 121> tmpMrLty <-c(0.4z 9・» 11.0z 10.^f 15.3, 14・6 13 2/ X4.7Z 15.4Z 10.5r 1D.9J > ploi | impxiif Lty^6ca| >rca<-(xnpurit ?-e)ceg<-1 tn (in pur it 产 rat e) J 1 -r.u : M .;, • . •« c«r ■] 丈再施9(蔑他tfffsva 屯in-nix)rate<-c(ZD, ZZ, 2仇 ZC r Z0z 、0, 32, 3G Z 3 0z 今 impMtLCy <-C(8.4, 9・5, 11.8Z 10.13・3, L4・8, 13 plot | Uiputlty-totcl6LXlft(lornula - lrwpurlty - cate) JSecidMala:XlhiQ Ftedlan 如 Soxs\unrar7(recj) ^ve.m,gerFrVi^习筋料X 救梧井桁黃花宝典\\R 语专 hiatocycimgev mvpart nlme ouch pgirmessphangorn picante广义加性模型相关 多变量分解线性及非线性混合效应模型 系统发弃比较 生态学数据分析系统发育分析群落系统发育多样性分析raster ffi 格数据分析与处理 seqinrDNA 序列分析sp空间数据处理spatstat spla ncs stats SDMTools vegan CRAN Task Views空间点格局分析,模型拟合与检验 空间与时空点格局分析R 统计学包物种分布模型工具植物与植物群落的排序,生物多样性计算中有对程序包的分类介绍4.3 R 程序包安装1.用函数(),如果已经连接到互联网,在括号中输入要安装的程序包洛称,选择镜像后,程序将自动下载并安装程序 包。
《r语言实战》菜鸟学习笔记(一)

《r语⾔实战》菜鸟学习笔记(⼀)打算学习⼀下r语⾔(windows),不知道从什么地⽅开始学习,加上本⼈的数理统计基础⽐较薄弱,所以就漫⽆⽬的的从⽹上找教程。
其实我逛的最多的⽹站还是知乎,读了好多很好的答案后,我选择了两本书,《153分钟学会r》《》。
前者⼤概扫了⼀眼,不太适合边看书边敲代码(我个⼈⽐较喜欢这种),所以后者就⽐较适合我,这套书还是⽐较适合菜鸟看的,我还看过《集体智慧编程》,很不错。
下⾯开始了第⼀段程序。
(博客园没有r语⾔选项,只好⽤plain txt了)age <- c(1,3,5,2,11,9,3,9,12,3)weight <- c(4.4,5.3,7.2,5.2,8.5,7.3,6.0,10.4,10.2,6.1)mean(weight)plot(age,weight)q()代码很简单,不多说了。
这段代码要注意的地⽅有:正斜杠,⼩数点后三位,均匀分布。
setwd("F:/R Code") #如果不存在需要使⽤dir.create()创建⽬录options()options(digits=3)x<-runif(20)#摘要统计量summary(x)#直⽅图hist(x)savehistory()save.image()q()接下来就要讨论r语⾔的数据结构了r语⾔包含了4中数据结构:向量,矩阵,数组和数据框。
1.向量是⼀维的a <- c(1,2,5,3,6,-2,4)2.矩阵是⼆维的cells <- c(1,26,24,68)rnames <- c("R1","R2")cnames <- c("C1", "C2")mymatrix <- matrix(cells,nrow=2, ncol=2, byrow=TRUE,dimnames=lilst(rnames,cnames)) #按⾏填充3.数组可以是多维的dim1 <-c("A1","A2")dim2 <- c("B1","B2","B3")dim3 <- c("C1","C2","C3","C4")#array(vector, dimanesions,dimnames)z <- array(1:24, c(2,3,4), dimnames=list(dim1,dim2,dim3))4.数据框这个就是⼤杂烩了patientID <- c(1,2,3,4)age <- c(25,34,28,52)diabetes <- c("Type1", "Type2", "Type1", "Type1")status <- c("Poor","Improved", "Excellent", "Poor")patientdata <- data.frame(patientID, age, diabetes, status)取数据框中的某⼀个元素:patientdata age,如果不想每⼀次都输⼊patientdata,可以使⽤attach() detach()或者单独使⽤函数with()来简化代码。
R语言笔记

Learning R from ScratchBlabla##通过在命令、变量、逗号等附近添加空格来提高R的可读性.##可使用control+tab键来在控制台console和图形设备graphic device间切换. >help.start():得到HTML 格式的帮助(等价于:帮助->html帮助)>?xxx or >help(x):得到任何特定名字的函数的帮助##对于关键字和运算符,与函数的帮助类似,但是需要加上引号,如:> ?'+' 或>?”+” #等价于help('+') help(“+”)>??xx :在help.start()启动的浏览页上,”Search Engine &Keywords”>objects() or>ls():用来显示当前保存在R 环境中的对象名字>ls(pat=“x”):只显示在名称中带有某个指定字符的对象>ls(pat=“^x”):只显示在名称中以某个指定字符开头的对象>ls()不能列出名称以点号开头的向量可使用ls(all = T)>history():看到之前保存的数据和命令。
>rm(x,y):删除对象>rm(list=ls(all=TRUE)): 删除内存中所有对象,all=TRUE可以省略>dir.create("c:/Users/Mr.Young/Desktop/R") 创建新的工作目录>getwd()和>setwd():获取/设置工作空间目录##临时修改,只针对当前文件>setwd(file="c:/users/Mr.Young/Documents")file可以省略,且该操作等价于“文件”菜单“change dir”>getwd()[1] "c:/users/Mr.Young/Documents" (目录的分隔符用“/”(slash)或“\\”)永久修改,R右键->属性->快捷方式->起始位置Windows下默认的分隔符为\ (backslash),注意更改.>example():显示函数的例子(不加引号)>list.files():查看当前目录下的文件>save(x,y,file=”d:/xy.Rdata”); #保存变量>load(”d:/xy.Rdata”); #载入变量%%:求余数%/%:整除逻辑与: &(拉丁文为et)(前后都要判断)or && ( “&&”前为F就结束,结果为F) 逻辑非: | (前后都要判断) or || (“||”前为T就结束,结果为T)##同一行中输入多条命令,用“;”隔开,否则另起一行。
R语言菜鸟练习笔记2

R语言笔记1.读入数据文件内容,并显示在屏幕上•显示数据变量名•names(d);•显示行数、列数•nrow(d), ncol(d)•设置输出有效位数•options(digits=4)>abc<-read.csv(file="C:/Users/user/Desktop/MEdata.csv",he ader=T)>abcX TAX GDP EXP IE1 1978 5.1928 36.056 11.2209 3.5502 1979 5.3782 40.926 12.8179 4.5463 1980 5.7170 45.929 12.2883 5.7004 1981 6.2989 50.088 11.3841 7.3535 1982 7.0002 55.900 12.2998 7.7136 1983 7.7559 62.162 14.0952 8.6017 1984 9.4735 73.627 17.0102 12.0108 1985 20.4079 90.767 20.0425 20.6679 1986 20.9073 105.085 22.0491 25.80410 1987 21.4036 122.774 22.6218 30.84211 1988 23.9047 153.886 24.9121 38.21812 1989 27.2740 173.113 28.2378 41.56013 1990 28.2186 193.478 30.8359 55.60114 1991 29.9017 225.774 33.8662 72.25815 1992 32.9691 275.652 37.4220 91.19616 1993 42.5530 369.381 46.4230 112.71017 1994 51.2688 502.174 57.9262 203.81918 1995 60.3804 632.169 68.2372 234.99919 1996 69.0982 741.636 79.3755 241.33820 1997 82.3404 816.585 92.3356 269.67221 1998 92.6280 865.316 107.9818 268.49722 1999 106.8258 911.250 131.8767 298.96223 2000 125.8151 987.490 158.8650 392.73224 2001 153.0138 1090.280 189.0258 421.83625 2002 176.3645 1204.756 220.5315 513.78226 2003 200.1731 1366.134 246.4995 704.83527 2004 241.6568 1609.566 284.8689 955.39128 2005 287.7854 1874.234 339.3028 1169.21829 2006 348.0435 2227.125 404.2273 1409.74030 2007 456.2197 2665.992 497.8135 1668.63731 2008 542.2379 3159.746 625.9266 1799.21532 2009 595.2159 3487.751 762.9993 1506.48133 2010 732.1079 4028.165 898.7416 2017.22234 2011 897.3839 4726.192 1092.4779 2364.02035 2012 1006.1428 5293.992 1259.5297 2441.60236 2013 1105.3070 5866.730 1402.1210 2582.529 RS COM INV DEP1 15.586 17.5910 8.008 2.10602 18.000 20.1150 8.565 2.81003 21.400 23.3120 9.109 3.95804 23.500 26.2790 9.610 5.23705 25.700 29.0290 12.304 6.75406 28.494 32.3110 14.301 8.92507 33.764 37.4200 18.329 12.14708 43.050 46.8740 25.432 16.22609 49.500 53.0210 31.206 22.385010 58.200 61.2610 37.917 30.814011 74.400 78.6810 47.538 38.222012 81.014 88.1260 44.104 51.964013 83.001 94.5090 45.170 71.196014 94.156 107.3060 55.945 92.449015 109.937 130.0010 80.801 117.573016 142.704 164.1210 130.723 152.035017 186.229 218.4420 170.421 215.188018 236.138 283.6970 200.193 296.623019 283.602 339.5590 229.135 385.208020 312.529 369.2150 249.411 462.798021 333.781 392.2930 284.062 534.075022 356.479 419.2040 298.547 596.218023 391.057 458.5460 329.177 643.324024 430.554 494.3590 372.135 737.624025 481.359 530.5660 434.999 869.106526 525.163 576.4980 555.666 1036.173127 595.010 652.1850 704.774 1195.553928 671.766 729.5870 887.736 1410.509929 791.452 825.7545 1099.982 1615.873030 935.716 963.3250 1373.239 1725.341931 1148.301 1116.7040 1728.284 2178.853532 1326.784 1235.8462 2245.988 2607.716633 1569.984 1407.5865 2516.838 3033.024934 1839.186 1689.5663 3114.851 3436.358935 2103.070 1905.8460 3746.947 3995.510436 2378.099 2121.8750 4470.744 4607.8504>names(abc)[1] "X" "TAX" "GDP" "EXP" "IE" "RS" "COM"[8] "INV" "DEP">nrow(abc)[1] 36>ncol(abc)[1] 9>options(digits=4)• 2.提取第一列(TAX)数据中的1993-2013部分,为x•显示数据x•使用散点图绘制该x数据> x<-abc[16:36,"TAX"]>plot(x)• 3.将x转换为时间序列数据•y<-ts(x,start=1993)•绘制时间序列•plot(y)> y<-ts(x,start=1993)> plot(y)• 4.整个数据集进行时间序列化•进行多变量序列绘图•ts.plot(td)•进行多变量序列的log绘图•ts.plot(log(td))•进行单变量序列绘图•plot.ts(td)•>ts.plot(y)•>ts.plot(log(y))•>plot.ts(y)• 5.变量解析绑定•attach(abc)•解绑•detach(abc)绑定之后,可用表头名作为变量直接操作,以下操作均是在绑定状态下进行的• 6.绘制两变量的散点图•••plot(GDP,TAX)•plot(TAX~GDP)•7.拟合线性回归模型•> LM<-lm(TAX~GDP, data=abc)•> LM••Call:•lm(formula = TAX ~ GDP, data = abc)••Coefficients:•(Intercept) GDP• -28.007 0.187>abline(-28.007,0l.187)。
R语言入门(经典)

查看帮助文件
1 help("t.test") 2 ?t.test 3 help.search("t.test") 4 apropos("t.test") 5 RGui>Help>Html help 6 查看R包pdf手册
帮助文件的内容
以lm函数为例: lm(stats) #函数名及所在包 Fitting Linear Models # 标题 Description #函数描述 Usage # 默认选项 Arguments # 参数 Details # 详情 Author(s) # 作者 References # 参考文献 Examples # 举例
boxplot(count ~ spray, data = InsectSprays) boxplot(count ~ spray, data = InsectSprays, col = "red")
R函数调用及其选项
函数的调用方法, 函数名+() 如 plot(), lm(),并 将对象放入括号中,“=”表示设定参数。例如:
txt文件,制表符间隔 csv文件,逗号间隔 一些R程序包(如foreign)也提供了直接读取 Excel, SAS, dbf, Matlab, spss, systat, Minitab文件的函数。
R语言知识点汇总及课后题梳理档1

课后题主要以本书为例,内容重点各个版本的都整理在一块了,大家自行查阅。
从不同的角度出发,对而会有不同的描述。
从实用角度,而是一个有着统计分析功能强大及强大作图功能的软件。
从编程角度,r语言是面向对象的向量化编程语言。
从计算角度,而是一种胃统计计算和图形显示而设计的集成环境。
从开发角度,而是一种开源的数据操作计算和图形显示工具的整合包有各种方式可以进行编程调用。
从架构角度,而是为统计计算和图形展示而设计的一个系统,包括一种编程语言,高水平图形展示函数,其他语言的接口以及调试工具。
R语言的主要优势。
一,作图美观,二,完全免费,三,算法覆盖广,四,软件扩展易,五强大的社区支持6,非过程模式七交互性八统计学特性正确的数据思维观数学思维能够帮助我们摒弃主观的偏见与看法。
统计思维是通过统计学表达数据的分布特征,相比于数学,统计思维在日常生活中的应用要明显而又简单的多,日常生活中接触的求和平均值,中位数,最大值等其实都是统计学的部部分。
描述描述就是对事物或对象的客观印象。
描述使用的指标通常是如下统计量,平均数,众数,中位数,方差,极差和四分位点。
概括实行成概念的过程,把大脑中所描述的对象中的某些指标抽离出来,并形成一种认知。
概括的意义在于用一两个简单的概念就能传递出大量的信息。
概括是在描述的基础上处理出来的概念。
分析就是将研究对象的整体分为各个部分,方面因素和层次。
描述获取数据的细节,概括得到数据的结构,分析得到想要的结论,分析区别与描述和概括一个非常重要的特征就是以目标为前提,以结果为导向。
分析是从描述与概括中抽离出能够实现目标的元素。
逻辑思维是人的理性认识阶段,使人运用概念,判断,推理等思维类型反映事物本质与规律的认识过程。
判断在前,推理在后,这是逻辑思维最重要的原则。
逻辑思维具体包括以下几点。
一上取/下钻思维。
下钻思维是显微镜原理。
2,求同/求异思维。
三,抽离/联合思维。
联合思维就是站在当事人的角度去思考和分析,这样才会理解人是何物。
R语言-菜鸟级课程

数 据 类 型
#? 1、如何创建一个矩阵 v<-matrix(1:12,nrow=3,byrow=T) #? 2、求矩阵的逆(需要方阵,且秩为行数) v2<-matrix(tan(1:16),nrow=4,byrow=T) qr(v2)$rank solve(v2) #? 3、求矩阵的特征值与特征向量(需要方阵) eigen(v2) ------------------------------------------------------#? 1、如何创建一个数据框 d<data.frame(ID=c(1,2,3,4,5),AGE=20:24,INCOME=c(2 3001,3232,10232,9923,1023)) #? 2、条件过滤及子集筛选 d2<-d[d$INCOME>10^4,c("ID","AGE")] d2<subset(d,d$INCOME>10^4,c("ID","AGE"),drop=TRU E) #? 3、数据框的拼接 d2<-cbind(d2,RNO=c("20","23"))
MeanDecreaseGini通过 基尼(Gini)指数计算每 个变量对分类树每个节点 上观测值的异质性的影响, 从而比较变量的重要性。 该值越大表示该变量的重 要性越大
如何用R分析数据、初步窥探数据
聚 类 分 析
Q&A
数据框(data.frame)
install.packages()
安 install.packages(c("xx","yy")) 装 R RCMD INSTALL "xxx.tar.gz" 包
R语言教程笔记-入门级1--不求甚解

R编程笔记一、R数据结构在R中,我们一直都在与对象(object)打交道。
1.存储类型(mode)实数型(real):整数(integer)、单精度(single)、双精度(double)虚数型(complex):如9 + 11i字符型(character, string):如"hello"(单双引号都行)逻辑型(logical):TRUE, FALSE (简写T, F)函数(function)表达式(expression)2. 结构化数据向量(vector):一列数值或字符矩阵(matrix):m行×n列(各列之间类型都相同)数据框(data frame):类似矩阵,但每一列的数据类型可以不同数组(array):多维度(不是多变量)列表(list):有诸多成员杂合在一起,这些成员可以是任意类型,甚至是list本身(及其灵活的数据类型)因子(factor):分类变量时间序列(ts):时间序列数据使用变量的时候要特别注意,R对大小写敏感!3.产生数据3.1 简单的规则序列> 1:10 # 井号是R的注释符号[1] 1 2 3 4 5 6 7 8 9 10> 10:1[1] 10 9 8 7 6 5 4 3 2 1> seq(1, 10, 0.5) # 等差数列[1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5[11] 6.0 6.5 7.0 7.5 8.0 8.5 9.0 9.5 10.0>rep(2, 5) # 重复相同的对象[1] 2 2 2 2 2> rep(1:3, times = 3) # 观察与下例的不同[1] 1 2 3 1 2 3 1 2 3> rep(1:3, each = 3)[1] 1 1 1 2 2 2 3 3 3> rep(1:3, 1:3)[1] 1 2 2 3 3 33.2产生结构化数据向量很容易用函数c()产生:> x = c(9, 1, 1)> x[1] 9 1 1> (x = c('Xie', 'Yi', 'Hui')) # 为什么用括号☺??????[1] "Xie" "Yi" "Hui"矩阵用matrix()产生:> matrix(1:10, 2) # 注意:默认按列排列[,1] [,2] [,3] [,4] [,5][1,] 1 3 5 7 9> matrix(1:10, nrow = 2, ncol = 5, byrow = T)[,1] [,2] [,3] [,4] [,5][1,] 1 2 3 4 5[2,] 6 7 8 9 10数据框用data.frame()产生> x = data.frame(1:5, 4:8) # 把若干个向量合成数据框> xX1.5 X4.81 142 2 53 3 64 4 75 5 8> x = cbind(x, c('A', 'B', 'C', 'D', 'E')) # 绑上一列字符(按列组合,rbind为按行组合)> xX1.5 X4.8 c("A", "B", "C", "D", "E")1 14 A2 2 5 B3 3 6 C4 4 7 D5 5 8 E>dimnames(x) # 看一下x的行列名[[1]][1] "1" "2" "3" "4" "5"[[2]][1] "X1.5"[2] "X4.8"[3] "c(\"A\", \"B\", \"C\", \"D\", \"E\")"> colnames(x) # 只看列名[1] "X1.5"[2] "X4.8"[3] "c(\"A\", \"B\", \"C\", \"D\", \"E\")"> colnames(x) = c('X1', 'X2', 'X3') # 改列名> x # 这样看起来就舒服多了X1 X2 X31 1 4 A2 2 5 B3 3 6 C4 4 7 D5 5 8 E因子用factor()产生列表用list()产生时间序列用ts()产生3.3外部读入数据剪贴板(clipboard),或者SQL、Access数据库(RODBC包)等例:D:\x.txt文件"V1" "V2" "V3" "V4" "V5"1 1 5 9 13 17> x = read.table('d:\\x.txt', header = T)> xV1 V2 V3 V4 V51 1 5 9 13 172 2 6 1014 184.运算4.1算术运算:+, -, *, /, %%(余数), %/%(整数商), ^(乘方)> 5%%2[1] 1> 5%/%2[1] 24.2逻辑运算:&, |, !(且、或、非);>, <, >=, <=, =="<-"是赋值符号,x<-9与x=9等价!小于负数加上空格x< -9或者x<(-9)> 1 == T[1] TRUE> 2 == T[1] FALSE> 0 == F[1] TRUE> 1:10 > 5[1] FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE5. 下标的使用向量、因子、时间序列x[i];矩阵、数据框x[i, j] x[i, ] x[, j];数组就是根据维度多打几个逗号而已x[i, j, k, …];列表要用双重中括号x[[i]]。
r语言菜鸟教程

r语言菜鸟教程r语言是一种用于数据分析和统计建模的编程语言。
它提供了许多强大的功能和包,使得数据处理变得更加简单和高效。
R语言的安装非常简单,只需从官方网站下载并按照指示进行安装即可。
安装完成后,就可以开始编写R代码了。
R语言中最基本的数据结构是向量(Vector)。
向量可以存储数值、字符、逻辑值等不同类型的数据。
我们可以使用c()函数来创建向量,如下所示:```num_vector <- c(1, 2, 3, 4, 5) # 创建数值型向量char_vector <- c("a", "b", "c", "d", "e") # 创建字符型向量logical_vector <- c(TRUE, FALSE, TRUE, TRUE, FALSE) # 创建逻辑型向量```除了向量,R语言还有其他的数据结构,如矩阵(Matrix)、数组(Array)、数据框(Data Frame)等。
这些数据结构可以用于存储和处理更复杂的数据。
R语言提供了丰富的函数和运算符来进行数据操作和统计分析。
例如,我们可以使用sum()函数计算向量中所有元素的和,使用mean()函数计算向量的平均值,使用sd()函数计算向量的标准差等。
除了内置的函数,R语言还支持用户自定义函数。
我们可以使用function关键字定义函数,并在需要时调用它们。
例如,下面是一个计算两个数之和的函数的定义和调用:```sum_numbers <- function(a, b) {result <- a + breturn(result)}sum_result <- sum_numbers(5, 3)```R语言的另一个重要特点是它的图形功能。
我们可以使用R语言的图形包(如ggplot2、plotly等)来创建各种类型的图表,如散点图、柱状图、饼图等。
R语言使用笔记_2012

2.5 矩阵运算 2.5.1 转置 t(A)
2.5.2 行列式 det()
2.5.3 向量内积
x%*%y
crossprod(x,y)======= t(x)%*%y
Example: x<-3 switch(x,2+2,mean(1:10),rnorm(4)) switch(2,2+2,mean(1:10),rnorm(4)) switch(6,2+2,mean(1:10),rnorm(4))
2.7.2 终止语句与空语句 break:终止循环,使程序跳到循环之外 空语句是 next,继续执行
2、多维数组 2.1 一维数组 dim() 例子: z<-1:12 dim(z)<-c(3,4)
结果: z
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10 [2,] 2 5 8 11 [3,] 3 6 9 12
2.2 多维数组 array() array(data = NA, dim = length(data), dimnames = NULL) data 是一个向量数据;dim 是数组各维的长度,默认为原向量长度,dimnames 是数组维名, 默认为空
2.5.5 矩阵乘法 和向量内积相同,只是要求 A*B 有相同的维数
2.5.6 生成对角阵和矩阵取对角运算 diag(v) 作用取决于变量。 v 是一个向量时,表示以 v 为对角元素的对角阵; v 是一个矩阵时,表示取矩阵的对角线上元素;
2.5.7 解线性方程组 求解 Ax=b 命令为 solve(A,b); 求矩阵 A 的逆,命令为 solve(A)
那些年倒腾的R语言学习笔记,全都在这里了~

那些年倒腾的R语言学习笔记,全都在这里了~今天这一篇整理一下我以往推送过的所有R语言相关文章,一来是方便大家的检索,二来也是阶段性学习的一次总结。
关于内容分类,我分成了学习心得篇、R语言基础、数据可视化、网络数据爬取,然后各自类别进行详细的再分类。
-----------------------------R语言学习心得篇:R语言基础:数据可视化:•ggplot2语法入门•R语言商务图表•信息图•地理信息可视化•动态可视化网络数据爬取:----------------------------------R语言学习心得篇:给R语言初学者的几个建议~学习R语言我都做了那些有趣的事情R语言基础入门:R:R语言笔记之——常用数据导入方式简介R语言数据重塑及导出操作R语言数据处理——数据合并与追加R VS Python:左右用R右手Python系列——字符串格式化输出左手用R右手Python系列——数据合并与追加左手用R右手Python系列——数据塑型与长宽转换左手用R右手Python系列——因子变量与分类重编码数据可视化:基础部分:R语言信息可视化——文字云R语言数据可视化之——TreeMapR语言学习笔记——柱形图R语言可视化——柱形图美化(簇状、堆积、百分比)R语言可视化——多系列柱形图(条形图)与分面组图美化技巧!R语言可视化——散点图及其美化技巧!R语言可视化——直方图及其美化技巧!R语言可视化——密度曲线图及其美化!R语言可视化——折线图、平滑曲线及路径图R语言可视化——面积(区域)图及其美化R语言可视化——箱线图及其美化技巧R语言可视化——极坐标变换与衍生图表类型R语言可视化——多边形与数据地图填充R语言可视化——用ggplot构造期待已久的雷达图当PowerBI遇到R语言配色与版式优化:R预设配色系统及自定义色板R语言颜色综合运用与色彩方案共享一个神奇的配色网站~R语言可视化——ggplot图表中的线条R语言可视化——图表美化与套用主题(上)R语言可视化——图表美化与套用主题(下)R语言可视化——ggplot图表配色技巧R语言可视化——图表嵌套(母子图)R语言可视化——ggplot携手plotly,让你的图表灵动起来!R语言可视化——图表排版之一页多图R语言可视化——ggplot的theme订制R语言可视化——ggplot图表系统中的形状R语言可视化——ggplot图表系统中的辅助线不经意间又发现了一个有趣又炫酷的包~用优雅的配色来缔造图表专业主义~R语言图表美化——巧用分面表达优化图表布局,做出堪比杂志级视觉体验的商务图表ggplot2又添新神器——ggthemr助你制作惊艳美图地图部分(ggplot2)一篇文章教你搞定JSON素材,从此告别SHP时代~大道至简——论如何最优雅的操纵json地图数据关于美国地图中的两个海外州坐标平移与原始投影问题~R语言可视化——关于ggplot所支持的数据地图素材类型一篇小短文助你打开数据可视化的任督二脉!数据地图多图层对象的颜色标度重叠问题解决方案ggplot2中如何自定义数据地图版面范围~关于数据地图的几个遗留问题解决方案R语言数据地图——美国地图R语言数据地图——全球填色地图数据地图系列7|R语言版(上)数据地图系列8|R语言版数据地图(下)R语言可视化——数据地图应用(东三省)R语言可视化——数据地图离散百分比填充(环渤海)R语言可视化——地图填充与散点图图层叠加R语言可视化——多图层叠加(离散颜色填充与气泡图综合运用)R语言可视化——地图与气泡图结合应用用R语言复盘美国总统大选结果~R语言可视化——ggplot绘制中心密度辐射图R语言可视化——中心放射状路径图你绝对想不到,数据地图还能这么玩~玩转数据地图系列之——地图上的迷你条形图一个小案例,教你如何从数据抓取、数据清洗到数据可视化一篇全是代码的数据可视化案例小魔方不想跟你说话,并向你扔了一堆代码~~~地图可视化之——移花接木REmap地图:R语言可视化——REmap动态地图R语言可视化——REmap(路径图)R语言可视化——REmapB函数R语言可视化——REmapC(填充地图)R语言可视化——REmapH(中心热度图)leaflet地图:动态地理信息可视化——leaflet在线地图简介动态地理信息可视化——散点地图系列动态地理信息可视化——leaflet构造路径图动态地理信息可视化——leaflet填充地图Leaflet在线地图进阶宝典——json素材操纵与图层面板控制leaflet在线地图进阶宝典之——高级辅助特性leaflet在线地图进阶宝典——高级交互特性leaflet的小搭档leaflet.minicharts来了,从此动态地图又多了一些乐趣~~~商务图表进阶:超强脑洞第二弹之——ggplot构造漏斗图超强脑洞第三弹之——ggplot构造瀑布图超强脑洞第四弹——ggplot构造甘特图超强脑洞第五弹——ggplot 构造连环饼图用R语言制作商务图表,让你的图表美出新高度~一场用R语言打造的商务图表视觉盛宴~流量结构分布图——桑基图(Sankey)流量结构分布图——炫酷和弦图Word天呀,气泡图居然还有这种操作~这么牛X的包,一般人我不告诉他信息图高仿:信息图表高仿——R语言仿一财经典线条比较图用ggplot轻松搞定太极图用ggplot来挑战数据可视化的上限~ggplot系列之脑洞大开鱼缸百分比信息图~ggplot制作分析仪表盘用ggplot2制作静态数据可视化报告!R语言数据可视化——仿网易数独圆环条形图重要的是图表思维,而不是工具让执着成为一种习惯——仿网易数独玫瑰气泡图是时候展现真正的技术了——让你的图表舞动起来~上帝视角——给世界一个特写~像电影一样记录数据可视化shiny仪表盘:用R-Shiny打造一个美美的在线Appshiny动态仪表盘——360度全空间无死角拖拉换肤功能的旋转地球shiny仪表盘应用——2016年美国大选数据可视化案例爬虫及数据可视化:用R语言抓取网页图片——从此高效存图告别手工时代经历过绝望之后,选择去知乎爬了几张图~一言不合就爬虫系列之——爬取小姐姐的秒拍MV教你如何优雅的用R语言调用有道翻译2017年的第一周,你吸了多少雾霾?用数据来聊聊国产电影~当大家都在讨论金刚狼3的时候,他们到底在说些什么~一篇文章揭开office配色模板的的神秘面纱~你知道经管类的核心期刊都分布在那里吗?这是一篇很务正业的可视化推送~(上篇)下篇(续)大连市2016年空气质量数据可视化~北京历史空气质量数据可视化~挑战不可能之——ggplot环形字体地图用emoji表情包来可视化北京市历史天气状况!实习僧招聘网爬虫数据可视化我也不敢相信自己竟然写过这么多代码,不过都是过去的事情了,以后要往前看,不断地优化代码,学习新东西的同时不断巩固旧知识,抱着一种归零的心态,总结、凝练、提升、创新~~~R语言学习笔记精华汇总!。
R语言学习过程各种笔记

数据挖掘与数据分析的主要区别是什么?数据分析就是为了处理原有计算方法、统计方法,着重点就是数据、算法、统计、数值。
数据挖掘是从庞大的数据库中分析出有目标数据群,筛选出利于决策的有效信息简单来说就是数据分析是针对以往取得的成绩,比如说哪方面做得好,哪方面需要改进;数据挖掘就是通过以前的成绩预测未来的发展的趋势,并且为决策者提供建议。
读excel时可以先复制再运行data <- read.table("clipboard", header = T, sep = '\t')在R语言中,使用“=”和“<-”到底有什么不同?就是等号和箭头号有什么区别,是完全一样还是局部不同?R里通常用符号”<-”代替其它语言里的”=”来作赋值符号。
因为前者敲起来比等号要麻烦,且大部分情况下两者是等价的,所以通常就愉懒依旧用”=”来赋值。
但要切记两者在某些时候是有区别的。
字面上的解释,可以认为”<-”是赋值,”=”是传值。
在函数调用中,func(x=1)与func(x<-1)是有区别的,前者调用完后变量x不会被保留,而后者会在工作区里保留变量x=1。
再如length(x=seq(1,10))计算完成后x不会被保留,而length(x<-seq(1,10))计算完后你会在工作区里发现x这个变量。
矩阵知识:1_矩阵的生成2_矩阵的四则运算3_矩阵的矩阵运算4_矩阵的分解1_1将向量定义成数组向量只有定义了维数向量(dim属性)后才能被看作是数组.比如:> z=1:12;> dim(z)=c(3,4);> z;[,1] [,2] [,3] [,4][1,] 1 4 7 10[2,] 2 5 8 11[3,] 3 6 9 12注意:生成矩阵是按列排列的。
1_2用array ( )函数构造多维数组用法为:array(data=NA,dim=length(data),dimnames=NULL)参数描述:data:是一个向量数据。
R语言菜鸟练习笔记 11
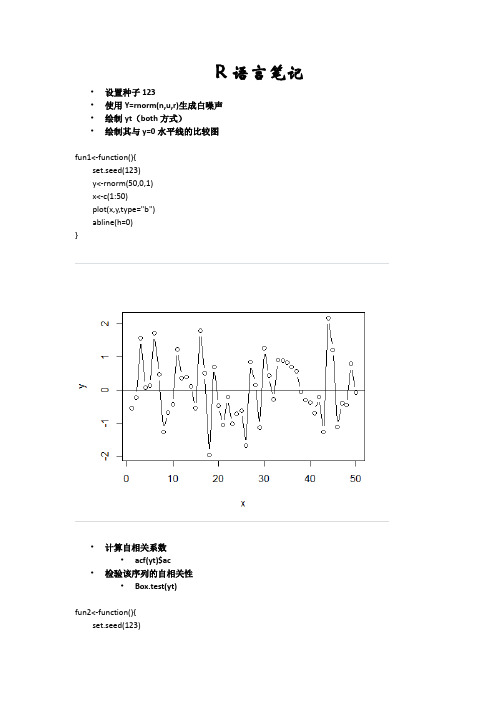
R语言笔记•设置种子123•使用Y=rnorm(n,u,r)生成白噪声•绘制yt(both方式)•绘制其与y=0水平线的比较图fun1<-function(){set.seed(123)y<-rnorm(50,0,1)x<-c(1:50)plot(x,y,type="b")abline(h=0)}•计算自相关系数•acf(yt)$ac•检验该序列的自相关性•Box.test(yt)fun2<-function(){set.seed(123)y<-rnorm(50)*10+10a<-acf(y)a$ac#Box.test(y)}•生成y=rnorm(50) * 10 + 10•生成y(t+1)=y(t) * 2 + rnorm(1)•生成y(t+2)=y(t+1) + y(t) * 2 + rnorm(1)•针对三个序列,分别•计算其自相关系数•检验该序列的自相关性fun3<-function(){set.seed(123)y<-c()y[1]<-1for(i in 2:50){y[i]<-y[i-1]*2+rnorm(1)}a<-acf(y)a$acBox.test(y)}fun4<-function(){set.seed(123)y<-c()y[1]<-1y[2]<-1for(i in 3:50){y[i]<-y[i-1]+y[i-2]*2+rnorm(1) }a<-acf(y)a$acBox.test(y)}•生成y=rnorm(50) * 10 + 10•生成y(t+1)=y(t) * 20 + rnorm(1)•生成y(t+2)=y(t+1)*10 - y(t) * 2 + rnorm(1)•针对三个序列,分别•计算其自回归fun51<-function(){y<-rnorm(50)*10+10plot(y)x11()pacf(y)LM<-lm(y~c(1:50))print(LM)}fun52<-function(n){y<-array(n)y[1]<-1for(i in 2:n){y[i]<-20*y[i-1]+rnorm(1) }plot(y)x11()pacf(y)LM<-lm(y~c(1:50))print(LM) }fun53<-function(n){y<-array(n)y[1]<-1y[2]<-1for(i in 3:n){y[i]<-10*y[i-1]-2*y[i-2]+rnorm(1) }plot(y)x11()pacf(y)LM<-lm(y~c(1:50))print(LM) }。
R语言笔记完整版

R语⾔笔记完整版R语⾔与数据挖掘:公式;数据;⽅法R语⾔特征1. 对⼤⼩写敏感2. 通常,数字,字母,. 和 _都是允许的(在⼀些国家还包括重⾳字母)。
不过,⼀个命名必须以 . 或者字母开头,并且如果以 . 开头,第⼆个字符不允许是数字。
3. 基本命令要么是表达式(expressions)要么就是赋值(assignments)。
4. 命令可以被 (;)隔开,或者另起⼀⾏。
5. 基本命令可以通过⼤括弧({和}) 放在⼀起构成⼀个复合表达式(compound expression)。
6. ⼀⾏中,从井号(#)开始到句⼦收尾之间的语句就是是注释。
7. R是动态类型、强类型的语⾔。
8. R的基本数据类型有数值型(numeric)、字符型(character)、复数型(complex)和逻辑型(logical),对象类型有向量、因⼦、数组、矩阵、数据框、列表、时间序列。
基础指令程序辅助性操作:运⾏q()——退出R程序tab——⾃动补全ctrl+L——清空consoleESC——中断当前计算调试查错browser() 和debug()——设置断点进⾏,运⾏到此可以进⾏浏览查看(具体调试看browser()帮助⽂档(c,n,Q))stop('your message here.')——输⼊参数不正确时,停⽌程序执⾏cat()——查看变量?帮助help(solve) 和 ?solve 等同solve——检索所有与solve相关的信息help("[[") 对于特殊含义字符,加上双引号或者单引号变成字符串,也适⽤于有语法涵义的关键字 if,for 和 functionhelp(package="rpart")——查看某个包help.start()——得到html格式帮助help.search()——允许以任何⽅式(话题)搜索帮助⽂档example(topic)——查看某个帮助主题⽰例apropos("keyword")——查找关键词keyword相关的函数RSiteSearch("onlinekey", restrict=fuction)——⽤来搜索邮件列表⽂档、R⼿册和R帮助页⾯中的关键词或短语(互联⽹)RSiteSearch('neural networks')准备⽂件⽬录设置setwd(<dir>)——设置⼯作⽂件⽬录getwd()——获取当前⼯作⽂件⽬录list.files()——查看当前⽂件⽬录中的⽂件加载资源search()——通过search()函数,可以查看到R启动时默认加载7个核⼼包。
R语言笔记

R语言笔记第一章R语言介绍1.将结果输出到文件sink("practice.txt") practice.txt需要在工作空间中,sink()加在程序前面,并且会一直生效> a第二章创建数据集(read.xl包)1.指定实例标识符a<- data.frame(ID, col1, col2, col3...., /doc/ad13408624.html,s=ID) 方便区分数据的行,比如ID之类2.读取txtread.table("D:/学习/R语言文件/practice.txt",sep="") txt分隔符为空3.读取csvread.table("D:/学习/R语言文件/餐饮.csv",sep=",") csv分隔符为逗号4.读取中文excellibrary(readxl, quietly=TRUE)a <- read_excel("D:/学习/R语言文件/餐饮(天善).xlsx") 这样读不会出现UTF-8乱码5.edit和fix区别a<-edit(a) edit需要赋值修改才会生效fix(a)fix不用赋值第三章图形初级1.图形的输出bmp("mtcars.bmp") mtcars.BMP文件需要先创建好plot(mtcars$mpg,mtcars$wt,type="b")dev.off()2.图形参数初始化opar<-par(no.readonly=TRUE)布局par(fig=c(0,0.5,0.1,0.6)) 水平0-0.5竖直0.1-0.6符号par(pch=2)线条par(lty=2)画图attach(iris)plot(Sepal.Length,Sepal.Width,col=c("red","blue"),main="1", xlab="2")辅助线abline(h=c(2,2.5,3),v=c(4,5,6))图例legend("topleft",title="5",pch=2,col=c("red","blue"),c("Sepal.Len gth","Sepal.Width "))detach(iris)结束par(opar)第四章基本数据管理(car包,plyr包)1.在原变量基础上创建新变量最好的方法a<-iristransform(a,sum=Sepal.Length+Sepal.Width)2.变量的重编码car包x<-c(10:100)recode(x,"lo:60='C';61:80='B';81-hi='A';else='NULL'")3.变量的重命名1.fix 不需要赋值2.plyr包rename(a,c("Sepal.Length"="b",Sepal.Width="c"))4.重编码为缺失值用2.5.排除缺失值na.rm=TRUE选项newdata<-na.omit(dataframe)6.日期值将字符串格式转换成日期格式(计算用)as.Date(c,"%d/%m/%Y") 红字为c的格式,不是输出格式注意Date的D为大写指定输出格式或者提取部分日期today<-Sys.Date()format(today,format="%d/%y/%m")format(today,format="%d")今天和现在Sys.Date()date()7.类型转换a<-as.character(a) 日期值相当于数字,不能用字符处理函数,需要先转换其他类型转换和判断is.numeric as.numeric下略8.数据排序attach(a)a<-a[order(-b,c),] 按b降序,再按a升序,注意数据框后面是中括号和逗号detach9.数据合并横向合并有公共列total<-merge(a,b,by=c("ID","SEX")无公共列total<-cbind(a,b) 行数相同并且排列相同纵向合并total<-rbind(a,b) 列要相同不需要顺序相同列数不相同时可以删除多的或者像少的里添加列赋值N10.取子集1.x<-data.frame[1:5,2:6] 取1到5行和2到6列2.最简单的方法,可以同时选择变量和观测s<-subset(iris,Petal.Length>1&Petal.Length<5,select=c(Sepal.Length,Sepa l.Width))数据框变量条件筛选行选择列11.抽样mysample<- iris [ sample (1:nrow(iris) , 10 , replace=TRUE),] 注意[ ] 和最后的逗号12.查看行名和列名names(iris)/doc/ad13408624.html,s(iris)第五章高级数据处理(reshape2包)1.将函数应用于数据框apply(data.frame,1或者2,fun) 1为对行应用fun,2为对列2.控制流循环for(var in seq) statementwhile(cond) statement条件if(cond) statementif(cond) statement1 else statementswitch3.数据折叠和分组aggregate(mtcars,by=list(mtcars$cyl,mtcars$gear),mean)将mtcars按照cyl和gear分组,并计算平均数4.reshape2包融合a<-melt(a,id=c("var1","var2".......)) 将数据整合重铸b<-dcast(a,rowvar1+rowvar2+...~colvar1+colvar2+... , fun) 选取想要的观测和变量第六章基本图形(vcd包,plotrix包,sm包,vioplot包)1.条形图作用对象是频数表table()a<-table(mtcars$mpg)数值条形图barplot(a)水平条形图barplot(a,horiz=TRUE)b<-mtcars[1:5,c(2,10)]分组条形图barplot(table(b),beside=TRUE)堆砌条形图barplot(table(b),beside=FALSE)脊状图(vcd包)特殊的堆砌条形图(高度是比例)spine(table(b))2.饼图(慎用)要用就用玫瑰图或者扇形图饼图pie (c(1,2,3,4),labels=c("a","b","c","d"))扇形图(plotrix包)fan.plot(c(1,2,3,4),labels=c("a","b","c","d"))3.直方图hist(mtcars$mpg,breaks=12,freq=FALSE) 概率密度hist(mtcars$mpg,breaks=12,freq=TRUE ) 频数4.核密度图(连续的概率密度直方图)画一组plot(density(mtcars$mpg))画多组sm包/doc/ad13408624.html,pare(mtcars$mpg,mtcar s$cyl)5.箱线图单个boxplot(mtcars$mpg)多组boxplot(mpg~cyl,data=mtcars)多组交叉比较cyl.f<-factor(mtcars$cyl)am.f<-factor(mtcars$am)boxplot(mpg~cyl.f*am.f,data=mtcars,varwidth=TRUE)小提琴图vioplot包x1<-mtcars$mpg[mtcars$cyl==4]x2<-mtcars$mpg[mtcars$cyl==6]x3<-mtcars$mpg[mtcars$cyl==8]vioplot(x1,x2,x3)6.点图普通点图dotchart(mtcars$mpg,labels=/doc/ad13408624 .html,s(mtcars))排序点图x<-mtcars[order(mtcars$mpg),] 1排序x$cyl<-factor(x$cyl) 2转因子dotchart(x$mpg,labels=/doc/ad13408624. html,s(x)) 3画图第七章基本统计分析(Hmisc包,psych 包,doBy包,gmodels 包,ggm包,MASS包)1.描述性统计分析summary(mtcars)sapply(mtcars,fivenum)Hmisc包describe(mtcars)psych包describe(mtcars)2分组描述性统计分析doBy包summaryBy(mpg+hp+wt~cyl+am,data=mtcars) 后面还可以加函数3.列联表一维table(mtcars$cyl)prop.table(table(mtcars$cyl)) 百分比列联表作用对象是table,不是向量prop.table(table(mtcars$cyl))*100二维table(mtcars$cyl,/doc/ad13408624.html,s(mtcar s)) 二维,前面是行,后面是列xtabs(~mtcars$cyl+mtcars$am) 和↑效果一样gmodels包CrossTable(mtcars$cyl,mtcars$am) 没别的就是好看三维table(mtcars$cyl,mtcars$am,mtcars$gear)xtabs(~mtcars$cyl+mtcars$am+mtcars$gear)ftable(xtabs(~mtcars$cyl+mtcars$am+mtcars$gear))4.独立性检验(针对类别变量,基于列联表)卡方检验chisq.test(table(mtcars$cyl,mtcars$gear)) 原假设:行和列独立Fisher检验fisher.test(table(Arthritis$Improved,Arthritis$Treatment)) 原假设:边界固定列联表行和列独立cochran-mantle-haenszel检验mantelhaen.test(xtabs(~Improved+Treatment+Sex,data=Art hritis))原假设:两个名义变量在第三个变量每一层中独立5.相关(针对数值变量,基于协方差矩阵)协方差矩阵cov<-cov(mtcars)相关矩阵cor(mtcars,use=控制缺失值,method=三种方法)偏相关ggm包pcor(c(1,2,3,4,5,6),cov) 控制3,4,5,6之后,1,2的偏相关关系6.相关关系检验cor.test(mtcars$mpg,mtcars$wt,method="pearson") person spearmankendall第八章回归(car包,leaps包)1.建立模型fit<-lm(mpg~wt,data=mtcars) 多元线性回归要先检查相关性,画图或者cor 2.展示模型输入模型名称显示参数summary 详细fitted 预测predict 预测confint 提供置信区间有点用plot 综合诊断图par(mfrow=c(2,2))plot(fit)3诊断模型car包正态性(图像应该是45度支线)qqPlot(fit,labels=/doc/ad13408624.html,s( mtcars),id.method="identify")带置信区间的qq图可以交互线性(图像应该是支线)crPlots(fit)同方差性(水平点随机分布在两侧)ncvTest(fit) 检验误差方差是否不变,零假设:误差方差不变spreadLevelPlot(fit) 还会给出一个建议幂次,接近1不需要换多重共线性vif(fit) sqrt(vif(fit))>2 就说明有多重共线性异常值的观测influencePlot(fit) 离群点y>2 或y<-2高杠杆x>0.2或x<-0.2强影响点圆圈大4 改进措施1.删除观测点dplyr包2.变量变换car包summary(powerTransform(mtcars$wt)) 注意作用对象是数据框3.删除多重共线性变量5模型比较anova(fit1,fit2) 需要一个模型完全包含另一个模型的变量AIC(fit1,fit2)6.选择最佳模型全子集回归leaps包fit1<-regsubsets(mpg~wt+disp+hp+drat+qsec,data=mtcars) plot(fit1,scale="adjr2") adjr2值最高的模型最好相当于r方第九章方差分析第十章功效分析第十一章中级绘图(car包,hexbin 包,corrgram包,vcd包)1.散点图attach(mtcars)plot(mpg,wt)abline(lm(wt~mpg),col="red",lty=2,lwd=2) 添加拟合直线变量要反向lines(lowess(mpg,wt)) 添加拟合曲线car包scatterplot(mpg~wt|cyl,legendplot=TRUE,id.method="ident ify",labels=/doc/ad13408624.html,s( mtcars),bo xplot="xy") 可以分组并交互的散点图,还可以加箱线图2.散点图矩阵pairs(~mpg+wt+disp+drat,data=mtcars)pairs(mtcars)car包scatterplotMatrix(mtcars,spread=FALSE,smoother.args=list(l ty=2))scatterplotMatrix(~mpg+wt+disp+drat,data=mtcars,spread=FA LSE,smoother.args=li st(lty=2))格式与自带函数基本相同3.高密度散点图hexbin包bin<-hexbin(iris$Sepal.Length,iris$Sepal.Width,xbin=50) xbin是指点的大小plot(bin)4.旋转三维散点图car包attach(mtcars)scatter3d(wt,mpg,disp)5.气泡图attach(mtcars)symbols(mpg,wt,circle=sqrt(disp/pi),inches=0.3)6.折线图plot(x,y,type="") p实心点,l直线,o实心点+直线,b虚心点+直线,c不画点的线,s和S阶梯式,h垂线,n建立坐标轴用7.相关图corrgram包corrgram(mtcars,order=TRUE,lower.panel=panel.shade,upp er.panel=panel.pie,text.panel=panel.txt,diag.panel=panel.minmax)8.马赛克图(三个以上类别变量)vcd包mosaic(~Class+Sex+Age+Survived,data=Titanic,shade=TR UE,legend=TRUE)根据残差上色残差图例第十二章重抽样和自住法第十三章广义线性模型1.logistic回归(Y为二值型变量)fit<-glm(y~x1+x2+x3+x4+...,data=data.frame,family=binomial()) 用summary(fit)看各个变量显著性,筛选变量用coef(fit)解释用测试集预测testdata$prob<-predict(fit,newdata=testdata,type="response")过度离势deviance(fit)/df.residual(fit) 残差偏差/残差自由度如比1大得多,则过度离势2.泊松回归(Y为计数型变量)fit<-glm(y~x1+x2+x3+x4+...,data=data.frame,family=poisson()) 解释,过度离势同上;预测不明第十四章主成分分析和因子分析(psych包)1.主成分分析psych包主成分个数选择fa.parallel(USJudgeRatings[,-1],fa="pc",n.iter=100,show.legend=FALSE)abline(h=1) 选择标准1.曲线>1 2.曲线>辅助线3最大拐点计算主成分pc<-principal(USJudgeRatings[,-1],nfactors=1)2.因子分析因子个数选择fa.parallel(USJudgeRatings[,-1],fa="fa",n.iter=100,show.legend=FALSE)abline(h=0) 选择标准1.曲线>0 2.曲线>辅助线3最大拐点提取因子fa<-fa(USJudgeRatings[,-1],fa="pa",nfactors=2) 方法用pa或者ml第十五章时间序列第十六章聚类分析(NbClust包,cluster包)1.分组聚类距离法d<-dist(scale(mtcars))fit<-hclust(d,method="average")plot(fit)缺点:无法选择适当的聚类个数选择聚类个数方法NbClust包选择聚类个数a<-read.table("D:/学习/R语言文件/nutrient.txt",sep="")a<-scale(a)devAskNewPage(ask=TRUE)fit<-NbClust(a,distance="euclidean",min.nc=2,max.nc=15,method=" average") table(fit$Best.n[1,])barplot(table(fit$Best.n[1,]))画出聚类图fit1<-cutree(fit,k=5)fit1 可以查看各个聚类数量aggregate(a,by=list(cluster=fit1),mean) 查看各个组统计量plot(fit1)2.划分聚类kmeans首先删除非数值型变量然后对数据scale然后用自定义函数wassplotnutrient<-read.table("D:/学习/R语言文件/nutrient.txt",sep="")scaled<-scale(nutrient) 中心化fit<-NbClust(scaled,min.nc=2,max.nc=15,method="kmeans") table(fit$Best.nc[1,])barplot(table(fit$Best.nc[1,])) 最高的是聚类个数fit.kmeans<-kmeans(scaled,3,nstart=25)cluster1<-as.data.frame(fit.kmeans$cluster) 可以先str(fit)看下结构total<-cbind(nutrient,cluster1) 必须转化成数据框才可以和原数据合并围绕中心点的划分(PAM)cluster包选择聚类个数用kmeansfit.pam<-pam(scaled,k=3,stand=TRUE)str(fit.pam) 看下结构找聚类变量cluster2<-as.data.frame(fit.pam$clustering) 转化为数据框total<-cbind(nutrient,cluster2)第十七章分类1. 逻辑回归(广义线性模型)(rpart包,rpart.plot 包,party包,randomForest包,e1071包)缺点:logistics回归只能对二值型变量分类,类别变量多于2个不能使用2. 经典决策树rpart包,rpart.plot包set.seed(1234)tree1<-rpart(Species~.,data=iris,method="class")plotcp(tree1) #选择虚线下最左侧的tree1$cptable #图看不出来时候用这个看#在最后一行的xerror±3+xstd范围内找xerror tree1.prune<-prune(tree1,cp=0.01) #cp值由上一行代码得出prp(tree1.prune,type=2,extra=104) #type=2显示标签extra=104显示占比#判断正确率tree1.predict<-predict(tree1.prune,iris,type="class")table(tree1.predict,iris$Species,dnn=c("predict","actual"))partykit包可以用条件树的方法画经典树plot(as.party(tree1))3. 条件决策树party包tree2<-ctree(Species~.,data=iris)plot(tree2)tree2.predict<-predict(tree2,iris,type="response")table(tree2.predict,iris$Species,dnn=c("predict","actual"))4. 随机森林randomForest包fit.forest<-randomForest(Species~.,data=iris,na.action=na.omit,importanc e=TRUE) fit.forest 直接给出正确/错误列联表plot(fit.forest) 画出错误/森林颗数图importance(fit.forest,type=2) 给出变量重要性predict.forest<-predict(fit.forest,iris) 预测table(predict.forest,iris$Species,dnn=c("predict","actual"))5. 支持向量机svm.fit<-svm(Species~.,data=iris)svm.fitsvm.predict<-predict(svm.fit,iris)table(svm.predict,iris$Species,dnn=c("predict","actual"))第十八章处理缺失数据(VIM包,mice包)1.识别缺失值is.na(iris) 数据大看着乱complete.cases(iris) 数据量上千会看着乱mice包md.pattern(a) 列表查看,还可以VIM包aggr(a) 画出图表,对大数据量直观,大体了解缺失值2.行删除new<-b[complete.cases(b),] 删除所有有缺失值的行选择聚类个数。
R语言初学者指南学习摘要

R语言初学者指南第一章引言函数功能示例? 访问帮助文件?boxplot# 添加注释#Add your comments hereboxplot 生成盒形图boxplot(y)boxplot(y~factor(x))log 自然对数log(2)log10 以10为底的对数log10(2)library 载入包library(MASS)setwd 设置工作目录setwd(“C:/AnyDirectory”)q 关闭R q()citation 提供对R的引用citation()第二章 R中的数据输入录入数据,并把数据系统地转化为标量(单值)、向量、矩阵、数据框或列表。
如何从Excel、ascii文件、数据库和其他统计程序中载入数据。
2.1 R中的第1步2.1.1 小型数据库中的数据录入#符号“<-”相当于“=”#变量名中不能出现“%,^,&,*,!,?,+,-,(),[],#,<>”因为这些符号中的大部分都是运算符。
#如果定义好了:> SQ.wing1<-sqrt(wing1)若要现实SQ.wing1的值,只需输入:>SQ.wing1或者把需要执行的命令放在圆括号内:> (SQ.wing1<-sqrt(wing1))2.1.2 应用c函数连接数据C()函数可以完成一个变量中存储多个值例如:>Wingcrd <- c(59, 55, 53.5, 55, 52.5, 57.5, 53, 55)如果查看Wingcrd的第一个值,则需要> Wingcrd [1]如果需要查看Wingcrd前五个值,则需要> Wingcrd [1:5]如果需要查看Wingcrd除了第二个值以外的其他值,则需要> Wingcrd [-2]-负号表示删除了这个值R有很多的内置函数,最基本的有sum, mean, max, min, median(中位数), var(方差)和sd(标准差)等。
r语言 日记法

r语言日记法篇一哎呀,今天可真是让我对 R 语言和日记法有了一堆想法!说起来,这 R 语言,也许对有些人来说就是小菜一碟,但对我这种菜鸟,简直就是个超级大难题!我觉得吧,它就像个神秘的魔法盒子,你不知道打开后会蹦出啥稀奇古怪的东西。
我整天对着那些代码抓耳挠腮,心里想着:“这到底是啥玩意儿啊?”今天学 R 语言的时候,我感觉自己就像个在迷宫里乱转的小老鼠,找不到出口。
那些函数、数据框啥的,一个个都好像在嘲笑我:“哈哈,你搞不定我们!”也许是我太笨了,可我就不信这个邪!再说说这日记法,我一开始觉得这能有啥用?不就是每天写点流水账嘛。
但是后来我发现,嘿,还真不是那么简单!写日记的时候,就好像在跟自己的内心聊天,把那些藏在心底的小秘密、小情绪都倒出来。
有一次,我心情特别差,可能是考试没考好,也许是跟朋友闹别扭了。
然后我就在日记里一通发泄,写着写着,我自己都觉得好笑,这点破事至于这么难受吗?这日记法啊,说不定还真有点神奇的魔力。
我在想,要是能把 R 语言和日记法结合起来,会咋样呢?是不是能把我每天学习 R 语言的痛苦和快乐都记录下来,然后分析分析,找到突破的办法?不过这也只是我的瞎想,谁知道行不行呢?哎呀,不管咋样,这学习的路还长着呢,我可得加油啦!篇二今天又是被 R 语言和日记法折磨的一天,我都快疯了!你说这 R 语言,它咋就那么难搞呢?我觉得它就像个脾气古怪的老头,一点都不友好。
我辛辛苦苦地去理解那些复杂的语法,可它却总是跟我作对,让我出错出错再出错!我真想大声问一句:“R 语言,你是不是故意为难我?”就拿今天做的那个练习题来说,我明明觉得自己的思路是对的,可结果就是不对。
我反复检查,眼睛都快看花了,还是找不出问题所在。
难道是我中了什么魔咒?也许是我还没掌握到 R 语言的精髓,可这精髓到底藏在哪里呢?再讲讲日记法,本来我觉得这应该是个轻松的事儿,不就是写写自己的心情嘛。
可当我真的开始写的时候,我却发现自己不知道从哪儿下笔。
读书笔记(R语言)生信菜鸟团

读书笔记(R语言)生信菜鸟团R与ASReml-R统计分析教程(林元震)中国林业出版社1-3章简单介绍了R的基本语法,然后第4章着重讲了各种统计方法,第5章讲R的绘图,最后一张讲ASReml-R这个包语法重点:1,install.packages(),library(),help(),example(),demo(),length() ,attribute(),class(),mode(),dim(),names(),str(),head(),tail()2,rep,seq,paste,array,matrix,data.frame,list,c(),factor(),3,缺失值处理(na.omit,na.rm=T),类型转换(as.numeric(),as.character(),as.factor(),as.logical())其中as.numeric()非常有用,在画图的时候经常需要加上,因为数据在处理的过程中经常被搞错成了字符串格式,而as.logical()可以进行分类,只有0,NA,NAN,NULL是FALSE4,排序,合并,分割成子集,数据整合重构(reshape2和plyr包) 可以先了解一些R语言自带的数据包(见附录1),然后试用一下aggregate函数,数据汇总,根据右边的因子来把左边的数据进行分割并处理一个函数5,控制语句,自编函数统计分析一、summary(), library(pastecs);options(digits=2);stat.desc(), libr ary(psych);describe()二、方差分析(analysis of variance,ANOVA)用来检验分组是否有显著差异1,单因素+重复,数据框,df=data.frame(yield,treat)fit=aov(yield~treat,data=df)可以用summary来查看这次分析结果summary(fit)用TukeyHSD(fit)进行多重比较,或者duncan.test(fit,”treat”,alpha=0.05)2,双因素无重复,数据框,df=data.frame(yield,treat1,treat2) fit=aov(yield~treat1+treat2,data=df)这时候做多重比较就比较复杂了,library(agricolae)Duncan.test(fit,”treat1”,alpha=0.5)Duncan.test(fit,”treat2”,alpha=0.5)3,双因素+重复,数据库首先要进行处理,把treat1和treat2合并成group来区分重复Df$group=sapply(df,function(x)paste(df$treat1,df$treat2,sep=””))然后fit=aov(yield~treat1+treat2+group,data=df)4,多元方差与此类似,不停的增加因子来区分变量及group三、随机分组的检验1,完全随机实验,等同于方差分析的单因素+重复(判断不同的处理是否有差异)2,单因素随机区组实验,等同于方差分析的双因素无重复,其中(区组这个因素是人为控制的差异,不需要检验,主要检验我们的不同的处理是否有差异)3,双因素随机区组实验,不等同于方差分析的双因素+重复,但是与之类似,其中重复这个变量与之前的group变量有点区别,这里是我们的区组,而不是treat1和treat2的简单组合,所以我们需要分析treat1和treat2处理间的差异,但同时不需要考虑区组的差异fit=aov(yield~treat1*treat2+block,data=df),如果treat1有2个水平,treat2有3个水平,那么之前的group应该是6个,但是我们的block是区组的个数,还是3个,数据是18个。
R语言学习笔记-内附实例及代码

R语言学习笔记-内附实例及代码(总18页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--R语言入门R是开源的统计绘图软件,也是一种脚本语言,有大量的程序包可以利用。
R中的向量、列表、数组、函数等都是对象,可以方便的查询和引用,并进行条件筛选。
R具有精确控制的绘图功能,生成的图可以另存为多种格式。
R编写函数无需声明变量的类型,能利用循环、条件语句,控制程序的流程。
R网络资源:R主页:R资源列表 NCEASR Graphical Manual统计之都:QuikR丁国徽的R文档:R语言中文论坛一、用函数(),[直接输入就可以联网,第一次的话之后选择镜像,然后选择包下载即可]如果已经连接到互联网,在括号中输入要安装的程序包名称,选择镜像后,程序将自动下载并安装程序包。
例如:要安装picante包,在控制台中输入("picante")已经安装了二. 安装本地zip包路径:Packages>install packages from local files选择本地磁盘上存储zip包的文件夹。
(文件,运行R的脚本,选择所在文档)三.调用程序包在控制台中输入如下命令 library(“picnate”)程序包内的函数的用法与R内置的基本函数用法一样。
四.程序包内部都有哪些函数分别有什么功能查询程序包内容最常用的方法:1 菜单帮助>Html帮助;2 查看pdf帮助文档五.查看函数的帮助文件函数的默认值是什么怎么使用使用时需要注意什么问题需要查询函数的帮助。
1 直接打开相关函数的说明和使用模板。
2 RGui>Help>Html help 同样的效果,同上3 apropos("")合理使用T 检验,五种模式的T 检验4 help("")帮助同1-25 ("")有关T 检验的一切东西都可以查出来。
R语言菜鸟练习笔记1

[31] -4.9284740 96.0699261 -52.7216334 4.2518115 -45.9512866 34. 2404426
[37] -55.5040050 -4.4156488 -47.3706595 -82.5223469 67.5399391 38. 0685795
> x<-runif(50,0,2) > y<-runif(50,0,2) > plot(x,y,main="散点图",xlab="横坐标",ylab="纵坐标")
> x<-matrix(1:30,5,6) >x
[,1] [,2] [,3] [,4] [,5] [,6] [1,] 1 6 11 16 21 26 [2,] 2 7 12 17 22 27 [3,] 3 8 13 18 23 28 [4,] 4 9 14 19 24 29 [5,] 5 10 15 20 25 30 > x[3,] [1] 3 8 13 18 23 28 > x[4,] [1] 4 9 14 19 24 29 > x[seq(1,3,2),]
[,1] [,2] [,3] [,4] [,5] [,6] [1,] 1 6 11 16 21 26 [2,] 3 8 13 18 23 28 > x[seq(1,3,2),seq(2,5,3)]
[,1] [,2] [1,] 6 21 [2,] 8 23
3.输入一个 10 元素的向量 求其平均值、最大值、最小值、和 对其进行排序输出 大->小 小->大 求其中位数(15 元素的中位数是?)