Reconfigurable Computing for Space-Time Adaptive Processing
A C Compiler for a Processor with a Reconfigurable Functional Unit

A C Compiler for a Processor with a ReconfigurableFunctional UnitZhi Alex Ye Nagaraj Shenoy Prithviraj BanerjeeDepartment of Electrical and Computer Engineering,Northwestern UniversityEvanston, IL 60201, USA{ye, nagaraj, banerjee}@ABSTRACTThis paper describes a C compiler for a mixed Processor/FPGA architecture where the FPGA is a Reconfigurable Functional Unit (RFU). It presents three compilation techniques that can extract computations from applications to put into the RFU. The results show that large instruction sequences can be created and extracted by these techniques. An average speedup of 2.6 is achieved over a set of benchmarks.1.INTRODUCTIONWith the flexibility of the FPGA, reconfigurable systems are able to get significant speedups for some applications. As the general purpose processor and the FPGA each has its own suitable area of applications, several architectures are proposed to integrate a processor with an FPGA in the same chip.In this paper, we talk about a C compiler for a Processor/FPGA system. The target architecture is Chimaera, which is a RISC processor with a Reconfigurable Functional Unit (RFU). We describe how the compiler identifies sequences of statements in a C program and changes them into RFU operations (RFUOPs). We show the performance benefits that can be achieved by such optimizations over a set of benchmarks.The rest of the paper is organized into five sections. Section 2 discusses related work. In Section 3, we give an overview of the Chimaera architecture. Section 4 discusses the compiler organization and implementation in detail. In this section, we first discuss a technique to enhance the size of the instruction sequence: control localization. Next, we describe the application of the RFU to SIMD Within A Register (SWAR) operations. Lastly, we introduce an algorithm to identify RFUOPs in a basic block. Section 5 demonstrates some experimental results. We summarize this paper in Section 6.2.RELATED WORKSeveral architectures have been proposed to integrate a processor with an FPGA [6,7,8,9,13,14,15]. The usage of the FPGA can be divided into two categories: FPGA as a coprocessor or FPGA as a functional unit.In the coprocessor schemes such as Garp[9], Napa[6], DISC[14], and PipeRench[7], the host processor is coupled with an FPGA based reconfigurable coprocessor. The coprocessor usually has the ability of accessing memory and performing control flow operations. There is a communication cost between the coprocessor and the host processor, which is several cycles or more. Therefore, these architectures tend to map a large portion of the application, e.g. a loop, into the FPGA. One calculation in the FPGA usually corresponds to a task that takes several hundred cycles or more.In the functional unit schemes such as Chimaera[8], OneChip[15], and PRISC[13], the host processor is integrated with an FPGA based Reconfigurable Functional Unit (RFU). One RFU Operation (RFUOP) can take on a task that usually requires several instructions on the host processor. As the functional unit is interfaced only with the register file, it cannot perform memory operations or control flow operations. The communication is faster than the coprocessor scheme. For example, in the Chimaera architecture, after an RFUOP’s configuration is loaded, an invocation of it has no overhead in communication. This gives such architecture a larger range of application. Even in cases where only a few instructions can be combined into one RFUOP, we could still apply the optimization if the execution frequency is high enough.3.CHIMAERA ARCHITECTUREIn this section, we review the Chimaera architecture to provide adequate background information for explaining the compiler support for this architecture. More information about Chimaera can be found in [8].The overall Chimaera architecture is shown in Figure 1. The main component of the system is the Reconfigurable Functional Unit (RFU), which consists of FPGA-like logic designed to support high-performance computations. It gets inputs from the host processor’s register file, or a shadow register file which duplicates a subset of the values in the host’s register file. The RFU is capable of computing data-dependent operations (e.g., tmp=r2-r3, r5=tmp+r1), conditional evaluations (e.g., "if (b>0) a=0; else a=1;"), and multiple sub-word operations (e.g., four instances of 8-bit addition).The RFU contains several configurations at the same time. An RFUOP instruction will activate the corresponding configuration in the RFU. An RFU configuration itself determines from whichregisters it reads its operands. A single RFUOP can read from all the registers connected to the RFU and then put the result on the result bus. The maximum number of input registers is 9 in Chimaera. Each RFUOP instruction is associated with a configuration and an ID. For example, an execution sequence “r2=r3<<2; r4=r2+r5; r6=lw 0(r4)” can be optimized to “r4=RFUOP #1; r6=lw 0(r4)”. Here #1 is the ID of this RFUOP and “r5+r3<<2” is the operation of the corresponding configuration. After an RFUOP instruction is fetched and decoded, the Chimaera processor checks the RFU for the configuration corresponding to the instruction ID. If the configuration is currently loaded in the RFU, the corresponding output is written to the destination register during the instruction writeback cycle. Otherwise, the processor stalls when the RFU loads the configuration.4. COMPILER IMPLEMENTATIONWe have developed a C compiler for Chimaera, which automatically maps some operations into RFUOPs. The generated code is currently run on a Chimaera simulator to gather performance information. A future version of the compiler will be integrated with a synthesis tool.The compiler is built using the widely available GCC framework. Figure 2 depicts the phase ordering of the implementation. The C code is parsed into the intermediate language of GCC: Register Transfer Language (RTL), which is then enhanced by several early optimizations such as common expression elimination, flow analysis, etc. The partially optimized RTL is passed through the Chimaera optimization phase, as will be explained below. The Chimaera optimized RTL is then processed by later optimization phases such as instruction scheduling, registers allocation, etc. Finally, the code for the target architecture is generated along with RFUOP configuration information.From the compiler’s perspective, we can consider an RFUOP as an operation with multiple register inputs and a single register output. The goal of the compiler is to identify the suitable multiple-input-single-output sequences in the programs and change them into RFUOPs.Chimaera Optimization consists of three steps: Control Localization, SWAR optimization and Instruction Combination.Due to the configuration loading time, these optimizations can be applied only in the kernels of the programs. Currently, we only optimize the innermost loop in the programs.The first step of Chimaera optimization is control localization.It will transform some branches into one macroinstruction to form a larger basic block. The second step is the SIMD Within A Register (SWAR) Optimization. This step searches the loop body for subword operations and unrolls the loop when appropriate.The third step is instruction combination. It takes a basic block as input and extracts the multiple-input-single-output patterns from the data flow graph. These patterns are changed into RFUOPs if they can be implemented in RFU. The following subsections discuss the three steps in detail.4.1 Control LocalizationIn order to get more speedup, we want to find larger and more RFUOPs. Intuitively, a larger basic block contains more instructions, thus has more chances of finding larger and more RFUOPs. We find that control localization technique [11][13] isFigure 1. The overall Chimaera architectureH o s t P r o c e s s o rFigure 2: Phase ordering of the C compiler for Chimaera(a)(b)Figure 3: Control Localization(a) control flow graph before control localization.Each oval is an instruction, and the dashed box marks the code sequence to be control localized.(b) control flow graph after control localizationuseful in increasing the size of basic blocks. Figure 3 shows an example of it. After control localization, several branches are combined into one macroinstruction, with multiple output and multiple input. In addition to enlarging the basic block, the control localization sometimes finds RFUOPs directly. When a macroinstruction has only one output, and all the operations in it can be implemented in the RFU, this macroinstruction can be mapped into an RFUOP. This RFUOP can speculatively compute all operations on different branch paths. The result on the correct path where the condition evaluates to true is selected to put into the result bus. This macro instruction is called as “CI macroin”and can be optimized by Instruction Combination.4.2SWAR OptimizationAs a method to exploit medium-grain data parallelism, SIMD (single instruction, multiple data) has been used in parallel computers for many years. Extending this idea to general purpose processors has led to a new version of SIMD, namely SIMD Within A Register (SWAR)[4]. The SWAR model partitions each register into fields that can be operated on in parallel. The ALUs are set up to perform multiple field-by-field operations. SWAR has been successful in improving the multimedia performance. Most of the implementations of this concept are called multimedia extensions, such as Intel MMX, HP MAX, SUN SPARC VIS, etc. For example, “PADDB A, B” is an instruction from Intel MMX. Both operands A and B are 64-bit and are divided into eight 8-bit fields. The instruction performs eight additions in parallel and stores the eight results to A.However, current implementations of SWAR do not support a general SWAR model. Some of their limitations are:•The input data must be packed and aligned correctly, causing packing and unpacking penalties sometimes.•Most of current hardware implementations support 8, 16 and 32-bit field size only. Other important sizes such as 2-bit and 10-bit are not supported.•Only a few operations are supported. When the operation for one item becomes complex, SIMD is impossible. For example, the following code does not map well to a simple sequence of SIMD operations:char out[100],in1[100],in2[100];for(i=0;i<100;i++) {if ((in1[i]-in2[i])>10)out[i]=in1[i]-in2[i];elseout[i]=10;}With the flexibility of the FPGA, the RFU can support a more general SWAR model without the above disadvantages. The only requirement is that the output fields should fit within a single register. The inputs don’t need to be stored in packed format, nor is there limitation on the alignment. In addition, complex operations can be performed. For example, the former example can be implemented in one RFUOP.Our compiler currently supports 8-bit field size, which is the size of “char” in C. In current implementation, the compiler looks for the opportunity to pack several 8-bit outputs into a word. In most cases, this kind of pattern exists in the loop with stride one. Therefore, the compiler searches for the pattern such that the memory store size is a byte and the address changes by one forunrolled four times. In the loop unrolling, conventional optimizations such as local register renaming and strength reduction are performed. In addition, the four memory stores are changed to four sub-register movements. For example,“store_byte r1,address;store_byte r2,address+1;store_byte r3,address+2;store_byte r4,address+3;”are changed into“(r5,0)=r1; (r5,1)=r2;(r5,2)=r3; (r5,3)=r4;”.The notation (r, n) refers to the n th byte of register r. We generate a pseudo instruction "collective-move" that moves the four sub-registers into a word register, e.g. “r5=(r5,0) (r5,1) (r5,2) (r5,3)”. In the data flow graph, the four outputs merge through this “collective-move” into one. Thus a multiple-input-single-output subgraph is formed. The next step, Instruction Combination, canrecognize this subgraph and change it to an RFUOP when appropriate. Finally, a memory store instruction is generated tostore the word register. The compiler then passes the unrolled copy to the instruction combination step.4.3Instruction CombinationThe instruction combination step analyzes a basic block and changes the RFU sequences into RFUOPs. It first finds out what instructions can be implemented in the RFU. It then identifies the RFU sequences. At last, it selects the appropriate RFU sequences and changes them into RFUOPs.We categorize instructions into Chimaera Instruction (CI) and Non-Chimaera Instruction (NCI). Currently CI includes logic operation, constant shift and integer add/subtract. The “collective_move”, “subregister movement” and “CI macroin” are also considered as CI. NCI includes other instructions such as multiplication/division, memory load/store, floating-point operation, etc.The algorithm FindSequences in Figure 4 finds all the maximum instruction sequences for the RFU. It colors each node in the data flow graph(DFG). The NCI instructions are marked as BLACK. A CI instruction is marked as BROWN when its output must be put into a register, that is, the output is live-on-exit or is the input of some NCI instructions. Other CI instructions are marked as WHITE. The RFU sequences are the subgraphs in the DFG that consists of BROWN nodes and WHITE nodes.The compiler currently changes all the identified sequences into RFUOPs. Under the assumption that every RFUOP takes one cycle and the configuration loading time can be amortized over several executions, this gives an upper bound of the speedup we could expect from Chimaera. In the future, we will take into account other factors such as the FPGA size, configuration loading time, actual RFUOP execution time, etc.5.EXPERIMENTAL RESULTSWe have tested the compiler’s output through a set of benchmarks on the Chimaera simulator. The simulator is a modification of SimpleScalar Simulator[3]. The simulated architecture has 32 general purpose 32-bit registers and 32 floating point registers. The instruction set is a superset of MIPS-IV ISA. Presently, the simulator executes the programs sequentially and gathers theEarly results on some benchmarks are presented in this section. Each benchmark is compiled in two ways: one is using “gcc -O2”, the other is using our Chimaera compiler. We studied the differences between the two versions of assembly codes as well as the simulation results. In the benchmarks, decompress.c and compress.c are from Honeywell benchmark[10], jacobi and life are from Raw benchmark[2], image reconstruction[12] and dct[1] are implementations of two program kernels of MPEG, image restoration is an image processing program. They are noted as dcmp, cmp, life, jcbi, dct, rcn and rst in the following figure.Table 1 shows the simulation results of the RFU optimizations. Insn1 and insn2 are the instruction counts without and with RFU optimization. The speedup is calculated as insn1/insn2. The following three columns IC, CL and SWAR stand for the portion of performance gain from Instruction Combination, Control Localization and SWAR respectively.The three optimizations give an average speedup of 2.60. The best speedup is up to 7.19.To illustrate the impact of each optimization on the kernel sizes, we categorize instructions into four types: NC, IC, CL and SWAR. NC is the part of instructions that cannot be optimized for Chimaera. NCI instructions and some non-combinable integer operations fall in this category. IC, CL and SWAR stand for the instructions that can be optimized by Instruction Combination, Control Localization and SWAR optimization respectively. Figure 5 shows the distribution of these four types of instructions in the program kernels. After the three optimizations, the kernel size can be reduced by an average of 37.5%. Of this amount, 22.3% is from Instruction Combination, 9.8% from Control Localization and 5.4% from SWAR.Table 1: Performance results over some benchmarks. The "avg" row is the average of all benchmarks.62.50%22.30%0%0%Figure 5: Distribution of the kernel instructionsFurther analysis shows that 58.4% of the IC portion comes from address calculation. For example, the following C code “int a[10], ...=a[i]” is translated to "r3=r2<<2, r4=r3+r1, r5=lw 0(r4)" in assembly. The first two instructions can be combined in Chimaera. The large portion of address calculation indicates that our optimizations can be applied to a wide range of applications, as long as they have complex address calculations in the kernel. Furthermore, as the address calculation is basically sequential, existing ILP architectures like superscalar and VLIW cannot take advantage of it. This suggests that we may expect speedup if we integrate a RFU into an advanced ILP architecture.Figure 6 illustrates the frequencies of different RFUOP sizes. For Instruction Combination and Control Localization, most of the sizes are from 2 to 6. These small sizes indicate that these techniques are benefiting from the fast communication of the functional unit scheme. In the coprocessor scheme, the communication overhead would make them prohibitive to apply. The SWAR optimization generally identifies much larger RFUOPs. The largest one comes from the image reconstruction benchmark, whose kernel is shown in Figure 7. In this case, a total of 52 instructions are combined in the RFU, which results in a speedup of 4.2.model. We have also simulated the architecture in an out-of-order execution environment. We considered a superscalar host processor, different latencies of RFUOPs, and configuration loading time. These results are reported in [16].In summary, the results show that the compilation techniques are able to create and find many instruction sequences for the RFU. Most of their sizes are several instructions, which demonstrate that the fast communication is necessary. The system gives an average speedup of 2.6.6.CONCLUSIONThis paper describes a C compiler for the Processor/FPGA architecture when the FPGA is served as a Reconfigurable Functional Unit (RFU).We have introduced an instruction combination algorithm to identify RFU sequences of instructions in a basic block. We have also shown that the control localization technique can effectively enlarge the size of the basic blocks and find some more sequences. In addition, we have illustrated the RFU support for SWAR. By introducing “sub-register movement” and “collective-move”, the instruction combination algorithm is able to identify complex SIMD instructions for the RFU.Finally, we have presented the experimental results, which demonstrate that these techniques can effectively create and identify larger and more RFU sequences. With the fast communication between RFU and the processor, the system can achieve considerable speedups.7.ACKNOWLEDGEMENTSWe would like to thank Scott Hauck for his contribution to this research. We would also like to thank the reviewers for their helpful comments. This work was supported by DARPA under Contract DABT-63-97-0035.8.REFERENCES[1]K. Atsuta, DCT implementation, http://marine.et.u-tokai.ac.jp/database/koichi.html.[2]J.Babb, M.Frank, et al. The RAW benchmark Suite:Computation Structures for General Purpose Computing. FCCM, Napa Vally, CA, Apr.1997[3] D. Burger, and T. Austin, The Simplescalar Tool Kit,University of Wisconsin-Madison Computer Sciences Department Technical Report #1342, June, 1997 [4]P. Faraboschi, et al. The Latest Word in Digital andMedia Processing, IEEE signal processing magazine, Mar 1998[5]R. J. Fisher, and H. G. Dietz, Compiling For SIMDWithin A Register, 1998 Workshop on Languages and Compilers for Parallel Computing, North Carolina, Aug 1998[6]M.B. Gokhale, et al. Napa C: Compiling for a HybridRISC/FPGA Architecture, FCCM 98, CA, USA[7]S. C. Goldstein, H. Schmit, M. Moe, M. Budiu, S.Cadambi, R. R. Taylor, and R. Laufer. PipeRench: A Coprocessor for Streaming Multimedia Acceleration, ISCA’99, May 1999, Atlanta, Georgia[8]S. Hauck, T. W. Fry, M. M. Hosler, J. P. Ka, TheChimaera Reconfigurable Functional Unit, IEEE Symposium on FPGAs for Custom Computing Machines, 1997[9]J. R. Hauser and J. Wawrzynek. GARP: A MIPSprocessor with a reconfigurable coprocessor.Proceedings of IEEE Workshop on FPGAs for Custom Computing Machines (FCCM), Napa, CA, April 1997.[10]Honeywell Inc, Adaptive Computing SystemsBenchmarking,/projects/acsbench/ [11]W. Lee, R. Barua, and et al. Space-Time Scheduling ofInstruction-Level Parallelism on a Raw Machine, MIT.ASPLOS VIII 10/98, CA, USA[12]S. Rathnam, et al. Processing the New World ofInteractive Media, IEEE signal processing magazine March 1998[13]R. Razdan, PRISC: Programmable Reduced InstructionSet Computers, Ph.D. Thesis, Harvard University, Division of Applied Sciences,1994[14]M. J. Wirthlin, and B. L. Hutchings. A DynamicInstruction Set Computer, FCCM, Napa Vally, CA, April, 1995[15]R. D. Wittig and P. Chow. OneChip: An FPGAProcessor with Reconfigurable Logic, FCCM, Napa Vally, CA, April, 1996[16]Z. A. Ye, A. Moshovos, P. Banerjee, and S. Hauck,"Chimaera, a high performance architecture with a tightly-coupled reconfigurable functional unit", submitted to the 27th International Symposium on Computer Architecture (ISCA-2000).。
嵌入式系统PPT课件

– 设计过程应该是逐步细化和逐步完善的过程
• 面向对象的方法 以类及交互模式为中心
27
系统软件结构的设计
• 结构化方法(SA/SD) • 面向对象的方法(OOA/OOD)
– UML建模
28
结构设计的验证
• 结构设计的正确性非常关键 – 详细设计和实现的基础,对开发周期、成本有很大影响
• 验证所关心的问题 – 结构设计是否满足功能、性能要求 – 能否实现
• 软硬件协同设计 • 功耗的优化设计 • 嵌入式操作系统 • 开发环境 • 成本和开发周期 • 代码优化 • 高效的输入和输出 • 测试环境
7
嵌入式系统软件技术面临的几大问题
• 嵌入式软件全生命周期开发工具链 • 硬件与软件的Co-Design: Verilog + C = ? • 驱动程序的设计和生成技术(嵌入式软件开发中
– EDA设计工具
基于S3C2440的多格式媒体播放器的设计与实现

技术创新《微计算机信息》(嵌入式与SOC)2010年第26卷第9-2期博士论坛基于S3C2440的多格式媒体播放器的设计与实现Design and Implementation of Multi-format Media Player based on S3C2440(中南大学)许雪梅徐蔚钦周文黄帅XUXue-meiXUWei-qinZHOUWenHUANGShuai摘要:设计了一种嵌入式多格式媒体播放器。
硬件系统采用三星公司ARM9系列的S3C2440芯片作为其核心,软件平台采用Linux操作系统,利用Mplayer编译的多种软件解码器,实现了一款可以播放各种常见格式的媒体播放器。
该系统完成了播放的各项功能,具有很好的用户图形交互界面,为嵌入式ARM播放器的开发打下良好的基础。
关键词:S3C2440;媒体播放器;嵌入式系统;用户图形界面中图分类号:TP37文献标识码:BAbstract:This paper researches the design of an embedded multi-format media player.The system selects S3C2440chip based on Samsung ARM9series as the core of hardware platform and embedded Linux as operating ing a variety of software decoder compiled in Mplayer,a media player that can play most of common format media have been realized.This system can complete vari-ous functions of playing and include a good graphical user interface.It lays a good foundation for development of embedded ARM players.Key words:S3C2440;Media player;Embedded system;Graphical user interface文章编号:1008-0570(2010)09-2-0012-021引言随着电子技术,多媒体技术及网络技术的快速发展,视频播放系统正在向嵌入式,网络化方向发展,多媒体组件逐渐成为系统中不可缺少的重要组成部分。
Finding community structure in networks using the eigenvectors of matrices

M. E. J. Newman
Department of Physics and Center for the Study of Complex Systems, University of Michigan, Ann Arbor, MI 48109–1040
We consider the problem of detecting communities or modules in networks, groups of vertices with a higher-than-average density of edges connecting them. Previous work indicates that a robust approach to this problem is the maximization of the benefit function known as “modularity” over possible divisions of a network. Here we show that this maximization process can be written in terms of the eigenspectrum of a matrix we call the modularity matrix, which plays a role in community detection similar to that played by the graph Laplacian in graph partitioning calculations. This result leads us to a number of possible algorithms for detecting community structure, as well as several other results, including a spectral measure of bipartite structure in neteasure that identifies those vertices that occupy central positions within the communities to which they belong. The algorithms and measures proposed are illustrated with applications to a variety of real-world complex networks.
可重构计算

可重构计算
可重构计算基于现场可编程门阵列——— FPGA.FPGA的编程技术主要有两种:一种是反 熔丝技术,即通常所说的电可擦写技术,但是这种技 术的可重构实时性太差;另一种是基于静态存储器 ( SRAM)可编程原理的FPGA编程技术,这种硬件 包含计算单元阵列,这些计算单元的功能由可编程 的配置位来决定.当前大多数的可重构设备是基 于静态存储器的,其实现计算单元的粒度随不同的 系统要求而不同.
可重构计算
传统的计算方式有两种: 一种是采用对通用微处理器进行软件编程 的方式,软件的方式通用性好, 但运算速度不 高 一种是采用A S IC 的方式. A S IC 方式处理 速度快, 但只能针对特定的算法, 通用性不 好
可重构计算
可重构计算(Reconfigurable Computing) 是在 软件的控制下, 利用系统中的可重用资源, 根据应 用的需要重新构造一个新的计算平台, 达到接近专 用硬件设计的高性能.具有可重构计算特征的系统 称为可重构系统. 简单地说,就是利用FPGA 逻辑实现计算任 务.有的称作自适应计算(adaptive computing) , 也有的称之为FPGA 计算.
3.独立处理单元模式 独立处理单元模式 属于这类系统的可重构逻辑部分一般包含多个 FPGA .这是一种最松散的耦合形式. 4.SoPC模式 模式 处理器,存储器和可编程逻辑集成在同一个 FPGA 芯片上, 称为单芯片可重构计算系统 (SoPC) .这种系统中CPU 和FPGA仍然是紧密 耦合的结构, 同时片上存储系统和CPU 与FPGA 接口能力则进一步提高了系统的性能.以往的 SoC (System on chip) 设计依赖于固定的ASIC , 而SoPC是以可编程逻辑器件取代ASIC , 越来越 多地成为系统级芯片设计的首选.
天基光学遥感图像的信噪比提升技术综述

航天返回与遥感第 45 卷 第 2 期102SPACECRAFT RECOVERY & REMOTE SENSING2024 年 4 月天基光学遥感图像的信噪比提升技术综述王智 1,2 魏久哲 1,2 王芸 1,2 李强 1,2(1 北京空间机电研究所,北京 100094)(2 先进光学遥感技术北京市重点实验室,北京 100094)摘 要 随着遥感技术的不断发展,天基光学遥感向全时域、智能化方向发展。
微光遥感因需要在夜间和晨昏时段等低照度条件下对地物进行探测,成像具有低对比度、低亮度、低信噪比的特性。
针对低信噪比特性会导致大量复杂物理噪声将图像景物特征淹没,严重影响地面目标识别与判读的情况,文章基于遥感成像的全链路物理模型,总结天基光学遥感图像信噪比提升的技术途径,分别对基于传统滤波的方式、基于物理模型的方式、基于深度学习的方式的研究现状进行分析,对比并总结各类方式中主要代表算法之间的特点及差异,对未来天基光学遥感图像信噪比提升的技术发展方向进行展望。
关键词 去噪算法 全链路模型 信噪比 遥感图像 天基遥感中图分类号:TP751 文献标志码:A 文章编号:1009-8518(2024)02-0102-12DOI:10.3969/j.issn.1009-8518.2024.02.010A Review of SNR Enhancement Techniques forSpace-Based Remote Sensing ImagesWANG Zhi1,2 WEI Jiuzhe1,2 WANG Yun1,2 LI Qiang1,2( 1 Beijing Institute of Space Mechanics & Electricity, Beijing 100094, China )( 2 Key Laboratory of Advanced Optical Remote Sensing Technology of Beijing, Beijing 100094, China )Abstract With the continuous development of the field of remote sensing, space-based remote sensing is developing in the direction of all-sky and intelligent. Since low-light remote sensing is used to detect ground objects under low illumination conditions such as night and morning and night periods, it results in the characteristics of low contrast, low brightness and low signal-to-noise ratio of remote sensing images, among which, low signal-to-noise ratio leads to a large number of complex physical noises drowning the image features, seriously affecting the recognition and interpretation of ground objects. This paper summarizes the actual full-link physical model based on optical remote sensing imaging and the technical approaches to improve the signal-to-noise ratio of remote sensing images, and summarizes the methods based on traditional filtering, physical model and deep learning respectively. By comparing the differences among the main representative algorithms of various methods, the paper summarizes their respective characteristics. The future development direction of the improvement of the signal-to-noise ratio of space-based remote sensing images is forecasted.Keywords denoising algorithm; full link model; SNR; remote sensing image; space-based remote sensing收稿日期:2023-11-03基金项目:国家自然科学基金重点项目(62331006)引用格式:王智, 魏久哲, 王芸, 等. 天基光学遥感图像的信噪比提升技术综述[J]. 航天返回与遥感, 2024, 45(2): 102-113.WANG Zhi, WEI Jiuzhe, WANG Yun, et al. A Review of SNR Enhancement Techniques for Space-Based Remote Sensing Images[J]. Spacecraft Recovery & Remote Sensing, 2024, 45(2): 102-113. (in Chinese)第 2 期王智 等: 天基光学遥感图像的信噪比提升技术综述103 0 引言随着航天技术的迅猛发展,航天遥感技术成为人类认识地球,寻找、利用、开发地球资源,了解全球变化以及气象观测的有效手段。
深度强化学习在自动驾驶中的应用研究(英文中文双语版优质文档)

深度强化学习在自动驾驶中的应用研究(英文中文双语版优质文档)Application Research of Deep Reinforcement Learning in Autonomous DrivingWith the continuous development and progress of artificial intelligence technology, autonomous driving technology has become one of the research hotspots in the field of intelligent transportation. In the research of autonomous driving technology, deep reinforcement learning, as an emerging artificial intelligence technology, is increasingly widely used in the field of autonomous driving. This paper will explore the application research of deep reinforcement learning in autonomous driving.1. Introduction to Deep Reinforcement LearningDeep reinforcement learning is a machine learning method based on reinforcement learning, which enables machines to intelligently acquire knowledge and experience from the external environment, so that they can better complete tasks. The basic framework of deep reinforcement learning is to use the deep learning network to learn the mapping of state and action. Through continuous interaction with the environment, the machine can learn the optimal strategy, thereby realizing the automation of tasks.The application of deep reinforcement learning in the field of automatic driving is to realize the automation of driving decisions through machine learning, so as to realize intelligent driving.2. Application of Deep Reinforcement Learning in Autonomous Driving1. State recognition in autonomous drivingIn autonomous driving, state recognition is a very critical step, which mainly obtains the state information of the environment through sensors and converts it into data that the computer can understand. Traditional state recognition methods are mainly based on rules and feature engineering, but this method not only requires human participation, but also has low accuracy for complex environmental state recognition. Therefore, the state recognition method based on deep learning has gradually become the mainstream method in automatic driving.The deep learning network can perform feature extraction and classification recognition on images and videos collected by sensors through methods such as convolutional neural networks, thereby realizing state recognition for complex environments.2. Decision making in autonomous drivingDecision making in autonomous driving refers to the process of formulating an optimal driving strategy based on the state information acquired by sensors, as well as the goals and constraints of the driving task. In deep reinforcement learning, machines can learn optimal strategies by interacting with the environment, enabling decision making in autonomous driving.The decision-making process of deep reinforcement learning mainly includes two aspects: one is the learning of the state-value function, which is used to evaluate the value of the current state; the other is the learning of the policy function, which is used to select the optimal action. In deep reinforcement learning, the machine can learn the state-value function and policy function through the interaction with the environment, so as to realize the automation of driving decision-making.3. Behavior Planning in Autonomous DrivingBehavior planning in autonomous driving refers to selecting an optimal behavior from all possible behaviors based on the current state information and the goal of the driving task. In deep reinforcement learning, machines can learn optimal strategies for behavior planning in autonomous driving.4. Path Planning in Autonomous DrivingPath planning in autonomous driving refers to selecting the optimal driving path according to the goals and constraints of the driving task. In deep reinforcement learning, machines can learn optimal strategies for path planning in autonomous driving.3. Advantages and challenges of deep reinforcement learning in autonomous driving1. AdvantagesDeep reinforcement learning has the following advantages in autonomous driving:(1) It can automatically complete tasks such as driving decision-making, behavior planning, and path planning, reducing manual participation and improving driving efficiency and safety.(2) The deep learning network can perform feature extraction and classification recognition on the images and videos collected by the sensor, so as to realize the state recognition of complex environments.(3) Deep reinforcement learning can learn the optimal strategy through the interaction with the environment, so as to realize the tasks of decision making, behavior planning and path planning in automatic driving.2. ChallengeDeep reinforcement learning also presents some challenges in autonomous driving:(1) Insufficient data: Deep reinforcement learning requires a large amount of data for training, but in the field of autonomous driving, it is very difficult to obtain large-scale driving data.(2) Safety: The safety of autonomous driving technology is an important issue, because once an accident occurs, its consequences will be unpredictable. Therefore, the use of deep reinforcement learning in autonomous driving requires very strict safety safeguards.(3) Interpretation performance: Deep reinforcement learning requires a lot of computing resources and time for training and optimization. Therefore, in practical applications, the problems of computing performance and time cost need to be considered.(4) Interpretability: Deep reinforcement learning models are usually black-box models, and their decision-making process is difficult to understand and explain, which will have a negative impact on the reliability and safety of autonomous driving systems. Therefore, how to improve the interpretability of deep reinforcement learning models is an important research direction.(5) Generalization ability: In the field of autonomous driving, vehicles are faced with various environments and situations. Therefore, the deep reinforcement learning model needs to have a strong generalization ability in order to be able to accurately and Safe decision-making and planning.In summary, deep reinforcement learning has great application potential in autonomous driving, but challenges such as data scarcity, safety, interpretability, computational performance, and generalization capabilities need to be addressed. Future research should address these issues and promote the development and application of deep reinforcement learning in the field of autonomous driving.深度强化学习在自动驾驶中的应用研究随着人工智能技术的不断发展和进步,自动驾驶技术已经成为了当前智能交通领域中的研究热点之一。
可重构计算
当前可重构计算或系统需要解决的问题
(1) 粒度问题.细粒度的可重构电路面积的使用 效率很低. (2) 如何改进结构来减少重构时间.在数据重载 时,FPGA端口对外呈高阻状态,重载后,才恢复对 外的逻辑功能.这就是所谓的重构时隙,将影响 系统功能的连续.如何克服或减少重构时隙,是 实现动态重构系统的瓶颈问题. (3) 数据传输和存储问题.现在的可重构芯片提 供的片上存储器太少,因而,许多重构计算的应用 需要更大的外部存储器.当前设计中,最迫切需 要优化解决的问题是Memory带宽和能耗.
可重构计算
可重构计算基于现场可编程门阵列——— FPGA.FPGA的编程技术主要有两种:一种是反 熔丝技术,即通常所说的电可擦写技术,但是这种技 术的可重构实时性太差;另一种是基于静态存储器 ( SRAM)可编程原理的FPGA编程技术,这种硬件 包含计算单元阵列,这些计算单元的功能由可编程 的配置位来决定.当前大多数的可重构设备是基 于静态存储器的,其实现计算单元的粒度随不同的 系统要求而不同.
可重构计算的分类
可重构计算又可按重构发生的时间分为静态重构 和动态重构. 静态重构是指在可重构件运行之前对其进行预先 配置, 在运行过程中其功能保持不变, 即运行过程 中不能对其进行重构. 动态重构是指在可可重构件运行的过程中可根据 需要对其实时进行配置, 改变其电路结构, 实现不 同的功能.
可重构计算系统的分类
Garp 是加州大学伯克利分校提出的一种可重构体系结构, 其 结构如图2 所示. 该结构中, 可重构阵列与一个通用的MIPS 处理器构成了一个混合式计算系统, 可重构阵列与通用处理 器共享内存和数据缓冲, 二者之间形成一种主协处理器的关 系. 该结构的优点是兼具了通用处理器的灵活性和可重构部 件的高速性. 通用处理器完成通用程序的处理, 对于特定的 循环和子程序, 则由可重构阵列在通用处理器的控制下实现 加速处理. Garp 结构一般集成在一个芯片上, 形成一个片上 系统.
CCF推荐国际学术期刊

CCF 推荐国际学术期刊中国计算机学会推荐国际学术期刊 (计算机系统与⾼性能计算)⼀、A类⼆、B类三、C类中国计算机学会推荐国际学术刊物(计算机⽹络)⼀、A类序号刊物简称刊物全称出版社⽹址1TOCS ACM Transactions on Computer Systems ACM 2TOC IEEE Transactions on ComputersIEEE 3TPDSIEEE Transactions on Parallel and Distributed SystemsIEEE序号刊物简称刊物全称出版社⽹址1TACO ACM Transactions on Architecture and Code OptimizationACM 2TAAS ACM Transactions on Autonomous and Adaptive SystemsACM 3TODAES ACM Transactions on Design Automation of Electronic SystemsACM 4TECS ACM Transactions on Embedded Computing Systemsn ACM 5TRETS ACM Transactions on Reconfigurable Technology and SystemsACM 6TOS ACM Transactions on StorageACM 7TCAD IEEE Transactions on COMPUTER-AIDED DESIGN of Integrated Circuits and Systems IEEE 8TVLSI IEEE Transactions on VLSI SystemsIEEE 9JPDC Journal of Parallel and Distributed Computing Elsevier 10 PARCOParallel ComputingElsevier 11Performance Evaluation: An International JournalElsevier序号刊物简称刊物全称出版社⽹址1 Concurrency and Computation: Practice and Experience Wiley 2DC Distributed ComputingSpringer 3FGCS Future Generation Computer Systems Elsevier 4Integration Integration, the VLSI JournalElsevier 5 JSA The Journal of Systems Architecture: Embedded Software DesignElsevier 6 Microprocessors and Microsystems: Embedded Hardware DesignElsevier 7JGC The Journal of Grid computing Springer 8TJSC The Journal of SupercomputingSpringer 9JETC The ACM Journal on Emerging Technologies in Computing SystemsACM 10JETJournal of Electronic Testing-Theory and ApplicationsSpringer序号刊物简称刊物全称出版社⽹址⼆、B类三、C类中国计算机学会推荐国际学术刊物 (⽹络与信息安全)⼀、A类⼆、B类1TON IEEE/ACM Transactions on NetworkingIEEE, ACM 2JSAC IEEE Journal of Selected Areas in Communications IEEE 3TMCIEEE Transactions on Mobile ComputingIEEE序号刊物简称刊物全称出版社⽹址1TOIT ACM Transactions on Internet Technology ACM 2TOMCCAP ACM Transactions on Multimedia Computing, Communications and Applications ACM 3TOSN ACM Transactions on Sensor Networks ACM 4CN Computer NetworksElsevier 5TOC IEEE Transactions on CommunicationsIEEE 6TWCIEEE Transactions on Wireless CommunicationsIEEE序号刊物简称刊物全称出版社⽹址1 Ad hoc NetworksElsevier 2CC Computer CommunicationsElsevier 3TNSM IEEE Transactions on Network and Service Management IEEE 4 IET CommunicationsIET 5JNCA Journal of Network and Computer Applications Elsevier 6MONETMobile Networks & Applications Springer 7 NetworksWiley 8PPNA Peer-to-Peer Networking and Applications Springer 9WCMC Wireless Communications & Mobile Computing Wiley.10Wireless NetworksSpringer序号刊物简称刊物全称出版社⽹址1TDSC IEEE Transactions on Dependable and Secure Computing IEEE 2TIFS IEEE Transactions on Information Forensics and Security IEEE 3Journal of CryptologySpringer序号刊物简称刊物全称出版社⽹址1TISSEC ACM Transactions on Information and System SecurityACM 2 Computers & SecurityElsevier 3 Designs, Codes and Cryptography Springer 4JCSJournal of Computer SecurityIOS Press三、C类中国计算机学会推荐国际学术刊物 (软件⼯程、系统软件与程序设计语⾔)⼀、A类⼆、B类三、C类序号刊物简称刊物全称出版社⽹址1CLSR Computer Law and Security Reports Elsevier 2 EURASIP Journal on Information Security Springer 3 IET Information SecurityIET 4IMCS Information Management & Computer Security Emerald 5ISTR Information Security Technical Report Elsevier 6IJISP International Journal of Information Security and PrivacyIdea GroupInc 7IJICS International Journal of Information and Computer SecurityInderscience8SCNSecurity and Communication NetworksWiley序号刊物简称刊物全称出版社⽹址1TOPLAS ACM Transactions on Programming Languages &SystemsACM 2TOSEM ACM Transactions on Software Engineering MethodologyACM 3TSEIEEE Transactions on Software EngineeringIEEE序号刊物简称刊物全称出版社⽹址1ASE Automated Software Engineering Springer 2 Empirical Software EngineeringSpringer 3 TSC IEEE Transactions on Service Computing IEEE 4 IETS IET SoftwareIET 5 IST Information and Software Technology Elsevier 6JFP Journal of Functional Programming Cambridge University Press7 Journal of Software: Evolution and Process Wiley 8JSS Journal of Systems and Software Elsevier 9RE Requirements Engineering Springer 10SCP Science of Computer Programming Elsevier 11SoSyM Software and System Modeling Springer 12SPE Software: Practice and ExperienceWiley 13STVRSoftware Testing, Verification and ReliabilityWiley序号刊物简称刊物全称出版社⽹址1 Computer Languages, Systems and Structures Elsevier 2IJSEKEInternational Journal on Software Engineering and Knowledge EngineeringWorld Scientific中国计算机学会推荐国际学术刊物 (数据库、数据挖掘与内容检索)⼀、A类⼆、B类三、C类3STTT International Journal on Software Tools for Technology TransferSpringer 4 Journal of Logic and Algebraic Programming Elsevier 5JWE Journal of Web EngineeringRinton Press 6 Service Oriented Computing and Applications Springer 7 SQJ Software Quality JournalSpringer 8TPLPTheory and Practice of Logic ProgrammingCambridge University Press序号刊物简称刊物全称出版社⽹址1TODS ACM Transactions on Database Systems ACM 2TOIS ACM Transactions on Information and SystemsACM 3TKDE IEEE Transactions on Knowledge and Data Engineering IEEE Computer Society 4VLDBJVLDB JournalSpringer-Verlag序号刊物简称刊物全称出版社⽹址1TKDD ACM Transactions on Knowledge Discovery from DataACM 2AEI Advanced Engineering Informatics Elsevier 3DKE Data and Knowledge Engineering Elsevier 4DMKD Data Mining and Knowledge Discovery Springer 5EJIS European Journal of Information Systems The OR Society6 GeoInformaticaSpringer 7IPM Information Processing and Management Elsevier 8 Information Sciences Elsevier 9ISInformation SystemsElsevier 10JASISTJournal of the American Society for Information Science and TechnologyAmerican Society for Information Science and Technology 11JWS Journal of Web SemanticsElsevier 12KIS Knowledge and Information Systems Springer 13TWEBACM Transactions on the WebACM序号刊物简称刊物全称出版社⽹址1DPD Distributed and Parallel Databases Springer 2I&M Information and Management Elsevier 3IPL Information Processing Letters Elsevier 4Information RetrievalSpringer中国计算机学会推荐国际学术刊物 (计算机科学理论)⼀、A类⼆、B类三、C类5IJCIS International Journal of Cooperative Information SystemsWorld Scientific 6IJGIS International Journal of Geographical Information ScienceTaylor &Francis 7IJIS International Journal of Intelligent Systems Wiley 8IJKM International Journal of Knowledge ManagementIGI 9IJSWIS International Journal on Semantic Web and Information SystemsIGI 10JCIS Journal of Computer Information Systems IACIS 11JDM Journal of Database Management IGI-Global 12JGITM Journal of Global Information Technology ManagementIvy League Publishing 13JIIS Journal of Intelligent Information Systems Springer 14JSISJournal of Strategic Information SystemsElsevier序号刊物简称刊物全称出版社⽹址1IANDC Information and Computation Elsevier 2SICOMPSIAM Journal on ComputingSIAM序号刊物简称刊物全称出版社⽹址1TALG ACM Transactions on Algorithms ACM 2TOCL ACM Transactions on Computational LogicACM 3TOMS ACM Transactions on Mathematical Software ACM 4 AlgorithmicaSpringer 5 Computational complexity Springer 6FAC Formal Aspects of Computing Springer 7 Formal Methods in System Design Springer 8 INFORMS Journal on ComputingINFORMS 9JCSS Journal of Computer and System Sciences Elsevier 10JGO Journal of Global Optimization Springer 11 Journal of Symbolic ComputationElsevier 12MSCS Mathematical Structures in Computer Science Cambridge University Press 13TCSTheoretical Computer ScienceElsevier序号刊物简称刊物全称出版社⽹址1 Annals of Pure and Applied Logic Elsevier2 Acta InformaticaSpringer 3Discrete Applied MathematicsElsevier中国计算机学会推荐国际学术期刊 (计算机图形学与多媒体)⼀、A类⼆、B类三、C类4 Fundamenta Informaticae IOS Press5 Higher-Order and Symbolic ComputationSpringer 6Information Processing Letters Elsevier 7JCOMPLEXITY Journal of ComplexityElsevier 8LOGCOMJournal of Logic and Computation Oxford University Press 9 Journal of Symbolic LogicAssociation for Symbolic Logic10LMCS Logical Methods in Computer Science LMCS 11SIDMA SIAM Journal on Discrete Mathematics SIAM 12Theory of Computing SystemsSpringer序号刊物简称刊物全称出版社⽹址1TOG ACM Transactions on GraphicsACM 2TIP IEEE Transactions on Image ProcessingIEEE 3TVCGIEEE Transactions on Visualization and Computer GraphicsIEEE序号刊物简称刊物全称出版社⽹址1TOMCCAP ACM Transactions on Multimedia Computing,Communications and Application ACM 2CAD Computer-Aided DesignElsevier 3CAGD Computer Aided Geometric Design Elsevier 4CGF Computer Graphics Forum Wiley 5GM Graphical ModelsElsevier 6 TCSVT IEEE Transactions on Circuits and Systems for Video TechnologyIEEE 7TMM IEEE Transactions on Multimedia IEEE 8JASA Journal of The Acoustical Society of AmericaAIP 9SIIMS SIAM Journal on Imaging Sciences SIAM 10Speech ComSpeech CommunicationElsevier序号刊物简称刊物全称出版社⽹址1CAVW Computer Animation and Virtual Worlds Wiley 2C&G Computers & Graphics-UKElsevier 3CGTA Computational Geometry: Theory and ApplicationsElsevier 4DCG Discrete & Computational Geometry Springer 5 IET Image Processing IET 6IEEE Signal Processing LetterIEEE中国计算机学会推荐国际学术刊物 (⼈⼯智能与模式识别)⼀、A类⼆、B类7JVCIR Journal of Visual Communication and Image Representation Elsevier 8MS Multimedia SystemsSpringer 9MTA Multimedia Tools and Applications Springer 10 Signal ProcessingElsevier 11 Signal procesing:image communication Elsevier 12TVCThe Visual ComputerSpringer序号刊物简称刊物全称出版社⽹址1AI Artificial IntelligenceElsevier 2TPAMI IEEE Trans on Pattern Analysis and Machine IntelligenceIEEE 3IJCV International Journal of Computer Vision Springer 4JMLRJournal of Machine Learning ResearchMIT Press序号刊物简称刊物全称出版社⽹址1TAP ACM Transactions on Applied Perception ACM 2TSLP ACM Transactions on Speech and Language Processing ACM 3 Computational LinguisticsMIT Press 4CVIU Computer Vision and Image Understanding Elsevier 5DKE Data and Knowledge Engineering Elsevier 6 Evolutionary ComputationMIT Press 7TAC IEEE Transactions on Affective Computing IEEE 8TASLP IEEE Transactions on Audio, Speech, and Language ProcessingIEEE 9 IEEE Transactions on CyberneticsIEEE 10TEC IEEE Transactions on Evolutionary Computation IEEE 11TFS IEEE Transactions on Fuzzy Systems IEEE 12TNNLS IEEE Transactions on Neural Networks and learning systemsIEEE 13IJAR International Journal of Approximate Reasoning Elsevier 14JAIR Journal of AI ResearchAAAI 15Journal of Automated ReasoningSpringer 16JSLHRJournal of Speech, Language, and Hearing ResearchAmerican Speech-Language Hearing Association 17 Machine Learning Springer 18 Neural Computation MIT Press 19Neural NetworksElsevier三、C类20Pattern Recognition Elsevier序号刊物简称刊物全称出版社⽹址1TALIP ACM Transactions on Asian LanguageInformation ProcessingACM3Applied Intelligence Springer 4AIM Artificial Intelligence in Medicine Elsevier 5Artificial Life MIT Press6AAMAS Autonomous Agents and Multi-AgentSystemsSpringer7Computational Intelligence Wiley 8Computer Speech and Language Elsevier9Connection Science Taylor & Francis10DSS Decision Support Systems Elsevier 11EAAI Engineering Applications of Artificial Intelligence Elsevier 12Expert Systems Blackwell/Wiley 13ESWA Expert Systems with Applications Elsevier 14Fuzzy Sets and Systems Elsevier15T-CIAIGIEEE Transactions on Computational Intelligence andAI in GamesIEEE16IET Computer Vision IET 17IET Signal Processing IET 18IVC Image and Vision Computing Elsevier 19IDA Intelligent Data Analysis Elsevier20IJCIA International Journal of ComputationalIntelligence and ApplicationsWorldScientific21IJDAR International Journal on Document Analysisand RecognitionSpringer22IJIS International Journal of Intelligent Systems Wiley23IJNS International Journal of Neural SystemsWorld Scientific24IJPRAI International Journal of Pattern Recognitionand Artificial IntelligenceWorldScientific25International Journal of Uncertainty,Fuzziness and KBSWorldScientific26JETAI Journal of Experimental and TheoreticalArtificial IntelligenceTaylor &Francis27KBS Knowledge-Based Systems Elsevier 28Machine Translation Springer 29Machine Vision and Applications Springer 30Natural Computing Springer31NLE Natural Language Engineering Cambridge University32NCA Neural Computing & Applications Springer 33NPL Neural Processing Letters Springer中国计算机学会推荐国际学术期刊 (⼈机交互与普适计算)⼀、A类⼆、B类三、C类中国计算机学会推荐国际学术期刊 (前沿、交叉与综合)⼀、A类⼆、B类34 NeurocomputingElsevier 35PAA Pattern Analysis and Applications Springer 36PRL Pattern Recognition Letters Elsevier 37 Soft ComputingSpringer 38WIASWeb Intelligence and Agent SystemsIOS Press序号刊物简称刊物全称出版社⽹址1TOCHI ACM Transactions on Computer-Human Interaction ACM 2IJHCSInternational Journal of Human Computer StudiesElsevier序号刊物简称刊物全称出版社⽹址1CSCW Computer Supported Cooperative Work Springer 2HCI Human Computer Interaction Taylor & Francis 3IWC Interacting with ComputersOxford University Press4UMUAIUser Modeling and User-Adapted InteractionSpringer序号刊物简称刊物全称出版社⽹址1BIT Behaviour & Information TechnologyTaylor & Francis 2IJHCI International Journal of Human-Computer Interaction Taylor & Francis3PMC Pervasive and Mobile Computing Elsevier 4PUCPersonal and Ubiquitous ComputingSpringer序号刊物简称刊物全称出版社⽹址1Proc. IEEE Proceedings of the IEEE IEEE 2JACMJournal of the ACMACM序号刊物简称刊物全称出版社⽹址1 BioinformaticsOxford UniversityPress 2 Briefings in BioinformaticsOxford UniversityPress3CognitionCognition :International Journal of Cognitive ScienceElsevier 4 PLOS Computational BiologyPublic Library of Science5TMI IEEE Transactions on Medical Imaging IEEE 6TGARSIEEE Transactions on Geoscience and Remote SensingIEEEIEEE Transactions on Intelligent三、C类7TITS Transportation Systems IEEE 8TR IEEE Transactions on Robotics IEEE 9TASAE IEEE Transactions on Automation Science and Engineering IEEE 10JCST Journal of Computer Science and TechnologySCIENCE PRESS/Springer 11JAMIA Journal of the American Medical Informatics AssociationBMJ Journals 12 Science China Information Sciences Science in China Press/Springer 13The Computer JournalOxford UniversityPress序号刊物简称刊物全称出版社⽹址1 BMC BioinformaticsBioMed Central 2 Cybernetics and SystemsTaylor &Francis 3 IEEE Geoscience and Remote Sensing Letters IEEE 4TITB IEEE Transactions on Information Technology in BiomedicineIEEE 5TCBB IEEE-ACM Transactions on Computational Biology and BioinformaticsIEEE/ACM6 IET Intelligent Transport Systems IET7 Medical Image Analysis Elsevier 8FCSFrontiers of Computer ScienceHigher Education Press。
计算机会议排名

ISSCC: IEEE Intl Solid-State Circuits Conf (0.87)
VLSI: IEEE Symp VLSI Circuits (0.87)
ICCAD: Intl Conf on Computer-Aided Design (0.86)
CODES+ISSS: Intl Conf on Hardware/Software Codesign & System Synthesis (0.86)
RTSS: IEEE Real-Time Systems Symposium (0.53)
VLSI Design: IEEE Intl Conf on VLSI Design / India (0.51)
HPCC: IEEE Int'l. Conf. on High Performance Computing & Communications (0.51)
CHES: Cryptographic Hardware and Embedded Systems (0.67)
PPSC: SIAM Conf on Parallel Processing for Scientific Computing (0.65)
NOSA: Nordic Symposium on Software Architecture (0.64)
GCC: Intl Conf on Grid and Cooperative Computing (0.54)
ICPADS: Intl Conf on Parallel and Distributed Systems (0.53)
RTCSA: IEEE Real-Time Computing Systems and Applications (0.53)
Meta-address architecture for parallel, dynamicall
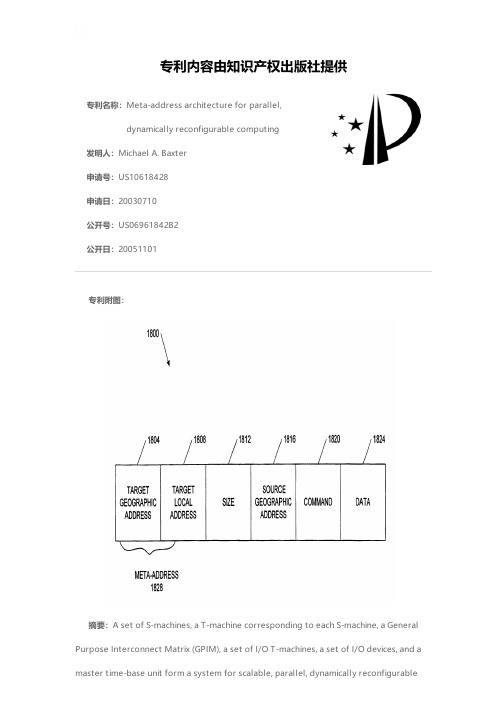
专利名称:Meta-address architecture for parallel,dynamically reconfigurable computing发明人:Michael A. Baxter申请号:US10618428申请日:20030710公开号:US06961842B2公开日:20051101专利内容由知识产权出版社提供专利附图:摘要:A set of S-machines, a T-machine corresponding to each S-machine, a General Purpose Interconnect Matrix (GPIM), a set of I/O T-machines, a set of I/O devices, and a master time-base unit form a system for scalable, parallel, dynamically reconfigurablecomputing. Each S-machine is a dynamically reconfigurable computer having a memory, a first local time-base unit, and a Dynamically Reconfigurable Processing Unit (DRPU). The DRPU is implemented using a reprogrammable logic device configured as an Instruction Fetch Unit (IFU), a Data Operate Unit (DOU), and an Address Operate Unit (AOU), each of which are selectively reconfigured during program execution in response to a reconfiguration interrupt or the selection of a reconfiguration directive embedded within a set of program instructions. Each reconfiguration interrupt and each reconfiguration directive references a configuration data set specifying a DRPU hardware organization optimized for the implementation of a particular Instruction Set Architecture (ISA). The IFU directs reconfiguration operations, instruction fetch and decode operations, memory access operations, and issues control signals to the DOU and the AOU to facilitate instruction execution. The DOU performs data computations, and the AOU performs address computations. Each T-machine is a data transfer device having a common interface and control unit, one or more interconnect I/O units, and a second local time-base unit. The GPIM is a scalable interconnect network that facilitates parallel communication between T-machines. The set of T-machines and the GPIM facilitate parallel communication between S-machines. The T-machines also control the transfer of data between S-machines in the network, and provide the addressing operations required. A meta-address is used to provide scalable bit-addressable capability to every S-machine.申请人:Michael A. Baxter地址:Sunnyvale CA US国籍:US代理机构:Fenwick & West LLP更多信息请下载全文后查看。
共轭梯度求解器的FPGA设计与实现

共轭梯度求解器的FPGA设计与实现第31卷第9期20l1年9月计算机应用JournalofComputerApplicationsV o1.31No.9Sep.2011文章编号:1001—9081(2011)09—2571—03doi:10.3724/SP.J.1087.2011.02571 共轭梯度求解器的FPGA设计与实现宋庆增,顾军华(I.河北工业大学电气工程学院,天津300401;2.河北工业大学计算机科学与软件学院,天津300401)(*********************)摘要:针对共轭梯度(CG)迭代算法软件执行效率低,实时性差的缺点,提出一种基于现场可编程逻辑门阵列(FPGA)平台的CG迭代求解器.设计采用软硬件结合的方式构建整个系统,CG协处理器执行CG迭代算法中计算量大,控制简单的代码.以达到硬件加速的目的.控制复杂,计算量较少的代码则依旧在微处理上执行.设计采用行交错数据流,使得整个系统完全无停顿的运行,提高了计算性能.实验结果表明,与软件执行相比,硬件CG协处理器可以获得最高5.7倍的性能加速.关键词:可重构计算;稀疏线性方程组;现场可编程逻辑门阵列;共轭梯度法;行交错数据流中图分类号:TP31文献标志码:ADesignandimplementation0fc0IIjugategradientiterativesolveronFPGA SONGQing—zeng.GUJun—hua(1.SchoolofElectricalEngineeringandAutomation,HebeiUniversityofTec hnology,Tianjin300401,China;2.SchoolofComputerScienceandEngineering,ltebeiUniversityofTechnol ogy,Tianjin300401,China)Abstract:Toovercomethedisadvantageofinefficientandbadreal-timecapab ilityinsoftwareversionConjugateGradient(CG)iterativesolver,aCGiterativesolverwasdesignedandimplementedonF ieldProgrammableGateArray(FPGA)platform.ThedesignofCGiterativesolverWasbasedonhardware/softwareC O—design.HardwareCGCO—processor implementedthecodeofenol3‟nouscomputationandsimplecontrol,whichc ouldacceleratethesystem.Thecodeofcontrol complexityandlesscalculationwasstillperformedinthemicroprocessor.Th euseofrow—interleaveddataflowcouldmakethesystemnottostalltoimproveperformance.Theexperimentalresultsillustrate thathardwareCGiterativesolvercanspeed”pabout5.7timesoverthesoftwareversionofthesamealgorithm. Keywords:reconfigurablecomputing;sparselinearequations;FieldProgra mmableGateArray(FPGA);conjugategradientalgorithm;rOW—interleaveddataflow0引言共轭梯度(ConjugateGradient,CG)法是求解稀疏线性方程组的有效数值迭代算法,具有较快的收敛速度和二次终止性等优点.石油勘探,大气模拟,电磁场数值计算等领域导出的大规模线性方程组常利用共轭梯度法求解.目前,共轭梯度求解器的实现主要包括两类,即通用处理器(Genera1. PurposeProcessor,GPP)和专用集成电路(Application—Specific IntegratedCircuit,ASIC).GPP方法灵活性强,然而其广泛的灵活性是以牺牲系统的性能和速度为代价换来的,对共轭梯度算法的性能低下,尤其是求解大规模稀疏线性系统.ASIC法用特定的集成电路,以完全硬件的方式来实现计算任务.尽管ASIC在尺寸(晶体管的数量),复杂性和性能实现上都是最佳的,但是设计和制造它是一个非常耗时和代价昂贵的过程.近年来,可重构器件的迅速发展极大地弥补了专用ASIC的不足.基于现场可编程逻辑门阵列(FieldProgrammableGateArray,FPGA)的可重构计算系统可获得接近于专用ASIC的计算能力,又可以在应用环境发生变化时改变配置实现新的功能,兼顾了通用GPP的可编程性和专用ASIC的高效性.对于CG迭代算法,Jacobi迭代算法等计算密集型的数值算法,可重构计算系统具有巨大的速度和功耗优势”I2].本文在基于FPGA的可重构计算平台上设计和实现了一种硬件CG求解器.设计采用软硬件结合的方法构建整个系统,将自定义的硬件电路作为CG协处理器同NiosH软核处理器耦合在一起.CG协处理器完成计算稠密,控制简单的代码,以达到硬件加速的目的.实验结果表明,相对于运行在CPU上的软件实现,CG协处理器可以得到一定的计算性能的加速.l相关工作自然科学和工程中,很多问题都将归结为求解下面的线性方程组:Ax=b(1)其中:A是n×n维的稀疏矩阵,x是n维未知量,b是n维右端项.稀疏线性方程组求解的迭代算法中,CG迭代法是最常用的一种方法.该方法具有算法简单,存储需求小等优点,十分适合于大规模的问题,在诸多领域得到了广泛的应用.CG 迭代算法的搜索方向是互相共轭的,因此具有非常快的收敛速度J.图1给出了CG迭代的算法流程.CG主函数完成初始化,控制迭代次数等操作,主迭代子程序则完成主要的计算任务.收稿日期:2011—03—21;修回13期:201l一06—03.基金项目:科技人员服务企业行动项目(2009GJA20014).作者简介:宋庆增(1980一),男,河北保定人,博士研究生,主要研究方向:智能信息处理,电磁场数值解,可重构计算;顾军华(1966一)男,河北赵县人,教授,博士,博士生导师,主要研究方向:智能信息处理,电磁场数值解.2572计算机应用第31卷迭图1CG迭代算法主迭代程序主要由下面的计算任务组成:q:Apt=(,)/(q,P)r=,——f‟fx”l:X+矿=(“,”)/(,)P”=rk”+p其中:(,N)表示向量和J】,,的内积.CG迭代算法同时具有计算稠密和控制复杂的特点,因此,将整个算法完全映射到FPGA芯片中并不是合理的处理方式.通常的做法是对CG迭代算法进行软硬件划分,将计算稠密,控制简单的部分以硬件电路的方式执行,以达到硬件加速的目的,算法的其余部分则依旧以软件的形式存在.目前,基于FPGA的CG求解器的研究已经取得了一些研究成果.Morris等人在可重构计算机上设计和实现了稀疏线性方程组的CG迭代求解,采用基于FPGA和GPP混合设计的方法,将算法的计算稠密部分在FPGA硬件进行加速. Lopes等人为了求解稠密线性方程组,采用CG算法,与通常的处理方式不同,其在单个芯片上实现了整个EG算法,因此其扩展性很差,只能处理不超过60维的稠密线性方程组. 已有的算法的要么使用CRS格式J,要么是稠密矩阵,很少针对偏微分方程导出的稀疏线性系统进行优化设计.偏微分方程通过有限元法和有限差分法导出的大规模稀疏线性方程组往往具有规则的结构,本文针对这类规则的稀疏线性方程组,对硬件CG求解器采用更加适合的稀疏矩阵存储格式和行交错的数据流,进行了优化设计.2系统架构设计随着半导体技术的进步,FPGA的运算速度和存储空间都得到了很大的提高,功能变得更加强大灵活,这使得在其上实现并行数值计算成为可能.然而,并非所有的算法都适合在FPGA实现.可重构硬件使用类似于ASIC的基于空间并行的执行方式,使其只适合执行程序中计算量大,拥有规则的数据访问模式,控制简单的那部分”计算密集型”代码;而算法中存在的一些计算量相对较少,访问模式比较随机,控制比较复杂的代码则不适合采用硬件执行.为执行这部分程序,则需要在可重构系统集成一个计算能力相对较弱的通用微处理器.本文采用在FPGA内部生成NiosⅡ软核的方法,构建可重构计算系统.NiosⅡ作为可重构系统的通用微处理器,执行不适合采用硬件执行的代码,系统的整体架构如图2.图2CG系统架构整个可重构计算系统由四个模块组成:DMA模块,NiosⅡ模块,CG协处理器和外部存储器模块,四个模块通过高速总线连接在一起.其中,NiosⅡ执行控制比较复杂,计算量较少的代码,主要的计算任务由CG协处理器的硬件电路完成. 外部存储器存储计算需要的数据,DMA模块则负责数据的交换.根据程序代码自身的性质,对CG算法进行软硬件划分,确定使用CG协处理器执行的代码是设计的第一步,也是最为关键的一步.不合理的划分,将导致非常低的计算性能,不能达到性能加速的目的.将整个CG算法的主迭代映射到FPGA执行是可行的实现方式,但是这种方式只适合小规模的稀疏线性系统,可扩展性很差,一般不采用这种设计方式. CG算法的主迭代程序执行一次,需要执行一次稀疏矩阵乘向量(q=Ap),二次归约操作((r,,)和(q)),三次向量操作(r=r—tq,=x+tp,P=,+卢p),以及少量的标量操作.其中95%的计算时间用于稀疏矩阵乘向量操作,是整个迭代算法的主体.稀疏矩阵乘向量同时满足计算密集和操作简单的条件,适合以硬件电路的方式执行.因此,本文将稀疏向量乘矩阵映射到CG协处理器中以硬件电路的方式执行,其余部分依旧作为软件,在处理器上执行.3CG协处理器设计CG协处理器的主要功能是高效地完成稀疏矩阵乘向量.稀疏矩阵乘向量不止是CG迭代设计的核心,更被广泛地用于各种数值方法.CG协处理器由接口模块,计算模块和控制模块组成.接口模块由符合高速总线标准的接口电路组成, 与高速总线相连负责数据的输入与输出;计算模块由一组计算单元(ProcessElement,PE)阵列和局部存储器组成;控制模块的主要功能是控制整个系统的正常运行.计算模块是整个系统的重点,其他模块的设计都依附于计算模块的设计.计算模块所使用的浮点计算单元都是深度流水的,因此具有很高的运行频率.整个设计的数据通路以流水和并行化的方式进行组织,充分发挥FPGA的计算潜力. 图3模块划分3.1稀疏矩阵存储格式与稠密矩阵乘向量不同,稀疏矩阵的每一行的元素个数很少,这将导致在FPGA平台上实现稀疏矩阵乘向量的计算效率很大程度上取决于稀疏矩阵的存储策略J.而不合理的存储格式使得系统无法高度并行和流水的运行,最终导致性能的下降.有限元或有限差分法得到的稀疏矩阵一般具有很规则的结构,Ellpack.Itpack格式充分体现了这种矩阵的稀疏结构的特点,具有在FPGA上执行计算效率高的优点.该存储格式假设稀疏矩阵的每行至多有Ⅳd个非零元素,需要两个大小为n?Na的实浮点数矩阵和整型矩阵存储. COEF矩阵用来记录稀疏矩阵中的非零元素,每一行的非零元对应存储在COEF(1:n,1:)中,JCOEF矩阵用来存储COEF中每个元素对应的列号.3.2计算模块实现并行稀疏矩阵乘向量的方法有很多种,其中,内积方第9期宋庆增等:共轭梯度求解器的FPGA设计与实现2573 法是最为重要的并行矩阵乘向量实现方法,这种方法将整个计算分解为n次的向量内积:=∑A(2)如图4,设计采用完全的乘加二叉树组成计算阵列.假设稀疏矩阵的每一行的元素数目为m,矩阵的维数rt.内积法将需要m个浮点乘法器,m一1个浮点加法器和至少nXm 局部存储单元.向量X存储在局部存储器中,由于一个局部存储器在一个时钟周期只能提供一个的值,因此向量X需要m 个备份.y图4并行稀疏矩阵乘向量每个时钟周期,都有r/t个COEF和JCOEF数值进入计算阵列.JCOEF整数值作为向量的地址值,在计算阵列的存储器中得到一个X值提供给浮点乘法器,COEF的数值作为另一个乘数提供给浮点乘法器.由于采用完全并行和流水的数据流设计,完成整个计算所需的时钟周期数为n+Fibm]+,这里为浮点加法的延迟,为浮点乘法的延迟,rlbm]表示向上取整.受硬件规模的限制,FPGA上局部存储器的规模,和能实现的浮点加法和乘法的数目s也是有限的,一般有这样的关系:min(s,w/n)≤m≤17,.因此,完全并行的内积设计只适合小规模的稀疏矩阵,对中等规模以上的稀疏矩阵乘向量,无法在FPGA上实现完全并行的设计.如图5,本文将完全并行的操作分解为并行模块和串行模块两部分,其中并行模块采用与完全并行操作相同的乘加二叉树,只是规模缩小为k,这里k≤min(s,w/n)(本例中k= 4).每个时钟周期,并行的乘加二叉树将生成一个数据(部分的内积结果),串行模块将其累加,生成最终的计算结果.串行模块的设计是整个设计的难点之一,不合理的设计将导致整个系统的流水停顿.C_-J…}C¨+l+.;C+:!C+s:2.3行交错数据流众所周知,浮点加法器都是深度流水的,显然简单的反馈加法设计将导致流水停顿,单集的归约电路法虽然能减少流水的停顿时间,但不能完全消除流水停顿.多集归约电路的设计能避免流水停顿,但是其设计复杂,资源消耗更多,同时复杂的设计将降低整个系统的运行频率.为了避免任何的流水停顿和提高整个系统的运行频率,采用行交错数据流作为内部数据流.如图5,采用一组BUFFER将原本严格的行优先输入的数据改成行交错数据. 下面给出了一个实际的例子,其中交错参数.=3,与浮点加法器的延迟相同.由于交错参数和加法延迟完全一致,交错数据流正好可以使浮点加法器完全无停顿的运行,提高整个系统的性能.交错数据流:原始顺序:l2345678910l1l2131415l6l718交错顺序:171328143915410165l1l761218完整的串行模块由一个浮点加法器,一组生成交错数据流的BUFFER和控制电路组成.BUFFERER模块为浮点加法器生成内部行交错数据流,控制电路控制整个串行模块的运行.这里只是为了说明交错数据流的设计思想,没有给出完整的串行模块的设计.4分析与实验QuartusII9.0和NiosII9.0作为编程工具,在Altera公司的EP2C70芯片上实现了完整的设计.对照组采用运行在PC机上的程序,其CPU采用IntelPentiumD2.8GHZ(双核),内存为512MB.测试矩阵采用佛罗里达大学的稀疏矩阵集,表1给出了测试矩阵的性质,每个稀疏矩阵运行1000 次取其平均计算时间,时问单位为秒.与CPU上以软件方式执行相比,CG协处理器计算速度要比CPU快2倍左右,最高可以得到5.7倍的性能加速.图5分解电路表1性能加速比协处理器计算性能峰值P的计算公式为P一浮点计算器的数目X运行频率.由于CG协处理器包含4个浮点乘法器和4个浮点加法器,运行频率为114MHz,因此8xl14:912MFLOPS=0.912GFLOPS.这里GFLOPS和MFLOPS都是浮点计算性能的单位,其中一个GFLOPS约等于每秒10次浮点运算.表2给出了CG协处理器运行测试矩阵时的实际计算性能,计算性能都在0.4GFLOPS以上,最高能达到0.77GFLOPS.与软件执行不同,FPGA上执行往往能达到计算峰值的50%以上,甚至80%.因此当采用更先进芯片和集成更多计算单元时,可以得到更好的计算性能.(下转第2588页)2588计算机应用第3l卷图1O车载播放器硬件实物图4结语图1l车载播放器音频播放截图AtomZ510是Intel推出的系列嵌入式处理器之一,搭载有最新款SCH控制芯片,主要面向车载娱乐,工业控制与自动化,多媒体网络电话等嵌入式计算领域,提供Windows/ Linux多操作系统支持.AtomZ510具备低功耗的特性,支持高清,板载1GB内存,搭载有SCHUSI5WP桥片,提供丰富的接口,使用户可根据需要方便的扩充自己需要的接口.Atom 7510的这些特性,为利用它制作一款高性能的车载播放器提供了优越条件.本文的播放器建立在Atom7510基础之上,具备图形播放界面,操作简单便捷;同时支持音频,视频播放,支持多种格式的音视频文件,支持所有主流视频编解码标准,支持高清,功能强大,具有很大的实用价值.参考文献:[1】殷建红.国内车载娱乐信息系统发展现状及趋势【J】.汽车与配件,2009(11):40—42.【2】MACARIOG,TORCHIANOM,VIOLANTEM.Anin.vehiclein—fotainmentsoftwarearchitecturebasedongoogleandroid【C】//SIES,09:IEEEInternationalSymposiumonIndustrialEmbedded Systems.Piscataway,NJ:IEEE,2009:257—260.[3】IntelCorporation.IntelSystemControllerHub【EB/OL].【2010一Ol一26】./design/chipsets/embedded/datashts/319537.pdf[4】李建,许勇,苏平.基于Atom的移动装置远程监控系统设计【J】. 计算机系统应用,2010,19(4):5—8.[5]张江洪.基于AU6840的车载音乐播放器系统设计【J】.吉首大学:自然科学版,2009,30(2):63—65.[6]王建国,马然.基于Aul200处理器的车载多媒体电脑设计【J】. 计算机工程,2009,35(23):243—245.【7]张海滨,李挥,吴晔,等.嵌入式高清播放器的设计与实现【J】.计算机工程与设计,2010,31(13):3084—3087.[8】李巍,贾克斌.MPlayer播放器在嵌入式平台上的应用fJ】.测控技术,2007,26(增刊):286—289.[9]MPlayer工作组.MPlayer一电影播放器【CP/OL】.【2010—10 —24】.http://www.mplayerhq.hu.【l0]毕厚杰,王健.新一代视频压缩编码标准——H.264/A VC【M】.2 版.北京:人民邮电出版社,2009.【11】BICKFORDBL,BROWNAK doraaccessplayerwithplaylist2001—02一o6.【12】[13】V ehicleaudiosystemhavingran-control:US,6185163BI【P].粱夫或,李娟,门爱东.现代视频编码关键技术及其发展【J】.电力系统通信,2006,27(3):l一4.BUTLERN,BA TOURJ-N,TUCKERD,eta1.In—vehiclemuhime—diasystem:US,7571038B2[P】.2009—08一o4.(上接第2573页)表2CG协处理器的计算性能本文针对CG迭代算法的特点,在基于FPGA的可重构硬件平台上设计和实现了优化的硬件CG迭代求解器.有效的软硬件划分技术将CG代码被分割成两部分,分别以硬件和软件的方式执行.采用Ellpack—Itpack格式作为矩阵存储格式,内部电路生成行交错数据流,提高了整个系统的计算性能.实验结果表明,与软件实现相比,本设计平均可以得到2倍左右的计算性能加速.参考文献:【l】MORRISGR,PRASANNA VK,ANDERSONRD.Ahybrid印一proachformappingconjugategradientontoanFPGAaugmented recontigurablesupercomputer【el//FCCM‟06:Proceedingsofthe14thIEEESymposiumField?-programmableCustomComputingMa?? chines.Washington,DC:IEEEComputerSociety,2006:3—12.【2]KASBAHSJ,DAMMIW.Thejacobimethodinreeonfi~rable hardware[C】//WCE2007:ProceedingsoftheWorldCongresson [3】[4][5】【6】【7】【8】Engineering.[S.1.]:NewswoedLimited,2007,2:823—827. LOPESAR,CONSTANTINIDESGA.AhishthroughputFPGA—basedfloatingpointconjugategradientimplementation[C】//ARC8:Proceedingsofthe4thInternationalWorkshoponRecon—figurableComputing:Architectures,ToolsandApplications,LNCS 4943.Berlin:Springer?Verlag.2008:75—86.BAKOSJD,NAGARKK.Exploitingmatrixsymmetrytoimprove FPGA—acceleratedconjugategradient【C】//FCCM2009:17thAn- nualIEEEInternationalSymposiumonFieldProgrammableCustom ComputingMachines.Washington,DC:IEEEComputerSociety, 2009:223—226.SUNJ,PETERSONG.Sparsematrix—vectormultiplicationdesign onFPGAs【C】//FCCM2007:15thAnnualIEEEInternational SymposiumonFieldProgrammableCustomComputingMachines. Washington,DC:IEEEComputerSociety,2007:349—352. ZHUOL,PRASANNA VK.Scalablehybriddesignsforlinearalge- braonreconfignrablecomputingsystems[J1.IEEETransactionsoll Computers,2008,57(12):1661—1675.ROLDAOA,CONSTANTINIDESG.AhighthroughputFlea- basedfloatingpointconjugategradientimplementationfordensema- trices【J].ACMTransactionsonReeonfigurableTechnologyandSystems,2010,3(1):1—19.WANGY,BOYDS.Fastmodelpredictivecontrolusingonlineopti- mization[J].IEEETransactionsonControlSystemsTechnology. 2010,18(2):267—278.CONSTANTINIDESGA.Tutoilalpaper:parallelarchitecturesfor modelpredictivecontrol【C】//ECC‟09:ProceedingsofEuropean ControlConference.Washington,De:IEEEControlSystemSocie? ty.2009:138—143.。
riscv架构试题答案

riscv架构试题答案一、选择题1. RISC-V 架构中的“RISC”代表什么?A. Reduced Instruction Set ComputingB. Register-based Instruction Set ComputingC. Reduced Instruction Set ComputerD. Reconfigurable Instruction Set Computing 答案:C2. RISC-V 架构的地址空间是多少位?A. 32位B. 48位C. 64位D. 可配置,32位或64位答案:D3. RISC-V 指令集中,哪条指令用于实现函数调用?A. JALB. JALRC. BEQD. BLT答案:A4. 在 RISC-V 架构中,X0 寄存器的名称是什么?A. ZEROB. RAC. SPD. GP答案:B5. RISC-V 架构中的特权级别有几个?A. 2个B. 3个C. 4个D. 5个答案:B二、填空题1. RISC-V 架构的指令集可以分为两大类:__________指令和__________指令。
答案:用户级用户级特权级2. RISC-V 架构中,__________寄存器用于存储返回地址,通常在函数调用时使用。
答案:RA3. RISC-V 架构提供了__________和__________两种类型的加载和存储指令,以支持不同的内存对齐需求。
答案:偏移量立即值4. 在 RISC-V 架构中,__________指令用于实现条件分支。
答案:BEQ5. RISC-V 架构的__________寄存器用于指向堆栈顶部,并在函数调用和返回时用于保存和恢复寄存器状态。
答案:SP三、简答题1. 请简述 RISC-V 架构的特点。
答:RISC-V 是一种开放标准的指令集架构(ISA),具有以下特点:- 开源开放:RISC-V 是完全开源的,任何人都可以免费使用其规范,并根据需要进行修改。
未来的航空母舰英语作文600字

未来的航空母舰英语作文600字Future Aircraft Carriers: A Vision of Naval Supremacy.Aircraft carriers, the behemoths of the modern navies, wield immense power and strategic significance. As technology continues to advance at an unprecedented pace, the future of aircraft carriers holds excitingpossibilities that will reshape the dynamics of naval warfare.Unveiling the Next Generation: Hybrid-Electric Power.The next generation of aircraft carriers is poised to be powered by a hybrid-electric propulsion system that combines traditional fossil fuels with advanced electric motors. This cutting-edge technology offers a myriad of benefits. Hybrid-electric carriers consume less fuel, reducing operating costs and increasing their endurance at sea. Additionally, they generate less noise and emissions, making them more environmentally friendly and operationallystealthier.Integrated Air and Missile Defense Systems.Advanced air and missile defense systems will be indispensable on future aircraft carriers. These sophisticated systems will utilize a combination of radar, sensors, and interceptors to create an impenetrable shield against aerial threats. Laser weapons and electromagnetic railguns are also being developed to provide additional layers of defense, neutralizing incoming missiles and hostile aircraft with pinpoint accuracy.Unmanned Aerial Systems (UAS)。
可重构计算(Reconfigurable Computing)

发展趋势
…
…
系统互连的趋势
交换式结构代替总线式 高速串行点对点连接代替并行总线 基于包交换的协议代替独立控制信号 异步协议代替同步协议 传统意义上的互联走向通信模式? 为可重构互连带来了机会? 模块化 异步性
“拆”和“聚”
光互连让“拆”成为了可能: 长距离传输,带宽 可重构计算为“聚”提供了支持: 编制新的应用程序时,可直接调用共享内存或消息 传递算法模块,利用已有成果,加速程序的开发。一个应 用程序可能包括对三类结构库函数的并行调用。例如程序 员开发通过投票方式确定基因比对结果的程序(一组数据 调用三组函数库独立处理,结果比对,2:1为执行完), 机器将自动调整为三部分(SMP、MPP、Cluster),并行 执行三个独立的程序,数据可以共享!
DSAG:光互连-“拆”;RC-“聚”,聚的过程需要重构 研究RC体系结构理论和方法对DSAG理论的指导 研究如何利用现有的RC技术和产品构建DSAG
RC的研究主题
体系结构 逻辑,连接 软件技术 描述,编译,开发环境 快速可重构技术 实时性,更高的动态性 应用 ASIC(小雨点卡),design/verification(龙芯),DSAG (?)
可重构计算(Reconfigurable Computing)
李磊 eniac@ 智能中心HPC-OG组 2003-10-22
内容
RC:what&why RC的体系结构 RC的研究项目 RC与DSAG
RC:What & Why
可重构计算:Reconfigurable Computing, RC FPGA-based RC 历史:50年代,80年代 目标:"the performance of hardware with the flexibility of software." ASIC-专用,processor-通用 性能-成本 我们的目的
一种针对COTS器件的抗辐射加固方法

一种针对COTS器件的抗辐射加固方法梁健;张润宁;赵帅【摘要】随着商用现货(COTS)器件在空间任务中的广泛应用,COTS器件的抗辐射加固显得尤为重要,针对COTS器件在空间环境下易受宇宙射线和高能粒子冲击而产生辐射效应的特点,文章结合三模冗余(TMR)技术与现场可编程门阵列(FPGA)的重构技术,提出了一种基于TMR的可重构星载处理单元抗辐射加固方法.通过基于Markov过程的可靠度分析可知,冗余和重构技术相结合可以使处理单元具有更强的容错能力.文章利用实验模拟验证了该星载处理单元的各项关键技术,结果表明:此处理单元能够屏蔽单模故障,并能够定位和修复由空间复杂环境引发的软错误.【期刊名称】《航天器工程》【年(卷),期】2016(025)004【总页数】6页(P81-86)【关键词】星载处理单元;冗余;可重构;商用现货【作者】梁健;张润宁;赵帅【作者单位】航天东方红卫星有限公司,北京 100094;航天东方红卫星有限公司,北京 100094;西北工业大学,西安710072【正文语种】中文【中图分类】V473空间环境中存在较多的宇宙射线和高能粒子,运行在这种复杂环境下的航天器的计算系统很容易受到这些粒子和射线的冲击而产生辐射效应。
当前,在空间处理系统中,现场可编程门阵列(FPGA)以其低功耗、灵活性、通用性、高集成性等优点获得了广泛的应用。
基于静态随机存储器(SRAM)型的商用现货(COTS)FPGA器件很容易受到高能粒子的影响而产生辐射效应[1-3]。
而基于Flash架构的FPGA器件有较强的抗辐射性能,对由空间高能粒子引发的固件错误具有免疫能力,但是基于Flash架构的FPGA器件逻辑资源有限,不具备嵌入式软处理器的能力,故运算和处理能力受限,直接应用于复杂的星务管理和运算具有一定的局限性[4-5]。
传统的三模冗余(TMR)技术可以有效屏蔽单模故障,但表决器本身并不具备抗辐射能力,或者表决器由简单的逻辑开关组成,控制与协调能力不足[6-7]。
嵌入式软件开发技术与方法 PPT课件

30%
20%
10%
0% 4-bits
8-bits 16-bits 32-bits 64-bits Special
Programming Languages
90%
80%
70%
60%
50%
40%
30%
20%
10%
0%
Assemble C language C++
Java
language
1998-99 1999-00 2000-01
28
软件仿真开发环境
嵌入式软件开发人员只需要了解所使用的编程 语言、编译器及其使用方法、操作系统系统 API接口及系统函数,就可以实施并完成嵌入 式软件的程序设计,生成虚拟机环境下可运行 的可执行程序。
可以在宿主机环境下查看到运行的结果,进行 运行结果的分析,并反复进行软件的调试,最 终生成一个认可的可执行软件。待时机条件具 备时安装到目标机上运行。
与动态连接库或运行时库进行链接,生成一个可执 行程序,作为文件存放在磁盘上。 运行:通过操作系统的加载程序,将可执行文件从 磁盘加载到内存,运行。 桌面系统可运行许多程序,可快速容易地加载运行。
19
如何构建嵌入式应用程序-2
嵌入式系统软件
工具 软件组件 过程:编译器或汇编器产生一个或多个目标文件,
29
实时软件分析设计方法
嵌入式实时软件系统的生命周期分为以下几个阶段: 需求分析与详细说明:对系统功能及性能的需求进行
描述。 系统设计:任务分解, 定义任务间接口关系。 任务设计:按模块方式设计每个任务,定义模块间接
口。 模块设计与实现:完成每个模块的详细设计、编码和
单元测试。 任务与系统集成:任务单独运行及并发运行调试,查
双目立体相机中实时匹配算法的FPGA实现

双目立体相机中实时匹配算法的FPGA实现单洁;唐垚;姜晖【摘要】在双目立体相机中,利用图像处理计算场景深度信息是一项关键技术.通过研究立体视觉图像匹配原理,提出一种基于FPGA的立体图像实时匹配算法的实现方法.该算法以Census变换为基础借助于像素在邻域中灰度相对值的排序进行相似度比较,来实现区域立体匹配;在左右一致性约束下采用多窗口相关匹配方法改善深度不连续图像的匹配质量,提高匹配准确度.利用FPGA流水线和并行处理技术实现了双目立体相机的实时图像匹配.结果表明,该图像匹配结构具有较高的吞吐率和处理速度,可以工作在97.3MHz频率下实现1024×1024灰度图像30f/s的实时处理.【期刊名称】《激光与红外》【年(卷),期】2013(043)012【总页数】5页(P1406-1410)【关键词】双目立体相机;实时图像匹配;多窗口相关匹配;FPGA【作者】单洁;唐垚;姜晖【作者单位】西安邮电大学通信与信息工程学院,陕西西安710121;西安邮电大学通信与信息工程学院,陕西西安710121;西安邮电大学通信与信息工程学院,陕西西安710121【正文语种】中文【中图分类】TP391.41;TN911.731 引言随着机器视觉的发展,立体视觉系统得到越来越广泛的应用[1-2]。
双目立体相机采用两台相机,模拟人眼成像原理,先通过寻找两个相机中图像对应点的光学,得到各个点处的视差,再根据视差信息和相机的投影模型恢复出原始景物的深度信息。
所以,在通过立体相机计算场景信息的深度过程中,图像获取、相机标定、图像匹配和三维重建成为了关键技术。
根据匹配基元的不同,图像匹配可分为区域匹配[1-2]、特征匹配[1]和相位匹配[2-4]。
其中,区域匹配以区域相似度为匹配基元,基本原理是在基准图上选取一个模板窗口,在配准图上选取同样大小的一组窗口,再将这些窗口与基准图中的模板窗口进行相似度比较,找出与模板窗口最相似的窗口,那么该窗口的中心点就是模板窗口中心点的匹配点,两点的横坐标差即为视差[1]。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Reconfigurable Computing for Space-Time Adaptive ProcessingNikhil D. Gupta , John K. Antonio , and Jack M. WestDepartment of Computer ScienceBox 43104Texas Tech University Lubbock, TX 79409-3104 USATel: 806-742-1659{gupta, antonio, west}@1. IntroductionSpace-time adaptive processing (STAP) refers to a class of signal processing techniques used to process returns of an antenna array radar system [4]. STAP algorithms are designed to extract desired target signals from returns comprised of Doppler shifts,ground clutter, and jamming interference. STAP simultaneously and adaptively combines the signals received on multiple elements of an antenna array – the spatial domain – and from multiple pulse repetition periods – the temporal domain.The output of STAP is a weighted sum of multiple returns,where the weights for each return in the sum are calculated adaptively and in real-time. The most computationally intensive portion of most STAP approaches is the calculation of the adaptive weight values. Calculation of the weights involves solving a set of linear equations based on an estimate of the covariance matrix associated with the radar return data.Existing approaches for STAP typically rely on the use of multiple digital signal processors (DSPs) or general-purpose processors (GPPs) to calculate the adaptive weights. These approaches are often based on solving multiple sets of linear equations and require the calculation of numerous vector inner products. This paper proposes the use of FPGAs as vector co-processors capable of performing inner product calculation.Two different “inner-product co-processor” designs are introduced for use with the host DSP or GPP. The first has a multiply-and-accumulate structure, and the second uses a reduction-style tree structure having two multipliers and an adder.2.STAP Weight Calculation2.1 Basic FormulationThe STAP algorithm assumed here is known as K th -order Doppler factored STAP, which is classified as a partially adaptive technique. Due to the space limitation, it will not be possible to fully explain this algorithm. Instead, the focus here will be on the necessary notation and core calculations required to determine the values of the adaptive weights. For more information on STAP,the reader is referred to [1, 4].Determining the values for the n -vector of adaptive weights,denoted by w r, involves solving a system of linear equations of the form:s w v r =Ψ,(1)This work was supported by DARPA under contract number F30602-97-2-0297where s ris a known n -vector called the steering vector and Ψis an estimate of the covariance matrix, which is determined based on the sampled radar returns.Ψis derived based on space-time data matrix X , which is an n × N matrix defined by:[]N x x x X rr r ... 21=. Based on this the definition,Ψis given by:H X X N1=Ψ (2)2.2 QR-Decomposition and Conjugate GradientThe QR-decomposition approach is a direct approach for solving a system of linear equations. The QR approach always gives an exact solution and the complexity of the algorithm is fixed. It involves performing a QR-decomposition on the matrix X T , the result of which is an N N ×orthogonal matrix Q and an N n ×upper triangular matrix R such that X = QR . The final result is obtained by forward and backward substitution. For more details the reader is referred to [1].The conjugate gradient approach is an iterative method that provides a general means for solving a system of linear equations [2]. For the system of equations given in Eq. (1), it is based on the idea of minimizing the following function:w s w w w f T r r r r −Ψ=21)(.(3)The function f is minimized when its gradient is zero, i.e.,0=−Ψ=∇s w f rr , which corresponds to the solution to the original system of linear equations. The very repetitive and regular numerical structure of the conjugate gradient update equations makes it a prime candidate for implementation on an FPGA system.Numerical studies were conducted using Matlab implementations of the QR-decomposition and CG methods on actual STAP data collected by the Multi-Channel Airborne Radar Measurement (MCARM) system of Rome Lab [3].Further details of this study can be found in [6].3. Inner-Product FPGA Co-ProcessorEach of the two methods outlined above requires calculating a number of inner products. Given enough resources, all the inner products could be done in parallel on FPGAs. Because the available system has only two FPGAs [5],the computations was divided among the host processor and the FPGA board. The two schemes that were implemented are outlined below. For both schemes, the data vectors are assumed to be in block-floating-point format [9]. Additionally, themultiplier implementation is based on discussion in [7] and the adder unit uses 4-bit carry-look-ahead adders [8] in each stage of the adder pipe.3.1 Multiply-and-Accumulate ImplementationIn the first implementation shown in Figure 1, the FPGA is configured to perform the multiply-and-accumulate operations on the input vectors. The implementation consists of a multiply unit and an accumulator, which is composed of a normalization unit and an adder. The normalization unit shifts the binary point of theprior to the addition. The output of the adder is fed back and accumulated with the next product term.The single cycle multiply-and-accumulate is achieved by pipelining each unit of the implementation. This unit reads in two operands and performs two operations per cycle. Thus, the unit reduces two N -vectors to a constant number of partial sums equal to the number of stages in the accumulator pipe. The implementation allocates approximately 88% of the configurable logic blocks (CLBs) on the Xilinx 4028EX FPGA. The implementation can be clocked at 40MHz, thus giving a throughput of 80 million block-floating-point operations per second.3.2 Multiply-and-Add ImplementationFigure 2 illustrates the second implementation that performs an inner product, i.e., a multiply-and-add operation on the two input vectors. The design incorporates two 16-bit multiply units and an adder. By using this approach, two multiplies can be performed in parallel, and afterwards, the adder computes the sum of the two products.A challenge associated with this implementation is that four 16-bit input operands, i.e., 64 bits, are required per computation cycle. Unfortunately, the data-path to the FPGA board is only 36-bits wide. The solution to this problem involves clocking the input state machine at twice the frequency of the multiply-and-add state machine, and registering the first two operands for one input state machine clock cycle.The multiply-and-add unit reads in four operands and performs three block-floating-point operations per cycle. Thus,the two input N -vectors are reduced to an N /2-vector of partial sums. This implementation, however, involves an additional N /2 addition operations to obtain the inner product result. For this implementation, approximately 99% of the available CLBs on the Xilinx 4028EX FPGA are required. In summary, for a fixed clock rate, the second design can provide a higher throughput, but requires more computation from the host (to perform the final summation of the partial sums).4. References[1]K. C. Cain, J. A. Torres, and R. T. Williams, “Real-TimeSpace-Time Adaptive Processing Benchmark ”, Mitre TR:MTR 96B0000021, Mitre, Bedford, MA, February 1997.[2] D. G. Luenberger, Linear and Nonlinear Programming ,Second Edition, Addison-Wesley, Reading, MA, 1984.[3]Real-Time MCARM Data Sets, .[4] J. Ward, Space-Time Adaptive Processing for AirborneRadar , Technical Report 1015, Massachusetts Institute of Technology, Lincoln Laboratory, Lexington, MA, 1994.[5]Wild-One Hardware Reference Manual 11927-0000Revision 0.1, Annapolis Micro Systems Inc., MD, 1997.[6]Nikhil D. Gupta, Reconfigurable Computing for Space-Time Adaptive Processing , MS Thesis Proposal, TTU,/darpa/reconfigurable/, 1997.[7] T.T. Do, H.Kropp, P. Pirsch, “Implementation of PipelinedMultipliers on Xilinx FPGAs,” Proceedings of the 7th International Workshop on Field-Programmable Logic and Applications , Springer Verlag, September1997[8] M. Morris Mano, Digital Logic and Computer Design ,Second Edition, Prentice Hall, Englewood Cliffs, NJ, 1992[9]W. W. Smith, J. M. Smith , Handbook of Real-Time FastFourier Transforms , IEEE Press, New York, NY, 1995add unit on WildOne FPGA board.。