GoogleProtoBuf开发者指南
go语言中protocol buffer简介

go语言中protocol buffer简介
Protocol Buffer(简称protobuf)是一种语言无关、平台无关、
可扩展的序列化数据结构的协议。
它由Google开发,用于解决数据交
换和持久化存储的问题。
protobuf使用类似于XML和JSON的结构化数据表示形式,但具有更高的效率和更小的存储空间。
与XML和JSON不同,protobuf提供了更紧凑的二进制编码格式,以及自动生成的代码,用于在不同编程语言之间进行高效的数据互通。
使用protobuf,开发人员可以在定义数据结构之后,使用专门的编译
器将结构定义转换为对应的编程语言代码。
这样一来,开发人员就可
以在不同的系统中使用不同的编程语言,而不必担心数据交换的问题。
protobuf可以用于网络通信、数据持久化、配置文件等许多领域。
它支持数据的版本化,允许在不破坏旧有代码的情况下,向已定义的
结构添加新的字段。
protobuf还提供了灵活的扩展机制,允许开发人
员添加额外的字段和消息类型。
总的来说,protobuf是一种方便、高效、可扩展的数据交换格式,适用于多种应用领域。
它的简洁性和可读性使得数据传输和存储更加
高效,并且能够在不同的编程语言之间进行无缝的数据交流。
C#使用googleprotocolbuffer协议

C#使⽤googleprotocolbuffer协议简介google protocolbuffer,google 提供了三种语⾔的实现:java、c++ 和 python,每⼀种实现都包含了相应语⾔的编译器以及库⽂件。
由于它是⼀种⼆进制的格式,⽐使⽤ xml 进⾏数据交换快许多。
可以把它⽤于分布式应⽤之间的数据通信或者异构环境下的数据交换。
作为⼀种效率和兼容性都很优秀的⼆进制数据传输格式,可以⽤于诸如⽹络传输、配置⽂件、数据存储等诸多领域。
以下介绍下C#使⽤protocolbuffer下载 protobuf-csharp-port-2.4.1.521-release-binaries.zipproto ⽂件//import "Base.proto"; 添加引⽤⽂件⽅式package Proto;message LoginRsp{required int32 Result = 1;//0:失败,1:成功optional bytes Cause = 2;optional bytes guid = 4;//唯⼀标识请求,可选}required 必填项optional 可选项repeated list项协议⽣成把下载⽂件中的protoc.exe、ProtoGen.exe、Google.ProtocolBuffers.dll这些⽂件和bat⽂件、proto⽂件放⼊同⼀个⽂件夹⽣成协议bat⽂件格式:@echo onprotoc --descriptor_set_out=LoginRsp.protobin --include_imports LoginRsp.protoprotogen LoginRsp.protobin会在该⽂件中⽣成 LoginRsp.cs⽣成要发送协议数据Proto.LoginRsp.Builder builder = new Proto.LoginRsp.Builder();builder.Result = 1;builder.Cause = ByteString.CopyFrom(Cause, Encoding.Default);builder.Guid= ByteString.CopyFrom(Guid, Encoding.Default); //string 转 ByteString , ByteString 是 Protocol buffer 的类型。
GoogleProtoBuf开发者指南-

GoogleProtoBuf开发者指南-文档名称:ProtoBuf开发者指南-非官方不完整版ProtoBuf开发指南-非官方不完整版这个文档用于指导开发的,属于非官方发布版本进行选译的,并不完整。
供参考使用。
1概览欢迎来到protocolbuffer的开发者指南文档,一种语言无关、平台无关、扩展性好的用于通信协议、数据存储的结构化数据串行化方法。
1.1什么是protocolbufferProtocolBuffer是用于结构化数据串行化的灵活、高效、自动的方法,有如某ML,不过它更小、更快、也更简单。
你可以定义自己的数据结构,然后使用代码生成器生成的代码来读写这个数据结构。
你甚至可以在无需重新部署程序的情况下更新数据结构。
1.2他们如何工作你首先需要在一个.proto文件中定义你需要做串行化的数据结构信息。
每个ProtocolBuffer信息是一小段逻辑记录,包含一系列的键值对。
这里有个非常简单的.proto文件定义了个人信息:meagePeron{ requiredtringname=1;requiredint32id=2;optionaltringemail=3;enumPhoneType{第1页共22页文档名称:ProtoBuf开发者指南-非官方不完整版MOBILE=0;HOME=1;WORK=2;}meagePhoneNumber{requiredtringnumber=1;optionalPhoneTypetype=2[default=HOME];}repeatedPhoneNumberphone=4;}有如你所见,消息格式很简单,每个消息类型拥有一个或多个特定的数字字段,每个字段拥有一个名字和一个值类型。
值类型可以是数字(整数或浮点)、布尔型、字符串、原始字节或者其他ProtocolBuffer类型,还允许数据结构的分级。
你可以指定可选字段,必选字段和重复字段。
你可以在一旦你定义了自己的报文格式(meage),你就可以运行ProtocolBuffer编译器,将你的.proto文件编译成特定语言的类。
Protocol Buffer入门

protobuf介绍按照官网的描述:protobuf是google提供的一个开源序列化框架。
主要应用于通信协议,数据存储中的结构化数据的序列化。
它类似于XML,JSON这样的数据表示语言,其最大的特点是基于二进制,因此比传统的XML表示高效短小得多。
虽然是二进制数据格式,但并没有因此变得复杂,开发人员通过按照一定的语法定义结构化的消息格式,然后送给命令行工具,工具将自动生成相关的类,可以支持java、c++、python等语言环境。
通过将这些类包含在项目中,可以很轻松的调用相关方法来完成业务消息的序列化与反序列化工作。
protobuf的优势1、语言中立2、平台中立3、高效性protobuf入门(eclipse下java环境的搭建)更多案例请查阅源代码包protobuf-2.3.0.zip 里面有关于各种支持语言(java,C++,python等)的案例。
1、下载jar包 protobuf-java-2.3.0.jar2、下载编译器protoc.exe3、新建java工程test_protobuf4、导入protobuf-java-2.3.0.jar包5、导入编译器protoc.exe到项目下6、在项目下建存放文件.proto的文件夹proto7、编写message并放在proto文件夹下,有关编写规范和说明请参考官网文档,在这里我引用官网的例子,创建addressbook.proto代码如下:package tutorial;option java_package = "com.example.tutorial";option java_outer_classname = "AddressBookProtos";message Person {required string name = 1;required int32 id = 2; // Unique ID number for this person. optional string email = 3;enum PhoneType {MOBILE = 0;HOME = 1;WORK = 2;}message PhoneNumber {required string number = 1;optional PhoneType type = 2 [default = HOME];}repeated PhoneNumber phone = 4;}// Our address book file is just one of these.message AddressBook {repeated Person person = 1;}8、编译addressbook.proto成指定的java类命令行下进入编译器所在目录,执行如下命令protoc -I=proto/ --java_out=src proto/addressbook.proto其中,src为生成的java类的目标位置,这里我们选择项目的默认包,proto/addressbook.proto表示我们的proto文件,运行后即生成java类,生成的java类被放在了package com.example.tutorial中。
protobuf_map_用法_概述说明以及解释

protobuf map 用法概述说明以及解释1. 引言1.1 概述在当前大数据时代,数据结构的高效管理和传输成为了极为重要的问题。
Google 开源的Protocol Buffers(简称protobuf)作为一种轻量级和高效的数据序列化格式,被广泛应用于各类系统间的数据通信和存储操作中。
其中,protobuf map作为protobuf中的一种特殊数据类型,在处理键值对映射关系时具有独特而强大的优势。
本文旨在全面介绍protobuf map的用法,从基本介绍到详细使用方法,并以实际项目中常见场景进行应用示例。
通过阅读本文,读者将能够深入理解protobuf map及其适用性,并掌握相关技术实践经验。
1.2 文章结构本文正文内容分为五个主要部分。
首先是引言部分,概括介绍了文章涉及的话题背景和目标。
接下来,在第二部分中,我们将回顾protobuf基础知识,并对protobuf map进行定义和特点的详细说明,以便读者更好地理解其原理和机制。
第三部分将重点讲解protobuf map在实际使用中的各种操作方法,包括声明、定义、添加、读取、遍历、更新和删除等方面。
第四部分将通过三个实际应用场景,展示protobuf map在不同领域的实际应用,并着重强调其在配置管理系统、学生成绩管理系统和订单处理系统中的价值。
最后,在第五部分中,我们将对全文内容进行总结,并对protobuf map的发展前景和拓展可能性进行展望。
1.3 目的本文的目标是通过详细介绍protobuf map的用法和应用示例,帮助读者全面了解protobuf map在数据管理和传输过程中的优势和具体操作方法。
通过阅读本文,读者将能够掌握protobuf map的核心概念、定义以及使用技巧,进而在实际项目中灵活运用该功能解决相关问题。
以上为文章“1. 引言”部分内容,请根据需要进行调整或添加详细信息。
2. protobuf map 用法的基本介绍:2.1 protobuf基础知识回顾Protobuf,即Protocol Buffers,是一种由Google开发的数据序列化格式。
protobuf编译教程

protobuf编译教程protobuf(Protocol Buffers)是一种轻量级的数据序列化格式,由Google开发,用于结构化数据的存储和交换。
它具有高效、可扩展和跨语言的特点,支持多种编程语言。
本文将详细介绍protobuf 的编译过程,以帮助读者快速上手并充分利用这一工具。
一、安装protobuf编译器首先,我们需要安装protobuf编译器,可以从Google的官方仓库中下载最新的编译器版本。
protobuf的编译器支持多个操作系统,包括Windows、Linux和MacOS。
1.1 下载编译器:进入Google的protobuf官方仓库(1.2 安装编译器:解压下载的二进制文件,并将可执行文件所在的路径添加到系统的PATH环境变量中,以便在命令行中可以直接使用protobuf编译器。
二、编写.proto文件protobuf使用.proto文件来定义数据结构和消息格式,类似于定义一个类或者接口。
在这里,我们将演示一个简单的示例,以更好地理解.proto文件的编写。
2.1 定义消息类型:打开一个文本编辑器,创建一个名为example.proto的文件,并在文件中编写以下内容:syntax = "proto3";message Person {string name = 1;int32 age = 2;repeated string hobbies = 3;}在这个示例中,我们定义了一个名为Person的消息类型,其中包含name、age和hobbies三个字段。
2.2 语法说明:- "syntax = proto3"指定protobuf使用proto3版本的语法。
- "message Person"定义了一个名为Person的消息类型。
- "string name = 1"定义了一个名为name的字符串字段,并将字段标识符设置为1。
ProtoBuf快速参考指南说明书

RProtoBuf Quick Reference GuideDirk Eddelbuettel a ,Romain François b ,and Murray Stokely ca ;b https://romain.rbind.io/;c https://This version was compiled on February 7,2020Example protofile.Read proto descriptionfiles.Create amessage.Serialize a message to a file or binaryconnection.Read a message from a file or binaryconnection}.Get/Setfields.Message methods.has Indicates if a message has a given field.cloneCreates a clone of the messageisInitialized Indicates if a message has all its required fields set serializeserialize a message to a file or a binary connection or retrieve the message payload as a raw vector clear Clear one or several fields of a message,or the entire messagesize The number of elements in a message fieldbytesize The number of bytes the message would take once se-rializedswap swap elements of a repeated field of a message set set elements of a repeated field fetch fetch elements of a repeated field add add elements to a repeated field strthe R structure of the message as.character character representation of a messagetoString character representation of a message (same asas.character )update updates several fields of a message at oncedescriptorget the descriptor of the message type of this messageMore info.Full Vignette vignette("RProtoBuf-intro")JSS Paper vignette("RProtoBuf-paper")Protocol Buffers https:///protocol-buffers/RProtoBufhttps:///eddelbuettel/rprotobufhttps:///package=RProtoBuf RProtoBuf Vignette |February 7,2020|1–1。
protobuf在go中的使用方法

protobuf在go中的使用方法protobuf(Protocol Buffers)是Google开发的一种数据序列化格式,由于其高效的传输和存储能力,广泛应用于网络通信、持久化存储和数据交换等领域。
本文将以“protobuf在Go中的使用方法”为主题,详细介绍protobuf在Go语言中的使用步骤和注意事项。
# 1. 安装protobuf和Go插件在开始使用protobuf之前,我们需要先安装protobuf和Go插件。
首先,我们需要从protobuf的官方网站(下载完成后,将protoc可执行文件放置在系统路径中,以便在命令行中直接调用。
另外,为了在Go中使用protobuf,我们还需要安装对应的Go插件。
在命令行中执行以下命令进行安装:go get -u github/golang/protobuf/{proto,protoc-gen-go}安装完成后,我们就可以开始使用protobuf了。
# 2. 编写protobuf文件首先,我们需要定义我们的数据结构,并使用protobuf的语法进行标注。
下面,我们以学生为例,创建一个学生信息的protobuf文件(student.proto):protobufsyntax = "proto3";message Student {string id = 1;string name = 2;int32 age = 3;}在上面的例子中,我们定义了一个`Student`消息类型,包含了学生的ID,姓名和年龄字段。
# 3. 生成Go代码编写好protobuf文件后,我们需要使用protoc工具将其编译成Go语言的代码。
在命令行中执行以下命令:protoc go_out=. student.proto上述命令会在当前目录下生成student.pb.go文件,其中包含了与protobuf文件对应的Go结构体及相关方法。
# 4. 在Go中使用protobuf在我们生成了protobuf的Go代码后,就可以在Go中进行使用了。
protobuf编译教程 -回复

protobuf编译教程-回复protobuf编译教程。
Protobuf(Protocol Buffers)是一种语言无关、平台无关、可扩展的数据序列化格式,由Google开发。
在分布式系统中,数据的传输和存储是非常重要的一环,而Protobuf能够高效地序列化和反序列化数据,使得数据的传输更加快速高效,同时还可以节省带宽和存储空间。
本文将详细介绍protobuf的编译过程,为读者提供一步一步的指导。
第一步:安装protobuf编译器在开始编译之前,我们需要先安装protobuf编译器。
Protobuf官方提供了针对不同操作系统的安装包,我们可以根据自己的操作系统下载相应的安装程序,并按照提示进行安装。
第二步:编写.proto文件在开始编译之前,我们需要先编写一个.proto文件来定义数据的结构。
Proto文件是一个纯文本文件,可以使用任何文本编辑器来编写。
下面是一个简单的例子:syntax = "proto3";message Person {string name = 1;int32 age = 2;repeated string hobbies = 3;}在.proto文件中,我们需要使用Protobuf提供的语法来定义消息类型。
在上面的例子中,我们定义了一个名为Person的消息类型,其中包含name、age和hobbies三个字段。
字段可以有不同的类型,例如string 表示字符串类型,int32表示32位整数类型,repeated表示一个字段是可重复的。
第三步:编译.proto文件一旦我们编写好了.proto文件,就可以使用protobuf编译器将其编译为对应语言的类文件或代码。
下面是一个命令行的例子:protoc -I=<proto文件所在目录> <语言>=<输出目录> <proto文件> 其中,-I参数用于指定.proto文件所在的目录,<语言>参数用于指定要生成的代码的语言,<输出目录>参数用于指定生成的代码的输出目录,<proto文件>参数用于指定要编译的.proto文件。
googleprotobuf安装与使用

googleprotobuf安装与使⽤ google protobuf是⼀个灵活的、⾼效的⽤于序列化数据的协议。
相⽐较XML和JSON格式,protobuf更⼩、更快、更便捷。
google protobuf是跨语⾔的,并且⾃带了⼀个编译器(protoc),只需要⽤它进⾏编译,可以编译成Java、python、C++、C#、Go等代码,然后就可以直接使⽤,不需要再写其他代码,⾃带有解析的代码。
更详细的介绍见:protobuf安装1、下载protobuf代码 /2、安装protobuf tar -xvf protobuf cd protobuf ./configure --prefix=/usr/local/protobuf make make check make install⾄此安装完成^_^,下⾯是配置:(1) vim /etc/profile,添加 export PATH=$PATH:/usr/local/protobuf/bin/ export PKG_CONFIG_PATH=/usr/local/protobuf/lib/pkgconfig/ 保存执⾏,source /etc/profile。
同时在~/.profile中添加上⾯两⾏代码,否则会出现登录⽤户找不到protoc命令。
(2) 配置动态链接库 vim /etc/ld.so.conf,在⽂件中添加/usr/local/protobuf/lib(注意: 在新⾏处添加),然后执⾏命令: ldconfig.proto⽂件 .proto⽂件是protobuf⼀个重要的⽂件,它定义了需要序列化数据的结构。
使⽤protobuf的3个步骤是:1 在.proto⽂件中定义消息格式2 ⽤protobuf编译器编译.proto⽂件3 ⽤C++/Java等对应的protobuf API来写或者读消息程序⽰例(C++版) 该程序⽰例的⼤致功能是,定义⼀个Persion结构体和存放Persion的AddressBook,然后⼀个写程序向⼀个⽂件写⼊该结构体信息,另⼀个程序从⽂件中读出该信息并打印到输出中。
googleprotobuf使用

googleprotobuf使⽤If you get the source from github, you need to generate the configure script first:$ ./autogen.shThis will download gtest source (which is used for C++ Protocol Buffer unit-tests) to the current directory and run automake, autoconf, etc. to generate the configure script and various template makefiles.运⾏这个会下载gtest(google单元测试框架)。
由于google访问不了,这个这个没有成功。
tar zxvf protobuf-2.4.1.tar.gzcd protobuf-2.4.1./configuremakemake checkmake install安装结束。
验证:查看是否安装成功:protoc --version如果出现:libprotoc 2.4.1 则说明安装成功!如果出现错误:tar zxvf protobuf-2.5.0.tar.gz./configuremakemake checkmake install安装结束。
验证:查看是否安装成功:protoc --version如果出现:libprotoc 2.5.0 则说明安装成功!如果出现错误:protoc: error while loading shared libraries: libprotobuf.so.0: cannot openshared object file: No such file or directoryThe issue is that Ubuntu 8.04 doesn't include /usr/local/lib inlibrary paths.To fix it for your current terminal session, just type inexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib 安装完成后在终端下执⾏ vim ~/.profile (我加在了/etc/profile⾥) 打开配置⽂件,在该⽂件中添加 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib 然后保存退出,接下来执⾏ source ~/.profile 是配置⽂件修改⽣效,最后执⾏ protoc --version 查看protobuf版本以是否安装成功root@iZ23onhpqvwZ:~/ms/protobuf/protobuf-2.5.0# protoc --version libprotoc 2.5.0转:1、在.proto⽂件中定义消息格式2、使⽤protobuf编译器3、使⽤c++ api来读写消息windows protobuf编译我下载的是2.6.1的版本打开vsprojects⽬录,⾥⾯有⼀个.sln⽂件,打开vsprojects⾥⾯有⼀个readme.txt,告诉了如何安装:This directory contains project files for compiling Protocol Buffers using MSVC. This is not the recommended way to do Protocol Buffer development --we prefer to develop under a Unix-like environment -- but it may be more accessible to those who primarily work with MSVC.Compiling and Installing========================1) Open protobuf.sln in Microsoft Visual Studio.2) Choose "Debug" or "Release" configuration as desired.*3) From the Build menu, choose "Build Solution". Wait for compiling to finish.4) From a command shell, run tests.exe and lite-test.exe and check that alltests pass.5) Run extract_includes.bat to copy all the public headers into a separate "include" directory (under the top-level package directory).6) Copy the contents of the include directory to wherever you want to putheaders.7) Copy protoc.exe wherever you put build tools (probably somewhere in yourPATH).8) Copy libprotobuf.lib, libprotobuf-lite.lib, and libprotoc.lib wherever youput libraries.* To avoid conflicts between the MSVC debug and release runtime libraries, when compiling a debug build of your application, you may need to link against adebug build of libprotobuf.lib. Similarly, release builds should link againstrelease libs.DLLs vs. static linking=======================Static linking is now the default for the Protocol Buffer libraries. Due toissues with Win32's use of a separate heap for each DLL, as well as binary compatibility issues between different versions of MSVC's STL library, it is recommended that you use static linkage only. However, it is possible tobuild libprotobuf and libprotoc as DLLs if you really want. To do this,do the following:1) Open protobuf.sln in MSVC.2) For each of the projects libprotobuf, libprotobuf-lite, and libprotoc, dothe following:2a) Right-click the project and choose "properties".2b) From the side bar, choose "General", under "Configuration Properties".2c) Change the "Configuration Type" to "Dynamic Library (.dll)".2d) From the side bar, choose "Preprocessor", under "C/C++".2e) Add PROTOBUF_USE_DLLS to the list of preprocessor defines.3) When compiling your project, make sure to #define PROTOBUF_USE_DLLS. When distributing your software to end users, we strongly recommend that you do NOT install libprotobuf.dll or libprotoc.dll to any shared location.Instead, keep these libraries next to your binaries, in your application'sown install directory. C++ makes it very difficult to maintain binary compatibility between releases, so it is likely that future versions of these libraries will *not* be usable as drop-in replacements.If your project is itself a DLL intended for use by third-party software, we recommend that you do NOT expose protocol buffer objects in your library's public interface, and that you statically link protocol buffers into yourlibrary.ZLib support============If you want to include GzipInputStream and GzipOutputStream(google/protobuf/io/gzip_stream.h) in libprotoc, you will need to do a few additional steps:1) Obtain a copy of the zlib library. The pre-compiled DLL at works.2) Make sure zlib's two headers are in your include path and that the .lib fileis in your library path. You could place all three files directly into thevsproject directory to compile libprotobuf, but they need to be visible toyour own project as well, so you should probably just put them into theVC shared icnlude and library directories.3) Right-click on the "tests" project and choose "properties". Navigate thesidebar to "Configuration Properties" -> "Linker" -> "Input".4) Under "Additional Dependencies", add the name of the zlib .lib file (e.g.zdll.lib). Make sure to update both the Debug and Release configurations.5) If you are compiling libprotobuf and libprotoc as DLLs (see previoussection), repeat steps 2 and 3for the libprotobuf and libprotoc projects.If you are compiling them as static libraries, then you will need to linkagainst the zlib library directly from your own app.6) Edit config.h (in the vsprojects directory) and un-comment the line that#defines HAVE_ZLIB. (Or, alternatively, define this macro via the projectsettings.)Notes on Compiler Warnings==========================The following warnings have been disabled while building the protobuf librariesand compiler. You may have to disable some of them in your own project aswell, or live with them.C4018 - 'expression' : signed/unsigned mismatchC4146 - unary minus operator applied to unsigned type, result still unsignedC4244 - Conversion from'type1' to 'type2', possible loss of data.C4251 - 'identifier' : class'type' needs to have dll-interface to be used byclients of class'type2'C4267 - Conversion from'size_t' to 'type', possible loss of data.C4305 - 'identifier' : truncation from'type1' to 'type2'C4355 - 'this' : used in base member initializer listC4800 - 'type' : forcing value to bool'true' or 'false' (performance warning)C4996 - 'function': was declared deprecatedC4251 is of particular note, if you are compiling the Protocol Buffer libraryas a DLL (see previous section). The protocol buffer library uses templates inits public interfaces. MSVC does not provide any reasonable way to exporttemplate classes from a DLL. However, in practice, it appears that exportingtemplates is not necessary anyway. Since the complete definition of anytemplate is available in the header files, anyone importing the DLL will justend up compiling instances of the templates into their own binary. TheProtocol Buffer implementation does not rely on static template members beingunique, so there should be no problem with this, but MSVC prints warningnevertheless. So, we disable it. Unfortunately, this warning will also beproduced when compiling code which merely uses protocol buffers, meaning youmay have to disable it in your code too.按照上⾯的很难成功,搞了n次,终与⽣成了,参考下⾯的。
GoogleProtocolBuffer协议

GoogleProtocolBuffer协议
1. Protocol Buffers 简介
Protocol Buffers (ProtocolBuffer/ protobuf )是Google公司开发的⼀种数据描述语⾔,类似于XML能够将结构化数据序列化,可以使⽤该技术来持久化数据或者序列化成⽹络传输的数据。
主要⽤于数据存储、通信协议等⽅⾯。
现阶段⽀持C++、JAVA、Python、Objective-C、C#、Javascript等6种编程语⾔。
Googel 公司 2015-12-31 更新了最新的版本Version 3.0.0-beta-2,相⽐较⼀些其他的XML技术⽽⾔,该技术的⼀个明显特点就是更加节省空间(以⼆进制流存储)、速度更快以及更加灵活
同XML相⽐,Protocol buffers在序列化结构化数据⽅⾯有许多优点(google官⽅提出):
更简单
数据描述⽂件只需原来的1/10⾄1/3
解析速度是原来的20倍⾄100倍
减少了⼆义性⽣
成了更容易在编程中使⽤的数据访问类
2. 相关链接
在⽹上已有不少热⼼园友或⼤⽜撰写了关于 Protocol Buffers 的博客或⽂章,这⾥对 Protocol Buffers 的介绍就不再赘述了,相关连接如下: Protocol Buffers 下载
Google Protocol Buffer 的使⽤和原理
Protocol Buffers 浅析
开源点评: Protocol Buffers
Protocol Buffers for Objecttive-c。
Protobuf语言指南(proto3)

Protobuf语⾔指南(proto3)Protobuf 语⾔指南(proto3)Protocol Buffer是Google的语⾔中⽴的,平台中⽴的,可扩展机制的,⽤于序列化结构化数据 - 对⽐XML,但更⼩,更快,更简单。
您可以定义数据的结构化,然后可以使⽤特殊⽣成的源代码轻松地在各种数据流中使⽤各种语⾔编写和读取结构化数据。
定义消息类型先来看⼀个⾮常简单的例⼦。
假设你想定义⼀个“搜索请求”的消息格式,每⼀个请求含有⼀个查询字符串、你感兴趣的查询结果所在的页数,以及每⼀页多少条查询结果。
可以采⽤如下的⽅式来定义消息类型的.proto⽂件了:1 syntax = "proto3";23 message SearchRequest {4 string query = 1;5 int32 page_number = 2;6 int32 result_per_page = 3;7 }该⽂件的第⼀⾏指定您正在使⽤proto3语法:如果您不这样做,protobuf 编译器将假定您正在使⽤。
这必须是⽂件的第⼀个⾮空的⾮注释⾏。
所述SearchRequest消息定义了三个字段(名称/值对),对应着我需要的消息内容。
每个字段都有⼀个名称和类型。
指定字段类型在上⾯的⽰例中,所有字段都是:两个整数(page_number和result_per_page)和⼀个字符串(query)。
但是,您还可以为字段指定合成类型,包括和其他消息类型。
分配标识号正如上述⽂件格式,在消息定义中,每个字段都有唯⼀的⼀个数字标识符。
这些标识符是⽤来在消息的中识别各个字段的,⼀旦开始使⽤就不能够再改变。
注:[1,15]之内的标识号在编码的时候会占⽤⼀个字节。
[16,2047]之内的标识号则占⽤2个字节。
所以应该为那些频繁出现的消息元素保留 [1,15]之内的标识号。
切记:要为将来有可能添加的、频繁出现的标识号预留⼀些标识号。
ProtoBuf开发者指南

ProtoBuf开发者指南ProtoBuf开发者指南该文档旨在向开发者提供有关ProtoBuf(Protocol Buffers)的详细信息,以帮助他们了解和有效地使用ProtoBuf。
1:简介1.1 什么是ProtoBuf?1.2 ProtoBuf的优势1.3 ProtoBuf的应用领域2:安装和配置2.1 安装ProtoBuf编译器2.2 配置ProtoBuf环境变量2.3 集成ProtoBuf到开发环境3:定义Proto文件3.1 语法概览3.2 消息定义3.3 字段类型3.4 枚举类型3.5 自定义选项3.6 定义包3.7 导入其他Proto文件4:编译Proto文件4.1 使用Proto编译器4.2 目标语言代码4.3 编译选项4.4 示例代码5:序列化和反序列化5.1 序列化数据5.2 反序列化数据5.3 处理未知字段5.4 使用Proto扩展6:使用ProtoBuf进行通信6.1 使用ProtoBuf序列化消息 6.2 使用ProtoBuf反序列化消息 6.3 使用ProtoBuf与网络通信6.4 使用ProtoBuf进行跨语言通信7: ProtoBuf高级功能7.1 自定义序列化和反序列化逻辑7.2 扩展ProtoBuf功能7.3 性能优化技巧7.4 版本兼容性考虑附件:本文档附带以下附件:- ProtoBuf示例代码- ProtoBuf编译器安装包- 其他相关资料法律名词及注释:1: ProtoBuf:Protocol Buffers的简称,一种用于序列化结构化数据的语言无关、平台无关、可扩展的机制。
2:开发者:在本文档中指代ProtoBuf的使用者。
3:消息定义:在ProtoBuf中用于定义数据结构的语法。
4:字段类型:指消息中的不同字段可能的数据类型,如整型、字符串等。
5:枚举类型:一种特殊的字段类型,提供一组预先定义的值。
6:自定义选项:用于向ProtoBuf编译器传递额外参数,定制代码行为。
Protobuf使用手册

Protobuf使用手册第1章定义.proto 文件首先我们需要编写一个proto 文件,定义我们程序中需要处理的结构化数据,在protobuf 的术语中,结构化数据被称为Message。
proto 文件非常类似java 或者C 语言的数据定义,可以使用C或C++风格的注释。
下面是一个proto文件的例子。
1 / 72一个proto文件主要包含package定义、message定义和属性定义三个部分,还有一些可选项。
1.1定义packagePackage在c++中对应namespace。
对于Java,包声明符会变为java的一个包,除非在.proto文件中提供了一个明确有java_package。
2 / 721.2定义messageMessage在C++中对应class。
Message中定义的全部属性在class 中全部为private的。
Message的嵌套使用可以嵌套定义,也可以采用先定义再使用的方式。
Message的定义末尾可以采用java方式在不加“;”,也可以采用C++定义方式在末尾加上“;”,这两种方式都兼容,建议采用java定义方式。
向.proto文件添加注释,可以使用C/C++/java风格的双斜杠(//)语法格式。
1.3定义属性属性定义分为四部分:标注+类型+属性名+属性顺序号+[默认值],其示意如下所示。
[默认值]标注类型属性名属性顺序号required string name= 1[default=””];其中属性名及C++和java语言类似,不再解释;下面分别对标注、类型和属性顺序号加以详细介绍。
其中包名和消息名以及其中变量名均采用java的命名规则——驼峰式命名法,驼峰式命名法规则见附件1。
3 / 721.3.1标注标注包括“required”、“optional”、“repeated”三种,其中required表示该属性为必选属性,否则对应的message“未初始化”,debug模式下导致断言,release模式下解析失败;optional表示该属性为可选属性,不指定,使用默认值(int或者char 数据类型默认为0,string默认为空,bool默认为false,嵌套message 默认为构造,枚举则为第一个)repeated表示该属性为重复字段,可看作是动态数组,类似于C++中的vector。
ProtocolBuffers(Protobuf)官方文档--Protobuf语言指南

ProtocolBuffers(Protobuf)官⽅⽂档--Protobuf语⾔指南约定:为⽅便书写,ProtocolBuffers在下⽂中将已Protobuf代替。
本指南将向您描述如何使⽤protobuf定义i结构化Protobuf数据,包括.proto⽂件语法和如何使⽤.proto⽂件⽣成数据存取类。
作为⼀个参考指南,本⽂档将以⽰例的形式⼀步步向您介绍Protobuf的特点。
您可以参考您所选择的语⾔的⽰例。
--------------------------------------⼩⼩的分割线-----------------------------------------定义⼀个消息类型⾸先,看⼀个⾮常简单的例⼦,⽐如说你想定义⼀个搜索请求消息,每个搜索请求都有⼀个查询的字符串(关键字:⽐如我们上百度搜索《报告⽼板》),和我们搜索出来的⼀个感兴趣的⽹页,以及搜索到的所有⽹页总数。
来看看这个.proto⽂件是如何定义的。
1 message SearchRequest {2 required string query = 1;3 optional int32 page_number = 2;4 optional int32 result_per_page = 3;5 }这个"搜索请求"消息指定了三个字段(名称/属性组合),每⼀个你想要包含在这类型的信息内的东西,都必须有⼀个字段,每个字段有⼀个名称和类型!指定字段类型在上⾯的⽰例中,所有的字段都是标量类型():两个整数(integers:page_number和result_per_page)和⼀个字符串(string:query:查询的关键字),不过你可以在你的字段内指定符合类型。
包括枚举类型()和其他的消息类型分配指定标签号如你所见,每个消息的字段都有⼀个唯⼀的数字标签,这些标签⽤来表⽰你的字段在⼆进制消息()中处的位置。
protobuf系列---------下载、编译与使用
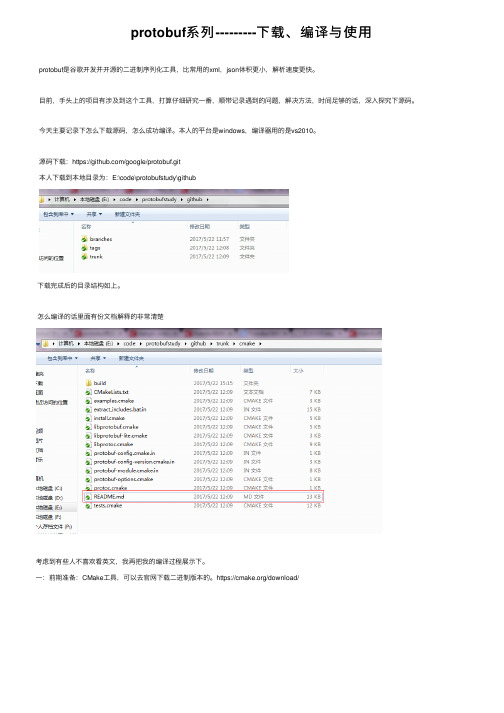
protobuf系列---------下载、编译与使⽤protobuf是⾕歌开发并开源的⼆进制序列化⼯具,⽐常⽤的xml,json体积更⼩,解析速度更快。
⽬前,⼿头上的项⽬有涉及到这个⼯具,打算仔细研究⼀番,顺带记录遇到的问题,解决⽅法,时间⾜够的话,深⼊探究下源码。
今天主要记录下怎么下载源码,怎么成功编译。
本⼈的平台是windows,编译器⽤的是vs2010。
源码下载:https:///google/protobuf.git本⼈下载到本地⽬录为:E:\code\protobufstudy\github下载完成后的⽬录结构如上。
怎么编译的话⾥⾯有份⽂档解释的⾮常清楚考虑到有些⼈不喜欢看英⽂,我再把我的编译过程展⽰下。
⼀:前期准备:CMake⼯具,可以去官⽹下载⼆进制版本的。
https:///download/安装到本地后,如 C:\Program Files\CMake\bin ,然后打开命令⾏设置下环境变量E:\code\protobufstudy\github>set PATH=%PATH%;C:\Program Files (x86)\CMake\bin(ps:命令⾏最好切换到下载的源码⽬录下,这样与本⼈讲述的⼀致)这时就能使⽤cmake命令了,否则会说cmake不是内部命令什么的。
然后进⼊源码⽬录,E:\code\protobufstudy\github>cd trunkE:\code\protobufstudy\github\trunk>进⼊源码下⾯的cmake⽬录,E:\code\protobufstudy\github\trunk>cd cmakeE:\code\protobufstudy\github\trunk\cmake>创建build⽬录,E:\code\protobufstudy\github\trunk\cmake>mkdir build & cd buildE:\code\protobufstudy\github\trunk\cmake\build>创建solution⽬录, E:\code\protobufstudy\github\trunk\cmake\build>mkdir solution & cd solutionE:\code\protobufstudy\github\trunk\cmake\build\solution>执⾏cmake指令,cmake -G "Visual Studio 10 2010 Win64" ^-DCMAKE_INSTALL_PREFIX=../../../../install ^../.. (暂且叫cmake指令1)如果会报错误,找不到cl.exe,请设置下cl.exe的环境变量E:\code\protobufstudy\github\trunk\cmake\build\solution>set PATH=%PATH%;C:\Program Files (x86)\Microsoft Visual Studio 11.0\VC\bin (这个是你本地的cl.exe所在⽬录)再次执⾏cmake指令1,如果还报错误,找不到mspdb100.dll,请设置下mspdb100.dll的环境变量E:\code\protobufstudy\github\trunk\cmake\build\solution>set PATH=%PATH%;D:\Program Files (x86)\Microsoft Visual Studio 10.0\Common7\IDE (这个是你本地的mspdb100.dll所在⽬录)再次执⾏cmake指令1,如果还报错误,没有找到gmock⽬录,要么下载下gmock,https:///google/googlemock.git ⽬录为E:\code\protobufstudy\github\trunk\gmock,本⼈懒,没有下载,那么久更改下cmake执⾏。
GoogleProtocolBuffers安装以及简单使用

GoogleProtocolBuffers安装以及简单使用简介:Protocol Buffers是Google公司开发的一种数据描述语言,类似于XML能够将结构化数据序列化,可用于数据存储、通信协议等方面。
现阶段支持C++、JAVA、Python等三种编程语言。
相比较于XML,Protocol Buffer更简单,数据描述文件只需原来的1/10至1/3,解析速度是原来的20倍至100倍,减少了二义性,生成了更容易在编程中使用的数据访问类等优点。
Protocol Buffers安装:本文只陈述windows下用VS的情况。
(1) 首先下载得到文件protobuf-2.4.1.zip并解压缩,下载地址:https:///google/protobuf/releases/ google把protobuf的项目地址迁移到github后,大家不用翻墙也能访问了。
(2) 用VS打开vsprojects目录下的protobuf.sln。
(可以查看vsprojects目录下的readme文件,里面也有编译及安装步骤)(3) 编译。
(4) 运行脚步文件extract_includes.bat,运行后会在当前目录下产生include文件夹,里面放的是Protocol Buffers的头文件。
(5) 拷贝include下的文件夹到你VC目录下的include文件夹下。
(6) 拷贝protoc.exe到你希望放置的地方(以后我们就是用这个程序生成代码的,可以把这个程序所在的路径加入到PATH环境变量里)。
(7) 拷贝libprotobuf.lib, libprotobuf-lite.lib,和libprotoc.lib 到你VC目录下的lib文件夹下。
一个简单的例子:关于简单例子的描述我打算使用Protobuf和C++开发一个十分简单的例子程序。
该程序由两部分组成。
第一部分被称为Writer,第二部分叫做Reader。
protobuf使用方法

protobuf使用方法protobuf(Protocol Buffers)是谷歌开源的一种轻便高效的数据交换格式,它能够将结构化数据序列化为二进制数据,支持多种语言,如C++、Java、Python等。
protobuf主要用于通信协议、数据存储等场景,能够提高数据交换和存储的效率。
本文将详细介绍protobuf的使用方法,包括定义消息结构、序列化和反序列化等。
一、定义消息结构在protobuf中,消息结构是由.proto文件定义的,它包含消息类型、字段名称和数据类型等信息。
下面是一个.proto文件的示例:```syntax = "proto3";package mypackage;message Person {string name = 1;int32 age = 2;repeated string phone_numbers = 3;}```以上.proto文件定义了一个名为Person的消息结构,它包含三个字段:name、age和phone_numbers。
其中name和phone_numbers是string类型,age是int32类型,而phone_numbers是一个可重复的字段,即可以包含多个值。
在.proto文件中,还可以定义枚举类型、服务等信息,具体可以参考protobuf官方文档。
二、生成代码定义完消息结构后,需要使用protobuf编译器将.proto文件编译成相应语言的代码。
protobuf编译器支持多种语言,如C++、Java、Python等。
以Java为例,执行以下命令可以将.proto文件编译成Java代码:```protoc --java_out=./java/. person.proto```其中--java_out=./java/.表示生成的Java代码存放在./java/目录下,person.proto是.proto文件的路径。
三、序列化和反序列化在Java中,可以使用protobuf提供的API来对消息进行序列化和反序列化。
protobuf语法指南

1. 概述前两篇文章,我们概括介绍《Google Protocol Buffers 概述》以及带领大家简单的《Google Protocol Buffers 入门》,接下来,再稍微详细一点介绍Protocol Buffers书写语言。
该篇文章主要讲解如何使用PB语言构建数据,包括.proto文件语法及如果使用.proto文件生成数据存取类。
本篇主要包括:•定义一个PB message类型•介绍PB 数据类型•Optional字段及其默认值•枚举类型•使用其他Message类型作为filed类型•嵌套类型•更新Message2.定义一个PB message类型假如现在需要定义搜索请求的message格式,每条message包含三个字段:搜索语句(query string),需要的返回结果页数(page_number),以及该页上的结果数。
可如下定义.proto文件。
该message定义声明三个字段(name/value pairs),每个字段有一个名字和类型。
2.1 声明字段类型上例中,所有的字段类型均为标准类型:两个整型和一个字符串类型。
当然,也可以指定复合类型:枚举类型和其他自定义message类型。
2.2 给字段赋值数字标签从上例中可以发现,message中定义的每个字段都有一个唯一的数字标签。
该标签的作用是在二进制message中唯一标示该字段,一旦定义该字段的值就不能够再更改。
有一点需要强调:1~15的数字标签编码后仅占一个字节(byte),包括数字标签和字段类型。
16~2047的数字标签占两个字节(byte)。
因此,1~15的数字标签应该用于最频繁出现的元素。
设计时要考虑到不要一次用完1~15的标签,要考虑到将来也可能出现频繁出现的元素。
最小的数字标签是1,最大的数字标签是2的29次方-1,也即 536,870,911。
但是并不是这之间所有的数字标签你都能用,例如19000~19999。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ProtoBuf开发指南 - 非官方不完整版这个文档用于指导开发的,属于非官方发布版本进行选译的,并不完整。
供参考使用。
1 概览欢迎来到protocol buffer的开发者指南文档,一种语言无关、平台无关、扩展性好的用于通信协议、数据存储的结构化数据串行化方法。
本文档面向希望使用protocol buffer的Java、C++或Python开发者。
这个概览介绍了protocol buffer,并告诉你如何开始,你随后可以跟随编程指导( /apis/protocolbuffers/docs/tutorials.html )深入了解protocol buffer编码方式( /apis/protocolbuffers/docs/encoding.html)。
API 参考文档( /apis/protocolbuffers/docs/reference/overview .html )同样也是提供了这三种编程语言的版本,不够协议语言( /apis/protocolbuffers/docs/proto.html )和样式( /apis/protocolbuffers/docs/style.html )指导都是编写 .proto 文件。
1.1 什么是protocol bufferProtocolBuffer是用于结构化数据串行化的灵活、高效、自动的方法,有如XML,不过它更小、更快、也更简单。
你可以定义自己的数据结构,然后使用代码生成器生成的代码来读写这个数据结构。
你甚至可以在无需重新部署程序的情况下更新数据结构。
1.2 他们如何工作你首先需要在一个 .proto 文件中定义你需要做串行化的数据结构信息。
每个ProtocolBuffer信息是一小段逻辑记录,包含一系列的键值对。
这里有个非常简单的 .proto 文件定义了个人信息:message Person {required string name=1;required int32 id=2;optional string email=3;enum PhoneType {MOBILE=0;HOME=1;WORK=2;}message PhoneNumber {required string number=1;optional PhoneType type=2 [default=HOME];}repeated PhoneNumber phone=4;}有如你所见,消息格式很简单,每个消息类型拥有一个或多个特定的数字字段,每个字段拥有一个名字和一个值类型。
值类型可以是数字(整数或浮点)、布尔型、字符串、原始字节或者其他ProtocolBuffer类型,还允许数据结构的分级。
你可以指定可选字段,必选字段和重复字段。
你可以在( /apis/protocolbuffers/docs/proto.html )找到更多关于如何编写 .proto 文件的信息。
一旦你定义了自己的报文格式(message),你就可以运行ProtocolBuffer编译器,将你的 .proto 文件编译成特定语言的类。
这些类提供了简单的方法访问每个字段(像是 query() 和 set_query() ),像是访问类的方法一样将结构串行化或反串行化。
例如你可以选择C++语言,运行编译如上的协议文件生成类叫做Person 。
随后你就可以在应用中使用这个类来串行化的读取报文信息。
你可以这么写代码:Person person;person.set_name("John Doe");person.set_id(1234);person.set_email("jdoe@");fstream.output("myfile",ios::out | ios::binary);person.SerializeToOstream(&output);然后,你可以读取报文中的数据:fstream input("myfile",ios::in | ios:binary);Person person;person.ParseFromIstream(&input);cout << "Name: " << () << endl;cout << "E-mail: " << person.email() << endl;你可以在不影响向后兼容的情况下随意给数据结构增加字段,旧有的数据会忽略新的字段。
所以如果使用ProtocolBuffer作为通信协议,你可以无须担心破坏现有代码的情况下扩展协议。
你可以在API参考( /apis/protocolbuffers/docs/reference/overview .html )中找到完整的参考,而关于ProtocolBuffer的报文格式编码则可以在( /apis/protocolbuffers/docs/encoding.html)中找到。
1.3 为什么不用XML?ProtocolBuffer拥有多项比XML更高级的串行化结构数据的特性,ProtocolBuffer:∙更简单∙小3-10倍∙快20-100倍∙更少的歧义∙可以方便的生成数据存取类例如,让我们看看如何在XML中建模Person的name和email字段:<person><name>John Doe</name><email>jdoe@</email></person>对应的ProtocolBuffer报文则如下:#ProtocolBuffer的文本表示#这不是正常时使用的二进制数据person {name: "John Doe"email: "jdoe@"}当这个报文编码到ProtocolBuffer的二进制格式( /apis/protocolbuffers/docs/encoding.html )时(上面的文本仅用于调试和编辑),它只需要28字节和100-200ns的解析时间。
而XML的版本需要69字节(除去空白)和5000-10000ns的解析时间。
当然,操作ProtocolBuffer也很简单:cout << "Name: " << () << endl;cout << "E-mail: " << person.email() << endl;而XML的你需要:cout << "Name: "<< person.getElementsByTagName("name")->item(0)->innerText()<< endl;cout << "E-mail: "<< person.getElementsByTagName("email")->item(0)->innerText() << end;当然,ProtocolBuffer并不是在任何时候都比XML更合适,例如ProtocolBuffer 无法对一个基于标记文本的文档建模,因为你根本没法方便的在文本中插入结构。
另外,XML是便于人类阅读和编辑的,而ProtocolBuffer则不是。
还有XML 是自解释的,而 ProtocolBuffer仅在你拥有报文格式定义的 .proto 文件时才有意义。
1.4 听起来像是为我的解决方案,如何开始?下载包( /p/protobuf/downloads/ ),包含了Java、Python、C++的ProtocolBuffer编译器,用于生成你需要的IO类。
构建和安装你的编译器,跟随README的指令就可以做到。
一旦你安装好了,就可以跟着编程指导( /apis/protocolbuffers/docs/tutorials.html )来选择语言-随后就是使用ProtocolBuffer创建一个简单的应用了。
1.5 一点历史ProtocolBuffer最初是在Google开发的,用以解决索引服务器的请求、响应协议。
在使用ProtocolBuffer之前,有一种格式用以处理请求和响应数据的编码和解码,并且支持多种版本的协议。
而这最终导致了丑陋的代码,有如:if (version==3) {...}else if (version>4) {if (version==5) {...}...}通信协议因此变得越来越复杂,因为开发者必须确保,发出请求的人和接受请求的人必须同时兼容,并且在一方开始使用新协议时,另外一方也要可以接受。
ProtocolBuffer设计用于解决这一类问题:∙很方便引入新字段,而中间服务器可以忽略这些字段,直接传递过去而无需理解所有的字段。
∙格式可以自描述,并且可以在多种语言中使用(C++、Java等)然而用户仍然需要手写解析代码。
随着系统的演化,他需要一些其他的功能:∙自动生成编码和解码代码,而无需自己编写解析器。
∙除了用于简短的RPC(Remote Procedure Call)请求,人们使用ProtocolBuffer来做数据存储格式(例如BitTable)。
∙RPC服务器接口可以作为 .proto 文件来描述,而通过ProtocolBuffer的编译器生成存根(stub)类供用户实现服务器接口。
ProtocolBuffer现在已经是Google的混合语言数据标准了,现在已经正在使用的有超过48,162种报文格式定义和超过12,183个 .proto 文件。
他们用于RPC 系统和持续数据存储系统。
2语言指导本指导描述了如何使用ProtocolBuffer语言来定义结构化数据类型,包括 .proto 文件的语法和如何生成存取类。
这是一份指导手册,一步步的例子使用文档中的多种功能,查看入门指导( /apis/protocolbuffers/docs/tutorials.html )选择你的语言。
2.1 定义一个消息类型@waiting …2.2 值类型@waiting …2.3 可选字段与缺省值@w aiting …2.4 枚举@waiting …2.5 使用其他消息类型@waiting …2.6 嵌套类型@waiting …2.7 更新一个数据类型@waiting …2.8 扩展@waiting …2.9 包@waiting …2.10 定义服务@waiting …2.11 选项@waiting …2.12 生成你的类@waiting …3代码风格指导本文档提供了 .proto 文件的代码风格指导。