SPSS logistic回归分析
多因素logistic回归分析spss

多因素logistic回归分析spssLogistic回归分析是一种用来研究影响离散变量的因素的方法,该方法的输出是一个logistic模型,这一模型可以用于预测变量的值,即预测该变量的值有多高的概率会取各种可能的取值。
简言之,logistic回归分析的主要目的是把客观的结果(例如,是否改变某个政策,是否感染某种疾病等)变成可预测的离散变量,以便分析影响客观结果的各种因素。
Spss可以提供多因素logistic回归分析,这种分析可用于识别影响离散变量(例如,是否改变某个政策,是否感染某种疾病等)的多个因素之间的关联。
该分析需要有一个组合变量作为自变量,以及一个离散变量作为因变量。
例如,如果您要研究性别和年龄两个因素如何影响某种疾病的发生率,那么性别和年龄两个因素就是组合变量,而疾病的发生率则是因变量。
1.建立变量和分类(上述示例中需要建立性别和年龄两个变量,以及分类变量的可能的取值)。
2.执行logistic回归分析。
打开spss,并在“分析”菜单中打开多元分析,然后点击“逻辑回归”,并选择您要研究的变量和分类。
3.生成回归模型和检验其统计学意义。
在spss中,您可以使用类似“回归系数”之类的描述性统计学方法来估算回归模型,并可以使用“p-值”来判断回归模型中各变量的统计学意义。
4.Interpret模型。
根据p值判断各变量的统计学意义,进而分析影响离散变量的多个因素之间的关联。
四、总结Logistic回归分析是一种用来研究影响离散变量的因素的方法,spss可以提供多因素logistic回归分析,这种分析可用于识别影响离散变量的多个因素之间的关联,spss中步骤:建立变量和分类,执行logistic回归分析,生成回归模型和检验其统计学意义,Interpret模型。
SPSS实验8-二项Logistic回归分析
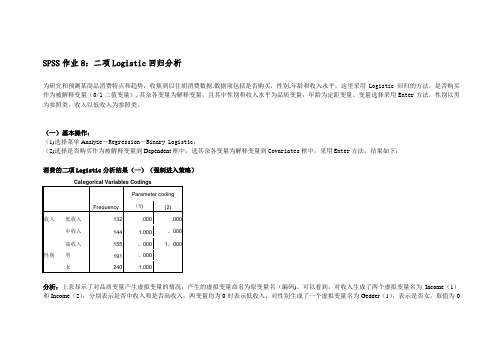
SPSS作业8:二项Logistic回归分析为研究和预测某商品消费特点和趋势,收集到以往胡消费数据.数据项包括是否购买,性别,年龄和收入水平。
这里采用Logistic回归的方法,是否购买作为被解释变量(0/1二值变量),其余各变量为解释变量,且其中性别和收入水平为品质变量,年龄为定距变量。
变量选择采用Enter方法,性别以男为参照类,收入以低收入为参照类。
(一)基本操作:(1)选择菜单Analyz e-Regression-Binary Logistic;(2)选择是否购买作为被解释变量到Dependent框中,选其余各变量为解释变量到Covariates框中,采用Enter方法,结果如下:消费的二项Logistic分析结果(一)(强制进入策略)Categorical Variables CodingsFrequency Parameter coding (1) (2)收入低收入132 .000 .000中收入144 1.000 。
000高收入155 。
000 1。
000性别男191 。
000女240 1.000分析:上表显示了对品质变量产生虚拟变量的情况,产生的虚拟变量命名为原变量名(编码)。
可以看到,对收入生成了两个虚拟变量名为Income(1)和Income(2),分别表示是否中收入和是否高收入,两变量均为0时表示低收入;对性别生成了一个虚拟变量名为Gedder(1),表示是否女,取值为0时表示为男。
消费的二项Logistic 分析结果(二)(强制进入策略)Block 0: Beginning BlockClassification Table a,bObserved Predicted是否购买 Percentage Correct不购买购买Step 0是否购买不购买 269 0 100。
购买162。
0 Overall Percentage62。
4a 。
Constant is included in the model 。
SPSS专题2 回归分析(线性回归、Logistic回归、对数线性模型)

19
Correlation s lif e_ expectanc y _ f emale(y ear) .503** .000 164 1.000 . 192 .676**
cleanwateraccess_rura... life_expectancy_femal... Die before 5 per 1000
Model 1 2
R .930
a
R Square .866 .879
Model 1
df 1 54 55 2 53 55
Regres sion Residual Total Regres sion Residual Total
Mean Square 54229.658 155.861 27534.985 142.946
2
回归分析 • 一旦建立了回归模型 • 可以对各种变量的关系有了进一步的定量理解 • 还可以利用该模型(函数)通过自变量对因变量做 预测。 • 这里所说的预测,是用已知的自变量的值通过模型 对未知的因变量值进行估计;它并不一定涉及时间 先后的概念。
3
例1 有50个从初中升到高中的学生.为了比较初三的成绩是否和高中的成绩 相关,得到了他们在初三和高一的各科平均成绩(数据:highschool.sav)
50名同学初三和高一成绩的散点图
100
90
80
70
60
高 一成 绩
50
40 40
从这张图可以看出什么呢?
50 60 70 80 90 100 110
4
初三成绩
还有定性变量 • 该数据中,除了初三和高一的成绩之外,还有 一个定性变量 • 它是学生在高一时的家庭收入状况;它有三个 水平:低、中、高,分别在数据中用1、2、3 表示。
利用SPSS进行logistic回归分析(二元、多项)

线性回归是很重要的一种回归方法,但是线性回归只适用于因变量为连续型变量的情况,那如果因变量为分类变量呢?比方说我们想预测某个病人会不会痊愈,顾客会不会购买产品,等等,这时候我们就要用到logistic回归分析了。
Logistic回归主要分为三类,一种是因变量为二分类得logistic回归,这种回归叫做二项logistic回归,一种是因变量为无序多分类得logistic回归,比如倾向于选择哪种产品,这种回归叫做多项logistic回归。
还有一种是因变量为有序多分类的logistic回归,比如病重的程度是高,中,低呀等等,这种回归也叫累积logistic回归,或者序次logistic回归。
二值logistic回归:选择分析——回归——二元logistic,打开主面板,因变量勾选你的二分类变量,这个没有什么疑问,然后看下边写着一个协变量。
有没有很奇怪什么叫做协变量?在二元logistic回归里边可以认为协变量类似于自变量,或者就是自变量。
把你的自变量选到协变量的框框里边。
细心的朋友会发现,在指向协变量的那个箭头下边,还有一个小小的按钮,标着a*b,这个按钮的作用是用来选择交互项的。
我们知道,有时候两个变量合在一起会产生新的效应,比如年龄和结婚次数综合在一起,会对健康程度有一个新的影响,这时候,我们就认为两者有交互效应。
那么我们为了模型的准确,就把这个交互效应也选到模型里去。
我们在右边的那个框框里选择变量a,按住ctrl,在选择变量b,那么我们就同时选住这两个变量了,然后点那个a*b的按钮,这样,一个新的名字很长的变量就出现在协变量的框框里了,就是我们的交互作用的变量。
然后在下边有一个方法的下拉菜单。
默认的是进入,就是强迫所有选择的变量都进入到模型里边。
除去进入法以外,还有三种向前法,三种向后法。
一般默认进入就可以了,如果做出来的模型有变量的p值不合格,就用其他方法在做。
再下边的选择变量则是用来选择你的个案的。
spsslogistic回归分析结果解读

spsslogistic回归分析结果解读
本文分析了使用SPSS Logistic回归分析的结果,以了解不同变量之间
是否存在潜在关系。
Logistic回归是一种用于预测调查中的变量组合能够预测调查的结果的
机器学习技术。
在这种情况下,我们使用Logistic回归来预测一个变量
(假设为购买行为)和其他变量(价格,品牌认知度等)之间的关系。
特别是,我们可以评估价格是否是客户决定购买商品的重要影响因素。
SPSS Logistic回归分析的结果表明,在本例中,我们发现价格是一个
重要的影响因素。
我们看到,价格的变化程度会影响客户购买商品的可能性:客户可能更愿意购买相对较低的价格,而对于较高的价格则更不可能购买。
此外,品牌认知度也会影响客户是否愿意购买:客户对品牌认知度越高,购
买概率越高。
这可能是因为客户更倾向于信任已经熟悉的品牌而忽略未熟悉
的品牌,或者可能是因为客户更了解该品牌的商品及其优缺点,因此可以作
出的更明智的购买决策。
因此,本次分析表明,价格和品牌认知度在客户决定购买商品时都有重
要的影响。
商家应考虑这些因素,以确保它们的产品在客户面前具有足够的
吸引力和优势,使其愿意购买。
SPSS--logistic回归分析

小结
谢谢大家!
基础知识
通过下例复习相关概念 如:研究患某疾病与饮酒的关联性
患病率 P1=? P2=?
基础知识
二分类logistic回归模型
回归系数的意义
多因素logistic回归分析时,对回归系数 的解释都是指在其他所有自变量固定的 情况下的优势比。 存在因素间交互作用时,logistic回归系 数的解释变得更为复杂,应特别小心。
适用条件
因变量为二分类变量或某事件的发生率 自变量与Logit(P)之间为线性关系 残差合计为0,且服从二项分布 各观测间相互独立 参数估计方法:最大似然法
例1
研究急性心肌梗塞(AMI)患病与饮酒的关 系,采用横断面调查。
SPSS基本操作
哑变量设置
为了便于解释,对二分类变量按0、1编码 如果对二项分类变量按+1、-1编码,结果? 分类变量必须转化。如地区对血压的影响。 等级资料,当等级之间量度不一时必须转化。 连续资料不宜直接进入方程时,转化为等级 资料或分类资料。
多因素统计分析 1. 因变量为计量资料,多重现性回归 2. 因变量为分类变量,logistic回归
பைடு நூலகம்
Logistic回归模型
按研究设计分类: 1. 非配对设计:非条件logistic回归模型 2. 配对病例对照:条件logistic回归模型
按反应变量分类: 1. 二分类logistic回归模型(常用) 2. 多分类无序logistic回归模型(常用) 3. 多分类有序logistic回归模型(常用)
logistic 回归
海南医学院公共卫生学院 卫生统计学教研室 赵婵娟
chanjuan850@
内容
基本概念 基本步骤 基本操作 基本结果解释
手把手教你SPSS二分类Logistic回归分析

手把手教你SPSS二分类Logistic回归分析木教程手把手教您用SPSS做Logistic回归分析,目录如下:一、数据格式二、对数据的分析理解三、S PSS做Logistic回归分析操作步骤3. 1线性关系检验假设3.2多重共线检验假设3.3离群值、杠杆点和强影响点的识别3. 4 Logistic回归分析四、S PSS计算结果的解释五、结果结论的撰写一、数据格式某研究者想了解年龄、性别、BMI和总胆固醇(TC)预测患心脏病(CVD)的能力,招募了100例研究对象,记录了年龄(age)、性别(gender)、BMI,测量血中总胆固醇水平(TC),并评估研究对象目前是否患有心脏病(CVD)o部分数据如图1。
二、对问题分析使用Logistic模型前,需判断是否满足以下7项假设。
假设1:因变量(结局)是二分类变量。
假设2:有至少1个自变量,自变量可以是连续变量,也可以是分类变量。
假设3:每条观测间相互独立。
分类变量(包括因变量和自变量)的分类必须全而且每一个分类间互斥。
假设4:最小样本量要求为自变量数目的15倍,但一些研究者认为样木量应达到自变量数目的50倍。
假设5:连续的自变量与因变量的logit转换值之间存在线性关系。
假设6:自变量之间无多重共线性。
假设7:没有明显的离群点、杠杆点和强影响点。
假设1-4取决于研究设计和数据类型,本研究数据满足假设1- 4o 那么应该如何检验假设5-7,并进行Logistic回归呢?三、SPSS操作3. 1检验假设5:连续的自变量与因变量的logit转换值之间存在线性关系。
连续的自变量与因变量的logit转换值之间是否存在线性关系,可以通过多种方法检验。
这里主要介绍Box-Tidwell方法, 即将连续自变量与其自然对数值的交互项纳入回归方程。
本研究中,连续的自变量包括age、BMI、TCo使用Box-Tidwell 方法时,需要先计算age、BMI、TC的自然对数值,并命名为ln_age> ln_BMI> ln_TCo(1)计算连续自变量的自然对数值以age 为例,计算age 的自然对数值ln_age 的SPSS 操作如下。
spss二元logistic回归分析结果解读

spss的二元logistic回归
SPSS(Statistical Product and Service Solutions)是一款数据统计与分析软件。
SPSS软件可以提供全面高级的统计分析,方便易用可快速操作,可缩小数据科学与数据理解之间的差距;在具体的应用方向方面,SPSS提供了高级统计分析、大量机器学习算法、文本分析等功能,具备开源可扩展性,可与大数据的集成,并能够无缝部署到应用程序中。
Logistic回归:主要用于因变量为分类变量(如疾病的缓解、不缓解,评比中的好、中、差等)的回归分析,自变量可以为分类变量,也可以为连续变量。
变量为二分类的称为二项logistic回归,因变量为多分类的称为多元logistic回归。
Odds:称为比值、比数,是指某事件发生的可能性(概率)与不发生的可能性(概率)之比。
OR(OddsRatio):比值比,优势比。
二元logistic回归是研究二分类反应变量和多个解释变量间回归关系的统计学分析方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
回归系数β与ORi
X与Y的关联
β=0,OR=1,
无关
β>1,OR>1 , 有关,危险因素
β<1,OR<1, 有关,保护因子
事件发生率很小,OR≈RR。
二、logistic回归模型的参数估计
1. 模型中的参数(βi)估计
,
ln
P 1 P
=
0
1 X1
2
X
2
m
X
m
通常用最大似然函数 (maximum likelihood estimate, MLE)估计β, 由统计软件包完成。
ln P 1 P
=
0
1 X1
2
X
2
m
X
m
检验方法(讲义260-261页) 1)似然比检验 (likelihood ratio test) 2)Wald检验
30(a) 10( b)
70(c) 90(d)
a+c
b+d
危险因素
x= 1 x= 0
p1 1-p1
p0 1-p0
a p1 a c
有暴露因素人群中发病的比例
多元回归模型的的 i概念
logit(p)
ln
1
P P
=
0
1
X1
mXm
i 反映了在其他变量固定后,X=1与x=0相
比发生Y事件的对数优势比。
截距(常数)
回归系数
在有多个危险因素(Xi)时
多个变量的logistic回归模型方程的线性表达:
logit(p)
ln
1
P P
=
0
1 X 1
2
X1, x2
1
x ) 1 e k
( 0 1xk ....k xk )
2.模型中参数的意义
ln
P 1 P
=
0
1 X 1
OR e
如X=1,0两分类,则OR的1-α可信区间 估计公式
e(bj u / 2Sbj )
S 为回归系数 bj 的标准误
例:
一个研究吸烟、饮酒与食道癌关系的病例-对 照资料(886例),试作logistic回归分析。
变量的赋值
1 Y 0
食管癌患者 对照:非食管癌
1 X1 0
吸烟 不吸烟
1 X 2 0
log itP1 log itP0
P1(y=1/x=1)的概率 P0(y=1/x=0)的概率
(0 1x1) (0 x0 ) 1x1
OR e
OR P1 /(1 P1) odds1 P0 /(1 P0 ) odds0
Y 发病=1 不发病=0
Y 发病=1 不发病=0
危险因素
x= 1 x= 0
例:暴露因素 高血压史(x1):有 或无 高血脂史(x2): 有 或 无 吸烟(x3): 有或无
冠心病结果 有 或无
研究问题可否用多元线性回归方法?
yˆ a b1x1 b2x2 bmxm
1.多元线性回归方法要求 Y 的取值为计量 的连续性随机变量。
2.多元线性回归方程要求Y与X间关系为线 性关系。
p( y 1)
1
P概率
1
1 exp[(0 x)]
z 0 1x
0.5
Β为正值,x越 大,结果y=1发 生的可能性(p) 越大。
-3 -2 -1 0 1
Z值 23
图16-1 Logistic回归函数的几何图形
几个logistic回归模型方程
p1
P( y
1/
x
1)
e0 x 1 e0 x
e0 x P( y 0 / x 1) 1 1 e0 x 1 p1
2. logistic回归模型方程
一个自变量与Y关系的回归模型
如:y:发生=1,未发生=0 x : 有=1, 无=0,
记为p(y=1/x)表示某暴露因素状态下,
结果y=1的概率(P)模型。
e0 x
或
P( y 1/ x) 1 e0 x
1
p(y 1/ x)
1 exp[(0 x)]
模型描述了应变量p与x的关系
e0 p0 P( y 1/ x 0) 1 e0
e0 P( y 0 / x 0) 1 1 e0 1 p0
logistic回归模型方程的线性表达
对logistic回归模型的概率(p)做logit变
换, log it( p) ln( p ) 1 p
方程如下:
线形 关系
y log it( p) 0 1x1 Y~(-∞至+∞)
Β0(常数项):暴露因素Xi=0时,个体发病 概率与不发病概率之比的自然对数比值。
ln
1
P(y 1/ x P(y 0 /
x
0) 0)
=
0
i 的含义:某危险因素,暴露水平变化时,即
Xi=1与Xi=0相比,发生某结果(如发病)优势 比的对数值。
ln
OR
ln
P1 P0
/(1 /(1
P1 ) P0 )
饮酒 不饮酒
经logistic回归计算后得 b0 =-0.9099, b1 =0.8856, b2
=l0n.(52p61), 0.9099 0.8856x1 0.5261x2 方程1表达p :
exp( ) OR
exp(0.8856) OR 2.4244
控制饮酒因素后, 吸烟与不吸烟相比 患食管癌的优势比 为2.4倍
第一节 logistic回归
1.基本概念 logistic回归要求应变量(Y)取值为分类变量
(两分类或多个分类)
1 Y
0
出现阳性结果 (发病、有效、死亡等) 出现阴性结果 (未发病、无效、存活等)
自变量(Xi)称为危险因素或暴露因素,可为连续变 量、等级变量、分类变量。 可有m个自变量X1, X2,… Xm
3.多元线性回归结果 Yˆ 不能回答“发生
与否” logistic回归方法补充多元线性回归的不足
Logistic回归方法
该法研究是 当 y 取某值(如y=1)发生的概率(p)与
某暴露因素(x)的关系。
p(y 1/ x) f (x),即p f (x)
P(概率)的取值波动0~1范围。 基本原理:用一组观察数据拟合Logistic模型, 揭示若干个x与一个因变量取值的关系,反映y 对x的依存关系。
logistic回归分析
logistic回归为概率型非线性 回归模型,是研究分类观察 结果(y)与一些影响因素(x) 之间关系的一种多变量分析 方法
问题提出:
医学研究中常研究某因素存在条件下某结果是否 发生?以及之间的关系如何?
因素(X)
疾病结果(Y)
x1,x2,x3…XK
发生
Y=1
不发生 Y=0
exp(0.5261) OR 1.6923
OR的可信区间估计
吸烟与不吸烟患食管癌OR的95%可信区间:
饮酒与不饮酒OR的95%可信区间:
三、Logistic 回归模型的假设检验
1.检验一:对建立的整个模型做检验。
说明自变量对Y的作用是否有统计意义。
H0 : 1 2 m 0
H1 : 各(j j 1,2,,m)不全为0