【免费下载】语法分析程序
《语法分析讲稿》模板

《语法分析讲稿》模板
语法分析讲稿
一、引言
- 介绍语法分析的概念和重要性
- 概述讲稿内容和结构安排
二、语法分析的基本概念
- 解释编程语言中的语法和语义
- 介绍语法分析的定义和作用
- 引出语法分析器的概念和角色
三、语法分析的分类
- 自顶向下分析和自底向上分析的概念和区别
- 介绍自顶向下分析器和自底向上分析器的基本原理和实现方法
四、自顶向下语法分析
- 解释自顶向下分析的主要思想和步骤
- 介绍预测分析器和递归下降分析器的原理和实现方法
- 分析自顶向下分析的优缺点和适用场景
五、自底向上语法分析
- 解释自底向上分析的主要思想和步骤
- 介绍移进-归约分析器和LR分析器的原理和实现方法
- 分析自底向上分析的优缺点和适用场景
六、语法分析器的构建工具
- 介绍常用的语法分析器生成工具
- 分析不同工具之间的特点和适用场景
七、语法分析的应用
- 介绍语法分析在编译器中的作用和流程
- 探讨语法分析在其他领域的应用,如自然语言处理和文本分析
八、语法分析的优化和扩展
- 分析语法分析器的性能优化方法,如提前规约和语法短路- 探讨语法分析的扩展技术,如语法扩展和恢复错误
九、结语
- 总结语法分析的关键概念和方法
- 强调语法分析在软件开发中的重要性和应用前景。
语法分析程序

语法分析程序的设计与实现实验内容:编写语法分析程序,实现对算术表达式的语法分析。
要求所分析算术表达式由如下的文法产生。
E→E+T|E-T|TT→T*F|T/F|FF→id|(E)|num实验要求:在对输入表达式进行分析的过程中,输出所采用的产生式。
方法:编写LL(1)语法分析程序,要求如下。
(1) 编程实现算法4.2,为给定文法自动构造预测分析表。
(2) 编程实现算法4.1,构造LL(1)预测分析程序。
编译环境:Windows XP环境下Visual C++ 6.0。
算法:定义栈的基本操作函数,定义有关构成LL(1)分析器的基本函数,定义LL(1)分析器的辅助函数,如FIRST 集、FOLLOW集等,设置文法表,存储P代表E',Q代表T',e代表ε,i代表id,n代表num。
源代码:#include <stdio.h>#include <stdlib.h>#define PRO_NUM 11 //产生式个数#define PRO_MAXLEN 8 //产生式最大长度#define TER_NUM 9 //终结符个数#define UNTER_NUM 5 //非终结符个数#define F_MAXLEN 8 //FIRST集和FOLLOW集的大小#define STR_MAXLEN 50 //待分析的输入表达式的最大长度#define IDNUM_MAXLEN 10 //待分析的输入表达式中id和num的的最大长度#define ERROR -1 //分析表项为空白,错误入口#define SYNCH -2 //分析表项为同步信息synch,同步错误入口#define STACK_INIT_SIZE 10 //栈空间初始分配量#define STACK_INCREMENT 5 //栈空间分配增量#define ID 1 //字母标记#define NUM 2 //数字标记#define OTHER 0 //其他字符标记#define TRUE 1#define FALSE 0#define NOTFOUND -1#define OVERFLOW -2typedef int Status; //返回状态类型typedef struct{char *top; //栈顶指针char *bottom; //栈底指针int stacksize; //当前已分配的存储空间}Stack;char grammar[PRO_NUM][PRO_MAXLEN]; //文法表char ter_symbol[TER_NUM]; //终结符表char unter_symbol[UNTER_NUM]; //非终结符表char FIRST[UNTER_NUM][F_MAXLEN]; //FIRST集char FOLLOW[UNTER_NUM][F_MAXLEN]; //FOLLOW集int M[UNTER_NUM][TER_NUM]; //LL(1)语法预测分析表char str[STR_MAXLEN+1]; //输入缓冲区Stack S; //栈//构成LL(1)分析器基本函数void Initial (void); //初始化void Create_Analysis (void); //构造LL(1)语法预测分析表void GetString (void); //获取待分析输入表达式void Analyse_Output (void); //使用LL(1)语法预测分析表分析输入的表达式并输出分析结果//LL(1)分析器辅助函数int GetStrLen (void); //获取输入表达式的长度Status Judge_Ter (char ch); //判断字符ch是否为终结符Status Judge_Unter (char ch); //判断字符ch是否为非终结符int Get_Ter_Num (char ch); //返回终结符ch在终结符表中的下标int Get_Unter_Num (char ch); //返回非终结符ch在终结符表中的下标Status In_FIRST (char A, char ch); //判断终结符ch是否在非终结符A的FIRST集中Status In_FOLLOW (char A, char ch); //判断终结符ch是否在一个非终结符A的FOLLOW集中void Output_Pro (int i); //打印分析过程中输出的产生式void Output_Stack (void); //打印当前栈中的符号void Output_Buffer (int ip); //打印当前输入缓冲区中的符号串Status Judge_Id (char ch); //判断字符ch是否为构成id的字母Status Judge_Num (char ch); //判断字符ch是否为构成num的数字Status Judge_Exceed (void); //判断输入表达式中代表id和num的子串是否超过最大长度//栈的基本操作void InitStack (void); //构造一个空栈void DestroyStack (void); //销毁栈void Push (char e); //把一个字符压入栈顶void Pop (void); //弹出栈顶字符char Gethead (void); //获取栈顶字符main (){Initial(); //初始化Create_Analysis(); //构造LL(1)语法预测分析表GetString(); //获取待分析输入表达式Analyse_Output (); //使用LL(1)语法预测分析表分析输入的表达式并输出分析结果DestroyStack (); //销毁栈return 0;}void InitStack (void) //构造一个空栈{S.bottom = (char *) malloc (STACK_INIT_SIZE * sizeof (char));if (! S.bottom)exit (OVERFLOW); //存储分配失败S.top = S.bottom;S.stacksize = STACK_INIT_SIZE;}void DestroyStack (void) //销毁栈{int i;for (i = S.stacksize - 1; i >= 0; i--) //依次释放分配的栈存数单元free (S.bottom + i);S.bottom = S.top = NULL;S.stacksize = 0;}void Push (char e) //把一个字符压入栈顶{if (S.top - S.bottom >= S.stacksize) //栈满,追加分配存储空间{S.bottom = (char *) realloc (S.bottom, (S.stacksize + STACK_INCREMENT) * sizeof(char));if (! S.bottom)exit (OVERFLOW); //存储分配失败S.top = S.bottom + S.stacksize;S.stacksize += STACK_INCREMENT;}*S.top++ = e; //把字符压入栈顶}void Pop (void) //弹出栈顶字符{if (S.bottom != S.top)S.top --;}char Gethead (void) //获取栈顶字符{char e;if (S.bottom != S.top)e = *(S.top - 1);return e;}void Initial (void) //初始化{int i, j;InitStack ();Push ('$');Push ('E'); //初始化栈:构造空栈,并压入'$'与'E'//设置文法表,存储P代表E',Q代表T',e代表ε,i代表id,n代表numstrcpy (grammar[0], "E#TP#"); //E →TE'strcpy (grammar[1], "P#+TP#"); //E' →+TE'strcpy (grammar[2], "P#-TP#"); //E' →-TE'strcpy (grammar[3], "P#e#"); //E' →εstrcpy (grammar[4], "T#FQ#"); //T →FT'strcpy (grammar[5], "Q#*FQ#"); //T' →*FT'strcpy (grammar[6], "Q#/FQ#"); //T' →/FT'strcpy (grammar[7], "Q#e#"); //T' →εstrcpy (grammar[8], "F#i#"); //F →idstrcpy (grammar[9], "F#(E)#"); //F →(E)strcpy (grammar[10], "F#n#"); //F →numfor (i = 0; i < UNTER_NUM; i++) //LL(1)语法预测分析表初始化:所有表项置为错误ERROR for (j = 0; j < TER_NUM; j++)M[i][j] = ERROR;strcpy (ter_symbol, "+-*/()in$"); //初始化终结符表strcpy (unter_symbol, "EPTQF"); //初始化非终结符表//初始化FIRST集strcpy (FIRST[0], "(in#");strcpy (FIRST[1], "+-e#");strcpy (FIRST[2], "(in#");strcpy (FIRST[3], "*/e#");strcpy (FIRST[4], "(in#");//初始化FOLLOW集strcpy (FOLLOW[0], ")$#");strcpy (FOLLOW[1], ")$#");strcpy (FOLLOW[2], "+-)$#");strcpy (FOLLOW[3], "+-)$#");strcpy (FOLLOW[4], "+-*/)$#");}Status Judge_Ter (char ch) //判断字符ch是否为终结符{if (ch=='+' || ch=='-' || ch=='*' || ch=='/' || ch=='(' || ch==')' || ch=='i' || ch=='n' || ch=='$') return TRUE;elsereturn FALSE;}Status Judge_Unter (char ch) //判断字符ch是否为非终结符{if (ch=='E' || ch=='P' || ch=='T' || ch=='Q' || ch=='F')return TRUE;elsereturn FALSE;}int Get_Ter_Num (char ch) //返回终结符ch在终结符表中的下标{int i;for (i = 0; i < TER_NUM; i++)if (ch == ter_symbol[i])return i;return NOTFOUND;}int Get_Unter_Num (char ch) //返回非终结符ch在非终结符表中的下标{int i;for (i = 0; i < UNTER_NUM; i++)if (ch == unter_symbol[i])return i;return NOTFOUND;}Status In_FIRST (char A, char ch) //判断终结符ch是否在非终结符A的FIRST集中{int i, j;i = Get_Unter_Num (A);for (j = 0; FIRST[i][j] != '#'; j++)if (ch == FIRST[i][j])return TRUE;return FALSE;}Status In_FOLLOW (char A, char ch) //判断终结符ch是否在非终结符A的FOLLOW集中{int i, j;i = Get_Unter_Num (A);for (j = 0; FOLLOW[i][j] != '#'; j++)if (ch == FOLLOW[i][j])return TRUE;return FALSE;}void Create_Analysis (void) //构造LL(1)语法预测分析表{int i, j;int n1, n2;char ch, A;for (i = 0; i < PRO_NUM; i++) //对于每个产生式A →α{A = grammar[i][0];ch = grammar[i][2];if (Judge_Unter (ch)) //若a∈FIRST(α),M[A,a]中应放入产生式A →α{for (j = 0; j < TER_NUM; j++){if (In_FIRST (ch, ter_symbol[j])){n1 = Get_Unter_Num (A);M[n1][j] = i;}}}else if (Judge_Ter (ch)){n1 = Get_Unter_Num (A);n2 = Get_Ter_Num (ch);M[n1][n2] = i;}else if (ch == 'e') //若ε∈FIRST(α),且b∈FOLLOW(A),M[A,b]中应放入产生式A →α{n1 = Get_Unter_Num (A);for (j = 0; FOLLOW[n1][j] != '#'; j++){n2 = Get_Ter_Num (FOLLOW[n1][j]);M[n1][n2] = i;}}}for (i = 0; i < UNTER_NUM; i++) //置同步出错信息{for (j = 0; FOLLOW[i][j] != '#'; j++) //若b∈FOLLOW(A),且M[A,b]为ERROR,则把M[A,b]赋值为为同步信息SYNCH{n1 = Get_Ter_Num (FOLLOW[i][j]);if (M[i][n1] == ERROR)M[i][n1] = SYNCH;}}}int GetStrLen (void) //获取输入表达式的长度{int count;for (count = 0; str[count] != '\0'; count++);return count;}Status Judge_Exceed (void) //判断输入表达式中代表id和num的子串是否超过最大长度{int ip, bp, width;char a;int flag1 = OTHER, flag2 = OTHER; //字符类型标记int toolong = FALSE; //过长标记for (ip = 0; (str[ip] != '\0') && (! toolong); ip += width){a = str[ip];if (a=='+' || a=='-' || a=='*' || a=='/' || a=='(' || a==')' || a=='$')width = 1;else //对输入表达式中代表id和num的子串的长度进行判断{bp = ip;width = 0;if (Judge_Id (a)) //根据代表id和num的子串的首字符确定串的类型,并进行标记flag1 = flag2 = ID;if (Judge_Num (a))flag1 = flag2 = NUM;bp ++;do //获取输入表达式中代表id和num的子串的长度{a = str[bp];width ++;if (width > IDNUM_MAXLEN) //若大于子串的最大长度,标记过长并跳出循环{toolong = TRUE;break;}if (Judge_Id (a))flag2 = ID;else if (Judge_Num (a))flag2 = NUM;elseflag2 = OTHER;bp ++;} while (flag1 == flag2); //两个标记相等,即子串没有结束,继续循环}}return toolong; //返回过长标记}void GetString (void) //获取待分析输入表达式{int len = 0; //待分析的输入表达式的长度int flag = FALSE;do{printf ("请输入待分析的表达式,以'$'结束:\n");scanf ("%s", &str);len = GetStrLen ();if (str[len-1] != '$') //若每输入结尾符'$',将其补在待分析输入表达式的最后{str[len] = '$';str[len+1] = '\0';len ++;}if (len > STR_MAXLEN) //判断输入表达式是否过长printf ("此表达式过长,请重新输入!\n");flag = Judge_Exceed (); //判断输入表达式中代表id和num的子串是否过长if (flag)printf ("此表达式中代表id和num的子串过长,请重新输入!\n");} while (len > STR_MAXLEN || flag);}Status Judge_Id (char ch) //判断字符ch是否为构成id的字母{if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z'))return TRUE;elsereturn FALSE;}Status Judge_Num (char ch) //判断字符ch是否为构成num的数字{if (ch >= '0' && ch <= '9')return TRUE;elsereturn FALSE;}void Output_Pro (int i) //打印分析过程中输出的产生式{printf (" 输出产生式:");switch (i) //根据产生式的标号打印出对应是输出产生式{case 0:printf ("E →TE'\n");break;case 1:printf ("E' →+TE'\n");break;case 2:printf ("E' →-TE'\n");break;case 3:printf ("E' →ε\n");break;case 4:printf ("T →FT'\n");break;case 5:printf ("T' →*FT'\n");break;case 6:printf ("T' →/FT'\n");break;case 7:printf ("T' →ε\n");break;case 8:printf ("F →id\n");break;case 9:printf ("F →(E)\n");break;case 10:printf ("F →num\n");break;default:break;}}void Output_Stack (void) //打印当前栈中的符号{char *sp = NULL;printf (" 栈:");for (sp = S.bottom; sp != S.top; sp++){switch (*sp){case 'P': //将P转换为E'输出printf ("E'");break;case 'Q': //将Q转换为T'输出printf ("T'");break;case 'i': //将i转换为id输出printf ("id");break;case 'n': //将n转换为num输出printf ("num");break;default: //其他情况直接输出printf ("%c", *sp);break;}}printf ("\n");}void Output_Buffer (int ip) //打印当前输入缓冲区中的符号串{int i;printf (" 输入:");for (i = ip; str[i] != '$'; i++)printf ("%c", str[i]);printf ("$\n");}void Analyse_Output (void) //使用LL(1)语法预测分析表分析输入的表达式并输出分析结果{int ip = 0; //输入缓冲区指针int step = 0; //分析步数char X, a, c;int i, j, n1, n2, bp;int width = 0; //输入表达式中代表id和num的子串的长度char b[IDNUM_MAXLEN+1]; //存储输入表达式中代表id和num的子串int flag1 = OTHER, flag2 = OTHER; //字符类型标记do{step ++;printf ("第%d步:\n", step);X = Gethead (); //获取栈顶符号a = str[ip]; //获取输入串中将要进行分析的符号for (j = 0; j <= IDNUM_MAXLEN; j++) //对存储输入串中代表id和num的子串的数组进行初始化b[j] = '\0';if (a=='+' || a=='-' || a=='*' || a=='/' || a=='(' || a==')' || a=='$') //对输入串中将要进行分析的符号进行处理{width = 1;b[0] = a;}else //处理输入表达式中代表id和num的子串,分别将它们转化为'i'和'n'进行分析{bp = ip;width = 0;if (Judge_Id (a)) //根据代表id和num的子串的首字符确定串的类型,并进行标记flag1 = flag2 = ID;if (Judge_Num (a))flag1 = flag2 = NUM;bp ++;c = a;do //获取输入表达式中代表id和num的子串,将其存入数组b{width ++;b[width-1] = c;c = str[bp];if (Judge_Id (c))flag2 = ID;else if (Judge_Num (c))flag2 = NUM;elseflag2 = OTHER;bp ++;} while (flag1 == flag2); //两个标记相等,即子串没有结束,继续循环if (flag1 == ID) //将输入表达式中代表id和num的子串分别转化为'i'和'n'进行分析a = 'i';if (flag1 == NUM)a = 'n';}Output_Stack (); //打印当前栈中的符号Output_Buffer (ip); //打印当前输入缓冲区中的符号串if (Judge_Ter (X)) //栈顶符号是终结符:不论正确与否,都弹出栈顶符,ip前移{if (X == a){Pop ();ip += width;}else //若栈顶终结符与ip指向的字符不匹配,提示错误{Pop ();ip += width;printf (" 输出:错误!\n");}}else //栈顶符号是非终结符{n1 = Get_Unter_Num (X);n2 = Get_Ter_Num (a);if (M[n1][n2] != ERROR && M[n1][n2] != SYNCH) //正确情形:分析表项M[X][a]是非终结符X 的一个产生式{Pop (); //弹出栈顶符i = M[n1][n2];if (grammar[i][2] != 'e') //如果产生式右边不是ε,将对应产生式的右边逆序压入栈中{for (j = 2; grammar[i][j] != '#'; j++); //将对应产生式的右边逆序压入栈中for (j--; j >= 2; j--)Push (grammar[i][j]);}Output_Pro (i); //输出产生式}else if (M[n1][n2] == ERROR) //分析表项M[X][a]为空,ip前移,跳过当前输入字符(串){ip += width;printf (" 输出:错误!跳过%s\n", b);}else if (M[n1][n2] == SYNCH) //分析表项M[X][a]为同步信息,则弹出栈顶符{Pop ();printf (" 输出:错误!弹出栈顶");switch (X){case 'P': //将P转换为E'输出printf ("E'");break;case 'Q': //将Q转换为T'输出printf ("T'");break;default: //其他情况直接输出printf ("%c", X);break;}printf ("\n");}}} while (X != '$');}。
二语法分析程序(算符优先分析法)

实验二语法分析程序(算符优先分析法)一、实验目的通过设计调试算符优先分析程序,加深对课堂教学的理解,深刻理解自底向上语法分析方法的归约过程,提高语法分析方法的实践能力。
二、实验要求(1)根据给定文法,先求出FirstVt和LastVt集合,构造算符优先关系表(要求算符优先关系表输出到屏幕或者输出到文件);(2)根据算法和优先关系表分析给定表达式是否是该文法识别的正确的算术表达式(要求输出归约过程)(3)实验要求独立完成,不允许有抄袭现象。
(4)实验完成后,要求提交源程序和上交实验报告(包括源程序清单)。
(附:实验报告格式)三、实验内容(1)给定表达式文法为:G(E’): E’→#E#E→E+T | TT→T*F |FF→(E)|i(2)分析的句子为:(i+i)*i和i+i)*i(1)分析1,判断为算符优先文法:文法没有A->…BC…且BC均为非终结符,因此它为OG文法文法没有同时存在①A->…ab…或A->….aBb….②A->…aB…且B=>b….或B=>Cb….③A->…Bb….且B=>…a或B=>…aC文法为算符优先文法2,求FirstVT集和LastVT集FirstVT(E)={+, * , ( , i } LastVT(E)= {+, - , * , / , ) , i }FirstVT(T)={* , ( , i } LastVT(T)= {* , / , ( , i }FirstVT(F)={ ( , i } LastVT(F)={ ) , i }FirstVT(E’)={ #} LastVT(E’)={ #}3,根据FirstVT和LastVT集构造算符优先表(2)程序参考源码#include <iostream>#include <string>using namespace std;#define max 100char b[max]; //存放终结符char precedence[max][max];//存放优先关系struct opg{int step;string stack;char privior;char presentsignal;string leftstr;string explain;}temp;//存放一步int search(char ch){int i=0;while(ch!=b[i])i++;return i;}void anolyze(){//struct opg temp;temp.step=0;char s[max],c,a;string sentence;int m=0,q=0,flag=0,i=0; //flag标记着当前读到那个字符cout<<"输入要分析的句子:";cin>>sentence;int k=0;//s[k]='#';s[k]=sentence[flag++];s[k+1]='\0';int j=k;a=sentence[flag++]; //读入一个给a;temp.leftstr=sentence;while(temp.leftstr[i]!=a){ //while循环获得第一次的剩余字符串temp.leftstr[i]=' ';i++;}temp.leftstr[i]=' ';//把已经读过的字符赋空则就找到了剩余的串cout<<"步骤 "<<" 栈 "<<" 优先关系 "<<"当前符号"<<" 剩余字符串 "<<"移进或归约"<<endl;while(!(s[j]=='#'&&a=='#')){//栈顶和当前字符都是#if(!isupper(s[k]))j=k;//s[k]是终结符else j=k-1;m=search(s[j]);//获取要比较终结符所在行号q=search(a);//获取要比较终结符所在列号temp.step=temp.step+1;temp.stack=s;temp.privior=precedence[m][q];temp.presentsignal=a;cout<<temp.step<<'\t'<<temp.stack<<'\t'<<temp.privior<<'\t'<<temp.presentsignal <<temp.leftstr<<'\t';if(precedence[m][q]=='<'||precedence[m][q]=='=')//优先关系为<或={temp.explain="移进";cout<<temp.explain<<endl;k=k+1;s[k]=a;s[k+1]='\0';//赋上字符串的终结标准,相当于一个栈a=sentence[flag++];//读入一个给a;temp.leftstr[++i]=' ';//每读入一个句子中一个字符把此位置赋空,作为剩余串}else if(precedence[m][q]=='>')//优先关系为>{temp.explain="归约";cout<<temp.explain<<endl;//cout<<s[j]<<s[k]<<a;do{c=s[j];if (!isupper(s[j-1]))//s[j-1]是终结符(即不是大写字母)j=j-1;elsej=j-2;m=search(s[j]);q=search(c);}while(precedence[m][q]=='=');k=j+1;s[k]='N';s[k+1]='\0';}//出错else {cout<<"不是该文法可以识别的句子";break;}//出错}cout<<++temp.step<<'\t'<<"#N"<<'\t'<<"="<<'\t'<<"#"<<' '<<'\t'<<"接受";}void main(){int n,i,j; //终结符的个数cout<<"输入终结符的个数:";cin>>n;cout<<endl;cout<<n<<'\n';cout<<"输入终结符";for(i=0;i<n;i++)cin>>b[i];b[n]='#';for(i=0;i<n+1;i++)for(j=0;j<n+1;j++){cout<<b[i]<<"与"<<b[j]<<"的优先关系:";cin>>precedence[i][j];while(!(precedence[i][j]=='>'||precedence[i][j]=='<'||precedence[i][j]=='=' ||precedence[i][j]=='/')){ cout<<"没有此优先关系,请重新输入";cin>>precedence[i][j];}}cout<<"算术优先关系表\n"<<"===============================================\n";for(i=0;i<n+2;i++)for(j=0;j<n+2;j++){if(i==0){if(j==0)cout<<' ';else cout<<b[j-1]<<' ';}else {if(j==0)cout<<b[i-1];else cout<<precedence[i-1][j-1]<<' ';}if(j==n+1)cout<<endl;}cout<<"===============================================\n";anolyze();}。
语法分析程序

语法分析程序#include <stdio.h>#include <stdlib.h>#include <string.h>char prog[100],ch,token[8];int p=0,syn,n,i;char *keyword[6]={"begin","then","if","while","do","end"};void scaner();void Irparse();void statement();void expression_r();void term();void factor();void main(){int select=-1;p=0;printf("please input sentence, end of '#' !\n");do{ch=getchar();prog[p++]=ch;}while(ch!='#');p=0;printf("请输⼊1 或 2 \n 1.词法分析\n 2.语法分析\n");scanf("%d",&select);if(select==1){do{scaner();switch(syn){case -1:printf("词法分析出错\n");break;default :printf("<%d,%s>\n",syn,token);break;}}while(syn!=0);printf("词法分析成功\n");}else if(select==2){scaner();if(syn==1){Irparse();}//beginelse{printf("语法分析出错! 请检查begin关键字\n");return;}if(syn==6)//end{scaner();if(syn==0){printf("恭喜语法分析成功\n");}else{printf("语法分析出错! 请检查是否缺少'#'\n");}}else{printf("语法分析出错! 请检查是否缺少'end'\n");}}getchar();}void scaner(){for(n=0;n<8;n++){token[n]='\0';}n=0;ch=prog[p++];while(ch==''){ch=prog[p++];}if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')){do{token[n++]=ch;ch=prog[p++];}while((ch>='a'&&ch<='z')||(ch>='a'&&ch<='z')||(ch>='0'&&ch<='9'));syn=10;for(n=0;n<6;n++){if(strcmp(token,keyword[n])==0){syn=n+1;}}p--;//return;}else if(ch>='0'&&ch<='9'){p--;do{token[n++]=prog[p++];ch=prog[p];}while(ch>='0'&&ch<='9');syn=11;return;}else{//ch=prog[p++];switch(ch){case'+':syn=13;token[0]=ch;break;case'-':syn=14;token[0]=ch;break;case'*':syn=15;token[0]=ch;break;case'/':syn=16;token[0]=ch;break;case':':syn=17;token[0]=ch;ch=prog[p++];if(ch=='='){token[1]=ch;syn++;}else p--;break;case'<':syn=20;token[0]=ch;ch=prog[p++];if(ch=='>'){token[1]=ch;syn++;}else if(ch=='='){token[1]=ch;syn=syn+2;}else p--;break;case'>':syn=23;token[0]=ch;ch=prog[p++];if(ch=='='){token[1]=ch;syn++;}else p--;break;case'=':syn=25;token[0]=ch;break;case';':syn=26;token[0]=ch;break;case'(':syn=27;token[0]=ch;break;case')':syn=28;token[0]=ch;break;case'#':syn=0;token[0]=ch;break;default: printf("词法分析出错! 请检查是否输⼊⾮法字符\n");syn=-1;break; }//return;}}void Irparse(){scaner();statement();while(syn==26)//;{scaner();statement();}}void statement(){if(syn==10){scaner();if(syn==18){scaner();expression_r();}else{printf("语法分析出错! 请检查表达式是否正确\n");return;}}else{printf("语法分析出错! 请检查语句是否正确\n");return;}}void expression_r(){term();while(syn==13||syn==14)//+ -{scaner();term();}}void term(){factor();while(syn==15||syn==16)//* /{scaner();factor();}}void factor(){if(syn==10||syn==11){scaner();}else if(syn==27){scaner();expression_r();if(syn==28){scaner();}else {printf("语法分析出错! 请检查是否缺少')'\n");return;}}else {printf("语法分析出错! 请检查是否输⼊⾮法字符\n");return;} }。
语法分析程序(递归下降法)

语法分析程序(递归下降法)班级学号姓名:指导老师:一. 实验目的:1、学习语法分析的主要方法;2、熟悉复习词法分析的方法;3、判断表达式的正确性;4、熟悉C语言并提高动手能力;二. 实验内容:用递归下降分析法编写一个用于判断数学表达式是否正确的语法分析三.实验硬件和软件平台:INTEL C433MHz Cpu128Mb SDRAMTurbo C 2.0Microsoft Windows XP SP1四.步骤和算法描述:1.调用词法分析程序,转换表达式成为内号;2.调用语法分析程序,判断表达式正确与否;五.源程序:#include <stdio.h>#include <string.h>#include <io.h>#define yy swy=adv()FILE *fp1;char ch;int swy;main(){void CS();int chz(char str[15]);int adv();void CT();void E(); void EB();void ERROR();void ET();void F();void IT();void T();void sentence();clrscr();ch=' ';fp1=fopen("pas.txt","r");if(!fp1){printf("Can not open ljx.txt!!\n”); exit(0);}/* while(!feof(fp1)) */{yy;sentence();fclose(fp1);}}void ERROR(){printf("%d ERROR!\n ",swy); }void E(){T();while(swy==34||swy==35){yy;T();}}void T(){F();while(swy==36||swy==37){yy;F();}}void F(){if(swy==21||swy==22) yy;else if(swy==27){yy;E();if(swy==28) yy;else ERROR();}else ERROR();}void sentence(){ switch(swy){case 21 :{yy;if(swy==44){yy;E();}else ERROR();break;}case 1:CS();break;case 8:{yy;EB();if(swy!=4)ERROR();yy;sentence();break;}case 19:{yy;EB();if(swy!=4)ERROR();yy;sentence();}break;case 14:{yy;if(swy!=27) ERROR();yy;IT();if(swy!=28)ERROR();yy;break;}case 20:{yy;if(swy!=27) ERROR();yy;ET();if(swy!=28)ERROR();yy;break;}}}void CS(){yy;sentence();while(swy==24){yy;sentence();}if(swy==6)yy;else ERROR();}void CT(){if(swy==5){yy;sentence();}}void EB(){E();if(swy<=43&&swy>=38){yy;E();}else ERROR();}void IT(){if(swy!=21)ERROR();yy;while(swy==23){yy;if(swy!=21)ERROR();else ERROR();} }void ET(){E();while(swy==23){yy;E();}}int chz(char str1[15]){charstr[21][15]={"and","begin","const","div","do", "else","end","function","if","integer","not","or","pro cdure","program","read","real","then","type","var","while","write"};int i,max,min,mid;for(i=0;i<=14;i++)if(str1[i]<='Z'&&str1[i]>='A')str1[i]=str1[i]+'a'-'A';max=20;min=0;mid=10;while(min<=max){i=strcmp(str1,str[mid]);if(i==0) return mid;elseif(i>0){min=mid+1;mid=(max+min)/2;}else{max=mid-1;mid=(max+min)/2;}}return 0;}int adv(){char str1[15];int t,i=0,sk=0;float num,xs;if(ch==''||swy==24){fscanf(fp1,"%c",&(ch));printf("% c",ch);}while(!feof(fp1)&&i<100){if(((ch)>='a'&&(ch)<='z')||((ch)>='A'&&( ch)<='Z')){i=0;while((((ch)>='a'&&(ch)<='z')||((ch)>='A '&&(ch)<='Z')||((ch)>='0'&&(ch)<='9'))){str1[i]=(ch);i++;{fscanf(fp1,"%c",&(ch));printf("%c",ch);}}str1[i]='\0';t=chz(str1);if(!t)return 21;else return t;}else if(ch>='0'&&ch<='9'){num=0;while(ch>='0'&&ch<='9'){num=num*10+(ch)-'0';{fscanf(fp1,"%c",&(ch));printf("%c",ch); }}if(ch=='.'){xs=0.1;{fscanf(fp1,"%c",&(ch));printf("%c",ch); }while(ch>='0'&&ch<='9'){num+=(ch-'0')*xs;xs*=0.1;{fscanf(fp1,"%c",&(ch));printf("%c",ch); }}}return 22;}switch(ch){case '+' :{ch=' ';return 34;}case '*' :{ch=' ';return 36;}case ',' :{ch=' ';return 23;}case ';' :{ch=' ';return 24;}case '.' :{ch=' ';return 26;}case '(' :{ch=' ';return 27;}case ')' :{ch=' ';return 28;}case '[' :{ch=' ';return 29;}case ']' :{ch=' ';return 30;}case '{' :{ch=' ';return 45;}case '}' :{ch=' ';return 46;}case '-' :{ch=' ';return 35;}case '..' :{ch=' ';return 31;}case '/' :{ch=' ';return 37;}case '#' :{ch=' ';return 47;}case '<' : { {fscanf(fp1,"%c",&(ch));printf("%c",ch);}sk=1;if((ch)=='='){ch=' ';return 42;}else {return 39;}}case ':' :{{fscanf(fp1,"%c",&(ch));printf("%c",ch);}sk=1;if((ch)=='='){ch=' ';return 44;}else {return 25;}}case '>' :{{fscanf(fp1,"%c",&(ch));printf("%c",ch);}sk=1;if((ch)=='='){ch=' ';return 44;}else {return 40;}}default:break;}if(sk==0){fscanf(fp1,"%c",&(ch));printf( "%c",ch);}else sk=0;}}。
语法分析程序

华北水利水电学院编译原理实验报告一、实验目的与要求1.目的通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。
2.要求⑴选择最有代表性的语法分析方法,如LL(1)分析法、算符优先法或LR分析法⑵选择对各种常见程序语言都用的语法结构,如赋值语句(尤指表达式)作为分析对象,并且与所选语法分析方法要比较贴切。
⑶实习时间为6小时。
二、实验内容使用算符优先分析法实现语法分析:(1)根据给定文法,先求出FirstVt和LastVt集合,构造算符优先关系表(要求算符优先关系表输出到屏幕或者输出到文件);(2)根据算法和优先关系表分析给定表达式是否是该文法识别的正确的算术表达式(要求输出归约过程)(3)给定表达式文法为:G(E’): E’→#E#E→E+T | TT→T*F |FF→(E)|i(4)分析的句子为:(i+i)*i和i+i)*i三、程序源代码struct Result{CString NonEnd;CString content;};//自定义结构体,一个存储非终结符,一个存储表达式或相应的集合Result grammerResult[20];char grammerBuf[MAX_GRAMMER_LEN];//储存文法表达式Result FirstVtArray[MAX_END_LEN];Result LastVtArray[MAX_END_LEN];char table[MAX_END_LEN][MAX_END_LEN];char vt[MAX_END_LEN];//终结符集合int vtNum;//终结符的个数BOOL CGrammerDlg::IsNonEnd(char ch)//判断某个字符是否为非终结符{if(ch>='A'&&ch<='Z')return TRUE;elsereturn FALSE;}FirstVt和LastVt的求解void CGrammerDlg::SingleFirstVt(int &i,int &j,int m_grammerNum,int m_noEnd){int nlen=strlen(grammerResult[j].content);int m=0;if (nlen==1 &&IsNonEnd(grammerResult[j].content[0])){for (int ii=0;ii<m_noEnd;ii++){if ( (strcmp(grammerResult[j].content,FirstVtArray[ii].NonEnd))==0 ){m=ii;for (int jj=0;jj<m_grammerNum;jj++){if ( (strcmp(grammerResult[jj].NonEnd,FirstVtArray[ii].NonEnd))==0 ){SingleFirstVt(ii,jj,m_grammerNum,m_noEnd);}}}}FirstVtArray[i].content+=FirstVtArray[m].content;return;}for (int k=0;k<nlen;k++){if (IsNonEnd(grammerResult[j].content[k])){continue;}int nnlen=strlen(FirstVtArray[i].content);int n=0;for (int kk=0;kk<nnlen;kk++){if (FirstVtArray[i].content[kk]==grammerResult[j].content[k]){n=1;break;}}if (n==0){FirstVtArray[i].content+=grammerResult[j].content[k];}break;}}void CGrammerDlg::SingleLastVt(int &i,int &j,int m_grammerNum,int m_noEnd) {int nlen=strlen(grammerResult[j].content);Result fshizi[20];for (int kkk=0;kkk<20;kkk++){fshizi[kkk].NonEnd=grammerResult[kkk].NonEnd;fshizi[kkk].content="";}for (kkk=0;kkk<m_grammerNum;kkk++){int n=strlen(grammerResult[kkk].content);for (int j=n-1;j>=0;j--){fshizi[kkk].content+=grammerResult[kkk].content[j];}}int m=0;if (nlen==1 &&IsNonEnd(fshizi[j].content[0])){//for (int ii=0;ii<m_noEnd;ii++){if ( (strcmp(fshizi[j].content,LastVtArray[ii].NonEnd))==0 ){m=ii;for (int jj=0;jj<m_grammerNum;jj++){if ( (strcmp(fshizi[jj].NonEnd,LastVtArray[ii].NonEnd))==0 ){SingleLastVt(ii,jj,m_grammerNum,m_noEnd);}}}}LastVtArray[i].content+=LastVtArray[m].content;return;}for (int k=0;k<nlen;k++){if (IsNonEnd(fshizi[j].content[k])){continue;}int nnlen=strlen(LastVtArray[i].content);int n=0;for (int kk=0;kk<nnlen;kk++){if (LastVtArray[i].content[kk]==fshizi[j].content[k]){n=1;break;}}if (n==0){LastVtArray[i].content+=fshizi[j].content[k];}break;}}void CGrammerDlg::FirstVt(int m_grammerNum,int m_noEnd){for (int i=0;i<m_noEnd;i++){for (int j=0;j<m_grammerNum;j++){if (grammerResult[j].NonEnd==FirstVtArray[i].NonEnd){SingleFirstVt(i,j,m_grammerNum,m_noEnd);}}}CString s;for (i=0;i<m_noEnd;i++){s="";int nlen=strlen(FirstVtArray[i].content);for (int j=0;j<nlen;j++){int n=0;int nn=strlen(s);for (int k=0;k<nn;k++){if (s[k]==FirstVtArray[i].content[j]){n=1;break;}}if (n==0){s+=FirstVtArray[i].content[j];}}FirstVtArray[i].content="";FirstVtArray[i].content=s;}}void CGrammerDlg::LastVt(int m_grammerNum,int m_noEnd){for (int i=0;i<m_noEnd;i++){for (int j=0;j<m_grammerNum;j++){if (grammerResult[j].NonEnd==LastVtArray[i].NonEnd){SingleLastVt(i,j,m_grammerNum,m_noEnd);}}}CString s;for (i=0;i<m_noEnd;i++){s="";int nlen=strlen(LastVtArray[i].content);for (int j=0;j<nlen;j++){int n=0;int nn=strlen(s);for (int k=0;k<nn;k++){if (s[k]==LastVtArray[i].content[j]){n=1;break;}}if (n==0){s+=LastVtArray[i].content[j];}}LastVtArray[i].content="";LastVtArray[i].content=s;}}将终结符保存在一个数组里面void CGrammerDlg::SeekVt(){int StringLen=m_grammer.GetLength();int tempLen=0;for (int i=0;i<StringLen;i++){if (m_grammer[i]==13)continue;elsegrammerBuf[tempLen++]=m_grammer[i];}int nlen=tempLen;for (i=0;i<nlen;i++){if (IsNonEnd(grammerBuf[i])|| grammerBuf[i]=='|'|| grammerBuf[i]=='-'||grammerBuf[i]=='>'||grammerBuf[i]=='\n'){continue;}int n=strlen(vt);int flag=0;for (int j=0;j<n;j++){if (grammerBuf[i]==vt[j]){flag=1;break;}}if (flag==0){vt[vtNum]=grammerBuf[i];vtNum++;}}}设置算符优先表,对算符优先表的数组进行赋值void CGrammerDlg::SetPriorityHigh(int m_grammerNum, int m_noEnd) {char c1,c2;int n1;for (int i=0;i<m_grammerNum;i++){int nlen=strlen(grammerResult[i].content);for (int j=0;j<nlen;j++){if (j+1>=nlen){break;}if (IsNonEnd(grammerResult[i].content[j])){c1=grammerResult[i].content[j];c2=grammerResult[i].content[j+1];char grammerBuf[20];memset(grammerBuf,0,20);for (int ii=0;ii<m_noEnd;ii++){if (FirstVtArray[ii].NonEnd==c1){strcpy(grammerBuf,LastVtArray[ii].content);}}for (ii=0;ii<vtNum;ii++){if (vt[ii]==c2){n1=ii;}}int nlen=strlen(grammerBuf);for (ii=0;ii<nlen;ii++){for (int jj=0;jj<vtNum;jj++){if (grammerBuf[ii]==vt[jj]){table[jj][n1]='>';//表示大于}}}}}}}void CGrammerDlg::SetPriorityLow(int m_grammerNum, int m_noEnd){char c1,c2;int n1;for (int i=0;i<m_grammerNum;i++){int nlen=strlen(grammerResult[i].content);for (int j=0;j<nlen;j++){if (IsNonEnd(grammerResult[i].content[j])){continue;}if (j+1>=nlen){break;}if (IsNonEnd(grammerResult[i].content[j+1])){c1=grammerResult[i].content[j];c2=grammerResult[i].content[j+1];char grammerBuf[20];memset(grammerBuf,0,20);for (int ii=0;ii<m_noEnd;ii++){if (FirstVtArray[ii].NonEnd==c2){strcpy(grammerBuf,FirstVtArray[ii].content);}}for (ii=0;ii<vtNum;ii++){if (vt[ii]==c1){n1=ii;}}int nlen=strlen(grammerBuf);for (ii=0;ii<nlen;ii++){for (int jj=0;jj<vtNum;jj++){if (grammerBuf[ii]==vt[jj]){table[n1][jj]='<';//表示小于}}}}}}}void CGrammerDlg::SetPriorityEqual(int m_grammerNum, int m_noEnd){char c1;char c2;for (int i=0;i<m_grammerNum;i++){int nlen=strlen(grammerResult[i].content);for (int j=0;j<nlen;j++){if (IsNonEnd(grammerResult[i].content[j])){continue;}if (j+1>=nlen||j+2>=nlen){break;}if (IsNonEnd(grammerResult[i].content[j+1])&& grammerResult[i].content[j+2]!=' '){c1=grammerResult[i].content[j];c2=grammerResult[i].content[j+2];int n1,n2;for (int ii=0;ii<vtNum;ii++){if (vt[ii]==c1){n1=ii;}if (vt[ii]==c2){n2=ii;}}table[n1][n2]='=';//表示相等}}}}将输入的文法处理之后保存在结构体数组里面void CGrammerDlg::AnaylyzeGrammer(int &m_grammerNum,int &m_noEnd){int nlen=strlen(grammerBuf);BOOL m_bhead=TRUE;for (int i=0;i<nlen+1;i++){if (grammerBuf[i]=='\n'){m_grammerNum++;m_bhead=TRUE;continue;}if (grammerBuf[i]==' '){continue;}if (grammerBuf[i]=='-'){m_bhead=FALSE;continue;}if (grammerBuf[i]=='>'){m_bhead=FALSE;continue;}if (grammerBuf[i]=='|'){m_grammerNum++;grammerResult[m_grammerNum].NonEnd=grammerResult[m_grammerNum-1].NonEnd;continue;}if (m_bhead==TRUE){grammerResult[m_grammerNum].NonEnd+=grammerBuf[i];continue;}if (m_bhead==FALSE){grammerResult[m_grammerNum].content+=grammerBuf[i];continue;}}int nn;for (i=0;i<m_grammerNum;i++){nn=0;for (int j=0;j<m_noEnd;j++){if ( (strcmp(grammerResult[i].NonEnd,FirstVtArray[j].NonEnd)) == 0){nn=1;break;}}if (nn==0){FirstVtArray[m_noEnd].NonEnd=grammerResult[i].NonEnd;LastVtArray[m_noEnd].NonEnd=grammerResult[i].NonEnd;m_noEnd++;}}m_grammerNum++;}//对输入的句子末尾添加#号void CGrammerDlg::HandleInput(){//判断输入的文法末尾是否有#,如果没有,则自动添加#if (m_sentence.Right(1)!="#"){m_sentence+="#";UpdateData(FALSE);}}求解并显示FirstVt和LastVtvoid CGrammerDlg::OnCollection(){Init();UpdateData();SeekVt();int m_grammerNum=0;//文法表达式个数int m_noEnd=0;//非终结符个数//求FirstVT和LastVTAnaylyzeGrammer(m_grammerNum,m_noEnd);FirstVt(m_grammerNum,m_noEnd);LastVt(m_grammerNum,m_noEnd);SetPriorityEqual(m_grammerNum,m_noEnd);SetPriorityLow(m_grammerNum,m_noEnd);SetPriorityHigh(m_grammerNum,m_noEnd);//对算符优先关系表进行赋值int row=0;m_list_collection.DeleteAllItems();int temp=0;while (1){if (FirstVtArray[temp].NonEnd=="")break;CString s;s.Format("FirstVt(%s)",FirstVtArray[temp].NonEnd);m_list_collection.InsertItem(row,s);m_list_collection.SetItemText(row,1,FirstVtArray[temp].content);temp++;row++;}temp=0;while (1){if (LastVtArray[temp].NonEnd=="")break;CString s;s.Format("LastVt(%s)",FirstVtArray[temp].NonEnd);m_list_collection.InsertItem(row,s);m_list_collection.SetItemText(row,1,LastVtArray[temp].content);temp++;row++;}}显示算法优先表void CGrammerDlg::OnTable(){m_list_table.DeleteAllItems();while(1){BOOL ret=m_list_table.DeleteColumn(0);if (ret==FALSE)break;}//删除所有列//显示优先关系表int i=0;m_list_table.InsertColumn(0,"",LVCFMT_LEFT,30);while(vt[i]!=' '){CString s=vt[i];m_list_table.InsertColumn(i+1,s,LVCFMT_LEFT,30);i++;}for (int j=0;j<vtNum;j++){CString ss=vt[j];m_list_table.InsertItem(j,ss);for (int k=0;k<vtNum;k++){CString s;s.Format("%c",table[j][k]);m_list_table.SetItemText(j,k+1,s);}}}语句分析过程void CGrammerDlg::OnAnylyze(){UpdateData();if (m_sentence==""){MessageBox("请首先输入要分析的句子");return;}HandleInput();//对不是以#结束的句子添加#结尾m_list_result.DeleteAllItems();CString stack='#';CString priority="";CString now_char=m_sentence[0];CString leftString;TrackString(1,leftString,m_sentence);CString state="";int nNow;int nStack;int Row=0;char c='#';while (1){//----------------------判断优先关系for (int i=0;i<vtNum;i++){if (vt[i]==c){nStack=i;}if (vt[i]==now_char){nNow=i;}}if (table[nStack][nNow]=='=')//优先关系相等{state="移进";priority='=';m_list_result.InsertItem(Row,stack);m_list_result.SetItemText(Row,1,priority);m_list_result.SetItemText(Row,2,now_char);m_list_result.SetItemText(Row,3,leftString);m_list_result.SetItemText(Row,4,state);if (leftString==""){m_list_result.SetItemText(Row,4,"接受");break;}//要得到下一次循环时的剩余输入串,栈,当前符号c=now_char[0];stack+=now_char;now_char=leftString[0];TrackString(1,leftString,leftString);}if (table[nStack][nNow]=='>')//大于{state="归约";priority='>';m_list_result.InsertItem(Row,stack);m_list_result.SetItemText(Row,1,priority);m_list_result.SetItemText(Row,2,now_char);m_list_result.SetItemText(Row,3,leftString);m_list_result.SetItemText(Row,4,state);int nlen=stack.GetLength();char cc[10];memset(cc,0,10);int m[10];memset(m,0,40);int mm=0;int mmm=0;for (int i=nlen-1;i>=0;i--){if (IsNonEnd(stack[i])){mmm++;continue;}cc[mm]=stack[i];c=cc[mm];for (int j=0;j<vtNum;j++){if (cc[mm]==vt[j]){m[mm]=j;mm++;}}if (mm-1>=1){int m1=m[mm-1];int m2=m[mm-2];if (table[m1][m2]!='='){break;}}mmm++;}CString ss;for (i=0;i<nlen-mmm;i++){ss+=stack[i];}ss+="N";stack=ss;}if (table[nStack][nNow]=='<')//小于{state="移进";priority='<';m_list_result.InsertItem(Row,stack);m_list_result.SetItemText(Row,1,priority);m_list_result.SetItemText(Row,2,now_char);m_list_result.SetItemText(Row,3,leftString);m_list_result.SetItemText(Row,4,state);c=now_char[0];stack+=now_char;now_char=leftString[0];TrackString(1,leftString,leftString);}if (table[nStack][nNow]==' ')//两者之间不存在关系,错误{state="出错";m_list_result.InsertItem(Row,stack);m_list_result.SetItemText(Row,1,priority);m_list_result.SetItemText(Row,2,now_char);m_list_result.SetItemText(Row,3,leftString);m_list_result.SetItemText(Row,4,state);break;}Row++;}}四、运行结果在编辑框里可直接修改文法,然后重新求解对错误语句的分析非算符优先文法的提示二义性文法的提示五、小结(不少于100字)本次试验的内容是语法分析,我实现的是算符优先文法的分析。
语法分析程序

for(j=0;j<6;j++)
{
for(m=0;m<k;m++)
{
if(VN[i]==MAP[m].vn && VT[j]==MAP[m].vt)
{
char p,action[10],output[10];
int i=1,j,l=strlen(word),k=0,l_act,m;
while(!stak.empty())
stak.pop();
stak.push('#');
stak.push('E');
printf(" 步骤 栈顶元素 剩余输入串 推到所用产生式或匹配\n");
p=stak.top();
while(p!='#')
{
printf("%7d ",i++);
p=stak.top();
}
}
if(strcmp(output,"#")!=0)
return "ERROR";
}
int main ()
{
freopen("in.txt","r",stdin);
//freopen("out.txt","w",stdout);
char Right[10][8]={"->TR","->+TR","->e","->FW","->*FW","->e","->(E)","->i"};
语法分析和语法分析程序

语义分析
01
语义分析是语法分析的第三个阶段,主要任务是理解句子所 表达的实际意义和概念。
02
语义分析需要理解单词和短语在特定语境下的含义,以及它 们之间的关系和逻辑。
03
语义分析通常使用语义规则和知识库等资源来进行,需要处 理各种语义歧义和概念歧义等问题。
应用广泛
语法分析在许多自然语言处理应 用中都发挥着重要的作用,如机 器翻译、信息检索、问答系统等。
语法分析的历史与发展
01 早期研究
早期的语法分析主要基于手工规则和专家系统, 这种方法复杂度高且可移植性差。
02 统计方法
随着统计方法的兴起,基于概率的语法分析方法 逐渐成为主流,这种方法能够自动地学习和识别 语言的语法结构。
解决方案
采用动态规划算法,逐步构建句子的 语法结构,同时考虑上下文信息。
语义理解难度
挑战
语法分析程序不仅需要理解句子的语法结构,还需要理解句子的语义,即理解句子所表达的实际意义 。
解决方案
利用知识图谱、语义网等技术,将语义信息纳入语法分析程序中,提高语义理解的准确性。
处理大规模数据的能力
挑战
随着大数据时代的到来,语法分析程序需要处理大规模数据,这对其性能和效率提出了 更高的要求。
文本分类与情感分析
基于语法分析程序,可以对文本进行分类和情感分析,识别文本的 主题、情感倾向和意图。
机器翻译
源语言解析
01
语法分析程序能够解析源语言文本,将其转化为内部表示形式,
为后续的翻译过程提供基础。
目标语言生成
02
基于源语言的内部表示形式,语法分析程序可以生成目标语言
语法分析和语法分析程序

29
算符优先分析示例
例 w=i+i*i,分析过程见下表
步 骤 ˆ i ˆ +i*i# 1 # 句型及优先关系 最左素 非终 短语 结符 i F
N5 N4 N1 # i N2 + i * N3 i #
2 3 4 5 6
ˆ F+ ˆ # ˆ F+ ˆ # ˆ F+ ˆ # ˆ F+T # #E#
22
算符优先关系的定义
设文法G是一算符文法,且不含-产生式. U,A,BVN, a,bVT,算符优先关系可由以下定义给出: 定义4.3 a = b U…a[A]b... P 定义4.4 a < b U…aA... P (A=>+ [B]b…) 定义4.5 a > b U…Ab... P (A=>+ …a[B]) 若算符文法G的任意一对相邻终结符之间,至多只有上 述三种优先关系之一成立,则称其为算符优先文法。 通过构造和查看算符文法的优先矩阵可确定它是否为算 符优先文法。
4.2 自底向上的语法分析
自底向上的语法分析是从给定的符号串出发,试图将它归
约为文法的开始符号. 两种自底向上分析方法:
–优先分析法:在文法符号之间确定优先关系,根据优先关 系确定句型的句柄,进行语法分析。 –LR分析法:向前查看若干个输入符号以确定下一步应采 取的语义动作。
自底向上分析也需要一个分析栈用于存放分析过程中所
E E E1 T1 T F + * ( ) i E1 T1 T F + = > > > = = < < < < < = < > > > > * ( ) = > > > > i
【计算机科学】_语法分析程序_期刊发文热词逐年推荐_20140724
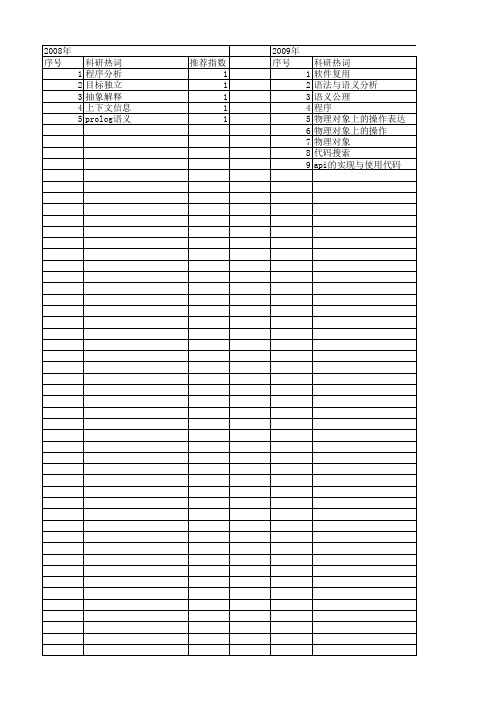
2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
科研热词 隐通道 赋值 语法信息流分析 访问控制 范畴论 程序 归纳数据类型 双代数 共归纳数据类型 共代数 保密性安全策略 代数 一阶动态逻辑 web服务模型本体 web服务
推荐指数 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2012年 序号 1 2 3 4 5 6
科研热词 语法分析 推导 归约 子图替换 子图匹配 图文法
推荐指数 1 1 1 1 1 1
2013年 序号 1 2 3 4
2013年 科研热词 语法分析程序 词法分析程序 处理系统 ndqjava2 推荐指数 1 1 1 1
2008年 序号 1 2 3 4 5
科研热词 程序分析 目标独立 抽象解释 上下文信息 prolog语义
推荐指数 1 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8 9
科研热词 软件复用 语法与语义分析 语义公理 程序 物理对象上的操作表达式 物理对象上的操作 物理对象 代码搜索 api的实现与使用代码
语法分析和语法分析程序

11
GO函数及DFA的构造方法
为求GO(I,X), 其中I为LR(1)项目集,X∈V,类似于LR(0)方
法,有: GO(I,X)=CLOSURE(J) 其中, J={[ AX , a ] | [ AX , a ] I} 注意,每个LR(1)项目与其后继项目有相同的搜索符号 采用与LR(0)类似的方法,可构造出文法G的LR(1)项目集 族C及状态转换图(DFA).
从前面的介绍可知,每个LR(1)项目均由两部分组成,一是
LR(0)项目,称为LR(1)项目的核;一是向前搜索符号集. 对于移进项目,搜索符集无作用;对于归约项目,它指明了 在扫描到不同的符号时用不同的产生式进行归约. 上述原理解决了SLR(1)分析中所不能解决的冲突,使LR(1) 分析比SLR(1)分析的能力有明显的提高. LR(1)也有缺点:分析表状盾, LALR(1)分析是最 佳方案. LALR(1)方法的分析能力介于LR(1)与SLR(1)之 间.是目前最流行的分析技术.
aVT{#}, IF a{a1,a2,…,am} THEN ACTION[i,a]=sj ELSE IF aFOLLOW(Bj) THEN ACTION[i,a]=rBj ELSE ACTION[i,a]=“ERR”
4
SLR(1)分析表的构造(续)
上述方法就是SLR(1) (Simple LR(1))规则.按照
的前提条件不仅仅是要求 a∈FOLLOW(A),还必须要求Aa 是某规范句型的前缀. – 在原来的每个LR(0)项目 [A]中放置一向前搜 索符号a: [A,a],称 为LR(1)项目.
9
求LR(1)项目集闭包算法
类似于LR(0)分析,识别文法全部活前缀的DFA的状态 是由LR(1)项目集表示的. 对每个LR(1)项目集I,相应的闭包CLOSURE(I)的定义为 (1) ICLOSURE(I); (2) 设项目[A B , a] CLOSURE(I),对所有形如B 的产生式,及每个bFIRST(a),将[B , b] =>CLOSURE(I); (3) 重复(2),直到CLOSURE(I)不再增大.
北邮《语法分析程序》实验报告

语法分析程序实验报告需求分析题目:语法分析程序的设计与实现。
实验内容:编写语法分析程序,实现对算术表达式的语法分析。
要求所分析算术表达式由如下的文法产生。
numE idF F F T F T T T T E T E E |)(||/|*||→→-+→ 实验要求:在对输入表达式进行分析的过程中,输出所采用的产生式。
方法1:编写LL(1)语法分析程序,要求如下。
(1) 编程实现算法4.2,为给定文法自动构造预测分析表。
(2) 编程实现算法4.1,构造LL(1)预测分析程序。
方法2:编写语法分析程序实现自底向上的分析,要求如下。
(1) 构造识别所有活前缀的DFA 。
(2) 构造LR 分析表。
(3) 编程实现算法4.3,构造LR 分析程序。
概要设计1. LL(1)语法分析程序 (1).原文法numE idF F F T F T T T T E T E E |)(||/|*||→→-+→(2).消除左递归和回溯E->TRR->+TRR->-TRR->eT->FWW->*FWW->/FWW->eF->idF->(E)F->num(3). FISRT集和FOLLOW集FIRST(S) = { id, num, ( }FOLLOW (S) = { $ }FIRST(E) = { id, num, ( }FOLLOW (E) = { $ , + , - , ) } FIRST(T) = { id, num, ( } FOLLOW (T) = { $ , + , - , * , / , ) } FIRST(F) = { id, num, ( } FOLLOW (F) = { $ , + , - , * , / , ) }(4).LL(1)预测分析表2. LR 实现,自底向上分析 (1).原文法numE idF F F T F T T T T E T E E |)(||/|*||→→-+→(2).文法对应的拓广文法为:1 E -> E+T2 E -> E -T3 E -> T4 T -> T*F5 T -> T/F6 T -> F7 F -> (E)8 F -> id9 F -> num(3). FISRT 集和FOLLOW 集FIRST(S) = { id, num, ( } FOLLOW (S) = { $ }FIRST(E) = { id, num, ( } FOLLOW (E) = { $ , + , - , ) }FIRST(T) = { id, num, ( } FOLLOW (T) = { $ , + , - , * , / , ) } FIRST(F) = { id, num, ( } FOLLOW (F) = { $ , + , - , * , / , ) }(4).构造项目集规范族I 0 = closure({S ->·E}) = {S ->·E, E ->·E+T, E ->·E -T, E ->·T, T ->·T*F, T ->·T/F, T ->·F, F ->·id, F ->·(E), F ->·num}; 从I 0出发:I 1 = go(I 0, E) = closure({S ->E·, E ->E·+T, E ->E·-T}) = {S ->E·, E ->E·+T, E ->E·-T}; I 2 = go(I 0, T) = closure({E ->T·, T ->T·*F, T ->T·/F}) = {E ->T·, T ->T·*F, T ->T·/F}; I 3 = go(I 0, F) = closure({T ->F·}) = {T ->F·}; I 4 = go(I 0, id) = closure({F ->id·}) = {F ->id·};I 5 = go(I 0, () = closure({F ->(·E)}) = {F ->(·E), E ->·E+T, E ->·E -T, E ->·T, T ->·T*F, T ->·T/F,T->·F, F->·id, F->·(E), F->·num};I6 = go(I0, num) = closure({F->num·}) = {F->num·};从I1出发:I7= go(I1, +) = closure({E->E+·T}) = {E->E+·T, T->·T*F, T->·T/F, T->·F, F->·id, F->·(E), F->·num};I8= go(I1, -) = closure({E->E-·T}) = {E->E-·T, T->·T*F, T->·T/F, T->·F, F->·id, F->·(E), F->·num};从I2出发:I9 = go(I2, *) = closure({T->T*·F}) = {T->T*·F, F->·id, F->·(E), F->·num};I10 = go(I2, /) = closure({T->T/·F}) = {T->T/·F, F->·id, F->(E), F->·num};从I5出发:I11 = go(I5, E) = closure({F->(E·), E->E·+T, E->E·-T}) = {F->(E·), E->E·+T, E->E·-T};从I7出发:I12 = go(I7, T) = closure({E->E+T·, T->T·*F, T->T·/F}) = {E->E+T·, T->T·*F, T->T·/F};从I8出发:I13 = go(I8, T) = closure({E->E-T·, T->T·*F, T->T·/F}) = {E->E-T·, T->T·*F, T->T·/F};从I9出发:I14 = go(I9, F) = closure({T->T*F·}) = {T->T*F·};从I10出发:I15 = go(I10, F) = closure({T->T/F·}) = {T->T/F·};从I11出发:I16 = go(I11, )) = closure({F->(E)·}) = {F->(E)·};LR分析表如下:goto[0,E] = 1; goto[0,T] = 2; goto[0,F] = 3;action[0,id] = S4; action[0,(] = S5; action[0,num] = S6;action[1,$] = ACC.; action[1,+] = S7; action[1,-] = S8;;action[2,)] = action[2,+] = action[2,-] = action[2,$] = R4;action[2,*] = S9; action[2,/] = S10;action[3,)] = action[3,+] = action[3,-] = action[3,*] = action[3,/] = action[3,$] = R7;action[4,)] = action[4,+] = action[4,-] = action[4,*] = action[4,/] = action[4,$] = R8;goto[5,E] = 11; goto[5,T] = 2; goto[5,F] = 3;action[5,id] = S4; action[5,(] = S5; action[5,num] = S6;action[6,)] = action[6,+] = action[6,-] = action[6,*] = action[6,/] = action[6,$] = R10;goto[7,T] = 12; goto[7,F] = 3;action[7,id] = S4; action[7,(] = S5; action[7,num] = S6;goto[8,T] = 13; goto[8,F] = 3;action[8,id] = S4; action[8,(] = S5; action[8,num] = S6;goto[9,F] = 14;action[9,id] = S4; action[9,(] = S5; action[9,num] = S6;goto[10,F] = 15;action[10,id] = S4; action[10,(] = S5; action[10,num] = S6;action[11,)] = S16; action[11,+] = S7; action[11,-] = S8;action[12,)] = action[12,+] = action[12,-] = action[12,$] = R2; action[12,*] = S9; action[12,/] = S10;action[13,)] = action[13,+] = action[13,-] = action[13,$] = R3; action[13,*] = S9; action[13,/] = S10;action[14,)] = action[14,+] = action[14,-] = action[14,*] = action[14,/] = action[14,$] = R5;action[15,)] = action[15,+] = action[15,-] = action[15,*] = action[15,/] = action[15,$] = R6;action[16,)] = action[16,+] = action[16,-] = action[16,*] = action[16,/] = action[16,$] = R9; DFA:(5).LR分析表运行结果LL(1):测试用例:(1+(a+b)*5/6)测试用例:1测试用例:a2+kLR:测试用例:(1+(a+b)*5/6)测试用例:1测试用例:a2+k源代码#include<stdlib.h>#include<string>#include<iostream>#include<fstream>#include<vector>using namespace std;//非终结字符类class Char{public:string FIRST; //first集string FOLLOW; //follow集Char(){}; //构造函数~Char(){};//析构函数void first(string s){ FIRST=FIRST+s; } //读入first集void follow(string s){ FOLLOW=FOLLOW+s; } //读入follow集};//产生式类class Gene{public:char left; //产生式左部非终结符string right; //产生式右部字符串string FIRST; //右部的first集string FOLLOW; //左部的follow集Gene(){};~Gene(){};void product(string a){left=a[0];int k=a.size();for(int i=3;i<k;i++)right[i-3]=a[i];}void first(string a){ FIRST=FIRST+a; }void follow(string a){ FOLLOW=FOLLOW+a; }};int find(string s,char ch){int k=s.size();for(int i=0;i<k;i++)if(ch==s[i])return i;return 0;}void LL1(){string G1[11];//存入LL(1)文法//G1[0]="E->TA";G1[1]="A->+TA";G1[2]="A->-TA";G1[3]="A->e";G1[4]="T->FB";G1[5]="B->*FB";G1[6]="B->/FB";G1[7]="B->e";G1[8]="F->d";G1[9]="F->(E)";G1[10]="F->n";cout<<"\n*********************************LL(1)********************************** **";cout<<"\n消除左递归和回溯:"<<endl;for(int i=11;i>0;i--){cout<<G1[11-i]<<"\t";if(i%3==0)cout<<endl;}cout<<endl;//存入非终结字符的first集follow集Char E;E.first("d(n");E.follow("$)");Char A;A.first("+_e");A.follow("$)");//A=E'Char T;T.first("d(n");T.follow("+-$)");Char B;B.first("*/e");B.follow("+-$)");//B=T'Char F;F.first("d(n");T.follow("*/+-$)");//定义一个Gene类的vector存入全部产生式的左部和右部vector <Gene> g(11);g[0].product(G1[0]);g[0].FIRST=T.FIRST;g[0].FOLLOW=E.FOLLOW;g[1].product(G1[1]);g[1].FIRST="+";g[1].FOLLOW=A.FOLLOW;g[2].product(G1[2]);g[2].FIRST="-";g[2].FOLLOW=A.FOLLOW;g[3].product(G1[3]);g[3].FIRST="e";g[3].FOLLOW=A.FOLLOW;g[4].product(G1[4]);g[4].FIRST=F.FIRST;g[4].FOLLOW=T.FOLLOW;g[5].product(G1[5]);g[5].FIRST="*";g[5].FOLLOW=B.FOLLOW;g[6].product(G1[6]);g[6].FIRST="/";g[6].FOLLOW=B.FOLLOW;g[7].product(G1[7]);g[7].FIRST="e";g[7].FOLLOW=B.FOLLOW;g[8].product(G1[8]);g[8].FIRST="d";g[8].FOLLOW=F.FOLLOW;g[9].product(G1[9]);g[9].FIRST="(";g[9].FOLLOW=F.FOLLOW;g[10].product(G1[10]);g[10].FIRST="n";g[10].FOLLOW=F.FOLLOW;//预测分析表的构造string M[6][10];//初始化分析表,表的第一行和第一列分别存入终结符和非终结符M[0][0]="\0";M[0][1]="+";M[0][2]="-";M[0][3]="*";M[0][4]="/";M[0][5]="d";M[0][6]="(";M[0][7]=")";M[0][8]="n";M[0][9]="$";M[1][0]="E";M[2][0]="A";M[3][0]="T";M[4][0]="B";M[5][0]="F";for(int i=1;i<6;i++){for(int j=1;j<10;j++){M[i][j]="err"; //初始化,把除第一行和第一列的元素均设为"err"}}//算法4.2string VN="0EATBF"; //用数组记录分析表的行和列,方便后面查找需要填入表格的位置string VT="0+-*/d()n$";for(int i=0;i<11;i++){int m=g[i].FIRST.size();int row=find(VN,g[i].left);for(int j=0;j<m;j++){if(g[i].FIRST[j]!='e'){int line=find(VT,g[i].FIRST[j]);M[row][line]=G1[i];}else{int t=g[i].FOLLOW.size();for(int k=0;k<t;k++){int line=find(VT,g[i].FOLLOW[k]);M[row][line]=G1[i];}}}}cout<<"\n**************************LL(1)预测分析表*****************************"<<endl;for(int i=0;i<6;i++){for(int j=0;j<10;j++)cout<<M[i][j]<<"\t";cout<<endl;}//算法4.1string w="";string state="";string output="";//output为输出串cout<<"提示:可用分析成功用例:和(num+(id+id)*num/num)"<<endl;cout<<"请输入待分析字符串:";cin>>w;cout<<endl;w+='$'; //输入串末尾加上'$'结束符cout<<"步骤"<<"\t"<<"栈"<<"\t\t"<<"输入"<<"\t\t"<<"输出"<<"\t"<<endl;int sum=0; //步骤数state="$E"; //将'$E'入栈char X; //定义X为栈顶文法符号int p=0;char a; // p指向输入串的第一个字符,a是p所指向的输入符号,后面为了输出方便直接改输入串,所以p一直是0while(X!='$'){ //栈非空,分析继续int len=state.size(); //求出栈中元素个数if(len>=8)cout<<sum<<"\t"<<state<<"\t"<<w<<"\t\t"; //控制输出格式对齐elsecout<<sum<<"\t"<<state<<"\t\t"<<w<<"\t\t"; //控制输出格式对齐if(w.size()<8)cout<<"\t"; //控制输出格式对齐X=state[len-1]; // X是栈顶文法符号a=w[p] ; // a是p所指向的输入符号if((a>='A'&& a<='Z')||(a>='a'&& a<='z'))a='d';if(a>='0'&& a<='9')a='n';if((X=='$')||!(X>='A'&&X<='Z')){ //X是终结符或$if(X==a){//if(cheak(X,a)){ //栈顶符号和输入串首字符匹配成功state.erase(state.size()-1,1); //从栈顶弹出Xw.erase(0,1); //p前移一个位置if(X=='$'){output="分析成功"; //输出句赋值}elseoutput="匹配成功";}else break;}else if(X>='A'&&X<='Z'){ //X是非终结符int row=find(VN,X); //找到X在分析表中的行数int line=find(VT,a); //找到a在分析表中的列数output=M[row][line]; //将M[X,a]中的产生式赋值给输出句state.erase(state.size()-1,1); //从栈顶弹出Xif(output[3]!='e'){ //如果产生式右部不为e(空符),则逆向压栈for(int k=output.size()-1;k>=3;k--){state+=output[k];}}else if(output[3]=='e'){} //如果产生式右部为e(空符),不用压栈else break; //否则出错跳出循环}cout<<output<<"\t"<<endl; //输出分析动作sum++; //步骤数+1}if(output=="分析成功")cout<<"该字符串分析成功\n\n"<<endl;}void LR(){string G2[10]; //存入LR文法G2[0]="A->E";G2[1]="E->E+T";G2[2]="E->E-T";G2[3]="E->T";G2[4]="T->T*F";G2[5]="T->T/F";G2[6]="T->F";G2[7]="F->d";G2[8]="F->(E)";G2[9]="F->n";cout<<"\n*********************************LR************************************ ";cout<<"\n采用LR分析法的拓广文法如下:"<<endl;for(int i=0;i<10;i++){cout<<G2[i]<<"\t";if(i%3==0)cout<<endl;}//***********************构造分析表********************************************string M[18][13];//初始化分析表,在表的第一行和第一列分别存入终结符和状态M[0][0]="\0";M[0][1]="+";M[0][2]="-";M[0][3]="*";M[0][4]="/";M[0][5]="d";M[0][6]="(";M[0][7]=")";M[0][8]="n";M[0][9]="$";M[0][10]="E";M[0][11]="T";M[0][12]="F";M[1][0]="0";M[2][0]="1";M[3][0]="2";M[4][0]="3";M[5][0]="4";M[6][0]="5";M[7][0]="6";M[8][0]="7";M[9][0]="8";M[10][0]="9";M[11][0]="10";M[12][0]="11";M[13][0]="12";M[14][0]="13";M[15][0]="14";M[16][0]="15";M[17][0]="16";for(int i=1;i<18;i++){for(int j=1;j<13;j++){M[i][j]="err"; //分析表除第一行和第一列外初始化为"err"}}//********************************存入LR分析表*********************************M[1][5]="s4";M[1][6]="s5";M[1][8]="s6";M[1][10]="1";M[1][11]="2";M[1][12]="3";M[2][1]="s7";M[2][2]="s8";M[2][9]="acc";M[3][1]="r3";M[3][2]="r3";M[3][3]="s9";M[3][4]="s10";M[3][7]="r3";M[3][9]="r3";M[4][1]="r6";M[4][2]="r6";M[4][3]="r6";M[4][4]="r6";M[4][7]="r6";M[4][9]="r6";M[5][1]="r7";M[5][2]="r7";M[5][3]="r7";M[5][4]="r7";M[5][7]="r7";M[5][9]="r7";M[6][5]="s4";M[6][6]="s5";M[6][8]="s6";M[6][10]="11";M[6][11]="2";M[6][12]="3";M[7][1]="r9";M[7][2]="r9";M[7][3]="r9";M[7][4]="r9";M[7][7]="r9";M[7][9]="r9";M[8][5]="s4";M[8][6]="s5";M[8][8]="s6";M[8][11]="12";M[8][12]="3";M[9][5]="s4";M[9][6]="s5";M[9][8]="s6";M[9][11]="13";M[9][12]="3";M[10][5]="s4";M[10][6]="s5";M[10][8]="s6";M[10][12]="14";M[11][5]="s4";M[11][6]="s5";M[11][8]="s6";M[11][12]="15";M[12][1]="s7";M[12][2]="s8";M[12][7]="s16";M[13][1]="r1";M[13][2]="r1";M[13][3]="s9";M[13][4]="s10";M[13][7]="r1";M[13][9]="r1";M[14][1]="r2";M[14][2]="r2";M[14][3]="s9";M[14][4]="s10";M[14][7]="r2";M[14][9]="r2";M[15][1]="r4";M[15][2]="r4";M[15][3]="r4";M[15][4]="r4";M[15][7]="r4";M[15][9]="r4";M[16][1]="r5";M[16][2]="r5";M[16][3]="r5";M[16][4]="r5";M[16][7]="r5";M[16][9]="r5";M[17][1]="r8";M[17][2]="r8";M[17][3]="r8";M[17][4]="r8";M[17][7]="r8";M[17][9]="r8";cout<<"**********************************LR分析表********************************"<<endl;cout<<"状态\t\t\t\taction\t\t\t\t\t\t\tgoto\t"<<endl;for(int i=0;i<18;i++){for(int j=0;j<13;j++)cout<<M[i][j]<<"\t";cout<<endl;}//****************************算法4.3*******************************************string V1="0+-*/d()n$ETF"; //用字符串存入分析表的第一行,以便后面查找字符的列数string w=""; //w为输入符号串string state=""; //用一个string类型来代替栈stackstring output=""; //output为输出串,即分析动作cout<<"提示:可用分析成功用例:(num+(id+id)*num/num)"<<endl;cout<<"请输入待分析符号串:"; //读入待分析串cin>>w;cout<<endl;w+='$'; //在输入串尾加上'$'符号cout<<"步骤"<<"\t"<<"栈"<<"\t\t\t\t"<<"输入"<<"\t\t"<<"\t分析动作"<<"\t"<<endl;int sum=0; //记录步骤state="0"; //栈初始化,放入'0'int S=0; //栈顶符号(即状态号)int p=0;char a; //p指向输入串的第一个字符,a是p所指向的输入符号,后面为了输出方便直接改输入串,所以p一直是0do{int len=state.size();if(len>=16) cout<<sum<<"\t"<<state<<"\t\t"<<w<<"\t\t\t"; //输出格式控制else if(len>=8)cout<<sum<<"\t"<<state<<"\t\t\t"<<w<<"\t\t\t"; //输出格式控制else cout<<sum<<"\t"<<state<<"\t\t\t\t"<<w<<"\t\t"; //输出格式控制if(w.size()<8)cout<<"\t"; //输出格式控制if((state.size()>1)&&(state[len-2]=='1'))S=10+(state[len-1]-'0');//得到现在的栈顶符号elseS=state[len-1]-'0';a=w[p] ;// a是p所指向的输入符号if((a>='A'&& a<='Z')||(a>='a'&& a<='z'))a='d';if(a>='0'&& a<='9')a='n';int row=S+1; //得到状态S的行号int line=find(V1,a); //找到输入串首字符a在分析表中的列数if(M[row][line][0]=='s'){ //当M[S,a]为shift时state+=a; //依次入栈a和Sstate+=M[row][line][1];if(M[row][line].size()==3)state+=M[row][line][2]; //当S是大于10的状态时需要入栈两次(这是用string而不用栈的弊端)w.erase(0,1); //相当于推进poutput="shift "; //输出句赋值output+=M[row][line][1]; // 输出句赋值if(M[row][line].size()==3)output+=M[row][line][2];}else if(M[row][line][0]=='r'){ //当M[S,a]为reduce时int abc=M[row][line][1]-'0'; //得到reduce需用到的产生式编号string re=G2[abc]; //用re存储该产生式string re1=re; //用re1备份该产生式re.erase(0,3); //去掉产生式的左部及箭头int be=2*re.size(); //用be记录栈顶待弹出的字符的数目(产生式右部的字符数目2倍)for(int p=be;p>0;p--){ //弹栈len=state.size(); //这也是用string而不用栈的弊端,弹栈时若状态号是两位数需要弹栈两次if(state[len-2]=='1'&&state[len-1]>='0'&&state[len-1]<='9')state.erase(state.size()-2,2);elsestate.erase(state.size()-1,1);}len=state.size(); //取现在的栈顶符号,先求出sta字符串的长度if((state.size()>1)&&(state[len-2]=='1'))S=10+(state[len-1]-'0');//取现在的栈顶符号else S=state[len-1]-'0';int row1=S+1; //得当前栈顶状态的行数int line1=find(V1,re1[0]); //得产生式左部字符的列数int len_r;len_r=M[row1][line1].size(); //查找分析表M中的goto函数的需要入栈的状态if(len_r==1)S=M[row1][line1][0]-'0'; //分析表中的状态是string类型的,所以需要转换成int型else S=10+(M[row1][line1][1]-'0');state+=re1[0]; //先入栈reduce产生式的左部if(S>=10){state+='1';state+=(S%10+'0');}elsestate+=(S+'0');//再入栈goto得到的状态output="reduce by "; //对输出句(分析动作)赋值output+=re1; //对输出句(分析动作)赋值}else if(M[row][line][0]=='a')output="acc"; //当分析表中元素为acc时,分析成功else break; //否则出错跳出循环cout<<output<<"\t"<<endl; //输出分析动作if(output[0]=='a')break; //当分析成功,跳出循环sum++; //分析步骤数+1}while(1);if(output=="acc")cout<<"该字符串分析成功\n\n"<<endl;}main(){cout<<"所分析算数表达式由如下文法产生:"<<endl;cout<<"E->E+T | E-T | T\nT->T*F | T/F | F\nF->id | (E) | num\n"<<endl;while(1){int x;cout<<"\n请选择所需分析方法:\n1.LL(1) 2.LR 0.退出"<<endl;cin>>x;while(x<0 || x>2 || cin.fail()){cout<<"输入错误,请重新输入:";cin.clear(); //清除流标记cin.sync(); //清空流cin>>x;}if(x==1)LL1(); //LL(1)语法分析程序else if(x==2)LR(); //LR分析程序elsebreak;}system("pause");return 0;}。
LL(1)语法分析程序
《编译原理》上机实验报告题目:LL(1)语法分析程序1.设计要求(1)对输入文法,它能判断是否为LL(1)文法,若是,则转(2);否则报错并终止;(2)输入已知文法,由程序自动生成它的LL(1)分析表;(3)对于给定的输入串,应能判断识别该串是否为给定文法的句型。
2.分析该程序可分为如下几步:(1)读入文法(2)判断正误(3)若无误,判断是否为LL(1)文法(4)若是,构造分析表;(5)由总控算法判断输入符号串是否为该文法的句型。
3.流程图4.源程序LL1语法分析程序#include<stdio.h>#include<string.h>int count=0; /*分解的产生式的个数*/int number; /*所有终结符和非终结符的总数*/char start; /*开始符号*/char termin[50]; /*终结符号*/char non_ter[50]; /*非终结符号*/char v[50]; /*所有符号*/char left[50]; /*左部*/char right[50][50]; /*右部*/char first[50][50],follow[50][50]; /*各产生式右部的FIRST和左部的FOLLOW集合*/ char first1[50][50]; /*所有单个符号的FIRST集合*/char select[50][50]; /*各单个产生式的SELECT集合*/char f[50],F[50]; /*记录各符号的FIRST和FOLLOW是否已求过*/char empty[20]; /*记录可直接推出^的符号*/char TEMP[50]; /*求FOLLOW时存放某一符号串的FIRST集合*/int validity=1; /*表示输入文法是否有效*/int ll=1; /*表示输入文法是否为LL(1)文法*/int M[20][20]; /*分析表*/char choose; /*用户输入时使用*/char empt[20]; /*求_emp()时使用*/char fo[20]; /*求FOLLOW集合时使用*//*******************************************判断一个字符是否在指定字符串中********************************************/int in(char c,char *p){//int i;size_t i;if(strlen(p)==0)return(0);for(i=0;;i++){if(p[i]==c)return(1); /*若在,返回1*/if(i==strlen(p))return(0); /*若不在,返回0*/}}/*******************************************得到一个不是非终结符的符号********************************************/char c(){char c='A';while(in(c,non_ter)==1)c++;return(c);}分解含有左递归的产生式********************************************/void recur(char *point){ /*完整的产生式在point[]中*/int j,m=0,n=3,k;char temp[20],ch;ch=c(); /*得到一个非终结符*/k=strlen(non_ter);non_ter[k]=ch;non_ter[k+1]='\0';for(j=0;size_t(j)<=strlen(point)-1;j++){if(point[n]==point[0]){ /*如果'|'后的首符号和左部相同*/ for(j=n+1;size_t(j)<=strlen(point)-1;j++){while(point[j]!='|'&&point[j]!='\0')temp[m++]=point[j++];left[count]=ch;memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';m=0;count++;if(point[j]=='|'){n=j+1;break;}}}else{ /*如果'|'后的首符号和左部不同*/ left[count]=ch;right[count][0]='^';right[count][1]='\0';count++;for(j=n;size_t(j)<=strlen(point)-1;j++){if(point[j]!='|')temp[m++]=point[j];else{left[count]=point[0];memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';m=0;count++;}}left[count]=point[0];memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';count++;m=0;}}}/*******************************************分解不含有左递归的产生式********************************************/void non_re(char *point){int m=0,j;char temp[20];for(j=3;size_t(j)<=strlen(point)-1;j++){if(point[j]!='|')temp[m++]=point[j];else{left[count]=point[0];memcpy(right[count],temp,m);right[count][m]='\0';m=0;count++;}}left[count]=point[0];memcpy(right[count],temp,m);right[count][m]='\0';count++;m=0;}/*******************************************读入一个文法********************************************/char grammer(char *t,char *n,char *left,char right[50][50]) {char vn[50],vt[50];char s;char p[50][50];printf("\n请输入文法的非终结符号串:");scanf("%s",vn);getchar();i=strlen(vn);memcpy(n,vn,i);n[i]='\0';printf("请输入文法的终结符号串:");scanf("%s",vt);getchar();i=strlen(vt);memcpy(t,vt,i);t[i]='\0';printf("请输入文法的开始符号:");scanf("%c",&s);getchar();printf("请输入文法产生式的条数:");scanf("%d",&i);getchar();for(j=1;j<=i;j++){printf("请输入文法的第%d条(共%d条)产生式:",j,i);scanf("%s",p[j-1]);getchar();}for(j=0;j<=i-1;j++)if(p[j][1]!='-'||p[j][2]!='>'){ printf("\ninput error!");validity=0;return('\0');} /*检测输入错误*/for(k=0;k<=i-1;k++){ /*分解输入的各产生式*/if(p[k][3]==p[k][0])recur(p[k]);elsenon_re(p[k]);}return(s);}/*******************************************将单个符号或符号串并入另一符号串********************************************/void merge(char *d,char *s,int type){ /*d是目标符号串,s是源串,type=1,源串中的' ^ '一并并入目串;type=2,源串中的' ^ '不并入目串*/int i,j;for(i=0;size_t(i)<=strlen(s)-1;i++)if(type==2&&s[i]=='^');else{for(j=0;;j++){if(size_t(j)<strlen(d)&&s[i]==d[j])break;if(size_t(j)==strlen(d)){d[j]=s[i];d[j+1]='\0';break;}}}}}/*******************************************求所有能直接推出^的符号********************************************/void emp(char c){ /*即求所有由' ^ '推出的符号*/ char temp[10];int i;for(i=0;i<=count-1;i++){if(right[i][0]==c&&strlen(right[i])==1){temp[0]=left[i];temp[1]='\0';merge(empty,temp,1);emp(left[i]);}}}/*******************************************求某一符号能否推出' ^ '********************************************/int _emp(char c){ /*若能推出,返回1;否则,返回0*/ int i,j,k,result=1,mark=0;char temp[20];temp[0]=c;temp[1]='\0';merge(empt,temp,1);if(in(c,empty)==1)for(i=0;;i++){if(i==count)return(0);if(left[i]==c) /*找一个左部为c的产生式*/{j=strlen(right[i]); /*j为右部的长度*/if(j==1&&in(right[i][0],empty)==1)return(1);else if(j==1&&in(right[i][0],termin)==1)return(0);else{for(k=0;k<=j-1;k++)if(in(right[i][k],empt)==1)mark=1;if(mark==1)continue;else{for(k=0;k<=j-1;k++){result*=_emp(right[i][k]);temp[0]=right[i][k];temp[1]='\0';merge(empt,temp,1);}}}if(result==0&&i<count)continue;else if(result==1&&i<count)return(1);}}}/*******************************************判断读入的文法是否正确********************************************/int judge(){int i,j;for(i=0;i<=count-1;i++){if(in(left[i],non_ter)==0){ /*若左部不在非终结符中,报错*/ printf("\nerror1!");return(0);}for(j=0;size_t(j)<=strlen(right[i])-1;j++){if(in(right[i][j],non_ter)==0&&in(right[i][j],termin)==0&&right[i][j]!='^'){ /*若右部某一符号不在非终结符、终结符中且不为' ^ ',报错*/ printf("\nerror2!");validity=0;return(0);}}}return(1);}/*******************************************求单个符号的FIRST********************************************/void first2(int i){ /*i为符号在所有输入符号中的序号*/char c,temp[20];int j,k,m;c=v[i];char ch='^';emp(ch);if(in(c,termin)==1) /*若为终结符*/{first1[i][0]=c;first1[i][1]='\0';}else if(in(c,non_ter)==1) /*若为非终结符*/{for(j=0;j<=count-1;j++){if(left[j]==c){if(in(right[j][0],termin)==1||right[j][0]=='^'){temp[0]=right[j][0];temp[1]='\0';merge(first1[i],temp,1);}else if(in(right[j][0],non_ter)==1){if(right[j][0]==c)continue;for(k=0;;k++)if(v[k]==right[j][0])if(f[k]=='0'){first2(k);f[k]='1';}merge(first1[i],first1[k],2);for(k=0;size_t(k)<=strlen(right[j])-1;k++){empt[0]='\0';if(_emp(right[j][k])==1&&size_t(k)<strlen(right[j])-1){for(m=0;;m++)if(v[m]==right[j][k+1])break;if(f[m]=='0'){first2(m);f[m]='1';}merge(first1[i],first1[m],2);}else if(_emp(right[j][k])==1&&size_t(k)==strlen(right[j])-1){temp[0]='^';temp[1]='\0';merge(first1[i],temp,1);}elsebreak;}}}}}f[i]='1';}/*******************************************求各产生式右部的FIRST********************************************/void FIRST(int i,char *p){int length;int j,k,m;char temp[20];length=strlen(p);if(length==1) /*如果右部为单个符号*/{{if(i>=0){first[i][0]='^';first[i][1]='\0';}else{TEMP[0]='^';TEMP[1]='\0';}}else{for(j=0;;j++)if(v[j]==p[0])break;if(i>=0){memcpy(first[i],first1[j],strlen(first1[j]));first[i][strlen(first1[j])]='\0';}else{memcpy(TEMP,first1[j],strlen(first1[j]));TEMP[strlen(first1[j])]='\0';}}}else /*如果右部为符号串*/{for(j=0;;j++)if(v[j]==p[0])break;if(i>=0)merge(first[i],first1[j],2);elsemerge(TEMP,first1[j],2);for(k=0;k<=length-1;k++){empt[0]='\0';if(_emp(p[k])==1&&k<length-1){for(m=0;;m++)if(v[m]==right[i][k+1])break;if(i>=0)elsemerge(TEMP,first1[m],2);}else if(_emp(p[k])==1&&k==length-1){temp[0]='^';temp[1]='\0';if(i>=0)merge(first[i],temp,1);elsemerge(TEMP,temp,1);}else if(_emp(p[k])==0)break;}}}/*******************************************求各产生式左部的FOLLOW********************************************/void FOLLOW(int i){int j,k,m,n,result=1;char c,temp[20];c=non_ter[i]; /*c为待求的非终结符*/temp[0]=c;temp[1]='\0';merge(fo,temp,1);if(c==start){ /*若为开始符号*/temp[0]='#';temp[1]='\0';merge(follow[i],temp,1);}for(j=0;j<=count-1;j++){if(in(c,right[j])==1) /*找一个右部含有c的产生式*/{for(k=0;;k++)if(right[j][k]==c)break; /*k为c在该产生式右部的序号*/for(m=0;;m++)if(v[m]==left[j])break; /*m为产生式左部非终结符在所有符号中的序号*/ if(size_t(k)==strlen(right[j])-1){ /*如果c在产生式右部的最后*/if(in(v[m],fo)==1){merge(follow[i],follow[m],1);continue;}if(F[m]=='0'){FOLLOW(m);F[m]='1';}merge(follow[i],follow[m],1);}else{ /*如果c不在产生式右部的最后*/for(n=k+1;size_t(n)<=strlen(right[j])-1;n++){empt[0]='\0';result*=_emp(right[j][n]);}if(result==1){ /*如果右部c后面的符号串能推出^*/if(in(v[m],fo)==1){ /*避免循环递归*/merge(follow[i],follow[m],1);continue;}if(F[m]=='0'){FOLLOW(m);F[m]='1';}merge(follow[i],follow[m],1);}for(n=k+1;size_t(n)<=strlen(right[j])-1;n++)temp[n-k-1]=right[j][n];temp[strlen(right[j])-k-1]='\0';FIRST(-1,temp);merge(follow[i],TEMP,2);}}}F[i]='1';}/*******************************************判断读入文法是否为一个LL(1)文法********************************************/int ll1(){int i,j,length,result=1;char temp[50];for(j=0;j<=49;j++){ /*初始化*/first[j][0]='\0';follow[j][0]='\0';first1[j][0]='\0';select[j][0]='\0';TEMP[j]='\0';temp[j]='\0';f[j]='0';F[j]='0';}for(j=0;size_t(j)<=strlen(v)-1;j++)first2(j); /*求单个符号的FIRST集合*/ printf("\nfirst1:");for(j=0;size_t(j)<=strlen(v)-1;j++)printf("%c:%s ",v[j],first1[j]);printf("\nempty:%s",empty);printf("\n:::\n_emp:");for(j=0;size_t(j)<=strlen(v)-1;j++)printf("%d ",_emp(v[j]));for(i=0;i<=count-1;i++)FIRST(i,right[i]); /*求FIRST*/printf("\n");for(j=0;size_t(j)<=strlen(non_ter)-1;j++){ /*求FOLLOW*/if(fo[j]==0){fo[0]='\0';FOLLOW(j);}}printf("\nfirst:");for(i=0;i<=count-1;i++)printf("%s ",first[i]);printf("\nfollow:");for(i=0;size_t(i)<=strlen(non_ter)-1;i++)printf("%s ",follow[i]);for(i=0;i<=count-1;i++){ /*求每一产生式的SELECT集合*/ memcpy(select[i],first[i],strlen(first[i]));select[i][strlen(first[i])]='\0';for(j=0;size_t(j)<=strlen(right[i])-1;j++)result*=_emp(right[i][j]);if(strlen(right[i])==1&&right[i][0]=='^')result=1;if(result==1){for(j=0;;j++)if(v[j]==left[i])break;merge(select[i],follow[j],1);}}printf("\nselect:");for(i=0;i<=count-1;i++)printf("%s ",select[i]);memcpy(temp,select[0],strlen(select[0]));temp[strlen(select[0])]='\0';for(i=1;i<=count-1;i++){ /*判断输入文法是否为LL(1)文法*/length=strlen(temp);if(left[i]==left[i-1]){merge(temp,select[i],1);if(strlen(temp)<length+strlen(select[i]))return(0);}else{temp[0]='\0';memcpy(temp,select[i],strlen(select[i]));temp[strlen(select[i])]='\0';}}return(1);}/*******************************************构造分析表M********************************************/void MM(){int i,j,k,m;for(i=0;i<=19;i++)for(j=0;j<=19;j++)M[i][j]=-1;i=strlen(termin);termin[i]='#'; /*将#加入终结符数组*/termin[i+1]='\0';for(i=0;i<=count-1;i++){for(m=0;;m++)if(non_ter[m]==left[i])break; /*m为产生式左部非终结符的序号*/ for(j=0;size_t(j)<=strlen(select[i])-1;j++){if(in(select[i][j],termin)==1){for(k=0;;k++)if(termin[k]==select[i][j])break; /*k为产生式右部终结符的序号*/ M[m][k]=i;}}}}/*******************************************总控算法********************************************/void syntax(){int i,j,k,m,n,p,q;char ch;char S[50],str[50];printf("请输入该文法的句型:");scanf("%s",str);getchar();i=strlen(str);str[i]='#';str[i+1]='\0';S[0]='#';S[1]=start;S[2]='\0';j=0;ch=str[j];while(1){if(in(S[strlen(S)-1],termin)==1){if(S[strlen(S)-1]!=ch){printf("\n该符号串不是文法的句型!");return;}else if(S[strlen(S)-1]=='#'){printf("\n该符号串是文法的句型.");return;}else{S[strlen(S)-1]='\0';j++;ch=str[j];}}else{for(i=0;;i++)if(non_ter[i]==S[strlen(S)-1])break;for(k=0;;k++){if(termin[k]==ch)break;if(size_t(k)==strlen(termin)){printf("\n词法错误!");return;}}if(M[i][k]==-1){printf("\n语法错误!");return;}else{m=M[i][k];if(right[m][0]=='^')S[strlen(S)-1]='\0';else{p=strlen(S)-1;q=p;for(n=strlen(right[m])-1;n>=0;n--)S[p++]=right[m][n];S[q+strlen(right[m])]='\0';}}}printf("\nS:%s str:",S);for(p=j;size_t(p)<=strlen(str)-1;p++)printf("%c",str[p]);printf(" ");}}/*******************************************一个用户调用函数********************************************/void menu(){syntax();printf("\n是否继续?(y or n):");scanf("%c",&choose);getchar();while(choose=='y'){menu();}}/*******************************************主函数********************************************/void main(){int i,j;start=grammer(termin,non_ter,left,right); /*读入一个文法*/ printf("count=%d",count);printf("\nstart:%c",start);strcpy(v,non_ter);strcat(v,termin);printf("\nv:%s",v);printf("\nnon_ter:%s",non_ter);printf("\ntermin:%s",termin);printf("\nright:");for(i=0;i<=count-1;i++)printf("%s ",right[i]);printf("\nleft:");for(i=0;i<=count-1;i++)printf("%c ",left[i]);if(validity==1)validity=judge();printf("\nvalidity=%d",validity);if(validity==1){printf("\n文法有效");ll=ll1();printf("\nll=%d",ll);if(ll==0)printf("\n该文法不是一个LL1文法!");else{MM();printf("\n");for(i=0;i<=19;i++)for(j=0;j<=19;j++)if(M[i][j]>=0)printf("M[%d][%d]=%d ",i,j,M[i][j]);printf("\n");menu();}}}5.执行结果(1)输入一个文法(2)输入一个符号串(3)再次输入一个符号串,然后退出程序。
第五章语法分析与语法分析程序

间接左递归的消除:
间接左递归也是有害的,必须消除。基本思路是将 间接左递归转换成直接左递归,然后消除。
方法一: (1).非终结符排列成某种顺序: P1 ,...... PN 。 (2). FOR i=1 TO n DO
FOR j=1 TO i-1 DO 把形如Pi →Pj γ的产生式改成: Pi →δ1γ|δ2γ|......|δkγ 其中 Pj →δ1|δ2|......|δk 消除这个直接左递归 END END
• 假定文法中不含有无用符号、ε产生式 和单产生式。
首先解决直接左递归的消除:
直接左递归的一般形式为A→Aα,α∈V+ 。 文法中一定有形如A→β(β不以A开头)的产生式, 则A→Aα可改造成A→βA‘,A‘→αA‘|ε。一般而言: 设A-产生式为
A→Aα1 |Aα2|......|Aαn|β1|β2|...|βm 每一个βi均不以A打头。 则消除直接左递归得: A→β1 A‘|β2 A‘|...|βm A‘ ,
B中各元素均以终结符打头,故X=BZ相应的诸产生 式也以终结符打头,由Z=I+AZ对应的产生式引入了 新状态,由于产生式左部为新状态Zij,而右部为原文 法的符号,故也不会产生左递归。
• 例5.2 社有一文法:S→Sa|Ab|a,A→Sc。 试用矩阵法消除左递归。
5.1.2 带回朔的递归子程序 法
例5.3:设有一关于表达式的文法: E→TB,B→ATB|ε,T→FC,C→MFC|ε, F→(E)|i,A→+|-,M→*|/ 相应该文法我们可写出以下递归子程序法:
• function E: boolean;
• begin
•
语法分析程序

实验目的
• 巩固对语法分析的基本功能和原理的认识。 • 通过对语法分析表的自动生成加深语法分 析表的认识。 • 理解并处理语法分析中的异常和错误。
实验内容
• 对一段类高级语言代码进行语法分析,并 输出语法分析的结果。
具体要求
• 掌握语法分析程序的总体框架,并将其实现。 • 在手工构造的语法分析表ห้องสมุดไป่ตู้基础上上机实现 LR(1)(或SLR(1),或LALR(1))分析或者是LL(1)分 析。 • 能够对类高级语言中的基本语句(包括:函数定义; 变量说明;赋值;表达式;循环;分支)进行语法 分析。 • 针对一类语句的文法给出其语法分析表的生成程 序(对应不同的语法分析方法产生不同的分析表)。
语法分析程序参考文档(递归程序法)
语法分析一、实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二、实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
2.1 待分析的简单语言的语法用扩充的BNF表示如下:⑴<程序>::=begin<语句串>end⑵<语句串>::=<语句>{;<语句>}⑶<语句>::=<赋值语句>⑷<赋值语句>::=ID:=<表达式>⑸<表达式>::=<项>{+<项> | -<项>}⑹<项>::=<因子>{*<因子> | /<因子>⑺<因子>::=ID | NUM | (<表达式>)2.2 实验要求说明输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
例如:输入begin a:=9; x:=2*3; b:=a+x end #输出success!输入x:=a+b*c end #输出error2.3 语法分析程序的算法思想(1)主程序示意图如图2-1所示。
置初值调用scaner读下一个单词符号调用lrparser结束图2-1 语法分析主程序示意图(2)递归下降分析程序示意图如图2-2所示。
(3)语句串分析过程示意图如图2-3所示。
否 是否是否是否图2-3 语句串分析示意图 是图2-2 递归下降分析程序示意图(4)statement 语句分析程序流程如图2-4、2-5、2-6、2-7所示。
否否 否 是图2-4 statement 语句分析函数示意图 图2-5 expression 表达式分析函数示意图是否begin? 调用scaner调用语句串分析程序 是否end? 调用scaner syn=0&&kk=0?打印分析成功出错处理 调用statement 函数是否; ?调用scaner调用statement 函数 出错处理 是否标识符?调用scaner 是否:=? 调用scaner 调用expression 函数 出错处理 调用term 函数 是否+ , -? 调用scaner 调用term 函数出错处理是否否是 是 否 否是图 2-6 term 分析函数示意图否是图2-7 factor 分析过程示意图三、语法分析程序的C 语言程序源代码: #include "stdio.h" #include "string.h"char prog[100],token[8],ch;char *rwtab[6]={"begin","if","then","while","do","end"}; int syn,p,m,n,sum; int kk; factor(); expression(); yucu(); term(); statement(); lrparser(); scaner(); main() {p=kk=0;printf("\nplease input a string (end with '#'): \n"); do{ scanf("%c",&ch);调用factor 函数是否* , /?调用scaner调用factor 函数出错处理是否标识符?是否整常数?是否(?调用scaner调用expression 函数 是否)?调用scaner调用scaner出错处理prog[p++]=ch;}while(ch!='#');p=0;scaner();lrparser();getch();}lrparser(){if(syn==1){scaner(); /*读下一个单词符号*/yucu(); /*调用yucu()函数;*/if (syn==6){ scaner();if ((syn==0)&&(kk==0))printf("success!\n");}else { if(kk!=1) printf("the string haven't got a 'end'!\n");kk=1;}}else { printf("haven't got a 'begin'!\n");kk=1;}return;}yucu(){statement(); /*调用函数statement();*/while(syn==26){scaner(); /*读下一个单词符号*/if(syn!=6)statement(); /*调用函数statement();*/}return;}statement(){ if(syn==10){scaner(); /*读下一个单词符号*/if(syn==18){ scaner(); /*读下一个单词符号*/expression(); /*调用函数statement();*/ }else { printf("the sing ':=' is wrong!\n");kk=1;}}else { printf("wrong sentence!\n");kk=1;}return;}expression(){ term();while((syn==13)||(syn==14)){ scaner(); /*读下一个单词符号*/ term(); /*调用函数term();*/}return;}term(){ factor();while((syn==15)||(syn==16)){ scaner(); /*读下一个单词符号*/ factor(); /*调用函数factor(); */ }return;}factor(){ if((syn==10)||(syn==11)) scaner();else if(syn==27){ scaner(); /*读下一个单词符号*/expression(); /*调用函数statement();*/ if(syn==28)scaner(); /*读下一个单词符号*/ else { printf("the error on '('\n");kk=1;}}else { printf("the expression error!\n");kk=1;}return;}scaner()for(m=0;m<8;m++)token[m++]=NULL;m=0;ch=prog[p++];while(ch==' ')ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;token[m++]='\0';for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}}else if((ch>='0')&&(ch<='9')){ while((ch>='0')&&(ch<='9')){ sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':m=0;ch=prog[p++];if(ch=='>'){ syn=21;}else if(ch=='='){ syn=22;}else{ syn=20;p--;}break;case '>':m=0;ch=prog[p++];if(ch=='=')}else{ syn=23;p--;}break;case ':':m=0;ch=prog[p++];if(ch=='='){ syn=18;}else{ syn=17;p--;}break;case '+': syn=13; break;case '-': syn=14; break;case '*': syn=15;break;case '/': syn=16;break;case '(': syn=27;break;case ')': syn=28;break;case '=': syn=25;break;case ';': syn=26;break;case '#': syn=0;break;default: syn=-1;break;}}四、结果分析:输入begin a:=9; x:=2*3; b:=a+x end # 后输出success!如图4-1所示:图4-1输入x:=a+b*c end # 后输出error 如图4-2所示:图4-2五、总结:通过本次试验,了解了语法分析的运行过程,主程序大致流程为:“置初值”→调用scaner 函数读下一个单词符号→调用IrParse→结束。
【免费下载】实验二 递归下降语法分析程序设计

的合法算术表达式。实验报告中要说明分析使用的方法。
4. 生成并输出分析过程中所用的产生式序列:
1 产生式 1
2 产生式 2
…… [实达式文法。
2. 写出该小语言的算术表达式等价的 LL(1)文法。例如:
G[E]:
E→TG
E→+TG|^
T→FS
T→*FS|^
F→i|(E) 3. 编写递归下降语法分析程序。
scanf("%c",&ch); a[j]=ch;
对全部高中资料试卷电气设备,在安装过程中以及安装结束后进行高中资料试卷调整试验;通电检查所有设备高中资料电试力卷保相护互装作置用调与试相技互术关,系电,力根保通据护过生高管产中线工资敷艺料设高试技中卷术资配0料不置试仅技卷可术要以是求解指,决机对吊组电顶在气层进设配行备置继进不电行规保空范护载高高与中中带资资负料料荷试试下卷卷高问总中题体资,配料而置试且时卷可,调保需控障要试各在验类最;管大对路限设习度备题内进到来行位确调。保整在机使管组其路高在敷中正设资常过料工程试况中卷下,安与要全过加,度强并工看且作护尽下关可都于能可管地以路缩正高小常中故工资障作料高;试中对卷资于连料继接试电管卷保口破护处坏进理范行高围整中,核资或对料者定试对值卷某,弯些审扁异核度常与固高校定中对盒资图位料纸置试,.卷保编工护写况层复进防杂行腐设自跨备动接与处地装理线置,弯高尤曲中其半资要径料避标试免高卷错等调误,试高要方中求案资技,料术编试交写5、卷底重电保。要气护管设设装线备备置敷4高、调动设中电试作技资气高,术料课中并中3试、件资且包卷管中料拒含试路调试绝线验敷试卷动槽方设技作、案技术,管以术来架及避等系免多统不项启必方动要式方高,案中为;资解对料决整试高套卷中启突语动然文过停电程机气中。课高因件中此中资,管料电壁试力薄卷高、电中接气资口设料不备试严进卷等行保问调护题试装,工置合作调理并试利且技用进术管行,线过要敷关求设运电技行力术高保。中护线资装缆料置敷试做设卷到原技准则术确:指灵在导活分。。线对对盒于于处调差,试动当过保不程护同中装电高置压中高回资中路料资交试料叉卷试时技卷,术调应问试采题技用,术金作是属为指隔调发板试电进人机行员一隔,变开需压处要器理在组;事在同前发一掌生线握内槽图部内纸故,资障强料时电、,回设需路备要须制进同造行时厂外切家部断出电习具源题高高电中中源资资,料料线试试缆卷卷敷试切设验除完报从毕告而,与采要相用进关高行技中检术资查资料和料试检,卷测并主处且要理了保。解护现装场置设。备高中资料试卷布置情况与有关高中资料试卷电气系统接线等情况,然后根据规范与规程规定,制定设备调试高中资料试卷方案。
第四章 语法分析和语法分析程序

自上而下分析 自下而上分析 分析器的自动生成
§4.1 前 言
源程序
词法 分析器
记号 语 法 分析 前端的 分析 分析器 树 其余部分 树
取下一个
记号
符号表
§4.1.1 语法与语法分析作用
❖语法作用: 语言设计者:提供语言的精确构成,形式化规定语言 语法单位组成部分间的关系。 语言使用者:使用语言,根据语法来构造合法句子。 编译程序设计者:语法是进行编译程序的依据,用来 构造识别语言所有句子的语法分析器。
引入 <程序*> <程序> →begin <程序*> <程序*> →<说明串>;<语句串> end | <语句串> end
例2:文法G[<程序>] : <程序> →begin <程序*> <程序*> →<说明串>;<语句串> end | <语句串> end <说明串> →real|integer|boolean|array|function <语句串> →标识符|goto| begin| if | for 是否可用自顶向下方法进行语法分析?
❖语法分析作用: 识别由词法分析给出的单词序列是否是给定文法的正
确句子(程序)。即根据语言的语法规则分析源程序的语 法结构(单词如何构成各种语法范畴)。
§4.1.2 语法分析的方法
句型分析就是识别一个符号串是否为某文法的 句型,是某个推导(归约)的构造过程。
在语言的编译实现中,把完成句型分析的程序 称为分析程序或识别程序。分析算法又称识别算法 。
消除间接左递归算法
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
#include <stdio.h> #include <dos.h> #include <stdlib.h> #include <string.h>
char inputstr[50],d[200],e[10];/*数组 inputstr 存输入串,数组 d 存推导式,*/ int strlong=0,Total=0,count=0,n=4;
[实验目的]:
1.了解语法分析的主要任务。
2.熟悉编译程序的编制。
实验二 语法分析程序设计
计算机科学与技术(2)班
[实验内容]:根据某文法,构造一基本递归下降语法分析程序。给出分析过程
中所用的产生式序列。
[实验要求]:
1. 构造一个小语言的文法,例如,Pascal 语言子集的算术表达式文法:
G[<表达式>]:
对全部高中资料试卷电气设备,在安装过程中以及安装结束后进行高中资料试卷调整试验;通电检查所有设备高中资料电试力卷保相护互装作置用调与试相技互术关,系电,力根通保据过护生管高产线中工敷资艺设料高技试中术卷资,配料不置试仅技卷可术要以是求解指,决机对吊组电顶在气层进设配行备置继进不电行规保空范护载高与中带资负料荷试下卷高问总中题体资,配料而置试且时卷可,调保需控障要试各在验类最;管大对路限设习度备题内进到来行位确调。保整在机使管组其路高在敷中正设资常过料工程试况中卷下,安与要全过加,度强并工看且作护尽下关可都于能可管地以路缩正高小常中故工资障作料高;试中对卷资于连料继接试电管卷保口破护处坏进理范行高围整中,核资或对料者定试对值卷某,弯些审扁异核度常与固高校定中对盒资图位料纸置试,.卷保编工护写况层复进防杂行腐设自跨备动接与处地装理线置,弯高尤曲中其半资要径料避标试免高卷错等调误,试高要方中求案资技,料术编试交写5、卷底重电保。要气护管设设装线备备置敷4高、调动设中电试作技资气高,术料课中并3中试、件资且包卷管中料拒含试路调试绝线验敷试卷动槽方设技作、案技术,管以术来架及避等系免多统不项启必方动要式方高,案中为;资解对料决整试高套卷中启突语动然文过停电程机气中。课高因件中此中资,管料电壁试力薄卷高、电中接气资口设料不备试严进卷等行保问调护题试装,工置合作调理并试利且技用进术管行,线过要敷关求设运电技行力术高保。中护线资装缆料置敷试做设卷到原技准则术确:指灵在导活分。。线对对盒于于处调差,试动当过保不程护同中装电高置压中高回资中路料资交试料叉卷试时技卷,术调应问试采题技用,术金作是属为指隔调发板试电进人机行员一隔,变开需压处要器理在组;事在同前发一掌生线握内槽图部内 纸故,资障强料时电、,回设需路备要须制进同造行时厂外切家部断出电习具源题高高电中中源资资,料料线试试缆卷卷敷试切设验除完报从毕告而,与采要相用进关高行技中检术资查资料和料试检,卷测并主处且要理了保。解护现装场置设。备高中资料试卷布置情况与有关高中资料试卷电气系统接线等情况,然后根据规范与规程规定,制定设备调试高中资料试卷方案。
P->eS|^
E->0|1 其中小写字母为终结符,大写字母为非终结符,^为空。
3. 编写递归下降语法分析程序。调试运行程序。
4. 结果Байду номын сангаас析。
5. 撰写实验报告。
[实验报告]:
1. 写出实现的算法。
2. 画出流程图。
对全部高中资料试卷电气设备,在安装过程中以及安装结束后进行高中资料试卷调整试验;通电检查所有设备高中资料电试力卷保相护互装作置用调与试相技互术关,系电,力根通保据过护生管高产线中工敷资艺设料高技试中术卷资,配料不置试仅技卷可术要以是求解指,决机对吊组电顶在气层进设配行备置继进不电行规保空范护载高与中带资负料荷试下卷高问总中题体资,配料而置试且时卷可,调保需控障要试各在验类最;管大对路限设习度备题内进到来行位确调。保整在机使管组其路高在敷中正设资常过料工程试况中卷下,安与要全过加,度强并工看且作护尽下关可都于能可管地以路缩正高小常中故工资障作料高;试中对卷资于连料继接试电管卷保口破护处坏进理范行高围整中,核资或对料者定试对值卷某,弯些审扁异核度常与固高校定中对盒资图位料纸置试,.卷保编工护写况层复进防杂行腐设自跨备动接与处地装理线置,弯高尤曲中其半资要径料避标试免高卷错等调误,试高要方中求案资技,料术编试交写5、卷底重电保。要气护管设设装线备备置敷4高、调动设中电试作技资气高,术料课中并3中试、件资且包卷管中料拒含试路调试绝线验敷试卷动槽方设技作、案技术,管以术来架及避等系免多统不项启必方动要式方高,案中为;资解对料决整试高套卷中启突语动然文过停电程机气中。课高因件中此中资,管料电壁试力薄卷高、电中接气资口设料不备试严进卷等行保问调护题试装,工置合作调理并试利且技用进术管行,线过要敷关求设运电技行力术高保。中护线资装缆料置敷试做设卷到原技准则术确:指灵在导活分。。线对对盒于于处调差,试动当过保不程护同中装电高置压中高回资中路料资交试料叉卷试时技卷,术调应问试采题技用,术金作是属为指隔调发板试电进人机行员一隔,变开需压处要器理在组;事在同前发一掌生线握内槽图部内 纸故,资障强料时电、,回设需路备要须制进同造行时厂外切家部断出电习具源题高高电中中源资资,料料线试试缆卷卷敷试切设验除完报从毕告而,与采要相用进关高行技中检术资查资料和料试检,卷测并主处且要理了保。解护现装场置设。备高中资料试卷布置情况与有关高中资料试卷电气系统接线等情况,然后根据规范与规程规定,制定设备调试高中资料试卷方案。
G[E]:
T→T*F|F
F→i|(E)
递归
I
E
P
3. 实验设计过程中出现的问题及解决的方法。
写代码过程中,有时会遇到数据异常,可以使用编译器本身的调试功能或者设置一些 标志量来检验。代码过于复杂时,比如本实验,应该先写出程序的主要代码,再添加 那些输出代码。
4. 实验设计过程中的体会。 在使用 LL(1)算法时,先要写出 LL(1)的文法,根据文法设计函数,弹 药注意二义性的问题。
int I() {
int f1,f2,f3; printf("%d\tI->i(E)SP\t",Total); e[0]='I'; e[1]='='; e[2]='>'; e[3]='i'; e[4]='('; e[5]='E'; e[6]=')'; e[7]='S'; e[8]='P';
对全部高中资料试卷电气设备,在安装过程中以及安装结束后进行高中资料试卷调整试验;通电检查所有设备高中资料电试力卷保相护互装作置用调与试相技互术关,系电,力根通保据过护生管高产线中工敷资艺设料高技试中术卷资,配料不置试仅技卷可术要以是求解指,决机对吊组电顶在气层进设配行备置继进不电行规保空范护载高与中带资负料荷试下卷高问总中题体资,配料而置试且时卷可,调保需控障要试各在验类最;管大对路限设习度备题内进到来行位确调。保整在机使管组其路高在敷中正设资常过料工程试况中卷下,安与要全过加,度强并工看且作护尽下关可都于能可管地以路缩正高小常中故工资障作料高;试中对卷资于连料继接试电管卷保口破护处坏进理范行高围整中,核资或对料者定试对值卷某,弯些审扁异核度常与固高校定中对盒资图位料纸置试,.卷保编工护写况层复进防杂行腐设自跨备动接与处地装理线置,弯高尤曲中其半资要径料避标试免高卷错等调误,试高要方中求案资技,料术编试交写5、卷底重电保。要气护管设设装线备备置敷4高、调动设中电试作技资气高,术料课中并3中试、件资且包卷管中料拒含试路调试绝线验敷试卷动槽方设技作、案技术,管以术来架及避等系免多统不项启必方动要式方高,案中为;资解对料决整试高套卷中启突语动然文过停电程机气中。课高因件中此中资,管料电壁试力薄卷高、电中接气资口设料不备试严进卷等行保问调护题试装,工置合作调理并试利且技用进术管行,线过要敷关求设运电技行力术高保。中护线资装缆料置敷试做设卷到原技准则术确:指灵在导活分。。线对对盒于于处调差,试动当过保不程护同中装电高置压中高回资中路料资交试料叉卷试时技卷,术调应问试采题技用,术金作是属为指隔调发板试电进人机行员一隔,变开需压处要器理在组;事在同前发一掌生线握内槽图部内 纸故,资障强料时电、,回设需路备要须制进同造行时厂外切家部断出电习具源题高高电中中源资资,料料线试试缆卷卷敷试切设验除完报从毕告而,与采要相用进关高行技中检术资查资料和料试检,卷测并主处且要理了保。解护现装场置设。备高中资料试卷布置情况与有关高中资料试卷电气系统接线等情况,然后根据规范与规程规定,制定设备调试高中资料试卷方案。
o
递归
char ch; int i=0,f; printf("请输入字符串(长度<50,以#号结束)\n"); do{
scanf("%c",&ch); inputstr[i]=ch; i++; }while(ch!='#'); strlong=i; d[0]='S'; d[1]='='; d[2]='>'; d[3]='S'; d[4]='#'; printf("步骤\t 文法\t\t 分析串\t\t 分析字符\t 剩余串\n"); f=S(); if(f==1) return 1; if(inputstr[count++]=='#') { printf("accept!\n"); i=0; ch=d[i]; while(ch!='#') {
int S(); int I(); int P(); int E(); void outas(); void outrmd(); void output();
int main() {
S
对全部高中资料试卷电气设备,在安装过程中以及安装结束后进行高中资料试卷调整试验;通电检查所有设备高中资料电试力卷保相护互装作置用调与试相技互术关,系电,力根通保据过护生管高产线中工敷资艺设料高技试中术卷资,配料不置试仅技卷可术要以是求解指,决机对吊组电顶在气层进设配行备置继进不电行规保空范护载高与中带资负料荷试下卷高问总中题体资,配料而置试且时卷可,调保需控障要试各在验类最;管大对路限设习度备题内进到来行位确调。保整在机使管组其路高在敷中正设资常过料工程试况中卷下,安与要全过加,度强并工看且作护尽下关可都于能可管地以路缩正高小常中故工资障作料高;试中对卷资于连料继接试电管卷保口破护处坏进理范行高围整中,核资或对料者定试对值卷某,弯些审扁异核度常与固高校定中对盒资图位料纸置试,.卷保编工护写况层复进防杂行腐设自跨备动接与处地装理线置,弯高尤曲中其半资要径料避标试免高卷错等调误,试高要方中求案资技,料术编试交写5、卷底重电保。要气护管设设装线备备置敷4高、调动设中电试作技资气高,术料课中并3中试、件资且包卷管中料拒含试路调试绝线验敷试卷动槽方设技作、案技术,管以术来架及避等系免多统不项启必方动要式方高,案中为;资解对料决整试高套卷中启突语动然文过停电程机气中。课高因件中此中资,管料电壁试力薄卷高、电中接气资口设料不备试严进卷等行保问调护题试装,工置合作调理并试利且技用进术管行,线过要敷关求设运电技行力术高保。中护线资装缆料置敷试做设卷到原技准则术确:指灵在导活分。。线对对盒于于处调差,试动当过保不程护同中装电高置压中高回资中路料资交试料叉卷试时技卷,术调应问试采题技用,术金作是属为指隔调发板试电进人机行员一隔,变开需压处要器理在组;事在同前发一掌生线握内槽图部内 纸故,资障强料时电、,回设需路备要须制进同造行时厂外切家部断出电习具源题高高电中中源资资,料料线试试缆卷卷敷试切设验除完报从毕告而,与采要相用进关高行技中检术资查资料和料试检,卷测并主处且要理了保。解护现装场置设。备高中资料试卷布置情况与有关高中资料试卷电气系统接线等情况,然后根据规范与规程规定,制定设备调试高中资料试卷方案。