Base64二进制流与文件相互转换
atob和btoa的实现方法 -回复

atob和btoa的实现方法-回复关于atob和btoa的实现方法在Web 开发中,经常会遇到需要在二进制数据和文本之间进行转换的情况。
而atob和btoa就是这样一对用于在字符串和二进制数据之间进行转换的方法。
本文将一步一步地解释atob和btoa的实现方法,并探讨它们的实际应用。
在回答atob和btoa的实现方法之前,我们首先需要了解它们的基本定义和用途。
atob是一个接受一个编码的Base64字符串作为参数,并返回解码后的二进制数据的方法。
Base64是一种用于将二进制数据转换成可打印字符串的编码方式,它由A-Z、a-z、0-9、+和/这64个字符组成。
因此,atob 可以将Base64编码的字符串恢复成原始的二进制数据。
btoa正好相反,它接受一个二进制数据作为参数,并返回一个Base64编码的字符串。
btoa常用于将二进制数据转换成可在文本环境中传输的字符串。
现在让我们来看看如何实现atob方法。
实现atob方法的第一步是将Base64字符串转换成字符编码的二进制数据。
我们可以使用JavaScript内置的方法`atob`来完成这个过程。
javascriptfunction atob(base64) {return window.atob(base64);}这样我们就可以使用`atob`方法将Base64编码的字符串转换成二进制数据。
但是需要注意的是,`atob`方法只在浏览器环境中可用,如果在其他环境中使用,需要借助其他库或自行实现Base64解码算法。
接下来,我们将探讨如何实现btoa方法。
实现btoa方法的第一步是将二进制数据转换成Base64编码的字符串。
我们可以使用JavaScript内置的方法`btoa`来完成这个过程。
javascriptfunction btoa(binary) {return window.btoa(binary);}这样我们就可以使用`btoa`方法将二进制数据转换成Base64编码的字符串。
ctf编码格式

ctf编码格式
在CTF(Capture The Flag)比赛中,常见的编码格式包括Base64、Hex、ASCII、URL编码、ROT13等。
1. Base64编码:将二进制数据转换为可打印字符,常用于表示二进制文件
或数据的文本表示形式。
2. ASCII编码:将字符转换为对应的ASCII码值。
3. Hex编码(十六进制编码):将二进制数据转换为十六进制表示形式。
4. URL编码:将URL中的特殊字符转换为特定格式,以便在URL中传输和处理。
5. ROT13编码:这是一种将字母表中的字母移动13位的编码方式,常用
来作为简单的隐写术。
此外,还有Morse Code、RSA、AES等加密算法也可能会在CTF比赛中
使用。
这些只是一些常见的编码和加密方式,实际上还有许多其他编码和加密方式可能会在CTF比赛中使用。
JavaScript实现Base64编码转换

JavaScript实现Base64编码转换简介Base64是⼀种基于64个可打印字符来表⽰⼆进制数据的表⽰⽅法。
由于2的6次⽅等于64,所以每6个⽐特为⼀个单元,对应某个可打印字符。
三个字节有24个⽐特,对应于4个Base64单元,即3个字节需要⽤4个可打印字符来表⽰。
它可⽤来作为电⼦邮件的传输编码。
在Base64中的可打印字符包括字母A-Z、a-z、数字0-9,这样共有62个字符,此外的两个可打印符号在不同的系统中⽽不同,⼀般为+和/。
转换原理Base64的直接数据源是⼆进制序列(Binary Sequence)。
当然,你也可以将图⽚、⽂本和⾳视频转换成⼆进制序列,再然后转换为Base64编码。
我们这⾥讨论的是如何将⼆进制转换为Base64编码,对于如何将图⽚,⽂本和⾳视频转换为⼆进制序列敬请期待。
在转换前,先定义⼀张索引表,这张表规定了如何转换:转换的时候我们先将⼆进制序列分组,每6个⽐特为⼀组。
但是如果编码的字节数不能被3整除,那么最后就会多出1个或两个字节,可以使⽤下⾯的⽅法进⾏处理:先使⽤0字节值在末尾补⾜,使其能够被3整除,然后再进⾏base64的编码。
在编码后的base64⽂本后加上⼀个或两个'='号,代表补⾜的字节数。
也就是说,当最后剩余⼀个⼋位字节(⼀个byte)时,最后⼀个6位的base64字节块有四位是0值,最后附加上两个等号;如果最后剩余两个⼋位字节(2个byte)时,最后⼀个6位的base字节块有两位是0值,最后附加⼀个等号。
参考下表:JavaScript实现Base64原理明⽩了以后,实现起来就很容易了。
define(function(require, exports, module) {var code = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/".split(""); //索引表 /*** @author laixiangran@* @description 将⼆进制序列转换为Base64编码* @param {String}* @return {String}*/function binToBase64(bitString) {var result = "";var tail = bitString.length % 6;var bitStringTemp1 = bitString.substr(0, bitString.length - tail);var bitStringTemp2 = bitString.substr(bitString.length - tail, tail);for (var i = 0; i < bitStringTemp1.length; i += 6) {var index = parseInt(bitStringTemp1.substr(i, 6), 2);result += code[index];}bitStringTemp2 += new Array(7 - tail).join("0");if (tail) {result += code[parseInt(bitStringTemp2, 2)];result += new Array((6 - tail) / 2 + 1).join("=");}return result;}/*** @author laixiangran@* @description 将base64编码转换为⼆进制序列* @param {String}* @return {String}*/function base64ToBin(str) {var bitString = "";var tail = 0;for (var i = 0; i < str.length; i++) {if (str[i] != "=") {var decode = code.indexOf(str[i]).toString(2);bitString += (new Array(7 - decode.length)).join("0") + decode;} else {tail++;}}return bitString.substr(0, bitString.length - tail * 2);}/*** @author laixiangran@* @description 将字符转换为⼆进制序列* @param {String} str* @return {String}*/function stringToBin(str) {var result = "";for (var i = 0; i < str.length; i++) {var charCode = str.charCodeAt(i).toString(2);result += (new Array(9 - charCode.length).join("0") + charCode);}return result;}/*** @author laixiangran@* @description 将⼆进制序列转换为字符串* @param {String} Bin*/function BinToStr(Bin) {var result = "";for (var i = 0; i < Bin.length; i += 8) {result += String.fromCharCode(parseInt(Bin.substr(i, 8), 2));}return result;}exports.base64 = function(str) {return binToBase64(stringToBin(str));}exports.decodeBase64 = function(str) {return BinToStr(base64ToBin(str));}})将图⽚数据进⾏Base64编码将图⽚数据转换为Base64,⾸先要获取到图⽚的⼆进制数据。
blob协议

blob协议Blob协议。
Blob协议是一种用于在网络上传输二进制大对象(Binary Large Object)的协议。
它的全称是Binary Large Object,即二进制大对象。
在网络传输中,二进制大对象通常是指一些较大的数据,比如图片、视频、音频等。
这些数据通常比较庞大,传输起来会比较耗费时间和资源。
因此,为了更高效地传输这些数据,就需要使用一种专门的协议来进行处理。
Blob协议就是为了解决这一问题而设计的。
在传统的HTTP协议中,传输二进制大对象通常是通过Base64编码的方式来进行的。
Base64编码可以将二进制数据转换成文本数据,从而可以在HTTP协议中进行传输。
但是,由于Base64编码会使数据变大约1/3,因此在传输大数据时效率不高。
而Blob协议则可以直接传输二进制数据,无需进行Base64编码,因此在传输大数据时更加高效。
Blob协议的使用非常简单,只需要使用URL.createObjectURL()方法即可将二进制数据转换成一个URL,然后就可以将这个URL作为资源链接进行传输。
这样就可以避免使用Base64编码,提高了传输效率。
另外,Blob协议还可以用于将二进制数据存储到本地,或者在浏览器端进行处理。
在实际开发中,Blob协议被广泛应用于各种领域。
比如,前端开发中常常需要处理图片、视频等大数据,而Blob协议可以提供更高效的传输方式;又如,在一些需要上传文件的场景中,也可以使用Blob协议来进行文件的传输和处理;另外,Blob协议还可以用于实现一些特殊的功能,比如在浏览器端生成并下载文件等。
总的来说,Blob协议是一种用于在网络上传输二进制大对象的高效协议。
它可以避免Base64编码带来的数据膨胀问题,提高了传输效率。
在实际开发中,Blob协议有着广泛的应用前景,可以为开发人员提供更加高效的数据传输和处理方式。
因此,对于开发人员来说,了解和掌握Blob协议是非常重要的。
base64 解码 原理

base64 解码原理
Base64是一种编码方式,它将二进制数据转换为可打印字符
的ASCII格式。
其原理如下:
1. 将待编码的数据划分为连续的24位(即3个字节)的分组。
2. 将每个24位的分组划分为4个6位的子分组。
3. 根据Base64编码表,将每个6位的子分组转换为对应的可
打印字符。
4. 如果最后的输入数据长度不足3个字节,会进行填充操作。
一般使用'='字符进行填充。
这样,在Base64编码中,一个3字节的二进制数据通过编码
后会变成4个字符,并且编码后的数据长度总是为4的倍数。
当需要对Base64编码进行解码时,可以按照以下步骤进行:
1. 将待解码的数据划分为连续的4个字符的分组。
2. 根据Base64解码表,将每个字符的编码值转换为对应的6
位二进制数据。
3. 将每个6位的子分组合并为一个24位的分组。
4. 将每个24位的分组划分为3个8位的子分组,并转换为对
应的字节数据。
5. 如果解码后的数据长度大于待解码的数据长度,则剔除填充的字节。
通过以上步骤,就可以将Base64编码的数据解码回原始的二
进制数据。
需要注意的是,Base64编码只是一种编码方式,它并不对数
据进行加密或压缩。
它主要用于在文本协议中传输二进制数据,或者在文本环境中嵌入二进制数据。
base64加密原理

base64加密原理Base64加密原理。
Base64是一种用64个字符来表示任意二进制数据的方法,它由美国国家标准局制定的一种基于64个可打印字符来表示二进制数据的方法。
在计算机网络中,经常使用Base64编码来传输非文本数据。
那么,Base64加密的原理是什么呢?首先,我们需要了解Base64编码的字符集。
Base64编码使用了A-Z、a-z、0-9这62个字符,再加上"+"和"/"两个符号,一共64个字符。
这些字符是根据ASCII码表来的,分别对应着0到63这64个数字。
其次,Base64加密的原理是将输入的数据按照3个字节一组进行分割,每组3个字节共24个比特,然后再将这24个比特分成4组,每组6个比特。
接着,将这4组6个比特的数字作为索引,查表得到对应的Base64编码字符。
在进行Base64加密时,如果输入的数据不足3个字节,会进行补位操作。
具体来说,如果输入的数据不足3个字节,会在末尾补上1个或2个“=”号,以此来表示补位的情况。
Base64加密的原理可以用如下的伪代码来表示:1. 将输入数据按照3个字节一组进行分割。
2. 将每组3个字节的数据转换为4组6个比特的数字。
3. 将这4组6个比特的数字作为索引,查表得到对应的Base64编码字符。
4. 如果输入的数据不足3个字节,进行补位操作,末尾补上1个或2个“=”号。
通过上述原理,我们可以看到Base64加密是一种简单而有效的数据加密方式。
它能够将任意的二进制数据转换为可打印字符,方便在各种场景下进行传输和存储。
同时,Base64编码也是一种常见的数据传输方式,例如在电子邮件、HTTP协议、图片传输等领域都有广泛的应用。
然而,需要注意的是,Base64编码并不是一种加密算法,它只是一种编码方式。
因为Base64编码的原理是将二进制数据转换为可打印字符,而并没有进行加密操作,所以并不具备加密算法的安全性。
base编码解码算法 -回复

base编码解码算法-回复Base编码解码算法是一种常用的数据转换技术,通过将数据按照特定的规则进行编码和解码,实现数据的转换和传输。
在计算机科学和信息技术领域,Base编码解码算法被广泛应用于网络通信、数据存储和文件传输等方面。
本文将逐步介绍Base编码解码算法的原理、应用场景以及具体实现步骤。
一、Base编码解码算法的原理Base编码解码算法是一种将任意数据转换为不同进制进行表示的方法。
其中,Base代表进制的基数,常见的Base有Base64、Base32、Base16等。
Base64是最为常用的一种Base编码解码算法,它可以将任意二进制数据转换为纯文本的形式进行传输和存储。
Base64是一种将8位二进制数据按照每6位进行分组,然后根据特定的映射表将每组6位转换为一个可打印字符的编码算法。
具体的转换过程如下:1. 将待编码的数据按照8位分组,如果数据长度不是8的倍数,需要在末尾添加0或者特定填充字符。
2. 将每个8位数据转换为6位二进制数据,例如将“01101101”转换为“011011”。
3. 将每个6位二进制数据转换为十进制数,例如将“011011”转换为27。
4. 根据Base64的映射表,将每个十进制数转换为相应的可打印字符,例如将27转换为字符‘b’。
通过以上过程,就可以将二进制数据转换为Base64编码。
二、Base编码解码算法的应用场景Base编码解码算法在实际应用中具有广泛的应用场景。
以下列举几个常见的应用场景:1. 网络通信:在网络通信中,数据必须以文本形式进行传输,而二进制数据无法直接传输。
通过使用Base编码解码算法,可以将二进制数据转换为文本数据进行传输,确保数据的正确接收和解析。
2. 数据存储:在一些特定的数据存储场景中,只能存储文本数据而无法存储二进制数据。
通过使用Base编码解码算法,可以将二进制数据转换为文本数据进行存储。
3. 文件传输:在文件传输过程中,为了节约传输时间和带宽,有时会采用对文件进行压缩和编码的方式。
javabase64编码和图片互相转换

Java base64编码和图片互相转换* @Descriptionmap 将图片文件转化为字节数组字符串,并对其进行Base64编码处理* @author temdy* @Date 2015-01-26* @param path 图片路径* @returnpublic static String imageToBase64(String path) {// 将图片文件转化为字节数组字符串,并对其进行Base64编码处理byte[] data = null;// 读取图片字节数组try {InputStream in = new FileInputStream(path);data = new byte[in.available()];in.read(data);in.close();} catch (IOException e) {e.printStackTrace();// 对字节数组Base64编码BASE64Encoder encoder = new BASE64Encoder();return encoder.encode(data);// 返回Base64编码过的字节数组字符串* @Descriptionmap 对字节数组字符串进行Base64解码并生成图片* @author temdy* @Date 2015-01-26* @param base64 图片Base64数据* @param path 图片路径* @returnpublic static boolean base64ToImage(String base64, String path) {// 对字节数组字符串进行Base64解码并生成图片if (base64 == null){ // 图像数据为空return false;BASE64Decoder decoder = new BASE64Decoder();try {// Base64解码byte[] bytes = decoder.decodeBuffer(base64);for (int i = 0; i bytes.length; ++i) {if (bytes[i] 0) {// 调整异常数据bytes[i] += 256;// 生成jpeg图片OutputStream out = new FileOutputStream(path);out.write(bytes);out.flush();out.close();return true;} catch (Exception e) {return false;}。
base64 原理

base64 原理
Base64是一种将二进制数据转化为可打印字符的编码方法,
它由64个可打印字符构成,包括大小写字母、数字和两个额
外字符。
Base64编码是一种常用的数据传输和存储方法,它
常被用于电子邮件、图片传输以及其他需要将二进制数据转化为文本形式的场景中。
Base64编码的原理是将3个字节的二进制数据编码为4个可
打印字符。
首先,将二进制数据按照8位分组,每组3个字节。
接下来,将每个分组的24个比特位划分为4组,每组6个比
特位。
然后,将每组6位数字转换为相应的Base64字符。
具体转换步骤如下:
1. 将每个字节拆分为两个6位的数字。
2. 根据Base64字符对应的编码表,将每个6位数字转换为相
应的Base64字符。
3. 如果二进制数据不是3个字节的倍数,会出现不够3个字节的情况。
在最后一个字节的后面添加0,使其满足3个字节的
倍数。
如果不够一个字节的情况下,会使用特殊字符'='进行填充。
解码时,将4个Base64字符转换为3个字节的二进制数据,
遵循与编码相反的步骤即可。
根据Base64字符对应的编码表,将每个字符转换为6位数字,然后将4个6位数字合并为3个
字节的二进制数据。
Base64编码的好处是可以将二进制数据以文本形式进行传输,
同时避免了在不同系统中字符集的兼容性问题。
但是Base64编码会使数据体积增大约1/3,因为3个字节的二进制数据转换为4个字节的Base64字符串。
Python实现图像的二进制与base64互转

Python实现图像的⼆进制与base64互转⽬录函数使⽤1.图像转base64编码2.图像转⼆进制编码3.图像保存成⼆进制⽂件并读取⼆进制4.⼆进制转图像5.base64转图像6.互转7.⼆进制转base648.base64转⼆进制函数使⽤def base64_to_image(base64_code):img_data = base64.b64decode(base64_code)img_array = numpy.fromstring(img_data, numpy.uint8)# img_array = np.frombuffer(image_bytes, dtype=np.uint8) #可选image_base64_dec = cv2.imdecode(img_array, cv2.COLOR_RGB2BGR)return image_base64_decdef image_to_base64(full_path):with open(full_path, "rb") as f:data = f.read()image_base64_enc = base64.b64encode(data)image_base64_enc = str(image_base64_enc, 'utf-8')return image_base64_enc#传base64img_bytes = request.json["img_stream"]img_cv = base64_to_image(img_bytes)uuid_str = str(uuid.uuid1())img_path = uuid_str +".jpg"cv2.imwrite(img_path,img_cv)1.图像转base64编码import cv2import base64def cv2_base64(image):img = cv2.imread(image)binary_str = cv2.imencode('.jpg', img)[1].tostring()#编码base64_str = base64.b64encode(binary_str)#解码base64_str = base64_str.decode('utf-8')myjson={"bs64":cv2_base64("1.jpg")}print(myjson)return base64_str2.图像转⼆进制编码import cv2import base64def cv2_binary(image):img = cv2.imread(image)binary_str = cv2.imencode('.jpg', img)[1].tostring()#编码print(binary_str)# base64_str = base64.b64encode(binary_str)#解码# base64_str = base64_str.decode('utf-8')# print(base64_str)return binary_strcv2_binary("1.jpg")# 或者image_file =r"1.jpg"image_bytes = open(image_file, "rb").read()print(image_bytes)# ⼆进制数据3.图像保存成⼆进制⽂件并读取⼆进制# python+OpenCV读取图像并转换为⼆进制格式⽂件的代码# coding=utf-8'''Created on 2016年3⽉24⽇使⽤Opencv读取图像将其保存为⼆进制格式⽂件,再读取该⼆进制⽂件,转换为图像进⾏显⽰@author: hanchao'''import cv2import numpy as npimport structimage = cv2.imread("1.jpg")# imageClone = np.zeros((image.shape[0],image.shape[1],1),np.uint8)# image.shape[0]为rows# image.shape[1]为cols# image.shape[2]为channels# image.shape = (480,640,3)rows = image.shape[0]cols = image.shape[1]channels = image.shape[2]# 把图像转换为⼆进制⽂件# python写⼆进制⽂件,f = open('name','wb')# 只有wb才是写⼆进制⽂件fileSave = open('patch.bin', 'wb')for step in range(0, rows):for step2 in range(0, cols):fileSave.write(image[step, step2, 2])for step in range(0, rows):for step2 in range(0, cols):fileSave.write(image[step, step2, 1])for step in range(0, rows):for step2 in range(0, cols):fileSave.write(image[step, step2, 0])fileSave.close()# 把⼆进制转换为图像并显⽰# python读取⼆进制⽂件,⽤rb# f.read(n)中n是需要读取的字节数,读取后需要进⾏解码,使⽤struct.unpack("B",fileReader.read(1))函数# 其中“B”为⽆符号整数,占⼀个字节,“b”为有符号整数,占1个字节# “c”为char类型,占⼀个字节# “i”为int类型,占四个字节,I为有符号整形,占4个字节# “h”、“H”为short类型,占四个字节,分别对应有符号、⽆符号# “l”、“L”为long类型,占四个字节,分别对应有符号、⽆符号fileReader = open('patch.bin', 'rb')imageRead = np.zeros(image.shape, np.uint8)for step in range(0, rows):for step2 in range(0, cols):a = struct.unpack("B", fileReader.read(1))imageRead[step, step2, 2] = a[0]for step in range(0, rows):for step2 in range(0, cols):a = struct.unpack("b", fileReader.read(1))imageRead[step, step2, 1] = a[0]for step in range(0, rows):for step2 in range(0, cols):a = struct.unpack("b", fileReader.read(1))imageRead[step, step2, 0] = a[0]fileReader.close()cv2.imshow("source", image)cv2.imshow("read", imageRead)cv2.imwrite("2.jpg",imageRead)cv2.waitKey(0)4.⼆进制转图像def binary_cv2(bytes):file = open("4.jpg","wb")file.write(bytes)binary_cv2("bytes")#或者from PIL import Imageimport ioimg = Image.open(io.BytesIO("bytes"))img.save("5.jpg")5.base64转图像def base64_cv2(base64code):img_data = base64.b64decode(base64code)file = open("2.jpg","wb")file.write(img_data)file.close()base64_cv2("base64code")============================================with open("1.txt","r") as f:img_data = base64.b64decode(f.read())file = open("3.jpg","wb")file.write(img_data)file.close()6.互转def base64_to_image(base64_code):img_data = base64.b64decode(base64_code)img_array = numpy.fromstring(img_data, numpy.uint8)image_base64_dec = cv2.imdecode(img_array, cv2.COLOR_RGB2BGR)return image_base64_dec #图像矩阵,需要cv2.imwrite写⼊cv2.imwrite("1.jpg",img)def image_to_base64(full_path):with open(full_path, "rb") as f:data = f.read()image_base64_enc = base64.b64encode(data)image_base64_enc = str(image_base64_enc, 'utf-8')return image_base64_enc7.⼆进制转base64def binary_base64(binary):img_stream = base64.b64encode(binary)bs64 = img_stream.decode('utf-8')print(bs64)8.base64转⼆进制import base64bs64 = ""img_data = base64.b64decode(bs64)print(img_data)以上就是Python实现图像的⼆进制与base64互转的详细内容,更多关于Python图像⼆进制转base64的资料请关注其它相关⽂章!。
二进制转文本

二进制转文本
二进制转文本操作是将二进制字符串转换为文本的过程。
二进制字符串的每个字符都表示0或1的信息,因为计算机只能处理0和1,因此二进制字符串是计算机可以理解的最小单位。
文本是由字母、数字和符号等字符组成的字符串,要将二进制转换为文本,就需要一种转换算法,将二进制字符串转换为对应文本字符串。
通常将二进制转换成文本有三种方法:
1.ASCII编码。
ASCII是英文字符的一种编码,可以将每个字符编码成一个二进制字符串,将二进制字符串转换成文本的过程就是ASCII编码的过程。
2. Unicode编码。
Unicode是一种多文种编码,它包括了各种世界语言,可以将每个字符编码成一个二进制字符串,将二进制字符串转换成文本的过程就是Unicode编码的过程。
3. Base64编码。
Base64编码比较常用,它可以将二进制字符串分割为6位一组,将每组6位二进制转换成一个字符,转换成Base64编码后的字符串,将Base64编码转换成文本的过程就是Base64解码的过程。
二进制转换文本的操作方法虽然不同,但它们的本质都是将二进制字符串转换成文本字符串的过程。
base64 解析

base64 解析Base64是网络上常用的一种数据编码方式,用来把任意二进制数据编码为ASCII字符,以便可以在邮件和网页上传输。
以下是Base64编码的具体实现原理和流程:1.二进制数据转换为六位的二进制数。
将二进制数据转换成六位的二进制数,可以利用一种称为位填充的技术。
2. 为转换出来的六位二进制码选择一个标准化字符表。
Base64编码选用了一个标准的64个字符的字符集,包括大小写26个英文字母,0-9的10个数字,和+、/、=等特殊符号。
3.六位二进制码和标准字符表中的字符一一对应。
将每6位二进制码与字符表中的字符一一对应,就可以得到一个对应的字符串,便是Base64编码的最终结果。
4. 使用等号(=)对末尾进行填充因为在转换过程中可能出现6位不够的情况,故而需要填充,Base64采用全部填充字符,使每一组数据都是8个字节,即使最后一组数据不够8个字节,在末尾也要补足等号(=)来实现对8个字节的填充。
从以上可知,Base64是一种十分简单有效的编码方式,它的使用广泛,用于各种位图、文本文件以及其他任意二进制数据文件的传输。
Base64编码的应用由于Base64编码具有简单有效的特点,因此它的应用非常广泛。
1.子邮件电子邮件可以对传输的数据进行Base64编码,由于Base64编码具有简单有效的特点,因此,它可以用来传输文本文件,图片文件等二进制文件。
2.密Base64编码可以用来实现简单的加密,使用Base64编码进行加密,可以实现简单的数据加密,以保护数据安全。
3. HTTP认证Base64编码用于HTTP认证中对密码进行了加密,HTTP认证中要求将用户名和密码使用Base64编码,以保证用户信息的安全性。
4.络协议Base64编码在网络协议中占据重要的地位,因为它可以把二进制数据转换为可传输的ASCII字符,从而实现网络传输。
总结Base64编码简单有效,由于它的简单有效,因此它的使用非常广泛,可以用于电子邮件、加密、HTTP认证以及网络协议。
Base64原理廖雪峰

base64阅读: 87704小结Base64是一种任意二进制到文本字符串的编码方法,常用于在URL、Cookie、网页中传输少量二进制数据。
)版权声明:本文为博主原创文章,未经博主允许不得转载。
Base64用途1.用于对SOHO级路由器(网关设备)管理员帐户密码的加密2.流媒体网站对于播放的流媒体文件的路径的加密3.迅雷等下载软件对下载链接地址的加密Base64算法Base64编码要求把3个8位字节(3*8=24)转化为4个6位的字节(4*6=24),之后在6位的前面补两个0,形成8位一个字节的形式。
Base64类函数:unsigned int CreateMatchingEncodingBuffer (unsignedint p_InputByteCount,char**p_ppEncodingBuffer);创建匹配于编码的缓存空间。
参数:1输入字节数,2进行编码需要的缓存空间;返回值:缓存空间大小。
unsignedint CreateMatchingDecodingBuffer (char*p_pInputBufferString,char**p_ppDecodingBuffer );创建匹配于解码的缓存空间。
参数:1解码对象缓存,2进行解码需要的缓存空间;返回值:缓存空间大小。
void EncodeBuffer (char*p_pInputBuffer,unsignedint p_InputBufferLength,char*p_pOutputBufferString);进行编码。
参数:1明文,2明文长度,3密文输出。
unsigned int DecodeBuffer (char*p_pInputBufferString,char*p_pOutputBuffer);进行解码。
参数:1密文,2明文;返回值:明文长度C++实现:[cpp]view plain copy1./************************************************2.* *3.* CBase64.h *4.* Base 64 de- and encoding class *5.* *6.* ============================================ *7.* *8.* This class was written on 28.05.2003 *9.* by Jan Raddatz [jan-raddatz@web.de] *10.* *11.* ============================================ *12.* *13.* Copyright (c) by Jan Raddatz *14.* This class was published @ *15.* 28.05.2003 *16.* *17.************************************************/18.19.#pragma once20.21.#include <afx.h>22.#include <stdlib.h>23.#include <math.h>24.#include <memory.h>25.const static unsigned int MAX_LINE_LENGTH = 76;26.27.const static char BASE64_ALPHABET [64] =28.{29.'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', // 0 - 930.'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', // 10 - 1931.'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', // 20 - 2932.'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', // 30 - 3933.'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', // 40 - 4934.'y', 'z', '0', '1', '2', '3', '4', '5', '6', '7', // 50 - 5935.'8', '9', '+', '/'// 60 - 6336.};37.38.const static char BASE64_DEALPHABET [128] =39.{40. 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 0 - 941. 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 10 - 1942. 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 20 - 2943. 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 30 - 3944. 0, 0, 0, 62, 0, 0, 0, 63, 52, 53, // 40 - 4945. 54, 55, 56, 57, 58, 59, 60, 61, 0, 0, // 50 - 5946. 0, 61, 0, 0, 0, 0, 1, 2, 3, 4, // 60 - 6947. 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, // 70 - 7948. 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, // 80 - 8949. 25, 0, 0, 0, 0, 0, 0, 26, 27, 28, // 90 - 9950. 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, // 100 - 10951. 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, // 110 - 11952. 49, 50, 51, 0, 0, 0, 0, 0 // 120 - 12753.};54.55.enum56.{57. UNABLE_TO_OPEN_INPUT_FILE,58. UNABLE_TO_OPEN_OUTPUT_FILE,59. UNABLE_TO_CREATE_OUTPUTBUFFER60.};61.62.class CBase6463.{64.public:65. CBase64 ();66.67. unsigned int CalculateRecquiredEncodeOutputBufferSize (unsigned int p_InputByteCount);68. unsigned int CalculateRecquiredDecodeOutputBufferSize (char* p_pInputBufferString);69.70.void EncodeByteTriple (char* p_pInputBuffer, unsigned int InputCharacters, char* p_pOutputBuffer);71. unsigned int DecodeByteQuartet (char* p_pInputBuffer, char* p_pOutputBuffer);72.73.void EncodeBuffer (char* p_pInputBuffer, unsigned int p_InputBufferLength, char*p_pOutputBufferString);74. unsigned int DecodeBuffer (char* p_pInputBufferString, char* p_pOutputBuffer);75.76. unsigned int CreateMatchingEncodingBuffer (unsigned int p_InputByteCount, char** p_ppEncodingBuffer);77. unsigned int CreateMatchingDecodingBuffer (char* p_pInputBufferString, char** p_ppDecodingBuffer);78.79. unsigned int EncodeFile (char* p_pSourceFileName, char* p_pEncodedFileName);80. unsigned int DecodeFile (char* p_pSourceFileName, char* p_pDecodedFileName);81.};1./************************************************2.* *3.* CBase64.cpp *4.* Base 64 de- and encoding class *5.* *6.* ============================================ *7.* *8.* This class was written on 28.05.2003 *9.* by Jan Raddatz [jan-raddatz@web.de] *10.* *11.* ============================================ *12.* *13.* Copyright (c) by Jan Raddatz *14.* This class was published @ *15.* 28.05.2003 *16.* *17.************************************************/18.#include "stdafx.h"19.#include "CBase64.h"20.21.22.CBase64::CBase64 ()23.{24.}25.26.unsigned int CBase64::CalculateRecquiredEncodeOutputBufferSize (unsigned intp_InputByteCount)27.{28.div_t result = div (p_InputByteCount, 3);29.30. unsigned int RecquiredBytes = 0;31.if (result.rem == 0)32. {33.// Number of encoded characters34. RecquiredBytes = result.quot * 4;35.36.// CRLF -> "\r\n" each 76 characters37. result = div (RecquiredBytes, 76);38. RecquiredBytes += result.quot * 2;39.40.// Terminating null for the Encoded String41. RecquiredBytes += 1;42.43.return RecquiredBytes;44. }45.else46. {47.// Number of encoded characters48. RecquiredBytes = result.quot * 4 + 4;49.50.// CRLF -> "\r\n" each 76 characters51. result = div (RecquiredBytes, 76);52. RecquiredBytes += result.quot * 2;53.54.// Terminating null for the Encoded String55. RecquiredBytes += 1;56.57.return RecquiredBytes;58. }59.}60.61.unsigned int CBase64::CalculateRecquiredDecodeOutputBufferSize (char* p_pInputBufferString)62.{63. unsigned int BufferLength = strlen (p_pInputBufferString);64.65.div_t result = div (BufferLength, 4);66.67.if (p_pInputBufferString [BufferLength - 1] != '=')68. {69.return result.quot * 3;70. }71.else72. {73.if (p_pInputBufferString [BufferLength - 2] == '=')74. {75.return result.quot * 3 - 2;76. }77.else78. {79.return result.quot * 3 - 1;80. }81. }82.}83.84.void CBase64::EncodeByteTriple (char* p_pInputBuffer, unsigned int InputCharacters, char* p_pOutputBuffer)85.{86. unsigned int mask = 0xfc000000;87. unsigned int buffer = 0;88.89.90.char* temp = (char*) &buffer;91. temp [3] = p_pInputBuffer [0];92.if (InputCharacters > 1)93. temp [2] = p_pInputBuffer [1];94.if (InputCharacters > 2)95. temp [1] = p_pInputBuffer [2];96.97.switch (InputCharacters)98. {99.case 3:100. {101. p_pOutputBuffer [0] = BASE64_ALPHABET [(buffer & mask) >> 26];102. buffer = buffer << 6;103. p_pOutputBuffer [1] = BASE64_ALPHABET [(buffer & mask) >> 26];104. buffer = buffer << 6;105. p_pOutputBuffer [2] = BASE64_ALPHABET [(buffer & mask) >> 26];106. buffer = buffer << 6;107. p_pOutputBuffer [3] = BASE64_ALPHABET [(buffer & mask) >> 26];108.break;109. }110.case 2:111. {112. p_pOutputBuffer [0] = BASE64_ALPHABET [(buffer & mask) >> 26];113. buffer = buffer << 6;114. p_pOutputBuffer [1] = BASE64_ALPHABET [(buffer & mask) >> 26];115. buffer = buffer << 6;116. p_pOutputBuffer [2] = BASE64_ALPHABET [(buffer & mask) >> 26];117. p_pOutputBuffer [3] = '=';118.break;119. }120.case 1:121. {122. p_pOutputBuffer [0] = BASE64_ALPHABET [(buffer & mask) >> 26];123. buffer = buffer << 6;124. p_pOutputBuffer [1] = BASE64_ALPHABET [(buffer & mask) >> 26];125. p_pOutputBuffer [2] = '=';126. p_pOutputBuffer [3] = '=';127.break;128. }129. }130.}131.132.unsigned int CBase64::DecodeByteQuartet (char* p_pInputBuffer, char* p_pOut putBuffer)133.{134. unsigned int buffer = 0;135.136.if (p_pInputBuffer[3] == '=')137. {138.if (p_pInputBuffer[2] == '=')139. {140. buffer = (buffer | BASE64_DEALPHABET [p_pInputBuffer[0]]) << 6;141. buffer = (buffer | BASE64_DEALPHABET [p_pInputBuffer[1]]) << 6;142. buffer = buffer << 14;143.144.char* temp = (char*) &buffer;145. p_pOutputBuffer [0] = temp [3];146.147.return 1;148. }149.else150. {151. buffer = (buffer | BASE64_DEALPHABET [p_pInputBuffer[0]]) << 6; 152. buffer = (buffer | BASE64_DEALPHABET [p_pInputBuffer[1]]) << 6; 153. buffer = (buffer | BASE64_DEALPHABET [p_pInputBuffer[2]]) << 6;154. buffer = buffer << 8;155.156.char* temp = (char*) &buffer;157. p_pOutputBuffer [0] = temp [3];158. p_pOutputBuffer [1] = temp [2];159.160.return 2;161. }162. }163.else164. {165. buffer = (buffer | BASE64_DEALPHABET [p_pInputBuffer[0]]) << 6; 166. buffer = (buffer | BASE64_DEALPHABET [p_pInputBuffer[1]]) << 6; 167. buffer = (buffer | BASE64_DEALPHABET [p_pInputBuffer[2]]) << 6; 168. buffer = (buffer | BASE64_DEALPHABET [p_pInputBuffer[3]]) << 6; 169. buffer = buffer << 2;170.171.char* temp = (char*) &buffer;172. p_pOutputBuffer [0] = temp [3];173. p_pOutputBuffer [1] = temp [2];174. p_pOutputBuffer [2] = temp [1];175.176.return 3;177. }178.179.return -1;180.}181.182.void CBase64::EncodeBuffer(char* p_pInputBuffer, unsigned int p_InputBuffer Length, char* p_pOutputBufferString)183.{184. unsigned int FinishedByteQuartetsPerLine = 0;185. unsigned int InputBufferIndex = 0;186. unsigned int OutputBufferIndex = 0;187.188. memset (p_pOutputBufferString, 0, CalculateRecquiredEncodeOutputBufferS ize (p_InputBufferLength));189.190.while (InputBufferIndex < p_InputBufferLength)191. {192.if (p_InputBufferLength - InputBufferIndex <= 2)193. {194. FinishedByteQuartetsPerLine ++;195. EncodeByteTriple (p_pInputBuffer + InputBufferIndex, p_InputBuf ferLength - InputBufferIndex, p_pOutputBufferString + OutputBufferIndex); 196.break;197. }198.else199. {200. FinishedByteQuartetsPerLine++;201. EncodeByteTriple (p_pInputBuffer + InputBufferIndex, 3, p_pOutp utBufferString + OutputBufferIndex);202. InputBufferIndex += 3;203. OutputBufferIndex += 4;204. }205.206.if (FinishedByteQuartetsPerLine == 19)207. {208. p_pOutputBufferString [OutputBufferIndex ] = '\r';209. p_pOutputBufferString [OutputBufferIndex+1] = '\n';210. p_pOutputBufferString += 2;211. FinishedByteQuartetsPerLine = 0;212. }213. }214.}215.216.unsigned int CBase64::DecodeBuffer (char* p_pInputBufferString, char* p_pOu tputBuffer)217.{218. unsigned int InputBufferIndex = 0;219. unsigned int OutputBufferIndex = 0;220. unsigned int InputBufferLength = strlen (p_pInputBufferString);221.222.char ByteQuartet [4];223.224.while (InputBufferIndex < InputBufferLength)225. {226.for (int i = 0; i < 4; i++)227. {228. ByteQuartet [i] = p_pInputBufferString [InputBufferIndex]; 229.230.// Ignore all characters except the ones in BASE64_ALPHABET 231.if ((ByteQuartet [i] >= 48 && ByteQuartet [i] <= 57) || 232. (ByteQuartet [i] >= 65 && ByteQuartet [i] <= 90) || 233. (ByteQuartet [i] >= 97 && ByteQuartet [i] <= 122) || 234. ByteQuartet [i] == '+' || ByteQuartet [i] == '/' || ByteQua rtet [i] == '=')235. {236. }237.else238. {239.// Invalid character240. i--;241. }242.243. InputBufferIndex++;244. }245.246. OutputBufferIndex += DecodeByteQuartet (ByteQuartet, p_pOutputBuffe r + OutputBufferIndex);247. }248.249.// OutputBufferIndex gives us the next position of the next decoded cha racter250.// inside our output buffer and thus represents the number of decoded c haracters251.// in our buffer.252.return OutputBufferIndex;253.}254.255.unsigned int CBase64::CreateMatchingEncodingBuffer (unsigned int p_InputByt eCount, char** p_ppEncodingBuffer)256.{257. unsigned int Size = CalculateRecquiredEncodeOutputBufferSize (p_InputBy teCount);258. (*p_ppEncodingBuffer) = (char*) malloc (Size);259. memset (*p_ppEncodingBuffer, 0, Size);260.return Size;261.}262.263.unsigned int CBase64::CreateMatchingDecodingBuffer (char* p_pInputBufferStr ing, char** p_ppDecodingBuffer)264.{265. unsigned int Size = CalculateRecquiredDecodeOutputBufferSize (p_pInputB ufferString);266. (*p_ppDecodingBuffer) = (char*) malloc (Size+1);267. memset (*p_ppDecodingBuffer, 0, Size+1);268.return Size+1;269.}270.271.unsigned int CBase64::EncodeFile (char* p_pSourceFileName, char* p_pEncoded FileName)272.{273. CFile InputFile;274. CFile OutputFile;275.276.if (!InputFile.Open (p_pSourceFileName, CFile::modeRead))277.return UNABLE_TO_OPEN_INPUT_FILE;278.279.if (!OutputFile.Open (p_pEncodedFileName, CFile::modeCreate|CFile::mode Write))280.return UNABLE_TO_OPEN_OUTPUT_FILE;281.282.char InputBuffer [19 * 3];283.char* pOutputBuffer;284. CreateMatchingEncodingBuffer (sizeof (InputBuffer), &pOutputBuffer); 285.286.if (pOutputBuffer == 0)287.return UNABLE_TO_CREATE_OUTPUTBUFFER;288.289. unsigned int ReadBytes = 0;290.while ((ReadBytes = InputFile.Read (InputBuffer, sizeof (InputBuffer))) != 0)291. {292. EncodeBuffer (InputBuffer, ReadBytes, pOutputBuffer);293. OutputFile.Write (pOutputBuffer, strlen (pOutputBuffer));294. }295.296. OutputFile.Flush ();297. OutputFile.Close ();298. InputFile.Close ();299.300.return 0;301.}302.303.unsigned int CBase64::DecodeFile (char* p_pSourceFileName, char* p_pDecoded FileName)304.{305. CStdioFile InputFile;306. CFile OutputFile;307.308.if (!InputFile.Open (p_pSourceFileName, CFile::modeRead))309.return UNABLE_TO_OPEN_INPUT_FILE;310.311.if (!OutputFile.Open (p_pDecodedFileName, CFile::modeCreate|CFile::mode Write))312.return UNABLE_TO_OPEN_OUTPUT_FILE;313.314. CString InputBuffer;315.char OutputBuffer[64];316.317. unsigned int ReadBytes = 0;318.while ((ReadBytes = InputFile.ReadString (InputBuffer)) != 0)319. {320. InputBuffer.Remove ('\r');321. InputBuffer.Remove ('\n');322. unsigned int DecodedBytes = DecodeBuffer ((LPTSTR) (LPCTSTR) InputB uffer, OutputBuffer);323. OutputFile.Write (&OutputBuffer [0], DecodedBytes);324. }325.326. OutputFile.Flush ();327. OutputFile.Close ();328. InputFile.Close ();329.330.return 0;331.}。
二进制totext

二进制totext将二进制数据转换为文本数据的过程通常称为二进制到文本的编码。
有几种常见的方法可以实现这个转换:1.Base64编码:•Base64编码是一种常见的二进制到文本的编码方法。
它将二进制数据转换为由64个字符组成的文本字符串。
•在Java中,可以使用Base64类进行编码和解码。
import java.util.Base64;public class BinaryToTextExample {public static void main(String[] args) {byte[] binaryData = { /* your binary data here */ };// 编码String encodedText =Base64.getEncoder().encodeToString(binaryData);System.out.println("Encoded Text: " + encodedText);// 解码byte[] decodedData =Base64.getDecoder().decode(encodedText);System.out.println("Decoded Data: " + newString(decodedData));}}2.ASCII编码:•ASCII编码是一种将字符转换为数字的标准方法,可以将二进制数据转换为ASCII字符。
•请注意,使用ASCII编码可能会导致数据膨胀,因为每个字节都被转换为两个字符。
public class BinaryToTextExample {public static void main(String[] args) {byte[] binaryData = { /* your binary data here */ };// 使用ASCII编码将二进制数据转换为文本String asciiText = new String(binaryData);System.out.println("ASCII Text: " + asciiText);}}选择编码方法取决于你的需求,Base64通常是更常见和高效的选择,特别是在处理二进制数据的网络传输和存储中。
Base64编码详解
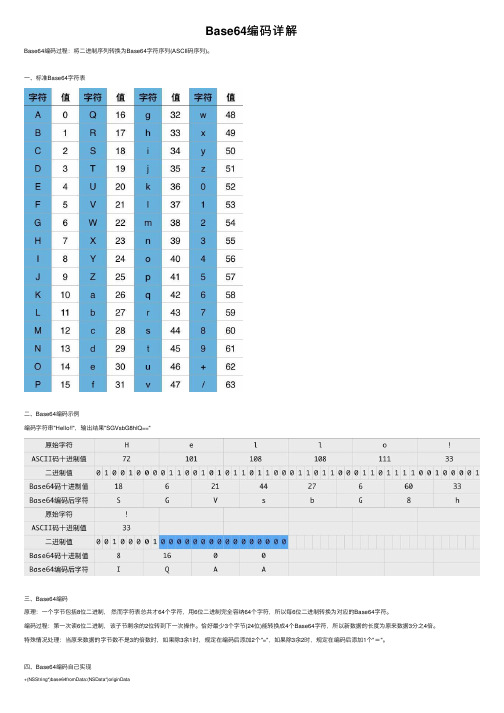
Base64编码详解Base64编码过程:将⼆进制序列转换为Base64字符序列(ASCII码序列)。
⼀、标准Base64字符表⼆、Base64编码⽰例编码字符串"Hello!!",输出结果"SGVsbG8hIQ=="三、Base64编码原理:⼀个字节包括8位⼆进制,然⽽字符表总共才64个字符,⽤6位⼆进制完全容纳64个字符,所以每6位⼆进制转换为对应的Base64字符。
编码过程:第⼀次读6位⼆进制,该⼦节剩余的2位转到下⼀次操作。
恰好最少3个字节(24位)能转换成4个Base64字符,所以新数据的长度为原来数据3分之4倍。
特殊情况处理:当原来数据的字节数不是3的倍数时,如果除3余1时,规定在编码后添加2个"=",如果除3余2时,规定在编码后添加1个"="。
四、Base64编码⾃⼰实现+(NSString*)base64fromData:(NSData*)originData{const uint8_t* input = (const uint8_t*)[originData bytes];NSInteger originLength = [originData length];static char table[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";NSMutableData* encodeData = [NSMutableData dataWithLength:((originLength + 2) / 3) * 4];uint8_t* output = (uint8_t*)encodeData.mutableBytes;NSInteger i;for (i=0; i < originLength; i += 3) {NSInteger value = 0;NSInteger j;for (j = i; j < (i + 3); j++) {value <<= 8;if (j < originLength) {value |= (0xFF & input[j]);}}NSInteger theIndex = (i / 3) * 4;output[theIndex + 0] = table[(value >> 18) & 0x3F];output[theIndex + 1] = table[(value >> 12) & 0x3F];output[theIndex + 2] = (i + 1) < originLength ? table[(value >> 6) & 0x3F] : '=';output[theIndex + 3] = (i + 2) < originLength ? table[(value >> 0) & 0x3F] : '=';}return [[NSString alloc] initWithData:encodeData encoding:NSASCIIStringEncoding];}五、NSData官⽅提供的Base64编码接⼝/* Create an NSData from a Base-64 encoded NSString using the given options. By default, returns nil when the input is not recognized as valid Base-64.*/- (nullable instancetype)initWithBase64EncodedString:(NSString *)base64String options:(NSDataBase64DecodingOptions)options NS_AVAILABLE(10_9, 7_0); /* Create a Base-64 encoded NSString from the receiver's contents using the given options.*/- (NSString *)base64EncodedStringWithOptions:(NSDataBase64EncodingOptions)options NS_AVAILABLE(10_9, 7_0);/* Create an NSData from a Base-64, UTF-8 encoded NSData. By default, returns nil when the input is not recognized as valid Base-64.*/- (nullable instancetype)initWithBase64EncodedData:(NSData *)base64Data options:(NSDataBase64DecodingOptions)options NS_AVAILABLE(10_9, 7_0);/* Create a Base-64, UTF-8 encoded NSData from the receiver's contents using the given options.*/- (NSData *)base64EncodedDataWithOptions:(NSDataBase64EncodingOptions)options NS_AVAILABLE(10_9, 7_0);。
Base64编码与解码详解

Base64编码与解码详解Base64 是基于 64 个可打印字符 A-Z、a-z、0-9、+、/ 来表⽰⼆进制数据的表⽰⽅法,常⽤于数据在⽹络中的传输。
本篇将分别介绍其编码、解码以及实际运⽤。
Base64 编码Base64 本质是⼀种将⼆进制转为⽂本的⽅案。
基本规则如下:编码时候选⽤ 64 (⼤⼩写英⽂字母,数字,+ /)个字符以及⽤作补位的=来表⽰在编码的时候,将3个字节变为4个字节,4个字节的⾼两位都⽤ 00 来填充,后 6 位来表⽰ 64 个字符。
以⼀个实际的例⼦ "YOU" 为例,其编码过程如下:由上表格可知 "YOU"对应的 Base64 编码为:"WU9V"。
对于要待编码的字符数如果不是 3 的倍数时候,会⽤ 0 去填充,编码出来后⽤ = 号表⽰,如: "ME" 其编码如下:Base64 解码将 4 个字节变为 3 个字节;将 24 bit 左移 16 位,与 255 进⾏与操作,获得第⼀个字符,将 24 bit 左移 8 位,与 255 进⾏与操作,获得第⼆个字符,将 24 bit 与 255 进⾏与操作,获取第三个字符Base64 实现与运⽤场景在 Node 中提供 Buffer 模块,可以进⾏⼆进制或者字符与 Base64 的想换转换,其代码如下:const buf2 = Buffer.alloc(2);buf2.write("M", 0);buf2.write("E", 1);buf2.toString("base64"); //TUU=// base64 解码const decodeBase64 = new Buffer("TUU=", "base64").toString(); //MEBase64 有着⼴泛的使⽤,如:对不⽀持⼆进制传输的场景,将⼆进制数据编码成 Base64 传输给服务器Base64 编码图⽚MIME, 电⼦邮件系统中使⽤ Base64 编码后传输。
[C++算法_BASE64]BASE64编码格式转换技术(非算法)基础理论
![[C++算法_BASE64]BASE64编码格式转换技术(非算法)基础理论](https://img.taocdn.com/s3/m/a80e35322e60ddccda38376baf1ffc4ffe47e221.png)
[C++算法_BASE64]BASE64编码格式转换技术(⾮算法)基础理论按照RFC2045的定义, Base64被定义为:Base64内容传送编码被设计⽤来把任意序列的8位字节描述为⼀种不易被⼈直接识别的形式。
(The Base64 Content-Transfer-Encoding is designed to represent arbitrary sequences of octets in a form that need not be humanly readable.)Base64是⽹络上最常见的⽤于传输8Bit字节代码的编码⽅式之⼀,在发送电⼦邮件时,服务器认证的⽤户名和密码需要⽤Base64编码,附件也需要⽤Base64编码。
下⾯简单介绍Base64算法的原理Base64是⽹络上最常见的⽤于传输8Bit字节代码的编码⽅式之⼀,⼤家可以查看RFC2045~RFC2049,上⾯有MIME的详细规范。
Base64要求把每三个8Bit的字节转换为四个6Bit的字节(3*8 = 4*6 = 24),然后把6Bit再添两位⾼位0,组成四个8Bit的字节,也就是说,转换后的字符串理论上将要⽐原来的长1/3。
这样说会不会太抽象了?不怕,我们来看⼀个例⼦:转换前 aaaaaabb ccccdddd eeffffff转换后 00aaaaaa 00bbcccc 00ddddee 00ffffff应该很清楚了吧?上⾯的三个字节是原⽂,下⾯的四个字节是转换后的Base64编码,其前两位均为0。
转换后,我们⽤⼀个码表来得到我们想要的字符串(也就是最终的Base64编码),这个表是这样的:(摘⾃RFC2045)Table 1: The Base64 AlphabetValue Encoding Value Encoding Value Encoding Value Encoding0 A 17 R 34 i 51 z1 B 18 S 35 j 52 02 C 19 T 36 k 53 13 D 20 U 37 l 54 24 E 21 V 38 m 55 35 F 22 W 39 n 56 46 G 23 X 40 o 57 57 H 24 Y 41 p 58 68 I 25 Z 42 q 59 79 J 26 a 43 r 60 810 K 27 b 44 s 61 911 L 28 c 45 t 62 +12 M 29 d 46 u 63 /13 N 30 e 47 v14 O 31 f 48 w (pad) =15 P 32 g 49 x16 Q 33 h 50 y让我们再来看⼀个实际的例⼦,加深印象!转换前 10101101 10111010 01110110转换后 00101011 00011011 00101001 00110110⼗进制 43 27 41 54对应码表中的值 r b p 2所以上⾯的24位编码,编码后的Base64值为 rbp2解码同理,把 rbq2 的⼆进制位连接上再重组得到三个8位值,得出原码。
二进制编码字符串

二进制编码字符串是将二进制数据编码为字符串格式
的过程。
在计算机科学中,二进制编码是一种常见的数据表示方法,因为它使用两种不同的符号(通常是0和1)来表示数据。
将二进制数据转换为字符串格式通常是为了方便存储、传输或显示。
以下是将二进制数据转换为字符串的几种常见方法:Base64编码:这是一种常见的二进制编码方法,用于将二进制数据转换为ASCII字符串。
Base64编码使用
26个英文字母(A-Z和a-z)和10个数字(0-9)以及两个
特殊字符(+和/)来表示二进制数据。
通过将这些字符组合成4个字符的块,可以表示任意长度的二进制数据。
十六进制编码:十六进制编码使用16个不同的符号来表示二进制
数据,包括10个数字(0-9)和6个字母(A-F或a-f)。
每个十六进制字符可以表示4位二进制数据。
URL编码:URL 编码(也称为百分比编码)是一种将字符转换为适合在URL 中传输的格式的方法。
URL编码使用特定的编码表将字符转换为二进制数据,然后使用Base64编码将这些二进制数据转换为字符串。
这些是将二进制数据转换为字符串的常见方法。
根据特定的应用需求,您可以选择适合您需求的编码方法。