基于消息传递并行进程迁移技术的研究与实现
跨进程传递指针的方法

跨进程传递指针的方法跨进程传递指针的方法取决于所使用的操作系统和编程语言。
在大多数操作系统中,进程之间的内存空间是隔离的,因此直接传递指针是不可能的。
然而,有一些方法可以实现跨进程传递指针的效果:1. 使用共享内存:通过共享内存,两个进程可以访问同一块物理内存区域。
这可以通过使用系统调用(如shmget、shmat和shmdt)在Unix-like系统上实现,或者使用特定的库(如库)在Windows上实现。
使用共享内存时,需要小心同步和互斥问题,以避免竞态条件和死锁。
2. 使用消息传递:进程之间可以通过发送和接收消息来传递指针。
这种方法需要定义一个消息协议,其中包含指向数据的指针。
常见的消息传递系统包括套接字、管道、信号量、共享内存等。
这种方法比直接传递指针更安全,因为它可以避免指针的非法访问和潜在的内存泄漏问题。
3. 使用文件映射:文件映射是一种将文件作为共享内存的机制,可以在进程之间共享数据。
通过将文件映射到进程的地址空间中,一个进程可以读取和修改另一个进程的数据。
这种方法需要在文件系统级别进行操作,并可能需要额外的权限和配置。
4. 使用远程过程调用(RPC):RPC是一种允许一个进程通过网络调用另一个进程中的函数的方法。
通过RPC,一个进程可以请求另一个进程执行某个操作,并将结果返回给调用者。
RPC通常使用序列化技术将数据转换为可以在网络上传输的格式,并在另一端进行反序列化以恢复原始数据。
这种方法需要在网络级别进行通信,并可能涉及到额外的传输开销和安全性问题。
需要注意的是,跨进程传递指针存在一定的风险和复杂性。
直接操作指针可能会导致竞态条件、死锁、数据损坏或安全漏洞等问题。
因此,在实现跨进程通信时,建议使用更加安全和抽象的方法,如消息传递、文件映射或RPC 等。
实验三-进程通讯实验报告

实验三进程通讯实验报告【姓名】【学号】【实验题目】进程通讯——消息队列与共享存储区【实验目的】(1)掌握进程间通讯的编程方法;(2)加深对进程并发执行的理解;(3)学习利用消息队列和共享存储区实现进程通信的方法。
【实验内容】设计一个多进程并发运行的程序,它由不同的进程完成下列工作:(1)接收键盘输入进程负责接收用户的键盘输入,并以适当的方式将由键盘获得的数据交给其它进程处理。
(2)显示进程负责全部数据显示任务,包括键盘输入数据的显示和提示信息的显示。
(3)分发数据进程将键盘输入的数据分为3类,即字母、数字和其它,并分别将字母写入文件letter.txt 中,数字写入文件number.txt中,除字母和数字外其它数据丢弃。
【实验要求】1、程序能以适当的方式提示用户输入数据;2、提示用户有数据被丢弃;3、全部的显示任务必须由显示进程完成;4、整个程序能够连续处理多组输入数据,直到用户输入“quit”字符串,整个程序结束;5、进一步要求:同时采用共享存储区和消息2种方法实现进程之间的通信,并比较这2种通信方法的利弊。
【实验方法】1、利用fork()函数创建2个子进程,用一个父进程和两个子进程完成上面的三个实验任务,用子进程1实现分发数据任务,子进程2实现接受键盘输入任务,父进程实现全部的显示任务。
2、同时通过共享存储区和消息队列两种进程通讯方式实现上面三个进程之间的同步和互斥。
3、利用while()循环、kill()函数和signal()函数实现连续多组数据输入。
【程序结构】·数据结构:消息队列、字符数组;·程序结构:顺序结构、if-else分支结构和while循环结构;·主要算法:无特别算法【实验结果】1、有代表性的执行结果:[stud13@localhost stud13]$ cc ipc.c[stud13@localhost stud13]$ ./a.outPlease input a line:∟operatingsystem01234-=,.Your message is:operatingsystem01234-=,.The characters deserted are:-=,.Please input a line:∟xushengju6651001!@#$%^&*()Your message is:xushengju6651001!@#$%^&*()The characters deserted are:!@#$%^&*()Please input a line:∟Hello123Your message is:Hello123Please input a line:∟quit[stud13@localhost stud13]$ cat letter.txtOperatingsystemxushengjuHello[stud13@localhost stud13]$ cat number.txt 012346651001123[stud13@localhost stud13]$2、结果分析及解释:在创建子进程1时,由于先返回子进程的ID号,msgrcv(msgid,&msg,BUFSIZE,0,0)一直都是非0值,故循环等待。
《进程管理》课件

和协作。
进程迁移
02
为了提高系统可靠性和可用性,分布式系统支持进程迁移,确
保关键任务能够持续运行。
负载均衡
03
分布式系统通过负载均衡技术,将任务分配到不同节点上执行
,提高系统整体性能。
THANKS
感谢观看
当系统中存在多个等待资源的进程,且每 个进程都持有至少一个资源并等待获取被 其他进程持有的资源时,就会产生死锁。
通过设置资源分配顺序或限制资源请求量 来避免饥饿。
• 死锁预防
• 死锁避免
通过破坏死锁产生的必要条件来预防死锁 ,例如预先分配资源、设置最大需求量等 。
在分配资源时进行检测和限制,避免产生 死锁,例如银行家算法。
进程的状态及其转换
总结词
阐述进程的三种基本状态及转换关系
详细描述
进程状态分为新建、运行、阻塞和就绪等状态。新建状态是进程被创建时的状态,运行状态是进程获 得CPU并执行的状态,阻塞状态是进程等待某个条件成立而暂时无法执行的状态,就绪状态是进程已 具备运行条件但未获得CPU时的状态。不同状态之间可以相互转换。
进程管理在操作系统中的应用
01
02
03
进程调度
操作系统通过进程调度算 法,合理分配系统资源, 确保进程能够高效地运行 。
进程同步
操作系统提供进程同步机 制,实现多个进程之间的 协同工作,避免资源竞争 和死锁。
进程通信
进程之间通过消息传递、 共享内存等方式进行通信 ,实现数据交换和协同工 作。
多核处理器下的进程管理技术
进程与程序的区别和联系
总结词
比较进是程序的一次执行过程,具有动态特性和独立性。 程序是静态的,而进程是动态的。程序是永存的,进程是暂时的。程序是过程的代码, 而进程是执行这些代码的过程。一个程序可以对应多个进程,但一个进程不能对应多个
面向异构数据的迁移学习技术研究

面向异构数据的迁移学习技术研究引言在当今数据驱动的社会中,数据的异构性已经成为一个普遍存在的问题。
不同来源、不同类型、不同结构的数据之间存在着差异,这给机器学习任务带来了挑战。
迁移学习作为一种解决这一问题的方法,已经引起了广泛关注。
本文将探讨面向异构数据的迁移学习技术研究,分析其应用场景、方法和挑战,并展望其未来发展方向。
应用场景面向异构数据的迁移学习技术在许多实际应用中发挥着重要作用。
以医疗领域为例,医疗数据通常包含多种类型和来源,如电子病历、医学影像和生物标志物等。
利用已有领域(如图像识别)上训练得到的模型进行迁移学习,可以加速新领域(如肿瘤诊断)上模型训练过程,并提高预测性能。
另一个应用场景是自然语言处理领域。
自然语言处理任务中常常需要处理来自于不同领域或社交媒体平台的文本数据,这些数据的特点各不相同,如语言风格、词汇表和语法结构等。
通过将已有数据上训练得到的模型迁移到新领域上,可以避免从头开始训练模型,提高模型的泛化能力和性能。
迁移学习方法面向异构数据的迁移学习方法可以分为基于特征的方法和基于模型的方法。
基于特征的方法主要关注如何将不同领域或类型数据中提取到的特征进行对齐。
这些方法通常通过对源领域和目标领域中提取到的特征进行映射或转换,使得它们在相同或相似分布下更加接近。
常用的技术包括主成分分析、典型相关分析和核规范相关分析等。
基于模型的方法则更加关注如何在不同领域或类型数据上共享知识。
这些方法通常通过共享参数、共享层或共享结构等方式来实现跨领域知识传递。
例如,在深度神经网络中,可以通过在预训练网络上微调参数来将已有知识迁移到新任务上。
挑战与展望面向异构数据迁移学习技术面临着一些挑战。
首先,数据的异构性导致了数据分布的不一致,这给迁移学习带来了困难。
如何有效地对齐不同领域或类型数据的分布,是一个需要解决的问题。
其次,迁移学习需要在源领域和目标领域之间建立联系。
然而,在现实应用中,源领域和目标领域之间往往存在着巨大差异,这使得建立联系变得困难。
linux进程迁移原理

linux进程迁移原理
Linux进程迁移是指将正在运行的进程从一个处理器移动到另
一个处理器上执行的过程。
进程迁移的原理涉及到操作系统的调度器、进程状态保存和恢复、以及多处理器系统的协调工作。
首先,进程迁移涉及到操作系统的调度器。
在多处理器系统中,不同的处理器上可能有不同的负载情况,为了实现负载均衡,操作
系统的调度器会根据系统的负载情况动态地调整进程的分配情况。
当某个处理器负载过重或者其他处理器负载较轻时,调度器会考虑
将运行中的进程迁移到其他处理器上执行,以实现系统资源的最优
利用。
其次,进程迁移涉及到进程状态的保存和恢复。
在进行进程迁
移时,操作系统需要保存正在运行进程的状态,包括寄存器的内容、内存映射、打开的文件等信息。
然后将这些状态信息传输到目标处
理器上,并在目标处理器上恢复这些状态,使得进程可以在新的处
理器上继续执行,而不会丢失任何运行状态。
此外,进程迁移还涉及到多处理器系统的协调工作。
在多处理
器系统中,不同处理器之间需要进行协调和通信,以确保进程迁移
的顺利进行。
这包括在进行迁移时暂停进程的执行、传输进程状态信息、在目标处理器上重新调度进程等操作。
总的来说,Linux进程迁移的原理涉及到操作系统调度器的负载均衡、进程状态的保存和恢复、以及多处理器系统的协调工作。
这些原理的相互配合使得进程可以在多处理器系统中高效地进行迁移,从而实现系统资源的最优利用和性能的提升。
并行任务调度算法研究

非确定性调度技术又称为随机搜索调度技术 ,它主要是通 过有导向的随机选择来搜索问题的解空间而并不是单纯的随 机搜索 。这类技术组合前面搜索结果的知识和特定的随机搜 索特点来产生新的结果 。遗传算法是最流行和使用最广泛的 该类技术 ,它们的调度时间一般高于使用其他技术的调度算 法 ,适合于某一种任务图的控制参数优化集并不适合于另一种 类型的任务图 ,即对新的任务图遗传算法需要长时间的训练学 习 。另外 ,模拟退火方法也属于该类型技术 。
考虑到任务图的基本信息以及处理单元本身和其互连结 构的基本信息是否在应用程序执行前可以得到 ,已经调度好的 任务是否可以由于其处理单元失效而实时迁移等因数可以把 并行任务调度算法分为两大类 。一类假设任务图和处理单元 相关的信息在程序执行前可以精确获取 ,调度好的任务节点不 能迁移 ,基于这类假设的调度算法称为静态调度算法 ,也叫编 译时间调度算法 ;反之则称为动态调度算法 ,也叫实时调度算 法 。前者存在如何精确获取所需信息的问题 ,但其可凭借成熟 的模型组织有效而具体的启发式算法 ,文献中大多数算法均属 于此类算法 ;后者需要程序实时执行期间得到相应调度信息来 调度任务 ,有许多不确定因数存在 ,调度开销一般较大 ,但在大 型分布式系统如网格计算中该类算法不失为有效的方法 ,也适 合于含有条件分支和循环的任务图调度 。本文讨论的并行任 务调度算法主要限于第一类 。图 1 就已有的并行任务调度算 法进行了粗略的分类 。
第 11 期
马 丹等 :并行任务调度算法研究
·91 ·
并行任务调度算法研究
马 丹1 , 张 薇1 ,2 , 李肯立1
(1. 华中科技大学 计算机学院 , 湖北 武汉 430074 ; 2. 武汉军械士官学校 , 湖北 武汉 430075)
ipcd协议

ipcd协议一、概述IPC(Inter-Process Communication,进程间通信)是计算机科学中的一个重要概念,它指的是在多个进程之间进行数据交换和通信的机制和技术。
而ipcd协议则是一种特定的IPC协议,用于在不同的进程之间进行高效的通信。
二、ipcd协议的特点ipcd协议具有以下几个特点:1. 跨平台兼容性ipcd协议设计时考虑了跨平台的兼容性,因此可以在不同的操作系统和硬件平台上进行使用。
这使得ipcd协议成为一种非常灵活和通用的IPC解决方案。
2. 高效的数据传输ipcd协议采用了高效的数据传输机制,能够在进程间快速地传输大量的数据。
它使用了一种优化的数据编码和解码算法,以及高速的数据传输通道,从而实现了高效的数据传输。
3. 可靠性和安全性ipcd协议在设计时考虑了通信的可靠性和安全性。
它采用了一系列的机制来确保数据的可靠传输,包括错误检测和纠正、数据重传等。
同时,ipcd协议还提供了安全的认证和加密机制,以保护通信过程中的数据安全。
4. 灵活的通信模式ipcd协议支持多种通信模式,包括点对点通信、发布订阅模式等。
这使得ipcd协议可以适应不同的通信场景和需求,提供灵活的通信方式。
三、ipcd协议的应用场景ipcd协议可以在各种不同的应用场景中使用,以下是几个常见的应用场景:1. 分布式系统在分布式系统中,不同的进程可能运行在不同的计算节点上,它们需要进行数据交换和通信。
ipcd协议可以提供高效的进程间通信机制,使得分布式系统中的各个进程能够快速地进行数据传输和通信。
2. 并行计算在并行计算中,多个进程可能同时执行不同的任务,它们之间需要进行数据交换和协调。
ipcd协议可以提供高效的数据传输和通信机制,使得并行计算中的各个进程能够快速地进行数据交换和协作。
3. 消息队列ipcd协议可以作为消息队列的基础协议,用于实现消息的发布和订阅。
它可以提供高效的消息传输和通信机制,使得消息队列能够快速地进行消息的发布和订阅。
并行编程原理与实践

并行编程原理与实践一、并行编程概述并行编程是指利用多个处理器或计算机核心同时执行程序,以提高程序的性能和效率。
在多核CPU和分布式系统的背景下,越来越多的应用程序需要实现并行计算。
但是,并行编程也带来了许多挑战,比如线程同步、数据共享等问题。
二、并行编程模型并行编程模型是指描述并行计算过程的抽象概念和方法。
常见的并行编程模型包括共享内存模型和消息传递模型。
1. 共享内存模型共享内存模型是指所有处理器都可以访问同一个物理内存空间,并且可以通过读写共享变量来进行通信。
在共享内存模型中,线程之间可以通过锁机制来同步访问共享变量,以避免数据竞争。
2. 消息传递模型消息传递模型是指不同处理器之间通过发送和接收消息来进行通信。
在消息传递模型中,每个处理器都有自己的私有内存空间,不能直接访问其他处理器的内存空间。
因此,在消息传递模型中需要使用特殊的通信库来实现进程之间的通信。
三、并行编程技术1. 多线程编程多线程编程是指利用多个线程同时执行程序,以提高程序的性能和效率。
在多线程编程中,需要注意线程同步、数据共享等问题。
2. OpenMPOpenMP是一种基于共享内存模型的并行编程技术,它提供了一组指令集,可以在C、C++和Fortran等语言中实现并行计算。
OpenMP 采用“指导性注释”的方式来控制程序的并行执行。
3. MPIMPI是一种基于消息传递模型的并行编程技术,它可以在分布式系统中实现进程之间的通信。
MPI提供了一组函数库,可以在C、C++和Fortran等语言中实现并行计算。
4. CUDACUDA是NVIDIA公司推出的针对GPU的并行编程技术。
CUDA允许开发者使用C语言来编写GPU程序,并且提供了丰富的API函数库来支持各种计算任务。
5. MapReduceMapReduce是Google公司推出的分布式计算框架,它可以将大规模数据集分成若干个小块进行处理,并且通过网络传输将结果汇总起来。
MapReduce采用函数式编程思想,将计算过程抽象成映射和归约两个阶段。
单个计算机实现并行处理的途径_理论说明

单个计算机实现并行处理的途径理论说明1. 引言1.1 概述随着计算机技术的发展和进步,人们对于提高计算机性能和处理效率的需求也日益增加。
并行处理作为一种有效的解决方案被广泛应用于各种领域,如科学计算、数据分析等。
在传统的观念中,实现并行处理一般需要多台计算机之间进行协作,并且通常需要进行复杂的系统配置和网络设置。
然而,单个计算机实现并行处理也成为了一种备受关注的研究领域。
1.2 文章结构本文将重点探讨单个计算机实现并行处理的途径以及相关理论知识。
文章分为五个部分:引言、单个计算机实现并行处理的途径、基于任务划分的并行模型、基于数据划分的并行模型和结论。
在引言部分,我们将对整篇文章进行概述,并介绍本文各个部分的内容安排。
1.3 目的本文旨在通过理论说明,介绍单个计算机实现并行处理的方法和技术。
通过深入探讨并发与并行的区别、多线程技术以及SIMD架构等内容,读者将能够了解到单个计算机实现并行处理的基本概念和原理。
此外,我们还将介绍基于任务划分和数据划分的并行模型,包括任务划分思想、数据一致性问题、分布式共享内存系统的实现原理、数据通信与同步机制,以及并行算法设计与优化方法等内容。
最后,在结论部分,我们将总结单个计算机实现并行处理的途径方法及其优缺点,并展望未来研究方向和发展趋势。
通过本文的阅读,读者将能够深入了解单个计算机实现并行处理的理论知识,并掌握相关技术和方法,从而提高计算机性能和处理效率。
这对于在科学研究、工程应用和数据处理等领域中面临大规模计算需求的人们具有重要意义。
2. 单个计算机实现并行处理的途径2.1 并发和并行的区别在讨论单个计算机实现并行处理的途径之前,我们首先要明确并发(concurrency)与并行(parallelism)的区别。
并发是指多个任务交替进行,通过任务间的切换快速响应每个任务的需求。
而并行则表示多个任务同时执行,通过利用多核或多处理器来加速任务处理。
尽管两者都涉及多任务处理,但并发更侧重于提高系统资源利用率和提升用户体验,而并行更强调提高计算性能和加速任务完成时间。
intel mpi原理

intel mpi原理Intel MPI是一种基于消息传递接口(Message Passing Interface,MPI)的编程库,用于在Intel架构上实现并行计算。
它提供了一套高性能的通信和同步机制,使得并行应用程序能够在多个处理器之间进行消息传递,并实现并行计算的任务划分和负载均衡。
本文将介绍Intel MPI的原理和工作机制。
Intel MPI的原理基于MPI标准,该标准定义了一系列的函数和语义规范,用于在分布式内存系统中进行并行计算的消息传递。
MPI 标准的目标是提供一种统一的编程接口,使得不同的并行计算环境能够实现互操作性。
Intel MPI作为一种基于MPI标准的实现,提供了对Intel架构的优化和支持,以提供更高的性能和可扩展性。
Intel MPI的工作机制主要包括进程通信、进程管理和任务调度三个方面。
进程通信是Intel MPI的核心功能之一。
在并行计算中,不同的进程之间需要进行消息传递,以实现数据的交换和协同计算。
Intel MPI通过提供一系列的通信函数,如发送(send)、接收(receive)和同步(synchronize)等,来支持进程之间的消息传递。
这些通信函数可以根据应用程序的需要进行灵活的调用,以实现不同的通信模式,如点对点通信、广播通信和规约通信等。
此外,Intel MPI 还提供了高效的通信协议和算法,如基于RDMA(Remote DirectMemory Access)的通信方式,以提高通信性能和可扩展性。
进程管理是Intel MPI的另一个重要功能。
在并行计算中,需要对多个进程进行管理和调度,以实现任务的分配和负载均衡。
Intel MPI通过提供一系列的进程管理函数,如进程创建(create)、进程销毁(destroy)和进程同步(synchronize)等,来支持进程的管理和协同。
这些函数可以根据应用程序的需要进行灵活的调用,以实现不同的进程管理策略,如静态进程划分和动态进程迁移等。
高性能计算中的并行编程模型介绍

高性能计算中的并行编程模型介绍高性能计算(High-Performance Computing,HPC)是一种利用大规模计算机系统进行高效计算和解决复杂问题的技术。
在高性能计算中,为了提高计算效率和处理大规模数据,使用并行编程模型是必不可少的。
并行编程模型是一种在多个处理单元(如CPU、GPU等)上同时执行代码的方法,能够实现任务的分解和并发执行,提高计算速度和系统的整体性能。
并行编程模型主要有以下几种:共享内存模型、分布式内存模型以及混合模型。
共享内存模型是指多个处理单元共享同一个内存空间,在该模型中,所有的处理单元可以同时访问和修改共享内存中的数据。
共享内存模型的最大优势在于简单易用,程序员只需要在编写代码时考虑数据的同步和互斥。
常用的共享内存编程模型包括OpenMP和POSIX线程。
OpenMP(Open Multi-Processing)是一种支持并行编程的API,可以通过在代码中添加一些特殊的指令来实现并行化。
通过使用OpenMP,程序员可以简单地将串行代码转化为并行代码。
OpenMP使用的指令主要包括#pragma omp并行指令、#pragmaomp for指令以及#pragma omp critical指令等。
这些指令可以指定代码块并行执行、循环并行化以及实现临界区保护等。
OpenMP适用于共享内存系统,对于多核CPU和SMP(Symmetric Multi-Processing)系统,具有较好的扩展性。
POSIX线程(Pthreads)是一种标准的共享内存并行编程模型,可以在多线程环境下创建和管理线程。
Pthreads使用的函数库包括pthread_create、pthread_join和pthread_mutex等,可以创建线程、等待线程结束并实现互斥和同步。
使用Pthreads编写的并行程序可以同时利用多个CPU核心进行计算,有效地提高了程序的执行速度。
分布式内存模型是指多个处理单元之间通过消息传递来共享数据,每个处理单元拥有自己的本地内存。
一种基于SDN和MPTCP的多径并行传输技术

%&引言
现今互联网中数据集规模呈现指数级的增长多路传输控 制协议 6/=?1H4?< ?>42;61;;1@2 :@2?>@=H>@?@:@=ZEDCE 作为传 输层协议可以通过多径传输技术充分挖掘和利用现有的网络 资源将数据剥离到多个子流中来利用两个网络端点之间的 多个路径 网络层根据路由转发协议自动地转发这些数据流 多路径允许在一个逻辑连接中使用多条物理链路从而增加带 宽利用率提高冗余和稳定性以及在某些环境中无缝切换# 可以利用网络状态信息合理分配 ZEDCE流量以此使多条网络 路径进行并行传输由于不同路径的丢包率时延带宽等参数 存在差异这些差异可能造成多路径传输效率低下如何有效 地利用这些具有差异的路径合理地进行路径选择和流量分配 成为多径并行传输的关键点!
!"#$%&'$ D<1;H4H8>H>@H@;89 ?@:@2?>@=?<8ZEDCE?>4RR1:?<>@/.< ?<8TQ+:@2?>@==8>?@16H>@I8?<8H4>4==8=?>42;61;;1@2 >4?84::@>912.?@?<828?K@>L ;?4?87D<1;H4H8>/;89 ?<8H>@H@;89 K198;?91;0@12?>@/?12.4=.@>1?<6 1?:<@;84;8?@R4I41=4J=8 H4?< ;8?;K1?< ?<8K198;?J429K19?< 429 4;64==8>=12L .4H R@>84:< ZEDCE:@228:?1@2 429 ?<82 1?/;89 ?<8>4?1@@R?<84I41=4% J=8H4?< :4H4:1?34;?<8H>@J4J1=1?3?<4??<8?>4RR1:K4;4==@:4?89 ?@?<8H4?< R/>?<8>>89/:89 ?<8J429K19?< 91RR8>82:8@R?<8 ;/JR=@K7S124==3 J3;8??12./H ?<8S=@@9=1.<?;16/=4?1@2 8XH8>1682?H=4?R@>6 ?<8>8;/=?H>@I8;?<4??<8;:<868:42 4I@19 91R% R8>82?H4?<;@RZEDCE.@12.?<>@/.< ?<8;468H4?< 429 8RR8:?1I8=3/;8?<8H4?< ?@82<42:8?<8H4>4==8=?>42;61;;1@2 8RR1:182% :37 ()* +,%-# ZEDCE6/=?1H4?< ?>42;61;;1@2 :@2?>@=H>@?@:@= 6/=?1%H4?< >@/?12. ;@R?K4>8%98R1289 28?K@>L ?>4RR1:4==@:4?1@2
面向多线程编程的并行计算模型研究与实现

面向多线程编程的并行计算模型研究与实现引言随着计算机科学和技术的不断发展,人们对并行计算的需求越来越大。
并行计算在加快计算速度、提高系统性能和解决复杂问题等方面发挥着重要作用。
而多线程编程作为一种常见的并行计算模型,在高性能计算、数据处理和分布式计算等领域都得到广泛应用。
本文将围绕面向多线程编程的并行计算模型展开研究与实现。
一、并行计算模型的基本概念和分类1.1 并行计算模型的定义并行计算模型是指在多个处理器或线程之间进行任务划分和协同工作的一种方式。
它可以将一个任务分解成若干个子任务,并利用不同的多线程或处理器同时进行计算,以提高整个系统的计算速度和性能。
1.2 并行计算模型的分类常见的并行计算模型主要包括共享内存模型和消息传递模型。
共享内存模型是指多个线程或处理器之间通过读写共享内存的方式进行通信和数据交换,例如OpenMP;消息传递模型则是通过消息传递的方式在不同线程或处理器之间进行通信和数据交换,例如MPI。
二、面向多线程编程的并行计算模型研究2.1 共享内存模型共享内存模型是一种基于共享内存机制的并行计算模型,它主要通过读写共享内存的方式来进行线程之间的通信和数据交换。
该模型具有编程简单、易于理解和易于调试的特点,适用于对共享数据频繁访问的并行计算任务。
常用的共享内存编程接口包括OpenMP和POSIX线程库等。
2.2 消息传递模型消息传递模型是基于消息传递机制的并行计算模型,它通过消息的发送和接收来实现线程之间的通信和数据交换。
该模型适用于分布式环境下的并行计算任务,可以充分利用分布式计算资源,并进行高效的通信和数据传输。
常用的消息传递编程接口包括MPI和PVM等。
三、面向多线程编程的并行计算模型实现3.1 共享内存编程实现共享内存编程实现是通过对共享内存区域的读写操作来实现线程之间的通信和数据交换。
在实现过程中,首先需要定义共享内存区域,并在不同线程之间进行数据同步和互斥访问的控制。
并行计算与分布式存储技术在信息科学中的创新与实践

并行计算与分布式存储技术在信息科学中的创新与实践随着信息技术的不断发展,计算和存储需求呈现爆发式增长,传统的计算和存储系统已经无法满足日益增长的数据处理能力。
在这样的背景下,并行计算和分布式存储技术应运而生,成为信息科学领域的创新与实践的关键。
一、并行计算技术的创新与实践并行计算指的是将一个计算任务分解成多个子任务,并通过多个计算单元同时执行,以提高计算速度和处理能力。
并行计算技术的发展得益于计算机硬件和软件的进步,尤其是多核处理器和并行计算框架的广泛应用。
通过并行计算技术,我们能够更高效地完成各种复杂的计算任务,如图像处理、数据挖掘和模拟仿真等。
并行计算从单机到集群、从高性能计算到云计算,不断创新和实践。
例如,高性能计算领域使用的超级计算机基于并行计算技术,通过拥有大量计算节点和高速互连网络,实现对大规模计算任务的快速处理。
而云计算则通过虚拟化技术和分布式资源管理,将计算能力提供给用户,实现按需分配和弹性扩展。
二、分布式存储技术的创新与实践分布式存储是指将数据存储在多个节点上,以提高存储容量、可靠性和访问速度。
与传统的集中式存储相比,分布式存储具有更好的可扩展性和容错性。
分布式存储技术的创新主要体现在数据分布、副本管理和数据访问等方面。
数据分布是指将数据划分成多个部分,并分别存储在不同的节点上。
通过数据划分和分布,我们可以充分利用多节点的存储容量,以提高整体存储能力。
同时,数据的分布也可以保护数据免受单点故障的影响,增强数据的可靠性。
副本管理是指在分布式存储系统中管理数据的多个副本。
通过在不同的节点上存储多个副本,可以实现数据的冗余备份和故障恢复。
当某个节点发生故障时,系统可以使用其他副本快速替代,保障数据的可用性和持久性。
数据访问是指用户如何通过分布式存储系统访问和获取数据。
分布式存储系统通常提供统一的接口和协议,使用户可以透明地访问分布在不同节点上的数据。
同时,分布式存储系统也需要具备高效的路由和负载均衡机制,以提供快速的数据访问和响应。
《高性能计算技术》重点及复习题

高性能计算技术复习题题型:单项选择10题,每题3分,共30分综合题(问答、写代码,分析计算等)共6题,共70分。
考试时间:2小时1.解释以下基本概念HPC, HPCC, Distributed comput ing, Meta computi ng. Grid comput ingMIMD, SIMD, SISDPVR SMR MPP, DSM, Cluster, Co nstellationUMA, NUMA, CC_NUMA, CORMA, NORMAHPC: High Performanee Computing高性能计算,即并行计算。
在并行计算机或分布式计算机等高性能计算系统上所做的超级计算。
HPCC High Performanee Computing and Communication 高性能计算与通信。
指分布式高性能计算、高速网络和In ternet的使用。
Distributed computing:分布式计算。
在局域网环境下进行的计算。
比起性能来说,它更注重附加功能。
一个计算任务由多台计算机共同完成,由传统的人和软件之间的交互变成软件和软件之间的数据交互。
Meta computing:元计算技术是将一组通过广域网连接起来的性质不同的计算资源集合起来,作为一个单独的计算环境向用户提供计算服务。
一个良好的元计算系统主要由三个部分组成:一是尽量简单而又可靠的使用界面;二是资源管理系统;三是良好的编程模型和高效可靠的运行时环境。
元计算是网格计算的初级形态。
Grid computing:网格计算。
利用互联网把分散在不同地理位置的电脑组织撑一个"虚拟的超级计算机”,其中每一台参与计算的计算机就是一个“节点”,而整个计算是由成千上万个“节点”组成的“一张网格”。
MIMD :多指令多数据流。
每台处理机执行自己的指令,操作数也是各取各的。
ISISMIMD arch it vet HIT with shared memorySIMD :单指令多数据流。
操作系统期末试卷

操作系统期末试卷2005-2006学年第⼀学期操作系统期末试卷班级学号姓名成绩I. 填空.(30分,每空1分)1. 在系统中,没有程序运⾏时,CPU做什么?忙等(从中选择⼀个答案:暂停、忙等、等待中断、休眠)。
2. 引⼊多道程序技术带来的主要好处是提⾼了CPU利⽤率;但如果多道程序数⽬太多,则会造成⼀种称为抖动现象的问题。
3. 导致进程状态从运⾏→就绪转换的原因是超时,进程的时间⽚到期。
4. 进程调度算法(FCFS,SPN,SRT,RR, FB)中对各种类型的进程(如CPU 密集型或I/O密集型进程)都能平等对待的是RR时间⽚轮转和FB 多级反馈队列。
a. 0, 99 429 330+99b. 2, 78 189 111+78c. 1, 265 缺段211<2656. 在⼀个物理空间为232字节的纯分页系统中,如果虚拟地址空间⼤⼩为212页,页的⼤⼩为512字节,那么:a. ⼀个虚拟地址有多少位?21b. ⼀个页框有多少字节?512c. 在⼀个物理地址中⽤多少位来指明对应的页框?23d. 页表的长度为多少(即页表中表项数⽬为多少)?212 (4096)7. ⽬前常⽤的⽂件⽬录结构是树型(多级)⽬录结构。
8. 适合磁盘的外存分配模式是:连续、链接、索引。
9. 进程迁移是指将⼀个进程的状态,从⼀台机器转移到另⼀台机器上,从⽽使该进程能在⽬标机上执⾏.10. 分布式系统中的关键机制是进程间通信。
中间件提供了标准的编程接⼝和协议,掩藏了不同⽹络协议和操作系统之间的复杂细节和差异,其实现基于消息传递和远程过程调⽤两种机制。
11. 操作系统安全⾥说的⾝份鉴别机制的作⽤是识别请求存取的⽤户,并判断它的合法性。
12. 根据美国国防部的划分,计算机系统的安全从低到⾼分为哪4等?D,C,B,A (按从低到⾼的顺序)。
13. 正误判断题:a.在SPOOLing系统中,对⽤户进程的设备申请,系统将物理字符设备按时间⽚⽅式分配给⽤户进程使⽤。
异构网络环境下多径并行传输若干关键技术研究

异构网络环境下多径并行传输若干关键技术研究摘要随着互联网技术和网络应用的不断发展,异构网络作为一种新型的网络架构,已经成为未来网络的重要发展方向之一。
然而,在异构网络环境下,由于网络中的各种网络链路和设备具有不同的特性,因此传统的单一路径传输已经不能满足多媒体实时传输、大数据传输等需求。
为解决这一问题,多路径并行传输技术应运而生。
本文将探讨异构网络环境下多路径并行传输的若干关键技术,包括网络测量、负载均衡、拥塞控制、可靠性保证等。
关键词:异构网络,多路径并行传输,网络测量,负载均衡,拥塞控制,可靠性保证AbstractWith the continuous development of Internet technology and network applications, heterogeneous networks have become an important development direction of future networks. However, in the heterogeneous network environment, due to the different characteristics of various network links and devices in the network, traditional single-path transmission can no longer meet the requirements of real-time multimedia transmission, large data transmission and other requirements. To solve this problem, multipath parallel transmission technology has emerged. This paper will explore several key technologies of multipath parallel transmission in heterogeneous network environment, including network measurement, load balancing, congestion control, reliabilityguarantee, etc.Keywords: heterogeneous network, multipath parallel transmission, network measurement, load balancing, congestion control, reliability guarantee1. 异构网络的概念及研究现状异构网络是一种由不同类型的网络组成的网络结构,包括有线网络、无线网络、传感器网络、卫星网络等。
贵州大学2013届毕业研究生优秀学位论文公示
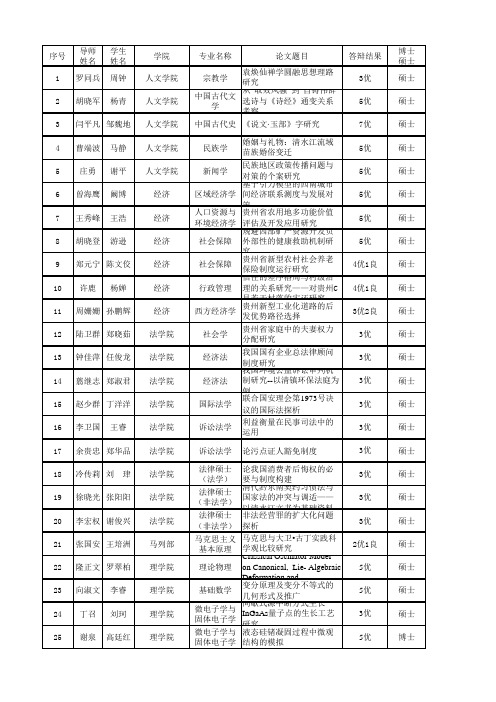
专业名称 教学
论文题目
答辩结果 3优 5优 7优 5优 5优 5优 5优 5优 4优1良 4优1良 3优2良 3优 3优 3优 3优 3优 3优 3优 3优 3优 2优1良 5优 5优 3优 5优
博士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 硕士 博士
植物营养学 黔薏苡1号营养特征与调控研究
5优 5优
5优
硕士 硕士
硕士
野生动植物 小蓬竹[Drepanostachyum 保护与利用 luodianense (Yi et R.S 贵州山羊品种GFI1B和RERG 动物遗传育 Wang) Keng f.]遗传多样性 罗卫星 陈 志 动物科学学院 种与繁殖 基因表达、多克隆抗体制 备及多态性与生长性状的 “金英黄归汤”对小鼠乳 王鲁 李圆方 动物科学学院 基础兽医 腺上皮TLR4信号转导的影 刘济明 王敏 林学院 周英 张敏 生命科学学院 药物化学 微生物学 植物学 响 太子参特征图谱的研究与 质量综合评价体系的建立 谢瓦氏曲霉间型变种有性 发育调控基因flbA的克隆及 功能分析 烟草毛状根与AM真菌双重
郑元宁 陈文佼 许鹿 杨婵
周姗姗 孙鹏辉 陆卫群 郑晓茹 钟佳萍 任俊龙 翦继志 郑淑君 赵少群 丁洋洋 李卫国 王睿
余贵忠 郑华品 冷传莉 刘 珒 徐晓光 张阳阳 李宏权 谢俊兴 张国安 王培洲 隆正文 罗翠柏 向淑文 丁召 谢泉 李睿 刘珂 高廷红
论我国消费者后悔权的必 要与制度构建 法律硕士 清代黔东南契约习惯法与 (非法学) 国家法的冲突与调适—— 法律硕士 以清水江文书为基础资料 非法经营罪的扩大化问题 (非法学) 探析 马克思主义 马克思与大卫•古丁实践科 基本原理 学观比较研究 Classical Oscillator Model 理论物理 on Canonical, LieAlgebraic Deformation and 变分原理及变分不等式的 基础数学 几何形式及推广 微电子学与 间歇式源中断方式生长 固体电子学 InGaAs量子点的生长工艺 微电子学与 研究 液态硅锗凝固过程中微观 固体电子学 结构的模拟
机器学习知识:机器学习中的多任务学习与迁移学习

机器学习知识:机器学习中的多任务学习与迁移学习机器学习是近年来发展迅速的前沿领域,在人工智能技术应用的众多方面得到广泛应用。
机器学习的一个重要问题是多任务学习与迁移学习。
本文将从定义、应用案例、方法与未来发展方向等多个方面来介绍这两个问题。
一、多任务学习多任务学习(Multi-task Learning, MTL)通常是指在同一个模型中学习多个相关任务的技术。
在这种情况下,多个任务相互影响,每个任务的性能可以由其他任务互补的信息来提高。
因此,多任务学习可以更有效地利用数据、提高模型的预测能力和泛化能力。
多任务学习的应用范围非常广泛。
例如,在图像处理中,可以使用多任务学习来同时处理文本和图像,从而提高文本检测和图像识别的准确性。
在自然语言处理中,可以使用多任务学习来处理自然语言生成和文本分类,从而提高自然语言生成的质量。
在医疗领域,可以使用多任务学习来预测病人的状况、治疗方案和风险等,从而提高医疗预测和预测精度。
多任务学习有多种方法和模型,例如联合学习、交替优化、共享隐层等。
联合学习是指在整个学习过程中共同学习多个任务和模型。
交替优化是指在学习过程中,模型根据特定顺序逐个任务进行优化。
共享隐层是指将不同任务的特征进行共享,从而降低模型的复杂度。
二、迁移学习迁移学习(Transfer Learning)指的是在不同的任务、数据或领域之间,利用之前已学习到的知识来改进现有任务的技术。
在迁移学习中,已学习的知识可以来自于同一领域的其他任务,或者来自于不同领域的任务。
因此,迁移学习可以更好地利用以前学习的知识,从而提高模型的预测能力和泛化能力。
迁移学习的典型应用包括自然语言处理、计算机视觉和机器人等领域。
例如,在自然语言处理中,可以使用迁移学习来处理表达式不同但存在相关性的任务,如情感分析和垃圾邮件过滤。
在计算机视觉中,可以使用迁移学习来处理类似的任务,如目标检测和图像分割。
在机器人领域中,可以使用迁移学习来提高机器人的动作决策能力和自适应能力。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2.根据用户或管理程序的要求来创建全新MPI任务拓 扑mig_schema;
3.mpirun根据mig schema中的MPI任务拓扑向各节点 上的lamd服务发出恢复请求;
4.1amd接收到恢复请求后,从本地或其它节点获取检查 点文件之后,调用BLCR命令cr restarz恢复进程,并与lamd 重链接;
4进程迁移的实现
圳/Migration进程迁移的实现分为检查点保存与异
地卷回两个部分,其中LAM环境重链接与通讯通道重建模 块发挥了关键作用。 4.1 MPI任务的检查点机制
LAM/Migration应用同步检查点协议来保证记录MPI 任务正常运行期间的一致状态。检查点文件保存在集群可靠 共享存储设备NAS上。检查点操作入I:/是mpirun进程,具 体流程如下(如图2所示)。
现MPI整体任务在节.最之间的自由迁移,其迁移功能对应用程序透明,智能化程度高,并可应用于集群节点客错与负
裁均衡,有效提高集群的可用性。
关键词MPI,高可用,检查点,卷回,进程迁移
中图法分类号TP338.8
文献标识码A
Research on Implementation of Message Passing Based Parallel Process Migration LIU Tian-tian YANG Sheng-chun OU Zho/149-hong YUAN You-guang (Wuhan Digital Engineering Institute,Wuhan 430074,China)
2研究现状
目前国外已开发出ห้องสมุดไป่ตู้干具有容错功能的MPI算平台,如
应用CoCheek检查点软件实现容错的tuMPI[“,Starfishc引, MPICH一Ⅵ们等,但都没有解决MPI进程迁移这一难题。 Jiarmong Caor5]提出的MPI进程迁移方案是通过修改检查点 文件中的数据实现的,当检查点文件的内容或数量较大时,将 产生巨大开销,且灵活性差。Chao wan毋6。提出的Job Pause Service机制由于不能迁移任务主进程mpirun,因此不能真正 实现整体任务迁移,当mpirun进程所在节点发生故障时,仍 无法避免整体任务的崩溃。
2.在MPI层添加通讯通道重建模块(Communication Channel Rebuilder,CC-Rebuilder):MPI进程迁移后,更新 MPI进程间的通讯路由,重建进程间的消息通道。
LAM环境重链接模块与通讯通道重建模块是实现进程 迁移的两大支撑,具体实现将在第4节阐述。LAM/Migra- tion的MPI层与LAM层共同实现同步检查点算法(coordi— hated checkpoint protoc01),并配合内核检查点模块BLCR实 现MPI任务检查点的保存工作。因为CC-Rebuilder与RTE- Relinker分别在MPI层和LAM层实现,所以LAM/Migra— tion的进程迁移功能对应用程序完全透明,而且MPI进程在 CC-Rebuilder与RTE-Relinker的协助下,可自主完成LAM 环境重链接、通讯路由更新、消息通道重建,无需任何外界或 人工干预,充分体现出LAM/Migration的智能化。
本文基于MPI-1规范,以扩展MPI运行环境的容错能力 为目标,选用IAnux 2.6与Lpd订/MPI.7.3作为开发平台,突 破了MPI进程迁移这一关键技术,成功开发出LAM/Migra— tion原型系统,实现MPI进程在任意节点之间的自由迁移, 有效提高了系统可用性。其特点如下:
①MPI容错功能扩展:通过将检查点软件BLCR(Berke. Icy Lab’S Checkpoint/Restart)与LAM/MYI相结合,实现 MPI整体任务状态的保存与任务的卷回恢复。
节点上的lamd重链接并重建消息通道,这需要RTE-Relinker 和CC-Rebuilder共同支持。值得注意的是,各MPI进程在将
各自一gps结构发送给mpirun之前,必须感知mpirun迁移的 新地址,即各MPl进程必须更新与mpirun之间的路由。而 在mpirun启动中,只有lamd服务知道其地址信息,LAM/ Migration应用lamd与MPI进程间的通讯将mpinm的地址
1.mpirun接收到用户或系统管理程序的检查点命令之 后,向所有节点的MPI服务进程lamd广播检查点请求信号;
2.各节点上的lamd将该检查点信号转发给本地MPI进 程;
3.为了记录MPI任务一致状态,各MPI进程在自身检 查点产生之前必须相互协调地做一些准备工作,包括清空 MPI进程之间的在途消息(on-fly—message),释放共享内存、 文件、信号量、套接字等BLCR不能保存的资源。在所有 MPI进程完成准备工作之后生成检查点;
int4 gps_node#
//MPI进程所在节点编号
int4 gps_pid;
IIMPT进程的PTD号
int4 gps idx!
//对应本地Iamd保存的索引号
int4 gps grankst //在整个通讯环境中的rank号
}l
图3进程地址信息~gps结构
4.5 mpirtm进程的迁移 同MPI进程相似,在mpirun进程迁移时,同样必须同新
存在app sehama中,其反映了各MPI进程与所在节点的映 射关系。进程迁移改变了原始任务拓扑,所以LAM/Migra- tion在进程迁移操作中。mpirun将根据迁移状况刨建新的任 务拓扑mig_schema来对应新的映射关系。 4.3 LAM环境重链接模块RTE-Relinker
MPI进程在运行之初(被BI.(:R恢复时),是普通linux 进程。只有同LAM环境链接之后才进化为MPI进程。对进 程迁移而言,检查点文件中所记录的链接信息已无意义。 RTE-Relinker根据新节点的位置信息,协助迁移进程与 LAM环境的重链接。 4.4消息通道重建模块CC-Rebuilder
Keywards MPI,High availability,Checkpoint,Rollback,Process migration
1 引言
MPI是并行程序设计的工业标准,因良好的可移植性被 广泛应用于集群计算中。MPI任务中的进程与计算节点的 映射关系是固定的,随着集群规模不断增加,进程崩溃、异常 关机、节点硬件故障以及电磁干扰引起的节点间歇故障等,将 造成系统可用度成指数下降。当某一个进程失效时,整个任 务将面临崩溃。大型工程计算任务执行时间长,一旦发生上 述事件,整个任务将重新执行,导致计算资源与时间的浪费。 所以要求MPI具备容错能力来保证系统在故障期间仍能为 用户提供正确的、不间断的服务[1]。
程的新一gps结构广播给其它MPI进程,并对各进程的一gps 队列进行更新,如gps—node成员更新为新节点的节点号。随
后各进程将各自全新的一gps结构发送给mpirun进程,由
mpirun组成全新一gps队列回送给各脚I进程,这样全体
MPI进程的一gps结构队列都得到了更新。
struct_gps{
Abstract Hi【gh availability plays more and more important role in paralleled computing.This paper developed a new computing platfoFnl named LAM/Migration,which introduced process migration ability into LAM/MPI_By migrating whole MPI application among cluster nodes freely,the process migration function is intelligentized and transparent for application.LAM/Migration can implement node fault tolerance and load balance of cluster and improve the availability of cluster effectively.
检查点与卷回恢复技术(Checkpoint and Rollback Reco- very)是分布式计算常用的容错方法。MPI应用检查点记录 任务正常运行过程中的一致性状态,并存到可靠存储介质上。 当系统发生故障后,根据检查点将任务卷回到故障前的一致 状态继续执行,避免整个任务的重新执行。该方法可以解决 操作系统崩溃、应用程序出错等软件方面的问题,缺点是 MPI进程只能在原节点上卷回,如果原节点因硬件故障不可 再使用时,该进程就被丢失,整个任务也将崩溃。因此,为了 对节点的硬件故障进行容错。必须将故障节点上的MPI进程 迁移到其它正常节点上运行,这是LAM/Migration所解决的 主要问题。
第36卷第4期
圣QQ!生4旦
计算机科学
鱼里巳坚!曼!坠i兰坠堡
Vo.1.36.№4
垒P!:2QQ竺.
基于消息传递并行进程迁移技术的研究与实现
刘天田杨升春欧中红袁由光 (武汉数字工程研究所武汉430074)
摘要高可用在并行计算环境中的地位日益突出。实现LAM/Migration扩展了LAM/MPI的进程迁移功能,可实
MPI进程消息通道的重建需要一gps结构的支持,该结构 包含描述MPI进程的地址信息,具体成员如图3所示。每个
MPI进程都保存一个一gps队列,通过该队列可同任意MPI 进程建立消息通道进行消息传递。进程迁移使进程的地址信
息发生改变,检查点文件中保存的一gps信息已不可使用。 CC-Rebuilder迁移进程完成LAM环境重链接之后,将该进
·167·
信息传送给MPI进程,实现路由更新。 图4展示了较极端的迁移情况。MPI任务由mpirun进