Spring驱动Hibernate的实现
SpringMVC+Spring+Hibernate框架整合原理,作用及使用方法

SpringMVC+Spring+Hibernate框架整合原理,作⽤及使⽤⽅法SSM框架是spring MVC ,spring和mybatis框架的整合,是标准的MVC模式,将整个系统划分为表现层,controller层,service层,DAO层四层使⽤spring MVC负责请求的转发和视图管理spring实现业务对象管理,mybatis作为数据对象的持久化引擎原理:SpringMVC:1.客户端发送请求到DispacherServlet(分发器)2.由DispacherServlet控制器查询HanderMapping,找到处理请求的Controller3.Controller调⽤业务逻辑处理后,返回ModelAndView4.DispacherSerclet查询视图解析器,找到ModelAndView指定的视图5.视图负责将结果显⽰到客户端Spring:我们平时开发接触最多的估计就是IOC容器,它可以装载bean(也就是我们中的类,当然也包括service dao⾥⾯的),有了这个机制,我们就不⽤在每次使⽤这个类的时候为它初始化,很少看到关键字new。
另外spring的aop,事务管理等等都是我们经常⽤到的。
Mybatis:mybatis是对jdbc的封装,它让数据库底层操作变的透明。
mybatis的操作都是围绕⼀个sqlSessionFactory实例展开的。
mybatis通过配置⽂件关联到各实体类的Mapper⽂件,Mapper⽂件中配置了每个类对数据库所需进⾏的sql语句映射。
在每次与数据库交互时,通过sqlSessionFactory拿到⼀个sqlSession,再执⾏sql命令。
使⽤⽅法:要完成⼀个功能:1. 先写实体类entity,定义对象的属性,(可以参照数据库中表的字段来设置,数据库的设计应该在所有编码开始之前)。
2. 写Mapper.xml(Mybatis),其中定义你的功能,对应要对数据库进⾏的那些操作,⽐如 insert、selectAll、selectByKey、delete、update等。
Hibernate+Spring多数据库解决方案

Hibernate+Spring多数据库解决方案我以前在项目中的探索和实践,写出来与大家分享。
大家有其他好的方式,也欢迎分享。
环境:JDK 1.4.x , Hibernate 3.1, Spring 2.0.6, JBOSS4.0, 开发模式: Service + DAO我们项目中需要同时使用多个数据库. 但 Hibernate 不能直接支持,为此我们对比了网上网友的方案,自己做了一点探索。
1. Demo需求我们的项目使用一个全省的公共库加十多个地市库的架构。
本文主要说明原理,将需求简化为两库模型。
主库:User管里,主要是系统管理,鉴权等数据;订单库:Order 管理,存放订单等业务性数据。
2. 原理:1) Hibernate 的每个配置文件对应一个数据库,因此多库需要做多个配置文件。
本文以两个为例:主库 hibernate_sys.cfg.xml,订单库 hibernate_order.cfg.xml每个库,Hibernate 对应一个 sessionFactory 实例,因此Hibernate 下的多库处理,就是在多个 sessionFactory 之间做好路由。
2) sessionFactory 有个 sessionFactory.getClassMetadata(voClass) 方法,返回值不为空时,表示该 VO 类在该库中(hbm.xml文件配置在了对应的hibernate.cfg.xml中),该方法是数据路由的核心和关键所在。
因此, User.hbm.xml 配置在 hibernate_sys.cfg.xml ,Order数据位于配置到 hibernate_order.cfg.xml3)多库处理时,需要使用 XA 事务管理。
本例中使用 Jboss4.0 来做JTA事务管理;用JOTM,其他应用服务器原理相同。
3. 实现1)为做多 sessionFactory 实例的管理,设计 SessionFactoryManager 类,功能就是做数据路由,控制路由的核心是 sessionFactoryMap 属性,它按dbFlag=sessionFactory 的方式存储了多个库的引用。
hibernate的基本用法

hibernate的基本用法Hibernate是一个开源的Java框架,用于简化数据库操作。
它为开发人员提供了一个更加简单、直观的方式来管理数据库,同时也提高了应用程序的性能和可维护性。
本文将逐步介绍Hibernate的基本用法,包括配置、实体映射、数据操作等。
一、配置Hibernate1. 下载和安装Hibernate:首先,我们需要下载Hibernate的压缩包并解压。
然后将解压后的文件夹添加到Java项目的构建路径中。
2. 创建Hibernate配置文件:在解压后的文件夹中,可以找到一个名为"hibernate.cfg.xml"的文件。
这是Hibernate的主要配置文件,我们需要在其中指定数据库连接信息和其他相关配置。
3. 配置数据库连接:在"hibernate.cfg.xml"文件中,我们可以添加一个名为"hibernate.connection.url"的属性,用于指定数据库的连接URL。
除此之外,还需要指定数据库的用户名和密码等信息。
4. 配置实体映射:Hibernate使用对象关系映射(ORM)来将Java类映射到数据库表。
我们需要在配置文件中使用"mapping"元素来指定实体类的映射文件。
这个映射文件描述了实体类与数据库表之间的对应关系。
二、实体映射1. 创建实体类:我们需要创建一个Java类,用于表示数据库中的一行数据。
这个类的字段通常与数据库表的列对应。
同时,我们可以使用Hibernate提供的注解或XML文件来配置实体的映射关系。
2. 创建映射文件:可以根据个人喜好选择使用注解还是XML文件来配置实体类的映射关系。
如果使用XML文件,需要创建一个与实体类同名的XML文件,并在其中定义实体类与数据库表之间的映射关系。
3. 配置实体映射:在配置文件中,我们需要使用"mapping"元素来指定实体类的映射文件。
spring4.x + hibernate4.x 配置详解

spring4.x + hibernate4.x 配置详解关于spring和hibernate的使用以及特征等等,在此不再啰嗦,相信大家也都知道,或者去搜索一下即可。
本篇博文的内容主要是我最近整理的关于spring4.x 和hibernate 4.x 相关配置和使用方式,当然spring3.x以及hibernate4.x也可以借鉴。
首先是配置文件web.xml 增加以下代码即可<!-- 加载spring相关的配置文件--><context-param><param-name>contextConfigLocation</param-name><param-value>classpath*:/applicationContext.xml</param-value> </context-param><!-- 启用spring监听--><listener><listener-class>org.springframework.web.context.ContextLoaderListener</l istener-class></listener>然后建立 applicationContext.xml 文件,src下。
文件内容如下,注释我尽量写的很详细<beans xmlns:xsi="/2001/XMLSchema-instance"xmlns="/schema/beans"xmlns:aop="http://ww /schema/aop"xmlns:context="/schema/context"xmlns:tx="ht tp:///schema/tx"xmlns:cache="/schema/cache"xmlns:p="http:// /schema/p"xsi:schemaLocation="/schema/beans /schema/beans/spring-beans-4.0.xsd/schema/aop/schema/aop/spring-aop-4.0.xsd/schema/context/schema/context/spring-context-4.0.xsd/schema/tx/schema/tx/spring-tx-4.0.xsd/schema/cache http://www.springframewor /schema/cache/spring-cache-4.0.xsd"><!-- 引入properties文件--><context:property-placeholder location="classpath*:/appConfig.properties"/> <!-- 定义数据库连接池数据源bean destroy-method="close"的作用是当数据库连接不使用的时候,就把该连接重新放到数据池中,方便下次使用调用--> <bean id="dataSource"class="boPooledDataSourc e"destroy-method="close"><!-- 设置JDBC驱动名称--><property name="driverClass"value="${jdbc.driver}"/><!-- 设置JDBC连接URL --><property name="jdbcUrl"value="${jdbc.url}"/><!-- 设置数据库用户名--><property name="user"value="${ername}"/><!-- 设置数据库密码--><property name="password"value="${jdbc.password}"/><!-- 设置连接池初始值--><property name="initialPoolSize"value="5"/></bean><!-- 配置sessionFactory --><bean id="sessionFactory"class="org.springframework.orm.hibernate4.LocalSessionFactoryBean"><!-- 数据源--><property name="dataSource"ref="dataSource"/><!-- hibernate的相关属性配置--><property name="hibernateProperties"><value><!-- 设置数据库方言-->hibernate.dialect=org.hibernate.dialect.MySQLDialect<!-- 设置自动创建|更新|验证数据库表结构-->hibernate.hbm2ddl.auto=update<!-- 是否在控制台显示sql -->hibernate.show_sql=true<!-- 是否格式化sql,优化显示-->hibernate.format_sql=true<!-- 是否开启二级缓存-->e_second_level_cache=false<!-- 是否开启查询缓存-->e_query_cache=false<!-- 数据库批量查询最大数-->hibernate.jdbc.fetch_size=50<!-- 数据库批量更新、添加、删除操作最大数-->hibernate.jdbc.batch_size=50<!-- 是否自动提交事务-->hibernate.connection.autocommit=true<!-- 指定hibernate在何时释放JDBC连接-->hibernate.connection.release_mode=auto<!-- 创建session方式hibernate4.x 的方式-->hibernate.current_session_context_class=org.springframework.or m.hibernate4.SpringSessionContext<!-- javax.persistence.validation.mode默认情况下是auto的,就是说如果不设置的话它是会自动去你的classpath下面找一个bean-validation**包所以把它设置为none即可-->javax.persistence.validation.mode=none</value></property><!-- 自动扫描实体对象tdxy.bean的包结构中存放实体类--><property name="packagesToScan"value="tdxy.bean"/> </bean><!-- 定义事务管理--><bean id="transactionManager"class="org.springframework.orm.hibernate4.HibernateTransactionManager "><property name="sessionFactory"ref="sessionFactory"/> </bean><!-- 定义Autowired 自动注入bean --><bean class="org.springframework.beans.factory.annotation.AutowiredAnnotati onBeanPostProcessor"/><!-- 扫描有注解的文件base-package 包路径--><context:component-scan base-package="tdxy"/><tx:advice id="txAdvice"transaction-manager="transactionManager"> <tx:attributes><!-- 事务执行方式REQUIRED:指定当前方法必需在事务环境中运行,如果当前有事务环境就加入当前正在执行的事务环境,如果当前没有事务,就新建一个事务。
Struts、Spring、Hibernate三大框架的原理和优点

Struts的原理和优点.Struts工作原理MVC即Model—View—Controller的缩写,是一种常用的设计模式。
MVC 减弱了业务逻辑接口和数据接口之间的耦合,以及让视图层更富于变化。
MVC的工作原理,如下图1所示:Struts 是MVC的一种实现,它将Servlet和JSP 标记(属于J2EE 规范)用作实现的一部分。
Struts继承了MVC的各项特性,并根据J2EE的特点,做了相应的变化与扩展.Struts的工作原理,视图:主要由JSP生成页面完成视图,Struts提供丰富的JSP 标签库: Html,Bean,Logic,Template等,这有利于分开表现逻辑和程序逻辑。
控制:在Struts中,承担MVC中Controller角色的是一个Servlet,叫ActionServlet。
ActionServlet是一个通用的控制组件。
这个控制组件提供了处理所有发送到Struts的HTTP请求的入口点。
它截取和分发这些请求到相应的动作类(这些动作类都是Action类的子类)。
另外控制组件也负责用相应的请求参数填充Action From(通常称之为FromBean),并传给动作类(通常称之为ActionBean)。
动作类实现核心商业逻辑,它可以访问java bean 或调用EJB。
最后动作类把控制权传给后续的JSP 文件,后者生成视图。
所有这些控制逻辑利用Struts-config.xml文件来配置。
模型:模型以一个或多个java bean的形式存在。
这些bean分为三类:Action Form、Action、JavaBean or EJB.Action Form通常称之为FormBean,封装了来自于Client的用户请求信息,如表单信息。
Action通常称之为ActionBean,获取从ActionSevlet传来的FormBean,取出FormBean中的相关信息,并做出相关的处理,一般是调用Java Bean或EJB等。
基于Spring和Hibernate的JavaEE数据持久层的研究与实现

据的 C U R D。目前 , 我们使用 的绝大 多数数据 库是关
系型数据 库 , 设 计 和开 发往 往 又 是 面 向对 象 的方 而 式 , 了提高数 据访 问的效 率 , 为 持久 层 的解 决方 案就
合理划 分数据持久 层体 系结构 : 用 I 使 Oc
技术 , 数据 源 信 息 注 入 到数 据操 作层 中 , 数 据 将 使 源层 和数 据操 作层 进 行分 离 , 降低 数据 源 和数 据 操
wh l i e,t e I t g a i n o p i g a d Hi e n t r m e r o sr c s a n r sr c u e wh c si c o d n e wih d t h n e r to f S r n n b r a e f a wo k c n t u t n i f a t u t r i h i n a c r a c t a a p r it n i r e s e tte ,ma i g p s i l h o s o p l g s k n o sb e t e l o e c u i .Th y t m sh g l t b e lx b e a d e p n i l . n e s se i i h y s a l ,fe i l n x a sb e
关键词 jv 企 业 版 aa 数 据持 久 层 控制反转 面 向 方 面 编 程
中 图分 类 号
TP 1. 2 3 11
S u n a i a i n of J v EE t dy a d Re lz t o a a Per i t nt Ti r b s d on sse e a e
Ke o d J v EE,d t e s t n i r OC,AOP yw r s aa a a p r i e tte ,I s
基于Spring、Struts和Hibernate的研究生教育管理系统的设计与实现

关键词 : 研究生教 育管理 开 源 框架 S rn Sr t H b r ae pig tus ie n t 中图分类号 : P3 T 文献标 识 码 : A 文章编号 : 6 3 9 ( 0 8 l ( ) 0 3 - 2 1 7 - 7 12 0 )la- 0 6 0 2
1究背景
研 究生 教 育 是 我 国 高 等 教 育 的 重 要 组 成 部 分 , 负 着 为 国 家 培 养 高 级 人 才 的 重 担 要 使 命 , 重 视 的 程 度 日益 增 加 。 与 本 科 受 生 教 育 相 比 , 研 究 生 年 龄 来 看 , 们 已 经 从 他 属 于 比 较 成 熟 的一 群 , 研 究 生 生 源 组 成 且 比较 复杂 , 在社 会 经验 、人生 阅历 、生 活 方 式 等 许 多 方 面 都 有 较 大 差 异 , 别 是 部 分 特 学生 已组 成 家庭 ; 学 习方 式 上 看 , 究 生 从 研 已 跳 出 了 以 班 级 为单 位 的 集 体 授 课 形 式 , 变 成 了 几个 学 生 直 接 面 对 导 师 的 个 性化 教 学 ; 学 习 内 容来 看 , 究 生 也 已从 被 动 的 从 研 解 惑 和 接 收 变 成 了 主 动 的探 索 和 研 究 ; 研 究 生 根 据 各 自的研 究 方 向 , 立 进 行 选 课 , 独 进 入课题研究后 更是以课题 研究为 中心 , 进 行 独 立 的研 究 和 实 验 …。 框 架 是 一 种 可 复 用 的 、 可 适 配 的 软 件 , 有 灵 活 的结 构 便 于 扩 展 。 使 用 合 适 它 的框 架 , 以 节 省 设计 人 员 的时 间 , 其 有 可 使 更 多 的精 力 从 事 业 务 逻 辑 本 身 的 分 析 与 研 究 , 且 成 熟 的 框 架 本 身 就 是 对 系 统 质 量 并 的 保障 。文 中将 采 用 目前 流 行 的 三 种 轻 量
达梦Hibernate Spring集成开发示例
达梦Hibernate Spring集成开发示例DM是武汉华工达梦数据库有限公司推出的新一代高性能、高安全性的数据库产品。
它具有开放的、可扩展的体系结构,高性能事务处理能力,以及低廉的维护成本。
DM是完全自主开发的数据库软件,其安全级别达到了国内所有数据库产品中的最高级---B1级。
在这里我准备用时下比较流行的开发工具,Hibernate和Spring,达梦数据库。
以及MyEclipse来完成一个简单的应用。
数据库采用达梦5.01、用达梦创建一个test数据库,再创建一个user表,再创建两个字段username和password。
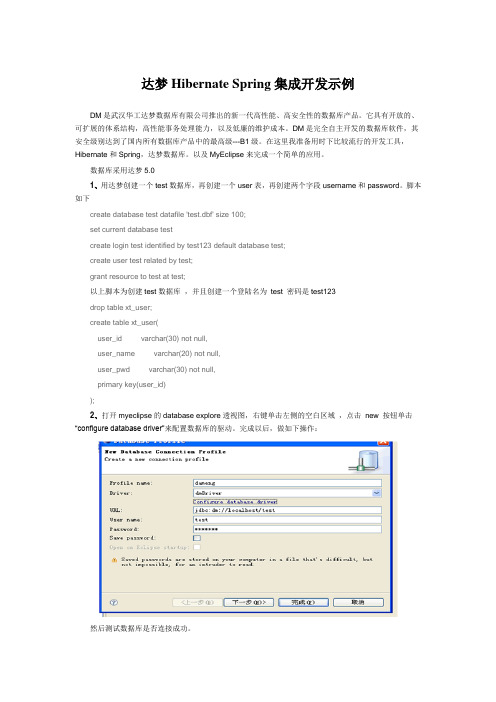
脚本如下create database test datafile 'test.dbf' size 100;set current database testcreate login test identified by test123 default database test;create user test related by test;grant resource to test at test;以上脚本为创建test数据库,并且创建一个登陆名为test 密码是test123drop table xt_user;create table xt_user(user_id varchar(30) not null,user_name varchar(20) not null,user_pwd varchar(30) not null,primary key(user_id));2、打开myeclipse的database explore透视图,右键单击左侧的空白区域,点击new 按钮单击“configure database driver”来配置数据库的驱动。
完成以后,做如下操作:然后测试数据库是否连接成功。
如果测试成功显示如下图:1.新建一个web项目testSpring 2.引入Spring包注意:这里为了省得以后再添加spring的相关包,所以一次性的选中了所有的包。
Spring的HibernateTemplate

使用spring的hibernateTemplate的方法分类:Struts+Hibernate+Spring2009-05-22 15:486178人阅读评论(6)收藏举报使用spring的hibernateTemplate的方法- [spring]版权声明:转载时请以超链接形式标明文章原始出处和作者信息及本声明/logs/24775065.html1.管理SessionFactory使用Spring整合Hibernate时我们不需要hibernate.cfg.xml文件。
首先,在applicationContext.xml中配置数据源(dataSource)bean和session工厂(sessionFactory)bean。
其中,在配置session工厂bean 时,应该注入三个方面的信息:●数据源bean●所有持久化类的配置文件●Hibernate的SessionFactory的属性Hibernate的SessionFactory的属性信息又包括两个内容,一,Hibernate的连接方法;二,不同数据库连接,启动时的选择。
2.为HibernateTemplate注入SessionFactory对象,通过HibernateT emplate来持久化对象Spring提供了HibernateTemplate,用于持久层访问,该模板无需打开Session及关闭Session。
它只要获得SessionFactory的引用,将可以只能地打开Session,并在持久化访问结束后关闭Session,程序开发只需完成持久层逻辑,通用的操作(如对数据库中数据的增,删,改,查)则有HibernateTemplate完成。
HibernateTemplate有三个构造函数,不论是用哪一种构造,要使HibernateTemplate能完成持久化操作,都必须向其传入一个SessionFactory的引用。
HibernateTemplate的用法有两种,一种是常规的用法,另一种是复杂的用。
hibernate框架的工作原理

hibernate框架的工作原理Hibernate框架的工作原理Hibernate是一个开源的ORM(Object-Relational Mapping)框架,它将Java对象映射到关系型数据库中。
它提供了一种简单的方式来处理数据持久化,同时也提供了一些高级特性来优化性能和可维护性。
1. Hibernate框架的基本概念在开始讲解Hibernate框架的工作原理之前,需要先了解一些基本概念:Session:Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
SessionFactory:SessionFactory是一个线程安全的对象,它用于创建Session对象。
通常情况下,应用程序只需要创建一个SessionFactory对象。
Transaction:Transaction是对数据库操作进行事务管理的接口。
在Hibernate中,所有对数据库的操作都应该在事务中进行。
Mapping文件:Mapping文件用于描述Java类与数据库表之间的映射关系。
它定义了Java类属性与数据库表字段之间的对应关系。
2. Hibernate框架的工作流程Hibernate框架主要分为两个部分:持久化层和业务逻辑层。
其中,持久化层负责将Java对象映射到数据库中,并提供数据访问接口;业务逻辑层则负责处理业务逻辑,并调用持久化层进行数据访问。
Hibernate框架的工作流程如下:2.1 创建SessionFactory对象在应用程序启动时,需要创建一个SessionFactory对象。
SessionFactory是一个线程安全的对象,通常情况下只需要创建一个即可。
2.2 创建Session对象在业务逻辑层需要进行数据访问时,需要先创建一个Session对象。
Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
2.3 执行数据库操作在获取了Session对象之后,就可以执行各种数据库操作了。
springMVC与hibernate整合实例

SpringMVC的搭建一直以来接触到的都是SSH的框架,形成了MVC模式,本来并没有想着去弄另一个MVC模式,但现在springMVC模式很热,所以我也学习一下,首先我声明一下,这个框架我也是在网上找了一些资料才完成的,源文件等也是利用的网上的现成的,但是有对其进行修改。
下面来详细的说一说这个模式的搭建。
首先在spring中是以controller来作为控制器(相当于SSH中的action),其他的和SSH框架没有区别。
因为Spring是基于注解的,所以在整个的模式中都是采用注解的方式来处理,这个项目是用springMVC+hibernate一起来搭建的。
这个项目的搭建我花了很久的时间,也弄了蛮久才成功,希望日后能更加完善!理解更加的深入。
一:整体框架的结构图以及所需的jar包。
这里spring是3.0.1,hibernate是用的3.6,数据库是用的mysql 5.6 ,前提工作是要建立好一个数据库,我这里是名为springmvc的数据库来进行操作,这里是采用的hibernate自动更新的方式,所以可以不需要建表只需要建立起数据库就好。
项目框架的代码结构:二:开始搭建环境。
1,首先把上面所需的包添加进来后,我们要在/WEB-INF目录下的web.xml里面添加spring的监听器,以及相关的配置。
源码如下:<?xml version="1.0"encoding="UTF-8"?><web-app version="2.5"xmlns="/xml/ns/javaee"xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/xml/ns/javaee/xml/ns/javaee/web-app_2_5.xsd"><display-name>s3h3</display-name><context-param><param-name>contextConfigLocation</param-name><param-value>classpath:applicationContext*.xml</param-value> </context-param><listener><listener-class>org.springframework.web.context.ContextLoaderList ener</listener-class></listener><servlet><servlet-name>spring</servlet-name><servlet-class>org.springframework.web.servlet.DispatcherServlet</se rvlet-class><init-param><param-name>contextConfigLocation</param-name><param-value>/WEB-INF/spring-servlet.xml</param-value> </init-param><load-on-startup>1</load-on-startup></servlet><servlet-mapping><servlet-name>spring</servlet-name><!-- 这里在配成spring,下边也要写一个名为spring-servlet.xml的文件,主要用来配置它的controller --> <url-pattern>*.do</url-pattern></servlet-mapping><welcome-file-list><welcome-file>index.html</welcome-file><welcome-file>index.htm</welcome-file><welcome-file>index.jsp</welcome-file><welcome-file>default.html</welcome-file><welcome-file>default.htm</welcome-file><welcome-file>default.jsp</welcome-file></welcome-file-list></web-app>2,接下来可以编写spring的配置文件,来整合hibernate,主要的配置写在一个专门存放配置文件的源码目录下config文件夹下,这里的applicationContext.xml是spring的主要配置文件,包括数据源等的配置。
springboot中使用jpa下hibernate的ddl-auto方式

springboot中使⽤jpa下hibernate的ddl-auto⽅式⽬录使⽤jpa下hibernate的ddl-autoddl-auto的配置spring.jpa.hibernate.ddl-auto的配置具体的关系见下使⽤jpa下hibernate的ddl-auto今天做⼀个报表的功能,发现⼀个表中的shopProductId都为null,但在程序中判断⽤的是shopProductId,⽽且表中有productId 不为null,在查找原因的途中,才得知是有⼈将productId改为了shopProductId,但是数据没有更新过去。
遇到这种情况,我们怎么能查看到某些字段被改变了呢?由于我们⽤的框架是springBoot+jap-hibernate,然后在jpa下的hibernate,在application配置⽂件中,有ddl-auto的配置ddl-auto:create每次运⾏该程序,没有表格会新建表格,表内有数据会清空ddl-auto:create-drop每次程序结束的时候会清空表ddl-auto:update每次运⾏程序,没有表格会新建表格,表内有数据不会清空,只会更新ddl-auto:validate运⾏程序会校验数据与数据库的字段类型是否相同,不同会报错把ddl-auto改为validate时,我们启动项⽬时,会提⽰哪⼀个字段被更改,这样我们在发布上线时,会及时发现,不⾄于出现错误。
⽽正常运⾏的时候,⼀般设置为update属性。
spring.jpa.hibernate.ddl-auto的配置spring.jpa.hibernate.ddl-auto 可以显式设置 spring.jpa.hibernate.ddl-auto ,标准的Hibernate属性值有 none,validate,update,create,create-drop。
Spring Boot 会根据数据库是否是内嵌类型,选择⼀个默认值。
javaEE笔试复习题

一、单选题1.下面关于数据持久化概念的描述,错误的是(D)A、保存在内存中数据的状态是瞬时状态B、持久状态的数据在关机后数据依然存在C、数据可以由持久状态转换为瞬时状态D、将数据转换为持久状态的机制称为数据持久化2.Java Web应用中往往通过设置不同作用域的属性来达到通讯的目的。
如果某个对象只在同一请求中共享,通过调用哪个类(C)的setAttribute方法设置属性。
A、HttpServletRequestB、ServletRequestListenerC、HttpSessionD、ServletContext3.POJO的作用是(C)A、普通的Java对象映射数据库元组B、数据访问C、对象的赋值D、保存客户端对象4.在三层结构中,数据访问层承担的责任是(B)A、定义实体类B、数据的增删改查操作C、业务逻辑的描述D、页面展示和控制转发5.下列哪个接口用于获取关于数据库的信息(D)A、StatementB、PreparedStatementC、ConnectionD、DatabaseMetaData6.JDBC包含多个类,其中Java.sql.ResultSet类属于(C)A、JDBC控制类B、JDBC类C、JDBC接口类D、JDBC异常类7.以下关于SessionFactory的说法哪些正确(B)A、对于每个数据库事务,应该创建一个SessionFactory对象。
B、一个SessionFactory对象对应一个数据库存储源。
C、SessionFactory是重量级的对象,不应该随意创建。
如果系统中只有一个数据库存储源,需要创建多个。
D、SessionFactory的load()方法用于加载持久化对象。
8.以下哪些不属于Session的方法(C)A、load()B、save()C、open()D、saveOrUpdate()9.在持久化层,对象分为的状态不包括(B)A、瞬时(Transient)B、新建(New)C、脱管(Detached)D、持久(Persistent)10.实现equals和hashCode最显而易见的作用是(A)A、比较两个对象标识符的值B、比较数据库的两条数据C、比较两个组建是否部署在同一个应用服务器上D、对象与字段的映射11.在三层结构中,数据访问层承担的责任是(B)A、定义实体类B、数据的增删改查操作C、业务逻辑的描述D、页面展示和控制转发12.Hibernate配置文件中,不包含下面的(A)A、“对象-关系映射”信息B、数据关联的配置C、show_sql等参数的配置D、数据库连接信息13.下面创建Criteria对象的语句中正确的是(D)A、Criteria c = query.createCriteria();B、Criteria c = query.addCriteria();C、Criteria c = session.createCriteria();D、Criteria c = session.createCriteria(User.class);14.以下关于SessionFactory的说法哪些正确(B)A、对于每个数据库事务,应该创建一个SessionFactory对象。
Spring和Hibernate的整合应用研究

摘
要: 通过对 S r g和 H brae pi n ient 框架各 自特性 的研究 , S r g和 H brae的整合应 用 的原 因进行 了分 对 pn i ient
析, 并结合具体 的实例进行 阐述 。S r g p n 杰出 的事务管理能力 和 良好 的持 久层封装 , 大节省 了 Hb ra i 大 ie t n e应 用程 序的代码量 , 从而提 高了生产率。 同时 ,p n Sr g和 H brae的整合应 用 , 建 了符合 MV i ient 构 C设计模 式的系
对于传统 的基 于特定 事务资源 的事 务处理
分发挥各 自特点, 是能否高效率实现开发工作 的
关键 。 笔者 在从 事 Jv aa平 台 的管 理 系 统 项 目开 发
在 图 1a 所 示 情况 下 , () 对象 直接 创建所 需 对 象 和 c, 这将 导致 代 码 的 紧耦 合 。对 象 和 c的 任何 改 动 都 将 导 致 对 象 的 重 新 编 译 。在 图 1 ( ) 示情 况 下 , 用 IC机 制 , 象 在 更 高层 创 b所 使 o 对 建 并 传递 到需 要使用 它 们 的其 他 对象 中 。
统架构 , 实现 了功能层次之间 的松散耦合 , 使整个系统具备 了良好的稳定性 、 可伸缩性和可扩展性 。 关键 词 : 整合 ;p n ; brae S r gHi nt i e
中 图 法分 类 号 :P 1 T3 1 文献标识码 : A
基 于 We b的各种 开源框 架 在 JE 2 E应 用开 发
维普资讯
第2 卷 第4 9 期
20 年4 07 月
武 汉 理 工 大 学 学 报 ・信 息 与 管 理 工 程 版
Struts2.5+Hibernate3.1+Spring应用开发实例(图)

Struts2.5+Hibernate3.1+Spring应用开发实例.(Hibernate和Spring是新的知识点,先单独强化,然后再整合训练)任务一:Hibernate(10课时)该任务包括两个部分内容一是Hibernate的基础知识,二是实际完成一个Hibernate应用。
要求:掌握Hibernate的基础知识,掌握开发Hibernate应用的方法。
任务二:Sping(10课时)该任务包括两个部分内容一是介绍Spring的基础知识,二是完成一个Spirng 应用。
要求:掌握Spring的基础知识,掌握开发Spirng应用的方法。
任务三:Hibernate和Spring的联合开发(8课时)使用Hibernate和Spring框架完成Java应用开发要求:掌握使用Hibernate和Spring框架开发Java应用程序的过程。
任务四:基于Struts+Hibernate+Spring的网上购物系统开发(28课时)结合Hibernate和Spring改写《Java Web 应用开发项目教程》的前台要求:掌握使用Struts+Hibernate+Spring框架开发网上购物系统的方法实训要求:1.每位同学独立完成2.每部分内容按时提交代码和学习报告(总成绩由每次的节点成绩统计获得)软件环境需求:1.操作系统:WindowsXP2.数据库及驱动程序:Microsoft SQLServer 2005 JDBC3.JDK: JDK64.IDE:MyEclipse7.05.服务器:Tomcat6.0任务一Hibernate1.1Hibernate基础知识1.Hibernate简介Hibernate是一种Java语言下的对象-关系映射解决方案,它是一种自由、开源的轻量级框架,用于将面向对象的对象模型映射到传统的关系数据库中。
Hibernate对JDBC进行了轻量级的对象封装,不仅提供从Java数据类型到SQL数据类型的ORM映射,还提供数据查询和数据缓存功能,大幅度减少开发时人工使用SQL 和JDBC 处理数据的时间,使得Java程序员可以完全使用面向对象的编程思维通过Hibernata API操作关系数据库。
Spring框架核心原理解析

Spring框架核心原理解析Spring框架作为一个被广泛应用的开源框架,具备强大的功能和灵活性,为Java应用程序开发提供了便捷的解决方案。
它的成功之处在于其核心原理的设计和实现。
本文将对Spring框架的核心原理进行解析,以帮助读者更好地理解该框架的内部机制。
一、依赖注入(Dependency Injection)依赖注入是Spring框架的核心概念之一。
它的基本原理是通过将对象之间的依赖关系交由框架来管理,从而降低了类之间的耦合性。
在Spring框架中,通过配置文件或注解的方式描述对象之间的依赖关系,框架根据这些描述将所需的对象注入到相应的位置。
二、控制反转(Inversion of Control)控制反转是依赖注入的基础概念,也被称为IoC。
它的核心思想是将对象的创建和管理交给框架来完成,而不是由对象自身负责。
在Spring框架中,通过IoC容器来实现控制反转,容器负责创建、初始化和管理应用程序中的对象,开发者只需要关注对象的使用即可。
三、面向切面编程(Aspect-Oriented Programming)面向切面编程是Spring框架的另一个核心原理。
它的目的是实现横切关注点的模块化,提供更好的代码复用和解耦。
在Spring框架中,通过AOP技术可以将一系列与业务逻辑无关的功能和代码片段,比如事务管理、日志记录等,抽离出来,以切面的方式织入到应用程序中。
四、模块化设计(Modular Design)Spring框架采用模块化的设计思想,将各种功能和组件划分为不同的模块,以便更好地管理和维护。
每个模块都有清晰的职责和功能,可以根据实际需求进行选择和组合。
常用的Spring模块包括核心容器模块、数据访问模块、Web开发模块等,开发者可以灵活地按需引入。
五、灵活的扩展性和可插拔性Spring框架具备良好的扩展性和可插拔性,可以根据具体需求进行灵活的配置和定制。
开发者可以使用自定义的扩展点和接口来实现个性化的功能需求,比如自定义的数据访问层、认证授权模块等。
hibernate项目开发的一般步骤

Hibernate 是一个开源的对象关系映射(ORM)框架,它可以将 Java 对象映射到关系型数据库中。
使用 Hibernate 进行项目开发的一般步骤如下:
1. 配置 Hibernate:首先需要在项目中添加 Hibernate 的相关依赖,并在配置文件中进行相关配置,如连接数据库的 URL、用户名和密码等。
2. 创建实体类:根据数据库表的结构,创建相应的 Java 实体类。
这些类需要继承自Hibernate 的某个抽象类或接口,并包含相应的属性和注解。
3. 创建映射文件:为每个实体类创建一个映射文件,用于描述实体类与数据库表之间的映射关系。
映射文件通常是以`.hbm.xml`为扩展名的文件。
4. 编写 DAO 类:使用 Hibernate 提供的 API 编写数据访问对象(DAO)类,用于对数据库进行操作。
DAO 类通常包含用于插入、更新、删除和查询数据的方法。
5. 编写业务逻辑:在服务层编写业务逻辑代码,调用 DAO 类进行数据库操作。
6. 测试:编写测试代码,对业务逻辑进行测试。
7. 部署和运行:将项目部署到服务器上,并运行应用程序。
需要注意的是,在使用 Hibernate 进行项目开发时,需要遵循一些最佳实践,如延迟加载、缓存优化等,以提高系统的性能和可维护性。
以上是使用 Hibernate 进行项目开发的一般步骤,具体的步骤和实现方式可能因项目的需求和架构而有所不同。
基于Spring+Hibernate框架的农业信息化平台系统的设计与实现

维普资讯
第 5期
王可 : 于 S) n 基 1i l g+}t nae框 架的农 业 信息 化平 台系统的 设 计与 实现 I) l 1 c t
摘要: 集成 S r g与 Hi rae pi n b n t框架技术构建 基于 J E e 2 E的 We b应片可 以提 高 J E J 2 E项 目的可重用性 。介绍 了
使用技术 的原理及组合 Sr g Hbm t框架 的 We 应用。并给出在该框架 下设计 的农业信息 化平 台 系统的实 pn + i a i e e b
文 章 编号 :17 —7 2 2 0 0 一6 21 6 II4 (0 7)5I 2 5 ) 1
基 于 S rn +Hien t 架 的 农 业 信 息 化 平 台 p ig b r ae框 系统 的设 计 与 实现
王 可
( 西南 交通 大 学软 交换 实验 室 , 四川 成都 6 0 3 ) 10 1
的. E N T等 We b服务技 术体 系 。虽 然 JE 2 E为 基于 We b的企业应用提供 了优秀 的支持 , 面对 . E 但 . T的快速开发 , N
JE 2 E庞大的体系显得有些臃肿。与 JE 2 E重量级体系相对应, 在开发农业信息化平 台系统时引入了轻量级 We 框 b 架—一 Srg+Hi rae pi n b nt e 。这个轻量级 wl 框 架一方 面保持 了 JE e b 2 E的优势 , 另一方 面也简化 了 、e vb的开发 。
2 2 轻量 级 We 架概 述 . b框
针 对上述 问题 , 类似 于 S r g的轻量 级框 架 由此 产生 。所 谓的轻 量级 , pi n 并不 是 功能 弱 、 设计 简 陋 、 实现 粗糙 、
Hibernate的工作原理

Hibernate的工作原理Hibernate是一个开源的Java持久化框架,它能够将Java对象映射到关系型数据库中,并提供了一套简单而强大的API,使得开辟人员能够更加方便地进行数据库操作。
Hibernate的工作原理主要包括以下几个方面:1. 对象关系映射(ORM):Hibernate使用对象关系映射技术将Java对象与数据库表之间建立起映射关系。
开辟人员只需要定义好实体类和数据库表之间的映射关系,Hibernate就能够自动地将Java对象持久化到数据库中,或者将数据库中的数据映射成Java对象。
2. 配置文件:Hibernate通过一个配置文件来指定数据库连接信息、映射文件的位置以及其他一些配置信息。
配置文件通常是一个XML文件,其中包含了数据库驱动类、连接URL、用户名、密码等信息。
开辟人员需要根据自己的数据库环境进行相应的配置。
3. SessionFactory:Hibernate的核心组件是SessionFactory,它负责创建Session对象。
SessionFactory是线程安全的,通常在应用程序启动时创建一次即可。
SessionFactory是基于Hibernate配置文件和映射文件来构建的,它会根据配置文件中的信息来创建数据库连接池,并加载映射文件中的映射信息。
4. Session:Session是Hibernate的另一个核心组件,它代表了与数据库的一次会话。
每一个线程通常会有一个对应的Session对象。
Session提供了一系列的方法,用于执行数据库操作,如保存、更新、删除、查询等。
开辟人员通过Session对象来操作数据库,而不直接与JDBC打交道。
5. 事务管理:Hibernate支持事务的管理,开辟人员可以通过编程方式来控制事务的提交或者回滚。
在Hibernate中,事务是由Session来管理的。
开辟人员可以通过调用Session的beginTransation()方法来启动一个事务,然后根据需要进行提交或者回滚。
SpringMVC+Hibernate4+Spring3整合开发实现CRUD

·在实现CRUD之前,我想你的开发环境已经搭建好了,我们就不作搭建的说明了,直接进入正题;一般搭建环境都是项目经理的事情,项目经理搭建完环境,就会把环境放到svn服务器上,你只需要从服务器上检出项目环境开发即可;File→Inport→SVN→从SVN检出项目我的资源库已经创建好了,你从视图中打开资源库视图创建一个资源库就好了,选择项目文件夹finish即可;·我们首先要生成简单Java类,也称POJO类,既然有添加hibernate的开发支持,当然要用hibernate提供的功能了,那我们首先编写一个数据库创建脚本,其中包括最常用的字段即可,就编写一个雇员表吧;USE mysql ;DROP TABLE emp ;CREATE TABLE emp(empno INT AUTO_INCREMENT ,ename VARCHAR(30) NOT NULL ,hiredate DATE ,sal VARCHAR(50) NOT NULL ,CONSTRAINT pk_nid PRIMARY KEY(empno)) ;·用hibernate生成一个表的对应的简单java类,打开DB Browser视图→找到对应的表右键→hibernate Reverse Engineering……这个界面就按照下图的设置,下图中没显示的部分,取消勾选,不做设置;·配置完成之后,会生成一个以表名称为类名的一个简单java类,不过首字母大写,采用的annotation注解的方式和数据表配置了映射关系,生成的类会有一些警告,压制一些就OK了,生成的构造方法没有任何用处,删掉即可,一些注释也可以删掉了,另外增加一个toString()方法,这样在做一些异常调试的时候很方便,此类我做了一点简单的注释,可以一看;Emp.javapackage cn.oracle.pojo;import java.util.Date;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.GeneratedValue;import javax.persistence.Id;import javax.persistence.Table;import javax.persistence.Temporal;import javax.persistence.TemporalType;@SuppressWarnings("serial")→压制警告用的@Entity→代表这一个实体,与数据表映射对应;@Table(name = "emp", catalog = "mysql")→此设置了这个实体对应的数据库名称和表名称;name 属性是表名称,catalog 是你用到数据库的名字;public class Emp implements java.io.Serializable {private Integer empno;→对应的字段名称;private String ename; →对应的字段名称;private Date hiredate; →对应的字段名称;private String sal; →对应的字段名称;@Id→表示这个字段值主键,唯一的@GeneratedValue→表示此字段自动增长,@Column(name = "empno", unique = true, nullable = false)→对应表中的列的属性,name 表示列名称,unique表示唯一性,nullable表示是否为空;public Integer getEmpno() {return this.empno;}public void setEmpno(Integer empno) {this.empno = empno;}@Column(name = "ename", nullable = false, length = 30)→length表示长度public String getEname() {return this.ename;}public void setEname(String ename) {this.ename = ename;}@Temporal(TemporalType.DATE)→专门标注日期的;@Column(name = "hiredate", length = 10)public Date getHiredate() {return this.hiredate;}public void setHiredate(Date hiredate) {this.hiredate = hiredate;}@Column(name = "sal", nullable = false, length = 50)public String getSal() {return this.sal;}public void setSal(String sal) {this.sal = sal;}@Overridepublic String toString() {return"Emp [empno=" + empno + ", ename=" + ename + ", hiredate="+ hiredate + ", sal=" + sal + "]";}}·简单java类完成是第一步,然后我们需要配置数据库连接了,这是正常的思维模式,也就是最基本的JDBC开发思维模式,但是这一步spring已经在配置的时候已经交给了spring管理了数据库的连接池,只要得到对应的bean就可以得到数据库连接了,也就能操作数据库了;数据库连接类也就相当于spring给我们提供好了,那接下来就是编写接口了,首先编写DAO层接口,DAO(data access Object) 叫做数据访问对象,首先,我们利用泛型编写一个公共的DAO接口,实现基本的CRUD ,当数据表非常多的时候编写此公共的接口很节省代码的;IDAO.javapackage cn.oracle.dao;import java.util.List;public interface IDAO<K,V> {/*** 增加一条数据;* @param vo 简单Java类对象;* @return返回一个boolean对象,增加成功返回true,增加失败返回false;* @throws Exception*/public boolean doCreate(V vo)throws Exception;/*** 更新一条数据;* @param vo 简单Java类对象;* @return返回一个boolean对象,更新成功返回true,更新失败返回false;* @throws Exception*/public boolean doUpdate(V vo)throws Exception;/*** 删除一条数据;* @param id 简单Java类对象的id;* @return返回一个boolean对象,删除成功返回true,删除失败返回false;* @throws Exception*/public boolean doRemove(int id)throws Exception;/*** 查询出一条数据,* @param id 数据对应的id* @return返回一个简单java类对象;* @throws Exception*/public K findById(int id)throws Exception;/*** 查询所有的数据;* @return返回一个简单Java类对象;* @throws Exception*/public List<V> findAll()throws Exception;/*** 模糊查询,也是分页要用的一个方法;* @param column 列名称* @param keyWord 关键字* @param currentPage 当前页* @param lineSize 每页现实的数据条目* @return返回一个List集合;* @throws Exception*/public List<V> findAll(String column,String keyWord,IntegercurrentPage,Integer lineSize)throws Exception;/*** 统计模糊查询的条目* @param column 列名称* @param keyWord 关键字* @return返回一个整数* @throws Exception*/public int getAllCount(String column,String keyWord)throws Exception;}·公共的接口开发完成了,我们接下来就开发IEmpDAO接口,这个接口直接继承IDAO 接口即可,是不是很方便,直接继承即可,如果你需要扩充什么方法的话,直接编写方法即可,package cn.oracle.dao;import cn.oracle.pojo.Emp;public interface IEmpDAO extends IDAO<Integer, Emp> {}·然后当然是编写接口的实现类了,也就是编写方法的具体实现,EmpDAOImpl.javapackage cn.oracle.dao.impl;import java.util.List;import javax.annotation.Resource;import org.hibernate.Criteria;import org.hibernate.Query;import org.hibernate.SessionFactory;import ponent;import cn.oracle.dao.IEmpDAO;import cn.oracle.pojo.Emp;@Component→这个就是Annotation注解,其实你可以理解为在applicationContext.xml文件之中配置了一个bean<bean id=”empDAOImpl” class=”cn.oracle.dao.impl.EmpDAOImpl”>→Component<property name=”sessionFactory” ref=”sessionFactory”/>→Resource</bean>public class EmpDAOImpl implements IEmpDAO {@Resourceprivate SessionFactory sessionFactory;@Overridepublic boolean doCreate(Emp vo) throws Exception {return this.sessionFactory.getCurrentSession().save(vo) != null;}→使用Session接口的save方法来保存数据;@Overridepublic boolean doUpdate(Emp vo) throws Exception {String hql="UPDATE Emp AS e SET e.ename=?,e.hiredate=?,e.sal=? WHERE e.empno=?";Query query=this.sessionFactory.getCurrentSession().createQuery(hql);query.setString(0, vo.getEname());query.setDate(1, vo.getHiredate());query.setString(2, vo.getSal());return query.executeUpdate()>0;}→使用Query实现更新;@Overridepublic boolean doRemove(int id) throws Exception {String hql="DELETE FROM Emp As e WHERE e.empno=?";Query query=this.sessionFactory.getCurrentSession().createQuery(hql);query.setInteger(0, id);return query.executeUpdate()>0;}→使用Query接口实现删除;@Overridepublic Emp findById(int id) throws Exception {return (Emp) this.sessionFactory.getCurrentSession().get(Emp.class, id);}→使用Session接口查询数据;@SuppressWarnings("unchecked")@Overridepublic List<Emp> findAll() throws Exception {Criteriacriteria=this.sessionFactory.getCurrentSession().createCriteria(Emp.class);List<Emp> all=criteria.list();return all;} →使用criteria接口实现全部查询;@SuppressWarnings("unchecked")@Overridepublic List<Emp> findAll(String column, String keyWord,Integer currentPage, Integer lineSize) throws Exception { String hql="FROM Emp AS e WHERE e."+column+" LIKE ?";Query query=this.sessionFactory.getCurrentSession().createQuery(hql);query.setString(0, "%"+keyWord+"%");query.setFirstResult((currentPage-1)*lineSize);query.setMaxResults(lineSize);return (List<Emp>)query.list();}→使用query接口实现分页模糊查询;@Overridepublic int getAllCount(String column, String keyWord) throws Exception { String hql="SELECT COUNT(e.empno) FROM Emp AS e WHERE "+column+" LIKE ?";Query query=this.sessionFactory.getCurrentSession().createQuery(hql);query.setString(0, "%"+keyWord+"%");Integer count=((Long)query.uniqueResult()).intValue();return count;} →使用query接口完成统计;}·编写完成DAO层之后,我们就要做的就是编写服务层了,也就是对DAO层接口的调用,IEmpService.javapackage cn.oracle.service;import java.util.List;import java.util.Map;import cn.oracle.pojo.Emp;public interface IEmpService {public boolean insert(Emp vo)throws Exception;public boolean update(Emp vo)throws Exception;public boolean delete(int id)throws Exception;public Emp get(int id)throws Exception;public List<Emp> list()throws Exception;public Map<String ,Object> list(String column,String keyWord,Integer currentPage,Integer lineSize)throws Exception;}·接口编写完成,之后我们就应该编写实现类了;EmpServiceImpl.javapackage cn.oracle.service.impl;import java.util.HashMap;import java.util.List;import java.util.Map;import javax.annotation.Resource;import org.springframework.stereotype.Service;import cn.oracle.dao.IEmpDAO;import cn.oracle.pojo.Emp;import cn.oracle.service.IEmpService;@Service Service层的专用Annotation注解;public class EmpServiceImpl implements IEmpService {@Resourceprivate IEmpDAO empDAO;@Overridepublic boolean insert(Emp vo) throws Exception {return this.empDAO.doCreate(vo);}@Overridepublic boolean update(Emp vo) throws Exception {return this.empDAO.doUpdate(vo);}@Overridepublic boolean delete(int id) throws Exception {return this.empDAO.doRemove(id);}@Overridepublic Emp get(int id) throws Exception {return this.empDAO.findById(id);}@Overridepublic List<Emp> list() throws Exception {return this.empDAO.findAll();}@Overridepublic Map<String, Object> list(String column, String keyWord,Integer currentPage, Integer lineSize) throws Exception { Map<String ,Object> map=new HashMap<String,Object>();map.put("allEmps", this.empDAO.findAll(column, keyWord, currentPage, lineSize));map.put("allCount", this.empDAO.getAllCount(column, keyWord));return map;}}·到此,后台业务层的增删改查就完成了,然后就是控制器的编写了,我们用的是springmvc的话,自然编写起来很方便的;EmpAction.javapackage cn.oracle.action;import java.util.List;import javax.annotation.Resource;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import org.springframework.stereotype.Controller;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestMethod;import org.springframework.web.servlet.ModelAndView;import cn.oracle.pojo.Emp;import cn.oracle.service.IEmpService;@Controller→spring mvc的专用annotation注解,代表一个控制器;@RequestMapping("/pages/front/emp/*") →映射路径public class EmpAction {@Resourceprivate IEmpService empService;@RequestMapping(value="emp_list.jsp",method=RequestMethod.GET)public ModelAndView list(HttpServletRequest request,HttpServletResponse response){List<Emp> allEmps=null;try {allEmps=this.empService.list();} catch (Exception e) {e.printStackTrace();}ModelAndView mav=new ModelAndView();mav.setViewName("/pages/front/emp/emp_list.jsp");mav.addObject("allEmps", allEmps);System.out.println(allEmps); 我们就用一个简单的连接做测试,如果后台输出了这些对象的话,说明我们就完成了页面的操作了;return mav;}}如果后台有输出这些信息,说明你的所有配置正常,开发CRUD没任何问题的;。