ZFS文件系统ARC缓存
zfs使用心得

zfs使用心得【原创实用版3篇】目录(篇1)1. ZFS 简介2. ZFS 的特点3. ZFS 的使用方法4. ZFS 的优点5. ZFS 的缺点6. 总结正文(篇1)1. ZFS 简介ZFS(Zettabyte File System)是一种高性能、可扩展的文件系统,主要用于存储大量数据。
ZFS 是由 Sun Microsystems 公司开发的,现在由 OpenZFS 社区维护。
ZFS 的特点是数据完整性高、可扩展性强、性能优秀,因此在企业级存储领域得到了广泛应用。
2. ZFS 的特点ZFS 具有以下几个显著特点:(1)数据完整性:ZFS 支持数据校验和,可以检测和修复数据错误,保证数据的完整性。
(2)可扩展性:ZFS 支持无限大的文件系统,可以存储大量数据。
(3)高性能:ZFS 具有高效的磁盘 I/O 调度算法,可以提高系统的磁盘吞吐量。
3. ZFS 的使用方法要使用 ZFS,首先需要在操作系统中安装 ZFS 模块。
在 Linux 系统中,可以通过安装 zfs-tools 软件包来获得 ZFS 支持。
在 FreeBSD 系统中,ZFS 已经被集成到内核中,无需额外安装。
目录(篇2)1.ZFS 简介2.ZFS 的主要特点3.ZFS 的实际应用4.ZFS 的未来发展前景正文(篇2)【ZFS 简介】ZFS(Zettabyte File System)是一种用于管理大规模数据的文件系统,最早由 Sun Microsystems 公司开发。
ZFS 的主要特点是数据可靠性高、可扩展性强以及性能优越。
它能够提供大量的数据存储和处理能力,因此非常适合用于企业级服务器和大型数据中心。
【ZFS 的主要特点】1.数据可靠性:ZFS 采用了一种名为“数据完整性”的技术,可以确保数据的完整性和可靠性。
即使在硬盘故障或者意外断电的情况下,ZFS 也能够自动修复数据,确保数据的安全。
2.可扩展性:ZFS 可以轻松地扩展到数百 TB 甚至数 PB 的存储空间,满足大规模数据的存储需求。
ZFS存储池类型
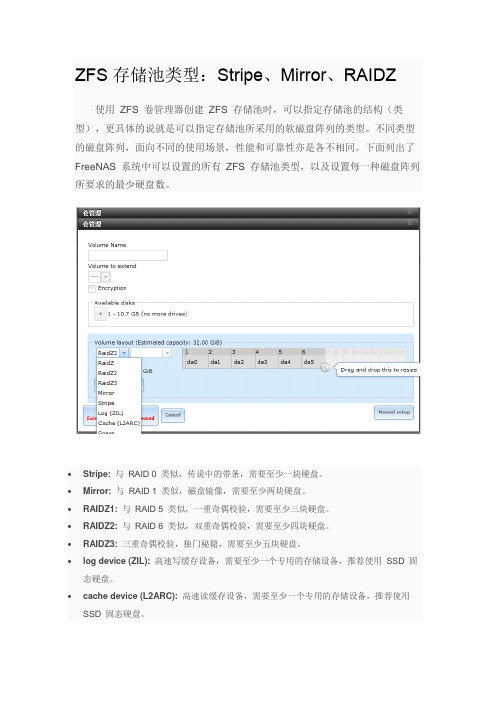
ZFS存储池类型:Stripe、Mirror、RAIDZ使用ZFS 卷管理器创建ZFS 存储池时,可以指定存储池的结构(类型),更具体的说就是可以指定存储池所采用的软磁盘阵列的类型。
不同类型的磁盘阵列,面向不同的使用场景,性能和可靠性亦是各不相同。
下面列出了FreeNAS 系统中可以设置的所有ZFS 存储池类型,以及设置每一种磁盘阵列所要求的最少硬盘数。
∙Stripe:与RAID 0 类似,传说中的带条,需要至少一块硬盘。
∙Mirror:与RAID 1 类似,磁盘镜像,需要至少两块硬盘。
∙RAIDZ1:与RAID 5 类似,一重奇偶校验,需要至少三块硬盘。
∙RAIDZ2:与RAID 6 类似,双重奇偶校验,需要至少四块硬盘。
∙RAIDZ3:三重奇偶校验,独门秘籍,需要至少五块硬盘。
∙log device (ZIL):高速写缓存设备,需要至少一个专用的存储设备,推荐使用SSD 固态硬盘。
∙cache device (L2ARC):高速读缓存设备,需要至少一个专用的存储设备,推荐使用SSD 固态硬盘。
除去log device (ZIL)和cache device (L2ARC)这两种专用高速缓存设备不谈,在这里列举一下其余类型的性能和可靠性对比。
性能对比Stripe > MirrorStripe > RAIDZ1 > RAIDZ2 > RAIDZ3数据可靠性Mirror > StripeRAIDZ3 > RAIDZ2 > RAIDZ1 > StripeSolaris ZFS 快照和克隆使用指南zfs快照概述:快照是文件系统或卷的只读副本。
快照几乎可以即时创建,而且最初不占用池中的其他磁盘空间。
但是,当活动数据集中的数据发生更改时,快照通过继续引用旧数据占用磁盘空间,从而阻止释放该空间。
ZFS 快照具有以下特征:■可在系统重新引导后存留下来。
■理论最大快照数是264。
zfs 参数

ZFS 参数什么是ZFS?ZFS(Zettabyte File System)是一种先进的文件系统和逻辑卷管理器,它在存储管理方面提供了许多独特的功能和优势。
ZFS最初由Sun Microsystems开发,并在2005年以开源软件的形式发布。
它被设计用于处理大容量、高性能和高可靠性的存储需求,并具有自我修复和数据完整性保护等关键功能。
ZFS 的参数在使用ZFS时,我们可以通过调整一些参数来优化其性能和功能。
下面是一些常见的ZFS参数及其作用:1. ashiftashift参数指定了磁盘扇区大小的对数值。
默认情况下,它设置为9,表示512字节扇区大小。
如果您使用的是4KB扇区大小的磁盘,应将ashift设置为12。
正确设置ashift可以提供更好的性能和空间利用率。
2. recordsizerecordsize参数定义了每个文件记录(或块)的大小。
默认情况下,它设置为128KB。
根据不同的工作负载,您可能需要调整此值以获得最佳性能。
3. compressioncompression参数指定了数据压缩算法。
ZFS提供了多种压缩算法可供选择,包括lz4、gzip、zle等。
通过启用压缩,您可以节省存储空间并提高读写性能。
4. atimeatime参数控制是否记录文件的访问时间。
默认情况下,它设置为on,表示每次访问文件时都会更新访问时间。
如果您对访问时间不感兴趣,可以将其设置为off以提高性能。
5. syncsync参数指定了数据同步策略。
默认情况下,它设置为standard,表示数据会在写入磁盘之前进行同步。
如果您对数据的持久性要求不高,可以将其设置为disabled以提高写入性能。
6. primarycache 和 secondarycacheprimarycache参数定义了ZFS文件系统的主缓存策略,默认设置为all,表示所有读取都从内存中进行。
secondarycache参数定义了ZFS文件系统的二级缓存策略,默认设置也是all。
zfs 参数

zfs 参数ZFS(Zettabyte File System)是一种文件系统,它是由Sun Microsystems为FreeBSD、OpenSolaris和illumos 等操作系统开发的。
ZFS是一种高性能、可扩展的文件系统,它具有许多优秀的特性,如数据完整性、可扩展性、高可用性等。
在ZFS中,有许多参数可以配置和调整,以优化文件系统的性能和可靠性。
以下是一些常用的ZFS参数:1.ashift:这个参数用于设置文件系统簇(block)的大小,它决定了文件系统能够支持的最大文件大小。
通常,较大的簇大小可以提高文件系统的性能,但会减少磁盘空间的利用率。
2.checksum:这个参数用于设置文件系统的校验和算法,它可以确保文件数据的完整性。
ZFS支持多种校验和算法,如CRC32、SHA256等。
3.compression:这个参数用于设置文件系统的压缩算法,它可以减少磁盘空间的占用。
ZFS支持多种压缩算法,如LZJB、ZLE、Zstandard等。
4.dedup:这个参数用于设置文件系统的重复数据删除功能。
当多个文件具有相同的内容时,ZFS可以将其合并,以节省磁盘空间。
5.logbias:这个参数用于设置文件系统日志的偏斜度,它可以影响日志的性能和磁盘空间的利用率。
6.spa_size:这个参数用于设置文件系统的最大存储空间,它决定了文件系统能够存储的最大数据量。
7.spd_max:这个参数用于设置文件系统的最大I/O并发数,它可以影响文件系统的性能。
8.txg_timeout:这个参数用于设置文件系统事务组的超时时间,它可以影响文件系统的可靠性和性能。
以上仅是ZFS的一些常用参数,实际上还有很多其他的参数可以调整和配置。
在使用ZFS时,需要根据实际情况选择合适的参数配置。
更灵活,更易用 — ZFS storage 统一存储介绍

<Insert Picture Here>更灵活,更易用-----Oracle ZFS St 更灵活 更易用 O l Storage 统一存储介绍存储需求持续大幅度成长P PBFile Based: 79.3% CAGRSource: IDCBlock based: 31% CAGR2存储需求持续大幅度成长Greater Demand For Storage Capacity And Performance2009 New Digital Data2020 New Digital Data44X Growth800 Exabytes 35,000 Exabytes•© 2010 Oracle Corporation – Proprietary and Confidential3定义存储效率(Storage Efficiency) ( g y)• 使用最低成本来进行数字数据的存放 保护及管理 使用最低成本来进行数字数据的存放、保护及管理 • 可降低数据中心的电力 散热及空间成本 可降低数据中心的电力、散热及空间成本4存储已经成为数据中心 最大的成本提高存储效率数据中心最迫切的需求• 数据存储的效率必须提高• 根据调查用户将其一份资料重复存放超过15份 • 政府法规对数据保留需求持续上升• 数据重复删除及数据压缩是关键需求• 有50%的IDC响应目前有使用数据重复删除的需求• 电力、散热及机架空间效率是不可缺少的评估要点 • 存储集中化是客户IT计划里面排名前10名的重点项目5Oracle ZFS Storage 统一存储系统重新定义统一存储系统(Unified Storage)• 同时提供文件(File)及数据块(block)服务 ( ) ( )• 只要买一套硬件,一个价格,一次提供10种数据通讯服务• 内置先进的数据服务• 集群(Clustering),远程数据复制(Replication), 快照( Snapshot),数 据复制(Cone),数据重复删除(Deduplication),数据压缩 (Compression),自动精简配置(thin provisioning),闪存(Flash), (Compression) 自动精简配置(thin provisioning) 闪存(Flash) 在 线实时分析功能( Analytics),病毒扫描(Virus scan)• 可选择不同的主机接口(interconnect)• 可同一台机器安装以太网接口(Ethernet), 光纤 (Fibre channel)及 Infiniband• 可选择的应用程序• Oracle Solaris或Linux, Windows, virtualization•66Oracle ZFS Storage g全新第二代统一存储系统•标准功能 •内含所有主流通讯协议 •7120 •7320 •内含先进的数据服务功能 •入门型l • • 入门型l •7420 •单控制器机型 支持操作系统及应用程序 •单控制器机型 •Oracle Solaris • Oracle Enterprise Linux •高扩充能力机型 •支持集群功能 •Oracle VM • VMware • Windows •Oracle数据库、 Oracle Middleware及Oracle应用程序等 支持超过50种以上的商业应用程序 •7720 • 新的产品特点 •高密度存储机型 •密度及容量:可集中化存储容量最大可达1PB •支持集群功能 •闪存容量倍增: 最大可达4TB读取闪存及432GB写入闪存 •更多的运算能力: 每个控制器最大可达32个核,效能比前一代提升50%•77完整的存储功能下列功能皆包含在ZFS Storage上-不需额外付费购买 Storage上 不需额外付费购买数据通讯协义• Fibre Channel • iSCSI • Infiniband over IP/RDMA • iSER • SRP • NFS v3 and v4 • CIFS • HTTPNew! • WebDAV数据服务数据管理• FTP • ZFS NDMP v4• Browser and CLI Interface • Single, Double & Triple Parity RAID (RAIDZ, Z2, Z3) • Management Dashboard • Mi Mirroring & Triple Mirroring i T i l Mi i • Hardware/component view • Hybrid Storage Pool • Role-based Access Control • End-to-End Data Integrity • Remote Replication • Phone Home • Snapshots and Clones • Event and Threshold based • Quota(s) Alerting • In-line Dedup • Dtrace Analytics • Compression • Scripting • Thin Provisioning • Antivirus via ICAP Protocol • Workflow Automation • Online Data Migration New!Advanced Networking • • Clustering g •DFS Standalone New! Namespace •Source Aware Routing•Oracle Internal and Confidential8内置先进的存储技术提供更高的使用效率进一步让存储系统更有效率 • 内置重复数据删除技术(in-line, Deduplication) • 降低整体数据存放的存储空间 • 内置数据压缩(Compression) • 整合重复数据删除技术让空间使用更加有效率 • 内置存储自动精简配置(Thin-provisioning) • 能够有效的满足客户端容量需求并优化存储系统的空间使用率 • 内置混合存储池架构(Hybrid Storage Pools, HSPs) • 整合内存,闪存及大容量硬盘科技降低电力及机架空间的需求 • 内置多样先进的数据保护功能(D 内置多样先进的数据保护功能(Data P Protection capabilities) i bili i ) • 快照+数据远程复制,允许3块数据盘故障的RAID-Z3等先进数据 保护功能9Oracle先进的重复数据删除技术让使用存储 空间上更有效率• 实时重复数据删除:当数据产生时就进行重复数据删除操作 实时重复数据删除 当数据产生时就进行重复数据删除操作• 当友商存储系统使用重复数据删除操作时,必须是采用列表(Schedule)方式并于背景模 式(POST)下运作,会大幅降低存储效能 • Sun ZFS存储系统因为有强大的运算处理器及内存可以实时进行重复数据删除功能• Oracle重复数据删除使用256-bit的检查更严谨• ZFS存储系统的重复数据技术采用256位同位检查(256-bit checksum)比起竞争友商的 重复数据技术只采用16位同位检查(16 bit 重复数据技术只采用16位同位检查(16-bit checksum)更加严谨• Oracle重复数据删除可以于更大的文件系统上运作• ZFS存储系统的数据重复删除技术可以在单一576TB的文件系统上运作,比竞争友商的 存储系统的数据重复删除技术只能在单一16TB的文件系统上运作更有效率• Oracle采用数据块(Block-level)进行重复数据比对• 数据块比文件的重复数据删除技术对于虚拟主机的使用环境上更有效率10内置ZFS数据压缩功能驱动更高的效率及效能• 内置ZFS压缩功能• 减少整体磁盘使用空间• 客户实际使用各种不同非结构化数据的应用程序验证,确实可以大幅度减少整体磁盘使用空间 • 一般情况下有2倍压缩率 (或50%空间减少)• 减少整体数据量,提高有效输出带宽(Throughput)• 不仅是节省存储空间,还提升了存储系统效能 • 数据压缩功能启动时可以让数据快速读写,减少存取(I/O)频率• 可以与数据重复删除功能一起使用有加倍的效果• 提供无与伦比的硬件处理能力11•玛拉基.麦凯布 玛拉基 麦凯布 •(Malachi McCabe) •经理 Signature Styles • 信息管理部门 •Signature Styles Signature “我们看到于ZFS统一存储系统可以对公司内的非结构化数据提供多达 我们看到于ZFS统 存储系统可以对公司内的非结构化数据提供多达 73%的数据压缩比例”12ZFS混合存储池于存储集中化的环境下提供效能且帮助客户省钱• ZFS混合存储池可以智能判断数据使用状况及自动 在内存,闪存及磁盘之间迁移 • 不断优化存储系统性能和效率–优化 $/GB/s及 $/IOP 效能 • 管理单一混合存储池是非常简单的•内存 •(DRAM) •写入用 闪存(ZIL)•读取闪存 (L2ARC)“我最感兴趣的是,混合存储池提供不亚于内存等级 的速度(或称接近内存等级的效能)来存取Oracle 能 数据库内的数据。
arc缓存算法

arc缓存算法
ARC(Adaptive Replacement Cache)是一种用于缓存替换算法
的高级算法,它结合了最近使用(LRU)和最少使用(LFU)两种算
法的优点,以适应不同的访问模式和数据特性。
ARC算法由IBM研
究员Nimrod Megiddo和Dharmendra S. Modha于2003年提出,是
一种自适应的缓存算法,能够根据访问模式和数据特性自动调整缓
存大小和替换策略。
ARC算法将缓存分为两个部分:T1和T2。
T1是最近使用的数据
集合,类似于LRU算法,当缓存未命中时,新数据会被放入T1中。
T2是最频繁使用的数据集合,类似于LFU算法,当T1中的数据被
频繁访问时,会被移动到T2中。
当缓存替换时,ARC算法会根据T1
和T2中的数据访问情况来决定替换哪些数据,以最大程度地提高缓
存命中率。
ARC算法还引入了两个参数:p和c。
p参数用于控制T1和T2
的大小,当T1的命中率高时,p会增加;当T2的命中率高时,p会
减少。
c参数用于控制T1和T2之间的替换策略,当T1和T2的命
中率接近时,c会增加;当T1和T2的命中率差距较大时,c会减少。
总的来说,ARC算法通过综合考虑最近使用和最频繁使用两种
算法的特点,以及根据访问模式和数据特性自动调整缓存大小和替
换策略,能够有效地提高缓存命中率,减少缓存替换的开销,提高
系统性能。
ARC算法在实际应用中已经被证明具有很好的性能表现,被广泛应用于各种存储系统和数据库系统中。
第07章_ZFS文件系统

ZFS组件命名规则 ZFS组件命名规则
不允许空组件 每个组件只能包含字母数字字符以及以下四个特 殊字符: 殊字符: 下划线 (_) 连字符 (-) 冒号 (:) 句点 (.) 池名称必须以字母开头, 池名称必须以字母开头,但不允许使用起始序列 c[0-9]。此外,不允许使用以mirror、raidz或 c[0-9]。此外,不允许使用以mirror、raidz或 spare开头的池名称, spare开头的池名称,因为这些名称是保留的 开头的池名称
8 北京万博天地网络技术股份有限公司 版权所有
部署ZFS硬件环境 部署ZFS硬件环境 # touch /reconfigure /reconfigure文件的创建会迫使 /reconfigure文件的创建会迫使Solaris在启 文件的创建会迫使Solaris在启 动的时候检查是否存在新安装的硬件 关闭电源,插入新磁盘。如果使用的是SCSI 关闭电源,插入新磁盘。如果使用的是SCSI 磁盘要确保所添加的磁盘与系统中的其他 设备具有不同的目标号码; 设备具有不同的目标号码;然后重新启动 计算机 # format 进入系统后,调用format命令检查新磁盘 进入系统后,调用format命令检查新磁盘 的状态, 的状态,以确定要操作的磁盘
第七章
ZFS文件系统 ZFS文件系统
本章目标 了解ZFS文件系统的特点 了解ZFS文件系统的特点 掌握配置ZFS的基本方法 掌握配置ZFS的基本方法
2
北京万博天地网络技术股份有限公司 版权所有
本章内容
7.1 ZFS 文件系统概述 ZFS 文件系统概述
7.2 ZFS文件系统的使用 ZFS文件系统的使用
3
北京万博天地网络技术股份有限公司 版权所有
PVE解决ZFS内存高占用ARC

PVE解决ZFS内存⾼占⽤ARC简介:由于使⽤的是淘汰⼯作站,都不算什么服务器,所以使⽤了ZFS的软raid⽅案来保证数据安全。
但是ZFS太先进了,⽽且当年是为sun的⼯作站设计的,所以它使⽤了⼤量的内存来做数据缓存。
我这⼩鸡可承受不住这个内存消耗,直接要消耗⼤约50%的物理内存。
我们要根据⾃⼰的实际情况,来对ARC缓存进⾏限制。
⼀:zfs arc缓存介绍算了吧,搜了⼏个介绍,都是⼜臭⼜长的理论⽂章。
我简单说⼀下吧,硬件raid卡会有缓存,还有电池,保证raid的数据稳定。
zfs的raid,就像软raid,通过计算机的计算来实现raid,但是缓存从哪⾥来?内存啊,速度⽐硬盘快的多,⽽sun的 Solaris,以前就是怪物⼀样的超级⼤内存,所以ZFS在设计的时候,就很耗内存,移植到linux之后还带着这样的基因,占⽤50%的物理内存做zfs缓存。
⼆:检查内存占⽤反正我的16G内存⽼鸡,就占了⼀半多⼀点,系统还得占点。
cockpit,pve,这两个的管理页⾯都能看到。
三:设置arc最⼤内存这就是ZFS允许减⼩允许使⽤ARC⼤⼩的最⼤⼤⼩的原因。
此设置在/etc/modprobe.d/zfs.conf⽂件中完成。
例如,如果您希望ARC永远不要超过32 GB,请添加以下⾏:options zfs zfs_arc_max=34359738368我设置为1Goptions zfs zfs_arc_max=1073741824简单设置命令为:echo“options zfs zfs_arc_max = 1073741824”>> /etc/modprobe.d/zfs.conf根据你的物理内存,⾃⼰计算吧,1G:1*1024*1024*1024*1024如果根⽂件系统也使⽤了ZFS,你必须在每次修改该参数后更新initramfs,如下:update-initramfs –u四:测试效果反正我的是从8G多变成1G多了。
arc原理

arc原理ARC原理是一种将信息进行压缩和编码的算法,可以在网络传输和存储过程中提高效率和节省空间。
本文将从ARC原理的基本概念、实现原理、优势和应用场景等方面进行阐述。
一、ARC原理的基本概念ARC是自适应替换缓存(Adaptive Replacement Cache)的缩写,是一种用于缓存替换算法的策略。
它结合了最近使用(Least Recently Used,LRU)和最近未使用(Least Frequently Used,LFU)两种算法,通过自适应地调整缓存的大小和替换策略来提高缓存的命中率。
二、ARC原理的实现原理ARC算法通过两个指针来维护一个缓存中的数据集合,分别是T1和T2。
T1用于存储最近使用的数据,T2用于存储最近未使用的数据。
当有新的数据需要加入缓存时,ARC算法会根据数据在T1和T2中的情况来决定替换哪个数据。
具体来说,如果新的数据在T1中,则将T1中最不常使用的数据替换出去;如果新的数据在T2中,则将T2中最不常使用的数据替换出去。
三、ARC原理的优势1. 自适应性:ARC算法根据实际情况自动调整缓存的大小和替换策略,能够适应不同的应用场景和数据类型,提高缓存的命中率。
2. 高效性:ARC算法通过维护两个指针来进行替换操作,相比于传统的LRU算法,可以更加高效地进行缓存替换,减少替换的次数。
3. 灵活性:ARC算法结合了LRU和LFU两种算法,可以根据实际需求灵活选择使用哪种算法,提高缓存的性能和效果。
四、ARC原理的应用场景1. 网络传输:在网络传输过程中,ARC算法可以用于对数据进行压缩和编码,在保证数据完整性的前提下,提高传输效率和节省带宽。
2. 数据库缓存:在数据库系统中,ARC算法可以应用于缓存管理,提高数据库的查询性能和响应速度。
3. 文件系统:在文件系统中,ARC算法可以应用于缓存文件的读取和写入,提高文件的访问速度和效率。
4. 嵌入式系统:在嵌入式系统中,由于资源受限,ARC算法可以用于对数据进行压缩和编码,在提高性能的同时,节省系统资源的使用。
openzfs 读写流程

openzfs 读写流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!OpenZFS 读写流程。
1. 应用程序写入数据。
应用程序将数据写入 OpenZFS 文件系统中。
减少ZFS文件系统ARC缓存的方法

减少ZFS文件系统ARC缓存的方法减少ZFS文件系统ARC缓存的方法编写:易柯楠 201412081. ARC缓存简介ZFS文件系统是Solaris 11系统的默认文件系统,ZFS文件系统简介可见附录。
ZFS使用在内存中建立缓存的方式来提升性能,这种做法在海量数据时尤为有效。
ZFS的缓存使用ARC(Adjustable Replacement Cache)算法,它是基于IBM的Megiddo和Modha提出的ARC 淘汰算法演化而来的。
所以这个缓存通常被称为ARC缓存。
Solaris系统中有两个内核参数来限制ARC缓存的大小:zfs_arc_min:确定ARC缓存的最小大小,设置单位为字节。
默认64MB。
zfs_arc_max:确定ARC缓存的最大大小,设置单位为字节。
默认在内存少于4 GB的系统上为物理内存的75%,在内存大于4 GB的系统上为物理内存减去1 GB。
这两个内核参数都是使用容量单位来设定的,并不能根据物理内存的大小来自动调节,所以在Solaris 11.2系统上增加了一个内核参数,使用百分比来设定:user_reserve_hint_pct:设置留给应用程序的物理内存百分比。
查阅Oracle官方文档,并没有给出详细的说明,经试验,默认值应为0,且zfs_arc_min、zfs_arc_max参数依然有效,即user_reserve_hint_pct参数确定的ARC缓存占用量低于zfs_arc_min时,取zfs_arc_min的容量;高于zfs_arc_max时,取zfs_arc_max的容量。
该参数在Solaris 11.2之前的系统中不存在。
2. 内存占用情况及产生的问题使用以下命令可以查看内存使用明细:echo “::memstat” | mdb -k在一台16GB的机器上,进行大量IO操作后(充分建立缓存),运行以上命令,如下图:可以看到“ZFS File Data”一项占据了8.1GB之多,使用51%的物理内存。
ZFS存储池类型
ZFS存储池类型:Stripe、Mirror、RAIDZ使用ZFS 卷管理器创建ZFS 存储池时,可以指定存储池的结构(类型),更具体的说就是可以指定存储池所采用的软磁盘阵列的类型。
不同类型的磁盘阵列,面向不同的使用场景,性能和可靠性亦是各不相同。
下面列出了FreeNAS 系统中可以设置的所有ZFS 存储池类型,以及设置每一种磁盘阵列所要求的最少硬盘数。
∙Stripe:与RAID 0 类似,传说中的带条,需要至少一块硬盘。
∙Mirror:与RAID 1 类似,磁盘镜像,需要至少两块硬盘。
∙RAIDZ1:与RAID 5 类似,一重奇偶校验,需要至少三块硬盘。
∙RAIDZ2:与RAID 6 类似,双重奇偶校验,需要至少四块硬盘。
∙RAIDZ3:三重奇偶校验,独门秘籍,需要至少五块硬盘。
∙log device (ZIL):高速写缓存设备,需要至少一个专用的存储设备,推荐使用SSD 固态硬盘。
∙cache device (L2ARC):高速读缓存设备,需要至少一个专用的存储设备,推荐使用SSD 固态硬盘。
除去log device (ZIL)和cache device (L2ARC)这两种专用高速缓存设备不谈,在这里列举一下其余类型的性能和可靠性对比。
性能对比Stripe > MirrorStripe > RAIDZ1 > RAIDZ2 > RAIDZ3数据可靠性Mirror > StripeRAIDZ3 > RAIDZ2 > RAIDZ1 > StripeSolaris ZFS 快照和克隆使用指南zfs快照概述:快照是文件系统或卷的只读副本。
快照几乎可以即时创建,而且最初不占用池中的其他磁盘空间。
但是,当活动数据集中的数据发生更改时,快照通过继续引用旧数据占用磁盘空间,从而阻止释放该空间。
ZFS 快照具有以下特征:■可在系统重新引导后存留下来。
■理论最大快照数是264。
ZFS文件系统

/bonwick/zh/category/ZFS ZFS介绍文件系统的工作归结为:当被请求读取块时,它应该返回上次写到此块的数据。
如果它做不到这一点(由于磁盘脱机或数据已经被损坏或篡改),那么它应该能检测并返回错误。
难以置信的是,大多数文件系统未能做到这一点。
它们依赖底层硬件来检测和报告错误。
如果磁盘返回坏数据,一般文件系统甚至无法检测到这一点。
即使我们可以假设所有磁盘都是完美的,数据也很容易在传输中受到损坏:控制器bug、DMA 奇偶校验错误等等。
您知道的只是数据离开磁盘片时是完好无缺的。
如果将数据当作一个包,则这就像UPS 所说的那样,“我们保证您的包裹在我们包装时没有损坏”。
这根本不是您寻求的保证。
过程中的损坏不仅仅是一个学术问题:甚至像糟糕的供电这样的小事都可能导致无提示数据损坏。
任何昂贵的存储阵列都无法解决这个问题。
I/O 路径仍然易受攻击,但它变得更长:不管阵列存在什么样的硬件和固件bug,在离开磁盘片之后,数据必须要能够存活。
如果您位于SAN 上,您将使用磁盘固件读盘器设计的网络。
上帝保佑您。
怎么办?一种选择是在每个磁盘块中存储校验和。
大多数现代磁盘驱动器可以使用比通常的512 字节略大的扇区来格式化,通常是520 或528。
这些额外的字节可用于存放块校验块。
但有效利用此校验和要比想象中困难:校验和的有效性极大地依赖于它的存储位置和它的评估时间。
在许多存储阵列中(请参阅Dell|EMC PowerVault paper 中的一个典型示例,当中有这些问题的完整描述),数据与其阵列内的校验和进行比较。
不幸的是,这没有多少用处。
它不会检测常见的固件bug,比如幻象写(上一次写操作,但实际上从未对磁盘执行过),因为数据和校验和存储为单元,所以它们是自我一致的(self-consistent),即使当磁盘返回坏数据时。
从阵列到主机的其他I/O 路径仍不受保护。
简而言之,这种块校验和提供了一种好的方法来确保阵列产品不会比它所包含的磁盘可靠性低,但也仅此而已。
什么是ZFS文件系统?ZFS概念及特点简介

什么是ZFS⽂件系统?ZFS概念及特点简介什么是 ZFS?ZFS(Zettabyte File System)是由SUN公司的Jeff Bonwick领导设计的⼀种基于Solaris的⽂件系统,最初发布于20014年9⽉14⽇。
SUN被Oracle收购后,现在称为Oracle Solaris ZFS。
ZFS全称是 Zettabyte File System,单个ZFS⽂件系统最多⽀持 256 quadrillion zettabytes (ZB), 1ZB等于2的70次⽅字节。
相对于传统的EXT、XFS、JFS、ReiserFS或NTFS,ZFS的⼀个重要侧重点就是突出了对数据完整性的保护。
ZFS ⽂件系统是⼀种⾰新性的新⽂件系统,可从根本上改变⽂件系统的管理⽅式,并具有⽬前⾯市的其他任何⽂件系统所没有的功能和优点。
ZFS 强健可靠、可伸缩、易于管理。
因为其先进性,ZFS被称为最后的操作系统,21世纪最好的操作系统,也曾经被苹果⽤于Mac OSX 10.5操作系统中,但是当Mac OSX10.6雪豹发布时,⼤家发现苹果完全弃⽤了ZFS。
原因可能是,当Oracle收购SUN时,Oracle⾃⼰已经有了开源⽂件系统BTRFS,外界认为它⽆⼒分⾝继续ZFS的开发;另⼀⽅⾯,Netapp称ZFS⽂件系统侵犯其WAFL专利技术,综合这些,苹果最终停⽌⽀持ZFS⽂件系统。
ZFS 池存储ZFS 使⽤存储池的概念来管理物理存储。
以前,⽂件系统是在单个物理设备的基础上构造的。
为了利⽤多个设备和提供数据冗余性,引⼊了卷管理器的概念来提供单个设备的表⽰,以便⽆需修改⽂件系统即可利⽤多个设备。
此设计增加了更多复杂性,并最终阻碍了特定⽂件系统的继续发展,因为这类⽂件系统⽆法控制数据在虚拟卷上的物理放置。
ZFS 可完全避免使⽤卷管理。
ZFS 将设备聚集到存储池中,⽽不是强制要求创建虚拟卷。
存储池说明了存储的物理特征(设备布局、数据冗余等),并充当可以从其创建⽂件系统的任意数据存储库。
浅析ZFS文件系统及应用

f 与 。 应@ { j I I 用
下来我们看几个个例 子 , () 1创建一个 无冗余的p o。 ol
# z o lc e t a k c d p o r ae t n l4 0 t
贝特性 , 这些就 完全消除了RAI 5 D 的Wrt Hoe 陷。 AI 2 i l缺 e R DZ 也 是 同理 , 是可 以使用双奇偶 允许阵列 中丢失两个磁盘 。 但 安装一个
RAI Z 或 者 RAI 2阵 列 非 常 简 单 , 需 要 发 布 一 条 命 令 。 D ( DZ ) 只
()t 一 个 两 路 mirr 2g 建 ] ro
# z o l r ae my o l mir r c td0 c d p o ce t p o r o l3 l4 0 t
图 3zso p n oa i f no e s lr s
2 . 9简单 且有 效 的管理 及 示例
使 用Z S F 命令 , 就相 当于你使用了一种简短而有效的命令来管 理 系统 。 例如 , 个5 一 磁盘RAI Z D 阵列可 以设置采 用单命令 :
c td 50 0
E 2 . 2 _ 2
学 术 论 坛
据。 唯一的解决方案 就是 , 如果整个s ie t p 发生过量 写入 , r 那么就会 生成一个正确 的奇偶块 。 RAI 通过使用 一个不同宽度 的条带来解 决这个 问题 , DZ 这样
每 次 写入 实 际 上 是 一个 完全 的 条 带 写 入 。 加 上 Z S 写入 时 才 拷 再 F的
—
姝
—
弘 饼 Ⅸ 挑 娟 苦 i
f
强 行 删 除
f n R
m
强制执行创建池操作 , 甚至正在被 其他 的文件 系统所
ZFS文件系统和Sun

ZFS文件系统和Sun x4500数据服务器在互联网行业的应用Xinfeng.liu@2008年6月简介在Web 2.0的时代,互联网上的数据呈现了爆炸性的增长。
大型互联网客户迫切需要一种大容量、廉价、节省空间的存储解决方案。
Sun Fire x4500服务器结合Solaris的ZFS文件系统很好地满足了这种需求。
Sun Fire X4500 服务器可以提供四路 x64 服务器的卓越性能,最多可在 4U 机架空间内提供 48 TB 最高密度存储。
该系统包含2 个双核 AMD Opteron 处理器,16GB内存,并内置了6个SATAII的磁盘控制器,48块热插拔的磁盘,以及4个千兆网口。
该系统可以提供高数据吞吐量,而成本只是传统解决方案的一半。
Solaris 10包含的ZFS文件系统是对传统文件系统的一次革命性的创新设计,ZFS解决了文件系统的完整性、安全性和可伸缩性以及管理困难等重要难题。
ZFS文件系统是世界上第一个128位的文件系统,其存储容量和文件数量几乎只受硬件的限制,非常适合互联网上的大数据量的应用。
而且ZFS文件系统的checksum和transactional 的操作方式实现了端对端的数据安全,减少了为保证数据的高可靠性对昂贵硬件的依赖,大大降低了存储成本。
另外,ZFS文件系统的管理非常简便,采用了存储池的管理,并包含了传统的卷管理器的功能,但无需传统卷管理器的复杂的命令操作。
由于ZFS的独特设计,ZFS文件系统无需mount,无需fsck,无需journaling,大大地简化了日常维护。
ZFS文件系统已包含在Solaris 10或opensolaris中,无需另外下载并且是免费的和开源的。
本文主要介绍ZFS文件系统和Sun x4500服务器作为互联网上文件服务器的典型应用和优化。
其内容包括:●ZFS文件系统的特点和调优●ZFS文件系统的部署规划建议●Sun x4500作为文件服务器的系统调优ZFS文件系统的特点和调优ZFS文件系统在设计上与传统的文件系统有很大的不同。
zfs 读写流程

zfs 读写流程
ZFS(Zettabyte File System)是一种文件系统,主要用于存储和管理大量数据。
ZFS的读写流程主要包括以下几个步骤:
1. 客户端发送读或写请求:客户端向ZFS发送读或写请求,请求中包含要读取或写入的文件路径和偏移量等信息。
2. 数据校验:ZFS会根据数据的校验和来判断数据是否正确。
如果数据校验和与客户端发送的数据不一致,ZFS会返回错误信息给客户端。
3. 数据压缩:ZFS支持数据压缩功能,可以在写入数据时对数据进行压缩,以减少存储空间的使用。
在读取数据时,ZFS会自动解压缩数据并返回给客户端。
4. 数据缓存:ZFS使用缓存来提高读写性能。
在写入数据时,ZFS会将数据缓存在内存中,以便更快地读取。
在读取数据时,如果数据已经在缓存中,ZFS可以直接从缓存中返回数据,而不需要从磁盘中读取。
5. 数据持久化:ZFS支持将数据持久化到磁盘中。
在写入数据时,ZFS会将数据写入到磁盘中,确保数据的可靠存储。
在读取数据时,ZFS会从磁盘中读取数据并返回给客户端。
6. 数据传输:ZFS使用协议将数据传输给客户端或从客户端接收数据。
常见的协议包括NFS、CIFS等。
7. 数据加密:ZFS支持数据加密功能,可以对数据进行加密处理,以保护数据的机密性和完整性。
总的来说,ZFS的读写流程包括数据校验、压缩、缓存、持久化、传输和加密等功能,可以确保数据的可靠存储和高效访问。
zfs文件系统原理

zfs文件系统原理ZFS文件系统原理ZFS是一种先进的文件系统,它采用了许多创新的技术来提供高性能、高可靠性和易用性。
它最早由Sun Microsystems开发,并在2005年发布为开源软件,随后成为许多操作系统的标配文件系统。
ZFS的核心原理是“Copy-on-Write”(写时复制),它通过在写入数据时进行复制,从而实现了对数据的保护和高效的快照功能。
下面我们将详细介绍ZFS文件系统的原理。
1. 数据存储和文件系统结构ZFS使用了一种称为“对象集”(Object Set)的数据存储结构,它将文件系统中的文件和目录组织成一系列的对象。
每个对象都有一个唯一的标识符,可以通过该标识符来访问和操作对象。
这种结构可以提供高效的数据访问和管理。
2. 写时复制ZFS使用写时复制技术来实现数据的保护和快照功能。
当写入数据时,ZFS首先将数据写入新的位置,然后再更新文件系统的元数据。
这样可以避免在写入过程中出现数据损坏或丢失的问题。
同时,ZFS还可以创建快照,即保存文件系统在某一时刻的状态,以便在需要时进行恢复或回滚。
3. 数据校验和纠错ZFS采用了强大的数据校验和纠错机制,可以保证数据的完整性和可靠性。
每个数据块都有一个校验和,用于检测数据是否被损坏。
在读取数据时,ZFS会自动根据校验和进行纠错,如果发现数据损坏,可以通过冗余数据块进行修复。
4. 存储池和磁盘管理ZFS使用存储池(Pool)来管理物理磁盘,它将多个磁盘组合成一个逻辑单元,提供统一的存储空间。
存储池可以动态地添加或移除磁盘,从而实现了灵活的扩展和管理。
此外,ZFS还支持数据压缩和数据的自动分级存储,以提高存储效率。
5. 快照和克隆ZFS的快照功能可以创建文件系统的镜像副本,以便在需要时恢复数据或进行测试。
快照只记录文件系统中的变化部分,因此可以在短时间内创建大量的快照而不占用过多的存储空间。
此外,ZFS还支持克隆,即通过复制快照来创建新的文件系统。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
减少ZFS文件系统ARC缓存的方法减少ZFS文件系统ARC缓存的方法
1. ARC缓存简介
ZFS文件系统是Solaris 11系统的默认文件系统,ZFS文件系统简介可见附录。
ZFS使用在内存中建立缓存的方式来提升性能,这种做法在海量数据时尤为有效。
ZFS的缓存使用ARC(Adjustable Replacement Cache)算法,它是基于IBM的Megiddo和Modha提出的ARC 淘汰算法演化而来的。
所以这个缓存通常被称为ARC缓存。
Solaris系统中有两个内核参数来限制ARC缓存的大小:
zfs_arc_min:确定ARC缓存的最小大小,设置单位为字节。
默认64MB。
zfs_arc_max:确定ARC缓存的最大大小,设置单位为字节。
默认在内存少于4 GB的系统上为物理内存的75%,在内存大于4 GB的系统上为物理内存减去1 GB。
这两个内核参数都是使用容量单位来设定的,并不能根据物理内存的大小来自动调节,所以在Solaris 11.2系统上增加了一个内核参数,使用百分比来设定:
user_reserve_hint_pct:设置留给应用程序的物理内存百分比。
查阅Oracle官方文档,并没有给出详细的说明,经试验,默认值应为0,且zfs_arc_min、zfs_arc_max参数依然有效,即user_reserve_hint_pct参数确定的ARC缓存占用量低于zfs_arc_min时,取zfs_arc_min的容量;高于zfs_arc_max时,取zfs_arc_max的容量。
该参数在Solaris 11.2之前的系统中不存在。
2. 内存占用情况及产生的问题
使用以下命令可以查看内存使用明细:
echo “::memstat” | mdb -k
在一台16GB的机器上,进行大量IO操作后(充分建立缓存),运行以上命令,如下图:
可以看到“ZFS File Data”一项占据了8.1GB之多,使用51%的物理内存。
ARC缓存是弹性的,其设计思想是尽量多地使用空闲内存来加速(其实Windows Vista之后的版本也使用类似的思想),当有程序申请内存时,释放ARC缓存来满足程序的需求。
这样的机制看上去没有什么问题,而且在大型机及海量数据的情况下的确是一个很好的解决方案。
但是这都是为高性能机器准备的,在我们公司使用的四路、两路服务器上也没什么问题,但是到了E32这类低成本方案的机器(4GB内存,奔腾CPU,性能不及我们的笔记本)上就可能导致内存不足。
原因是:应用程序申请较大内存时,ARC缓存来不及释放,导致应用程序申请内存失败而出现错误。
如果是Oracle数据库申请内存失败,则会导致数据库退出;如果是系统核心进程申请内存失败,则会导致系统重启或卡死。
3. 建议的配置方法
通常,仅需在4GB内存的低成本机器上进行配置。
上文已经讲了相应的内核参数,所以在不同的系统上可以进行不同的设置,以下方法均已验证有效。
3.1. Solaris 11.2之前的版本(比如Solaris 11.0)
通过设置zfs_arc_max内核参数来限制ARC缓存使用量,修改/etc/system文件,在最后加入新的一行,内容如下:
set zfs:zfs_arc_max=100000000
含义是将ARC缓存的最大内存使用量限制在100MB(数字不是很精确)。
4GB内存的机器建议使用这个限制值,其他内存的机器可以不设置,或放宽到数百兆,或几GB,视自己需求。
3.2. Solaris 11.2
Solaris 11.2提供了user_reserve_hint_pct内核参数,这是一个更好的方法。
也是修改/etc/system 文件,在最后加入新的一样,内容如下:
set user_reserve_hint_pct=80
含义是将80%的物理内存留给程序,因为是百分比,所以在不同内存的机器上都可以这么设置。
3.3. 验证
可以使用kstat -m zfs命令查看c_max属性的值,即zfs_arc_max,但此命令无法查看user_reserve_hint_pct内核参数的作用。
最直接的验证方法为进行大IO操作(比如复制一个大文件),然后使用上文的echo “::memstat” | mdb –k命令查看“ZFS File Data”的内存使用量。
4. 附录
4.1. ZFS文件系统简介
ZFS文件系统的英文名称为Zettabyte File System,是第一个128位文件系统,可以说是当前最
先进的文件系统,在文件系统的发展史上具有划时代意义。
ZFS最初是由Sun公司为Solaris操作系统开发的文件系统,之后Sun公司开放了其源代码,鉴于ZFS的优异特性,它已经被迁移至Free BSD、Net BSD、Mac OS等Unix系统,以及众多的Linux 发行版本。
简要来说,ZFS的先进性表现在:
➢支持ZB级的超大容量。
一个存储池支持256ZB,最大支持2^64个存储池。
这也是为什么叫“ZFS”的原因。
➢跨越了物理存储设备。
在ZFS之前的文件系统都是被禁锢在物理设备之中的,而ZFS划时代地使用“存储池”的概念来管理物理存储空间。
一个存储池最大可以拥有2^64个卷(比如硬盘)。
➢使用一种写时拷贝事务模型技术以及完备的校验和技术,支持自优化,自动校验数据完整性。
Sun甚至没有为ZFS提供文件系统检查工具,因为不需要。
➢RAID-Z技术,文件系统即可组成RAID。
➢极强的伸缩性,易于管理。
➢优秀的性能,较ext3文件系统约有30%-40%的提升。