STATA 多组计量 比较的非参数检验命令与输出结果说明
统计学回归分析结果输出stata命令

统计学回归分析结果输出stata命令标题:统计学回归分析结果输出Stata命令摘要:本文将介绍如何使用Stata命令进行统计学回归分析,并详细讨论分析结果的输出。
我们将按照从简到繁、由浅入深的方式,逐步探讨回归分析的基本内容,并为读者提供深入理解和灵活运用的指导。
正文:一、简介统计学回归分析是研究变量之间关系的重要工具,它可以揭示自变量对因变量的影响程度,并用数学模型来表达这种关系。
而使用Stata 进行统计学回归分析时,我们可以通过一系列命令来实现数据的建模、参数估计和结果输出。
接下来,我们将详细介绍这些Stata命令的具体用法。
二、数据准备在进行回归分析之前,首先需要准备好相关的数据。
假设我们要分析自变量X对因变量Y的影响,我们需要确保X和Y的数据都已经导入到Stata中,并使用`describe`命令来查看数据的基本情况。
三、简单线性回归我们将介绍如何进行简单线性回归分析。
使用`regress`命令可以实现简单线性回归的参数估计,并输出相关的统计信息和检验结果。
我们可以输入以下命令实现对因变量Y关于自变量X的简单线性回归分析:```regress Y X```四、多元线性回归若因变量Y受多个自变量的影响时,我们需要进行多元线性回归分析。
同样,可以使用`regress`命令来实现多元线性回归的参数估计,并输出相关的统计信息。
我们可以输入以下命令实现多元线性回归分析:```regress Y X1 X2 X3```五、结果输出在进行回归分析后,我们通常会关注回归系数的估计值、显著性检验和可决系数等信息。
使用`estimates table`命令可以将这些结果输出为表格形式,以便更清晰地了解回归分析的结果。
我们可以输入以下命令实现回归结果的输出:```estimates table```六、回归诊断在获得回归分析结果后,我们还需要进行一些诊断检验来验证回归模型的适宜性。
使用`predict`命令可以生成预测值和残差值,而`predictnl`命令可以计算异方差调整的标准误。
(完整版)STATA第二章描述性统计命令与输出结果说明

第二章描述性统计命令与输出结果说明上述数据也可以用变量x表示血磷测定值,分组变量group=0表示患者组和group=1表示健康组(如:患者组中第一个数据为2.6,则x=2.6,group=0;又如:健康组中第三个数据为1.98,则x为1.98以及group为1),并假定这些数据已以STATA格式存入ex2a.dta文件中。
计算资料均数,标准差命令summarize,以述资料为例:. summarizeVariable Obs Mean Std. Dev. Min Maxx1 11 4.710909 1.302977 2.6 6.53x2 13 3.354615 1.304368 1.67 5.78Mean 均值;Std.Dev.标准差即:本例中急性克山病患者组的样本数为11,血磷测定值均数为4.711(mg%),相应的标准差为1.303,最小值为2.6以及最大值为6.53;健康组的样本量为13,血磷测定值均数为3.3546,相应的标准差为1.3044,最小值为1.67以及最大值为5.78。
计算资料均数,标准差,中位数,低四分位数和高四分位数的命令summarize 以及子命令detail,仍以述资料为例:. summarize x1 x2,detailx1Percentiles Smallest1% 2.6 2.65% 2.6 3.2410% 3.24 3.73 Obs 1125% 3.73 3.73 Sum of Wgt. 1150% 4.73 Mean 4.710909Largest Std. Dev. 1.30297775% 5.78 5.5890% 6.4 5.78 Variance 1.69774995% 6.53 6.4 Skewness -.081344699% 6.53 6.53 Kurtosis 1.809951x2Percentiles Smallest1% 1.67 1.675% 1.67 1.9810% 1.98 1.98 Obs 1325% 2.33 2.33 Sum of Wgt. 1350% 3.6 Mean 3.354615Largest Std. Dev. 1.30436875% 4.17 4.1790% 4.82 4.57 Variance 1.70137795% 5.78 4.82 Skewness .296394399% 5.78 5.78 Kurtosis 1.875392.结果:Percentiles 显示了从1%到99%的分位数的取值。
(完整)stata命令总结,推荐文档

stata11常用命令注:JB统计量对应的p大于0.05,则表明非正态,这点跟sktest和swilk 检验刚好相反;dta为数据文件;gph为图文件;do为程序文件;注意stata要区别大小写;不得用作用户变量名:_all _n _N _skip _b _coef _cons _pi _pred _rc _weight doublefloat long int in if using with命令:读入数据一种方式input x y1 42 5.53 6.24 7.75 8.5endsu/summarise/sum x 或 su/summarise/sum x,d对分组的描述:sort groupby group:su x%%%%%tabstat economy,stats(max) %返回变量economy的最大值%%stats括号里可以是:mean,count(非缺失观测值个数),sum(总和),max,min,range,%% sd,var,cv(变易系数=标准差/均值),skewness,kurtosis,median,p1(1%分位%% 数,类似地有p10, p25, p50, p75, p95, p99),iqr(interquantile range = p75 – p25)_all %描述全部_N 数据库中观察值的总个数。
_n 当前观察值的位置。
_pi 圆周率π的数值。
listgen/generate %产生数列egen wagemax=max(wage)clearuseby(分组变量)set more 1/0count %计数gsort +x (升序)gsort -x (降序)sort x 升序;并且其它变量顺序会跟着改变label var y "消费" %添加标签describe %描述数据文件的整体,包括观测总数,变量总数,生成日期,每个变量的存储类型(storage type),标签(label)replace x5=2*y if x!=3 %替换变量值replace age = 25 in 107 %令第107个观测中age为25rename y2 u %改变变量名drop in 2 %删除全部变量的第2行drop if x==. 删去x为缺失值的所有记录keep if x<2 %保留小于2的数据,其余变量跟随x改变keep in 2/10 %保留第2-10个数keep x1-x5 %保留数据库中介于x1和x5间的所有变量 (包括x1和x5),其余变量删除ci x1 x2,by(group) %算出置信区间,不过先前对group要先排序,即sort group;%by的意思逐个进行cii 12 3.816667 0.2710343, level(90) %已知均值,方差,计算90%的置信区间cii 10 2 %obs=10,mean=2,以二项分布形式,计算置信区间centile x,centile(2.5 25 50 75 97.5) %取分位数correlate/corr x y z %相关系数pwcorr x y,sig %给出原假设r=0的命令%如果变量非服从正态分布,则spearman x yregress/reg mean year %回归方程建立 reg y x,noconstant %无常数项predict meanhat %预测拟合值predict e,residual %得到残差estat hettest % 异方差检验dwstat % Durbin-Watson自相关检验vif % 方差膨胀因子logit y x1 x2 x3 (y取0或1,是被解释变量,x1-x3是被解释变量) %logit 回归probit y x1 x2 x3 (y取0或1,是被解释变量,x1-x3是被解释变量) %probit 回归tobit y x1 x2 x3 (y取值在0和1之间,是被解释变量,x1-x3是被解释变量) %tobit回归sktest e %残差正态性检验 p>0.05则接受原假设,即服从正态分布;%% sktest是基于变量的偏度和斜度(正态分布的偏度为0,斜度为3)swilk x %基于Shapiro-Wilk检验%%p值越小,越倾向于拒绝零假设,也就是变量越有可能不服从正态分布xi %生成虚拟变量tabulat gender,summ(math) %用gender指标对math进行分类,返回两类math 的mean、std、freqtabulate=tab %gen f=int((shengao-164)/3)*3+164 组距为3tabulate 变量名 [, generate(新变量) missing nofreq nolabel plot ] %%%%%generate(新变量) // 按分组变量产生哑变量nofreq // 不显示频数nolabel // 不显示数值标记plot // 显示各组频数图示missing // 包含缺失值cell // 显示各小组的构成比(小组之和为 1) column // 按栏显示各组之构成(各栏总计为 1)row // 按行显示各组之构成(各行总计为 1) %%%%%求和,求最小?mod(x,y) %求余数means %返回三种平均值di normprob(1.96)di invnorm(0.05)di binomial(20,5,0.5)di invbinomial(20,5,0.5)di tprob(10,2)di invt(10.0.05)di fprob(3,27,1)di invfprob(3,27,0.05)di chi2(3,5)di invchi2(3,0.05)stack x y z,into(e) %把三列合成一列xpose,clear %矩阵转置append using d:\0917.dta %把已打开的文件(x y z)跟0917里的(x y z)合并,是竖向合并,即观察值合并;merge using D:\0917.dta %把已打开的文件(x y z)跟0917里的(a b)合并,是横向合并,即变量合并;format x %9.2e %科学记数format x %9.2f %2位小数%产生随机数%1 产生20个在(0,1)区间上均匀分布的随机数uniform()set seed 100set obs 20gen r=uniform()list%clear 清除内存set seed 200 设置种子数为 200set obs 20 设置样本量为 20range no 1 20 建立编号 1 至 20gen r=uniform() 产生在(0,1)均匀分布的随机数gen group=1 设置分组变量 group 的初始值为 1sort r 对随机数从小到大排序replace group=2 in 11/20 设置最大的 10 个随机数所对应的记录为第2组,即:最小的10个随机数所对应的记录为第1组sort no 按照编号排序list 显示随机分组的结果也可以list if group==1和list no if group==1%2 产生10个服从正态分布N(100,6^2)的随机数invnorm(uniform())*sigma+u clear 清除内存set seed 200 设置种子数为 200set obs 10 设置样本量为 10 gen x=invnorm(uniform())*6+100 产生服从 N(100,6^2)的随机数list画图注意有些图前面要加histogram 直方图line 折线图scatter 散点图scatter y x,c(l) s(d) b2("(a)")graph twoway connected y x 连点图graph bar (sum) var2,over(var1) blabel(total) %条形图. graph bar p52 p72,by(d). graph bar p52 p72,over(d). graph bar p52 p72,by(d) stack. graph bar p52 p72,over(d) stack////////////数据如下%d p52 p72%1 163.2 27.4%2 72.5 83.6%3 57.2 178.2histogram x,bin(8) norm %画直方图,加正态分数线graph pie a b o ab if area==1,plabel(_all percent) %画饼图graph pie var2, over(var1) plabel(_all percent) %饼图graph pie p52 p72,by(d) %饼图graph box y1 %箱体图qnorm x %qq图lfit y x %回归直线graph matrix gender economy math 多变量散点图line yhat x||scatter y x,c(.l) s(O.) xline(12) yline(5.4) %线形图&散点图有一些通用的选项可以给图形“润色”:标题title(“string”) (string可为任意的字符串,下同)脚注note(“string”)横座标标题xtitle(“string”)纵座标标题ytitle(“sting”)横座标范围 xaxis(a,b) (a<b为两个数字,下同)纵座标范围 yaxis(a,b)插入文字 text (该命令既要指定插入文字的内容,也要指定插入的位置)插入图例 legend (该命令既要指定图例的内容,也要指定其位置)绘制散点图和线条的两个主要的选择项为:connect(c...c) //连接各散点的方式,c表示:或简写为c(c...c) . 不连接 (缺省值)l 用直线连接L 沿x方向只向前不向后直线连接m 计算中位数并用直线连接s 用三次平滑曲线连接J 以阶梯式直线条连接|| 用直线连接在同一纵向上的两点II 同 ||, 只是线的顶部和底部有一个短横Symbol(s...s) // 表示各散点的图形,s 表示:或简写为s(s...s) O 大圆圈 (缺省值)S 大方块T 大三角形o 小圆圈d 小菱形p 小加号. 小点i 无符号[varname] 用变量的取值代码表示[_n] 用点的记录号表示数学函数等都要与generate、replace、display一起使用,不能单独使用程序文件douse d:\0917.dtareg y xline y x,saving(d:\d4)按ctrl+D执行字符串操作函数:length(s) %长度函数,计算s的长度, 如,displength("ab")的结果是2substr(s,n1,n2) %子串函数,获得从s的n1个字符开始的n2个字符组成的字符串,disp substr("abcdef",2,3)的结果是"bcd"string(n) %将数值n转换成字符串函数,如,dispstring(41)+"f"的结果是"41f"real(s) %将字符串s转换成数值函数,如,dispreal("5.2")+1的结果是6.2upper(s) %转换成大写字母函数,如,disp upper("this")的结果是"THIS"lower(s) %转换成小写字母函数,如disp lower("THIS")的结果是"this"index(s1,s2) %子串位置函数,计算s2在s1中第一次出现的起始位置, 如果s2不在s1中, 则结果为0。
STATA多组计量比较的非参数检验命令与输出结果说明

第五章多组计量资料比较的非参数检验命令与输出结果说明本节STATA 命令摘要秩和检验 ( Mann,Whitney and Wilcoxon 非参数检验)对于计量资料不满足正态分布要求或方差不齐性,但样本资料之间是独立抽取的,则可以应用秩和检验方法进行比较两组资料的中位数是否有差异。
STATA命令为:ranksum 观察变量, by( 分组变量)例:研究不同饲料对雌鼠体重增加的关系。
表中用x表示雌鼠体重增加(克),用group=1表示高蛋白饲料组以及用group=2 表示低蛋白饲料组。
无效假设 Ho:两组增加体重的中位数相同。
ranksum x, by(group)①为第二组(低饲料组)的秩的和;② 若效假设成立,则第二组的秩的和期望值为70;③秩和统计检验量z;④对于无效假设Ho对应的p值。
在本例中,虽然第二组的秩和为而期望值估计为70,但p值为,所以根据该资料和统计结果一般不能认为用高蛋白饲料喂养能明显增加雌鼠的体重。
多组资料中位数比较(完全随机化设计资料的检验)对于完全随机化设计资料的比较,若各组资料不全服从正态分布(即:至少有一组的资料均不服从正态分布)或各组的资料方差不齐性,则可以用Kruskal and Wallis方法进行检验(Ho:各组的中位数相同)。
STATA命令为:kwallis观察变量,by(分组变量)例:50只小鼠随机分配到5个不同饲料组,每组10只小鼠。
在喂养一定时间后,测定鼠肝中的铁的含量(mg/g)如表所示:试比较各组鼠肝中铁的含量是否有显着性差别。
用x表示鼠肝中铁的含量以及用group=1,2,3,4,5分别表示对应的5个组。
kwallis x, by(group)①为各组的秩和值;②为该统计量的c2检验值;③为无效假设检验所对应的p值。
本例结果表明:5组的中位数有显着的差异。
即:5个不同饲料组的小鼠肝脏中铁的含量有显着差异,说明小鼠肝脏中铁的含量与喂养的饲料有关。
STATA 多组计量 比较的非参数检验命令与输出结果说明

第五章多组计量资料比较的非参数检验命令与输出结果说明本节STATA? 命令摘要秩和检验 ( Mann,Whitney and Wilcoxon 非参数检验)对于计量资料不满足正态分布要求或方差不齐性,但样本资料之间是独立抽取的,则可以应用秩和检验方法进行比较两组资料的中位数是否有差异。
STATA命令为:ranksum?? 观察变量, by( 分组变量)例:研究不同饲料对雌鼠体重增加的关系。
表中用x表示雌鼠体重增加(克),用group=1表示高蛋白饲料组以及用group=2 表示低蛋白饲料组。
无效假设 Ho:两组增加体重的中位数相同。
ranksum x,? by(group)①为第二组(低饲料组)的秩的和;② 若效假设成立,则第二组的秩的和期望值为70;③秩和统计检验量z;④对于无效假设Ho对应的p值。
在本例中,虽然第二组的秩和为49.5而期望值估计为70,但p值为0.0832,所以根据该资料和统计结果一般不能认为用高蛋白饲料喂养能明显增加雌鼠的体重。
多组资料中位数比较(完全随机化设计资料的检验)对于完全随机化设计资料的比较,若各组资料不全服从正态分布(即:至少有一组的资料均不服从正态分布)或各组的资料方差不齐性,则可以用Kruskal and Wallis方法进行检验(Ho:各组的中位数相同)。
STATA命令为:kwallis?观察变量,by(分组变量)例:50只小鼠随机分配到5个不同饲料组,每组10只小鼠。
在喂养一定时间后,测定鼠肝中的铁的含量(mg/g)如表所示:试比较各组鼠肝中铁的含量是否有显着性差别。
用x?表示鼠肝中铁的含量以及用group=1,2,3,4,5分别表示对应的5个组。
kwallis? x, by(group)①为各组的秩和值;②为该统计量的c2检验值;③为无效假设检验所对应的p值。
本例结果表明:5组的中位数有显着的差异。
即:5个不同饲料组的小鼠肝脏中铁的含量有显着差异,说明小鼠肝脏中铁的含量与喂养的饲料有关。
Stata统计分析命令

Stata统计分析命令一、winorize极端值处理范围:一般在1%和99%分位做极端值处理,对于小于1%的数用1%的值赋值,对于大于99%的数用99%的值赋值。
1、Stata中的单变量极端值处理:tata11.0,在命令窗口输入“finditwinor”后,系统弹出一个窗口,安装winor模块安装好模块之后,就可以调用winor命令,命令格式:winorvar1,gen(newvar)p(0.01)或者在命令窗口中输入:cintallwinor安装winor命令。
winor命令不能进行批量处理。
2、批量进行winorize极端值处理:简介:winor2winorizeortrim(iftrimoptionipecified)thevariableinvarlitat particularpercentilepecifiedbyoptioncut(##).Indefult,newvariable willbegeneratedwithauffi某\variablewiththeirwinorizedortrimmedone.相比于winor命令的改进:(1)可以批量处理多个变量;(2)不仅可以winor,也可以trimming;(3)附加了by()选项,可以分组winor或trimming;(4)增加了replace选项,可以不必生成新变量,直接替换原变量。
范例:某-winorat(p1p99),getnewvariable\.yuenlw88,clear.winor2wage某-left-trimmingat2thpercentile.winor2wage,cut(2100)trim某-winorvariableby(indutryouth),overwritetheoldvariable.winor2wageh our,replaceby(indutryouth)使用方法:1.请将winor2.ado和winor2.thlp放置于tata12\\ado\\bae\\w文件夹下;2.输入helpwinor2可以查看帮助文件;二、描述性统计1、ummarize命令格式:u、um或者ummarize[varlit][if][in][weight][,option]如果ummarize或um后不加任何变量,则默认对数据中的所有变量进行描述统计option选项:detail表示产生更加详细的统计变量Separator(n)表示每n个变量画一条分界线,n=0表示禁止使用分界线Summarize描述统计输出表中包含:样本容量、平均数、标准差、最小值和最大值2、tabtat命令格式:tabtat[varlit][if][in][weight][,option]option选项:tat(tatname)表示设定所需要的统计量col(tat)或c()表示将结果报表转置统计量:mean:平均数count/n:观测值数目um:加总ma某/min:最大值/最小值range:极差d:标准差cv:变异系数emean:平均标准误差kewne:偏度var:方差kurtoi:峰度median/p50:中位数p#:#%百分位数例如:tabtat[varlit],tat(countmeandmedianminma某range)col(tat)3、描述性统计结果输出到word或E某cel用um做的描述性统计:logout,ave(miaohutongji)wordreplace:um用tabtat做的描述性统计:logout,ave(miaohutongji)wordreplace:tabtat[varlit],tat(countmean dmedianminma某range)col(tat)分组描述:byortvar:三、相关性分析(一)相关性分析1、Pearon相关系数命令格式:correlate(简写:cor或corr)[varlit][if][in][weight][,option]2、pearman相关系数命令格式:pearman[varlit],tat(rhop)3、在Stata中,命令corr用于计算一组变量间的协方差或相关系数矩阵;4、命令pwcorr可用于计算一组变量中两两变量的相关系数,同时还可以对相关系数的显著性进行检验;option选项中加上ig可显示显著性水平:pwcorr[varlit],ig5、命令pcorr用于计算一组变量中两两变量的偏相关系数并进行显著性检验。
stata命令总结

表2-1: 回归分析相关命令一览命令用途anova 方差和协方差分析heckman Heckman 筛选模型intreg 离散型变量模型,包括Tobit 、cnreg 和intregivreg 工具变量法(IV 或2SLS)newey Newey-West 标准差设定下的回归prais 针对序列相关的Prais-Winsten, Cochrane-Orcutt, or Hildreth-Lu 回归qreg 分量回归reg OLS 回归sw 逐步回归法reg3 三阶段最小二乘回归rreg 稳健回归(不同于方差稳健型回归,即White 方法)sureg 似无相关估计svyheckman 调查数据的Heckman 筛选模型svyintreg 调查数据的间断变量回归svyregress 调查数据的线性回归tobit Tobit 回归treatreg treatment 效应模型truncreg 截断回归表2-2: 时间序列命令一览命令用途clemao1 允许结构突变的单位根检验zandrewsdfullerdfglspperroncoin 单方程协整检验dwstat 参考dwstat2 , durbina2durbinh表2-3: Panel Data 模型相关命令一览I命令模型统计描述相关命令:xtdes 变量类型,数据类型描述xtsum 基本统计量xttab 按表格形式列示xtpattern 面板数据的模式估计相关命令:xtreg 面板数据模型(固定效应、随机效应)xtregar 含有AR(1) 干扰项的固定效应和随机效应面板数据模型xtgls 截面-时序混合模型,可处理异方差、组内序列相关和组间相关性xtpcse OLS or Prais-Winsten models with panel-corrected standard errorsxtrchh Hildreth-Houck random coefficients modelsxtivreg 面板模型的工具变量或两阶段最小二乘法估计xtabond Arellano-Bond(1991) 线性动态面板数据模型估计xtabond2 Arellano-Bover(1995) 系统GMM 动态面板数据模型估计xttobit Tobit 随机效应面板模型xtintreg Random-effects interval data regression modelsxtlogit Fe, Re, Pa logit modelsxtprobit Re, Pa probit modelsxtcloglog Re, Pa cloglog modelsxtpoisson Fe, Re, Pa Poisson modelsxtnbreg Fe, Re, Pa negative binomial modelsxtfrontier 面板随机前沿模型xthtylor Hausman-Taylor estimator for error-components models表2-4: Panel Data 模型相关命令一览II命令模型假设检验相关:test Wald 检验,如时间效应联合显著性检验xttest0 随机效应检验xttest1 面板序列相关检验xttest2 adsxtserial Wooldridge 一阶序列相关检验xtab Arellano 面板一阶序列相关检验hausman Hausman 检验面板单位根和协整相关:xtunit stata提供的检验方法ipshin IPS(2003)面板单位根检验levilin Levin,Lin和Chu(LLC, 2002)面板单位根检验madfuller Sarno-Taylor(1998) 面板单位根检验xtfisher Maddala和Wu(1999),基于P 值的面板单位根检验表2-5: Post-estimation Commands命令名称用途adjust 列示预测结果的均质,适于多种回归分析,可分组列示estimates 估计结果的存储、再显示、列表比较等hausman Hausman 模型识别检验lincom 获得参数的线性组合,在Logit 模型中可以获得系数线性组合的OR 值linktest 但方程link 识别检验,用y 对O y 和O y2 回归lrtest 似然比(LR)检验mfx 计算边际效应和弹性系数nlcom 系数的非线性组合predict 获得拟合值、残差等predictnl 获得非线性估计的拟合值、残差等test 线性约束的假设检验,Wald 检验testnl 非线性约束的假设检验vce 列示参数估计值的方差-协方差矩阵表2-6: 二维图种类一览图形种类简单描述scatter scatterplotline line plotconnected connected-line plotscatteri scatter with immediate argumentsarea line plot with shadingbar bar plotspike spike plotdropline dropline plotdot dot plotrarea range plot with area shadingrbar range plot with barsrspike range plot with spikesrcap range plot with capped spikesrcapsym range plot with spikes capped with symbols rscatter range plot with markersrline range plot with linesrconnected range plot with lines and markerstsline time-series plottsrline time-series range plotmband median-band line plotmspline spline line plotlowess LOWESS line plotlfit linear prediction plotqfit quadratic prediction plotfpfit fractional polynomial plotlfitci linear prediction plot with CIsqfitci quadratic prediction plot with CIsfpfitci fractional polynomial plot with CIsfunction line plot of functionhistogram histogram plotkdensity kernel density plot表2-7: 二维图选项一览选项类别简单描述added line options draw lines at specified y or x values added text option display text at specified (y,x) value axis options labels, ticks, grids, log scalestitle options titles, subtitles, notes, captionslegend option legend explaining what means what scale(#) resize text, markers, and line widthsregion options outlining, shading, aspect ratio, sizeaspect option constrain aspect ratio of plot regionscheme(schemename) overall lookby(varlist, ...) repeat for subgroupsnodraw suppress display of graphname(name, ...) specify name for graphsaving(filename, ...) save graph in fileadvanced options difficult to explain表2-9: 模拟分析相关命令一览命令用途备注抽样相关:corr2data 产生具有指定相关性的数据仅适用于模拟相关分析drawnorminvnorm(uniform()) 产生服从标准正态分布的随机数函数,可调节均值和方差matuniform(r,c) 产生均匀分布函数sample 从现有数据中进行非重复随机抽样参考bsamplesim arma 产生服从ARIMA 过程的随机变量需要下载Bootstrap 相关:bootstrapbsbstatbsampleMC 相关:simulate MC simulationjknife 类似于MCpermutepostfile 存储MC 的结果statsbyexp list。
stata多个组别比例的检验

stata多个组别比例的检验
1. 使用卡方检验
在Stata中,可以使用tabulate命令来计算多个组别比例的卡方检验,语法如下:
tabulate var1 var2 [weight] [if exp] [, options]
其中,var1和var2是要比较的两个变量,weight是可选参数,用于指定权重变量,if exp是可选参数,用于指定筛选条件,options是可选参数,用于指定输出结果的格式。
例如,我们要检验性别(var1)和收入水平(var2)之间的关系,可以使用以下命令:
tabulate var1 var2
此外,Stata还提供了chi2命令来计算卡方检验,语法如下:
chi2 var1 var2 [weight] [if exp] [, options]
2. 使用Fisher检验
在Stata中,可以使用tabulate命令来计算多个组别比例的Fisher检验,语法如下:
tabulate var1 var2 [weight] [if exp] [, options] fisher
其中,var1和var2是要比较的两个变量,weight是可选参数,用于指定权重变量,if exp是可选参数,用于指定筛选条件,options是可选参数,用于指定输出结果的格式,fisher表示使用Fisher 检验。
例如,我们要检验性别(var1)和收入水平(var2)之间的关系,可以使用以下命令:
tabulate var1 var2, fishe。
stata的f检验命令

stata的f检验命令文章标题:深入解析Stata中的F检验命令摘要:本文将对Stata中的F检验命令进行深入研究和解析,从基本概念到实际应用,为读者提供详细的指导和理解。
我们将从什么是F检验开始,逐步介绍其原理、应用场景以及如何在Stata中进行操作。
通过本文的阅读,读者将能够更好地理解F检验的背景和原理,并能熟练地在Stata中运用F检验命令进行数据分析。
1. 什么是F检验1.1 F检验的基本概念1.2 F检验的假设检验原理1.3 F统计量的计算方法2. F检验的应用场景2.1 单因素方差分析中的F检验2.2 多元回归分析中的F检验2.3 重复测量设计中的F检验3. 在Stata中使用F检验命令3.1 数据导入与准备3.2 单因素方差分析中的F检验3.3 多元回归分析中的F检验3.4 重复测量设计中的F检验4. F检验结果的解读与可视化分析4.1 F统计量的解读4.2 P值的解读4.3 效应量的计算与解读4.4 结果的可视化分析5. F检验的局限性和注意事项5.1 数据正态性的检验前提5.2 样本容量对F检验的影响5.3 其他相关统计检验的补充6. 对F检验的观点和理解6.1 F检验在统计学中的重要性6.2 F检验在实际数据分析中的应用6.3 F检验的局限性和替代方法结论:通过本文的阅读和学习,读者对Stata中的F检验命令的相关知识和应用方法应具有一定的了解。
我们也要认识到F检验的局限性,并在实际数据分析中综合应用其他统计方法以获得更准确和全面的结论。
希望本文能够为读者提供有价值的参考和帮助。
1. F检验在多元回归分析中的应用多元回归分析是一种用于研究多个自变量对因变量的影响的统计方法。
在进行多元回归分析时,需要对自变量的整体影响进行评估,而F检验则提供了一种评估自变量整体影响是否显著的方法。
F检验在多元回归分析中的应用非常广泛。
它可以用来判断模型整体的显著性,即自变量是否对因变量的解释具有统计学意义。
stata组间差异检验命令

stata组间差异检验命令
基本语法:
xi: oneway 变量列表[if 条件] [in 数据库] , by(分组变量) cases(观测次数) [选项]
变量列表:拟检验的变量列表,可以包括多个变量;
条件:if选项指定的if控制表达式;
数据库:in选项指定的数据库;
分组变量:by选项指定的分组变量;
观测次数:cases选项指定的观测次数,可以是正整数,也可以是gt_min(每个组观测次数必须大于某一数,比如gt_min(5),即每个组至少需要有5个观测数据);
选项:xi:的各种选项,这里只写出选项汇总,详细的每个选项的作用还是需要参考文档才可以理解。
STATA面板数据模型操作命令讲解
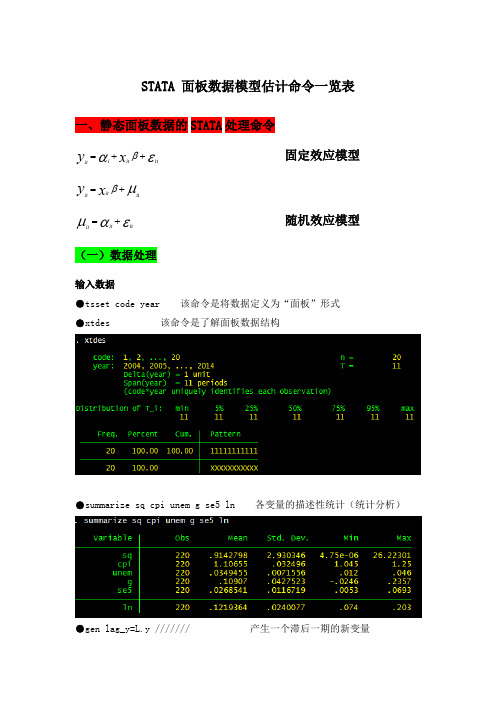
STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令固定效应模型εαβit ++=x y it i it μβit +=x y it it随机效应模型εαμit +=it it (一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
Stata教程

第一章 Stata 概貌§1.1 Stata的功能、特点和背景Stata是一个用于分析和管理数据的功能强大又小巧玲珑的实用统计分析软件,由美国计算机资源中心(Computer Resource Center)研制。
从1985至1998的十四年时间里,已连续推出1.1,1.2,1.3,1.4,1.5,……及2.0,2.1,3.0,3.1,4.0,5.0,6.0等多个版本,通过不断更新和扩充,内容日趋完善。
它同时具有数据管理软件、统计分析软件、绘图软件、矩阵计算软件和程序语言的特点,又在许多方面别具一格。
Stata融汇了上述程序的优点,克服了各自的缺点,使其功能更加强大,操作更加灵活、简单,易学易用,越来越受到人们的重视和欢迎。
Stata的突出特点是只占用很少的磁盘空间,输出结果简洁,所选方法先进,内容较齐全,制作的图形十分精美,可直接被图形处理软件或字处理软件如WORD等直接调用。
一、 Stata的数据管理能力1.Stata的数据管理空间受计算机的操作系统和计算机扩展内存的影响。
对640k内存的微机,3.1版本的Stata可以管理2400个记录×99个变量,并随计算机扩展内存的增加而增加;对4.0的WINDOWS版本,Stata可以管理4800个记录×99个变量;对WINDOWS 95下的5.0版本,可根据计算机的配置情况设置变量数和记录数,如32M扩展内存的计算机,可处理2千万个数据。
变量数和记录数可以互相交易(trade),即减少记录数可以增加变量数,减少变量数可以增加记录数。
2.可以将分组变量转换成指示变量(哑变量),将字符串变量映射成数字代码。
3.可以对数据文件进行横向和纵向链接,可以将行数据转为列数据,或反之。
4.可以恢复、修改执行过的命令。
5.可以利用数值函数或字符串函数产生新变量。
6.可以从键盘或磁盘读入数据。
二、 Stata的统计功能Stata的统计功能很强,除了传统的统计分析方法外,还收集了近20年发展起来的新方法,如Cox比例风险回归,指数与Weibull回归,多类结果与有序结果的logistic回归,Poisson回归、负二项回归及广义负二项回归,随机效应模型等。
STATA第二章描述性统计命令与输出结果说明

第二章描述性统计命令与输出结果说明例:某地测定克山病患者与克山病健康人的血磷测定值如下表据。
上述数据也可以用变量x表示血磷测定值,分组变量gr oup=0表示患者组和grou p=1表示健康组(如:患者组中第一个数据为2.6,则x=2.6,group=0;又如:健康组中第三个数据为1.98,则x为1.98以及gr oup为1),并假定这些数据已以ST ATA格式存入ex2a.dta文件中。
计算资料均数,标准差命令s u mmar ize,以述资料为例:. summarizeVariable Obs Mean Std. Dev. Min Maxx1 11 4.710909 1.302977 2.6 6.53x2 13 3.354615 1.304368 1.67 5.78Mean 均值;Std.Dev.标准差即:本例中急性克山病患者组的样本数为11,血磷测定值均数为4.711(mg%),相应的标准差为1.303,最小值为2.6以及最大值为6.53;健康组的样本量为13,血磷测定值均数为3.3546,相应的标准差为1.3044,最小值为1.67以及最大值为5.78。
计算资料均数,标准差,中位数,低四分位数和高四分位数的命令summari ze 以及子命令det ail,仍以述资料为例:. summarize x1 x2,detailx1Percentiles Smallest1% 2.6 2.65% 2.6 3.2410% 3.24 3.73 Obs 1125% 3.73 3.73 Sum of Wgt. 1150% 4.73 Mean 4.710909Largest Std. Dev. 1.30297775% 5.78 5.5890% 6.4 5.78 Variance 1.69774995% 6.53 6.4 Skewness -.081344699% 6.53 6.53 Kurtosis 1.809951x2Percentiles Smallest1% 1.67 1.675% 1.67 1.9810% 1.98 1.98 Obs 1325% 2.33 2.33 Sum of Wgt. 1350% 3.6 Mean 3.354615Largest Std. Dev. 1.30436875% 4.17 4.1790% 4.82 4.57 Variance 1.70137795% 5.78 4.82 Skewness .296394399% 5.78 5.78 Kurtosis 1.875392.结果:Percen tiles显示了从1%到99%的分位数的取值。
STATA 第四章 t检验和单因素方差分析命令输出结果说明

i ng si n第四章 t 检验和单因素方差分析命令与输出结果说明·单因素方差分析单因素方差分析又称为Oneway ANOVA ,用于比较多组样本的均数是否相同,并假 定:每组的数据服从正态分布,具有相同的方差,且相互独立,则无效假设。
原假设:H 0:各组总体均数相同。
在STATA 中可用命令:oneway 观察变量 分组变量[, means bonferroni]其中子命令bonferroni 是用于多组样本均数的两两比较检验。
例:测定健康男子各年龄组的淋巴细胞转化率(%),结果见表,问:各组的淋巴细 胞转化率的均数之间的差别有无显著性?健康男子各年龄组淋巴细胞转化率(%)的测定结果:11-20 岁 组:58 61 61 62 63 68 70 70 74 7841-50 岁 组:54 57 57 58 60 60 63 64 6661-75 岁 组:43 52 55 56 60用变量x 表示这些淋巴细胞转化率以及用分组变量group=1,2,3分别表示 11-20岁组,41-50岁组和61-75岁组,即:数据表示为:x 586161626368707074785457group 111111111122x 575860606364664352555660group 222222233333则 用 STATA 命 令:oneway x group, mean bonferroni| Summary of xgroup | Mean ①-------------+------------1 | 66.52 | 59.8888893 | 53.2------+------------Total | 61.25 ②Analysis of VarianceSource SS df MS F Prob > F------------------------------------------------------------------------------- Between groups 616.311111③ 2 ④ 308.155556⑤ 9.77⑥ 0.0010⑦Within groups 662.188889⑧ 21⑨ 31.5328042⑴-------------------------------------------------------------------------------Total 1278.50 23 55.586956(2)Bartlett's test for equal variances:chi2(2) = 2.1977 (3)Prob>chi2=0.333Comparison of x by group(Bonferroni)Row Mean- |Col Mean | 1 2-------------- --|--------------------------------------2 | -6.61111 (4)| 0.054 (5)|3 | -13.3 (6) -6.68889(8)| 0.001 (7) 0.134 (9)①对应三个年龄组的淋巴细胞转化率的均数;②三组合并在一起的总的样本均数;③组间离均差平方和;④组间离均差平方和的自由度;⑤组间均方和(即:⑤=③/④);⑧组内离均差平方和;⑨组内离均差平方和的自由度;(1)组内均方和(即:(1)=⑧/⑨);⑥为F 统计值(即为⑤/(1));⑦为相应的p值;(2)为方差齐性的Bartlett检验;(3)方差齐性检验相应的p值;(4)第二组的淋巴细胞转化率样本均数—第一组的淋巴细胞转化率的样本均数的差;(5)第二和第一组均数差的显著性检验所对应p 值;(6)第三组的淋巴细胞转化率样本均数—第一组的淋巴细胞转化率的样本均数的差;(7)第三和第一组均数差的显著性检验所对应的 p 值;(8)第三组的淋巴细胞转化率样本均数—第二组的淋巴细胞转化率的样本均数的差;(9)第三和第二组均数差的显著性检验所对应的p 值。
Stata软件探索非参数回归模型的结果

Stata软件探索⾮参数回归模型的结果在Enrique Pinzon的⽂章⾥讨论了当我们不想对函数形式做任何假设时如何进⾏回归分析——使⽤npregress命令。
使⽤margins和marginsplot命令,他通过提问和回答有关结果的⼏个问题得出结论。
最近,我⼀直在思考所有不同类型的问题,可以使⽤⾮参数回归后或任何类型的回归后的margins来回答。
margins和marginsplot是探索模型结果和绘制多种推理的有⼒⼯具。
在这篇⽂章中,我将展⽰如何询问和回答具体的问题,以及如何根据您的⾮参数回归的结果来探索整个响应⾯。
我们使⽤的数据集包括三个协变量——三个层次连续变量x1、x2和分类变量a。
如果您想继续,您可以通过输⼊以下内容来使⽤这些数据,use /users/kmacdonald/blog/npblog让我们先来看看我们的模型在这⾥,我主要演⽰如何使⽤margins。
所以在估计标准错误时,我只使⽤了10个引导复制(⼀个⾮常⼩的数字)。
在实际研究中,您肯定希望使⽤npregress命令和后续的margins命令来进⾏更多的复制。
npregress输出包括对x1、x2的影响估计和估计结果的a级别,但是这些估计可能不⾜以回答我们在研究中需要解决的⼀些重要问题。
下⾯,我将⾸先向您们展⽰如何利⽤x1,x2和a的不同组合来探索⾮线性响应⾯y的期望值。
例如,假设您的结果变量是对药物的反应,您想知道⼀个体重为150磅、胆固醇⽔平为每毫升220毫克的⼥性的预期值。
那么对于⼀个具有相同特征的男性呢?这些期望是如何在⼀系列的体重和胆固醇⽔平上发⽣变化的。
我还将演⽰如何回答有关⼈⼝平均、反事实、治疗效果等问题。
这些正是政策制定者所提出的问题类型。
平均来说,⼀个变量如何影响他们感兴趣的⼈群?举个例⼦,假设您的结果变量是20多岁的个⼈的收⼊。
这个群体的预期收⼊是多少,⼈⼝平均值?他们都是⾼中毕业⽣,⽽不是他们所观察到的教育⽔平,那么他们的期望值if是多少呢?如果他们都是⼤学毕业⽣呢?这些价值观在⼤学教育中的作⽤有什么不同?这些只是您能回答的问题类型的⼏个例⼦。
Stata教程:描述性统计命令与输出结果说明

本节STATA命令摘要by分组变量:]summarize变量名1变量名2…变量名m[,detail]ci变量名1变量名2…变量名m[,level(#)binomialpoissonexposure(varname)by(分组变量)]cii样本量均数标准差[,level(#)]tab1变量名[,generate(变量名)]·资料特征描述(均数,中位数,离散程度)例:某地测定克山病患者与克山病健康人的血磷测定值如下表(数据摘自四川医学院主编的卫生统计学,1978出版,p21):患者2.63.243.733.734.324.735.185.585.786.406.53健康人1.671.981.982.332.342.503.603.734.144.174.574.825.78并假定这些数据已以STATA格式存入ex2.dta文件中,其中变量x1为患者的血磷测定值数据,变量x2为健康人的血磷测定值数据。
上述数据也可以用变量x表示血磷测定值,分组变量group=0表示患者组和group=1表示健康组(如:患者组中第一个数据为2.6,则x=2.6,group=0;又如:健康组中第三个数据为1.98,则x为1.98以及group为1),并假定这些数据已以STATA格式存入ex2a.dta文件中。
计算资料均数,标准差命令summarize,以述资料为例:useex2,clearsummarizex1x2结果:变量样本数均数标准差最小值最大值Variable|ObsMeanStd.Dev.MinMax---------+x1|114.7109091.3029772.66.53x2|133.3546151.3043681.675.78即:本例中急性克山病患者组的样本数为11,血磷测定值均数为4.711(mg%),相应的标准差为1.303,最小值为2.6以及最大值为6.53;健康组的样本量为13,血磷测定值均数为3.3546,相应的标准差为1.3044,最小值为1.67以及最大值为5.78。
STATA面板数据模型操作命令讲解
STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令固定效应模型εαβit ++=x y it i it μβit +=x y it it随机效应模型εαμit +=it it (一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
bootstrap检验的stata命令

bootstrap检验的stata命令Bootstrap检验是一种非参数统计方法,用于估计统计量的抽样分布或参数的置信区间。
它的主要思想是通过从原始样本中有放回地抽取多个样本来构建近似的抽样分布,从而进行统计推断。
在Stata中,我们可以使用bootstrap命令来进行Bootstrap检验。
我们需要明确要进行Bootstrap检验的统计量。
假设我们想要检验某个样本的均值是否显著不同于某个特定的值。
我们可以使用bootstrap命令来进行检验。
具体命令如下:```bootstrap mean = r(mean), reps(1000) seed(123)```在上述命令中,mean代表要估计的统计量,r(mean)表示使用Stata 自带的mean函数计算样本均值作为估计值。
reps(1000)表示进行1000次Bootstrap抽样,seed(123)表示设置随机数种子为123,以保证结果的可重复性。
运行上述命令后,Stata会输出Bootstrap估计值的分布情况,包括均值、标准误、置信区间等。
我们可以使用命令di来显示这些结果:```di "Bootstrap mean: " r(mean)di "Standard error: " r(se)di "95% Confidence interval: " "[" r(p1) ", " r(p99) "]"```在上述命令中,r(mean)代表Bootstrap估计值的均值,r(se)代表标准误,r(p1)和r(p99)分别代表置信区间的下限和上限。
除了对样本均值进行Bootstrap检验外,我们还可以对其他统计量进行Bootstrap检验,比如样本中位数、相关系数等。
具体命令和解释如下:```bootstrap median = r(median), reps(1000) seed(123)```在上述命令中,median代表要估计的统计量,r(median)表示使用Stata自带的median函数计算样本中位数作为估计值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第五章多组计量资料比较的非参数检验命令与输出结果说明本节STATA? 命令摘要
秩和检验 ( Mann,Whitney and Wilcoxon 非参数检验)
对于计量资料不满足正态分布要求或方差不齐性,但样本资料之间是独立抽取的,则可以应用秩和检验方法进行比较两组资料的中位数是否有差异。
STATA命令为:ranksum?? 观察变量, by( 分组变量)
例:研究不同饲料对雌鼠体重增加的关系。
表中用x表示雌鼠体重增加(克),用group=1表示高蛋白饲料组以及用group=2 表示低蛋白饲料组。
无效假设 Ho:两组增加体重的中位数相同。
ranksum x,? by(group)
①为第二组(低饲料组)的秩的和;② 若效假设成立,则第二组的秩的和期望值为70;
③秩和统计检验量z;④对于无效假设Ho对应的p值。
在本例中,虽然第二组的秩和为49.5而期望值估计为70,但p值为0.0832,所以根据该资料和统计结果一般不能认为用高蛋白饲料喂养能明显增加雌鼠的体重。
多组资料中位数比较(完全随机化设计资料的检验)
对于完全随机化设计资料的比较,若各组资料不全服从正态分布(即:至少有一组的资料均不服从正态分布)或各组的资料方差不齐性,则可以用Kruskal and Wallis方法进行检验(Ho:各组的中位数相同)。
STATA命令为:
kwallis?观察变量,by(分组变量)
例:50只小鼠随机分配到5个不同饲料组,每组10只小鼠。
在喂养一定时间后,测定鼠肝中的铁的含量(mg/g)如表所示:试比较各组鼠肝中铁的含量是否有显着性差别。
用x?表示鼠肝中铁的含量以及用group=1,2,3,4,5分别表示对应的5个组。
kwallis? x, by(group)
①为各组的秩和值;②为该统计量的c2检验值;③为无效假设检验所对应的p值。
本例结果表明:5组的中位数有显着的差异。
即:5个不同饲料组的小鼠肝脏中铁的含量有显着差异,说明小鼠肝脏中铁的含量与喂养的饲料有关。