STATA教程
使用Stata进行数据分析的教程

使用Stata进行数据分析的教程第一章:介绍StataStata是一种统计软件,经常被研究人员和学者用于数据分析和统计建模。
它提供了强大的数据处理和分析功能,可以应用于不同领域的研究项目。
本章介绍了Stata的基本功能和特点,包括数据管理、数据操作和Stata的界面等。
1.1 Stata的起源和发展Stata最初是由James Hardin和William Gould创建的,旨在为统计学家和社会科学研究人员提供一个数据分析工具。
随着时间的推移,Stata得到了广泛的应用,并逐渐发展成为一种强大的统计软件。
1.2 Stata的功能和特点Stata提供了许多数据处理和分析函数,包括描述性统计、回归分析、因子分析和生存分析等。
它还具有数据的管理功能,可以导入、导出和编辑数据文件。
Stata的界面友好,并且支持批处理和交互模式。
第二章:数据管理与准备在进行数据分析之前,首先需要准备和管理数据集。
本章将详细介绍Stata中的数据导入、数据清洗和数据变换等操作。
2.1 数据导入与导出Stata可以导入各种格式的数据文件,包括CSV、Excel和SPSS 等。
同时,Stata也支持将分析结果导出为不同的格式,如PDF和HTML等。
2.2 数据清洗和缺失值处理在实际研究中,数据常常存在缺失值和异常值。
Stata提供了处理缺失值和异常值的方法,可以通过删除、替换或插补来处理这些问题。
2.3 数据变换和指标构造数据变换是指将原始数据转化为适合分析的形式,常见的变换包括对数变换、差分和标准化等。
指标构造是指根据已有变量构造新的变量,如计算平均值和构造虚拟变量等。
第三章:描述性统计和数据可视化描述性统计是对数据集的基本统计特征进行总结和分析,而数据可视化则是通过图表和图形展示数据的特征和关系。
本章将介绍在Stata中进行描述性统计和数据可视化的方法。
3.1 中心趋势和离散程度的度量通过计算平均值、中位数和众数等指标来描述数据的中心趋势。
stata入门教程
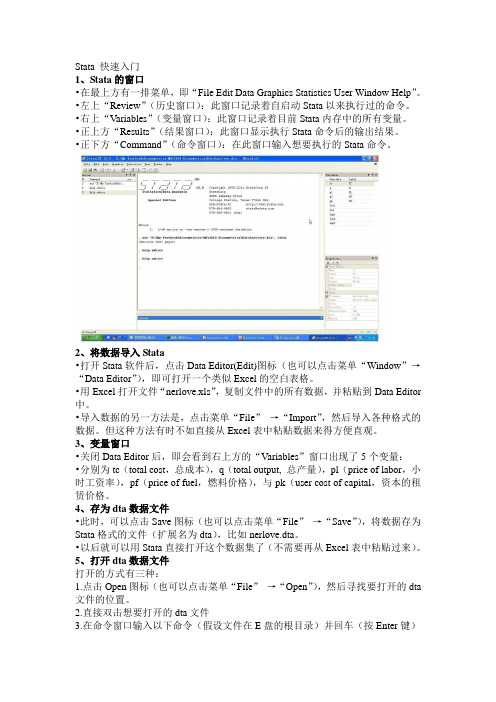
Stata 快速入门1、Stata的窗口•在最上方有一排菜单,即“File Edit Data Graphics Statistics User Window Help”。
•左上“Review”(历史窗口):此窗口记录着自启动Stata以来执行过的命令。
•右上“Variables”(变量窗口):此窗口记录着目前Stata内存中的所有变量。
•正上方“Results”(结果窗口):此窗口显示执行Stata命令后的输出结果。
•正下方“Command”(命令窗口):在此窗口输入想要执行的Stata命令。
2、将数据导入Stata•打开Stata软件后,点击Data Editor(Edit)图标(也可以点击菜单“Window”→“Data Editor”),即可打开一个类似Excel的空白表格。
•用Excel打开文件“nerlove.xls”,复制文件中的所有数据,并粘贴到Data Editor 中。
•导入数据的另一方法是,点击菜单“File”→“Import”,然后导入各种格式的数据。
但这种方法有时不如直接从Excel表中粘贴数据来得方便直观。
3、变量窗口•关闭Data Editor后,即会看到右上方的“Variables”窗口出现了5个变量:•分别为tc(total cost,总成本),q(total output, 总产量),pl(price of labor,小时工资率),pf(price of fuel,燃料价格),与pk(user cost of capital,资本的租赁价格。
4、存为dta数据文件•此时,可以点击Save图标(也可以点击菜单“File”→“Save”),将数据存为Stata格式的文件(扩展名为dta),比如nerlove.dta。
•以后就可以用Stata直接打开这个数据集了(不需要再从Excel表中粘贴过来)。
5、打开dta数据文件打开的方式有三种:1.点击Open图标(也可以点击菜单“File”→“Open”),然后寻找要打开的dta 文件的位置。
stata17 中文操作手册

stata17 中文操作手册Stata 17 中文操作手册Stata是一款广泛应用于数据分析和统计建模的统计软件,它能够帮助用户进行各种数据处理和分析任务。
本操作手册将带领您了解如何在Stata 17中进行常见的数据操作、统计分析和图表制作等操作。
请按照以下步骤进行操作:1. 数据导入和保存在Stata 17中,您可以使用"import"命令将外部数据文件导入Stata工作环境。
例如,您可以使用"import excel"命令导入Excel文件,使用"import delimited"命令导入CSV文件。
导入后,您可以使用"save"命令将数据保存为Stata格式的文件,以便以后使用。
2. 数据清理与转换在进行数据分析之前,您可能需要对数据进行清理和转换。
Stata提供了一系列命令来实现这些操作。
例如,使用"drop"命令可以删除数据集中的某些变量或观测值,使用"rename"命令可以重新命名变量,使用"generate"命令可以创建新的变量。
3. 描述性统计分析Stata 17提供了大量的命令和功能来进行描述性统计分析。
例如,使用"summarize"命令可以计算变量的均值、标准差、最大值和最小值等统计量,使用"tabulate"命令可以生成交叉表并计算频数和百分比等。
4. 统计推断在进行统计推断时,Stata 17提供了各种命令来进行假设检验和参数估计。
例如,使用"ttest"命令可以进行单样本或双样本均值差异的t 检验,使用"regress"命令可以进行线性回归分析。
5. 绘图功能Stata 17具备强大的绘图功能,能够绘制各种类型的图表以可视化数据。
例如,使用"histogram"命令可以绘制直方图,使用"scatter"命令可以绘制散点图,使用"line"命令可以绘制折线图。
STATA实用教程

STATA实用教程STATA是一种统计分析软件,广泛应用于数据分析、统计建模、数据可视化等领域。
它具有强大的数据处理能力和丰富的统计功能,能够快速、准确地处理大规模的数据集。
下面是一些STATA实用教程,帮助初学者快速上手该软件。
1.STATA基本操作STATA的基本操作包括数据导入和导出、数据集处理、变量管理等。
首先要学会使用STATA命令行界面和菜单栏来进行操作,了解STATA常用的命令和语法,掌握STATA常用的数据结构,如数据集、变量类型等。
同时,还需要学会使用STATA的帮助文档和网络资源,解决自己在使用过程中遇到的问题。
2.数据的描述性统计STATA可以进行各种描述性统计,例如计算均值、中位数、标准差、四分位数等,了解数据的分布情况。
可以利用summarize、describe等命令来进行描述性统计,还可以使用tabulate、histogram等命令进行变量的频数统计和画出直方图。
3.数据清洗和转换在实际应用中,数据往往需要进行清洗和转换。
STATA提供了一系列的命令,用于数据的清洗和转换。
比如,drop、keep命令可以删除不需要的变量或观察值;rename、recode命令可以对变量进行重命名和重新编码;reshape、merge命令可以进行数据重塑和合并等操作。
4.统计分析STATA提供了许多常用的统计方法和模型,可以进行统计分析。
例如,t检验、方差分析、线性回归、Logistic回归、生存分析、聚类分析等。
用户可以使用STATA内置的命令来进行统计分析,也可以使用STATA扩展包来进行更加复杂的分析。
5.高级数据处理STATA还提供了一些高级数据处理方法,如面板数据分析、时间序列分析、密度估计、非参数统计等。
这些方法对于处理复杂的数据结构和模型非常有用。
通过学习STATA的面板数据命令如xtreg、xtsum等,可以进行面板数据分析;通过学习STATA的时间序列命令如arima、xtdes等,可以进行时间序列分析。
Stata教程(免费)

第一章 Stata 概貌§1.1 Stata的功能、特点和背景Stata是一个用于分析和管理数据的功能强大又小巧玲珑的实用统计分析软件,由美国计算机资源中心(Computer Resource Center)研制。
从1985至1998的十四年时间里,已连续推出1.1,1.2,1.3,1.4,1.5,……及2.0,2.1,3.0,3.1,4.0,5.0,6.0等多个版本,通过不断更新和扩充,内容日趋完善。
它同时具有数据管理软件、统计分析软件、绘图软件、矩阵计算软件和程序语言的特点,又在许多方面别具一格。
Stata融汇了上述程序的优点,克服了各自的缺点,使其功能更加强大,操作更加灵活、简单,易学易用,越来越受到人们的重视和欢迎。
Stata的突出特点是只占用很少的磁盘空间,输出结果简洁,所选方法先进,内容较齐全,制作的图形十分精美,可直接被图形处理软件或字处理软件如WORD等直接调用。
一、 Stata的数据管理能力1.Stata的数据管理空间受计算机的操作系统和计算机扩展内存的影响。
对640k内存的微机,3.1版本的Stata可以管理2400个记录×99个变量,并随计算机扩展内存的增加而增加;对4.0的WINDOWS版本,Stata可以管理4800个记录×99个变量;对WINDOWS 95下的5.0版本,可根据计算机的配置情况设置变量数和记录数,如32M扩展内存的计算机,可处理2千万个数据。
变量数和记录数可以互相交易(trade),即减少记录数可以增加变量数,减少变量数可以增加记录数。
2.可以将分组变量转换成指示变量(哑变量),将字符串变量映射成数字代码。
3.可以对数据文件进行横向和纵向链接,可以将行数据转为列数据,或反之。
4.可以恢复、修改执行过的命令。
5.可以利用数值函数或字符串函数产生新变量。
6.可以从键盘或磁盘读入数据。
二、 Stata的统计功能Stata的统计功能很强,除了传统的统计分析方法外,还收集了近20年发展起来的新方法,如Cox比例风险回归,指数与Weibull回归,多类结果与有序结果的logistic回归,Poisson回归、负二项回归及广义负二项回归,随机效应模型等。
STATA软件实证分析操作指南

STATA软件实证分析操作指南第一章:引言1.1 研究背景1.2 研究目的1.3 研究意义第二章:STATA软件简介2.1 STATA软件概述2.2 STATA软件的特点2.3 STATA软件的应用领域第三章:STATA软件安装与启动3.1 软件安装3.2 软件启动3.3 界面功能介绍第四章:数据导入与管理4.1 数据导入4.1.1 导入Excel数据4.1.2 导入文本数据4.2 数据清洗与管理4.2.1 缺失值处理4.2.2 重复观察处理第五章:描述性统计分析5.1 数据摘要5.1.1 平均值、标准差与变异系数 5.1.2 中位数与四分位数5.2 数据分布5.2.1 频数与频率分布表5.2.2 直方图与箱线图5.3 数据关联5.3.1 相关系数5.3.2 散点图第六章:假设检验与参数估计6.1 单样本假设检验6.1.1 单样本t检验6.1.2 单样本比例检验6.2 双样本假设检验6.2.1 独立样本t检验6.2.2 成对样本t检验6.2.3 独立样本比例检验6.3 参数估计6.3.1 置信区间估计6.3.2 线性回归模型的参数估计第七章:数据可视化7.1 散点图与折线图7.2 饼图与柱状图7.3 热力图与地理图第八章:高级数据分析8.1 面板数据分析8.1.1 面板数据描述性统计8.1.2 面板数据回归分析8.2 生存分析8.2.1 生存曲线估计8.2.2 生存率比较第九章:模型诊断与改进9.1 残差分析9.2 多重共线性检验9.3 模型改进与比较第十章:输出结果与报告10.1 输出结果保存10.2 命令日志保存10.3 输出结果报告生成结语本文针对STATA软件进行了全面的实证分析操作指南,从软件安装与启动、数据导入与管理、描述性统计分析、假设检验与参数估计、数据可视化、高级数据分析、模型诊断与改进、输出结果与报告等方面进行了详细的讲解和操作指导。
通过学习本指南,读者将能够灵活运用STATA软件进行实证分析,并得到准确的分析结果,并能将结果以专业的方式呈现。
STATA使用教程

STATA使用教程第一章:介绍 StataStata 是一款统计分析软件,广泛应用于经济学、社会科学、健康科学和医学研究等领域。
本章将介绍 Stata 软件的基本特点、适用范围和主要功能。
1.1 Stata 的特点Stata 是一款功能强大、易于使用的统计软件。
不同于其他统计软件,Stata 具有灵活性高、数据处理效率好的优点。
它支持多种数据文件格式,可以处理大规模的数据集,并且具有丰富的数据处理、统计分析和图形展示功能。
1.2 Stata 的适用范围Stata 软件适用于各类研究领域,涵盖了经济学、社会科学、医学、健康科学等多个领域。
它广泛应用于定量分析、回归分析、面板数据分析、时间序列分析等领域,可用于统计推断、数据可视化和模型建立等任务。
1.3 Stata 的主要功能Stata 软件提供了丰富的功能模块,包括数据导入导出、数据清洗、数据管理、描述性统计、推断统计、回归分析、面板数据分析、时间序列分析、图形展示等。
这些功能模块为用户提供了全面且灵活的数据分析工具。
第二章:Stata 数据处理数据处理是统计分析的前置工作,本章将介绍 Stata 软件的数据导入导出、数据清洗和数据管理等功能。
2.1 数据导入导出Stata 支持导入多种文件格式的数据,如文本文件、Excel 文件和 SAS 数据集等。
用户可以使用内置命令或者图形界面进行导入操作,导入后的数据可以存储为 Stata 数据文件(.dta 格式),方便后续的数据处理和分析。
2.2 数据清洗数据清洗是数据处理的重要环节,Stata 提供了多种数据清洗命令,如缺失值处理、异常值处理和数据类型转换等。
用户可以根据实际情况选择合适的数据清洗操作,确保数据的准确性和完整性。
2.3 数据管理数据管理是有效进行数据处理的关键,Stata 提供了许多数据管理命令,如数据排序、数据合并、数据分割和数据标记等。
这些命令可以帮助用户高效地对数据进行管理和组织,提高数据处理效率。
stata教程

stata教程Stata 是一种广泛应用于统计分析的软件,拥有强大的数据处理和建模能力。
本教程将介绍 Stata 的一些基础操作和常用命令,帮助您快速上手使用该软件。
1. 安装和启动 Stata在开始使用Stata 之前,您需要先安装该软件。
安装完成后,双击图标启动 Stata。
2. 导入数据使用 Stata 进行统计分析的第一步是导入数据。
可以通过命令 `use` 来加载已有的 Stata 数据集,或者使用 `import` 命令导入其它格式的数据文件。
3. 数据处理Stata 提供了许多数据处理的命令,比如 `drop` 可以删除某些变量或观察值,`rename` 可以修改变量名,`generate` 可以创建新变量等。
4. 描述性统计描述性统计是对数据的基本概况进行分析,可以使用命令`summarize` 来获取平均值、标准差等统计量,使用 `tabulate`命令生成频数表,还可以通过 `graph` 命令绘制直方图或散点图等图形。
5. 假设检验假设检验用于验证某个统计假设是否成立。
Stata 提供了多种假设检验的命令,比如 `ttest` 可以进行单样本或独立样本 t 检验,`anova` 可以进行方差分析等。
6. 回归分析回归分析是一种常用的建模方法,可以用于研究变量之间的关系。
在Stata 中,可以使用`regress` 命令进行简单线性回归,使用 `logit` 命令进行逻辑回归等。
7. 图形输出Stata 可以生成各种类型的图形输出,比如线图、散点图、柱状图等。
可以使用`graph export` 命令将图形导出为图片文件,方便在报告中使用。
8. 编写批处理脚本如果需要重复执行一组命令,可以将这些命令写入批处理脚本。
Stata 支持编写批处理脚本来自动化数据处理和分析的过程。
以上是关于 Stata 的基础教程,希望能帮助您快速入门并熟练使用该软件进行数据分析。
更多高级功能和命令,请参考Stata 官方文档或相关教程。
STATA统计分析软件使用教程

STATA统计分析软件使用教程引言STATA统计分析软件是一款功能强大、使用广泛的统计分析软件,广泛应用于经济学、社会学、医学和其他社会科学领域的研究中。
本教程将介绍STATA的基本操作和常用功能,并提供实例演示,帮助读者快速上手使用。
第一章:STATA入门1.1 安装与启动首先,下载并安装STATA软件。
完成安装后,点击软件图标启动STATA。
1.2 界面介绍STATA的界面分为主窗口、命令窗口和结果窗口。
主窗口用于数据显示,命令窗口用于输入分析命令,结果窗口用于显示分析结果。
1.3 数据导入与保存使用命令`use filename`导入数据,使用命令`save filename`保存当前数据。
1.4 基本命令介绍常用的基本命令,如`describe`用于显示数据的基本信息、`summarize`用于计算变量的统计描述等。
第二章:数据处理与变量管理2.1 数据选择与筛选通过命令`keep`和`drop`选择和删除数据的特定变量和观察值。
2.2 数据排序与重编码使用命令`sort`对数据进行排序,使用命令`recode`对变量进行重编码。
2.3 缺失值处理介绍如何检测和处理数据中的缺失值,包括使用命令`missing`和`recode`等。
第三章:数据分析3.1 描述性统计介绍如何使用STATA计算和展示数据的描述性统计量,如均值、标准差、最大值等。
3.2 统计检验介绍如何进行常见的统计检验,如t检验、方差分析、卡方检验等。
3.3 回归分析介绍如何进行回归分析,包括一元线性回归、多元线性回归和逻辑回归等。
3.4 生存分析介绍如何进行生存分析,包括Kaplan-Meier生存曲线和Cox比例风险模型等。
第四章:图形绘制与结果解释4.1 图形绘制基础介绍如何使用STATA进行常见的数据可视化,如散点图、柱状图、折线图等。
4.2 图形选项与高级绘图介绍如何通过调整图形选项和使用高级绘图命令,进一步美化和定制图形。
Stata教程(免费)

第一章 Stata 概貌§1.1 Stata的功能、特点和背景Stata是一个用于分析和管理数据的功能强大又小巧玲珑的实用统计分析软件,由美国计算机资源中心(Computer Resource Center)研制。
从1985至1998的十四年时间里,已连续推出1.1,1.2,1.3,1.4,1.5,……及2.0,2.1,3.0,3.1,4.0,5.0,6.0等多个版本,通过不断更新和扩充,内容日趋完善。
它同时具有数据管理软件、统计分析软件、绘图软件、矩阵计算软件和程序语言的特点,又在许多方面别具一格。
Stata融汇了上述程序的优点,克服了各自的缺点,使其功能更加强大,操作更加灵活、简单,易学易用,越来越受到人们的重视和欢迎。
Stata的突出特点是只占用很少的磁盘空间,输出结果简洁,所选方法先进,内容较齐全,制作的图形十分精美,可直接被图形处理软件或字处理软件如WORD等直接调用。
一、 Stata的数据管理能力1.Stata的数据管理空间受计算机的操作系统和计算机扩展内存的影响。
对640k内存的微机,3.1版本的Stata可以管理2400个记录×99个变量,并随计算机扩展内存的增加而增加;对4.0的WINDOWS版本,Stata可以管理4800个记录×99个变量;对WINDOWS 95下的5.0版本,可根据计算机的配置情况设置变量数和记录数,如32M扩展内存的计算机,可处理2千万个数据。
变量数和记录数可以互相交易(trade),即减少记录数可以增加变量数,减少变量数可以增加记录数。
2.可以将分组变量转换成指示变量(哑变量),将字符串变量映射成数字代码。
3.可以对数据文件进行横向和纵向链接,可以将行数据转为列数据,或反之。
4.可以恢复、修改执行过的命令。
5.可以利用数值函数或字符串函数产生新变量。
6.可以从键盘或磁盘读入数据。
二、 Stata的统计功能Stata的统计功能很强,除了传统的统计分析方法外,还收集了近20年发展起来的新方法,如Cox比例风险回归,指数与Weibull回归,多类结果与有序结果的logistic回归,Poisson回归、负二项回归及广义负二项回归,随机效应模型等。
教你快速上手使用Stata进行数据处理和分析

教你快速上手使用Stata进行数据处理和分析快速上手使用Stata进行数据处理和分析第一章:Stata软件的介绍和安装Stata是一款功能强大的统计分析软件,广泛应用于各个学科领域的数据处理和分析工作中。
它提供了强大的数据管理、数据处理和数据分析功能,能够帮助用户高效地完成各种统计任务。
1.1 Stata软件的特点和应用领域Stata具有易于使用的界面、丰富的数据处理和分析功能,可以满足不同用户对数据分析的需求。
它被广泛应用于社会科学、经济学、医学、生物学等领域的数据处理和分析工作中。
1.2 Stata软件的安装和系统要求Stata软件的安装非常简单,只需按照安装向导进行操作即可。
同时,为了保证软件的正常运行,用户需要满足一定的系统要求,比如合适的操作系统版本、足够的内存和硬盘空间等。
第二章:Stata基本命令和语法在使用Stata进行数据处理和分析之前,我们需要了解一些基本的命令和语法。
下面是一些常用的命令和语法:2.1 数据导入和导出命令Stata可以导入多种数据格式,如Excel、CSV、SPSS等,通过命令"import"和"export"可以实现数据的导入和导出。
2.2 数据的描述性统计和图表命令Stata提供了丰富的命令来计算和展示数据的描述性统计信息,比如平均值、标准差、频数等。
通过命令"summarize"和"graph"可以生成相应的统计表和图表。
2.3 数据的清洗和转换命令在实际的数据处理中,我们经常需要对数据进行清洗和转换。
Stata提供了一系列的命令来处理缺失值、异常值、重复值等问题,比如命令"drop"和"replace"等。
第三章:Stata高级数据处理和分析技巧除了基本的命令和语法,Stata还提供了一些高级的数据处理和分析技巧,可以帮助用户更加高效地完成工作。
Stata软件操作教程

Stata软件操作教程第15章:面板数据分析面板数据是指在时间上具有一定连续性的多个个体观测值,例如不同地区连续多年的经济数据、同一个企业在多个时间点的财务数据等。
面板数据具有时间序列和截面两个维度,因此在分析面板数据时需要考虑个体间的相关性和时间序列的影响。
在Stata中,面板数据的操作和分析可以使用如下的一些命令:1. 导入面板数据:使用`use`命令导入面板数据文件,例如`use filename, clear`,其中filename为数据文件名。
2. 面板数据的描述性统计:使用`summarize`命令计算面板数据的平均值、标准差等描述性统计量。
例如,`summarize varname, detail`计算变量varname的描述性统计量。
3. 面板数据的时间序列图:使用`tsline`命令绘制面板数据的时间序列图。
例如,`tsline varname`绘制变量varname的时间序列图。
4. 固定效应模型(Fixed Effects Model):使用`xtreg`命令估计固定效应模型,该模型考虑了个体间的固定效应。
例如,`xtreg dependent var independent var, fe`估计固定效应模型。
5. 随机效应模型(Random Effects Model):使用`xtreg`命令估计随机效应模型,该模型考虑了个体间的随机效应。
例如,`xtreg dependent var independent var, re`估计随机效应模型。
6. 混合效应模型(Mixed Effects Model):使用`xtmixed`命令估计混合效应模型,该模型既考虑了个体间的固定效应,又考虑了个体间的随机效应。
例如,`xtmixed dependent var independent var ,groupvar:`估计混合效应模型。
7. 模型检验和诊断:使用`xttest0`命令进行固定效应模型的F检验;使用`xtserial`命令进行个体效应的序列相关性检验;使用`xtgee`命令进行广义估计方程的估计和推断。
STATA实用教程

STATA实用教程接下来,了解STATA的基本操作。
在STATA窗口的命令行中,可以输入分析的指令,按下回车键即可执行。
同时,还可以通过菜单栏中的各种选项来进行操作,比如导入数据、保存结果等。
可以通过命令help来查看STATA的帮助文档,帮助解决一些操作上的问题。
在进行数据分析前,需要先导入数据。
STATA支持多种数据文件格式,比如CSV和Excel。
可以通过命令import来导入数据文件,根据文件路径和格式指定导入的方式。
导入后,可以使用命令describe来查看数据文件的基本情况,比如变量名、变量类型等。
数据导入完成后,可以进行各种统计分析。
常用的命令包括:summarize(统计描述性统计量)、correlation(计算变量之间的相关系数)、regress(进行回归分析)、anova(进行方差分析)等。
这些命令可以根据具体的需求进行参数设置,比如指定自变量和因变量,进行分组分析等。
数据分析完成后,可以进行结果的可视化。
STATA提供了多种绘图函数,比如scatter plot、histogram、line plot等。
可以通过相应的命令来生成图表,同时可以根据需要进行样式和布局的调整。
生成的图表可以保存为图片格式,方便后续的使用和报告编写。
除了基本的数据分析和可视化外,STATA还支持一些高级的统计方法和模型。
比如面板数据分析、生存分析、因子分析等。
可以通过命令进行设置和估计,得到相应的结果。
同时,STATA还支持编写自定义的程序和命令,方便用户在需要时进行重复操作或扩展功能。
最后,对于初学者来说,还可以通过学习一些STATA的实例和案例来提高应用能力。
可以寻找一些数据集和问题,尝试使用STATA进行分析和解决。
也可以参考一些学术论文或教材,了解其他研究者是如何使用STATA进行数据分析的。
总之,STATA是一款功能强大、使用方便的统计分析软件。
通过本文提供的实用教程,初学者可以迅速上手使用STATA进行数据分析。
使用Stata进行统计分析和数据可视化的教程

使用Stata进行统计分析和数据可视化的教程Stata是一种常用的统计分析软件,广泛应用于社会科学、经济学和健康科学等领域的数据分析和可视化。
本文将为大家提供一个使用Stata进行统计分析和数据可视化的教程,包括数据导入、数据处理、统计分析和数据可视化等内容。
首先,我们需要了解Stata软件的基本操作。
一、Stata软件的基本操作1. 安装与启动:将Stata软件下载并安装在电脑上,然后双击桌面上的图标启动程序。
2. 导入数据:在Stata中,可以通过多种方式导入数据,如Excel表格、文本文件和数据库等。
使用命令“import excel”导入Excel表格数据,命令“import delimited”导入文本文件数据。
导入数据后,可以使用“describe”命令查看数据的结构和变量的属性。
3. 数据浏览与修改:使用“browse”命令可以打开数据集的浏览窗口,查看数据的内容。
要对数据进行修改,可以使用“generate”或“replace”命令创建或修改变量的值。
4. 数据子集选择:使用“keep”和“drop”命令选择需要分析的变量或观测。
5. 数据排序:使用“sort”命令可以按照指定的变量对数据进行排序。
二、数据处理与统计分析1. 描述统计分析:使用“summarize”命令计算变量的均值、方差、最大值、最小值等统计指标。
可以使用“tabulate”命令生成频数表和交叉表。
使用“histogram”命令生成直方图,“scatter”命令生成散点图。
2. t检验与方差分析:使用“ttest”命令进行两样本t检验,使用“oneway”命令进行方差分析。
3. 回归分析:使用“regress”命令进行线性回归分析。
可以使用“predict”命令创建预测值,并使用“estat”命令计算回归结果的统计量。
4. 面板数据分析:对于面板数据,使用“xtset”命令设置面板数据的结构,然后使用面板数据专用的命令进行分析,如“xtreg”进行面板数据的固定效应模型分析。
stata入门操作总结

Stata入门操作总结
1. 导入数据:
方法一:点击文件选项,选择导入,根据数据类型选择即可。
方法二:进入数据编辑器界面,点击“文件”选择打开。
注意,该方式只能打开.dta文件,若数据量较小建议在Excel 中的打开,全选后复制,粘贴至数据编辑器中。
2. 修改变量标签:
在数据编辑器的属性窗口直接输入即可。
在命令窗口输入label variable 城市“city”,注意var后面的跟变量名称,即使是汉字也不需要加引号。
3. 检视数据:
输入命令describe(可简写为d)看数据集中变量名称、标签等。
若想看某几个变量的具体数据,则输入命令:list A B C。
也可通过逻辑关系来定义数据集子集,比如列出C变量大于等于10000的数据,则使用命令:list A C if C>=10000。
这里注意下其他表示关系的逻辑符号有“==”(等于)、“~=”(不等于,也可以用“!”)。
4. 进行假设检验:T检验(又称学生t检验)用于统计量服从正态分布,但方差未知的情况。
具体操作包括单样本t检验、独立样本t检验和配对样本t检验,分别用于检验总体方差未知、正态数据或近似正态的单样本均值是否与已知的总体均值相等,两对独立的正态数据或近似正态的样本的均值是否相等(可根据总体方差是否相等分类讨论),以及一对配对样本的均值的差是否等于某一个值。
以上是Stata入门操作总结,希望对您有所帮助。
STATA基础教程
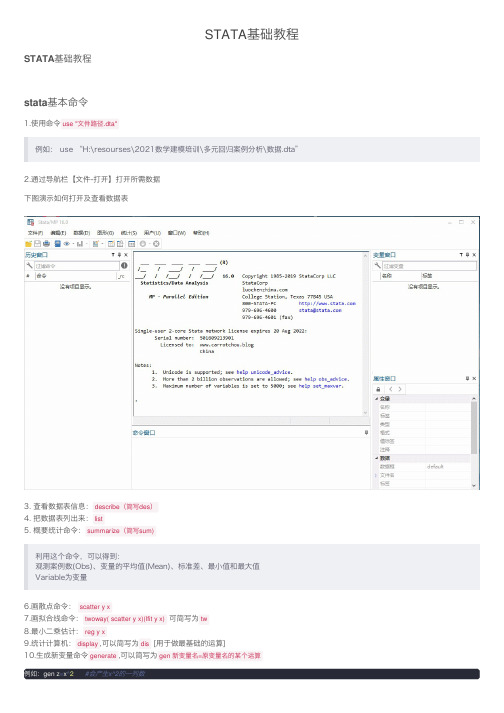
STATA基础教程STATA基础教程
stata基本命令
1.使⽤命令use "⽂件路径.dta"
例如: use “H:\resourses\2021数学建模培训\多元回归案例分析\数据.dta”
2.通过导航栏【⽂件-打开】打开所需数据
下图演⽰如何打开及查看数据表
3. 查看数据表信息:describe(简写des)
4. 把数据表列出来:list
5. 概要统计命令:summarize(简写sum)
利⽤这个命令,可以得到:
观测案例数(Obs)、变量的平均值(Mean)、标准差、最⼩值和最⼤值
Variable为变量
6.画散点命令: scatter y x
7.画拟合线命令:twoway( scatter y x)(lfit y x) 可简写为tw
8.最⼩⼆乘估计:reg y x
9.统计计算机:display,可以简写为dis [⽤于做最基础的运算]
10.⽣成新变量命令generate,可以简写为gen 新变量名=原变量名的某个运算
例如:gen z=x^2#会产⽣x^2的⼀列数
11.去除变量的命令:drop 某变量名
例如:drop z #z那⼀栏就不见了,被删除了
12.提取残差的命令:reg y x,紧跟第⼆条命令:predict e,res 边学习边补充~。
stata 教程

stata 教程Stata是一种强大的统计分析软件,广泛应用于经济学、社会科学、生物统计学等领域。
本教程将介绍Stata的基本操作和常用功能,帮助您快速入门。
1. Stata的界面和基本操作- 打开Stata软件后,会出现一个命令行界面。
您可以直接在命令行输入Stata命令进行操作。
- 菜单栏提供了常用的功能选项,包括打开数据文件、保存结果、运行程序等。
- 数据编辑窗口可以对数据进行编辑和处理。
- 结果窗口会显示Stata命令的执行结果和输出信息。
2. 导入和导出数据- 使用`import`命令可以导入各种格式的数据文件,如CSV、Excel、SPSS等。
- 使用`export`命令可以将Stata数据文件保存为其他格式的文件。
3. 数据的描述性统计- 使用`summarize`命令可以计算数据的基本统计量,如均值、中位数、标准差等。
- 使用`tabulate`命令可以制作数据的列联表和交叉报表。
- 使用`graph`命令可以绘制数据的直方图、散点图等。
4. 数据的清洗和处理- 使用`drop`命令可以删除数据中的变量或观察。
- 使用`rename`命令可以修改变量的名称。
- 使用`generate`命令可以生成新的变量,并进行数值计算和逻辑判断。
5. 统计分析- 使用`regress`命令可以进行回归分析。
- 使用`ttest`命令可以进行单样本或双样本t检验。
- 使用`correlate`命令可以计算变量之间的相关系数。
6. 编写和运行程序- 使用`do`命令可以运行存储在.do文件中的Stata程序。
- 使用`foreach`和`forvalues`命令可以进行循环操作。
- 使用`if`和`else`命令可以进行条件判断。
这些是Stata的基本操作和常用功能,希望对您的学习和使用有所帮助。
通过实践和深入了解Stata的不同命令和功能,您将能够灵活地进行数据处理和统计分析。
STATA基本操作入门

STATA基本操作入门1.数据导入在STATA中,可以导入多种格式的数据文件,如Excel、CSV和文本文件。
最常用的命令是"import excel"和"import delimited"。
例如,要导入名为"data.xlsx"的Excel文件,可以使用以下命令:```import excel using "data.xlsx", sheet("Sheet1") firstrow clear```这里,"using"指定了文件路径和文件名,"sheet"指定了工作表名称(如果有多个工作表),"firstrow"表示第一行是变量名。
2.数据清洗在导入数据后,通常需要进行数据清洗,包括处理缺失值、异常值和重复值等。
STATA提供了一些常用的命令来处理这些问题。
- 缺失值处理:使用"drop"命令删除带有缺失值的观测值,使用"egen"命令创建新变量来表示缺失值。
- 异常值处理:可以使用描述性统计命令(如"summarize")来查找异常值,并使用"drop"命令删除异常值所对应的观测值。
- 重复值处理:使用"deduplicate"命令删除重复的观测值,或使用"egen"命令创建新变量来表示重复值。
3.变量操作在STATA中,可以对变量进行各种操作,如创建变量、重命名变量、计算变量和合并变量等。
- 创建变量:可以使用"generate"命令创建新变量,并赋予其数值或字符值。
- 重命名变量:使用"rename"命令将变量重命名为新的名称。
- 计算变量:使用"egen"命令计算新变量,例如,可以使用"egen mean_var = mean(var)"计算变量"var"的均值,并将结果赋值给新的变量"mean_var"。
计量经济学软件Stata15.0应用教程 课件 第二章 基本操作

第一节准备工作
一 、更改路径
在命令窗口(Command)输入:
pwd
然后回车 。pwd是指显示当前工作路径 在命令窗口输入:
dir 然后回车 。dir是指显示当前系统文件的设定
二 、命令注释
( 1) 注释方式
①将双斜杠“// ”放在命令后面 。指“// ”后面的内容是对该条命令的注释说明 ,注释内容以绿色显 示 ,执行命令时会跳过注释内容。
②* 表示*之后的整行内容都是注释,不会被执行。 ③/*
*/
( 2) 练习注释 新建do文档 ,在do文档中输入下面的命令及注释 , 练习到能熟练的注释命令的程度。
sysuse auto,clear //打开系统自带数据auto ,注意逗号为英文状态
reg price mpg weight //OLS回归,被解释变量为price,解释变量为mpg weight
histx2 //查看x2的直方图 ,看是否符合正态分布。 sktest x2 swilk x2
sfrto,clear
reg price weight mpg foreign //先回归
predict e,r //r 即residal ,将残差保存为变量e
三 、数据导入
方法一 :菜单导入excel 、txt等格式的数据 ,针对大量数据。 方法二: 复制粘贴法 ,针对少量数据。 方法三:命令法 ,针对少量数据。
四 、打开dta格式数据
Stata数据是以dta结尾的数据 ,如何打开Stata格式的数据呢?这是最简单不过的 事情了。
方法一: 鼠标拖拽法 方法二: 菜单法 方法三: 命令法 打开系统自带数据是sysuse+文件名 , 如: sysuse auto //打开Stata系统自带数据auto
stata-第一章-基本操作

2021/5/23
12
练习1.2
打开stata数据 删除private变量 只保留stkcd year两个变量 删除2008年的数据 只保留2010年的数据 将year变量改名为y 将y的标签设置为年度
2021/5/23
13
1.3描述数据
count,看看有多少样本
drop if year==2010,删除所有2010年的变量 drop year,删除year这个变量 drop _all,删除所有变量
注意:stata值的等号全为双等号,单等号是赋值命令, 在以后的操作中,注意=号和==号的区别。
2021/5/23
11
打开stata数据 use "D:\Teach课件\STATA\data\corgov.dta",clear keep命令是drop命令的反向命令
save "D:\Teach课件\STATA\data\corgov9910.dta",replace
br
2021/5/23
20
merge命令
数据表之间横向合并,追加新的变量
insheet using "D:\Teach课件\STATA\data\corgov.csv",clear sort stkcd year save "D:\Teach课件\STATA\data\corgov.dta",replace insheet using "D:\Teach课件\STATA\data\earning.csv",clear sort stkcd year merge stkcd year using "D:\Teach课件\STATA\data\corgov.dta" tab _merge(数值为1表示表一有,表二没有;2表示表二有表一没有;
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
行调整,并将调整后的成绩记为math_female
– dis 3>5 //dis是display的简写,显示结果为0 ,表示关系式不对 – dis 3<5 //显示结果为1,表示关系式正确 – dis 4==4 //显示结果为1,表示关系式正确 – 在进行关系运算中一定要注意缺失值,因为在STA明忽略缺失值的严重后果。假 定有如下的学生成绩数据,由于John缺考, 因此成绩缺失。
– [by varlist:] command [varlist] [=exp] [if exp] [in range] [weight] [, options]
– 一般性格式中包含有如下几个组成部分:命令(command)、变量 列表(varlist)、分类(by)、赋值(=exp)、条件(if exp)、 范围(in range)、权重(weight)、可选项(options)。其中, [ ]表示可有可无的项,否则为必选项,显然只有 command 是必不可 少的。下面我们将结合具体的例子来讲解各个组成部分的含义及功 能。
于5000或者价格超过10000的国外车的转速 – 注意,在 STATA 中,和(&)优先于或(|)。问下面的命令代表什么含
义? – list turn if (price<5000)|(price>10000)&(foreign==1)
第五讲、命令语句结构与运算符
• 命令语句的格式
– 通过前面几讲的学习,相信大家对命令多少有了点自己的了解。本 讲将介绍STATA命令语句的一般性格式:
代数运算
“加”
+
或“字
符相加”
“减”
-
或“负
号”
*
乘
/ ^ sqrt()
除 指数 开方
逻辑运算
&
“与” 或“和”
关系运算
>
大于
|
或
<
小于
~
“非” 或“不”
>=
大于等 于
!
“非” 或“不”
<=
小于等 于
==
等于
~=或! =
不等于
第五讲、命令语句结构与运算符
• 代数运算
– 代数运算是最基本的数据处理,它包括包括加(+)、减(-)、乘(*)、 除(/),幂(^)和负数(-)。在进行代数运算时,如果遇到缺失值、 运算不可行时(比如除数为零)或运算不用执行时均会得到缺失值。
– 现在假定学校想了解数学成绩在80~90分 和90分以上的人数,有人写出如下命令进 行统计
– gen Math_9=(Math>=90)//成绩在90及 以上的
– gen Math_8=(Math<90)&(Math>=80)//成 绩在80~90之间
– list Math Math_9 Math_8//显示结果
和字符型数据3相加就会出错。 – scalar a= 5+ “3”//将数值2和字符3相加,结果出错 – type mismatch – r(109);
第五讲、命令语句结构与运算符
• 关系运算
– 关系运算包括大于、小于、等于;大于等于、小于等于、不等于等多种比 较关系。特别要注意的是,STATA中的等于符号为“==”,是两个等号连 写在一起,表示比较两边的关系式是否相等,它不同于“=”。“=”的 含义是将等号右边的值赋予左边的变量,这是一个赋值号。当关系式满足 是,显示结果为1(表示关系式正确),否则显示结果为0(表示关系式错 误)
第五讲、命令语句结构与运算符
• 运算符与运算
– 对数据进行加工,不可避免 的会涉及到数据的运算。 STATA共有四种运算:代数 运算、字符运算、逻辑运算 和关系运算。各种运算的运 算符见右表。
– 运算的优先级(从高到 低):!(或~),^,-(负 号),/,*,-(减), +,!=(或 ~=),>,<,<=,>=,==,&,| 当 忘记或者无法确定优先序的 时候,最好用括号将优先序 表达出来,在最里层括号中 的表示式将被优先执行
– 显然这种统计方式是错误的,因为他将缺 考的John的数学成绩当成超过90分来处理。
Stu_id 1 2 3 4 5 6
Name John Marry Jack Tom Jerry Jim
Chinese . 80 78 77 87 87
Math . 90 60 85 86 60
第五讲、命令语句结构与运算符
• 逻辑运算
– 逻辑运算符包括非(!或者~),和(&)、或(|)三种,大量运用在条 件和判断语句中。
– sysuse auto.dta, clear //导入系统自带的汽车数据文件 – list if (price>5000)&(foreign==1)//显示价格超过5000的国外车的基本
特征 – list turn if ((price<5000)|(price>10000))&(foreign==1)//显示价格小
第五讲、命令语句结构与运算符
• 字符运算
– 当需要把两个字符进行连接时,同样可以用加号(+)来完成。比如,把 “我”和“爱你”合并在一起,命令为:
– scalar a= “I”+ “Love U”//将字符I和Love U连接并赋予a。注意:引 号必须是在英文半角状态,否则出错。
– scalar list a// 显示a的内容 – 不可以将不同类型的数据进行相加,否则将出错。例如,把数值型数据2
对外经济贸易大学金融学院 谢海滨 International Business School, UIBE
计量经济软件及应用
STATA硕士研究生班
第五讲、命令语句结构与运算符
STATA是当前最为流行 的统计计量分析之一
STATA的广泛应用:
-1.运算符及运算 -2.命令语句结构
->1 命令(command) ->2 变量(varlist) ->3 分类变量(by varlist) ->4 赋值(=exp) ->5 条件(if exp) ->6 范围(in range) ->7 加权(weight) ->8 可选(option)