TD数据库常用表
td数据库语法

td数据库语法
数据库是一种组织和存储数据的工具。
TD数据库(Teradata Database)是一种关系型数据库管理系统,用于处理大规模数据。
以下是TD数据库的一些基本语法:
1.数据定义语句:用于创建表、索引和其他数据库对象。
例如:
C R EATE TABLE表名(
列名1 数据类型,
列名2 数据类型,
...
);
2.数据操纵语句:用于插入、更新、删除和查询数据。
例如:
I NSERT INTO 表名(列名1,列名2,...)
V ALUES (值1,值2,...);
U PDATE 表名
S ET 列名1 = 值1,列名2 = 值2,...
W HERE 条件;
D ELETE FROM 表名
W HERE 条件;
S ELECT 列名1,列名2,...
F R OM 表名
W HERE 条件;
3.数据控制语句:用于控制数据库的访问权限和事务处理。
例如:
GRANT 权限名TO 用户名;
R EVOKE 权限名FROM 用户名;
B EGIN TRANSACTION;
C OMMIT;
R OLLBACK;
4.数据聚合函数:用于对数据进行汇总和统计。
例如:
S U M(列名),MAX(列名),MIN(列名),COUNT(*);
5.查询优化:使用EXPLAIN命令分析查询计划的执行计划。
例如:
E XPLAIN SELECT ...;
这些仅为TD数据库语法的基本概述。
td数据库语法

td数据库语法【最新版】目录1.TD 数据库简介2.TD 数据库语法基础3.TD 数据库语法进阶4.TD 数据库语法实例正文【TD 数据库简介】TD 数据库,全称为 Taobao Data,是阿里巴巴集团旗下的一种数据存储系统。
TD 数据库主要用于存储和处理阿里巴巴集团各大电商平台的数据,例如淘宝、天猫等。
TD 数据库具有高性能、高并发、高可靠性等特点,适用于大规模数据存储和分析。
【TD 数据库语法基础】TD 数据库的语法基础主要包括表、字段、数据类型、主键、索引等概念。
以下是一些基础语法:1.表:用于存储数据,由字段组成。
例如:```CREATE TABLE IF NOT EXISTS `table_name` (`id` INT(11) NOT NULL AUTO_INCREMENT,`field1` VARCHAR(255) NOT NULL,`field2` INT(11) NOT NULL,PRIMARY KEY (`id`),KEY `field1` (`field1`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;```2.字段:表中的数据单元,用于存储具体信息。
例如:`id`、`field1`、`field2`等。
3.数据类型:用于定义字段的数据种类。
例如:INT、VARCHAR、DATE 等。
4.主键:用于唯一标识表中的记录的字段。
例如:`id`字段。
5.索引:用于提高查询速度的辅助结构。
例如:`KEY `field1`(`field1`)`。
【TD 数据库语法进阶】除了基础语法,TD 数据库还支持一些高级功能,例如:1.聚合函数:用于对表中的数据进行统计和汇总。
例如:`COUNT()`、`SUM()`等。
2.查询语句:用于查询表中的数据。
例如:`SELECT * FROM table_name WHERE field1="value1"`。
表格代码大全

表格代码大全表格代码大全表格代码代码:<table border="1" bordercolorlight="#ffffff"bordercolordark="#ffffff" width="200" cellpadding="0" cellspacing="0"><tr align="center"> <td bgcolor="#B7B7B7" bordercolorlight="#000000" bordercolordark="#eeeeee" >立</td><td bgcolor="#B7B7B7" bordercolorlight="#000000" bordercolordark="#eeeeee" >表</td></tr><tr align="center"> <td bgcolor="#B7B7B7" bordercolorlight="#000000" bordercolordark="#eeeeee" >体</td><td bgcolor="#B7B7B7" bordercolorlight="#000000" bordercolordark="#eeeeee" >格</td></tr></table>二、表格边框和单元格的特殊效果。
td数据库语法

td数据库语法摘要:一、引言二、td数据库简介1.什么是td数据库2.td数据库的发展历程三、td数据库的语法规则1.数据类型2.变量与常量3.运算符与表达式4.控制结构5.函数与过程6.表与视图7.索引与约束8.触发器与存储过程四、td数据库的应用领域1.数据存储与查询2.数据处理与分析3.系统开发与设计五、td数据库的发展趋势与展望1.技术创新与升级2.行业应用的拓展3.我国td数据库产业的机遇与挑战正文:一、引言随着信息技术的飞速发展,数据库作为计算机科学中的重要领域,日益受到人们的关注。
td数据库作为一种功能强大、易于使用的数据库,逐渐成为广大开发者和学习者的首选。
本文将详细介绍td数据库的语法规则及其应用领域,以帮助读者更好地了解和使用td数据库。
二、td数据库简介td数据库,全称为“TinyDB”,是一款轻量级、高性能的嵌入式数据库。
它适用于各种场景,如物联网、智能硬件、移动应用等,尤其适合资源受限的环境。
td数据库具有易用、高效、可扩展性强等特点,为开发者提供了便捷的数据存储和管理方案。
2.1 什么是td数据库td数据库是一款面向对象的嵌入式数据库,支持多种数据类型、数据存储和数据查询功能。
它具有较小的体积、较低的内存占用和较快的数据访问速度,可满足各种小型应用的需求。
2.2 td数据库的发展历程td数据库起源于2009年,经过多年的发展,已经推出了多个版本。
随着技术的不断进步,td数据库在功能、性能和兼容性方面都得到了显著提升,逐渐成为嵌入式数据库领域的一颗新星。
三、td数据库的语法规则要熟练使用td数据库,首先需要掌握其语法规则。
以下是对td数据库语法规则的详细介绍:3.1 数据类型td数据库支持基本数据类型和自定义数据类型。
基本数据类型包括整型、浮点型、字符串型、布尔型等;自定义数据类型可以根据需要定义结构体、枚举等。
3.2 变量与常量在td数据库中,可以使用变量和常量来表示数据。
web前端中table的各种用法

Web前端中,表格(table)是一种常用的HTML元素,用于展示和组织数据。
在实际开发过程中,表格的使用非常普遍,可以用于展示各种数据,比如排行榜、商品列表、数据报表等等。
本文将介绍Web 前端中table的各种用法,包括但不限于表格的基本结构、样式调整、事件处理、响应式布局等方面,帮助读者更好地掌握表格的灵活运用。
一、表格的基本结构在HTML中,表格由table、tr、td等元素构成。
其中,table是表格的容器,tr代表表格的一行,td代表表格中的单元格。
下面是一个简单的表格结构示例:```html<table><tr><td>尊称</td><td>芳龄</td></tr><tr><td>张三</td><td>25</td></tr><tr><td>李四</td><td>28</td></tr></table>```上面的代码定义了一个包含尊称和芳龄信息的简单表格,每个tr代表一行数据,每个td代表一个单元格。
这是表格的基本结构,我们可以根据实际需求,灵活运用这些元素,构建不同形式的表格。
二、表格的样式调整1. 表格边框样式在CSS中,可以通过border属性来设置表格的边框样式,具体示例如下:```csstable {border: 1px solid #000;}td {border: 1px solid #000;}```上面的代码定义了表格和单元格的边框样式,可以根据需要调整border的值,实现不同的边框效果。
2. 表格的宽度和高度除了边框样式,我们还可以通过CSS来设置表格的宽度和高度,具体示例如下:```csstable {width: 100;}td {height: 30px;}```上面的代码定义了表格的宽度为100,单元格的高度为30px,这样可以让表格在页面中占据合适的空间,使页面布局更加美观。
tdsql原理

tdsql原理全文共四篇示例,供读者参考第一篇示例:TD-SQL全称为Time Division-SQL,是一种基于时间划分的SQL 语言,主要用于处理时序数据的查询与分析。
TD-SQL的引入,使得SQL语言在处理时间序列数据时更加高效和灵活。
TD-SQL的设计,融合了传统的SQL语法和时间序列数据库的特性,使得用户没有必要学习新的语法和接口,就可以轻松地处理时间序列数据。
TD-SQL的原理基于以下几个核心概念:时间窗口、时间序列数据、时间函数和时间索引。
时间窗口是TD-SQL中一个非常重要的概念,用于限定查询的时间范围。
时间序列数据是TD-SQL中的主要数据类型,用于描述随时间变化的数据。
时间函数是TD-SQL中特有的函数,用于处理时间序列数据,比如对时间序列数据进行统计、计算平均值等操作。
时间索引是TD-SQL中的一种索引方式,用于加速基于时间条件的查询操作。
在TD-SQL中,用户可以利用时间窗口对时间序列数据进行筛选和聚合操作,从而方便地进行时序数据分析。
用户可以使用时间窗口来查询某一天、某一周或某一个月的数据,还可以使用时间窗口来计算时间序列数据的移动平均值、方差等统计指标。
通过时间函数的使用,用户可以进一步对时间序列数据进行复杂的计算和分析,比如计算两个时间序列数据之间的相关性、预测未来时间序列数据的走势等。
TD-SQL的设计,旨在提高用户处理时序数据的效率和便利性。
它不仅支持传统的SQL查询方式,还集成了丰富的时间序列数据处理函数,方便用户对时间序列数据进行进一步的分析。
TD-SQL还支持时间索引的使用,提高了查询的速度和性能。
TD-SQL是一种高效、灵活的处理时序数据的SQL语言,为用户提供了更加便捷的时序数据分析工具。
通过掌握TD-SQL的原理和使用方法,用户可以更加轻松地处理各种时序数据,为业务决策提供有力支持。
TD-SQL的应用范围广泛,可用于金融、医疗、工业等领域的数据分析与挖掘工作。
td数据库语法

TD数据库语法1. 什么是TD数据库TD数据库(Treasure Data)是一种云原生的数据管理和分析平台,旨在帮助企业实现大规模数据的实时处理和分析。
它提供了一套强大的查询和分析工具,可以帮助用户快速获取和分析数据,从而支持业务决策和数据驱动的创新。
2. TD数据库的查询语法TD数据库的查询语法采用类似于SQL的结构,但也有一些特定的语法和函数。
下面是一些常见的查询语法:2.1 SELECT语句SELECT语句用于从数据库中选择特定的列或字段。
SELECT column1, column2, ...FROM table_nameWHERE condition;其中,column1, column2, …是要选择的列名,table_name是要查询的表名,condition是查询的条件。
2.2 WHERE子句WHERE子句用于过滤查询结果,只返回满足特定条件的行。
SELECT column1, column2, ...FROM table_nameWHERE condition;其中,condition是一个逻辑表达式,用于指定要返回的行的条件。
2.3 ORDER BY子句ORDER BY子句用于对查询结果进行排序。
SELECT column1, column2, ...FROM table_nameORDER BY column_name [ASC|DESC];其中,column_name是要排序的列名,ASC表示升序排序,DESC表示降序排序。
2.4 GROUP BY子句GROUP BY子句用于根据一个或多个列对查询结果进行分组。
SELECT column1, function(column2), ...FROM table_nameGROUP BY column1;其中,function是一个聚合函数,用于对分组后的数据进行计算,如SUM、AVG等。
2.5 JOIN子句JOIN子句用于将多个表连接起来,根据共同的列或字段进行关联查询。
关于TD各项属性

一、严重等级致命:1.客户端、服务器死机或者不响应2.数据库死锁3.客户端异常退出4.客户端无法正常连接服务器5.需求未实现,或者实现的功能与需求完全不符6.核心功能出现异常A.数据备份时,漏备份表B.日终流程报错,无法继续正常运行C.日终数据处理时,对不该处理的数据进行了处理,对应该处理的数据没有进行处理D.菜单或功能按钮一点就报异常,导到无法继续进行操作或提交申请;E.引起用户无法登录的问题,如验证码无法获取.一进入登录页面就报客户异常.用户输入正确的信息也不能正常登录.F.多导出或导入申请数据或少导出或导入申请数据;G.页面上缺少关键功能按钮,导到申请不能提交或不能查询;7.严重的数值计算或插入数据表错误A.金额,份额,申请日期,清算日期,划款状态,扣款状态,基金帐号,交易帐号等关键字段值写入数据库错误8.提交的测试包问题A.后台服务不能正常启动B.程序无法正常编译通过9.页面问题A.A基金公司的页面或提示信息或签订的协议内容上出现了B基金公司的名称严重:1.实现的功能与需求不符2.核心功能的性能较差3.非核心功能出现异常A.查询或报表一点就报错;B.导入,导出的数据信息总数正确,但数据信息中的数据错误.如业务代码转译,交易帐号重新获取等;C.传给接口的数据不正确;4.安全性问题5.轻微的数值计算错误6.脚本问题A.脚本漏提交;B.脚本运行报错;C.脚本运行后,将数据库中的数据修改错误;7.页面或界面问题A.页面显示混乱,如大篇幅的文字或图片重叠.头尾位置颠倒等B.页面数据显示与数据库中的不一致;如金额,份额,清算日期,申请日期,扣划款状态等;C.页面或界面上的数据出现乱码.一般:1.非核心功能的性能较差2.核心功能的TAB键顺序不对3.容错性差A.在应该输入数字的地方输入了字母,系统没有给出提示,导致最终的操作失败4.易用性差A.下拉框中的数据有成百上千个,程序可以过滤一些无效数据而未进行过滤,造成用户操作不方便5.显示不完整A.字段的显示宽度不够,不能完整显示信息6.界面问题A.文字描述混乱,用户无法做出合理的判断次要:1.非核心功能的TAB键顺序不对2.长操作没有进度提示3.输入区域和只读区域没有明显区分4.提示信息不准确5.颜色刺眼6.文字在高亮之后看不清楚7.页面或界面问题A.页面上控件不对齐B.数据显示不对齐C.报表数据写到表格外,但不影响阅读优化:1.界面风格不统一2.布局不合理3.字体与界面不协调4.图片和图标的含义不明确5.按钮大小不一致6.文字的对齐方式不合理7.数据显示的先后顺序不合理二、遗留标志有关T DBUG遗留标志界定,会严重影响到产品测试遗漏统计,由于此数据会由技术办公布可能会影响到事业部对产品的考核,由于网上交易的特殊性画了个图来界定“遗留标志”应该如何填写。
TD信息元素详解

信息元素功能性定义作者:李欣目录目录 (1)信息元素功能性定义 (11)1 核心网信息元素 (11)1.1 CN Information elements (11)1.2 CN Domain System Information (11)1.3 CN Information info (11)1.4 IMEI (11)1.5 IMSI (GSM-MAP) (11)1.6 Intra Domain NAS Node Selector (11)1.7 Location Area Identification (12)1.8 NAS message (12)1.9 NAS system information (GSM-MAP) (12)1.10 Paging record type identifier (12)1.11 PLMN identity (12)1.12 PLMN Type (12)1.13 P-TMSI (GSM-MAP) (12)1.14 RAB identity (12)1.15 Routing Area Code (12)1.16 Routing Area Identification (13)1.17 TMSI (GSM-MAP) (13)2 UTRAN 移动信息元素 (13)2.1 Cell Access Restriction (13)2.2 Cell identity (13)2.3 Cell selection and re-selection info for SIB3/4 (13)2.4 Cell selection and re-selection info for SIB11/12 (13)2.5 Mapping Info (14)2.6 URA identity (14)3 UE 信息元素 (14)3.1 Activation time (14)3.2 Capability Update Requirement (14)3.3 Cell update cause (15)3.4 Ciphering Algorithm (15)3.5 Ciphering mode info (15)3.6 CN domain specific DRX cycle length coefficient (15)3.7 CPCH Parameters (15)3.8 C-RNTI (15)3.9 DRAC system information (15)3.10 Void (16)3.11 Establishment cause (16)3.12 Expiration Time Factor (16)3.13 Failure cause (16)3.14 Failure cause and error information (16)3.15 Initial UE identity (16)3.16 Integrity check info (16)3.17 Integrity protection activation info (17)3.18 Integrity protection Algorithm (17)3.19 Integrity protection mode info (17)3.20 Maximum bit rate (17)3.21 Measurement capability (17)3.22 Paging cause (17)3.23 Paging record (17)3.24 PDCP capability (17)3.25 Physical channel capability (18)3.26 Protocol error cause (18)3.27 Protocol error indicator (18)3.28 RB timer indicator (18)3.29 Redirection info (18)3.30 Re-establishment timer (18)3.31 Rejection cause (18)3.32 Release cause (18)3.33 RF capability FDD (19)3.34 RLC capability (19)3.35 RLC re-establish indicator (19)3.36 RRC transaction identifier (19)3.37 Security capability (19)3.38 START (19)3.39 Transmission probability (19)3.40 Transport channel capability (20)3.41 UE multi-mode/multi-RAT capability (20)3.42 UE radio access capability (20)3.43 UE Timers and Constants in connected mode (21)3.44 UE Timers and Constants in idle mode (21)3.45 UE positioning capability (21)3.46 URA update cause (21)3.47 U-RNTI (21)3.48 U-RNTI Short (21)3.49 UTRAN DRX cycle length coefficient (21)3.50 Wait time (21)3.51 UE Specific Behavior Information 1 idle (21)3.52 UE Specific Behavior Information 1 interRAT (22)4 无线承载信息元素 (22)4.0 Default configuration identity (22)4.1 Downlink RLC STATUS info (22)4.2 PDCP info (22)4.3 PDCP SN info (22)4.4 Polling info (22)4.5 Predefined configuration identity (23)4.6 Predefined configuration value tag (23)4.7 Predefined RB configuration (23)4.8 RAB info (23)4.9 RAB info Post (23)4.10 RAB information for setup (23)4.11 RAB information to reconfigure (24)4.12 NAS Synchronization indicator (24)4.13 RB activation time info (24)4.14 RB COUNT-C MSB information (24)4.15 RB COUNT-C information (24)4.16 RB identity (24)4.17 RB information to be affected (24)4.18 RB information to reconfigure (25)4.19 RB information to release (25)4.20 RB information to setup (25)4.21 RB mapping info (25)4.22 RB with PDCP information (25)4.23 RLC info (25)4.24 Signaling RB information to setup (26)4.25 Transmission RLC Discard (26)5 传输信道信息元素 (26)5.1 Added or Reconfigured DL TrCH information (26)5.2 Added or Reconfigured UL TrCH information (27)5.3 CPCH set ID (27)5.4 Deleted DL TrCH information (27)5.5 Deleted UL TrCH information (27)5.6 DL Transport channel information common for all transport channels (27)5.7 DRAC Static Information (27)5.8 Power Offset Information (28)5.9 Predefined TrCH configuration (28)5.10 Quality Target (28)5.11 Semi-static Transport Format Information (28)5.12 TFCI Field 2 Information (28)5.13 TFCS Explicit Configuration (28)5.14 TFCS Information for DSCH (TFCI range method) (29)5.15 TFCS Reconfiguration/Addition Information (29)5.16 TFCS Removal Information (29)5.17 Void (29)5.18 Transport channel identity (29)5.19 Transport Format Combination (TFC) (29)5.20 Transport Format Combination Set (29)5.21 Transport Format Combination Set Identity (29)5.22 Transport Format Combination Subset (29)5.23 Transport Format Set (29)5.24 UL Transport channel information common for all transport channels (30)6 物理信道信息元素 (30)6.1 AC-to-ASC mapping (30)6.2 AICH Info (30)6.3 AICH Power offset (30)6.4 Allocation period info (30)6.5 Alpha (30)6.6 ASC Setting (30)6.7 Void (31)6.8 CCTrCH power control info (31)6.9 Cell parameters Id (31)6.10 Common timeslot info (31)6.11 Constant value (31)6.12 CPCH persistence levels (31)6.13 CPCH set info (31)6.14 CPCH Status Indication mode (31)6.15 CSICH Power offset (32)6.16 Default DPCH Offset Value (32)6.17 Downlink channelisation codes (32)6.18 Downlink DPCH info common for all RL (32)6.19 Downlink DPCH info common for all RL Post (32)6.20 Downlink DPCH info common for all RL Pre (32)6.21 Downlink DPCH info for each RL (32)6.22 Downlink DPCH info for each RL Post (33)6.23 Downlink DPCH power control information (33)6.24 Downlink information common for all radio links (33)6.25 Downlink information common for all radio links Post (33)6.26 Downlink information common for all radio links Pre (33)6.27 Downlink information for each radio link (33)6.28 Downlink information for each radio link Post (33)6.29 Void (33)6.30 Downlink PDSCH information (33)6.31 Downlink rate matching restriction information (34)6.32 Downlink Timeslots and Codes (34)6.33 DPCH compressed mode info (34)6.34 DPCH Compressed Mode Status Info (34)6.35 Dynamic persistence level (34)6.36 Frequency info (34)6.37 Individual timeslot info (35)6.38 Individual Timeslot interference (35)6.39 Maximum allowed UL TX power (35)6.40 Void (35)6.41 Midamble shift and burst type (35)6.42 PDSCH Capacity Allocation info (35)6.43 PDSCH code mapping (36)6.44 PDSCH info (36)6.45 PDSCH Power Control info (36)6.46 PDSCH system information (36)6.47 PDSCH with SHO DCH Info (36)6.48 Persistence scaling factors (36)6.49 PICH Info (36)6.50 PICH Power offset (37)6.51 PRACH Channelisation Code List (37)6.52 PRACH info (for RACH) (37)6.53 PRACH partitioning (37)6.54 PRACH power offset (37)6.55 PRACH system information list (37)6.56 Predefined PhyCH configuration (38)6.57 Primary CCPCH info (38)6.58 Primary CCPCH info post (38)6.59 Primary CCPCH TX Power (38)6.60 Primary CPICH info (38)6.61 Primary CPICH Tx power (38)6.62 Primary CPICH usage for channel estimation (38)6.63 PUSCH info (38)6.64 PUSCH Capacity Allocation info (38)6.65 PUSCH power control info (39)6.66 PUSCH system information (39)6.67 RACH transmission parameters (39)6.68 Radio link addition information (39)6.69 Radio link removal information (39)6.70 SCCPCH Information for FACH (39)6.71 Secondary CCPCH info (39)6.72 Secondary CCPCH system information (40)6.73 Secondary CPICH info (40)6.74 Secondary scrambling code (40)6.75 SFN Time info (40)6.76 SSDT cell identity (40)6.77 SSDT information (40)6.78 STTD indicator (40)6.79 TDD open loop power control (41)6.80 TFC Control duration (41)6.81 TFCI Combining Indicator (41)6.82 TGPSI (41)6.83 Time info (41)6.84 Timeslot number (41)6.85 TPC combination index (41)6.86 TSTD indicator (41)6.87 TX Diversity Mode (41)6.88 Uplink DPCH info (41)6.89 Uplink DPCH info Post (42)6.90 Uplink DPCH info Pre (42)6.91 Uplink DPCH power control info (42)6.92 Uplink DPCH power control info Post (42)6.93 Uplink DPCH power control info Pre (42)6.94 Uplink Timeslots and Codes (42)6.95 Uplink Timing Advance (42)6.96 Uplink Timing Advance Control (43)7 测量信息元素 (43)7.1 Additional measurements list (43)7.2 Cell info (43)7.3 Cell measured results (43)7.4 Cell measurement event results (44)7.5 Cell reporting quantities (44)7.6 Cell synchronization information (44)7.7 Event results (44)7.8 FACH measurement occasion info (45)7.9 Filter coefficient (45)7.10 HCS Cell re-selection information (45)7.11 HCS neighboring cell information (45)7.12 HCS Serving cell information (45)7.13 Inter-frequency cell info list (46)7.14 Inter-frequency event identity (46)7.15 Inter-frequency measured results list (46)7.16 Inter-frequency measurement (46)7.17 Inter-frequency measurement event results (47)7.18 Inter-frequency measurement quantity (47)7.19 Inter-frequency measurement reporting criteria (47)7.20 Inter-frequency measurement system information (47)7.21 Inter-frequency reporting quantity (47)7.22 Inter-frequency SET UPDATE (48)7.23 Inter-RAT cell info list (48)7.24 Inter-RAT event identity (48)7.25 Inter-RAT info (48)7.26 Inter-RAT measured results list (48)7.27 Inter-RAT measurement (49)7.28 Inter-RAT measurement event results (49)7.29 Inter-RAT measurement quantity (49)7.30 Inter-RAT measurement reporting criteria (49)7.31 Inter-RAT measurement system information (50)7.32 Inter-RAT reporting quantity (50)7.33 Intra-frequency cell info list (50)7.34 Intra-frequency event identity (50)7.35 Intra-frequency measured results list (50)7.36 Intra-frequency measurement (50)7.37 Intra-frequency measurement event results (51)7.38 Intra-frequency measurement quantity (51)7.39 Intra-frequency measurement reporting criteria (51)7.40 Intra-frequency measurement system information (51)7.41 Intra-frequency reporting quantity (52)7.42 Intra-frequency reporting quantity for RACH reporting (52)7.43 Maximum number of reported cells on RACH (52)7.44 Measured results (52)7.45 Measured results on RACH (52)7.46 Measurement Command (52)7.47 Measurement control system information (53)7.48 Measurement Identity (53)7.49 Measurement reporting mode (53)7.50 Measurement Type (53)7.51 Measurement validity (53)7.52 Observed time difference to GSM cell (53)7.53 Periodical reporting criteria (53)7.54 Primary CCPCH RSCP info (54)7.55 Quality measured results list (54)7.56 Quality measurement (54)7.57 Quality measurement event results (54)7.58 Quality measurement reporting criteria (54)7.59 Quality reporting quantity (54)7.60 Reference time difference to cell (54)7.61 Reporting Cell Status (55)7.62 Reporting information for state CELL_DCH (55)7.63 SFN-SFN observed time difference (55)7.64 Time to trigger (55)7.65 Timeslot ISCP info (55)7.66 Traffic volume event identity (55)7.67 Traffic volume measured results list (55)7.68 Traffic volume measurement (55)7.69 Traffic volume measurement event results (56)7.70 Traffic volume measurement object (56)7.71 Traffic volume measurement quantity (56)7.72 Traffic volume measurement reporting criteria (56)7.73 Traffic volume measurement system information (56)7.74 Traffic volume reporting quantity (56)7.75 UE internal event identity (56)7.76 UE internal measured results (57)7.77 UE internal measurement (57)7.78 UE internal measurement event results (57)7.79 UE internal measurement quantity (57)7.80 UE internal measurement reporting criteria (57)7.81 Void (58)7.82 UE Internal reporting quantity (58)7.83 UE Rx-Tx time difference type 1 (58)7.84 UE Rx-Tx time difference type 2 (58)7.85 UE Transmitted Power info (58)7.86 UE positioning Ciphering info (58)7.87 UE positioning Error (58)7.88 UE positioning GPS acquisition assistance (59)7.89 UE positioning GPS almanac (59)7.90 UE positioning GPS assistance data (59)7.91 UE positioning GPS DGPS corrections (59)7.92 UE positioning GPS ionospheric model (59)7.93 UE positioning GPS measured results (59)7.94 UE positioning GPS navigation model (60)7.95 UE positioning GPS real-time integrity (60)7.96 UE positioning GPS reference time (60)7.97 UE positioning GPS UTC model (61)7.98 UE positioning IPDL parameters (61)7.99 UE positioning measured results (61)7.100 UE positioning measurement (61)7.101 UE positioning measurement event results (61)7.102 Void (62)7.103 UE positioning OTDOA assistance data for UE-assisted (62)7.104 Void (62)7.105 UE positioning OTDOA measured results (62)7.106 UE positioning OTDOA neighbor cell info (62)7.107 UE positioning OTDOA quality (63)7.108 UE positioning OTDOA reference cell info (63)7.109 UE positioning position estimate info (64)7.110 UE positioning reporting criteria (64)7.111 UE positioning reporting quantity (64)7.112 T ADV info (65)8 其它信息元素 (65)8.1 BCCH modification info (65)8.2 BSIC (65)8.3 CBS DRX Level 1 information (65)8.4 Cell Value tag (65)8.5 Inter-RAT change failure (65)8.6 Inter-RAT handover failure (66)8.7 Inter-RAT UE radio access capability (66)8.8 Void (66)8.9 MIB Value tag (66)8.10 PLMN Value tag (66)8.11 Predefined configuration identity and value tag (66)8.12 Protocol error information (66)8.13 References to other system information blocks (66)8.14 References to other system information blocks and scheduling blocks (67)8.15 Rplmn information (67)8.16 Scheduling information (67)8.17 SEG COUNT (67)8.18 Segment index (67)8.19 SIB data fixed (67)8.20 SIB data variable (67)8.21 SIB type (67)8.22 SIB type SIBs only (67)9 ANSI-41 Information elements (68)10 Multiplicity values and type constraint values (68)信息元素功能性定义消息是由多个信息元素组合而成,信息元素根据其功能的不同划分为:核心网域信息元素、UTRAN 移动信息元素、UE 信息元素、无线承载信息元素、传输信道信息元素、物理信道信息元素和测量信息元素。
td数据库语法

td数据库语法摘要:1.TD 数据库简介2.TD 数据库语法基础3.TD 数据库的常用命令4.TD 数据库的应用实例正文:1.TD 数据库简介TD 数据库,全称Taobao Database,是阿里巴巴集团开源的一款高性能、可扩展的分布式数据库。
TD 数据库具有高并发、高吞吐量、低延迟等特点,广泛应用于电商、金融、物流等行业。
2.TD 数据库语法基础TD 数据库的语法基于SQL(结构化查询语言),兼容MySQL 的语法规范。
TD 数据库支持大部分标准的SQL 语句,如CREATE、ALTER、INSERT、SELECT、UPDATE、DELETE 等。
3.TD 数据库的常用命令(1)数据定义命令- CREATE:创建表、视图、索引等数据库对象。
- ALTER:修改表、视图、索引等数据库对象的结构。
- DROP:删除表、视图、索引等数据库对象。
(2)数据操作命令- INSERT:向表中插入数据。
- SELECT:从表中查询数据。
- UPDATE:更新表中的数据。
- DELETE:删除表中的数据。
(3)数据控制命令- GRANT:授权给用户或角色操作数据库对象的权限。
- REVOKE:撤销用户或角色操作数据库对象的权限。
4.TD 数据库的应用实例TD 数据库在阿里巴巴集团内部广泛应用,例如在淘宝、天猫等电商平台中,用于存储商品信息、用户信息、订单信息等。
通过TD 数据库的高性能处理能力,保证了电商平台在双11 等大促活动期间的稳定运行。
总之,TD 数据库作为一款国产分布式数据库,凭借其高性能、可扩展等优势,在国内外市场逐渐崭露头角。
TD移植详细操作步骤

TD(TestDirector)数据库备份和数据库移植公司买了新的服务器,需要把以前服务器进行资源整合与迁移。
之前TD就是放在一台配置稍好的PC机上,现在要移植到专业服务器上去。
我们公司的TD属于集成式部署的,即应用程序与数据库在同一台机器上的。
在网上找了好多资料,经过了数次失败的教训后,终于移植成功了。
作为自己工作成果的总结,我觉得必须分享出来,以便遇到相同问题的同事、朋友参考。
详细步骤如下:移植说明:源:PC机,机器名为:TDServer42TD版本:8.0 项目数据库类型:SQL SERVER2000目标:服务器,机器名为:TDServer190TD版本:8.0 项目数据库类型:SQL SERVER2000第一步:备份源机器中的相关数据1、备份DomsInfo文件夹中的所有内容,该文件夹在系统安装盘下的如下位置:盘符(如:C:/)/Program files/Common files/Mercury Interactive文件夹里面2、备份TD_Dir文件夹中的所有内容3、确认要移植的TD项目数据库未被破坏,并进行备份第二步:移植数据至目标服务器1、在目标服务器上安装TD8.0和SQL SERVER2000;2、把源机器上的DomsInfo文件夹拷贝到目标服务器相应的目录下替换DomsInfo文件夹3、修改DomsInfo文件夹下的doms.mdb数据库文件,操作步骤如下:1)用Access打开doms.mdb数据库文件,默认口令为tdtdtd;2)修改Admin数据表,打开该表并修改Admin_pswd 的密码,如果你不想修改以前的Admin用户的密码也可以不进行该操作。
3)修改DBServers数据表,打开该表并修改DB_CONNSTR_FORMAT字段的第二行Data Source的值为新TD服务器名称(TDServer190)。
4)修改Params数据表,打开该表并修改ACIServer、SiteScopeurl行对应的Param_Value字段值用新TD服务器名称(TDServer190)替换旧TD服务器的名称(TDServer42)。
TDSQL简介
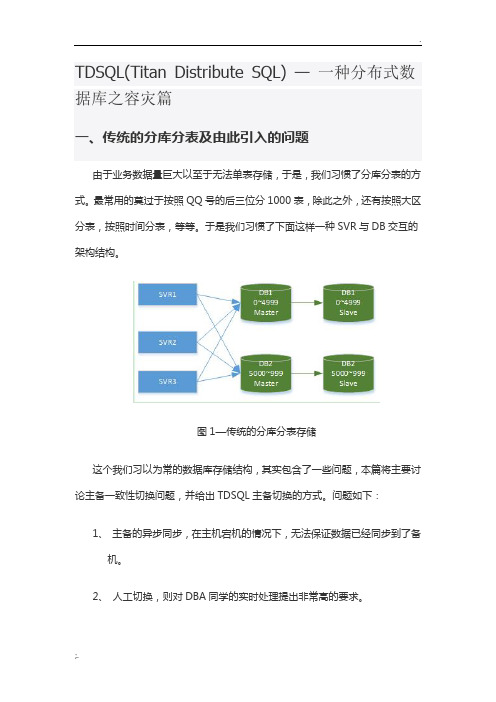
TDSQL(Titan Distribute SQL) —一种分布式数据库之容灾篇一、传统的分库分表及由此引入的问题由于业务数据量巨大以至于无法单表存储,于是,我们习惯了分库分表的方式。
最常用的莫过于按照QQ号的后三位分1000表,除此之外,还有按照大区分表,按照时间分表,等等。
于是我们习惯了下面这样一种SVR与DB交互的架构结构。
图1—传统的分库分表存储这个我们习以为常的数据库存储结构,其实包含了一些问题,本篇将主要讨论主备一致性切换问题,并给出TDSQL主备切换的方式。
问题如下:1、主备的异步同步,在主机宕机的情况下,无法保证数据已经同步到了备机。
2、人工切换,则对DBA同学的实时处理提出非常高的要求。
3、自动切换,可能出现不同SVR对于主DB的健康状态判断不一致,造成不同SVR把数据写入到不同DB的情况即——脑裂。
4、即使通过仲裁节点来统一调度SVR连向主DB或者备DB,如果流程处理的不好,也可能因为SVR感知切换的时间差在短时间内造成脑裂。
如何解决上面的问题,业界给出了很多的方案,例如国外有Galera这种通过协议插件来实现一致性的方案(但这种方案在跨IDC时的性能非常差),国内也有阿里RDS,TDDL,360的atlas中间件,但上述的方案要么在主备切换的一致性,要么在主动切换,要么在性能上都会有或多或少的问题,因此我们在参考上述方案的基础上实现了今天要给大家介绍的方案Titan Distribute SQL —TDSQL。
二、TDSQL主备切换方案2.1 TDSQL容灾架构图二、TDSQL容灾架构图二是一个大家熟悉的具备调度能力的分布式集群,下面分别来介绍一个各个模块的作用及如何互动。
DB——图中的绿色部分,是集群的核心部分,也就是mysql节点。
为了实现主备的强一致性和较高的性能,这里必须使用我们在Mariadb 基础上进行二次开发的MySQL。
注意,只有主DB提供写服务,其它DB会被Agent自动设置成只读。
td数据库语法

td数据库语法TD数据库是一种分布式数据库,其使用的SQL查询语法与传统的关系型数据库类似,但也有一些特殊的语法和功能。
一、数据定义语言(DDL)1.创建表:在TD数据库中,可以使用CREATE TABLE语句创建表。
例如,创建一个名为“employees”的表,其中包含ID、姓名和年龄字段:```CREATE TABLE employees (id INT PRIMARY KEY,name VARCHAR(50),age INT);```2.删除表:使用DROP TABLE语句从数据库中删除表。
例如,删除名为“employees”的表:```DROP TABLE employees;```3.修改表:可以使用ALTER TABLE语句修改表的结构,如添加、删除或修改列。
例如,向名为“employees”的表添加一个新的“department”列:```ALTER TABLE employeesADD COLUMN department VARCHAR(50);```二、数据操作语言(DML)1.插入数据:使用INSERT INTO语句将一条或多条数据插入到表中。
例如,将一条员工记录插入到“employees”表中:```INSERT INTO employees (id, name, age, department)VALUES (1, 'John Doe', 25, 'HR');```2.更新数据:使用UPDATE语句更新表中的数据。
例如,将名为“John Doe”的员工的年龄更新为30岁:```UPDATE employeesSET age = 30WHERE name = 'John Doe';```3.删除数据:使用DELETE FROM语句删除表中的数据。
例如,删除名为“John Doe”的员工记录:```DELETE FROM employeesWHERE name = 'John Doe';```4.查询数据:使用SELECT语句从表中检索数据。
关于TD数据库(附图解)

【摘要】TestDir ector,(以下简称TD)它是Mercu ry Interac tive 公司推出的基于WEB浏览器环境下的测试管理工具。
通过TD的流程控制可以规范软件企业的测试流程、改善测试质量、减轻测试人员的负担、提高工作效率。
在接触TD过程中仍然存在着很多未知领域等待着我们这些从事软件测试工作的同行去研究去拓展,如何更有效的使用TD提高我们的测试管理,将是我们继续研究关注的方向。
本文总结了我们在移植TD项目方面的一些经验和技巧,希望对大家有所帮助。
【关键词】项目移植集成工作环境分布式工作环境这里我们先将以上的几个名词解释一下:项目移植:这里说的项目移植是指将已经建立的TD项目整体文件在保证数据安全和完整的前提下移植到其他服务器的过程,这个过程包括以下几个方面(1)数据库的移植(2)项目文件的移植(3)项目配置文件的移植。
经过移植后的T D项目可以实现双机备份的功能。
集成工作环境:我们把TD服务程序和TD使用的数据库存放在同一台计算机上的这种工作环境称为集成工作环境。
这种工作环境节省成本,维护较复杂,不利于数据的安全性。
分布式工作环境:我们把TD服务器程序和TD后台使用的数据库存放在不同机器上,也就是使用单独的一台计算机作为TD项目的数据库服务器,TD服务程序通过网络访问数据库服务器,这种工作环境称为分步式工作环境。
这种环境的成本较高,但是利用维护,数据的安全性较高。
对一些专业性的企业尤其是需要将TD开放到Inter net上,我们建议使用这种工作环境。
移植说明基于IIS WEB服务下的TD服务程序支持的数据库有ACCES S,SQL SERVER、SYBASE、ORACLE。
由于ACCES S数据库的迁移比较容易本文就不介绍,本文主要讨论S QLSERVER数据库的移植。
TDengine常用指令汇总

TDengine常⽤指令汇总最近公司正在启⽤TDengine作为物联⽹实时数据的存储数据库,但作为国产开源软件的发光体,⽬前这个数据库的使⽤⽅式,我还不是很熟悉,特此记录和总结⼀些使⽤技巧。
会持续更新……1.修改⽤户密码 taos 数据库 `root`⽤户的默认密码为: taosdata,安装好taos数据库后,可以通过:alter user root pass `your password` 进⾏修改2.登录数据库 taos -uroot -p123456 ; //备注:我root账户的密码是123456,当我使⽤:taos-u root -p 123456;进⾏登录会报错。
参数连在⼀起:taos-u root-p123456就可以执⾏,不知道为什么。
3.数据库操作#创建库(如果不存在)keep 字段是指⽂件在表存储的时间,默认是天:create database if not exists mydb keep 365 days 10 blocks 4;#使⽤库:use mydb;#删除库:drop database mydb;#删除库(如果存在):drop database if exists mydb;#显⽰所有数据库:show databases;#修改数据库⽂件压缩标志位:alter database mydb comp 2;#修改数据库副本数:alter database mydb replica 2;#修改数据⽂件保存的天数:alter database mydb keep 365;#修改数据写⼊成功所需要的确认数:alter database mydb quorum 2;#修改每个VNODE (TSDB) 中有多少cache⼤⼩的内存块:alter database mydb blocks 100;4.表操作#创建表,创建表时timestamp 字段必须为第⼀个字段类型,为主键:create table if not exists mytable(column_name timestamp, column_name int,……);#根据超级表创建⼦表,这样建表之后,⼦表会复制除去超级表⾥⾯的tags字段外的所有字段;create table table_name using super_table tags (column_value,column_value……);#删除数据表drop table if exists mytable;#显⽰当前数据库下的所有数据表信息show tables;#显⽰当前数据库下的所有数据表信息show tables like "%table_name%";#获取表的结构信息describe mytable;#表增加列alter table mytable add column addfield int;#表删除列alter table mytable drop column addfield;5.超级表操作#创建超级表#创建STable, 与创建表的SQL语法相似,但需指定TAGS字段的名称和类型。
HTML表格,table,thead,tbody,tfoot,th,tr,td,的属性以及。。。

HTML表格,table,thead,tbody,tfoot,th,tr,td,的属性以及。
在HTML中表格是作为⼀个整体来解析的,解析完才会在页⾯显⽰,如果表格很复杂很长,加载时间很长,⽤户体验就不好。
所以这⾥就要⽤到表格结构标签,解析⼀部分就显⽰⼀部分,不⽤等表格全部加载完再显⽰。
表格结构标签(添加这三个标签时,要注意不能影响⽹页布局):<thead></thead> 表头部(放表格的标题之类)<tbody></tbody> 表主体(放表格主体数据)<tfoot></tfoot> 表脚注 (放表格脚注)在写代码时:不论上⾯<thead>,<tfoot>,<tbody>顺序如何,在页⾯显⽰时,总是按照:<thead> <tbody> <tfoot>的顺序呈现出来的。
------------------结构化表格标签:<table><caption>表格标题,⼀个表只有⼀个</caption><thead><!--表头部--><tr><th></th><!--表头单元格,粗体,居中--><th></th></tr><tr><th></th><!--表头单元格,粗体,居中--><th></th></tr></thead><!--表头部--><tbody><!--表主体--><tr><td></td><td></td></tr><tr><td></td><td></td></tr></tbody><!--表主体--><tfoot><!--表脚注--><tr><td></td><td></td></tr></tfoot><!--表脚注--></table>-------------------------------------------------table表格属性width pixles, % 规定表格的宽度align left,center,right 表格相对周围元素的对齐⽅式 (这⾥是整个表格相对于⽹页进⾏移动居中的,⽽不是定义表格⾥⾯的内容)border pixels 表格变宽的宽度bgcolor rgb(x,x,x),#xxxxxx,ColorName 表格的背景颜⾊cellpadding pixels,% 单元格与其他内容之间的空⽩cellspacing pixels,% 单元格之间的空⽩frame 属性值规定外侧边框的哪个部分是可见的。
td数据库的index函数

td数据库的index函数
Index函数是Teradata数据库中一种非常重要的函数,它有助于提高数据库性能,提高查询和更新数据的效率和性能。
Index函数在Teradata中一般用于优化查询语句。
它可以在SELECT查询中用于访问特定
的表或索引中的行,以及在UPDATE和DELETE查询中用于访问特定的表或索引中的行。
这种方法有助于提高查询的性能,因为系统可以更快地访问需要的数据,而不是遍历整个表。
Index函数可以以单列或多列方式定义索引,它们可以是数字,字符串或日期类型。
索引
允许系统以指数级的时间搜索特定表列中的数据,这样用户就可以更快地检索所需的信息。
例如,一个索引可以按姓氏或生日排序,从而大大提高了在一大堆人名中搜索特定人的效率。
Index函数也可以被用来构建视图,它们可以有助于加快特定表的访问速度,也可以用于
在存储过程中检索记录。
此外,它可以帮助消除两个或以上表之间的重复内容,这将有助
于改善数据库的存储性能。
因此,Index函数可以有效地提高Teradata数据库的性能,提高查询和更新数据的效率。
它可以减少查询的执行时间,并且提高了系统的查询和更新性能。
也可以消除两个或以上
表之间的重复内容,从而节省系统的存储空间。
简而言之,Index函数在Teradata数据库
中非常重要,它既方便又有效,能够大大提高数据库的性能。
TD安装图解

Test Director 安装配置发布: 2009-1-17 02:18 | 作者: 本站整理| 来源: 本站整理| 查看: 88次字号: |TD的安装1,操作系统由于要使用IIS和SQL SERVER数据库,考虑到运行的稳定性,选用的操作系统为WIN2000 SERVER 或WIN 2003 SERVER 版。
2,安装IIS安装TD工具前一定要先安装IIS服务。
3,安装MS-SQL SERVERTD的支持的数据库有Sybase、MS-SQL SERVER、Oracle和Access,以用来存储TD项目的相关数据。
在这里我们使用MS-SQL SERVER做为TD的连接数据库。
至于SQL SERVER的安装就很简单了,在这里就不多说了。
4,安装TD1)在安装好IIS与MS-SQL SERVER后,进行TD的安装。
进入到图下步骤时,输入:Maintenance no.:KSQMQSQ-HQSQDQS-Q3QSQ3S-Q2SSQI8License no.:B343P-44B44-43444-6444S2)【Next】后,进入到图下步骤,默认是选择了Access 做为TD的数据库,我们同时选择MS-SQL SERVER。
3)【Next】后,进入到图下步骤,此时注意,MS SQL Alias最好更改为当前的SQL Server名,我当前的为“LJZ”。
否则在安装完成后,必须再对客户端网络实名进行设置。
4)【Next】后,1. TD项目的备份与还原备份TD的重要信息,以在TD系统出现灾难性故障后能够保全TD数据的安全和完整,并且为快速的恢复系统和数据提供保障。
TD备份要注意三方面的同时备份,备份前要停止TD的服务,以及MS-SQL的服务。
1)首先是对TD的重要配置信息备份,把C:\Program Files\Common Files\Mercury Interactive\DomsInfo\目录下的文件进行拷贝备份。
tdengine 入门教程 基础概念和知识点

tdengine 入门教程基础概念和知识点TDengine是一款高效的开源时序数据库,采用了列式存储和多维索引等技术,能够快速存储和查询大规模时序数据。
本教程将介绍TDengine 的基础概念和知识点,帮助读者快速了解 TDengine 并上手使用。
1. 时序数据时序数据是指按照时间顺序排列的数据,比如气象数据、传感器数据、股票行情数据等。
时序数据通常包含时间戳和值两个维度,其中时间戳表示数据的产生时间,值表示数据本身的数值。
2. TDengine 数据模型TDengine 的数据模型采用了类似关系数据库的表格结构,每个表格包含多个数据列。
不同于关系数据库,TDengine 的表格中每个数据列都是时序数据,即每个数据列都包含时间戳和值两个维度。
3. TDengine 数据库TDengine 数据库是指一组表格和索引的集合,每个数据库都有一个唯一标识符。
TDengine 支持多个数据库,每个数据库可以独立管理和使用。
4. TDengine 节点TDengine 节点是指 TDengine 数据库的一个实例,每个节点包含多个数据库和相关配置信息。
多个节点可以组成一个分布式集群,共同处理大规模时序数据。
5. TDengine SQLTDengine SQL 是 TDengine 提供的一种查询语言,类似于传统关系数据库的 SQL 语言。
通过 TDengine SQL,用户可以对 TDengine 数据库进行数据查询、修改、删除等操作。
6. TDengine APITDengine API 是 TDengine 提供的一组编程接口,支持多种编程语言,包括 C、Java、Python 等。
通过 TDengine API,用户可以在程序中直接访问和操作 TDengine 数据库,实现更加灵活和自定义的应用场景。
总之,TDengine 是一款强大的时序数据库,具有高效、可扩展和易用等优点。
通过本教程的介绍,读者可以快速了解 TDengine 的基础概念和知识点,为后续的 TDengine 应用和开发打下基础。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
TD数据库常用表以及字段的介绍(一)(2009-04-28 14:15:57)转载分类:TD测试管理工具标签:td数据库表itØ ALL_LISTS表该表包含这些字段:AL_ITEM_ID, AL_FATHER_ID, AL_DESCRIPTION,AL_NO_OF_SONS, AL_SYSTEM, AL_ABSOLUTE_PATH, AL_VIEW_ORDER, AL_MEMO, AL_ATTACHMENT, AL_ITEM_VERSION, AL_VER_STATMP, AL_VTS。
其中前两个字段用于构建层次关系,这个表里面放的内容比较杂乱,像案例的类型定义(MANUAL / WR-AUTOMATED…)、案例的状态定义(Passed / Failed)、Bug的优先级定义(1-Low / 2-Medium…)、Bug的状态定义(Open / Closed…)等,都是保存在这个表中。
另外,在TD客户端(IE)中,Test Plan页面中显示的左边那棵案例树中的所有目录节点的定义,也都保存在这张表中,目录间的层次关系正是通过AL_ITEM_ID和AL_FATHER_ID 字段来关联的,AL_DESCRIPTION字段中则存放目录名,AL_NO_OF_SONS字段中是该目录下面的子目录个数。
Ø TEST表该表用来保存案例的定义,其字段比较多,关键的几个字段:TS_TEST_ID: 案例的IDTS_NAME: 案例名TS_STEPS: 案例的设计步骤个数TS_PATH: 如果是自动化测试案例,该案例对应的自动化测试脚本在当前这个项目所对应的根目录下的相对路径,这里保存的是存放脚本的目录的名字,也可能是多级目录TS_SUBJECT: 在案例树中,案例所在的目录节点的ID,这个字段可以和ALL_LISTS 表中的AL_ITEM_ID字段关联起来TS_STATUS: 案例当前的状态TS_RESPONSIBLE: 案例负责人TS_CREATION_DATE: 创建日期TS_DESCRIPTION: 案例描述TS_TYPE: 案例的类型,如MANUAL、VAPI-XP-TEST、LR-SCENARIO等TS_EXEC_STATUS: 案例的执行结果,按照TD的逻辑,一个案例可以被加到多个测试集中运行若干遍,这里这个字段总是保存案例最后一次被执行的执行结果。
不清楚为什么TD 要在TEST表中设计这个字段,我只发现这个字段在TD运行测试集后修改案例相关的需求(Requirements)的状态时有用到,其他地方似乎是不会需要访问这个字段的。
TS_VTS: 该记录最后一次被修改的时间Ø DESSTEPS表该表用来放案例的设计步骤,相对来说这个表就比较简单:DS_TEST_ID: 设计步骤对应的案例的IDDS_STEP_ID: 设计步骤的IDDS_STEP_ORDER: 步骤的顺序号DS_STEP_NAME: 步骤名,如果通过IE客户端增加步骤时,默认生成的步骤名是Step n DS_DESCRIPTION: 步骤的内容描述DS_EXPECTED: 期望值CYCL_FOLD、CYCLE、TESTCYCL和RUN这几张表是和Test Set相关的。
通过TD提供的案例树,用户可以对案例按照自己的意愿进行一定方式的组织(比如按测试的内容或者背测系统的版本等),而Test Set则提供了另外一种组织案例的手段,它允许用户在一个Test Set中添加若干案例。
Test Set有点像测试概念中的Suite,TD的Test Set和案例的关系,算是一种比较松散的Suite-Case关系,TD中允许将一个案例添加到若干个Test Set 中,并且运行一个案例在同一个Test Set中被添加多次,而每一次添加都是添加了案例的一个。
Ø CYCL_FOLD表该表用来存放Test Set的目录结构(树的目录节点)。
CF_ITEM_ID: 存放目录节点的IDCF_ITEM_NAME: 目录节点的名称CF_ITEM_PATH: 通过CF_ITEM_ID和CF_FATHER_ID这两个字段的值做级联,可以创建出Test Set的目录结构树,但这种创建树的方式相对来说比较繁琐,需要反复的进行级联查询。
可能TD的设计者也是为了解决这种不方便的情况,增加了CF_ITEM_PATH这个字段。
该字段的值是由ABCD等构成的字符串,Root下的第一级目录为AAAA加上单个的字母A、B、C、D等,ABCD等代表了显示树时该节点在父目录下的顺序。
再次级的目录由父目录的CF_ITEM_PATH值后面加A、B、C、D等构成,依次类推。
使用CF_ITEM_PATH字段的值,可以更方便的创建目录树,和查询某个目录节点下面的所有子节点(包括次级子节点)。
CF_FATHER_ID: 父目录节点的IDCF_VIEW_ORDER: 从名字来看应该是表示该目录节点在同级节点中的显示顺序的,但从IE客户端上实际看到的情况,并不是如此,所以不清楚这个字段的作用CF_VER_STAMP和CF_VTS: 这两个字段可能和目录节点的版本管理有关系,发现在更改节点的名称时,这两个字段的值会发生变化,CF_VER_STAMP的值会顺序递增CF_NO_OF_SONS: 子节点的个数Ø CYCLE表该表用来存放Test Set,也就是Test Set树中叶子节点。
CY_CYCLE_ID: Test Set的IDCY_CYCLE: Test Set的名字CY_OPEN_DATE和CY_CLOSE_DATE: 该Test Set的状态变成Open和Close的日期。
一个Test Set被创建的时候,默认的就是处于Open状态的CY_STATUS: Test Set的状态,就两种状态,Open或者CloseCY_DESCRIPTION: 不清楚这个字段有啥用,怎么折腾都没让这个字段出现内容CY_COMMENT: Test Set的说明CY_CYCLE_VER_STAMP和CY_VTS: 和CYCL_FOLD表中的CF_VER_STAMP和CF_VTS类似,在更改Test Set名字的时候这两个字段的值会发生变化。
由此也可以看出,TD的数据库设计里面,名字叫XX_VER_STAMP和XX_VTS的字段(XX是表名的缩写),应该都是起类似的作用CY_FOLDER_ID: 该Test Set所在的目录节点的ID,这个字段和CYCL_FOLD表中的CF_ITEM_ID字段对应Ø TESTCYCL表该表用来存放Test Set和该Set中的案例间的对应关系。
前面也有提到Test Set是一种组织案例的手段,一个Test Set中可以有若干案例,这种包含关系就是在TESTCYCL表中记录的。
TC_CYCLE_ID: Test Set的IDTC_TEST_ID: 案例的IDTC_CYCLE: 用TD用了比较长的一段时间了,发现数据库里面这个字段的值一直是空的,从名字来看应该是和CYCLE表中的CY_CYCLE字段对应的,所以估计这个字段在时间的代码开发中没有按当初的设计来使用TC_TEST_ORDER: 案例在Test Set中的出现顺序TC_TEST_INSTANCE: 一个案例可以在同一个Test Set中被添加多次,每次添加的都会增加一个新的记录,这些记录之间没有联系,TC_TEST_INSTANCE字段就是用来区分同一个Test Set中同一个案例的多个添加记录的TC_STATUS: 案例的状态,刚刚添加的案例是No Run状态TC_TESTER_NAME和TC_ACTUAL_TESTER: 前者是该案例的负责人(Responsible Tester),后者是实际执行该案例的人TC_EXEC_DATE和TC_EXEC_TIME: 当案例的状态发生改变时,这两个字段就会被更新,以记录发生改变的时间TC_HOST_NAME: TD最强的功能之一呢,就是可以和MR公司的其他产品如QTP、LOADRUNNER等联合起来使用,TD负责管理案例、执行计划等,而将具体的执行(也就是自动化测试的执行)功能交给各种自动化测试工具去完成,而这些自动化测试工具呢,是不要求一定要和TD安装在同一台PC上的,所以案例可以被指定是在哪台PC上执行,TC_HOST_NAME字段就是用来记录执行案例的PC的名称的Ø RUN表一个Test Set可以被运行若干遍,一个Test Set中的案例也可以被运行若干遍,每一遍执行的结过都需要进行记录,RUN表就是用来完成这个使命的。
RN_CYCLE_ID: Test Set的IDRN_TEST_ID: 案例的IDRN_RUN_ID: 索引IDRN_TEST_INSTANCE: 用于区分同一个Test Set中的同名案例,RN_CYCLE_ID、RN_TEST_ID和RN_TEST_INSTANCE这3个字段的值能唯一确定某个Test Set中的某个案例的一系列运行结果RN_RUN_NAME: TD执行案例时会自动生成这个名字,当然用户也可以通过TD客户端修改RN_EXECUTION_DATE、RN_EXECUTION_TIME和RN_DURATION: 执行时间和执行所花费的时间RN_STATUS: 该次执行的结过,Passed或者Failed等RN_TESTER_NAME: 实际执行的用户RN_PATH: 一般执行自动化测试案例时,都会有日志生成,这个字段存放该次执行时产生的日志文件的路径。
这个字段的值应该是那些自动化测试工具来充填的。