数据结构7-查找、排序
数据结构第7章-答案

一、单选题C01、在一个图中,所有顶点的度数之和等于图的边数的倍。
A)1/2 B)1 C)2 D)4B02、在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的倍。
A)1/2 B)1 C)2 D)4B03、有8个结点的无向图最多有条边。
A)14 B)28 C)56 D)112C04、有8个结点的无向连通图最少有条边。
A)5 B)6 C)7 D)8C05、有8个结点的有向完全图有条边。
A)14 B)28 C)56 D)112B06、用邻接表表示图进行广度优先遍历时,通常是采用来实现算法的。
A)栈 B)队列 C)树 D)图A07、用邻接表表示图进行深度优先遍历时,通常是采用来实现算法的。
A)栈 B)队列 C)树 D)图A08、一个含n个顶点和e条弧的有向图以邻接矩阵表示法为存储结构,则计算该有向图中某个顶点出度的时间复杂度为。
A)O(n) B)O(e) C)O(n+e) D)O(n2)C09、已知图的邻接矩阵,根据算法思想,则从顶点0出发按深度优先遍历的结点序列是。
A)0 2 4 3 1 5 6 B)0 1 3 6 5 4 2 C)0 1 3 4 2 5 6 D)0 3 6 1 5 4 2B10、已知图的邻接矩阵同上题,根据算法,则从顶点0出发,按广度优先遍历的结点序列是。
A)0 2 4 3 6 5 1 B)0 1 2 3 4 6 5 C)0 4 2 3 1 5 6 D)0 1 3 4 2 5 6D11、已知图的邻接表如下所示,根据算法,则从顶点0出发按深度优先遍历的结点序列是。
A)0 1 3 2 B)0 2 3 1 C)0 3 2 1 D)0 1 2 3A12、已知图的邻接表如下所示,根据算法,则从顶点0出发按广度优先遍历的结点序列是。
A)0 3 2 1 B)0 1 2 3 C)0 1 3 2 D)0 3 1 2A13、图的深度优先遍历类似于二叉树的。
A)先序遍历 B)中序遍历 C)后序遍历 D)层次遍历D14、图的广度优先遍历类似于二叉树的。
查找排序
解:① 先设定3个辅助标志: low,high,mid, 显然有:mid= (low+high)/2 ② 运算步骤:
(1) low =1,high =11 ,故mid =6 ,待查范围是 [1,11]; (2) 若 S[mid] < key,说明 key[ mid+1,high] , 则令:low =mid+1;重算 mid= (low+high)/2;. (3) 若 S[mid] > key,说明key[low ,mid-1], 则令:high =mid–1;重算 mid ; (4)若 S[ mid ] = key,说明查找成功,元素序号=mid; 结束条件: (1)查找成功 : S[mid] = key (2)查找不成功 : high<low (意即区间长度小于0)
while(low<=high)
{ mid=(low+high)/2; if(ST[mid].key= = key) return (mid); /*查找成功*/
else if( key< ST[mid].key) high=mid-1; /*在前半区间继续查找*/ else } return (0); /*查找不成功*/
4 5 6 7
0
1
2
90
10
(c)
20
40
K=90
80
30
60
Hale Waihona Puke 25(return i=0 )
6
讨论:怎样衡量查找效率?
——用平均查找长度(ASL)衡量。
如何计算ASL?
查找排序PPT课件

low=1; high=n;
while(low<=high)
{ mid=(low+high)/2;
if(ST[mid].key= = key) return (mid); /*查找成功*/
else if( key< ST[mid].key) high=mid-1; /*在前半区间继续查找*/
若k==r[mid].key,查找成功 若k<r[mid].key,则high=mid-1 若k>r[mid].key,则low=mid+1
❖重复上述操作,直至low>high时,查找失败 特点:比顺序查找方法效率高。最坏的情况下,需要比较 log2n次。
8
折半查找举例: 已知如下11个元素的有序表:
low
mid
( 08, 14, 23, 37, 46, 55, 68, 79,
low mid
high=mid-1
( 08, 14, 23, 37, 46, 55, 68, 79,
low=mid+1
high
mid
( 08, 14, 23, 37, 46, 55, 68, 79,
low
mid
( 08, 14, 23, 37, 46, 55, 68, 79,
5
讨论:怎样衡量查找效率?
——用平均查找长度(ASL)衡量。
如何计算ASL?
分析: 查找第1个元素所需的比较次数为1; 查找第2个元素所需的比较次数为2; …… 查找第n个元素所需的比较次数为n;
总计全部比较次数为:1+2+…+n = (1+n)n/2 因为是计算某一个元素的平均查找次数,还应当除以n, (假设查找任一元素的概率相同) 即: ASL=(1+n)/2 ,时间效率为 O(n)
数据结构实验8 查找与排序

注意事项:在磁盘上创建一个目录,专门用于存储数据结构实验的程序。
因为机房机器有还原卡,请同学们将文件夹建立在最后一个盘中,以学号为文件夹名。
实验八查找和排序一、实验目的掌握运用数据结构两种基本运算查找和排序,并能通过其能解决应用问题。
二、实验要求1.掌握本实验的算法。
2.上机将本算法实现。
三、实验内容为宿舍管理人员编写一个宿舍管理查询软件, 程序采用交互工作方式,其流程如下:建立数据文件,数据结构采用线性表,存储方式任选(建议用顺序存储结构),数据元素是结构类型(学号,姓名,性别,房号),元素的值可从键盘上输入,可以在程序中直接初始化。
数据文件按关键字(学号、姓名、房号)进行排序(排序方法任选一种),打印排序结果。
(注意字符串的比较应该用strcmp(str1,str2)函数)查询菜单: (查找方法任选一种)1. 按学号查询2. 按姓名查询3. 按房号查询打印任一查询结果(可以连续操作)。
参考:typedef struct {char sno[10];char sname[2];int sex; //以0表示女,1表示男int roomno;}ElemType;struct SqList{ElemType *elem;int length;};void init(SqList &L){L.elem=(ElemType *)malloc(MAXSIZE*sizeof(ElemType));L.length=0;}void printlist(SqList L){ int i;cout<<" sno name sex roomno\n";for(i=0;i<L.length;i++)cout<<setw(7)<<L.elem[i].sno<<setw(10)<<L.elem[i].sname<<setw(3)<<L.elem[i].sex<<setw(6) <<L.elem[i].roomno<<endl;}。
数据结构——查找,顺序查找,折半查找

实验五查找的应用一、实验目的:1、掌握各种查找方法及适用场合,并能在解决实际问题时灵活应用。
2、增强上机编程调试能力。
二、问题描述1.分别利用顺序查找和折半查找方法完成查找。
有序表(3,4,5,7,24,30,42,54,63,72,87,95)输入示例:请输入查找元素:52输出示例:顺序查找:第一次比较元素95第二次比较元素87 ……..查找成功,i=**/查找失败折半查找:第一次比较元素30第二次比较元素63 …..2.利用序列(12,7,17,11,16,2,13,9,21,4)建立二叉排序树,并完成指定元素的查询。
输入输出示例同题1的要求。
三、数据结构设计(选用的数据逻辑结构和存储结构实现形式说明)(1)逻辑结构设计顺序查找和折半查找采用线性表的结构,二叉排序树的查找则是建立一棵二叉树,采用的非线性逻辑结构。
(2)存储结构设计采用顺序存储的结构,开辟一块空间用于存放元素。
(3)存储结构形式说明分别建立查找关键字,顺序表数据和二叉树数据的结构体进行存储数据四、算法设计(1)算法列表(说明各个函数的名称,作用,完成什么操作)序号 名称 函数表示符 操作说明1 顺序查找 Search_Seq 在顺序表中顺序查找关键字的数据元素2 折半查找 Search_Bin 在顺序表中折半查找关键字的数据元素3 初始化 Init 对顺序表进行初始化,并输入元素4 树初始化 CreateBST 创建一棵二叉排序树5 插入 InsertBST 将输入元素插入到二叉排序树中6 查找 SearchBST在根指针所指二叉排序树中递归查找关键字数据元素 (2)各函数间调用关系(画出函数之间调用关系)typedef struct { ElemType *R; int length;}SSTable;typedef struct BSTNode{Elem data; //结点数据域 BSTNode *lchild,*rchild; //左右孩子指针}BSTNode,*BSTree; typedef struct Elem{ int key; }Elem;typedef struct {int key;//关键字域}ElemType;(3)算法描述int Search_Seq(SSTable ST, int key){//在顺序表ST中顺序查找其关键字等于key的数据元素。
《数据结构》教案

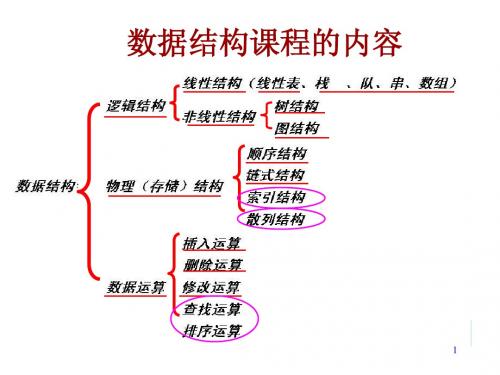
《数据结构》教案信息技术学院软件教研室课程说明【目的】1.数据结构是研究数据组织、存储和运算的一般方法的学科。
——理解并掌握数据的各种数据结构的原理与算法。
2. 学会分析研究计算机加工的数据结构的性质,以便为应用涉及的数据选择适当的逻辑结构、存储结构及其相应的算法,并初步掌握算法的时间分析和空间分析的技术。
3.数据结构是编程的基础。
程序=数据结构+算法——能够以数据结构为基础,进行复杂程序编程,且符合软件工程的规范。
4.数据结构课程重点是培养学生的数据抽象能力。
【内容】1.数据结构的基本概念(第1章)2、线性表(第2、3、4、5章)3、树(第6章)4、图(第7章)5、查找和排序(第9、10、11章)【参考书】1.数据结构严蔚敏清华大学出版社2. 数据结构(c语言篇)——习题与解析(修订版)李春葆清华大学出版社【教学安排】第1章绪论【教学目的】1.数据结构的基本概念,介绍数据和数据结构等名词和术语。
2.描述算法的类C语言3.从时间和空间角度分析算法的方法【教学要求】掌握基本概念,了解抽象数据类型,掌握计算语句频度和估算算法时间复杂度,熟悉类C语言的书写规范。
【教学重点与难点】描述算法的类C语言;抽象数据类型的概念;算法复杂性的分析方法【教学追记】1、熟悉各名词、术语的含义,掌握基本概念,特别是数据结构的三个方面(逻辑结构、存储结构、及其运算)。
数据的逻辑结构和存储结构之间的关系。
分清哪些是逻辑结构的性质,哪些是存储结构的性质。
2、了解抽象数据类型的定义、表示和实现方法。
3、理解算法五个要素的确切含义:①动态有穷性(能执行结束);②确定性(对于相同的输入执行相同的路径);③有输入;④有输出;⑤可行性(用以描述算法的操作都是足够基本的)。
4、掌握计算语句频度和估算算法时间复杂度的方法。
5、熟悉类C语言的书写规范,对学过C++的学生,比较输入/输出语句cin /cout;动态分配内存语句new与C语言的区别。
数据结构-7顺序查找与二分查找

i=m+1=8,j=8, m=(i+j)/2=8。 r[m]>k : 在左半部分继续查找。
i=8, j=m-1=7 ,
i>j: 查找失败
存储结构
key info 0 1 k1 2 k2 3 k3
…………
n kn
typedef struct { keytype key; ………….
} elemtype;
分块有序表的结构可以分为两部分: 1、线性表本身是顺序存储结构 2、再建立一个索引表,线性表中每个子表建立一个索引节点
。索引节点包括两部分:一是数据域,一是指针域。数据域存 放对应子表中的最大元素值,指针域用于指示子表第一个元素 的在整个表中序号。
分块查找
template<class T> struct indnode {
key=32
d (1) 27
i=1
d (2) 36
i=2
d (3) 32i=3 Nhomakorabead (4) 18
此时d(i)=key,数组中的第3个位置
如果输入查找的元素值key=22
d (1) 27 i=1
d (2) 36 i=2
d (3) 32 i=3
d (4) 18
i=4 i=5 此时i等于5,超过数组中元素个数,找不到
T key; int k; };
上图查找过程:首先查找索引表,确定查找的子表,然后再相应的子表中 应顺序表查找法查找。
• int blksearch(record r[],index idx[],keytype key)
•{
• int i=0,j;
• while(i<idxN)
•{
• if(key<=idx[i].key){
数据结构查找与排序

第二部分 排序
• 各种排序算法的特性
– 时间性能(最好、最坏、平均情况) – 空间复杂度 – 稳定性
• 常见排序算法
– 堆排序-堆的定义,创建堆,堆排序(厦大3次,南航2次,南大3次) – 快速排序 – 基数排序 – 插入排序 – 希尔排序 – 冒泡排序 – 简单选择排序 – 归并排序
一、基于选择的排序
• 快速排序算法关键字的比较和交换也是跳跃式进行的,所以快速排序 算法也是一种不稳定的排序方法。
• 由于进行了递归调用,需要一定数量的栈O(log2n)作为辅助空间
例如
1、快速排序算法在 数据元素按关键字有序的 情况下最不利于发挥其长处。
2、设关键字序列为:49,38,66,80,70,15,22,欲对该序列进行从小到大排序。 采用待排序列的第一个关键字作为枢轴,写出快速排序法的一趟和二趟排序之 后的状态
49
49
38
66
38
10
90
75
10
20
90
75
66
20
10
38
20
90
75
66
49
2.序列是堆的是( C )。 A.{75, 65, 30, 15, 25, 45, 20, 10} B.{75, 65, 45, 10, 30, 25, 20, 15} C.{75, 45, 65, 30, 15, 25, 20, 10} D.{75, 45, 65, 10, 25, 30, 20, 15}
➢ 依靠“筛选”的过程
➢ 在线性时间复杂度下创建堆。具体分两步进行: 第一步,将N个元素按输入顺序存入二叉树中,这一步只要求满 足完全二叉树的结构特性,而不管其有序性。
第二步,按照完全二叉树的层次遍历的反序,找到第一个非叶子结点, 从该结点开始“筛选”,调整各结点元素,然后按照反序,依次做筛选,直到做 完根结点元素,此时即构成一个堆。
数据结构复习--排序和查找

数据结构复习--排序和查找现在正在学习查找和排序,为了节省时间提⾼效率,就正好边学习边整理知识点吧!知识点⼀:⼆分查找/折半查找1.⼆分查找的判定树(选择题)下列⼆叉树中,可能成为折半查找判定树(不含外部结点)的是: (4分)1.2.3.4.注:折半查找判定树是⼀棵⼆叉排序树,它的中序遍历结果是⼀个升序序列,可以在选项中的树上依次填上相应的元素。
虽然折半查找可以上取整也可以下取整但是⼀个查找判定树只能有⼀种取整⽅式。
如果升序序列是偶数个,那么终点应该偏左多右少。
在2选项中,由根节点左⼦树4个节点⽽右⼦树5个节点可以确定⽤的是向下取整策略,但是它的左⼦节点在左⼦树种对应的终点左边2个,右边个,明显是上取整策略,策略没有统⼀,所以是错的。
其他的选项类似分析。
2.⼆分查找法/折半查找法已知⼀个长度为16的顺序表L,其元素按关键字有序排列。
若采⽤⼆分查找法查找⼀个L中不存在的元素,则关键字的⽐较次数最多是: (2分)1. 72. 63. 54. 4 注:⼀次找到最边界的那⼀个树的情况下有最多次数 这个题中结点数16是个偶数:第⼀次(0+15)/2 7 第⼆次(8+15)/2 11第三次(12+15)/2 14 第四次(14+15)/2 14 第五次(15+15)/2 15(下取整的就向右计算求最多次数)第⼀次(0+15)/2 8 第⼆次(0+7)/2 4 第三次(0+3)/2 2 第四次(0+1)/2 0第五次(0+0)/2 0(下取整的话就向左求最多次数)若结点数是奇数15:第⼀次(0+14)/2 7 第⼆次( 0+6)/2 3 第三次(0+2)/2 1第四次(0+0)/2 0第⼀次(0+14)/2 7 第⼆次(8+14)/2 11 第三次(12+14)/2 13第四次(14+14)/2 0这时候向左或者向右都是OK的(因为得到的数都是能够被2整除的)但是划重点了折半查找⼀个有序表中不存在的元素,若向下取整,则要最多⽐较[log2n]+1次,若向上取整,则要最多⽐较[log2(n+1)],其实就是求树的深度.(这⼀块⾃⼰的说法可能不够准确,希望⼤家看到有问题的可以指出来)结合实际,我们⽤[log2n]+1来算更简单并且计算[log2n]要取整数,因为可能会存在不是满⼆叉树的情况。
数据结构第七章 排序

name 张涛 赵亮
冯博远 王强 李燕
7.2
基本原理
插入排序
每次将一个待排序的对象,按其关键字大小, 插入到前面已经排序好的一组对象的适当位臵上, 直到对象全部插入为止。
直接插入排序(Insert Sort)
希尔排序(Shell Sort)
7.2.1
直接插入排序
R[1]---R[i-1]
08 08
16 16
第三次
08
16
21
25* 25
49
希尔排序中d(间隔量)的取法 Shell最初的方案是 d= n/2, d=d/2, 直到d=1; Knuth的方案是d= d/3+1;
其它方案有:都取奇数为好;d互质为好 等等。
希尔排序的稳定性
如序列: 21 25 排序后为:08 16
R[0]有两个作用:
其一: 进入查找循环之前,保存 R[i] 的副本,使之不至 于因记录的后移而丢失R[i]中的内容; 其二: 在 while 循环时,“监视”下标变量 j 是否越界, 一旦越界(j<0),R[0]自动控制while循环的结束, 从而 避免了在while 循环内的每一次都要检测 j 是否越界( 即 省略了循环条件j>=0)。 因此,把 R[0] 称为“监视哨”。
第七章 排 序
本章内容
排序的概念和有关知识
常用的几种排序方法的基本思想、排序过 程和算法实现 各种排序算法的时间复杂度分析
学生成绩表
学号 姓名 高数 英语 总分
005 010 002
018 004
Chen Lin Gao Hong Wang Na
ZhangYang Zhao Pen
84 69 90
数据结构教案7-8

课题
教学 目的 要求
第 7 章 查找 1.理解查找的基本概念和术语
章节
2.掌握线性表的顺序查找和二分法查找方法及算法实现。
3.掌握二叉排序树的生成和查找方法。
4.掌握散列表的构造方法、查找过程及解决冲突的方法。
教学重点 基于线性表的查找方法;二叉排序树;散列表
教学难点 平衡二叉树;哈希表处理冲突的方法
(1)必须采取顺序存储结构;(2)必须按关键字大小排序的有序表。
二分查找过程:
取表的中间记录关键字与查找 key 进行比较,三种情况:
相等:查找成功;
小于:要查找的记录只可能在表的后半部分;
大于:要查找的记录只可能在表的前半部分。
经过—次比较就可将查找范围缩小一半。如此反复进行,直到找到
给定关键字 key 记录,查找成功;当前查找范围为空,查找失败。
折半查找的过程可描述为:
⑴ low=1;high=length
⑵ 若 low>high,则查找失败
⑶
mid
low
high 2
若 key<L.r[mid].key,则 high=mid-1,转⑵
若 key>L.r[mid].key,则 low=mid+1,转⑵
若 key=L.r[mid].key,则查找成功,返回 mid
50
92
②若它的右子树非空,则右子树上所有结点的值
8
19
31
24
354249515 2229
38 46
53
均大于根结点的值;
43 60 70 98
③左、右子树本身又各是一棵二叉排序树。
图 7-4 一棵二叉排序树
3
数据结构常用操作

数据结构常用操作数据结构是计算机科学中的关键概念,它是组织和管理数据的方法。
常用的数据结构包括数组、链表、树、图和队列等。
在实际的编程中,我们经常需要对数据结构进行一些操作,如添加、删除和查找等。
以下是一些常用的数据结构操作。
1.添加元素:将新元素插入到数据结构中。
对于数组,可以通过在指定索引位置赋值来添加元素。
对于链表,可以通过创建新节点并调整指针来实现。
对于树和图,可以添加新节点或边来扩展结构。
2.删除元素:从数据结构中移除指定元素。
对于数组,可以通过将元素设置为特定值来删除。
对于链表,可以遍历链表并删除匹配的节点。
对于树和图,可以删除指定节点或边。
3.查找元素:在数据结构中指定元素。
对于有序数组,可以使用二分查找来提高效率。
对于链表,可以遍历链表并比较每个节点的值。
对于树和图,可以使用深度优先(DFS)或广度优先(BFS)等算法进行查找。
4.遍历元素:按照其中一种顺序遍历数据结构中的所有元素。
对于数组和链表,可以使用循环来遍历每个元素。
对于树,可以使用先序、中序或后序遍历来访问每个节点。
对于图,可以使用DFS或BFS来遍历每个节点。
5.排序元素:对数据结构中的元素进行排序。
对于数组,可以使用快速排序、归并排序等常用算法。
对于链表,可以使用插入排序或选择排序等算法。
对于树和图,可以使用DFS或BFS进行遍历并将元素排序。
6.查找最小/最大值:在数据结构中查找最小或最大值。
对于有序数组,最小值在索引0的位置。
对于链表,可以遍历链表并比较每个节点的值。
对于树,可以遍历树的左子树或右子树来找到最小或最大值。
7.合并数据结构:将两个数据结构合并成一个。
对于有序数组,可以先将两个数组合并成一个,然后再排序。
对于链表,可以将一个链表的尾节点连接到另一个链表的头节点。
对于树和图,可以将两个结构合并成一个,保持其关系。
8.拆分数据结构:将一个数据结构拆分成多个。
对于有序数组,可以根据一些值将数组拆分为两个子数组。
数据结构简单排序

数据结构简单排序一、简介数据结构是计算机科学中重要的概念之一,它用于组织和存储数据,以便于访问和修改。
而排序算法则是数据结构中的重要内容,它可以将无序的数据按照特定规则进行排列,提高数据的查找和处理效率。
本文将介绍数据结构中的简单排序算法。
二、冒泡排序冒泡排序是最基础的排序算法之一,它通过不断比较相邻元素并交换位置,将较大或较小的元素逐步“冒泡”到数组的末尾或开头。
具体步骤如下:1. 从数组第一个元素开始比较相邻元素。
2. 如果前一个元素大于后一个元素,则交换它们的位置。
3. 继续向后比较相邻元素,并交换位置直到最后一个元素。
4. 重复以上步骤直到整个数组有序。
三、选择排序选择排序也是一种简单且常用的排序算法。
它通过不断寻找最小值或最大值,并将其放在已排好序部分的末尾或开头。
具体步骤如下:1. 找到当前未排序部分中最小值(或最大值)。
2. 将该值与未排序部分第一个元素交换位置。
3. 将已排序部分的末尾(或开头)指针向后(或前)移动一位。
4. 重复以上步骤直到整个数组有序。
四、插入排序插入排序是一种简单但高效的排序算法,它通过将未排序部分中的每个元素插入已排好序部分中的合适位置,逐步构建一个有序数组。
具体步骤如下:1. 将第一个元素视为已排好序部分,将第二个元素作为未排序部分中的第一个元素。
2. 将未排序部分中的第一个元素插入已排好序部分中合适的位置。
3. 将已排好序部分扩展至包含前两个元素,并将未排序部分中的下一个元素插入到合适位置。
4. 重复以上步骤直到整个数组有序。
五、希尔排序希尔排序是一种高效且简单的改进版插入排序算法。
它通过对数据进行多次局部交换和移动,使得数据更快地接近有序状态。
具体步骤如下:1. 定义一个增量值h,将数组按照间隔h划分成若干子数组。
2. 对每个子数组进行插入排序操作。
3. 缩小增量h,重复以上操作直到h=1。
4. 对整个数组进行插入排序操作。
六、归并排序归并排序是一种高效且稳定的排序算法。
数据结构C语言版(第2版)严蔚敏人民邮电出版社课后习题答案

数据结构( C语言版)(第 2版)课后习题答案李冬梅2015.3目录第 1 章绪论 (1)第 2 章线性表 (5)第 3 章栈和队列 (13)第 4 章串、数组和广义表 (26)第 5 章树和二叉树 (33)第 6 章图 (43)第 7 章查找 (54)第 8 章排序 (65)第1章绪论1.简述下列概念:数据、数据元素、数据项、数据对象、数据结构、逻辑结构、存储结构、抽象数据类型。
答案:数据:是客观事物的符号表示,指所有能输入到计算机中并被计算机程序处理的符号的总称。
如数学计算中用到的整数和实数,文本编辑所用到的字符串,多媒体程序处理的图形、图像、声音、动画等通过特殊编码定义后的数据。
数据元素:是数据的基本单位,在计算机中通常作为一个整体进行考虑和处理。
在有些情况下,数据元素也称为元素、结点、记录等。
数据元素用于完整地描述一个对象,如一个学生记录,树中棋盘的一个格局(状态)、图中的一个顶点等。
数据项:是组成数据元素的、有独立含义的、不可分割的最小单位。
例如,学生基本信息表中的学号、姓名、性别等都是数据项。
数据对象:是性质相同的数据元素的集合,是数据的一个子集。
例如:整数数据对象是集合N={0 ,± 1,± 2,, } ,字母字符数据对象是集合C={‘A’,‘B’, , ,‘Z’,‘ a’,‘ b’, , ,‘z ’} ,学生基本信息表也可是一个数据对象。
数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。
换句话说,数据结构是带“结构”的数据元素的集合,“结构”就是指数据元素之间存在的关系。
逻辑结构:从逻辑关系上描述数据,它与数据的存储无关,是独立于计算机的。
因此,数据的逻辑结构可以看作是从具体问题抽象出来的数学模型。
存储结构:数据对象在计算机中的存储表示,也称为物理结构。
抽象数据类型:由用户定义的,表示应用问题的数学模型,以及定义在这个模型上的一组操作的总称。
具体包括三部分:数据对象、数据对象上关系的集合和对数据对象的基本操作的集合。
数据结构(Java语言描述)第七章 查找

第七章 查找
目录
1 查找
2 静态查找表
第七章 查找
动态查找表 哈希表 小结
总体要求
•掌握顺序查找、折半查找的实现方法; •掌握动态查找表(包括:二叉排序树、二叉平衡树 、B-树)的构造和查找方法; •掌握哈希表、哈希函数冲突的基本概念和解决冲突 的方法。
7.1基本概念
1、数据项 数据项是具有独立含义的标识单位,是数据不可分 割的最小单位。 2、数据元素 数据元素数是据由项若(名干) 数据项构成的数据单位,是在某
}
性能分析:i 0 1 2 3 4
5 13 19 21 37
Ci 3 4 2 3 4
查找成功:
比较次数 = 路径上的结点数
比较次数 = 结点 4 的层数
比较次数
2
56 7 56 64 75 1 34
判定树
5
8 9 10 80 88 92 2 34
查找37 8
树的深度
0
3
6
9
≤=
log2n +1
1
4
}
【算法7-1】初始化顺序表 public SeqTable(T[] data,int n){
elem=new ArrayList<ElemType<T>>(); ElemType<T> e; for(int i=0;i<n;i++){
e=new ElemType<T>(data[i]); elem.add(i, e); } length=n; }
前者叫作最大查找长度(Maximun Search Length),即 MSL。后者叫作平均查找长度(Average Search Length) ,即ASL。
数据结构-第九章 查找

数据结构-第九章查找数据结构第九章查找在计算机科学中,数据结构是组织和存储数据的方式,以便能够高效地进行访问、操作和管理。
而查找,作为数据结构中的一个重要概念,在我们处理和分析数据的过程中起着关键作用。
查找,简单来说,就是在一组数据中寻找特定的元素。
这听起来似乎很简单,但实际上,它涉及到一系列复杂的算法和策略,以确保能够快速准确地找到我们所需的信息。
让我们先来了解一下顺序查找。
顺序查找是最简单也是最直观的查找方法。
它的基本思想就是从数据集合的开头,逐个元素地进行比较,直到找到目标元素或者遍历完整个集合。
这种方法对于小型数据集或者数据没有特定规律的情况是可行的,但效率相对较低。
想象一下,你要在一本没有索引的电话簿中查找一个人的号码,只能从头开始一个一个地翻,这就是顺序查找的过程。
与顺序查找相对的是二分查找。
二分查找要求数据集合是有序的。
它通过不断地将数据集一分为二,比较目标元素与中间元素的大小,从而缩小查找范围。
这种方法的效率比顺序查找高得多。
比如说,要在一本按照姓名拼音排序的电话簿中查找一个人,我们可以先比较中间的名字,如果目标在前面,就只在前半部分继续查找,反之则在后半部分查找,如此反复,大大提高了查找的速度。
除了上述两种常见的查找方法,还有哈希查找。
哈希查找的核心是通过一个哈希函数将元素映射到一个特定的位置。
哈希函数的设计至关重要,一个好的哈希函数能够使得元素均匀地分布在哈希表中,减少冲突的发生。
当我们要查找一个元素时,通过哈希函数计算出其可能的位置,然后进行比较。
如果哈希函数设计得不好,可能会导致大量的冲突,从而影响查找效率。
在实际应用中,选择合适的查找方法取决于多个因素。
数据的规模是一个重要的考虑因素。
如果数据量较小,顺序查找可能就足够了;但对于大规模的数据,二分查找或者哈希查找通常更合适。
数据的分布情况也会影响选择。
如果数据分布比较均匀,哈希查找可能效果较好;如果数据有序,二分查找则更具优势。
数据结构:第7章 图4-拓扑排序和关键路径

拓扑排序算法
拓扑排序方法: (1)在AOV网中选一个入度为0的顶点(没有前驱) 且输出之; (2)从AOV网中删除此顶点及该顶点发出来的所 有有向边; (3)重复(1)、(2)两步,直到AOV网中所有 顶点都被输出或网中不存在入度为0的顶点。
从拓扑排序步骤可知,若在第3步中,网中所有顶 点都被输出,则表明网中无有向环,拓扑排序成功。 若仅输出部分顶点,网中已不存在入度为0的顶点, 则表明网中有有向环,拓扑排序不成功。
拓扑序列:C1--C2--C3 (3)
C12 C9 C10
C7 C8 C6
C11
拓扑序列:C1--C2--C3--C4 (4)
C7
C12
C12
C8
C8 C9 C10
C6
C9 C10
C6
C11
C11 拓扑序列:C1--C2--C3--C4--C5
(5)
拓扑序列:C1--C2--C3--C4--C5--C7 (6)
在 (b)中,我们用一种有向图来表示课程开设
拓扑排序
1.定义 给出有向图G=(V,E),对于V中的顶点的线性序列 (vi1,vi2,...,vin),如果满足如下条件:若在G中从 顶点 vi 到vj有一条路径,则在序列中顶点vi必在 顶点 vj之前;则称该序列为 G的一个拓扑序列。 构造有向图的一个拓扑序列的过程称为拓扑排序。 2.说明 (1)在AOV网中,若不存在回路,则所有活动可排成 一个线性序列,使得每个活动的所有前驱活动都排 在该活动的前面,那么该序列为拓扑序列. (2)拓扑序列不是唯一的.
2.AOV网实际意义
现代化管理中, 通常我们把计划、施工过程、生产流程、 程序流程等都当成一个工程,一个大的工程常常被划分 成许多较小的子工程,这些子工程称为活动。在整个工 程实施过程中,有些活动开始是以它的所有前序活动的 结束为先决条件的,必须在其它有关活动完成之后才能 开始,有些活动没有先决条件,可以 安排在任意时间开 始。AOV网就是一种可以形象地反映出整个工程中各个 活动之间前后关系的有向图。例如,计算机专业学生的 课程开设可看成是一个工程,每一门课程就是工程中的 活动,下页图给出了若干门所开设的课程,其中有些课 程的开设有先后关系,有些则没有先后关系,有先后关 系的课程必须按先后关系开设,如开设数据结构课程之 前必须先学完程序设计基础及离散数学,而开设离散数 学则必须先并行学完数学、程序设计基础课程。
游戏开发中常用数据结构和算法

游戏开发中常用数据结构和算法在游戏开发中,高效的数据结构和算法是至关重要的。
它们能够帮助我们优化游戏性能、提高游戏的实时性和响应性。
下面将介绍几个常用的数据结构和算法。
1. 数组(Array):数组是最简单和常见的数据结构之一,它是一种线性的数据结构,可以在O(1)的时间复杂度内通过索引直接访问和修改元素。
在游戏开发中,数组常用于存储元素的集合,比如游戏的角色列表、道具列表等。
2. 链表(Linked List):链表是另一种常见的数据结构,与数组不同,链表中的元素在物理内存上可以不连续。
链表的插入和删除操作非常高效,但是查找元素的速度较慢。
在游戏中,链表常用于实现队列、栈等数据结构,以及管理对象的内存分配和释放。
3. 哈希表(Hash Table):哈希表是一种根据关键字直接访问内存存储位置的数据结构,它可以在常数时间内进行插入、删除和查找操作。
哈希表在游戏开发中广泛应用于实现快速查找和存储,比如实体管理、碰撞检测等方面。
4. 树(Tree):树是一种层次结构的数据结构,由节点和边构成。
在游戏中,常用的树包括二叉树、平衡二叉树(如AVL树和红黑树)、B树等。
树在游戏开发中常用于实现场景图、游戏对象层级等。
5. 图(Graph):图是一种表示多对多关系的数据结构,由节点和边组成。
在游戏中,图常用于表示游戏地图、NPC关系等。
常见的图算法包括广度优先(BFS)和深度优先(DFS)等。
6.排序算法:排序算法是游戏开发中的常用算法之一,用于对数据进行排序。
常用的排序算法包括冒泡排序、插入排序、选择排序、快速排序、归并排序等。
选择合适的排序算法可以提高游戏中排序操作的效率。
7.查找算法:查找算法用于在数据结构中查找目标元素。
常用的查找算法包括线性查找、二分查找、哈希查找等。
选择合适的查找算法可以提高游戏中查找操作的效率。
8.图形学算法:在游戏开发中,图形学算法是不可或缺的。
常用的图形学算法包括裁剪算法(如Cohen-Sutherland算法和Liang-Barsky算法)、扫描线算法、光照模型算法(如Phong光照模型)等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验7:查找、排序
一、实验目的
深入了解各种内部排序方法及效率分析。
二、问题描述
各种内部排序算法的时间复杂度分析,试通过随机数据比较算法的关键字比较次数和关键字移动次数。
三、实验要求
1、对起泡排序、直接插入排序、简单选择排序、快速排序、希尔排序、堆排序这六种
常用排序算法进行比较。
2、待排序表的表长不超过100;其中数据用伪随机数产生程序产生。
1、至少要用6组不同的输入数据做比较。
2、要对实验结果做简单分析。
四、实验环境
PC微机
DOS操作系统或 Windows 操作系统
Turbo C 程序集成环境或 Visual C++ 程序集成环境
五、实验步骤
1、根据问题描述写出基本算法。
2、设计六种排序算法并用适当语言实现。
3、输入几组随机数据,并对其关键字比较次数和关键字移动次数的比较。
4、对结果进行分析。
5、进行总结。
六、测试数据
数据有随机数产生器产生。
七、实验报告要求
实验报告应包括以下几个部分:
1、问题描述。
2、六种排序算法描述。
3、实现算法的程序。
4、调试程序。
5、比较各算法中的关键字比较次数和关键字移动次数。
八、思考题
1、试着将数据按散列法存储,并设计好解决冲突的方法,在此基础上实现增、删查询
等操作。
2、试构造存放C语言中32个关键字的查找表,并希望达到的平均查找长度不超过2。