Atempo_LB_2010
Materials science and engineering, an introductionChapter 12 Structures and properties of ceramics

1496T_c12_414-459 12/31/05 10:16 Page 415
2nd REVISE PAGES
Learning Objectives
After careful study of this chapter you should be able to do the following:
in crystalline ceramic materials influence the crystal structure: the magnitude of
the electrical charge on each of the component ions, and the relative sizes of the
cations and anions. With regard to the first characteristic, the crystal must be
cause they have given up their valence electrons to the nonmetallic ions, or
anions, which are negatively charged. Two racteristics of the component ions
1496T_c12_414-459 12/31/05 10:16 Page 416
2nd REVISE PAGES
416 • Chapter 12 / Structures and Properties of Ceramics
Table 12.1 For Several Ceramic Materials, Percent Ionic Character of the Interatomic Bonds
rbgm包用户手册:Atlantis生态系统模型的盒子几何模型(BGM)文件和拓扑工具说明书

Package‘rbgm’October14,2022Type PackageTitle Tools for'Box Geometry Model'(BGM)Files and Topology for theAtlantis Ecosystem ModelVersion0.1.0Depends R(>=3.2.2),raster,spImports dplyr,geosphere,rlang,reproj,sfheadersSuggests bgmfiles,covr,knitr,rmarkdown,roxygen2,testthatDescription Facilities for working with Atlantis box-geometry model(BGM)files.Atlantis is a deterministic,biogeochemical,whole-of-ecosystem model.Functions are provided to read from BGMfiles directly,preserving theirinternal topology,as well as helper functions to generate spatial data from thesemesh forms.This functionality aims to simplify the creation and modification of box and geometry as well as the ability to integrate with other data sources. NeedsCompilation noByteCompile yesLicense GPL-3RoxygenNote7.1.0Encoding UTF-8URL https://research.csiro.au/atlantis/BugReports https:///AustralianAntarcticDivision/rbgm/issues/ VignetteBuilder knitrAuthor Michael D.Sumner[aut,cre]Maintainer Michael D.Sumner<******************>Repository CRANDate/Publication2020-04-1205:30:04UTC12rbgm-package R topics documented:rbgm-package (2)bgmfile (3)boxSpatial (4)build_dz (5)nodeSpatial (6)Index8 rbgm-package Utilities for BGMfiles for AtlantisDescriptionTools for handling network data for Atlantis from box-geometry model(BGM)filesrbgm features•read.bgmfiles and faithfully store all information so it can be round-tripped•conversion from.bgm forms to Spatial classes(lines and polygons)•(not yet implemented:write to.bgm)I.Importbgmfile read directly from a.bgmfileII.ConversionboxSpatial convert boxes to a SpatialPolygonsDataFramefaceSpatial convert faces to a SpatialLinesDataFrameboundarySpatial convert boundary to a single-row SpatialPolygonsDataFramenodeSpatial obtain all vertices as pointspointSpatial obtain all instances of vertices as pointsIII.Miscellaneousbuild_dz Build Atlantis dz Valuesbgmfile3bgmfile Read BGMDescriptionRead geometry and full topology from BGMfiles.Usagebgmfile(x,...)read_bgm(x,...)Argumentsx path to a bgmfile...ignored for nowDetailsBGM is afile format used for the’Box Geometry Model’in the Atlantis Ecosystem Model.This function reads everything from the.bgmfile and returns it as linked tables.See AlsoSee helper functions to convert the bgm tables to‘Spatial‘objects,boxSpatial,faceSpatial, nodeSpatial,boundarySpatial,pointSpatialExampleslibrary(bgmfiles)bfile<-sample(bgmfiles(),1L)bgm<-bgmfile(bfile)str(bgm)4boxSpatial boxSpatial Convert to spatial formatDescriptionTake the output of bgmfile and return a Spatial object or a sf object.UsageboxSpatial(bgm)box_sp(bgm)box_sf(bgm)boundarySpatial(bgm)boundary_sp(bgm)boundary_sf(bgm)node_sp(bgm)point_sp(bgm)faceSpatial(bgm)face_sp(bgm)face_sf(bgm)Argumentsbgm output of a BGMfile,as returned by bgmfileDetailsNote that the‘_sp‘forms are aliased to original functions called‘*Spatial‘,and now have‘_sf‘counterparts to return that format.ValueSpatial*object or sf object•box_sp SpatialPolygonsDataFrame•face_sp SpatialLinesDataFrame•boundary_sp SpatialPolygonsDataFramebuild_dz5•node_sp SpatialPointsDataFrame•point_sp SpatialPointsDataFrame•box_sf sf with sfc_POLYGON column•face_sf sf with sfc_LINESTRING column•boundary_sf sf with sfc_POLYGON column•node_sf sf with sfc_POINT column•point_sf sf with sfc_POINT columnWarningThe sf objects created by‘box_sf()‘,‘node_sf()‘,‘face_sf()‘,‘boundary_sf()‘and‘point_sf()‘were not created by the sf package.They were created with reference to the sf format prior to November 2019.If you have problems it may be necessary to recreate the’crs’part of the of the object with code like‘x<-box_sf(bgm);library(sf);st_crs(x)<-st_crs(attr(x$geometry,"crs")$proj)‘.Get in touch([create an issue](https:///AustralianAntarcticDivision/rbgm/issues))if you have any troubles.Examplesfname<-bgmfiles::bgmfiles(pattern="antarctica_28")bgm<-bgmfile(fname)spdf<-box_sp(bgm)sfdf<-box_sf(bgm)sldf<-face_sp(bgm)plot(spdf,col=grey(seq(0,1,length=nrow(bgm$boxes))))plot(sldf,col=rainbow(nrow(bgm$faces)),lwd=2,add=TRUE)build_dz Build Atlantis dz ValuesDescriptionBuild dz layer values for Atlantis from a bottom value,up through successive intervals.Each value is the positive offset required to rise to the top of the current interval.Usagebuild_dz(z,zlayers=c(-Inf,-2000,-1000,-750,-400,-300,-200,-100,-50,-20,0) )Argumentsz lowermost valuezlayers intervals of layer valuesDetailsOffset values are returned to move from z against the intervals in zlayers.The intervals are assumed to be sorted and increasing in value from-Inf inity.Once the maximum layer is reached the result is padded by that top value.Valuenumeric vector of offset valuesExamples##sanity testsbuild_dz(-5000)build_dz(-1500)##build_dz(300)##errorbuild_dz(0)##ok##datadd<-c(-4396.49,-2100.84,-4448.81,-411.96,-2703.56,-5232.96,-4176.25,-2862.37,-3795.6,-1024.64,-897.93,-1695.82,-4949.76, -5264.24,-2886.81)##all values in a matrix for checking##[zlayers,dd]dzvals<-sapply(dd,build_dz)##process into textf1<-function(x)sprintf("somelabel,%i,%s",x,paste(build_dz(dd[x]),collapse=",")) tex1<-sapply(seq(length(dd)),f1)##for examplef2<-function(x){sprintf("morelabel,%i,%s",x,paste(as.integer(build_dz(dd[x])),collapse=","))}tex2<-sapply(seq(length(dd)),f2)nodeSpatial Vertices as Spatial points.DescriptionObtain all vertices as a SpatialPointsDataFrame or a sf dataframe.UsagenodeSpatial(bgm)node_sf(bgm)pointSpatial(bgm)point_sf(bgm)Argumentsbgm BGM object from bgmfileDetailsNodes are the unique coordinates(or vertices),points are the instances of those coordinates that exist in the model.point_sp or point_sf return all instances of the vertices with information about which boxes they belong to.node_sp and node_sf return all vertices.ValueSpatialPointsDataFrame or sf data frameWarningThe sf objects created by‘box_sf()‘,‘node_sf()‘,‘face_sf()‘,‘boundary_sf()‘and‘point_sf()‘were not created by the sf package.They were created with reference to the sf format prior to November 2019.If you have problems it may be necessary to recreate the’crs’part of the of the object with code like‘x<-node_sf(bgm);library(sf);st_crs(x)<-st_crs(attr(x$geometry,"crs")$proj)‘.Get in touch([create an issue](https:///AustralianAntarcticDivision/rbgm/issues))if you have any troubles.Examplesfname<-bgmfiles::bgmfiles(pattern="antarctica_28")bgm<-bgmfile(fname)spnode<-node_sp(bgm)names(spnode)nrow(spnode)##only unique verticesnrow(bgm$vertices)sppoints<-point_sp(bgm)names(sppoints)nrow(sppoints)names(point_sf(bgm))Indexbgmfile,2,3,4,7boundary_sf(boxSpatial),4boundary_sp(boxSpatial),4 boundarySpatial,2,3boundarySpatial(boxSpatial),4box_sf(boxSpatial),4box_sp(boxSpatial),4boxSpatial,2,3,4build_dz,2,5face_sf(boxSpatial),4face_sp(boxSpatial),4faceSpatial,2,3faceSpatial(boxSpatial),4node_sf,7node_sf(nodeSpatial),6node_sp,7node_sp(boxSpatial),4nodeSpatial,2,3,6point_sf,7point_sf(nodeSpatial),6point_sp,7point_sp(boxSpatial),4pointSpatial,2,3pointSpatial(nodeSpatial),6rbgm-package,2read_bgm(bgmfile),3Spatial,4SpatialLinesDataFrame,2,4 SpatialPointsDataFrame,5–7 SpatialPolygonsDataFrame,2,48。
2010 ada standards for accessible design _ ada

"2010 ADA Standards for Accessible Design" refers to the accessibility guidelines published by the Americans with Disabilities Act (ADA) in 2010. The ADA is a federal law in the United States that aims to ensure equal access and opportunity for people with disabilities in various aspects of society, including buildings, public spaces, and transportation. The 2010 standards provide specific requirements and recommendations to make buildings and facilities more accessible and usable by individuals with disabilities. These standards cover a wide range of elements, such as entrances, ramps, stairs, restrooms, doorways, and signs. The goal is to remove barriers and create an environment that is inclusive and accommodating for people with diverse disabilities.The ADA standards are designed to ensure that people with disabilities can independently access and navigate public and private spaces, enabling them to participate fully in social, economic, and civic activities. Adhering to these standards helps promote equality, dignity, and independence for individuals with disabilities.It's important to note that the ADA standards may be updated or modified over time to reflect changing accessibility needs and best practices. staying up-to-date with the latest guidelines is crucial for designers, builders, and facility managers to ensure compliance and provide accessible environments.。
EMC-1

Radiocommunications Labelling (Electromagnetic Compatibility) Notice 2008 as amendedmade under section 182 of theRadiocommunications Act 1992Compilation start date: 1 March 2013Includes amendments up to: Radiocommunications Labelling (ElectromagneticCompatibility) Amendment Notice 2013 (No. 1) Prepared by the Office of Parliamentary Counsel, CanberraAbout this compilationThe compiled instrumentThis is a compilation of the Radiocommunications Labelling (Electromagnetic Compatibility) Notice 2008 as amended and in force on 1 March 2013. It includes any amendment affecting the compiled instrument to that date.This compilation was prepared on 1 March 2013.The notes at the end of this compilation (the endnotes) include information about amending Acts and instruments and the amendment history of each amended provision. Uncommenced provisions and amendmentsIf a provision of the compiled instrument is affected by an uncommenced amendment, the text of the uncommenced amendment is set out in the endnotes.Application, saving and transitional provisions for amendmentsIf the operation of an amendment is affected by an application, saving or transitional provision, the provision is set out in the endnotes.ModificationsIf a provision of the compiled instrument is affected by a textual modification that is in force, the text of the modifying provision is set out in the endnotes.Provisions ceasing to have effectIf a provision of the compiled instrument has expired or otherwise ceased to have effect in accordance with a provision of the instrument, details of the provision are set out in the endnotes.Radiocommunications Labelling (Electromagnetic Compatibility)Notice 2008iContentsPart 1—Preliminary11.1 Name of Notice 11.2 Commencement 11.3 Revocation 11.4 Definitions 11.5 Meaning of compliance records 41.6 Meaning of description of the device51.6A Meaning of medium risk device61.7 Meaning of device that complies with New Zealand labelling legislation61.8 Other interpretation 6 Part 2—Application of Notice82.1 Devices to which this Notice applies 82.2 Devices to which this Notice does not apply—general 82.3 Devices to which this Notice does not apply—New Zealand devices 82.4 Relationship between this Notice and the Telecommunications Labelling(Customer Equipment and Customer Cabling) Notice 200182.5 Relationship between this Notice and the Radiocommunications Devices(Compliance Labelling) Notice 200382.6 Devices incorporating a radiocommunications transmitter 9 Part 3—Form and placement of compliance labels103.1 Compliance labels 103.2 Compliance labels for low risk devices 113.3 Who must apply a compliance label to a device? 113.4 Durability of compliance label 113.5 Format of compliance label 123.6 Placement of compliance label 123.6A Electronic labelling 123.7 Explanatory documentation to be supplied with a device 12 Part 4—Conditions for application of compliance label144.1 Application of Part 4 144.2 Use of RCM subject to registration on national database or issue of suppliercode number 144.2A Registration on national database 144.2B Use of C-Tick mark 154.2C Issue of supplier code number 154.3 Meeting compliance levels 154.3A Declaration of conformity 164.4 Compliance level 1—low risk device 164.5 Compliance level 2—medium risk device 164.6 Compliance level 3—high risk device 164.7 Additional requirements for variants 16 Part 5—Compliance records175.1 Compliance records—general requirements 175.2 Keeping records 175.3 Availability of compliance records for inspection 175.4 Provision of information to authorised officer 175.5 Request for test reports from accredited testing body 185.6 Evidence of compliance with applicable standard under section 5.5 18 Part 6—Special requirements for supply of devices after changes toapplicable standard or this Notice196.1 Devices labelled with a compliance label before this Notice 196.2 Changes to an applicable standard 196.3 Transitional—devices to which IEC, CISPR or AS/NZS standards apply 196.4 Transitional—devices to which EN standard applies 20 Part 7—Requirements to be met after labels applied—devices imported from New Zealand217.1 Purpose of Part 7 217.2 Provision of information to authorised officer 21 Schedule 1—Technical standards22 Schedule 2—Devices to which this Notice does not apply23 Schedule 3—Compliance marks25 Part 1—The C-Tick mark25 Part 2—The RCM26 Endnotes 27 Endnote 1—Legislation history27 Endnote 2—Amendment history28 Endnote 3—Application, saving and transitional provisions30 Endnote 4—Uncommenced amendments31 Endnote 5—Misdescribed amendments32ii Radiocommunications Labelling (Electromagnetic Compatibility)Notice 2008Preliminary Part 1Section 1.1Radiocommunications Labelling (Electromagnetic Compatibility)Notice 20081Part 1—Preliminary1.1 Name of NoticeThis Notice is the Radiocommunications Labelling (ElectromagneticCompatibility) Notice 2008.Note: The predecessor to this Notice was the Radiocommunications (Compliance Labelling—Incidental Emissions) Notice 2001, which is revoked by section 1.3 of this Notice. 1.2 CommencementThis Notice commences on the day after it is registered.1.3 RevocationThe Radiocommunications (Compliance Labelling—Incidental Emissions)Notice 2001, made on 2 November 2001, is revoked.1.4 DefinitionsIn this Notice:accredited, in relation to a test report, means a report that was produced by thefollowing process:(a) the test was conducted by an accredited testing body;(b) the test was conducted against an applicable standard;(c) at the time the test was conducted, the applicable standard was within theterms of the accredited testing body’s accreditation, designation,notification or recognition.accredited testing body means a laboratory:(a) that is a testing body; and(b) that is:(i) accredited by NATA to conduct testing against an applicablestandard; or(ii) accredited, by a body that has entered into a mutual recognitionagreement with NATA, to conduct testing against an applicablestandard; or(iii) designated, notified or recognised, under an agreement about mutualrecognition on conformity assessment to which Australia is a party, toconduct testing against an applicable standard.Act means the Radiocommunications Act 1992.agent, of a manufacturer or importer, means a person who is authorised inwriting by the manufacturer or importer to act in Australia as an agent of themanufacturer or importer for Division 7 of Part 4.1 of the Act.Part 1 PreliminarySection 1.4applicable standard, in relation to a device, means any of the followingstandards insofar as those standards relate to interference toradiocommunications or to any uses or functions of devices:(a) a standard referenced for the device in the Radiocommunications(Electromagnetic Compatibility) Standard 2008;(b) a standard mentioned in the table in Schedule 1.Note: The list of applicable standards may be found at the website address.au/standards/emc.AS/NZS, in relation to the prefix of a document, has the meaning given bysubsection 1.8(1).AS/NZS 4417.1 means the Australian/New Zealand Standard Marking ofelectrical and electronic products to indicate compliance with regulations—Part 1: General rules for use of the mark published by Standards Australia.authorised officer means:(a) an inspector under subsection 267(1) of the Act; or(b) a person authorised in writing by ACMA for this Notice.battery-powered device means a device that is not capable of being connected,directly or indirectly, to an external power supply.built-in display, for a device, means an electronic display or screen integral tothe device, and does not include a display or screen that can be usedindependently of the device.CISPR, in relation to the prefix of a document, has the meaning given bysubsection 1.8(3).competent body means a body accredited by NATA under subsection 183(3) ofthe Act.compliance label means a label that complies with the requirements mentionedin Part 3.Note: Section 2.4 extends some references to ‘compliance label’ in this Notice to include acompliance label under the Telecommunications Labelling (Customer Equipment andCustomer Cabling) Notice 2001.compliance mark means any of the marks mentioned in Schedule 3.compliance records has the meaning given by section 1.5.C-Tick mark means the mark set out in Part 1 of Schedule 3.declaration of conformity means a declaration that:(a) is in a form approved by the ACMA; or(b) contains the information required in that approved form, whether or not thedeclaration is accompanied by other material.Note: The ACMA makes approved forms available on its website at.au/complianceforms.2Radiocommunications Labelling (Electromagnetic Compatibility)Notice 2008Preliminary Part 1Section 1.4Radiocommunications Labelling (Electromagnetic Compatibility)Notice 20083description of the device has the meaning given by section 1.6.device has the meaning given by subsection 9(1) of the Act.device that complies with New Zealand labelling legislation has the meaning given by section 1.7.EN, in relation to the prefix of a document, has the meaning given by subsection 1.8(4).fixed installation means a particular combination of 1 or more devices that is assembled, installed and intended to be used permanently at a predetermined location.high risk device means a device described as ‘Group 2 ISM equipment’ inAS/NZS CISPR 11:2004 (2nd Edition).IEC, in relation to the prefix of a document, has the meaning given by subsection 1.8(2).low risk device means a device that is neither:(a) a medium risk device; nor(b) a high risk device.medium risk device has the meaning given by section 1.6A.NATA means the National Association of Testing Authorities, Australia. national database means a database designated in writing by the ACMA for the purposes of Part 4.Note: A database may be designated by the ACMA for the purposes of Part 4 even if it forms part of another database or also serves purposes other than purposes provided for in thisNotice.New Zealand labelling legislation means:(a) the Radiocommunications (EMC Standards) Notice 2004 (No. 2) of NewZealand; and(b) the Radiocommunications (Radio Standards) Notice 2007 of New Zealand; as in force from time to time.RCM means the Regulatory Compliance Mark set out in Part 2 of Schedule 3. supplier, in relation to a device, means a person in Australia who is:(a) the manufacturer or the importer of the device; or(b) an agent of the manufacturer or importer of the device.supplier code number means a code number issued to a person:(a) in accordance with a notice made by ACMA under section 407 of theTelecommunications Act 1997; or(b) in accordance with a notice made by ACMA under section 182 of the Act;orPart 1 PreliminarySection 1.54Radiocommunications Labelling (Electromagnetic Compatibility)Notice 2008(c) by Standards Australia International Limited, in accordance with AS/NZS4417.1. technical construction file means documentary material in English that includes a report produced by a competent body assessing a device against the requirements of an applicable standard, in which the report: (a) identifies the device assessed; and(b) identifies the applicable standard against which the device was assessed;and(c) includes a statement by the competent body stating that, in the opinion ofthe competent body, the device complies with the applicable standard. test report means a report in English produced by a testing body or an accredited testing body assessing a device against the requirements of an applicable standard, that:(a) identifies the device tested; and(b) identifies the applicable standard against which the assessment was made;and(c) includes a statement by the testing body or accredited testing body statingthat the device complies with each relevant requirement of the applicable standard. testing body means a laboratory that has the equipment, resources and technical capability to conduct testing to an applicable standard.variant means a version of a device that is not identical to the original device but is not sufficiently different from the original device to affect the application to that version of a standard that applies to the original device.working day , in relation to a request, means a day other than: (a) a Saturday or a Sunday; or(b) a day that is a public holiday or an Australian Public Service holiday in theplace where the request is made.1.5 Meaning of compliance recordsIn this Notice, the compliance records for a kind of device are mentioned in the table.Item For this device ... these are the compliance records ...1a device other than a low risk device or a variant(a) a description of the device; and (b) a declaration of conformity; and(c) a test report or a technical construction file; and(d) for a device to which a compliance label is not applied because of section 3.6—the records mentioned in subsection 3.6(3); and(e) a copy of any explanatory documentation required by section 3.7Preliminary Part 1Section 1.6Radiocommunications Labelling (Electromagnetic Compatibility)Notice 20085Item For this device ... these are the compliance records ...2 a low risk device that hasnot been labelled or hasbeen labelled otherwisethan as required orprovided for by this Noticea description of the device3 a low risk device that hasbeen labelled as requiredor provided for by thisNotice (a) a description of the device; and(b) a declaration of conformity4 a variant of a device otherthan a low risk device (a) a description of the variant; and(b) a declaration of conformity that relates to the variant; and(c) a test report or a technical construction file for the originaldevice; and(d) for a device to which a compliance label is not appliedbecause of section 3.6—the records mentioned insubsection 3.6(3); and(e) a statement by the supplier about the variant that ismentioned in subsection 4.7(2)5 a variant of a low riskdevice that has not beenlabelled or has beenlabelled otherwise than asrequired or provided for bythis Noticea description of the variant6 a variant of a low riskdevice that has beenlabelled as required orprovided for by this Notice (a) a description of the variant; and(b) a declaration of conformity that relates to the variantNote: Items 3 and 6 of the above table do not apply to a device if that device is labelled solely to comply with State or Territory electrical safety legislation and is not required to beara compliance label by this Notice.1.6 Meaning of description of the deviceIn this Notice, a description of the device must contain sufficient information fora person to determine whether the device is the same as a device for which adeclaration of conformity, test report or statement by a competent body wasprepared, and:(a) must include the model number for the device and, if relevant, any relatedmodel numbers for the device; and(b) must include the version of any software or firmware incorporated into orsupplied with the device where changes in that software or firmware mayaffect compliance with the applicable standard; and(c) may include a photograph, or photographs, of the device showing thedevice’s internal and external aspects (including the printed circuit boards).Part 1 PreliminarySection 1.6A1.6A Meaning of medium risk device(1) In this Notice, subject to subsection (2), a device is a medium risk device if it isnot a high risk device and contains 1 or more of the following:(a) a switch mode power supply;(b) a transistor switching circuit;(c) a microprocessor;(d) a commutator;(e) a slip-ring motor;(f) an electronic device operating in a switching mode or a non-linear mode.(2) A battery-powered device is not a medium risk device unless the ACMA hasdeclared the device to be a medium risk device under subsection (3).(3) The ACMA may declare, in writing, that a particular battery-powered devicespecified in the declaration is a medium risk device if:(a) the common operation of the device causes radio emissions; and(b) those radio emissions have caused, or are likely to cause, interference,disruption or disturbance to other devices or to radiocommunicationsservices; and(c) the device is not a high risk device.(4) A declaration under subsection (3) is not a legislative instrument for thepurposes of the Legislative Instruments Act 2003.1.7 Meaning of device that complies with New Zealand labelling legislationIn this Notice, a device that complies with New Zealand labelling legislation isa device that bears a New Zealand compliance mark in accordance with the NewZealand labelling legislation.1.8 Other interpretation(1) A reference in this Notice to a document with the prefix ‘AS/NZS’ is a referenceto a document that is a joint Australian and New Zealand Standard approved forpublication on behalf of the Standards organisations of those countries.(2) A reference in this Notice to a document with the prefix ‘IEC’ is a reference to adocument that is an International Electrotechnical Commission Standardapproved for publication.(3) A reference in this Notice to a document with the prefix ‘CISPR’ is a referenceto a document that is an International Special Committee on Radio InterferenceStandard approved for publication.(4) A reference in this Notice to a document with the prefix ‘EN’ is a reference to adocument that is a European Committee for Electrotechnical StandardizationStandard approved for publication.6Radiocommunications Labelling (Electromagnetic Compatibility)Notice 2008Preliminary Part 1Section 1.8Radiocommunications Labelling (Electromagnetic Compatibility)Notice 20087(5) Reference may be made in this Notice to a standard mentioned in this section bynumber alone without inclusion of the edition or year of publication of thestandard.Examples1 AS/NZS 4417.1:1996 may be referred to as AS/NZS 4417.1.2 CISPR 22:2005 may be referred to as CISPR 22.Part 2 Application of NoticeSection 2.1Part 2—Application of Notice2.1 Devices to which this Notice appliesThis Notice applies to a device:(a) that is:(i) manufactured in Australia; or(ii) imported into Australia;for supply in Australia; and(b) to which an applicable standard applies.Note: Section 5 of the Act contains the following definition:supply includes supply (including re-supply) by way of sale, exchange, lease, hire orhire-purchase.2.2 Devices to which this Notice does not apply—generalThis Notice does not apply to a device that is mentioned in Schedule 2.2.3 Devices to which this Notice does not apply—New Zealand devicesParts 3, 4 and 5 of this Notice do not apply to a device that:(a) is imported into Australia from New Zealand for supply; and(b) is a device that complies with New Zealand labelling legislation.Note 1: The effect of this section is to exempt the devices from the labelling requirements ofthis Notice.Note 2: Section 1.7 explains when a device is a device that complies with New Zealandlabelling legislation.2.4 Relationship between this Notice and the Telecommunications Labelling(Customer Equipment and Customer Cabling) Notice 2001If a device to which this Notice applies is also customer equipment or customercabling to which the Telecommunications Labelling (Customer Equipment andCustomer Cabling) Notice 2001, as in force from time to time, applies:(a) the requirements in this Notice are additional to the requirements under thatNotice; and(b) Part 3 of this Notice does not apply in relation to the device; and(c) a reference in this Notice (except section 1.4) to a compliance labelincludes a reference to a compliance label under that Notice.2.5 Relationship between this Notice and the Radiocommunications Devices(Compliance Labelling) Notice 2003If a device to which this Notice applies contains a device, or incorporates adevice to which the Radiocommunications Devices (Compliance Labelling)8Radiocommunications Labelling (Electromagnetic Compatibility)Notice 2008Application of Notice Part 2Section 2.6Radiocommunications Labelling (Electromagnetic Compatibility)Notice 20089Notice 2003, as in force from time to time, applies, the requirements in thisNotice are additional to the requirements in that Notice.Note: An effect of section 2.5 is that a compliance mark can only be applied to a device if the device complies with the requirements of this Notice and the RadiocommunicationsDevices (Compliance Labelling) Notice 2003.2.6 Devices incorporating a radiocommunications transmitter(1) If a device (a parent device) contains or incorporates a radiocommunicationstransmitter, the transmitter must be switched off, or placed in an idle state, beforethe parent device is assessed for compliance against this Notice.Note: Subsection 7(2) of the Act contains the definition of radiocommunications transmitter.(2) For the avoidance of doubt, if a parent device contains or incorporates aradiocommunications transmitter, the transmitter need not comply with thisNotice.Part 3 Form and placement of compliance labelsSection 3.1Part 3—Form and placement of compliance labels3.1 Compliance labelsRequirement for devices (other than low risk devices) to bear compliance label(1) If an applicable standard applies to a device that is not a low risk device, and thedevice complies with the standard, the device must bear a compliance label,consisting of either:(a) the RCM; or(b) if the label is applied before 1 March 2016—either of the compliancemarks.Note 1: The effect of section 4.2 is that a supplier must not apply a compliance label, consisting of the RCM to a device unless:(a) the supplier is registered on the national database; or(b) if the ACMA has not designated in writing a national database for the purposes ofPart 4—the supplier has been issued a supplier code number.Note 2: The effect of section 4.2B is that a supplier must not apply a compliance label,consisting of the C-Tick mark to a device unless the supplier has been issued a suppliercode number by the ACMA. In accordance with section 4.2C, the ACMA will ceaseissuing supplier code numbers at the time the ACMA designates in writing a nationaldatabase.Note 3: The effect of section 2.3 is to exempt a device that:(a) is imported into Australia from New Zealand for supply; and(b) bears a New Zealand compliance mark that complies with New Zealand labellinglegislation,from the requirement for the device to bear a compliance label.Note 4: Section 3.2 deals with the relationship between low risk devices and the labellingobligations. Suppliers must meet the same compliance level and record-keepingobligations in relation to low risk devices even if a compliance label has not beenapplied to the device.Note 5: A device that does not comply with an applicable standard is defined bysubsection 9(2) of the Act to be a non-standard device, and is regulated underDivision 2 of Part 4.1 of the Act.Note 6: Paragraph 2.4(b) provides that Part 3 of this Notice does not apply in relation to adevice to which the Telecommunications Labelling (Customer Equipment andCustomer Cabling) Notice 2001 applies. Consequently, a device that is to be labelledwith an A-Tick mark under the Telecommunications Labelling (Customer Equipmentand Customer Cabling) Notice 2001 before 1 March 2016 is not required to be labelledwith a compliance mark under this Notice.Location of compliance label(2) Subject to sections 3.6 and 3.6A, the compliance label must be placed on thedevice on a place that is accessible by the user.Note: Section 3.6 deals with situations where applying a label to the surface of a device is not possible or practicable. Section 3.6A gives a supplier the option of labelling some typesof devices electronically.10Radiocommunications Labelling (Electromagnetic Compatibility)Notice 2008Form and placement of compliance labels Part 3Section 3.2Radiocommunications Labelling (Electromagnetic Compatibility)Notice 200811(3) A label is not accessible if it is necessary to use a specialised tool to gain accessto it.3.2 Compliance labels for low risk devices(1) The supplier of a low risk device may choose whether or not to apply acompliance label to the device.Note: Section 4.2 applies to a supplier that chooses to apply a compliance label to a low risk device.(2) A low risk device must comply with an applicable standard that is applicable toit, whether or not it has a compliance label applied to it.(3) If a supplier chooses not to apply a compliance label to a low risk device then,for the application of the following provisions of this Notice, the low risk deviceis taken to have a compliance label applied to it:(a) section 3.7;(b) Part 4 (other than section 4.3A);(c) Part 5.Note: The effect of applying these provisions to a low risk device is to require the supplier to comply with record-keeping obligations, whether or not the low risk device has acompliance label applied to it.3.3 Who must apply a compliance label to a device?(1) If a device that is required to have a compliance label attached is manufacturedin Australia, the compliance label must be applied to the device by:(a) the manufacturer; or(b) an agent of the manufacturer; or(c) a person who is authorised by the manufacturer or agent to apply the labelor mark on behalf of the manufacturer or agent.(2) If a device that is required to have a compliance label attached is manufacturedoutside Australia, the compliance label must be applied to the device by:(a) the importer; or(b) an agent of the importer; or(c) a person who is authorised by the importer or agent to apply the label ormark on behalf of the importer or agent.3.4 Durability of compliance label(1) A compliance label must be durable.(2) A compliance label must be applied to a device:(a) permanently; or(b) in a way that makes removal or obliteration difficult.Part 3 Form and placement of compliance labelsSection 3.53.5 Format of compliance labelA compliance mark must be at least 3 mm high.Note: This Notice does not prevent a supplier from applying its own additional supplieridentification details onto a device.3.6 Placement of compliance label(1) If it is not possible to apply a compliance label to the surface of a device becauseof the size or physical nature of the device, or it is not practical to apply acompliance label to the surface of a device, the compliance label must be appliedto:(a) the external surface of the packaging used for the device; and(b) the documentation (including any warranty or guarantee certificates) thataccompanies the device when it is supplied to the user.(2) The compliance label applied to the external surface of the packaging used forthe device must:(a) occupy an area that is greater than 1% of that external surface; and(b) be clearly visible.(3) The supplier must make and keep a record of:(a) the reasons why subsection (1) applies to the device; and(b) where each compliance label is applied.3.6A Electronic labelling(1) A supplier may apply a compliance label to a device using the built-in display ofthe device.(2) The supplier must ensure that the documentation that accompanies the devicewhen it is supplied to the user sets out a method for displaying the compliancelabel.(3) The compliance label must be applied to the device in a way that would make itdifficult to prevent the display of the label when the method set out in thedocumentation is used.(4) Subsection 3.1(2) and sections 3.4 and 3.6 do not apply to a label applied underthis section.3.7 Explanatory documentation to be supplied with a deviceIf it is possible for a device to be installed or operated incorrectly, to the extentthat the device will be used in a way that the device does not comply with anapplicable standard for the device, the supplier of the device must supplydocumentation with the device that sets out specifications for correct installationand operation to minimise that possibility.Example12Radiocommunications Labelling (Electromagnetic Compatibility)Notice 2008。
DNV-RP-F204 (2010-10) RISER FATIGUE

RISER FATIGUE
OCTOBER 2010
DET NORSKE VERITAS
FOREWORD
DET NORSKE VERITAS (DNV) is an autonomous and independent foundation with the objectives of safeguarding life, property and the environment, at sea and onshore. DNV undertakes classification, certification, and other verification and consultancy services relating to quality of ships, offshore units and installations, and onshore industries worldwide, and carries out research in relation to these functions. DNV service documents consist of amongst other the following types of documents: — Service Specifications. Procedual requirements. — Standards. Technical requirements. — Recommended Practices. Guidance. The Standards and Recommended Practices are offered within the following areas: A) Qualification, Quality and Safety Methodology B) Materials Technology C) Structures D) Systems E) Special Facilities F) Pipelines and Risers G) Asset Operation H) Marine Operations J) Cleaner Energy
Atomic Decomposition by Basis pursuit

SIAM R EVIEWc2001Society for Industrial and Applied Mathematics Vol.43,No.1,pp.129–159Atomic Decomposition by BasisPursuit ∗Scott Shaobing Chen †David L.Donoho ‡Michael A.Saunders §Abstract.The time-frequency and time-scale communities have recently developed a large number ofovercomplete waveform dictionaries—stationary wavelets,wavelet packets,cosine packets,chirplets,and warplets,to name a few.Decomposition into overcomplete systems is not unique,and several methods for decomposition have been proposed,including the method of frames (MOF),matching pursuit (MP),and,for special dictionaries,the best orthogonal basis (BOB).Basis pursuit (BP)is a principle for decomposing a signal into an “optimal”superpo-sition of dictionary elements,where optimal means having the smallest l 1norm of coef-ficients among all such decompositions.We give examples exhibiting several advantages over MOF,MP,and BOB,including better sparsity and superresolution.BP has interest-ing relations to ideas in areas as diverse as ill-posed problems,abstract harmonic analysis,total variation denoising,and multiscale edge denoising.BP in highly overcomplete dictionaries leads to large-scale optimization problems.With signals of length 8192and a wavelet packet dictionary,one gets an equivalent linear program of size 8192by 212,992.Such problems can be attacked successfully only because of recent advances in linear and quadratic programming by interior-point methods.We obtain reasonable success with a primal-dual logarithmic barrier method and conjugate-gradient solver.Key words.overcomplete signal representation,denoising,time-frequency analysis,time-scale anal-ysis, 1norm optimization,matching pursuit,wavelets,wavelet packets,cosine pack-ets,interior-point methods for linear programming,total variation denoising,multiscale edges,MATLAB code AMS subject classifications.94A12,65K05,65D15,41A45PII.S003614450037906X1.Introduction.Over the last several years,there has been an explosion of in-terest in alternatives to traditional signal representations.Instead of just represent-ing signals as superpositions of sinusoids (the traditional Fourier representation)we now have available alternate dictionaries—collections of parameterized waveforms—of which the wavelets dictionary is only the best known.Wavelets,steerable wavelets,segmented wavelets,Gabor dictionaries,multiscale Gabor dictionaries,wavelet pack-∗Publishedelectronically February 2,2001.This paper originally appeared in SIAM Journal onScientific Computing ,Volume 20,Number 1,1998,pages 33–61.This research was partially sup-ported by NSF grants DMS-92-09130,DMI-92-04208,and ECS-9707111,by the NASA Astrophysical Data Program,by ONR grant N00014-90-J1242,and by other sponsors./journals/sirev/43-1/37906.html†Renaissance Technologies,600Route 25A,East Setauket,NY 11733(schen@).‡Department of Statistics,Stanford University,Stanford,CA 94305(donoho@).§Department of Management Science and Engineering,Stanford University,Stanford,CA 94305(saunders@).129D o w n l o a d e d 08/09/14 t o 58.19.126.38. R e d i s t r i b u t i o n s u b j e c t t o S I A M l i c e n s e o r c o p y r i g h t ; s e e h t t p ://w w w .s i a m .o r g /j o u r n a l s /o j s a .p h p130S.S.CHEN,D.L.DONOHO,AND M.A.SAUNDERSets,cosine packets,chirplets,warplets,and a wide range of other dictionaries are now available.Each such dictionary D is a collection of waveforms (φγ)γ∈Γ,with γa parameter,and we envision a decomposition of a signal s ass =γ∈Γαγφγ,(1.1)or an approximate decomposition s =m i =1αγi φγi +R (m ),(1.2)where R (m )is a residual.Depending on the dictionary,such a representation de-composes the signal into pure tones (Fourier dictionary),bumps (wavelet dictionary),chirps (chirplet dictionary),etc.Most of the new dictionaries are overcomplete ,either because they start out that way or because we merge complete dictionaries,obtaining a new megadictionary con-sisting of several types of waveforms (e.g.,Fourier and wavelets dictionaries).The decomposition (1.1)is then nonunique,because some elements in the dictionary have representations in terms of other elements.1.1.Goals of Adaptive Representation.Nonuniqueness gives us the possibility of adaptation,i.e.,of choosing from among many representations one that is most suited to our purposes.We are motivated by the aim of achieving simultaneously the following goals .•Sparsity.We should obtain the sparsest possible representation of the object—the one with the fewest significant coefficients.•Superresolution.We should obtain a resolution of sparse objects that is much higher resolution than that possible with traditional nonadaptive approaches.An important constraint ,which is perhaps in conflict with both the goals,follows.•Speed.It should be possible to obtain a representation in order O (n )or O (n log(n ))time.1.2.Finding a Representation.Several methods have been proposed for obtain-ing signal representations in overcomplete dictionaries.These range from general approaches,like the method of frames (MOF)[9]and the method of matching pursuit (MP)[29],to clever schemes derived for specialized dictionaries,like the method of best orthogonal basis (BOB)[7].These methods are described briefly in section 2.3.In our view,these methods have both advantages and shortcomings.The principal emphasis of the proposers of these methods is on achieving sufficient computational speed.While the resulting methods are practical to apply to real data,we show below by computational examples that the methods,either quite generally or in important special cases,lack qualities of sparsity preservation and of stable superresolution.1.3.Basis Pursuit.Basis pursuit (BP)finds signal representations in overcom-plete dictionaries by convex optimization:it obtains the decomposition that minimizes the 1normof the coefficients occurring in the representation.Because of the nondif-ferentiability of the 1norm,this optimization principle leads to decompositions that can have very different properties fromthe MOF—in particular,they can be m uch sparser.Because it is based on global optimization,it can stably superresolve in ways that MP cannot.D o w n l o a d e d 08/09/14 t o 58.19.126.38. R e d i s t r i b u t i o n s u b j e c t t o S I A M l i c e n s e o r c o p y r i g h t ; s e e h t t p ://w w w .s i a m .o r g /j o u r n a l s /o j s a .p h pATOMIC DECOMPOSITION BY BASIS PURSUIT131BP can be used with noisy data by solving an optimization problem trading offa quadratic misfit measure with an 1normof coefficients.Examples show that it can stably suppress noise while preserving structure that is well expressed in the dictionary under consideration.BP is closely connected with linear programming.Recent advances in large-scale linear programming—associated with interior-point methods—can be applied to BP and can make it possible,with certain dictionaries,to nearly solve the BP optimization problem in nearly linear time.We have implemented primal-dual log barrier interior-point methods as part of a MATLAB [31]computing environment called Atomizer,which accepts a wide range of dictionaries.Instructions for Internet access to Atomizer are given in section 7.3.Experiments with standard time-frequency dictionaries indicate some of the potential benefits of BP.Experiments with some nonstandard dictionaries,like the stationary wavelet dictionary and the heaviside dictionary,indicate important connections between BP and methods like Mallat and Zhong’s [29]multiscale edge representation and Rudin,Osher,and Fatemi’s [35]total variation-based denoising methods.1.4.Contents.In section 2we establish vocabulary and notation for the rest of the article,describing a number of dictionaries and existing methods for overcomplete representation.In section 3we discuss the principle of BP and its relations to existing methods and to ideas in other fields.In section 4we discuss methodological issues associated with BP,in particular some of the interesting nonstandard ways it can be deployed.In section 5we describe BP denoising,a method for dealing with problem (1.2).In section 6we discuss recent advances in large-scale linear programming (LP)and resulting algorithms for BP.For reasons of space we refer the reader to [4]for a discussion of related work in statistics and analysis.2.Overcomplete Representations.Let s =(s t :0≤t <n )be a discrete-time signal of length n ;this may also be viewed as a vector in R n .We are interested in the reconstruction of this signal using superpositions of elementary waveforms.Traditional methods of analysis and reconstruction involve the use of orthogonal bases,such as the Fourier basis,various discrete cosine transformbases,and orthogonal wavelet bases.Such situations can be viewed as follows:given a list of n waveforms,one wishes to represent s as a linear combination of these waveforms.The waveforms in the list,viewed as vectors in R n ,are linearly independent,and so the representation is unique.2.1.Dictionaries and Atoms.A considerable focus of activity in the recent sig-nal processing literature has been the development of signal representations outside the basis setting.We use terminology introduced by Mallat and Zhang [29].A dic-tionary is a collection of parameterized waveforms D =(φγ:γ∈Γ).The waveforms φγare discrete-time signals of length n called atoms .Depending on the dictionary,the parameter γcan have the interpretation of indexing frequency,in which case the dictionary is a frequency or Fourier dictionary,of indexing time-scale jointly,in which case the dictionary is a time-scale dictionary,or of indexing time-frequency jointly,in which case the dictionary is a time-frequency ually dictionaries are complete or overcomplete,in which case they contain exactly n atoms or more than n atoms,but one could also have continuum dictionaries containing an infinity of atoms and undercomplete dictionaries for special purposes,containing fewer than n atoms.Dozens of interesting dictionaries have been proposed over the last few years;we focusD o w n l o a d e d 08/09/14 t o 58.19.126.38. R e d i s t r i b u t i o n s u b j e c t t o S I A M l i c e n s e o r c o p y r i g h t ; s e e h t t p ://w w w .s i a m .o r g /j o u r n a l s /o j s a .p h p132S.S.CHEN,D.L.DONOHO,AND M.A.SAUNDERSin this paper on a half dozen or so;much of what we do applies in other cases as well.2.1.1.T rivial Dictionaries.We begin with some overly simple examples.The Dirac dictionary is simply the collection of waveforms that are zero except in one point:γ∈{0,1,...,n −1}and φγ(t )=1{t =γ}.This is of course also an orthogonal basis of R n —the standard basis.The heaviside dictionary is the collection of waveforms that jump at one particular point:γ∈{0,1,...,n −1};φγ(t )=1{t ≥γ}.Atoms in this dictionary are not orthogonal,but every signal has a representation s =s 0φ0+n −1 γ=1(s γ−s γ−1)φγ.(2.1)2.1.2.Frequency Dictionaries.A Fourier dictionary is a collection of sinusoidalwaveforms φγindexed by γ=(ω,ν),where ω∈[0,2π)is an angular frequency variable and ν∈{0,1}indicates phase type:sine or cosine.In detail,φ(ω,0)=cos(ωt ),φ(ω,1)=sin(ωt ).For the standard Fourier dictionary,we let γrun through the set of all cosines with Fourier frequencies ωk =2πk/n ,k =0,...,n/2,and all sines with Fourier frequencies ωk ,k =1,...,n/2−1.This dictionary consists of n waveforms;it is in fact a basis,and a very simple one:the atoms are all mutually orthogonal.An overcomplete Fourier dictionary is obtained by sampling the frequencies more finely.Let be a whole number >1and let Γ be the collection of all cosines with ωk =2πk/( n ),k =0,..., n/2,and all sines with frequencies ωk ,k =1,..., n/2−1.This is an -fold overcomplete system.We also use complete and overcomplete dictionaries based on discrete cosine transforms and sine transforms.2.1.3.Time-Scale Dictionaries.There are several types of wavelet dictionaries;to fix ideas,we consider the Haar dictionary with “father wavelet”ϕ=1[0,1]and “mother wavelet”ψ=1(1/2,1]−1[0,1/2].The dictionary is a collection of transla-tions and dilations of the basic mother wavelet,together with translations of a father wavelet.It is indexed by γ=(a,b,ν),where a ∈(0,∞)is a scale variable,b ∈[0,n ]indicates location,and ν∈{0,1}indicates gender.In detail,φ(a,b,1)=ψ(a (t −b ))·√a,φ(a,b,0)=ϕ(a (t −b ))·√a.For the standard Haar dictionary,we let γrun through the discrete collection ofmother wavelets with dyadic scales a j =2j /n ,j =j 0,...,log 2(n )−1,and locations that are integer multiples of the scale b j,k =k ·a j ,k =0,...,2j −1,and the collection of father wavelets at the coarse scale j 0.This dictionary consists of n waveforms;it is an orthonormal basis.An overcomplete wavelet dictionary is obtained by sampling the locations more finely:one location per sample point.This gives the so-called sta-tionary Haar dictionary,consisting of O (n log 2(n ))waveforms.It is called stationary since the whole dictionary is invariant under circulant shift.A variety of other wavelet bases are possible.The most important variations are smooth wavelet bases,using splines or using wavelets defined recursively fromtwo-scale filtering relations [10].Although the rules of construction are more complicated (boundary conditions [33],orthogonality versus biorthogonality [10],etc.),these have the same indexing structure as the standard Haar dictionary.In this paper,we use symmlet -8smooth wavelets,i.e.,Daubechies nearly symmetric wavelets with eight vanishing moments;see [10]for examples.D o w n l o a d e d 08/09/14 t o 58.19.126.38. R e d i s t r i b u t i o n s u b j e c t t o S I A M l i c e n s e o r c o p y r i g h t ; s e e h t t p ://w w w .s i a m .o r g /j o u r n a l s /o j s a .p h pATOMIC DECOMPOSITION BY BASIS PURSUIT133Time 00.5100.20.40.60.81(c) Time DomainFig.2.1Time-frequency phase plot of a wavelet packet atom.2.1.4.Time-Frequency Dictionaries.Much recent activity in the wavelet com-munities has focused on the study of time-frequency phenomena.The standard ex-ample,the Gabor dictionary,is due to Gabor [19];in our notation,we take γ=(ω,τ,θ,δt ),where ω∈[0,π)is a frequency,τis a location,θis a phase,and δt is the duration,and we consider atoms φγ(t )=exp {−(t −τ)2/(δt )2}·cos(ω(t −τ)+θ).Such atoms indeed consist of frequencies near ωand essentially vanish far away from τ.For fixed δt ,discrete dictionaries can be built fromtim e-frequency lattices,ωk =k ∆ωand τ = ∆τ,and θ∈{0,π/2};with ∆τand ∆ωchosen sufficiently fine these are complete.For further discussions see,e.g.,[9].Recently,Coifman and Meyer [6]developed the wavelet packet and cosine packet dictionaries especially to meet the computational demands of discrete-time signal pro-cessing.For one-dimensional discrete-time signals of length n ,these dictionaries each contain about n log 2(n )waveforms.A wavelet packet dictionary includes,as special cases,a standard orthogonal wavelets dictionary,the Dirac dictionary,and a collec-tion of oscillating waveforms spanning a range of frequencies and durations.A cosine packet dictionary contains,as special cases,the standard orthogonal Fourier dictio-nary and a variety of Gabor-like elements:sinusoids of various frequencies weighted by windows of various widths and locations.In this paper,we often use wavelet packet and cosine packet dictionaries as exam-ples of overcomplete systems,and we give a number of examples decomposing signals into these time-frequency dictionaries.A simple block diagram helps us visualize the atoms appearing in the decomposition.This diagram,adapted from Coifman and Wickerhauser [7],associates with each cosine packet or wavelet packet a rectangle in the time-frequency phase plane.The association is illustrated in Figure 2.1for a cer-tain wavelet packet.When a signal is a superposition of several such waveforms,we indicate which waveforms appear in the superposition by shading the corresponding rectangles in the time-frequency plane.D o w n l o a d e d 08/09/14 t o 58.19.126.38. R e d i s t r i b u t i o n s u b j e c t t o S I A M l i c e n s e o r c o p y r i g h t ; s e e h t t p ://w w w .s i a m .o r g /j o u r n a l s /o j s a .p h p134S.S.CHEN,D.L.DONOHO,AND M.A.SAUNDERS2.1.5.Further Dictionaries.We can always merge dictionaries to create mega-dictionaries;examples used below include mergers of wavelets with heavisides.2.2.Linear Algebra.Suppose we have a discrete dictionary of p waveforms and we collect all these waveforms as columns of an n -by-p matrix Φ,say.The decompo-sition problem(1.1)can be written Φα=s ,(2.2)where α=(αγ)is the vector of coefficients in (1.1).When the dictionary furnishes a basis,then Φis an n -by-n nonsingular matrix and we have the unique representation α=Φ−1s .When the atoms are,in addition,mutually orthonormal,then Φ−1=ΦT and the decomposition formula is very simple.2.2.1.Analysis versus Synthesis.Given a dictionary of waveforms,one can dis-tinguish analysis from synthesis .Synthesis is the operation of building up a signal by superposing atoms;it involves a matrix that is n -by-p :s =Φα.Analysis involves the operation of associating with each signal a vector of coefficients attached to atoms;it involves a matrix that is p -by-n :˜α=ΦT s .Synthesis and analysis are very differ-ent linear operations,and we must take care to distinguish them.One should avoid assuming that the analysis operator ˜α=ΦT s gives us coefficients that can be used as is to synthesize s .In the overcomplete case we are interested in,p n and Φis not invertible.There are then many solutions to (2.2),and a given approach selects a particular solution.One does not uniquely and automatically solve the synthesis problemby applying a sim ple,linear analysis operator.We now illustrate the difference between synthesis (s =Φα)and analysis (˜α=ΦTs ).Figure 2.2a shows the signal Carbon .Figure 2.2b shows the time-frequency structure of a sparse synthesis of Carbon ,a vector αyielding s =Φα,using a wavelet packet dictionary.To visualize the decomposition,we present a phase-plane display with shaded rectangles,as described above.Figure 2.2c gives an analysis of Carbon ,with the coefficients ˜α=ΦT s ,again displayed in a phase plane.Once again,between analysis and synthesis there is a large difference in sparsity.In Figure 2.2d we compare the sorted coefficients of the overcomplete representation (synthesis)with the analysis coefficients.putational Complexity of Φand ΦT .Different dictionaries can im-pose drastically different computational burdens.In this paper we report compu-tational experiments on a variety of signals and dictionaries.We study primarily one-dimensional signals of length n ,where n is several thousand.Signals of this length occur naturally in the study of short segments of speech (a quarter-second to a half-second)and in the output of various scientific instruments (e.g.,FT-NMR spec-trometers).In our experiments,we study dictionaries overcomplete by substantial factors,say,10.Hence the typical matrix Φwe are interested in is of size “thousands”by “tens-of-thousands.”The nominal cost of storing and applying an arbitrary n -by-p matrix to a p -vector is a constant times np .Hence with an arbitrary dictionary of the sizes we are interested in,simply to verify whether (1.1)holds for given vectors αand s would require tens of millions of multiplications and tens of millions of words of memory.In contrast,most signal processing algorithms for signals of length 1000require only thousands of memory words and a few thousand multiplications.Fortunately,certain dictionaries have fast implicit algorithms .By this we mean that Φαand ΦT s can be computed,for arbitrary vectors αand s ,(a)without everD o w n l o a d e d 08/09/14 t o 58.19.126.38. R e d i s t r i b u t i o n s u b j e c t t o S I A M l i c e n s e o r c o p y r i g h t ; s e e h t t p ://w w w .s i a m .o r g /j o u r n a l s /o j s a .p h pATOMIC DECOMPOSITION BY BASIS PURSUIT135Time0.5100.20.40.60.81Time0.5100.20.40.60.81(d) Sorted CoefficientsSynthesis: SolidAnalysis: Dashed Fig.2.2Analysis versus synthesis of the signal Carbon .storing the matrices Φand ΦT ,and (b)using special properties of the matrices to accelerate computations.The most well-known example is the standard Fourier dictionary for which we have the fast Fourier transform algorithm.A typical implementation requires 2·n storage locations and 4·n ·J multiplications if n is dyadic:n =2J .Hence for very long signals we can apply Φand ΦT with much less storage and time than the matrices would nominally require.Simple adaptation of this idea leads to an algorithm for overcomplete Fourier dictionaries.Wavelets give a more recent example of a dictionary with a fast implicit algorithm;if the Haar or S8-symmlet is used,both Φand ΦT may be applied in O (n )time.For the stationary wavelet dictionary,O (n log(n ))time is required.Cosine packets and wavelet packets also have fast implicit algorithms.Here both Φand ΦT can be applied in order O (n log(n ))time and order O (n log(n ))space—much better than the nominal np =n 2log 2(n )one would expect fromnaive use of the m atrix definition.For the viewpoint of this paper,it only makes sense to consider dictionaries with fast implicit algorithms.Among dictionaries we have not discussed,such algorithms may or may not exist.2.3.Existing Decomposition Methods.There are several currently popular ap-proaches to obtaining solutions to (2.2).2.3.1.Frames.The MOF [9]picks out,among all solutions of (2.2),one whose coefficients have minimum l 2norm:min α 2subject toΦα=s .(2.3)The solution of this problemis unique;label it α†.Geometrically,the collection of all solutions to (2.2)is an affine subspace in R p ;MOF selects the element of this subspace closest to the origin.It is sometimes called a minimum-length solution.There is aD o w n l o a d e d 08/09/14 t o 58.19.126.38. R e d i s t r i b u t i o n s u b j e c t t o S I A M l i c e n s e o r c o p y r i g h t ; s e e h t t p ://w w w .s i a m .o r g /j o u r n a l s /o j s a .p h p136S.S.CHEN,D.L.DONOHO,AND M.A.SAUNDERSTime0.5100.20.40.60.81Time0.5100.20.40.60.81Fig.2.3MOF representation is not sparse.matrix Φ†,the generalized inverse of Φ,that calculates the minimum-length solution to a systemof linear equations:α†=Φ†s =ΦT (ΦΦT )−1s .(2.4)For so-called tight frame dictionaries MOF is available in closed form.A nice example is the standard wavelet packet dictionary.One can compute that for all vectors v ,ΦT v 2=L n · v 2,L n =log 2(n ).In short Φ†=L −1n ΦT .Notice that ΦTis simply the analysis operator.There are two key problems with the MOF.First,MOF is not sparsity preserving .If the underlying object has a very sparse representation in terms of the dictionary,then the coefficients found by MOF are likely to be very much less sparse.Each atom in the dictionary that has nonzero inner product with the signal is,at least potentially and also usually,a member of the solution.Figure 2.3a shows the signal Hydrogen made of a single atom in a wavelet packet dictionary.The result of a frame decomposition in that dictionary is depicted in a phase-plane portrait;see Figure 2.3c.While the underlying signal can be synthesized from a single atom,the frame decomposition involves many atoms,and the phase-plane portrait exaggerates greatly the intrinsic complexity of the object.Second,MOF is intrinsically resolution limited .No object can be reconstructed with features sharper than those allowed by the underlying operator Φ†Φ.Suppose the underlying object is sharply localized:α=1{γ=γ0}.The reconstruction will not be α,but instead Φ†Φα,which,in the overcomplete case,will be spatially spread out.Figure 2.4presents a signal TwinSine consisting of the superposition of two sinusoids that are separated by less than the so-called Rayleigh distance 2π/n .We analyze these in a fourfold overcomplete discrete cosine dictionary.In this case,reconstruction by MOF (Figure 2.4b)is simply convolution with the Dirichlet kernel.The result is the synthesis fromcoefficients with a broad oscillatory appearance,consisting not of twoD o w n l o a d e d 08/09/14 t o 58.19.126.38. R e d i s t r i b u t i o n s u b j e c t t o S I A M l i c e n s e o r c o p y r i g h t ; s e e h t t p ://w w w .s i a m .o r g /j o u r n a l s /o j s a .p h pATOMIC DECOMPOSITION BY BASIS PURSUIT137Fig.2.4Analyzing TwinSine with a fourfold overcomplete discrete cosine dictionary.but of many frequencies and giving no visual clue that the object may be synthesized fromtwo frequencies alone.2.3.2.Matching Pursuit.Mallat and Zhang [29]discussed a general method for approximate decomposition (1.2)that addresses the sparsity issue directly.Starting froman initial approxim ation s (0)=0and residual R (0)=s ,it builds up a sequence of sparse approximations stepwise.At stage k ,it identifies the dictionary atomthat best correlates with the residual and then adds to the current approximation a scalar multiple of that atom,so that s (k )=s (k −1)+αk φγk ,where αk = R (k −1),φγk and R (k )=s −s (k ).After m steps,one has a representation of the form(1.2),with residual R =R (m ).Similar algorithms were proposed by Qian and Chen [39]for Gabor dictionaries and by Villemoes [48]for Walsh dictionaries.A similar algorithm was proposed for Gabor dictionaries by Qian and Chen [39].For an earlier instance of a related algorithm,see [5].An intrinsic feature of the algorithmis that when stopped after a few steps,it yields an approximation using only a few atoms.When the dictionary is orthogonal,the method works perfectly.If the object is made up of only m n atoms and the algorithmis run for m steps,it recovers the underlying sparse structure exactly.When the dictionary is not orthogonal,the situation is less clear.Because the algorithmis m yopic,one expects that,in certain cases,it m ight choose wrongly in the first few iterations and end up spending most of its time correcting for any mistakes made in the first few terms.In fact this does seem to happen.To see this,we consider an attempt at superresolution.Figure 2.4a portrays again the signal TwinSine consisting of sinusoids at two closely spaced frequencies.When MP is applied in this case (Figure 2.4c),using the fourfold overcomplete discrete cosine dictionary,the initial frequency selected is in between the two frequencies making up the signal.Because of this mistake,MP is forced to make a series of alternating corrections that suggest a highly complex and organized structure.MPD o w n l o a d e d 08/09/14 t o 58.19.126.38. R e d i s t r i b u t i o n s u b j e c t t o S I A M l i c e n s e o r c o p y r i g h t ; s e e h t t p ://w w w .s i a m .o r g /j o u r n a l s /o j s a .p h p138S.S.CHEN,D.L.DONOHO,AND M.A.SAUNDERSFig.2.5Counterexamples for MP.misses entirely the doublet structure.One can certainly say in this case that MP has failed to superresolve.Second,one can give examples of dictionaries and signals where MP is arbitrarily suboptimal in terms of sparsity.While these are somewhat artificial,they have a character not so different fromthe superresolution exam ple.DeVore and Temlyakov’s Example.Vladimir Temlyakov,in a talk at the IEEE Confer-ence on Information Theory and Statistics in October 1994,described an example in which the straightforward greedy algorithmis not sparsity preserving.In our adapta-tion of this example,based on Temlyakov’s joint work with DeVore [12],one constructs a dictionary having n +1atoms.The first n are the Dirac basis;the final atomin-volves a linear combination of the first n with decaying weights.The signal s has an exact decomposition in terms of A atoms,but the greedy algorithm goes on forever,with an error of size O (1/√m )after m steps.We illustrate this decay in Figure 2.5a.For this example we set A =10and choose the signal s t =10−1/2·1{1≤t ≤10}.The dictionary consists of Dirac elements φγ=δγfor 1≤γ≤n andφn +1(t )=c,1≤t ≤10,c/(t −10),10<t ≤n,with c chosen to normalize φn +1to unit norm.Shaobing Chen’s Example.The DeVore–Temlyakov example applies to the original MP algorithmas announced by Mallat and Zhang in 1992.A later refinem ent of the algorithm(see Pati,Rezaiifar,and Krishnaprasad [38]and Davis,Mallat,and Zhang [11])involves an extra step of orthogonalization.One takes all m terms that have entered at stage m and solves the least-squares problemmin (αi )s −m i =1αi φγi2D o w n l o a d e d 08/09/14 t o 58.19.126.38. R e d i s t r i b u t i o n s u b j e c t t o S I A M l i c e n s e o r c o p y r i g h t ; s e e h t t p ://w w w .s i a m .o r g /j o u r n a l s /o j s a .p h p。
Some Classes of Invertible Matrices in GF(2)

Some Classes of Invertible Matrices in GF(2)James S.Plank∗Adam L.Buchsbaum‡Technical Report UT-CS-07-599Department of Electrical Engineering and Computer ScienceUniversity of TennesseeAugust16,2007The home for this paper is /∼plank/plank/papers/CS-07-599.html.Please visit that link for up-to-date information about the publication status of this and related papers.AbstractInvertible matrices in GF(2)are important for constructing MDS erasure codes.This paper proves that certain classes of matrices in GF(2)are invertible,plus some additional properties about invertible matrices.1IntroductionWe are concerned with the question of whether certain matrices in GF(2)are invertible.This question is important when designing erasure codes for storage applications.If an erasure code is composed solely of exclusive-or operations [1,2,3,4,5,8,9],then it may be represented as a matrix-vector product in GF(2).The act of decoding transforms an original distribution matrix into a square decoding matrix that must be inverted.The process is described for general GF(2w)by Plank[7]and isfirst used in GF(2)by Blomer et al.[2].As such,a fundamental part of defining MDS erasure codes is to construct distribution matrices that result in invertible decoding matrices.This paper does not delve into erasures codes,but instead proves that certain classes of matrices in GF(2)are invertible.It also proves some properties of invertible matrices.2NomenclatureIn GF(2),each element is either0or1;addition is the binary exclusive-or operator(denoted⊕),and multiplication is the binary and operator.When we refer to a matrix M w,that means that M w is a square matrix in GF(2)with w rows and columns.Other information about the matrix is included in the subscripts.We refer to the element in row r and column c of M w as M w[r,c].These are zero-indexed,so the top-left element of M w is M w[0,0],and the bottom-right element of M w is M w[w−1,w−1].We perform arithmetic of row and column indices in M w over the commutative ring Z/w Z.We denote the quantity x modulo w by x w.In particular,because x+w w=x w,we have−1w=w−1w.When context disambiguates,we drop the extra notation;e.g.,−1w=w−1.∗Department of Electrical Engineering and Computer Science,University of Tennessee,Knoxville,TN37996,plank@.‡AT&T Labs-Research,Shannon Laboratory,180Park Avenue,Florham Park,NJ07932,alb@.12.1InvertibilityOne way to test whether a square matrix M is invertible is to perform Gaussian Elimination on it until it is in upper triangular form.Then M is invertible if and only if the result is unit upper triangular.(Basic facts about invertibilityof matrices under simple operations are available in many textbooks,e.g.,Lancaster and Tismenetsky[6].)We define steps of Gaussian Elimination as follows.Let c be the leftmost column with at least two1’s in some M w;let r be the topmost row such that M w[r,c]=1and M w[r,c ]=0for0≤c <c.Then one step of Gaussian Elimination or Elimination Step replaces every row r =r such that M w[r ,c]=1with the sum of rows r and r .An example is in Figure1.Thefirst step of Gaussian Elimination for the matrix in Figure1(a)replaces row2with thesum of rows0and2,and row3with the sum of rows0and3.The resulting matrix is in Figure1(b).(a)(b)(c)Figure1:One step of Gaussian Elimination,and deleting rows and columns that are upper-triangular.When the leftmost columns of a matrix M w have zeros below the main diagonal—i.e.,M[i,j]=0for0≤i< and i<j<w—we say the leftmost columns are in upper triangular form or are upper triangular;if inaddition M w[i,i]=1for0≤i< ,we say the leftmost columns are in unit upper triangular form or are unit upper triangular.Assume the leftmost columns of M w are unit upper triangular,and construct matrix M w ,where w =w− ,by deleting the leftmost columns and top rows of M w.Then M w is invertible iff M w is invertible.For example,since the leftmost two columns of the matrix in Figure1(b)are in unit upper triangular form,we may delete the leftmost two columns and the top two rows to produce the matrix in Figure1(c).This matrix is not invertible; therefore,the matrices in Figures1(a)and1(b)are also not invertible.There are other simple operations that preserve invertibility.Thefirst are what we call row shifting and columnshifting.There are four variants.Each takes an original matrix M w and constructs a new matrix M w∗as follows:•Shifting up by r rows:M w∗[i,j]=M w[i+r w,j],for0≤i,j<w.•Shifting down by r rows:M w∗[i,j]=M w[i−r w,j],for0≤i,j<w.•Shifting left by c columns:M w∗[i,j]=M w[i,j+c w],for0≤i,j<w.•Shifting right by c columns:M w∗[i,j]=M w[i,j−c w],for0≤i,j<w.Obviously,shifting M w up by r rows is equivalent to shifting it down by w−r rows,and shifting M w left by rcolumns is equivalent to shifting it right by w−r columns.Swapping rows and columns preserves invertibility,andsubstituting any row with the sum of it and another row also preserves invertibility.Examples are in Figure2.We denote by I w(rsp.,I w→c)the w×w identity matrix(rsp.,shifted c columns to the right)and by0w the w×w matrix of all zeros.Finally,we say a matrix class M is invertible iff all matrices in M are invertible.3The Matrix Classes D w d,s and S w d,sWe now define two classes of matrices:D w d,s and S w d,s.In both:w>2,0<d<w,and0<s<w.The letters are short for“different”and“same”.We define D w d,s,0to be the base element of D w d,s.We construct D w d,s,0as follows:•Start with D w d,s,0=I w+I w→d.2(a)(b)(c)(d)(e)Figure2:Operations that preserve invertibility.(a)is the original matrix.(b)shifts(a)up by three rows,or down by four rows.(c)shifts(a)left by four rows,or right by three rows.(d)swaps rows3and6.(e)replaces row6with the sum of rows3and6.•Set D w d,s,0[0,w−1]=D w d,s,0[0,w−1]⊕1.•Set D w d,s,0[s,d+s−1w]=D w d,s,0[s,d+s−1w]⊕1.There are w elements of D w d,s,denoted D w d,s,0,...,D w d,s,w−1.D w d,s,i is equal to D w d,s,0shifted i rows down and i columns to the right.Therefore,all elements of D w d,s have the same invertibility.Figure3gives various examples.The intuition is that elements of D w d,s are composed of two diagonals that differ by d columns.There are two extra bits flipped in the matrix,which are s rows apart and adjacent to different diagonals.D73,2,0D73,2,2D73,2,6D71,3,0D71,3,3Figure3:Various examples of matrices in D w d,s.The definition of S w d,s is similar,except the two extra bits that areflipped are adjacent to the same diagonal.As with D w d,s,we define a base element S w d,s,0as follows:•Start with S w d,s,0=I w+I w→d.•Set S w d,s,0[0,w−1]=S w d,s,0[0,w−1]⊕1.•Set S w d,s,0[s,s−1w]=S w d,s,0[s,s−1w]⊕1.As with D w d,s,there are w elements of S w d,s,denoted S w d,s,0,...,S w d,s,w−1.S w d,s,i is equal to S w d,s,0shifted i rows down and i columns to the right.Note that when w is even,there are only w/2distinct elements of S w d,s,because S w d,s,i is .We give examples of S w d,s in Figure4.equal to S wd,s,i+w2w4Simple Relationships on D w d,s and S w d,s that Preserve InvertibilityWe use the following relationships on D w d,s and S w d,s.Lemma1D w d,s is invertible iff D w w−d,w−s is invertible.3S73,2,0S73,2,2S71,3,0S76,3,0S62,3,0=S62,3,3Figure4:Various examples of matrices in S w d,s.D113,4,0D118,7,0Figure5:D118,7,0is constructed from D113,4,0by shifting it four rows up and(4+3)rows to the left.Proof:D w w−d,w−s,0can be derived by shifting D w d,s,0s rows up and s+d columns left.2 Figure5demonstrates Lemma1.Lemma2S w d,s is invertible iff S w d,w−s is invertible.Proof:S w d,s,w−s is identical to S w d,w−s,0.2 Lemma3For s>1,D w d,s is invertible iff S w d,s is invertible.Proof:S w d,s,0can be constructed from D w d,s,0by substituting row s with row s plus row(s−1).2 Figure6demonstrates Lemma3.D113,4,0S113,4,0Figure6:S113,4,0is constructed from D113,4,0by substituting row4with row4plus row3.Lemma4For0<s<w−1,S w d,s is invertible iff S w w−d,s is invertible.Proof:S w w−d,s,0can be constructed from S w d,s,0byfirst substituting row s with row s plus row(s−1)and row0with row0plus row w−1,and then shifting the result d columns to the left.24(a)(b)(c)(d)S113,4,0S118,4,0Figure7:(b)is created by substituting row4with row4plus row3.(c)is created by substituting row0with row0 plus row10.(d)is created by shifting left three columns.Lemma4is demonstrated by Figure7,where each step of converting S113,4,0to S118,4,0is shown.The constraints on s in Lemmas3and4are due to the following.When s=1,adding rows0and1does not have the desired effect of moving row s’s one from one diagonal to the other,because row0has three ones.When s=w−1, adding rows0and w−1has the same problem.For convenience in the sequel,we consider invertibility to be an equivalence relation,so two matrices or matrix classes are equivalent iff they are both invertible or both not invertible.5Our Target Class of Matrices,L,and the Grand Liberation TheoremWe define the class L to be the union of all D w d,s such that:•w>1is odd.•GCD(d,w)=1.•If d is even,s=w−d2.•If d is odd,s=w−d2.Theorem5(The Grand Liberation Theorem)All matrices in L are invertible.The rest of this paper proves the theorem.After demonstrating a few special cases,which include D31,1,the proof proceeds as follows:1.We prove by induction that D w2,w−1is invertible for all odd w.2.For d>2,wefirst show that for any odd d there exists some even d such that D wd,w−d2is equivalent to D wd ,w−d 2.Hence we restrict our attention to even d>2.3.We show that for any even d>2,D wd,w−d2is equivalent to S wd,d2.4.We show that the derived S wd,d2is equivalent to some S wd ,w 2with2<w <w,w even,and GCD(w ,d )=1.5.We show that any S w d,w2with even w>2and GCD(w,d)=1is equivalent to some D w d ,s ∈L such thatw <w.6.A second inductive argument completes the proof,as we can iterate Steps2–5until w =3or d =2in Step5.55.1Step 1:Base Cases for the Global InductionFirst,there are only two D 3d,s ∈L :D 31,1and D 32,2.Their base elements are shown in Figure 8(a)and (b).It is easyto verify that they are invertible.Additionally,Figure 8(c)shows D 52,4,4,which will be used below.It is also easy to verify that it is invertible.(a)(b)(c)(d)(e)D 31,1,0D 32,2,0D 52,4,4D 112,10,10D 112,10,10after two stepsof Gaussian Elimination.Figure 8:Base cases for the inductive proof.We now prove that D w2,w −1is invertible for all odd w .We have already shown in Figure 8that this is truefor w =3and w =5.Let w >5be odd,and assume by induction that D w 2,w −1is invertible for odd 1<w<w .Consider D w 2,w −1,w −1.An example is D 112,10,10,depicted in Figure 8(d).This matrix has a very speci fic format:Allelements of I and I →2are set to one,as are D w 2,w −1,w −1[w −1][w −2]and D w2,w −1,w −1[w −2][w −1].Now,perform two steps of Gaussian Elimination.This will set D w 2,w −1,w −1[w −2,0]and D w2,w −1,w −1[w −1,1]to zero,and D w 2,w −1,w −1[w −2,2]and D w2,w −1,w −1[w −1,3]to one.Figure 8(e)demonstrates for w =11.The resulting matrix’s first two columns are unit upper triangular,so the first two rows and columns may be deleted.Thisyields D w −22,w −3,w −3,which is of the form D w 2,w −1,w −1for some odd 1<w <w .By induction,D w2,w −1,w −1isinvertible.Therefore,D w2,w −1is invertible for all odd w >1.5.2Steps 2–4:Reducing the Problem to S wd,w 2for w Even,GCD (w,d )=1Now consider any D w d,w −d 2∈L such that d is odd.By Lemma 1,this is equivalent to D w w −d,w −w −d 2.Since w −d is an even number,D w w−d,w −w −d 2∈L .Therefore,every element D wd,s ∈L for which d is odd has a corresponding element D w d ,s ∈L for which d is even.Thus we need only prove that the elements D wd,w −d 2∈L with even d are invertible.We proved above that D w 2,w −1is invertible,so we now prove that D wd,w −d 2is invertible for even d >2.Therefore,consider D wd,w −d2such that d >2is even,w >3is odd,and GCD (w,d )=1.Since d >2,it follows that w −w −12=w −12≤w −d 2≤w −2.Since w >3,the smallest value that w −d 2may be is 5−12=2.Therefore,by Lemma 3,D w d,w −d 2is equivalent to S w d,w −d 2,which by Lemma 2is equivalent to S w d,w −(w −d 2)=S wd,d 2.So now consider S w d,d 2,w −d2−1.An example is S 176,3,13,depicted in Figure 9(a).Suppose w >2d .(w will notequal 2d ,because GCD (w,d )=1.)Perform d steps of Gaussian Elimination on S wd,d2,w −d 2−1.This moves the ones in rows w −d through w −1from columns 0through d −1to columns d through 2d −1.In our example of S 176,3,13,six steps of Gaussian Elimination are shown in Figure 9(b).Therefore,when we delete the first d rows and columnsof the resulting matrix,we are left with S w −dd,d2,w −d −d 2−1.Note:w −d is odd;w −d >d ;and since GCD (w,d )=1,GCD (w −d,d )=1.Our example continues in Figure 9(c),where we delete the first six rows and columns ofFigure 9(b)to get S 116,3,7.Iterate this process until it yields S wd,d 2,w −d2−1for d <w <2d .We now perform (w −d )steps of Gaussian Elimination.This moves the leftmost ones in rows (w −d )through (2(w −d )−1)over d columns to the right.Whenwe delete the first w −d rows and columns,we are left with S d d−(w −d ),d 2,d 2−1=S d2d −w,d 2,d 2−1.Since GCD (w,d )=1,GCD (d,2d −w )=1as well.6(a)(b)(c)(d)(e)S 176,3,13Six Elimination StepsS 116,3,7Five Elimination StepsS 61,3,2Figure 9:An example of converting S w d,d 2to S dx,d 2for w =17and d =6.Figure 9(d)shows 11−6=5steps of Gaussian Elimination of S 116,3,7,and Figure 9(e)shows that S 61,3,2results when we delete the first five rows and columns from Figure 9(d).We have thus reduced the original problem to the following:Given S wd ,w2with even w >2and GCD (w ,d )=1,determine whetherS wd ,w2invertible.We address this in the next section.5.3Steps 5–6:Proving that S wd,w 2is Invertible for w Even,GCD (w,d )=1Since w >2,it follows that 1<w 2<w −1.Therefore,by Lemma 4,S w d,w 2is equivalent to S w w −d,w 2,so we may assume that d >w 2.We’re going to break this proof into two cases.The first is when d >w 2+1.Consider S wd,w 2,w2−1.An example of this is S 1611,8,7displayed in Figure 10(a).We perform w −d steps of Gaussian Elimination on S wd,w2,w 2−1.Since d >w 2+1,we know that w −d <w2−1,so the w −d steps of Gaussian Elimination simply move the leftmost ones in rows (w −d )through (2(w −d )−1)over d columns to the right.Deleting the first w −d rows and columnsfrom the matrix,we are left with S d 2d −w,w 2,d −w 2−1.These steps are shown in Figures 10(b)and (c),as S 1611,8,7is converted into into S 116,8,2.(a)(b)(c)S 1611,8,75Elimination StepsS 116,8,2Figure 10:An example of converting S w d,w 2to S d2d −w,w 2for w =16and d =11.As before,since GCD (w,d )=1,we know that GCD (2d −w,d )=1.That w is even implies that 2d −w isalso even.Moreover,since d >w 2+1,we know that 2d −w >1.Therefore,by Lemma 3,S d2d −w,w 2is equivalent to D d 2d −w,w 2.Finally:d −2d −w2=2d −2d +w 2=w 2.7Therefore,D d2d−w,w2=D d2d−w,d−2d−w2,which is an element of L.By induction,D d2d−w,d−2d−w2is invertible,imply-ing that S w d,w2is invertible.The second case is for S w d,w2when d=w2+1and GCD(w,w2+1)=1.An example is S169,8,7shown inFigure11(a).Again,we will perform w−d elimination steps.We will do this in two parts,however.In thefirst part,we perform w−d−1elimination steps.This moves the leftmost ones in rows(w−d)through(2(w−d)−2) over d columns to the right.This is pictured in Figure11(b).The last elimination step replaces two rows of the matrix, because row(w−d)has an extra one adjacent to the diagonal.Therefore,both rows(w−d)and(2(w−d)−1) move their leftmost ones into the column(w−1).This is pictured in Figure11(c).(a)(b)(c)(d)S169,8,76Elimination Steps1More S92,8,0Figure11:An example of converting S w d,w2to S d2,d−1when d=w2+1for w=16.When thefirst w−d rows and columns are deleted from the matrix,we are left with S d2d−w,w2,0.Since d=w2+1,this is equal to S d2,d−1,0(shown as S92,8,0in Figure11(d)).That w>2is even implies that d=w2+1>2isodd,so d−1>1;thus by Lemma3,S d2,d−1is equivalent to D d2,d−1,which we proved invertible in Section5.1. Therefore S w d,w2is invertible.Q.E.D.6The Class O and the Little Liberation TheoremWe now define a third class of matrices,O w d such that w>d≥1.We define O w d,0to be the base element of O w d and construct O w d,0as follows:•Start with O w d=I w+I w→d.•Set O w d,0[0,w−1]=O w d,0[0,w−1]⊕1.Thus,O w d,0is similar to D w d,s,0and S w d,s,0,except it only has one extra one in it,in the top-right corner.There are w elements of O w d,denoted O w d,0,...,O w d,w−1.O w d,i is equal to O w d,0shifted i rows down and i columns to the right. Therefore,all elements of O w d are equivalent.We show some examples of matrices in O w d in Figure12.(a)(b)(c)(d)O73,0O73,6O74,6O21,1Figure12:Examples of matrices in O w d.We start with a simple lemma:8Lemma 6O w d is invertible iff O ww −d is invertible.Proof:O w w −d,w −1can be derived by replacing row w −1of O w d,w −1with the sum of rows w −1and w −2,and shiftingthe resulting matrix d columns to the left.An example is in Figure 12,where O 74,6may be obtained by replacing row 6of O 73,6with the sum of rows 5and 6,and shifting the result three columns to the left.2De fine O to be the union of all O wd such that GCD (w,d )=1.Theorem 7(The Little Liberation Theorem)All matrices in O are invertible.Proof:This proof is far simpler than that of the Grand Liberation Theorem.It,too,is inductive.We start with the base case O 21,an element of which is pictured in Figure 12(d).This matrix is already in unit upper triangular form and is therefore invertible.Now,consider O w d ∈O and suppose by induction that O wd∈O is invertible for all 1≤d <w <w .By Lemma 6and the hypothesis that GCD (w,d )=1,we may assume that d <w 2,or else we consider O ww −d in lieu of O w d .Performing d elimination steps on O w d,w −1moves the leftmost ones in rows w −d through w −1over d columnsto the right.Since d <w 2,these ones will not be moved to the diagonal,nor will the one at O wd,w −1[w −1,w −2]be affected.Therefore deleting the leftmost d columns,which are now unit upper triangular,and top d rows leaves O w −d d,w −d −1.Since GCD (w,d )=1,GCD (w −d,d )=1,and therefore O w −d d,w −d −1∈O .By induction,O w −d dis invertible;therefore O wd is invertible.2An example is depicted in Figure 13where O 125,11is converted to O 75,6by five elimination steps.(a)(b)(c)O 125,11Five elimination stepsO 75,6Figure 13:An example of converting O wd,w −1to O w −d d,w −d −1.7Some Trivial Properties of Matrices in GF (2)The following two lemmas are likely folklore,but we include them for completeness.Lemma 8If some matrix M w has precisely w ones,then M w is invertible iff it is a permutation matrix.Proof:Any permutation matrix is invertible.Conversely,if M w has precisely w ones but is not a permutation matrix,then some row or column contains all zeros,in which case M w is not invertible.2Lemma 9Let M w 1and M w 2be permutation matrices.The sum M w 1+M w2is not invertible.Proof:Let M w =M w 1+M w 2.Suppose there exist r and c such that M w 1[r,c ]=M w2[r,c ]=1.Then row r of M w contains all zeros,so M w is not invertible.Thus,we assume there are no such r and c ;in this case,M has precisely two ones in each row and column.We prove by induction that such matrices are not invertible.The base case is shown in Figure 14(a),which depicts the only M 2with two ones in each row and column.This matrix is clearly not invertible.9Now,let matrix M w for some w>2have exactly two ones in each row and column.Let rows r1and r2be the two rows that have ones in column zero,and let c1,c2>0be such that M w[r1,c1]=M w[r2,c2]=1.Swap row r1with row0,and perform one elimination step.This will set M w[r2,0]=0and M w[r2,c1]=M w[r2,c1]⊕1.If c1=c2, then all of row r2’s elements become zero,so M w is not invertible.If c1=c2,then deleting thefirst row and column leaves a matrix M w−1with exactly two ones in each row and column.By induction,this new matrix in not invertible; therefore M w is also not invertible.2(a)(b)(c)(d)(e)(f)M2.M7,After one elimination M7,After one M6.c1=c2=3.step,Row4is all zeros.c1=3,c2=2.elimination step.Figure14:Matrices with two ones in each row and column.We show examples of the elimination step in Figure14(b)-(f).In Figure14(b),the elimination step,depicted in Figure14(c)turns row4into all zeros.In Figure14(d),the elimination step of the matrix M7results in Figure14(e), which is equivalent to a matrix M6(Figure14(f)).8A Final Theorem on the Invertibility of a Type of(k+2)w×kw MatrixLet row r of some matrix M w contain precisely one one—we call such a row an identity row—and let the one be in column c.By cofactor expansion,deleting row r and column c yields an equivalent matrix M w−1.The remaining theorem concerns a(k+2)×k block matrix A,structured as follows and pictured in Figure15:•Each block is w×w.•Block A[i,i]=I w for0≤i<k.•Blocks A[i,j]=A[j,i]=0w for0≤i<j<k.•Block A[k,j]=I w for0≤j<k.•Block A[k+1,j]=X j for0≤j<k and some given X j.Consider the class A∗of k+22 block matrices induced by deleting any two rows of blocks from A.Theorem10All matrices in A∗are invertible iff(1)every X i is invertible,and(2)for0≤i<j<k,X i+X j is invertible.Proof:Let A∈A∗.There are four cases.Case1:A is composed of thefirst k rows of blocks of A,which form I kw.Case2:A is composed of row k and any k−1of thefirst k rows of blocks of A.Now,A has(k−1)w identity rows.Deleting these rows and their associated columns yields I w.Case3:A is composed of row k+1and any k−1of thefirst k rows of blocks of A;let i be the omitted row of blocks from thefirst k.Again,A has(k−1)w identity rows,which we can delete with their associated columns to yield X i,so A is equivalent to X i.10Figure15:The(k+2)×k block matrix A of w×w matrices over GF(2).Figure16:The2w×2w matrix that results when w(k−2)identity rows are deleted from A in Case4.Case4:A is composed of rows k,k+1,and any k−2of thefirst k rows of blocks of A;let i and j be the omitted rows of blocks from thefirst k.Now A has(k−2)w identity rows,which we can delete with their associated columns to yield the matrix pictured in Figure16.Now,perform w elimination steps on this matrix.For each r and c such that X i[r,c]=1,the elimination step for column c will replace row w+r with the sum of rows w+r and c.This will set X i[r,c]=0and X j[r,c]=X j[r,c]⊕1. After the elimination steps,the leftmost w columns will be upper triangular,and deleting them leaves X i+X j. Therefore,A is equivalent to X i+X j.29AcknowledgementsThis material is based upon work supported by the National Science Foundation under grants CNS-0437508and CNS-0615221.References[1]M.Blaum,J.Brady,J.Bruck,and J.Menon.EVENODD:An efficient scheme for tolerating double disk failuresin RAID architectures.IEEE Transactions on Computing,44(2):192–202,February1995.[2]J.Blomer,M.Kalfane,M.Karpinski,R.Karp,M.Luby,and D.Zuckerman.An XOR-based erasure-resilientcoding scheme.Technical Report TR-95-048,International Computer Science Institute,August1995.[3]P.Corbett,B.English,A.Goel,T.Grcanac,S.Kleiman,J.Leong,and S.Sankar.Row diagonal parity for doubledisk failure correction.In4th Usenix Conference on File and Storage Technologies,San Francisco,CA,March 2004.11[4]J.L.Hafner.WEA VER Codes:Highly fault tolerant erasure codes for storage systems.In F AST-2005:4th UsenixConference on File and Storage Technologies,pages211–224,San Francisco,December2005.[5]J.L.Hafner.HoVer erasure codes for disk arrays.In DSN-2006:The International Conference on DependableSystems and Networks,Philadelphia,June2006.IEEE.[6]ncaster and M.Tismenetsky.The Theory of puter Science and Applied Mathematics.Aca-demic Press,San Diego,CA,second edition,1985.[7]J.S.Plank.A tutorial on Reed-Solomon coding for fault-tolerance in RAID-like systems.Software–Practice&Experience,27(9):995–1012,September1997.[8]J.S.Plank and L.Xu.Optimizing Cauchy Reed-Solomon codes for fault-tolerant network storage applications.InNCA-06:5th IEEE International Symposium on Network Computing Applications,Cambridge,MA,July2006.[9]J.J.Wylie and R.Swaminathan.Determining fault tolerance of XOR-based erasure codes efficiently.In DSN-2007:The International Conference on Dependable Systems and Networks,Edinburgh,Scotland,June2007.IEEE.12。
NBU基础知识整理
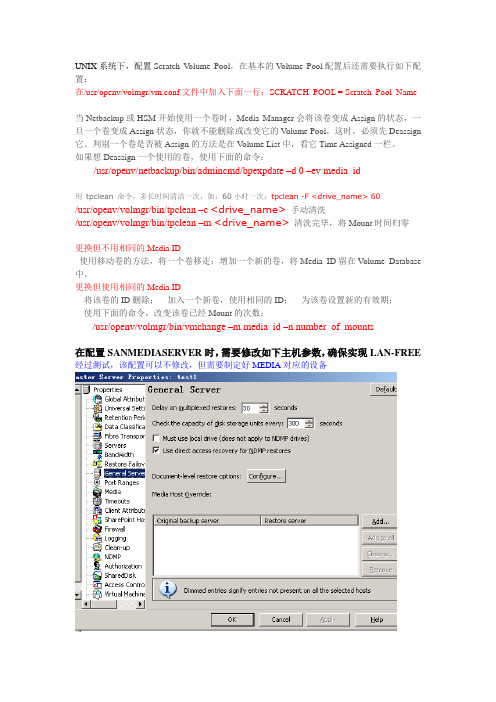
UNIX系统下,配置Scratch V olume Pool,在基本的V olume Pool配置后还需要执行如下配置:在/usr/openv/volmgr/vm.conf文件中加入下面一行:SCRATCH_POOL = Scratch_Pool_Name当Netbackup或HSM开始使用一个卷时,Media Manager会将该卷变成Assign的状态,一旦一个卷变成Assign状态,你就不能删除或改变它的V olume Pool,这时,必须先Deassign 它。
判别一个卷是否被Assign的方法是在Volume List中,看它Time Assigned一栏。
如果想Deassign一个使用的卷,使用下面的命令:/usr/openv/netbackup/bin/admincmd/bpexpdate –d 0 –ev media_id用tpclean 命令,多长时间清洁一次,如:60小时一次:tpclean -F <drive_name> 60/usr/openv/volmgr/bin/tpclean –c <drive_name>手动清洗/usr/openv/volmgr/bin/tpclean –m <drive_name>清洗完毕,将Mount时间归零更换但不用相同的Media ID使用移动卷的方法,将一个卷移走;增加一个新的卷,将Media ID留在V olume Database 中。
更换但使用相同的Media ID将该卷的ID删除;加入一个新卷,使用相同的ID;为该卷设置新的有效期;使用下面的命令,改变该卷已经Mount的次数:/usr/openv/volmgr/bin/vmchange –m media_id –n number_of_mounts在配置SANMEDIASERVER时,需要修改如下主机参数,确保实现LAN-FREE 经过测试,该配置可以不修改,但需要制定好MEDIA对应的设备Check_converage:确认备份策略备份内容2.相关检查命令启动NBU的图形管理界面:/usr/openv/netbackup/bin/jnbSA &1) 检查NBU进程状态:需要每天监控activity monitor,确认在备份服务器上运行的进程有:avrd、vmd、tldd、ltid、bprd、nbdbd、bpdbm、bpsched、bpjobd。
1999.Multilevel Hypergraph Partitioning__Applications in VLSI Domain

Multilevel Hypergraph Partitioning:Applications in VLSI DomainGeorge Karypis,Rajat Aggarwal,Vipin Kumar,Senior Member,IEEE,and Shashi Shekhar,Senior Member,IEEE Abstract—In this paper,we present a new hypergraph-partitioning algorithm that is based on the multilevel paradigm.In the multilevel paradigm,a sequence of successivelycoarser hypergraphs is constructed.A bisection of the smallesthypergraph is computed and it is used to obtain a bisection of theoriginal hypergraph by successively projecting and refining thebisection to the next levelfiner hypergraph.We have developednew hypergraph coarsening strategies within the multilevelframework.We evaluate their performance both in terms of thesize of the hyperedge cut on the bisection,as well as on the runtime for a number of very large scale integration circuits.Ourexperiments show that our multilevel hypergraph-partitioningalgorithm produces high-quality partitioning in a relatively smallamount of time.The quality of the partitionings produced by ourscheme are on the average6%–23%better than those producedby other state-of-the-art schemes.Furthermore,our partitioningalgorithm is significantly faster,often requiring4–10times lesstime than that required by the other schemes.Our multilevelhypergraph-partitioning algorithm scales very well for largehypergraphs.Hypergraphs with over100000vertices can bebisected in a few minutes on today’s workstations.Also,on thelarge hypergraphs,our scheme outperforms other schemes(inhyperedge cut)quite consistently with larger margins(9%–30%).Index Terms—Circuit partitioning,hypergraph partitioning,multilevel algorithms.I.I NTRODUCTIONH YPERGRAPH partitioning is an important problem withextensive application to many areas,including very largescale integration(VLSI)design[1],efficient storage of largedatabases on disks[2],and data mining[3].The problemis to partition the vertices of a hypergraphintois definedas a set ofvertices[4],and the size ofa hyperedge is the cardinality of this subset.Manuscript received April29,1997;revised March23,1998.This workwas supported under IBM Partnership Award NSF CCR-9423082,by theArmy Research Office under Contract DA/DAAH04-95-1-0538,and by theArmy High Performance Computing Research Center,the Department of theArmy,Army Research Laboratory Cooperative Agreement DAAH04-95-2-0003/Contract DAAH04-95-C-0008.G.Karypis,V.Kumar,and S.Shekhar are with the Department of ComputerScience and Engineering,Minneapolis,University of Minnesota,Minneapolis,MN55455-0159USA.R.Aggarwal is with the Lattice Semiconductor Corporation,Milpitas,CA95131USA.Publisher Item Identifier S1063-8210(99)00695-2.During the course of VLSI circuit design and synthesis,itis important to be able to divide the system specification intoclusters so that the inter-cluster connections are minimized.This step has many applications including design packaging,HDL-based synthesis,design optimization,rapid prototyping,simulation,and testing.In particular,many rapid prototyp-ing systems use partitioning to map a complex circuit ontohundreds of interconnectedfield-programmable gate arrays(FPGA’s).Such partitioning instances are challenging becausethe timing,area,and input/output(I/O)resource utilizationmust satisfy hard device-specific constraints.For example,ifthe number of signal nets leaving any one of the clustersis greater than the number of signal p-i-n’s available in theFPGA,then this cluster cannot be implemented using a singleFPGA.In this case,the circuit needs to be further partitioned,and thus implemented using multiple FPGA’s.Hypergraphscan be used to naturally represent a VLSI circuit.The verticesof the hypergraph can be used to represent the cells of thecircuit,and the hyperedges can be used to represent the netsconnecting these cells.A high quality hypergraph-partitioningalgorithm greatly affects the feasibility,quality,and cost ofthe resulting system.A.Related WorkThe problem of computing an optimal bisection of a hy-pergraph is at least NP-hard[5].However,because of theimportance of the problem in many application areas,manyheuristic algorithms have been developed.The survey byAlpert and Khang[1]provides a detailed description andcomparison of such various schemes.In a widely used class ofiterative refinement partitioning algorithms,an initial bisectionis computed(often obtained randomly)and then the partitionis refined by repeatedly moving vertices between the twoparts to reduce the hyperedge cut.These algorithms oftenuse the Schweikert–Kernighan heuristic[6](an extension ofthe Kernighan–Lin(KL)heuristic[7]for hypergraphs),or thefaster Fiduccia–Mattheyses(FM)[8]refinement heuristic,toiteratively improve the quality of the partition.In all of thesemethods(sometimes also called KLFM schemes),a vertex ismoved(or a vertex pair is swapped)if it produces the greatestreduction in the edge cuts,which is also called the gain formoving the vertex.The partition produced by these methodsis often poor,especially for larger hypergraphs.Hence,thesealgorithms have been extended in a number of ways[9]–[12].Krishnamurthy[9]tried to introduce intelligence in the tie-breaking process from among the many possible moves withthe same high gain.He used a Look Ahead()algorithm,which looks ahead uptoa move.PROP [11],introduced by Dutt and Deng,used a probabilistic gain computation model for deciding which vertices need to move across the partition line.These schemes tend to enhance the performance of the basic KLFM family of refinement algorithms,at the expense of increased run time.Dutt and Deng [12]proposed two new methods,namely,CLIP and CDIP,for computing the gains of hyperedges that contain more than one node on either side of the partition boundary.CDIP in conjunctionwithand CLIP in conjunction with PROP are two schemes that have shown the best results in their experiments.Another class of hypergraph-partitioning algorithms [13]–[16]performs partitioning in two phases.In the first phase,the hypergraph is coarsened to form a small hypergraph,and then the FM algorithm is used to bisect the small hypergraph.In the second phase,these algorithms use the bisection of this contracted hypergraph to obtain a bisection of the original hypergraph.Since FM refinement is done only on the small coarse hypergraph,this step is usually fast,but the overall performance of such a scheme depends upon the quality of the coarsening method.In many schemes,the projected partition is further improved using the FM refinement scheme [15].Recently,a new class of partitioning algorithms was devel-oped [17]–[20]based upon the multilevel paradigm.In these algorithms,a sequence of successively smaller (coarser)graphs is constructed.A bisection of the smallest graph is computed.This bisection is now successively projected to the next-level finer graph and,at each level,an iterative refinement algorithm such as KLFM is used to further improve the bisection.The various phases of multilevel bisection are illustrated in Fig.1.Iterative refinement schemes such as KLFM become quite powerful in this multilevel context for the following reason.First,the movement of a single node across a partition bound-ary in a coarse graph can lead to the movement of a large num-ber of related nodes in the original graph.Second,the refined partitioning projected to the next level serves as an excellent initial partitioning for the KL or FM refinement algorithms.This paradigm was independently studied by Bui and Jones [17]in the context of computing fill-reducing matrix reorder-ing,by Hendrickson and Leland [18]in the context of finite-element mesh-partitioning,and by Hauck and Borriello (called Optimized KLFM)[20],and by Cong and Smith [19]for hy-pergraph partitioning.Karypis and Kumar extensively studied this paradigm in [21]and [22]for the partitioning of graphs.They presented new graph coarsening schemes for which even a good bisection of the coarsest graph is a pretty good bisec-tion of the original graph.This makes the overall multilevel paradigm even more robust.Furthermore,it allows the use of simplified variants of KLFM refinement schemes during the uncoarsening phase,which significantly speeds up the refine-ment process without compromising overall quality.METIS [21],a multilevel graph partitioning algorithm based upon this work,routinely finds substantially better bisections and is often two orders of magnitude faster than the hitherto state-of-the-art spectral-based bisection techniques [23],[24]for graphs.The improved coarsening schemes of METIS work only for graphs and are not directly applicable to hypergraphs.IftheFig.1.The various phases of the multilevel graph bisection.During the coarsening phase,the size of the graph is successively decreased;during the initial partitioning phase,a bisection of the smaller graph is computed,and during the uncoarsening and refinement phase,the bisection is successively refined as it is projected to the larger graphs.During the uncoarsening and refinement phase,the dashed lines indicate projected partitionings and dark solid lines indicate partitionings that were produced after refinement.G 0is the given graph,which is the finest graph.G i +1is the next level coarser graph of G i ,and vice versa,G i is the next level finer graph of G i +1.G 4is the coarsest graph.hypergraph is first converted into a graph (by replacing each hyperedge by a set of regular edges),then METIS [21]can be used to compute a partitioning of this graph.This technique was investigated by Alpert and Khang [25]in their algorithm called GMetis.They converted hypergraphs to graphs by simply replacing each hyperedge with a clique,and then they dropped many edges from each clique randomly.They used METIS to compute a partitioning of each such random graph and then selected the best of these partitionings.Their results show that reasonably good partitionings can be obtained in a reasonable amount of time for a variety of benchmark problems.In particular,the performance of their resulting scheme is comparable to other state-of-the art schemes such as PARABOLI [26],PROP [11],and the multilevel hypergraph partitioner from Hauck and Borriello [20].The conversion of a hypergraph into a graph by replacing each hyperedge with a clique does not result in an equivalent representation since high-quality partitionings of the resulting graph do not necessarily lead to high-quality partitionings of the hypergraph.The standard hyperedge-to-edge conversion [27]assigns a uniform weightofisthe of the hyperedge,i.e.,thenumber of vertices in the hyperedge.However,the fundamen-tal problem associated with replacing a hyperedge by its clique is that there exists no scheme to assign weight to the edges of the clique that can correctly capture the cost of cutting this hyperedge [28].This hinders the partitioning refinement algo-rithm since vertices are moved between partitions depending on how much this reduces the number of edges they cut in the converted graph,whereas the real objective is to minimize the number of hyperedges cut in the original hypergraph.Furthermore,the hyperedge-to-clique conversion destroys the natural sparsity of the hypergraph,significantly increasing theKARYPIS et al.:MULTILEVEL HYPERGRAPH PARTITIONING:APPLICATIONS IN VLSI DOMAIN 71run time of the partitioning algorithm.Alpert and Khang [25]solved this problem by dropping many edges of the clique randomly,but this makes the graph representation even less accurate.A better approach is to develop coarsening and refinement schemes that operate directly on the hypergraph.Note that the multilevel scheme by Hauck and Borriello [20]operates directly on hypergraphs and,thus,is able to perform accurate refinement during the uncoarsening phase.However,all coarsening schemes studied in [20]are edge-oriented;i.e.,they only merge pairs of nodes to construct coarser graphs.Hence,despite a powerful refinement scheme (FM with theuse oflook-ahead)during the uncoarsening phase,their performance is only as good as that of GMetis [25].B.Our ContributionsIn this paper,we present a multilevel hypergraph-partitioning algorithm hMETIS that operates directly on the hypergraphs.A key contribution of our work is the development of new hypergraph coarsening schemes that allow the multilevel paradigm to provide high-quality partitions quite consistently.The use of these powerful coarsening schemes also allows the refinement process to be simplified considerably (even beyond plain FM refinement),making the multilevel scheme quite fast.We investigate various algorithms for the coarsening and uncoarsening phases which operate on the hypergraphs without converting them into graphs.We have also developed new multiphase refinement schemes(-cycles)based on the multilevel paradigm.These schemes take an initial partition as input and try to improve them using the multilevel scheme.These multiphase schemes further reduce the run times,as well as improve the solution quality.We evaluate their performance both in terms of the size of the hyperedge cut on the bisection,as well as on run time on a number of VLSI circuits.Our experiments show that our multilevel hypergraph-partitioning algorithm produces high-quality partitioning in a relatively small amount of time.The quality of the partitionings produced by our scheme are on the average 6%–23%better than those produced by other state-of-the-art schemes [11],[12],[25],[26],[29].The difference in quality over other schemes becomes even greater for larger hypergraphs.Furthermore,our partitioning algorithm is significantly faster,often requiring 4–10times less time than that required by the other schemes.For many circuits in the well-known ACM/SIGDA benchmark set [30],our scheme is able to find better partitionings than those reported in the literature for any other hypergraph-partitioning algorithm.The remainder of this paper is organized as follows.Section II describes the different algorithms used in the three phases of our multilevel hypergraph-partitioning algorithm.Section III describes a new partitioning refinement algorithm based on the multilevel paradigm.Section IV compares the results produced by our algorithm to those produced by earlier hypergraph-partitioning algorithms.II.M ULTILEVEL H YPERGRAPH B ISECTIONWe now present the framework of hMETIS ,in which the coarsening and refinement scheme work directly with hyper-edges without using the clique representation to transform them into edges.We have developed new algorithms for both the phases,which,in conjunction,are capable of delivering very good quality solutions.A.Coarsening PhaseDuring the coarsening phase,a sequence of successively smaller hypergraphs are constructed.As in the case of mul-tilevel graph bisection,the purpose of coarsening is to create a small hypergraph,such that a good bisection of the small hypergraph is not significantly worse than the bisection di-rectly obtained for the original hypergraph.In addition to that,hypergraph coarsening also helps in successively reducing the sizes of the hyperedges.That is,after several levels of coarsening,large hyperedges are contracted to hyperedges that connect just a few vertices.This is particularly helpful,since refinement heuristics based on the KLFM family of algorithms [6]–[8]are very effective in refining small hyperedges,but are quite ineffective in refining hyperedges with a large number of vertices belonging to different partitions.Groups of vertices that are merged together to form single vertices in the next-level coarse hypergraph can be selected in different ways.One possibility is to select pairs of vertices with common hyperedges and to merge them together,as illustrated in Fig.2(a).A second possibility is to merge together all the vertices that belong to a hyperedge,as illustrated in Fig.2(b).Finally,a third possibility is to merge together a subset of the vertices belonging to a hyperedge,as illustrated in Fig.2(c).These three different schemes for grouping vertices together for contraction are described below.1)Edge Coarsening (EC):The heavy-edge matching scheme used in the multilevel-graph bisection algorithm can also be used to obtain successively coarser hypergraphs by merging the pairs of vertices connected by many hyperedges.In this EC scheme,a heavy-edge maximal 1matching of the vertices of the hypergraph is computed as follows.The vertices are visited in a random order.For eachvertex are considered,and the one that is connected via the edge with the largest weight is matchedwithandandofsize72IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION(VLSI)SYSTEMS,VOL.7,NO.1,MARCH1999Fig.2.Various ways of matching the vertices in the hypergraph and the coarsening they induce.(a)In edge-coarsening,connected pairs of vertices are matched together.(b)In hyperedge-coarsening,all the vertices belonging to a hyperedge are matched together.(c)In MHEC,we match together all the vertices in a hyperedge,as well as all the groups of vertices belonging to a hyperedge.weight of successively coarser graphs does not decrease very fast.In order to ensure that for every group of vertices that are contracted together,there is a decrease in the hyperedge weight in the coarser graph,each such group of vertices must be connected by a hyperedge.This is the motivation behind the HEC scheme.In this scheme,an independent set of hyperedges is selected and the vertices that belong to individual hyperedges are contracted together.This is implemented as follows.The hyperedges are initially sorted in a nonincreasing hyperedge-weight order and the hyperedges of the same weight are sorted in a nondecreasing hyperedge size order.Then,the hyperedges are visited in that order,and for each hyperedge that connects vertices that have not yet been matched,the vertices are matched together.Thus,this scheme gives preference to the hyperedges that have large weight and those that are of small size.After all of the hyperedges have been visited,the groups of vertices that have been matched are contracted together to form the next level coarser graph.The vertices that are not part of any contracted hyperedges are simply copied to the next level coarser graph.3)Modified Hyperedge Coarsening(MHEC):The HEC algorithm is able to significantly reduce the amount of hyperedge weight that is left exposed in successively coarser graphs.However,during each coarsening phase,a majority of the hyperedges do not get contracted because vertices that belong to them have been contracted via other hyperedges. This leads to two problems.First,the size of many hyperedges does not decrease sufficiently,making FM-based refinement difficult.Second,the weight of the vertices(i.e.,the number of vertices that have been collapsed together)in successively coarser graphs becomes significantly different,which distorts the shape of the contracted hypergraph.To correct this problem,we implemented a MHEC scheme as follows.After the hyperedges to be contracted have been selected using the HEC scheme,the list of hyperedges is traversed again,and for each hyperedge that has not yet been contracted,the vertices that do not belong to any other contracted hyperedge are contracted together.B.Initial Partitioning PhaseDuring the initial partitioning phase,a bisection of the coarsest hypergraph is computed,such that it has a small cut, and satisfies a user-specified balance constraint.The balance constraint puts an upper bound on the difference between the relative size of the two partitions.Since this hypergraph has a very small number of vertices(usually less than200),the time tofind a partitioning using any of the heuristic algorithms tends to be small.Note that it is not useful tofind an optimal partition of this coarsest graph,as the initial partition will be sub-stantially modified during the refinement phase.We used the following two algorithms for computing the initial partitioning. Thefirst algorithm simply creates a random bisection such that each part has roughly equal vertex weight.The second algorithm starts from a randomly selected vertex and grows a region around it in a breadth-first fashion[22]until half of the vertices are in this region.The vertices belonging to the grown region are then assigned to thefirst part,and the rest of the vertices are assigned to the second part.After a partitioning is constructed using either of these algorithms,the partitioning is refined using the FM refinement algorithm.Since both algorithms are randomized,different runs give solutions of different quality.For this reason,we perform a small number of initial partitionings.At this point,we can select the best initial partitioning and project it to the original hypergraph,as described in Section II-C.However,the parti-tioning of the coarsest hypergraph that has the smallest cut may not necessarily be the one that will lead to the smallest cut in the original hypergraph.It is possible that another partitioning of the coarsest hypergraph(with a higher cut)will lead to a bet-KARYPIS et al.:MULTILEVEL HYPERGRAPH PARTITIONING:APPLICATIONS IN VLSI DOMAIN 73ter partitioning of the original hypergraph after the refinement is performed during the uncoarsening phase.For this reason,instead of selecting a single initial partitioning (i.e.,the one with the smallest cut),we propagate all initial partitionings.Note that propagation of.Thus,by increasing the value ofis to drop unpromising partitionings as thehypergraph is uncoarsened.For example,one possibility is to propagate only those partitionings whose cuts arewithinissufficiently large,then all partitionings will be maintained and propagated in the entire refinement phase.On the other hand,if the valueof,many partitionings may be available at the coarsest graph,but the number of such available partitionings will decrease as the graph is uncoarsened.This is useful for two reasons.First,it is more important to have many alternate partitionings at the coarser levels,as the size of the cut of a partitioning at a coarse level is a less accurate reflection of the size of the cut of the original finest level hypergraph.Second,refinement is more expensive at the fine levels,as these levels contain far more nodes than the coarse levels.Hence,by choosing an appropriate valueof(from 10%to a higher value such as 20%)did not significantly improve the quality of the partitionings,although it did increase the run time.C.Uncoarsening and Refinement PhaseDuring the uncoarsening phase,a partitioning of the coarser hypergraph is successively projected to the next-level finer hypergraph,and a partitioning refinement algorithm is used to reduce the cut set (and thus to improve the quality of the partitioning)without violating the user specified balance con-straints.Since the next-level finer hypergraph has more degrees of freedom,such refinement algorithms tend to improve the solution quality.We have implemented two different partitioning refinement algorithms.The first is the FM algorithm [8],which repeatedly moves vertices between partitions in order to improve the cut.The second algorithm,called hyperedge refinement (HER),moves groups of vertices between partitions so that an entire hyperedge is removed from the cut.These algorithms are further described in the remainder of this section.1)FM:The partitioning refinement algorithm by Fiduccia and Mattheyses [8]is iterative in nature.It starts with an initial partitioning of the hypergraph.In each iteration,it tries to find subsets of vertices in each partition,such that moving them to other partitions improves the quality of the partitioning (i.e.,the number of hyperedges being cut decreases)and this does not violate the balance constraint.If such subsets exist,then the movement is performed and this becomes the partitioning for the next iteration.The algorithm continues by repeating the entire process.If it cannot find such a subset,then the algorithm terminates since the partitioning is at a local minima and no further improvement can be made by this algorithm.In particular,for eachvertexto the other partition.Initially allvertices are unlocked ,i.e.,they are free to move to the other partition.The algorithm iteratively selects an unlockedvertex is moved,it is locked ,and the gain of the vertices adjacentto[8].For refinement in the context of multilevel schemes,the initial partitioning obtained from the next level coarser graph is actually a very good partition.For this reason,we can make a number of optimizations to the original FM algorithm.The first optimization limits the maximum number of passes performed by the FM algorithm to only two.This is because the greatest reduction in the cut is obtained during the first or second pass and any subsequent passes only marginally improve the quality.Our experience has shown that this optimization significantly improves the run time of FM without affecting the overall quality of the produced partitionings.The second optimization aborts each pass of the FM algorithm before actually moving all the vertices.The motivation behind this is that only a small fraction of the vertices being moved actually lead to a reduction in the cut and,after some point,the cut tends to increase as we move more vertices.When FM is applied to a random initial partitioning,it is quite likely that after a long sequence of bad moves,the algorithm will climb74IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI)SYSTEMS,VOL.7,NO.1,MARCH1999Fig.3.Effect of restricted coarsening .(a)Example hypergraph with a given partitioning with the required balance of 40/60.(b)Possible condensed version of (a).(c)Another condensed version of a hypergraph.out of a local minima and reach to a better cut.However,in the context of a multilevel scheme,a long sequence of cut-increasing moves rarely leads to a better local minima.For this reason,we stop each pass of the FM algorithm as soon as we haveperformedto be equal to 1%of the number ofvertices in the graph we are refining.This modification to FM,called early-exit FM (FM-EE),does not significantly affect the quality of the final partitioning,but it dramatically improves the run time (see Section IV).2)HER:One of the drawbacks of FM (and other similar vertex-based refinement schemes)is that it is often unable to refine hyperedges that have many nodes on both sides of the partitioning boundary.However,a refinement scheme that moves all the vertices that belong to a hyperedge can potentially solve this problem.Our HER works as follows.It randomly visits all the hyperedges and,for each one that straddles the bisection,it determines if it can move a subset of the vertices incident on it,so that this hyperedge will become completely interior to a partition.In particular,consider ahyperedgebe the verticesofto partition 0.Now,depending on these gains and subject to balance constraints,it may move one of the twosets .In particular,if.III.M ULTIPHASE R EFINEMENT WITHR ESTRICTED C OARSENINGAlthough the multilevel paradigm is quite robust,random-ization is inherent in all three phases of the algorithm.In particular,the random choice of vertices to be matched in the coarsening phase can disallow certain hyperedge cuts,reducing refinement in the uncoarsening phase.For example,consider the example hypergraph in Fig.3(a)and its two possible con-densed versions [Fig.3(b)and (c)]with the same partitioning.The version in Fig.3(b)is obtained by selectinghyperedgesto be compressed in the HEC phase and then selecting pairs ofnodesto be compressed inthe HEC phase and then selecting pairs ofnodesand apartitioningfor ,be the sequence of hypergraphsand partitionings.Given ahypergraphandorpartition,,are collapsedtogether to formvertexof,thenvertex belong。
H.264 mpeg-4 part 10 white paper

(reference)
(1 or 2 previously encoded frames)
F'n-1
P
(reconstructed)
F'n
uF'n
Filter
+
D'n
X
T-1 Q-1 Reorder Entropy decode
+
NAL
Figure 2-2 AVC Decoder
2.1
ቤተ መጻሕፍቲ ባይዱ
Encoder (forward path)
H.264 / MPEG-4 Part 10 White Paper Overview of H.264 1. Introduction
H.264 / MPEG-4 Part 10 : Overview
Broadcast television and home entertainment have been revolutionised by the advent of digital TV and DVD-video. These applications and many more were made possible by the standardisation of video compression technology. The next standard in the MPEG series, MPEG4, is enabling a new generation of internet-based video applications whilst the ITU-T H.263 standard for video compression is now widely used in videoconferencing systems. MPEG4 (Visual) and H.263 are standards that are based on video compression (“video coding”) technology from circa. 1995. The groups responsible for these standards, the Motion Picture Experts Group and the Video Coding Experts Group (MPEG and VCEG) are in the final stages of developing a new standard that promises to significantly outperform MPEG4 and H.263, providing better compression of video images together with a range of features supporting high-quality, low-bitrate streaming video. The history of the new standard, “Advanced Video Coding” (AVC), goes back at least 7 years. After finalising the original H.263 standard for videotelephony in 1995, the ITU-T Video Coding Experts Group (VCEG) started work on two further development areas: a “short-term” effort to add extra features to H.263 (resulting in Version 2 of the standard) and a “long-term” effort to develop a new standard for low bitrate visual communications. The long-term effort led to the draft “H.26L” standard, offering significantly better video compression efficiency than previous ITU-T standards. In 2001, the ISO Motion Picture Experts Group (MPEG) recognised the potential benefits of H.26L and the Joint Video Team (JVT) was formed, including experts from MPEG and VCEG. JVT’s main task is to develop the draft H.26L “model” into a full International Standard. In fact, the outcome will be two identical) standards: ISO MPEG4 Part 10 of MPEG4 and ITU-T H.264. The “official” title of the new standard is Advanced Video Coding (AVC); however, it is widely known by its old working title, H.26L and by its ITU document number, H.264 [1]. 2. H.264 CODEC In common with earlier standards (such as MPEG1, MPEG2 and MPEG4), the H.264 draft standard does not explicitly define a CODEC (enCOder / DECoder pair). Rather, the standard defines the syntax of an encoded video bitstream together with the method of decoding this bitstream. In practice, however, a compliant encoder and decoder are likely to include the functional elements shown in Figure 2-1 and Figure 2-2. Whilst the functions shown in these Figures are likely to be necessary for compliance, there is scope for considerable variation in the structure of the CODEC. The basic functional elements (prediction, transform, quantization, entropy encoding) are little different from previous standards (MPEG1, MPEG2, MPEG4, H.261, H.263); the important changes in H.264 occur in the details of each functional element. The Encoder (Figure 2-1) includes two dataflow paths, a “forward” path (left to right, shown in blue) and a “reconstruction” path (right to left, shown in magenta). The dataflow path in the Decoder (Figure 2-2) is shown from right to left to illustrate the similarities between Encoder and Decoder.
Online Stochastic Modelling for Network-Based GPS Real-Time Kinematic Positioning

114
Journal of Global Positioning Systems
Model, Distance-Based Linear Interpolation Method, Linear Interpolation Method, Lower-Order Surface Model and Least-Square Collocation (Fotopoulos & Cannon, 2001). However, Dai et al (2001) demonstrated that the performances of all of these methods are similar.
Received: 16 November 2004 / Accepted: 8 July 2005
Abstract. Baseline length-dependent errors in GPS RTK positioning, such as orbit uncertainty, and atmospheric effects, constrain the applicable baseline length between reference and mobile user receiver to perhaps 10-15km. This constraint has led to the development of networkbased RTK techniques to model such distance-dependent errors. Although these errors can be effectively mitigated by network-based techniques, the residual errors, attributed to imperfect network functional models, in practice, affect the positioning performance. Since it is too difficult for the functional model to define and/or handle the residual errors, an alternative approach that can be used is to account for these errors (and observation noise) within the stochastic model. In this study, an online stochastic modelling technique for network-based GPS RTK positioning is introduced to adaptively estimate the stochastic model in real time. The basis of the method is to utilise the residuals of the previous segment results in order to estimate the stochastic model at the current epoch. Experimental test results indicate that the proposed stochastic modelling technique improves the performance of the least squares estimation and ambiguity resolution.
Native Instruments MASCHINE MIKRO MK3用户手册说明书

The information in this document is subject to change without notice and does not represent a commitment on the part of Native Instruments GmbH. The software described by this docu-ment is subject to a License Agreement and may not be copied to other media. No part of this publication may be copied, reproduced or otherwise transmitted or recorded, for any purpose, without prior written permission by Native Instruments GmbH, hereinafter referred to as Native Instruments.“Native Instruments”, “NI” and associated logos are (registered) trademarks of Native Instru-ments GmbH.ASIO, VST, HALion and Cubase are registered trademarks of Steinberg Media Technologies GmbH.All other product and company names are trademarks™ or registered® trademarks of their re-spective holders. Use of them does not imply any affiliation with or endorsement by them.Document authored by: David Gover and Nico Sidi.Software version: 2.8 (02/2019)Hardware version: MASCHINE MIKRO MK3Special thanks to the Beta Test Team, who were invaluable not just in tracking down bugs, but in making this a better product.NATIVE INSTRUMENTS GmbH Schlesische Str. 29-30D-10997 Berlin Germanywww.native-instruments.de NATIVE INSTRUMENTS North America, Inc. 6725 Sunset Boulevard5th FloorLos Angeles, CA 90028USANATIVE INSTRUMENTS K.K.YO Building 3FJingumae 6-7-15, Shibuya-ku, Tokyo 150-0001Japanwww.native-instruments.co.jp NATIVE INSTRUMENTS UK Limited 18 Phipp StreetLondon EC2A 4NUUKNATIVE INSTRUMENTS FRANCE SARL 113 Rue Saint-Maur75011 ParisFrance SHENZHEN NATIVE INSTRUMENTS COMPANY Limited 5F, Shenzhen Zimao Center111 Taizi Road, Nanshan District, Shenzhen, GuangdongChina© NATIVE INSTRUMENTS GmbH, 2019. All rights reserved.Table of Contents1Welcome to MASCHINE (23)1.1MASCHINE Documentation (24)1.2Document Conventions (25)1.3New Features in MASCHINE 2.8 (26)1.4New Features in MASCHINE 2.7.10 (28)1.5New Features in MASCHINE 2.7.8 (29)1.6New Features in MASCHINE 2.7.7 (29)1.7New Features in MASCHINE 2.7.4 (31)1.8New Features in MASCHINE 2.7.3 (33)2Quick Reference (35)2.1MASCHINE Project Overview (35)2.1.1Sound Content (35)2.1.2Arrangement (37)2.2MASCHINE Hardware Overview (40)2.2.1MASCHINE MIKRO Hardware Overview (40)2.2.1.1Browser Section (41)2.2.1.2Edit Section (42)2.2.1.3Performance Section (43)2.2.1.4Transport Section (45)2.2.1.5Pad Section (46)2.2.1.6Rear Panel (50)2.3MASCHINE Software Overview (51)2.3.1Header (52)2.3.2Browser (54)2.3.3Arranger (56)2.3.4Control Area (59)2.3.5Pattern Editor (60)3Basic Concepts (62)3.1Important Names and Concepts (62)3.2Adjusting the MASCHINE User Interface (65)3.2.1Adjusting the Size of the Interface (65)3.2.2Switching between Ideas View and Song View (66)3.2.3Showing/Hiding the Browser (67)3.2.4Showing/Hiding the Control Lane (67)3.3Common Operations (68)3.3.1Adjusting Volume, Swing, and Tempo (68)3.3.2Undo/Redo (71)3.3.3Focusing on a Group or a Sound (73)3.3.4Switching Between the Master, Group, and Sound Level (77)3.3.5Navigating Channel Properties, Plug-ins, and Parameter Pages in the Control Area.773.3.6Navigating the Software Using the Controller (82)3.3.7Using Two or More Hardware Controllers (82)3.3.8Loading a Recent Project from the Controller (84)3.4Native Kontrol Standard (85)3.5Stand-Alone and Plug-in Mode (86)3.5.1Differences between Stand-Alone and Plug-in Mode (86)3.5.2Switching Instances (88)3.6Preferences (88)3.6.1Preferences – General Page (89)3.6.2Preferences – Audio Page (93)3.6.3Preferences – MIDI Page (95)3.6.4Preferences – Default Page (97)3.6.5Preferences – Library Page (101)3.6.6Preferences – Plug-ins Page (109)3.6.7Preferences – Hardware Page (114)3.6.8Preferences – Colors Page (114)3.7Integrating MASCHINE into a MIDI Setup (117)3.7.1Connecting External MIDI Equipment (117)3.7.2Sync to External MIDI Clock (117)3.7.3Send MIDI Clock (118)3.7.4Using MIDI Mode (119)3.8Syncing MASCHINE using Ableton Link (120)3.8.1Connecting to a Network (121)3.8.2Joining and Leaving a Link Session (121)4Browser (123)4.1Browser Basics (123)4.1.1The MASCHINE Library (123)4.1.2Browsing the Library vs. Browsing Your Hard Disks (124)4.2Searching and Loading Files from the Library (125)4.2.1Overview of the Library Pane (125)4.2.2Selecting or Loading a Product and Selecting a Bank from the Browser (128)4.2.3Selecting a Product Category, a Product, a Bank, and a Sub-Bank (133)4.2.3.1Selecting a Product Category, a Product, a Bank, and a Sub-Bank on theController (137)4.2.4Selecting a File Type (137)4.2.5Choosing Between Factory and User Content (138)4.2.6Selecting Type and Character Tags (138)4.2.7Performing a Text Search (142)4.2.8Loading a File from the Result List (143)4.3Additional Browsing Tools (148)4.3.1Loading the Selected Files Automatically (148)4.3.2Auditioning Instrument Presets (149)4.3.3Auditioning Samples (150)4.3.4Loading Groups with Patterns (150)4.3.5Loading Groups with Routing (151)4.3.6Displaying File Information (151)4.4Using Favorites in the Browser (152)4.5Editing the Files’ Tags and Properties (155)4.5.1Attribute Editor Basics (155)4.5.2The Bank Page (157)4.5.3The Types and Characters Pages (157)4.5.4The Properties Page (160)4.6Loading and Importing Files from Your File System (161)4.6.1Overview of the FILES Pane (161)4.6.2Using Favorites (163)4.6.3Using the Location Bar (164)4.6.4Navigating to Recent Locations (165)4.6.5Using the Result List (166)4.6.6Importing Files to the MASCHINE Library (169)4.7Locating Missing Samples (171)4.8Using Quick Browse (173)5Managing Sounds, Groups, and Your Project (175)5.1Overview of the Sounds, Groups, and Master (175)5.1.1The Sound, Group, and Master Channels (176)5.1.2Similarities and Differences in Handling Sounds and Groups (177)5.1.3Selecting Multiple Sounds or Groups (178)5.2Managing Sounds (181)5.2.1Loading Sounds (183)5.2.2Pre-listening to Sounds (184)5.2.3Renaming Sound Slots (185)5.2.4Changing the Sound’s Color (186)5.2.5Saving Sounds (187)5.2.6Copying and Pasting Sounds (189)5.2.7Moving Sounds (192)5.2.8Resetting Sound Slots (193)5.3Managing Groups (194)5.3.1Creating Groups (196)5.3.2Loading Groups (197)5.3.3Renaming Groups (198)5.3.4Changing the Group’s Color (199)5.3.5Saving Groups (200)5.3.6Copying and Pasting Groups (202)5.3.7Reordering Groups (206)5.3.8Deleting Groups (207)5.4Exporting MASCHINE Objects and Audio (208)5.4.1Saving a Group with its Samples (208)5.4.2Saving a Project with its Samples (210)5.4.3Exporting Audio (212)5.5Importing Third-Party File Formats (218)5.5.1Loading REX Files into Sound Slots (218)5.5.2Importing MPC Programs to Groups (219)6Playing on the Controller (223)6.1Adjusting the Pads (223)6.1.1The Pad View in the Software (223)6.1.2Choosing a Pad Input Mode (225)6.1.3Adjusting the Base Key (226)6.2Adjusting the Key, Choke, and Link Parameters for Multiple Sounds (227)6.3Playing Tools (229)6.3.1Mute and Solo (229)6.3.2Choke All Notes (233)6.3.3Groove (233)6.3.4Level, Tempo, Tune, and Groove Shortcuts on Your Controller (235)6.3.5Tap Tempo (235)6.4Performance Features (236)6.4.1Overview of the Perform Features (236)6.4.2Selecting a Scale and Creating Chords (239)6.4.3Scale and Chord Parameters (240)6.4.4Creating Arpeggios and Repeated Notes (253)6.4.5Swing on Note Repeat / Arp Output (257)6.5Using Lock Snapshots (257)6.5.1Creating a Lock Snapshot (257)7Working with Plug-ins (259)7.1Plug-in Overview (259)7.1.1Plug-in Basics (259)7.1.2First Plug-in Slot of Sounds: Choosing the Sound’s Role (263)7.1.3Loading, Removing, and Replacing a Plug-in (264)7.1.4Adjusting the Plug-in Parameters (270)7.1.5Bypassing Plug-in Slots (270)7.1.6Using Side-Chain (272)7.1.7Moving Plug-ins (272)7.1.8Alternative: the Plug-in Strip (273)7.1.9Saving and Recalling Plug-in Presets (273)7.1.9.1Saving Plug-in Presets (274)7.1.9.2Recalling Plug-in Presets (275)7.1.9.3Removing a Default Plug-in Preset (276)7.2The Sampler Plug-in (277)7.2.1Page 1: Voice Settings / Engine (279)7.2.2Page 2: Pitch / Envelope (281)7.2.3Page 3: FX / Filter (283)7.2.4Page 4: Modulation (285)7.2.5Page 5: LFO (286)7.2.6Page 6: Velocity / Modwheel (288)7.3Using Native Instruments and External Plug-ins (289)7.3.1Opening/Closing Plug-in Windows (289)7.3.2Using the VST/AU Plug-in Parameters (292)7.3.3Setting Up Your Own Parameter Pages (293)7.3.4Using VST/AU Plug-in Presets (298)7.3.5Multiple-Output Plug-ins and Multitimbral Plug-ins (300)8Using the Audio Plug-in (302)8.1Loading a Loop into the Audio Plug-in (306)8.2Editing Audio in the Audio Plug-in (307)8.3Using Loop Mode (308)8.4Using Gate Mode (310)9Using the Drumsynths (312)9.1Drumsynths – General Handling (313)9.1.1Engines: Many Different Drums per Drumsynth (313)9.1.2Common Parameter Organization (313)9.1.3Shared Parameters (316)9.1.4Various Velocity Responses (316)9.1.5Pitch Range, Tuning, and MIDI Notes (316)9.2The Kicks (317)9.2.1Kick – Sub (319)9.2.2Kick – Tronic (321)9.2.3Kick – Dusty (324)9.2.4Kick – Grit (325)9.2.5Kick – Rasper (328)9.2.6Kick – Snappy (329)9.2.7Kick – Bold (331)9.2.8Kick – Maple (333)9.2.9Kick – Push (334)9.3The Snares (336)9.3.1Snare – Volt (338)9.3.2Snare – Bit (340)9.3.3Snare – Pow (342)9.3.4Snare – Sharp (343)9.3.5Snare – Airy (345)9.3.6Snare – Vintage (347)9.3.7Snare – Chrome (349)9.3.8Snare – Iron (351)9.3.9Snare – Clap (353)9.3.10Snare – Breaker (355)9.4The Hi-hats (357)9.4.1Hi-hat – Silver (358)9.4.2Hi-hat – Circuit (360)9.4.3Hi-hat – Memory (362)9.4.4Hi-hat – Hybrid (364)9.4.5Creating a Pattern with Closed and Open Hi-hats (366)9.5The Toms (367)9.5.1Tom – Tronic (369)9.5.2Tom – Fractal (371)9.5.3Tom – Floor (375)9.5.4Tom – High (377)9.6The Percussions (378)9.6.1Percussion – Fractal (380)9.6.2Percussion – Kettle (383)9.6.3Percussion – Shaker (385)9.7The Cymbals (389)9.7.1Cymbal – Crash (391)9.7.2Cymbal – Ride (393)10Using the Bass Synth (396)10.1Bass Synth – General Handling (397)10.1.1Parameter Organization (397)10.1.2Bass Synth Parameters (399)11Working with Patterns (401)11.1Pattern Basics (401)11.1.1Pattern Editor Overview (402)11.1.2Navigating the Event Area (404)11.1.3Following the Playback Position in the Pattern (406)11.1.4Jumping to Another Playback Position in the Pattern (407)11.1.5Group View and Keyboard View (408)11.1.6Adjusting the Arrange Grid and the Pattern Length (410)11.1.7Adjusting the Step Grid and the Nudge Grid (413)11.2Recording Patterns in Real Time (416)11.2.1Recording Your Patterns Live (417)11.2.2Using the Metronome (419)11.2.3Recording with Count-in (420)11.3Recording Patterns with the Step Sequencer (422)11.3.1Step Mode Basics (422)11.3.2Editing Events in Step Mode (424)11.4Editing Events (425)11.4.1Editing Events with the Mouse: an Overview (425)11.4.2Creating Events/Notes (428)11.4.3Selecting Events/Notes (429)11.4.4Editing Selected Events/Notes (431)11.4.5Deleting Events/Notes (434)11.4.6Cut, Copy, and Paste Events/Notes (436)11.4.7Quantizing Events/Notes (439)11.4.8Quantization While Playing (441)11.4.9Doubling a Pattern (442)11.4.10Adding Variation to Patterns (442)11.5Recording and Editing Modulation (443)11.5.1Which Parameters Are Modulatable? (444)11.5.2Recording Modulation (446)11.5.3Creating and Editing Modulation in the Control Lane (447)11.6Creating MIDI Tracks from Scratch in MASCHINE (452)11.7Managing Patterns (454)11.7.1The Pattern Manager and Pattern Mode (455)11.7.2Selecting Patterns and Pattern Banks (456)11.7.3Creating Patterns (459)11.7.4Deleting Patterns (460)11.7.5Creating and Deleting Pattern Banks (461)11.7.6Naming Patterns (463)11.7.7Changing the Pattern’s Color (465)11.7.8Duplicating, Copying, and Pasting Patterns (466)11.7.9Moving Patterns (469)11.8Importing/Exporting Audio and MIDI to/from Patterns (470)11.8.1Exporting Audio from Patterns (470)11.8.2Exporting MIDI from Patterns (472)11.8.3Importing MIDI to Patterns (474)12Audio Routing, Remote Control, and Macro Controls (483)12.1Audio Routing in MASCHINE (484)12.1.1Sending External Audio to Sounds (485)12.1.2Configuring the Main Output of Sounds and Groups (489)12.1.3Setting Up Auxiliary Outputs for Sounds and Groups (494)12.1.4Configuring the Master and Cue Outputs of MASCHINE (497)12.1.5Mono Audio Inputs (502)12.1.5.1Configuring External Inputs for Sounds in Mix View (503)12.2Using MIDI Control and Host Automation (506)12.2.1Triggering Sounds via MIDI Notes (507)12.2.2Triggering Scenes via MIDI (513)12.2.3Controlling Parameters via MIDI and Host Automation (514)12.2.4Selecting VST/AU Plug-in Presets via MIDI Program Change (522)12.2.5Sending MIDI from Sounds (523)12.3Creating Custom Sets of Parameters with the Macro Controls (527)12.3.1Macro Control Overview (527)12.3.2Assigning Macro Controls Using the Software (528)13Controlling Your Mix (535)13.1Mix View Basics (535)13.1.1Switching between Arrange View and Mix View (535)13.1.2Mix View Elements (536)13.2The Mixer (537)13.2.1Displaying Groups vs. Displaying Sounds (539)13.2.2Adjusting the Mixer Layout (541)13.2.3Selecting Channel Strips (542)13.2.4Managing Your Channels in the Mixer (543)13.2.5Adjusting Settings in the Channel Strips (545)13.2.6Using the Cue Bus (549)13.3The Plug-in Chain (551)13.4The Plug-in Strip (552)13.4.1The Plug-in Header (554)13.4.2Panels for Drumsynths and Internal Effects (556)13.4.3Panel for the Sampler (557)13.4.4Custom Panels for Native Instruments Plug-ins (560)13.4.5Undocking a Plug-in Panel (Native Instruments and External Plug-ins Only) (564)14Using Effects (567)14.1Applying Effects to a Sound, a Group or the Master (567)14.1.1Adding an Effect (567)14.1.2Other Operations on Effects (574)14.1.3Using the Side-Chain Input (575)14.2Applying Effects to External Audio (578)14.2.1Step 1: Configure MASCHINE Audio Inputs (578)14.2.2Step 2: Set up a Sound to Receive the External Input (579)14.2.3Step 3: Load an Effect to Process an Input (579)14.3Creating a Send Effect (580)14.3.1Step 1: Set Up a Sound or Group as Send Effect (581)14.3.2Step 2: Route Audio to the Send Effect (583)14.3.3 A Few Notes on Send Effects (583)14.4Creating Multi-Effects (584)15Effect Reference (587)15.1Dynamics (588)15.1.1Compressor (588)15.1.2Gate (591)15.1.3Transient Master (594)15.1.4Limiter (596)15.1.5Maximizer (600)15.2Filtering Effects (603)15.2.1EQ (603)15.2.2Filter (605)15.2.3Cabinet (609)15.3Modulation Effects (611)15.3.1Chorus (611)15.3.2Flanger (612)15.3.3FM (613)15.3.4Freq Shifter (615)15.3.5Phaser (616)15.4Spatial and Reverb Effects (617)15.4.1Ice (617)15.4.2Metaverb (619)15.4.3Reflex (620)15.4.4Reverb (Legacy) (621)15.4.5Reverb (623)15.4.5.1Reverb Room (623)15.4.5.2Reverb Hall (626)15.4.5.3Plate Reverb (629)15.5Delays (630)15.5.1Beat Delay (630)15.5.2Grain Delay (632)15.5.3Grain Stretch (634)15.5.4Resochord (636)15.6Distortion Effects (638)15.6.1Distortion (638)15.6.2Lofi (640)15.6.3Saturator (641)15.7Perform FX (645)15.7.1Filter (646)15.7.2Flanger (648)15.7.3Burst Echo (650)15.7.4Reso Echo (653)15.7.5Ring (656)15.7.6Stutter (658)15.7.7Tremolo (661)15.7.8Scratcher (664)16Working with the Arranger (667)16.1Arranger Basics (667)16.1.1Navigating Song View (670)16.1.2Following the Playback Position in Your Project (672)16.1.3Performing with Scenes and Sections using the Pads (673)16.2Using Ideas View (677)16.2.1Scene Overview (677)16.2.2Creating Scenes (679)16.2.3Assigning and Removing Patterns (679)16.2.4Selecting Scenes (682)16.2.5Deleting Scenes (684)16.2.6Creating and Deleting Scene Banks (685)16.2.7Clearing Scenes (685)16.2.8Duplicating Scenes (685)16.2.9Reordering Scenes (687)16.2.10Making Scenes Unique (688)16.2.11Appending Scenes to Arrangement (689)16.2.12Naming Scenes (689)16.2.13Changing the Color of a Scene (690)16.3Using Song View (692)16.3.1Section Management Overview (692)16.3.2Creating Sections (694)16.3.3Assigning a Scene to a Section (695)16.3.4Selecting Sections and Section Banks (696)16.3.5Reorganizing Sections (700)16.3.6Adjusting the Length of a Section (702)16.3.6.1Adjusting the Length of a Section Using the Software (703)16.3.6.2Adjusting the Length of a Section Using the Controller (705)16.3.7Clearing a Pattern in Song View (705)16.3.8Duplicating Sections (705)16.3.8.1Making Sections Unique (707)16.3.9Removing Sections (707)16.3.10Renaming Scenes (708)16.3.11Clearing Sections (710)16.3.12Creating and Deleting Section Banks (710)16.3.13Working with Patterns in Song view (710)16.3.13.1Creating a Pattern in Song View (711)16.3.13.2Selecting a Pattern in Song View (711)16.3.13.3Clearing a Pattern in Song View (711)16.3.13.4Renaming a Pattern in Song View (711)16.3.13.5Coloring a Pattern in Song View (712)16.3.13.6Removing a Pattern in Song View (712)16.3.13.7Duplicating a Pattern in Song View (712)16.3.14Enabling Auto Length (713)16.3.15Looping (714)16.3.15.1Setting the Loop Range in the Software (714)16.3.15.2Activating or Deactivating a Loop Using the Controller (715)16.4Playing with Sections (715)16.4.1Jumping to another Playback Position in Your Project (716)16.5Triggering Sections or Scenes via MIDI (717)16.6The Arrange Grid (719)16.7Quick Grid (720)17Sampling and Sample Mapping (722)17.1Opening the Sample Editor (722)17.2Recording Audio (724)17.2.1Opening the Record Page (724)17.2.2Selecting the Source and the Recording Mode (725)17.2.3Arming, Starting, and Stopping the Recording (729)17.2.5Checking Your Recordings (731)17.2.6Location and Name of Your Recorded Samples (734)17.3Editing a Sample (735)17.3.1Using the Edit Page (735)17.3.2Audio Editing Functions (739)17.4Slicing a Sample (743)17.4.1Opening the Slice Page (743)17.4.2Adjusting the Slicing Settings (744)17.4.3Manually Adjusting Your Slices (746)17.4.4Applying the Slicing (750)17.5Mapping Samples to Zones (754)17.5.1Opening the Zone Page (754)17.5.2Zone Page Overview (755)17.5.3Selecting and Managing Zones in the Zone List (756)17.5.4Selecting and Editing Zones in the Map View (761)17.5.5Editing Zones in the Sample View (765)17.5.6Adjusting the Zone Settings (767)17.5.7Adding Samples to the Sample Map (770)18Appendix: Tips for Playing Live (772)18.1Preparations (772)18.1.1Focus on the Hardware (772)18.1.2Customize the Pads of the Hardware (772)18.1.3Check Your CPU Power Before Playing (772)18.1.4Name and Color Your Groups, Patterns, Sounds and Scenes (773)18.1.5Consider Using a Limiter on Your Master (773)18.1.6Hook Up Your Other Gear and Sync It with MIDI Clock (773)18.1.7Improvise (773)18.2Basic Techniques (773)18.2.1Use Mute and Solo (773)18.2.2Create Variations of Your Drum Patterns in the Step Sequencer (774)18.2.3Use Note Repeat (774)18.2.4Set Up Your Own Multi-effect Groups and Automate Them (774)18.3Special Tricks (774)18.3.1Changing Pattern Length for Variation (774)18.3.2Using Loops to Cycle Through Samples (775)18.3.3Load Long Audio Files and Play with the Start Point (775)19Troubleshooting (776)19.1Knowledge Base (776)19.2Technical Support (776)19.3Registration Support (777)19.4User Forum (777)20Glossary (778)Index (786)1Welcome to MASCHINEThank you for buying MASCHINE!MASCHINE is a groove production studio that implements the familiar working style of classi-cal groove boxes along with the advantages of a computer based system. MASCHINE is ideal for making music live, as well as in the studio. It’s the hands-on aspect of a dedicated instru-ment, the MASCHINE hardware controller, united with the advanced editing features of the MASCHINE software.Creating beats is often not very intuitive with a computer, but using the MASCHINE hardware controller to do it makes it easy and fun. You can tap in freely with the pads or use Note Re-peat to jam along. Alternatively, build your beats using the step sequencer just as in classic drum machines.Patterns can be intuitively combined and rearranged on the fly to form larger ideas. You can try out several different versions of a song without ever having to stop the music.Since you can integrate it into any sequencer that supports VST, AU, or AAX plug-ins, you can reap the benefits in almost any software setup, or use it as a stand-alone application. You can sample your own material, slice loops and rearrange them easily.However, MASCHINE is a lot more than an ordinary groovebox or sampler: it comes with an inspiring 7-gigabyte library, and a sophisticated, yet easy to use tag-based Browser to give you instant access to the sounds you are looking for.What’s more, MASCHINE provides lots of options for manipulating your sounds via internal ef-fects and other sound-shaping possibilities. You can also control external MIDI hardware and 3rd-party software with the MASCHINE hardware controller, while customizing the functions of the pads, knobs and buttons according to your needs utilizing the included Controller Editor application. We hope you enjoy this fantastic instrument as much as we do. Now let’s get go-ing!—The MASCHINE team at Native Instruments.MASCHINE Documentation1.1MASCHINE DocumentationNative Instruments provide many information sources regarding MASCHINE. The main docu-ments should be read in the following sequence:1.MASCHINE MIKRO Quick Start Guide: This animated online guide provides a practical ap-proach to help you learn the basic of MASCHINE MIKRO. The guide is available from theNative Instruments website: https:///maschine-mikro-quick-start/2.MASCHINE Manual (this document): The MASCHINE Manual provides you with a compre-hensive description of all MASCHINE software and hardware features.Additional documentation sources provide you with details on more specific topics:►Online Support Videos: You can find a number of support videos on The Official Native In-struments Support Channel under the following URL: https:///NIsupport-EN. We recommend that you follow along with these instructions while the respective ap-plication is running on your computer.Other Online Resources:If you are experiencing problems related to your Native Instruments product that the supplied documentation does not cover, there are several ways of getting help:▪Knowledge Base▪User Forum▪Technical Support▪Registration SupportYou will find more information on these subjects in the chapter Troubleshooting.Document Conventions1.2Document ConventionsThis section introduces you to the signage and text highlighting used in this manual. This man-ual uses particular formatting to point out special facts and to warn you of potential issues.The icons introducing these notes let you see what kind of information is to be expected:This document uses particular formatting to point out special facts and to warn you of poten-tial issues. The icons introducing the following notes let you see what kind of information canbe expected:Furthermore, the following formatting is used:▪Text appearing in (drop-down) menus (such as Open…, Save as… etc.) in the software andpaths to locations on your hard disk or other storage devices is printed in italics.▪Text appearing elsewhere (labels of buttons, controls, text next to checkboxes etc.) in thesoftware is printed in blue. Whenever you see this formatting applied, you will find thesame text appearing somewhere on the screen.▪Text appearing on the displays of the controller is printed in light grey. Whenever you seethis formatting applied, you will find the same text on a controller display.▪Text appearing on labels of the hardware controller is printed in orange. Whenever you seethis formatting applied, you will find the same text on the controller.▪Important names and concepts are printed in bold.▪References to keys on your computer’s keyboard you’ll find put in square brackets (e.g.,“Press [Shift] + [Enter]”).►Single instructions are introduced by this play button type arrow.→Results of actions are introduced by this smaller arrow.Naming ConventionThroughout the documentation we will refer to MASCHINE controller (or just controller) as the hardware controller and MASCHINE software as the software installed on your computer.The term “effect” will sometimes be abbreviated as “FX” when referring to elements in the MA-SCHINE software and hardware. These terms have the same meaning.Button Combinations and Shortcuts on Your ControllerMost instructions will use the “+” sign to indicate buttons (or buttons and pads) that must be pressed simultaneously, starting with the button indicated first. E.g., an instruction such as:“Press SHIFT + PLAY”means:1.Press and hold SHIFT.2.While holding SHIFT, press PLAY and release it.3.Release SHIFT.1.3New Features in MASCHINE2.8The following new features have been added to MASCHINE: Integration▪Browse on , create your own collections of loops and one-shots and send them directly to the MASCHINE browser.Improvements to the Browser▪Samples are now cataloged in separate Loops and One-shots tabs in the Browser.▪Previews of loops selected in the Browser will be played in sync with the current project.When a loop is selected with Prehear turned on, it will begin playing immediately in-sync with the project if transport is running. If a loop preview starts part-way through the loop, the loop will play once more for its full length to ensure you get to hear the entire loop once in context with your project.▪Filters and product selections will be remembered when switching between content types and Factory/User Libraries in the Browser.▪Browser content synchronization between multiple running instances. When running multi-ple instances of MASCHINE, either as Standalone and/or as a plug-in, updates to the Li-brary will be synced across the instances. For example, if you delete a sample from your User Library in one instance, the sample will no longer be present in the other instances.Similarly, if you save a preset in one instance, that preset will then be available in the oth-er instances, too.▪Edits made to samples in the Factory Libraries will be saved to the Standard User Directo-ry.For more information on these new features, refer to the following chapter ↑4, Browser. Improvements to the MASCHINE MIKRO MK3 Controller▪You can now set sample Start and End points using the controller. For more information refer to ↑17.3.1, Using the Edit Page.Improved Support for A-Series Keyboards▪When Browsing with A-Series keyboards, you can now jump quickly to the results list by holding SHIFT and pushing right on the 4D Encoder.▪When Browsing with A-Series keyboards, you can fast scroll through the Browser results list by holding SHIFT and twisting the 4D Encoder.▪Mute and Solo Sounds and Groups from A-Series keyboards. Sounds are muted in TRACK mode while Groups are muted in IDEAS.。
ARM系列文档

Cortex™-A9 NEON™ Media ProcessingEngineRevision: r4p0Technical Reference ManualCortex-A9 NEON Media Processing EngineTechnical Reference ManualCopyright ©2008-2012 ARM. All rights reserved.Release InformationThe following changes have been made to this book.Change history Date Issue Confidentiality Change04 April 2008A Non-Confidential First release for r0p010 July 2008B Non-Confidential Restricted Access Second release for r0p012 Dec 2008C Non-Confidential Restricted Access First release for r1p024 September 2009D Non-Confidential Restricted Access First release for r2p027 November 2009E Non-Confidential Unrestricted Access Second release for r2p027 April 2010F Non-Confidential Unrestricted Access First release for r2p221 July 2011G Non-Confidential First release for r3p026 March 2012G2Non-Confidential First release for r4p0 Proprietary NoticeWords and logos marked with ® or ™ are registered trademarks or trademarks of ARM® in the EU and other countries, except as otherwise stated below in this proprietary notice. Other brands and names mentioned herein may be the trademarks of their respective owners.Neither the whole nor any part of the information contained in, or the product described in, this document may be adapted or reproduced in any material form except with the prior written permission of the copyright holder.The product described in this document is subject to continuous developments and improvements. All particulars of the product and its use contained in this document are given by ARM in good faith. However, all warranties implied or expressed, including but not limited to implied warranties of merchantability, or fitness for purpose, are excluded.This document is intended only to assist the reader in the use of the product. ARM shall not be liable for any loss or damage arising from the use of any information in this document, or any error or omission in such information, or any incorrect use of the product.Where the term ARM is used it means “ARM or any of its subsidiaries as appropriate”.Confidentiality StatusThis document is Non-Confidential. The right to use, copy and disclose this document may be subject to license restrictions in accordance with the terms of the agreement entered into by ARM and the party that ARM delivered this document to.Product StatusThe information in this document is final, that is for a developed product.Web AddressContentsCortex-A9 NEON Media Processing Engine Technical Reference ManualPrefaceAbout this book (v)Feedback (viii)Chapter1Introduction1.1About the Cortex-A9 NEON MPE ............................................................................ 1-21.2Applications .............................................................................................................1-41.3Product revisions ..................................................................................................... 1-5Chapter2Programmers Model2.1About this programmers model ................................................................................ 2-22.2New Advanced SIMD and VFP features .................................................................. 2-42.3Supported formats ................................................................................................... 2-52.4Advanced SIMD and VFP register access ............................................................... 2-62.5Register summary .................................................................................................. 2-102.6Register descriptions ............................................................................................. 2-11Chapter3Instruction Timing3.1About instruction cycle timing .................................................................................. 3-23.2Writing optimal VFP and Advanced SIMD code ...................................................... 3-33.3Cortex-A9 NEON MPE instructions .........................................................................3-43.4Instruction-specific scheduling ................................................................................. 3-9Appendix A RevisionsPrefaceThis preface introduces the Cortex-A9 NEON™ Media Processing Engine (MPE) TechnicalReference Manual. It contains the following sections:•About this book on page v•Feedback on page viii.About this bookThis book is for the Cortex-A9 NEON MPE.Product revision statusThe r n p n identifier indicates the revision status of the product described in this book, where:r n Identifies the major revision of the product.p n Identifies the minor revision or modification status of the product.Intended audienceThis book is written for system designers, system integrators, and verification engineers whoare designing a System-on-Chip (SoC) device that uses the Cortex-A9 NEON MPE. The bookdescribes the external functionality of the Cortex-A9 MPE.Using this bookThis book is organized into the following chapters:Chapter1 IntroductionRead this for an introduction to the Cortex-A9 implementation of the ARMAdvanced SIMD media processing architecture.Chapter2 Programmers ModelRead this for a description of the Cortex-A9 NEON programmers model.Chapter3 Instruction TimingRead this for a description of the cycle timings of instructions on the Cortex-A9NEON MPE.Appendix A RevisionsRead this for a description of the technical changes between released issues of thisbook.GlossaryThe ARM Glossary is a list of terms used in ARM documentation, together with definitions forthose terms. The ARM Glossary does not contain terms that are industry standard unless theARM meaning differs from the generally accepted meaning.See ARM Glossary, /help/topic/com.arm.doc.aeg0014-/index.html. ConventionsConventions that this book can use are described in:•Typographical conventionsTypographical conventionsThe typographical conventions are:italic Introduces special terminology, denotes cross-references, and citations.bold Highlights interface elements, such as menu names. Denotes signalnames. Also used for terms in descriptive lists, where appropriate.monospace Denotes text that you can enter at the keyboard, such as commands, fileand program names, and source code.monospace Denotes a permitted abbreviation for a command or option. You can enterthe underlined text instead of the full command or option name.monospace italic Denotes arguments to monospace text where the argument is to bereplaced by a specific value.monospace bold Denotes language keywords when used outside example code.< and > Enclose replaceable terms for assembler syntax where they appear in codeor code fragments. For example:MRC p15, 0 <Rd>, <CRn>, <CRm>, <Opcode_2>SMALL CAPITALS Applies when the relevant term is used in body text. For example:IMPLEMENTATION DEFINED, IMPLEMENTATION SPECIFIC,UNKNOWN, and UNPREDICTABLE.Additional readingThis section lists publications by ARM and by third parties.See Infocenter, , for access to ARM documentation.ARM publicationsThis book contains information that is specific to this product. See the following documents forother relevant information:•Cortex-A9 Technical Reference Manual (ARM DDI0388)•Cortex-A9 MPCore Technical Reference Manual (ARM DDI0407)•Cortex-A9 Floating-Point Unit Technical Reference Manual (ARM DDI0408)•Cortex-A9 MBIST Controller Technical Reference Manual (ARM DDI0414)•Cortex-A9 Configuration and Sign-Off Guide (ARM DII0146)•CoreSight™ PTM™-A9 Technical Reference Manual (ARM DDI0401)•CoreSight PTM-A9 Configuration and Sign-Off Guide (ARM DII0161)•CoreSight PTM-A9 Integration Manual (ARM DII0162)•CoreSight Program Flow Trace Architecture Specification (ARM IHI0035)•AMBA® Level 2 Cache Controller (L2C-310) Technical Reference Manual (ARM DDI0246)•L220 Cache Controller Technical Reference Manual (ARM DDI0329)•AMBA AXI Protocol Specification (ARM IHI0022)•AMBA Specification (ARM IHI0011)•ARM Architecture Reference Manual, ARMv7-A and ARMv7-R edition (ARM DDI0406)•RealView™ Compilation Tools Developer Guide (ARM DUI0203)•RealView ICE and RealView Trace User Guide (ARM DUI0155)•Intelligent Energy Controller Technical Overview (ARM DTO0005).Other publicationsThis section lists relevant documents published by third parties:•ANSI/IEEE Std 754-1985, IEEE Standard for Binary Floating-Point Arithmetic.FeedbackARM welcomes feedback on this product and its documentation.Feedback on this productIf you have any comments or suggestions about this product, contact your supplier and give:•The product name.•The product revision or version.•An explanation with as much information as you can provide. Include symptoms anddiagnostic procedures if appropriate.Feedback on contentIf you have comments on content then send an e-mail to errata@. Give:•the title•the number, ARM DDI 0409H•the page numbers to which your comments apply• a concise explanation of your comments.ARM also welcomes general suggestions for additions and improvements.NoteA RM tests the PDF only in Adobe Acrobat and Acrobat Reader, and cannot guarantee thequality of the represented document when used with any other PDF reader.Chapter1IntroductionThis chapter introduces the Cortex-A9 implementation of the ARM Advanced SIMD mediaprocessing architecture. It contains the following sections:•About the Cortex-A9 NEON MPE on page1-2•Applications on page1-4•Product revisions on page1-5.Introduction1.1About the Cortex-A9 NEON MPEThe Cortex-A9 NEON MPE extends the Cortex-A9 functionality to provide support for theARM v7 Advanced SIMD and Vector Floating-Point v3 (VFPv3) instruction sets. TheCortex-A9 NEON MPE supports all addressing modes and data-processing operationsdescribed in the ARM Architecture Reference Manual.The Cortex-A9 NEON MPE features are:•SIMD and scalar single-precision floating-point computation•scalar double-precision floating-point computation•SIMD and scalar half-precision floating-point conversion•8, 16, 32, and 64-bit signed and unsigned integer SIMD computation•8 or 16-bit polynomial computation for single-bit coefficients•structured data load capabilities•dual issue with Cortex-A9 processor ARM or Thumb instructions•independent pipelines for VFPv3 and Advanced SIMD instructions•large, shared register file, addressable as:—thirty-two 32-bit S (single) registers—thirty-two 64-bit D (double) registers—sixteen 128-bit Q (quad) registers.See the ARM Architecture Reference Manual for details of the information that the MPEcan hold in the different register formats.The Cortex-A9 NEON MPE provides high-performance SIMD vector operations for:•unsigned and signed integers•single bit coefficient polynomials•single-precision floating-point values.The operations include:•addition and subtraction•multiplication with optional accumulation•maximum or minimum value driven lane selection operations•inverse square-root approximation•comprehensive data-structure load instructions, including register-bank-resident tablelookup.See the ARM Architecture Reference Manual for details of the Advanced SIMD instructions.NoteT he Advanced SIMD architecture extension, its associated implementations, and supportingsoftware, are commonly referred to as NEON™ technology.1.1.1VFPv3 architecture hardware supportThe Cortex-A9 NEON MPE hardware supports single and double-precision add, subtract,multiply, divide, multiply and accumulate, and square root operations as described in the ARMVFPv3 architecture. It provides conversions between 16-bit, 32-bit and 64-bit floating-pointformats and ARM integer word formats, with special operations to perform conversions inround-towards-zero mode for high-level language support.All instructions are available in both the ARM and Thumb instruction sets supported by the Cortex-A9 processor family.The Cortex-A9 NEON MPE provides an optimized solution in performance, power, and area for embedded and media intensive applications.ARMv7 deprecates the use of VFP vector mode. The Cortex-A9 NEON MPE hardware does not support VFP vector operations. In this manual, the term vector refers to Advanced SIMD integer, polynomial and single-precision vector operations. The Cortex-A9 NEON MPE provides high speed VFP operation without support code. However, if an application requires VFP vector operation, then it must use support code. See the ARM Architecture Reference Manual for information on VFP vector operation support.NoteT his manual gives information specific to the Cortex-A9 NEON MPE implementation of the ARM Advanced SIMD and VFPv3 extensions. See the ARM Architecture Reference Manual for full instruction set and usage details.1.2ApplicationsThe Cortex-A9 NEON MPE provides mixed-data type SIMD and high-performance scalarfloating-point computation suitable for a wide spectrum of applications such as:•personal digital assistants and smartphones for graphics, voice compression anddecompression, user interfaces, Java interpretation, and Just In Time (JIT) compilation •games machines for intensive three-dimensional graphics, digital audio and in-gamephysics effects such as gravity•printers and MultiFunction Peripheral (MFP) controllers for high-definition colorrendering•set-top boxes for high-end digital audio and digital video, and interactivethree-dimensional user interfaces•automotive applications for engine management, power train computation, and in-carentertainment and navigation.1.3Product revisionsThis section describes the differences in functionality between product revisions:r0p0 - r1p0 There are no functionality changes although you must use the Cortex-A9 revisionr1p0 design with revision r1p0 NEON MPE.r1p0 - r2p0 There are no functionality changes although you must use the Cortex-A9 revisionr2p0 design with this revision r2p0 NEON MPE.r2p0 - r2p1 There are no functionality changes although you must use the Cortex-A9 revisionr2p1 design with this revision r2p1 NEON MPE.r2p1 - r2p2 There are no functionality changes.r2p2 - r3p0 There are no functionality changes.r3p0 - r4p0 There are no functionality changes.Chapter2Programmers ModelThis chapter describes the Cortex-A9 NEON MPE programmers model. It contains the followingsections:•About this programmers model on page2-2•New Advanced SIMD and VFP features on page2-4•Supported formats on page2-5•Advanced SIMD and VFP register access on page2-6•Register summary on page2-10•Register descriptions on page2-11.2.1About this programmers modelThis section introduces the VFPv3 and Advanced SIMD implementation provided by theCortex-A9 NEON MPE. In addition it provides information on initializing the Cortex-A9NEON MPE ready for application code execution. These are described in:•Advanced SIMD and VFP feature identification registers•Enabling Advanced SIMD and floating-point support.In addition to features provided in previous combined Advanced SIMD and VFPimplementations, the Cortex-A9 NEON MPE provides:•half-precision, 16-bit, floating-point value conversion•support for emulation of VFPv3-D32 and VFPv3-D16.See the ARM Architecture Reference Manual for more information.2.1.1Advanced SIMD and VFP feature identification registersThe Cortex-A9 NEON MPE implements the ARMv7 Advanced SIMD and VFP extensions.Software can identify these extensions and the features they provide, using the featureidentification registers. The extensions are in the coprocessor space for coprocessors CP10 andCP11. You can access the registers using the VMRS and VMSR instructions, for example:VMRS <Rd>, FPSID ; Read Floating-Point System ID RegisterVMRS <Rd>, MVFR1 ; Read Media and VFP Feature Register 1VMSR FPSCR, <Rt> ; Write Floating-Point System Control RegisterSee Advanced SIMD and VFP register access on page2-6 for a description of the registers.In addition there are coprocessor access control registers. See Non-secure Access ControlRegister on page2-7 and Coprocessor Access Control Register on page2-6.2.1.2Enabling Advanced SIMD and floating-point supportFrom reset, both the Advanced SIMD and VFP extensions are disabled. Any attempt to executeeither a NEON or VFP instruction results in an Undefined Instruction exception being taken. Toenable software to access Advanced SIMD and VFP features ensure that:•Access to CP10 and CP11 is enabled for the appropriate privilege level. See CoprocessorAccess Control Register on page2-6.•If Non-secure access to the Advanced SIMD features or VFP features is required, theaccess flags for CP10 and CP11 in the NSACR must be set to 1. See Non-secure AccessControl Register on page2-7.In addition, software must set the FPEXC.EN bit to 1 to enable most Advanced SIMD and VFPoperations. See Floating-Point Exception Register on page2-13.When Advanced SIMD and VFP operation is disabled because FPEXC.EN is 0, all AdvancedSIMD and VFP instructions are treated as undefined instructions except for execution of thefollowing in privileged modes:• a VMSR to the FPEXC or FPSID register• a VMRS from the FPEXC, FPSID, MVFR0 or MVFR1 registers.Example2-1 on page2-3 shows how to enable the Advanced SIMD and VFP in ARM UnifiedAssembly Language (UAL). This code must be executed in privileged mode.Example2-1 Enabling Advanced SIMD and VFP MRC p15,0,r0,c1,c0,2 ; Read CPACR into r0ORR r0,r0,#(3<<20) ; OR in User and Privileged access for CP10ORR r0,r0,#(3<<22) ; OR in User and Privileged access for CP11BIC r0, r0, #(3<<30) ; Clear ASEDIS/D32DIS if setMCR p15,0,r0,c1,c0,2 ; Store new access permissions into CPACRISB ; Ensure side-effect of CPACR is visibleMOV r0,#(1<<30) ; Create value with FPEXC (bit 30) set in r0VMSR FPEXC,r0 ; Enable VFP and SIMD extensionsAt this point the Cortex-A9 processor can execute Advanced SIMD and VFP instructions.NoteO peration is U NPREDICTABLE if you configure the Coprocessor Access Control Register (CPACR) so that CP10 and CP11 do not have identical access permissions.2.2New Advanced SIMD and VFP featuresThe Cortex-A9 NEON MPE implements the following new features in the ARMv7 AdvancedSIMD and VFP architectures:•Half-precision floating-point value conversion•Independent Advanced SIMD and VFP disable•Dynamically configurable VFP register bank size.Full details of the new instructions and control register fields are in the ARM ArchitectureReference Manual.2.2.1Half-precision floating-point value conversionThe half-precision floating-point value conversion adds support for both IEEE and the commongraphic representation, referred to as alternative-half-precision representation, of 16-bitfloating-point values. This provides a smaller memory footprint for applications requiring largenumbers of lower-precision floating-point values to be stored, while avoiding the overhead ofconversion in software.Additional VFP and Advanced SIMD instructions enable conversion of both individual valuesand vectors of values to and from single-precision floating-point representation. These valuescan then be processed using the rest of the VFP and Advanced SIMD instructions.See Floating-Point Status and Control Register on page2-11 for how to select IEEE oralternative half-precision modes.2.2.2Independent Advanced SIMD and VFP disableThe independent Advanced SIMD disables permit Cortex-A9 implementations with Cortex-A9NEON MPE to behave as though only the VFP extension were present. This lets you enableoptimal operating-system task scheduling between Cortex-A9 multi-processor clusterscontaining both Cortex-A9 NEON MPE and floating-point only units.The Cortex-A9 processor provides support for preventing use of this feature throughNon-secure access. See Non-secure Access Control Register on page2-7 and CoprocessorAccess Control Register on page2-6.2.2.3Dynamically configurable VFP register bank sizeThe dynamically configurable VFP register bank size provides additional support for bothVFPv3-D16 and VFPv3-D32 mixed multiprocessor clusters. Cortex-A9 NEON MPEimplements thirty-two 64-bit double-precision registers. VFP-only implementations are onlyrequired to support sixteen double-precision registers. This register bank disable control enablesemulation of a 16-entry double-precision register file, providing both enhanced compatibilityand more flexible task scheduling.Additional control is provided in the Non-Secure Access Control Register. See Non-secureAccess Control Register on page2-7 and Coprocessor Access Control Register on page2-6.2.3Supported formatsTable2-1 shows the formats supported for each of the Advanced SIMD and VFPv3 instructionsets implemented by the Cortex-A9 NEON MPE. All signed integers are two's complementrepresentations.Table2-1 Supported number formatsFormat Advanced SIMD VFPv38-bit signed/unsigned integer Yes No16-bit signed/unsigned integer Yes No32-bit signed/unsigned integer Yes Yes a64-bit signed/unsigned integer Yes No16-bit half-precision floating-point Yes a Yes a32-bit single-precision floating-point Yes Yes64-bit double-precision floating-point No Yes8-bit polynomials Yes No16-bit polynomials Yes Noa.For conversion purposes only.2.4Advanced SIMD and VFP register accessTable2-2 shows the system control coprocessor registers, accessed through CP15, thatdetermine access to Advanced SIMD and VFP registers, where:•CRn is the register number within CP15•Op1 is the Opcode_1 value for the register•CRm is the operational register•Op2 is the Opcode_2 value for the register.Table2-2 Coprocessor Access Control registersCRn Op1CRm Op2Name Descriptionc10c02CPACR See Coprocessor Access Control Registerc10c12NSACR See Non-secure Access Control Register on page2-72.4.1Coprocessor Access Control RegisterThe CPACR Register sets access rights for the coprocessors CP10 and CP11, that enable theCortex-A9 NEON MPE functionality. This register also enables software to determine if aparticular coprocessor exists in the system.The CPACR Register is:• a read/write register common to Secure and Non-secure states•accessible in privileged modes only•has a reset value of 0.Figure2-1 shows the CPACR Register bit assignments.Figure2-1 CPACR Register bit assignments Table2-3 shows the CPACR Register bit assignments.Table2-3 Coprocessor Access Control Register bit assignments Bits Field Function[31]ASEDIS Disable Advanced SIMD extension functionality:0 No instructions are disabled.1 Disables all instruction encodings identified in the ARM Architecture Reference Manual asbeing part of the Advanced SIMD extensions but that are not VFPv3 instructions.[30]D32DIS Disable use of D16-D31 of the VFP register file:0 No instructions are disabled.1 Disables all instruction encodings identified in the ARM Architecture Reference Manual asbeing VFPv3 instructions if they access any of registers D16-D31.[29:24]-See the Cortex-A9 Technical Reference Manual.Table2-3 Coprocessor Access Control Register bit assignments (continued) Bits Field Function[23:22]CP11Defines access permissions for the coprocessor. Access denied is the reset condition and is the behavior for nonexistent coprocessors.b00Access denied. Attempted access generates an Undefined Instruction exception.b01Privileged mode access only.b10Reserved.b11Privileged and User mode access.[21:20]CP10Defines access permissions for the coprocessor. Access denied is the reset condition and is the behavior for nonexistent coprocessors.b00Access denied. Attempted access generates an Undefined Instruction exception.b01Privileged mode access only.b10Reserved.b11Privileged and User mode access.[19:0]-See the Cortex-A9 Technical Reference Manual.Access to coprocessors in the Non-secure state depends on the permissions set in the Non-secureAccess Control Register.Attempts to read or write the CPACR Register access bits depend on the corresponding bit foreach coprocessor in Non-secure Access Control Register. Table2-4 shows the results ofattempted access to coprocessor access bits for each mode.Table2-4 Results of access to the CRACR Register NSACR[11:10]Secure privileged Non-secure privileged Secure or Non-secure Userb00R/W RAZ/WI Access prohibited ab01R/W R/W Access prohibited aer privilege access generates an Undefined Instruction exception.To access the CPACR Register, read or write CP15 with:MRC p15, 0,<Rd>, c1, c0, 2 ; Read Coprocessor Access Control RegisterMCR p15, 0,<Rd>, c1, c0, 2 ; Write Coprocessor Access Control RegisterWhen the CPACR is updated, the change to the register is guaranteed to be visible only after thenext Instruction Synchronization Barrier (ISB) instruction. When this register is updated,software must ensure that no instruction that depends on the new or old register values is issuedbefore the ISB instruction.Normally, software uses a read, modify, write sequence to update the CPACR, to avoidunwanted changes to the access settings for other coprocessors.NoteY ou must enable CP10 and CP11 in the CPACR Register before accessing any Advanced SIMDor VFP system registers.2.4.2Non-secure Access Control RegisterThe NSACR Register defines the Non-secure access rights for the Cortex-A9 NEON MPE andother system functionality.The NSACR Register is:• a read/write register in Secure state• a read-only register in Non-secure state•only accessible in privileged modes.Figure2-2 shows the bit assignments of the NSACR Register relevant to the Cortex-A9 MPE.See the Cortex-A9 Technical Reference Manual for details of other fields in this register.Figure2-2 NSACR Register bit assignments Table2-5 shows the NSACR Register bit assignments.Table2-5 NSACR Register bit assignments Bits Field Function[31:16]-See the Cortex-A9 Technical Reference Manual.[15]NSASEDIS Disable Non-secure Advanced SIMD extension functionality:0 Full access provided to CPACR.ASEDIS.1 The CPACR.ASEDIS bit when executing in Non-secure state has a fixed value of 1 andwrites to it are ignored.[14]NSD32DIS Disable Non-secure use of D16-D31 of the VFP register file:0 Full access provided to CPACR.D32DIS.1 The CPACR.D32DIS bit when executing in Non-secure state has a fixed value of 1 andwrites to it are ignored.[13:12]-See the Cortex-A9 Technical Reference Manual.[11]CP11Permission to access coprocessor 11:0 Secure access only. This is the reset value.1 Secure or Non-secure access.[10]CP10Permission to access coprocessor 10:0 Secure access only. This is the reset value.1 Secure or Non-secure access.[9:0]-See the Cortex-A9 Technical Reference Manual.To access the NSACR Register, read or write CP15 with:MRC p15, 0,<Rd>, c1, c1, 2 ; Read Non-secure Access Control Register dataMCR p15, 0,<Rd>, c1, c1, 2 ; Write Non-secure Access Control Register dataTable2-6 on page2-9 shows the results of attempted access for each mode.。
On Sequential Monte Carlo Sampling Methods for Bayesian Filtering

methods, see (Akashi et al., 1975)(Handschin et. al, 1969)(Handschin 1970)(Zaritskii et al., 1975). Possibly owing to the severe computational limitations of the time these Monte Carlo algorithms have been largely neglected until recently. In the late 80’s, massive increases in computational power allowed the rebirth of numerical integration methods for Bayesian filtering (Kitagawa 1987). Current research has now focused on MC integration methods, which have the great advantage of not being subject to the assumption of linearity or Gaussianity in the model, and relevant work includes (M¨ uller 1992)(West, 1993)(Gordon et al., 1993)(Kong et al., 1994)(Liu et al., 1998). The main objective of this article is to include in a unified framework many old and more recent algorithms proposed independently in a number of applied science areas. Both (Liu et al., 1998) and (Doucet, 1997) (Doucet, 1998) underline the central rˆ ole of sequential importance sampling in Bayesian filtering. However, contrary to (Liu et al., 1998) which emphasizes the use of hybrid schemes combining elements of importance sampling with Markov Chain Monte Carlo (MCMC), we focus here on computationally cheaper alternatives. We describe also how it is possible to improve current existing methods via Rao-Blackwellisation for a useful class of dynamic models. Finally, we show how to extend these methods to compute the prediction and fixed-interval smoothing distributions as well as the likelihood. The paper is organised as follows. In section 2, we briefly review the Bayesian filtering problem and classical Bayesian importance sampling is proposed for its solution. We then present a sequential version of this method which allows us to obtain a general recursive MC filter: the sequential importance sampling (SIS) filter. Under a criterion of minimum conditional variance of the importance weights, we obtain the optimal importance function for this method. Unfortunately, for numerous models of applied interest the optimal importance function leads to non-analytic importance weights, and hence we propose several suboptimal distributions and show how to obtain as special cases many of the algorithms presented in the literature. Firstly we consider local linearisation methods of either the state space model 3
EN61558-2-6 (english)

INTERNATIONALSTANDARD 61558-2-6Première éditionFirst edition1997-02Numéro de référenceReference numberCEI/IEC 61558-2-6: 1997Sécurité des transformateurs, blocs d'alimentation et analogues –Partie 2:Règles particulières pour les transformateursde sécurité pour usage généralSafety of power transformers, power supply unitsand similar –Part 2:Particular requirements for safety isolatingtransformers for general usePUBLICATION GROUPÉE DE SÉCURITÉGROUP SAFETY PUBLICATIONINTERNATIONALSTANDARD 61558-2-6Première éditionFirst edition1997-02Sécurité des transformateurs, blocs d'alimentation et analogues –Partie 2:Règles particulières pour les transformateursde sécurité pour usage généralSafety of power transformers, power supply unitsand similar –Part 2:Particular requirements for safety isolatingtransformers for general useLPour prix, voir catalogue en vigueurFor price, see current catalogueCODE PRIX PRICE CODE © IEC 1997 Droits de reproduction réservés ⎯ Copyright - all rights reservedAucune partie de cette publication ne peut être reproduite ni utiliséesous quelque forme que ce soit et par aucun procédé, électroniqueou mécanique, y compris la photocopie et les microfilms, sansl'accord écrit de l'éditeur.No part of this publication may be reproduced or utilized in any form or by any means, electronic or mechanical, including photocopying and microfilm, without permission in writing from the publisher.International Electrotechnical Commission 3, rue de Varembé Geneva, Switzerland Telefax: +41 22 919 0300e-mail: inmail@iec.ch IEC web site http: //www.iec.ch International Electrotechnical Commission PUBLICATION GROUPÉE DE SÉCURITÉGROUP SAFETY PUBLICATIONINTERNATIONAL ELECTROTECHNICAL COMMISSION_________SAFETY OF POWER TRANSFORMERS, POWER SUPPLY UNITSAND SIMILAR −Part 2: Particular requirements for safety isolating transformersfor general useFOREWORD1)The IEC (International Electrotechnical Commission) is a worldwide organization for standardization comprisingall national electrotechnical committees (IEC National Committees). The object of the IEC is to promote international co-operation on all questions concerning standardization in the electrical and electronic fields. To this end and in addition to other activities, the IEC publishes International Standards. Their preparation is entrusted to technical committees; any IEC National Committee interested in the subject dealt with may participate in this preparatory work. International, governmental and non-governmental organizations liaising with the IEC also participate in this preparation. The IEC collaborates closely with the International Organization for Standardization (ISO) in accordance with conditions determined by agreement between the two organizations.2)The formal decisions or agreements of the IEC on technical matters express, as nearly as possible, aninternational consensus of opinion on the relevant subjects since each technical committee has representation from all interested National Committees.3)The documents produced have the form of recommendations for international use and are published in the formof standards, technical reports or guides and they are accepted by the National Committees in that sense.4)In order to promote international unification, IEC National Committees undertake to apply IEC InternationalStandards transparently to the maximum extent possible in their national and regional standards. Any divergence between the IEC Standard and the corresponding national or regional standard shall be clearly indicated in the latter.5)The IEC provides no marking procedure to indicate its approval and cannot be rendered responsible for anyequipment declared to be in conformity with one of its standards.6)Attention is drawn to the possibility that some of the elements of this International Standard may be the subjectof patent rights. The IEC shall not be held responsible for identifying any or all such patent rights. International Standard IEC 61558-2-6 has been prepared by IEC technical committee 96: Small power transformers, reactors and power supply units and special transformers, reactors and power supply units: Safety requirements.It has the status of a group safety publication in accordance with IEC Guide 104: Guide for the drafting of safety standards, and the role of Committees with safety pilot functions and safety group functions (1984).The text of this standard is based on the following documents:FDIS Report on voting96/50/FDIS96/73/RVDFull information on the voting for the approval of this standard can be found in the report on voting indicated in the above table.This part 2 is intended to be used in conjunction with IEC 61558-1. It was established on the basis of the first edition (1997) of that standard.This part 2 supplements or modifies the corresponding clauses in IEC 61558-1, so as to convert that publication into the IEC standard: Particular requirements for safety isolating transformers for general use.When a particular subclause of part 1 is not mentioned in this part 2, that subclause applies as far as is reasonable. Where this standard states "addition", "modification" or "replacement", the relevant text of part 1 is to be adapted accordingly.This Standard replaces Chapter III, Section 1 of IEC 742.In this standard, the following print types are used:–requirements proper: in roman type;–test specifications: in italic type;–explanatory matter: in smaller roman type.In the text of the standard the words in bold are defined in clause 3.Subclauses which are additional to those in part 1 are numbered starting from 101; supplementary annexes are entitled AA, BB, etc.SAFETY OF POWER TRANSFORMERS, POWER SUPPLY UNITSAND SIMILAR −Part 2: Particular requirements for safety isolating transformersfor general use1 ScopeReplacement:This part 2 of IEC 61558 applies to stationary or portable, single-phase or polyphase, air-cooled safety isolating transformers, associated or otherwise, having a rated supply voltage not exceeding 1000 V a.c. and rated frequency not exceeding 500 Hz, the rated output not exceeding:–10 kVA for single-phase transformers;–16 kVA for polyphase transformers.This standard is also applicable to safety isolating transformers without limitation of the rated output; however such transformers are considered as special transformers and are subjected to an agreement between the purchaser and the supplier.The no-load output voltage and the rated output voltage does not exceed:50 V a.c. r.m.s. and/or120 V ripple-free d.c.between conductors or between any conductor and earth.This standard is applicable to dry type transformers. The windings may be encapsulated or non-encapsulated.2 Normative referencesThis clause of part 1 is applicable.3 DefinitionsThis clause of part 1 is applicable.4 General requirementsThis clause of part 1 is applicable.5 General notes on testsThis clause of part 1 is applicable.6 RatingsThis clause of part 1 is applicable except as follows:Addition:6.101The rated output voltage shall not exceed 50 V a.c. and/or 120 V ripple-free d.c.For a.c. the preferred values for the rated output voltage are: 6 V, 12 V, 24 V, 42 V and 48 V.6.102The rated output shall not exceed 10 kVA for single-phase transformers and 16 kVA for polyphase transformers except for special safety isolating transformers.Preferred values for the rated output are:–25 VA, 40 VA, 63 VA, 100 VA, 160 VA, 250 VA, 400 VA, 630 VA, 1000 VA, 1600 VA, 2500 VA, 4000 VA, 6300 VA, 10 000 VA for single-phase transformers;–630 VA, 1000 VA, 1600 VA, 2500 VA, 4000 VA, 6300 VA, 10 000 VA and 16 000 VA for polyphase transformers.6.103The rated frequency shall not exceed 500 Hz.6.104The rated supply voltage shall not exceed 1000 V a.c.7 ClassificationThis clause of part 1 is applicable.8 Marking and other informationThis clause of part 1 is applicable except as follows:8.11Addition:Addition:8.101For transformers intended for connection to the supply by means of a cable or cord anda plug, an instruction sheet or the like shall be delivered with the transformer, drawing the attention of the user to the fact that the output circuit(s) shall be installed and protected in accordance with national wiring rules.9 Protection against accessibility to hazardous live partsThis clause of part 1 is applicable except as follows:9.2Addition before the first paragraph:Live parts at no-load output voltage not exceeding 35 V peak a.c. or 60 V ripple-free d.c. may be accessible.Addition of the following new text after the second dash:–parts giving access to live parts which are normally connected to an output circuit, which due to the nature of its use, is accessible, provided that, for no-load output voltages exceeding 35 V peak a.c. or 60 V ripple-free d.c. only one pole becomes accessible.10 Change of input voltage settingThis clause of part 1 is applicable except as follows:Addition:10.101Portable transformers shall have only one rated supply voltage unless the transformer is not capable of producing an output voltage in excess of the limits allowed in the scope if the higher marked voltage is accidentally connected to the lower voltage winding.NOTE – For the purpose of this requirement, a portable transformer provided with a device for adjusting the input connections to suit supply voltages over a range of not more than 10 % of the value corresponding with the midpoint of that range, is not considered to be a transformer with more than one supply voltage.11 Output voltage and output current under loadThis clause of part 1 is applicable.12 No-load output voltageThis clause of part 1 is applicable except as follows:Addition:12.101The no-load output voltage shall not exceed 50 V a.c. and on 120 V ripple-free d.c. under any circumstances even when independent output windings which are not intended to be connected in series are connected in series.12.102The difference between the output voltages at no-load and at rated output shall not be excessive.Compliance with the requirements of 12.101 and 12.102 is checked by measuring the no-load output voltage, when the transformer, at ambient temperature, is connected to the rated supply voltage at rated frequency.The difference between the value measured and the output voltage measured during the test of clause 11, expressed as a percentage of the latter voltage, shall not exceed the value shown in table 101.NOTE –The ratio is defined as follows:U U U no-load load load−×100Table 101 – Output voltage deviation Type of transformer Ratio between output voltage at no-loadand at rated output%Inherently short-circuit proof transformers:–up to and including 63 VA 100–over 63 VA up to and including 630 VA 50–over 630 VA 20Other transformers:–up to and including 10 VA 100–over 10 VA up to and including 25 VA 50–over 25 VA up to and including 63 VA 20–over 63 VA up to and including 250 VA 15–over 250 VA up to and including 630 VA 10–over 630 VA 513 Short-circuit voltageThis clause of part 1 is applicable.14 HeatingThis clause of part 1 is applicable.15 Short-circuit and overload protectionThis clause of part 1 is applicable.16 Mechanical strengthThis clause of part 1 is applicable.17 Protection against harmful ingress of dust, solid objects and moistureThis clause of part 1 is applicable.18 Insulation resistance and dielectric strengthThis clause of part 1 is applicable.19 ConstructionThis clause of part 1 is applicable except as follows:Replacement:19.1The input and output circuits shall be electrically separated from each other, and the construction shall be such that there is no possibility of any connection between these circuits, either directly or indirectly, through other metal parts.Compliance is checked by inspection, taking clauses 18, 19 and 26 into consideration.19.1.1The insulation between the input and output winding(s) shall consist of double or reinforced insulation, unless the requirements of 19.1.3 are complied with.In addition, the following applies:–for class I transformers, the insulation between the input windings and the body shall consist of basic insulation, and the insulation between the output windings and the body shall consist of supplementary insulation;–for class II transformers, the insulation between the input windings and the body, and between the output windings and the body, shall consist of double or reinforced insulation.19.1.2For class I transformers where an intermediate metal part (e.g. the iron core), not connected to the body, is located between the input and output windings, the insulation between the input and output windings via the intermediate metal part shall consist of double or reinforced insulation, and, for class II transformers, the insulation between the input windings and the body and between the output windings and the body via the intermediate metal part shall consist of double or reinforced insulation. The insulation between the intermediate metal part and the input or output windings shall in both cases consist of at least basic insulation.NOTE – An intermediate metal part which is separated from one of the input or output windings by double or reinforced insulation is considered as being connected to the other winding.19.1.3For class I transformers, the insulation between the input and output windings may consist of basic insulation plus protective screening instead of double or reinforced insulation, provided the following conditions are complied with:–the insulation between the input winding and the protective screen shall comply with the requirements for basic insulation (rated for the input voltage);–the insulation between the protective screen and the output winding shall comply with the requirements for basic insulation (rated for the output voltage);–the protective screen shall, unless otherwise specified, consist of a metal foil or of a wire wound screen extending at least to the full width of one of the windings adjacent to the screen; a wire wound screen shall be wound tight without space between the turns;–the lead-out wire of the protective screen shall have a cross-section at least corresponding to the rated current of the overload device to ensure that, if a breakdown of insulation should occur, the overload device will open the circuit before the lead-out is destroyed;–the lead-out wire shall be soldered to the protective screen or fixed in an equally reliable manner.NOTE – For the purpose of this subclause, the term "windings" does not include internal circuits.Examples of construction of windings are given in annex M of part 1.19.1.4For transformers intended for connection to the mains by means of a plug, the alternative with basic insulation plus protective screening is not allowed.Addition:19.101Portable transformers having a rated output not exceeding 630 VA shall be of class II.19.102There shall be no connection between the output winding and the body or the protective earthing circuit, if any. However, such a connection is allowed for associated transformers provided that it is allowed by the relevant equipment standard.19.103Transformers shall not be provided with capacitors which electrically connect input and output circuits.Compliance is checked by inspection.19.104The input and output terminals for the connection of external wiring shall be so located that the distance, measured at the point of introduction of the conductor, from input to output clamping units of these terminals is not less than 25 mm. If that distance is achieved by a barrier, this barrier shall be of insulating material and be permanently fixed to the transformer.Compliance is checked by inspection and by measurement disregarding intermediate metal parts.20 ComponentsThis clause of part 1 is applicable except as follows:20.3Addition:Plugs and socket-outlets on the output side shall comply with IEC 884-2-4 and IEC 906-3.21 Internal wiringThis clause of part 1 is applicable.22 Supply connection and other external flexible cable or cordsThis clause of part 1 is applicable.23 Terminals for external conductorsThis clause of part 1 is applicable.24 Provision for protective earthingThis clause of part 1 is applicable.25 Screw and connectionThis clause of part 1 is applicable.26 Creepage distances, clearances and distances through insulation This clause of part 1 is applicable except as follows:Box 1 of table 13, table C.1 and table D.1 is not applicable.27 Resistance to heat, abnormal heat, fire and trackingThis clause of part 1 is applicable.28 Resistance to rustingThis clause of part 1 is applicable.AnnexesThe annexes of part 1 are applicable except as follows:Annex CMaterial group II This annex of part 1 is applicable except as follows:Box 1 of table C.1 is not applicable.Annex DMaterial group I This annex of part 1 is applicable except as follows:Box 1 of table D.1 is not applicable.___________Standards SurveyWe at the IEC want to know how our standards are used once they are published.The answers to this survey will help us to improve IEC standards and standard related information to meet your future needsWould you please take a minute to answer the survey on the other side and mail or fax to:Customer Service Centre (CSC)International Electrotechnical Commission 3, rue de VarembéCase postale 1311211 Geneva 20Switzerland orFax to: CSC at +41 22 919 03 00Thank you for your contribution to the standards making process.RÉPONSE PAYÉESUISSECustomer Service Centre (CSC)International Electrotechnical Commission 3, rue de VarembéCase postale 1311211 GENEVA 20SwitzerlandEnquête sur les normesLa CEI se préoccupe de savoir comment ses normes sont accueillies et utilisées.Les réponses que nous procurera cette enquête nous aideront tout à la fois à améliorer nos normes et les informations qui les concernent afin de toujours mieux répondre à votre attente.Nous aimerions que vous nous consacriez une petite minute pour remplir le questionnaire joint que nous vous invitons à retourner au:Centre du Service Clientèle (CSC)Commission Electrotechnique Internationale 3, rue de VarembéCase postale 1311211 Genève 20SuisseTélécopie: IEC/CSC +41 22 919 03 00Nous vous remercions de la contribution que vous voudrez bien apporter ainsi à la Normalisation InternationaleRÉPONSE PAYÉESUISSECentre du Service Clientèle (CSC)Commission Electrotechnique Internationale 3, rue de VarembéCase postale 1311211 GENÈVE 20SuissePublications de la CEI préparées IEC publications preparedpar le Comité d’Etudes n° 96by Technical Committee No. 9661558: — Sécurité des transformateurs, blocs d'alimentation et analogues.61558-1 (1997)Partie 1: Règles générales et essais.61558-2-1 (1997)Partie 2: Règles particulières pour les trans-formateurs d'isolement à enroulements séparéspour usage général.61558-2-4 (1997)Partie 2: Règles particulières pour les trans-formateurs de séparation des circuits pour usagegénéral.61558-2-6 (1997)Partie 2: Règles particulières pour les trans-formateurs de sécurité pour usage général.61558-2-7 (1997)Partie 2: Règles particulières pour les trans-formateurs pour jouets.61558-2-17 (1997)Partie 2: Règles particulières pour les trans-formateurs pour alimentation à découpage.61558: — Safety of power transformers, power supply units and similar.61558-1 (1997)Part 1: General requirements and tests.61558-2-1 (1997)Part 2: Particular requirements for separatingtransformers for general use.61558-2-4 (1997)Part 2: Particular requirements for isolatingtransformers for general use.61558-2-6 (1997)Part 2: Particular requirements for safety isolatingtransformers for general use.61558-2-7 (1997)Part 2: Particular requirements for transformers fortoys.61558-2-17 (1997)Part 2: Particular requirements for transformers forswitch mode power supplies.Publication 61558-2-6。
B2常用人机命令

创源操作<CREA TE-ORIGIN(4610):ORGTYPE=”ORGRTG”,ORGTASK=”002”,REFORG=”001”.<DISPLAY-ORIGIN(5293)<MODIFY-ORIGIN(5294)<REMOVE-ORIGIN(4897)<CREA TE-SUBGRP(3918):SUBGRP=”SUBG02”,AREACODE=K’898,ORGCH=”002”, <ORGRTG=”002”,ORGRST=”001”,ORGIN=1,ORGTREE=ORGT15.<MODIFY-SUBGRP(3917):<REMOVE-SUBGRP(3919):<DISPLAY-SUBGRP(3920):.<DISPLAY-SCO-INFO(788):SCO=SUBSC,SUBGRP=2,FACIL=X,NTRADDR=X,OPTION=X. <MODIFY-SCO-INFO(791)<CREA TE-SCO-INFO(8634)<REMOVE-SCO-INFO(8635)<DISPLAY-ORGDEP-TREE(8639):DGTSTR=K’XX,ORGTREE=ORGT1.<MODIFY-ORGDEP-TREE(8640):DGTSTR=K’XX,ORGTREE=ORGT1,COMTREE=COMT1. <MODIFY-ORGDEP-TREE:DGTSTR=K’XX,ORGTREE=ORGT1,COMTREE=REMOVE.<EXTEND-ORGDEP-TREE(8641):DGTSTR=K’X,ORGTREE=ORGT1(字冠要先连到公共树)<CONTRACT-ORGDEP-TREE(8642): DGTSTR=”XX”,ORGTREE=ORGT1.<DISPLAY-TREE-NAME:ORGTREE(COMTREE)<MODIFY-TREE-NAME公共树字冠操作<DISPLAY-DGTSTR-ROUTING(3858):DGTSTR=”XXX”,COMTREE=COMT1.<EXTEND-DGTSTR-ROUTING(3861):DGTSTR=”XXX”,COMTREE=COMT1.CAUSDGTS=10&11&12&13&14&15<CONTRACT-DGTSTR-ROUTING(3862):DGTSTR=”XXX”,COMTREE=COMT1<MODIFY-DGTSTR-ROUTING(3859):DGTSTR=”XXX”,COMTREE=COMT1,REFTREE=COMT1, REFDGSTR=”XXX”.<REMOVE-DGTSTR-ROUTING(3860):DGTSTR=”XXX”,COMTREE=COMT1.限制树操作<DISPLAY-DGTSTR-RESTR(3865): DGTSTR=”XXX”,COMTREE=COMT1<MODIFY-DGTSTR-RESTR(3864): DGTSTR=”XX”,COMTREE=COMT1,RSTLEV=NORES. <EXTEND-DGTSTR-RESTR(3866): DGTSTR=”XXX”,COMTREE=COMT1<CONTRACT-DGTSTR-RESTR(3867): DGTSTR=”XXX”,COMTREE=COMT1LD POS操作<DISPLAY-DGTSTR-LDPOS(3868):<CREA TE-DGTSTR-LDPOS(8735):<EXTEND-DGTSTR-LDPOS(3869):<CONTRACT-DGTSTR-LDPOS(3870):<REMOVE-DGTSTR-LDPOS(8734):ANNM<DISPLAY-ANNM-COMP(4388):ORGANNM=”XX”<DISPLAY-ANNM-ROUTING(3857):<CREA TE-ANNM-ROUTING(3854)::RTGTYPE=X,RTGINFO=X,ANNMID=XX<MODIFY-ANNM-ROUTING(3856):<REMOVE-ANNM-ROUTING(3855):<DISPLAY-ANNM-LOCA TION:(4128)<MODIFY-ANNM-LOCA TION:(4129)<CREA TE-ANNM-LOCA TION:(3834)<REMOVE-ANNM-LOCA TION:(3835)CAUSE<DISPLAY-CAUSE(3853):<MODIFY-CAUSE(3852):SERVMNEM=XXX,CAUSE=XX,ORGIN=X.<DISPLAY-CAUSE-TRANSL(4127):CAUSE=ALL.BARRING<DISPLAY-BARRING-NAME(3830):.<MODIFY-BARRING-NAME(3832)<CREA TE-BARRING-NAME(3831)<REMOVE-BARRING-NAME(3833)<DISPLAY-BARRING-TABLE:(7657)<MODIFY-BARRING-TABLE:(7658)<DISPLAY-BARRING-PROGRAM(4386):BCGICBAR(BCGOCBAR,ICBARPGM,OCBARPGM)=ALL<MODIFY-BARRING-PROGRAM(5939)IN NTRADDR<DISPLAY-IN-NTRADDR(5940)<MODIFY-IN-NTRADDR(5941)<DISPLAY-CALL-TRACE(4385)ROUTING-CALENDAR<DISPLAY-ROUTING-CALENDAR:(7478):YEAR=2005,CALENDAR=HOCAL(WEEKCAL) <CREA TE-ROUTING-CALENDAR:(7475)<REMOVE-ROUTING-CALENDAR:(7477)<MODIFY-ROUTING-CALENDAR:(7476)AREACODE<CREA TE-AREACODE(3871):.<DISPLAY-AREACODE(3873):<REMOVEAREACODE(3872)千群相关操作<DISPLAY-DN-PLAN(7157):AREACODE=K'21,DN="5996".<MODIFY-DN-PLAN(7156):AREACODE=K'21,DN="59967",LEAFSTA T=CONNECT.(NOTCON.)<EXTEND-DN-PLAN(3875):AREACODE=K'21,OLDDN="59966",NEWDN="59966+++".(扩1000号码)<CONTRACT-DN-PLAN(3876):AREACODE=K'21,OLDDN="59966+++",NEWDN="59966".计费树及计费相关操作<DISPLAY-CHARGING-PROFDA TA.<CREA TE-ORGCH:ORGCH=”002”.<DISPLAY-CHARGING-DGTSTR: DGTSTR=”XXX”,COMTREE=COMT1<CONTRACT-CHARGING-DGTSTR: DGTSTR=”XXX”,COMTREE=COMT1<EXTEND-CHARGING-DGTSTR: DGTSTR=”XXX”,COMTREE=COMT1<REMOVE-CHARGING-DGTSTR: DGTSTR=”XXX”,COMTREE=COMT1<MODIFY-CHARGING-DGTSTR: DGTSTR=”XXX”,COMTREE=COMT1,ORGCHL1=XXXLCD1=”XXX”.<DISPLAY(MODIFY,CREA TE,REMOVE)-CHARGING-RESULT:LCD=”XXXX”.<DISPLAY-PULSE-TARIFF:TARNAME=”XXX”<MODIFY-PULSE-TARIFF:TARNAME=”XXX”,RSQNBR=1(2.3),RSQPDA T1=180&2&”180”&-1&1&”60”.<4224:1 <4224:4<DISPLAY-CHARGING-SCALE:TARGRP=ALL.<MODIFY-CHARGING-SCALE:TARGRP=XX,3=0&0&1,4=0&0&1,5=0&0&1<DISPLAY-FACILITY-CHARGING:FACTYPE=ALL.创BCG的WAC特服计费表<MODIFY-FACILITY-CHARGING:CREA TE:FACTYPE=PNP&BCGEXT,ACCTYPE=INVOKE&WAC,TYPERAF=FACIL,CGCDPTY=CG,TARNAME=:”TAR002”,DBLNG=DBLNG,STRTSTOP=CHSUBASW&STOP,TARSEL=NEWCH,LINEMTR=3&0,NWPLSTR=0,SSPLSTR=0.DOR相关操作<DISPLAY-ACCOUNT-DGSTR:DGSTR=K’96244,COMTREE=”COMT1”<HANDLE-ACCOUNT-DGTSTR: DGTSTR = K'96244,COMTREE=”COMT1”,REMOVE(CREA TE,CONTRACT,EXTEND)<DISPLAY-ACCOUNT-ZONE:DESTACO=X,ORGACO=X.<MODIFY-ACCOUNT-ZONE:DESTACO=X,ORGACO=X,ACOZONE=X.<DISPLAY-ACCOUNT:ACOZNE=X.<MODIFY-ACCOUNT:ACOZNE=X,ACOCLASS,ACOKIND,ACOGRP.NED操作< (5575):STA TUS.<DISPLAY-NED:START,TABLE=”DGTSRTGA”,SELECT=”DGTSTR”&”033”&”034”<DISPLAY-NED:START,TABLE=”DGTSRTGA”,SELECT=”RTGINFO”&”TKGID”&”TKGID”<COLLECT-NED:START,TABLE=”DGTSRTGA”(25708T) 字冠DGTSCHAN (25712T) 计费树DGTSA TTR,(25735T) 字冠属性ORDDGTSA(25723T) 源树DGTSRSTA(25728T) 限制ORIGIN (25704T)源REA 10101,25708 D:\XXXdisplay-ned:start,errinf,TABLE="DGTSRTGA".黑白名单主叫鉴权N7,TKG,DID相关操作开7号流程1.<CREA TE-N7LOG-NETWORK: LOGNET=”NA T”,SSF=NA T,PROTSTD=ITU,PCFORMA T=8&8&8&0.<DISPLAY-N7LOG-NETWORK:LOGNET=ALL.<DISPLAY-N7PARM:LOGNET=ALL.<MODIFY-N7PARM:LOGNET=”NA T”,OPC=”21 8 220”.<DISPLAY-N7-DEST:EXCHNAME=ALL,LOGNET=ALL,DETAIL=ALL.2.<CREA TE-N7-DEST:CEXCHNAM=”LSTP1”,LOGNET=NA T,DEST1=”21 8 1”,CRTESID1=”LSTP1”.(路由也创出来了)<DISPLAY-N7-LKSET:LKSET=ALL.3.<CREA TE-N7-LKSET: CLKSET=”LSTP1”,LOGNET=NA T,DEST=”21 8 1”.<DISPLAY-N7SIGMOD:DETAIL=TML,MODTYPE=(IPMT,CCSM,ALL)4.<CREA TE-N7-SIGMOD:SIGMOD=H’4,TN2=”LSTP1_01”.5.<EXTEND-N7-LKSET:LKSET=”LSTP1”,SLC=0,CCSMEN=H’4&2,DTMEN=H’102&16,LKPARSET=HCCMGR64(IPTMGR64)6.<CHANGE-N7LINK-STA TUS:LKSET=XX,SLC=X,FUNCTION=ACTIV A TE(DEACT,FRCDEACT,ACTLOOP,ACTTST).<241:CCSMEN=ALL(LKSET=XXX)SLC=ALL,DETAIL=SWSTA T,CONFIG.7.<EXTEND-N7RTES:RTRSID=LSTP1,LKSET=LSTP1,RTEPRIO=1,COMBLKS=NOTAPPL. <DISPLAY-N7RTES:RTESID=ALL,DETAIL=ALL.对于准直连<CREA TE-N7-DEST:CEXCHNAM=”L_6681”,LOGNET1=NET,DEST1=”21 9 219”,CRTESID1=”L_6681”.<EXTEND-N7RTES:RTESID=L_6681,LKSET=LSTP1,RTEPRIO=1,COMBLKS=NOTAPPL. <DISPLAY-N7RTES(250):RTESID=ALL,DETAIL=MTPOVW.(TRAFFIC)RTESTA TS删七号流程<reduce-n7rtes:rtesid=xxxx,lkset=xxxx<117:na1=h’xxx,tslist1=xx<220:slc=x,lkset=xx,function=deact.<reduce-n7-lkset:lkset=xxx,slc=xx.<remove-n7-lkset:lkset=xx<remove-n7-dest:exchname=xxx.<modify-n7parm:opc=remove,lognet=xxxx,opcind=xx(如果有多OPC,将OPC都删掉)<remove-n7log-network:lognet=xxx.中继部分<create-route:rte=”l_6681”.<create-tkg:tkg=l_6681_d1”&”l_6681_d1”,reftkg=ref_isup.<modify-tkg:tkg=l_6681_d1,destn7=”21 9 219”&nat,…<CREA TE-TKGCOM<create-srtgblk:srtgblk=”l_6681”,tkgcchn=l_6681_1.<create-rtgblk:rtgblk=”l_6681”,srtgblk1=l_6681,autodep.<extend-tkg(1561):tkg=l_6681_d1,na1=h’xxx,tslist1(75)=1&&31(all),newtksq1(83)=101(cic码)&1(系统号),100.<DISPLAY-N7TRDIST:LKSET=XXX,DETAIL=TRAFFIC.<4285:LKSET=XXXX,11=0&&1(SLS)&0(SLC),12=2&&3&113=4&&5&0,14=6&&7&1,15=8 &&9&0,16=10&&11&1,17=12&&13&0,18=14&&15&1<DISPLAY-DID(84):SCO=ALL,DETAIL=NORM.<REMOVE-DID:(4075)<MODIFY-DID:(83)<MODIFY-ALCA TEL-DID(8647):<CREA TE-DID(82):SCO=ALL,DESTGRP=ALL,TOC=ALL,DESTDID=DID_08&REF& DID_01.用户操作<CREATE-SINGLE-SUBSCR(5289):DN=K’X,NA=H’Y,LAN=Z,22=1&4.(创用户) <REMOVE-SINGLE-SUBSCR:DN=K’X.(删除)<MODIFY-SINGLE-SUBSCR:DN=K’X,……(修改)<DISPLAY-SINGLE-SUBSCR:DN=K’X (显示)<CHANGE-PORT(3170):NA=H’X,LAN=Y,NANEW=H’Z,LANNEW=K,FSZE.特服参见其他文档PABX操作BCG操作统计TKG:<act-tkg-rep15m:tkg=l_6681_d1,recperd=00&00&24&00,outset=35,outperd=00&15,strdate=3&13,recpatt=1.ADL:<8758:RECPERD=0&0&24&0,RECPATT=A,OUTPERD=1&0,OUTSET=8597.TDC:<5905:CREATE,TDC=34,DGTSTR1=K’6681.<ACT-TDC:TDC=34.ADL:<act-tdc-reposm(8760):recperd=0&0&24&0,recpatt=a,outset=1,strdate=3&13,tdc=1.<act-tkg-reposm:tkg=l_6681_d1,计数器:<1676:entlist=137&116&142mtkg=l_6681_d1,recpatt=a,recperd=0&0&24&0,outperd=0&15,outset=1,strdate=3&13.CE过载观察<activate-oeovld-observ(25):strdate=3&13,outperd=0&15,strtime=13&30,lceid=h’xxxx,outset=1.Link负载报告1)<activate-link-meas(6355):recpatt=a,strdate=3&13,outperd=0&15,recperd=0&0&24&0,table=1,link1=h’4&2,link2=h’5&2,history,mode=physical,outset=1.2)<n7-log-file:reflect.(display table value)3)<5440:act=-306&-309&-311&-506&-507.激活TABLE表。
RFC 1323

APPENDIX C: Changes from RFC-1072, RFC-1185 (30)APPENDIX D: Summary of Notation (31)APPENDIX E: Event Processing (32)Security Considerations (37)Jacobson, Braden, & Borman [Page 1] RFC 1323 TCP Extensions for High Performance May 1992Authors' Addresses (37)1. INTRODUCTIONThe TCP protocol [Postel81] was designed to operate reliably overalmost any transmission medium regardless of transmission rate,delay, corruption, duplication, or reordering of segments.Production TCP implementations currently adapt to transfer rates inthe range of 100 bps to 10**7 bps and round-trip delays in the range 1 ms to 100 seconds. Recent work on TCP performance has shown thatTCP can work well over a variety of Internet paths, ranging from 800 Mbit/sec I/O channels to 300 bit/sec dial-up modems [Jacobson88a].The introduction of fiber optics is resulting in ever-highertransmission speeds, and the fastest paths are moving out of thedomain for which TCP was originally engineered. This memo defines a set of modest extensions to TCP to extend the domain of itsapplication to match this increasing network capability. It is based upon and obsoletes RFC-1072 [Jacobson88b] and RFC-1185 [Jacobson90b].There is no one-line answer to the question: "How fast can TCP go?". There are two separate kinds of issues, performance and reliability, and each depends upon different parameters. We discuss each in turn.1.1 TCP PerformanceTCP performance depends not upon the transfer rate itself, butrather upon the product of the transfer rate and the round-tripdelay. This "bandwidth*delay product" measures the amount of data that would "fill the pipe"; it is the buffer space required atsender and receiver to obtain maximum throughput on the TCPconnection over the path, i.e., the amount of unacknowledged data that TCP must handle in order to keep the pipeline full. TCPperformance problems arise when the bandwidth*delay product islarge. We refer to an Internet path operating in this region as a "long, fat pipe", and a network containing this path as an "LFN"(pronounced "elephan(t)").High-capacity packet satellite channels (e.g., DARPA's WidebandNet) are LFN's. For example, a DS1-speed satellite channel has a bandwidth*delay product of 10**6 bits or more; this corresponds to 100 outstanding TCP segments of 1200 bytes each. Terrestrialfiber-optical paths will also fall into the LFN class; forexample, a cross-country delay of 30 ms at a DS3 bandwidth(45Mbps) also exceeds 10**6 bits.There are three fundamental performance problems with the current TCP over LFN paths:Jacobson, Braden, & Borman [Page 2] RFC 1323 TCP Extensions for High Performance May 1992(1) Window Size LimitThe TCP header uses a 16 bit field to report the receivewindow size to the sender. Therefore, the largest windowthat can be used is 2**16 = 65K bytes.To circumvent this problem, Section 2 of this memo defines a new TCP option, "Window Scale", to allow windows larger than 2**16. This option defines an implicit scale factor, whichis used to multiply the window size value found in a TCPheader to obtain the true window size.(2) Recovery from LossesPacket losses in an LFN can have a catastrophic effect onthroughput. Until recently, properly-operating TCPimplementations would cause the data pipeline to drain withevery packet loss, and require a slow-start action torecover. Recently, the Fast Retransmit and Fast Recoveryalgorithms [Jacobson90c] have been introduced. Theircombined effect is to recover from one packet loss perwindow, without draining the pipeline. However, more thanone packet loss per window typically results in aretransmission timeout and the resulting pipeline drain andslow start.Expanding the window size to match the capacity of an LFNresults in a corresponding increase of the probability ofmore than one packet per window being dropped. This couldhave a devastating effect upon the throughput of TCP over an LFN. In addition, if a congestion control mechanism basedupon some form of random dropping were introduced intogateways, randomly spaced packet drops would become common,possible increasing the probability of dropping more than one packet per window.To generalize the Fast Retransmit/Fast Recovery mechanism to handle multiple packets dropped per window, selectiveacknowledgments are required. Unlike the normal cumulativeacknowledgments of TCP, selective acknowledgments give thesender a complete picture of which segments are queued at the receiver and which have not yet arrived. Some evidence infavor of selective acknowledgments has been published[NBS85], and selective acknowledgments have been included in a number of experimental Internet protocols -- VMTP[Cheriton88], NETBLT [Clark87], and RDP [Velten84], andproposed for OSI TP4 [NBS85]. However, in the non-LFNregime, selective acknowledgments reduce the number of Jacobson, Braden, & Borman [Page 3] RFC 1323 TCP Extensions for High Performance May 1992 packets retransmitted but do not otherwise improveperformance, making their complexity of questionable value.However, selective acknowledgments are expected to becomemuch more important in the LFN regime.RFC-1072 defined a new TCP "SACK" option to send a selective acknowledgment. However, there are important technicalissues to be worked out concerning both the format andsemantics of the SACK option. Therefore, SACK has beenomitted from this package of extensions. It is hoped thatSACK can "catch up" during the standardization process.(3) Round-Trip MeasurementTCP implements reliable data delivery by retransmittingsegments that are not acknowledged within some retransmission timeout (RTO) interval. Accurate dynamic determination of an appropriate RTO is essential to TCP performance. RTO isdetermined by estimating the mean and variance of themeasured round-trip time (RTT), i.e., the time intervalbetween sending a segment and receiving an acknowledgment for it [Jacobson88a].Section 4 introduces a new TCP option, "Timestamps", and then defines a mechanism using this option that allows nearlyevery segment, including retransmissions, to be timed atnegligible computational cost. We use the mnemonic RTTM(Round Trip Time Measurement) for this mechanism, todistinguish it from other uses of the Timestamps option.1.2 TCP ReliabilityNow we turn from performance to reliability. High transfer rateenters TCP performance through the bandwidth*delay product.However, high transfer rate alone can threaten TCP reliability by violating the assumptions behind the TCP mechanism for duplicatedetection and sequencing.An especially serious kind of error may result from an accidental reuse of TCP sequence numbers in data segments. Suppose that an"old duplicate segment", e.g., a duplicate data segment that wasdelayed in Internet queues, is delivered to the receiver at thewrong moment, so that its sequence numbers falls somewhere within the current window. There would be no checksum failure to warn of the error, and the result could be an undetected corruption of the data. Reception of an old duplicate ACK segment at thetransmitter could be only slightly less serious: it is likely to Jacobson, Braden, & Borman [Page 4] RFC 1323 TCP Extensions for High Performance May 1992 lock up the connection so that no further progress can be made,forcing an RST on the connection.TCP reliability depends upon the existence of a bound on thelifetime of a segment: the "Maximum Segment Lifetime" or MSL. An MSL is generally required by any reliable transport protocol,since every sequence number field must be finite, and thereforeany sequence number may eventually be reused. In the Internetprotocol suite, the MSL bound is enforced by an IP-layermechanism, the "Time-to-Live" or TTL field.Duplication of sequence numbers might happen in either of twoways:(1) Sequence number wrap-around on the current connectionA TCP sequence number contains 32 bits. At a high enoughtransfer rate, the 32-bit sequence space may be "wrapped"(cycled) within the time that a segment is delayed in queues.(2) Earlier incarnation of the connectionSuppose that a connection terminates, either by a properclose sequence or due to a host crash, and the sameconnection (i.e., using the same pair of sockets) isimmediately reopened. A delayed segment from the terminated connection could fall within the current window for the newincarnation and be accepted as valid.Duplicates from earlier incarnations, Case (2), are avoided byenforcing the current fixed MSL of the TCP spec, as explained inSection 5.3 and Appendix B. However, case (1), avoiding thereuse of sequence numbers within the same connection, requires an MSL bound that depends upon the transfer rate, and at high enough rates, a new mechanism is required.More specifically, if the maximum effective bandwidth at which TCP is able to transmit over a particular path is B bytes per second, then the following constraint must be satisfied for error-freeoperation:2**31 / B > MSL (secs) [1]The following table shows the value for Twrap = 2**31/B inseconds, for some important values of the bandwidth B:Jacobson, Braden, & Borman [Page 5] RFC 1323 TCP Extensions for High Performance May 1992 Network B*8 B Twrapbits/sec bytes/sec secs_______ _______ ______ ______ARPANET 56kbps 7KBps 3*10**5 (~3.6 days)DS1 1.5Mbps 190KBps 10**4 (~3 hours)Ethernet 10Mbps 1.25MBps 1700 (~30 mins)DS3 45Mbps 5.6MBps 380FDDI 100Mbps 12.5MBps 170Gigabit 1Gbps 125MBps 17It is clear that wrap-around of the sequence space is not aproblem for 56kbps packet switching or even 10Mbps Ethernets. On the other hand, at DS3 and FDDI speeds, Twrap is comparable to the 2 minute MSL assumed by the TCP specification [Postel81]. Moving towards gigabit speeds, Twrap becomes too small for reliableenforcement by the Internet TTL mechanism.The 16-bit window field of TCP limits the effective bandwidth B to 2**16/RTT, where RTT is the round-trip time in seconds[McKenzie89]. If the RTT is large enough, this limits B to avalue that meets the constraint [1] for a large MSL value. Forexample, consider a transcontinental backbone with an RTT of 60ms(set by the laws of physics). With the bandwidth*delay productlimited to 64KB by the TCP window size, B is then limited to1.1MBps, no matter how high the theoretical transfer rate of thepath. This corresponds to cycling the sequence number space inTwrap= 2000 secs, which is safe in today's Internet.It is important to understand that the culprit is not the largerwindow but rather the high bandwidth. For example, consider a(very large) FDDI LAN with a diameter of 10km. Using the speed of light, we can compute the RTT across the ring as(2*10**4)/(3*10**8) = 67 microseconds, and the delay*bandwidthproduct is then 833 bytes. A TCP connection across this LAN using a window of only 833 bytes will run at the full 100mbps and canwrap the sequence space in about 3 minutes, very close to the MSL of TCP. Thus, high speed alone can cause a reliability problemwith sequence number wrap-around, even without extended windows.Watson's Delta-T protocol [Watson81] includes network-layermechanisms for precise enforcement of an MSL. In contrast, the IP Jacobson, Braden, & Borman [Page 6] RFC 1323 TCP Extensions for High Performance May 1992 mechanism for MSL enforcement is loosely defined and even moreloosely implemented in the Internet. Therefore, it is unwise todepend upon active enforcement of MSL for TCP connections, and it is unrealistic to imagine setting MSL's smaller than the currentvalues (e.g., 120 seconds specified for TCP).A possible fix for the problem of cycling the sequence space would be to increase the size of the TCP sequence number field. Forexample, the sequence number field (and also the acknowledgmentfield) could be expanded to 64 bits. This could be done either by changing the TCP header or by means of an additional option.Section 5 presents a different mechanism, which we call PAWS(Protect Against Wrapped Sequence numbers), to extend TCPreliability to transfer rates well beyond the foreseeable upperlimit of network bandwidths. PAWS uses the TCP Timestamps option defined in Section 4 to protect against old duplicates from thesame connection.1.3 Using TCP optionsThe extensions defined in this memo all use new TCP options. Wemust address two possible issues concerning the use of TCPoptions: (1) compatibility and (2) overhead.We must pay careful attention to compatibility, i.e., tointeroperation with existing implementations. The only TCP option defined previously, MSS, may appear only on a SYN segment. Every implementation should (and we expect that most will) ignoreunknown options on SYN segments. However, some buggy TCPimplementation might be crashed by the first appearance of anoption on a non-SYN segment. Therefore, for each of theextensions defined below, TCP options will be sent on non-SYNsegments only when an exchange of options on the SYN segments has indicated that both sides understand the extension. Furthermore, an extension option will be sent in a <SYN,ACK> segment only ifthe corresponding option was received in the initial <SYN>segment.A question may be raised about the bandwidth and processingoverhead for TCP options. Those options that occur on SYNsegments are not likely to cause a performance concern. Opening a TCP connection requires execution of significant special-casecode, and the processing of options is unlikely to increase thatcost significantly.On the other hand, a Timestamps option may appear in any data orACK segment, adding 12 bytes to the 20-byte TCP header. We Jacobson, Braden, & Borman [Page 7] RFC 1323 TCP Extensions for High Performance May 1992 believe that the bandwidth saved by reducing unnecessaryretransmissions will more than pay for the extra header bandwidth. There is also an issue about the processing overhead for parsingthe variable byte-aligned format of options, particularly with aRISC-architecture CPU. To meet this concern, Appendix A contains a recommended layout of the options in TCP headers to achievereasonable data field alignment. In the spirit of HeaderPrediction, a TCP can quickly test for this layout and if it isverified then use a fast path. Hosts that use this canonicallayout will effectively use the options as a set of fixed-formatfields appended to the TCP header. However, to retain thephilosophical and protocol framework of TCP options, a TCP must be prepared to parse an arbitrary options field, albeit with lessefficiency.Finally, we observe that most of the mechanisms defined in thismemo are important for LFN's and/or very high-speed networks. For low-speed networks, it might be a performance optimization to NOT use these mechanisms. A TCP vendor concerned about optimalperformance over low-speed paths might consider turning theseextensions off for low-speed paths, or allow a user orinstallation manager to disable them.2. TCP WINDOW SCALE OPTION2.1 IntroductionThe window scale extension expands the definition of the TCPwindow to 32 bits and then uses a scale factor to carry this 32-bit value in the 16-bit Window field of the TCP header (SEG.WND in RFC-793). The scale factor is carried in a new TCP option, Window Scale. This option is sent only in a SYN segment (a segment with the SYN bit on), hence the window scale is fixed in each direction when a connection is opened. (Another design choice would be tospecify the window scale in every TCP segment. It would beincorrect to send a window scale option only when the scale factor changed, since a TCP option in an acknowledgement segment will not be delivered reliably (unless the ACK happens to be piggy-backedon data in the other direction). Fixing the scale when theconnection is opened has the advantage of lower overhead but thedisadvantage that the scale factor cannot be changed during theconnection.)The maximum receive window, and therefore the scale factor, isdetermined by the maximum receive buffer space. In a typicalmodern implementation, this maximum buffer space is set by default Jacobson, Braden, & Borman [Page 8] RFC 1323 TCP Extensions for High Performance May 1992 but can be overridden by a user program before a TCP connection is opened. This determines the scale factor, and therefore no newuser interface is needed for window scaling.2.2 Window Scale OptionThe three-byte Window Scale option may be sent in a SYN segment by a TCP. It has two purposes: (1) indicate that the TCP is prepared to do both send and receive window scaling, and (2) communicate a scale factor to be applied to its receive window. Thus, a TCPthat is prepared to scale windows should send the option, even if its own scale factor is 1. The scale factor is limited to a power of two and encoded logarithmically, so it may be implemented bybinary shift operations.TCP Window Scale Option (WSopt):Kind: 3 Length: 3 bytes+---------+---------+---------+| Kind=3 |Length=3 |t|+---------+---------+---------+This option is an offer, not a promise; both sides must sendWindow Scale options in their SYN segments to enable windowscaling in either direction. If window scaling is enabled,then the TCP that sent this option will right-shift its truereceive-window values by 't' bits for transmission inSEG.WND. The value 't' may be zero (offering to scale, while applying a scale factor of 1 to the receive window).This option may be sent in an initial <SYN> segment (i.e., asegment with the SYN bit on and the ACK bit off). It may also be sent in a <SYN,ACK> segment, but only if a Window Scale op- tion was received in the initial <SYN> segment. A Window Scale option in a segment without a SYN bit should be ignored.The Window field in a SYN (i.e., a <SYN> or <SYN,ACK>) segment itself is never scaled.2.3 Using the Window Scale OptionA model implementation of window scaling is as follows, using the notation of RFC-793 [Postel81]:* All windows are treated as 32-bit quantities for storage in Jacobson, Braden, & Borman [Page 9] RFC 1323 TCP Extensions for High Performance May 1992 the connection control block and for local calculations.This includes the send-window (SND.WND) and the receive-window (RCV.WND) values, as well as the congestion window.* The connection state is augmented by two window shift counts, Snd.Wind.Scale and Rcv.Wind.Scale, to be applied to theincoming and outgoing window fields, respectively.* If a TCP receives a <SYN> segment containing a Window Scaleoption, it sends its own Window Scale option in the <SYN,ACK> segment.* The Window Scale option is sent with t = R, where Ris the value that the TCP would like to use for its receivewindow.* Upon receiving a SYN segment with a Window Scale optioncontaining t = S, a TCP sets Snd.Wind.Scale to S and sets Rcv.Wind.Scale to R; otherwise, it sets bothSnd.Wind.Scale and Rcv.Wind.Scale to zero.* The window field (SEG.WND) in the header of every incomingsegment, with the exception of SYN segments, is left-shifted by Snd.Wind.Scale bits before updating SND.WND:SND.WND = SEG.WND << Snd.Wind.Scale(assuming the other conditions of RFC793 are met, and usingthe "C" notation "<<" for left-shift).* The window field (SEG.WND) of every outgoing segment, withthe exception of SYN segments, is right-shifted byRcv.Wind.Scale bits:SEG.WND = RCV.WND >> Rcv.Wind.Scale.TCP determines if a data segment is "old" or "new" by testingwhether its sequence number is within 2**31 bytes of the left edge of the window, and if it is not, discarding the data as "old". To insure that new data is never mistakenly considered old and vice- versa, the left edge of the sender's window has to be at most2**31 away from the right edge of the receiver's window.Similarly with the sender's right edge and receiver's left edge.Since the right and left edges of either the sender's orreceiver's window differ by the window size, and since the sender and receiver windows can be out of phase by at most the windowsize, the above constraints imply that 2 * the max window size Jacobson, Braden, & Borman [Page 10] RFC 1323 TCP Extensions for High Performance May 1992 must be less than 2**31, ormax window < 2**30Since the max window is 2**S (where S is the scaling shift count) times at most 2**16 - 1 (the maximum unscaled window), the maximum window is guaranteed to be < 2*30 if S <= 14. Thus, the shiftcount must be limited to 14 (which allows windows of 2**30 = 1Gbyte). If a Window Scale option is received with a tvalue exceeding 14, the TCP should log the error but use 14instead of the specified value.The scale factor applies only to the Window field as transmittedin the TCP header; each TCP using extended windows will maintainthe window values locally as 32-bit numbers. For example, the"congestion window" computed by Slow Start and CongestionAvoidance is not affected by the scale factor, so window scalingwill not introduce quantization into the congestion window.3. RTTM: ROUND-TRIP TIME MEASUREMENT3.1 IntroductionAccurate and current RTT estimates are necessary to adapt tochanging traffic conditions and to avoid an instability known as"congestion collapse" [Nagle84] in a busy network. However,accurate measurement of RTT may be difficult both in theory and in implementation.Many TCP implementations base their RTT measurements upon a sample of only one packet per window. While this yields an adequateapproximation to the RTT for small windows, it results in anunacceptably poor RTT estimate for an LFN. If we look at RTTestimation as a signal processing problem (which it is), a datasignal at some frequency, the packet rate, is being sampled at alower frequency, the window rate. This lower sampling frequencyviolates Nyquist's criteria and may therefore introduce "aliasing" artifacts into the estimated RTT [Hamming77].A good RTT estimator with a conservative retransmission timeoutcalculation can tolerate aliasing when the sampling frequency is"close" to the data frequency. For example, with a window of 8packets, the sample rate is 1/8 the data frequency -- less than an order of magnitude different. However, when the window is tens or hundreds of packets, the RTT estimator may be seriously in error, resulting in spurious retransmissions.If there are dropped packets, the problem becomes worse. Zhang Jacobson, Braden, & Borman [Page 11] RFC 1323 TCP Extensions for High Performance May 1992 [Zhang86], Jain [Jain86] and Karn [Karn87] have shown that it isnot possible to accumulate reliable RTT estimates if retransmitted segments are included in the estimate. Since a full window ofdata will have been transmitted prior to a retransmission, all of the segments in that window will have to be ACKed before the next RTT sample can be taken. This means at least an additionalwindow's worth of time between RTT measurements and, as the error rate approaches one per window of data (e.g., 10**-6 errors perbit for the Wideband satellite network), it becomes effectivelyimpossible to obtain a valid RTT measurement.A solution to these problems, which actually simplifies the sender substantially, is as follows: using TCP options, the sender places a timestamp in each data segment, and the receiver reflects these timestamps back in ACK segments. Then a single subtract gives the sender an accurate RTT measurement for every ACK segment (whichwill correspond to every other data segment, with a sensiblereceiver). We call this the RTTM (Round-Trip Time Measurement)mechanism.It is vitally important to use the RTTM mechanism with bigwindows; otherwise, the door is opened to some dangerousinstabilities due to aliasing. Furthermore, the option isprobably useful for all TCP's, since it simplifies the sender.3.2 TCP Timestamps OptionTCP is a symmetric protocol, allowing data to be sent at any time in either direction, and therefore timestamp echoing may occur in either direction. For simplicity and symmetry, we specify thattimestamps always be sent and echoed in both directions. Forefficiency, we combine the timestamp and timestamp reply fieldsinto a single TCP Timestamps Option.Jacobson, Braden, & Borman [Page 12] RFC 1323 TCP Extensions for High Performance May 1992 TCP Timestamps Option (TSopt):Kind: 8Length: 10 bytes+-------+-------+---------------------+---------------------+ |Kind=8 | 10 | TS Value (TSval) |TS Echo Reply (TSecr)| +-------+-------+---------------------+---------------------+ 1 1 4 4The Timestamps option carries two four-byte timestamp fields.The Timestamp Value field (TSval) contains the current value of the timestamp clock of the TCP sending the option.The Timestamp Echo Reply field (TSecr) is only valid if the ACK bit is set in the TCP header; if it is valid, it echos a times- tamp value that was sent by the remote TCP in the TSval fieldof a Timestamps option. When TSecr is not valid, its valuemust be zero. The TSecr value will generally be from the most recent Timestamp option that was received; however, there areexceptions that are explained below.A TCP may send the Timestamps option (TSopt) in an initial<SYN> segment (i.e., segment containing a SYN bit and no ACKbit), and may send a TSopt in other segments only if it re-ceived a TSopt in the initial <SYN> segment for the connection.3.3 The RTTM MechanismThe timestamp value to be sent in TSval is to be obtained from a(virtual) clock that we call the "timestamp clock". Its valuesmust be at least approximately proportional to real time, in order to measure actual RTT.The following example illustrates a one-way data flow withsegments arriving in sequence without loss. Here A, B, C...represent data blocks occupying successive blocks of sequencenumbers, and ACK(A),... represent the corresponding cumulativeacknowledgments. The two timestamp fields of the Timestampsoption are shown symbolically as <TSval= x,TSecr=y>. Each TSecrfield contains the value most recently received in a TSval field. Jacobson, Braden, & Borman [Page 13]RFC 1323 TCP Extensions for High Performance May 1992 TCP A TCP B<A,TSval=1,TSecr=120> ------><---- <ACK(A),TSval=127,TSecr=1><B,TSval=5,TSecr=127> ------><---- <ACK(B),TSval=131,TSecr=5>. . . . . . . . . . . . . . . . . . . . . .<C,TSval=65,TSecr=131> ------><---- <ACK(C),TSval=191,TSecr=65>(etc)The dotted line marks a pause (60 time units long) in which A had nothing to send. Note that this pause inflates the RTT which Bcould infer from receiving TSecr=131 in data segment C. Thus, in one-way data flows, RTTM in the reverse direction measures a value that is inflated by gaps in sending data. However, the following rule prevents a resulting inflation of the measured RTT:A TSecr value received in a segment is used to update theaveraged RTT measurement only if the segment acknowledgessome new data, i.e., only if it advances the left edge of the send window.Since TCP B is not sending data, the data segment C does notacknowledge any new data when it arrives at B. Thus, the inflated RTTM measurement is not used to update B's RTTM measurement.3.4 Which Timestamp to EchoIf more than one Timestamps option is received before a replysegment is sent, the TCP must choose only one of the TSvals toecho, ignoring the others. To minimize the state kept in thereceiver (i.e., the number of unprocessed TSvals), the receivershould be required to retain at most one timestamp in theconnection control block.Jacobson, Braden, & Borman [Page 14] RFC 1323 TCP Extensions for High Performance May 1992 There are three situations to consider:(A) Delayed ACKs.Many TCP's acknowledge only every Kth segment out of a group of segments arriving within a short time interval; thispolicy is known generally as "delayed ACKs". The data-sender TCP must measure the effective RTT, including the additional time due to delayed ACKs, or else it will retransmitunnecessarily. Thus, when delayed ACKs are in use, thereceiver should reply with the TSval field from the earliest unacknowledged segment.。
IRIG_Standard

Published by Secretariat Range Commanders Council U.S. Army White Sands Missile Range, New Mexico 88002-5110
THIS DOCUMENT IS AVAILABLE ON THE RANGE COMMANDERS WEBSITE AT /RCC
IRIG STANDARD 200-04
TELECOMMUNICATIONS AND TIMING GROUP
IRIG SERIAL TIME CODE FORMATS
WHITE SANDS MISSILE RANGE REAGAN TEST SITE YUMA PROVING GROUND DUGWAY PROVING GROUND ABERDEEN TEST CENTER NATIONAL TRAINING CENTER ELECTRONIC PROVING GROUND NAVAL AIR WARFARE CENTER WEAPONS DIVISION NAVAL AIR WARFARE CENTER AIRCRAFT DIVISION NAVAL UNDERSEA WARFARE CENTER DIVISION, NEWPORT PACIFIC MISSILE RANGE FACILITY NAVAL UNDERSEA WARFARE CENTER DIVISION, KEYPORT NAVAL STRIKE AND AIR WARFARE CENTER 30TH SPACE WING 45TH SPACE WING AIR FORCE FLIGHT TEST CENTER AIR ARMAMENT CENTER AIR WARFARE CENTER ARNOLD ENGINEERING DEVELOPMENT CENTER BARRY M. GOLDWATER RANGE UTAH TEST AND TRAINING RANGE NATIONAL NUCLEAR SECURITY ADMINISTRATION (NEVADA)
List of Authors

ii
Executive Summary
Wireless infrastructure is evolving towards a heterogeneous wireless access network including diverse radio technologies offering a range of quality assured services. The evolution towards multi-system networks requires an efficient network management as well as interoperability across subsystems, to achieve seamless service continuity. This document provides a state of the art for multi-system dynamic engineering and presents the global project requirements. It is organized as follows: A brief introduction to the heterogeneous networks is presented, followed by the multi-system concept considered in the Gandalf project. The aim of the Gandalf project is to use large scale network monitoring, advanced RRM rules and appropriate quality of service evaluation in order to achieve automation of network management tasks in a multi-system environment. The network management is responsible for efficient operation of the multi-system network. Automated management has been tested or is currently under development for both GSM and UMTS radio access networks. In a multi-system context, network and radio resource management will become increasingly complex. Section 2 gives an overview of the network management including existing solutions in GSM or UMTS systems, auto-tuning architecture in GSM networks, fuzzy logic based RRM controller, as well as multi-system network management and automated troubleshooting. The project requirements are worked out in Section 3. The network elements of the considered radio access networks as well as the requirements for implementing advanced radio resource management are identified. The requirements for the Gandalf multi-system testbed, simulator, and the automated troubleshooting tool are presented. Section 4 describes the representative scenarios for multisystem networks to evaluate the main concepts that the Gandalf project will investigate to improve the overall system performance. These concepts include advanced radio resource management, seamless mobility, load balancing and self-tuning. Finally, a brief conclusion endD2.1 Initial scenarios and project requirements
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
5
Atempo整体解决方案 整体解决方案
May 2010 | © Atempo, Inc. All Rights Reserved
6
理想的桌面系统CDP保护解决方案
Atempo Live Backup
7
被忽视的桌面系统保护
桌面系统特点
๏ ๏ ๏ ๏ ๏
应用CDP技术能自动和实时地保护最终用户的数据
Live Backup CDP执行过程 执行过程 CDP的优势 的优势
•
最高级别的实时保护 持续备份对比传统计划备份 RPO=0;RTO<分钟 高效自动完成 快速精准颗粒度恢复
CLIENT
变化数据块
SERVER
• • • •
• •
•
检测到变化的数据 复制变化的数据到本 地缓存 将数据发送到Live Backup服务器
17
灵活的保护策略
๏
多种保护策略
- 系统级、文件级及灾难恢复 - 指定分区、指定目录、指定文件类型
举例
VIP 系统级全保护 设计部 CAD等各种图纸类 项目部 Office类数据 技术部 某文件夹
๏
分组策略管理
- 为不同的组及个人指定不同的保护策略
๏
自定义宏策略
- 根据需求自定义保护和排除策略
May 2010 | © Atempo, Inc. All Rights Reserved
倡导“端到端全业务系统数字资产管理” 倡导“端到端全业务系统数字资产管理”理念 实现对数据保护 归档及复制和容灾的一体化管理 数据保护, 实现对数据保护, 归档及复制和容灾的一体化管理
May 2010 | © Atempo, Inc. All Rights Reserved 3
组管理 修改策略
硬件唯一号识别验证 历史行为追踪机制
报表查看
May 2010 | © Atempo, Inc. All Rights Reserved
22
实时监控及统计工具
๏
实时流量监控
- 全图形即时进、出流量监控
๏
全面数据统计
- 存储空间使用状况统计 - 客户端状态统计 - 各级别恢复动作统计 - 数据的类型、变化频率分析
WAN
服务器) 后台存储设备 (Live Backup服务器) 服务器
• •
在Wintel 平台上使用以磁盘为主的存储设备 利用Microsoft SQL 服务器作为数据管理引擎
客户端
服务器端
May 2010 | © Atempo, Inc. All Rights Reserved
๏
用户界面复杂
- 不适用于IT水平相对薄弱的桌面用户 - 占用桌面系统资源太多
太复杂了, 太复杂了, 快来帮忙吧! 快来帮忙吧!
May 2010 | © Atempo, Inc. All Rights Reserved
9
理想的桌面系统保护
๏
用户的角度
๏ ๏ ๏
• •
以磁盘为基础的存储设备 Microsoft SQL服务器
May 2010 | © Atempo, Inc. All Rights Reserved
16
离线支持
即使最终用户处于漫游或离线状态, 即使最终用户处于漫游或离线状态,数据也能得到有效保护
离线状态
๏ ๏
——简单的点击安装链接 —— ——无需配置,一分钟即 可完成
May 2010 | © Atempo, Inc. All Rights Reserved
21
完善的安全机制
• • • • • ๏ ๏ ๏ ๏
安全的传输与存储 支持128位的加密算法 结合数据库的安全措施 镜像文件与恢复密钥文件分离 网络直接恢复 特征缩定, 特征缩定,控制终端用户权限 管理权限委派
Atempo Inc. 美国安腾普公司 2010.5
1
提纲
๏
Atempo公司简介 桌面系统的CDP保护解决方案 Live Backup
๏
๏
Q&A
May 2010 | © Atempo, Inc. All Rights Reserved
2
Atempo--专业数据保护及管理软件厂商 专业数据保护及管理软件厂商
May 2010 | © Atempo, Inc. All Rights Reserved
23
远程WEB部署及管理 部署及管理 远程
๏
支持WEB方式分发安装及升级 方式分发安装及升级 支持
- 方便多用户环境集中部署
๏
提供远程WEB管理控制台 管理控制台 提供远程
用户数量多、分散 无法统一进行有效数据管理 网络带宽有限 移动办公特点 IT知识相对薄弱
70%的IP分配给了桌面系统 60%的数据存于桌面系统 90%的桌面系统从无备份
社 会 服 务 企业数据中心 员工桌面系统
May 2010 | © Atempo, Inc. All Rights Reserved
๏
May 2010 | © Atempo, Inc. All Rights Reserved
14
完全透明
能够在不中断最终用户正常工作和不增加网络负荷的情况下轻松地备份数据。 能够在不中断最终用户正常工作和不增加网络负荷的情况下轻松地备份数据。
Live Backup提供了完全透明的解决方案 提供了完全透明的解决方案
May 2010 | © Atempo, Inc. All Rights Reserved
10
理想的CDP解决方案 解决方案Live Backup 理想的 解决方案
CDP
Continue Data Protection 实时、持续数据保护
Atempo Live Backup
๏ ๏ ๏ ๏
成立于1992年,总部位于美国加州的Palo Alto 年 总部位于美国加州的 成立于 北美、欧洲和亚洲的13个国家有分公司或办事处 北美、欧洲和亚洲的13个国家有分公司或办事处 上万家企业级用户 专注于基于软件的数据保护和管理领域
๏ ๏ ๏ ๏
提供基于统一平台的各种数据保护和管理解决方案 解决方案覆盖业务核心处理、 解决方案覆盖业务核心处理、业务终端触发及业务数字资产长期归档 08年进入国内市场 已设立北京及上海 广州办事处 年进入国内市场,已设立北京及上海 年进入国内市场 已设立北京及上海/广州办事处 已设立中国区技术支持中心及省会城市级的二级支持中心
- 便于管理员灵活登陆管理
May 2010 | © Atempo, Inc. All Rights Reserved
24
多种快速恢复方式
用户自助恢复
系统状态回滚及裸机灾难恢复
Web Recovery
May 2010 | © Atempo, Inc. All Rights Reserved
18
网络带宽的优化使用
๏
块级增量传输
- 仅传输变化的数据块
๏
全局重复数据删除
- 只传输新的数据块
๏ ๏
用户端自动带宽优化调整 用户自助的网络带宽控制
- 可根据用户IT水平或级别设定是否开启
May 2010 | © Atempo, Inc. All Rights Reserved
May 2010 | © Atempo, Inc. All Rights Reserved
• • •
Live Backup产品架构 产品架构
C/S结构 结构
客户代理( 客户端) 客户代理( Live Backup客户端 客户端
• • • •
检测文件内容的变化 复制变化的数据块到本地缓存 适时将数据迁移至服务器存储设备 提供用户界面以便于客户自行恢复
8
传统桌面系统保护软件的局限
๏
需要设定备份时间策略
- 无法应对多用户开关机不统一 - 仅在备份时间点工作,其余时间不能实现保护
๏
每次备份重新传输整个变化文件
- 对网络带宽造成严重负荷 - 过多占用存储空间
刚丢的文件找不 到!
网速太慢了! 网速太慢了!
๏
无网络不能工作
-在远程以及移动的环境不能很好的工作
12
Live Backup – 主要特点
独特的专利技术专注于产品的高性能, 独特的专利技术专注于产品的高性能,同时其简便的用户界面为最终用户带来全新的体验
Live Backup主要特点 主要特点
持续数据保护(CDP) 数据保护 重复数据消除和块级备份 数据消除和块级备份 块级备 完全透明 对异构环境的支持 异构环 提供离线 提供离线支持 自助文件恢复 自助文件恢复 系统回滚和裸机灾难恢复 和裸机灾难 完善的安全控制 集中管理和远 集中管理和远程控制
May 2010 | © Atempo, Inc. All Rights Reserved
13
Live Backup工作原理 工作原理
客户端
文档A 变化数据一 变化数据二
CACHE
变化数据三
服务器
๏ ๏ ๏
基于I/O事件驱动,捕捉每个变化 只发送变化的新内容 Block Level,带宽压力小 本地磁盘缓存机制,离线状态可用
25
一、用户自助恢复 用户自助恢复
通过恢复向导使最终用户能轻松地恢复文件和目录,在没有IT IT人员的帮助下也能使系统回滚到原有 通过恢复向导使最终用户能轻松地恢复文件和目录,在没有IT人员的帮助下也能使系统回滚到原有 的状态
鼠标右键集成恢复选项
仅需一个点击便可进入恢复界面
Backup恢复向导 Live Backup恢复向导
Atempo主要合作伙伴 主要合作伙伴
应用 合作伙伴
存储 合作伙伴
系统 合作伙伴
May 2010 | © Atempo, Inc. All Rights Reserved