基于回归支持向量机的信息检索
【计算机科学】_检索技术_期刊发文热词逐年推荐_20140727
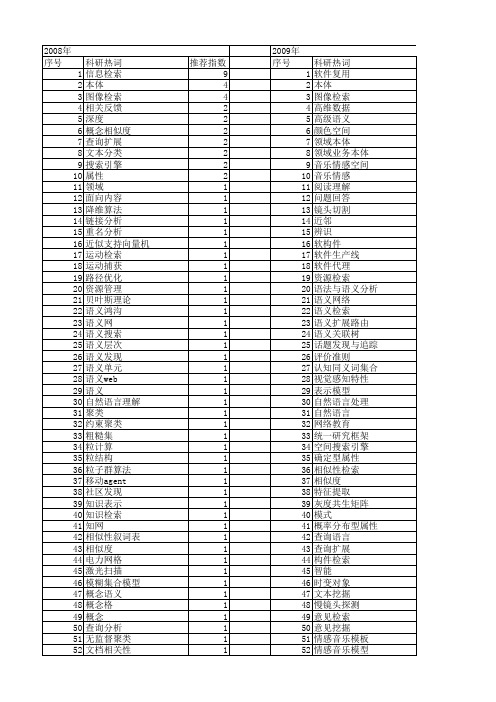
科研热词 软件复用 本体 图像检索 高维数据 高级语义 颜色空间 领域本体 领域业务本体 音乐情感空间 音乐情感 阅读理解 问题回答 镜头切割 近邻 辨识 软构件 软件生产线 软件代理 资源检索 语法与语义分析 语义网络 语义检索 语义扩展路由 语义关联树 话题发现与追踪 评价准则 认知同义词集合 视觉感知特性 表示模型 自然语言处理 自然语言 网络教育 统一研究框架 空间搜索引擎 确定型属性 相似性检索 相似度 特征提取 灰度共生矩阵 模式 概率分布型属性 查询语言 查询扩展 构件检索 智能 时变对象 文本挖掘 慢镜头探测 意见检索 意见挖掘 情感音乐模板 情感音乐模型
科研热词 信息检索 本体 图像检索 相关反馈 深度 概念相似度 查询扩展 文本分类 搜索引擎 属性 领域 面向内容 降维算法 链接分析 重名分析 近似支持向量机 运动检索 运动捕获 路径优化 资源管理 贝叶斯理论 语义鸿沟 语义网 语义搜索 语义层次 语义发现 语义单元 语义web 语义 自然语言理解 聚类 约柬聚类 粗糙集 粒计算 粒结构 粒子群算法 移动agent 社区发现 知识表示 知识检索 知网 相似性叙词表 相似度 电力网格 激光扫描 模糊集合模型 概念语义 概念格 概念 查询分析 无监督聚类 文档相关性
情感计算 情感极性 情感化 情感分类 工作流模板 工作流 宏块类型 多重探测 多媒体信息检索 基于构件的软件开发 基于内容视频检索 基于内容的音乐检索 图像语义 图像分割 回归型支持向量机 印章 刻面分类 元数据 位置敏感的哈希 代码搜索 主题选取 wordnet web文本分类 p2p mpeg压缩域 api的实现与使用代码
推荐指数 9 4 4 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
基于支持向量机语义分类的两种图像检索方法

收 稿 日期 : 0 90 — 0 2 0 — 91
降低 分类 的难 度 , 在每一 级分 类 时 , 采取 贝 叶斯分类 的
方法 . 们假设 图像类 别 是 固 定 的 而且 每 类 图像 的先 他
基 于 支 持 向 量 机 语 义 分 类 的 两 种 图像 检 索 方 法
廖绮 绮 , 李翠 华
( f大 学 信 息 科 学 与 技 术 学 院 , 建 厦 f 6 0 5 厦 - 1 福 -3 10 ) 1
摘 要 :为了更好 的解决 基于内容的 图像检 索 问题 , 出 了 2种 基 于语 义的 图像检 索 方法. 1种 是基 于支持 向量 机 提 第
信息检索系统导论期末考试题库

信息检索系统导论期末考试题库一、选择题1.下列哪项不属于信息检索的关键技术?(B )A.信息抽取B.文本挖掘C.自动文摘D.链接分析2.TREC测试集主要包括3个部分,下列选项中不是TREC测试集的一部分的是:(C )A.主题B.文档集合C.关键词D.相关性判断3.对向量空间模型、布尔模型及概率模型的表述有误的一项是:(D )A.向量空间模型与布尔模型相比具有较大的优势B.向量空间模型无法揭示索引项之间的关系,因而向量空间模型在理论上还是不够完善C.布尔模型是最早提出的信息检索模型D.概率模型也称二值独立检索模型。
它是在向量空间模型的基础上为解决检索中存在的一些不确定性而引入的。
4 利用文献后面所附的参考文献进行检索的方法称为(A )A.追溯法B.直接法C.抽查法D.综合法5、逻辑“与”运算符是用来组配()A.不同检索概念,用于扩大检索范围B.相近检索概念,扩大检索范围C.不同检索概念,用于缩小检索范围D.相近检索概念,缩小检索范围6、在《中国学术期刊全文数据库》中,不可以进行()检索A.逻辑与B.逻辑或C.逻辑非D.位置7、若想在《中国学术期刊全文数据库》中提高检索结果的查准率,可使用()A.在结果中检索B.优先算符C.或者D.位置检索9、下列检索式中,哪一种属于逻辑“与”?( B )A.室内装饰+室外装饰B.音乐﹡教学C.神雕侠侣–电视剧D.火星︱金星10、下列不属于查询构造方法的是:()A 分类查询B 单一词查询C 布尔查询D 上下文查询11、PageRank算法的理论基础是随机冲浪模型,该模型描述了网络用户对网页的访问行为。
下列不属于用户访问行为特点的是:()A 用户选择的起始网页是固定的B 用户会从起始网页含有的超链接中随机选择一个页面继续浏览C 当用户沿着超链接前进了一定数量的网页后,可能会对本主题厌倦,这时用户会重新随机选择一个网页进行浏览D 用户会重复以上的过程若干次12、信息过滤系统是应用信息过滤技术处理信息的应用系统,下列对其特点的说法错误的是:()A 信息过滤系统是针对无结构的或半结构化的数据设计的信息系统,这与传统的数据库应用有着本质的区别B 信息过滤系统只处理文本信息C 信息过滤系统一般处理的数据为输入信息流D 信息过滤系统要包含一组对用户过滤需求的描述13、《中国学术期刊全文数据库》提供的文献内容特征检索途径有()A.机构B.篇名/关键词/摘要C.中文刊名D.作者14、维护倒排文件通常需要的操作有( D )文档或文档集合。
基于支持向量机的二次距离约束图像检索技术

Dx )∑aex + ( = e ( 6 , K )
i= J
圈 1 “ a " " e 、eg ti .ms “al 3类图像 的查全率和查准率比较 rn e
摘要 :相 关反 馈 技 术是 图像检 索过 程 中 的一 种 交 互 式技 术 。
r 1f 茎 [o + : 1 r ,
将 结果 回 馈 给 用 户 。 关键词 : 向量机 二次距离约束 相关反馈
“)∑ ( + 孙 ) = 6
i
S p 按照公式(计算 图像 的约束距离 Sxm) t5 e 1 ) ( 。 , Se6对约束距离 Sx, 进行排序返 回用户所需要 图像。 t p ( m) 支持 向量 机的无约束反馈图像检索的思想是 :若用户要对 为 了便于分析 比较 , 将无约束 的反馈算 法标记为 A , 4将二次 个图像进行检索 , 训练样本就 由 个样本组成 , 在用户反馈 过程 中, 用户给出的反馈模式是对一幅图像做 出相关或不相关 的 约束算法标记 为 A + 4。 评价 。 此方法不考虑图像在空间分布形式 。 直接进行分类。 在整个 3 试 验及结 果分析 图像特征空间 中, 通过训练样本训练 , 构造最优分类面 , 根据图像 距离最优分类面的距离判断与示例图像相似程度 。 最后按距离排 31实验环境 . 序。 将结果反馈给用户。 为验证本文提 出的算法的有效性 , 实现 了一个 网络环境下基 于 内容图像检 索系统 , 系统 用 VsaC +6 该 i l+ . u 0编程 ,用 S L Q 2 二次约束距离的反馈检索 Sr r00 e e20 建立图像特征库和图像库 。在 Wi o s 00P f — v n w 0 re d 2 os 在支持 向量机的无 约束反馈图像检索方法 中, 若距离最优分 s n 操作系统下实现。 ia ol r tt’ l ’ f n ●, ●● ● 如 H ● 如 , t a  ̄ rt 类面的距离越小 。 认为两幅图像越相似。然而这种相似性度量并 7 t i - l , T口 ・ ● 抽 T t ・ ∞ t r●● Q ●l, - f i, O S . 0 ‘ S 不能代表 图像在语义上的相似性。 我们不知道在语义上相似 的一 04 . 类图像在特征空间 中的分布形式 , 若要知道其在特 征空 间中的分 =9 , .5 §03 . 布形 式需要对空间作大量的参数估计 , 这个对于图像检索很不现 O 2 S 0.2 实, 我们不能让用户提供大量的训练样本 。支持向量机作为统计 O I S 0 1 . 学习 的方 法, 提供 的只是两类模式 的识别 , 而图像检索的 目标是 OO . 5 0 提供用户感兴趣 的图像 , 回一系列接近示 例图像的图像 。 返 。 I Io l-. f t m^ : . 吐 经过学习后最优分类 面能在语义上近 似的区分图像在语义 上的差别 , 在最优分类 面内的图像之 间也有相似程度的区别 。对 于每次查 询, 可以通过用户回馈 回来 的信息 , S M学 习得到最 用 V e 1 ;O口 优分类 面 , 对于最优分类面 内的图像可 以认为是用户所需要 的图 ; o. 8 量 o 7 像。 用户 回馈 回来的图像 中标记为正例的图像可以看作为图像 的 “6 nS 语义信息 ,其在特 征空间中的聚类中心认 为是查询的语义 中心 o‘ O 3 点。 而对于最优分类面外 的图像 , 考虑到学 习回馈不是一次完成 , nl 每次进行 反馈学 习最优分类 面都会变化 , 因而不能忽略最优分类 面外 的图像。 事实上图像 的语义在特征空 间中也不是完全可 以分
支持向量机PPT课件

支持向量机ppt课件
https://
REPORTING
2023
目录
• 支持向量机概述 • 支持向量机的基本原理 • 支持向量机的实现步骤 • 支持向量机的应用案例 • 支持向量机的未来发展与挑战 • 总结与展望
2023
PART 01
支持向量机概述
REPORTING
详细描述
传统的支持向量机通常是针对单个任务进行训练和预测,但在实际应用中,经常需要处理多个相关任务。多任务 学习和迁移学习技术可以通过共享特征或知识,使得支持向量机能够更好地适应多个任务,提高模型的泛化性能。
深度学习与神经网络的结合
总结词
将支持向量机与深度学习或神经网络相结合,可以发挥各自的优势,提高模型的性能和鲁棒性。
模型训练
使用训练集对支持向量机模型进行训练。
参数调整
根据验证集的性能指标,调整模型参数,如惩罚因子C和核函数类 型等。
模型优化
采用交叉验证、网格搜索等技术对模型进行优化,提高模型性能。
模型评估与调整
性能评估
使用测试集对模型进行 评估,计算准确率、召 回率、F1值等指标。
模型对比
将支持向量机与其他分 类器进行对比,评估其 性能优劣。
模型调整
根据评估结果,对模型 进行调整,如更换核函 数、调整参数等,以提 高性能。
2023
PART 04
支持向量机的应用案例
REPORTING
文本分类
总结词
利用支持向量机对文本数据进行分类 ,实现文本信息的有效管理。
详细描述
支持向量机在文本分类中发挥了重要 作用,通过对文本内容的特征提取和 分类,能够实现新闻分类、垃圾邮件 过滤、情感分析等应用。
基于模糊支持向量机的面向语义图像检索算法

S ma tc b s d i g ere a l o i m sn u z u p r e t rma h n e n i — a e ma e r ti v la g rt h u i g f z y s p o tv c o c i e
H A G We —u Q NT a— , A G Z e —u U N ny , I unf T N hnh a a
t r so ma e n n r d c n he mi — m b rhi—u c in f z u o v c o c i e it ma e r t e a , o ti e h u e fi g sa d ito u i g t n me e s p f n to uzy s pp  ̄ e tr ma h n n o i g er v l i ba n d te
第 2 卷 第 5期 8
2】1年 5月 【 I
计 算 机 应 用 研 究
Ap l ain Ree rho mp tr pi t s ac fCo u es c o
V0 . 8 N0 5 12 . Ma 0 1 v2 1
基 于 模 糊 支 持 向量 机 的 面 向 语 义 图 像 检 索 算 法 书
关键 词 :面向语 义的 图像检 索 ;模糊 支持 向量机 ;最 小隶属度 ;不可分 区域
中图分类 号 :T 3 1 P 9
文 献标 志码 :A
文 章编 号 :1 0 — 6 5 2 1 ) 5 18 —4 0 1 3 9 ( 0 1 0 — 9 7 0
di1 . 9 9 ji n 10 —6 5 2 1 .5 O 1 o : 0 3 6 / .s . 0 1 3 9 . 0 1 0 . 1 2 s
基于支持向量机的文本分类研究

本文将 介绍基于支持向量机 (v ) s Ms 的文本分类基 本原 哩、 方法, 并给出 实现的例子。 2 文本 分类的基本原理 文本分类可以描述为这样一个 问题 :对于 每个新 到的 文本 .计算机 自动 判断它与 系统蜘 定的各 个文 本类别之 间
l( ct + (i=I( iop it o P ) P ) c t g ( i g( ) t ∑P i ) ( c ) /l /
其中 , 表示某特征词 , i 示第 i t c表 个类 , ≤i I p t 1 ≤f, () R
兄的统计量 ( 如频度 、 集中度 、 分布度等) 来选择该类别的局
3 支持 向■ 机 (V ) S MS
若 f )=1 ( z ,则 x 于用户定义的领域类 ,否则重复上 属 述过程 , x 使 加入该类。z () = x 可有 三种形式, 系统采用 本
径 向基 函数 ( B ) RF。
4 .系统 实 现 4 1训练 文档 集 的 采 集 .
支 持向量机 (V 是 一种建立在统计学习理论基础上 S M) 的机器学习方法, 它具有以下 4个理论要点 :1 非线性映射 () 是理论的基础;()对特征空间划分 的最优超平面 ( 眦 I 2 叩
特征。词集合 Wi Wi,… Wi , , ,l , =【 l m . wiI】其中 Wi 表 示条件概率。 i m 勾第 m个特征词 。 i L 表示该类 别的特征词 数。 所有类别的局 2 2特征词的权重
M a 2 02 v 0 Ge e lNo 9 nr . 5 a
l9 l
维普资讯
Kn t eg r oo d eWol l d
一
CDA-LEVELⅢ模拟题一

CDA-LEVELⅢ模拟题(一)一、单选题1对于分类器的性能,我们需要不同维度来进行综合衡量,以下不属于分类器评价或比较尺度的有?A.预测准确度B.查全率C.模型描述的简洁度D.计算复杂度正确答案:C,解析:模型描述简洁度不属于模型评价指标2下面有关分类算法的准确率,查全率,F1值的描述,错误的是?A.准确率是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率B查全率回旨检索出的相关文档数和文档库中所有的相关文档数的瞬,衡量的是检索系统的查全率C.正确率、查全率和F值取值触0和1之间,数值降国,查准率或查全率就越高D.为了解决准确率和查全率冲突问题,引入了fi分数正确答案:C ,解析:无解析3回归树是可以日于回归的决策树模型,一个回归树又寸应着输入空间(即特征空间)的一个划分以及在划分单元上的输出值。
以下哪个指标可用于回归树中的模型上降A.Adjusted R2B.F-measureC.AUCD.Precision & Recall正确答案:A,解析:F-measure. AUC、Precisin & Recall是分类模型的评价指标4 序列模式挖掘(sequence pattern mining )是指挖掘相对时间或其他模式出现频率高的模式典型的应用还是限于离散型的序列。
下列哪个选项不属于序列模式的时限约束?,A.最大跨度约束B.主键约束C.最小间隔和最大间隔约束D.窗口大小约束正确答案:B,解析:序列模式的时限约束包括最壮度约束、最大间隔和最小间隔约束、窗口大小约束5 Apriroi算法中,候选序列的个数比候选项集的个数大得多,产生更多候选的原因有?A.l个项在项集中最多出现一次,但一个事件可以在序列中出现多次B.一个事件在序列中最多出现一次,但一个项在项集中可以出现多次C.次序在序列中和项集中都是重要的D.序列和以合并正确答案:A,解析:无解析6 考虑下面的频繁3-项集的集合:{1, 2. 3}, {1, 2. 4}, {1, 2, 5}, {1, 3, 4}, {1, 3, 5),{1,4,5}, {2, 3, 5}, {3, 4, 5}假定数据集中只有5个项,采用合并策略,由候选产生过程得到4-项集不包含:A.1, 2, 3, 4B.1, 2, 3, 5C.1, 2, 4, 5D.1, 3, 4, 5正确答案:C,解析:无解析7广为流传的“啤酒与尿布”的故事,其背后的模型实际上是哪一类?A.分类(Classification)B.分群(Clustering)C.关联(Assciation)D.预测(Prediction)正确答案:C,解析:"啤酒与尿布”是关联规则的经典故事8 Apriori算法,最有可能可用来解决以下哪个问题?A电子商务网站向顾客推荐商品的广告B.信用卡欺诈识C.电信用户离网预警D预测GDP与工业产值之间的关系正确答案:A,解析:Apriori算法是关联规则挖掘算法,它利用逐层搜索的迭代方法找出数据库中项集的关系,以形成规则9在聚类(Clustering)的问题中,若缄字段属性都是二元属性(Binary Variable),根据下表,下列何者是Jaccard Coefficient计算数据间品巨离的公式?答案:A,10以下哪个选项是分割式聚类算法?A.K-MeansB.Centroid MetohdC.Ward's MethodD.以上皆非正确答案:A,解析:无解析11在机器学习中,非监督学习主要用来分类.其中重要的两种就是聚类分析和主成分分析,下列那个选项不是聚类分析的算法A.Two-StepQ B.FP-GrowthC.Centrid MethodD.Ward's Method正确答案:B,解析:FP-Growth是关联分析算法12、下列哪种集成方法,会重复抽取训练数据集中的数据,且每笔被抽中的概率始终保持一样?A.袋装法(Bagging)B.提升法(Boosting)C.随机森林(Random Forest)D.以上皆是正确答案:A,解析:无解析13 提升法Boosting是一种可以用来减小监督式学习中偏差的机器学习算法。
一种新的基于SVM的相关反馈图像检索算法_许月华

本文提出了一种新的基于的相关反馈算法。
我们SVM 认为检索过程中的样本集合是一个动态增长的集合。
对于用户每次反馈的图像,可以分为感兴趣的样本正例和不感兴()趣的样本反例两类,用来更新原有的样本集合。
通过不断()的积累,样本集合会逐渐达到学习的要求,从而解决SVM 上述算法中样本不足的困难。
本文算法的第个改进之处在2于考虑了检索过程中历史信息的利用。
每一次新的反馈之后,旧的权值经过衰减和新的权值共同决定图像库中所有图像的排序。
实验结果证明了文中算法的有效性和系统检索能力的提高。
支持向量机1 (SVM)给定线性可分样本(x i ,y i …),i=1,,N, y i ∈,,{-11}x i ∈R d 。
0b w x+=⋅假定某个超平面可以将正例与反例分开称之为(()g x b w x =+⋅分类超平面,对应分类函数为。
最优分类) 面是令正例和反例之间的距离最大化的分类超平面。
将g(x )w 归一化之后,求解最优分类面的问题等价于最小化,目标函数为:2min ()12w w Φ= (1)()10i i y w x b ⋅+−≥公式的约束条件为:(1)i=1, 2, … , N i α定义个算子N Lagrange ,i=1,…。
求解该二次优化, N ∑==N i i i i x w y 1αx i 问题,可以得到最优分类面,其中,是 位于分类间隔面上的样本,称为支持向量。
分类函数为:()()b y sign f x x x i i i i +•=∑α (2)在数据不是线性可分的情况下,一方面,引入惩SVM 罚系数和松弛系数C ξi ,…,修改目标函数为:i=1, , N()()()11,2Ni C w w w φξ•=+∑⋅(3)另外,注意到公式中仅仅出现了点积的形式(2)xx ji •。
假设先将数据映射到某个欧氏空间,映射ψ:H ψ : R d →H ()()i j x x Ψ•Ψ则公式中的点积转化为中的点积。
信息检索系统中的文本分类与推荐算法

信息检索系统中的文本分类与推荐算法引言随着互联网的快速发展和信息爆炸的时代到来,人们面临着海量的信息,如何高效地获取相关的信息变得越来越重要。
信息检索系统作为一个有效的工具成为人们处理信息的重要手段之一。
其中,文本分类和推荐算法作为信息检索系统中的重要组成部分,在提高检索系统的效率和准确性方面发挥着重要的作用。
一、文本分类1.1 概述文本分类是将一篇文本按照它的内容和主题进行分类的过程。
通过文本分类,我们可以将大量的文本按照一定的标准和规则进行划分,使得用户可以更加方便地获取所需的信息。
1.2 文本分类的方法在文本分类中,常见的方法有基于规则的分类、基于统计的分类和基于机器学习的分类。
1.2.1 基于规则的分类基于规则的分类方法是依据事先定义好的规则和特征来进行分类的。
通过提取文本中的特征,如词频、关键字等,然后根据设计好的规则进行分类。
1.2.2 基于统计的分类基于统计的分类方法是通过统计文本中的词频等特征信息,然后利用统计学原理对文本进行分类。
常见的方法有朴素贝叶斯分类算法、支持向量机等。
1.2.3 基于机器学习的分类基于机器学习的分类方法是利用机器学习的算法对文本进行分类。
通过构建训练集和测试集,将文本转化为机器学习算法能够处理的形式,如词袋模型、向量空间模型等,然后利用机器学习算法进行分类。
二、推荐算法2.1 概述推荐算法是信息检索系统中的重要组成部分。
通过分析用户的兴趣、需求等信息,推荐算法可以为用户提供个性化的推荐结果,提高用户的满意度和使用效果。
2.2 推荐算法的方法在推荐算法中,常见的方法有基于内容的推荐、协同过滤推荐和混合推荐算法。
2.2.1 基于内容的推荐基于内容的推荐是依据物品的特征和用户的兴趣进行推荐的。
通过分析物品的属性和用户的喜好,将用户喜欢的物品推荐给其他相似兴趣的用户。
2.2.2 协同过滤推荐协同过滤推荐是通过分析用户之间的关系,利用用户的历史行为和偏好进行推荐的。
基于支持向量机的文本分类方法研究

,
挖掘支持向量机在文本分类 中的应用潜力 ,解决文本分类中存在的问题 ;二是研究支持 向量机在文卒分类 应用中存在的尚未解决或尚未完全解决的问题 , 针对文本分类的特点 ,提出提高支持向量机在文本分类中
维普资讯
第 2 卷第 1 4 期
20 年 1 08 月
齐 齐 哈 尔 大 学 学 报
J u n l f qh rUnv r i o r a ia ie st o Qi y
Vo .4No 1 1 . . 2
Jn,0 8 a. 0 2
视。
在基于机器学习方法的文本分类应用研究 中,基于支持向量机 的研究方法 由于具有性能上的优势,近
年来一直是数据挖掘和信息检索领域的研究热门。与其它文本分类方法相 比,使用支持向量机 主要具有如 下优 卜 :
1 文本数据向量维数很高 。对于高维问题 ,支持 向量机具有其它机器学习方法不可 比拟的优势 ; ) 2 文本向量特征相关性大 , 多文本分类算法建立在特征独立性假设基础上 , ) 许 受特征相关 I的影响较 生 大 ,而支持向量机对于特征相关性不敏感 ; 3文本 向量存在高维稀疏 问题 , ) 一些文本分类算法不同时适合于稠密特征矢量与稀疏特征矢量的情况 , 但支持向量机对此不敏感 ;
推式支持向量机的方法 , 在少量有标签样本和大量无标签样本所构成的混合文本训练集上训练支持向量机 。 陈毅松等对 Jah s oci 提出的方法进行 了改进 , m 提出了一种渐进直推式支持 向量机学 习算法等 。 epl等研 L oo d
究 了不同的文本表示模型对支持向量机分类性能的影响。为了实现基于语义概念的文本分类 , ia Sl o s等提 出了一个基于语义核的支持向量机文本分类器 ,它利用词与词之间的语义关系构造 了一个新的矩阵,并把 这个矩阵加人支持向量机径向基核 函数的定义 中, 取得了更好的分类效果。 rt n i Cii i 等通过构造潜在语义 sa n 核 ,在核定义的特征空间实现潜在语义索引 , 对将语义信息与支持向量机方法结合起来实现文本分类作 了 尝试。 在学 习模型中加人领域的先验知识有可能改善学 习模型的泛化能力 , 为此 , a ao Ss n 研究了如何利用 s 虚样本方法将文本先验知识引人支持向量机的学 习过程。李辉等也对如何在支持向量机的学 习过程中加人 文本先验知识进行了研究 。另外 ,研究者们还提 出了许多解决超文本分类的支持向量机方法等等。 近三年来 ,基于支持向量机的文本分类研究 主要集 中在文本分类训练算法 、文本分类模型的建立 、支 持中文分类的支持向量机分类方法 、 函数的设计 以及在支持向量机上结合其他机器学习方法的研究上 , 核 如模糊支持向量机 、并行多类分类支持 向量机等 ¨ ,但总体上来说 ,这些研究都是以提高分类速度 、
信息检索中的文本分类与聚类算法

信息检索中的文本分类与聚类算法信息检索是一门研究如何从大量的文本数据中获取有用信息的学科。
在信息检索中,文本分类与聚类算法是常用的技术手段。
本文将对信息检索中的文本分类与聚类算法进行介绍和探讨。
一、文本分类算法文本分类是将一篇文本分配到预定义的类别中的过程。
文本分类算法可以帮助我们对文本进行快速的分类和组织。
下面将介绍几种常用的文本分类算法。
1. 朴素贝叶斯算法朴素贝叶斯算法是一种基于概率的文本分类算法。
它假设文本中的每个特征都是相互独立的,并基于这个假设计算文本属于某个类别的概率。
朴素贝叶斯算法在文本分类中具有较高的准确度和效率。
2. 支持向量机算法支持向量机算法是一种基于机器学习的文本分类算法。
它通过将文本映射到高维空间中,找到一个最优的超平面来划分不同类别的文本。
支持向量机算法在处理高维度的文本特征时具有较强的分类能力。
3. K近邻算法K近邻算法是一种基于实例的文本分类算法。
它通过比较待分类文本与已知类别文本之间的相似度,将待分类文本归入与其最相似的K个已知类别文本的类别中。
K近邻算法简单易懂,但在处理大规模文本数据时计算复杂度较高。
二、文本聚类算法文本聚类是将文本按照其相似性进行分组的过程。
文本聚类算法可以帮助我们发现数据中的隐藏结构和主题。
下面将介绍几种常用的文本聚类算法。
1. K均值算法K均值算法是一种基于距离的文本聚类算法。
它通过计算文本之间的距离,将文本分为K个簇。
K均值算法简单易实现,但对初始簇中心的选择敏感,并且需要事先预定簇的个数。
2. 层次聚类算法层次聚类算法是一种自底向上或自顶向下的文本聚类算法。
它通过计算文本之间的相似度,将相似度高的文本归为一类,并逐步合并形成聚类层次结构。
层次聚类算法可以灵活地处理不同数量的聚类。
3. DBSCAN算法DBSCAN算法是一种基于密度的文本聚类算法。
它通过定义文本的密度和邻域范围来划分聚类,可以发现任意形状和大小的簇。
DBSCAN算法对异常值和噪声点具有较好的鲁棒性。
支持向量机在基于内容的图像检索中的应用

2007年第16期周刊考试2.2高职计算机专业人才培养的评价体系高职计算机专业人才培养评价体系应当包含如下几个相互依存的方面:(1)课程设置的评价。
当前高职计算机专业的课程设置仍是以培养学生的计算机原理和基础知识为主,学生参与实际项目的动手能力、解决问题能力、专业运用能力均较欠缺。
合理的课程设置应当使学生通过在校学习,在具备一定理论知识的基础上,具有独立开展专业工作的能力。
现在计算机各专业的课程情况是大而全,但深度和强度不够。
如依次开设C语言程序设计、C#程序设计、基于.NET的数据库程序设计等,虽然这些课程确有一定的连贯性和层次性,有利于学生逐次掌握编程技巧。
但由于这些课程安排的教学课时数大多在60学时左右,学生深入实际解决具体问题均较少涉及,这正是我们课程设置急需改进的地方。
课程设置的评价,既要评价课程设置的科学性、合理性,还要评价课程设置是否有利于学生实际应用能力和专业技能的培养。
(2)师资水平及教学方法的评价。
学生能力的培养是和教师的知识水平、实践经验和教学方法分不开的。
如果老师能够带着学生进行实际的综合布线工作,能够指导学生亲手组建局域网,教学效果定会大大提高。
现在职业院校教师的学历层次都比较高,缺乏的是实际经验。
学校应当有意识地组织教师接受这方面的培训,从而使教师具备从理论教学到实践教学转变的能力。
有必要制定一套能够激发教师更注重实践教学,更注重对学生动手能力培养的师资水平评价方案。
(3)实验室建设的评价。
实验室应是一个模拟现实的工作环境,其软硬件设施应能为学生提供实际工作需要的各种技能培训。
调查显示,在实际工作中,计算机专业人才最欠缺的是对工具和方法的应用不熟、经验不足。
因此,实验室应当成为学生从学校走向实际工作的桥梁,成为培养学生专业技能、熟悉社会工作环境、锻炼动手能力和培养工作自信心的重要场所。
实验室设备、实验课程的安排、实验课的实施等应当成为我们专业建设和专业教学评价的关键指标。
自然语言处理的信息检索案例分享

自然语言处理的信息检索案例分享自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个重要分支,它致力于使计算机能够理解和处理人类自然语言的方式。
在信息爆炸的时代,如何高效地从大量的文本数据中获取有用的信息成为了一个重要的问题。
本文将分享一些自然语言处理在信息检索方面的案例,展示其在实际应用中的价值。
一、文本分类文本分类是信息检索中的一个重要任务,它的目标是将给定的文本分到预定义的类别中。
例如,对于一篇新闻文章,我们可以使用自然语言处理的技术将其分类为体育、科技、娱乐等不同的类别。
文本分类可以帮助我们快速准确地找到感兴趣的文本,提高信息检索的效率。
自然语言处理中的文本分类算法通常基于机器学习方法,如朴素贝叶斯、支持向量机等。
这些算法可以通过训练样本来学习文本的特征和类别之间的关系,然后将这些模型应用于新的文本数据。
通过不断优化算法和特征选择,我们可以提高文本分类的准确性和效率。
二、情感分析情感分析是自然语言处理中的一个热门研究方向,它的目标是识别文本中的情感倾向,如积极、消极或中性。
情感分析可以应用于社交媒体数据、产品评论等场景,帮助我们了解用户对某个产品、事件或话题的态度和情感。
情感分析的方法主要包括基于规则的方法和基于机器学习的方法。
基于规则的方法通过定义一系列规则来识别文本中的情感词汇和情感强度,然后根据规则进行情感分类。
而基于机器学习的方法则通过训练样本来学习情感词汇和情感之间的关系,然后将这些模型应用于新的文本数据。
情感分析的准确性和效果受到训练数据的质量和特征选择的影响。
三、问答系统问答系统是自然语言处理中的一个重要应用领域,它的目标是根据用户提出的问题,从大量的文本数据中找到与问题相关的答案。
问答系统可以帮助用户快速获取所需的信息,提高信息检索的效率。
问答系统的实现通常包括两个主要步骤:问题理解和答案生成。
在问题理解阶段,系统需要理解用户的问题,并将其转化为机器可以理解的形式。
掌握语义分析和信息检索的基本方法

掌握语义分析和信息检索的基本方法语义分析和信息检索是自然语言处理中两个重要的研究领域,它们旨在实现对大规模文本数据的语义理解和有效检索。
本文将介绍语义分析和信息检索的基本方法,包括词嵌入、文本分类、语义关系抽取等。
一、词嵌入词嵌入(Word Embedding)是一种将词语映射到低维向量空间的技术,它可以在机器学习和自然语言处理任务中使用。
目前最常用的词嵌入方法是基于神经网络的Word2Vec和GloVe。
这些方法通过训练大规模文本数据集,将词语表示为向量,使得语义相似的词在向量空间中距离较近。
二、文本分类文本分类是指将文本按照预定义的类别进行分类的任务。
常见的文本分类方法包括:朴素贝叶斯分类器、支持向量机、逻辑回归等。
这些方法通常使用词袋模型表示文本特征,然后通过训练分类模型来实现文本分类。
三、语义关系抽取语义关系抽取是指从文本中自动识别和提取实体间的语义关系。
常见的语义关系抽取方法有:基于规则的方法和基于机器学习的方法。
基于规则的方法通常通过手动定义规则来进行关系抽取,而基于机器学习的方法则通过训练分类模型来实现自动化的关系抽取。
四、信息检索信息检索是指从大规模文本数据中检索出与用户查询相关的信息。
常见的信息检索方法包括:基于向量空间模型的检索、基于概率模型的检索和基于深度学习的检索。
这些方法通过建立索引、计算查询与文档之间的匹配程度来实现信息检索。
在语义分析和信息检索任务中,还可以使用一些其他的技术来提高性能,例如:命名实体识别、关键词提取、句法分析等。
通过综合运用这些技术,可以大大提高语义分析和信息检索的效果。
除了基本方法之外,还有一些前沿的研究方向和技术应用可以进一步推动语义分析和信息检索的发展。
例如,基于深度学习和神经网络的方法在语义分析和信息检索中取得了显著的进展,如利用深度学习模型进行文本分类和命名实体识别。
此外,将知识图谱和语义表示模型结合起来,可以实现更精确的语义分析和信息检索。
文本分类的关键技术

文本分类的关键技术文本分类是自然语言处理领域中的一项重要任务,它是指将一个文本分配到预定义的类别或标签中。
这样的技术在信息检索、情感分析、垃圾邮件过滤、新闻分类等领域都有很广泛的应用。
文本分类的关键技术包括特征提取、模型选择和评估方法等方面,下面我们就来详细介绍一下文本分类的关键技术。
一、特征提取二、模型选择在进行文本分类任务时,选择合适的模型也是非常重要的。
常见的文本分类模型包括朴素贝叶斯、支持向量机(SVM)、逻辑回归、决策树、随机森林、深度学习等。
朴素贝叶斯是一种基于贝叶斯定理和特征条件独立假设的分类算法,它在文本分类任务中表现良好且计算速度快。
SVM是一种常用的二分类算法,它通过在特征空间中找到一个最优的超平面来进行分类。
逻辑回归是一种广义线性模型,可以用于处理多分类问题。
决策树和随机森林是基于树结构的分类算法,它们在处理文本特征不平衡和噪声较多的情况下表现较好。
深度学习模型如卷积神经网络(CNN)、循环神经网络(RNN)和长短时记忆网络(LSTM)等在文本分类任务中也有很好的表现。
在实际应用中,需要根据具体的任务和数据情况选择合适的模型。
三、评估方法评估文本分类模型的性能是非常重要的,常用的评估方法包括准确率、召回率、F1值、ROC曲线和AUC值等。
准确率(Precision)是指分类器正确分类的样本数占总样本数的比例,召回率(Recall)是指分类器正确分类的正样本数占实际正样本数的比例。
F1值是准确率和召回率的调和平均数,能综合反映分类器的性能。
ROC曲线是以假阳性率为横坐标,真阳性率为纵坐标绘制的曲线,AUC值是ROC曲线下的面积,用来评估分类器的整体性能。
除了这些基本的评估指标外,还可以考虑使用交叉验证、混淆矩阵、学习曲线等方法来评估模型的性能。
文本分类是一个非常重要的自然语言处理任务,它的应用场景非常广泛。
在进行文本分类任务时,特征提取、模型选择和评估方法是非常关键的技术。
希望通过本文的介绍,读者能够更好地理解文本分类的关键技术,为实际应用提供一定的参考和帮助。
文本分类技术在信息检索中的应用研究

文本分类技术在信息检索中的应用研究一、概述信息检索系统是一种能够帮助用户从海量的文本中快速找到所需信息的工具。
随着互联网的迅速发展,文本数据的规模不断扩大,信息检索系统的效率和精度成为越来越重要的问题。
文本分类技术作为一种非常重要的自然语言处理技术,已经被广泛应用于信息检索领域。
本文将主要介绍文本分类技术在信息检索中的应用研究。
二、文本分类技术概述文本分类技术是指根据文本的内容、语言形式和统计特征等特点将文本划分到不同的类别中去的技术。
在信息检索系统中,文本分类可以用于自动识别文本的主题、类型等信息,从而提高检索效率和精度。
常用的文本分类技术包括基于规则的分类方法、基于统计的分类方法和基于机器学习的分类方法。
1.基于规则的分类方法基于规则的分类方法通常使用人工定义的规则来进行文本分类。
这种方法的优点在于可以掌握分类过程的细节,并且分类结果比较准确。
但是,由于要手动编写分类规则,所以这种方法的适用范围比较有限。
2.基于统计的分类方法基于统计的分类方法利用统计学原理和模型来进行文本分类。
这种方法的优点在于不需要人工制定分类规则,系统可以自动从大量的文本中学习归纳规则,适用范围比较广。
常用的基于统计的分类方法包括朴素贝叶斯分类器和支持向量机分类器等。
3.基于机器学习的分类方法基于机器学习的分类方法则是利用机器学习技术来进行文本分类。
这种方法的优点在于可以适应不同类型的文本,具有很好的泛化性能。
常见的基于机器学习的分类方法包括决策树分类器、神经网络分类器等。
三、文本分类技术在信息检索中的应用文本分类技术在信息检索中的应用主要包括以下几个方面:1.文本分类文本分类技术可以用于对文本进行自动分类。
例如,在搜索引擎中,可以利用文本分类技术对搜索结果进行分类,如新闻、图片、视频等,从而将搜索结果更好地呈现给用户。
2.筛选垃圾邮件垃圾邮件是一种严重干扰正常邮件使用的问题。
文本分类技术可以识别垃圾邮件,从而将其自动过滤掉,保证用户收到的是有用的邮件。
数据库与知识发现中的信息检索和分类

数据库与知识发现中的信息检索和分类随着互联网的发展以及信息化进程的推进,人们对于信息的需要越来越迫切。
然而,信息爆炸的时代也给人们带来了新的问题:海量的信息需要被整合、分类、检索和管理。
为此,数据库与知识发现成为了信息管理领域中的重要分支,其中的信息检索和分类技术更是成为了解决信息管理问题的重要手段。
一、数据库与知识发现中的信息检索数据库是信息系统中的核心,其主要作用是存储和管理数据。
在大型信息系统中,数据种类繁多,其中包括结构化数据和非结构化数据。
前者是指以表格、关系等结构形式呈现的数据,比如在关系型数据库中存储的数据;非结构化数据则是指以文本、图像、音频等形式呈现的数据,比如在文件系统中存储的文本文件、图像和音频文件。
这些数据中包含了大量的信息,但是这些信息并不一定适合直接使用。
这时就需要通过信息检索技术将需要的信息从数据中检索出来。
信息检索是指从大量的非结构化或半结构化数据中通过对关键字或查询语句进行处理,找出与其匹配的数据,并通过各种方式展现给用户的过程。
传统的信息检索方法主要是基于文本关键字的检索方法,用户输入一个或多个与信息相关的关键字,然后系统返回包含这些关键字的文档。
然而,这种方法存在着一些问题:首先,无法对检索结果进行有效的排序和分类,用户需要花费大量时间来查找其需要的信息;其次,由于用户输入的关键字可能存在歧义,因此导致检索结果的准确性和召回率无法得到保证。
近年来,随着自然语言处理和机器学习等技术的不断发展,信息检索技术也得到了快速的发展和改进,针对上述问题提出了更为有效的解决方案。
1.1 基于语义的信息检索基于语义的信息检索是一种将自然语言处理技术与信息检索技术结合起来的方法,旨在提高信息检索的准确率和召回率。
该方法通过将自然语言处理技术应用到信息检索中,将关键字之间的语义相似性考虑在内,从而更好地理解用户的查询意图,提高检索结果的质量。
如今,基于语义的信息检索已成为信息检索技术中的重要分支之一。
《2024年时间序列数据分类、检索方法及应用研究》范文

《时间序列数据分类、检索方法及应用研究》篇一一、引言时间序列数据,指的是按时间顺序排列的序列数据,具有明显的时序性和动态变化特点。
随着信息化时代的到来,时间序列数据在金融、医疗、交通、能源等众多领域得到了广泛应用。
对这些数据的分类和检索成为了数据分析和处理的重要环节。
本文将针对时间序列数据的分类、检索方法进行详细的研究,并探讨其在实际应用中的价值。
二、时间序列数据分类时间序列数据的分类主要依据数据的特征和属性进行。
常见的分类方法包括:1. 基于统计特征的分类:通过计算时间序列的统计特征,如均值、方差、标准差等,将数据划分为不同的类别。
这种方法适用于具有明显统计规律的时间序列数据。
2. 基于机器学习的分类:利用机器学习算法,如支持向量机、神经网络等,对时间序列数据进行训练和分类。
这种方法适用于数据量大、特征复杂的场景。
3. 基于模式识别的分类:通过识别时间序列数据中的模式,如周期性、趋势性等,将数据划分为不同的类别。
这种方法适用于具有明显模式特征的时间序列数据。
三、时间序列数据检索方法时间序列数据的检索主要依赖于高效的检索算法和索引结构。
常见的检索方法包括:1. 基于相似性的检索:通过计算时间序列数据之间的相似性,如欧氏距离、动态时间规整等,实现数据的检索。
这种方法适用于需要查找相似数据的应用场景。
2. 基于索引的检索:通过构建索引结构,如R树、B树等,加速时间序列数据的检索速度。
这种方法适用于数据量大、实时性要求高的场景。
3. 结合机器学习的检索:利用机器学习算法对时间序列数据进行训练,将训练结果作为检索依据。
这种方法适用于需要深度挖掘数据特征的应用场景。
四、时间序列数据应用研究时间序列数据在各个领域都有广泛的应用价值,如金融市场的预测、医疗健康的监测、交通流量的分析等。
以下是一些具体的应用研究:1. 金融市场预测:通过对股票价格、交易量等时间序列数据进行分类和检索,实现股票价格的预测和交易策略的制定。
面向航天领域知识管理的信息采集与分类应用研究

面向航天领域知识管理的信息采集与分类应用研究我国航天事业蓬勃发展,在日益发达的互联网、大数据和知识经济时代,为应对海量信息资源,作为知识密集型的航天从业机构,开始引入知识管理相关理论与技术,以有效挖掘、组织、管理、利用和传承领域的核心知识资源。
知识获取是知识管理过程中的基础环节,而知识获取相关系统的设计实施需要诸多关键技术支撑,如信息采集、文本分类、信息抽取、知识图谱、语义网络等自然语言处理、数据挖掘相关的技术。
近年来,对信息的获取与处理技术在学术界和实际应用中有了突飞猛进的发展,本文将对航天领域知识管理系统中知识获取环节的信息采集和文本自动分类两个关键技术进行应用研究。
航天领域的知识信息冗杂多样,包含于相关企业及科研机构的生产研究过程中产生的大量文档,也贮藏在巨大庞杂的互联网信息资源中。
针对航天领域信息的这些特点,实施有效知识管理首先迫切需要的关键技术是如何高效准确获取行业情报信息,并能有效组织管理信息,进而才能实现进一步的信息抽取、知识挖掘。
对于航天情报信息的高效获取,能够在满足科研人员对航天情报数量大、专业性强、新颖及时、完整准确需求的同时,避免从庞杂异构的互联网中大海捞针,降低信息获取成本;而对于航天信息的自动分类,可以准确高效地组织已有的或获取到的杂乱无章的信息,能够帮助快速建设航天领域知识库,优化信息检索系统的信息组织结构和检索效果,满足从业人员对领域知识的进一步的挖掘需求。
因此本文面向航天领域知识管理进行的信息采集与文本自动分类关键技术的应用研究具有重要的现实意义和实用价值。
本文的主要研究工作如下:(1)介绍面向航天领域知识管理进行信息采集和文本分类两个关键技术应用研究的背景及意义;调研知识管理及其在航天领域应用的发展现状,信息采集和文本分类技术及其在航天领域内应用的发展现状。
(2)研究基于主题爬虫的航天领域情报采集方法,设计航天情报采集主题爬虫的总体框架,实现相关程序部件,并基于主题向量空间模型和支持向量机(SVM)二类分类器两种方法实现主题判定模型,与基于关键词匹配的方法进行对比实验验证。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于回归支持向量机的信息检索*韩咏1,齐浩亮1,杨沐昀2,李生21黑龙江工程学院,哈尔滨,1500502哈尔滨工业大学,哈尔滨,150001E-mail: haoliang.qi@摘要:从本质上看,信息检索应按照文档满足用户信息需求程度进行排序,因此当前以分类和排序策略为主流的研究方式存在与信息检索目标相关性较弱的缺点。
本文尝试使用回归分析策略,以文档满足用户的信息需求程度作为回归分析的目标值,利用回归支持向量机构建信息检索模型。
该模型不仅提供了融合不同来源特征的灵活框架,而且由于使用回归支持向量机寻找具有ε不敏感损失的回归函数,因此具有良好的泛化性能。
通过在TREC测试数据上的实验表明,本文模型性能优于目前主流的基于语言模型的信息检索方法。
关键词:信息检索;回归分析;支持向量机;再采样Information Retrieval Based onSupport Vector Machine RegressionHAN Yong1, QI Haoliang1, YANG Muyun2, LI Sheng2State Key Lab of Intelligent Technology and Systems Tsinghua University, Beijing 100084E-mail: haoliang.qi@Abstract: The task of IR is to rank the documents according to the degree which satisfies the user information need, so the current models based on classification and ranking poorly correlate with the IR target. The regression method is explored in this paper for IR, and the degree is used as regression target value. Support Vector Machine Regression (SVMR)is adopted in the framework because it provides a flexible framework to incorporate arbitrary features. SVMR was used to find a regression function with ε insensitive loss, which allows good generalization. The effectiveness of the approach was evaluated on the task of ad hoc retrieval using two TREC English test sets. Results show that the new model outperforms the state-of-the-art language modeling approaches Keywords: information retrieval; regression analysis; support vector machine; resample1 引言随着信息时代的到来,各种信息资源越来越丰富,信息检索(Information Retrieval,IR)系统成为人们获取信息必不可少的工具。
信息检索的任务是在待检索文档集中依据用户信息需求,按相关程度对文档进行排序,作为对检索用户所提出查询的回应。
影响信息检索系统性能的因素有很多,其中最为关键的是信息检索建模。
Pont和Croft于1998年提出的语言模型在信息在信息检索领域产生重大影响,不仅具有坚实的理论基础,而且在实验中取得了很好的效果,是当前最为成功的方法之一[1]。
语言模型是典型的参数化推理方法,存在经典体系的缺点,如大规模多变量的分析计算引起的“维数灾难”、实际数据的分布差*国家自然科学基金重点项目(60435020)、国家自然科学基金项目(60873105)、黑龙江省自然科学基金项目(F2007-14)、黑龙江省科技攻关计划项目(GZ07A108)、哈尔滨市科技局青年创新人才项目(2009RFQXG213)异导致的基于经典的统计分布函数方法失效等[2]。
为了克服其存在的缺点,近年来在许多领域获得成功的判别学习模型也被引入到信息检索中,成为当前的研究主流方法。
在信息检索中的应用的判别学习方法一般采用两种策略:分类的方法和排序方法方法。
Nallapat 将信息检索视为分类问题[3],使用了支持向量机(Support Vector Machine, SVM)和最大熵(Maximum Entropy)两种算法,结果并不理想,性能明显低于语言模型;Cooper的分段逻辑回归算法(Staged Logistic Regression)[4],但性能也不佳。
其原因在于将信息检索视为分类问题从而存在以下问题:1)分类与检索的任务(按文档的相关度排序)并不直接相关,仅是弱相关;2)信息检索中训练样本太少,且面临严重的数据不平衡(Unbalance Data)。
将信息检索视为对文档的排序,在排序框架下解决检索问题是最近几年的新进展。
这方面的工作包括:Gao、Qi和 Xia等采用基于感知器算法的排序算法[5],Cao、Xu和Li的改进Ranking SVM算法[6],微软公司为信息检索提出了RankNet算法[7],并进行了应用[8,9,10]。
文献[11,12]使用表排序策略而不是上述这些工作的基于文档序对数的排序,取得了更好的效果。
在排序算法框架下解决检索与以往的模型相比,提高了与信息检索任务的相关度,但与信息检索的任务还不直接相关,影响了检索的性能的进一步提升。
本文将信息检索视为回归分析问题,尝试回归分析的框架下,引入回归支持向量机这一典型判别学习方法[13]解决检索问题。
所谓回归问题就是在训练样本上找到一个函数,它可以从输入域近似映射到实数值上。
而对于信息检索来说,文档的相关度就是回归分析的回归值,这样与信息检索的任务高度一致,因此它能够取得良好的效果。
传统上,使用系统输出和训练值之间的偏差的平方和作损失函数,即最小二乘法优化参数。
回归支持向量机与传统的回归分析相比,引入了ε不敏感损失函数,它可以忽略真值某个上下范围内的误差,具有优化的泛化界。
在大噪声的情况下,回归支持向量机的性能明显优于原始的最小二乘法[14],而在信息检索中存在大量很难拟和的样本。
将它应用到信息检索中,可以避免将检索视为分类问题(如最大熵模型、支持向量机模型)和生成模型(如语言模型)带来的问题,取得良好的效果。
在信息检索中使用回归分析框架,还可以充分利用最新的人工标注语料进一步提升性能,如微软公司标注了5等级相关性,TREC 2005在部分TRACK 上标注了3等级相关性。
我们模型的有效性在TREC ad hoc测试中得到了验证。
实验结果表明,我们的模型性能高于当前主流的基于语言模型的信息检索方法。
本文的随后部分安排如下。
第二部分介绍了面向信息检索的回归支持向量机。
第三部分是实验结果及结果讨论。
最后是本文的结论和未来工作。
2 基于回归支持向量机的信息检索本节阐述基于回归支持向量机的信息检索。
首先简单介绍模型中使用的特征集,然后介绍使用回归支持向量机优化参数;最后讨论如何处理数据不平衡问题,这是将回归支持向量机应用到信息检索时特有的问题。
2.1 特征集本文使用的特征包括一元文法特征、二元文法特征和语言学特征。
文中的特征集包含n 个特征f i(q, c, d),其中i = 1,2,…, n,式中的C为概念,例如组块是一种概念,二元文法中相邻词也构成概念;q 为用户查询,d 为待检索的文档。
特征f i (q, c, d)是一个映射,该映射将(q, c, d) 映射到一个实数,即f i (q, c, d) ∈ℜ。
使用向量表示方法,有f (q,c,d) ∈ℜN ,即f (q,c,d) = {f 1(q,c,d), f 2(q,c,d), …, f N (q,c,d)}。
这些特征包括:z f 1(.) 是一元文法特征,是一元文法概率的对数值,也就是f 1(q, d) = ∑i log(P (q i |d));z f 2(.) 是二元文法特征,是二元文法概率的对数值,也就是 f 2(q, d) = ∑i log(P (q i |q i-1,d)); z f 3(.) 是文档模型特征,是文档模型的概率的对数值,也就是 f 3(q, c, d) = ∑i log(P (h i |h i-1, d)),h i 为相关的概念模型的中心词(Head Word ); zf i (.)是n-3个概念特征,其中i = 4,…,n 。
它们的值可以是相关概念模型(例如名词短语、动词短语、形容词短语)的概率的对数值,也可以根据发启式规规分配(如factoid )。
文献[5]描述了特征集的详细信息。
2.2 基于回归支持向量机的学习支持向量机作为一种新兴的分类算法广泛应用于模式识别的各个分支,已经发展成为机器学习中一个独立的子领域。
在线性可分的情况下,感知器算法寻找任意一个能够区分样本的超平面。
如图1a,这是一个二维线性可分的例子,灰色的区域表示表示所有可能将数据正确分类的分类面集合。
而支持向量机算法寻找具有最大间隔的超平面。
该超平面是感知器寻找的分类超平面中的一个特例。
该超平面是唯一存在的, 并且是所有能够区分样本的超平面中最优的,它有良好的泛化性能力[14],如图1 b 所示。
最优分类面是距离支持向量(图1b 中的点1、2、3)的距离最远的超平面f=0。
支持向量机算法也被扩展到解决回归问题,被称为回归支持向量机。
回归支持向量机与传统的回归分析相比,引入了ε不敏感损失函数,它可以忽略真值某个上下范围内的误差,具有优化的泛化界。
该模型解决了回归问题和时间序列预测问题,在很多领域获得了成功应用。
本文应用线性回归支持向量机解决检索问题。
给定包含 个样本(x i ,y i )的训练集,其中x i 为n 维空间中的向量,y i 为实数。
设待估计线性回归函数为f (x)w x+b =i (1)图1 最优超平面其中b ∈R ,X 为特征向量f 。
回归支持向量机中的ε不敏感损失函数等价于支持向量机中的松弛变量,最小化的目标函数为:2i i=11||w ||C (())2L y f x +−∑(2) 其中(())L y f x −为每一个样本上损失。