Hibernate优化
Hibernate3.6(开发必看)
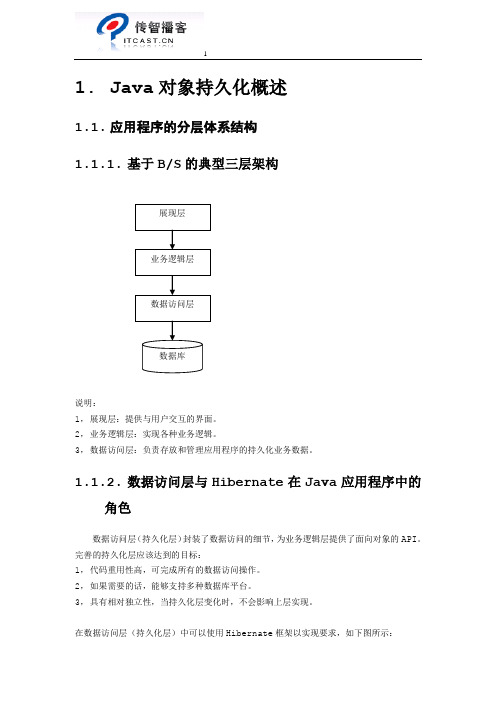
1.Java对象持久化概述1.1.应用程序的分层体系结构1.1.1.基于B/S的典型三层架构说明:1,展现层:提供与用户交互的界面。
2,业务逻辑层:实现各种业务逻辑。
3,数据访问层:负责存放和管理应用程序的持久化业务数据。
1.1.2.数据访问层与Hibernate在Java应用程序中的角色数据访问层(持久化层)封装了数据访问的细节,为业务逻辑层提供了面向对象的API。
完善的持久化层应该达到的目标:1,代码重用性高,可完成所有的数据访问操作。
2,如果需要的话,能够支持多种数据库平台。
3,具有相对独立性,当持久化层变化时,不会影响上层实现。
在数据访问层(持久化层)中可以使用Hibernate框架以实现要求,如下图所示:1.2.软件模型1.2.1.各种模型的说明概念模型:模拟问题域中的真实实体。
描述每个实体的概念和属性及实体间关系。
不描述实体行为。
实体间的关系有一对一、一对多和多对多。
关系数据模型:在概念模型的基础上建立起来的,用于描述这些关系数据的静态结构。
有以下内容组成:1,若干表2,表的所有索引3,视图4,触发器5,表与表之间的参照完整性域模型:在软件的分析阶段创建概念模型,在软件设计阶段创建域模型。
组成部分:1,具有状态和行为的域对象。
2,域对象之间的关联。
域对象(domain object):构成域模型的基本元素就是域对象。
对真实世界的实体的软件抽象,也叫做业务对象(Business Object,BO)。
域对象可代表业务领域中的人、地点、事物或概念。
域对象分为以下几种:1,实体域对象:通常是指业务领域中的名词。
(plain old java object,简单Java 对象)。
2,过程域对象:应用中的业务逻辑或流程。
依赖于实体域对象,业务领域中的动词。
如发出订单、登陆等。
3,事件域对象:应用中的一些事件(警告、异常)。
1.2.2.域对象间的关系关联:类间的引用关系。
以属性定义的方式表现。
依赖:类之间访问关系。
Hibernate+Spring多数据库解决方案

Hibernate+Spring多数据库解决方案我以前在项目中的探索和实践,写出来与大家分享。
大家有其他好的方式,也欢迎分享。
环境:JDK 1.4.x , Hibernate 3.1, Spring 2.0.6, JBOSS4.0, 开发模式: Service + DAO我们项目中需要同时使用多个数据库. 但 Hibernate 不能直接支持,为此我们对比了网上网友的方案,自己做了一点探索。
1. Demo需求我们的项目使用一个全省的公共库加十多个地市库的架构。
本文主要说明原理,将需求简化为两库模型。
主库:User管里,主要是系统管理,鉴权等数据;订单库:Order 管理,存放订单等业务性数据。
2. 原理:1) Hibernate 的每个配置文件对应一个数据库,因此多库需要做多个配置文件。
本文以两个为例:主库 hibernate_sys.cfg.xml,订单库 hibernate_order.cfg.xml每个库,Hibernate 对应一个 sessionFactory 实例,因此Hibernate 下的多库处理,就是在多个 sessionFactory 之间做好路由。
2) sessionFactory 有个 sessionFactory.getClassMetadata(voClass) 方法,返回值不为空时,表示该 VO 类在该库中(hbm.xml文件配置在了对应的hibernate.cfg.xml中),该方法是数据路由的核心和关键所在。
因此, User.hbm.xml 配置在 hibernate_sys.cfg.xml ,Order数据位于配置到 hibernate_order.cfg.xml3)多库处理时,需要使用 XA 事务管理。
本例中使用 Jboss4.0 来做JTA事务管理;用JOTM,其他应用服务器原理相同。
3. 实现1)为做多 sessionFactory 实例的管理,设计 SessionFactoryManager 类,功能就是做数据路由,控制路由的核心是 sessionFactoryMap 属性,它按dbFlag=sessionFactory 的方式存储了多个库的引用。
Hibernate学习笔记

Hibernate项目的构建与配置1.在项目里倒入Hibernate所必须的Jar包(1)Hibernate框架可以使用在任何的Java项目里,并不一定是Web项目。
只需要在项目里倒入Hibernate所必须要使用的jar包就可以了。
(2)在Hibernate的官网下载hibernate-release-4.2.2.Final.zip解压,要使用Hibernate必须导入的jar包就在目录“hibernate-release-4.2.2.Final\lib\required”下。
倒入此路径下的所有jar包就可以了。
2.配置hibernate.cfg.xml文件(1)配置hibernate.cfg.xml文件可以参考“\project\etc”目录下的hibernate.cfg.xml文件与hibernate.properties文件。
(2)使用Hibernate连接MySQL的hibernate.cfg.xml配置文件如下:<hibernate-configuration><session-factory>(设置显示Hibernate产生的SQL语句)<property name="show_sql">true</property>(设置MySQL的SQL语法的方言)<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>(设置MySQL的驱动程序)<property name="hibernate.connection.driver_class">org.gjt.mm.mysql.Driver</property>(设置MySQL的数据库路径、用户名、密码)<property name="hibernate.connection.url">jdbc:mysql:///java</property><property name="ername">root</property><property name="hibernate.connection.password">lizhiwei</property>(设置当数据库要保存的表不存在时,就新建表)<property name="hibernate.hbm2ddl.auto">update</property>(设置对象与数据库表的关系映射文件)<mapping resource="vo/User.hbm.xml"/></session-factory></hibernate-configuration>(3)此配置文件一般放在项目的src目录下。
hibernate sql写法

hibernate sql写法Hibernate是一个开源的、高效的、强大的Java持久化框架,它提供了面向对象的方式来操作关系型数据库。
使用Hibernate,开发者可以以一种简单、灵活的方式进行数据库操作,而无需编写大量的SQL 语句。
在Hibernate中,我们可以通过编写映射文件或注解来定义实体类与数据库表之间的映射关系,通过Session对象来执行对数据库的操作。
在Hibernate中,SQL语句可以通过多种方式来编写。
下面将针对Hibernate中的SQL编写进行详细介绍。
1. HQL(Hibernate Query Language)Hibernate Query Language(HQL)是一种面向对象的查询语言,它类似于SQL语句,但是使用的是实体类和属性名,而不是表名和列名。
HQL可以实现对实体对象的查询、更新和删除等操作。
以下是HQL的一些常用语法:-查询所有的实体对象:FROM实体类名-条件查询:FROM实体类名WHERE条件-投影查询:SELECT属性列表FROM实体类名-排序查询:FROM实体类名ORDER BY属性ASC/DESC-分页查询:FROM实体类名LIMIT开始位置,查询数量HQL的编写与SQL类似,但是可以直接使用实体类和属性名,从而更加面向对象。
例如,以下HQL语句可以查询出所有年龄大于18岁的用户:FROM User WHERE age > 182.原生SQL查询除了HQL,Hibernate还支持原生的SQL查询。
原生SQL查询可以直接编写传统的SQL语句,但是需要使用Session对象的createNativeQuery方法来执行。
以下是原生SQL查询的一些常用语法:-执行查询:session.createNativeQuery("SELECT * FROM表名").getResultList()-执行更新或删除:session.createNativeQuery("UPDATE/DELETE FROM表名WHERE条件").executeUpdate()-参数绑定:Query.setParameter(参数名,参数值)原生SQL查询可以更灵活地操作数据库,但是需要注意SQL语句的安全性和兼容性问题。
Java Web应用系统性能优化指南

Java Web应用系统性能优化指南随着互联网的不断发展,Web应用系统正在成为企业级应用系统的主要形式。
而Java作为Web应用系统开发的主要语言,其高可靠性和开发效率带来的便利,正被越来越多的企业所接受。
但是,Java Web应用系统的性能问题也越来越受到开发人员和运维人员的关注。
因此,本文将从多个角度探讨Java Web应用系统的性能优化,帮助开发人员和运维人员更好地解决性能问题。
1. 优化数据库数据库是Web应用系统中最常用的组件之一,也是性能瓶颈所在之一。
因此,通过对数据库进行优化,可以大大提高整个系统的性能。
1.1 数据库读写分离在数据库中,读操作和写操作所消耗的资源是不一样的,为了提高数据库的性能,通常需要将读写操作分离。
即通过主从复制的方式,将读操作分配到从库上,将写操作分配到主库上。
这样可以避免读写操作之间的竞争,提高系统的并发处理能力。
1.2 使用索引索引是数据库优化的重要手段之一,通过建立适当的索引,可以加快数据查询的速度。
但是,在使用索引时需要注意,适当的索引可以提高查询速度,但是过多的索引会增加数据库的维护成本,并且会降低更新操作的效率。
1.3 数据库连接池数据库的连接是比较耗费系统资源的,为了避免频繁建立和关闭数据库连接,通常使用连接池来管理数据库连接。
连接池会维护一定数量的数据库连接,并且在需要时分配给请求方使用,请求完成后将连接释放回连接池。
使用连接池可以避免频繁地连接和关闭数据库,提高系统的性能。
2. 优化代码代码问题也是影响Web应用系统性能的一个关键因素。
通过对代码进行优化,可以提高系统的稳定性和性能。
2.1 避免双重循环在编写代码时,需要注意避免双重循环。
双重循环是比较消耗系统资源的,会导致系统的响应速度变慢。
因此,在处理大量数据时,应该尽量避免使用双重循环。
2.2 使用缓存使用缓存可以减轻数据库的负担,提高系统的响应速度。
缓存是一种内存数据存储技术,可以将常用的数据存储在内存中,提高系统访问速度。
优化数据库的八种方法

优化数据库的八种方法优化数据库是提高数据库性能和效率的重要手段之一。
下面将介绍八种常见的数据库优化方法。
一、合理设计数据库结构数据库结构的设计直接影响数据库的性能和效率。
在设计数据库时,应注意以下几点:1. 表的字段应设置合理的数据类型和长度,避免浪费存储空间和计算资源。
2. 为表添加适当的索引,以加快查询速度。
索引应根据查询的频率和类型进行选择。
3. 合理划分表和字段的关系,避免冗余和重复数据。
使用范式化的设计可以提高数据的一致性和完整性。
二、优化查询语句优化查询语句是提高数据库性能的关键。
以下是一些优化查询语句的方法:1. 调整查询语句的顺序,将最常用和最重要的条件放在前面,以提高查询效率。
2. 避免使用通配符查询,如“%”,会导致全表扫描,影响性能。
3. 使用合适的连接方式,如INNER JOIN、LEFT JOIN等,减少不必要的数据读取。
4. 避免在WHERE子句中使用函数,函数会导致索引失效,影响查询效率。
三、优化索引索引是提高数据库查询效率的重要手段。
以下是一些优化索引的方法:1. 选择合适的索引类型,如B树索引、哈希索引等,根据查询的类型和频率进行选择。
2. 避免在索引列上使用函数或运算符,这会导致索引失效。
3. 定期对索引进行优化和重建,以保证索引的有效性和性能。
四、合理使用缓存缓存是提高数据库访问速度的重要手段。
以下是一些合理使用缓存的方法:1. 使用数据库缓存,如Redis、Memcached等,可以减少对数据库的访问次数。
2. 合理设置缓存时间,避免缓存数据过期或过长时间没有更新。
3. 使用缓存预热,提前加载常用数据到缓存中,减少用户访问时的延迟。
五、分表分库当数据库数据量庞大时,可以考虑进行分表分库操作,以减轻单个数据库的压力。
以下是一些分表分库的方法:1. 根据业务需求和数据特点,将数据划分到不同的表或数据库中。
2. 使用分片技术,将数据按照一定规则分布到多个数据库中。
12种接口优化的通用方案

引言:接口优化是软件开发中非常重要的一环,它直接影响到系统的性能、用户体验和安全性。
在上一篇文章中,我们介绍了6种接口优化的通用方案。
在本文中,我们将继续探讨接口优化的另外6种通用方案,为大家提供更多的实用技巧和建议。
概述:1.使用缓存机制2.优化数据库查询3.异步处理请求4.压缩和减少网络传输5.限制和控制接口访问频率6.定期清理过期数据正文内容:一、使用缓存机制:1.使用内存缓存:将接口返回数据存储在服务器的内存中,避免频繁查询数据库,提高接口响应速度。
2.使用分布式缓存:将接口返回数据存储在分布式缓存中,提高可扩展性和容错性。
二、优化数据库查询:1.使用索引:为经常被查询的字段创建索引,加快查询速度。
2.批量操作:将多个查询合并为一个批量操作,减少与数据库的交互次数。
三、异步处理请求:1.使用消息队列:将接口请求放入消息队列中异步处理,提高接口的并发处理能力。
2.异步请求结果通知:在接口返回较慢的情况下,返回一个接口请求ID,供客户端轮询获取结果。
四、压缩和减少网络传输:1.压缩接口返回数据:使用压缩算法对接口返回数据进行压缩,减少网络传输的数据量。
2.减少冗余数据:返回数据时只返回客户端需要的字段,减少数据传输量,提高数据传输效率。
五、限制和控制接口访问频率:1.接口访问频率限制:设置每个用户或每个IP地质每分钟/小时/天可访问的接口次数,防止接口被恶意刷接口攻击。
2.使用验证码:对于需要频繁访问的接口,可以使用验证码来确认用户的真实身份。
六、定期清理过期数据:1.数据库定时清理:定期删除过期的缓存数据,避免数据堆积导致数据库性能下降。
2.内存缓存定期清理:定期清理过期的内存缓存数据,释放内存空间。
总结:本文介绍了12种接口优化的通用方案,涵盖了缓存机制、数据库查询优化、异步处理请求、压缩和减少网络传输、限制和控制接口访问频率以及定期清理过期数据等方面。
这些方案可以帮助开发者提高系统的性能、用户体验和安全性,值得在实际项目中加以应用和实践。
hibernate官方文档

第一篇:官方文档的处理方法,摘自官方在迁移原先用JDBC/SQL实现的系统,难免需要采用hibernat native sql支持。
1.使用SQLQueryhibernate对原生SQL查询执行的控制是通过SQLQuery接口进行的.1Session.createSQLQuery();1.1标量查询最基本的SQL查询就是获得一个标量(数值)的列表。
1sess.createSQLQuery("SELECT * FROM CATS").list();2sess.createSQLQuery("SELECT ID, NAME, BIRTHDATE FROM CATS").list();将返回一个Object数组(Object[])组成的List,数组每个元素都是CATS表的一个字段值。
Hibernate会使用ResultSetMetadata来判定返回的标量值的实际顺序和类型。
如果要避免过多的使用ResultSetMetadata,或者只是为了更加明确的指名返回值,可以使用addScalar()。
1sess.createSQLQuery("SELECT * FROM CATS")2 .addScalar("ID", Hibernate.LONG)3 .addScalar("NAME", Hibernate.STRING)4 .addScalar("BIRTHDATE", Hibernate.DATE)这个查询指定了:SQL查询字符串,要返回的字段和类型.它仍然会返回Object数组,但是此时不再使用ResultSetMetdata,而是明确的将ID,NAME和BIRTHDATE 按照Long, String和Short类型从resultset中取出。
同时,也指明了就算query 是使用*来查询的,可能获得超过列出的这三个字段,也仅仅会返回这三个字段。
基于HIBERNATE的数据库访问优化

图 1 软件体 系结构模型演变图
阶段一实现 了应用层与数据层的分离。数据层用来保存需
迫切 , 是具有现实意义的 。 也
HIE N T B R A E是一种 的持久层框 架 , 采用 O M机 制实现 数 R
据持久 化。HIE N T B R A E是一种 O M 映射工 具 , 不仅提供 了 R 它 从 JV A A类 到 数 据 表 的 映 射 , 提 供 了 数 据 查 询 和 恢 复 等 也
第2 9卷 第 7期
21 0 2年 7月
计 算机应 用与软 件
Co u e p iai n n o t r mp t rAp lc t s a d S f o wa e
Vo . . 129 No 7
J 12 1 u. 0 2
基 于 HI E N E 的数 据 库 访 问优化 B R AT
i lme tt e d t e ss n e l y r h a e r s t p i z aa a e o ea in e ce c y i rv n sd t e sse c a e c e s mp e n h a a p rit c a e .T e p p rti o o t e e mie d t b s p rt f i n y b mp o i g i aa p r i n e ly r a c s o i t t
o t z t n me h n s p i ai c a im. HI ER mi o B NAT — a e p ritn a e a a a e a c s f ce c p i z t n p l y i t e d i r v d, t e E b s d e ss t l y r d tb s c e s e in y o t e i miai oi s r d a mp o e o c i n hn c e k d b e n p l d t n ol n y tm aa a e a c s p i z t n p a t e r cie r s l r i d f rd ti d s g e t n .T e h c e y b i g a p i o e r l e me ts se d t b s c e s o t miai r c i .P a t e ut ae ct o e al u g si s h o c c s e e o
hibernat批量处理和存取大对象

InputStream inputStream = user.getPhoto().getBinaryStream(); FileOutputStream fileOutputStream = new FileOutputStream("c:\\workspace\\photo_save.jpg"); byte[] buf = new byte[1]; int len = 0; while((len = inputStream.read(buf)) != -1) { fileOutputStream.write(buf, 0, len); } inputStream.close(); fileOutputStream.close(); System.out.println("save photo to c:\\workspace\\photo_save.jpg"); session.close();
可以定义一个User类別,让属性包括 java.sql.Blob和java.sql.Clob,如下: import java.sql.Blob; import java.sql.Clob; public class User { private Integer id; private String name; private Integer age; private Blob photo; private Clob resume;
从资料库中取得资料
Session session = sessionFactory.openSession(); User user = (User) session.load(User.class, new Integer(1)); System.out.print(user.getAge() + "\t" + user.getName() + "\t"); String resume = user.getResume().getSubString(1, (int) user.getResume().length()); System.out.println(resume);
java学习经验Hibernate总结

Hibernate工作原理及为什么要用?一原理:1.读取并解析配置文件2.读取并解析映射信息,创建SessionFactory3.打开Sesssion4.创建事务Transaction5.持久化操作6.提交事务7.关闭Session。
8.关闭SessionFactory为什么要用:1. 对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
2. Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。
他很大程度的简化DAO层的编码工作3. hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
4. hibernate的性能非常好,因为它是个轻量级框架。
映射的灵活性很出色。
它支持各种关系数据库,从一对一到多对多的各种复杂关系。
二Hibernate 的核心接口及其作用1 Configuration类:配置Hibernate启动Hibernate创建SessionFactory对象2 SessionFactory:初始化Hibernate创建Session对象线程安全—同一实例被多个线程共享重量级:代表一个数据库内部维护一个连接池2.1 openSession():总是创建新的session,需要手动close()2.2 getCurrentSession() : 必须在hibernate.cfg.xml设置session 上下文事务自动提交并且自动关闭session.从上下文环境中获得session,如果当时环境中不存就创建新的.如果环境中存在就使用环境中的,而且每次得到的都是同一个session (在session提交之前,提交之后就是新的了) 应用在一个session中有多个不同DAO操作处于一个事务时3 Session:负责保存、更新、删除、加载和查询对象轻量级--可以经常创建或销毁3.1 Load与get方法的区别:简单理解:load是懒加载,get是立即加载.load方法当使用查出来的对象时并且session未关闭,才会向数据库发sql, get会立即向数据库发sql返回对象3.3 merge(); 合并对象更新前会先select 再更新3.4clear()清空缓存,flush()将session中的数据同步到数据库两者组合使用于批量数据处理3.4Transaction commit() rollback()JPA: java persistence API 提供了一组操作实体bean的注解和API规范SchemaExporthiberante的生成数据库表(及其他ddl)的工具类可以通过这个工具类完成一些ddl四Hibernate查询查询语言主要有:HQL 、QBC (Query By Criteria条件查询) 、 Native SQLHql:1、属性查询2、参数查询、命名参数查询3、关联查询4、分页查询5、统计函数五优化抓取策略连接抓取(Join fetching)使用 OUTER JOIN(外连接)来获得对象的关联实例或者关联集合查询抓取(Select fetching)另外发送一条 SELECT 语句抓取当前对象的关联实体或集合另外可以配置hibernate抓取数量限制批量抓取(Batch fetching)另外可以通过集合过滤来限制集合中的数据量使用session.createFilter(topic.getReplies(),queryString).list();检索策略延迟检索和立即检索(优先考虑延迟检索)N+1问题指hibernate在查询当前对象时查询相关联的对象查询一端时会查询关联的多端集合对象解决方案:延迟加载连接抓取策略二级缓存集合过滤 BatchSize限制记录数量映射建议使用双向一对多关联,不使用单向一对多灵活使用单向一对多关联不用一对一,用多对一取代配置对象缓存,不使用集合缓存一对多集合使用Bag,多对多集合使用Set继承类使用显式多态表字段要少,表关联不要怕多,有二级缓存撑腰Hibernbate缓存机制性能提升的主要手段Hibernate进行查询时总是先在缓存中进行查询,如缓存中没有所需数据才进行数据库的查询.Hibernbate缓存:一级缓存 (Session级别)二级缓存(SessionFactory级别)查询缓存 (基于二级缓存存储相同参数的sql查询结果集)一级缓存(session缓存)Session缓存可以理解为session中的一个map成员, key为OID ,value为持久化对象的引用在session关闭前,如果要获取记录,hiberntae先在session缓存中查找,找到后直接返回,缓存中没有才向数据库发送sql三种状态的区别在于:对象在内存、数据库、session缓存三者中是否有OID临时状态内存中的对象没有OID, 缓存中没有OID,数据库中也没有OID 执行new或delete()后持久化状态内存中的对象有OID, 缓存中有OID,数据库中有OIDsave() load() get() update() saveOrUpdate() Query对象返回的集合游离(脱管)状态内存中的对象有OID, 缓存中没有OID,数据库中可能有OIDflush() close()后使用session缓存涉及三个操作:1将数据放入缓存2从缓存中获取数据3缓存的数据清理4二级缓存SessionFactory级别SessionFactory级别的缓存,它允许多个Session间共享缓存一般需要使用第三方的缓存组件,如: Ehcache Oscache、JbossCache等二级缓存的工作原理:在执行各种条件查询时,如果所获得的结果集为实体对象的集合,那么就会把所有的数据对象根据OID放入到二级缓存中。
Hibernate 模糊查询

Hibernate 模糊查询以下是用 hibernate的HQL(面向对象的查询语言)实现模糊查询的3种方式,其中方式一是这三中方式中最理想的方式,至少方式一可以有效的防止由于查询条件中需要参数的增多导致的代码长度太长出现代码折行的情况(代码太长会给后期的维护和测试带来很大的不便)。
但是还有比他更理想的方式,因为方式一在定义 strSQL时使用String ,这就势必会造成当变量过多时strSQL自身太长的问题。
一个比较有效的改进办法就是将String 改进为StringBuffer来处理。
方法一:java 代码1.public List listUncertainClasses(Object OId) throws Exception{2. Session session=HibernateUtil.getSessionFactory().getCurrentSession();3. session.beginTransaction();4. String strSQL="from Classes as a where a.classno like :name";5. Query query = session.createQuery(strSQL);6. query.setString("name", "%"+OId+"%");7. List result=query.list();8.for(int i=0;i9. Classes classes=(Classes)result.get(i);10. String classname=classes.getClassname();11. String classno=classes.getClassno();12. String specName=classes.getSpeciality().getName();13. String departName=classes.getSpeciality().getDepartment().getName();14. System.out.println(departName+"\t"+specName+"\t"+classname+"\t"+classno);15. }16. session.getTransaction().commit();17.return result;18.}方法二:java 代码1.public List listUncertainClasses_01(Object OId) throws Exception{2. Session session=HibernateUtil.getSessionFactory().getCurrentSession();3. session.beginTransaction();4. List result=session.createQuery("from Classes as a where a.classno like '%"+OId+"%'").list();5.for(int i=0;i6. Classes classes=(Classes)result.get(i);7. String classname=classes.getClassname();8. String classno=classes.getClassno();9. String specName=classes.getSpeciality().getName();10. String departName=classes.getSpeciality().getDepartment().getName();11. System.out.println(departName+"\t"+specName+"\t"+classname+"\t"+classno);12. }13. session.getTransaction().commit();14.return result;15.}方法三:java 代码1.public List listUncertainClasses_02(Object OId) throws Exception{2. Session session=HibernateUtil.getSessionFactory().getCurrentSession();3. session.beginTransaction();4. List result=session.createQuery("from Classes as a where a.classno like :name").setParameter("pid",OId).list();5.for(int i=0;i6. Classes classes=(Classes)result.get(i);7. String classname=classes.getClassname();8. String classno=classes.getClassno();9. String specName=classes.getSpeciality().getName();10. String departName=classes.getSpeciality().getDepartment().getName();11. System.out.println(departName+"\t"+specName+"\t"+classname+"\t"+classno);12. }13. session.getTransaction().commit();14.return result;15.}。
hibernate的flush方法

hibernate的flush方法Hibernate是一个开源的对象关系映射工具,提供了数据库操作的抽象层,使开发者可以使用面向对象的方式进行数据库操作。
Hibernate的flush方法是用于将Hibernate会话中的变化同步到数据库的操作。
在Hibernate中,会话(Session)是表示开发者与数据库之间的一次连接。
开发者可以通过向会话中添加、修改和删除对象来操作数据库。
而flush方法则是将这些变化同步到数据库。
在什么情况下需要使用flush方法呢?1. 当开发者需要保证数据的完整性时,可以使用flush方法。
当开发者添加、修改或删除了对象之后,调用flush方法会立即将这些变化同步到数据库。
2. 当开发者需要检查数据是否已经被持久化时,可以使用flush方法。
在调用flush方法之后,数据将被立即同步到数据库,可以通过查询数据库来验证数据是否已经被保存。
3. 当开发者需要在事务之外使用最新的数据时,可以使用flush方法。
在Hibernate中,默认情况下,事务提交之前,所有的数据变化只是在会话缓存中进行维护,而不会立即同步到数据库。
但是,如果开发者需要在事务之外查询到最新的数据,可以在查询之前调用flush方法,确保数据已经更新到数据库中。
4. 当开发者需要将数据库操作的异常抛出时,可以使用flush方法。
在执行数据库操作过程中,如果发生了异常,Hibernate会自动回滚事务,但不会抛出异常。
如果开发者希望在发生异常时得到通知,可以在执行数据库操作之前调用flush方法,如果操作失败,会抛出异常。
实际上,flush方法执行的操作如下:1.将会话中的持久化对象的状态同步到数据库。
持久化对象的状态包括新增、修改和删除。
2.将会话中的变化同步到数据库的操作也会级联到关联对象。
如果一些持久化对象发生了变化,与之关联的其他对象也会受到影响。
3. 执行flush操作不会结束当前事务,会话仍然处于打开状态,可以继续进行操作。
hibernate sql 占位符 表名 写法 -回复

hibernate sql 占位符表名写法-回复Hibernate是一个开源的Java持久化框架,广泛应用于各种Java项目中。
在使用Hibernate进行数据库操作时,经常需要用到SQL占位符,同时还需指定表名。
本文将详细介绍Hibernate SQL占位符和表名的写法,并逐步回答有关问题。
首先,什么是SQL占位符?在SQL语句中,占位符用于指示在运行时将要替换的值。
使用占位符可以增加查询的安全性和可维护性。
常见的SQL 占位符有问号(?)和冒号(:),Hibernate支持使用这两种占位符进行查询操作。
下面以一个简单的例子来说明Hibernate SQL占位符的使用方法。
假设有一个User表,包含id、name和age字段,我们需要查询年龄大于等于指定值的用户。
使用SQL占位符,可以将查询语句写为:javaString sql = "SELECT * FROM User WHERE age >= ?";Query query = session.createNativeQuery(sql);query.setParameter(1, 18);List<User> users = query.getResultList();在这个例子中,我们使用了问号占位符,并通过setParameter方法设置了参数的值,即年龄的下限为18。
这样,Hibernate会将占位符替换为实际的参数值,然后执行查询操作。
除了问号占位符,Hibernate还支持使用命名参数,即冒号占位符。
这种方式可以提高代码的可读性,特别是当SQL语句中有多个参数时。
同样以查询User表为例,使用冒号占位符的写法如下:javaString sql = "SELECT * FROM User WHERE age >= :minAge"; Query query = session.createNativeQuery(sql);query.setParameter("minAge", 18);List<User> users = query.getResultList();在这个例子中,我们在SQL语句中使用了冒号占位符:minAge,并通过setParameter方法将参数名和参数值绑定在一起。
Hibernate4在开发当中的一些改变

Hibernate4的改动较大只有spring3.1以上版本能够支持,Spring3.1取消了HibernateTemplate,因为Hibernate4的事务管理已经很好了,不用Spring再扩展了。
这里简单介绍了hibernate4相对于hibernate3配置时出现的错误,只列举了问题和解决方法,详细原理如果大家感兴趣还是去自己搜吧,网上很多。
1. Spring3.1去掉了HibernateDaoSupport类。
hibernate4需要通过getCurrentSession()获取session。
并且设置<propkey="hibernate.current_session_context_class">org.springframework.orm.hibe rnate4.SpringSessionContext</prop>(在hibernate3的时候是thread和jta)。
2. 缓存设置改为<propkey="hibernate.cache.provider_class">net.sf.ehcache.hibernate.EhCacheProvi der</prop><propkey="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhC acheRegionFactory</prop>3. Spring对hibernate的事务管理,不论是注解方式还是配置文件方式统一改为:<bean id="txManager"class="org.springframework.orm.hibernate4.HibernateTransactionManager" ><property name="sessionFactory"><ref bean="sessionFactory"/></property></bean>4. getCurrentSession()事务会自动关闭,所以在有所jsp页面查询数据都会关闭session。
浅谈Hibernate的flush机制

浅谈Hibernate的flush机制随着Hibernate在Java开发中的广泛应用,我们在使用Hibernate进行对象持久化操作中也遇到了各种各样的问题。
这些问题往往都是我们对 Hibernate缺乏了解所致,这里我讲个我从前遇到的问题及一些想法,希望能给大家一点借鉴。
这是在一次事务提交时遇到的异常。
an assertion failure occured (this may indicate a bug in Hibernate, bu t is more likely due to unsafe use of the session)net.sf.hibernate.AssertionFailure: possible nonthreadsafe access to sessi on注:非possible non-threadsafe access to the session (那是另外的错误,类似但不一样)这个异常应该很多的朋友都遇到过,原因可能各不相同。
但所有的异常都应该是在flush或者事务提交的过程中发生的。
这一般由我们在事务开始至事务提交的过程中进行了不正确的操作导致,也会在多线程同时操作一个Session时发生,这里我们仅仅讨论单线程的情况,多线程除了线程同步外基本与此相同。
至于具体是什么样的错误操作那?我给大家看一个例子(假设Hibernate配置正确,为保持代码简洁,不引入包及处理任何异常)SessionFactory sf = new Configuration().configure().buildSessionFactory() ;Session s = sf.openSession();Cat cat = new Cat();Transaction tran = s.beginTransaction(); (1)s.save(cat); (2) (此处同样可以为update delete)s.evict(cat); (3)mit(); (4)s.close();(5)这就是引起此异常的典型错误。
Hibernate批处理操作优化(批量插入、更新与删除)

Hibernate批处理操作优化(批量插入、更新与删除)在项目的开发过程之中,由于项目需求,我们常常需要把大批量的数据插入到数据库。
数量级有万级、十万级、百万级、甚至千万级别的。
如此数量级别的数据用Hibernate做插入操作,就可能会发生异常,常见的异常是OutOfMemoryError(内存溢出异常)。
首先,我们简单来回顾一下Hibernate插入操作的机制。
Hibernate要对它内部缓存进行维护,当我们执行插入操作时,就会把要操作的对象全部放到自身的内部缓存来进行管理。
谈到Hibernate的缓存,Hibernate有内部缓存与二级缓存之说。
由于Hibernate对这两种缓存有着不同的管理机制,对于二级缓存,我们可以对它的大小进行相关配置,而对于内部缓存,Hibernate就采取了“放任自流”的态度了,对它的容量并没有限制。
现在症结找到了,我们做海量数据插入的时候,生成这么多的对象就会被纳入内部缓存(内部缓存是在内存中做缓存的),这样你的系统内存就会一点一点的被蚕食,如果最后系统被挤“炸”了,也就在情理之中了。
我们想想如何较好的处理这个问题呢?有的开发条件又必须使用Hibernate来处理,当然有的项目比较灵活,可以去寻求其他的方法。
笔者在这里推荐两种方法:(1):优化Hibernate,程序上采用分段插入及时清除缓存的方法。
(2):绕过Hibernate API ,直接通过 JDBC API 来做批量插入,这个方法性能上是最好的,也是最快的。
对于上述中的方法1,其基本是思路为:优化Hibernate,在配置文件中设置hibernate.jdbc.batch_size参数,来指定每次提交SQL的数量;程序上采用分段插入及时清除缓存的方法(Session实现了异步write-behind,它允许Hibernate显式地写操作的批处理),也就是每插入一定量的数据后及时的把它们从内部缓存中清除掉,释放占用的内存。
Hibernate学习总结

一.对象语言和操作数据库不匹配:模型不匹配(阻抗不匹配)①.可以使用JDBC手动转换;sql参数和jdbc中用对象赋值②.使用ORM(Object Relation Mapping对象关系映射)框架:hibernate 二.Hibernate安装配置①.配置文件Hibernate.cfg.xml和Hibernate.properties②.映射文件xxx.hbm.xml:对象模型和关系模型的映射三.开发流程1.由Domain Object -> mapping -> db2.有DB开始,用工具生成mapping和Domain Object3.由配置文件开始四.Domain Object限制1.默认的构造方法(必须的)2.有无意义的标示符id(主键) 可选3.非final的,对懒加载有影响可选Configuration SessionFactory Session Transaction Query CriteriaConfiguration类Configuration类负责配置并启动Hibernate,创建SessionFactory对象。
在Hibernate的启动的过程中,Configuration类的实例首先定位映射文档位置、读取配置,然后创建SessionFactory 对象。
SessionFactory接口SessionFactory接口负责初始化Hibernate。
它充当数据存储源的代理,并负责创建Session对象。
这里用到了工厂模式。
需要注意的是SessionFactory并不是轻量级的,因为一般情况下,一个项目通常只需要一个SessionFactory就够,当需要操作多个数据库时,可以为每个数据库指定一个SessionFactory。
Session接口Session接口负责执行被持久化对象的CRUD操作(CRUD的任务是完成与数据库的交流,包含了很多常见的SQL语句。
数据库优化的常见问题与解决方案

数据库优化的常见问题与解决方案在当今信息时代,数据库扮演着重要的角色,被广泛应用于各行各业。
然而,随着数据量不断增大和应用需求不断增长,数据库性能和效率的问题也日益凸显。
为了解决这些问题,数据库优化成为了亟待解决的任务。
本文将介绍数据库优化的常见问题及解决方案。
一、查询性能问题查询性能是数据库优化中最常见的问题之一。
当应用程序发出查询请求后,如果查询花费过多的时间,会导致用户等待时间过长,严重影响用户体验。
以下是一些常见的查询性能问题及解决方案。
1. 缺乏索引:索引是提高查询性能的关键因素。
如果数据库中的表没有正确的索引,查询将变得缓慢。
解决方案是对频繁查询的列添加索引,并确保索引的选择和使用合理。
2. 大量连表查询:当需要通过多个表进行连表查询时,可能会导致性能下降。
解决方案可以是通过使用JOIN语句进行优化,减少不必要的数据传输,或者考虑使用冗余数据进行优化。
3. 数据库设计问题:数据库设计不当也会导致查询性能问题。
例如,表的字段过多、表之间关系不清晰等。
解决方案是通过重新设计数据库结构,合理拆分或合并表,优化数据模型。
二、索引优化问题索引是提高数据库查询性能的关键组成部分,但是索引的选择和使用也可能会面临一些问题。
以下是一些常见的索引优化问题及解决方案。
1. 过多的索引:虽然索引可以加快查询速度,但是过多的索引也会导致性能下降。
每个索引都会占用存储空间,同时维护索引也需要时间。
解决方案是评估每个索引的必要性,并删除不必要的索引。
2. 错误的索引选择:选择不当的索引可能无法提高查询性能。
解决方案是根据实际查询需求,选择适当的索引类型(如B树索引、哈希索引等)和列进行索引优化。
3. 索引失效:当索引的选择性较低或者数据分布不均匀时,索引的效果可能会变差。
解决方案是重新评估索引的选择性,并考虑使用函数索引、联合索引等方式进行优化。
三、表结构优化问题数据库表结构的设计也会对数据库的性能产生重要影响。
Hibernete基本概念
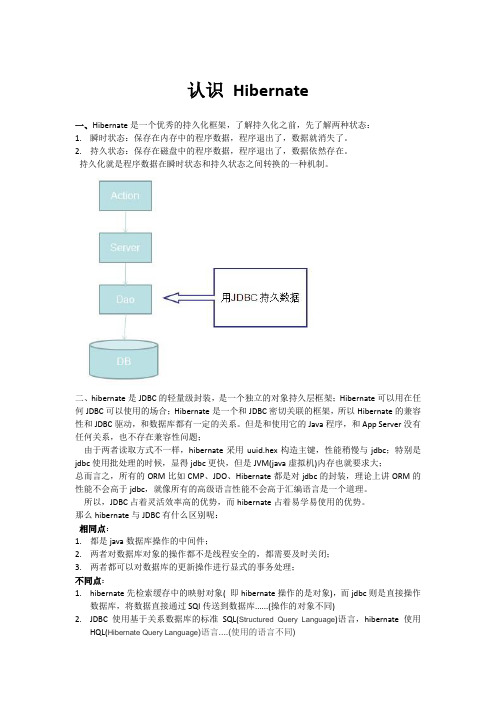
认识Hibernate一、Hibernate是一个优秀的持久化框架,了解持久化之前,先了解两种状态:1.瞬时状态:保存在内存中的程序数据,程序退出了,数据就消失了。
2.持久状态:保存在磁盘中的程序数据,程序退出了,数据依然存在。
持久化就是程序数据在瞬时状态和持久状态之间转换的一种机制。
二、hibernate是JDBC的轻量级封装,是一个独立的对象持久层框架;Hibernate可以用在任何JDBC可以使用的场合;Hibernate是一个和JDBC密切关联的框架,所以Hibernate的兼容性和JDBC驱动,和数据库都有一定的关系。
但是和使用它的Java程序,和App Server没有任何关系,也不存在兼容性问题;由于两者读取方式不一样,hibernate采用uuid.hex构造主键,性能稍慢与jdbc;特别是jdbc使用批处理的时候,显得jdbc更快,但是JVM(java虚拟机)内存也就要求大;总而言之,所有的ORM比如CMP、JDO、Hibernate都是对jdbc的封装,理论上讲ORM的性能不会高于jdbc,就像所有的高级语言性能不会高于汇编语言是一个道理。
所以,JDBC占着灵活效率高的优势,而hibernate占着易学易使用的优势。
那么hibernate与JDBC有什么区别呢:相同点:1.都是java数据库操作的中间件;2.两者对数据库对象的操作都不是线程安全的,都需要及时关闭;3.两者都可以对数据库的更新操作进行显式的事务处理;不同点:1.hibernate先检索缓存中的映射对象( 即hibernate操作的是对象),而jdbc则是直接操作数据库,将数据直接通过SQl传送到数据库......(操作的对象不同)2.JDBC使用基于关系数据库的标准SQL(Structured Query Language)语言,hibernate使用HQL(Hibernate Query Language)语言....(使用的语言不同)3.Hibernate操作的数据是可持久化的,也就是持久化的对象属性的值,可以和数据库中保持一致,而jdbc操作数据的状态是瞬时的,变量的值无法和数据库中一致....(数据状态不同)三、ORM(Object Relational Mapping)对象关系映射完成对象数据到关系型数据映射的机制,称为:对象·关系映射,简ORM总结:Hibernate是一个优秀的对象关系映射机制,通过映射文件保存这种关系信息;在业务层以面向对象的方式编程,不需要考虑数据的保存形式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
∙Hibernate优化方法解析∙ 2009-06-16 16:27 hulongzhou hulongzhou博客我要评论(0)本文对Hibernate优化方法进行了总结、介绍和解析,文章分为五个方面:批量修改和删除、使用SQL执行批量操作、提升数据库查询的性能、使用正确的抓取策略和查询性能提升小结五个部分。
Hibernate优化方法一:批量修改和删除在Hibernate 2中,如果需要对任何数据进行修改和删除操作,都需要先执行查询操作,在得到要修改或者删除的数据后,再对该数据进行相应的操作处理。
在数据量少的情况下采用这种处理方式没有问题,但需要处理大量数据的时候就可能存在以下的问题:◆占用大量的内存。
◆需要多次执行update/delete语句,而每次执行只能处理一条数据。
以上两个问题的出现会严重影响系统的性能。
因此,在Hibernate 3中引入了用于批量更新或者删除数据的HQL语句。
这样,开发人员就可以一次更新或者删除多条记录,而不用每次都一个一个地修改或者删除记录了。
如果要删除所有的User对象(也就是User对象所对应表中的记录),则可以直接使用下面的HQL语句:delete User而在执行这个HQL语句时,需要调用Query对象的executeUpdate()方法,具体的实例如下所示:String HQL="delete User";Query query=session.createQuery(HQL);int size=query.executeUpdate();采用这种方式进行数据的修改和删除时与直接使用JDBC的方式在性能上相差无几,是推荐使用的正确方法。
如果不能采用HQL语句进行大量数据的修改,也就是说只能使用取出再修改的方式时,也会遇到批量插入时的内存溢出问题,所以也要采用上面所提供的处理方法来进行类似的处理。
Hibernate优化方法二:使用SQL执行批量操作在进行批量插入、修改和删除操作时,直接使用JDBC来执行原生态的SQL语句无疑会获得最佳的性能,这是因为在处理的过程中省略或者简化了以下处理内容:● HQL语句到SQL语句的转换。
● Java对象的初始化。
● Java对象的缓存处理。
但是在直接使用JDBC执行SQL语句时,有一个最重要的问题就是要处理缓存中的Java 对象。
因为通过这种底层方式对数据的修改将不能通知缓存去进行相应的更新操作,以保证缓存中的对象与数据库中的数据是一致的。
Hibernate优化方法三:提升数据库查询的性能数据库查询性能的提升也是涉及到开发中的各个阶段,在开发中选用正确的查询方法无疑是最基础也最简单的。
1 、SQL语句的优化使用正确的SQL语句可以在很大程度上提高系统的查询性能。
获得同样数据而采用不同方式的SQL语句在性能上的差距可能是十分巨大的。
由于Hibernate是对JDBC的封装,SQL语句的产生都是动态由Hibernate自动完成的。
Hibernate产生SQL语句的方式有两种:一种是通过开发人员编写的HQL语句来生成,另一种是依据开发人员对关联对象的访问来自动生成相应的SQL语句。
至于使用什么样的SQL语句可以获得更好的性能要依据数据库的结构以及所要获取数据的具体情况来进行处理。
在确定了所要执行的SQL语句后,可以通过以下三个方面来影响Hibernate所生成的SQL语句:◆HQL语句的书写方法。
◆查询时所使用的查询方法。
◆对象关联时所使用的抓取策略。
2 、使用正确的查询方法在前面已经介绍过,执行数据查询功能的基本方法有两种:一种是得到单个持久化对象的get()方法和load()方法,另一种是Query对象的list()方法和iterator()方法。
在开发中应该依据不同的情况选用正确的方法。
get()方法和load()方法的区别在于对二级缓存的使用上。
load()方法会使用二级缓存,而get()方法在一级缓存没有找到的情况下会直接查询数据库,不会去二级缓存中查找。
在使用中,对使用了二级缓存的对象进行查询时最好使用load()方法,以充分利用二级缓存来提高检索的效率。
list()方法和iterator()方法之间的区别可以从以下几个方面来进行比较。
◆执行的查询不同list()方法在执行时,是直接运行查询结果所需要的查询语句,而iterator()方法则是先执行得到对象ID的查询,然后再根据每个ID值去取得所要查询的对象。
因此,对于list()方式的查询通常只会执行一个SQL语句,而对于iterator()方法的查询则可能需要执行N+1条SQL语句(N为结果集中的记录数)。
iterator()方法只是可能执行N+1条数据,具体执行SQL语句的数量取决于缓存的情况以及对结果集的访问情况。
◆缓存的使用list()方法只能使用二级缓存中的查询缓存,而无法使用二级缓存对单个对象的缓存(但是会把查询出的对象放入二级缓存中)。
所以,除非重复执行相同的查询操作,否则无法利用缓存的机制来提高查询的效率。
iterator()方法则可以充分利用二级缓存,在根据ID检索对象的时候会首先到缓存中查找,只有在找不到的情况下才会执行相应的查询语句。
所以,缓存中对象的存在与否会影响到SQL语句的执行数量。
◆对于结果集的处理方法不同list()方法会一次获得所有的结果集对象,而且它会依据查询的结果初始化所有的结果集对象。
这在结果集非常大的时候必然会占据非常多的内存,甚至会造成内存溢出情况的发生。
iterator()方法在执行时不会一次初始化所有的对象,而是根据对结果集的访问情况来初始化对象。
因此在访问中可以控制缓存中对象的数量,以避免占用过多缓存,导致内存溢出情况的发生。
使用iterator()方法的另外一个好处是,如果只需要结果集中的部分记录,那么没有被用到的结果对象根本不会被初始化。
所以,对结果集的访问情况也是调用iterator()方法时执行数据库SQL语句多少的一个因素。
所以,在使用Query对象执行数据查询时应该从以上几个方面去考虑使用何种方法来执行数据库的查询操作。
Hibernate优化方法四:使用正确的抓取策略所谓抓取策略(fetching strategy)是指当应用程序需要利用关联关系进行对象获取的时候,Hibernate获取关联对象的策略。
抓取策略可以在O/R映射的元数据中声明,也可以在特定的HQL或条件查询中声明。
Hibernate 3定义了以下几种抓取策略。
连接抓取(Join fetching)连接抓取是指Hibernate在获得关联对象时会在SELECT语句中使用外连接的方式来获得关联对象。
查询抓取(Select fetching)查询抓取是指Hibernate通过另外一条SELECT语句来抓取当前对象的关联对象的方式。
这也是通过外键的方式来执行数据库的查询。
与连接抓取的区别在于,通常情况下这个SELECT语句不是立即执行的,而是在访问到关联对象的时候才会执行。
子查询抓取(Subselect fetching)子查询抓取也是指Hibernate通过另外一条SELECT语句来抓取当前对象的关联对象的方式。
与查询抓取的区别在于它所采用的SELECT语句的方式为子查询,而不是通过外连接。
批量抓取(Batch fetching)批量抓取是对查询抓取的优化,它会依据主键或者外键的列表来通过单条SELECT语句实现管理对象的批量抓取。
以上介绍的是Hibernate 3所提供的抓取策略,也就是抓取关联对象的手段。
为了提升系统的性能,在抓取关联对象的时机上,还有以下一些选择。
立即抓取(Immediate fetching)立即抓取是指宿主对象被加载时,它所关联的对象也会被立即加载。
延迟集合抓取(Lazy collection fetching)延迟集合抓取是指在加载宿主对象时,并不立即加载它所关联的对象,而是到应用程序访问关联对象的时候才抓取关联对象。
这是集合关联对象的默认行为。
延迟代理抓取(Lazy proxy fetching)延迟代理抓取是指在返回单值关联对象的情况下,并不在对其进行get操作时抓取,而是直到调用其某个方法的时候才会抓取这个对象。
延迟属性加载(Lazy attribute fetching)延迟属性加载是指在关联对象被访问的时候才进行关联对象的抓取。
介绍了Hibernate所提供的关联对象的抓取方法和抓取时机,这两个方面的因素都会影响Hibernate的抓取行为,最重要的是要清楚这两方面的影响是不同的,不要将这两个因素混淆,在开发中要结合实际情况选用正确的抓取策略和合适的抓取时机。
◆抓取时机的选择在Hibernate 3中,对于集合类型的关联在默认情况下会使用延迟集合加载的抓取时机,而对于返回单值类型的关联在默认情况下会使用延迟代理抓取的抓取时机。
对于立即抓取在开发中很少被用到,因为这很可能会造成不必要的数据库操作,从而影响系统的性能。
当宿主对象和关联对象总是被同时访问的时候才有可能会用到这种抓取时机。
另外,使用立即连接抓取可以通过外连接来减少查询SQL语句的数量,所以,也会在某些特殊的情况下使用。
然而,延迟加载又会面临另外一个问题,如果在Session关闭前关联对象没有被实例化,那么在访问关联对象的时候就会抛出异常。
处理的方法就是在事务提交之前就完成对关联对象的访问。
所以,在通常情况下都会使用延迟的方式来抓取关联的对象。
因为每个立即抓取都会导致关联对象的立即实例化,太多的立即抓取关联会导致大量的对象被实例化,从而占用过多的内存资源。
◆抓取策略的选取对于抓取策略的选取将影响到抓取关联对象的方式,也就是抓取关联对象时所执行的SQL语句。
这就要根据实际的业务需求、数据的数量以及数据库的结构来进行选择了。
在这里需要注意的是,通常情况下都会在执行查询的时候针对每个查询来指定对其合适的抓取策略。
指定抓取策略的方法如下所示:User user = (User) session.createCriteria(User.class).setFetchMode("permissions", FetchMode.JOIN).add( Restrictions.idEq(userId) ).uniqueResult();Hibernate优化方法五:查询性能提升小结在本小节中介绍了查询性能提升的方法,关键是如何通过优化SQL语句来提升系统的查询性能。
查询方法和抓取策略的影响也是通过执行查询方式和SQL语句的多少来改变系统的性能的。
这些都属于开发人员所应该掌握的基本技能,避免由于开发不当而导致系统性能的低下。
在性能调整中,除了前面介绍的执行SQL语句的因素外,对于缓存的使用也会影响系统的性能。