基于Redis的开源分布式服务Codis
codis采集监控指标

codis采集监控指标【实用版】目录1.Codis 简介2.Codis 采集监控指标的方法3.Codis 采集监控指标的优势4.总结正文一、Codis 简介Codis 是一个开源的分布式 Redis 缓存解决方案,其目的是为了解决单个 Redis 实例的可扩展性和可用性问题。
Codis 采用多 Master 多Slave 架构,将数据分布在多个 Redis 实例上,从而实现了水平扩展。
此外,Codis 还提供了数据持久化、高可用、监控等功能,使得 Redis 集群在面对海量数据和复杂场景时更加稳定可靠。
二、Codis 采集监控指标的方法Codis 提供了丰富的监控指标,这些指标可以帮助用户了解集群的运行状况,及时发现并解决问题。
Codis 采集监控指标的方法主要有以下几种:1.基于 Prometheus 的监控Codis 提供了 Prometheus 的监控接口,用户可以通过 Prometheus 来采集 Codis 集群的各种指标。
Prometheus 是一个流行的开源监控工具,支持多种数据采集方式,如拉取、推送等,可以根据需求灵活配置。
2.基于 Stats 的监控Codis 内置了 Stats 模块,可以实时统计集群的各种指标,如连接数、吞吐量、内存使用率等。
用户可以通过查询 Stats 接口来获取这些指标的数据。
3.基于日志的监控Codis 的日志模块可以记录集群的各种操作和事件,用户可以通过分析日志来获取监控指标。
此外,Codis 还提供了日志的查询接口,可以方便地检索和分析日志数据。
三、Codis 采集监控指标的优势Codis 采集监控指标具有以下优势:1.丰富的监控指标Codis 提供了丰富的监控指标,可以满足用户对集群的各方面了解需求。
这些指标包括连接数、吞吐量、内存使用率、CPU 使用率等,可以帮助用户全面掌握集群的运行状况。
2.灵活的监控方式Codis 支持多种监控方式,如基于 Prometheus 的监控、基于 Stats 的监控、基于日志的监控等。
redis6种策略

redis6种策略Redis是一种流行的开源内存数据库,它提供了多种策略来处理数据。
本文将介绍Redis的六种策略,包括数据持久化、主从复制、高可用性、分布式缓存、事务处理和发布订阅。
一、数据持久化数据持久化是Redis的核心特性之一,它允许将内存中的数据保存到硬盘中,以防止数据丢失。
Redis提供了两种数据持久化策略:RDB和AOF。
1. RDB(Redis DataBase)是一种快照式的持久化策略,它会将数据保存为二进制文件。
RDB的优点是文件体积小、加载速度快,适合用于备份和恢复数据。
缺点是在发生故障时可能会有数据丢失。
2. AOF(Append Only File)是一种追加式的持久化策略,它会将每个写操作追加到文件末尾。
AOF的优点是可以提供更好的数据安全性,因为每个操作都会被记录下来。
缺点是文件体积相对较大,加载速度相对较慢。
二、主从复制主从复制是一种将数据从一个Redis服务器复制到多个Redis服务器的策略,用于提高系统的读写性能和可用性。
主从复制的过程分为三个步骤:复制初始化、全量复制和增量复制。
1. 复制初始化:从服务器连接主服务器,并通过发送SYNC命令来进行复制初始化。
2. 全量复制:主服务器将自己的数据发送给从服务器,从服务器接收并加载数据。
3. 增量复制:主服务器将自己的写操作发送给从服务器,从服务器接收并执行写操作,从而保持数据的一致性。
主从复制可以提高系统的读写性能,同时还可以提供故障切换和负载均衡的功能。
三、高可用性高可用性是指系统在发生故障时能够保持正常运行的能力。
Redis 提供了多种策略来实现高可用性,包括哨兵模式和集群模式。
1. 哨兵模式:哨兵模式是通过监控主服务器的状态来实现高可用性。
当主服务器发生故障时,哨兵会自动将一个从服务器升级为主服务器,从而保证系统的可用性。
2. 集群模式:集群模式是通过将数据分布在多个节点上来实现高可用性。
当某个节点发生故障时,其他节点会自动接管该节点的工作,从而保证系统的可用性。
Codis 官方使用文档 豌豆荚redis分布式集群

Codis 官方使用文档豌豆荚redis分布式集群Codis 是一个分布式Redis 解决方案, 对于上层的应用来说, 连接到Codis Proxy 和连接原生的Redis Server 没有明显的区别(不支持的命令列表), 上层应用可以像使用单机的Redis 一样使用, Codis 底层会处理请求的转发, 不停机的数据迁移等工作, 所有后边的一切事情, 对于前面的客户端来说是透明的, 可以简单的认为后边连接的是一个内存无限大的Redis 服务.Codis 由四部分组成:▪Codis Proxy (codis-proxy)▪Codis Manager (codis-config)▪Codis Redis (codis-server)▪ZooKeepercodis-proxy 是客户端连接的Redis 代理服务, codis-proxy 本身实现了Redis 协议, 表现得和一个原生的Redis 没什么区别(就像Twemproxy), 对于一个业务来说, 可以部署多个codis-proxy, codis-proxy 本身是无状态的.codis-config 是Codis 的管理工具, 支持包括, 添加/删除Redis 节点, 添加/删除Proxy 节点, 发起数据迁移等操作. codis-config 本身还自带了一个http ser ver, 会启动一个dashboard, 用户可以直接在浏览器上观察Codis 集群的运行状态.codis-server 是Codis 项目维护的一个Redis 分支, 基于2.8.21 开发, 加入了slot 的支持和原子的数据迁移指令. Codis 上层的codis-proxy 和codis-config 只能和这个版本的Redis 交互才能正常运行.Codis 依赖ZooKeeper 来存放数据路由表和codis-proxy 节点的元信息, codi s-config 发起的命令都会通过ZooKeeper 同步到各个存活的codis-proxy.Codis 支持按照Namespace 区分不同的产品, 拥有不同的product name 的产品, 各项配置都不会冲突.Build codis-proxy & codis-config1 2 3 4 5 go get -u -d /wandoulabs/codiscd $GOPA TH/src//wandoulabs/codis./bootstrap.shmake gotest建议只通过go get命令来下载codis,除非你非常熟悉go语言的目录引用形式从而不会导致代码放错地方。
使用Codis搭建redis集群服务

使用Codis搭建redis集群服务一. 应用场景redis 作为数据结构存储引擎,有着很多优点•高性能•单机引擎可以达到5-10W qps•数据结构全面,支持快速开发业务•string,list,set,sorted set, hashes问题:•存储容量受限单机最大容量即为单机内存最大容量•单机数据的持久化依赖aof和rdb机制,如果机器整个down 掉,服务不可用二. redis集群选型正是由于单机redis引擎有着这样的问题,所以,基本每个互联网公司都有自己的redis集群化方案。
•在redis客户端lib中实现数据的分片并主从部署redis实例•优点:简单,性能损耗小•缺点:扩容方案复杂•集群化候选方案1、NetFlix对Dynamo的开源通用实现DynomiteDynomite是NetFlix对亚马逊分布式存储引擎Dynamo的一个开源通用实现,使用C/C++语言编写、以代理的方式实现的Redis缓存集群方案。
Dynomite不仅能够将基于内存的Redis和Memcached打造成分布式数据库,还支持持久化的MySQL、BerkeleyDB、LevelDB等数据库,并具有简单、高效、支持跨数据中心的数据复制等优点。
Dynomite的最终目标是提供数据库存储引擎不能提供的简单、高效、跨数据中心的数据复制功能。
Dynomite遵循Apache License 2.0开源协议发布,更多关于Dynomite的信息请查看NetFlix技术博客对Dynomite的介绍。
2、Twitter的Redis/Memcached代理服务TwemproxyTwemproxy是一个使用C语言编写、以代理的方式实现的、轻量级的Redis代理服务器,它通过引入一个代理层,将应用程序后端的多台Redis实例进行统一管理,使应用程序只需要在Twemproxy上进行操作,而不用关心后面具体有多少个真实的Redis或Memcached实例,从而实现了基于Redis和Memcached的集群服务。
Redis在云原生架构中的应用与可扩展性考量

Redis在云原生架构中的应用与可扩展性考量Redis(Remote Dictionary Server)是一个开源的内存数据结构存储系统,广泛应用于云原生架构中。
在云原生架构中,Redis被用于缓存、消息队列、分布式锁等多个方面,以提高系统的性能和可扩展性。
本文将重点探讨Redis在云原生架构中的应用,并讨论可扩展性的相关考量。
一、Redis在缓存中的应用在云原生架构中,缓存是提高系统性能的关键一环。
Redis作为一个高性能的缓存存储系统,具有以下几个特点:1. 内存存储:Redis将数据存储在内存中,可以快速读取和写入数据,大大提高了系统的响应速度。
2. 数据结构多样性:Redis支持多种数据结构,包括字符串、哈希、列表、集合和有序集合等,可以根据具体需求选择最适合的数据结构。
3. 持久化支持:Redis支持数据的持久化,可以将内存中的数据定期或实时写入磁盘,以防止数据丢失。
在云原生架构中,缓存的数据通常存储在分布式缓存系统中,而Redis正是一种常用的分布式缓存系统。
通过将Redis节点部署在不同的物理或虚拟机上,可以实现缓存的分布式存储,提高了系统的可用性和可扩展性。
二、Redis在消息队列中的应用消息队列是云原生架构中常用的一种异步通信方式,用于实现系统之间的解耦和异步处理。
Redis提供了可靠的消息队列服务,通过将消息写入Redis的列表或发布订阅通道,实现了消息的异步发布和订阅。
在使用Redis作为消息队列时,需要考虑以下几个方面:1. 消息的顺序性:Redis的列表是按照入队顺序存储消息的,可以保证消息的顺序性。
但在跨节点的分布式环境中,需要额外的机制来确保消息的消费顺序。
2. 消息的可靠性:Redis的列表和发布订阅通道都是非持久化的,一旦Redis节点宕机,消息可能会丢失。
因此,在使用Redis作为消息队列时,需要考虑消息的持久化和重试机制,以确保消息的可靠性。
3. 消息的消费者管理:Redis提供了多个消费者订阅同一个通道或者消费同一个列表的功能。
(一)redis是什么,用来做什么,优缺点

(⼀)redis是什么,⽤来做什么,优缺点⼀、redis是什么 Redis(全称:Remote Dictionary Server 远程字典服务)是⼀个开源的使⽤ANSI 编写、⽀持⽹络、可基于内存亦可持久化的⽇志型、Key-Value nosql ,并提供多种语⾔的API。
⼆、redis的应⽤场景 1、缓存 缓存现在⼏乎是所有中⼤型⽹站都在⽤的必杀技,合理的利⽤缓存不仅能够提升⽹站访问速度,还能⼤⼤降低数据库的压⼒。
Redis提供了键过期功能,也提供了灵活的键淘汰策略,所以,现在Redis⽤在缓存的场合⾮常多。
2、排⾏榜 很多⽹站都有排⾏榜应⽤的,如京东的⽉度销量榜单、商品按时间的上新排⾏榜等。
Redis提供的有序集合数据类构能实现各种复杂的排⾏榜应⽤。
3、计数器 什么是计数器,如电商⽹站商品的浏览量、视频⽹站视频的播放数等。
为了保证数据实时效,每次浏览都得给+1,并发量⾼时如果每次都请求数据库操作⽆疑是种挑战和压⼒。
Redis提供的incr命令来实现计数器功能,内存操作,性能⾮常好,⾮常适⽤于这些计数场景。
4、分布式会话 集群模式下,在应⽤不多的情况下⼀般使⽤容器⾃带的session复制功能就能满⾜,当应⽤增多相对复杂的系统中,⼀般都会搭建以Redis等内存数据库为中⼼的session服务,session不再由容器管理,⽽是由session服务及内存数据库管理。
5、分布式锁 在很多互联⽹公司中都使⽤了分布式技术,分布式技术带来的技术挑战是对同⼀个资源的并发访问,如全局ID、减库存、秒杀等场景,并发量不⼤的场景可以使⽤数据库的悲观锁、乐观锁来实现,但在并发量⾼的场合中,利⽤数据库锁来控制资源的并发访问是不太理想的,⼤⼤影响了数据库的性能。
可以利⽤Redis的setnx功能来编写分布式的锁,如果设置返回1说明获取锁成功,否则获取锁失败,实际应⽤中要考虑的细节要更多。
6、社交⽹络 点赞、踩、关注/被关注、共同好友等是社交⽹站的基本功能,社交⽹站的访问量通常来说⽐较⼤,⽽且传统的关系数据库类型不适合存储这种类型的数据,Redis提供的哈希、集合等数据结构能很⽅便的的实现这些功能。
python redis-om使用原理 -回复

python redis-om使用原理-回复Redis是一个开源的键值存储系统,常用于缓存、队列和分布式存储等场景。
Redis官方提供了多种客户端库,其中之一就是redis-py。
而redis-py 中的redis-py-cluster模块则在redis-py的基础上提供了对Redis Cluster集群的支持。
redis-py-cluster使用python redis模块进行了封装,提供了更高层次的接口和功能,使得开发者可以更加便捷地与Redis Cluster进行交互。
本文将深入探讨redis-py-cluster的使用原理,并逐步分析它是如何实现对Redis Cluster的支持的。
一、Redis Cluster简介Redis Cluster是Redis的分布式解决方案之一,它将数据分布在多个节点上,提供了分布式缓存和存储的能力。
在Redis Cluster中,每个节点负责处理一部分数据,同时也负责将数据迁移到其他节点上,以实现数据的平衡和容错性。
Redis Cluster通过使用槽位(slot)来划分数据,一共有16384个槽位。
每个槽位可以存放一个键值对,每个节点负责处理一部分槽位。
当需要访问某个键值对时,Redis Cluster会根据键值对的哈希值确定该键值对所在的槽位,并将请求转发到负责该槽位的节点上。
二、redis-py-cluster的使用方式redis-py-cluster提供了RedisCluster这个类,开发者可以通过实例化RedisCluster对象来与Redis Cluster进行交互。
在实例化RedisCluster 对象时,需要传入一个节点列表和一些其他的配置。
节点列表用于指定Redis Cluster中的节点地址,配置则用于指定连接的一些参数和行为。
下面是一个示例代码,展示了如何实例化RedisCluster对象:pythonfrom rediscluster import RedisClusterstartup_nodes = [{'host': '127.0.0.1', 'port': 7000},{'host': '127.0.0.1', 'port': 7001},{'host': '127.0.0.1', 'port': 7002}]rc = RedisCluster(startup_nodes=startup_nodes,decode_responses=True)在上面的代码中,我们指定了一个包含了三个节点的节点列表,并将其传递给RedisCluster的startup_nodes参数。
Codis搭建与使用

Codis 高可用负载均衡群集的搭建与使用声明此篇文章,涉及到东西比较多,文章比较长,适合耐心的童鞋们阅读,生产环境部署可参考此篇文章。
Codis 并不太适合key 少,但是value 特别大的应用,而且你的key 越少,value 越大,最后就会退化成单个redis 的模型(性能还不如raw redis),所以Codis 更适合海量Key, value比较小(<= 1 MB) 的应用。
codis-proxy 提供连接集群redis服务的入口codis-redis-group 实现redis读写的水平扩展,高性能codis-redis 实现redis实例服务,通过codis-ha实现服务的高可用实验环境网络拓扑图群集架构图机器与应用列表System version: CentOS 6.5IP: 192.168.43.130 hostname: vmware-130apps: keepalived+haproxyMaster,zookeeper_1,codis_proxy_1, codis_config, codis_server_master,slaveIP: 192.168.43.131 hostname: vmware-131apps: zookeeper_2, codis_proxy_2, codis_server_master,slaveIP: 192.168.43.132 hostname: vmware-132apps: keepalived + haproxy Backup, zookeeper_3, codis_proxy_3, codis_server_master,slaveVIP: 192.168.43.100 Port: 45001备注:由于是虚拟测试环境,非生产环境,所以一台机器跑多个应用,如应用于生产环境,只需把应用分开部署到相应机器上即可。
一、初始化CentOS系统1. 使用镜像站点配置好的yum安装源配置文件cd /etc/yum.repos.d//bin/mv CentOS-Base.repo CentOS-Base.repo.bakwget /.help/CentOS6-Base-163.repo接下来执行如下命令,检测yum是否正常yum clean all #清空yum缓存yum makecache #建立yum缓存然后使用如下命令将系统更新到最新rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY* #导入签名KEY到RPMyum upgrade -y #更新系统内核到最新2. 关闭不必要的服务for sun in `chkconfig --list|grep 3:on|awk '{print $1}'`;do chkconfig --level 3 $sun off;done for sun in `chkconfig --list|grep 5:on|awk '{print $1}'`;do chkconfig --level 5 $sun off;done for sun in crond rsyslog sshd network;do chkconfig --level 3 $sun on;donefor sun in crond rsyslog sshd network;do chkconfig --level 5 $sun on;done3. 安装依赖包yum install -y gcc make g++ gcc-c++ automake lrzsz openssl-devel zlib-* bzip2-* readline* zlib-* bzip2-*4. 创建软件存放目录mkdir /data/packages5. 软件包版本以及下载地址:jdk1.8.0_45zookeeper-3.4.6go1.4.2pcre-8.37haproxy-1.4.22keepalived-1.4.26cd /data/packageswget /zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gzwget /static/go/go1.4.2.linux-amd64.tar.gzwget ftp:///pub/software/programming/pcre/pcre-8.37.tar.gzwget /software/keepalived-1.2.16.tar.gz通过浏览器自行下载:6. 重启系统[root@vmware-130 ~]# init 6二、部署Zookeeper群集1.配置hosts文件( zookeeper节点机器上配置)[root@vmware-130 ~]# vim /etc/hosts192.168.43.130 vmware-130192.168.43.131 vmware-131192.168.43.132 vmware-1322.安装java 坏境 ( zookeeper节点机器上配置 )[root@vmware-130 ~]# cd /data/packages[root@vmware-130 packages ]# tar zxvf jdk-8u45-linux-x64.tar.gz -C /usr/local [root@vmware-130 packages ]# cd /usr/local[root@vmware-130 local ]# ln -s jdk1.8.0_45 java3. 安装Zookeeper ( zookeeper节点机器上配置 )cd /data/packagestar zxvf zookeeper-3.4.6.tar.gz -C /usr/localln -s zookeeper-3.4.6 zookeepercd /usr/local/zookeeper/4.设置环境变量 ( zookeeper节点机器上配置 )vim /etc/profileJAVA_HOME=/usr/local/javaJRE_HOME=$JAVA_HOME/jreZOOKEEPER_HOME=/usr/local/zookeeperJAVA_FONTS=/usr/local/java/jre/lib/fontsCLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jarPATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$ZOOKEEPER_HOME/binexport JAVA_HOME PATH CLASSPATH JRE_HOME ZOOKEEPER_HOME#生效环境变量source /etc/profile5. 修改zookeeper配置文件( zookeeper节点机器上配置 )vi /usr/local/zookeeper/conf/zoo.cfgtickTime=2000initLimit=10syncLimit=5clientPort=2181autopurge.snapRetainCount=500autopurge.purgeInterval=24dataDir=/data/zookeeper/datadataLogDir=/data/zookeeper/logsserver.1=192.168.43.130:2888:3888server.2=192.168.43.131:2888:3888server.3=192.168.43.132:2888:3888#创建数据目录和日志目录( zookeeper节点机器上配置)mkdir -p /data/zookeeper/datamkdir -p /data/zookeeper/logs6. 在zookeeper节点机器上创建myid文件,节点对应id在43.130机器上创建myid,并设置为1与配置文件zoo.cfg里面server.1对应。
Codis 官方使用文档 豌豆荚redis分布式集群资料

Codis 官方使用文档豌豆荚redis分布式集群Codis 是一个分布式Redis 解决方案, 对于上层的应用来说, 连接到Codis Proxy 和连接原生的Redis Server 没有明显的区别(不支持的命令列表), 上层应用可以像使用单机的Redis 一样使用, Codis 底层会处理请求的转发, 不停机的数据迁移等工作, 所有后边的一切事情, 对于前面的客户端来说是透明的, 可以简单的认为后边连接的是一个内存无限大的Redis 服务.Codis 由四部分组成:▪Codis Proxy (codis-proxy)▪Codis Manager (codis-config)▪Codis Redis (codis-server)▪ZooKeepercodis-proxy 是客户端连接的Redis 代理服务, codis-proxy 本身实现了Redis 协议, 表现得和一个原生的Redis 没什么区别(就像Twemproxy), 对于一个业务来说, 可以部署多个codis-proxy, codis-proxy 本身是无状态的.codis-config 是Codis 的管理工具, 支持包括, 添加/删除Redis 节点, 添加/删除Proxy 节点, 发起数据迁移等操作. codis-config 本身还自带了一个http ser ver, 会启动一个dashboard, 用户可以直接在浏览器上观察Codis 集群的运行状态.codis-server 是Codis 项目维护的一个Redis 分支, 基于2.8.21 开发, 加入了slot 的支持和原子的数据迁移指令. Codis 上层的codis-proxy 和codis-config 只能和这个版本的Redis 交互才能正常运行.Codis 依赖ZooKeeper 来存放数据路由表和codis-proxy 节点的元信息, codi s-config 发起的命令都会通过ZooKeeper 同步到各个存活的codis-proxy.Codis 支持按照Namespace 区分不同的产品, 拥有不同的product name 的产品, 各项配置都不会冲突.Build codis-proxy & codis-config1 2 3 4 5 go get -u -d /wandoulabs/codiscd $GOPA TH/src//wandoulabs/codis./bootstrap.shmake gotest建议只通过go get命令来下载codis,除非你非常熟悉go语言的目录引用形式从而不会导致代码放错地方。
codis原理 -回复

codis原理-回复[Codis原理]是一种分布式的Redis集群中间件,该中间件在多台Redis 服务器之间进行分片和代理,以提高系统的可扩展性和并发性。
本文将逐步介绍Codis的工作原理和关键组件。
1. Codis概述Codis是由小米公司开源的一种Redis集群中间件,其目的是为了解决传统的单机Redis在高并发、大数据量的场景下的性能问题。
Codis通过对Redis进行分片和代理,将数据分散存储在多台Redis服务器上,并提供代理服务,使得客户端可以透明地访问整个分布式Redis集群。
2. Codis的架构Codis的架构由多个组件组成。
其中包括:- Codis-Proxy:负责将客户端请求路由到正确的Redis分片服务器,并将响应返回给客户端。
Codis-Proxy维护了整个Redis集群的拓扑结构,并根据一致性哈希算法将数据映射到不同的Redis分片服务器上。
- Codis-Server:实际上是Redis服务器,它存储和处理数据。
每个Codis-Server负责存储整个Redis集群的部分数据。
- Codis-Fe:负责提供管理功能,如监控、负载均衡和故障恢复。
Codis-Fe通过与Codis-Proxy和Codis-Server通信来提供这些功能。
3. Codis的工作流程当一个客户端发送一个Redis请求时,工作流程如下:1) 客户端向Codis-Proxy发送Redis请求。
2) Codis-Proxy根据一致性哈希算法确定请求应该路由到哪个Redis分片服务器。
3) Codis-Proxy将请求转发给目标Redis分片服务器。
4) Redis分片服务器处理请求,并将结果返回给Codis-Proxy。
5) Codis-Proxy将结果返回给客户端。
整个过程中,客户端完全不需要了解整个分布式Redis集群的拓扑结构,它只需要与Codis-Proxy通信即可。
4. Codis的数据分片机制Codis将数据分片到不同的Redis分片服务器上,以实现数据的分布和负载均衡。
Codis与RedisCluster的原理详解
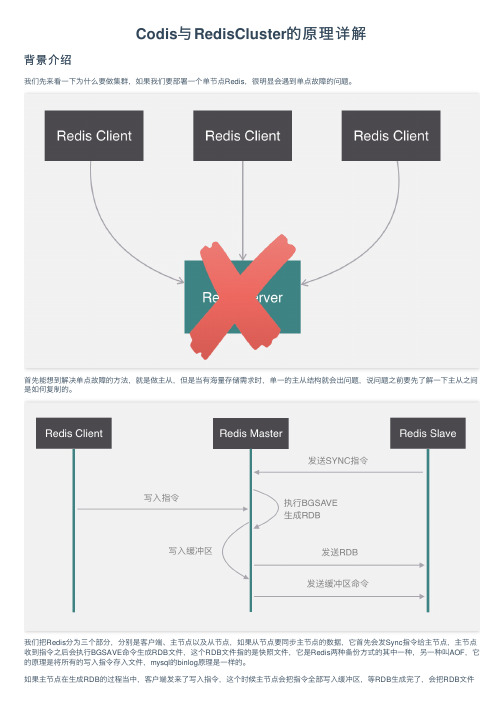
Codis与RedisCluster的原理详解背景介绍我们先来看⼀下为什么要做集群,如果我们要部署⼀个单节点Redis,很明显会遇到单点故障的问题。
⾸先能想到解决单点故障的⽅法,就是做主从,但是当有海量存储需求时,单⼀的主从结构就会出问题,说问题之前要先了解⼀下主从之间是如何复制的。
我们把Redis分为三个部分,分别是客户端、主节点以及从节点,如果从节点要同步主节点的数据,它⾸先会发Sync指令给主节点,主节点收到指令之后会执⾏BGSAVE命令⽣成RDB⽂件,这个RDB⽂件指的是快照⽂件,它是Redis两种备份⽅式的其中⼀种,另⼀种叫AOF,它的原理是将所有的写⼊指令存⼊⽂件,mysql的binlog原理是⼀样的。
如果主节点在⽣成RDB的过程当中,客户端发来了写⼊指令,这个时候主节点会把指令全部写⼊缓冲区,等RDB⽣成完了,会把RDB⽂件发送给从节点,最后再把缓冲区的指令发送给从节点。
这样就完成了整个的复制。
我们刚才说单纯地做主从是有缺陷的,这个缺陷就是如果我们要存储海量的数据,那么BGSAVE指令⽣成的RDB⽂件会⾮常巨⼤,这个⽂件传送给从节点也会⾮常慢,如果缓冲区命令很多的话,从节点同步数据时也会执⾏很久,所以,要解决单点问题和海量存储问题,还是要考虑做集群。
Redis常见集群⽅案Redis集群⽅案⽬前主流的有三种,分别是Twemproxy、Codis和Redis Cluster。
Twemproxy,是推特开源的,它最⼤的缺点就是⽆法平滑的扩缩容,⽽Codis解决了Twemproxy扩缩容的问题,⽽且兼容了Twemproxy,它是由豌⾖荚开源的,和Twemproxy都是代理模式。
其实Codis能发展起来的⼀个主要原因是它是在Redis官⽅集群⽅案漏洞百出的时候率先成熟稳定的。
以现在的Redis官⽅集群⽅案,这两个好像没有太⼤差别了,不过我也没有去做性能测试,不清楚哪个最好。
Redis Cluster是由官⽅出品的,⽤去中⼼化的⽅式实现,不属于代理模式,今天主要讲codis,redis cluster后⾯也会过⼀下。
redis实现分布式session的解决方案

redis实现分布式session的解决⽅案⽬录⼀、⾸先Session⼆、分布式Session补充:⼀、⾸先SessionSession 是客户端与服务器通讯会话技术,⽐如浏览器登陆、记录整个浏览会话信息。
session存放在服务器,关闭浏览器不会失效。
Session实现原理客户对向服务器端发送请求后,Session 创建在服务器端,返回Sessionid给客户端浏览器保存在本地,当下次发送请求的时候,在请求头中传递sessionId获取对应的从服务器上获取对应的Sesison 请求过程:服务器端接受到客户端请求,会创建⼀个session,使⽤响应头返回 sessionId给客户端。
客户端获取到sessionId后,保存到本地。
下次请求:客户端将本地的sessionId通过请求头发送到服务器。
服务器从请求头获取到对应的sessionId,使⽤sessionId在本地session内存中查询。
HttpSession session = request.getSession();//默认创建⼀个session 默认值为true 没有找到对应的session ⾃动创建sessionHttpSession session = request.getSession(false)//true的情况是客户端使⽤对应的sessionId查询不到对应的session 会直接创建⼀个新的session 如果有的话直接覆盖之前的//false 客户端使⽤对应的sessionId查询不到对应的session 不会创建新的sessionsession 包括 sessionId和sessionValuesession本⾝是临时的 token(令牌)与 sessionId很相似保证了临时且唯⼀玩下session:前提需要安装nginx配置如下:host⽂件:c:\windows\system32\drivers\etc访问 时候⾛的nginx的服务器域名然后默认监听的端⼝号80。
Redis分布式解决方案-Coids

Redis分布式解决⽅案-CoidsCodis 是⼀个分布式 解决⽅案, 对于上层的应⽤来说, 连接到 CodisProxy 和连接原⽣的 Redis Server 没有明显的区别 (不⽀持的命令列表), 上层应⽤可以像使⽤单机的 Redis ⼀样使⽤, Codis 底层会处理请求的转发, 不停机的数据迁移等⼯作, 所有后边的⼀切事情, 对于前⾯的客户端来说是透明的, 可以简单的认为后边连接的是⼀个内存⽆限⼤的 Redis 服务.Codis 由四部分组成:Codis Proxy (codis-proxy) 实现redis协议,由于本⾝是⽆状态的,因此可以部署很多个节点Codis Manager (codis-config) 是codis的管理⼯具,包括添加/删除redis节点添加删除proxy节点,发起数据迁移等操作,⾃带httpserver,⽀持管理后台⽅式管理配置Codis Redis (codis-server) 是codis维护的redis分⽀,基于2.8.21分⽀,加⼊了slot的⽀持和原⼦的数据迁移命令;codis-proxy和codis-config只能和这个版本的redis交互才能正常运⾏ZooKeeper ⽤于codis集群元数据的存储,维护codis集群节点Codis优缺点– 优点· 对客户端透明,与codis交互⽅式和redis本⾝交互⼀样· ⽀持在线数据迁移,迁移过程对客户端透明· 有简单的管理和监控界⾯· ⽀持⾼可⽤,⽆论是redis数据存储还是代理节点· ⾃动进⾏数据的均衡分配· 最⼤⽀持1024个redis实例,存储容量海量· ⾼性能– 缺点· 采⽤⾃有的redis分⽀,不能与原版的redis保持同· 如果codis的proxy只有⼀个的情况下,redis的性能会下降20%左右· 某些命令不⽀持,⽐如事务命令muti· 国内开源产品,活跃度相对弱⼀些Codis架构Codis的性能(代理+两个redis节点⾸先需要安装go环境wget /golang/go1.4.1.linux-amd64.tar.gz解压tar -zxvf go1.4.1.linux-amd64.tar.gz下载zookeeperwget /apache/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz 解压vi ~/.bash_profile配置go环境变量还有zk homevi ~/.bash_profilePATH=$PATH:$HOME/binexport PATHJAVA_HOME=/java/jdk1.7.0_76PATH=$JAVA_HOME/bin:$PATHCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOMEexport CLASSPATHZOOKEEPER_HOME=/java/zookeeper-3.4.6GOROOT=/java/goexport GOPATH=/java/codisPATH=$PATH:$GOROOT/bin:$GOPATH/bin:$ZOOKEEPER_HOME/bin export PATH令环境变量⽣效source ~/.bash_profile创建codis⽬录mkdir codis下载codis代码go get -u -d /CodisLabs/codis进⼊到coids⾥⾯执⾏make 编译代码编译完成后会在bin⽬录下⾯产⽣3个可执⾏⽂件修改config.ini⽂件vi config.ini进⼊zk⽬录启动zkcd /java/zookeeper-3.4.6/bin./zkServer.sh start通过jps命令查看zk是否启动codis启动步骤./codis-config -c ../config.ini dashboard 你也可以在后⾯加上 & 表⽰后台启动可以查看zk⾥⾯的数据然后初始化slots./codis-config -c ../config.ini slot init这些slot的信息都会保存在zk⾥⾯复制⼀份redis的配置⽂件过来 ,然后启动然后添加⼀个group server每⼀个Servicegroup 作为⼀个Redis服务器组存在,只允许有⼀个master,可以有多个slave,group id 仅⽀持⼤于1的整数添加成功分配slot启动codis-proxy./codis-proxy -c ../config.ini -L ./proxy.log --cpu=1 --addr=192.168.247.103:19000 --http-addr=192.168.247.103:11000· Addr为代理绑定的ip和端⼝· --cpu为代理使⽤的cpu核数,与虚拟机的配置有关,⼀般跟核数相同· http-addr⽤于测试的地址· -L 指定代理的⽇志⽂件把代理状态修改为online访问11000端⼝查看到proxy的id,然后修改codis proxy的状态./codis-config -c ../config.ini proxy online proxy_1也可以通过dashboard 查看连接proxy./redis-cli -p 19000 -h 192.168.247.103通过java 客户端连接 codisPom.xml<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.8.0</version><type>jar</type><scope>compile</scope></dependency><dependency><groupId>io.codis.jodis</groupId><artifactId>jodis</artifactId><version>0.3.1</version></dependency><dependency><groupId>com.wandoulabs.jodis</groupId><artifactId>jodis</artifactId><version>0.2.2</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><type>jar</type><scope>test</scope></dependency>Java代码:JedisResourcePool jedisPool = RoundRobinJedisPool.create().curatorClient("192.168.247.103:2181", 30000).zkProxyDir("/zk/codis/db_test/proxy").build(); try (Jedis jedis = jedisPool.getResource()) {jedis.set("foo", "bar");String value = jedis.get("foo");System.out.println(value);}删除刚刚设置的key运⾏程序查看结果Codis⾼可⽤ codis-haCodis-ha 需要单独安装 codis-hago get /ngaut/codis-ha进⼊codis-ha⽬录执⾏build命令go build启动codis-hanohup ./codis-ha --codis-config=192.168.247.103:18087 --productName=test– codis-config:指定配置服务地址– productName:产品名称– nohup是把⽇志输出重定向到nohup⽂件⼀共启动了2个codisKill掉其中⼀个codiskill -9 16914nohup.out 输出⽇志刷新 dashboard 页⾯原来的master 的状态被改变为 offine , slave 被提升为 master 然后重新启动 6379⽇志信息原来的6379变为了 slave虽然可以⾼可⽤是可以⾃动切换,但是在实际应⽤场景还是要注意下应⽤场景因为redis本⾝的主从复制是异步⽅式, 异步⽅式就没有办法保证数据的完整性,数据没有最终的保证.如果并发⾼了,每秒的操作多了,执⾏的很快,在master宕掉的话,slave可能跟不上,导致slave可能会抛弃⼀些数据.数据就会出现不⼀致⼀般的话,我们使⽤redis来存储数据,如果出现这种情况,也会在redis中获取不到的时候重新在存储数据到redis⾥⾯,所以⼀般是不⽤担⼼主从复制导致数据不⼀致所产⽣的问题。
分布式缓存Redis使用方法

分布式缓存Redis使用方法Redis是一种开源的分布式缓存系统,它存储数据在内存中,因此可以实现高效的数据读写性能。
下面将详细介绍Redis的使用方法。
##2.配置- `port`:Redis服务器监听的端口,默认为6379- `bind`:Redis服务器绑定的IP地址,默认为127.0.0.1,表示只能本地连接。
- `daemonize`:是否以守护进程方式运行,默认为no。
- `logfile`:日志文件路径,默认为stdout,即打印到标准输出。
- `dir`:持久化数据存储的目录,默认为./。
对于初学者来说,可以保持默认配置即可。
如果有需要,还可以配置Redis的主从复制、哨兵模式、集群等功能。
##3.启动与关闭启动Redis服务器需要在终端中执行以下命令:```$ redis-server /path/to/redis.conf```其中`/path/to/redis.conf`是Redis配置文件的路径。
启动后,Redis服务器将开始监听指定的端口。
如果需要在后台运行Redis服务器,可以在启动命令后面添加`--daemonize yes`参数。
关闭Redis服务器可以直接结束Redis进程,或者执行以下命令:```$ redis-cli shutdown```## 4. Redis命令行客户端Redis提供了一个命令行客户端`redis-cli`,可以用于与Redis服务器进行交互。
在终端中执行以下命令即可启动Redis命令行客户端:```$ redis-cli```连接到Redis服务器后,可以执行一些常用的Redis命令,如:`GET`、`SET`、`DEL`等。
这些命令用于获取键对应的值、设置键值对、删除键值对等操作。
```$ set key1 value1$ get key1$ del key1```还可以使用一些其他的高级命令,如:`INCR`(递增键的值)、`TTL`(获取键的剩余生存时间)等。
python rediscluster 参数

python rediscluster 参数RedisCluster是一个分布式内存数据结构,它提供了高性能、可扩展的数据存储解决方案。
在Python中,RedisCluster可以通过Redis客户端库(如redis-py)进行操作。
在使用RedisCluster时,了解其相关参数是非常重要的,这些参数可以帮助您优化RedisCluster的性能和可扩展性。
下面将介绍一些常用的RedisCluster参数。
一、节点参数RedisCluster由一组节点组成,每个节点都存储一部分数据。
在RedisCluster中,可以使用节点参数来配置节点的角色和行为。
以下是一些常用的节点参数:1.nodes:节点列表,指定RedisCluster中的节点。
每个节点应包含节点的IP地址和端口号。
2.node_id:节点唯一标识符,用于标识节点。
默认情况下,RedisCluster会自动生成节点ID。
3.replicas:指定复制节点的列表,用于提高数据可用性和容错性。
复制节点将存储主节点的部分数据,并在主节点故障时接管数据。
4.max_clients:指定每个节点的最大客户端数,用于控制节点的负载。
5.hash_max_zipmap:指定每个节点的哈希表最大压缩映射的大小,用于控制内存使用量。
二、配置参数RedisCluster的配置参数包括数据类型、存储方式、集群通信等。
以下是一些常用的配置参数:1.dataset:指定RedisCluster的数据集大小,即最大可存储的数据量。
2.replicas_depth:指定复制深度,即从主节点复制到复制节点的数据量。
3.cluster_enabled:启用或禁用RedisCluster功能。
默认情况下,RedisCluster是启用的。
4.cluster_config_epoch:集群配置epoch,用于标识集群配置的版本号。
5.cluster_enabled_slaves:启用或禁用从节点,以控制从节点是否参与数据读取和复制。
如何部署分布式 Redis 集群

如何部署分布式 Redis 集群Redis 是一个开源的高性能 key-value 存储系统,它支持多种数据结构,如字符串、哈希、列表、集合等。
在实际应用中,Redis 常常用于缓存、消息队列、解决计数器、限速、分布式锁等场景中。
但是,在高并发、大数据量的应用场景中,单机 Redis 存在单点故障、容量瓶颈等问题。
为了解决这些问题,我们可以考虑使用 Redis 的分布式部署方式。
本文将介绍如何部署分布式 Redis 集群。
1. Redis 集群概述Redis 集群是一种分布式的 Redis 部署方式,它通过将数据分散到多个节点上,实现数据的高可用和水平扩展。
Redis 集群有以下几个特点:(1)分布式架构:Redis 集群由多个节点组成,每个节点都存储着一部分数据,节点之间通过 Gossip 协议交换信息,实现数据的分布式管理。
(2)自动数据迁移:当新增或删除节点时,Redis 集群会自动将数据迁移到新的节点,保证数据的一致性和高可用性。
(3)高可用性:Redis 集群采用主从复制机制,每个主节点都有若干个从节点,当主节点出现故障时,从节点会立即接管主节点的工作,确保服务的高可用性。
(4)数据分区:Redis 集群将数据分散到多个节点上,每个节点负责不同的数据分区,避免了单机 Redis 存在的容量瓶颈。
2. Redis 集群部署前准备工作在部署 Redis 集群之前,需要完成以下准备工作:(1)安装 Redis:在部署 Redis 集群前,需要在每个节点上安装 Redis,确保各节点软件版本一致。
(2)配置文件修改:修改每个节点的配置文件,可以通过Redis 集群提供的 redis-trib.rb 工具自动生成配置文件,并在配置文件中设置集群密码、节点 IP 和端口等参数。
(3)安装 Ruby 环境:redis-trib.rb 工具依赖 Ruby 环境,需要安装 Ruby。
3. Redis 集群部署步骤(1)创建节点:创建 Redis 集群的第一步是创建 Redis 节点。
Redis缓存如何实现分布式会话管理

Redis缓存如何实现分布式会话管理Redis是一个高性能的键值数据库,常用于缓存、会话管理等场景。
在分布式系统中,会话管理是一个重要的课题,而Redis的缓存机制可以很好地支持分布式会话管理的实现。
本文将介绍Redis缓存如何实现分布式会话管理。
一、背景在分布式系统中,不同的服务之间需要进行会话管理,即在用户登录后,系统能够识别用户身份,诸如用户权限、购物车信息等与该用户相关的数据都可以被正确地管理和读取。
而在传统的单节点架构下,这些会话信息是存储在服务器的内存中的。
而在分布式系统中,不同的应用服务器之间需要共享这些会话信息,以保证用户在不同的节点上都能够正常使用系统。
二、使用Redis实现分布式会话管理在分布式系统中,可以通过将会话信息存储在Redis缓存中,实现分布式的会话管理。
1. 会话信息存储在用户登录成功后,将会话信息存储在Redis缓存中。
可以将用户ID作为Key,会话信息作为Value存储在Redis中。
例如:Key: user_idValue: session_info2. 会话信息的获取与更新在用户发起请求时,系统可以根据用户ID从Redis中获取到会话信息。
通过将Redis设置为分布式缓存,不同的应用服务器可以共享这些会话信息。
在需要更新会话信息时,将新的会话信息覆盖旧的信息即可。
3. 会话信息的过期管理为了避免会话信息一直存储在Redis中导致内存占用过高,可以设置会话信息的过期时间。
在Redis中可以通过设置Key的过期时间来自动清理过期的会话信息。
通过合理设置过期时间,可以实现会话信息的自动管理。
4. 分布式锁的应用在分布式环境下,可能会出现多个应用服务器同时对同一个会话信息进行读写操作的情况。
为了保证数据的一致性,可以使用分布式锁来实现对会话信息的互斥访问。
Redis中的分布式锁可以确保同一时间只有一个应用服务器能够对会话信息进行读写操作,从而避免数据的冲突。
5. 负载均衡与高可用性在分布式系统中,通常会使用负载均衡来实现请求的分发,以提高系统的性能和可用性。
Redis分布式技术介绍与应用场景

Redis分布式技术介绍与应用场景目录1、为什么使用Redis (3)2、使用Redis 的常见问题 (4)3、单线程的Redis 为什么这么快 (4)4、Redis 的数据类型及使用场景 (7)5、Redis 的过期策略和内存淘汰机制 (8)6、Redis 和数据库双写一致性问题 (9)7、如何应对缓存穿透和缓存雪崩问题 (9)8、如何解决Redis 的并发竞争Key 问题 (10)9、总结 (12)绝大部分写业务的程序员,在实际开发中使用Redis 的时候,只会Set Value 和Get Value 两个操作,对Redis 整体缺乏一个认知。
这里对Redis 常见问题做一个总结,解决大家的知识盲点。
1、为什么使用Redis在项目中使用Redis,主要考虑两个角度:性能和并发。
如果只是为了分布式锁这些其他功能,还有其他中间件Zookpeer 等代替,并非一定要使用Redis。
性能:如下图所示,我们在碰到需要执行耗时特别久,且结果不频繁变动的SQL,就特别适合将运行结果放入缓存。
这样,后面的请求就去缓存中读取,使得请求能够迅速响应。
特别是在秒杀系统,在同一时间,几乎所有人都在点,都在下单。
执行的是同一操作———向数据库查数据。
为什么我们做分布式使用Redis?根据交互效果的不同,响应时间没有固定标准。
在理想状态下,我们的页面跳转需要在瞬间解决,对于页内操作则需要在刹那间解决。
并发:如下图所示,在大并发的情况下,所有的请求直接访问数据库,数据库会出现连接异常。
这个时候,就需要使用Redis 做一个缓冲操作,让请求先访问到Redis,而不是直接访问数据库。
为什么我们做分布式使用Redis?2、使用Redis 的常见问题∙缓存和数据库双写一致性问题∙缓存雪崩问题∙缓存击穿问题∙缓存的并发竞争问题3、单线程的Redis 为什么这么快这个问题是对Redis 内部机制的一个考察。
很多人都不知道Redis 是单线程工作模型。
codis监控指标清单 -回复

codis监控指标清单-回复Codis监控指标清单Codis是一个在开源Redis之上构建的分布式Redis解决方案。
它提供了高可用性、高性能以及自动数据分片功能,使得业务能够在分布式环境中轻松管理和访问Redis集群。
为了更好地监控Codis集群的运行状态和性能表现,我们需要了解和掌握一些关键性能指标。
本文将为您介绍Codis 监控指标清单,并逐步解释其含义和监控方法。
1. Redis连接数Redis连接数是指当前与Redis节点建立的活跃连接数。
Codis监控连接数的目的是为了确保集群能够处理来自各个客户端的请求,以及监测Redis节点是否存在连接泄露或者过多的空闲连接。
对于Codis来说,我们可以通过监控Redis节点的connected_clients指标来了解当前连接数的情况,如果该指标过高,则可能说明存在连接误用或者Codis实例配置不合理。
2. Redis缓存命中率Redis缓存命中率是指Redis在缓存中找到所需数据的比例。
对于Codis 集群而言,缓存命中率是一个非常关键的性能指标,它反映了Codis能否在Redis集群中高效地定位所需的数据。
我们可以通过监控Redis节点的keyspace_hits和keyspace_misses指标来计算缓存命中率。
keyspace_hits代表成功找到缓存的次数,keyspace_misses代表未找到缓存的次数,缓存命中率= keyspace_hits / (keyspace_hits + keyspace_misses)。
较高的缓存命中率通常意味着更好的性能。
3. Redis内存使用率Redis内存使用率是指Redis节点当前使用的内存占Redis分配的最大内存的比例。
Codis的内存使用率指标非常重要,因为它直接关系到Redis 集群是否能够处理更多的数据请求,并且防止出现内存溢出的情况。
我们可以通过监控Redis节点的used_memory和maxmemory指标来计算内存使用率。
redis 协议和 jdbc 协议格式

Redis协议与JDBC协议一、Redis协议Redis协议是一种基于文本的协议,用于在客户端和Redis服务器之间进行通信。
它使用简单的命令格式,使得客户端可以向服务器发送命令,并接收服务器的响应。
Redis协议使用ASCII码进行编码,以换行符作为命令的结束标志。
命令和参数之间使用空格分隔,而参数值中的空格可以使用引号括起来。
例如,以下是一个Redis协议的命令示例:SET key value这个命令将设置一个名为"key"的键的值为"value"。
除了简单的命令外,Redis协议还支持批量操作和多条命令。
客户端可以将多个命令批量发送给服务器,以提高性能和效率。
服务器将按照顺序执行批量操作中的命令,并将结果返回给客户端。
在Redis协议中,响应是由服务器返回给客户端的。
响应以一个带有响应类型的字符开头,后面跟着响应的正文。
不同类型的响应有不同的格式,但大多数响应都以"+"或"-"字符开头,表示响应的正文是字符串形式。
例如:+OK这个响应表示请求已成功执行。
二、JDBC协议格式JDBC(Java Database Connectivity)协议格式是一种用于Java应用程序与关系型数据库进行通信的标准协议。
它提供了一种通用的方法,使Java应用程序能够使用SQL(Structured Query Language)语句与各种不同类型的数据库进行交互。
JDBC协议格式基于SQL语言构建,并使用一种基于文本的通信协议来与数据库服务器进行通信。
它通过驱动程序来与不同的数据库系统进行交互,这些驱动程序实现了JDBC API(应用程序接口),并提供了与特定数据库系统的连接和通信功能。
以下是JDBC协议格式的主要组成部分:1.JDBC URL(统一资源定位符):用于指定要连接的数据库的位置和名称。
它包含有关数据库类型、主机名、端口号、数据库名称等信息的参数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于Redis的开源分布式服务Codis
Redis在豌豆荚的使用历程——单实例==》多实例,业务代码中做sharding==》单个Twemproxy==》多个Twemproxy==》Codis,豌豆荚自己开发的分布式Redis服务。
在大规模的Redis使用过程中,他们发现Redis受限于多个方面:单机内存有限、带宽压力、单点问题、不能动态扩容以及磁盘损坏时的数据抢救。
Redis通常有3个使用途径:客户端静态分片,一致性哈希;通过Proxy分片,即Twemproxy;还有就是官方的Redis Cluster,但至今无一个新版本。
随后刘奇更详细的分析了为什么不使用Twemproxy和Redis Cluster:
Twemproxy:最大的痛点是无法平滑的扩容或者缩容,甚至修改配置都需要重启服务;其次,不可运维,甚至没有Dashboard。
Redis Cluster(官方):无中心化设计,程序难以编写;代码有点吓人,clusterProcessPacket 函数有426行,人脑难以处理所有的状态切换;迟迟没有正式版本,等了4年之久;目前还缺乏最佳实践,没有人编写Redis Cluster的若干条注意事项;整个系统高度耦合,升级困难。
虽然我们有众多的选择,比如Tair、Couchbase等,但是如果你需要更复杂和优秀的数据结构,Redis可称为不二之选。
基于这个原因,在Redis之上,豌豆荚设计了Codis,并将之开源。
Codis
既然重新设计,那么Codis首先必须满足自动扩容和缩容的需求,其次则是必须避免单点故障和单点带宽不足,做一个高可用的系统。
在这之后,基于原有的遗留系统,还必须可以轻松地将数据从Twemproxy迁移到Codis,并实现良好的运维和监控。
基于这些,Codis的设计跃然纸面:
然而,一个新系统的开发并不是件容易的事情,特别是一个复杂的分布式系统。
刘奇表示,虽然当时团队只有3个人,但是他们几乎考量了可以考量的各种细节:
∙尽量拆分,简化每个模块,同时易于升级
∙每个组件只负责自己的事情
∙Redis只作为存储引擎
∙Proxy的状态
∙Redis故障判定是否放到外部,因为分布式系统存活的判定异常复杂
∙提供API让外部调用,当Redis Master丢失时,提升Slave为Master
∙图形化监控一切:slot状态、Proxy状态、group状态、lock、action等等
而在考量了一切事情后,另一个争论摆在了眼前——Proxy或者是Smart Client:Proxy拥有更好的监控和控制,同时其后端信息亦不易暴露,易于升级;而Smart Client拥有更好的性能,及
更低的延时,但是升级起来却比较麻烦。
对比种种优劣,他们最终选择了Proxy,无独有偶,在codis开源后,twitter的一个分享提到他们也是基于proxy的设计。
Codis主要包含Codis Proxy(codis-proxy)、Codis Manager(codis-config)、Codis Redis (codis-server)和ZooKeeper四大组件,每个部分都可动态扩容。
codis-proxy 。
客户端连接的Redis代理服务,本身实现了Redis协议,表现很像原生的Redis (就像 Twemproxy)。
一个业务可以部署多个 codis-proxy,其本身是无状态的。
codis-config。
Codis 的管理工具,支持添加/删除Redis节点、添加/删除Proxy节点、发起数据迁移等操作。
codis-config自带了一个http server,会启动一个dashboard,用户可以在浏览器上观察 Codis 集群的运行状态。
codis-server。
Codis 项目维护的一个Redis分支,加入了slot的支持和原子的数据迁移指令。
ZooKeeper。
Codis依赖ZooKeeper来存放数据路由表和codis-proxy节点的元信息,
codis-config发起的命令会通过 ZooKeeper同步到各个存活的codis-proxy。
最后,刘奇还介绍详细的了Codis中Migration、lock (rwlock)等操作的实现过程和原理,以及从Twemproxy迁移到Codis的详细操作。
更多Codis详情可移步Clodis开源页GitHub
欢迎大家关注微信号opendotnet,微信公众号名称:dotNET跨平台。
扫下面的二维码或者收藏下面的二维码关注吧(长按下面的二维码图片、并选择识别图中的二维码)。