MTK 数字图像的缩放算法
mtk 消噪算法

mtk 消噪算法
在mtk(MediaTek,联发科技)的消噪算法中,存在多种参数和设置,这些参数和设置对于控制降噪效果和图像质量具有重要意义。
以下是一些关键参数:
1. scalemode(0-3):这个参数控制内核(模板)的降噪处理。
其中,0表示使用较小的核进行降亮噪和降彩噪处理,效果基本不生效;1表示使用较小的核降亮噪,较大的核降彩噪;2表示使用较大的核降亮噪,较小的核降彩噪;3表示使用较大的核降亮噪和彩噪,降噪效果非常强。
2. PTC:这个参数用于整体降彩噪,随着ISO的增大,PTC的值也逐渐增大。
一般来说,低ISO时应尽量保持默认较小的值,高ISO值可以稍高一些,但太高可能会导致整体色彩流失。
3. Kernel chroma noise reduction(K_TH_C:0-8):这个参数用于控制内核(模板)的尺寸大小。
Chroma kernel size = max chroma kernel * ANR_K_TH_C/8。
4. C_L_DIFF_TH:这个参数用于防止溢色。
此外,还有边角降噪参数corner NR等,这个值越大,降噪越强。
以上内容仅供参考,如需更多信息,建议访问联发科官网或咨询相关技术人员。
图像处理技术中的图像缩放与重采样方法

图像处理技术中的图像缩放与重采样方法图像缩放与重采样是图像处理中常见的操作,用于改变图像的尺寸大小。
在数字图像处理领域,图像缩放与重采样方法有多种,其中最常用的包括最邻近插值法、双线性插值法、双三次插值法等。
本文将针对这些常见的图像缩放与重采样方法进行详细介绍。
最邻近插值法是一种简单粗暴的方法,它的原理是将目标图像中每个像素的值直接对应到原图像中的最邻近邻居像素值。
这种方法的优点是计算速度快,在图像放大时不会产生新的像素信息,但缺点是会导致图像出现锯齿状的马赛克效应,无法保持图像的细节。
双线性插值法是一种更加平滑的方法,它的原理是根据目标图像中每个像素的位置,计算其在原图像中的周围四个像素的加权平均值。
通过这种方法,可以在图像缩放时,保持图像的平滑性和连续性,在一定程度上弥补了最邻近插值法的不足。
然而,双线性插值法在处理非均匀纹理和边界时,可能会导致图像模糊和色彩失真的问题。
双三次插值法是一种更加精确的方法,它在双线性插值的基础上增加了更多的像素点计算,通过周围16个像素点的加权平均值来计算目标像素值。
这种方法对于图像细节的保留和复原效果更好,但同时也会增加计算量。
在实际应用中,双三次插值法通常被用于图像放大和缩小较大倍数的场景,以获得更好的图像质量。
除了上述的插值方法,还有一种特殊的重采样方法被广泛应用,称为快速傅里叶变换(FFT)方法。
该方法利用傅里叶变换的频域性质,通过对原始图像进行傅里叶变换、调整频域域值并对结果进行逆变换,从而完成图像缩放和重采样的过程。
FFT方法在一些特殊的应用场景中具有快速和高效的优势,但其在一般情况下常常需要与其他插值方法结合使用。
总结来说,图像缩放与重采样是图像处理中不可或缺的一部分,不同的缩放与重采样方法有着各自的优缺点。
在实际应用中,我们可以根据实际需求和资源限制选择适合的方法。
最邻近插值法适用于速度要求较高的情况,双线性插值法适用于一般的图像缩放和重采样操作,而双三次插值法适用于要求较高的图像放大和缩小操作。
图像缩放原理

图像缩放原理
图像缩放原理是指通过改变图像的尺寸,使其在不改变内容的情况下适应于不同的显示设备或应用场景。
最常见的图像缩放方法有插值法、双线性插值法和双三次插值法。
插值法是最简单的图像缩放方法之一,其原理是通过已知像素点的亮度值来估计未知像素点的亮度值。
常见的插值算法有最近邻插值和双线性插值。
最近邻插值法的原理是将目标图像的坐标映射到原图像中,并找到离目标坐标最近的点的亮度值作为目标点的亮度值。
这种方法简单快速,但可能会引入锯齿状的边缘效应。
双线性插值法的原理是通过目标点周围的四个邻近点的亮度值进行加权平均,来估计目标点的亮度值。
这种方法可以平滑边缘,但会导致图像模糊。
双三次插值法是一种更高级的插值方法,其原理是通过目标点周围的16个邻近点的亮度值进行加权平均。
这种方法可以在保持图像细节的同时,减少锐化和伪影效果。
除了插值法,还有一些其他的图像缩放方法,如基于小波变换的图像缩放方法和基于域仿射变换的图像缩放方法。
这些方法都以不同的原理和算法来实现图像的缩放,以满足不同应用场景的需求。
数字图像处理图像翻转,平移,缩放

数字图像处理图像翻转,平移,缩放第一篇:数字图像处理图像翻转,平移,缩放学号:Xb09680112班级:09通信工程(1)姓名:项德亮实验一图像几何变换一.实验目的1.熟悉MATLAB中的图像处理工具箱。
2.熟悉MATLAB中常用的图像处理函数。
3.掌握图像平移、图像旋转和图像缩放的基本原理与实现方法。
二.实验设备微机三.预习要求1.认真复习课件里的内容,并熟悉教材中第2章的内容。
2.了解imread()、imshow()、imhist()等函数的使用方法。
四.实验内容及步骤实验内容:1.熟悉MATLAB图像处理工具箱的功能及常用的图像处理函数。
2.打开“Image Processing”工具箱里的Demos,查看“Spatial Transformation”中的第一个例子“Creating a Gallery of Transformed Images”,把所有源代码拷到一个m文件里运行,查看运行结果,给源代码添加注释。
然后再改变变换矩阵T里面的参数,再查看运行结果。
把改变参数后(每位同学可以任意改变)的m文件保存为SpatialTransformation.m。
3.编程实现图像的平移,平移量应该可调(即用一个向量或两个标量保存平移量),并显示对图像“view”的处理结果。
%平移clear;%读入图像imori=imread('view.bmp','bmp');imres=imori;[m,n]=size(imo ri);tx=60;ty=-40;%平移 for i=1:mfor j=1:nif tximres(i,j)=imori(i,j);elseimres(i,j)=255;end end end imshow(imres)%显示结果%显示结果4.编程实现图像的缩放,缩放系数可调,分别用两个变量或一个向量保存水平和垂直方向的缩放系数,并显示对图像“view”的处理结果。
图片缩放算法原理

图像缩放的双线性内插值算法的原理解析图像的缩放很好理解,就是图像的放大和缩小。
传统的绘画工具中,有一种叫做“放大尺”的绘画工具,画家常用它来放大图画。
当然,在计算机上,我们不再需要用放大尺去放大或缩小图像了,把这个工作交给程序来完成就可以了。
下面就来讲讲计算机怎么来放大缩小图象;在本文中,我们所说的图像都是指点阵图,也就是用一个像素矩阵来描述图像的方法,对于另一种图像:用函数来描述图像的矢量图,不在本文讨论之列。
越是简单的模型越适合用来举例子,我们就举个简单的图像:3X3 的256级灰度图,也就是高为3个象素,宽也是3个象素的图像,每个象素的取值可以是0-255,代表该像素的亮度,255代表最亮,也就是白色,0代表最暗,即黑色。
假如图像的象素矩阵如下图所示(这个原始图把它叫做源图,Source):234 38 2267 44 1289 65 63这个矩阵中,元素坐标(x,y)是这样确定的,x从左到右,从0开始,y从上到下,也是从零开始,这是图象处理中最常用的坐标系,就是这样一个坐标:---------------------->X|||||∨Y如果想把这副图放大为 4X4大小的图像,那么该怎么做呢?那么第一步肯定想到的是先把4X4的矩阵先画出来再说,好了矩阵画出来了,如下所示,当然,矩阵的每个像素都是未知数,等待着我们去填充(这个将要被填充的图的叫做目标图,Destination):? ? ? ?? ? ? ?? ? ? ?? ? ? ?然后要往这个空的矩阵里面填值了,要填的值从哪里来来呢?是从源图中来,好,先填写目标图最左上角的象素,坐标为(0,0),那么该坐标对应源图中的坐标可以由如下公式得出:srcX=dstX* (srcWidth/dstWidth) , srcY = dstY * (srcHeight/dstHeight)好了,套用公式,就可以找到对应的原图的坐标了(0*(3/4),0*(3/4))=>(0*0.75,0*0.75)=>(0,0),找到了源图的对应坐标,就可以把源图中坐标为(0,0)处的234象素值填进去目标图的(0,0)这个位置了。
图像缩放算法的研究及VLSI实现的开题报告

图像缩放算法的研究及VLSI实现的开题报告1. 研究背景图像缩放是数字图像处理中的基本操作之一,其作用是在不改变图像内容的情况下改变图像的大小。
在实际应用中,图像缩放经常用于图像压缩、图像增强、图像重构等领域。
因此,图像缩放算法的研究和实现具有重要意义。
在图像缩放算法的研究中,常用的算法包括双线性插值法、双立方插值法、最近邻插值法等。
这些算法各有优劣,并且在实际应用中需要根据情况选择不同的算法进行实现。
另外,随着VLSI技术的不断发展,基于硬件的图像缩放实现也越来越受到关注。
基于VLSI的图像缩放实现具有运行速度快、功耗低等优点,同时也面临着硬件设计复杂、成本高等挑战。
因此,本文将着重探讨图像缩放算法的研究以及基于VLSI的图像缩放实现。
2. 研究内容本文将从以下几个方面进行研究:(1)图像缩放算法的研究本文将对常用的图像缩放算法进行研究分析,包括双线性插值法、双立方插值法、最近邻插值法等,并比较各个算法的优缺点和适用场景。
(2)VLSI实现的图像缩放算法本文将基于FPGA平台进行VLSI实现的图像缩放算法。
主要研究内容包括硬件设计、异步处理、片上存储等方面,并建立完整的图像缩放VLSI实现体系。
(3)实验验证本文将设计实验对比图像缩放算法的运行速度、功耗等性能指标。
同时,通过对比不同算法的实现效果,验证本文的设计方法的有效性。
3. 研究意义本文将从两个方面具有研究意义:(1)图像缩放算法的优化本文将对常用的图像缩放算法进行研究和优化,从而提高算法的准确性和实用性。
(2)基于VLSI的图像缩放实现本文将以FPGA为代表的VLSI平台进行图像缩放实现,从而提高图像缩放处理的速度和效率。
这对于需要在实时环境下进行图像处理的应用具有重要意义。
4. 研究方法本文采用的研究方法主要包括理论分析、仿真实验和硬件实现等。
其中,理论分析主要对图像缩放算法进行研究和优化;仿真实验通过软件工具进行图像缩放算法实现和性能评测;硬件实现则基于FPGA平台进行图像缩放算法的VLSI实现。
清晰影像缩放原理

清晰影像缩放原理一、引言在数字图像处理和计算机视觉领域,图像的缩放是一项常见且重要的操作。
图像缩放可以改变图像的尺寸,使其适应不同的显示设备或应用场景。
在本文中,我们将深入探讨清晰影像缩放的原理及其相关算法。
二、图像缩放的概述图像缩放是将原始图像按照一定比例进行尺寸调整的过程。
常见的图像缩放操作包括放大和缩小。
放大操作将图像的尺寸增大,使细节更加清晰可见;缩小操作将图像的尺寸减小,适应于小尺寸的显示屏幕或存储空间。
三、图像缩放的方法图像缩放可以通过多种方法实现,下面介绍几种常用的图像缩放算法。
1. 最近邻插值最近邻插值是一种简单且高效的图像缩放方法。
该方法根据目标像素所在位置附近的最近邻像素的值来确定目标像素的值。
最近邻插值的缺点是会引入锯齿和失真。
2. 双线性插值双线性插值是一种常用的图像缩放方法。
该方法根据目标像素所在位置附近的四个相邻像素的值,通过线性插值得到目标像素的值。
双线性插值可以有效减少锯齿和失真。
3. 双三次插值双三次插值是一种更加高级的图像缩放方法。
该方法根据目标像素所在位置附近的16个相邻像素的值,通过三次插值得到目标像素的值。
双三次插值可以进一步提高图像质量,但计算复杂度更高。
四、图像缩放的问题与挑战图像缩放虽然可以改变图像的尺寸,但也会引入一些问题与挑战。
1. 失真问题图像缩放可能会引入失真,导致图像细节模糊或变形。
这是因为缩放操作会改变图像中像素的分布和排列方式,从而影响图像的质量。
2. 缩放比例问题图像缩放的比例选择也是一个挑战。
过大或过小的缩放比例都会导致图像质量下降。
因此,选择合适的缩放比例非常重要。
3. 实时缩放问题在实时图像处理或视频处理中,图像缩放需要在有限的时间内完成。
对于大尺寸的图像或高分辨率的视频,实时缩放是一项具有挑战性的任务。
五、图像缩放的改进与应用为了克服图像缩放的问题与挑战,研究人员提出了许多改进的图像缩放算法。
这些算法包括多尺度图像金字塔、超分辨率重建等。
图像缩放算法的优化

图像缩放算法的优化在现今数字图像处理领域,图像缩放是一个非常重要的任务。
图像缩放的目的是改变图像的尺寸大小,但同时保持图像的分辨率和质量,不会使得图像失真。
然而,在进行图像缩放时,往往需要投入大量的计算资源和时间,尤其对于大型高分辨率的图片。
因此,如何优化图像缩放算法,达到快速而准确的图像缩放效果,是一个值得研究的课题。
传统的图像缩放算法传统的图像缩放算法有最近邻插值算法、双线性插值算法、三次卷积插值算法等。
其中最近邻插值算法是最简单的图像缩放算法之一,它将目标像素点的灰度值等同于距离目标像素点最近的一个原始像素点的灰度值。
这种算法运算速度比较快,但在缩小图像时,会出现像素点失真的问题。
双线性插值算法则是普遍采用的缩放算法之一,它通过对四个近邻点的加权平均值计算目标像素点的值。
这种算法运算速度比较慢,但它可以保留更多的原始图像数据,避免了图片失真的情况。
三次卷积插值算法则是数学计算更为复杂的一种算法,它采用的是卷积方式。
它可以保留更多原始图像细节,同时在缩放后图像和原图之间没有过多失真。
这种算法在保证缩放效果的同时,也需要更高的运算时间和资源。
优化思路及方法针对传统图像缩放算法的不足,下面提出一些优化思路及方法。
1.基于硬件优化随着GPU的发展,越来越多的图像处理任务可以运用GPU计算,这也包括图像缩放。
因此,一种方法是通过GPU并行计算加速图像缩放。
GPU的并行计算能力远高于CPU,在处理大型高分辨率图像时可以提高运算速度和效率。
在GPU编程中,CUDA是为NVIDIA GPU编写通用目的的并行计算框架。
通过CUDA技术,使用者能够非常方便地利用GPU的优势高效计算,达到快速和高效的图像缩放效果。
2.基于算法优化在传统的图像缩放算法中,双线性插值算法的缩放效果既保证了图像质量,又提高了缩放的速度。
然而,它的缩放效果还有提高的空间。
一种基于双线性插值算法优化的方法是利用图像内容分析,对图像的每块区域进行自适应缩放。
图像缩小的原理

图像缩小的原理
图像缩小的原理是将图像中的每个像素点按比例减少其大小,从而实现整体的图像缩小。
在缩小的过程中,每个像素点的位置和颜色都会进行相应的调整,以保持图像的清晰度和细节。
具体来说,图像缩小通过对图像的采样和插值来实现。
首先,对原图像的每个像素点进行采样,即按照一定的规则选择出一部分像素点。
采样的目的是保留图像中的主要信息,同时减少像素点的数量。
然后,在采样得到的像素点的基础上,使用插值算法来生成缩小后的图像。
插值算法可以根据已知的像素点的位置和颜色,通过计算来推测其他位置上的像素点的颜色。
常用的插值算法有最邻近插值、双线性插值和双三次插值等。
最邻近插值是一种简单的插值算法,它通过选择离目标位置最近的已知像素点的颜色作为目标位置的像素点的颜色。
这种方法简单快速,但可能会导致图像边缘的锯齿状效果。
双线性插值是一种较为常用的插值算法,它通过计算目标位置周围的四个已知像素点的颜色来推测目标位置的像素点的颜色。
这种方法可以在一定程度上减少锯齿状效果,使缩小后的图像更加平滑。
双三次插值是一种更加高级的插值算法,它通过计算目标位置周围的16个已知像素点的颜色来推测目标位置的像素点的颜色。
这种方法在平滑缩小图像的同时,还可以保留更多的细节
信息。
通过采样和插值的组合,图像缩小可以在减小图像尺寸的同时保持图像的主要信息和细节,使缩小后的图像更加清晰和美观。
图像缩放算法

图像缩放算法摘要:首先给出一个基本的图像缩放算法,然后一步一步的优化其速度和缩放质量;高质量的快速的图像缩放全文分为:上篇近邻取样插值和其速度优化中篇二次线性插值和三次卷积插值下篇三次线性插值和MipMap链正文:为了便于讨论,这里只处理32bit的ARGB颜色;代码使用C++;涉及到汇编优化的时候假定为x86平台;使用的编译器为vc2005;为了代码的可读性,没有加入异常处理代码;测试使用的CPU为AMD64x2 4200+(2.37G) 和 Intel Core2 4400(2.00G);速度测试说明:只测试内存数据到内存数据的缩放测试图片都是800*600缩放到1024*768; fps表示每秒钟的帧数,值越大表示函数越快//////////////////////////////////////////////////////////////////////// //////////Windows GDI相关函数参考速度://====================================================================== ========// BitBlt 544.7 fps //is copy 800*600 to 800*600// BitBlt 331.6 fps //is copy 1024*1024 to 1024*1024// StretchBlt 232.7 fps //is zoom 800*600 to 1024*1024//////////////////////////////////////////////////////////////////////// ////////A: 首先定义图像数据结构:#define asm __asmtypedef unsigned char TUInt8; // [0..255]struct TARGB32 //32 bit color{TUInt8 B,G,R,A; // A is alpha};struct TPicRegion //一块颜色数据区的描述,便于参数传递{TARGB32* pdata; //颜色数据首地址long byte_width; //一行数据的物理宽度(字节宽度);//abs(byte_width)有可能大于等于width*sizeof(TARGB32);long width; //像素宽度long height; //像素高度};//那么访问一个点的函数可以写为:inline TARGB32& Pixels(const TPicRegion& pic,const long x,const long y) {return ( (TARGB32*)((TUInt8*)pic.pdata+pic.byte_width*y) )[x];}B: 缩放原理和公式图示:缩放后图片原图片(宽DW,高DH) (宽SW,高SH)(Sx-0)/(SW-0)=(Dx-0)/(DW-0) (Sy-0)/(SH-0)=(Dy-0)/(DH-0)=> Sx=Dx*SW/DW Sy=Dy*SH/DHC: 缩放算法的一个参考实现//给出一个最简单的缩放函数(插值方式为近邻取样,而且我“尽力”把它写得慢一些了:D)//Src.PColorData指向源数据区,Dst.PColorData指向目的数据区//函数将大小为Src.Width*Src.Height的图片缩放到Dst.Width*Dst.Height的区域中void PicZoom0(const TPicRegion& Dst,const TPicRegion& Src){if ( (0==Dst.width)||(0==Dst.height)||(0==Src.width)||(0==Src.height)) return;for (long x=0;x<Dst.width;++x){for (long y=0;y<Dst.height;++y){long srcx=(x*Src.width/Dst.width);long srcy=(y*Src.height/Dst.height);Pixels(Dst,x,y)=Pixels(Src,srcx,srcy);}}}//////////////////////////////////////////////////////////////////////// //////////速度测试://====================================================================== ========// PicZoom0 19.4 fps//////////////////////////////////////////////////////////////////////// ////////D: 优化PicZoom0函数a.PicZoom0函数并没有按照颜色数据在内存中的排列顺序读写(内部循环递增y行索引),将造成CPU缓存预读失败和内存颠簸导致巨大的性能损失,(很多硬件都有这种特性,包括缓存、内存、显存、硬盘等,优化顺序访问,随机访问时会造成巨大的性能损失)所以先交换x,y循环的顺序:void PicZoom1(const TPicRegion& Dst,const TPicRegion& Src){if ( (0==Dst.width)||(0==Dst.height)||(0==Src.width)||(0==Src.height)) return;for (long y=0;y<Dst.height;++y){for (long x=0;x<Dst.width;++x){long srcx=(x*Src.width/Dst.width);long srcy=(y*Src.height/Dst.height);Pixels(Dst,x,y)=Pixels(Src,srcx,srcy);}}}//////////////////////////////////////////////////////////////////////// //////////速度测试://====================================================================== ========// PicZoom1 30.1 fps//////////////////////////////////////////////////////////////////////// ////////b.“(x*Src.Width/Dst.Width)”表达式中有一个除法运算,它属于很慢的操作(比一般的加减运算慢几十倍!),使用定点数的方法来优化它;void PicZoom2(const TPicRegion& Dst,const TPicRegion& Src){if ( (0==Dst.width)||(0==Dst.height)||(0==Src.width)||(0==Src.height)) return;//函数能够处理的最大图片尺寸65536*65536unsigned long xrIntFloat_16=(Src.width<<16)/Dst.width+1; //16.16格式定点数unsigned long yrIntFloat_16=(Src.height<<16)/Dst.height+1; //16.16格式定点数//可证明: (Dst.width-1)*xrIntFloat_16<Src.width成立for (unsigned long y=0;y<Dst.height;++y){for (unsigned long x=0;x<Dst.width;++x){unsigned long srcx=(x*xrIntFloat_16)>>16;unsigned long srcy=(y*yrIntFloat_16)>>16;Pixels(Dst,x,y)=Pixels(Src,srcx,srcy);}}}//////////////////////////////////////////////////////////////////////// //////////速度测试://====================================================================== ========// PicZoom2 185.8 fps//////////////////////////////////////////////////////////////////////// ////////c. 在x的循环中y一直不变,那么可以提前计算与y相关的值; 1.可以发现srcy的值和x变量无关,可以提前到x轴循环之前;2.展开Pixels函数,优化与y相关的指针计算;void PicZoom3(const TPicRegion& Dst,const TPicRegion& Src){if ( (0==Dst.width)||(0==Dst.height)||(0==Src.width)||(0==Src.height)) return;unsigned long xrIntFloat_16=(Src.width<<16)/Dst.width+1;unsigned long yrIntFloat_16=(Src.height<<16)/Dst.height+1;unsigned long dst_width=Dst.width;TARGB32* pDstLine=Dst.pdata;unsigned long srcy_16=0;for (unsigned long y=0;y<Dst.height;++y){TARGB32*pSrcLine=((TARGB32*)((TUInt8*)Src.pdata+Src.byte_width*(srcy_16>>16))); unsigned long srcx_16=0;for (unsigned long x=0;x<dst_width;++x){pDstLine[x]=pSrcLine[srcx_16>>16];srcx_16+=xrIntFloat_16;}srcy_16+=yrIntFloat_16;((TUInt8*&)pDstLine)+=Dst.byte_width;}}//////////////////////////////////////////////////////////////////////// //////////速度测试://====================================================================== ========// PicZoom3 414.4 fps//////////////////////////////////////////////////////////////////////// ////////d.定点数优化使函数能够处理的最大图片尺寸和缩放结果(肉眼不可察觉的误差)受到了一定的影响,这里给出一个使用浮点运算的版本,可以在有这种需求的场合使用:void PicZoom3_float(const TPicRegion& Dst,const TPicRegion& Src){//注意: 该函数需要FPU支持if ( (0==Dst.width)||(0==Dst.height)||(0==Src.width)||(0==Src.height)) return;double xrFloat=1.000000001/((double)Dst.width/Src.width);double yrFloat=1.000000001/((double)Dst.height/Src.height);unsigned short RC_Old;unsigned short RC_Edit;asm //设置FPU的取整方式为了直接使用fist浮点指令{FNSTCW RC_Old // 保存协处理器控制字,用来恢复FNSTCW RC_Edit // 保存协处理器控制字,用来修改FWAITOR RC_Edit, 0x0F00 // 改为 RC=11 使FPU向零取整FLDCW RC_Edit // 载入协处理器控制字,RC场已经修改}unsigned long dst_width=Dst.width;TARGB32* pDstLine=Dst.pdata;double srcy=0;for (unsigned long y=0;y<Dst.height;++y){TARGB32* pSrcLine=((TARGB32*)((TUInt8*)Src.pdata+Src.byte_width* ((long)srcy)));/**//*double srcx=0;for (unsigned long x=0;x<dst_width;++x){pDstLine[x]=pSrcLine[(unsigned long)srcx];//因为默认的浮点取整是一个很慢//的操作! 所以才使用了直接操作FPU的内联汇编代码。
图像缩放算法
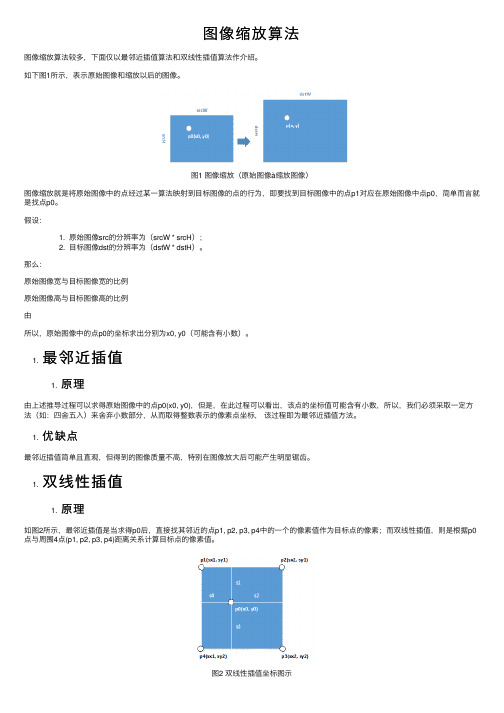
图像缩放算法图像缩放算法较多,下⾯仅以最邻近插值算法和双线性插值算法作介绍。
如下图1所⽰,表⽰原始图像和缩放以后的图像。
图1 图像缩放(原始图像à缩放图像)图像缩放就是将原始图像中的点经过某⼀算法映射到⽬标图像的点的⾏为,即要找到⽬标图像中的点p1对应在原始图像中点p0,简单⽽⾔就是找点p0。
假设:1. 原始图像src的分辨率为(srcW * srcH);2. ⽬标图像dst的分辨率为(dstW * dstH)。
那么:原始图像宽与⽬标图像宽的⽐例原始图像⾼与⽬标图像⾼的⽐例由所以,原始图像中的点p0的坐标求出分别为x0, y0(可能含有⼩数)。
1. 最邻近插值1. 原理由上述推导过程可以求得原始图像中的点p0(x0, y0),但是,在此过程可以看出,该点的坐标值可能含有⼩数,所以,我们必须采取⼀定⽅法(如:四舍五⼊)来舍弃⼩数部分,从⽽取得整数表⽰的像素点坐标,该过程即为最邻近插值⽅法。
1. 优缺点最邻近插值简单且直观,但得到的图像质量不⾼,特别在图像放⼤后可能产⽣明显锯齿。
1. 双线性插值1. 原理如图2所⽰,最邻近插值是当求得p0后,直接找其邻近的点p1, p2, p3, p4中的⼀个的像素值作为⽬标点的像素;⽽双线性插值,则是根据p0点与周围4点(p1, p2, p3, p4)距离关系计算⽬标点的像素值。
图2 双线性插值坐标图⽰通过计算得到的原始点为p0(x0, y0),则其4周的点分别为:x0的可能取值为:sx1 = (int)x0, sx2 = sx1 + 1y0的可能取值为:sy1 = (int)y0, sy2 = sy1 + 1图2中:s1 = y0 – sy1s2 = sx2 – x0s3 = 1.0 – s1s4 = 1.0 – s2假设p1, p2, p3, p4的像素值分别为v1, v2, v3, v4,则双线性插值计算p0点像素值v0公式为:v0 = v1*s1*s4 + v2*s1*s2 + v3*s2*s3 + v4*s3*s41. 优缺点1. 双线性内插值法计算量⼤,但缩放后图像质量⾼,不会出现像素值不连续的的情况。
J2ME插值算法实现图片的放大缩小

J2ME插值算法实现图片的放大缩小作者:阿泉文章来源:本站原创点击数:7649 更新时间:2005-1-26前段时间接触了一些数字图像处理的问题,在1位师兄的指导下,在j2me平台,完成了一些基本的2D图像处理算法。
就当是对这段知识做一下总结,决定把这些算法写出来,和各位朋友共同探讨。
这篇文章先介绍图像放大缩小的实现,程序是以Nokia S40的机器为平台实现的。
1、实现图形缩放的基本思想:图像的变形变换,简单的说就是把源图像每个点坐标通过变形运算转为目标图像相应点的新坐标,但是这样会导致一个问题就是目标点的坐标通常不会是整数。
所以我们在做放大变换时,需要计算生成没有被映射到的点;而在缩小变换时,需要删除一些点。
这里我们采用最简单的一种插值算法:“最近邻域法”。
顾名思义,就是把非整数坐标作一个四舍五入,取最近的整数点。
看下面的一个图片放大的例子,左图为原始图像,右图为放大1倍的图像。
里面的数字,表示所在像素的信息2、对于图片像素的操作:获取Image图片像素信息:标准的midp1.0没有提供获取图片像素信息的函数,对于NOKIA 的机器,我们可以采用Nokia SDK提供的API获取像素信息。
具体程序如下:g = image.getGraphics()DirectGraphics dg = DirectUtils.getDirectGraphics(g); dg.getPixels(short[] pixels, int offset, int scanlength, int x,int y, int width, int height, int format)参数介绍:short[] pixels:用于接收像素信息的数组int offset:这篇文章中的用到的地方,添0就可以了int scanlength:添图片的宽度就行了int x:添0int y:添0int width:图片宽度int height:图片高度int format:444,表示图形格式,好像Nokia S40的机器都是采用444格式表示RGB颜色的。
数字形状放缩

数字形状放缩随着数字技术的不断发展,数字图像的处理和编辑已成为人们日常生活中必不可少的一部分。
图像的大小和清晰度是衡量一个图像质量的两个主要指标,而数字形状的变换和放缩则是图像处理的重要方法之一。
数字形状放缩的原理和实现方法有哪些?本文将为您详细解析。
一、数字形状放缩的原理数字形状的放缩主要分为两种情况:等比例放缩和非等比例放缩。
等比例放缩指的是对数字形状的长和宽进行相同的缩放比例,而非等比例放缩则是对数字形状的长和宽进行不同的缩放比例。
等比例放缩的原理很简单,即通过对数字形状进行等比例缩放,来达到所需的放缩效果。
在等比例缩放时,数码图像中的每个像素位置都将按照相应的比例进行调整,这样不会改变图像本身的长宽比例关系。
例如,原来一个长方形图像的长宽比为2:1,如果对其进行等比例缩放,每个像素的位置将按2:1的比例进行缩放,长和宽都被缩小为原来的一半,即长宽变为1:0.5。
非等比例放缩则是对数字图形的长或宽进行缩放,或者同时对长和宽进行缩放,但缩放比例不同。
这样会改变图像的长宽比例关系,使图像变得扁平或拉长。
例如,对于一个正方形的图像,长宽比为1:1,如果对其进行非等比例缩放将会改变它的形状。
二、数字形状放缩的实现方法数字图像的放缩需要借助于数字图像处理软件来实现。
一般来说,数字图像处理软件中都会有图像缩放的功能,用户可以根据需要选择以下几种实现方法:1. 最近邻插值最近邻插值是一种简单的插值算法,它的原理是在缩小或放大时,用距离目标像素最近的已知像素值来更新自己的像素值。
这种方法实现简单快速,但结果不够平滑,容易产生锯齿状的边缘。
2. 双线性插值双线性插值是一种更高级的插值算法,它是通过使用目标像素周围的4个已知像素,插值计算出目标像素的值。
虽然这种方法比最近邻插值更慢,但它的结果更加平滑,较少出现锯齿状的边缘。
3. 双三次插值双三次插值是一种高级的插值算法,它是通过使用目标像素周围的16个已知像素及其权重值,插值计算出目标像素的值。
数字图像的放大缩小及旋转(“图像”相关文档)共8张

放大2倍后,图像边长增加了2倍,图像面积则增加4倍,由于图像
5 6 7 7 面积可以用图像像素总数表示,所以,图像像素总数应该是原图像的
double cx(与右邻点的x坐标之差)
设im新ag点e[邻i][j近]=(的in4t四)倍(个cx点。*c像y因*素pa值+此c分y*别,(1为-c原为x)*ppa图b,+pb(像,1p-cc,y中p)d*c, x每*pc一个像素被复制成4个像素放到新的放大图像
LOGO
6.2 缩放和旋转的编程实训
设新点邻近的四个点像素值分别为为pa,pb,pc,pd,
y=(int)floor(i*h/(double)h1);
x=(int)floor(j*w/(double)w1);
则:
pa=image[y][x];
pb=image[y][x+1];
pc=image[y+1][x];
2因此2,2原图2 像4中4每一0个0像i素m被a复ge制[成i4]个[像j素]放=到(新in的t放)大图(像中c,x*就c是y图*像p放a大+c2倍y的*(方1法-cx)*pb+ (1-
pc=image[y+1][x];
2 2 2 2 c4 y4)*0c0x*pc
+ (1-cx)*(1-cy)*pd+0.5 )
第六章 数字图像的放大缩小 及旋转
LOGO
6.1 缩放数字图像的实现方法
表6.1 1122
2240 5677
6633
表6.2
11112222 11112222
22224400
22224400
55667777 55667777 66663333 66663333
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
MTK 数字图像的缩放算法数字图像的缩放,是一个十分有趣的问题,又是一个看似简单,但又有些复杂的问题。
许多朋友在具备一定的计算机图形编程的基础知识以后,都可以自己设计出一些简单的位图缩放算法。
在计算机图形学和数字图像处理等学科里面,已经详细的研究过了数字图像缩放这个问题,并且已经有了成熟的算法。
一些朋友由于没有学习过计算机图形学和数字图像处理,所以凭借自己的想法设计的位图缩放算法存在许多缺陷。
在本文中,我将和大家一起来研究这个问题,并且学习前人所总结出来的算法。
图像的概念很容易理解,你睁开眼睛,所看到的都是图像了。
而一幅画、一张照片,则是现实生活中记录图像的手段和载体。
在科学上,我们需要对我们的研究对象建立起数学模型,因此有必要建立起图像的数学模型。
一幅图像的数学模型可以简单的定义如下:+-----------------------------------------------------+ Image = f(x, y); 其中 x, y 为 [0, 1] 上的实数对于灰度图像 Image 也为 [0, 1] 上的实数对于彩色图像Image 则由R, G, B 三个分量组成+-----------------------------------------------------+由于定义域和值域都在 [0, 1] 上,因此被称为连续图像模型连续图像模型可以精确而完整的刻画所要描述的图像,然而在现实世界中,绝大多数图像都是无法通过这个数学模型进行描述的,因为现实世界中的图像,是不可能通过函数解析式的方法进行描述的。
更多的时候,我们只能使用相机将现实图像的一部分信息,保存在胶片上,或者是使用画笔在画纸上绘制出图像。
正是由于图像的这个特点,我们所建立的连续的图像模型,对研究图像而言,并没有什么用武之地,而传统的数学研究方法也因此无法用运用到图像上。
为了更加有效的研究和处理图像,我们利用离散数学的理论知识,为现实图像建立起了数字图像模型,并且使用计算这个强大的工具来帮组我们研究和处理图像。
数字图像模型的定义如下:+-----------------------------------------------------+ Image = array(i, j); 通常情况下 i 是大于等于 0, 小于等于 w 的整数而 j 是大于等于 0, 小于等于 h 的整数 array 可以理解为一个矩阵 Image 的取值范围为大于等于 0, 小于等于 255的整数对于灰度图像 Image 表示某点的亮度值对于彩色图像 Image 则由 R, G, B三个分量组成+-----------------------------------------------------+其中的 w, h通常被称为一幅数字图像的宽度和高度。
这里,数字图像的宽度和高度,与一幅数字图像在显示器上实际的宽度和高度,有着一定的对应关系的,这个大家应该都很容易理解。
我们所要讨论的数字图像的缩放问题,就是要改变一幅图像的宽度和高度,并且使 array(i, j) 这个矩阵中的数据相应的改变,使得图像按比例的进行缩放。
在数字图像处理上,数字图像的缩放又被称作重采样滤波,这很抽象但是却又深刻揭示出数字图像缩放的本质。
当你将重采样滤波这个概念理解了,你会发现位图缩放是如此的简单明了,并会惊奇的发现重采样滤波是如此的神奇而深刻。
现在为了叙述的方便,我们将现实生活中所遇到的图像称为现实图像,将照片等称为物理图像,将连续图像模型成为连续图像,将数字图像模型成为数字图像或位图。
那么,我们来看看一幅数字图像的产生过程。
首先,需要使用相机对现实图像进行拍照,产生照片,即物理图像。
在物理图像中,仅仅记录了现实图像中的一部分信息。
然后要将照片放到扫描仪上进行扫描,这个过程中图像从物理图像变换为了数字图像,在计算机中产生通常所说的位图。
在图像从物理图像变换为数字图像这个过程中,最关键的地方就是采样与量化,这两个概念大家也许都非常熟悉,但是我们仍然需要深刻的理解和思考。
假如说,在扫描的过程中,我们将扫描的分辨率设置较大,也就是采样率设置较大,则扫描出来的数字图像的分辨率也较大,也就是图像的宽度和高度都较大,反之,则是变小。
让我们再来深刻的理解下重采样滤波这个概念,所谓重采样滤波,指的是根据数字图像,以某种方式重建出物理图像,并且对这个重建出来的物理图像,以所需要的采样率进行重新采样。
让我们来设想这样一个过程,我们有一幅宽高分别为 (w1, h1) 的位图 A,我们想要将其缩放为宽高为(w2, h2) 的位图 B. 我们可以通过这样的手段来完成缩放,也就是花一千块左右,买一台佳能的彩色激光打印机,将位图 A 用打印机打印出来。
然后再买一个惠普的扫描仪,以 (w2, h2)的扫描分辨率,将前面打印出来的图片扫描到电脑。
这样,我们就顺利地完成了位图的缩放。
当然,这样的做法成本太高,先后需要花去一千多块的大洋,而且费时又费力,是个理论上可行却不实用的办法。
但是,这个办法,足以生动而清晰地说明数字图像缩放的本质和方法。
让我们再来体会一下重采样滤波的深刻吧,即重建物理图像,然后以你所需要的分辨率进行重新采样。
在计算机世界里,数字图像是很容易描述的,用一个二维数组就可以简单的描述一幅数字图像。
然而,我们怎样才能从已有的数字图像,重建其物理图像呢?好好想想吧,想不出来就只快点准备两千块大洋,去买打印机和扫描仪吧。
不是吧大哥,难道我真要去买打印机,赶快揭晓答案。
好吧不开玩笑了,现在揭晓答案。
在计算机中,重建物理图像其实是一种计算模型而已,物理图像在计算机世界里面是无法真正的重建的,毕竟计算机是离散系统,而物理图像是连续的事物,计算机无法完整而精确的进行描述。
然而我们却可以找到多种的计算模型,来描述我们需要重建的物理图像。
需要注意的是,我们找到的是计算模型,然后我们要根据这个计算模型,来进行重新采样。
图像从现实图像到物理图像再到数字图像的变换过程,是一个不可逆的变换过程,在每一次变换过程中,都会丢失掉大量的信息,是不可逆的。
如果想要从数字图像重建物理图像,其实是在已有的数字图像数据的基础上,对物理图像做出的一种近似而已。
对于已有的数字图像,我们有多种计算模型,来重建物理图像,而这个重建的物理图像,一般都是通过前面所讲的连续图像模型来描述。
先介绍最简单的计算模型,最近邻算法。
请大家思考这样一些问题: 1. 我有一张 320 * 240 * 24bit色的 BMP 图片,对于图片上任一点 (i, j) 我们都可以知道它的 RGB 颜色值,但是如果我想知道 (101.3, 98.6) 点的颜色值,我们该怎么办呢? 2. 我希望将一张 320 * 240 *24bit 色的 BMP 图片,缩放为 1005 * 754 * 24bit 色的 BMP 图片,该如何进行重新采样呢?第一个问题,也就是数字图像缩放的第一步,重建物理图像。
如果我们采用最近邻算法,对于一个非整数的坐标点,我们选取距离这个点最近的整数坐标点的颜色值,作为其颜色值。
也就是说,我们简单的将 (101.3, 98.6) 的颜色值取为点 (101, 99) 的颜色值。
解决了这个问题,我们的脑子里面其实就放着一幅连续的图像了,并且对于这个连续图像上的任意一个像素点,我们都可以计算出其颜色值。
第二个问题,则是如何在重建起来的物理图像上进行重采样。
所谓采样,就是要取得每个需要采样的颜色值,也就是要用一个二重循环,处理完1005 * 754 个点,并且计算出每个点的颜色值。
简单的代码如下:+-------------------------------------------------------------------------+ DWORD color; int i; int j; for (j=0; j<754; j++) { for (i=0;i<1005; i++) { color = resample(i, j); // 计算重采样点的颜色值 putpixel(destbmp, i, j, color); // 将采样点绘制到目的位图上 } }+-------------------------------------------------------------------------+对于每个重采样点的颜色值的计算方法,则是需要根据原始的数字图像、你所选用的计算模型和由计算模型所重建的物理图像来共同决定。
对于我们上面的例子,可以先计算出宽高缩放比,进而建立起原始图像和目的图像中像素点的对应关系和变换公式,根据变换公式,计算出目的图像中 (i, j) 点在原始图像中对应的点的坐标 (x, y),根据重建物理图像的计算模型,计算出原始图像中 (x, y) 点的颜色值 c,然后将 c 作为结果绘制到目的图像中的 (i, j) 上。
当你处理完目的图像中的每一个像素点,也就完成了数字图像的缩放了。
对于我们所举的例子,可以写出如下的代码:+-------------------------------------------------------------------------+int w1 = 320; int h1 = 240; int w2 = 1005; int h2= 754; float xratio = (float) w1 / w2; float yratio = (float) h1 / h2; inti; int j; float x; float y; for (j=0; j<754; j++) { for(i=0; i<1005; i++) { x = i * xratio; y = j * yratio; color = getpixel(srcbmp, (int)(x + 0.5), (int)(y + 0.5)); putpixel(destbmp, i, j,color); } }+-------------------------------------------------------------------------+其中 | x = i * xratio; y = j * yratio; | 两句代码体现采样的位置,即在重建出来的图像的什么位置进行采样,而 | color = getpixel(srcbmp, (int)(x + 0.5),(int)(y + 0.5)); | 这句代码则体现了采样的结果,即在重建出来的图像的 (x, y) 处的采样的颜色值到底是多少。
请大家认真体会其中的深刻意义,所谓重建物理图像,实际上是无法真正重建的,也就是说这只是一种计算模型,一种方法。