kettle应用实践(转)
kettle 复杂转换示例

kettle 复杂转换示例"Kettle" 是一个开源的数据集成工具,也被称为 "Pentaho Data Integration" (PDI)。
它允许用户从多个源提取数据,进行转换和清洗,然后将数据加载到目标系统。
以下是一个简单的Kettle复杂转换示例,它涉及从一个CSV文件读取数据,进行一些转换,然后将结果写入另一个CSV文件。
1. 步骤1:从CSV文件读取数据假设我们有一个CSV文件,其内容如下:```pythonid,name,age1,John,252,Jane,303,Doe,40```首先,我们需要从CSV文件中读取数据。
为此,您需要创建一个“Table input”步骤,并指定CSV文件的路径。
2. 步骤2:转换数据接下来,我们可能希望添加一个新的列,该列是原始“age”列的两倍。
为此,您可以使用“Modified Java Script Value”步骤。
在脚本字段中,您可以编写以下代码:```javascriptvar age = age 2;```3. 步骤3:将数据写入CSV文件最后,我们将转换后的数据写入另一个CSV文件。
为此,您需要创建一个“Table output”步骤,并指定输出文件的路径。
确保在“Table output”步骤的配置中包含所有需要的列。
4. 连接步骤将“Table input”步骤连接到“Modified Java Script Value”步骤,然后将“Modified Java Script Value”步骤连接到“Table output”步骤。
这确保了数据从源传递到目标,同时经过所需的转换。
5. 运行作业完成所有步骤后,您可以在Kettle中运行作业以测试整个流程。
检查输出文件以确保数据已被正确读取、转换并写入。
请注意,这只是一个基本示例。
Kettle提供了许多其他功能和步骤,可以根据需要进行更复杂的转换和数据处理。
kettle实践经验总结

数据抽取工具Kettle实践经验小结杭州州力数据-陈力同步数据常见的应用场景包括以下4个种类型:1.只增加、无更新、无删除 (1)2.只更新、无增加、无删除 (3)3.增加+更新、无删除 (4)4.增加+更新+删除 (5)5.调用存储过程 (7)1无参数输入: (7)2、有参数输入 (8)1.只增加、无更新、无删除对于这种只增加数据的情况,可细分为以下2种类型:1) 基表存在更新字段。
通过获取目标表上最大的更新时间或最大ID,在“表输入”步骤中加入条件限制只读取新增的数据。
这里要注意的是,获取最大更新时间或最大ID时,如果目标表还没有数据,最大值会获取不了。
其中的一个解决方法是在“获取最大ID”步骤的SQL中,加入最小日期或ID的联合查询即可,如:SELECT MAX(ID) FROM(SELECT MAX(ID) AS ID FROM T1 UNION ALL SELECT 0 AS ID FROM DUAL)2) 基表不存在更新字段。
通过“插入/更新”步骤进行插入。
插入/更新步骤选项:2.只更新、无增加、无删除通过“更新”步骤进行更新。
更新选项:3.增加+更新、无删除通过“插入/更新”步骤进行插入。
区别是“插入/更新步骤”中的选项,去掉“不执行任何更新”的勾选:4.增加+更新+删除这种数据同步情况,可细分为以下2种情况:1) 源库有表保存删除、更新和新增的信息。
通过条件判断,分别进行“插入/更新”和“删除”即可,如下图所示。
2) 源库没有保存增删改信息Kettle提供了一种对比增量更新的机制处理这种情况,可通过“合并记录”步骤实现,该步骤的输入是新旧两个数据源,通过关键字进行数据值比对,对比结果分为以下4种类型:“Identical” : 关键字在新旧数据源中都存在,域值相同“changed” : 关键字在新旧数据源中都存在,但域值不同“new” :旧数据源中没有找到关键字“deleted”:新数据源中没有找到关键字两个数据源的数据都进入下一步骤,上述4种结果类型作为输出表的标志字段进行保存。
kettle的使用方法

kettle的使用方法Kettle是一种用于数据集成和转换的开源工具,也被称为Pentaho Data Integrator(PDI)。
它提供了一套功能强大的工具,可以帮助用户从不同的数据源中提取、转换和加载数据。
本文将介绍Kettle 的使用方法,帮助读者快速上手使用该工具。
一、安装Kettle您需要从Kettle官方网站下载最新版本的安装包。
安装包通常是一个压缩文件,您可以将其解压到您选择的目录中。
然后,通过运行解压后的文件夹中的启动脚本来启动Kettle。
二、连接数据源在使用Kettle之前,您需要先连接到您的数据源。
Kettle支持多种类型的数据源,包括关系型数据库、文件、Web服务等。
您可以使用Kettle提供的连接器来连接到您的数据源,或者根据需要自定义连接器。
连接成功后,您可以在Kettle中查看和操作您的数据。
三、创建转换在Kettle中,数据转换是通过创建转换作业来实现的。
转换作业是由一系列的转换步骤组成的,每个步骤都执行特定的数据操作。
您可以使用Kettle提供的各种转换步骤,如数据提取、数据过滤、数据转换、数据加载等,来构建您的转换作业。
四、配置转换步骤在创建转换作业后,您需要配置每个转换步骤的参数和选项。
例如,在数据提取步骤中,您需要指定要提取的数据源和查询条件。
在数据转换步骤中,您可以定义数据的转换逻辑,如数据清洗、数据合并、数据计算等。
在数据加载步骤中,您需要指定目标数据表和加载方式。
五、运行转换作业完成转换步骤的配置后,您可以运行整个转换作业,将数据从源数据源提取、转换和加载到目标数据源。
在运行转换作业之前,您可以选择性地预览转换结果,以确保数据操作的准确性和一致性。
Kettle还提供了调试功能,可以帮助您快速定位和解决转换作业中的问题。
六、调度转换作业除了手动运行转换作业之外,Kettle还支持将转换作业安排为定期执行的任务。
您可以使用Kettle提供的调度功能,根据您的需求设置转换作业的执行时间和频率。
ETL利器KETTLE实战应用解析之KETTLE应用场景和实战DEMO

1、应用场景这里简单概括一下几种具体的应用场景,按网络环境划分主要包括:∙表视图模式:这种情况我们经常遇到,就是在同一网络环境下,我们对各种数据源的表数据进行抽取、过滤、清洗等,例如历史数据同步、异构系统数据交互、数据对称发布或备份等都归属于这个模式;传统的实现方式一般都要进行研发(一小部分例如两个相同表结构的表之间的数据同步,如果sqlserver数据库可以通过发布/订阅实现),涉及到一些复杂的一些业务逻辑如果我们研发出来还容易出各种bug;∙∙前置机模式:这是一种典型的数据交换应用场景,数据交换的双方A和B网络不通,但是A和B都可以和前置机C连接,一般的情况是双方约定好前置机的数据结构,这个结构跟A和B的数据结构基本上是不一致的,这样我们就需要把应用上的数据按照数据标准推送到前置机上,这个研发工作量还是比较大的;∙∙文件模式: 数据交互的双方A和B是完全的物理隔离,这样就只能通过以文件的方式来进行数据交互了,例如XML格式,在应用A中我们开发一个接口用来生成标准格式的XML,然后用优盘或者别的介质在某一时间把XML数据拷贝之后,然后接入到应用B上,应用B 上在按照标准接口解析相应的文件把数据接收过来;∙综上3种模式如果我们都用传统的模式无疑工作量是巨大的,那么怎么做才能更高效更节省时间又不容易出错呢?答案是我们可以用一下Kettle-_-!2、DEMO实战2、1 实例1:数据库TestA中的UserA表到数据库TestB的UserB表1)为方便演示,我这边把Sql脚本贴出来,大家直接复制在sqlserver中运行即可,sql脚本如下:简单表之间交换2)Kettle实现方式功能简述:数据库TestA中的UserA表到数据库TestB的UserB表;实现流程:建立一个转换和一个作业Job;A:建立一个转换:打开Kettle.exe,选择没有资源库,进入主界面,新建一个转换,转换的后缀名为ktr,转换建立的步骤如下:步骤1:创建DB连接,选择新建DB连接,如下图,我们输入相应的Sqlserver配置信息之后点击Test按钮测试是否配置正确!我们需要建立两个DB连接,分别为TestA和TestB;步骤2:建立步骤和步骤关系,点击核心对象,我们从步骤树中选择【表输入】,如下图,这样拖拽一个表输入之后,我们双击表输入之后,我们自己可以随意写一个sql语句,这个语句表示可以在这个库中随意组合,只要sql语句没有错误即可,我这里只是最简单的把TestA中的所有数据查出来,语句为select * from usersA。
kettle 案例

kettle 案例【原创版】目录1.Kettle 简介2.Kettle 的功能与应用3.Kettle 的优势与局限性4.Kettle 案例分析5.Kettle 的未来发展前景正文1.Kettle 简介Kettle 是一款开源的数据集成工具,主要用于数据提取、转换和加载(ETL)过程。
它支持各种数据源和目标,包括数据库、Web 服务、文本文件等,并具有丰富的数据转换功能,如数据过滤、排序、聚合等。
Kettle 可以帮助用户简化复杂的数据集成任务,提高数据处理的效率和准确性。
2.Kettle 的功能与应用Kettle 的主要功能包括以下几个方面:(1)数据源连接:Kettle 支持多种数据源,如数据库、Web 服务、文本文件等,可以方便地连接到各种数据源进行数据处理。
(2)数据转换:Kettle 提供了丰富的数据转换功能,如数据过滤、排序、聚合等,可以满足各种复杂的数据处理需求。
(3)数据集成:Kettle 支持将多个数据源的数据集成到一起,便于进行数据分析和挖掘。
(4)任务调度:Kettle 可以根据业务需求,设置数据处理的时间、频率等,实现自动化的任务调度。
3.Kettle 的优势与局限性Kettle 的优势主要体现在以下几个方面:(1)开源免费:Kettle 是一款开源的数据集成工具,用户可以免费使用,降低了企业的成本。
(2)功能丰富:Kettle 支持多种数据源和目标,具有丰富的数据转换功能,可以满足各种复杂的数据处理需求。
(3)易用性强:Kettle 的界面友好,操作简单,用户可以快速上手。
然而,Kettle 也存在一些局限性,如性能较低、处理大数据量时效率不高等。
4.Kettle 案例分析以某企业为例,由于业务发展需要,需要将多个部门的数据进行整合,以便进行数据分析和决策。
采用 Kettle 后,可以方便地连接到各个部门的数据源,进行数据提取、转换和加载,最终实现数据的统一管理和分析。
5.Kettle 的未来发展前景随着大数据、云计算等技术的发展,数据集成需求越来越大。
kettle对不同类型文件数据进行转换的基本方法的实验总结

kettle对不同类型文件数据进行转换的基本方法的实验总结Kettle对不同类型文件数据进行转换的基本方法的实验总结导言在当今信息时代,数据的处理和转换是企业和个人不可或缺的重要任务。
而对于数据处理工具来说,Kettle(即Pentaho Data Integration)无疑是其中一员佼佼者。
它是一款开源的ETL (Extract-Transform-Load)工具,能够帮助用户快速、高效地处理各种类型的数据。
本文将着眼于Kettle在不同类型文件数据转换方面的基本方法进行实验总结,希望能够为读者提供一份有价值的参考。
一、CSV文件数据转换1.读取CSV文件CSV(Comma Separated Values)文件是一种常见的以逗号分隔的文本文件格式,常用于数据交换。
在Kettle中,我们可以通过添加"CSV输入"步骤来读取CSV文件数据。
在进行数据转换之前,我们有时需要将CSV文件中的数据格式进行调整。
将日期字段转换为日期类型、将数值字段转换为特定精度的数值类型等。
Kettle提供了"Select values"和"Modify"等步骤来满足这些需求。
3.数据清洗和过滤在实际的数据处理中,我们可能会遇到一些数据质量问题,比如缺失值、异常值等。
此时,我们可以使用Kettle提供的"Filter rows"和"Cleanse"等步骤来进行数据清洗和过滤,确保数据质量的可靠性和准确性。
二、Excel文件数据转换1.读取Excel文件与CSV文件不同,Excel文件是一种二进制文件格式,它包含了丰富的数据类型和复杂的表结构。
在Kettle中,我们可以通过添加"Excel 输入"步骤来读取Excel文件数据。
在进行读取时,我们需要注意选择适当的Sheet以及指定正确的列和行范围。
与CSV文件一样,我们通常需要对Excel文件中的数据进行格式转换。
kettle应用实践(转)

kettle应用实践(转)今天早上在网上看到了kettle发布了最新的版本,忽然想起最近其实做了不少工作应该是ETL工具的拿手好戏,赶紧下载下来看看,看是否能够在实际的工作中应用起来。
顺便讲一下,为啥看到kettle会两眼发光。
最近写了好几个小程序,用于从一个ftp去获取数据,然后转发至另一个ftp去,或者是从一个数据库获取数据然后保存至本地的数据库中,使用的是jdk中的Timer实现的定时调度,本来也没什么问题,连续运行几个月都不会出错。
可是最近网络不是太好,周期性抽风,ping包时,每5分钟大概会丢7-8个包,从而导致程序也会假死,过一段时间后就不正常干活了,估计是因为用了数据库连接池的问题,要是每次发起数据库连接可能就不会有问题了,偷懒也不想改了,因为网络最终肯定是会修好的 :-) 但是想试试ETL工具,因为后面还有一些类似的东西要处理,不想写代码了,用别人的轮子感觉比较好,呵呵首先下载了kettle的最新版,kettle3.1,解压后即可运行,一般的开发人员稍微摸索一下,看看例子简单的转换还是会做的,今天小试了一把,有几个注意点记下来。
1.使用资源库(repository)登录时,默认的用户名和密码是admin/admin2.当job是存放在资源库(一般资源库都使用数据库)中时,使用Kitchen.bat执行job时,需使用如下的命令行:Kitchen.bat /rep kettle /user admin /pass admin /job job名3.当job没有存放在资源库而存放在文件系统时,使用Kitchen.bat执行job时,需使用如下的命令行:Kitchen.bat /norep /file user-transfer-job.kjb4.可以使用命令行执行job后,就可以使用windows或linux的任务调度来定时执行任务了在一开始使用命令行方式执行job时,总是报如下的错误,琢磨了好长时间总算整明白正确的方式了。
kettle工具应用实例 -回复

kettle工具应用实例-回复什么是kettle工具?Kettle工具是一款开源的数据集成和ETL(Extract, Transform, Load)工具,也可以叫做Pentaho Data Integration。
它提供了一组强大的数据操作功能,可以将数据从不同的数据源中提取、转换和加载到目标系统中。
它支持多种类型的数据源和目标系统,并且具有强大的数据转换和清洗能力。
接下来,我们通过一个实例来了解kettle工具的应用。
假设我们是一个电子商务公司,我们有来自不同渠道的销售数据,包括线上平台、线下门店以及第三方分销渠道。
我们希望将这些数据集成到我们的数据仓库中,以便进行深入的分析和决策支持。
首先,我们需要连接到不同的数据源。
假设我们的在线平台使用MySQL 数据库,线下门店使用Oracle数据库,而第三方分销渠道使用API接口提供数据。
我们可以使用Kettle的“Database Connection”和“HTTP Client”组件来与这些数据源进行连接。
接下来,我们需要从不同的数据源中提取数据。
我们可以使用Kettle的“Table Input”和“HTTP Client”组件来执行SQL查询和发送HTTP请求,从而获取相关数据。
我们可以指定查询条件和字段映射,确保只获取我们需要的数据。
然后,我们需要对数据进行转换和清洗,以适应目标系统的要求。
例如,我们可能需要将日期格式进行转换,将字符串进行拼接或分割,将数据进行聚合等。
Kettle提供了一系列的数据转换和清洗组件,如“Select Values”,“Regex”,”Merge Join”等,以满足不同的需求。
在转换和清洗数据之后,我们可以使用Kettle的“Insert/Update”或“Bulk Load”组件将数据加载到我们的目标系统中。
这可以是一个数据仓库、数据湖或其他任何存储系统。
除了数据集成和转换之外,Kettle还提供了许多其他的功能,如数据校验、数据重复删除、数据合并、数据分割等。
kettle工具用法

kettle工具用法关于"kettle工具用法"的1500-2000字文章:Kettle工具是一款功能强大的开源数据集成工具,旨在简化和自动化数据导入、转换和输出的过程。
它拥有直观而强大的用户界面,可让用户通过图形化界面创建和管理数据管道。
本文将逐步回答Kettle工具的用法,涵盖安装、界面介绍、数据导入和转换、数据输出等方面。
一、安装Kettle工具首先,访问Kettle官方网站并下载最新版本的Kettle工具。
下载完成后,运行安装程序,并按照提示进行安装。
安装完成后,打开Kettle工具。
二、界面介绍打开Kettle工具后,你将看到一个主界面,其中包含了工具栏、转换面板和作业面板等。
工具栏上有各种按钮,用于打开、保存和运行数据转换和作业。
转换面板用于创建、编辑和管理数据转换,而作业面板用于创建和管理作业。
你可以通过拖放组件和连接器来建立转换和作业的流程。
三、数据导入数据导入是Kettle工具的一个重要功能,它允许将数据从各种来源导入到目标数据库或文件中。
在Kettle中,你可以通过以下步骤导入数据:1. 创建新的数据转换:在转换面板上右键单击,选择“新建转换”来创建一个新的数据转换。
2. 添加数据输入组件:在工具栏上选择“输入”,然后拖放数据源到转换面板上。
根据需要选择适当的输入类型,如CSV文件、数据库、Excel文件等。
3. 配置数据输入组件:选择添加到转换面板的数据输入组件,右键单击并选择“编辑”。
在配置窗口中,设置数据源的连接信息、查询语句和字段映射等。
4. 添加目标组件:与添加数据输入组件类似,选择“输出”按钮并拖放目标数据库或文件组件到转换面板上。
5. 配置目标组件:选择添加到转换面板的目标组件,右键单击并选择“编辑”。
在配置窗口中,设置目标数据库的连接信息、目标表或文件的格式等。
6. 连接输入和目标组件:在转换面板上,拖动鼠标从数据输入组件的输出连接器到目标组件的输入连接器上,建立数据流。
Kettle入门--作业和转换的使用
Kettle⼊门--作业和转换的使⽤
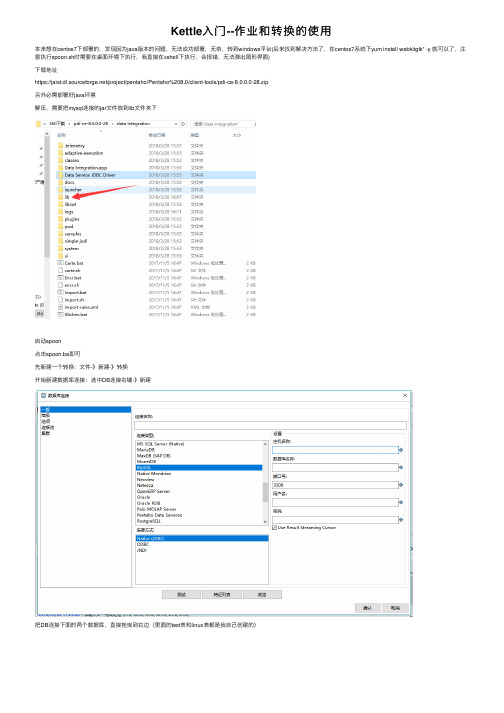
本来想在centos7下部署的,发现因为java版本的问题,⽆法成功部署,⽆奈,转到windows平台(后来找到解决⽅法了,在centos7系统下yum install webkitgtk* -y 就可以了,注意执⾏spoon.sh时需要在桌⾯环境下执⾏,我直接在xshell下执⾏,会报错,⽆法弹出图形界⾯)
下载地址
https:///project/pentaho/Pentaho%208.0/client-tools/pdi-ce-8.0.0.0-28.zip
另外必需部署好java环境
解压,需要把mysql连接的jar⽂件放到lib⽂件夹下
启动spoon
点击spoon.ba即可
先新建⼀个转换:⽂件-》新建-》转换
开始新建数据库连接:选中DB连接右键-》新建
把DB连接下⾯的两个数据库,直接拖曳到右边(⾥⾯的test表和linux表都是我⾃⼰创建的)
其中那个箭头是选中表输⼊后,按住shift键,连接到表输出
最后,点击执⾏,作业1标签(这个只是⽤来说明位置)下的倒三⾓运⾏按钮
查看linux表,有新插⼊的数据
效果
上⾯是转换的使⽤,现在我们来试⼀下作业的使⽤。
作业具体⽤处不是很清楚,我只是⽤到了其中⼀个定时执⾏的作⽤,下⾯来看⼀下例⼦(效果是每分钟执⾏以下上⾯的转换,zh.ktr是上⾯的转换执⾏时提⽰的保存位置)
看⼀下有没有成功⾃动执⾏(本来只有⼏条数据,然后跑了⼀晚上,直接变成两千多条)。
kettle循环遍历结果集传入转换

kettle循环遍历结果集传入转换标题:kettle循环遍历结果集并传入转换的实践与解析Kettle是一个开源的数据集成工具,它提供了图形化的界面来定义数据转换和工作流程。
本文将深入探讨如何在Kettle中实现循环遍历结果集并将其传入到转换中。
一、准备工作首先,我们需要准备一个包含待处理数据的结果集。
这可以是数据库查询结果,也可以是CSV文件或其他数据源。
然后,我们创建一个新的转换,并添加“表输入”步骤以获取这个结果集。
二、添加循环步骤在Kettle中,我们使用“迭代器”步骤来实现循环遍历。
因此,在转换中添加一个“迭代器”步骤,然后将“表输入”步骤的输出链接到“迭代器”步骤的输入。
三、配置迭代器步骤在打开的“迭代器”对话框中,我们可以看到有三个选项卡:“字段”,“条件”和“高级”。
在“字段”选项卡中,我们可以选择要用于循环的字段。
通常情况下,我们会选择一个表示行号或唯一标识符的字段,这样每次循环都会处理结果集中的一行数据。
在“条件”选项卡中,我们可以设置结束循环的条件。
例如,如果我们只想处理前100行数据,那么就可以在这里设置“行号<=100”的条件。
四、添加子转换在“迭代器”步骤中,我们需要指定一个子转换来进行实际的数据处理。
因此,我们先创建一个新的转换,并在这个转换中添加所需的数据处理步骤。
然后,在“迭代器”步骤的“子转换”选项卡中,选择我们刚刚创建的子转换。
五、配置子转换在子转换中,我们需要将从父转换传递过来的数据进行处理。
为此,我们在子转换中添加一个“获取变量”步骤,并在该步骤的“元数据”选项卡中选择“迭代器/游标”类型,这样就可以访问到父转换中的数据了。
六、运行转换现在,我们的转换已经配置完毕,可以运行了。
点击转换画布上的绿色三角形按钮,或者右键单击转换名称并选择“启动”,就可以开始运行转换了。
七、查看结果转换运行完成后,我们可以通过查看日志或输出文件来检查结果。
如果一切正常,我们应该可以看到每行数据都被正确地处理了。
kettle转换间传递参数

kettle转换间传递参数摘要:I.了解KettleA.Kettle 的简介B.Kettle 的功能和用途II.Kettle 转换间传递参数的重要性A.参数传递在数据转换过程中的作用B.提高数据处理效率和准确性的方法III.Kettle 转换间参数传递的方法A.常用参数传递方式1.输入/输出参数2.全局变量3.系统变量B.参数传递的实例分析IV.Kettle 转换间参数传递的实践应用A.实际案例分析B.最佳实践和注意事项V.总结A.Kettle 转换间参数传递的优势和意义B.对未来发展的展望正文:Kettle 是一款非常强大的开源数据集成工具,被广泛应用于数据仓库和ETL(提取、转换、加载)过程中。
它能够帮助用户轻松地完成数据的转换和处理任务,从而为后续的数据分析和决策提供支持。
在Kettle 中,转换间传递参数是实现高效数据处理的关键环节之一。
本文将重点介绍Kettle 转换间传递参数的重要性以及具体的方法和实践应用。
在数据转换过程中,参数传递能够有效地提高数据处理效率和准确性。
通过在不同的转换步骤之间传递参数,用户可以更加灵活地控制数据处理过程,实现各种复杂的数据转换需求。
同时,参数传递有助于降低数据处理过程中的错误率,提高数据质量。
在Kettle 中,有多种方法可以实现转换间参数传递。
其中,常用的方法包括输入/输出参数、全局变量和系统变量。
通过使用这些方法,用户可以实现不同转换步骤之间的数据共享,从而简化数据处理流程。
在实际应用中,Kettle 转换间参数传递可以帮助用户轻松地完成各种复杂的数据处理任务。
例如,在数据清洗和转换过程中,用户可以通过传递参数来控制数据处理逻辑,实现数据的自动处理。
此外,在数据合并和汇总过程中,参数传递也可以帮助用户快速地完成数据操作,提高工作效率。
总之,Kettle 转换间传递参数在数据处理过程中具有重要意义。
通过掌握Kettle 参数传递的方法和实践应用,用户可以更好地利用Kettle 工具,实现高效、准确的数据处理。
ETL利器Kettle实战应用解析系列一【Kettle使用介绍】

ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可少,这里我介绍一个我在工作中使用了3年左右的ETL工具Kettle,本着好东西不独享的想法,跟大家分享碰撞交流一下!在使用中我感觉这个工具真的很强大,支持图形化的GUI 设计界面,然后可以以工作流的形式流转,在做一些简单或复杂的数据抽取、质量检测、数据清洗、数据转换、数据过滤等方面有着比较稳定的表现,其中最主要的我们通过熟练的应用它,减少了非常多的研发工作量,提高了我们的工作效率,不过对于我这个.net研发者来说唯一的遗憾就是这个工具是Java编写的。
1、Kettle概念Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
2、下载和部署žKettle可以在/网站下载žž下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可3、Kettle环境配置(有Java环境的直接忽略此章节)3、1 安装java JDK1)首先到官网上下载对应JDK包,JDK1.5或以上版本就行;2)安装JDK;3)配置环境变量,附配置方式:安装完成后,还要对它进行相关的配置才可以使用,先来设置一些环境变量,对于Java来说,最需要设置的环境变量是系统路径变量path。
kettle列转行案例

kettle列转行案例以kettle列转行案例为题,列举以下10个案例,并对每个案例进行详细描述。
1. 数据库表之间的数据转换:使用kettle可以将一个数据库中的数据表转换为另一个数据库中的表。
例如,将MySQL数据库中的数据表转换为Oracle数据库中的表,可以通过kettle中的转换步骤来实现。
2. CSV文件转换为Excel文件:使用kettle可以将CSV格式的文件转换为Excel格式的文件。
通过kettle的输入步骤读取CSV文件,然后通过转换步骤将数据转换为Excel格式,最后通过输出步骤将数据写入到Excel文件中。
3. JSON数据转换为XML数据:使用kettle可以将JSON格式的数据转换为XML格式的数据。
通过kettle的输入步骤读取JSON数据,然后通过转换步骤将数据转换为XML格式,最后通过输出步骤将数据写入到XML文件中。
4. 数据库表数据转换为JSON数据:使用kettle可以将数据库表中的数据转换为JSON格式的数据。
通过kettle的输入步骤读取数据库表中的数据,然后通过转换步骤将数据转换为JSON格式,最后通过输出步骤将数据写入到JSON文件中。
5. Excel文件转换为数据库表:使用kettle可以将Excel文件中的数据转换为数据库表。
通过kettle的输入步骤读取Excel文件中的数据,然后通过转换步骤将数据转换为数据库表的格式,最后通过输出步骤将数据写入到数据库表中。
6. 数据库表数据清洗:使用kettle可以对数据库表中的数据进行清洗。
通过kettle的转换步骤,可以对数据进行去重、去空值、格式化等操作,从而得到清洗后的数据。
7. 数据库表数据合并:使用kettle可以将多个数据库表中的数据合并为一个表。
通过kettle的输入步骤读取多个数据库表中的数据,然后通过转换步骤将数据合并,最后通过输出步骤将合并后的数据写入到一个数据库表中。
8. 数据库表数据拆分:使用kettle可以将一个数据库表中的数据拆分为多个表。
设计和运行一个Kettle转换(trans)或作业(job)的几种方式

设计和运行一个Kettle转换(trans)或作业(job)的几种方式最近经常有 Kettle 爱好者问起 Kettle 的运行方式, 能否使用web 方式运行? 本文就 Kettle 的运行方式做一个简单的总结.可以有三种方式来设计 Kettle 的转换或作业(job):1. 通过客户端的方式, 就是使用 spoon 和 chef 这两个工具, 在最近的版本里(3.0 以后), chef 已经集成到了spoon 中, 只要通过 spoon 就可以设计转换和作业了.2. 通过 Java web start 的方式, 这种方式实际也使用Spoon, 不过对用户来说更方便, 直接在 web 页面上,就可以运行 Spoon 了.[@more@]3. 通过 API 的方式, 就是使用 kettle 提供的 API 来设计转换,在实际中, 一般只能通过这种方式设计比较简单的转换,而无法设计复杂的转换,这是由 web 界面的功能局限性决定的, 很难使用 web 方式设计一个像 spoon 一样的界面.API 的使用可以参考: 。
.一个已经设计好的 kettle 转换可以通过客户端的方式运行, 也可以通过 web 方式来运行.客户端是 Spoon(图形界面) 和 Pan(命令行) , web 方式可以有下面三种方法:1. 通过 Pentaho BI 平台来运行 kettle 转换, 需要配置 xaction 文件, 这个 xaction 文件就是 Pentaho 所谓的 solution,它是一个 xml 文件, xaction 文件里定义了一组动作序列( action sequence), 一个kettle 转换也是这个动作序列里的一个动作, 在 xaciton 文件里可以设置要转换的kettle 任务文件的名称、路径、转换输入参数、输出方式等。
这种执行方式在Pentaho 网站的文档(wiki)里有比较详细的说明,包括xaction 文件的格式,如何配置xaction 文件,如何在xaction 文件里加入kettle 的转换任务等。
利用 kettle 实现数据迁移的实验总结

数据迁移是指将数据从一个系统或评台移动到另一个系统或评台的过程。
在进行数据迁移时,我们通常需要借助一些工具来帮助我们高效地完成数据迁移任务。
Kettle 是一款功能强大的开源数据集成工具,它可以帮助用户实现数据的抽取、转换和加载(ETL)操作,非常适用于数据迁移的实施。
在本文中,我们将结合我们的实际经验,对利用Kettle 实现数据迁移的实验进行总结,并共享一些经验和教训。
一、实验背景1.1 实验目的在进行数据迁移的实验之前,我们首先需要明确实验的目的和意义。
数据迁移的目的通常是为了将数据从一个系统迁移到另一个系统,实现数据的共享、备份或者更新等操作。
我们希望通过本次实验,探索并验证 Kettle 工具在数据迁移中的实际效用,为以后的项目工作提供参考和借鉴。
1.2 实验环境在进行实验之前,我们需要搭建相应的实验环境,以确保实验的顺利进行。
在本次实验中,我们使用了一台装有 Windows 操作系统的服务器,并在上面成功安装了Kettle 工具。
我们还准备了两个数据源,分别用于模拟数据的来源和目的地,以便进行数据迁移的实验。
二、实验过程2.1 数据抽取在进行数据迁移之前,我们首先需要从数据源中抽取需要迁移的数据。
在本次实验中,我们使用 Kettle 工具的数据抽取功能,成功地将源数据抽取到 Kettle 中,并对数据进行了初步的清洗和处理。
通过Kettle 的直观界面和丰富的抽取组件,我们轻松地完成了数据抽取的工作,为后续的数据转换和加载操作奠定了基础。
2.2 数据转换在数据抽取之后,我们往往需要对数据进行一定的转换和处理,以满足目的系统的要求。
在本次实验中,我们利用 Kettle 的数据转换功能,对抽取得到的数据进行了格式化、清洗和加工操作。
Kettle 提供了丰富的转换组件和灵活的数据转换规则,让我们能够快速地实现各种复杂的数据转换需求。
Kettle 还支持可视化的数据转换设计,让我们可以直观地了解数据转换的过程和结果。
kettle转换实验报告

kettle转换实验报告Kettle转换实验报告摘要:本实验利用kettle工具进行数据转换实验,通过对不同数据源的导入、转换和导出操作,验证kettle工具在数据处理方面的高效性和灵活性。
实验结果表明,kettle工具能够快速、准确地完成数据转换任务,为数据处理工作提供了便利和支持。
引言:数据处理在现代社会中扮演着重要的角色,而数据转换作为数据处理的一项重要环节,对于数据的清洗、整合和分析具有至关重要的意义。
kettle作为一款强大的数据集成工具,被广泛应用于数据处理领域。
本实验旨在通过对kettle工具的使用,验证其在数据转换方面的实用性和效率。
实验过程:1. 数据导入:首先,我们选择了不同的数据源,包括Excel文件、CSV文件和数据库表。
通过kettle工具,我们成功地将这些不同格式的数据导入到kettle的数据处理平台中,并进行了初步的数据预览和分析。
2. 数据转换:接着,我们对导入的数据进行了一系列的转换操作,包括数据清洗、字段映射、数据合并等。
通过kettle的图形化界面和强大的转换功能,我们轻松地完成了这些数据转换任务,并且在转换过程中实时查看了转换结果。
3. 数据导出:最后,我们将转换后的数据导出到不同的目标数据源中,包括Excel文件、数据库表和CSV文件。
通过kettle工具的灵活性和多样的导出选项,我们成功地将数据转换后的结果导出到了目标数据源中。
实验结果:通过本次实验,我们验证了kettle工具在数据转换方面的高效性和灵活性。
通过kettle工具,我们能够快速、准确地完成数据转换任务,为数据处理工作提供了便利和支持。
同时,kettle工具的图形化界面和丰富的功能模块,使得数据转换工作变得更加直观和方便。
结论:综上所述,kettle工具作为一款强大的数据集成工具,在数据转换方面具有显著的优势和实用性。
通过本次实验,我们对kettle工具的使用有了更深入的了解,并且相信kettle工具将会在数据处理领域发挥越来越重要的作用。
kettle实操案例

kettle实操案例Kettles are an essential appliance in many households around the world. They are used to boil water for making tea, coffee, or otherhot beverages. The convenience and efficiency of a kettle make it a popular choice for those who enjoy a hot drink.电热水壶是许多家庭必不可少的家用电器之一。
它们被用来烧水,用于冲茶、咖啡或其他热饮料。
电热水壶的便利性和高效性使其成为喜欢喝热饮料的人们的首选。
One of the main benefits of using a kettle is the speed at which it can boil water. Unlike traditional stovetop kettles, electric kettles can boil water in a matter of minutes, making them ideal for those who are short on time. Whether you need a quick cup of tea in the morningor want to make instant soup in the evening, a kettle can help youget hot water fast.使用电热水壶的一个主要好处是它烧水的速度。
与传统的炉灶顶水壶不同,电热水壶可以在几分钟内煮沸水,这使得它成为时间紧张的人们的理想选择。
无论是早上需要迅速泡一杯茶,还是晚上想要煮一点速食汤,电热水壶都能帮助你迅速获得热水。
In addition to speed, electric kettles also offer convenience and ease of use. Most models come with automatic shut-off features, so you don't have to worry about the kettle boiling dry. They are also equipped with easy-to-read water level indicators, allowing you to easily see how much water is in the kettle without opening the lid. This makes it simple to fill the kettle with the right amount of water for your needs.除了速度外,电热水壶还提供了便利性和易用性。
2024版kettle使用教程(超详细)

分布式计算原理
阐述Kettle分布式计算的原理, 如何利用集群资源进行并行处理 和任务调度。
01 02 03 04
集群配置与部署
详细讲解Kettle集群的配置步骤, 包括环境准备、节点配置、网络 设置等。
集群监控与管理
介绍Kettle提供的集群监控和管 理工具,方便用户实时了解集群 状态和作业执行情况。
03
实战演练
以一个具体的实时数据处理任务为例, 介绍如何使用Kettle设计实时数据处理 流程。
案例四:Kettle在数据挖掘中应用
数据挖掘概念介绍
01
数据挖掘是指从大量数据中提取出有用的信息和知识的
过程,包括分类、聚类、关联规则挖掘等任务。
Kettle在数据挖掘中的应用
02
Kettle提供了丰富的数据处理和转换功能,可以方便地
Chapter
案例一:ETL过程自动化实现
ETL概念介绍
ETL即Extract, Transform, Load,是数据仓 库技术中重要环节,包括数据抽取、清洗、转 换和加载等步骤。
Kettle实现ETL过程
通过Kettle的图形化界面,可以方便地设计ETL流程, 实现数据的自动化抽取、转换和加载。
作业项配置
对作业项进行详细配置,包括数据源、目标库、 字段映射等。
作业项管理
支持作业项的复制、粘贴、删除等操作,方便快速构建作业。
定时任务设置与执行
定时任务设置
支持基于Cron表达式的定时任务设置,实现 周期性自动执行。
立即执行
支持手动触发作业执行,满足即时数据处理 需求。
执行日志查看
kettle 用法

Kettle是一款开源的ETL工具,使用Kettle可以轻松地实现数据集成、转换和加载等任务。
以下是Kettle的基本用法:1. 下载并解压Kettle:可以从官网下载Kettle的最新版本,然后解压到本地。
2. 创建转换任务:在Kettle中,可以使用“转换”标签页来创建转换任务。
首先,需要点击“新建”按钮创建一个新的转换任务。
然后,可以在左侧的“资源”面板中选择需要用到的转换组件,例如输入、输出、过滤器、连接器等。
将组件拖动到中间的画布中,并对其进行配置。
3. 连接输入和输出数据:在转换任务中,需要连接输入和输出数据。
可以通过拖动“输入”和“输出”组件到画布中,并使用箭头连接它们。
在连接时,可以设置数据的映射关系,例如将输入表中的某个字段映射到输出表中的某个字段。
4. 添加过滤器:在转换任务中,可以添加过滤器来筛选数据。
可以通过拖动“过滤器”组件到画布中,并对其进行配置。
可以设置过滤器的条件,例如筛选出年龄大于等于18岁的用户。
5. 配置连接信息:在转换任务中,需要配置连接信息,以便能够连接到数据源和目标数据库。
可以通过拖动“连接”组件到画布中,并对其进行配置。
需要设置连接的数据库类型、数据库的主机名、用户名、密码等信息。
6. 运行转换任务:在配置完转换任务后,可以点击“运行”按钮来执行转换任务。
在运行时,需要选择转换任务的输入和输出路径,并设置其他相关参数。
如果一切正常,转换任务将会执行成功,并将数据加载到目标数据库中。
以上是Kettle的基本用法,通过Kettle可以轻松地实现数据集成、转换和加载等任务。
如果需要更复杂的操作,可以参考Kettle的官方文档或者搜索相关教程进行学习。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
kettle应用实践(转)
今天早上在网上看到了kettle发布了最新的版本,忽然想起最近其实做了不少工作应该是ETL工具的拿手好戏,赶紧下载下来看看,看是否能够在实际的工作中应用起来。
顺便讲一下,为啥看到kettle会两眼发光。
最近写了好几个小程序,用于从一个ftp去获取数据,然后转发至另一个ftp去,或者是从一个数据库获取数据然后保存至本地的数据库中,使用的是jdk中的Timer实现的定时调度,本来也没什么问题,连续运行几个月都不会出错。
可是最近网络不是太好,周期性抽风,ping包时,每5分钟大概
会丢7-8个包,从而导致程序也会假死,过一段时间后就不正常干活了,估计是因为用了数据库连接池的问题,要是每次发起数据库连接可能就不会有问题了,偷懒也不想改了,因为网络最终肯定是会修好的 :-) 但是想试试ETL工具,因为后面还有一些类似的东西要处理,不想写代码了,用别人的轮子感觉比较好,呵呵
首先下载了kettle的最新版,kettle3.1,解压后即可运行,一般的开发人员稍微摸索一下,看看例子简单的转换还是会做的,今天小试了一把,有几个注意点记下来。
1.使用资源库(repository)登录时,默认的用户名和密码是admin/admin
2.当job是存放在资源库(一般资源库都使用数据库)中时,使用
Kitchen.bat执行job时,需使用如下的命令行:
Kitchen.bat /rep kettle /user admin /pass admin /job job名
3.当job没有存放在资源库而存放在文件系统时,使用Kitchen.bat执行
job时,需使用如下的命令行:
Kitchen.bat /norep /file user-transfer-job.kjb
4.可以使用命令行执行job后,就可以使用windows或linux的任务调度来
定时执行任务了
在一开始使用命令行方式执行job时,总是报如下的错误,琢磨了好长时间总算整明白正确的方式了。
Unexpected error during transformation metadata load
No repository defined!
下一步准备按照实际情况定制Job,做好了再写小结。
问答:Unexpected error during transformation metadata load
No repository defined!
这个问题你最后怎么解决的?
@吴悔
一开始我是将Job和Transfomation都是存放在资源库中的,然后使用Kitchen.bar执行时会报上述错误,后来登录kettle时,选择“不使用资源库”,直接将Job和Transfomation保存在本地文件中,再使用Kitchen.bat执行就没有问题了。
Kettle的第一个实践--从FTP上取文件,再放至另一个FTP上
这个实践其实不难,主要是有一个地方要注意,就是文件名通配符的写法,如果文件名格式为“TRANS_yyyymmdd.txt”,如TRANS_20081101.txt。
如果想匹配所有以TRANS开头的文本文件,在kettle中要写成这样:
TRANS_.*[0-9].txt。
最后在windows操作系统中配置定时任务就可以定期执行该Job了。
Job的图:
FTP配置信息:
Kettle的第二个实践--数据获取并转换
需求:
kettletest1数据库中有table_source数据表,结构如下:
1.Id 主键
2.t_id 数据时间
3.part_id 实例ID
4.yg 数据字段1
5.wg 数据字段2
该表中的数据对于不同的实例ID,一分钟一条数据,t_id字段表示数据的时间,精确到分钟。
kettletest2数据库中有table_target数据表,结构如下:
1.Id 主键
2.marketdate 数据日期,格式为 yyyy-MM-dd
3.pointtime 时间,格式为 HH:mm
4.pointnumber 时间的数字表示,00:01表示为1,00:00表示为1440
5.plantcode 实例Code
6.yg 数据字段1
7.wg 数据字段2
需定期将table_source表中的数据获取至table_target表中,并进行如下处理:
1、将t_id数据时间字段拆分为三个字段,分别为marketdate、pointtime、pointnumber。
a、marketdate取t_id的日期部分。
b、pointtime取t_id的时间部分。
c、pointnumber为时间的数字表示,等于hour*60+minute。
d、但当t_id的时间为某日的00:00时,需将其转化为24:00,并且marketdate需取日期的前一天。
如t_id为2008-12-04 00:00,则marketdate 为2008-12-03,pointtime为24:00,pointnumber为1440。
2、将part_id字段映射为plantcode字段,并根据如下规则进行转换:
part_id plantcode
3206 P01
3207 P02
3208 P03
测试中使用的数据库均为mysql数据库。
实战:
整个转换工作共分为三个步骤,如下图:
1、定义需获取的数据的日期
2、删除table_target表中已有数据,注意一定要将“执行SQl语句”面板中的“变量替换”要选上,否则SQL语句中的变量不会被替换,我刚开始没注意到这个地方,找问题找了半天。
3、获取table_source中的数据,并将其插入table_target表
3-1、获取table_source表的数据
3-2、值映射
3-3、字段选择
3-4、对t_id字段进行处理,增加了pointnumber字段。
在这一步骤中发现kettle的一个bug,就是不能在JavaScript中使用str2date函数,错误的具体信息参见:/browse/PDI-1827。
这个问题也折腾了好长时间,刚开始怎么也想不通这个函数使用时怎么会报错呢,后来只好从字符串中截取年、月、日信息。
该步骤中还存在另外一个使人困惑的问题,就是点击“测试脚本”按钮,会报错,但是执行job和transformation时则不会报错。
3-5、增加pointnumber字段至输出结果中
3-6、插入数据至table_target表
3-4步骤中的JavaScript代码如下:
var pointTimeStr = pointtime.getString(); var pointnumber = 1;
if (pointTimeStr == "00:00") {
var marketDateStr = marketdate.getString();
var marketDateYear = substr(marketDateStr, 0, 4);
var marketDateMonth = str2num(substr(marketDateStr, 5, 2))-1; var marketDateDay = substr(marketDateStr, 8, 2);
var date = new Date();
date.setYear(marketDateYear);
date.setMonth(marketDateMonth);
date.setDate(marketDateDay);
var temp1 = dateAdd(date, "d", -1);
marketdate.setValue(date2str(temp1, "yyyy-MM-dd"));
pointtime.setValue("24:00");
pointnumber = 1440;
} else {
var hourStr = pointTimeStr.substr(0, 2);
var hour = str2num(hourStr);
var minuteStr = pointTimeStr.substr(3, 5);
var minute = str2num(minuteStr);
pointnumber = hour * 60 + minute;
}
至此,整个转换工作完成,小结一下:
如果对kettle等etl工具比较熟悉的话,使用etl工具进行数据转换、抽取等事情还是比较方便的,比起写程序还是有优势的。
但是这个转换过程中遇到的kettle的两个bug比较让人头疼,觉得kettle好像还不是很稳定。