kettle经验总结
自己总结的Kettle使用方法和成果

KETTLE使用自己总结的Kettle使用方法和成果说明简介Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix 上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出.Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做.Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
Kettle可以在http://kettle。
pentaho。
org/网站下载到。
注:ETL,是英文Extract—Transform—Load 的缩写,用来描述将数据从来源端经过萃取(extract)、转置(transform)、加载(load)至目的端的过程.ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
下载和安装首先,需要下载开源免费的pdi-ce软件压缩包,当前最新版本为5.20。
0。
下载网址:/projects/pentaho/files/Data%20Integration/然后,解压下载的软件压缩包:pdi—ce—5。
2.0.0—209.zip,解压后会在当前目录下上传一个目录,名为data—integration。
由于Kettle是使用Java开发的,所以系统环境需要安装并且配置好JDK。
žKettle可以在http:///网站下载ž下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可。
运行Kettle进入到Kettle目录,如果Kettle部署在windows环境下,双击运行spoon.bat或Kettle.exe文件.Linux用户需要运行spoon。
sh文件,进入到Shell提示行窗口,进入到解压目录中执行下面的命令:# chmod +x spoon。
KETTLE使用经验总结

KETTLE使用经验总结《kettle使用经验总结》目录1. 软件安装 (1)1.1.安装说明 (1)1.2.安装JDK (1)1.3.安装PDI (1)1.4.创建资源库 (2)1.5.修改配置文件 (3)1.6.启动服务器 (6)2. 操作说明 (7)2.1.运行转换/作业 (7)2.2.转换的并行 (7)2.3.作业的并行 (9)2.4.集群的使用 (9)2.5.记录日志 (11)2.6.连接HBASE (16)2.7.读取XML文件 (26)2.8.连接HIVE2 (31)2.9.大字段处理 (35)3. 性能优化 (39)《kettle使用经验总结》3.1.利用好数据库性能 (39) 3.2.用并行或者集群解决好数据插入瓶颈 (40)3.3.增大提交的记录数及大字段数据处理 (40)3.4.全量抽取先抽取后建索引 (41)3.5.增量抽取注意去重数据量 (41)3.6.利用中间表分段处理数据 (42)3.7.聚合优先 (43)4. 常见问题解决 (43)4.1.大量数据抽取导致内存溢出 (43)4.2.字段值丢失 (43)4.3.输出记录数大于输入记录数 (43)《kettle使用经验总结》1.软件安装1.1.安装说明本文档对应的产品及版本是pdi-ce-5.4.0.1-130。
由于该产品使用java 开发,所以需要在服务器上配置java环境。
如果是linux系统,为了操作方便,可以在linux上部署服务器,Windows启动客户端。
1.2.安装jdk下载jdk1.7或以上安装包,安装成功后,配置java环境变量。
JAVA_HOME: java安装目录CLASSPATH:%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\ tools.jarPATH:添加%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;LINUX下配置环境变量:进入/etc/profile(系统)或.bash_profile(用户)export JAVA_HOME=/usr/local/java/jdk1.8.0_60export PATH=$JAVA_HOME/bin:$PATHexportCLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar配置完成后检查java -version 和$JAVA_HOME是否启用1.3.安装PDI地址/projects/data-integration/下载P DI二进制文件pdi-ce-5.4.0.1-130.zip到各服务器中并解压,data-integration目录里面包含了PDI所有内容。
kettle实验总结

kettle实验总结我们来了解一下kettle的基本概念和功能。
Kettle是一款基于图形化界面的工具,通过可视化的方式帮助用户构建数据整合和转换的过程。
它提供了丰富的组件和功能,用户可以通过拖拽组件、设置参数和连接组件的方式来构建数据处理流程。
Kettle支持多种数据源和格式,包括关系型数据库、文件、Web服务等,用户可以方便地从不同的数据源中提取数据,并进行预处理、转换和加载。
接下来,我们将探讨如何使用kettle进行数据整合和转换的实验。
在实验前,我们需要准备好数据源和目标数据库,并确保kettle已经正确安装和配置。
首先,我们需要创建一个kettle的工作空间,并在工作空间中创建一个转换(Transformation)。
转换是kettle 中的基本单位,它由一系列的步骤(Step)组成,每个步骤都是一个数据处理的单元。
在转换中,我们可以使用多个步骤来完成不同的数据处理任务。
例如,我们可以使用"输入"步骤从源数据库中提取数据,然后使用"过滤"步骤对数据进行筛选,再使用"转换"步骤进行数据转换,最后使用"输出"步骤将结果加载到目标数据库中。
在每个步骤中,我们可以设置相应的参数和选项,以满足具体的数据处理需求。
除了基本的数据处理步骤,kettle还提供了丰富的功能和插件,用于处理更复杂的数据转换任务。
例如,我们可以使用"维度表输入"步骤来处理维度表的数据,使用"合并记录"步骤来合并不同数据源的记录,使用"数据校验"步骤来验证数据的完整性等。
通过灵活地组合和配置这些步骤,我们可以实现各种复杂的数据整合和转换任务。
在进行实验时,我们还可以使用kettle提供的调试和监控功能,以确保数据处理流程的正确性和性能。
例如,我们可以使用"调试"功能逐步执行转换,并观察每个步骤的输入和输出结果,以及中间数据的变化情况。
kettle面试题总结

kettle面试题总结
1. Kettle是什么?它的主要作用是什么?
Kettle是一款开源的ETL工具,用于数据的抽取、转换和加载。
它可以从多种数据源中提取数据,对数据进行清洗、转换和合并,然后将数据加载到目标数据库或文件中。
Kettle可以帮助用户快速、高效地处理大量数据,提高数据处理的效率和准确性。
2. Kettle的核心组件有哪些?每个组件的作用是什么?
Kettle的核心组件包括:Spoon、Pan、Carte和Kitchen。
Spoon 是图形化界面,用于设计和管理转换和作业;Pan是命令行界面,用于执行转换和作业;Carte是自定义脚本引擎,用于扩展Kettle的功能;Kitchen是作业调度和监控工具,用于管理和维护Kettle的作业。
3. Kettle支持哪些数据源?如何配置数据源?
Kettle支持多种数据源,包括关系型数据库(如MySQL、Oracle 等)、非关系型数据库(如MongoDB、HBase等)、文件(如CSV、XML等)等。
在配置数据源时,需要在Spoon或Pan中选择相应的数据源类型,并填写相应的连接信息,如数据库地址、用户名、密码等。
4. Kettle如何处理数据转换?
Kettle使用转换(Transformation)来处理数据转换。
转换是一个由多个步骤组成的流程,每个步骤都可以对数据进行处理和操作。
用户可以在Spoon中设计和编辑转换,通过拖拽和配置各种步骤来实现数据的转换和处理。
kettle对不同类型文件数据进行转换的基本方法的实验总结

kettle对不同类型文件数据进行转换的基本方法的实验总结Kettle对不同类型文件数据进行转换的基本方法的实验总结导言在当今信息时代,数据的处理和转换是企业和个人不可或缺的重要任务。
而对于数据处理工具来说,Kettle(即Pentaho Data Integration)无疑是其中一员佼佼者。
它是一款开源的ETL (Extract-Transform-Load)工具,能够帮助用户快速、高效地处理各种类型的数据。
本文将着眼于Kettle在不同类型文件数据转换方面的基本方法进行实验总结,希望能够为读者提供一份有价值的参考。
一、CSV文件数据转换1.读取CSV文件CSV(Comma Separated Values)文件是一种常见的以逗号分隔的文本文件格式,常用于数据交换。
在Kettle中,我们可以通过添加"CSV输入"步骤来读取CSV文件数据。
在进行数据转换之前,我们有时需要将CSV文件中的数据格式进行调整。
将日期字段转换为日期类型、将数值字段转换为特定精度的数值类型等。
Kettle提供了"Select values"和"Modify"等步骤来满足这些需求。
3.数据清洗和过滤在实际的数据处理中,我们可能会遇到一些数据质量问题,比如缺失值、异常值等。
此时,我们可以使用Kettle提供的"Filter rows"和"Cleanse"等步骤来进行数据清洗和过滤,确保数据质量的可靠性和准确性。
二、Excel文件数据转换1.读取Excel文件与CSV文件不同,Excel文件是一种二进制文件格式,它包含了丰富的数据类型和复杂的表结构。
在Kettle中,我们可以通过添加"Excel 输入"步骤来读取Excel文件数据。
在进行读取时,我们需要注意选择适当的Sheet以及指定正确的列和行范围。
与CSV文件一样,我们通常需要对Excel文件中的数据进行格式转换。
kettle调研手记-技巧汇总
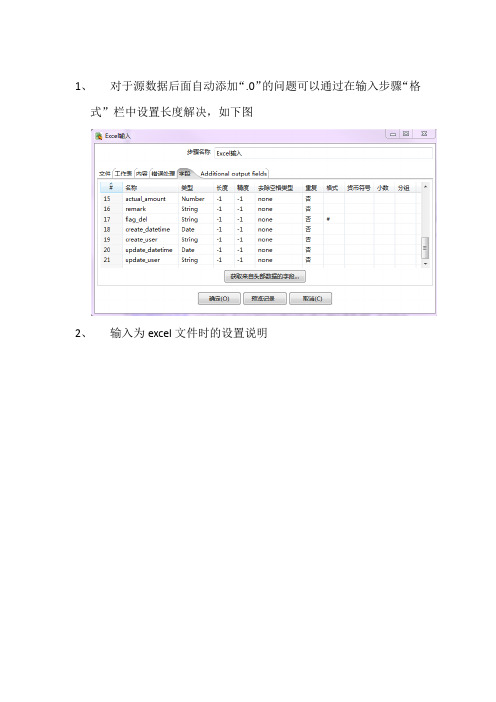
1、对于源数据后面自动添加“.0”的问题可以通过在输入步骤“格式”栏中设置长度解决,如下图2、输入为excel文件时的设置说明3、根据入库单号把明细中的金额求和后,更新到主表中,但是如果有的入库单号在主表中不存在则就会报错,这是数据问题,解决办法为,在更新步骤中设置一下”忽略查询失败”,则只对目标表中存在数据进行更新,如下图:4、使用资源库(repository)登录时,默认的用户名和密码是admin/admin5、当job是存放在资源库(一般资源库都使用数据库)中时,使用Kitchen.bat执行job时,需使用如下的命令行:Kitchen.bat /rep repository_name /user admin /pass admin /job job 名称> E:\\test.log其中repository_nameo为repository.xml中的repository,在最下面6、当job没有存放在资源库而存放在文件系统时,使用Kitchen.bat执行job时,需使用如下的命令行:Kitchen.bat /norep /file user-transfer-job.kjb7、资源名称最好不要用中文,如果程序在保持时的字符集跟系统不一致,就会造成repositories.xml文件中出现乱码,导致无法启动,解决方法是:到用户目录下找到repositories.xml。
将.kettle 文件夹删除,重写用英文名称创建后,成功启动。
8、在WINDOWS下自动执行的配置:先建一个bat文件,内容为:E:\work\kettle\pdi-ce-4.2.0-RC1\data-integration\Kitchen.bat /rep kettle_test /user admin /pass admin /job job的名称然后在windows中新建一个定时任务即可9、在LINUX下执行脚本命令:10、KETTLE所在目录/data-integration/kitchen.sh /reprepository_name /user admin /pass admin /job job名称> /opt/data_wash/log/test.log其中repository_nameo为repository.xml中的repository,在最下面11、Repository.xml在linux系统下的位置:$HOME/.kettle/repository.xml12、定义全局变量:在.kettle目录下,打开kettle.properties文件,以键值对的方式添加即可,如:变量名称=变量值,然后在kettle设置图中可以利用”Get Variables”步骤获取到13、在windows下,kettle的资源库中的数据库表名为小写,而在linux下则为大写,这一点需要注意,以移植时需要所导出表的插入sql脚本,否则会出现无法登录,找不到表的错误。
kettle使用总结

kettle使⽤总结Kettle使⽤笔记⼀、基本概念:1.1、资源库保存kettle脚本或转换、存放数据库连接的地⽅,可以建⽴多个数据库连接,使⽤时就⽆需每次重复建⽴1.2、数据库连接(db links)连接数据库的功能,需处理数据库中的数据时创建,可连接Oracle、SqlServer、MySQL、DB2等1.3、转换(trans)处理数据的ETL过程,⾥⾯存放许多处理数据的组件,完成后保存会⽣成⼀个ktl⽂件。
1.4、作业(job)⾃动、定时执⾏转换的步骤的名称,可以在⾃动执⾏转换的过程添加参数进⾏控制。
1.5、步骤(steps)转换和作⽤的每个操作都是⼀个步骤。
⼆、⼯具栏:2.1、资源库概念保存kettle脚本或转换的地⽅,相当于myeclipes的workspace,另⼀种保存kettle脚本或流程的⽅法是需要保存的时候⽤⽂件保存,点击另存为出现(PS:打开kettle的时候加载的也是资源库)2.2、资源库位置Tools -> 数据库-> 连接数据库2.3、数据库连接创建数据库连接的时候会同时创建数据库连接?右键点击新建转换-> 点击主对象树-> 右键DB连接->新建数据库连接(PS:创建数据库后可以点击Test 判断数据库连接创建成功了没!,Oracle RAC 环境下的数据库连接创建数据库连接的⽅法不同)三、基本操作:3.1、轮流发送模式和复制发送模式的区别如果获取的数据必须同时进⾏多步处理(⼀种⽅式是将数据复制后处理,⼀种是获取的数据进⾏轮流的间隔处理),设置⽅式为:选中Data Grid –> 点击右键–> 数据发送-> 选择轮流发送模式或复制发送模式下图为复制处理的⽅式:红框选中的标签为复制处理3.2、分离步骤的⽅法⽐如下图中分离出步骤”删除”的⽅法:选中”删除”->点击右键-> 点击分离步骤3.3、过滤错误数据的⽅法采集的数据保存到数据库的时候如果有错误就,整个ETL处理流程就会停⽌,可以⽤过滤错误的⽅法将错误的数据写到⽂本中,保证ETL流程继续执⾏步骤:在连接”表输出”和“⽂本⽂件输出2”的时候选择”Error Handing of step”效果如下图(PS:可以明确是哪个字段,那条数据出现的错误)3.4、查询步骤中数据详情的⽅法⽐如查看下图中”表输出”步骤的数据情况的步骤:选中”表输出” -> 点击右键-> 选择显⽰输⼊\输出字段四、转换组件介绍:4.1、核⼼对象-输⼊⽬录下组件4.1.1、表输⼊组件及属性4.1.1.1允许延迟转换像Oracled的BLOB类型字段,需要的时候开始不加载这些数据,最后输出的时候才进⾏4.1.1.2 替换SQL语句⾥的变量(只在Job⾥⾯应⽤)配置需注意的地⽅:1、SQL语句的条件必须⽤${}符合关联起来2、替换SQL语句⾥的变量必须勾选3、Job中的参数组件的设置及转换必须指明是哪个转换4.1.1.3 从步骤插⼊数据配置需注意的地⽅:1、从”获取系统信息”组件中输⼊的参数名称必须和表输⼊的字段名相同2、表输⼊的where 条件中的值⽤”?”代替3、从步骤插⼊数据必须勾选4、获取系统信息组件中的参数类型必须选“命令⾏参数1”5、执⾏JOB后,在参数输⼊栏中输⼊你的参数值4.1.1.4 表输⼊组件⾥的执⾏每⼀⾏?(必须和从步骤插⼊数据选项⼀起使⽤)配置需注意的地⽅:1、从”DataGrid”组件中输⼊的参数名称必须和表输⼊的字段名相同.且该字段有多个值2、表输⼊的where 条件中的值⽤”?”代替3、从步骤插⼊数据、执⾏每⼀⾏?两个选项必须勾选4.1.1.5 记录数量限制如果查询的数据有多条,可选择”记录数量限制”选项进⾏查询数据的数量进⾏限制,⽐如只取100条。
KETTLE使用经验总结

KETTLE使用经验总结1.熟悉KETTLE的基本概念和操作在开始使用KETTLE之前,建议先花一些时间了解KETTLE的基本概念和操作。
KETTLE的核心概念包括转换(Transformation)、作业(Job)、步骤(Step)、输入(Input)和输出(Output)等。
了解这些基本概念可以帮助你更好地理解和使用KETTLE。
2.认真设计转换和作业在使用KETTLE进行数据转换和加载之前,我们需要先认真设计转换和作业。
转换和作业的设计应该考虑到实际需求和数据流程,避免设计不合理或冗余的步骤。
同时,还需要考虑数据的质量和稳定性,以确保转换和作业的可靠性。
3.使用合适的步骤和功能KETTLE提供了很多不同的步骤和功能,我们需要选择和使用合适的步骤和功能来实现实际需求。
比如,如果需要从数据库中抽取数据,可以使用“表输入”步骤;如果需要将数据写入到数据库中,可以使用“表输出”步骤。
熟悉并正确使用这些步骤和功能,可以提高工作效率。
4.合理使用转换和作业参数KETTLE提供了转换和作业参数的功能,可以方便地传递参数和配置信息。
合理使用转换和作业参数可以使转换和作业更具灵活性和可重复性。
比如,可以使用作业参数来配置文件路径和数据库连接等信息,这样可以只修改参数值而不需要修改转换和作业的配置。
5.使用调试和日志功能在进行复杂的数据转换和加载时,很可能遇到问题和错误。
KETTLE 提供了调试和日志功能,可以帮助我们定位和解决问题。
比如,可以在转换和作业中插入“日志”步骤,将关键信息输出到日志文件中;还可以使用“调试”选项来跟踪转换和作业的执行过程。
6.定期备份和优化转换和作业转换和作业的备份和优化非常重要。
定期备份可以避免转换和作业的丢失和损坏;而优化转换和作业可以提高其执行性能。
比如,可以使用数据库索引来加快查询速度,可以使用缓存来减少数据库访问次数。
7.与其他工具和系统集成KETTLE可以与其他工具和系统进行集成和扩展。
kettle使用经验总结 -回复

kettle使用经验总结-回复首先,让我们来详细解释一下scaled dot product attention的概念和原理。
scaled dot product attention是一种在自然语言处理和机器翻译任务中非常常用的注意力机制。
它可以在序列到序列的模型中,将不同位置的信息融合在一起,进而提高模型在长序列上的性能。
在理解scaled dot product attention之前,我们需要先了解一下注意力机制。
注意力机制可以将不同位置的信息聚焦在一起,从而更好地进行信息传递和处理。
在一个典型的注意力机制中,我们有一个查询(query)向量和一系列键(keys)和值(values)向量。
注意力机制会为查询向量选择在键向量上的权重,然后将这些权重应用到值向量上,从而得到输出。
这个输出可以被用来计算模型的下一个状态或是最终的预测。
在scaled dot product attention中,我们使用了一个称为点积(dot product)的操作来计算查询向量和键向量之间的相似度。
具体来说,我们将查询向量和键向量的点积除以一个被称为缩放因子(scale factor)的数值。
这个缩放因子是一个与向量维度相关的固定数值。
通过这个缩放因子,我们可以控制点积的大小,从而对相似度进行缩放。
为了更好地理解scaled dot product attention的原理,我们可以将其分为几个重要的步骤:1. 输入:我们有一个查询向量Q,以及一系列的键向量K和值向量V。
这些向量可以由前一层的模型或是其他方式得到。
2. 相似度计算:我们首先计算查询向量Q与每个键向量K之间的点积相似度。
这可以通过将Q和K进行点乘得到。
然后,我们将点积除以缩放因子得到缩放的相似度。
3. 注意力权重:我们使用softmax函数来将缩放的相似度转换为注意力权重。
这样可以保证所有注意力权重的和为1。
softmax函数可以将原始的相似度值归一化。
ETL工具kettle学习总结

概览Kettle也叫PDI(全称是Pentaho Data Integeration),是一款开源的ETL工具,项目开始于2003年,2006年加入了开源的BI 组织Pentaho, 正式命名为PDI。
官方网站:/术语1.Transformation转换步骤,可以理解为将一个或者多个不同的数据源组装成一条数据流水线。
然后最终输出到某一个地方,文件或者数据库等。
2.Job作业,可以调度设计好的转换,也可以执行一些文件处理(比较,删除等),还可以ftp上传,下载文件,发送邮件,执行shell命令等,3.Hop 连接转换步骤或者连接Job(实际上就是执行顺序)的连线Transformation hop:主要表示数据的流向。
从输入,过滤等转换操作,到输出。
Job hop:可设置执行条件:1,无条件执行2,当上一个Job执行结果为true时执行3,当上一个Job执行结果为false时执行Kettle,etl设计及运行1.Kettle整体结构图Kettle整体结构图2.转换设计样例图绿色线条为hop,流水线转换设计样例3.运行方式使用java web start 方式运行的配置方法命令行方式1)Windows下执行kitchen.bat,多个参数之间以“/”分隔,Key和value以”:”分隔例如:kitchen.bat /file:F:\samples\demo-table2table.ktr /level:Basic /log:test123.log/file:指定转换文件的路径/level:执行日志执行级别/log: 执行日志文件路径2)Linux下执行kitchen.sh,多个参数之间以“-”分隔,Key和value以”=”分隔kitchen.sh -file=/home/updateWarehouse.kjb -level=Minimal如果设计的转换,Job是保存在数据库中,则命令如下:Kitchen.bat /rep:资源库名称/user:admin /pass:admin /job:job名4.Xml保存转换,job流程设计用户定义的作业可以保存在(xml格式)中或某一个特定的数据库中转换的设计文件以.ktr结尾(xml文格式),保存所有配置好的数据库连接,文件相对路径,字段映射关系等信息。
kettle常用的记录处理心得

kettle常用的记录处理心得
kettle常用的记录处理心得
在使用Kettle数据集成工具时,我们经常需要对数据进行记录处理,以便更好地进行数据分析和应用。
下面是我在使用Kettle的过程中总结的一些记录处理的心得:
1. 去重复:使用Kettle的“去重复”步骤可以帮助我们去掉重复的记录。
我们选择需要去重复的字段为主键,然后在处理过程中进行比较和过滤即可。
2. 过滤记录:使用Kettle的“过滤记录”步骤可以帮助我们排除不需要的记录,比如为空或特定数值的记录。
在过滤的过程中,我们可以使用正则表达式或自定义脚本进行过滤。
3. 合并记录:使用Kettle的“合并记录”步骤可以帮助我们将多个记录合并成一个记录。
在合并的过程中,我们需要选择合并的字段,并且可以根据需要拼接或聚合字段值。
4. 分割记录:使用Kettle的“分割记录”步骤可以帮助我们将一个记录分割成多个记录。
在分割的过程中,我们可以选择分割的方式,比如按照指定的分割符或按照字段值。
5. 排序记录:使用Kettle的“排序记录”步骤可以帮助我们对记录进行排序,以便更好地进行后续的数据分析和应用。
我们可以选择需要排序的字段和排序的方式,比如升序或降序。
总之,在使用Kettle处理记录时,我们需要根据数据的实际情况选择合适的处理方式,并在处理的过程中注意数据类型的转换和数据精度的保留,以便保证处理结果的准确性和可靠性。
在实践中多尝试,多摸索,相信你会有更多的记录处理心得。
kettle使用经验总结 -回复

kettle使用经验总结-回复Kettle使用经验总结在现代生活中,水壶是我们家庭中不可或缺的小电器之一。
它方便快捷地为我们提供了热水,无论是用来冲泡茶叶、咖啡还是做其他热饮料,都离不开水壶的帮助。
但是,不同的水壶在使用方法上可能会有所不同,本文将一步一步回答关于kettle使用的问题,帮助您更好地使用这一家庭必备工具。
第一步:购买合适的水壶在开始使用水壶之前,您需要购买一款合适的水壶。
市场上有许多不同类型的水壶可供选择,包括电水壶和传统水壶。
电水壶使用更加方便快捷,而传统水壶则可以直接放在火炉上加热。
考虑到电水壶的普遍使用和便捷性,本文将重点介绍如何使用电水壶。
第二步:了解水壶的基本部件在使用电水壶之前,您需要熟悉水壶的基本部件。
常见的电水壶通常由以下几个部分组成:1. 水壶底座:用于放置水壶并提供电力,通常带有电源插头和控制按钮。
2. 电源线:连接水壶底座和电源插座的线缆,确保电力供应。
3. 取手:用于握住水壶并倒水。
4. 盖子:盖住水壶的顶部,可防止水的溢出和蒸汽。
5. 口嘴:从水壶倒水的地方,通常带有过滤器。
根据您所购买的具体型号,水壶的部件可能会有所不同。
在使用之前,请先查看说明书以了解您所购买的水壶的特殊功能和部件。
第三步:填充水壶在开始使用之前,您需要仔细选择并填充水壶。
请注意以下几点:1. 水位线:大多数水壶上都有装水的水位线,确保不要超过该线。
如果您需要少量热水,可以根据需要调整水位。
2. 冷水:用冷水来填充水壶,而不是使用温水或热水。
这样可以避免热水烫伤和延长水壶的使用寿命。
3. 净化水质:如果您居住的地方水质较差,可以使用过滤器或瓶装水来填充水壶,以确保水的纯净度。
第四步:加热水壶在填充水壶后,将其放置在底座上并插上电源。
根据水壶上的控制按钮,选择所需的加热温度。
大多数电水壶都有不同的温度选项,如80C、90C 和100C。
根据您需要的热水温度,选择合适的选项。
一般来说,煮沸水时选择100C,而冲泡咖啡或绿茶时选择较低的温度。
利用 kettle 实现数据迁移的实验总结

数据迁移是指将数据从一个系统或评台移动到另一个系统或评台的过程。
在进行数据迁移时,我们通常需要借助一些工具来帮助我们高效地完成数据迁移任务。
Kettle 是一款功能强大的开源数据集成工具,它可以帮助用户实现数据的抽取、转换和加载(ETL)操作,非常适用于数据迁移的实施。
在本文中,我们将结合我们的实际经验,对利用Kettle 实现数据迁移的实验进行总结,并共享一些经验和教训。
一、实验背景1.1 实验目的在进行数据迁移的实验之前,我们首先需要明确实验的目的和意义。
数据迁移的目的通常是为了将数据从一个系统迁移到另一个系统,实现数据的共享、备份或者更新等操作。
我们希望通过本次实验,探索并验证 Kettle 工具在数据迁移中的实际效用,为以后的项目工作提供参考和借鉴。
1.2 实验环境在进行实验之前,我们需要搭建相应的实验环境,以确保实验的顺利进行。
在本次实验中,我们使用了一台装有 Windows 操作系统的服务器,并在上面成功安装了Kettle 工具。
我们还准备了两个数据源,分别用于模拟数据的来源和目的地,以便进行数据迁移的实验。
二、实验过程2.1 数据抽取在进行数据迁移之前,我们首先需要从数据源中抽取需要迁移的数据。
在本次实验中,我们使用 Kettle 工具的数据抽取功能,成功地将源数据抽取到 Kettle 中,并对数据进行了初步的清洗和处理。
通过Kettle 的直观界面和丰富的抽取组件,我们轻松地完成了数据抽取的工作,为后续的数据转换和加载操作奠定了基础。
2.2 数据转换在数据抽取之后,我们往往需要对数据进行一定的转换和处理,以满足目的系统的要求。
在本次实验中,我们利用 Kettle 的数据转换功能,对抽取得到的数据进行了格式化、清洗和加工操作。
Kettle 提供了丰富的转换组件和灵活的数据转换规则,让我们能够快速地实现各种复杂的数据转换需求。
Kettle 还支持可视化的数据转换设计,让我们可以直观地了解数据转换的过程和结果。
ETL工具kettle学习总结

概览Kettle也叫PDI(全称是Pentaho Data Integeration),是一款开源的ETL工具,项目开始于2003年,2006年加入了开源的 BI 组织 Pentaho, 正式命名为PDI。
官方网站:/术语1.Transformation转换步骤,可以理解为将一个或者多个不同的数据源组装成一条数据流水线。
然后最终输出到某一个地方,文件或者数据库等。
2.Job作业,可以调度设计好的转换,也可以执行一些文件处理(比较,删除等),还可以ftp上传,下载文件,发送邮件,执行shell命令等,3.Hop 连接转换步骤或者连接Job(实际上就是执行顺序)的连线Transformation hop:主要表示数据的流向。
从输入,过滤等转换操作,到输出。
Job hop:可设置执行条件:1,无条件执行2,当上一个Job执行结果为true时执行3,当上一个Job执行结果为false时执行Kettle,etl设计及运行1.Kettle整体结构图Kettle整体结构图2.转换设计样例图绿色线条为hop,流水线转换设计样例3.运行方式使用 java web start 方式运行的配置方法命令行方式1)Windows下执行kitchen.bat,多个参数之间以“/”分隔,Key和value以”:”分隔例如:kitchen.bat /file: F:\samples\demo-table2table.ktr /level:Basic /log:test123.log/file:指定转换文件的路径/level:执行日志执行级别/log: 执行日志文件路径2)Linux下执行kitchen.sh,多个参数之间以“-”分隔,Key和value以”=”分隔kitchen.sh -file=/home/updateWarehouse.kjb -level=Minimal如果设计的转换,Job是保存在数据库中,则命令如下:Kitchen.bat /rep:资源库名称 /user:admin /pass:admin /job:job名4.Xml保存转换,job流程设计用户定义的作业可以保存在(xml格式)中或某一个特定的数据库中转换的设计文件以.ktr结尾(xml文格式),保存所有配置好的数据库连接,文件相对路径,字段映射关系等信息。
kettle数据迁移实验总结

kettle数据迁移实验总结Kettle数据迁移实验总结一、实验目标本次实验的主要目标是学习和掌握Kettle工具的使用,实现数据的迁移。
希望通过本次实验,我们能理解并掌握Kettle的安装、配置及使用方法,提升在大数据环境下的数据处理和迁移能力。
二、实验过程1. Kettle的安装与配置:首先,我们按照官方文档的指引,下载并安装了Kettle。
然后,配置了Kettle的运行环境,包括设置环境变量和配置数据库连接等。
2. 数据源与目标配置:根据实验需求,我们选择了两个数据源和目标,分别为MySQL和Hive。
在Kettle中配置了相应的数据库连接信息,包括用户名、密码、数据库名等。
3. 建立转换任务:在Kettle中,我们根据需求创建了数据迁移任务。
首先,通过“View Database Connections”查看并配置数据库连接。
然后,通过“Design View”设计数据迁移的步骤和流程。
4. 数据清洗与转换:在数据迁移过程中,我们使用了Kettle的过滤器、转换器等工具,对原始数据进行了清洗和转换。
例如,去重、过滤无效数据、转换数据格式等。
5. 数据迁移与验证:最后,我们执行了数据迁移任务,将清洗和转换后的数据从源数据库迁移到目标数据库。
迁移完成后,对目标数据库中的数据进行验证,确保数据的准确性和完整性。
三、问题与解决方案在实验过程中,我们遇到了一些问题,以下是部分问题的描述和解决方案:1. 数据库连接失败:在配置数据库连接时,发现无法连接到指定的数据库。
经过检查,发现是数据库连接参数配置错误。
解决方案是核对并修正数据库连接参数,包括主机名、端口号、用户名、密码等。
2. 数据格式不匹配:在数据迁移过程中,发现源数据和目标数据的格式不匹配。
解决方案是使用Kettle的转换器工具,对数据进行格式转换,使其符合目标数据的格式要求。
3. 数据迁移速度慢:在执行数据迁移任务时,发现迁移速度较慢。
经过分析,发现是网络带宽和数据库性能瓶颈所致。
kettle使用经验总结

Kettle使用经验总结一、关于变量的使用在etl过程中难免不使用变量,所以就先介绍变量的使用。
其中可以使用kettle已经定义好的变量。
个人感觉最有用的就是“Internal.Job.Filename.Directory”。
这个变量为运行时变量,含义为启动的当前job的目录,是个相对路径。
可以在job中的作业转换名、日志文件名、转换文件名等任何可以使用到文件路径的地方使用。
这样很方便移植,不用每次当文件更改目录后或者移植到不同系统下需要一一更改每个步骤的路径,节省了许多不必要的时间。
还可以在Kettle的属性文件kettle.properties中设置环境变量。
此文件所在目录如下:$HOME/.kettle (Unix/Linux/OSX)C:\Documents and Settings\<username>\.kettle\kettle.properties (Windows) 使用变量的方法可以如下指定:${V ARIABLE}。
还可以设置运行时变量。
关于命令行启动job/trans直接设置动态变量还没有验证。
待验证后补充。
现在使用的是将参数输入到文本中,然后从文本取得变量的值再在各个trans中使用。
包含设置变量的trans里不能放置使用此变量的步骤,此变量只能在之后的trans/Job中才能使用。
使用的时候直接${varName}即可。
还有一种是使用局部变量可以直接用?代替。
这个需要注意的是在使用变量的步骤中有一个“从步骤插入数据”下拉列表,需要从中选择之前的变量。
对于全量提取和每天增量提取,可以将提取的过程作为一个通用的job,前面根据提取方式的不同连接不同的时间变量,后面提取的sql写为between…and…。
这样既实现了功能,又实现了代码复用。
但是需要注意的是格式问题,获取系统信息取到的时间格式形如“2009/08/10 00:00:00.000”。
如果将此时间使用js截断后再设置,格式会变成类似“Sat Aug 10 00:00:00 CST 2009”。
kettle完成总结

关于kettle工具及脚本开发的总结前一阶段,对质检、外汇局以及东软医疗等项目进行了业务流程的模拟实现以及在对应的业务中,使用kettle工具对业务涉及的数据抽取和转换进行了脚本实现。
经过这三个项目业务场景的模拟和演示,总结使用kettle开发数据处理脚本的设计思路、开发过程,得到了很多实用的经验,对kettle的使用以及其框架、接口等更加清楚和熟悉。
以上所述的三个项目的demo仅仅完成了核心业务数据处理的流程和逻辑,相关的增量抽取、循环读取文件目录、定时执行等逻辑都没有在demo中体现。
通过进一阶段的整理和总结,目前的核心业务需求不外乎DB到DB的数据直接抽取、根据DB信息生成特定格式XMl、解析已有XML并存入DB以及XML与XML之间的格式转换。
对于这些需求,通常采用以下手段进行设计和实现:1.尽量使用kettle脚本的方式处理数据的抽取、转换、载入等操作;2.Kettle脚本方式无法完成或者复杂度很高的业务交由java编码实现或者其他方式实现,如XSLT基于这个设计思路,下面将结合质检的业务流程对kettle的业务开发及流程设计思路进行分析和总结。
质检前置机数据处理分为四个步骤:步骤1:在指定位置读取企业端上传的XML报文,并存入E IG中间库;步骤2:读取中间库状态位为0(未上报)的报文信息,并交由X S LT进行转换;步骤3:解析转换后的XML报文,并将对应的数据存入业务库对应的字段中;步骤4:将业务库补录后的数据抽取出来生成平台端需要的格式的XML报文。
流程如下图所示:方案一:循环、增量、定时等逻辑交由编码控制,具体执行交由kettle企业端到EIG中间库的数据处理:由于现有kettle组件读取文件的方式是对文本内容进行字段解析和分割,因此并不符合业务中读取完整XML报文并存入数据库大字段的需求,因此针对步骤1采用java编码的方式读取文件内容并操作数据库保存读取的报文信息。
采用这种方式,循环读取报文目录、定时读取等既定规则的报文读取逻辑也均可通过硬编码方式实现。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Pan命令来执行转换,下面给出的是pan参数。
Kitchen 命令用于执行作业
Carte 用于添加新的执行引擎
Kettle的资源库和Carte的登录,密码都是用Encr加密的。
使用中遇到的问题及总结:
这两个组件用之前必须先对数据进行排序,否则数据会不准确。
而且merge join会很慢,尽量要少用。
这个组件默认auto commit false,所以如果要执行一些sql,必须在后面加commit。
貌似没什么用,其实也没什么用。
Kettle讲究有进有出,如果最后的没有输出,要加上这个空操作。
实际上测试不写也没问题。
执行java script,这个组件很强大,大部分用组件实现不了
的东西,都可以通过这个来转换。
而且可以调用自己写的java 类。
强大到不行~
这个组件很奇怪,顾名思义调用存储过程的,但实际上不能调用不传参数的存储过程。
如果有没有参数的存储过程,现在的解决方案是用sql脚本来执行。
一个设置变量,一个获得变量。
这个本来没什么要说的,但在实际应用中发现,在一个trans中设置的变量,在当前trans中并不一定能获得到,所以设计的时候先在一个trans中设置变量,然后在后续的trans中来获得就可以了。
让人惊喜的东西,大数据量导入,事实上让人近乎绝望,研究了一天依旧不会用。
而且我怀疑确实不能用。
其实这个组件无非是实现了copy命令,目前的解决方案,sql脚本,先汗一个,不知道跟这些组件相比效率会怎样。
三个亲兄弟,功能差不多,长的也很像,看了源码感觉,性能有差异,就性能而言,文本文件输入组件很差,它不如csv file input和fixed file input组件,因为后面的两者启用了java nio技术。
顺便提一句而已。
kettle内置性能监控,通过分析能知道哪一环节出现瓶颈。
以上是trans的内容,关于job相比而言简单一些,只是调用trans而已。
值得一说的是job 以start开始,这个start只能有一个。
当然不说很多人也会认为是只能有一个,
但我之所以这么说是因为一个trans可以有多个开始。
Start中可以设置job的定时启动,貌似做的很强大,实际用起来不知道怎么样,因为在之前的版本中job是不能定时调度的,要想调度只能用操作系统的定时任务来启动了。
浪费了一些时间:
花了一天半的时间研究了一下,kettle可以以web方式启动,最终发现跟以客户端启动没什么区别,相比感觉客户端的方式更好一些。
另一件浪费时间的事情就是花了接近两天的时间研究大批量导入,最终失败了,好在最后想到接近方案了,具体的上面有提到。
今后要做的可能有意义的事情:
Kettle提供api可以用java来控制,将来可以花些时间来研究一下这方面,这样做的意义是可以在java程序中调用kettle的job和trans,以后可以集成在其他程序中,感觉还是很强大的。
总结:
介绍这么多,其实只是kettle的冰山一角。
要想了解更多,要把kettle内置的例子多看一下,目录为E:\data-integration\samples\ 等你看完了之后发现会的依旧是冰山一角,因为例子很古老,多年之前的,很多组件并没有介绍。
目前为止,kettle提供的组件基本能满足需求,如果将来发现满足不了要求,可以这样做,Kettle暴露了一些接口,可以通过这些接口,来扩展开发新的组件。