内部排序代码
严蔚敏 数据结构第十章 内部排序的具体代码(c++,附测试数据)

int exchange = 1;
SortData temp;
while ( i < n && exchange ){
exchange = 0; //标志置为0,假定未交换
for ( int j = n-1; j >= i; j-- )
QSort(L,1,L.length);
}//QuickSort
//**************************************************
//直接选择排序
void SelectSort ( SortData V[ ], int n ) {
for ( int i = 0; i < n-1; i++ ) {
if LT(L.r[i].key,L.r[i-1].key){
L.r[0]=L.r[i];
for ( j = i-1; LT(L.r[0].key,L.r[j].key); --j )
L.r[j+1]=L.r[j];
L.r[j+1]=L.r[0];
//*******************************************
//直接插入排序
void InsertSort ( SqList &L ) {
//按非递减顺序对表进行排序,从后向前顺序比较
int i,j;
for ( i = 2; i <= L.length; ++ i)
low=1;high=i-1; //查找范围由1到i-1
while(low<=high){
数据结构-第十章-内部排序

0
1
2
3
4
5
6
7
8
i=5
MAXINT 49 2 3
MAXINT 49 6 3 MAXINT 49 6 3 MAXINT 49 6 8
38 1
38 1 38 1 38 1
65 97 5 0
65 5 65 5 65 5 97 0 97 0 97 0
76 4
76 4 76 4 76 4
13
27
49
i=6
最坏情况下,待排记录按关键字非递增有序 排列(逆序)时,第 i 趟时第 i+1 个对象 必须与前面 i 个对象都做排序码比较, 并且 每做1次比较就要做1次数据移动。总比较 次 数 为 (n+2)(n-1)/2 次 , 总 移 动 次 数 为 (n+4)(n-1)/2。 在平均情况下的排序码比较次数和对象移 动次数约为 n2/4。因此,直接插入排序的 时间复杂度为 O(n2)。 直接插入排序是一种稳定的排序方法。
折半插入排序 (Binary Insertsort)
基本思想 既然每个要插入记录之前的纪录 已经按关键字有序排列,在查找插入位 臵时就没有必要逐个关键字比较,可以 使用折半查找来实现。由此进行的插入 排序称之为折半插入排序。
折半插入排序的算法
void BInsertSort (SqList &L){ for (i=2;i<=L.length;++i){ L.r[0]=L.r[i]; low=1;high=i-1; //查找范围由1到i-1 while(low<=high){ m=(low+high)/2; if LT(L.r[0].key,L.r[m].key) high=m-1; else low=m+1; }//while 折半查找 for (j=i-1;j>=high+1;--j) L.r[j+1]=L.r[j]; //折半查找结束后high+1位臵即为插入位臵 L.r[high+1]=L.r[0]; }//for }//BInsertSort
内部排序比较 (实验报告+源程序)C++

实验报告3实验名称:数据结构与软件设计实习题目:内部排序算法比较专业:生物信息学班级:01 姓名:学号:实验日期:2010.07.24一、实验目的:比较冒泡排序、直接插入排序、简单选择排序、快速排序、希尔排序;二、实验要求:待排序长度不小于100,数据可有随机函数产生,用五组不同输入数据做比较,比较的指标为关键字参加比较的次数和关键字移动的次数;对结果做简单的分析,包括各组数据得出结果的解释;设计程序用顺序存储。
三、实验内容对各种内部排序算法的时间复杂度有一个比较直观的感受,包括关键字比较次数和关键字移动次数。
将排序算法进行合编在一起,可考虑用顺序执行各种排序算法来执行,最后输出所有结果。
四、实验编程结果或过程:1. 数据定义typedef struct { KeyType key; }RedType; typedef struct { RedType r[MAXSIZE+1]; int length;}SqList;2. 函数如下,代码详见文件“排序比较.cpp”int Create_Sq(SqList &L)void Bubble_sort(SqList &L)//冒泡排序void InsertSort(SqList &L)//插入排序void SelectSort(SqList &L) //简单选择排序int Partition(SqList &L,int low,int high) void QSort(SqList &L,int low,int high)//递归形式的快速排序算法void QuickSort(SqList &L)void ShellInsert(SqList &L,int dk)//希尔排序void ShellSort(SqList &L,int dlta[ ])3. 运行测试结果,运行结果无误,如下图语速个数为20元素个数为100错误调试无。
查找和排序算法的实现(实验七)

实验七查找和排序算法的实现一.实验目的及要求(1)学生在实验中体会各种查找和内部排序算法的基本思想、适用场合,理解开发高效算法的可能性和寻找、构造高效算法的方法。
(2)掌握运用查找和排序解决一些实际应用问题。
二.实验内容:(1)编程实现一种查找算法(如折半查找、二叉排序树的查找、哈希查找等),并计算相应的ASL。
(2)编程实现一种内部排序算法(如插入排序、快速排序等)。
三.实验主要流程、基本操作或核心代码、算法片段(该部分如不够填写,请另加附页)(1)编程实现一种查找算法(如折半查找、二叉排序树的查找、哈希查找等),并计算相应的ASL。
➢程序代码:折半查找:头文件:#define EQ(a,b) ((a)==(b))#define LT(a,b) ((a)<(b))#define maxlength 20typedef int ElemType;typedef struct{ElemType key;ElemType other;}card;//每条记录包含的数据项typedef struct{card r[maxlength];int length;}SSTable;//一张表中包含的记录容量void Create(SSTable &L);int Search(SSTable L,int elem);功能函数:#include"1.h"#include"stdio.h"void Create(SSTable &L){printf("新的线性表已经创建,请确定元素个数(不超过20)\n");scanf("%d",&L.length);printf("请按递增序列输入具体的相应个数的整数元素(空格隔开)\n");for(int i=0;i<L.length;i++){scanf("%d",&L.r[i].key);}}int Search(SSTable L,int elem){if(L.r[L.length-1].key<elem||L.r[0].key>elem){printf("表中没有该元素(不在范围内)\n");return 0;}int low=0,high=L.length-1;int mid;while(low<=high){mid=(low+high)/2;if(EQ(L.r[mid].key,elem)){printf("该元素在第%d位\n",mid+1); return 0;}else if(LT(elem,L.r[mid].key)){high=mid-1;}else{low=mid+1;}}printf("表中没有该元素(不在范围内)\n");return 0;}主函数:#include"stdio.h"#include"1.h"int main(){SSTable L;Create(L);printf("\n");printf("此时的线性表元素:\n");for(int a=0;a<L.length;a++){printf("%d ",L.r[a].key);}printf("\n");printf("\n");int elem;do{printf("请输入要查找的元素(输入000表示结束程序)\n");scanf("%d",&elem);if(elem!=000){Search(L,elem);}}while(elem!=000);return 0;}➢运行结果:(2)编程实现一种内部排序算法(如插入排序、快速排序等)。
数据结构课程设计—内部排序算法比较

数据结构课程设计—内部排序算法比较在计算机科学领域中,数据的排序是一项非常基础且重要的操作。
内部排序算法作为其中的关键部分,对于提高程序的运行效率和数据处理能力起着至关重要的作用。
本次课程设计将对几种常见的内部排序算法进行比较和分析,包括冒泡排序、插入排序、选择排序、快速排序和归并排序。
冒泡排序是一种简单直观的排序算法。
它通过重复地走访要排序的数列,一次比较两个数据元素,如果顺序不对则进行交换,并一直重复这样的走访操作,直到没有要交换的数据元素为止。
这种算法的优点是易于理解和实现,但其效率较低,在处理大规模数据时性能不佳。
因为它在最坏情况下的时间复杂度为 O(n²),平均时间复杂度也为O(n²)。
插入排序的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入,直到整个序列有序。
插入排序在数据量较小时表现较好,其平均时间复杂度和最坏情况时间复杂度也都是 O(n²),但在某些情况下,它的性能可能会优于冒泡排序。
选择排序则是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(或最大)元素,然后放到已排序序列的末尾。
以此类推,直到全部待排序的数据元素排完。
选择排序的时间复杂度同样为O(n²),但它在某些情况下的交换操作次数可能会少于冒泡排序和插入排序。
快速排序是一种分治的排序算法。
它首先选择一个基准元素,将数列分成两部分,一部分的元素都比基准小,另一部分的元素都比基准大,然后对这两部分分别进行快速排序。
快速排序在平均情况下的时间复杂度为 O(nlogn),最坏情况下的时间复杂度为 O(n²)。
然而,在实际应用中,快速排序通常表现出色,是一种非常高效的排序算法。
归并排序也是一种分治算法,它将待排序序列分成若干个子序列,每个子序列有序,然后将子序列合并成一个有序序列。
C语言八大排序算法
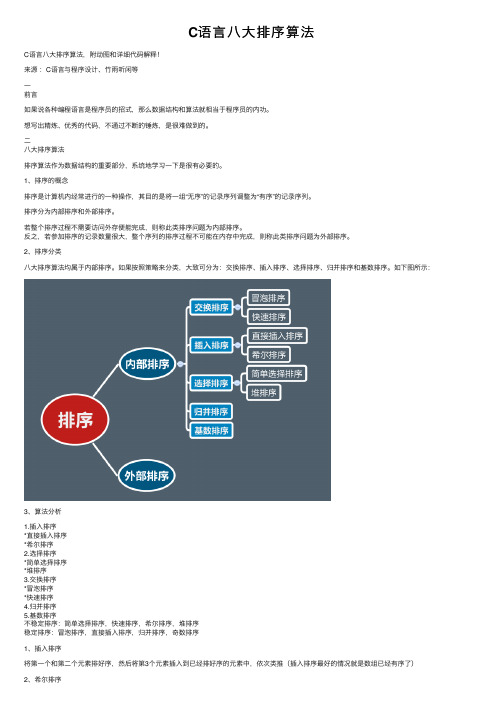
C语⾔⼋⼤排序算法C语⾔⼋⼤排序算法,附动图和详细代码解释!来源:C语⾔与程序设计、⽵⾬听闲等⼀前⾔如果说各种编程语⾔是程序员的招式,那么数据结构和算法就相当于程序员的内功。
想写出精炼、优秀的代码,不通过不断的锤炼,是很难做到的。
⼆⼋⼤排序算法排序算法作为数据结构的重要部分,系统地学习⼀下是很有必要的。
1、排序的概念排序是计算机内经常进⾏的⼀种操作,其⽬的是将⼀组“⽆序”的记录序列调整为“有序”的记录序列。
排序分为内部排序和外部排序。
若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序。
反之,若参加排序的记录数量很⼤,整个序列的排序过程不可能在内存中完成,则称此类排序问题为外部排序。
2、排序分类⼋⼤排序算法均属于内部排序。
如果按照策略来分类,⼤致可分为:交换排序、插⼊排序、选择排序、归并排序和基数排序。
如下图所⽰:3、算法分析1.插⼊排序*直接插⼊排序*希尔排序2.选择排序*简单选择排序*堆排序3.交换排序*冒泡排序*快速排序4.归并排序5.基数排序不稳定排序:简单选择排序,快速排序,希尔排序,堆排序稳定排序:冒泡排序,直接插⼊排序,归并排序,奇数排序1、插⼊排序将第⼀个和第⼆个元素排好序,然后将第3个元素插⼊到已经排好序的元素中,依次类推(插⼊排序最好的情况就是数组已经有序了)因为插⼊排序每次只能操作⼀个元素,效率低。
元素个数N,取奇数k=N/2,将下标差值为k的数分为⼀组(⼀组元素个数看总元素个数决定),在组内构成有序序列,再取k=k/2,将下标差值为k的数分为⼀组,构成有序序列,直到k=1,然后再进⾏直接插⼊排序。
3、简单选择排序选出最⼩的数和第⼀个数交换,再在剩余的数中⼜选择最⼩的和第⼆个数交换,依次类推4、堆排序以升序排序为例,利⽤⼩根堆的性质(堆顶元素最⼩)不断输出最⼩元素,直到堆中没有元素1.构建⼩根堆2.输出堆顶元素3.将堆低元素放⼀个到堆顶,再重新构造成⼩根堆,再输出堆顶元素,以此类推5、冒泡排序改进1:如果某次冒泡不存在数据交换,则说明已经排序好了,可以直接退出排序改进2:头尾进⾏冒泡,每次把最⼤的沉底,最⼩的浮上去,两边往中间靠16、快速排序选择⼀个基准元素,⽐基准元素⼩的放基准元素的前⾯,⽐基准元素⼤的放基准元素的后⾯,这种动作叫分区,每次分区都把⼀个数列分成了两部分,每次分区都使得⼀个数字有序,然后将基准元素前⾯部分和后⾯部分继续分区,⼀直分区直到分区的区间中只有⼀个元素的时候,⼀个元素的序列肯定是有序的嘛,所以最后⼀个升序的序列就完成啦。
abap 排序表写法

abap 排序表写法在ABAP中,排序表是一种常见的数据结构,用于存储相同类型的数据并按照特定的规则进行排序。
排序表通常由一个内部表和一个SORT语句组成。
首先,需要定义一个内部表来存储数据。
可以使用DATA语句来定义内部表,并指定列名和列类型。
例如,以下代码定义了一个内部表ITAB,其中包含两列:ID和NAME。
DATA ITAB TYPE STANDARD TABLE OF(ID TYPE I,NAME TYPE CHAR20).然后,需要将数据添加到内部表中。
可以使用APPEND语句将新行添加到内部表中。
例如,以下代码将一行数据添加到内部表ITAB中:APPEND VALUE#( ID = 1,NAME = 'John' )TO ITAB.一旦数据被添加到内部表中,SORT语句就可以用来对其进行排序。
SORT语句通常有几个参数,包括要排序的内部表,排序规则以及其他选项。
例如,以下代码将ITAB按照ID升序排序:SORT ITAB BY ID ASCENDING.在排序完成后,可以使用LOOP语句遍历排序表中的数据。
例如,以下代码输出ITAB中所有行的ID和NAME:LOOP AT ITAB INTO DATA(WA).WRITE: / WA-ID, WA-NAME.ENDLOOP.以上是ABAP排序表的基本写法。
在实际应用中,可能需要使用更多的排序选项和复杂的逻辑来操作排序表。
但是,理解这些基本的结构和语法,将为编写更高级的程序提供坚实的基础。
内部排序比较 (实验报告+源程序)C++

实验报告3实验名称:数据结构与软件设计实习题目:内部排序算法比较专业:生物信息学班级:01 姓名:学号:实验日期:2010.07.24一、实验目的:比较冒泡排序、直接插入排序、简单选择排序、快速排序、希尔排序;二、实验要求:待排序长度不小于100,数据可有随机函数产生,用五组不同输入数据做比较,比较的指标为关键字参加比较的次数和关键字移动的次数;对结果做简单的分析,包括各组数据得出结果的解释;设计程序用顺序存储。
三、实验内容对各种内部排序算法的时间复杂度有一个比较直观的感受,包括关键字比较次数和关键字移动次数。
将排序算法进行合编在一起,可考虑用顺序执行各种排序算法来执行,最后输出所有结果。
四、实验编程结果或过程:1. 数据定义typedef struct { KeyType key; }RedType; typedef struct { RedType r[MAXSIZE+1]; int length;}SqList;2. 函数如下,代码详见文件“排序比较.cpp”int Create_Sq(SqList &L)void Bubble_sort(SqList &L)//冒泡排序void InsertSort(SqList &L)//插入排序void SelectSort(SqList &L) //简单选择排序int Partition(SqList &L,int low,int high) void QSort(SqList &L,int low,int high)//递归形式的快速排序算法void QuickSort(SqList &L)void ShellInsert(SqList &L,int dk)//希尔排序void ShellSort(SqList &L,int dlta[ ])3. 运行测试结果,运行结果无误,如下图语速个数为20元素个数为100错误调试无。
java中sort方法

java中sort方法Java中sort方法1. 简介在Java中,sort方法是用于对数组或集合进行排序的常用方法。
它可以按照自然顺序或者指定的比较器来排序,使得元素按照一定的规则排列。
本文将详细介绍sort方法的用法和不同的排序方式。
2. 使用方法public static <T> void sort(List<T> list)public static <T> void sort(List<T> list, Comparator<? s uper T> c)public static void sort(int[] a)public static void sort(int[] a, int fromIndex, int toIn dex)public static void sort(long[] a)public static void sort(long[] a, int fromIndex, int toI ndex)public static void sort(short[] a)public static void sort(short[] a, int fromIndex, int to Index)public static void sort(char[] a)public static void sort(char[] a, int fromIndex, int toI ndex)public static void sort(byte[] a)public static void sort(byte[] a, int fromIndex, int toI ndex)public static void sort(float[] a)public static void sort(float[] a, int fromIndex, int to Index)public static void sort(double[] a)public static void sort(double[] a, int fromIndex, int t oIndex)public static <T> void sort(T[] a)public static <T> void sort(T[] a, int fromIndex, int to Index)sort方法有多个重载。
用Java实现常见的8种内部排序算法

⽤Java实现常见的8种内部排序算法⼀、插⼊类排序插⼊类排序就是在⼀个有序的序列中,插⼊⼀个新的关键字。
从⽽达到新的有序序列。
插⼊排序⼀般有直接插⼊排序、折半插⼊排序和希尔排序。
1. 插⼊排序1.1 直接插⼊排序/*** 直接⽐较,将⼤元素向后移来移动数组*/public static void InsertSort(int[] A) {for(int i = 1; i < A.length; i++) {int temp = A[i]; //temp ⽤于存储元素,防⽌后⾯移动数组被前⼀个元素覆盖int j;for(j = i; j > 0 && temp < A[j-1]; j--) { //如果 temp ⽐前⼀个元素⼩,则移动数组A[j] = A[j-1];}A[j] = temp; //如果 temp ⽐前⼀个元素⼤,遍历下⼀个元素}}/*** 这⾥是通过类似于冒泡交换的⽅式来找到插⼊元素的最佳位置。
⽽传统的是直接⽐较,移动数组元素并最后找到合适的位置*/public static void InsertSort2(int[] A) { //A[] 是给定的待排数组for(int i = 0; i < A.length - 1; i++) { //遍历数组for(int j = i + 1; j > 0; j--) { //在有序的序列中插⼊新的关键字if(A[j] < A[j-1]) { //这⾥直接使⽤交换来移动元素int temp = A[j];A[j] = A[j-1];A[j-1] = temp;}}}}/*** 时间复杂度:两个 for 循环 O(n^2)* 空间复杂度:占⽤⼀个数组⼤⼩,属于常量,所以是 O(1)*/1.2 折半插⼊排序/** 从直接插⼊排序的主要流程是:1.遍历数组确定新关键字 2.在有序序列中寻找插⼊关键字的位置* 考虑到数组线性表的特性,采⽤⼆分法可以快速寻找到插⼊关键字的位置,提⾼整体排序时间*/public static void BInsertSort(int[] A) {for(int i = 1; i < A.length; i++) {int temp = A[i];//⼆分法查找int low = 0;int high = i - 1;int mid;while(low <= high) {mid = (high + low)/2;if (A[mid] > temp) {high = mid - 1;} else {low = mid + 1;}}//向后移动插⼊关键字位置后的元素for(int j = i - 1; j >= high + 1; j--) {A[j + 1] = A[j];}//将元素插⼊到寻找到的位置A[high + 1] = temp;}}2. 希尔排序希尔排序⼜称缩⼩增量排序,其本质还是插⼊排序,只不过是将待排序列按某种规则分成⼏个⼦序列,然后如同前⾯的插⼊排序⼀般对这些⼦序列进⾏排序。
python实现十大经典算法

python实现⼗⼤经典算法排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进⾏排序,⽽外部排序是因排序的数据很⼤,⼀次不能容纳全部的排序记录,在排序过程中需要访问外存。
常见的内部排序算法有:插⼊排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序等。
⽤⼀张图概括:关于时间复杂度:1. 平⽅阶 (O(n2)) 排序各类简单排序:直接插⼊、直接选择和冒泡排序。
2. 线性对数阶 (O(nlog2n)) 排序快速排序、堆排序和归并排序。
3. O(n1+§)) 排序,§ 是介于 0 和 1 之间的常数。
希尔排序。
4. 线性阶 (O(n)) 排序基数排序,此外还有桶、箱排序。
关于稳定性:稳定的排序算法:冒泡排序、插⼊排序、归并排序和基数排序。
不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序。
名词解释:n:数据规模k:“桶”的个数In-place:占⽤常数内存,不占⽤额外内存Out-place:占⽤额外内存稳定性:排序后 2 个相等键值的顺序和排序之前它们的顺序相同冒泡排序冒泡排序(Bubble Sort)也是⼀种简单直观的排序算法。
它重复地⾛访过要排序的数列,⼀次⽐较两个元素,如果他们的顺序错误就把他们交换过来。
⾛访数列的⼯作是重复地进⾏直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越⼩的元素会经由交换慢慢“浮”到数列的顶端。
作为最简单的排序算法之⼀,冒泡排序给我的感觉就像 Abandon 在单词书⾥出现的感觉⼀样,每次都在第⼀页第⼀位,所以最熟悉。
冒泡排序还有⼀种优化算法,就是⽴⼀个 flag,当在⼀趟序列遍历中元素没有发⽣交换,则证明该序列已经有序。
但这种改进对于提升性能来说并没有什么太⼤作⽤。
1. 算法步骤1. ⽐较相邻的元素。
如果第⼀个⽐第⼆个⼤,就交换他们两个。
2. 对每⼀对相邻元素作同样的⼯作,从开始第⼀对到结尾的最后⼀对。
排序降序visualstudiocode代码

排序降序visualstudiocode代码在计算机科学中,排序是非常基础而重要的一个算法。
排序是将一组数据按照特定规则进行排列的过程。
排序可以按照升序排列,也可以按照降序排列。
在某些情况下,数据是需要按照降序排列的。
本文将介绍如何在Visual Studio Code代码编辑器中实现排序降序功能。
Visual Studio Code是一个轻量级的、开源的代码编辑器。
与其他代码编辑器相比,Visual Studio Code具有众多的特性和扩展功能。
其中之一是代码排序。
Visual Studio Code提供了一种简单而有效的方法来进行排序。
首先,你需要将数据输入代码编辑器中。
这可以通过多种方式实现,例如从剪切板中粘贴、从文件中读取数据等。
一旦数据输入完成,你需要创建一个函数来实现排序。
函数的代码将根据你所使用的算法而不同。
接着,你需要选择排序算法。
这个选择过程取决于数据的大小、要求以及性能方面的考虑。
对于一些较小的数据集合,插入排序可能是一个不错的选择。
对于更大的数据集合,快速排序和归并排序则是更好的选择之一。
假设你已经选择了排序算法,并且已经编写了完成排序的函数。
现在你需要将数据输入到函数中并调用该函数。
然后,你需要编写代码来输出排序后的结果。
这可以通过多种方式来实现。
你可以将结果输出到控制台,也可以将结果保存到文件中。
最简单的方式是将结果打印到控制台上。
接下来,我们将重点介绍如何实现冒泡排序算法。
冒泡排序是一种简单而直观的排序算法。
它的基本思想是对数组进行多次遍历,在每次遍历中比较相邻的两个元素,并根据需要交换它们的位置。
这样可以将数组中较小的元素“浮”到顶部,并将较大的元素“沉”到底部。
下面是一段Visual Studio Code代码,用于实现冒泡排序算法:```typescriptfunction bubbleSort(arr: number[]): number[] {let len = arr.length;for (let i = 0; i < len - 1; i++) {for (let j = 0; j < len - 1 - i; j++) {if (arr[j] < arr[j + 1]) {[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]];}}}return arr;}let arr = [3, 5, 1, 4, 2];console.log(bubbleSort(arr));```以上代码创建了一个名为bubbleSort的函数,用于实现冒泡排序算法。
内部排序-其它-地址排序(地址重排算法)

内部排序-其它-地址排序(地址重排算法)⽂字描述 当每个记录所占空间较多,即每个记录存放的除关键字外的附加信息太⼤时,移动记录的时间耗费太⼤。
此时,就可以像表插⼊排序、链式基数排序,以修改指针代替移动记录。
但是有的排序⽅法,如快速排序和堆排序,⽆法实现表排序。
这种情况下就可以进⾏“地址排序”,即另设⼀个地址向量指⽰相应记录的位置;同时在排序过程中不移动记录⽽移动记录地址向量中相应分量的内容。
见⽰意图,(b)是排序结束后的地址向量,地址相连adr[1,…,8]中的值表⽰排序后的记录的次序,r[adr[1]]为最⼩记录,r[adr[8]]为最⼤记录。
如果需要的话,可根据adr的值重排记录的物理位置。
重排算法如下: ⽐如要根据⽰意图中的(b)中地址向量重排原记录的话,由于(b)中的adr[1]=6, 则在暂存R(49)后,需要将R(13)从r[6]的位置移动到r[1]。
⼜因为adr[6]=2,则将R(65)从r[2]的位置移⾄r[6]的位置。
同理,将R(27)移⾄r[2]的位置,此时因adr[4]=1,则之前暂存的R(49)应该放在r[4]的位置上。
⾄此完成⼀个调整记录位置的⼩循环,此⼩循环完成后的记录及地址向量的状态如⽰意图(c)所⽰。
⽰意图算法分析地址排序不能算是独⽴的算法,只是在之前讨论的内部排序算法中,另设⼀个地址向量,⽤移动地址向量中的分量值代替移动记录⽽已。
地址重排算法中,因为每个⼩循环要暂存⼀个记录,所以辅助空间为1地址重排算法中,除需要暂存的记录外,所有记录均⼀次到位。
⽽每个⼩循环⾄少移动两个记录,则这样的⼩循环最多n/2个,所以重排算法中⾄多移动记录[3n/2]次,其时间复杂度为n。
代码实现1 #include <stdio.h>2 #include <stdlib.h>34#define DEBUG56#define EQ(a, b) ((a) == (b))7#define LT(a, b) ((a) < (b))8#define LQ(a, b) ((a) <= (b))910#define MAXSIZE 10011#define INF 100000012 typedef int KeyType;13 typedef char InfoType;14 typedef struct{15 KeyType key;16 InfoType otherinfo;17 }RedType;1819 typedef struct{20 RedType r[MAXSIZE+1];21//地址向量22int adr[MAXSIZE+1];23int length;24 }SqList;2526void PrintList(SqList L){27int i = 0;28 printf("下标值:");29for(i=0; i<=L.length; i++){30 printf("[%d] ", i);31 }32 printf("\n关键字:");33for(i=0; i<=L.length; i++){34if(EQ(L.r[i].key, INF)){35 printf(" %-3c", '-');36 }else{37 printf(" %-3d", L.r[i].key);38 }39 }40 printf("\n其他值:");41for(i=0; i<=L.length; i++){42 printf(" %-3c", L.r[i].otherinfo);43 }44 printf("\n地址值:");45for(i=0; i<=L.length; i++){46 printf(" %-3d", L.adr[i]);47 }48 printf("\n\n");49return ;50 }5152//堆采⽤顺序存储表⽰53 typedef SqList HeapType;5455/*56 *已知H->r[s,...,m]中记录的关键字除H->r[s].key之外均满⾜的定义57 *本函数调整H-r[s]的关键字,使H->r[s,...,m]成为⼀个⼤顶堆(对其中58 *记录的关键字⽽⾔)59*/60void HeapAdjust(HeapType *H, int s, int m)61 {62// RedType rc = H->r[s];63 RedType rc = H->r[H->adr[s]];64int rc_adr = H->adr[s];65int j = 0;66//沿key较⼤的孩⼦结点向下筛选67for(j=2*s; j<=m; j*=2){68//j为key较⼤的纪录的下标69if(j<m && LT(H->r[H->adr[j]].key, H->r[H->adr[j+1]].key))70 j+=1;71//rc应该插⼊位置s上72if(!LT(rc.key, H->r[H->adr[j]].key))73break;74 H->adr[s] = H->adr[j];75 s = j;76 }77//插⼊78 H->adr[s] = rc_adr;79 }8081/*82 * 对顺序表H进⾏堆排序83*/84void HeapSort(HeapType *H)85 {86 #ifdef DEBUG87 printf("开始堆排序,和之前的堆排序不同之处在于,移动地址向量代替移动记录。
C语言排序方法之内部排序

重复上述过程,直到“在一趟排序过程中没有进行 过交换记录的操作”为止
C语言排序方法之内部排序
37
例 1 4398 38 38 38 3183 13
2 3489 49 49 4193 132387 27
3 65 65 6153 142397 23780 30 4 9776 7163 162357 243790 3308 38 5 719637 172367 263750 3409 49 6 19237 732607 3605 65 7 293770 3706 76 8 3907 97
r[j]=r[j+1];
{ flag=0;
r[j+1]=x;
for(j=1;j<=m;j++)
初 第第第第 第 始 一二三四 五 关 趟趟趟趟 趟 键 字
C语言排序方法之内部排序
38
void bubble_sort(JD r[],int n)
{ int m,i,j,flag=1;
if(r[j].key>r[j+1].key)
JD x;
{ flag=1;
m=n-1;
x=r[j];
while((m>0)&&(flag==1))
内部排序
1、概述 2、插入排序 3、交换排序 4、选择排序 5、归并排序 6、基数排序
C语言排序方法之内部排序
1
1、概述
• 排序的分类:
内部排序:全部记录都可以同时调入内存进行的排序。 外部排序:文件中的记录太多,无法全部将其同时调入内 存进行的排序。
C语言排序方法之内部排序
数据结构c++顺序表、单链表的基本操作,查找、排序代码

} return 0; }
实验三 查找
实验名称: 实验3 查找 实验目的:掌握顺序表和有序表的查找方法及算法实现;掌握二叉排序 树和哈希表的构造和查找方法。通过上机操作,理解如何科学地组织信 息存储,并选择高效的查找算法。 实验内容:(2选1)内容1: 基本查找算法;内容2: 哈希表设计。 实验要求:1)在C++系统中编程实现;2)选择合适的数据结构实现查 找算法;3)写出算法设计的基本原理或画出流程图;4)算法实现代码 简洁明了;关键语句要有注释;5)给出调试和测试结果;6)完成实验 报告。 实验步骤: (1)算法设计 a.构造哈希函数的方法很多,常用的有(1)直接定址法(2)数字分析法;(3) 平方取中法;(4)折叠法;( 5)除留余数法;(6)随机数法;本实验采用的是除 留余数法:取关键字被某个不大于哈希表表长m的数p除后所得余数为哈 希地址 (2)算法实现 hash hashlist[n]; void listname(){ char *f; int s0,r,i; NameList[0].py="baojie"; NameList[1].py="chengቤተ መጻሕፍቲ ባይዱoyang"; ……………………………… NameList[29].py="wurenke"; for(i=0;i<q;i++){s0=0;f=NameList[i].py; for(r=0;*(f+r)!='\0';r++) s0+=*(f+r);NameList[i].k=s0; }} void creathash(){int i;
v[k-1]=v[k]; nn=nn-1; return ; } int main() {sq_LList<double>s1(100); cout<<"第一次输出顺序表对象s1:"<<endl; s1.prt_sq_LList(); s1.ins_sq_LList(0,1.5); s1.ins_sq_LList(1,2.5); s1.ins_sq_LList(4,3.5); cout<<"第二次输出顺序表对象s1:"<<endl; s1.prt_sq_LList(); s1.del_sq_LList(0); s1.del_sq_LList(2); cout<<"第三次输出顺序表对象s1:"<<endl; s1.prt_sq_LList(); return 0; } 运行及结果:
range.sort方法

range.sort方法在编程中,排序是一个常见的操作。
它可以帮助我们整理数据,使其按照特定的顺序排列。
在许多编程语言和库中,都有提供内置的排序函数或方法。
Python中的`range()`对象也提供了这样的一个方法——`sort()`. 本文将详细介绍这个方法的用法以及它的工作原理。
一、基本概念`sort()`是Python内建的一个方法,用于对列表进行排序。
对于`range()`对象来说,其内部实际上就是一个列表,因此也可以使用`sort()`方法对其进行排序。
不过需要注意的是,`sort()`会改变原来的范围对象(即它会创建一个新的已排序的子序列)。
如果你想保留原始的范围对象不变,那么需要使用其他的方法如`sorted()`来获取一个新的已排序的列表。
二、语法与参数调用`sort()`的基本格式如下:```pythonrange_object.sort(reverse=False)```其中,`range_object`是需要排序的`range()`对象的引用;`reverse`是一个可选参数,表示是否降序排序。
默认为升序排序。
如果设置为True,则从大到小排序。
三、示例代码及解释下面是一个简单的例子,展示了如何使用`sort()`方法对一个范围内的整数进行排序:```python# 定义范围并初始化为一些随机数r = range(10) # 创建一个包含从0到9的range对象random.shuffle(r) # 对这些数字打乱顺序print("原顺序:")for i in r:print(i, end=' ')# 使用sort()方法进行排序r.sort()print("\n排序后的结果:")for i in r:print(i, end=' ')```这段代码首先创建了一个包含了1-9的一些随机数的`range()`对象。
数据结构与算法-排序

假定待排序文件由 n 条记录组成,记录依次存储在 r[1]~r[n]中。使用简单冒泡排
序算法对待排序文件中的记录进行排序,具体处理流程如下。
(1)遍历待排序文件 r[1]~r[n],每访问一条记录 r[j]时,比较所访问记录排序关
键字与所访问记录后一记录排序关键字的大小,核对所访问记录 r[j]与所访问记录后一
则,此排序算法是不稳定的。例如, 给定待排序文件 A={1,2,3,1,4}和B={1,3,1,2,4},假定某
一排序算法对文件 A 和B 的排序结果分别为{1,1,2,3,4}和{1,1,2,3,4},由于文件 B 中存在多
项同为 1 的记录,且排序后同为 1 的记录相对位置发生了改变,因此,此算法是不稳定
排序
目
CONTENTS
录
01
排序的概述
02
插入排序算法
03
交换排序算法
04
选择排序算法
05
归并排序算法
06
分配排序算法
07
各种排序技术比较
08
本章小结
01
PART
排序的概述
排序是以某一数据项(称为排序关键字)为依据,将一组无序记录调整成一组有序
记录,形成有序表的过程。排序问题可以定义为以下形式。
件排序时,记录分组以及每趟排序结果如右
图所示。
插入排序算法
2.3希尔排序算法
第一趟排序时,增量 h=4,因此,以
h=4 为记录间隔,将待排序文件中的记录分
为 4 组:{r[1],r[5],r[9]}、{r[2],r[6]}、{r[3],r[7]}
和{r[4],r[8]},并分别对 4 组记录进行直接插入
排序的详细分类

排序的详细分类排序分为外部排序和内部排序,其中平时主要学习的是内部排序。
内部排序主要分为5⼤类:(ps:其中计数排序⼀般不做分析)1. 插⼊排序:1. 直接插⼊排序:每次处理就是将⽆序的数列中第⼀个元素与有序数列的元素从后到前⽐较,找到插⼊位置,将该元素插⼊到有序数列的适当的最终的位置上(稳定排序)。
算法过程/*直接插⼊排序*/#include<stdio.h>void insertSort(int arr[], int length);int main() {int a[5] = { 5,2,3,4,1 };insertSort(a, 5);for (int i = 0; i < 5; i++)printf("%5d", a[i]);}void insertSort(int arr[], int length) {int i, j, k;for (i = 1; i < length; i++) {if (arr[i] < arr[i - 1]) {k = arr[i];for (j = i - 1; arr[j] > k && j >= 0; j--) {//待插元素⼩于当前元素arr[j + 1] = arr[j];}arr[j + 1] = k;}}} 2.折半插⼊排序 算法过程/*折半插⼊排序:将⼀个新元素插⼊打已经拍好像的数组的过程,mid=(low+high)/2,判断插⼊元素是否⼩于参考元素,若是则选择low-high(high=mid-1)为插⼊区间,反之则选择low(low=mid+1)-high,直到low>high时,即将此位置之后所有元素后移⼀位,并将新元素插⼊a[high+1]*/#include<stdio.h>int main() {void BinSort(int a[], int n);void put(int r[], int n);int arr[] = { 9,8,7,6,5,4,3,2,1 };BinSort(arr, 9);put(arr, 9);}void BinSort(int a[], int n) {int i, j, high,low, mid,t;for (i = 1; i < n; i++) {low = 0;high = i - 1;t = a[i];while (low<=high){mid = (low + high) / 2;if (t < a[mid]) {high = mid - 1;}else{low = mid + 1;}}for (j = i - 1; j >=high+1; j--) {//high+1的元素后移a[j + 1] = a[j];}a[j + 1] = t;//插⼊选定的地点}}。
元组内部元素进行排序的方法

元组内部元素进行排序的方法元组是Python中的不可变序列类型,因此不能直接对元组进行排序。
如果需要对元组进行排序,可以先将元组转换为列表,对列表进行排序,然后再将排序后的列表转换回元组。
以下是一个示例代码,展示如何对元组进行排序:```python定义一个元组my_tuple = (3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5)将元组转换为列表my_list = list(my_tuple)对列表进行排序my_()将排序后的列表转换回元组sorted_tuple = tuple(my_list)输出排序后的元组print(sorted_tuple)```在上述代码中,我们首先定义了一个元组`my_tuple`,然后使用`list()`函数将其转换为列表`my_list`。
接下来,我们使用列表的`sort()`方法对列表进行排序。
最后,使用`tuple()`函数将排序后的列表转换回元组`sorted_tuple`,并将其输出。
需要注意的是,由于元组是不可变序列类型,因此转换回的元组与原始元组是不同的对象。
如果需要保持原始元组的顺序不变,可以使用`sorted()`函数来生成一个新的排序后的元组,如下所示:```python定义一个元组my_tuple = (3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5)使用sorted()函数生成一个新的排序后的元组sorted_tuple = sorted(my_tuple)输出排序后的元组print(sorted_tuple)```在上述代码中,我们使用`sorted()`函数对元组`my_tuple`进行排序,并生成一个新的排序后的元组`sorted_tuple`。
由于`sorted()`函数返回一个新的元组,因此不会改变原始元组的顺序。
最后,我们将排序后的元组输出。
常用的内部排序方法

常用的内部排序方法有:交换排序(冒泡排序、快速排序)、选择排序(简单选择排序、堆排序)、插入排序(直接插入排序、希尔排序)、归并排序、基数排序(一关键字、多关键字)。
一、冒泡排序:1.基本思想:两两比较待排序数据元素的大小,发现两个数据元素的次序相反时即进行交换,直到没有反序的数据元素为止。
2.排序过程:设想被排序的数组R[1..N]垂直竖立,将每个数据元素看作有重量的气泡,根据轻气泡不能在重气泡之下的原则,从下往上扫描数组R,凡扫描到违反本原则的轻气泡,就使其向上"漂浮",如此反复进行,直至最后任何两个气泡都是轻者在上,重者在下为止。
【示例】:49 13 13 13 13 13 13 1338 49 27 27 27 27 27 2765 38 49 38 38 38 38 3897 65 38 49 49 49 49 4976 97 65 49 49 49 49 4913 76 97 65 65 65 65 6527 27 76 97 76 76 76 7649 49 49 76 97 97 97 97二、快速排序(Quick Sort)1.基本思想:在当前无序区R[1..H]中任取一个数据元素作为比较的"基准"(不妨记为X),用此基准将当前无序区划分为左右两个较小的无序区:R[1..I-1]和R[I+1..H],且左边的无序子区中数据元素均小于等于基准元素,右边的无序子区中数据元素均大于等于基准元素,而基准X 则位于最终排序的位置上,即R[1..I-1]≤X.Key≤R[I+1..H](1≤I≤H),当R[1..I-1]和R[I+1..H]均非空时,分别对它们进行上述的划分过程,直至所有无序子区中的数据元素均已排序为止。
2.排序过程:【示例】:初始关键字[49 38 65 97 76 13 27 49]第一次交换后[27 38 65 97 76 13 49 49]第二次交换后[27 38 49 97 76 13 65 49]J向左扫描,位置不变,第三次交换后[27 38 13 97 76 49 65 49]I向右扫描,位置不变,第四次交换后[27 38 13 49 76 97 65 49]J向左扫描[27 38 13 49 76 97 65 49](一次划分过程)初始关键字[49 38 65 97 76 13 27 49]一趟排序之后[27 38 13]49 [76 97 65 49]二趟排序之后[13]27 [38]49 [49 65]76 [97]三趟排序之后13 27 38 49 49 [65]76 97最后的排序结果13 27 38 49 49 65 76 97三、简单选择排序1.基本思想:每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
#include<stdio.h>
#include<math.h>
#include<iostream.h>
#include<stdlib.h>
#define OK 1
#define FALSE 0
#define MAX_NUM 100
typedef int Status;
typedef int ElemType;
typedef struct SqList
{
ElemType r[MAX_NUM];
int length;
}SqList;
typedef SqList HeapType;
Status Exchange(ElemType &a,ElemType &b) {
ElemType t;
t=a;a=b;b=t;
return OK;
}
//直接插入排序
Status InsertSort(SqList &L)
{
int i,j;
for(i=2;i<=L.length;i++)
if(L.r[i]<L.r[i-1])
{
L.r[0]=L.r[i];
L.r[i]=L.r[i-1];
for(j=i-1;L.r[0]<L.r[j];j--)
L.r[j+1]=L.r[j];
L.r[j+1]=L.r[0];
}
return OK;
}
//希尔排序
void ShellInsert(SqList &L,int dk)
{
int i,j;
for(i=dk+1;i<=L.length;i++)
if(L.r[i]<L.r[i-dk])
{
L.r[0]=L.r[i];
for(j=i-dk;j>0&&L.r[0]<L.r[j];j-=dk)
L.r[j+dk]=L.r[j];
L.r[j+dk]=L.r[0];
}
}
Status ShellSort(SqList &L)
{
int i,j,t,n,dlta[10];
n=log(L.length)/log(2);
printf("请输入你要排序的趟数(系统将根据相关规则定义递增序列,但不能大于%d):\n",n);
cin>>t;
for(j=1,i=t-1;i>=0;i--,j<<=1)
dlta[i]=j+1;
dlta[t-1]--;
for(i=0;i<t;i++)
ShellInsert(L,dlta[i]);
return OK;
}
//冒泡排序
Status MPSort(SqList &L)
{
int i,j;
for(i=1;i<L.length;i++)
for(j=1;j<L.length;j++)
if(L.r[j]>L.r[j+1])
Exchange(L.r[j],L.r[j+1]);
return OK;
}
//快速排序
int Partition(SqList &L,int low,int high)
{
int pivotkey=L.r[low];
L.r[0]=L.r[low];
while(low<high)
{
while(low<high&&L.r[high]>=pivotkey) high--;
L.r[low]=L.r[high];
while(low<high&&L.r[low]<=pivotkey) low++;
L.r[high]=L.r[low];
}
L.r[low]=L.r[0];
return low;
}
void Qsort(SqList &L,int low,int high)
{
if(low<high)
{
int pivotloc=Partition(L,low,high);
Qsort(L,low,pivotloc-1);
Qsort(L,pivotloc+1,high);
}
}
Status QuickSort(SqList &L)
{
Qsort(L,1,L.length);
return OK;
}
//简单选择排序
int SelectMinKey(SqList L,int i)
{
int k;
for(k=i;i<L.length;)
if(L.r[k]>L.r[++i])
k=i;
return k;
}
Status SelectSort(SqList &L)
{
int i,j;
for(i=1;i<L.length;i++)
{
j=SelectMinKey(L,i);
if(i!=j) Exchange(L.r[i],L.r[j]);
}
return OK;
}
//堆排序
typedef SqList HeapType;
void HeapAdjust(HeapType &H,int s,int m) {
int j;
ElemType rc=H.r[s];
for(j=2*s;j<=m;j*=2)
{
if(j<m&&H.r[j]<H.r[j+1]) j++;
if(rc>=H.r[j]) break;
H.r[s]=H.r[j];
s=j;
}
H.r[s]=rc;
}
Status HeapSort(HeapType &H)
{
int i;
for(i=H.length/2;i>0;i--)
HeapAdjust(H,i,H.length);
for(i=H.length;i>1;i--)
{
Exchange(H.r[1],H.r[i]);
HeapAdjust(H,1,i-1);
}
return OK;
}
//归并排序
void Merge(ElemType SR[],ElemType TR[],int i,int m,int n) {
int j,k;
for(j=m+1,k=i;i<=m&&j<=n;k++)
{
if(SR[i]<SR[j]) TR[k]=SR[i++];
else TR[k]=SR[j++];
}
while(i<=m) TR[k++]=SR[i++];
while(j<=n) TR[k++]=SR[j++];
}
void MSort(ElemType SR[],ElemType TR1[],int s,int t) {
int m;
ElemType TR2[MAX_NUM];
if(s==t) TR1[s]=SR[s];
else
{
m=(s+t)/2;
MSort(SR,TR2,s,m);
MSort(SR,TR2,m+1,t);
Merge(TR2,TR1,s,m,t);
}
}
Status MergeSort(SqList &L)
{
MSort(L.r,L.r,1,L.length);
return OK;
}
//主函数
Status main()
{
SqList L;
int i,t,d;
loop:puts("请输入待排序数组的元素个数:");
cin>>L.length;
puts("请输入你要排序的数组:");
for(i=1;i<=L.length;i++)
cin>>L.r[i];
puts("请选择你想要使用的排序方式:1.直接插入排序,2.希尔排序,3.冒泡排序,\n4.快速排序,5.简单选择排序,6.堆排序,7.归并排序:");
cin>>t;
switch(t)
{
case 1:InsertSort(L);break;
case 2:ShellSort(L);break;
case 3:MPSort(L);break;
case 4:QuickSort(L);break;
case 5:SelectSort(L);break;
case 6:HeapSort(L);break;
case 7:MergeSort(L);
}
puts("排序后结果为:");
for(i=1;i<=L.length;i++)
printf("%-3d",L.r[i]);
putchar('\n');
puts("你想要退出程序吗?(Y/N)");
getchar();
if(getchar()=='N')
{
system("CLS");
goto loop;
}
system("pause");
return OK;
}。