史上最全快速排序法源代码
学习怎么用按键精灵制作游戏辅助——脚本源代码干货分享

学习怎么用按键精灵制作游戏辅助——脚本源代码干货分享一、用按键精灵确定人物朝向(以剑灵自动寻路为例)的代码在剑灵右上角的小地图里找色/找图,箭头坐标存储在(x1,y1),箭尾坐标存储在(x2,y2) FindColor1200,0,1920,300,"箭头颜色",x1,y1If x1 > 0 And y1> 0 ThenEnd IfFindColor1200,0,1920,300,"箭尾颜色",x2,y2If x1 > 0 And y1> 0 ThenEnd If'计算斜率/正切值斜率= (y1 - y2) / (x1 -x2)'计算角度角度= Atn(斜率)二、用按键精灵解决用户密码泄露问题的代码Function 加解密(源文件, 秘钥)Dim Z, iDim A, B, C加解密= ""If Len(源文件) = 0 Then’如果密码为空,则初始化为空加解密= ""Exit FunctionEnd If'调用Rnd函数使以后Rnd函数所产生的Rnd为相同的伪随机数列Z = Rnd(-秘钥)For i = 1 To Len(源文件)’将密码字符串一个一个字符通过加密,转换成另一个字符C = Mid(源文件, i, 1)A = Asc(C)B = Int(126 * Rnd) And&H7F’这里的&H7F,是指生成的伪随机代码,只取7位,以免数据溢出A = A Xor B’Xor是可逆的,第一次运行时是得到加密后的数据,再运行一次是得到解密后的数据C = Chr(A)加解密= 加解密+ CNextEnd Function举个例子吧~Function 加解密(源文件, 秘钥)Dim Z, iDim A, B, C加解密= ""If Len(源文件) = 0 Then加解密= ""Exit FunctionEnd If'调用Rnd函数使以后Rnd函数所产生的Rnd为相同的伪随机数列Z = Rnd(-密钥)For i = 1 To Len(源文件)C = Mid(源文件, i, 1)A = Asc(C)B = Int(126 * Rnd) And&H7FA = A Xor BC = Chr(A)加解密= 加解密+ CNextEnd FunctionEvent Form1.Load//获取小节名(如"e1df741f-d5ec-4ad7-969d-adb139c6a24f"),同一个Q文件生成的小节名不变a = GetMacroID()//获取到当前脚本/小精灵de ID加密文件=Plugin.File.ReadINI("e1df741f-d5ec-4ad7-969d-adb139c6a24f","Form1 .InputBox2.T ext", ".\uservar.ini")解密文件= 加解密(加密文件, 1234567890)'这里的1234567890是假使的密钥,可以修改,注意保密Form1.InputBox2.T ext = 解密文件End Event//写入密码信息源文件= Form1.InputBox2.T ext加密文件= 加解密(源文件, 1234567890)CallPlugin.File.WriteINI("e1df741f-d5ec-4ad7-969d-adb139c6a24f","Form1.InputBox2.T ext", 加密文件, ".\uservar.ini")//输出信息RunApp "notepad.exe"SayString Form1.InputBox1.T extKeyPress "Enter", 1SayString 源文件三、按键精灵快速排序的代码su = "6|1|2|7|9|3|4|5|10|8"su=Split(su, "|")L = UBound(su)Call ks(0, L)Function ks(L, B)If L > B ThenExit FunctionEnd If //判断数组上标下标是否超出范围i = Lj = Bkey =int( su(L) ) //数组第一位提取作为基数While j>iWhile int ( su(j)) >= key and j > i //要先从最右边开始找找到第一个小于key的数这里添加的j>i的判断是为了防止j的值不断递减导致下标越界j = j - 1WendWhile int (su(i)) <= key and j > i //从最左边开始找找到第一个大于key的数(这里的字符串数组需要转换为数值型)i = i + 1WendIf j>i then // 将和基数key对比得到的两个数对换将大于key的值往右边放小于key的值往左边放T = su(i)su(i) = su(j)su(j) = TEnd IfWend // 这个While 循环当i=j 第一轮比较完退出su(L) = su(i) // 重新设置数组第一个元素为基数su(i) = key// 基数归位(排完一轮之后左边的数<基数<右边的数那么基数就到了排序中它该在的位置。
源代码--数据结构与算法(Python版)chap10 排序

交换类
(2)快速排序 快速排序采用分而治之(Divide and Conquer)
的策略将问题分解成若干个较小的子问题,采用 相同的方法一一解决后,再将子问题的结果整合 成最终答案。快速排序的每一轮处理其实就是将 这一的基准数定位,直到所有的数都排序完成 为止。
21
快速排序的基本步骤:
1. 选定一个基准值(通常可选第一个元素); 2. 将比基准值小的数值移到基准值左边,形
14
• 交换类
交换类排序的基本思想是:通过交换无序序列 中的记录得到其中关键字最小或最大的记录,并将 其加入到有序子序列中,最终形成有序序列。交换 类排序可分为冒泡排序和快速排序等。
15
交换类
(1)冒泡排序 两两比较待排序记录的关键字,发现两
个记录的次序相反时即进行交换,直到没有 反序的记录为止。因为元素会经由交换慢慢 浮到序列顶端,故称之为冒泡排序。
3. 最后对这个组进行插入排序。步长的选法 一般为 d1 约为 n/2,d2 为 d1 /2, d3 为 d2/2 ,…, di = 1。
11
【例】给定序列(11,9,84,32,92,26,58,91,35, 27,46,28,75,29,37,12 ),步长设为d1 =5、d2 =3、 d3 =1,希尔排序过程如下:
for i in range(1,len(alist)):
#外循环n-1
for j in range(i,0,-1):
#内循环
if alist[j]<alist[j-1]:
alist[j],alist[j-1]=alist[j-1],alist[j] #交换
li=[59,12,77,64,72,69,46,89,31,9] print('before: ',li) insert_sort(li) print('after: ',li)
快速排序详解(lomuto划分快排,hoare划分快排,classic经典快排,dualp。。。

快速排序详解(lomuto划分快排,hoare划分快排,classic经典快排,dualp。
快速排序(lomuto划分快排,hoare划分快排,classic经典快排,dualpivot双轴快排)@⽬录⼀、快速排序思想快速排序的思想,是找出⼀个中轴(pivot),之后进⾏左右递归进⾏排序,关于递归快速排序,C程序算法如下。
void quick_sort(int *arr,int left,int right){if(left>right) return;int pivot=getPivot();quick_sort(arr,left,pivot-1);quick_sort(arr,pivot+1,right);}⼆、划分思想关于划分,不同的划分决定快排的效率,下⾯以lomuto划分和hoare划分来进⾏讲述思路1.lomuto划分思想:lomuto划分主要进⾏⼀重循环的遍历,如果⽐left侧⼩,则进⾏交换。
然后继续进⾏寻找中轴。
最后交换偏移的数和最左侧数,C程序代码如下。
/**lomuto划分*/int lomuto_partition(int *arr,int l,int r){int p=arr[l];int s=l;for(int i=l+1;i<=r;i++)if(arr[i]<p) {s++;int tmp=arr[i];arr[i]=arr[s];arr[s]=tmp;}int tmp=arr[l];arr[l]=arr[s];arr[s]=tmp;return s;}2.hoare划分思想:hoare划分思想是先从右侧向左进⾏寻找,再从左向右进⾏寻找,如果左边⽐右边⼤,则左右进⾏交换。
外侧还有⼀个嵌套循环,循环终⽌标志是⼀重遍历,这种寻找的好处就是,在⼀次遍历后能基本有序,减少递归的时候产⽣的⽐较次数。
这也是经典快排中所使⽤的⽅法/**hoare划分*/int hoare_partition(int *a,int l, int r) {int p = a[l];int i = l-1;int j = r+1 ;while (1) {do {j--;}while(a[j]>p);do {i++;}while(a[i] < p);if (i < j) {int temp = a[i];a[i] = a[j];a[j] = temp;}elsereturn j;}}3.经典快排的划分改进经典快排实际对hoare划分进⾏了少许改进,这个temp变量不需要每次找到左右不相等就⽴即交换,⽽是,暂时存放,先右边向左找,将左边放在右边,再左边向右找,把右边放左边,最后把初始temp变量放在左值。
php的9个经典排序算法

以下是使用PHP 实现的9个经典的排序算法:1. 冒泡排序```function bubble_sort($arr) {$n = count($arr);if ($n <= 1) {return $arr;}for ($i = 0; $i < $n; $i++) {for ($j = 0; $j < $n - $i - 1; $j++) {if ($arr[$j] > $arr[$j+1]) {$temp = $arr[$j+1];$arr[$j+1] = $arr[$j];$arr[$j] = $temp;}}}return $arr;}```2. 选择排序```function selection_sort($arr) {$n = count($arr);if ($n <= 1) {return $arr;}for ($i = 0; $i < $n; $i++) {$minIndex = $i;for ($j = $i+1; $j < $n; $j++) {if ($arr[$j] < $arr[$minIndex]) {$minIndex = $j;}}$temp = $arr[$i];$arr[$i] = $arr[$minIndex];$arr[$minIndex] = $temp;}return $arr;}```3. 插入排序```function insertion_sort($arr) {$n = count($arr);if ($n <= 1) {return $arr;}for ($i = 1; $i < $n; $i++) {$value = $arr[$i];$j = $i - 1;for (; $j >= 0; $j--) {if ($arr[$j] > $value) {$arr[$j+1] = $arr[$j];} else {break;}}$arr[$j+1] = $value;}return $arr;}```4. 快速排序```function quick_sort($arr) {$n = count($arr);if ($n <= 1) {return $arr;}$pivotIndex = floor($n/2);$pivot = $arr[$pivotIndex];$left = array();$right = array();for ($i = 0; $i < $n; $i++) {if ($i == $pivotIndex) {continue;} else if ($arr[$i] < $pivot) {$left[] = $arr[$i];} else {$right[] = $arr[$i];}}return array_merge(quick_sort($left), array($pivot), quick_sort($right));}```5. 归并排序```function merge_sort($arr) {$n = count($arr);if ($n <= 1) {return $arr;}$mid = floor($n/2);$left = array_slice($arr, 0, $mid);$right = array_slice($arr, $mid);$left = merge_sort($left);$right = merge_sort($right);$newArr = array();while (count($left) && count($right)) {$newArr[] = $left[0] < $right[0] ? array_shift($left) : array_shift($right);}return array_merge($newArr, $left, $right);}```6. 堆排序```function heap_sort(&$arr) {$n = count($arr);if ($n <= 1) {return;}build_heap($arr);for ($i = $n-1; $i > 0; $i--) {$temp = $arr[0];$arr[0] = $arr[$i];$arr[$i] = $temp;heapify($arr, 0, $i);}}function build_heap(&$arr) {$n = count($arr);for ($i = floor($n/2)-1; $i >= 0; $i--) {heapify($arr, $i, $n);}}function heapify(&$arr, $i, $n) {$left = 2*$i+1;$right = 2*$i+2;$largest = $i;if ($left < $n && $arr[$left] > $arr[$largest]) {$largest = $left;}if ($right < $n && $arr[$right] > $arr[$largest]) {$largest = $right;}if ($largest != $i) {$temp = $arr[$i];$arr[$i] = $arr[$largest];$arr[$largest] = $temp;heapify($arr, $largest, $n);}}```7. 希尔排序```function shell_sort($arr) {$n = count($arr);if ($n <= 1) {return $arr;}$gap = floor($n/2);while ($gap > 0) {for ($i = $gap; $i < $n; $i++) {$temp = $arr[$i];for ($j = $i-$gap; $j >= 0 && $arr[$j] > $temp; $j -= $gap) {$arr[$j+$gap] = $arr[$j];}$arr[$j+$gap] = $temp;}$gap = floor($gap/2);}return $arr;}```8. 计数排序```function counting_sort($arr) {$n = count($arr);if ($n <= 1) {return $arr;}$maxVal = max($arr);$countArr = array_fill(0, $maxVal+1, 0);for ($i = 0; $i < $n; $i++) {$countArr[$arr[$i]]++;}for ($i = 1; $i < $maxVal+1; $i++) {$countArr[$i] += $countArr[$i-1];}$tmpArr = array();for ($i = $n-1; $i >= 0; $i--) {$tmpArr[$countArr[$arr[$i]]-1] = $arr[$i];$countArr[$arr[$i]]--;}for ($i = 0; $i < $n; $i++) {$arr[$i] = $tmpArr[$i];}return $arr;}```9. 桶排序```function bucket_sort($arr) {$n = count($arr);if ($n <= 1) {return $arr;}$maxVal = max($arr);$bucketSize = 10;$bucketCount = floor($maxVal / $bucketSize) + 1;$buckets = array();for ($i = 0; $i < $bucketCount; $i++) {$buckets[$i] = array();}for ($i = 0; $i < $n; $i++) {$index = floor($arr[$i] / $bucketSize);array_push($buckets[$index], $arr[$i]);}$newArr = array();for ($i = 0; $i < $bucketCount; $i++) {$bucketArr = $buckets[$i];$len = count($bucketArr);if ($len > 1) {sort($bucketArr);}for ($j = 0; $j < $len; $j++) {array_push($newArr, $bucketArr[$j]);}}return $newArr;}```以上就是使用PHP 实现的9个经典的排序算法。
C语言八大排序算法
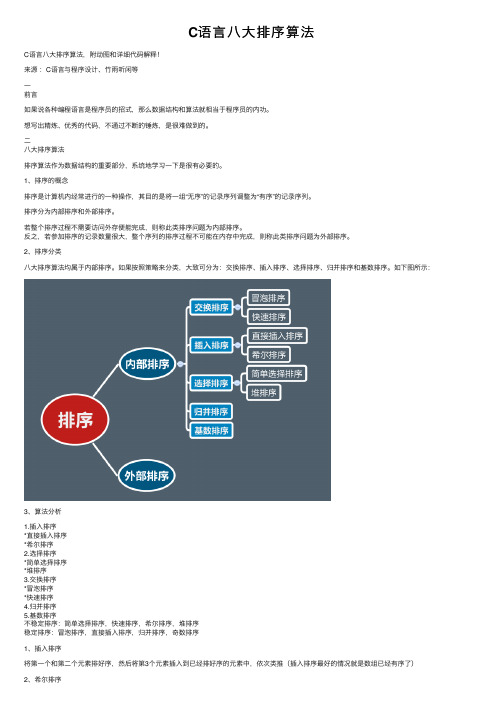
C语⾔⼋⼤排序算法C语⾔⼋⼤排序算法,附动图和详细代码解释!来源:C语⾔与程序设计、⽵⾬听闲等⼀前⾔如果说各种编程语⾔是程序员的招式,那么数据结构和算法就相当于程序员的内功。
想写出精炼、优秀的代码,不通过不断的锤炼,是很难做到的。
⼆⼋⼤排序算法排序算法作为数据结构的重要部分,系统地学习⼀下是很有必要的。
1、排序的概念排序是计算机内经常进⾏的⼀种操作,其⽬的是将⼀组“⽆序”的记录序列调整为“有序”的记录序列。
排序分为内部排序和外部排序。
若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序。
反之,若参加排序的记录数量很⼤,整个序列的排序过程不可能在内存中完成,则称此类排序问题为外部排序。
2、排序分类⼋⼤排序算法均属于内部排序。
如果按照策略来分类,⼤致可分为:交换排序、插⼊排序、选择排序、归并排序和基数排序。
如下图所⽰:3、算法分析1.插⼊排序*直接插⼊排序*希尔排序2.选择排序*简单选择排序*堆排序3.交换排序*冒泡排序*快速排序4.归并排序5.基数排序不稳定排序:简单选择排序,快速排序,希尔排序,堆排序稳定排序:冒泡排序,直接插⼊排序,归并排序,奇数排序1、插⼊排序将第⼀个和第⼆个元素排好序,然后将第3个元素插⼊到已经排好序的元素中,依次类推(插⼊排序最好的情况就是数组已经有序了)因为插⼊排序每次只能操作⼀个元素,效率低。
元素个数N,取奇数k=N/2,将下标差值为k的数分为⼀组(⼀组元素个数看总元素个数决定),在组内构成有序序列,再取k=k/2,将下标差值为k的数分为⼀组,构成有序序列,直到k=1,然后再进⾏直接插⼊排序。
3、简单选择排序选出最⼩的数和第⼀个数交换,再在剩余的数中⼜选择最⼩的和第⼆个数交换,依次类推4、堆排序以升序排序为例,利⽤⼩根堆的性质(堆顶元素最⼩)不断输出最⼩元素,直到堆中没有元素1.构建⼩根堆2.输出堆顶元素3.将堆低元素放⼀个到堆顶,再重新构造成⼩根堆,再输出堆顶元素,以此类推5、冒泡排序改进1:如果某次冒泡不存在数据交换,则说明已经排序好了,可以直接退出排序改进2:头尾进⾏冒泡,每次把最⼤的沉底,最⼩的浮上去,两边往中间靠16、快速排序选择⼀个基准元素,⽐基准元素⼩的放基准元素的前⾯,⽐基准元素⼤的放基准元素的后⾯,这种动作叫分区,每次分区都把⼀个数列分成了两部分,每次分区都使得⼀个数字有序,然后将基准元素前⾯部分和后⾯部分继续分区,⼀直分区直到分区的区间中只有⼀个元素的时候,⼀个元素的序列肯定是有序的嘛,所以最后⼀个升序的序列就完成啦。
acm算法源代码

| SPFA(SHORTEST PATH FASTER ALGORITHM) .............. 4 | 第K短路(DIJKSTRA)................................................... 5 | 第K短路(A*) .............................................................. 5 | PRIM求MST ..................................................................... 6 | 次小生成树O(V^2)....................................................... 6 | 最小生成森林问题(K颗树)O(MLOGM). ....................... 6 | 有向图最小树形图 ......................................................... 6
(O(NLOGN + Q)).............................................................19 | RMQ离线算法 O(N*LOGN)+O(1)求解LCA...............19 | LCA离线算法 O(E)+O(1).........................................20 | 带权值的并查集 ...........................................................20 | 快速排序 .......................................................................20 | 2 台机器工作调度........................................................20 | 比较高效的大数 ...........................................................20 | 普通的大数运算 ...........................................................21 | 最长公共递增子序列 O(N^2)....................................22 | 0-1 分数规划...............................................................22 | 最长有序子序列(递增/递减/非递增/非递减) ....22 | 最长公共子序列 ...........................................................23 | 最少找硬币问题(贪心策略-深搜实现) .................23 | 棋盘分割 .......................................................................23 | 汉诺塔 ...........................................................................23
数据结构经典代码(严蔚敏)

/* 线性表的顺序表示:类型和界面定义*//* 线性表的顺序表示:函数实现*//* 线性表的单链表表示:类型和界面函数定义*//* 线性表的单链表表示:函数实现*//* 线性表的顺序表示:类型和界面定义*//* 线性表的顺序表示:函数实现*//* 用顺序表解决josephus问题的算法*//* 用循环单链表解决josephus问题的算法*//*字符串的顺序表示*//* 字符串的链接表示 *//* 顺序栈表示:类型和界面函数声明 *//* 顺序栈表示:函数定义 *//* 栈链接表示:类型和界面函数声明 *//*栈链接表示:函数定义*//* 简化背包问题的递归算法*//* 简化背包问题的非递归算法*//* 迷宫问题的递归算法*//* 迷宫问题的非递归算法(栈实现)*//* 队列的顺序表示:类型和函数声明 *//* 队列的顺序表示:函数定义 *//*队列链接表示:类型和界面函数声明*//*队列链接表示:函数定义*//* 用队列解决农夫过河问题的算法*//* 树的长子-兄弟表示法*//* 树的父指针表示法*//* 树的子表表示法*//* 树的后根周游的递归算法*//* 树的先根周游的非递归算法*//* 树的中根周游的递归算法*//* 树的后根周游的递归算法*//* 树的广度优先周游算法*//* 二叉树的链接表示*//* 二叉树的顺序表示*//* 线索二叉树的定义,构造算法和中根周游算法*//* 二叉树前根周游的递归算法*//* 二叉树对称根周游的递归算法*//* 二叉树后根周游的递归算法*//* 二叉树后根周游的非递归算法*//* 本程序提供了用顺序表实现字典的存储表示定义*//* 本程序是用开地址法解决碰撞的散列表示方法,提供了字典的一些基本操作*//* 字典的二叉排序树实现,本程序实现了二叉排序树的基本操作的算法*/ /* 字典的AVL树实现*//* 本程序提供了用顺序表实现字典的情况下的顺序检索算法*//* 本程序提供了用顺序表实现字典的情况下的二分法检索算法*//* 本程序是用开地址法实现散列的检索算法*//* 二叉排序树的检索算法*//* AVL树的检索算法*//* 最佳二叉排序树是具有最佳检索效率的二叉排序树, 本程序提供了最佳二叉排序树的构造方法*//* 直接插入排序的算法源程序*//* 二分法插入排序的算法源程序*//* 表插入排序的算法源程序*//* shell排序的算法源程序 *//* 直接选择排序的算法源程序*//* 堆排序的算法源程序*//* 起泡排序的算法源程序*//* 快速排序的算法源程序*//* 基数排序的算法源程序*//* 二路归并排序算法的源程序*//* 用图邻接矩阵表示实现的一些基本运算*//* 用图邻接表表示实现的一些基本运算*//* 用邻接矩阵表示的图的广度优先周游算法*//* 用邻接表表示的图的广度优先周游算法*//* 用邻接矩阵表示的图的深度优先周游的递归算法*/ /* 用邻接矩阵表示的图的深度优先周游的非递归算法*/ /* 用邻接表表示的图的深度优先周游的非递归算法*/ /* 用邻接矩阵表示的图的Kruskal算法的源程序*//* 用邻接矩阵表示的图的prim算法的源程序*//* 用邻接矩阵表示的图的Dijkstra算法的源程序*//* 用邻接矩阵表示的图的Floyd算法的源程序*//* 用邻接表表示图的拓扑排序算法*//* 用邻接矩阵表示图的拓扑排序算法*//* 图的关键路径问题的算法*//* 背包问题的贪心法算法*//* 用动态规划法求组和数的算法*//* 用回溯法解决骑士周游问题的算法*//* 0/1背包问题的回溯法算法*//* 0/1背包问题的动态规划法算法*//* 0/1背包问题的分支定界法算法*//* 线性表的顺序表示:类型和界面定义*/#define TRUE 1#define FALSE 0#define SPECIAL -1/* 定义顺序表的大小。
源代码 - 副本

cout<<A[i]<<" ";
cout<<endl;
finish3=clock();
}
template<class T> //直接插入排序
void an<T>::insertsort(T A[],int n)
{
start1=clock();
#include<iostream.h>
#include<time.h>
#include<math.h>
#include<iomanip.h>
#include <stdlib.h>
//外部变量定义
int count1=0,bj1=0,yd1=0;
int count2=0,bj2=0,yd2=0;
count5++;
qsort(A,left,j-1);
qsort(A,j+1,right);
}
}
template<class T> //两路合并排序
void an<T>::merge(T A[],int i1,int j1,int i2,int j2)
{
T *temp=new T[j2-i1+1];
{
start6=clock();
int i1,j1,i2,j2;
int size=1;
while(size<n)
{
i1=0;
while(i1+size<n)
快速排序法c语言代码

快速排序法c语言代码快速排序法是一种非常高效的排序算法,它能够在最好情况下实现O(NlogN)的时间复杂度。
下面是快速排序法的C语言代码实现: ```#include <stdio.h>void quicksort(int arr[], int left, int right) {int i, j, pivot, temp;if (left < right) {pivot = left;i = left;j = right;while (i < j) {while (arr[i] <= arr[pivot] && i < right)i++;while (arr[j] > arr[pivot])j--;if (i < j) {temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}temp = arr[pivot];arr[pivot] = arr[j];arr[j] = temp;quicksort(arr, left, j - 1);quicksort(arr, j + 1, right);}}int main() {int arr[] = {10, 7, 8, 9, 1, 5};int n = sizeof(arr) / sizeof(arr[0]);quicksort(arr, 0, n - 1);printf('Sorted array: ');for (int i = 0; i < n; i++)printf('%d ', arr[i]);return 0;}```在main函数中,我们首先定义一个整型数组arr,并初始化它。
然后通过计算数组的长度n,调用quicksort函数进行排序。
quicksort函数接收三个参数:待排序数组arr,左边界left和右边界right。
数据结构与算法实验源代码

数据结构与算法实验源代码数据结构与算法实验源代码一、实验目的本实验旨在通过编写数据结构与算法的实验源代码,加深对数据结构与算法的理解,并提高编程能力。
二、实验环境本实验使用以下环境进行开发和测试:- 操作系统:Windows 10- 开发工具:IDEA(集成开发环境)- 编程语言:Java三、实验内容本实验包括以下章节:3.1 链表在本章节中,我们将实现链表数据结构,并实现基本的链表操作,包括插入节点、删除节点、查找节点等。
3.2 栈和队列在本章节中,我们将实现栈和队列数据结构,并实现栈和队列的基本操作,包括入栈、出栈、入队、出队等。
3.3 树在本章节中,我们将实现二叉树数据结构,并实现二叉树的基本操作,包括遍历树、搜索节点等。
3.4 图在本章节中,我们将实现图数据结构,并实现图的基本操作,包括广度优先搜索、深度优先搜索等。
3.5 排序算法在本章节中,我们将实现各种排序算法,包括冒泡排序、插入排序、选择排序、快速排序、归并排序等。
3.6 搜索算法在本章节中,我们将实现各种搜索算法,包括线性搜索、二分搜索、广度优先搜索、深度优先搜索等。
四、附件本文档附带实验源代码,包括实现数据结构和算法的Java源文件。
五、法律名词及注释5.1 数据结构(Data Structure):是指数据对象中数据元素之间的关系。
包括线性结构、树形结构、图形结构等。
5.2 算法(Algorithm):是指解决问题的一系列步骤或操作。
算法应满足正确性、可读性、健壮性、高效性等特点。
5.3 链表(Linked List):是一种常见的数据结构,由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。
5.4 栈(Stack):是一种遵循后进先出(LIFO)原则的有序集合,用于存储和获取数据。
5.5 队列(Queue):是一种遵循先进先出(FIFO)原则的有序集合,用于存储和获取数据。
5.6 树(Tree):是由节点组成的层级结构,其中一种节点作为根节点,其他节点按照父子关系连接。
快速排序讲解

快速排序讲解快速排序是一种常用的排序算法,其核心思想是分治和递归。
它的算法复杂度为O(nlogn),在大多数情况下具有较好的性能。
快速排序的过程可以简单概括为以下几个步骤:1. 选择基准元素:从待排序序列中选择一个元素作为基准元素,一般选择第一个或最后一个元素。
2. 分割操作:将待排序序列划分为两个子序列,使得左子序列中的元素都小于基准元素,右子序列中的元素都大于或等于基准元素。
这个过程又称为分区操作。
3. 递归排序:对左右两个子序列分别进行快速排序,直到所有的子序列都有序。
4. 合并操作:将左子序列、基准元素和右子序列合并为一个有序序列。
下面以一个示例来说明快速排序的具体过程。
假设有一个待排序序列[5, 2, 9, 3, 7, 6],我们选择第一个元素5作为基准元素。
我们从序列的第二个元素开始,依次与基准元素进行比较。
如果比基准元素小,则将该元素放在左边,否则放在右边。
在本例中,2小于5,所以将2放在左边;9大于5,所以将9放在右边;3小于5,所以将3放在左边;7大于5,所以将7放在右边;6大于5,所以将6放在右边。
此时,序列变为[2, 3, 5, 7, 6, 9]。
然后,我们进一步对左右两个子序列[2, 3]和[7, 6, 9]进行快速排序。
对于子序列[2, 3],我们选择2作为基准元素。
由于只有两个元素,无需再次分割,直接排好序即可。
对于子序列[7, 6, 9],我们选择7作为基准元素。
同样地,我们将小于7的元素放在左边,大于7的元素放在右边。
最终得到子序列[6, 7, 9]。
我们将左子序列[2, 3]、基准元素5和右子序列[6, 7, 9]合并起来,得到最终的有序序列[2, 3, 5, 6, 7, 9]。
通过以上步骤,我们完成了对待排序序列的快速排序。
快速排序的优点是原地排序,不需要额外的存储空间;在大多数情况下,它的性能优于其他常用的排序算法,如冒泡排序和插入排序。
然而,快速排序也有一些缺点,最主要的是对于已经有序的序列,它的性能会大打折扣,甚至退化到O(n^2)的时间复杂度。
数据结构源代码(全)

/*顺序表的操作#include<iostream>#include<stdlib.h>using namespace std;Release 13.12 rev 9501 (2013/12/25 19:25:45) gcc 4.7.1 Windows/unicode - 32 bit #define MAX_SIZE 100typedef struct{int *emel;int lenth;}Sq;void init(Sq &l);void create(Sq &l);void trval(Sq &l);void find_value(Sq &l);void find_position(Sq &l);void insert(Sq &l);void dele(Sq &l);int main(){Sq l;init(l);create(l);trval(l);find_value(l);find_position(l);insert(l);trval(l);dele(l);trval(l);return 0;}void init(Sq &l){l.emel =new int[MAX_SIZE];if(l.emel ==NULL){cout<<"\t申请空间失败!"<<endl;exit(1);}l.lenth=0;cout<<"\t成功申请空间!该顺序表的长度目前为:"<<l.lenth<<endl; }void create(Sq &l){cout<<"\t请输入你想输入元素的个数:";int x;cin>>x;if((x<1)&&(x>MAX_SIZE)){cout<<"\t你说输入的数不在范围里"<<endl;return;}int i;for(i=0;i<x;i++){cin>>l.emel[i];}l.lenth=x;cout<<"\t成功赋值!"<<endl;}void trval(Sq &l){int i;cout<<"l(";for(i=0;i<l.lenth;i++){cout<<l.emel[i]<<" ";}cout<<")"<<" 该顺序表现在的长度为:"<<l.lenth<<endl;}void find_value(Sq &l){int x,t=0;cout<<"\t请输入你要查找的值:";cin>>x;int i;for(i=0;i<l.lenth;i++){if(l.emel[i]==x){t=1;cout<<"\t成功找到该元素,它是顺序表的第"<<i+1<<"个元素!"<<endl;}}if(t==0){cout<<"\t无该元素!"<<endl;}}void find_position(Sq &l){int x;cout<<"\t请输入你要查找的位置:";cin>>x;int i;if((x<1)||(x>l.lenth)){cout<<"\t输入的值不在范围内!"<<endl;return;}for(i=1;i<=l.lenth;i++){if(i==x){cout<<"\t成功找到该元素,该值是"<<l.emel[i-1]<<endl;}}}void insert(Sq &l){int i,x,y;cout<<"\t请输入你要插入的位置";cin>>x;cout<<"\t请输入你要插入的值";cin>>y;if((x<1)||(x>l.lenth)){cout<<"\t输入的值不在范围内!"<<endl;return;}if(x==l.lenth){l.emel[l.lenth]=y;l.lenth=l.lenth+1;return;}for(i=l.lenth;i>=x;i--){l.emel[i]=l.emel[i-1];}l.emel[x-1]=y;l.lenth=l.lenth+1;}void dele(Sq &l){int i,x;cout<<"\t请输入你要删除位置:";cin>>x;if((x<1)||(x>l.lenth)){cout<<"\t输入的值不在范围内!"<<endl;return;}for(i=x-1;i<=l.lenth;i++){l.emel[i]=l.emel[i+1];}l.lenth=l.lenth-1;}成功申请空间!该顺序表的长度目前为:0请输入你想输入元素的个数:3852成功赋值!l(8 5 2 ) 该顺序表现在的长度为:3请输入你要查找的值:5成功找到该元素,它是顺序表的第2个元素!请输入你要查找的位置:3成功找到该元素,该值是2请输入你要插入的位置3请输入你要插入的值10l(8 5 2 10 ) 该顺序表现在的长度为:4请输入你要删除位置:3l(8 5 10 ) 该顺序表现在的长度为:3--------------------------------Process exited with return value 0Press any key to continue . . .*//*#include<stdio.h>#include<stdlib.h>typedef struct Link{int num;struct Link *next;}L;L* creat(L* head){head=(L *)malloc(sizeof(L));if(head==NULL){printf("头节点申请失败!\n");exit(-1);}head->next=NULL;return head;}void insert(L* head){int x,i;printf("请输入你想输入数据的个数:");scanf("%d",&x);L *p,*q;p=head;for(i=0;i<x;i++){q=(L *)malloc(sizeof(L));if(q==NULL){printf("新点申请失败!\n");exit(-1);}printf("请输入值:");scanf("%d",&q->num);q->next=NULL;p->next=q;p=q;}}void print(L* head){L *p;p=head->next;while(p!=NULL){printf("值为:%d\n",p->num);p=p->next;}}int main(){L *head;head=creat(head);printf("成功创建头节点!!!\n");insert(head);printf("成功输入数据!!!\n");print(head);return 0;}*//*线性表的操作#include<stdio.h>#include<stdlib.h>typedef struct Link{int num;struct Link *next;}L;L* creat(L* head){head=(L *)malloc(sizeof(L));if(head==NULL){printf("头节点申请失败!\n");exit(-1);}head->next=NULL;return head;}void init(L* head){int x,i;printf("请输入你想输入数据的个数:");scanf("%d",&x);L *p,*q;p=head;for(i=0;i<x;i++){q=(L *)malloc(sizeof(L));if(q==NULL){printf("新点申请失败!\n");exit(-1);}printf("请输入值:");scanf("%d",&q->num);q->next=p->next;p->next=q;}}int print(L* head){L *p;int lenth=0;p=head->next;printf("\t\tL(");while(p!=NULL){lenth++;printf("%d ",p->num);p=p->next;}printf(")\n");return lenth;}int insert(L *head,int lenth){printf("\t\t请输入你要插入的元素的位置:");int in;scanf("%d",&in);if(in<1 || in>lenth){printf("\t\t输入值不在范围内!");return -1;}L *p,*q;p=head->next;q=(L *)malloc(sizeof(L));if(q==NULL){printf("新点申请失败!\n");return -1;}printf("\t\t请为新节点输入值:");scanf("%d",&q->num);int i=0;while(p!=NULL){i++;if(i==in-1){q->next=p->next;p->next=q;}p=p->next;}lenth++;return lenth;}int dele(L *head,int lenth){printf("\t\t请输入你要删除的元素的位置:");int out;scanf("%d",&out);if(out<1 || out>lenth){printf("\t\t输入值不在范围内!");return -1;}L *p,*q;p=head->next;q=head;int i=0;while(p!=NULL){i++;if(i==out){q->next=p->next;}q=p;p=p->next;}lenth--;return lenth;}void find(L *head,int lenth){printf("\t\t请输入你要查找的元素的位置:");int finder;scanf("%d",&finder);if(finder<1 || finder>lenth){printf("\t\t输入值不在范围内!");return ;}L *p;p=head->next;int i=0;while(p!=NULL){i++;if(i==finder){printf("\t\t你要找的该位置所对应的值为:%d\n",p->num);}p=p->next;}}int main(){L *head;head=creat(head);printf("成功创建头节点!!!\n");init(head);printf("成功输入数据!!!\n");int len;len=print(head);printf("\t\t该线性表的长度为:%d\n",len);len=insert(head,len);len=print(head);printf("\t\t插入后线性表的长度为:%d\n",len);len=dele(head,len);len=print(head);printf("\t\t删除后该线性表的长度为:%d\n",len);find(head,len);return 0;}*//*顺序表的合并#include<iostream>using namespace std;struct LA{int *pa;int lenth;};struct LB{int *pb;int lenth;};struct LC{int *pc;int lenth;};void mergelist(LA la,LB lb,LC &lc);int main(){int x,y;LA la;LB lb;cout<<"\t\t请给线性表LA和LB指定长度:";cin>>x>>y;la.pa =new int(sizeof(int)*x);lb.pb =new int(sizeof(int)*y);int i;for(i=0;i<x;i++){cout<<"请输入表LA的值:";cin>>la.pa[i];}cout<<endl;la.lenth=x;for(i=0;i<y;i++){cout<<"请输入表LB的值:";cin>>lb.pb[i];}lb.lenth=y;cout<<"LA(";for(i=0;i<x;i++){cout<<la.pa[i]<<" ";}cout<<")"<<endl;cout<<"LB(";for(i=0;i<y;i++){cout<<lb.pb[i]<<" ";}cout<<")"<<endl;LC lc;mergelist(la,lb,lc);return 0;}void mergelist(LA la,LB lb,LC &lc){lc.lenth=la.lenth+lb.lenth;lc.pc=new int(sizeof(int)*lc.lenth);int *pa=la.pa,*pb=lb.pb,*pc=lc.pc;int *pa_last=la.pa+la.lenth-1;int *pb_last=lb.pb+lb.lenth-1;while(pa<=pa_last && pb<=pb_last){if(*pa <= *pb){*pc++=*pa++;}else{*pc++=*pb++;}}while(pa<=pa_last){*pc++=*pa++;}while(pb<=pb_last){*pc++=*pb++;}cout<<"LC(";int i=0;for(i=0;i<lc.lenth;i++){cout<<lc.pc[i]<<" ";}cout<<")"<<endl;}*///栈/*#include<iostream>using namespace std;#include<stdlib.h>#define MAXSIZE 100typedef struct{int *base;int *top;int stacksize;}Sqstack;int Initstack(Sqstack &s);void Push(Sqstack &s,int e);void StackTraverse(Sqstack &s);void Gettop(Sqstack &s);void Pop(Sqstack &s);int main(){Sqstack s;Initstack(s);cout<<"\t\t初始化栈成功!"<<endl;Push(s,2);cout<<"\t\t2入栈成功!"<<endl;Push(s,4);cout<<"\t\t4入栈成功!"<<endl;Push(s,6);cout<<"\t\t6入栈成功!"<<endl;Push(s,8);cout<<"\t\t8入栈成功!"<<endl;cout<<"\n由栈底至栈顶的元素为:";StackTraverse(s);Gettop(s);Pop(s);Gettop(s);return 0;}int Initstack(Sqstack &s){s.base=new int[MAXSIZE];if(s.base==NULL){exit(1);}s.top=s.base;s.stacksize=MAXSIZE;}void Push(Sqstack &s,int e){if(s.top-s.base==s.stacksize){exit(1);}*s.top++=e;}void StackTraverse(Sqstack &s){int *p=s.base,i=0;while(p<s.top){i++;cout<<*p++<<" ";}cout<<"\t\t栈的长度是"<<i<<endl;}void Gettop(Sqstack &s){if(s.base==s.top){exit(1);}cout<<"栈顶元素是:"<<*(s.top-1)<<endl; }void Pop(Sqstack &s){if(s.top==s.base){exit(1);}cout<<"出栈的第一个元素是:";cout<<*--s.top<<" "<<endl;}*///队列例题:/*#include<iostream>#include<stdlib.h>using namespace std;#define MAXQSIZE 100typedef struct{int *base;int front;int rear;}SqQueue;int InitQueue(SqQueue &q);int EnQueue(SqQueue &q,int x);int DeQueue(SqQueue &q);int main(){SqQueue q;InitQueue(q);EnQueue(q,1);EnQueue(q,3);EnQueue(q,5);EnQueue(q,7);DeQueue(q);DeQueue(q);DeQueue(q);DeQueue(q);return 0;}int InitQueue(SqQueue &q){q.base=new int[MAXQSIZE];if(q.base==NULL){exit(1);}q.front=0;q.rear=0;return 0;}int EnQueue(SqQueue &q,int x){if((q.rear+1)%MAXQSIZE==q.front){exit(0);}q.base[q.rear]=x;q.rear=(q.rear+1)%MAXQSIZE;return 0;}int DeQueue(SqQueue &q){if(q.front==q.rear){exit(0);}int x=q.base[q.front];q.front=(q.front+1)%MAXQSIZE;cout<<x<<endl;}*//*#include<iostream>#include<stdlib.h>using namespace std;typedef struct Qnode{int date;struct Qnode *next;}Qnode,*Queueptr;typedef struct{Queueptr front; //队头指针Queueptr rear; //队尾指针}LinkQueue;int InitQueue(LinkQueue &Q);void EnQueue(LinkQueue &Q,int e);void TrvalQueue(LinkQueue Q);void DeQueue(LinkQueue &Q);int main(){LinkQueue Q;InitQueue(Q);EnQueue(Q,1);cout<<"\t元素1入队成功!"<<endl;EnQueue(Q,3);cout<<"\t元素3入队成功!"<<endl;EnQueue(Q,5);cout<<"\t元素5入队成功!"<<endl;EnQueue(Q,7);cout<<"\t元素7入队成功!"<<endl;cout<<"\t队列的元素分别是:"<<endl;TrvalQueue(Q);cout<<"\t第一个出队的元素是:"<<endl;DeQueue(Q);cout<<"\n\t第一个元素出队完成之后队列中从队头至队尾的元素为:";TrvalQueue(Q);return 0;}int InitQueue(LinkQueue &Q){Q.rear=new Qnode;Q.front=Q.rear;if(Q.front==NULL){exit(0);}Q.front->next=NULL;return 0;}void EnQueue(LinkQueue &Q,int e){Qnode *p=new Qnode;if(!p){exit(1);}p->date=e;p->next=NULL;Q.rear->next=p; //连接Q.rear=p; //修改队尾指针}void TrvalQueue(LinkQueue Q){Qnode *p=Q.front->next;//队头元素while(Q.front!=Q.rear){cout <<p->date<<" ";Q.front=p;p=p->next;}cout<<endl;}void DeQueue(LinkQueue &Q){if(Q.front==Q.rear){return;}Qnode *p=Q.front->next;cout<<"\t"<<p->date<<endl;Q.front->next=p->next;if(Q.rear==p){Q.rear=Q.front;delete p;}}*//*//表达式求值#include<iostream>#include<stdlib.h>#include<stdio.h>using namespace std;#define MAXSIZE 100typedef struct{char *base;char *top;char num;}OPND; //数据栈typedef struct{char *base;char *top;char c;}OPTR; //符号栈int Initstack(OPND &op_n,OPTR &op_t);void Pushstack(OPND &op_n,char ch);void Pushstack(OPTR &op_t,char ch);char Popstack(OPND &op_n,char ch);char Popstack(OPTR &op_t,char ch);char Gettop(OPTR op_t);char Gettop(OPND op_n);int In(char ch);char Precede(char x,char y);char operate(char z,char x,char y);int main(){OPND op_n;OPTR op_t;Initstack(op_n,op_t);Pushstack(op_t,'#');char ch;char p;cin>>ch;while(ch!='#' || Gettop(op_t)!='#'){if(!In(ch)){Pushstack(op_n,ch);cin>>ch;}else{switch( Precede(Gettop(op_t),ch) ){case '<':Pushstack(op_t,ch);cin>>ch;break;case '>':char x,y,z;x=Popstack(op_t,x);y=Popstack(op_n,y);z=Popstack(op_n,z);Pushstack(op_n,operate(z,x,y));break;case '=':p=Popstack(op_t,p);cin>>ch;break;}}}cout<<"\t表达式结果是:"<<Gettop(op_n)<<endl;return 0;}int Initstack(OPND &op_n,OPTR &op_t){op_n.base=new char[MAXSIZE];op_t.base=new char[MAXSIZE];if((op_n.base==NULL) || (op_t.base==NULL)){exit(1);}op_n.top=op_n.base;op_t.top=op_t.base;op_n.num=MAXSIZE;op_t.c=MAXSIZE;return 0;}void Pushstack(OPND &op_n,char ch){if(op_n.top-op_n.base==op_n.num){return;}*op_n.top++=ch;cout<<ch<<" 入数字栈"<<endl;}void Pushstack(OPTR &op_t,char ch){if(op_t.top-op_t.base==op_t.c){return;}*op_t.top++=ch;cout<<ch<<" 入操作符"<<endl;}char Popstack(OPND &op_n,char ch)if(op_n.top==op_n.base){exit(1);}ch=*--op_n.top;cout<<ch<<" 出数字栈"<<endl;return ch;}char Popstack(OPTR &op_t,char ch){if(op_t.top==op_t.base){exit(1);}ch=*--op_t.top;cout<<ch<<" 出字符栈"<<endl;return ch;}char Gettop(OPTR op_t){char x;if(op_t.top==op_t.base){exit(1);}x=*(op_t.top-1);cout<<"得到操作符栈顶"<<x<<endl;return x;}char Gettop(OPND op_n){char x;if(op_n.top==op_n.base){exit(1);}x=*(op_n.top-1);cout<<"得到操作数栈顶"<<x<<endl;return x;}int In(char ch)if(ch=='+'||ch=='-'||ch=='*'||ch=='/'||ch=='('||ch==')'||ch=='#') {return 1;}else{return 0;}}char Precede(char x,char y){if(x=='+' || x=='-'){if(y=='+' || y=='-' || y==')' || y=='#'){return '>';}else{return '<';}}if(x=='*'||x=='/'){if(y=='('){return '<';}else{return '>';}}if(x=='('){if(y==')'){return '=';}else if(y=='+'||y=='-'||y=='*'||y=='/'||y=='('){return '<';}}if(x==')'){if(y!='('){return '>';}}if(x=='#'){if(y=='#'){return '=';}else if(y!=')'){return '<';}}}char operate(char z,char x,char y) {if(x=='+'){return (z-'0') + (y-'0')+48;}if(x=='-'){return (z-'0') - (y-'0')+48;}if(x=='*'){return (z-'0')* (y-'0')+48;}if(x=='/'){return (z-'0')/ (y-'0')+48;}}*//*#include<iostream>using namespace std;int main(){char a[10];char *b[10];char **c[10];return 0;}*//*#include<iostream>using namespace std;char f(char x,char y){return (x-'0') * (y-'0')+48;}int main(){char a='3',b='5';char p=f(a,b);cout<<p<<endl;return 0;}*///数列出队/*#include<iostream>#include<stdlib.h>using namespace std;typedef struct Qnode{int num;struct Qnode *next;}Qnode,*Queueptr;typedef struct{Queueptr front;Queueptr rear;}LinkQueue;int InitQueue(LinkQueue &Q);void EnQueue(LinkQueue &Q,int x); int DeQueue(LinkQueue &Q,int p); int main(){LinkQueue Q;InitQueue(Q);int x,i,y,num=0,e;cout<<"请输入总人数:";cin>>x;for(i=1;i<=x;i++){EnQueue(Q,i);}cout<<"请输入第几个数淘汰:";cin>>y;{for(i=0;i<y;i++){if(i!=y-1){e=DeQueue(Q,e);EnQueue(Q,e);}else{DeQueue(Q,e);num++;}}if(num==x-1){break;}}e=DeQueue(Q,e);cout<<"最后剩下的是:"<<e<<endl;return 0;}int InitQueue(LinkQueue &Q){Q.front=new Qnode;Q.rear=Q.front;if(Q.front==NULL){exit(1);}Q.front->next=NULL;}void EnQueue(LinkQueue &Q,int x){Qnode *p=new Qnode;if(!p){exit(1);}p->num=x;p->next=NULL;Q.rear->next=p;}int DeQueue(LinkQueue &Q,int e) {Qnode *p;if(Q.rear==Q.front){exit(0);}p=Q.front->next;e=p->num;Q.front->next=p->next;if(Q.rear==p){Q.front=Q.rear;}delete p;return e;}*//*二叉树#include<iostream>#include<stdlib.h>using namespace std;typedef struct BiTNode{char date;struct BiTNode *lchild,*rchild; }BiTNode,*BiTree;void CreateBiTree(BiTree &T);int Depth(BiTree T);int NodeCount(BiTree T);int LeavesNodeCount(BiTree T);int PreOrderTraverse(BiTree T);int InOrderTraverse(BiTree T);int PostOrderTraverse(BiTree T); int main(){BiTree T;CreateBiTree(T);cout<<"二叉树的深度为:"<<Depth(T)<<endl;cout<<"二叉树中结点个数为:"<<NodeCount(T)<<endl;cout<<"二叉树中叶子结点个数为:"<<LeavesNodeCount(T)<<endl;cout<<"先序遍历:";PreOrderTraverse(T);cout<<"\n中序遍历:";InOrderTraverse(T);cout<<"\n后序遍历:";PostOrderTraverse(T);cout<<endl;return 0;}void CreateBiTree(BiTree &T){cout<<"请为该节点赋值:";char ch;cin>>ch;if(ch=='#'){T=NULL;}else{T =new BiTNode;T->date=ch;CreateBiTree(T->lchild);CreateBiTree(T->rchild);}}int Depth(BiTree T){int m,n;if(T==NULL){return 0;}else{m=Depth(T->lchild);n=Depth(T->rchild);if(m>n){return m+1;}else{return n+1;}}}int NodeCount(BiTree T){if(T==NULL){return 0;}else{return NodeCount(T->lchild)+NodeCount(T->rchild)+1;}}int LeavesNodeCount(BiTree T){if(T==NULL){return 0;}else if(T->lchild==NULL && T->rchild==NULL){return 1;}else{return LeavesNodeCount(T->lchild)+LeavesNodeCount(T->rchild);}}int PreOrderTraverse(BiTree T){if(T!=NULL){cout<<T->date;PreOrderTraverse(T->lchild);PreOrderTraverse(T->rchild);}}int InOrderTraverse(BiTree T){if(T!=NULL){InOrderTraverse(T->lchild);cout<<T->date;InOrderTraverse(T->rchild);}}int PostOrderTraverse(BiTree T){if(T!=NULL){PostOrderTraverse(T->lchild);PostOrderTraverse(T->rchild);cout<<T->date;}}请为该节点赋值:-请为该节点赋值:+请为该节点赋值:a请为该节点赋值:#请为该节点赋值:#请为该节点赋值:*请为该节点赋值:b请为该节点赋值:#请为该节点赋值:#请为该节点赋值:-请为该节点赋值:c请为该节点赋值:#请为该节点赋值:#请为该节点赋值:d请为该节点赋值:#请为该节点赋值:#请为该节点赋值:/请为该节点赋值:e请为该节点赋值:#请为该节点赋值:#请为该节点赋值:f请为该节点赋值:#请为该节点赋值:#二叉树的深度为:5二叉树中结点个数为:11二叉树中叶子结点个数为:6先序遍历:-+a*b-cd/ef中序遍历:a+b*c-d-e/f后序遍历:abcd-*+ef/-Process returned 0 (0x0) execution time : 76.214 s Press any key to continue.*//*#include<iostream>#include<stdlib.h>#include<string.h>using namespace std;typedef struct{int weiget;int parent,lchild,rchild;}HTNode,*HuffmanTree;typedef char** HuffmanCode;void creat(HuffmanTree &HT,int n);void Select(HuffmanTree HT,int k,int &min1,int &min2); void creatcode(HuffmanTree HT,HuffmanCode &HC,int n); int min(HuffmanTree HT,int k);int main(){int n;cout<<"请输入叶子节点的个数:";cin>>n;HuffmanTree HT;creat(HT,n);HuffmanCode HC;creatcode(HT,HC,n);return 0;}void creat(HuffmanTree &HT,int n){if(n<1){exit(1);}int m=2*n-1,i;HT=new HTNode[m+1];for( i=1;i<=m;i++){HT[i].parent=0;HT[i].lchild=0;HT[i].rchild=0;}for(i=1;i<=n;i++){cout<<"请输入权值:";cin>>HT[i].weiget;}int s1,s2;for(i=n+1;i<=m;i++) //通过n-1次选择来合并创建{Select(HT,i-1,s1,s2);HT[s1].parent=i; //赋值,作为删除的标记HT[s2].parent=i;cout<<"s1:"<<s1<<" s2:"<<s2<<endl;HT[i].lchild=s1; //生成新节点HT[i].rchild=s2;HT[i].weiget=HT[s1].weiget+HT[s2].weiget;}}void Select(HuffmanTree HT,int k,int &min1,int &min2){min1=min(HT,k);min2=min(HT,k);}int min(HuffmanTree HT,int k){int i=0;int min;//存放weight最小且parent为-1的元素的序号int min_wei;//存放权值while(HT[i].parent!=0){i++;}min_wei=HT[i].weiget;min=i;for(;i<=k;i++){if(HT[i].weiget<min_wei && HT[i].parent==0){min_wei=HT[i].weiget;min=i;}}HT[min].parent=1;return min;}void creatcode(HuffmanTree HT,HuffmanCode &HC,int n){HC =new char *[n+1];char *cd=new char[n];cd[n-1]='\0';int i,start;//start指向最后,即编码结束符的位置int current,father;for(i=1;i<=n;i++){start=n-1;current=i;father=HT[i].parent;while(father!=0){--start;if(HT[father].lchild==current){cd[start]='0';}else{cd[start]='1';}current=father;father=HT[father].parent;}HC[i]=new char[n-start];strcpy(HC[i],&cd[start]);cout<<HT[i].weiget<<"对应的编码是:"<<HC[i]<<endl;}delete cd;}请输入叶子节点的个数:5请输入权值:1请输入权值:2请输入权值:3请输入权值:4请输入权值:5s1:1 s2:2s1:3 s2:6s1:4 s2:5s1:7 s2:81对应的编码是:0102对应的编码是:0113对应的编码是:004对应的编码是:105对应的编码是:11Process returned 0 (0x0) execution time : 4.003 s Press any key to continue.*///折半查找#include<iostream>#include<stdio.h>using namespace std;#define ENDFLAG 10000typedef int KeyType;typedef char* InfoType;typedef struct{KeyType key;InfoType otherinfo;}ElemType;typedef struct{ElemType *R;int length;}SSTable;void CreateSTable(SSTable &ST,int n){int i;ST.R=new ElemType[n+1];for(i=1;i<=n;i++){cout<<"请输入"<<i<<"个测试数据:";cin>>ST.R[i].key;}ST.length=n;}int Search_Bin1(SSTable ST,KeyType key){int low,high,mid;low=1;high=ST.length;while(low<=high){mid=(low+high)/2;if(key==ST.R[mid].key){return mid;}else if(key<ST.R[mid].key){high=mid-1;}else{low=mid+1;}}return 0;}int Search_Bin2(SSTable ST,int low,int high,KeyType key) {int mid;if(low>high){return 0;}mid=(low+high)/2;printf("%d+++++",key==ST.R[mid].key);if(key==ST.R[mid].key){return mid;}else if(key<ST.R[mid].key){return Search_Bin2(ST,low,mid-1,key);}else{return Search_Bin2(ST,mid+1,high,key);}}int main(){int n;KeyType key;SSTable ST;cout<<"请输入静态查找表长:";cin>>n;CreateSTable(ST,n);cout<<"请输入待查记录的关键字:";cin>>key;cout<<"Search_Bin1算法计算的位置为:"<<Search_Bin1(ST,key)<<endl;cout<<"Search_Bin2算法计算的位置为:"<<Search_Bin2(ST,1,ST.length,key)<<endl;return 0;}/*请输入静态查找表长:5请输入1个测试数据:1请输入2个测试数据:2请输入3个测试数据:3请输入4个测试数据:4请输入5个测试数据:5请输入待查记录的关键字:3Search_Bin1算法计算的位置为:3Search_Bin2算法计算的位置为:3Process returned 0 (0x0) execution time : 8.620 sPress any key to continue.*//*#include<iostream>using namespace std;typedef struct{int key;}ElemType;typedef struct BSTNode{ElemType date;struct BSTNode *lchild,*rchild;}BSTNode,*BSTree;void Create(BSTree &T);void Insert(BSTree &T,ElemType e);int InOrderTraverse(BSTree T);int main(){BSTree T;Create(T);InOrderTraverse(T);cout<<"\n中序遍历:";return 0;}void Create(BSTree &T){T=NULL;ElemType e;cout<<"请为节点赋值:(0为结束条件)";cin>>e.key;while(e.key!=0){Insert(T,e);cout<<"请为节点赋值:(0为结束条件)";cin>>e.key;}}void Insert(BSTree &T,ElemType e){if(!T){BSTree S;S=new BSTNode;S->date=e;S->lchild=NULL;S->rchild=NULL;T=S;}else if(e.key<T->date.key){Insert(T->lchild,e);}else{Insert(T->rchild,e);}}int InOrderTraverse(BSTree T){if(T!=NULL){InOrderTraverse(T->lchild);cout<<T->date.key<<" ";InOrderTraverse(T->rchild);}return 0;}请为节点赋值:(0为结束条件)12请为节点赋值:(0为结束条件)7请为节点赋值:(0为结束条件)17请为节点赋值:(0为结束条件)11请为节点赋值:(0为结束条件)16请为节点赋值:(0为结束条件)2请为节点赋值:(0为结束条件)13请为节点赋值:(0为结束条件)9请为节点赋值:(0为结束条件)21请为节点赋值:(0为结束条件)4请为节点赋值:(0为结束条件)02 4 7 9 11 12 13 16 17 21中序遍历:Process returned 0 (0x0) execution time : 23.808 s Press any key to continue.*/。
简单实用的c++快速排序模板类

(一)目标在实际问题的解决过程中,我们发现,很多问题都可以归结为对数据的排序和查询。
而查询的效率则在很大程度上依赖于排序的效率;尤其是在数据量达到海量级的时候。
因此,设计一个有效的排序算法是至关重要的。
本文设计了一个通用的c++ quicksort 模板类。
通过简单的提供一个data类,可以实现任意数据的快速排序算法,提高了开发效率。
(二)快速排序算法的思想最基本的快速排序的思想是基于分治策略的:对于输入的子序列l[p..r],如果规模足够小则直接进行排序,否则分三步处理:1 分解(divide):将输入的序列l[p..r]划分成两个非空子序列l[p..q]和l[q+1..r],使l[p..q]中任一元素的值不大于l[q+1..r]中任一元素的值。
2 递归求解(conquer):通过递归调用快速排序算法分别对l[p..q]和l[q+1..r]进行排序。
3 合并(merge):由于对分解出的两个子序列的排序是就地进行的,所以在l[p..q]和l[q+1..r]都排好序后不需要执行任何计算l[p..r]就已排好序。
(三)准备工作和源代码1 使用vc6建立console工程2 加入下面的模板类(快速排序的模板类。
):template<typename datatype>//datatype是模板参数,代表了欲排序的数据类型class quicksorttemp{public:quicksorttemp(){}~quicksorttemp(){}public:// 快速排序的实现,array是要排序数据的数组,nlower,nupper范围是0 ~ 数据总个数-1static void quicksort(datatype* array, int nlower, int nupper){// 测试是否排序完毕if (nlower < nupper){// 分解和分别进行排序int nsplit = partition (array, nlower, nupper);//数据切分为两个部分quicksort (array, nlower, nsplit - 1);//左半部分递归排序quicksort (array, nsplit + 1, nupper);//右半部分递归排序}}// 切分数据为左右两个部分,返回中间元素x的编号// 主要的过程就是:选择一个元素x作为分界点,将比x大的元素放到x右边,其余放到x左边。
学习怎么用按键精灵制作游戏辅助——脚本源代码干货分享
学习怎么用按键精灵制作游戏辅助——脚本源代码干货分享一、用按键精灵确定人物朝向(以剑灵自动寻路为例)的代码在剑灵右上角的小地图里找色/找图,箭头坐标存储在(x1,y1),箭尾坐标存储在(x2,y2) FindColor1200,0,1920,300,"箭头颜色",x1,y1If x1 > 0 And y1> 0 ThenEnd IfFindColor1200,0,1920,300,"箭尾颜色",x2,y2If x1 > 0 And y1> 0 ThenEnd If'计算斜率/正切值斜率= (y1 - y2) / (x1 -x2)'计算角度角度= Atn(斜率)二、用按键精灵解决用户密码泄露问题的代码Function 加解密(源文件, 秘钥)Dim Z, iDim A, B, C加解密= ""If Len(源文件) = 0 Then’如果密码为空,则初始化为空加解密= ""Exit FunctionEnd If'调用Rnd函数使以后Rnd函数所产生的Rnd为相同的伪随机数列Z = Rnd(-秘钥)For i = 1 To Len(源文件)’将密码字符串一个一个字符通过加密,转换成另一个字符C = Mid(源文件, i, 1)A = Asc(C)B = Int(126 * Rnd) And&H7F’这里的&H7F,是指生成的伪随机代码,只取7位,以免数据溢出A = A Xor B’Xor是可逆的,第一次运行时是得到加密后的数据,再运行一次是得到解密后的数据C = Chr(A)加解密= 加解密+ CNextEnd Function举个例子吧~Function 加解密(源文件, 秘钥)Dim Z, iDim A, B, C加解密= ""If Len(源文件) = 0 Then加解密= ""Exit FunctionEnd If'调用Rnd函数使以后Rnd函数所产生的Rnd为相同的伪随机数列Z = Rnd(-密钥)For i = 1 To Len(源文件)C = Mid(源文件, i, 1)A = Asc(C)B = Int(126 * Rnd) And&H7FA = A Xor BC = Chr(A)加解密= 加解密+ CNextEnd FunctionEvent Form1.Load//获取小节名(如"e1df741f-d5ec-4ad7-969d-adb139c6a24f"),同一个Q文件生成的小节名不变a = GetMacroID()//获取到当前脚本/小精灵de ID加密文件=Plugin.File.ReadINI("e1df741f-d5ec-4ad7-969d-adb139c6a24f","Form1 .InputBox2.T ext", ".\uservar.ini")解密文件= 加解密(加密文件, 1234567890)'这里的1234567890是假使的密钥,可以修改,注意保密Form1.InputBox2.T ext = 解密文件End Event//写入密码信息源文件= Form1.InputBox2.T ext加密文件= 加解密(源文件, 1234567890)CallPlugin.File.WriteINI("e1df741f-d5ec-4ad7-969d-adb139c6a24f","Form1.InputBox2.T ext", 加密文件, ".\uservar.ini")//输出信息RunApp "notepad.exe"SayString Form1.InputBox1.T extKeyPress "Enter", 1SayString 源文件三、按键精灵快速排序的代码su = "6|1|2|7|9|3|4|5|10|8"su=Split(su, "|")L = UBound(su)Call ks(0, L)Function ks(L, B)If L > B ThenExit FunctionEnd If //判断数组上标下标是否超出范围i = Lj = Bkey =int( su(L) ) //数组第一位提取作为基数While j>iWhile int ( su(j)) >= key and j > i //要先从最右边开始找找到第一个小于key的数这里添加的j>i的判断是为了防止j的值不断递减导致下标越界j = j - 1WendWhile int (su(i)) <= key and j > i //从最左边开始找找到第一个大于key的数(这里的字符串数组需要转换为数值型)i = i + 1WendIf j>i then // 将和基数key对比得到的两个数对换将大于key的值往右边放小于key的值往左边放T = su(i)su(i) = su(j)su(j) = TEnd IfWend // 这个While 循环当i=j 第一轮比较完退出su(L) = su(i) // 重新设置数组第一个元素为基数su(i) = key// 基数归位(排完一轮之后左边的数<基数<右边的数那么基数就到了排序中它该在的位置。
计算机10大经典算法

计算机10⼤经典算法算法⼀:快速排序法快速排序是由东尼·霍尔所发展的⼀种排序算法。
在平均状况下,排序 n 个项⽬要Ο(n log n)次⽐较。
在最坏状况下则需要Ο(n2)次⽐较,但这种状况并不常见。
事实上,快速排序通常明显⽐其他Ο(n log n) 算法更快,因为它的内部循环(inner loop)可以在⼤部分的架构上很有效率地被实现出来。
快速排序使⽤分治法(Divide and conquer)策略来把⼀个串⾏(list)分为两个⼦串⾏(sub-lists)。
算法步骤:1 .从数列中挑出⼀个元素,称为 “基准”(pivot),2. 重新排序数列,所有元素⽐基准值⼩的摆放在基准前⾯,所有元素⽐基准值⼤的摆在基准的后⾯(相同的数可以到任⼀边)。
在这个分区退出之后,该基准就处于数列的中间位置。
这个称为分区(partition)操作。
3. 递归地(recursive)把⼩于基准值元素的⼦数列和⼤于基准值元素的⼦数列排序。
递归的最底部情形,是数列的⼤⼩是零或⼀,也就是永远都已经被排序好了。
虽然⼀直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它⾄少会把⼀个元素摆到它最后的位置去。
算法⼆:堆排序算法堆排序(Heapsort)是指利⽤堆这种数据结构所设计的⼀种排序算法。
堆积是⼀个近似完全⼆叉树的结构,并同时满⾜堆积的性质:即⼦结点的键值或索引总是⼩于(或者⼤于)它的⽗节点。
堆排序的平均时间复杂度为Ο(nlogn) 。
算法步骤:1.创建⼀个堆H[0..n-1]2.把堆⾸(最⼤值)和堆尾互换3. 把堆的尺⼨缩⼩1,并调⽤shift_down(0),⽬的是把新的数组顶端数据调整到相应位置4. 重复步骤2,直到堆的尺⼨为1算法三:归并排序归并排序(Merge sort,台湾译作:合并排序)是建⽴在归并操作上的⼀种有效的排序算法。
该算法是采⽤分治法(Divide and Conquer)的⼀个⾮常典型的应⽤。
快速排序(C语言)-解析

快速排序(C语⾔)-解析快速排序快速排序是⼀种排序算法,对包含 n 个数的输⼊数组,最坏情况运⾏时间为O(n2)。
虽然这个最坏情况运⾏时间⽐较差,但快速排序通常是⽤于排序的最佳的实⽤选择,这是因为其平均性能相当好:期望的运⾏时间为O(nlgn),且O(nlgn)记号中隐含的常数因⼦很⼩。
另外,它还能够进⾏就地排序,在虚存环境中也能很好的⼯作。
快速排序(Quicksort)是对的⼀种改进。
快速排序由C. A. R. Hoare在1962年提出。
它的基本思想是:通过⼀趟排序将要排序的数据分割成独⽴的两部分,其中⼀部分的所有数据都⽐另外⼀部分的所有数据都要⼩,然后再按此⽅法对这两部分数据分别进⾏快速排序,整个排序过程可以进⾏,以此达到整个数据变成有序。
像合并排序⼀样,快速排序也是采⽤分治模式的。
下⾯是对⼀个典型数组A[p……r]排序的分治过程的三个步骤:分解:数组 A[p……r]被划分为两个(可能空)⼦数组 A[p……q-1] 和 A[q+1……r] ,使得 A[p……q-1] 中的每个元素都⼩于等于 A(q) , ⽽且,⼩于等于 A[q+1……r] 中的元素。
⼩标q也在这个划分过程中进⾏计算。
解决:通过递归调⽤快速排序,对于数组 A[p……q-1] 和 A[q+1……r] 排序。
合并:因为两个⼦数组是就地排序的,将它们的合并不需要操作:整个数组 A[p……r] 已排序。
下⾯的过程实现快速排序(伪代码):QUICK SORT(A,p,r)1if p<r2 then q<-PARTITION(A,p,r)3 QUICKSORT(A,p,q-1)4 QUICKSORT(A,q+1,r)为排序⼀个完整的数组A,最初的调⽤是QUICKSORT(A,1,length[A])。
数组划分: 快速排序算法的关键是PARTITION过程,它对⼦数组 A[p……r]进⾏就地重排(伪代码):PARTITION(A,p,r)1 x <- A[r]2 i <- p-13for j <- p to r-14do if A[j]<=x5 then i <- i+16 exchange A[i] <-> A[j]7 exchange A[i + 1] <-> A[j]8return i+1排序演⽰⽰例假设⽤户输⼊了如下数组:下标012345数据627389创建变量i=0(指向第⼀个数据), j=5(指向最后⼀个数据), k=6(为第⼀个数据的值)。
C#100例经典源代码

C#语言100例经典源代码程序1】题目:有1、2、3、4个数字,能组成多少个互不相同且无重复数字的三位数?都是多少?1.程序分析:可填在百位、十位、个位的数字都是1、2、3、4。
组成所有的排列后再去掉不满足条件的排列。
2.程序源代码:main(){int i,j,k;printf("\n");for(i=1;i<5;i++) /*以下为三重循环*/for(j=1;j<5;j++)for (k=1;k<5;k++){if (i!=k&&i!=j&&j!=k) /*确保i、j、k三位互不相同*/printf("%d,%d,%d\n",i,j,k);}}==============================================================【程序2】题目:企业发放的奖金根据利润提成。
利润(I)低于或等于10万元时,奖金可提10%;利润高于10万元,低于20万元时,低于10万元的部分按10%提成,高于10万元的部分,可可提成7.5%;20万到40万之间时,高于20万元的部分,可提成5%;40万到60万之间时高于40万元的部分,可提成3%;60万到100万之间时,高于60万元的部分,可提成1.5%,高于100万元时,超过100万元的部分按1%提成,从键盘输入当月利润I,求应发放奖金总数?1.程序分析:请利用数轴来分界,定位。
注意定义时需把奖金定义成长整型。
2.程序源代码:main(){long int i;int bonus1,bonus2,bonus4,bonus6,bonus10,bonus;scanf("%ld",&i);bonus1=100000*0.1;bonus2=bonus1+100000*0.75;bonus4=bonus2+200000*0.5;bonus6=bonus4+200000*0.3;bonus10=bonus6+400000*0.15;if(i<=100000)bonus=i*0.1;else if(i<=200000)bonus=bonus1+(i-100000)*0.075;else if(i<=400000)bonus=bonus2+(i-200000)*0.05;else if(i<=600000)bonus=bonus4+(i-400000)*0.03;else if(i<=1000000)bonus=bonus6+(i-600000)*0.015;elsebonus=bonus10+(i-1000000)*0.01;printf("bonus=%d",bonus);}==============================================================【程序3】题目:一个整数,它加上100后是一个完全平方数,再加上168又是一个完全平方数,请问该数是多少?1.程序分析:在10万以内判断,先将该数加上100后再开方,再将该数加上268后再开方,如果开方后的结果满足如下条件,即是结果。
数据结构课程设计排序算法总结

排序算法:(1) 直接插入排序 (2) 折半插入排序(3) 冒泡排序 (4) 简单选择排序 (5) 快速排序(6) 堆排序 (7) 归并排序【算法分析】(1)直接插入排序;它是一种最简单的排序方法,它的基本操作是将一个记录插入到已排好的序的有序表中,从而得到一个新的、记录数增加1的有序表。
(2)折半插入排序:插入排序的基本操作是在一个有序表中进行查找和插入,我们知道这个查找操作可以利用折半查找来实现,由此进行的插入排序称之为折半插入排序。
折半插入排序所需附加存储空间和直接插入相同,从时间上比较,折半插入排序仅减少了关键字间的比较次数,而记录的移动次数不变。
(3)冒泡排序:比较相邻关键字,若为逆序(非递增),则交换,最终将最大的记录放到最后一个记录的位置上,此为第一趟冒泡排序;对前n-1记录重复上操作,确定倒数第二个位置记录;……以此类推,直至的到一个递增的表。
(4)简单选择排序:通过n-i次关键字间的比较,从n-i+1个记录中选出关键字最小的记录,并和第i(1<=i<=n)个记录交换之。
(5)快速排序:它是对冒泡排序的一种改进,基本思想是,通过一趟排序将待排序的记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
(6)堆排序: 使记录序列按关键字非递减有序排列,在堆排序的算法中先建一个“大顶堆”,即先选得一个关键字为最大的记录并与序列中最后一个记录交换,然后对序列中前n-1记录进行筛选,重新将它调整为一个“大顶堆”,如此反复直至排序结束。
(7)归并排序:归并的含义是将两个或两个以上的有序表组合成一个新的有序表。
假设初始序列含有n个记录,则可看成是n个有序的子序列,每个子序列的长度为1,然后两两归并,得到n/2个长度为2或1的有序子序列;再两两归并,……,如此重复,直至得到一个长度为n的有序序列为止,这种排序称为2-路归并排序。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
#define MAX 10
#define SWAP(x,y) {int t; t = x; x = y; y = t;}
int partition(int[], int, int);
void quicksort(int[], int, int);
void main()
{ int q;
if(left < right)
{ q = partition(number, left, right);
quicksort(number, left, q-1);
quicksort(number, q+1, right);
}
}
//////////////////////////////////////代码2:(轴在中心)/////////////////////////////////////////////
#include <iostream>
#include <ctime>
#include<iomanip>
using namespace std;
#define MAX 10
#define SWAP(x,y) {int t; t = x; x = y; y = t;}
int partition(int[], int, int);
void quicksort(int[], int, int);
void main()
{ int number[MAX] = {0};
int i;
srand(time(NULL));
cout<<"排序前:";
for(i = 0; i < MAX; i++)
{ number[i] = rand() % 100;
if(i >= j) break;
SWAP(number[i], number[j]);
}
quicksort(number, left, i-1); // 对左边进行递归
quicksort(number, j+1, right); // 对右边进行递归
}
}
////////////////////////////////////////代码3:(轴选在最左侧)///////////////////////////////////
////////////////////////////////////////////////////////////////////
///////代码1 多数的教科书上所提及的版本(轴在最右侧)///////////////
#include <iostream>
#include <ctime>
#include<iomanip>
void quicksort(int[], int, int);
void main()
{ int number[MAX] = {0};
int i;
srand(time(NULL));
cout<<"排序前:";
for(i = 0; i < MAX; i++)
{ number[i] = rand() % 100;
cout<<setw(6)<<number[i];
}
quicksort(number, 0, MAX-1);
cout<<"\n排序后:";
for(i = 0; i < MAX; i++)
cout<<setw(6)<<number[i];
cout<<"\n";
}
int partition(int number[], int left, int right)
cout<<setw(6)<<number[i];
}
quicksort(number, 0, MAX-1);
cout<<"\n排序后:";
for(i = 0; i < MAX; i++)
cout<<setw(6)<<number[i];
cout<<"\n";
}
void quicksort(int number[], int left, int right)
}
number[left]=s; // 枢轴记录到位
return left; // 返回枢轴位置
}
void quicksort(int number[], int left, int right)
{ int q;
if(left < right)
{ q=partition(number, left, right);
#include <iostream>
#include <ctime>
#include<iomanip>
using namespace std;
#define MAX 10
#define SWAP(x,y) {int t; t = x; x = y; y = t;}
int partition(int[], int, int);
{ int i, j, s;
if(left < right)
{ s = number[(left+right)/2];
i = left - 1;
j = right + 1;
while(1)
{ while(number[++i] < s) ; // 向右找
while(number[--j] > s) ; // 向左找
quicksort(number, left, q-1);
quicksort(number, q+1, right);
}
}
史上最全快速排序法源代码
快速排序法(quick sort)是目前所公认最快的排序方法之一(视解题的对象而定),虽然快速排序法在最差状况下可以达O(n2),但是在多数的情况下,快速排序法的效率表现是相当不错的。
快速排序法的基本精神是在数列中找出适当的轴心,然后将数列一分为二,分别对左边与右边数列进行排序,而影响快速排序法效率的正是轴心的选择。
{ int number[MAX] = {0};
int i;
srand(time(NULL));
cout<<"排序前:";
for(i = 0; i < MAX; i++)
{ number[i] = rand() % 100;
cout<<setw(6)<<number[i];
}
quicksort(number, 0, MAX-1);
i = left-1 ;
for(j = left; j < right; j++)
{ if(number[j] <= s)
{i++;
SWAP(number[i], number[j]);
}
}
SWAP(number[i+1], number[right]);
return i+1;
}
void quicksort(int number[], int left, int right)
cout<<"\n排序后:";
for(i = 0; i < MAX; i++)
cout<<setw(6)<<number[i];
cout<<"\n";
}
int partition(int number[], int left, int right)
{ int i, j, s;
s = number[right];
{ int s;
s = number[left];
while(left<right)
{ // 从表的两端交替地向中间扫描
while(number[right]><s)
left++;
SWAP(number[left], number[right]);