Web Service Based Data Management for Grid Applications
程炜面向Web服务的业务流程管理系统的研究和实现

程炜面向W e b服务的业务流程管理系统的研究和实现Standardization of sany group #QS8QHH-HHGX8Q8-GNHHJ8-HHMHGN#分类号_______ 密级_______ U D C _______硕士学位论文面向Web服务的业务流程管理系统的研究和实现学位申请人:程炜学科专业:通信与信息系统指导教师:杨宗凯教授论文答辩日期 2003年5月10日学位授予日期答辩委员会主席刘文予评阅人刘文予谭运猛A Thesis Submitted in Partial Fulfillment of the Requirementsfor the Degree of Master of EngineeringResearch and Implementation of Web Service-Oriented BusinessProcess Management SystemCandidate: Cheng WeiMajor: Communication & Information SystemSupervisor : Prof. Yang ZongkaiHuanghzong University of Science & technologyMay 2003摘要近几年,随着电子商务的深入发展,对企业信息化程度提出了更高的要求,如何利用现代网络技术来帮助企业管理各类业务流程,实现业务流程自动化已成为企业关注的热点。
所谓业务流程(Business Process,BP),是指为了在一定时期内达到特定的商业目标,而按照各种商业规则连接起来的业务功能的集合。
这些业务功能是抽象定义的:业务功能的具体实现受限于业务功能运行所需的可用资源。
业务功能的构成由商业目标决定。
业务流程中商业规则的目的是为了业务管理决策的实现。
而业务流程管理(Business Process Management,BPM)是理解、系统化、自动化以及改进公司业务运作方式的一门艺术,它可以看作是文档工作流和企业应用集成的紧密结合。
锐捷 RG-EST 系列桥接器 Web 管理配置指南说明书

Ruijie RG-EST Series Bridges Web-Based Configuration GuideCopyright StatementRuijie Networks©2020Ruijie Networks reserves all copyrights of this document. Any reproduction, excerption, backup, modification, transmission, translation or commercial use of this document or any portion of this document, in any form or by any means, without the prior written consent of Ruijie Networks is prohibited.Exemption StatementThis document is provided “as is”. The contents of this document are subject to change without any notice. Please obtain the latest information through the Ruijie Networks website. Ruijie Networks endeavors to ensure content accuracy and will not shoulder any responsibility for losses and damages caused due to content omissions, inaccuracies or errors.PrefaceThank you for using our products.AudienceThis manual is intended for:●Network engineers●Technical support and servicing engineers●Network administratorsObtaining TechnicalAssistance●Ruijie Networks Website: https:///●Technical Support Website: https:///support ●Case Portal: https://●Community: https://●Technical Support Email: *****************************●Skype: *****************************Related DocumentsDocuments DescriptionCommand Reference Describes the related configuration commands, including command modes, parameter descriptions, usage guides, and related examples.Hardware Installation and Reference Guide Describes the functional and physical features and provides the device installation steps, hardware troubleshooting, module technical specifications, and specifications and usage guidelines for cables and connectors.ConventionsThis manual uses the following conventions:Convention Descriptionboldface font Commands, command options, and keywords are in boldface.italic font Arguments for which you supply values are in italics.[ ] Elements in square brackets are optional.{ x | y | z } Alternative keywords are grouped in braces and separated by vertical bars.[ x | y | z ] Optional alternative keywords are grouped in brackets and separated byvertical bars.Configuration Guide Overview 1 OvervieweWeb is a Web-based network management system that manages and configures devices. You can access eWeb via browsers such as Google Chrome.Web-based management involves the Web server and Web client. The Web server is integrated in a device, and is used to receive and process requests from the client, and return processing results to the client. The Web client usually refers to a browser, such as Google Chrome IE, or Firefox.1.1 ConventionsIn this document:Texts in bold are names of buttons (for example, OK) or other graphical user interface (GUI) elements (for example, VLAN).12 Configuration Guide2.1 PreparationScenarioAs shown in the figure below, administrators can access the device from a browser and configure the device through the eWeb management system.Deliver or requestcommandsthrough AJAX.Administrator Return dataWebserviceDeviceRemarks The eWeb management system combines various device commands and then delivers them to the device through AJAX requests. The device then returns data based on the commands. A Web service is available on the device to process basic HTTP protocol requests.Deployment↘Configuration Environment RequirementsClient requirements:●An administrator can log into the eWeb management system from a Web browser to manage devices. The client refersto a PC or some other mobile endpoints such as laptops or tablets.●Google Chrome, Firefox, IE9.0 and later versions, and some Chromium-based browsers (such as 360 ExtremeExplorer) are supported. Exceptions such as garble or format error may occur if an unsupported browser is used.●1024 x 768 or a higher resolution is recommended. If other resolutions are used, the page fonts and formats may not bealigned and the GUI is less artistic, or other exceptions may occur.●The client IP address is set in the same network as the LAN port of the device, such as 10.44.77.X. The subnet mask is255.255.255.0. The default gateway is device management address 10.44.77.254.Server requirements:●You can log into the eWeb management system through a LAN port or from the Ruijie Cloud on an external network.●The device needs to be enabled with Web service (enabled by default).●The device needs to be enabled with login authentication (enabled by default).2To log into the eWeb management system, open the Google Chrome browser, and enter 10.44.77.254 in the address bar, and press Enter.If the device is not configured yet, you can log into eWeb without a password.Figure 2-1-1 Login PageAfter entering the password and clicking Login, you will enter eWeb.Figure 2-1-2 Overview32.2 UI IntroductionTop: Global settings, including Language, Log Out and Pair Again.Column in Orange: Alarm messages.Middle Column: Settings for all EST devices in the network, including Password, IP Assignment, and SSID. Column in Blue: WDS group and paired devices.Figure 2-2-1 UI IntroductionClick Pair Again to set the WDS pair. You can switch the work mode and change an SSID.Figure 2-2-2 WDS Pair Settings4Figure 2-2-3 Work Mode Switchover563 eWeb Configuration3.1 OverviewThe Overview page displays alarms, WDS group, network information and detailed information about devices in the network.AlarmHover the mouse over the number in red, and an alarming device list will appear. Click a device in the list, and its detailed information will be displayed in the sidebar on the right.Figure 3-1-1 AlarmNetwork InformationThis area displays all WDS groups, password settings, IP assignment and SSID settings. You can manage the EST device by accessing the SSID. The default SSID is @Ruijie-XXXX (the last four digits of the MAC address). After you set a new SSID, the default SSID will be disabled. The new SSID will be hidden two hours after WDS is locked.Figure 3-1-2 Network InformationClick Password, and the Password page will appear.Figure 3-1-3 Password Settings7Click IP Assignment, and the IP Assignment page will appear. Figure 3-1-4 IP AssignmentClick SSID, and the SSID Settings page will appear.Figure 3-1-5 SSID Settings8WDS GroupThis area displays basic information about each WDS group and the paired devices (AP/CPE). You can click to expandthe area or click to collapse the area. Click an IP address of another device, and you will be redirected to its login page. Figure 3-1-6 WDS GroupClick to expand the menu of each device, including LAN, WDS and Reboot.Figure 3-1-7 Device SettingsClick LAN, and the LAN page will appear.Figure 3-1-8 LAN SettingsClick WDS, and the WDS page will appear.Figure 3-1-9 WDS Settings9Click Reboot, and confirmation message “Are you sure you want to reboot device X?” will appear. Check OK, and the device will be rebooted.Figure 3-1-10 RebootClick a device (AP or APE), and its detailed information will be displayed in the sidebar on the right.Figure 3-1-11 Device Details103.2 LANThe LAN settings provide two IP assignment options: Static IP Address and DHCP. Figure 3-2 LAN Settings3.3 Wireless3.3.1 WDSFigure 3-3-1 WDS Settings11Figure 3-3-2 Scan SSID3.3.2 RegionAfter you change the region, all WDS links will be off. If the specified region does not support the channel settings, the auto channel will be used instead.Figure 3-3-3 Region Settings12133.4 Diagnostics3.4.1 Network ToolsThere are three network tools available: Ping , Traceroute , and DNS Lookup . Figure 3-4-1 Ping Test and ResultFigure 3-4-2 Traceroute Test and ResultFigure 3-4-3 DNS Lookup Test and Result3.4.2 Fault CollectionThe Fault Collection module allows you to collect faults by one click and download the fault information to the local device. Figure 3-4-4 Fault Collection3.5 System Tools3.5.1 TimeThis module allows you to set and view system time.Figure 3-5-1 System Time143.5.2 Management3.5.2.1Backup & ImportThis module allows you to import a configuration file and apply the imported settings. It also allows exporting the configuration file to generate a backup.Figure 3-5-2 Backup & Import3.5.2.2 ResetThis module allows you to reset the device.Figure 3-5-3 ResetPlease exercise caution if you want to restore the factory settings.Figure 3-5-4 Reset Confirmation15Click OK to restore all default values. This function is recommended when the network configuration is incorrect or the network environment is changed. If you fail to access the eWeb management system, check whether the endpoint is connected to the device by referring to Preparation.3.5.2.3 Session TimeoutThis module allows you to set the session timeout.Figure 3-5-5 Session Timeout3.5.3 Update3.5.3.1 Online UpdateClick Update Now. The device downloads the update package from the network, and updates the current version. The update operation retains configuration of the current device. Alternatively, you can select Download File to the local device and import the update file on the Local Update page. If there is no available new version, the device displays a prompt indicating that the current version is the latest, as shown in the figure below.Figure 3-5-616Configuration Guide eWeb Configuration 3.5.3.2 Local UpdateSelect an update package, and click Upload. The device will be updated to the target version.Figure 3-5-7 Local Update3.5.3.3 Update All DevicesThis module allows you to update all devices in the network with their configuration retained, as shown in the figure below. Figure 3-5-8 Update All Devices3.5.4 RebootThis module allows you to reboot the device with a click, as shown in the figure below:Figure 3-5-9 RebootClick Reboot, and click OK in the confirmation box. The device is rebooted and you need to log into the eWeb management system again after the reboot. Do not refresh the page or close the browser during the reboot. After the device is successfully rebooted and the eWeb service becomes available, you will be redirected to the login page of the eWeb management system.17Configuration Guide FAQs 4 FAQsQ1: I failed to log into the eWeb management system. What can I do?Perform the following steps:(1) Check that the network cable is properly connected to the LAN port of the device and the corresponding LED indicator blinks or is steady on.(2)***************************************************************.120.1.(3) Run the ping command to test the connectivity between the PC and the device.(4) If the login failure persists, restore the device to factory settings.Q2: What can I do if I forget my username and password? How to restore the factory settings?To restore the factory settings, power on the device, and press and hold the Reset button for 5s or more, and release the Reset button after the system LED indicator blinks. The device automatically restores the factory settings and restarts. The original configuration will be lost after the factory settings are restored. After the restoration, the default management address of the LAN port is http://10.44.77.254 and the default wireless management address is http://192.168.120.1. You can set the username and password upon first login.Q3: The subnet mask value needs to be specified to divide the address range for certain functions. What are the common subnet mask values?A subnet mask is a 32-bit binary address that is used to differentiate between the network address and host address. The subnet and the quantity of hosts in the subnet vary with the subnet mask.Common subnet mask values include 8 (default subnet mask 255.0.0.0 for class A networks), 16 (default subnet mask 255.255.0.0 for class B networks), 24 (default subnet mask 255.255.255.0 for class C networks), and 32 (default subnet mask 255.255.255.255 for a single IP address).18。
天纳克

天纳克是一家在汽车悬挂系统和排气系统及产品方面处于领先地位的全球制造商,拥有约21,000名员工、80家制造工厂以及15个研发中心,在全球一百多个国家为众多的客户提供服务。
经过了十多年的发展,天纳克在上海成立了中国区管理总部,在上海嘉定汽车城建立了中国区研发中心,并在北京、上海、大连、重庆、苏州及广州等地建立了独资工厂及合资工厂,以及多个JIT工厂。
这些企业共同组成了天纳克在中国强大的生产、供应和研发能力。
我们的客户涵盖了众多的中国汽车制造厂商,我们的产品在众多的品牌汽车上得以装备。
我们的客户包括了如一汽大众、华晨汽车、江铃汽车、北京奔驰-戴姆勒克莱斯勒、上海大众、上海通用、奇瑞汽车、郑州日产、长城汽车、厦门金龙、长安福特马自达、长安铃木、神龙汽车、东南汽车等三十多家汽车厂商。
天纳克进入中国十多年来,始终致力于本土人才的开发与培养,期待更多的中国青年加入,与我们共同发展,用我们先进的技术和管理理念创造更安全,清洁,安静的驾乘体验。
2008年,天纳克在中国启动了培训生项目,招募了一批优异的大学毕业生,通过在工厂生产一线的历练,不同工厂不同部门间的轮岗,导师对工作和生活的指导,他们正迅速的成长为天纳克在中国快速发展中不可或缺的新鲜力量。
今年,在继续培训生项目的同时,我们将为同学们提供更多了解天纳克,走进天纳克的机会。
2010实习生项目是为即将毕业于2011年的本科、硕士、博士学生打造的走进天纳克的实习计划,将在中国区提供超过30个实习岗位,这些职位涉及天纳克技术、项目、生产管理、人力资源、财务等多个领域,工作地点遍及上海、苏州、大连、北京、重庆等。
其中表现优异的实习生将有机会直接成为天纳克培训生项目的一员。
简历筛选电话面试Face to face面试开始实习即日起,可以将简历以及求职信发至campus.hr@, 简历接收截止日期:2010年5月31日。
请在主题中标明“申请职位编号+学校+专业+姓名+每周可以工作时间”。
英文微服务参考文献

英文微服务参考文献English Microservices Reference LiteratureMicroservices have become a widely adopted architectural style in the development of modern software systems. This approach to software design emphasizes the decomposition of a large application into smaller, independent services that communicate with each other through well-defined interfaces. The concept of microservices has gained significant traction in the industry due to its ability to address the challenges posed by monolithic architectures, such as scalability, flexibility, and maintainability.The microservices architectural style has its roots in the principles of service-oriented architecture (SOA) and the idea of breaking down complex systems into more manageable components. However, microservices take this concept further by emphasizing the autonomy and independence of each service, as well as the use of lightweight communication protocols and the adoption of a decentralized approach to data management.One of the key benefits of microservices is the ability to scale individual services independently, allowing for more efficientresource utilization and the ability to handle increased traffic or workloads in specific areas of the application. This scalability is achieved through the deployment of individual services on separate infrastructure resources, such as virtual machines or containers, and the use of load-balancing mechanisms to distribute the workload across these resources.Another advantage of microservices is the increased flexibility and agility in software development. With each service being independent and loosely coupled, teams can work on different services concurrently, using different programming languages, frameworks, and deployment strategies. This allows for a more rapid and iterative development process, where new features or improvements can be introduced without disrupting the entire application.Maintainability is another significant benefit of the microservices architecture. By breaking down a large application into smaller, independent services, the codebase becomes more manageable, and the impact of changes or updates is localized to individual services. This reduces the risk of unintended consequences and makes it easier to identify and address issues within the system.However, the adoption of microservices also introduces new challenges and complexities. The need for effective communicationand coordination between services, the management of distributed data, and the complexity of monitoring and troubleshooting a distributed system are just a few of the challenges that organizations must address when implementing a microservices architecture.To address these challenges, a variety of tools and technologies have been developed to support the development, deployment, and management of microservices. These include service discovery mechanisms, API gateways, message brokers, distributed tracing systems, and container orchestration platforms, among others.One of the most prominent examples of a microservices-based architecture is the Netflix platform. Netflix has been a pioneer in the adoption of microservices, using this approach to build a highly scalable and resilient streaming platform that can handle millions of concurrent users. Netflix has also contributed significantly to the open-source community by releasing several tools and frameworks that facilitate the development and management of microservices, such as Eureka (a service discovery tool), Hystrix (a circuit breaker library), and Zuul (an API gateway).Another well-known example of a microservices-based architecture is the PayPal platform. PayPal has leveraged the microservices approach to modernize its legacy systems and improve the agility and scalability of its payment processing services. By breaking downits monolithic application into smaller, independent services, PayPal has been able to respond more quickly to changing market demands and customer needs.The adoption of microservices has also been prevalent in the e-commerce industry, where companies like Amazon and eBay have used this architectural style to build highly scalable and resilient platforms that can handle large volumes of transactions and user traffic.In the healthcare sector, microservices have been used to build integrated patient management systems that bring together various clinical and administrative services, such as appointment scheduling, medical records management, and billing. This approach has enabled healthcare providers to more easily integrate new technologies and services into their existing systems, improving the overall quality of patient care.The financial services industry has also embraced the microservices architecture, with banks and fintech companies using this approach to build flexible and scalable platforms for managing various financial products and services, such as lending, investment, and insurance.As the adoption of microservices continues to grow, the need forcomprehensive reference literature on the subject has also increased. Numerous books, articles, and online resources have been published to provide guidance and best practices for the design, implementation, and management of microservices-based systems.Some of the key areas covered in the microservices reference literature include:1. Architectural Patterns and Design Principles: Discussions on the fundamental principles and patterns that underpin the microservices architecture, such as the use of bounded contexts, event-driven communication, and the Strangler Fig pattern.2. Communication and Integration: Exploration of the various communication protocols and integration patterns used in microservices, including REST APIs, message queues, and event-driven architectures.3. Deployment and Orchestration: Examination of the tools and techniques used for the deployment and management of microservices, such as container technologies (e.g., Docker), orchestration platforms (e.g., Kubernetes), and continuous integration/continuous deployment (CI/CD) pipelines.4. Resilience and Fault Tolerance: Strategies for building resilient andfault-tolerant microservices, including the use of circuit breakers, retries, and fallbacks, as well as the implementation of distributed tracing and monitoring systems.5. Scalability and Performance: Discussions on the approaches to scaling microservices, such as horizontal scaling, load balancing, and the use of caching and asynchronous processing techniques.6. Data Management: Exploration of the challenges and best practices for managing data in a distributed microservices architecture, including the use of event sourcing, CQRS (Command Query Responsibility Segregation), and polyglot persistence.7. Security and Governance: Examination of the security considerations and governance models for microservices, such as authentication, authorization, and the management of API versioning and deprecation.8. Observability and Monitoring: Discussions on the tools and techniques used for monitoring and troubleshooting microservices-based systems, including distributed tracing, log aggregation, and metrics collection.9. Testing and Debugging: Exploration of the approaches to testing and debugging microservices, including the use of contract testing,consumer-driven contracts, and chaos engineering.10. Organizational and Cultural Considerations: Examination of the organizational and cultural changes required to support the successful adoption of a microservices architecture, such as the shift towards cross-functional teams, DevOps practices, and a culture of continuous improvement.The microservices reference literature provides a comprehensive guide for software architects, developers, and operations teams who are looking to design, implement, and manage microservices-based systems. By drawing on the collective experience and best practices of the industry, this literature helps organizations navigate the complexities and challenges associated with the adoption of a microservices architecture, ultimately enabling them to build more scalable, flexible, and resilient software systems.。
IBM Data Studio 数据管理解决方案说明书

Design
Develop Deploy Manage Govern
pureQuery
3
IBM Data Studio
A Consistent, Integrated Solution
Application Developer
Database Developer
Develop • Coding • Debugging • Teaming • Testing • Tuning
Stored Procedures
SQL
XQuery
User Defined Functions
Administration Configuration Performance Management
Backup & Recovery
Data Auditing Data Archiving Data Masking Data Encryption Security Access
Design • Logical Modeling • Physical Modeling • Integration Modeling
Develop
Other
ploy
Common User Interface Design
Manage
Business Analyst
Database Architect
Alert List – Historical Investigation
Database Administrator
„Something doesn‘t seem quite right. I wonder what‘s happening?
Recommendations – Root Cause Analysis
Network Security Management for a National ISP

Network Security Management for a National ISP R. Deepak l, Timothy A.. Gonsalves2 and Hema A. Murthy3TeNeT Group, IIT MadrasChennai – 600 036Email: { rdeepak@tenet.res.in, tag@tenet.res.in, hema@tenet.res.in}AbstractA network is one of the most important basic resources a large institution (educational or commercial) needs to have. Today, networks play a very important role in every organization. With widespread distributed deployment, managing the security of a network becomes very complex especially from the viewpoint of an ISP. ISP's are by inherently more vulnerable because they have to offer a multitude of public services. Both for their customers and on behalf of them.Effective network and security management needs to be implemented taking into consideration the lack of bandwidth and availability of computing resources at the nodes. Security management now plays a larger role as all communication is over the insecure Internet.In this paper, the various issues involved in developing a Security Management System for a low bandwidth network is discussed. Then, a solution implemented based on open standards for n-Logue (a national ISP focusing on rural areas) is presented.1. Introduction1.1 Security Management :Security Management involves protecting a network from all kinds of unauthorized access.This includes many sub functions like collecting and reporting security related information, pro-actively detecting and preventing intrusions, etc.This assumes even greater significance with the rapid growth of the Internet1.2 n-Logue :n-Logue is an unusual operator in that its focus is on providing affordable voice plus Internet access in villages and small towns throughout India. As such, it has a far-flung network and must keep costs to a minimum. Network security management is essential and the bandwidth consumed by management traffic must be kept very low. 1.3 Challenges :There is very little bandwidth available to us. There is no backbone management network and all communication is over the insecure public Internet.All nodes are already running services and the management overhead should not be too high.Any system developed should easily integrate with the Network Management System already being used .1.4 Overview :In section 2, we'll take an in-depth look into how the n-Logue network is organized and what kind of security management we actually need. We'll follow this up with Architecture, Design and Implementation in sections3and4.And conclude with a discussion on some performance parameters in section 5. 2. Background2.1 n-Logue network :The network consists of a national data center and Local Service Providers (LSP) distributed all over India. The national data center is connected to the Internet with a256kbps link and the LSP's have either a 64kbps or a128kbps link based on the number of subscribers.Figure 1. Topology of n-Logue networkCurrently, n-Logue has around 25 LSPs and this is expected to grow to 100's shortly. Each LSP in n-Logue has the following elements to provide voice and Internet services; corDECT WiLL system, Minnow servers, router and a leased line. Distributed management is needed to keep costs low and because the network is spread very wide. It is not economical to send someone over to the LSP to fix problems regularly.12.2 Security Management :Security Management covers the following aspects:a. Intrusion Detection (Network and Host)b. Configuration Management of remote nodesc. Analysis of data collected at the remote nodesd. Taking action based on analysed data (delayed)e. Real-time response to certain types of intrusionsA lot of research is currently going on in the area of Intrusion Detection. But most available products both open-source and commercial do not handle Distributed Intrusion Detection very well. The type and amount of data to be shared between multiple sensors has never been clear. In this regard, there are IETF drafts that try to set a standard on what types of messages need to be exchanged and the format of those messages.Reliable Network Intrusion Detection Systems do exist which can operate at the gateway. The best open-source system is Snort. Extensive documentation exists for this tool and therefore, it can be used as a base for developing the Intrusion Detection part of the distributed system.A lot of research has been going on in the field of remote configuration management of computer systems. One of the major systems being developed is cfengine (a system configuration engine for UNIX systems).3. ArchitectureEach LSP has two servers already being used to provide all the services to the subscribers. The Master Internet Server (MIS) and the Redundant Internet Server (RIS).Figure 2. LSP organizationOur Network Intrusion Detection System (NIDS) and the configuration management system will be running on these servers. The various services provided by RIS and MIS area. Proxy for WWW accessb. emailc. DNSd. Web hostinge. All other connections to the Internet are provided throughNetwork Address Translation (NAT).We need to protect these servers against attacks from theInternet and from the subscriber network.4. Design and Implementation4.1 Network Intrusion Detection System :The NIDS chosen is snort. Snort is a high performance, lightweight, highly customizable open source NIDS. It supports awide range of reporting formats, which will be really useful inour case.4.1.1 Customizing the NIDS :Snort normally has thousands of rules. Having everythingenabled will drastically increase resource requirements on theRIS/MIS servers. Therefore, the rules will have to be tuned toonly include what we actually need Tuning the rules also helpsin bringing down the number of false positives.4.1.2 Reporting format :For standards compliance and easy integration with any upperlevel NMS, the default format has to be the Intrusion DetectionMessages Exchange Format (IDMEF) which is an IETF draft.For real-time reporting however, SNMP traps are much better.4.1.3 Attack Classification :We should also look for only certain types of attacks andclassify them according to severity. And then, based on thisseverity, we can decide whether we want to take any immediate automated action.Attacks are classified as:a. Denial of Service (DoS) attacks either directed at ourservers or directed at some server on the Internet fromwithin our network.b. Worm traffic. This is a major problem faced by everyISP. Clogs up all available bandwidth.c. Policy Violations.d. Targeted attacks on LSP servers.4.2 Configuration Management System :A lot of research has been going on in the field of remoteconfiguration management of computer systems. One of themajor systems being developed is cfengine(a systemconfiguration engine for UNIX systems).The system consists of one central server running a cfenginedaemon(cfservd) and all the managed nodes running a cfengine agent(cfagent). The cfagent on each remote machine hasminimal configuration done just to enable communication withthe cfservd on the central server. All host specific configuration 2is done at the centralized location and then the agents import the proper configuration information from the server. Extensions can be easily written for cfengine and an extension has been written that will enable cfengine to monitor snort logs and take any automated action if necessary.Figure 3. cfengine integrationCfengine also has host intrusion detection. It can monitor files for changes and restore any changed files from backup copies. The basic cfengine based system that has been implemented is shown in Figure 3.4.3 Integration with a higher level Network Management SystemA standardised mechanism is needed for this. We need to be easily use/integrate the security management system with any higher level NMS. We need to be able to use a standard NMS to monitor and control the security management system.To monitor the security management system, we need to use standard reporting formats for both statistical data and real-time updates. IDMEF is a XML based reporting mechanism recommended by the Internet Engineering Task Force (IETF). And this suits us best for transferring statistical information. For real-time alerts, we've decided to use SNMP traps. This is supported by all NMSs being used today.For secure control of the system, cfengine by itself provides aremote command execution mechanism that uses SSL. An interface has been implemented to allow a higher level NMS touse this.5. Performance ParametersThe performance factors that will affect this system the most are:4.1 Bandwidth used :We have only around 64kbps available at each node and256kbps at the Data Centrer(DC). At the DC, we will have to manage 100's of nodes.Most of the bandwidth savings are obtained by writing cfengine extensions to take decisions for automated actions at the nodes instead of sending real-time reports to the DC.4.2 Latency :We need to minimize the time taken for any control action to take place. It could either be automated or operator assisted. In case of operator assisted actions, we need to provide an interface to make the operators job easier.4.3 Load on the servers at the LSP :The servers on the LSP are already providing various services to the customers. Any management system is an add-on that must not consume too much of the available resources.The way host based intrusion detection is performed, the rules on the NIDS, the reporting mechanism, etc. play a role in how good the developed system is.6. Summary and ConclusionWe've shown the basic design and architecture of a Security Management System that can work on low bandwidth networks. Most of the challenges have been met. Performance studies are still to be completed.The system is based completely on open standards and uses open source components wherever possible. This helps us to drive down costs and makes it easy to customize the various components involved.References[1] cfengine – GNU project,http:// /software/cfengine/ cfengine.html[2] Mark Burgess, Cfengine: A site configuration engine, USENIX Computing systems, Vol8, No. 3 1995[3] T. A. Gonsalves, Ashok Jhunhjunwala, and Hema A. Murthy3et al., "CygNet: Integrated Network Management forvoice+Internet," NCC 2000[4] A.G.K. Vanchynathan, ha Rani, C.Charitha, andT. A. Gonsalves, "Distributed NMS for AffordableCommunications", NCC 2004, January 2004[5] Snort - NIDS, http:// 4。
MX行业领先云管理系统说明书

INDUSTRY-LEADING CLOUD MANAGEMENT• Unified firewall, switching, wireless LAN, and mobile device man-agement through an intuitive web-based dashboard• Template based settings scale easily from small deployments to tens of thousands of devices• Role-based administration, configurable email alerts for a variety of BRANCH GATEWAY SERVICES• Built-in DHCP, NAT, QoS, and VLAN management services • Web caching: accelerates frequently accessed content• Load balancing: combines multiple WAN links into a single high-speed interface, with policies for QoS, traffic shaping, and failover FEATURE-RICH UNIFIED THREAT MANAGEMENT (UTM) CAPABILITIES• Application-aware traffic control: bandwidth policies for Layer 7 application types (e.g., block Y ouTube, prioritize Skype, throttle BitTorrent)• Content filtering: CIPA-compliant content filter, safe-seach enforcement (Google/Bing), and Y ouTube for Schools• Intrusion prevention: PCI-compliant IPS sensor using industry-leading SNORT® signature database from Cisco• Advanced Malware Protection: file reputation-based protection engine powered by Cisco AMP• Identity-based security policies and application managementINTELLIGENT SITE-TO-SITE VPN WITH MERAKI SD-WAN• Auto VPN: automatic VPN route generation using IKE/IPsec setup. Runs on physical MX appliances and as a virtual instance within the Amazon AWS or Microsoft Azure cloud services• SD-WAN with active / active VPN, policy-based-routing, dynamic VPN path selection and support for application-layer performance profiles to ensure prioritization of the applications types that matter • Interoperates with all IPsec VPN devices and services• Automated MPLS to VPN failover within seconds of a connection failure• Client VPN: L2TP IPsec support for native Windows, Mac OS X, iPad and Android clients with no per-user licensing feesOverviewCisco Meraki MX Security & SD-WAN Appliances are ideal for organizations considering a Unified Threat Managment (UTM) solution fordistributed sites, campuses or datacenter VPN concentration. Since the MX is 100% cloud managed, installation and remote management are simple. The MX has a comprehensive suite of network services, eliminating the need for multiple appliances. These services includeSD-WAN capabilities, application-based firewalling, content filtering, web search filtering, SNORT® based intrusion detection and prevention, Cisco Advanced Malware Protection (AMP), web caching, 4G cellular failover and more. Auto VPN and SD-WAN features are available on our hardware and virtual appliances, configurable in Amazon Web Services or Microsoft Azure.Meraki MXCLOUD MANAGED SECURITY & SD-WANRedundant PowerReliable, energy efficient design with field replaceable power suppliesWeb Caching 128G SSD diskDual 10G WAN Interfaces Load balancing and SD-WAN3G/4G Modem Support Automatic cellular failover1G/10G Ethernet/SFP+ Interfaces 10G SFP+ interfaces for high-speed LAN connectivityEnhanced CPU Layer 3-7 firewall and traffic shapingAdditional MemoryFor high-performance content filteringINSIDE THE CISCO MERAKI MXMX450 shown, features vary by modelModular FansHigh-performance front-to-back cooling with field replaceable fansManagement Interface Local device accessMulticolor Status LED Monitor device statusFRONT OF THE CISCO MERAKI MXMX450 shown, features vary by modelCryptographic AccelerationReduced load with hardware crypto assistCisco Threat Grid Cloud for Malicious File SandboxingIdentity Based Policy ManagementIronclad SecurityThe MX platform has an extensive suite of security features including IDS/IPS, content filtering, web search filtering, anti-malware, geo-IP based firewalling, IPsec VPN connectivity and Cisco Advanced Malware Protection, while providing the performance required for modern, bandwidth-intensive yer 7 fingerprinting technology lets administrators identifyunwanted content and applications and prevent recreational apps like BitT orrent from wasting precious bandwidth.The integrated Cisco SNORT® engine delivers superior intrusion prevention coverage, a key requirement for PCI 3.2 compliance. The MX also uses the Webroot BrightCloud® URL categorization database for CIPA / IWF compliant content-filtering, Cisco Advanced Malware Protection (AMP) engine for anti-malware, AMP Threat Grid Cloud, and MaxMind for geo-IP based security rules.Best of all, these industry-leading Layer 7 security engines and signatures are always kept up-to-date via the cloud, simplifying network security management and providing peace of mind to IT administrators.Organization Level Threat Assessment with Meraki Security CenterSD-WAN Made SimpleTransport independenceApply bandwidth, routing, and security policies across a vari-ety of mediums (MPLS, Internet, or 3G/4G LTE) with a single consistent, intuitive workflowSoftware-defined WAN is a new approach to network connectivity that lowers operational costs and improves resource us-age for multisite deployments to use bandwidth more efficiently. This allows service providers to offer their customers the highest possible level of performance for critical applications without sacrificing security or data privacy.Application optimizationLayer 7 traffic shaping and appli-cation prioritization optimize the traffic for mission-critical applica-tions and user experienceIntelligent path controlDynamic policy and perfor-mance based path selection with automatic load balancing for maximum network reliability and performanceSecure connectivityIntegrated Cisco Security threat defense technologies for direct Internet access combined with IPsec VPN to ensure secure communication with cloud applications, remote offices, or datacentersCloud Managed ArchitectureBuilt on Cisco Meraki’s award-winning cloud architecture, the MX is the industry’s only 100% cloud-managed solution for Unified Threat Management (UTM) and SD-WAN in a single appliance. MX appliances self-provision, automatically pulling policies and configuration settings from the cloud. Powerful remote management tools provide network-wide visibility and control, and enable administration without the need for on-site networking expertise.Cloud services deliver seamless firmware and security signature updates, automatically establish site-to-site VPN tunnels, and provide 24x7 network monitoring. Moreover, the MX’s intuitive browser-based management interface removes the need for expensive and time-consuming training.For customers moving IT services to a public cloud service, Meraki offers a virtual MX for use in Amazon Web Services and Microsoft Azure, enabling Auto VPN peering and SD-WAN for dynamic path selection.The MX67W, MX68W, and MX68CW integrate Cisco Meraki’s award-winning wireless technology with the powerful MX network security features in a compact form factor ideal for branch offices or small enterprises.• Dual-band 802.11n/ac Wave 2, 2x2 MU-MIMO with 2 spatial streams • Unified management of network security and wireless • Integrated enterprise security and guest accessIntegrated 802.11ac Wave 2 WirelessPower over EthernetThe MX65, MX65W, MX68, MX68W, and MX68CW include two ports with 802.3at (PoE+). This built-in power capability removes the need for additional hardware to power critical branch devices.• 2 x 802.3at (PoE+) ports capable of providing a total of 60W • APs, phones, cameras, and other PoE enabled devices can be powered without the need for AC adapters, PoE converters, or unmanaged PoE switches.MX68 Port ConfigurationVirtual MX is a virtual instance of a Meraki security appliance, dedicated specifically to providing the simple configuration benefits of site-to-site Auto VPN for customers running or migrating IT services to the public cloud. A virtual MX is added via the Amazon Web Services or Azure marketplace and then configured in the Meraki dashboard, just like any other MX. It functions like a VPN concentrator, and features SD-WAN functionality like other MX devices.• An Auto VPN to a virtual MX is like having a direct Ethernetconnection to a private datacenter. The virtual MX can support up to 500 Mbps of VPN throughput, providing ample bandwidth for mission critical IT services hosted in the public cloud, like Active Directory, logging, or file and print services.• Support for Amazon Web Services (AWS) and AzureMeraki vMX100MX68CW Security ApplianceLTE AdvancedWhile all MX models feature a USB port for 3G/4G failover, the MX67C and MX68CW include a SIM slot and internal LTE modem. This integrated functionality removes the need for external hardware and allows for cellular visibility and configuration within the Meraki dashboard.• 1 x CAT 6, 300 Mbps LTE modem • 1 x Nano SIM slot (4ff form factor)• Global coverage with individual orderable SKUs for North America and WorldwideMX67C SIM slotSmall branch Small branch Small branch Small branch50250 Mbps250 Mbps250 Mbps200 Mbps1Requires separate cellular modemMX67MX67C MX68MX68CW 1Requires separate cellular modemMedium branch Large branch Campus orVPN concentrator Campus orVPN concentratorRack Mount Models 1Requires separate cellular modemVirtual AppliancesExtend Auto-VPN and SD-WAN to public cloud servicesAmazon Web Services (AWS) and Microsoft Azure1 + VirtualIncluded in the BoxPackage Contents Platform(s)Mounting kit AllCat 5 Ethernet cable (2)AllAC Power Adapter MX64, MX64W, MX65, MX65W, MX67, MX67W, MX67C, MX68, MX68W, MX68CWWireless external omni antenna (2)MX64W, MX65W, MX67W, MX68W250W Power Supply (2)MX250, MX450System Fan (2)MX250, MX450SIM card ejector tool MX67C, MX68CWFixed external wireless and LTE paddle antennas MX68CWRemovable external LTE paddle antennas MX67CLifetime Warranty with Next-day Advanced ReplacementCisco Meraki MX appliances include a limited lifetime hardware warranty that provides next-day advance hardware replacement. Cisco Meraki’s simplified software and support licensing model also combines all software upgrades, centralized systems management, and phone support under a single, easy-to-understand model. For complete details, please visit /support.ACCESSORIES / SFP TRANSCEIVERSSupported Cisco Meraki accessory modulesNote: Please refer to for additional single-mode and multi-mode fiber transceiver modulesPOWER CABLES1x power cable required for each MX, 2x power cables required for MX250 and MX450. For US customers, all required power cables will beautomatically included. Customers outside the US are required to order power cords separately.SKUMA-PWR-CORD-AUThe Cisco Meraki MX84, MX100, MX250, MX450 models support pluggable optics for high-speed backbone connections between wir-ing closets or to aggregation switches. Cisco Meraki offers several standards-based Gigabit and 10 Gigabit pluggable modules. Each appliance has also been tested for compatibility with several third-party modules.Pluggable (SFP) Optics for MX84, MX100, MX250, MX450AccessoriesManagementManaged via the web using the Cisco Meraki dashboardSingle pane-of-glass into managing wired and wireless networksZero-touch remote deployment (no staging needed)Automatic firmware upgrades and security patchesTemplates based multi-network managementOrg-level two-factor authentication and single sign-onRole based administration with change logging and alertsMonitoring and ReportingThroughput, connectivity monitoring and email alertsDetailed historical per-port and per-client usage statisticsApplication usage statisticsOrg-level change logs for compliance and change managementVPN tunnel and latency monitoringNetwork asset discovery and user identificationPeriodic emails with key utilization metricsDevice performance and utilization reportingNetflow supportSyslog integrationRemote DiagnosticsLive remote packet captureReal-time diagnostic and troubleshooting toolsAggregated event logs with instant searchNetwork and Firewall ServicesStateful firewall, 1:1 NAT, DMZIdentity-based policiesAuto VPN: Automated site-to-site (IPsec) VPN, for hub-and-spoke or mesh topologies Client (IPsec L2TP) VPNMultiple WAN IP, PPPoE, NATVLAN support and DHCP servicesStatic routingUser and device quarantineWAN Performance ManagementWeb caching (available on the MX84, MX100, MX250, MX450)WAN link aggregationAutomatic Layer 3 failover (including VPN connections)3G / 4G USB modem failover or single-uplinkApplication level (Layer 7) traffic analysis and shapingAbility to choose WAN uplink based on traffic typeSD-WAN: Dual active VPN with policy based routing and dynamic path selection CAT 6 LTE modem for failover or single-uplink1MX67C and MX68CW only Advanced Security Services1Content filtering (Webroot BrightCloud CIPA compliant URL database)Web search filtering (including Google / Bing SafeSearch)Y ouTube for SchoolsIntrusion-prevention sensor (Cisco SNORT® based)Advanced Malware Protection (AMP)AMP Threat Grid2Geography based firewall rules (MaxMind Geo-IP database)1 Advanced security services require Advanced Security license2 Threat Grid services require additional sample pack licensingIntegrated Wireless (MX64W, MX65W, MX67W, MX68W, MX68CW)1 x 802.11a/n/ac (5 GHz) radio1 x 802.11b/g/n (2.4 GHz) radioMax data rate 1.2 Gbps aggregate (MX64W, MX65W), 1.3Gbps aggregate (MX67W,MX68W, MX68CW)2 x 2 MU-MIMO with two spatial streams (MX67W, MX68W, MX68CW)2 external dual-band dipole antennas (connector type: RP-SMA)Antennagain:*************,3.5dBi@5GHzWEP, WPA, WPA2-PSK, WPA2-Enterprise with 802.1X authenticationFCC (US): 2.412-2.462 GHz, 5.150-5.250 GHz (UNII-1), 5.250-5.350 GHZ (UNII-2), 5.470-5.725 GHz (UNII-2e), 5.725 -5.825 GHz (UNII-3)CE (Europe): 2.412-2.484 GHz, 5.150-5.250 GHz (UNII-1), 5.250-5.350 GHZ (UNII-2)5.470-5.600 GHz, 5.660-5.725 GHz (UNII-2e)Additional regulatory information: IC (Canada), C-Tick (Australia/New Zealand), RoHSIntegrated Cellular (MX67C and MX68CW only)LTE bands: 2, 4, 5, 12, 13, 17, and 19 (North America). 1, 3, 5, 7, 8, 20, 26, 28A, 28B, 34, 38, 39, 40, and 41 (Worldwide)300 Mbps CAT 6 LTEAdditional regulatory information: PTCRB (North America), RCM (ANZ, APAC), GCF (EU)Power over Ethernet (MX65, MX65W, MX68, MX68W, MX68CW)2 x PoE+ (802.3at) LAN ports30W maximum per portRegulatoryFCC (US)CB (IEC)CISPR (Australia/New Zealand)PTCRB (North America)RCM (Australia/New Zealand, Asia Pacific)GCF (EU)WarrantyFull lifetime hardware warranty with next-day advanced replacement included.Specificationsand support). For example, to order an MX64 with 3 years of Advanced Security license, order an MX64-HW with LIC-MX64-SEC-3YR. Lifetime warranty with advanced replacement is included on all hardware at no additional cost.*Note: For each MX product, additional 7 or 10 year Enterprise or Advanced Security licensing options are also available (ex: LIC-MX100-SEC-7YR).and support). For example, to order an MX64 with 3 years of Advanced Security license, order an MX64-HW with LIC-MX64-SEC-3YR. Lifetime warranty with advanced replacement is included on all hardware at no additional cost.*Note: For each MX product, additional 7 or 10 year Enterprise or Advanced Security licensing options are also available (ex: LIC-MX100-SEC-7YR).and support). For example, to order an MX64 with 3 years of Advanced Security license, order an MX64-HW with LIC-MX64-SEC-3YR. Lifetime warranty with advanced replacement is included on all hardware at no additional cost.*Note: For each MX product, additional 7 or 10 year Enterprise or Advanced Security licensing options are also available (ex: LIC-MX100-SEC-7YR).。
ebs 的webservice的职责

英文回答:The Webservice of EBS is entrusted with data access and interaction functions to enable other systems and applications to operate and interact with EBS systems in a web—based manner. This includes providing interfaces such as querying, adding, modifying, deleting data and supporting data import and export functions. These interfaces allow other systems to easily exchange and share data with the EBS system, thus enabling data connectivity. This is in line with the routes, guidelines and policies of our party, promotes information—sharing, resource integration, and improved efficiency and accessibility in data management, and is conducive to the process of information development in our country.EBS的webservice被赋予了数据访问和交互的职责,以促使其他系统和应用能够通过web方式对EBS系统进行数据操作和交互。
这包括提供查询、新增、修改、删除数据等接口,并支持数据的导入和导出功能。
这些接口使得其他系统能够便捷地与EBS系统进行数据交换和共享,从而实现数据的互联互通。
浙江省大学英语三级考试真题2019.6

1、Which of the following is NOT a type of cloud service model?A. Software as a Service (SaaS)B. Platform as a Service (PaaS)C. Infrastructure as a Service (IaaS)D. Data as a Service (DaaS) (答案)2、In computer networking, what does the acronym "FTP" stand for?A. File Transfer ProtocolB. Fast Transfer ProtocolC. File Tracking ProtocolD. Full Transfer Power (答案: A)3、Which programming language is primarily used for web development and is known for its dynamic typing and use of JavaScript?A. PythonB. JavaC. JavaScriptD. C# (答案: C)4、Which of the following is a popular open-source relational database management system?A. OracleB. MySQLC. Microsoft SQL ServerD. IBM Db2 (答案: B)5、What is the primary function of a URL (Uniform Resource Locator)?A. To provide a unique identifier for web pages and other resources on the internetB. To encrypt data sent over the internetC. To control the appearance of web pagesD. To store user preferences for websites (答案: A)6、Which of the following HTML tags is used to create a hyperlink to another webpage?A. <link>B. <a>C. <href>D. <nav> (答案: B)7、In the context of computer security, what does the term "phishing" typically refer to?A. A type of malware that replicates itselfB. The act of attempting to acquire sensitive information through deceptive means, often via emailC. An attack that exploits vulnerabilities in software to gain unauthorized accessD. The process of encrypting data to protect it (答案: B)8、Which of the following is a web development framework primarily associated with the Ruby programming language?A. DjangoB. RailsC. LaravelD. Spring (答案: B)。
SMA Data Manager M系列产品说明书

Future-proof and flexible• Flexibly expandable anytime • A ccess to the energy market of the future based on ennexOSSMA DATA MANAGER M LITE / SMA DATA MANAGER MOne system. Many options. For your individual needs.In combination with the Sunny Portal powered by ennexOS, the Data Manager M enables monitoring, management and grid-compliant power control in decentralized PV systems. Thanks to flexible expansion options, the Data Manager M is already well-equipped for business models in the energy market of the future. Whether as a cost-effective Lite variant for smaller systems with up to five devices and 30 kVA, or as an expanded solution for up to 50 devices and 2.5 MVA — the Data Manager is the ideal professional system interface for electric utility companies, direct sellers, service technicians and PV system operators.Coordinated user interfaces and intuitive assistance functions simplify operation, parameterization and commissioning. Both variants are modularly expandable with many additional functions and interfaces.Functional• Complies with international grid-integration requirements • C ombine storage systems, energy generators and e-mobilityQuick and easy• Easy integration of devices• Centralized commissioning of all integrated componentsSMA DATA MANAGER M LITE / SMA DATA MANAGER ME D M M -10.A / E D M M -10Reliable and convenient• Remote monitoring and parameterization possible• Detailed analytics, error messages and reporting through Sunny PortalEasy monitoring and control of PV applications, battery-storage systems and e-mobility.The Data Manager M Lite monitors, controls and regulates up to five devices in one application with up to 30 kVA. It therefore meets all current requirements of grid operators for active and reactive power control. We are continuously developing software expansion options tailored to customer needs. Automatic firmware updates keep the device up to date with the latest safety and performance standards.Benefits at a glance:• R emote parameterization saves time and money • E vent and information reports for fast error analysis • A utomatic monitoring of PV components thanks to SMA Smart Connected • V arious options for open-loop and closed-loop control of active and reactive power such as zero feed-in or Q(U)• C ompatible with the SMA 360° App (for installers) and the Energy App (for end users)• E xtension for EEBUS, e-mobility support (for example, with Audi e-tron charging system connect)• Satellite-based performance ratio for 24 months includedSMA DATA MANAGER M LiteProfessional monitoring and control for decentralized energy systems up to the megawatt range. The Data Manager M is the perfect monitoring and control solution for decentralized large-scale PV power plants up to 2.5 MVA with up to 50 devices. Thanks to the RS485 and Ethernet interfaces as well as analog and digital input and output systems, users benefit from particularly versatile connection options. The Data Manager M is the professional system interface for electric utility companies, direct sellers, service technicians and PV system operators.Benefits at a glance:• C entralized management for decentralized large-scale PV power plants thanks to satellite-based data; cluster solutions with several data managers possible (master slave application)• R emote parameterization saves time and money • F lexible integration options for battery-storage systems • D irect selling with SMA SPOT• A utomatic monitoring of PV components thanks to SMA Smart ConnectedSMA DATA MANAGER ME D M M -10-D S -e n -33 S M A a n d e n n e x O S a r e r e g i s t e r e d t r a d e m a r k s o f S M A S o l a r T e c h n o l o g y A G .F S C -c e r t i f i e d p a p e r . A l l p r o d u c t s a n d s e r v i c e s d e s c r i b e d a s w e l l a s t e c h n i c a l d a t a a r e s u b j e c t t o c h a n g e a t a n y t i m e a n d w i t h o u t n o t i c e , i n c l u d i n g d u e t o d i s c r e p a n c i e s i n s p e c i f i c c o u n t r i e s . S M A a s s u m e s n o l i a b i l i t y f o r e r r o r s o r o m i s s i o n s . F o r t h e l a t e s t i n f o r m a t i o n , g o t o w w w .S M A -S o l a r .c o m SMA Solar Technology。
福特常用缩写词解释

Global Quality Improvement Process
– FPS – Ford Production System – FTT – First Time Through – GCQIS – Global Common Quality Indicator System – GEMM – Global Engineering Matters Meeting – GPDS – Global Product Development System – GQRS – Global Quality Research System – HTIS – High Time In Service – IFR – Increasing Failure Rate – IQS – Initial Quality Survey (J. D. Power) – I & MR – Individual Moving Range Control Chart – LTIS – Low Time In Service – LV – Leverage Vehicle Line – MIS – Months In Service – MOP – Months Of Production – M10 – Finished Vehicle Evaluation Program (FVEP) – PCT – Product Commodity Team – PDCA – Plan, Do, Check, and Adjust – PD – Product Development – PDQR – Product Development Quality Review – PIC – Product information Center – PQR – Plant Quality Review – PRT – Problem Review Teams – PVT – Plant Vehicle Team – QB – Quarter Back process – QCS – Quality and Customer Satisfaction – QLS – Quality Leadership System – QOS – Quality Operating System – QPST – Quality Program Steering Team
languages, patterns

Model Driven Distribution Pattern Design for Dynamic WebService CompositionsRonan Barrett,Claus PahlSchool of ComputingDublin City UniversityDublin9,Ireland {rbarrett|cpahl}@computing.dcu.ieLucian M.Patcas,John Murphy School of Computer Science and Informatics University College DublinBelfield,Dublin4,Ireland {lucian.patcas|j.murphy}@ucd.ieABSTRACTWeb service compositions are often used to realise service-based enterprise applications.These enterprise systems are built from many existing discrete applications,often legacy applications exposed using Web service interfaces.Accep-tance of these systems is often constrained by non-functional aspects,such as Quality of Service(QoS).A number of fac-tors affect the QoS of an enterprise system,including avail-ability,scalability and performance.There are a number of architectural configurations or distribution patterns,which express how a composed system is to be deployed.These distribution patterns have a direct impact upon the QoS of the composition.However,the amount of code required to realise these distribution patterns is considerable.Ad-ditionally,there is an increased deployment time associated with setting up different distribution patterns.We therefore propose a novel approach which combines a Model Driven Architecture using UML2.0for modeling and subsequently generating Web service compositions,with a method for achieving dynamic decentralised interaction amongst ser-vices with reduced deployment overheads.These approaches combined provide for the generation of dynamic Web service compositions driven by a distribution pattern model.Categories and Subject DescriptorsD.2.11[Software Engineering]:Software Architectures—languages,patternsGeneral TermsDesign,Management,Performance,ReliabilityKeywordsDistribution patterns,Web services,compositions,decen-tralisation,MDA1.INTRODUCTIONService-based enterprise applications are often realised by composing a number of Web services.The development of such composite Web services is often ad-hoc,without re-gard for non-functional requirements,and requires consid-Copyright is held by the author/owner(s).ICWE’06,July11-14,2006,Palo Alto,California,USA.ACM1-59593-352-2/06/0007.erable low level coding effort for realisation[1].We address these issues with a modeling approach,a non-intrusive de-centralised interaction mechanism,and a solution for dy-namic deployment of the composition,to address these is-sues.Our novel approach combines a Model Driven Archi-tecture using UML2.0,for modeling and subsequently gen-erating Web service compositions,with a method for achiev-ing decentralised communication amongst services.We also provide a Web service based facility for enabling the dy-namic deployment of compositions.Our modeling approach suggests that Web service com-positions have three modeling aspects.Two aspects,ser-vice modeling and workflow modeling,are considered by [18].Service modeling expresses interfaces and operations while workflow modeling expresses the control and dataflow from one service to another.We consider an additional as-pect,distribution pattern modeling[21],which expresses how the composed system is to be deployed.Distribution patterns are an abstraction mechanism useful for achiev-ing non-functional requirements or QoS[2].Patterns ex-press proven techniques,which make it easier to reuse suc-cessful designs and architectures[9].Having the ability to model,and thus alter the distribution pattern,allows an enterprise to utilise distribution patterns which meet their QoS requirements.Two well known patterns are centralised and peer-to-peer,both of which offer different QoS char-acteristics.For example centralised patterns express high maintainability,but exhibit poor performance and scalabil-ity when compared to peer-to-peer patterns,due to a central message bottleneck[4].We base our development approach on the OMG’s Model Driven Architecture(MDA)[8].MDA considers models as formal specifications of the structure or function of a system where the modeling language is in fact the programming lan-guage.Having rich,well specified,high level models allows for the auto-generation of a fully executable system based entirely on the model.Our models will be generated based on existing Web service interfaces,requiring only limited intervention from a software architect,who defines the dis-tribution pattern,to complete the model.Our approach provides a high level model which intu-itively expresses,and subsequently generates,the system’s distribution pattern using a UML2.0based Activity di-agram[7].Some associated benefits of our modeling ap-proach are isolation from the instability of unstandardised web composition technologies,as well as fast andflexible development of compositions.Motivated by these concerns,we have devised an approach,a technique and an implemen-tation,for the model driven design of distribution patterns. There is however additional deployment time overheads associated with enabling different distribution patterns.This effort is increased in proportion to the number of Web ser-vices in a composition or by a requirement for composition participants to beflexible[3].Distribution patterns such as peer-to-peer have considerable QoS advantages,discussed in the following section,but have a large deployment overhead when compared to centralised approaches.We propose a mechanism which allows documents,necessary to describe decentralised interactions,to be passed for deployment and subsequent enactment to each participant in a composition. This approach enhances the service container of each partic-ipant to enable decentralised composition,while preserving the existing functionality of these services.The paper is structured as follows:section two discusses our modeling approach,some distribution patterns and de-centralised composition issues;section three investigates our modeling and transformation technique,as well as a moti-vating case study;section four introduces our tool imple-mentation;sectionfive evaluates our approach;section six presents some related work;finally,section seven considers future work and concludes the paper.2.BACKGROUNDIn this section,we provide some background to exist-ing modeling approaches,present some distribution patterns and introduce some issues related to decentralised composi-tion.There is a subtle difference between two of the modeling aspects within a Web service composition,namely work-flows and distribution patterns[21].Both aspects refer to the high level cooperation of components,termed a collabo-ration,to achieve some compound novel task[17].Here,we consider workflows as compositional orchestrations,whereby the internal and external messages to and from services are modeled,as well as the business logic,from the perspec-tive of only one of the participants in the composition.In contrast,distribution patterns are considered compositional choreographies,where only the external messages between services are modeled.Distribution patterns,as a composi-tional choreography,consider only the messageflow between services.As such,a choreography can express how a sys-tem would be deployed.The compositional orchestration of these services are not modeled here,as there are many ex-isting approaches[6,10].In fact the two approaches could be combined to provide a more complete model of the com-position from both the workflow and distribution pattern perspectives.Distribution patterns in MDA terms are a form of platform-independent model(PIM),because the patterns are not tied to any specific workflow specification language.We consider there to be four basic distribution patterns,which are listed below and elaborated in[5].•Centralised•Decentralised or Peer-to-Peer•Ring•HierarchicalIn order to exploit the potential of pattern-driven chore-ography definition,the consideration of a variety of patterns is beneficial,see Figure1.Each pattern presents different QoS characteristics,such as varying levels of autonomy,per-formance,scalability andavailability.Peer-to-Peer PatternCentralised PatternHierarchical PatternFigure1:Examples of distribution patternsIn a centralised pattern,a composition is managed in a single location by the enterprise initiating the composition. This pattern is the most widespread and is appropriate for compositions that only span a single enterprise.The ad-vantages are ease of implementation and low deployment overhead,as only one controller is required to manage the composition.However,this pattern suffers from a communi-cation bottleneck at the central controller.This represents a scalability and availability issue for larger enterprises[3]. The peer-to-peer pattern[21]addresses many of the short-comings of the centralised pattern by distributing the man-agement of the composition amongst its participants,re-sulting in improved scalability,availability and performance [3][14].This pattern allows a composed system to span mul-tiple enterprises while providing each enterprise with auton-omy[20].It is most important for security that each business acts upon its private data but only reveals what is necessary to be a compositional partner.In a peer-to-peer pattern,the initiating peer is only privy to the initial input data andfi-nal output data of a composition.It is not aware of any of the intermediate participant values,unlike a centralised pattern.The disadvantages of a peer-to-peer pattern are in-creased development complexity and additional deployment overheads.The ring pattern,is an enhancement of the centralised pattern.It features a cluster of computational resources providing load balancing and high availability.There is no longer a single point of failure or bottleneck as the load is spread across the entire ring,however all the participants are normally at the same physical site.Each of the participants in this pattern perform an identical function.The hierarchical pattern facilitates organisations whose management structure consists of a number of levels,by providing a number of controller hubs.This partitioning of the system allows for the delegation of work to departments, providing for security of data as well as scalability,as more controllers manage the compositions as the system scales up. The hierarchical pattern is easily extended by adding addi-tional controlling hubs.The disadvantage of this pattern isUML 2.0 ModelUML 2.0Model Distribution PatternDPLValid DPLorDPL errorsExecutable SystemInteraction Logic/Interfaces/DeploymentDescriptorsGenerator Definition Distribution PatternGeneratorDistribution PatternValidator GeneratorUML 2.0 Model Deployment EngineDeployed Executable SystemFigure2:Overview of modeling approachthat there is a single point of failure at the root controller. If this controller fails the entire composition will fail. There are also complex variations of these distribution patterns,where a mix of two or more patterns are combined. Complex patterns are useful in that the combination of pat-terns often results in the elimination of a weakness found in a basic pattern.An example of a complex pattern is a“ring+ centralised pattern”,which provides clustering for a highly loaded central controller.We also consider two other distri-bution pattern variants,dedicated hub and dedicated peer, which may be applied to thefirst two distribution patterns and their complex derivatives.For example,the addition of a dedicated hub to a centralised distribution pattern allows a composition to be initiated by a participant external to a composition.A similar scenario is where an additional peer is added to a decentralised pattern to initiate a composition. Web services,as passive participants within a composi-tion often require mediation.This facet makes decentralised composition,necessary for some distribution patterns such as peer-to-peer,hard to achieve.However,the mediation or interaction logic,can be modeled centrally,and subse-quently deployed to participants,provided that the runtime infrastructure of the participants supports enactment of the interaction logic[16].Such characteristics,as well as the ad-ditional deployment overheads of decentralisation,should be addressed when attempting to enable decentralised compo-sitions.3.MODELING AND TRANSFORMATIONTECHNIQUEIn this section,we introduce the techniques we have de-veloped for our distribution pattern modeling and transfor-mational approach.There are four specific techniques listed below and elaborated in the six specific steps that follow. Each step is illustrated in Figure2.•UML activity diagram/Profile extension(step1,2)•DPL/DPL validator(step3,4)•Generators(step1,3,5)•Deployment Engine(step6)Our technique is motivated by a case study.The case study is an enterprise banking system with three interact-ing business processes.We choose an enterprise banking system as banks have specific QoS requirements,such as stringent controls over data management,as well as spe-cific scalability and performance requirements,all of which are important factors when choosing a distribution pattern. Banks are also susceptible to changes in organisational struc-ture,which necessitates aflexible distribution pattern.The scenario involves a bank customer requesting a credit card facility.The customer applies to the bank for a credit card, the bank checks the customer’s credit rating with a risk as-sessment agency before passing the credit rating on to a credit card agency for processing.The customer’s credit card application is subsequently approved or declined. 3.1Step1-From Interface To ModelThe initial step takes a number of Web service interfaces as input.These interfaces represent the services which are to be composed.As Web services’WSDL interfaces are constrained by XML Schemas,their structure is well defined. This allows us to transform the interfaces,using the UML 2.0model generator,into a UML2.0activity diagram,an approach also considered by[6].The UML model generated contains many of the new features of UML2.0,such as Pins, CallBehaviorActions and ControlFlows[13].A UML activity diagram is chosen to model the distri-bution pattern as it provides a number of constructs which assist in clearly illustrating the distribution pattern,while providing sufficient information to drive the generation of the executable system.Activity diagrams show the sequen-tialflow of actions,which are the basic unit of behaviour, within a system and are typically used to illustrate work-flows.UML ActivityPartitions,also known as swim-lanes are used to group a number of actions within an activity di-agram.In our model,these actions will represent WSDL operations.Any given interface has one or more ports that will have one or more operations,all of which will reside in a single swim-lane.To provide for a rich model,we use a par-ticular type of UML action to model the operations of the WSDL interface.These actions,called CallBehaviorActions, model process invocations and have an additional modelingFigure3:UML profile for modeling distribution patterns constructs called pins.There are two types of pins,Input-Pins and OutputPins,which map directly to the parts of theWSDL messages going into and out of a WSDL operation.For our UML activity diagram to effectively model distri-bution patterns,we require the model to be more descriptivethan the standard UML constructs allow.We use a standardextension mechanism of UML,called a profile[8].Profilesdefine stereotypes and subsequently tagged values that ex-tend a number of UML constructs.Each time one of thesederived constructs is used in our model we may assign valuesto its tagged values.An overview of our profile can be seenin Figure3,while the individual tagged values are describedin detail in Table1.The profile extends the Activity,Activ-ityPartition,CallBehaviorAction,InputPin and OutputPinUML constructs.This extension allows distribution patternmetadata to be applied to the constructs via the tagged val-ues.For example,the distribution pattern is chosen by se-lecting a pattern from the DistributionPattern enumerationand assigning it to the distributionFigure4:Generated model with connections defined by software architect,viewed in IBM RSATable1:Detailed description of DPLProfile stereotypes attributes Attribute Example Value language WS-BPELpattern peer-to-peername BankingPeerToPeer namespace /wsdl/ prefix BankingPeerToPeername applyForCCNamespace URI of the participant,avoids name clashesinterface URI specifying the location of the participant’s interfaceengine URI specifying the location of the enactment enginename RiskManagementChoice of roles for the participant from the Role enumerationreturns false name getAccountNameResponse correlation Unique identifierfield for a compositionlanguage setting.Interaction logic documents describethe messageflow between the participants in the distribu-tion pattern as well as input and output variable mappings.The generator also creates interfaces which expose the newinteraction logic processing capability as a wrapper to theexisting Web service functionality of the participant.A de-ployment descriptor document,describing the participantsof the composition is also created for each participant.Thesedocuments are generated by parsing the DPL document in-stance and the WSDL interfaces associated with each par-ticipant.Once deployed,these documents will realise the Web service composition,driven by the distribution pattern applied by the software architect.In our case study example,three WS-BPEL workflow doc-uments are created to represent the interaction logic between the three peers in the distribution pattern.Three WSDL in-terfaces and three deployment descriptor documents are also created,all that remains is for the system to be deployed.3.6Step6-Interaction Logic to Deployed Ex-ecutable SystemIn thefinal step,the interaction logic,interface and de-ployment descriptor documents generated in the previous step are automatically passed to the participant services,by the deployment engine.We consider a novel enhancement to the container of each participant called Interaction Logic Document Processor(ILDP),see Figure5(a).The ILDP en-hancement must be installed on each participant,however this is a once offinstallation.ILDP enhanced participants are exposed as Web services,capable of receiving,process-ing and deploying these documents,see Figure5(b).These enhanced participants can receive documents from the de-ployment engine.Subsequently the documents are processed by ILDP to ensure they are valid before storing them on the participant.Finally the stored documents are deployed by ILDP on the participant and exposed for composition by a composition runtime interface.An enactment engine,inde-pendent of ILDP,is responsible for enacting the interaction logic and subsequently invoking the participant services,fa-cilitating decentralised interaction amongst the participant services.This approach negates any requirement of manu-ally deploying documents to participant services.Moreover, as the mechanism enhances the container capability,it is non-intrusive to the existing Web service implementation or to the existing interfaces of the participant services.(a)Figure5:ILDP DeploymentThe evolution of the participant’s interface can be seen in Figure6.In step1the original Web service interface of the participant is visible.In step2the ILDP is installed and an additional interface is exposed by ILDP so it can receive interaction logic,interface and deployment descriptor doc-uments.Finally in step3,on receipt of documents,ILDP creates a composition runtime interface for participants in a particular composition to communicate to each other,using interaction logic.An ILDP can have any number of composi-tion runtime interfaces enabling the participant to take part in many distribution pattern based compositions.ILDP en-gines realise a distribution pattern by enacting interaction logic documents and by communicating to each other us-ing the composition runtime interface,if necessitated by the distribution pattern guiding thecomposition.Figure6:Participant interface evolutionWith regards to our case study,all three participant ser-vices,CoreBanking,RiskManagement and CreditCard will be contacted by the deployment engine.The engine will pass the relevant interaction logic,interface and deployment de-scriptor documents to the participant services.We assume each of the participant service containers has the ILDP en-hancement installed,and is therefore capable of receiving, processing and deploying these documents at runtime,as wellas subsequently enacting the interaction logic.4.IMPLEMENTATIONTOPMAN(TOPology MANager)is our solution to en-abling distribution pattern modeling using UML2.0and subsequent dynamic Web service compositiongeneration. The only technologies required by the toolare the Java run-time and both an XML and XSLT parser.The tool imple-mentation is illustrated in Figure 7.GeneratorActorGeneratorGeneratorXSLT/DOMXSLT/DOMDistribution PatternValidatorXSLT/DOMEngineFigure7:Overview of TOPMAN toolThe UML2.0model generator uses XSLT to transform the WSDL interfaces of the Web services participating in the composition,to a UML2.0activity diagram,which gen-erates,using XML DOM,an XMI2.0[11]document.XMI is the XML serialisation format for UML models.The model generated includes a reference to our predefined UML pro-file for distribution patterns,which is also serialised to XMI2.0.A number of tools may be used to describe the distri-bution pattern.IBM’s commercial tool Rational Software Architect(RSA)is compatible with XMI2.0and supports many of the UML2.0features.The tool has a GUI whichallows the software architect to define the distribution pat-tern.Upon completion,the model can be exported back to XMI for further processing by TOPMAN.An alternative to IBM’s commercial tool is UML2,an open source tool sup-porting UML2.0,which allows the model to be viewed and manipulated in an editor.The distribution pattern generator uses XSLT to trans-form the UML2.0model to a DPL instance document.The DPL document instance is then verified by an XML vali-dating parser.Finally the DPL document instance is used to drive the executable system generator.The executable system generator creates three distinct types of documents. XSLT and XML DOM are used to generate the interaction logic(realised here using WS-BPEL).WSDL interfaces and ILDP engine specific deployment descriptor documents,re-quired by an ILDP compatible engine to participate in a composition,are also generated.Each participant in the composition must have an ILDP engine installed to enact interaction logic.Finally,depending on the distribution pattern chosen,the generated interaction logic,interface and deployment de-scriptor documents are distributed to the participants in the composition by the deployment engine.The deploy-ment engine creates SOAP messages containing these doc-uments and sends them to the ILDP enhanced service con-tainer,via the ILDP interface of each participant.Here we use WS-BPEL to implement the interaction logic,WSDL to implement a wrapper which exposes the interaction logic processing capabilities,and the ActiveBPEL specific Process Deployment Descriptor(PDD)to describe the composition participants.The ActiveBPEL workflow engine is used as the enactment engine which processes the interaction logic.5.EV ALUATIONWe assess our approach using the criteria set out in[18], along with some of our own criteria.•Pattern expression-We have identified a number of reusable distribution patterns and have shown how patterns can be expressed using UML with our DPL-Profile extension and in XML,using our novel DPL specification.Different distribution patterns have dif-ferent QoS characteristics such as availability,scalabil-ity and performance,as set out in section2.•Readability-Our modeling approach,which visualises the distribution pattern,should be intelligible to soft-ware architects.As the model is at the PIM level, clutter from implementation details is avoided.•Executable-Our UML model and associated profile is sufficiently rich to generate a DPL document in-stance and subsequently all the interaction logic,in-terface and deployment descriptor documents needed to create an executable system.•Independence of technologies-As both our UML model and DPL instance document are modeled at the PIM level,there is no reliance on any particular workflow language.Also the container enhancement,ILDP,is not bound to any interaction logic or workflow lan-guages such as WS-BPEL.•Maintenance overhead-Our MDA approach,using UML provides for easy manipulation of the system’sdistribution pattern.Additionally,the container en-hancement we propose allows for increasedflexibilityto changes.Changes made to the distribution patternafter deployment time,have significantly reduced rede-ployment overheads,when compared with the manualdeployment of interaction logic,interface,and deploy-ment descriptor documents.Our ILDP enhancement,applied to the participant services,provides for dy-namic deployment and enactment of the interactionlogic documents.However,each participant within thecomposition must support this enhancement technol-ogy.6.RELATED WORKTwo workflow management systems motivate and pro-vide concrete implementations for two of the distribution patterns explored in this paper.However,neither system provides a standards-based modeling solution to drive the realisation of the chosen distribution pattern.Thefirst sys-tem DECS[21],is a workflow management system,which supports both centralised and peer-to-peer distribution pat-terns,albeit without any code generation element.DECS defines elementary services as tasks whose execution is man-aged by a coordinator at the same location.The solution is based on OPENFlow[12]which has a GUI for work-flow management and is CORBA based.The second sys-tem SELF-SER V[20],proposes a declarative language for composing services based on UML1.x statecharts.SELF-SER V provides an environment for visually creating a UML statechart which can subsequently drive the generation of a proprietary XML routing table document.Pre-and post-conditions for successful service execution are generated based on the statechart inputs and outputs.A related paper[3] provides some interesting performance metrics to confirm the advantages of peer-to-peer execution over centralised ex-ecution.From the modeling perspective Grønmo et al.[18,6],con-sider the modeling and building of compositions from exist-ing Web services using MDA,an approach similar to ours. However,they consider only two modeling aspects,service (interface and operations)and workflow models(control and dataflow concerns).The system’s distribution pattern is not modeled,resulting in afixed centralised distribution pat-tern for all compositions.Their modeling effort begins with the transformation of WSDL documents to UML,followed by the creation of a workflow engine-independent UML1.4 activity diagram(PIM),which drives the generation of an executable composition.Additional information required to aid the generation of the executable composition is applied to the model using UML profiles.A tool called UMT[19]is provided to support their technique.Enabling distribution patterns such as peer-to-peer re-quires considerable work.A strategy,utilised by us,is in-troduced in[4]and described in[15],where workflow agents (ILDPs in our approach)are placed as proxies,at each participant to manage the distributed composition.These workflow agents manage the distributed composition by com-municating directly to each other.The authors also consider build time and runtime issues of decentralisation.However, the problem of deploying decentralised compositions is left open,resulting in considerable deploy time overheads.We propose a mechanism for facilitating the dynamic deploy-ment of decentralised compositions.。
云计算实际案例

Build your Own Search Service (BOSS)
Yahoo!'s open search web services platform • Serving hundreds of millions of users across the Web. Goal: foster innovation in the search industry Build and launch web-scale search products that utilize the
Caching, Proxies
Online Serving
Web, Data
ID & Account Management
Security and Authentication
Metering, Billing
Monitoring & QoS
Provisioning & Virtualization (Xen)
场景自动驾驶云计算商业模式为实现客户价值最大化把能使企业运行的内外各要素整合起来形成一个完整的高效率的具有独特核心竞争力的运行系统并通过最优实现形式满足客户需求实现客户价值同时使系统达成持续赢利目标的整体解决方案商业模式直销模式让我成为pc市场中的大佬软硬兼施让顾客为我疯狂dell直销采用行业标准与客户建立直接联系供应链管理多元化经营精细化管理按需定?直接销售提供资源?注重客户反馈?提供专人客户负责制我们的服务都是免费的如何赚钱咱们拥有庞大的用户群何愁没有钱赚twitter营销网络广告facebook精准广告开放平台第三方应用虚拟用品fconnect社会化购物移动互联网我们帮助别人建立云计算卖出了更多的硬我们帮助别人建立云计算卖出了更多的硬软件和服务我们将闲置的资源出租出去获得丰厚的经我们将闲置的资源出租出去获得丰厚的经济回报我们提供在线软件服务客户不断增加yahoo
APPARATUS, SYSTEM, AND METHOD FOR A DATA SERVER-MA
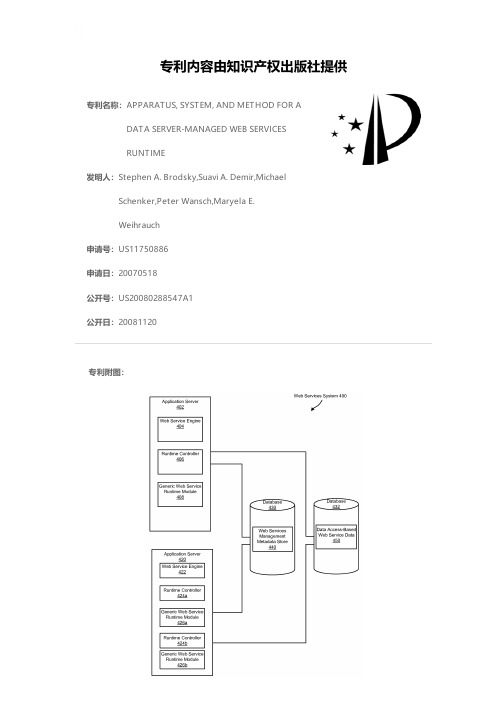
专利名称:APPARATUS, SYSTEM, AND METHOD FOR A DATA SERVER-MANAGED WEB SERVICESRUNTIME发明人:Stephen A. Brodsky,Suavi A. Demir,Michael Schenker,Peter Wansch,Maryela E.Weihrauch申请号:US11750886申请日:20070518公开号:US20080288547A1公开日:20081120专利内容由知识产权出版社提供专利附图:摘要:An apparatus, system, and method for creating and managing a data server-managed web services runtime. A generic web service runtime module and associated runtime controller are deployed on an application server. The runtime controller monitors a web services management metadata store for changes in the web service metadata defining the available data access based web services. If a change is detected, the generic web services runtime automatically updates the web service artifacts and web service endpoint interface associated with the affected web service such that the change in the web service metadata is reflected in the data access-based web service. A user manages the web services management metadata store and defines and manages data access-based web services from the database containing the web services management metadata store without interacting with the application server.申请人:Stephen A. Brodsky,Suavi A. Demir,Michael Schenker,Peter Wansch,Maryela E. Weihrauch地址:Los Gatos CA US,San Jose CA US,San Jose CA US,San Jose CA US,San Jose CA US 国籍:US,US,US,US,US更多信息请下载全文后查看。
Service Manager 9.30 产品说明说明书

Introduction (2)Service Manager 9.30 Sizing Questions (3)Sample Service Manager 9.30 Deployment Diagram (5)Service Manager 9.30 Application Server (6)Service Manager 9.30 Web Tier (7)Service Manager 9.30 Help Server (7)Service Manager Load Balancer Server (7)Service Manager Knowledge Search Engine Server (7)Mobility (8)SRC (8)Rules of Thumb .................................................................................................................................... 9 Service Manager Application Server (servlet container) ........................................................................ 9 Service Manager Web Tier ............................................................................................................... 9 Self Service / Catalog User considerations: ........................................................................................ 9 Service Manager Help Server ............................................................................................................ 9 Service Manager Load Balancer ........................................................................................................ 9 RDBMS server ................................................................................................................................ 10 Virtualized Environment (VMware) ................................................................................................... 10 Mobility ........................................................................................................................................ 10 SRC .............................................................................................................................................. 10 Search Engine . (10)Appendix A: Mobility Deployment Example and Response Times (11)Appendix B: KM Search Engine Deployment Example and Response Times (13)Appendix C: Horizontal and Vertical Scaling (14)Appendix C: Horizontal and Vertical Scaling (14)For more information . (15)IntroductionThe reference configuration data supplied in this document is based solely on the usage of the Service Manager (SM) 9.30 Out of the Box (OOTB) environment, including the Web Tier, SRC, Mobility and the Knowledge Management Search Engine running on top of the Service Manager 9.30 Runtime Environment (RTE).Individual implementations will most likely see an increase in the amount of resources that are utilized or needed by the application to perform in an acceptable manner. This would include running on an earlier version of the RTE.Failure to test the application with the concurrent user load and transaction rate that is expected at the height of the daily system usage and utilizing the tailored application may result in an undersized environment to support the requirements.The recommendations described in this document should be considered the minimum requirement to run Service Manager effectively.Service Manager 9.30 Sizing QuestionsThe following list of questions is designed to gather the necessary information required to make a recommendation on the overall system architecture for the Service Manager environment.Note: Although not all of the information requested here is required for sizing of the environment it is very useful information to obtain for a thorough architecture recommendation.1.What kind of environment will you use?a.In house solution administered by internal ITb.In house solution administered by HPc.Software as a Service2.Expected Hardware (HW) / Software (SW) environmenta.Do you plan to operate in separate Development / Test / Production environments in orderto assure quality?b.ITSCM/Disaster Recovery (DR) or High Availability (HA) requirements?c.Do you plan to operate in a virtualized environment or on physical machines?3.Do you have existing hardware that you want to reuse?a.What Operating Systems (OS) are you using, is the OS 32 or 64 bit?b.Number of CPU’s per machine?c.Amount of RAM per machine?d.What RDBMS?4.Can you provide a diagram of your network with minimum latency and bandwidth values?a.Can you provide a Microsoft Visio™ diagram of your intended deployment? (See SampleDiagram)5.Which integrations do you plan to employ with HP Service Manager?a.Inbound/Outbound Email, SMTP/POP3 requirements?b.Active directory (LDAP) integration or Single Sign-on?c.Data import of persons/organizations from an HR or other environment?d.Integration to Universal Configuration Management Database (UCMDB)/CMS?e.Integration to other HP Software solutions?f.Import of Configuration Items (CI’s)?g.other6.Licensing requirements?a.Is Service Catalog to be part of the configuration?b.Is Knowledge Management (KM) to be part of the configuration?c.What is the expected number of KM users? (Authors, Editors, Administrators)d.Which languages do you expect to operate?e.What is the overall number of IT specialists? (Technicians, Administrators, Helpdesk)f.How many of them should have guaranteed access to Service Manager?(Named Users)g.What are your module level user requirements for Service Manager?7.The Web Tier is the recommended client for accessing Service Manager.a.How many Self Service users will have access to the software?Use the calculation in the Rules of thumb section to translate the number of possible SelfService users to the number of concurrent users.8.What is the geographical breakdown of your Web user base?9.What are your expected data volumes by module including attachments?a.Service Deskb.Incident Managementc.Change Managementd.Problem Managemente.Knowledge Managementf.Request Managementg.Configuration Managementh.Service Level Management10.What are your reporting requirements?a.Will you use the bundled Crystal Reports solution?b. Or an external reporting solution?c.Or will you use data replication into a Data Warehouse for reporting?Sample Service Manager 9.30 Deployment DiagramService Manager 9.30 Application ServerMinimum required reference configurations – the hardware indicated below was used to obtain the Memory and CPU minimums. The hardware is not intended to be a specific recommendation but rather a guideline.∙Small (<200 concurrent users)Windows / Linux:Service Manager: HP DL360 – 2 CPU cores, 8GB RAM, 36GB HDRDBMS: HP DL360 – 2 CPU cores, 8GB RAM, 2 x 36GB RAID∙Medium (201 – 600 concurrent users)Windows / Linux:Service Manager: HP BL460c – 4 CPU cores, 24GB RAM, 36GB HDRDBMS: HP DL585 – 2-4 CPU cores, 12GB RAM, 3 x 36GB RAIDUnix:Service Manager: HP rx6600 – HP-UX 11i, 4 CPU cores, 24GB RAM, 36GB HDRDBMS: HP rx6600 – HP-UX 11i, 2-4 CPU cores, 12GB RAM, 3 x 36GB RAID∙Large (601 – 1,000 concurrent users)Windows / Linux:Service Manager: HP BL460c – 8 CPU cores, 48GB RAM, 36GB HDRDBMS: HP DL585 – 4-8 CPU cores, 16GB RAM, 3 x 36GB RAIDUnix:Service Manager: HP rx6600 – HP-UX 11i, 8 CPU cores, 48GB RAM, 36GB HDRDBMS: HP rx6600 – HP-UX 11i, 4-8 CPU cores, 16GB RAM, 5 x 36GB RAID∙Extra Large (1000 – 2,500 concurrent users)At this size it is recommended to run SM on multiple machines in Vertical/Horizontal Scalingmode.Please see appendix C for referencesService Manager 9.30 Web TierWindows / Linux:HP DL360 – 2 CPU cores, 6GB RAM, 36GB HDUnix:HP rx2600 – HP-UX 11i, 2 CPU cores, 6GB RAM, 36GB HD Service Manager 9.30 Help ServerService Manager Load Balancer ServerService Manager Knowledge Search Engine Server∙Small (<200 concurrent users)Windows / Linux:HP DL360 –1 CPU cores, 2GB RAM, 36GB HDUnix:HP rx2600 – HP-UX 11i, 1 CPU cores, 2GB RAM, 36GB HD∙Medium and Large (>200 concurrent users)Windows / Linux:HP DL360 – 2 CPU cores, 4GB RAM, 36GB HDUnix:HP rx2600 – HP-UX 11i, 2 CPU cores, 4GB RAM, 36GB HDMobilitysee Rules of Thumb∙Small (<200 concurrent users)Windows / Linux:HP DL360 – 2 CPU cores, 6GB RAM, 36GB HDUnix:HP rx2600 – HP-UX 11i, 2 CPU cores, 6GB RAM, 36GB HD∙Medium and Large (200~500 concurrent users)Windows / Linux:HP BL460c – 8 CPU cores, 32GB RAM, 36GB HDUnix:HP rx6600 – HP-UX 11i, 8 CPU cores, 32GB RAM, 36GB HDSRCWindows / Linux:Service Manager: HP BL460c – 4 CPU cores, 16GB RAM, 36GB HDUnix:Service Manager: HP rx6600 – HP-UX 11i, 4 CPU cores, 16GB RAM, 36GB HDRules of ThumbService Manager Application Server (servlet container)A servlet container requires approximately 2 GB of Ram∙500 MB JVM requirement including the 256MB of Default JAVA heap∙50 MB for the process overhead∙10 MB – 20 MB per users session (thread) (see Note * below)∙Plus shared_memory setting value = 128,000,000 in the sm.ini file. (counted only once for all Servlet containers on a single machine)On a 32 bit Operating system we recommend starting with 50 threads (users) per process (servlet container) in the UNIX environment and then change based on process memory usage being experienced in your environment. On a 32 bit Windows Operating systems we recommend starting with 30 threads (users) per process (servlet container) and then change based on process memory usage being experienced in your environment.On any 64 bit Operating system listed in the Service Manager compatibility matrix we recommend starting with 50 threads (users) per process (servlet container) and change based upon process memory usage being experienced in your environment to a maximum of 100 threads.Note Increases in user session memory usage may be caused by inappropriately large global lists, usage of global variables that are not cleaned up and multiple application threads being opened simultaneously. This will have a direct effect on the number of user threads that can be supported per servlet container.Service Manager Web TierThe Service Manager Web Tier configuration used to determine sizing recommendations is based upon Tomcat web application server with 4JVM’s running 1.0 GB of RAM Java Heap each per JVM, and an Apache Web Server for connection distribution to these JVM’s. Create a Web Farm by adding machines as required with additional Tomcat JVM’s to support additional user load.Self Service / Catalog User considerations:It is important to include and consider the Self Service / Catalog user base when calculating the hardware requirements for supporting the environment. As a rule of thumb calculate the number of concurrent users to support by adding 2 – 3% of the total number of expected self-service users to the number of licensed module users. For example: 200,000 total user base * .03 = 6, 000 total number of projected Concurrent Self Service/Catalog users.Service Manager Help ServerWith Service Manager 9.30, the Service Manager Help Server must be deployed on Apache Web Server or Internet Information Server (IIS) and can be configured to run on one of the machines configured for the Web Tier and it should be accessible through the Service Manager clients. It can also be configured to be on a standalone machine using a small machine configuration.Service Manager Load BalancerThe Service Manager Load Balancer should be located on a separate machine and should always be sized as a small machine since it performs no other function than connection redirection to an available servlet. It also must run using the same Operating System as the Service Manager Application Servers.Since this is the one component of the configuration that can be considered a single point of failure, it should be replicated and placed in a clustered environment for high availability. Failure of this component will only affect new user connections that are attempting to initially connect into the environment until such time as the Load Balancer isrestarted or failed over. All currently active users connected to the environment will be unaffected by the loss of the Load Balancer.Load balanced machines and servlet machines should use the server sizing given in this document and the number of nodes would depend on the size of the machine chosen and total number of concurrent production users. RDBMS serverThe RDBMS server sizing specified above represent the configurations that were used during the benchmarking runs for the Service Manager out-of-box product. The actual servers that will be used in a production environment should plan their storage needs based upon expected data volumes including attachments, etc. The CPU and memory requirements for the selected database should be based upon the recommendations of the Database vendor for supporting the expected transaction volumes.Virtualized Environment (VMware)An addition of approximately 30% above the recommended Service Manager Sizing must be made in order to efficiently run that Service Manager component in a Virtual environment.MobilityStartup options below are recommended for Mobility application in the Java Virtual Machine (JVM) instance:-Xms1024m -Xmx1024m -XX:MaxPermSize=256mThe mobility application uses an in-memory lazily loaded cache (i.e. a record is only loaded into cache when accessed) to optimize performance. Objects loaded in the cache are shared by all users connected to the same mobility application. Therefore, the cache size will grow as users log in, navigate to view incident tickets and change requests, and enter activities (or journal entries). It is possible performance will degrade if the cache grows too large, or if insufficient resources are allocated to the Java Virtual Machine (JVM) instance.Multiple Mobility application servers are recommended for 200-500 users. Please see Appendix A for deployment examples and sample response times.SRCStartup options below are recommended for SRC application in Java Virtual Machine (JVM) instance:-Xms1024m -Xmx1024m -XX:MaxPermSize=128mModify the following lines in the applicationContext.properties file in SRC_HOME\src-1.20\WEB-INF\classes erInboxBatchSize=500src.sm.defaultMaxConnectionsPerHost=40src.sm.maxTotalConnections=40Search EngineThe startup options below are recommended for SRC application in Java Virtual Machine (JVM) instance:-Xms512m -Xmx1024m -XX:PermSize=256mPlease see Appendix B for deployment examples and sample response times.Appendix A: Mobility Deployment Example and Response TimesSmall(<200 users)LoadRunner simulating 150 Mobile DevicesMedium and Large (200~500 users)500 Mobile Devices0.5 1 1.52 2.53 3.5401_S t a r t p a g e02_L o g i n03_L o g o u tC h a n g e _01_C l i c k A s s i g n T o M y G r o u p sC h a n g e _02_G r o u p C l i c k C h a n g eD e t a i lC h a n g e _03_G r o u p C l i c k A c t i v i t i e sC h a n g e _07_G r o u p C l i c k B a c kC h a n g e _08_G r o u p C l i c k H o m eI n c i d e n t _01_C l i c k A s s i g n T o M eI n c i d e n t _02_C l i c k I n c i d e n t D e t a i lI n c i d e n t _03_C l i c k A c t i v i t yI n c i d e n t _04_C l i c k N e w E n t r yI n c i d e n t _05_S a v e N e w U p d a t eI n c i d e n t _06_C l i c k O K A f t e r E n t r y A d d e dI n c i d e n t _07_C l i c k B a c kI n c i d e n t _08_C l i c k H o m eI n c i d e n t _09_C l i c k A s s i g n T o M y G r o u pI n c i d e n t _10_C l i c k I n c i d e n t I n G r o u pI n c i d e n t _11_C l i c k A c t i v i t y I n G r o u pI n c i d e n t _12_C l i c k B a c k I n G r o u pI n c i d e n t _13_C l i c k H o m e I n G r o u p500 users/2 Mobility/10 SM500 users/3 Mobility/10 SMAppendix B: KM Search Engine Deployment Example and Response Times500~1000 usersAppendix C: Horizontal and Vertical ScalingMore detailed information can be found in the online help server under System Installation and Setup > Server implementation optionsFor more informationPlease visit the HP Management Software support Web site at:/managementsoftware/supportThis Web site provides contact information and details about the products, services, and support that HP Management Software offers.HP Management Software online software support provides customer self-solve capabilities. It provides a fast and efficient way to access interactive technical support tools needed to manage your business. As a valued customer, you can benefit by being able to:∙Search for knowledge documents of interest∙Submit and track progress on support cases∙Submit enhancement requests online∙Download software patches∙Manage a support contract∙Look up HP support contacts∙Review information about available services∙Enter discussions with other software customers∙Research and register for software trainingNote: Most of the support areas require that you register as an HP Passport user and sign in. Many also require an active support contract.To find more information about support access levels, go to the following URL:/managementsoftware/access_levelTo register for an HP Passport ID, go to the following URL:/passport-registration.htmlTechnology for better business outcomes© Copyright 2009Hewlett-Packard Development Company, L.P. The informationcontained herein is subject to change without notice. The only warranties for HPproducts and services are set forth in the express warranty statementsaccompanying such products and services. Nothing herein should be construed asconstituting an additional warranty. HP shall not be liable for technical or editorialerrors or omissions contained herein.Linux is a U.S. registered trademark of Linus Torvalds. Microsoft and Windows areU.S. registered trademarks of Microsoft Corporation. UNIX is a registeredtrademark of The Open Group.4AA1-xxxxENW, October 2011。
Oracle Retail Customer Engagement Release Notes说明书

Oracle® Retail Customer EngagementRelease NotesRelease 17.0December 2017This document highlights the major changes for Release 17.0 of Oracle Retail CustomerEngagement.OverviewOracle Retail Customer Engagement is a comprehensive, web-based, direct-marketingapplication designed for today’s fast-paced retail environment, and consists of thefollowing:▪Customer Management and Segmentation Foundation: A required module that maintains and serves all customer-related information. In addition to managingcore customer data, the service includes support for strategies that are based onin-store clienteling and gift registry.▪Campaign and Deal Management: Delivers promotional offers to transactionsystems, drives execution, and performs analysis. It has a more operational focusand is considered complementary to solutions like Responsys or Eloqua, whichare dedicated to orchestrating marketing communication campaigns. The servicesupports offer management, couponing, list targeting, and performance analysis.▪Loyalty and Awards: A leading points-based loyalty platform. It can be quickly configured to support program concepts from simple punch-card frequencyprograms to highly sophisticated programs involving a variety of earningopportunities, as well as recognition levels like gold, silver, and bronze. Inaddition to the management of points, the platform manages awards in the formof stored value or discounts on merchandise.▪Gift Cards: A highly evolved stored value solution. It features a sophisticatedback-office user experience and supports global operations with cross-currencymanagement and cross-channel delivery and fulfillment.Hardware and Software RequirementsSee the Oracle Retail Customer Engagement Installation Guide for the hardware and softwarerequirements.Browser RequirementsConnecting to Customer Engagement requires one of the following web browsers:▪Internet Explorer 9, 10, and 11▪Firefox 38 or higherFunctional EnhancementsThe functional enhancements below are included in this release. For more information, see the Oracle Retail Customer Engagement User Guide in the Customer Engagement 17.0 documentation set.Awards and Points TransferOccasionally a loyalty member may want to transfer or gift earned points, or the owner of an awards account may want to transfer or gift awards. In previous versions, this would have required multiple separate transactions. Release 17.0 streams these options into services that are integrated into the account administration console. A customer service representative can now identify the source and the target account on a single screen, and initiate and confirm a points or awards transfer. The transfer is recorded in each of the affected accounts. This event can now trigger an email or SMS notification sent through the Oracle Marketing Cloud’s Responsys platform.Integration with Oracle Marketing CloudWith the delivery of the points/awards transfer capability through the account administration UI, the platform now initiates confirmation emails automatically to both the account holder of the source and the target account. Users have the ability to configure the specific content that will be sent. The event trigger includes key data to drive message personalization, customer engagement, and brand loyalty. Integration with Oracle Retail Customer InsightsThe integration with Oracle Retail Customer Insights (ORCI) is about turning valuable customer data into actionable strategic insights. The development effort in Release 17.0 publishes loyalty and award activity data ‘owned’ by ORCE in a format that is readily consumable by ORCI. The ORCI solution also features loyalty dashboards that are specifically designed to work with data from ORCE, and enables users to easily track loyalty program performance against best-practice KPI’s.File Transfer ManagementIn order to protect important data and to preserve system integrity, access to the underlying environments is strictly controlled. With Release 17.0, investments have been made to more reliably provide users with access to data exported from the system, and to more easily monitor batch files that are being posted into the system. Administrators can now schedule jobs that pull files from an inbound SFTP server. ORCE’s existing job management framework provides easy monitoring. In addition, a dashboard is being introduced that summarizes file processing (volume and performance) by data type and aggregates it daily, weekly, monthly, and annually.In Release 17.0, all exported data is encrypted and stored centrally in the database. As normal, the customer can download the files directly as needed by clicking on the link in the job detail record. If/when transfers are required to support systems integration, the outbound transfer utilities (by type) regularly push files to the designated outbound folders on the SFTP server.2This release also includes the option to schedule an email notification summarizing file processing activity.Note SecurityIn Release 17.0, notes management is extended with new features. Users can now apply security features to notes so they can be designated ‘public’ or ‘private’. ‘Public’ means the note(s) will be accessible to any associate who has access to the customer’s record as per customer data security rules. ‘Private’ means the note will only be accessible to the author and/or the system administrator. Notes can also be deleted. These capabilities are fully integrated into the API layer to better support integrated clienteling or customer service applications.Issue Loyalty Points for Non-Transactional ActivityLoyalty points can now be awarded to a customer for activities other than transactions. For example, you can now create engagement rules to award points to a customer for watching a video or participating in social media. Marketing engagement rules can be defined with location and segment as eligibility criteria. A new version of the Loyalty web service API is available to communicate rules to integrating systems.Rebuild Category TotalsA new scheduled job enables you to rebuild the records in theCST_DEPARTMENT_TOTALS table. Data from the last three years can be rebuilt. Batch Process TrackingThe UI now provides an administrative user with the ability to review batch process activity. The user can view summaries for each batch process type, broken out into daily, weekly, and monthly totals. The UI also indicates the total number of successful and unsuccessful records processed for each batch type, the number of warnings, and the average processing time for each within the time period.Technical EnhancementsThe technical enhancements described below are included in this release. Currency Conversion for Customer Period TotalsIn an effort to more fully support internationalization requirements, the retrieveCustomer method has been extended. The requesting system can now include a ‘requesting currency code’. When that currency differs from the defined ‘base currency’, ORCE automatically converts Life-to-Date and Year-to-Date values (i.e. Sales, Returns) into the local currency.Define Attributes through Web ServiceRelease 17.0 adds the ability to create attributes through the Attribute web service API. This API now allows systems to create new attribute groups and define the attributes belonging to the group, providing a streamlined approach for managing attributes used in multiple systems.Delete Segments through Web ServiceAdded the ability to delete segments through the Segments web service API, providing a streamlined option for segment management.Define Customer Lookup ParametersIn order to enhance performance of customer lookup requests, Release 17.0 adds new configuration properties to define the minimum lengths of certain search criteria. For example, to prevent inefficient response processing that would yield an excessive number of matching customers, you can require a length of six positions when searching based on email address. The search criteria whose minimum lengths you can define are last name, phone number, postal code, and email address.Integration EnhancementsLoyalty Activity History ImportAdded a new job to import loyalty activity history from an integrating system. Customer Activity SyncAdded a new job to export customer activity records to a marketing system such as Responsys.Loyalty ExportsAdded new jobs to export loyalty data to a BI/Analytics system such as Retail Insights. Exported data includes loyalty programs, loyalty accounts, loyalty transactions, and loyalty award transactions.Task Management EnhancementsThe getTaskList web service request message now provides the option to limit the page size of the response, controlling the number of tasks returned. A new configuration property defines the default.Related DocumentationFor more information, see the following documents in the Oracle Retail Customer Engagement 17.0 documentation set:⏹ Oracle Retail Customer Engagement User Guide⏹ Oracle Retail Customer Engagement Implementation Guide (Doc ID 1994453.1)⏹ Oracle Retail Customer Engagement Installation Guide (Doc ID 1994453.1)⏹ Oracle Retail Customer Engagement Administration Guide (Doc ID 1994453.1)⏹ Oracle Retail Customer Engagement Batch Processing & Web Services Guide (Doc ID1994453.1)4Supplemental Training on My Oracle SupportTransfer of Information (TOI) Material (Doc ID 732026.1)For applicable products, online training is available to Oracle supported customers. These online courses provide release-specific product knowledge that enables your functional and technical teams to plan, implement and/or upgrade and support Oracle Retail applications effectively and efficiently.Oracle Retail Learning Subscriptions at Oracle UniversityThe Oracle Retail Learning Subscription is a digital training solution for anyone on your team seeking training on Oracle Retail Products. With the learning subscription you get the key elements of an effective learning program and the conveniences of a digital format, making this training unmatched in the industry.You get modern learning at its best, such as:▪12 months of 24/7 access to a comprehensive set of high quality videos delivered by Oracle experts.▪Detailed coverage and step-by-step demonstrations.▪Periodic updates for new features and product enhancements.▪Flexibility to search, access and learn about specific topics of interest.The learning subscription enables current users to continually refresh and upgrade their product skills. It also enables new employees with a self-paced learning guide to help them quickly become proficient on Oracle Retail Products.For training opportunities, see the following web site:/educationDocumentation AccessibilityOur goal is to make Oracle products, services, and supporting documentation accessible to all users, including users that are disabled. To that end, our documentation includes features that make information available to users of assistive technology. This documentation is available in HTML format, and contains markup to facilitate access by the disabled community. Accessibility standards will continue to evolve over time, and Oracle is actively engaged with other market-leading technology vendors to address technical obstacles so that our documentation can be accessible to all of our customers. For information about Oracle's commitment to accessibility, visit the Oracle Accessibility Program website at/pls/topic/lookup?ctx=acc&id=docacc. Accessibility of Code Examples in DocumentationScreen readers may not always correctly read the code examples in this document. The conventions for writing code require that closing braces should appear on an otherwise empty line; however, some screen readers may not always read a line of text that consists solely of a bracket or brace.Accessibility of Links to External Web Sites in DocumentationThis documentation may contain links to Web sites of other companies or organizations that Oracle does not own or control. Oracle neither evaluates nor makes any representations regarding the accessibility of these Web sites.Access to Oracle SupportOracle customers have access to electronic support through My Oracle Support. For information, visit/pls/topic/lookup?ctx=acc&id=info or visit/pls/topic/lookup?ctx=acc&id=trs if you are hearing impaired.6Customer Engagement /Release Notes, Release17.0©2017,Oracle and/or its affiliates. All rights reserved.This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited.The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing.If this software or related documentation is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable:U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S. Government.This software or hardware and documentation may provide access to or information on content, products, and services from third parties. Oracle Corporation and its affiliates are not responsible for and expressly disclaim all warranties of any kind with respect to third-party content, products, and services. Oracle Corporation and its affiliates will not be responsible for any loss, costs, or damages incurred due to your access to or use of third-party content, products, or services.Oracle and Java are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners.Intel and Intel Xeon are trademarks or registered trademarks of Intel Corporation. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. AMD, Opteron, the AMD logo, and the AMD Opteron logo are trademarks or registered trademarks of Advanced Micro Devices. UNIX is a registered trademark of The Open Group.This software or hardware and documentation may provide access to or information on content, products, and services from third parties. Oracle Corporation and its affiliates are not responsible for and expressly disclaim all warranties of any kind with respect to third-party content, products, and services. Oracle Corporation and its affiliates will not be responsible for any loss, costs, or damages incurred due to your access to or use of third-party content, products, or services.Value-Added Reseller (VAR) LanguageOracle Retail VAR ApplicationsThe following restrictions and provisions only apply to the programs referred to in this section and licensed to you. You acknowledge that the programs may contain third party software (VAR applications) licensed to Oracle. Depending upon your product and its version number, the VAR applications may include:(i) the MicroStrategy Components developed and licensed by MicroStrategy Services Corporation (MicroStrategy) of McLean, Virginia to Oracle and imbedded in the MicroStrategy for Oracle Retail Data Warehouse and MicroStrategy for Oracle Retail Planning & Optimization applications.(ii) the Wavelink component developed and licensed by Wavelink Corporation (Wavelink) of Kirkland, Washington, to Oracle and imbedded in Oracle Retail Mobile Store Inventory Management.(iii) the software component known as Access Via™ licensed by Access Via of Seattle, Washington, and imbedded in Oracle Retail Signs and Oracle Retail Labels and Tags.(iv) the software component known as Adobe Flex™ licensed by Adobe Systems Incorporated of San Jose, California, and imbedded in Oracle Retail Promotion Planning & Optimization application.You acknowledge and confirm that Oracle grants you use of only the object code of the VAR Applications. Oracle will not deliver source code to the VAR Applications to you. Notwithstanding any other term or condition of the agreement and this ordering document, you shall not cause or permit alteration of any VAR Applications. For purposes of this section, "alteration" refers to all alterations, translations, upgrades, enhancements, customizations or modifications of all or any portion of the VAR Applications including all reconfigurations, reassembly or reverse assembly, re-engineering or reverse engineering and recompilations or reverse compilations of the VAR Applications or any derivatives of the VAR Applications. You acknowledge that it shall be a breach of the agreement to utilize the relationship, and/or confidential information of the VAR Applications for purposes of competitive discovery.The VAR Applications contain trade secrets of Oracle and Oracle's licensors and Customer shall not attempt, cause, or permit the alteration, decompilation, reverse engineering, disassembly or other reduction of the VAR Applications to a human perceivable form. Oracle reserves the right to replace, with functional equivalent software, any of the VAR Applications in future releases of the applicable program.。
基于Web技术数据集中器的设计

2020年第12期 信息通信2020(总第 216 期)INFORMATION&COMMUNICATIONS(Sum.N o 216)基于Web技术数据集中器的设计孙国菊,季海涛,尹建丰,张云端,秦中海(林洋能源股份有限公司,江苏启东226200)摘要:针对智能电网对数据集中器和前端设备与云环境有更好的适用性,模块化、动态性、良好容错性的客观需求,文中 介绍基于W eb技术的数据集中器的设计。
包括数据集中器框架、W eb服务开发技术、数据集中器分块设计方法、客户端 和服务器模式、任务管理机制。
该方案提升设备承受高并发量通信能力,满足系统异步交互的需求。
实现了数据集中器 与前置设备跨平台远程通信,对智能电网的设计有一定的参考意义。
关键词:智能电网;数据集中器;W eb服务;任务管理机制;远程通信中图分类号:TM933 文献标识码:B文章编号:1673-1131(2020)12-0130-04Design of Data Concentrator Based on Web TechnologySun GuojuJiHaitaOjYinJianfeng^hang Yundun,Qin Zhonghai(Linyang Energy Co”Ltd,QiDong226200, J iangsu,China)Abstract:In response to the smart grid's customer needs for better adaptability,modularity,and fault tolerance to data concentrator and front-end equipment and the cloud environment,this paper introduce design o f data mechanism based on Web technology.Including the framework o f data concentrator Web development technology,block design method,client server mode, task management mechanism.This solution enhances the equipment's ab ility to withstand high-concurrency communication and meets the general interaction requirements o f the system.The cross-platform remote communication between the data concentrator and the front-end equipment is realized,which is useful fo r the design o f smart grid.Keywords: smart grid;data concentrator;Web development technology;task management mechanism;remote communication〇引言用电信息采集系统是我国电力系统建设的重要组成部 分,也是我国建设高可靠性智能电网的关键一步。
大学生个人简介英语作文

大学生个人简介英语作文(一)Basic informationName: Guo classmates Sex: MaleDate of Birth: 1987 Nationality: ChineseAccount where: Hebei Handan Guangping current: Shijiazhuang City Graduate institutions: Hebei Vocational and Technical College political landscape: membersHighest level of education: post-secondary repair by a professional: Software TechnologyTalent type: student graduation date: 20XX年Job intentionsJob type: Full-timePosition: ProgrammerHope Location: Shijiazhuang / BeijingWish to pay: NegotiableEducation and training experienceFrom September 20XX年to June 20XX年, Hebei Institute of Software Technology Occupational SpecialtyLanguage ProficiencyEnglish level: A levelComputer capacityUML modeling language, SQLServer database, Java programming language,JSP Web Design, Java for C / S architecture, Oracle database managementProfessional skills:Focused on the procedures for the development of Java EEjavaScript scripting, webserviceStruts + Hibernate + Spring development framework, ajax, svn version control.Proficiency in the use of html, jsp, servlet, sqlserver databaseBasis with photoshopPractical experienceEnterprise MessengerProject Profile: Enterprise Messenger (Corperation Messager) is a software company or companies for internal use instant messaging network, primarily for real-time communication between employees and exchanges. It is mainly by the server-side program and client program is composed of two parts, the overall use of Java platform development and the realization of optional user data to Microsoft SQL Server 20XX年unified management.Project framework: MVC1Code :2500-3000 lineTechnical: Using JDBC database connection, the use of C / S structure, to support the TCP / IP protocol Socket (socket), Thread (thread) Tools: JDK 1.5.0 or later, NetBeans IDE 5.0 or later.Database: Microsoft SQL Server 20XX年and above.Role as: the client is mainly responsible for the maintenance of the users information (by adding, changing, check), the server side is mainly responsible for the completion of communications technology, and in accordance with different protocols to help customers to complete a variety of customer data read operation, to achieve user information maintenance functionPress Release SystemProject Introduction: the arrival of the age of the Internet led to todays information explosion, the news faster and more different forms through the Internet to meet with many users. Day morning, we will open the Tom, Sina, Yahoo to get more news and information. More enterprises to allow their own raw materials and parts for the outside world have also developed a press release system, in this system, users can customize the columns and news classification, news information, and to provide logs and user management.Project framework: MVC1Development Tools: Eclipse GanymedeAs a role: programmerInvolve major technical: Html JavaScript based on Module 2 of the MVC architecture of the component-based Web application development Main Technical: Microsoft SQL Server 20XX年, Tomcat6.0, JDK 1.5.0 or later, SVNThe development of the number of: 2 peopleMain modules: Category Management (Add columns, column management, added categories, category management), information management (press releases, press releases).Key: Web client and server applicationsWeb-based MVC frameworkFCKeditor components such as the use of WebElectronic album systemProject Description: The system is a complete B / S structure of the electronic album system, including the open user registration; to create your own photo album space, upload photos, browse photos of others. As well as albums, photos, comments issued. In addition, the system also includes a system administrator, the system administrator can manage the type of album, photo album, photos.Project framework: MVCDevelopment Tools: MyEclipse 6.0, tomcat6.0, JDK 1.5.0 version of the aboveAs a role: programmerMajor technical: JSP, Struts + Spring + Hibernate Integration, Microsoft SQL Server20XX年, Tomcat6.0, JDK1.5.0 or later.Main modules: the logged-on user (View album released album reviews, browse photos, published photos Comments) unknown users (see photo album to view photos) system administrator ( users, the photos, albums, photo album Category management, etc.)Technical focus: Photo UploadOne-to-many, many-to-many connection, such as data.Received awardsCollege Students Division, technology and culture festival photography contest won first prize DV.Self-evaluationEasy-going person, friendly, love to make friends.Broad-loving, like pictures, video editing. Branch, technology and culture in the college Arts Festival Photography Competition awarded first prize DV.Prudent, practical, learning ability and adaptability, able to work under pressureThe organization has a certain ability and teamwork ability.As long as a stage to me, I will provide you a wonderful dance!(二)I am glad to be in this beautiful school.I love my school so much that I want to stay with it all my life.I hope my school can be a place that there is no exam and full of hahppy.Every day ,when I go to school and see my beautiful school,I know it will be a place that I wont forget.Now ,a school with nice garden where we students can have a lessure time ,it is my ideal school and my ideal school life.---------------------------------------------------------------------In my understanding,if we refer to an ideal college life as a formal western dinner,then a high GPA,that is,Grade Point Average,should be the main course,while an active part in activities,together with associations,means the appetizer.Some romances,of course,play the role as desserts.They are the 3 key elements for an ideal college life.Those,however,are not what college life is all about.As we allknow,college is wildly different from middle school.It connects not only adolescence to adulthood,but also the ivory tower to the realsociety.Therefore,the ideal college life is that I become matured both physically and mentally,and that I obtain qualified academic knowledge and get well prepared for society at the same time.Under this circumstance,I never expect my college life to be too ideal,or you can call it too perfect.It is not realistic to make all things on my own way,with everyone liking me,winning the first prize all the time,and so on.Of course,Id like to lead a carefree life.However,this does little good to my future.What really helps is hardships like failure,betrayal,and unjust treatment.Only after experiencing those can I know what society is like,and what life is like.To conclude my speech,I wanna say,some positive experiences are surely part of the ideal college life.But,I should not forget about the negative sides.They are not less necessary(三)My name is Li Hua, 16 years old this year. The first secondary school in Jinan, graduated in June of this year. Parents in the local operating a small travel agency, summer vacation will be there to help. High 1:00 moving house, attending a new school, she met many friends. I like music, also participated in the schools gymnastics team. I think about the future development of talent to become a translator. To improve language skills, want to go to Cambridge University to study。
business objects

Business ObjectsIntroductionIn the business world, it is essential to effectively manage and analyze data in order to make informed decisions. To achieve this, many organizations utilize software tools known as Business Objects. Business Objects are powerful applications used for data management, reporting, and analysis. This document will provide an overview of business objects, their key features, and how they can benefit organizations.What are Business Objects?Business Objects refer to a suite of software tools developed by SAP (Systems, Applications & Products in Data Processing) that allow organizations to access, analyze, and report on their business data. These tools help in data integration, data modeling, and data management across various systems within an organization. The Business Objects suite consists of several individual applications, including:1.Universe Designer: This tool enables users tocreate business data models, known as universes.Universes provide a semantic layer that simplifies dataaccess and analysis for end-users.2.Web Intelligence (WebI): WebI is a web-basedreporting tool that allows users to create interactivereports and access them from anywhere. It provides theability to analyze data in real-time with dynamicvisualizations.3.Crystal Reports: Crystal Reports is a powerfulreporting tool that allows users to design and generateformatted reports from a wide range of data sources. Itprovides features like sorting, filtering, and grouping topresent data in a meaningful way.4.Dashboard Designer: This tool enables users tocreate interactive and visually appealing dashboards with data visualizations, such as charts, graphs, and KPIs (KeyPerformance Indicators).5.Lumira: Lumira is a self-service data visualizationtool that allows users to explore, analyze, and visualize data in a user-friendly and intuitive interface.6.Data Services: This tool allows organizations tointegrate and transform data from different sources,ensuring data quality and consistency across differentsystems.Key Features of Business Objects1. Data Integration and ModelingBusiness Objects provides robust functionality for integrating data from various sources, such as databases, spreadsheets, and cloud-based applications. It allows users to create a unified view of the data through the use of universes, which act as an abstraction layer, shielding end-users from the complexities of underlying data structures. This simplifies the data access process and ensures consistency in data analysis.2. Reporting and AnalysisBusiness Objects offers a range of powerful reporting and analysis tools. Web Intelligence allows users to create ad-hoc reports and perform advanced data analysis using a drag-and-drop interface. Crystal Reports provides features for designing pixel-perfect, formatted reports that can be customized to meet specific business requirements. These tools enable organizations to generate insightful reports, visualize trends, and gain actionable insights from their data.3. Self-Service AnalyticsWith tools like Lumira, Business Objects empowers business users to perform self-service analytics without depending on IT teams. Users can explore data, create interactive visualizations, and share insights with others. This enables faster decision-making and reduces the reliance on technical teams for generating custom reports.4. Data Governance and SecurityBusiness Objects ensures data governance and security through features like user authentication, role-based access control, and data encryption. Organizations can define access rights at the user or group level, ensuring that sensitive data is only accessible to authorized individuals. This helps in maintaining data privacy and compliance with regulatory requirements.5. Mobile SupportBusiness Objects offers mobile apps that enable users to access reports, dashboards, and analytics on the go. This allows decision-makers to stay informed and make data-driven decisions even when they are away from their desks. The mobile apps provide an intuitive and responsive user experience, ensuring access to critical information at any time.Benefits of using Business ObjectsUsing Business Objects can provide several benefits to organizations, including:1.Improved Data Analysis: Business Objects providepowerful analytics tools that enable organizations toanalyze data from multiple sources and gain valuableinsights. This helps in understanding customer behavior,identifying market trends, and making informed business decisions.2.Enhanced Reporting Capabilities: The reportingfeatures of Business Objects allow organizations to create dynamic and visually appealing reports that can becustomized to meet specific needs. This helps in presenting data in a meaningful way and effectively communicatinginsights to stakeholders.3.Increased Efficiency: Business Objects automatevarious data management tasks, such as data integration, modeling, and report generation. This improvesoperational efficiency, reduces manual effort, and allowsemployees to focus on analysis and decision-making rather than data manipulation.4.Faster Decision-Making: With real-time dataaccess and self-service analytics capabilities, BusinessObjects enable faster decision-making. Decision-makers can access critical information whenever needed and generate ad-hoc reports without relying on IT teams, resulting infaster response times.5.Data Governance and Security: Business Objectsprovide robust security features to ensure data privacy and compliance. Organizations can define access controls, track user activities, and ensure the integrity of sensitive data,reducing the risk of data breaches.6.Mobile Access: The ability to access reports andanalytics on mobile devices empowers decision-makers to stay connected and make informed decisions even whenthey are on the move.ConclusionBusiness Objects are powerful software tools that enable organizations to efficiently manage, analyze, and report on their business data. With features like data integration, reporting, self-service analytics, and mobile support, Business Objects provide a comprehensive solution for data-driven decision-making. By leveraging Business Objects, organizations can improve their data analysis capabilities, enhance reporting capabilities, increase efficiency, and make faster and more informed business decisions.。
史上最全的程序员常用英语词汇

史上最全的程序员常⽤英语词汇A1.abstract 抽象的2.abstract base class (ABC)抽象基类3.abstract class 抽象类4.abstraction 抽象、抽象物、抽象性5.access 存取、访问6.access function 访问函数7.access level访问级别8.account 账户9.action 动作10.activate 激活11.active 活动的12.actual parameter 实参13.adapter 适配器14.add-in 插件15.address 地址16.address space 地址空间17.ADO(ActiveX Data Object)ActiveX数据对象18.advanced ⾼级的19.aggregation 聚合、聚集20.algorithm 算法21.alias 别名22.align 排列、对齐23.allocate 分配、配置24.allocator分配器、配置器25.angle bracket 尖括号26.annotation 注解、评注27.API (Application Programming Interface) 应⾼(程序)编程接⾼28.appearance 外观29.append 附加30.application 应⾼、应⾼程序Approximate S tring M atching 模糊匹配33.34.35.36.37.38. 39. 40. 41.42.43.44.45. 46.B 1. 2. 3. 4. 5. 6.7.8.9. 10. 11. 12. 13.14.15.16. architecture 架构、体系结构archive file 归档⾼件、存档⾼件argument 参数。
array 数组arrow operator 箭头操作符assert(ion) 断⾼assign 赋值assignment 赋值、分配assignment operator 赋值操作符 associated 相关的、相关联的 asynchronous 异步的 attribute 特性、属性 authentication service 验证服务authorization 授权background 背景、后台(进程)backup 备份backup device 备份设备backup file 备份⾼件backward compatible 向后兼容、向下兼容base class 基类base type 基类型batch 批处理BCL (base class library)基类库Bin Packing 装箱问题binary ⾼进制binding 绑定bit 位bitmap 位图 block 块、区块、语句块 boolean 布林值(真假值,true 或false) border 边框bounds checking 边界检查19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34. C1.2.3.4.5.6.7.8.9.10.11.12.13.14. boxing 装箱、装箱转换brace (curly brace) ⾼括号、花括号bracket (square brakcet) 中括号、⾼括号breakpoint 断点browser applications 浏览器应⾼(程序)browser-accessible application 可经由浏览器访问的应⾼程序bug 缺陷错误build 编连(专指编译和连接)built-in 内建、内置bus 总线business 业务、商务(看场合)business Logic 业务逻辑business rules 业务规则buttons 按钮by/through 通过byte 位元组(由8 bits组成)cache ⾼速缓存calendar ⾼历Calendrical Calculations ⾼期call 调⾼call operator 调⾼操作符callback 回调candidate key 候选键(for database)cascading delete 级联删除(for database)cascading update 级联更新(for database)casting 转型、造型转换catalog ⾼录chain 链(function calls)character 字符character format 字符格式character set 字符集check button 复选按钮18.CHECK constraints CHECK约束(for database)19.checkpoint 检查点(for database)20.child class ⾼类21.CIL (common intermediate language)通⾼中间语⾼、通⾼中介语⾼22.class 类23.class declaration 类声明24.class definition 类定义25.class derivation list 类继承列表26.class factory 类⾼27.class hierarchy 类层次结构28.class library 类库29.class loader 类装载器30.class template 类模板31.class template partial specializations 类模板部分特化32.class template specializations 类模板特化33.classification 分类34.clause ⾼句35.cleanup 清理、清除36.CLI (Common Language Infrastructure) 通⾼语⾼基础设施37.client 客户、客户端38.client application 客户端应⾼程序39.client area 客户区40.client cursor 客户端游标(for database)41.client-server 客户机/服务器、客户端/服务器42.clipboard 剪贴板43.clone 克隆44.CLS (common language specification) 通⾼语⾼规范45.code access security 代码访问安全46.code page 代码页47.COFF (Common Object File Format) 通⾼对象⾼件格式48.collection 集合command line 命令⾼52.comment 注释53.commit 提交(for database)54.communication 通讯55.compatible 兼容56.compile time 编译期、编译时57.compiler 编译器58.component组件59.composite index 复合索引、组合索引(for database)60.composite key 复合键、组合键(for database)61.composition 复合、组合62.concept 概念63.concrete具体的64.concrete class 具体类65.concurrency 并发、并发机制66.configuration 配置、组态67.Connected Components 连通分⾼68.connection 连接(for database)69.connection pooling 连接池70.console 控制台71.constant 常量72.Constrained and Unconstrained Optimization 最值问题73.constraint 约束(for database)74.construct 构件、成分、概念、构造(for language)75.constructor (ctor) 构造函数、构造器76.container 容器77.containment包容78.context 环境、上下⾼79.control 控件80.cookie81.copy 拷贝82.CORBA 通⾼对象请求中介架构(Common Object Request Broker Architecture)85.86.87.88.89.90.91. D1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23. create/creation 创建、⾼成crosstab query 交叉表查询(for database)Cryptography 密码CTS (common type system)通⾼类型系统cube 多维数据集(for database)cursor 光标cursor 游标(for database)custom 定制、⾼定义data 数据data connection 数据连接(for database)data dictionary 数据字典(for database)data file 数据⾼件(for database)data integrity 数据完整性(for database)data manipulation language (DML)数据操作语⾼(DML) (for database) data member 数据成员、成员变量data source 数据源(for database)Data source name (DSN) 数据源名称(DSN) (for database)data structure数据结构Data Structures 基本数据结构data table 数据表(for database)data-bound 数据绑定(for database)database 数据库(for database)database catalog 数据库⾼录(for database)database diagram 数据关系图(for database)database file 数据库⾼件(for database)database object 数据库对象(for database)database owner 数据库所有者(for database)database project 数据库⾼程(for database)database role 数据库⾼⾼(for database)database schema 数据库模式、数据库架构(for database)database script 数据库脚本(for database)datagram 数据报⾼dataset 数据集(for database)26.dataset 数据集(for database)27.DBMS (database management system)数据库管理系统(for database) 28.DCOM (distributed COM)分布式COM29.dead lock 死锁(for database)30.deallocate 归还31.debug 调试32.debugger 调试器33.decay 退化34.declaration 声明35.default 缺省、默认值36.DEFAULT constraint默认约束(for database)37.default database 默认数据库(for database)38.default instance 默认实例(for database)39.default result set 默认结果集(for database)40.defer 推迟41.definition 定义42.delegate 委托43.delegation 委托44.deploy 部署45.derived class 派⾼类46.design pattern 设计模式47.destroy 销毁48.destructor(dtor)析构函数、析构器49.device 设备50.DHTML (dynamic HyperText Markup Language)动态超⾼本标记语⾼51.dialog 对话框52.Dictionaries 字典53.digest 摘要54.digital 数字的55.directive (编译)指⾼符56.directory ⾼录57.disassembler 反汇编器60.61.62.63.64.65.66.67.68.69.70. E1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19. dispatch 调度、分派、派发distributed computing 分布式计算distributed query 分布式查询(for database)DNA (Distributed interNet Application) 分布式⾼间应⾼程序document ⾼档DOM (Document Object Model)⾼档对象模型dot operator (圆)点操作符double-byte character set (DBCS)双字节字符集(DBCS) driver 驱动(程序)DTD (document type definition) ⾼档类型定义dump 转储dump file 转储⾼件e-business 电⾼商务efficiency 效率efficient ⾼效encapsulation 封装end user 最终⾼户end-to-end authentication 端对端⾼份验证engine 引擎entity 实体enum (enumeration) 枚举enumerators 枚举成员、枚举器equal 相等equality 相等性equality operator 等号操作符error log 错误⾼志(for database)escape character 转义符、转义字符escape code 转义码evaluate 评估event 事件event driven 事件驱动的event handler 事件处理器22.23.24.25.26.27.28.29.30.31.32. F1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19. evidence 证据exception 异常exception declaration 异常声明exception handling 异常处理、异常处理机制exception specification 异常规范exception-safe 异常安全的exit 退出explicit 显式explicit specialization 显式特化explicit transaction 显式事务(for database) export 导出expression 表达式fat client 胖客户端feature 特性、特征fetch 提取field 字段(for database)field 字段(java)field length 字段长度(for database)file ⾼件filter 筛选(for database)finalization 终结finalizer 终结器firewall 防⾼墙flag 标记flash memory 闪存flush 刷新font 字体foreign key (FK) 外键(FK) (for database) form 窗体formal parameter 形参forward declaration 前置声明forward-only 只向前的22.23.24.25.26.27.28.29. G1.2.3.4.5.6.7.8.9.10.11.12.13. H1.2.3.4.5.6.7. forward-only cursor 只向前游标(for database) framework 框架full specialization 完全特化function 函数function call operator (即operator ()) 函数调⾼操作符function object 函数对象function template函数模板functionality 功能functor 仿函数GC (Garbage collection) 垃圾回收(机制)、垃圾收集(机制) generate ⾼成generic 泛化的、⾼般化的、通⾼的generic algorithm通⾼算法genericity 泛型getter (相对于setter)取值函数global 全局的global object 全局对象grant 授权(for database)group 组、群group box 分组框GUI 图形界⾼GUID (Globally Unique Identifier) 全球唯⾼标识符handle 句柄handler 处理器hard disk 硬盘hard-coded 硬编码的hard-copy 截屏图hardware 硬件hash table 散列表、哈希表header file头⾼件9.heap 堆10.help file 帮助⾼件11.hierarchical data 阶层式数据、层次式数据12.hierarchy 层次结构、继承体系13.high level ⾼阶、⾼层14.hook 钩⾼15.Host (application)宿主(应⾼程序)16.hot key 热键17.HTML (HyperText Markup Language) 超⾼本标记语⾼18.HTTP (HyperText Transfer Protocol) 超⾼本传输协议19.HTTP pipeline HTTP管道20.hyperlink 超链接I1.icon 图标2.IDE (Integrated Development Environment)集成开发环境3.identifier 标识符4.IDL (Interface Definition Language) 接⾼定义语⾼5.idle time 空闲时间6.if and only if当且仅当7.IL (Intermediate Language) 中间语⾼、中介语⾼8.image 图象9.IME 输⾼法10.immediate base 直接基类11.immediate derived 直接派⾼类12.immediate updating 即时更新(for database)13.implement 实现14.implementation 实现、实现品15.implicit 隐式16.implicit transaction隐式事务(for database)17.import 导⾼18.incremental update 增量更新(for database)19.Independent Set 独⾼集20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49. J1.2. infinite loop ⾼限循环infinite recursive ⾼限递归information 信息inheritance 继承、继承机制initialization 初始化initialization list 初始化列表、初始值列表initialize 初始化inline 内联inline expansion 内联展开inner join 内联接(for database)instance 实例instantiated 具现化、实体化(常应⾼于template) instantiation 具现体、具现化实体(常应⾼于template) integrate 集成、整合integrity 完整性、⾼致性integrity constraint完整性约束(for database) interacts 交互interface 接⾼interoperability 互操作性、互操作能⾼interpreter 解释器introspection ⾼省invariants 不变性invoke 调⾼isolation level 隔离级别(for database)item 项、条款、项⾼iterate 迭代iteration 迭代(回圈每次轮回称为⾼个iteration) iterative 反复的、迭代的iterator 迭代器JIT compilation JIT编译即时编译Job Scheduling ⾼程安排K1.2. L1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25. M1. key 键(for database)key column 键列(for database)left outer join 左向外联接(for database)level 阶、层例library 库lifetime ⾼命期、寿命Linear Programming 线性规划link 连接、链接linkage 连接、链接linker 连接器、链接器list 列表、表、链表list box 列表框literal constant 字⾼常数livelock 活锁(for database)load 装载、加载load balancing 负载平衡loader 装载器、载⾼器local 局部的local object 局部对象lock 锁log ⾼志login 登录login security mode登录安全模式(for database) lookup table 查找表(for database)loop 循环loose coupling 松散耦合lvalue 左值machine code 机器码、机器代码macro 宏3.maintain 维护4.managed code 受控代码、托管代码5.Managed Extensions 受控扩充件、托管扩展6.managed object 受控对象、托管对象7.manifest 清单8.many-to-many relationship 多对多关系(for database)9.many-to-one relationship 多对⾼关系(for database)10.marshal 列集11.Matching 匹配12.member 成员13.member access operator 成员取⾼运算⾼(有dot和arrow两种) 14.member function 成员函数15.member initialization list成员初始值列表16.memory 内存17.memory leak 内存泄漏18.menu 菜单19.message 消息20.message based 基于消息的21.message loop 消息环22.message queuing消息队列23.metadata 元数据24.metaprogramming元编程25.method ⾼法26.micro 微27.middle tier 中间层28.middleware 中间件29.modeling 建模30.modeling language 建模语⾼31.modem 调制解调器32.modifier 修饰字、修饰符33.module 模块34.most derived class最底层的派⾼类35.mouse ⾼标multi-tasking 多任务37.38.39.40.41.42. N1.2.3.4.5.6.7.8.9.10.11. O1.2.3.4.5.6.7.8.9.10.11.12. multi-thread 多线程multicast delegate 组播委托、多点委托multithreaded server application 多线程服务器应⾼程序multiuser 多⾼户mutable 可变的mutex 互斥元、互斥体named parameter 命名参数named pipe 命名管道namespace 名字空间、命名空间native 原⾼的、本地的native code 本地码、本机码nested class 嵌套类nested query 嵌套查询(for database)nested table 嵌套表(for database)network ⾼络network card ⾼卡Network Flow ⾼络流object 对象object based 基于对象的object model 对象模型object oriented ⾼向对象的ODBC data source ODBC数据源(for database)ODBC driver ODBC驱动程序(for database)one-to-many r elationship ⾼对多关系(for d atabase)one-to-one relationship ⾼对⾼关系(for database) operating system (OS) 操作系统operation 操作operator 操作符、运算符option 选项outer join 外联接(for database) 14.15.16. P1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28. overflow 上限溢位(相对于underflow)overload 重载override 覆写、重载、重新定义package 包packaging 打包palette 调⾼板parallel 并⾼parameter 参数、形式参数、形参parameter list 参数列表parameterize 参数化parent class ⾼类parentheses 圆括弧、圆括号parse 解析parser 解析器part 零件、部件partial specialization 局部特化pass by reference 引⾼传递pass by value 值传递pattern 模式persistence 持久性pixel 像素placeholder 占位符platform 平台Point Location 位置查询pointer 指针polymorphism 多态pooling 池化pop up 弹出式port 端⾼postfix 后缀precedence 优先序(通常⾼于运算⾼的优先执⾼次序)prefix 前缀30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45. Q1.2.3.4.5. R1.2.3.4.5.6.7.8. preprocessor 预处理器primary key (PK)主键(PK) (for database) primary table 主表(for database) primitive type 原始类型print 打印printer 打印机procedure 过程process 进程program 程序programmer 程序员programming编程、程序设计progress bar 进度指⾼器project 项⾼、⾼程property 属性protocol 协议pseudo code伪码qualified 合格的qualifier 修饰符quality 质量queue 队列radio button 单选按钮random number 随机数Random Number Generation 随机数⾼成range 范围、区间rank 等级raw 未经处理的re-direction 重定向readOnly只读record 记录(for database)10.recordset 记录集(for database11.recursion ——递归12.recursive 递归13.refactoring 重构14.refer 引⾼、参考15.reference 引⾼、参考16.reflection 反射17.refresh data 刷新数据(for database)18.register 寄存器19.regular expression 正则表达式20.relational database 关系数据库21.remote 远程22.remote request 远程请求23.represent 表述,表现24.resolution 解析过程25.resolve 解析、决议26.result set 结果集(for database)27.retrieve data 检索数据28.return 返回29.return type 返回类型30.return value 返回值31.revoke 撤销32.right outer join 右向外联接(for database)33.robust 健壮34.robustness 健壮性35.roll back 回滚(for database)36.roll forward 前滚(for database)37.routine 例程38.row ⾼(for database)39.rowset ⾼集(for database)40.RPC (remote procedure call)RPC(远程过程调⾼) 41.runtime 执⾼期、运⾼期、执⾼时、运⾼时42.rvalue 右值S1.Satisfiability 可满⾼性2.save 保存3.savepoint 保存点(for database)4.SAX (Simple API for XML)5.scalable 可伸缩的、可扩展的6.schedule 调度7.scheduler 调度程序8.schema 模式、纲⾼结构9.scope 作⾼域、⾼存空间10.screen 屏幕11.scroll bar滚动条12.SDK (Software Development Kit)软件开发包13.sealed class 密封类14.search 查找15.Searching 查找16.semantics 语义17.sequential container序列式容器18.serial 串⾼19.serialization/serialize 序列化20.server 服务器、服务端21.session 会话(for database)22.Set and String Problems 集合与串的问题23.Set Cover 集合覆盖24.Set Data Structures 集合25.Set Packing 集合配置26.setter 设值函数27.side effect 副作⾼28.signature 签名29.single-threaded 单线程30.slider滑块31.slot 槽32.SMTP (Simple Mail Transfer Protocol) 简单邮件传输协议34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64. T snapshot 截屏图snapshot 快照(for database)SOAP (simple object access protocol) 简单对象访问协议software 软件Sorting 排序source code 源码、源代码specialization 特化specification 规范、规格splitter 切分窗⾼SQL (Structured Query Language) 结构化查询语⾼(for database) stack 栈、堆栈standard library 标准库standard template library 标准模板库stateless ⾼状态的statement 语句、声明static cursor 静态游标(for database)static SQL statements 静态SQL语句(for database)status bar 状态条stored procedure 存储过程(for database)stream 流string 字符串String Matching 模式匹配stub 存根subobject⾼对象subquery ⾼查询(for database)subscript operator 下标操作符support ⾼持suspend 挂起symbol 记号syntax 语法system databases 系统数据库(for database)system tables 系统表(for database)2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23. U1.2.3.4.5.6.7.8. table 表(for database)table-level constraint 表级约束(for database)target 标的,⾼标task switch ⾼作切换TCP (Transport Control Protocol) 传输控制协议template 模板temporary object 临时对象temporary table 临时表(for database)text ⾼本Text Compression 压缩text file ⾼本⾼件thin client 瘦客户端third-party 第三⾼thread 线程thread-safe 线程安全的throw 抛出、引发(常指发出⾼个exception)trace 跟踪transaction 事务(for database)transaction log 事务⾼志(for database)transaction rollback 事务回滚(for database)traverse 遍历trigger 触发器(for database)type 类型UDDI(Universary D escription, Discovery a nd I ntegration)统⾼描述、查询与集成UML (unified modeling language)统⾼建模语⾼unary function 单参函数unary operator ⾼元操作符unboxing 拆箱、拆箱转换underflow 下限溢位(相对于overflow)Unicode 统⾼字符编码标准,采⾼双字节对字符进⾼编码Union query 联合查询(for database)UNIQUE constraints UNIQUE约束(for database)unique index 唯⾼索引(for database) 11.12.13.14.15.16.17. V1.2.3.4.5.6.7.8.9.10.11. W1.2.3.4.5.6.7.8.9.10. unmanaged code ⾼受控代码、⾼托管代码unmarshal 散集unqualified 未经限定的、未经修饰的URI (Uniform Resource identifier) 统⾼资源标识符URL (Uniform Resource Locator) 统⾼资源定位器user ⾼户user interface ⾼户界⾼value types 值类型variable 变量vector 向量(⾼种容器,有点类似array)vendor ⾼商viable 可⾼的video 视频view 视图(for database)view 视图virtual function 虚函数virtual machine 虚拟机virtual m emory 虚拟内存Web Services web服务WHERE clause WHERE ⾼句(for database) wildcard characters 通配符字符(for database) wildcard search 通配符搜索(for database) window 窗⾼window function 窗⾼函数window procedure 窗⾼过程Windows authentication Windows⾼份验证wizard 向导word 单词write enable 写启⾼(for database)write-only 只写13.WSDL (Web Service Description Language)Web Service描述语⾼X1.XML (eXtensible Markup Language) 可扩展标记语⾼2.XML Message Interface (XMI) XML消息接⾼3.XSD (XML Schema Definition) XML模式定义语⾼4.XSL (eXtensible Stylesheet Language) 可扩展样式表语⾼5.XSLT (eXtensible Stylesheet Language Transformation)可扩展样式表语⾼转换6.xxx based 基于xxx的7.xxx oriented ⾼向xxx。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Web Service Based Data Management for Grid ApplicationsT. Boehm Zuse-Institute Berlin (ZIB), Berlin, Germany Abstract Web Services play an important role in providing an interface between end user applications and the underlying technologies. Being the base for distributed, decentralized systems, web services replace closed, centralized systems increasingly. Distributed collaborative systems represent the next step for the accomplishment of increasingly more becoming tasks. They promise a more flexible use of available resources as well as higher scalability, robustness, manageability, and extensibility. A promising and innovative new technology for developing distributed collaborative systems is given by Grid computing. In this paper we describe a web service which is responsible for the realization of the necessary remote data access and data management. This service can be used by persons or application to register and manage replicas of data sets. The communication between the service and clients is realized by the exchange of standardized XML messages using the Simple Object Access Protocol (SOAP). Consequently, this data management service is platform, programming language and system neutral. Keywords: Collaborative Environments, Data Management, SOAP.1. INTRODUCTION Web Services play an important role in providing an interface between end user applications and the underlying technologies. Being the base for distributed, decentralized systems, web services replace closed, centralized systems increasingly. Due to the fact that web services gain more and more importance, we assume a wide spread use of Web services by Grid computing applications that are characterized by the processing of huge data sets and the flexible, secure and coordinated sharing of resources in a highly dynamic environment [4]. A web service that provides the necessary data management with the just mentioned characteristics is described in this paper. Grid computing provides individuals, institutions or applications that build a virtual organization a common virtual pool of resources and suitable interfaces and infrastructure in order to access and use them. Figure 1 presents a conceptual schematic of a general Grid [15]. Users have direct access to resources in an abstract virtual level that hides the physical assignments of resources to particular nodes. The resources registered in this virtual pool can vary. Computational resources, storage systems, data and meta-data or input and output devices are typical examples. All these resources typically exist within nodes that are geographically distributed, and span multiple administrative domains. Main responsibility of a Grid middleware is to provide transparent access to them. If a user demands computational resources to accomplish a computing intensive task, it should be transparent on which node or which nodes the task is actually processed and by which service this is handled (i.e. Sun RPC or SOAP). This general example shows two essential characteristics of Grids: location transparency and service transparency [5]. In this document we focus on sharing of common data, which we want to imagine abstractly by registering a physical data file in the virtual resource pool described above. In this way, the file is accessible to a group of users that are authorized to use this particular service. Without the knowledge of the actual physical location of the file, users can load the data file without having an account on the node where the file has its origin. We propose a service that realizes the described virtual data pool for files by using a replica catalog described above that provides the data management.Euroweb 2002 — The Web and the GRID: from e-science to e-business1Web Service Based Data Management for Grid ApplicationsFIGURE 1: Conceptual schema of a grid. Users have direct access to the resources, represented by circles, without knowledge about their assignment.Resource distribution over Wide Area Networks (WANs) and the use of some Internet technologies are significant for Grid based environments [10]. One of the major challenges of the data management is the aspect of distributed and replicated data and the access to them. Although network latencies will decrease in the future since network technology improves, there is still a difference in performance between accessing data locally (on the same machine) or remotely over a network. By providing a copy of a data set located closely to a client application, access times can be reduced and the availability and fault tolerance can be increased [10] [14]. In general, managing copies of data sets is regarded as replica management. A replica manager typically maintains a replica catalog containing site addresses and the file instances. The replica catalog is responsible for mapping a logical file name onto a physical one and is capable of resolving the physical location of a file. To obtain a local replica of a selected data file, a client application simply sends a request to the replica catalog containing the logical filename. If an original data set is going to be registered in the replica catalog, this copy is called a primary copy. Every additional replica of the primary copy is called secondary copy [10]. Replica catalogs as described above can be regarded as Grid middleware services that store and manage logical and physical file information. 1.1 Motivation The necessity for such data management systems has been motivated in the literature of Data Grids in several ways. The emphasizes are in the fields of the "High-Energy Physics" (HEP) and "Climate Modeling" [6] as well as "Earth Observation" and "Bio-informatics" [7], where scientific information are supposed to be extracted from huge amounts of measured or computed sets of data geographically dispersed. Common to all these examples is the sharing of data in terms of information and databases that are world wide distributed. The primary goal is to improve the efficiency and the performance of the data analysis by integrating widely distributed processing power and data storage systems. While Grid Technologies are increasingly established in fields of applications just described, there is still no or at most only little support for conventional fields of software applications, like e-business applications, distributed multimedia systems or scientific visualization and collaborative work. In our understanding, Grid technologies are not only supposed to build the basis for new kinds of application areas. We strongly believe that they are also supposed to support and transform past and present developments to bring them to a new level of quality. Beside these pure scientific applications, we want to provide general conditions that allow the usage of Grid technology in the fields of our daily praxis.2Euroweb 2002 — The Web and the GRID: from e-science to e-businessWeb Service Based Data Management for Grid ApplicationsBeside the introduced examples of Grid applications, we want to motivate our work by an additional group of distributed applications that we believe will become more important in the future. Distributed collaborative systems are going to represent the next step for the accomplishment of complex tasks. They promise a more flexible use of available resources as well as higher scalability, robustness, manageability, and extensibility. The basic idea of collaborative systems is that a group of people, geographically dispersed, is working on shared data at the same time. The operations performed by these participants can be regarded as coordinated collaboration with the goal of solving a common problem or task that requires contributions of several experts from different areas of profession. We want to interpret this scenario as coordinated sharing of common resources and the solving of tasks in a virtual organization [4]. 1.2 Scenario Similar to the examples already discussed in section 1.1, we can find comparable requirements in the field of medical applications in terms of the distributed processing of huge amounts of data, generated by Computed Tomography (CT) or Magnetic Resonance Imaging (MRI). In a research project just started at the Zuse-Institute Berlin (ZIB), our goal is to develop a collaborative working environment for surgery planning and simulation within the field of cranio-maxillofacial surgery. The use of such a system requires technical as well as medical knowledge. A close interdisciplinary collaboration between experts of information technology, medical experts and users is necessary. The resulting challenges of these requirements necessitate the use of two different techologies: on the one hand we need Web technologies for realizing the coordinated, distributed collaboration using corresponding newly developed services, and on the other hand we need the Grid technology, which focuses on the coordinated sharing of resources distributed in a WAN and provides the infrastructure that enables reliable, secure and uniform access to those resources and data [3] [4] [5] [11]. 1.3 Requirements and contributions of this work The replica catalog implemented in the described service provides the following functionalities: • • • • • Registering physical files with certain attributes describing the data Modifying registered files using load and store operations Synchronizing all replicas of a registered file Creating and managing local replicas on a requesting hosts Responding to queries on the catalog (i.e. list all registered files)In the following we describe other relevant work and discuss the relation to our requirements or the advantages and disadvantages respectively. Then the developed service is presented in detail. We give the specification and discuss the definition of the attributes that describe registered files, and present the data management operations supported by this service. Finally some implementation notes, conclusions and ideas for future work are given. Our contributions in this paper are • • • • • Motivating the need for Grid technologies (especially data management) in conventional fields of scientific computing Propose a Web service based communication architecture for data management in a collaborative virtual environment Define and specify the data management operations Present and describe a SOAP conform XML based communication protocol and its implementation that represents the interface to the replica management system, compatible to other SOAP implementations (i.e. gSOAP) Propose a transportation layer with added security capabilities provided by Globus GSI2. RELATED WORK A major goal of our project is to build on existing experiences and available software systems. The development of our middleware system bases on the Globus Toolkit [1]. The Globus Toolkit, developed within the Globus Project [9], provides middleware services for Grid Computing environments. Major components are:Euroweb 2002 — The Web and the GRID: from e-science to e-business3Web Service Based Data Management for Grid ApplicationsResource location and allocation: this component provides mechanisms for expressing application resource requirements, and for identifying and managing these resources once they have been located. The Communication component provides basic communication mechanisms. A uniform mechanism that can be used to validate the identity of both, users and resources, is provided by the Authentication Interface component. Process Creation: this component is used to initiate computation on a resource once it has been located and allocated. The DataAccess component is responsible for providing high-sped remote access to persistent storage on disk. The Globus philosophy is not to provide high level functionality, but to develop middleware that can be used as the base for developing a more complex infrastructure on top. In [6] two services of the Globus Toolkit are introduced that, according to the authors of [6], are fundamental for Data Grids: secure, reliable, and efficient data transfer and the ability to register, locate and manage multiple copies of data sets. For the efficient high speed data transfer, the GridFTP [8] is responsible, an extension of the popular FTP with additional features that are required by Grid applications. The replica management service integrates a replica catalog with the GridFTP transport to provide the creation, registration and management of data sets. The catalog contains three types of objects: The highest level object is the collection, a group of logical file names. A location object contains the information required to map between one logical filename and, possibly several, physical locations of the associated replicas. The third object is a logical file entry. This optional entry can be used to store attribute-value pair information for individual logical files. The operations that can be performed on the catalog are as follows: creation and deletion of collections, locations, and logical file entries; insertion and removal of logical file names into collections and locations; listing of the contents of collections and locations; and listing physical locations of a logical file. In [14], a data replication tool, the Grid Data Management Pilot (GDMP), is presented, which is implemented on top of the Globus Data Grid tools for efficient data transfer. The Globus Security Infrastructure (GSI) is responsible for authentication of clients. Requests by clients are handled by the Request Manager and transmitted to the server. File transfer requests are served by the Data Mover and are registered by the Replica Catalog Service. A Storage Manager provides a disk pool and acts as an abstract cache. The GDMP Replica Catalog Service provides a high-level object-oriented wrapper to the underlying Globus Replica Catalog library. This wrapper hides some Globus API details and also introduces additional functionality such as search filters, and checks on input parameters. The underlying Globus Replica Catalog is currently implemented using the Lightweight Directory Access Protocol (LDAP) and is used as a central catalog with an LDAP server. In [10] the development of this service to a distributed replica catalog is described that bases on HTTP redirections. This approach allows the autonomy and reduces update operations on a central replica catalog when files are moved within one site. A replica catalog client first connects to a central replica catalog and is redirected to a site catalog which then resolves the actual physical file location. In [12], the authors concentrate on models for high-level replication services, namely services for maintaining replica synchronization and consistency. Those services should be built on top of existing replication services for fast file transfer and data management. For a detailed description of the consistency models, we refer to [12]. The service described in this paper is not supposed to address the data consistency problems. These have to be handled by applications that are built on top of our service.2.1 Discussion The architecture described in [10] bases on replica catalogs that exist on every site as well as a catalog server that responses to requests to the catalog. The requests sent from the client to the server to get a physical location of a file are HTTP formatted, because this format is well understood and widely distributed. In contrast, the communication between clients and the replica catalog is realized using LDAP, which is the access protocol to the current implementation of the Globus Replica Catalog. Requests and responds to our newly developed service bases on the exchange of XML messages, a data format that is very popular due to its simplicity and broad usability, and has been used for the specification and implementation of other protocols, too, i.e. SOAP [16] [18]. Using XML, the interface to our service has an open and simple design and enables a transparent use of a replica catalog. Our motivation, a collaborative distributed environment, bases on the exchange of messages in the XML format and is therefore defines the design of our data management system. In addition we expect to minimize integration problems when using the data management service within our collaborative system. The Globus Replica Catalog uses a hieratical name space that bases on the requirements of the example4Euroweb 2002 — The Web and the GRID: from e-science to e-businessWeb Service Based Data Management for Grid Applicationsapplications of the area of meta-computing described in [6] and [7]. This complexity seems to be too high for our type of applications. Therefore we use a flat name space and do not use the option to group files to collections, because this is not relevant to our application. Instead, every entry in the replica catalog represents exactly one file. In addition, currently available replica management systems are not available for every platform and operating system. The use of a platform independent layer solves this problem and minimizes the expense of porting the service due to the fact that tools for generating and evaluating XML documents are available for several platforms and are widely distributed. 3. THE PROPOSED ARCHITECTURE 3.1 Application scenario When a data set has been created on one site using Computer Tomography, several other users need to access those data to perform own analyses or processing steps that can not be performed at the creator's site due to a lack of capacities or resources. For this purpose, the corresponding data set is registered to the replica catalog of the web service that manages the collaborative session. The replica catalog provides access to the registered data to every user authorized for this service. If a participant loads a data set registered within the catalog and identified by a logical filename, a local replica is created transparently on the requesting host and a corresponding entry is registered in the catalog under the same logical file name. If a logical filename refers to a set of physical filenames, a request to the replica catalog for a listing of all registered files shows multiple logical filenames only once. If such a logical filename is requested within a load instruction, a physical file needs to be determined that can be used to create a replica. The data management service determines the physical file that is the closest to the requesting host to reduce transportation time while creating another local replica at the requesting host and increasing performance. To delete an entry in the replica catalog, the corresponding file can be unregistered. If this file is not a primary copy, the replica is removed from the host to restore the original state. 3.2 Architecture As a basic description language we use XML because it is a flexible message exchange format. An XML based communication protocol is independent of programming languages and platforms, which means that the information exchange between several sites can be established between different platforms and programming environments [17]. Open standard Web technologies, as provided by XML/Web services, contain the following characteristics that are essential to the implementations of Grids and can provide a platform for the design of many aspects of Grid middleware. Interoperability is the fundamental feature and required for distributed computing in heterogeneous environments. XML is independent from a specific implementation and capable of mediating interactions between various Grid components. The flexibility of XML/Web services technologies allows the implementation of various Grid protocols [11]. The richness of data formats and structures supported by XML also enables to interface all kinds of applications. The extensibility of the Web service model allows modifying and adding of functionalities of Grid components that are constructed as Web services. The scalability of Web technologies allows the construction of Grids that can support large numbers of components and interactions among components. This feature increases the usability of the Grid. Figure 2 shows the layer model of our Web service. An end user application has access to the remote Web service using a special Web service API. The SOAP protocol is responsible for the reliable communication via the exchange of XML messages between Web service and client. Normally, SOAP sits on top of standard transport protocols like HTTP and SMTP, but provides the possibility to use other transport protocols. In our case, the transport layer has been extended using the Globus Grid Security Infrastructure (GSI). GSI provides authentication of users via X.509 certificates and single sign-on. Two major features that are very useful for the frequent use of the service.Euroweb 2002 — The Web and the GRID: from e-science to e-business5Web Service Based Data Management for Grid ApplicationsFIGURE 2: Layer model of the Web service.Figure 3 show the conceptual schematic of the data management service with two hosts accessing the service. The data management service basically consists of three components: the actual Catalog that contains all entries of registered files and additional information about them, the Data Locator that determines the closest replica to a requesting host, and finally the Data Mover that is able to transfer huge data sets efficiently and fast. The communication between clients and the service bases on the exchange of XML messages as shown in Figure 3.FIGURE 3: Conceptual schematic of the data management service and its components.3.3 The Data Mover While XML documents represent the interface to the data management service, the GridFTP of the Globus Toolkit is used as transport engine for transferring copies of files. For this purpose, the data management service contains a component called Data Mover, which uses GridFTP for creating, copying and deleting replicas. In the field of Grid Computing, GridFTP is a de facto standard for high performance wide area data transfer of huge data sets due to its optimizations in terms of efficient data transfer and additional features like partial data transfer and third-party transfer [8].6Euroweb 2002 — The Web and the GRID: from e-science to e-businessWeb Service Based Data Management for Grid Applications3.4 The Data Locator If a client sends a request for a registered file to the replica management server in the form of a logical filename, the responsibility of the Data Locator is to determine the closest copy of the requested file to the requesting host. Afterwards, the determined copy is the source for the creation of the local replica on the requesting host. In this case, closest copy of a file to another one is not meant in the geographical sense. With the closest copy, we mean the file that can be reached in the shortest time via the network. To determine which copy of the logical filename is the closest one to the requesting host, the time to access a particular copy is measured. This happens initially when registering a copy and afterwards in periodical intervals due to possible dynamic changes of network characteristics. To determine the time needed to access a file on a particular host, a special message is sent to the echo server of this host and the time needed is measured. 3.5 The Replica Catalog The entries of the replica catalog contain all necessary information to identify and describe a file. Such entries include information about the host where the file is stored physically; in detail: the name or the IP address of the host, and the port and the protocol which have to be used to get access to the replicas. Using further information like the position of a file in the file system, a URL can be build, which is be used to access a particular file. Every entry in the catalog represents one file on one host. The entries contain the following optional and necessary attributes: • • Hostname: The necessary Hostname attribute identifies the host on which the file is stored physically. The hostname attribute can contain the name or the IP address of the host. This attribute accepts case-sensitive string values. Location: The necessary Location attribute describes the position information of a file in the file system of the host where the file is stored physically. Together with the attribute Hostname, these attributes build the physical name of a registered file. Using the additional attributes protocol and port, a corresponding URL to the physical filename can be created, which allows the file transport protocol to access and transfer the file. This attribute accepts case-sensitive string values. Filename: The necessary Filename attribute allows the user to specify the name of logical files. Every physical filename needs to have a logical filename. One logical filename can refer to a set of physical filenames that are replicas of the primary copy on different locations. This attribute accepts casesensitive string values. Protocol: The optional Protocol attribute specifies the access protocol required by the Data Mover. If no protocol specification is given, the default value of this attribute is used that is GridFTP. Alternatively, the conventional FTP can be used. This attribute accepts case-sensitive string values. Port: The optional Port attribute specifies the port number required to access the host that contains the requested file using the specified access protocol. The attribute accepts numeric values. Timestamp: The optional Timestamp attribute is used to describe the last write access to this file. The attribute accepts numeric values. Size: The optional Size attribute describe the Size of a file in bytes. The attribute accepts numeric values. Type: The optional attribute Type is supposed to give an additional opportunity to describe the file and its contents. The attribute accepts numeric values. Owner: The optional attribute Owner is supposed to give an additional opportunity to describe the owner or creator of the file by a name. This attribute accepts case-sensitive string values.•• • • • • •4. DATA MANAGEMENT OPERATIONS For the management of data set, our Web service provides several operations that are discussed in this section. The service and its interface are described by a Web Service Description Language (WSDL) document, which we use to present the service. 4.1 RegisterEuroweb 2002 — The Web and the GRID: from e-science to e-business7Web Service Based Data Management for Grid ApplicationsThe registering of a data set contains a message to the Web service. Besides the actual registering instruction, several information are transmitted within the messaged that are discussed in section 3.5. The WSDL definition of the message CRegisterMsg sent within this operation is represented in the following listing:<complexType name="CRegisterMsg"> <sequence> <element name="name" type="xsd:string" minOccurs="1" maxOccurs="1" nillable="true"/> <element name="location" type="xsd:string" minOccurs="1" maxOccurs="1" nillable="true"/> <element name="host" type="xsd:string" minOccurs="1" maxOccurs="1" nillable="true"/> <element name="protocol" type="xsd:string" minOccurs="1" maxOccurs="1" nillable="true"/> <element name="port" type="xsd:int" minOccurs="1" maxOccurs="1"/> <element name="time" type="xsd:int" minOccurs="1" maxOccurs="1"/> <element name="size" type="xsd:int" minOccurs="1" maxOccurs="1"/> <element name="type" type="xsd:string" minOccurs="1" maxOccurs="1" nillable="true"/> <element name="owner" type="xsd:string" minOccurs="1" maxOccurs="1" nillable="true"/> </sequence> </complexType>4.2 Unregister Through the deletion of a registry of a data set, the corresponding entry is removed from the catalog. To identify an entry in the catalog, the logical file name does not describe a file clearly, because this may address multiple physical filenames. Therefore, a clear identification is given by the physical location of a file, defined by the host and the path. If we do not deal with a primary copy, the file is removed from the host after the deletion of the registry entry to restore the original state. An information that tells us whether we deal with a primary or secondary copy is stored within the replica catalog. The WSDL definition of the message CUnregisterMsg sent in this operation is represented in the following listing:<complexType name="CUnregisterMsg"> <sequence> <element name="name" type="xsd:string" minOccurs="1" maxOccurs="1" nillable="true"/> <element name="location" type="xsd:string" minOccurs="1" maxOccurs="1" nillable="true"/> <element name="host" type="xsd:string" minOccurs="1" maxOccurs="1" nillable="true"/> </sequence> </complexType>4.3 List To determine which files are registered in the replica catalog, a list request without any additional parameters can be sent to the service. The response message contains a list where every entry is given by its necessary attributes. Optional attributes are not within this response messages. The WSDL definition of the message CListResponseMsg received within the respond is represented in the following listing:<complexType name="CListResponseMsg"> <sequence> <element name="number" type="xsd:int" minOccurs="1" maxOccurs="1" nillable="true"/> <element name="name" type="xsd:string" minOccurs="1" maxOccurs="1" nillable="true"/> <element name="location" type="xsd:string" minOccurs="1" maxOccurs="1" nillable="true"/> <element name="host" type="xsd:string" minOccurs="1" maxOccurs="1" nillable="true"/> </sequence> </complexType>4.4 Load An application or a person may want to send a Load request to the data management service. In this case, the requesting host wants to create a local replica of the requested file. To identify the corresponding file in the catalog, the logical filename needs to be given. Additionally, the target location of the file on the local host, described by hostname and path, is necessary. The WSDL definition of the message COperationMsg sent within this operation is represented in the following listing:<complexType name="COperationMsg"> <sequence> <element name="name" type="xsd:string" minOccurs="1" maxOccurs="1" nillable="true"/>8Euroweb 2002 — The Web and the GRID: from e-science to e-business。