汇编实验之字符串的排序
53.String sort 字符串排序的几种方法

简介在之前的一些排序算法中,主要是对一些数值的类型比较的比较多一点。
而对于字符串类型来说,它有一些特殊的性质。
如果按照传统的排序方法,对于字符串的比较性能其实还取决于字符串的长度以及相似程度。
实际上,对于一些字符集的取值在一个比较小的范围内的情况,我们可以有一些比较高效率的算法。
这里针对这些特殊的情况进行讨论。
假设给定的排序集合里元素,也就是每个字符都是在一个比较有限的范围里,比如说256个字符范围内。
那么,我们可以利用这个特性做一些高效的处理。
联想到之前讨论过的counting sort和radix sort方法。
这里就是利用了这个特性。
Key-Indexed counting在之前讨论couting sort的文章里,曾经针对需要排序的元素为数字的情况进行过讨论。
counting sort成立的一个前提是它里面所有的元素取值是在一个固定的范围内。
假设这个数组里元素能取的最大值是k,那么每次我们要排序的时候只需要声明一个长度为k的数组a。
每次碰到一个元素i就将a[i]对应的值加1。
这样就统计出来了所有从小到大的元素的值的分布。
剩下的就只是从小到达把这些值重新排列输出就可以了。
当然,在一些数字有一定长度而且它们的长度都一样的情况下。
我们可以利用从高到低或者从低到高位逐位排序的方式来对数组进行排序。
这就是radix sort的基本思路。
它本质上就是在每一位的排序上都使用了couting sort。
借鉴前面对于数字的排序,我们对于字符串数组的排序也可以采用类似的方式:Java代码1.int[] count = new int[R + 1];2.//计算每个字符出现的频率3.for(int i = 0; i < n; i++)4. count[a[i].charAt(d) + 1]++;5.//将每个字符出现的频率转换为所在的索引6.for(int r = 0; r < R; r++)7. count[r + 1] += count[r];8.//将字符分布到具体的数组位置9.for(int i = 0; i < n; i++)10. aux[count[a[i].charAt(d)]++] = a[i];11.//将结果拷贝回数组12.for(int i = 0; i < n; i++)13. a[i] = aux[i];上述代码里的R表示当前字符的取值范围。
汇编语言实验7实验报告

汇编语言实验7实验报告一、实验目的本次实验旨在通过汇编语言编写程序,实现对字符串的操作和输出。
二、实验内容1. 编写一个汇编程序,要求从键盘输入一个字符串,并将其逆序输出到屏幕上;2. 编写一个汇编程序,要求从键盘输入两个字符串,并将它们拼接起来后输出到屏幕上。
三、实验过程1. 字符串逆序输出程序首先,需要从键盘输入一个字符串。
为了方便起见,我们可以先规定字符串的最大长度为100。
接着,我们需要定义两个变量:```buffer db 100 ; 用于存储输入的字符串length dw ? ; 存储输入的字符串长度```其中,db代表定义字节型变量,dw代表定义双字节型变量。
然后,我们需要使用INT 21H中断来读取用户输入的字符串。
具体而言,我们可以使用下面这段代码:```mov ah, 0Ah ; 设置INT 21H功能号为0Ahmov dx, offset buffer ; 将buffer的地址传给DX寄存器int 21h ; 调用INT 21H中断```该代码会将用户输入的字符串存储在buffer中,并且将其长度存储在length变量中。
接着,我们需要将该字符串逆序输出到屏幕上。
为了实现这个功能,我们可以使用栈来存储字符串中的每个字符,并逐个弹出来输出。
具体而言,我们可以使用下面这段代码:```mov si, offset buffer + 1 ; 将si寄存器指向字符串的第一个字符mov cx, length ; 将cx寄存器设置为字符串长度dec cx ; 字符串长度需要减1reverse:push byte ptr [si] ; 将当前字符压入栈中inc si ; 指向下一个字符loop reverse ; 循环直到所有字符都被压入栈中mov ah, 02h ; 设置INT 21H功能号为02h,表示输出一个字符print:pop dx ; 弹出栈顶元素int 21h ; 输出该字符loop print ; 循环直到所有字符都被弹出并输出完毕```2. 字符串拼接程序首先,需要从键盘输入两个字符串。
字符串排序规则

字符串排序规则字符串排序是一种非常重要的数据处理方式,它能有效地排序出数据中有用的信息,从而更容易地进行数据分析和挖掘。
在许多实际应用场景中,为了使数据能够被正确、有效地处理,我们必须采用一定的字符串排序规则,才能对字符串进行排序。
首先,让我们来看看基本的字符串排序规则。
最常见的字符串排序规则是按字典顺序排序。
这种排序规则会按照字母表顺序将字符串排序,这样用户可以更容易地找到他们正在关注的字符串。
另外,字母数字混合排序也是一种常见的字符串排序规则,它将字符串按照字母和数字的组合方式进行排序,使用户能够更容易地找出有用的字符串。
除了这两种基础的字符串排序规则之外,还有一些附加的排序规则可供使用。
比如,可以按照字符串中的字符的字节数进行排序。
这样的排序规则有助于过滤出符合特定字节数要求的字符串。
另外,我们还可以按照字符串中字符出现的频率进行排序,目的是过滤掉那些频繁出现的字符串以节省内存空间。
另外,在字符串排序规则中,字符大小写规则也很重要。
比如,在Linux操作系统中,字符串是按照“大写字母在前,小写字母在后”的顺序进行排序的,这是一种常见的大小写规则。
另外,有些系统中,字符串排序是不区分大小写的,这时,大小写规则就不起作用了。
最后,在文本排序规则中,语言也是一个重要的因素。
不同的语言会有不同的排序规则,比如在西班牙语中,在排序字符串时,会将所有以“”开头的单词放在最前面,其它以“a”开头的单词放在最后面。
总之,字符串排序规则是处理字符串数据时不可或缺的重要规则,它有助于我们更有效地进行数据处理,从而更准确地挖掘有用的信息。
为了更好地掌握字符串排序规则,我们可以根据实际需要来进行学习,从而使数据处理更加高效。
汇编冒泡法排序

汇编实验报告实验题目:从键盘输入任意5个2位有符号十进制数,采用“冒泡法”进行升序排序,输出排序后的结果,并输出排序次数。
实验设计:实验要求用16位机的汇编语言完成,键盘上输入的的数据最终都会以ASCII码形式接受,输出也要求用ASCII码,因而我决定设计专门负责输入和输出的两个子程序。
但是由于要求输入的是有符号的而且是长度不一定不确定的十进制数,用一个子程序直接在输入时转换成二进制会比较麻烦,因而决定可以先以字符串的形式接受来自用户的数据,这样可以以最自由的形式接受数据,不仅数据长度问题可以解决,带不带‘+’‘-’符号也可以识别,而且方便查错。
排序的主要部分是比较简单的,学C的时候已经了解,况且数据结构课又重复了一遍,因而本次实验主要需要解决的还是输入输出、以及数据的转化问题。
我的程序结构比较简单,主要包含几个子程序:GET : 调用10号模块接收一串字符,放进缓存dataEXDTB:解析缓存中的符号数据,转化为二进制并存入数组ansEXBTD:对从BX传过来的二进制数解析,并在屏幕上输出相应的十进制数,无运算结果程序:DATAS SEGMENTDATA DB 21 DUP('$')ANS DW 10 DUP(0)TES DB 'RUN HRER','$'LEN DW 0TMP DW 0SIG DW 00HSTA DW 00H ;STA ANS[STA] IS DIGENT DB 0DH,0AH,'$'RNM DB 'READ 5 DIGITALS',0AH,0DH,'$'PRIT DB 'PAIXU:',0AH,0DH,'$'FINSH DB 'NEW ORDER:','$'EORR DB 'INPUT ERROR!',0AH,0DH,'$'CISHU DB 'EXCHANGE TIME:',0DH,0AH,'$'CIS DW 0EXIT DB 'ENTER A NUMBER TO EXIT',0AH,0DH,'$'DATAS ENDSSTACK SEGMENTTOPE DW 300H DUP(0)STACK ENDSCODES SEGMENTASSUME CS:CODES, DS:DATAS,SS:STACKSTART: ;先跳过写在开头的子程序MOV AX,DATASMOV DS,AXMOV AX,STACKMOV SS,AXMOV SP,00HJMP SART ;AH=09 OUPUT AH=10 INPUT,前面注意有两个字节没用从ds:dx+2开始才是 ;第一个是输入及字符数ENTE PROC ;ENTE DISPLAY '/N' ON THE SCREENPUSH AXPUSH DXMOV AX,OFFSET ENTMOV DX,AXMOV AH,09HINT 21HPOP DXPOP AXRETENTE ENDPGET PROC ;PROC GET READ A TWO BIT DIGITAL FROM USCERPUSH AX ;;DX HAS ADDRESSPUSH DXMOV DX,OFFSET DATAMOV AH,0AH ;GET A LINE OF NUMBERINT 21H;CALL ENTEPOP DXPOP AXRETGET ENDPEXDTB PROC ;PROC EXCHANGE SIGNED DIGITAL TO BINARYPUSH AXPUSH BXPUSH CXPUSH DX ;USE DX TO STORE ANS;ANS[STA] HAS RESULT XOR DX,DXXOR CX,CXMOV BX,OFFSET DATAINC BX ;DS:DX+1 IS THE NUMBER OF INPUTED CHAR MOV CL,[BX] ;cl HAS LENGTHXOR CH,CHINC BX ;NOW BX COME TO FIRST CHAR INPUTEDMOV AL,[BX]CMP AL,'-' ;TO CHECK IF IT IS SIGNJNZ POST ;WITHOUT '-',THAT WILL BE POSTIVEMOV WORD PTR[SIG], 0001H ;SET SIG 0001H IF NEGETIVE JMP SIGNEDPOST:MOV SIG,WORD PTR 0000H ;SET POSTIVECMP AL,'+' ;IF IT HAS '+',IGNORE ITJNE PASSSIGNED:INC BXSUB CX,01HJMP STLOP ;PASS THE SIGN + -PASS: ;DIRECTLY TO NUMBERSCMP AL,'0' ;IF IT IS NUMBERJL NOTHINGCMP AL,'9'JG NOTHINGMOV DL,ALSUB DL,'0'CMP CL,1JE POSTYSUB CX,01HSTLOP:MAINLOOP:MOV AL,[BX]SUB AL,'0'JS NOTHING ;JUMP IF AL-'0'< 0 , ILLEAGLE INPUT CMP AL,09H ;JUMP IF AL-'9'> 0 ,JG NOTHINGMOV DH,DL ;SHIFT DL TO TIMES 10SHL DH,01H ;SHIFT 2 TIMES 4SHL DH,01H ;DL=DL*4+DL=5*DLADD DL,DHSHL DL,01H ;DL=5*DL*2=10*DLADD DL,ALINC BXLOOP MAINLOOPTEST SIG,0001HJZ POSTY ;JUMP TO AVOID -DXNEG DLPOSTY:MOV BX,OFFSET ANSADD BX,STAMOV AL,DLCBWMOV [BX],AXJMP DONENOTHING: ;IF NOT NUMBER , RETURN 0MOV DX,OFFSET EORRMOV AH,09HINT 21HMOV BX,OFFSET ANSADD BX,STAMOV [BX],WORD PTR 0001HDONE:CALL ENTEPOP CXPOP BXPOP AXRETEXDTB ENDPEXBTD PROC ;PROC EXCHANGE BINARY NUMBER IN BX TO DIGITAL PUSH AXPUSH BXPUSH CXPUSH DXCALL ENTE ;DISPLAY '/N'TEST BX,8000HJZ POSTVMOV DL,'-'MOV AH,02HINT 21HNEG BX ;EXCHANGE TO POSTIVEPOSTV:MOV CX,1111HPUSH CXMOV AX,BXCWDMOV BX,10MLOOP:DIV BX ;DIV 10PUSH DX ;PUSH BX MOD 10CWDADD AX,00HJNZ MLOOPDSLOOP: ;DISPLAY NUMPOP DXCMP DX,1111HJE FINISHADD DL,'0'MOV AH,02HINT 21HJMP DSLOOPFINISH:;CALL ENTEPOP DXPOP CXPOP BXPOP AXRETEXBTD ENDPSART:MOV DX,OFFSET PRITMOV AH,09HINT 21HMOV DX,OFFSET RNMMOV AH,09INT 21HMOV CX,05HMOV WORD PTR[STA],0000HGETLOOP:CALL GET ;读入符号数CALL EXDTB ;转为二进制ADD WORD PTR[STA],0002H;存入数组ans LOOP GETLOOPMOV WORD PTR[CIS],00HARRAGE: ;排序MOV CX,05HSUB CX,0001HMOV BX,OFFSET ANSADD BX,CXADD BX,CXLOOP1:MOV TMP,CXPUSH BXLOOP2:MOV AX,WORD PTR[BX]SUB BX,0002HMOV DX,WORD PTR[BX]CMP AX,DXJNS BIGGERINC WORD PTR[CIS]MOV WORD PTR[BX],AXMOV 02H[BX],DXBIGGER:SUB WORD PTR[TMP],0001H JNZ LOOP2POP BXLOOP LOOP1WRITE: ;输出排好序的数MOV DX,OFFSET FINSHMOV AH,09HINT 21HMOV CX,05MOV WORD PTR[STA],0000HMOV BX,OFFSET ANSLOOPWR:PUSH BXADD BX,STAMOV DX,[BX]MOV BX,DXCALL EXBTDPOP BXADD WORD PTR[STA],0002HLOOP LOOPWRCALL ENTEMOV DX,OFFSET CISHUMOV AH,09HINT 21HMOV BX,[CIS]CALL EXBTDCALL ENTEMOV DX,OFFSET EXITMOV AH,09HINT 21HCALL GETMOV AX,4C00HINT 21HCODES ENDSEND START问题及调试:主要问题是数据的转化,当我们用C写程序时,直接可以用%开头的格式命令进行特定类型的数据输入输出,但是用汇编时就没有那么好办了,输入的时候要识别数据,输出也要转化数据。
汇编实验之字符串的排序

汇编实验之字符串的排序计算机原理实验室实验报告课程名称:计算机语言与汇编原理姓名学号班级成绩设备名称及软件环境实验名称汇编语言实现字符串排序(冒泡排序)实验日期一.实验内容利用汇编语言实现字符串排序,输出,查找等功能二.理论分析或算法分析在汇编语言中,需要调用外部模块(子程来/函数)来完成部分功能,调用printf函数将字符串显示在屏幕上。
printf函数属于C语言的库函数。
它的执行代码放在一个动态链接库(dynamic load library,DLL)中,这个动态库的名字叫msvcrt.dll。
一个DLL文件对应一个导入库,如msvcrt.dll的导入库是msvcrt.lib;kernel32.dll的导入库是kernel32.lib;user32.dll的导入库是user32.lib等。
导入库文件在Visual C++的库文件目录中,在链接生成可执行文件时使用。
可执行文件执行时,只需要DLL文件,不需要导入库。
printf PROTO C :dword,:vararg在汇编语言中,可以调用printf 函数。
在程序中要指明printf的调用规则以及它的参数类型:Printf PROTO: dword,:varargprintf使用C调用规则(参数自右至左入栈,由主程序平衡堆栈)。
第1个参数是一个双字(:dword),即字符串的地址。
vararg表示后面的其他参数个数可变,可以一个没有,也可以跟多个参数三.实现方法(含实现思路、程序流程图、实验电路图和源程序列表等)做一个缓冲区,串口接收数据往缓冲区里写!在串口接收完(可以是判断字符串长度,或者判断结束标识,如0D 0A就可以用来做判断)后,置标志,主程序查询标志,如果有效,从缓冲区头开始,与指定字符串进行比较,直到找到相应字符串,然后进行个字大小的排序,并最终输出排列的顺序表。
四.实验结果分析(含执行结果验证、输出显示信息、图形、调试过程中所遇的问题及处理方法等)Start: push cspop dspush cspop es ;使数据段、附加段与代码段同段Input_Str: Output Prompt_Str ;提示输入字符串lea dx,Buffer ;字符串缓冲区地址mov ah,0ahint 21hlea si,Buffer[1] ;实际输入的字符数地址cldlodsbtest al,0ffhjz Input_Str ;若直接回车,没有输入任何字符,则请重新输入mov cl,alxor ch,chxor bx,bx ;计数器清零,bh=元音字母计数器,bl=辅音字母计数器Vowel_conso:lodsbor al,20h ;转换成小写cmp al,'a'jb Next_One ;小于'a',不是字母,不计数cmp al,'z'ja Next_One ;大于'z',不是字母,不计数push cxlea di,Vowel ;元音字符串地址mov cx,5 ;元音字母个数repnz scasb ;扫描当前字母是否是元音字母jcxz $+6inc bh ;元音字母计数jmp short $+4inc bl ;辅音字母计数pop cxNext_One: loop Vowel_consoOutput Vowel_Prom ;提示显示元音字母个数mov al,bhxor ah,ahcall Dec_ASCII ;显示元音字母个数Output Conso_Prom ;提示显示辅音字母个数mov al,blxor ah,ahcall Dec_ASCII ;显示辅音字母个数mov ah,7 ;不带回显的键盘输入,即等待按键(暂停),结束程序int 21hExit_Proc: mov ah,4ch ;结束程序int 21hBuffer db 255,0 ;字符串缓冲区Code ENDSEND Start实验输出图形调试过程中出现的问题及其解决方法1.出现不能识别的字符串输出2.不能对现现有字符串进行排序3.原始字符串的书写输出出现混乱解决方法1.对原有需要比较的字符串检查其输入的完整性,和正确性。
字符串算法—字符串排序(上篇)

字符串算法—字符串排序(上篇) 本⽂将介绍键索引计数法、LSD基数排序、MSD基数排序。
1. 字符串(String) 我们来简单回顾⼀下字符串。
众所周知,字符串是编程语⾔中表⽰⽂本的数据类型。
它是⼀堆字符的组合,如 String S="String"。
我们可以知道字符串的长度:S.length()=6; 可以知道某个位置的字符是什么:S[0]="S"; S[5]="g"; 可以提取S中的⼀部分; 可以把两个字符串合并起来形成新字符串等等。
2. 字符串排序 如果我们要对⼀堆字符串像字典⼀样排序,怎么排?例如: 字典是怎么排序的呢? 按照英⽂字母表顺序a,b,c,d,...,y,w,我们得到了字母的⼤⼩排序:a<b<c<d<...<y<w。
sea和she相⽐,第⼀个字母相同,第⼆个字母e<h,故sea<she; sea和seashells相⽐,前三个字母相同,但seashells⽐sea长,故sea<seashells; seashells和sells相⽐,前两个字母相同,第三个字母a<l,故seashells<sells。
说到排序,我们⾃然想起了插⼊排序、、、,我们来回顾⼀下它们对N个对象进⾏排序的效率: 图中的CompareTo()就是对象之间⽐较⼤⼩的⽅法。
要想使⽤上述4种排序算法,必须提供⼀种对象之间⽐较⼤⼩的⽅法。
即程序需要知道对象a与对象b谁⼤谁⼩(或相等)。
如果对象是数字,那⽐较⽅法容易实现。
但如果对象是字符串,⽐较⽅法就复杂多了。
接下来,我们将介绍拥有⽐上述⽅法更⾼效率的字符串排序算法。
3. 键索引计数法(Key-indexed counting ) 讲算法之前,我们来先了解⼀下这些算法的基础:键索引计数法。
从例⼦⼊⼿:a[]是拥有⼀堆只有⼀个字符的string数组。
C语言实验报告-字符串排序

{output[i]=a[m];
m++;
}
}
}
void main()
{
char input[50];
char output[50];
scanf("%s",input);
my_sort(input,output);
printf("input:%s\n",input);
}
后来发现这实在是太麻烦了,就使用了字符函数isdigit代替switch语句,使程序代码缩短(能运行但无法得出想要结果的错误程序):
#include<stdio.h>
#include<string.h>
#include<ctype.h>
void my_sort(char input[],char output[])
{
char input[50];
char output[50];
scanf("%s",input);
my_sort(input,output);
printf("%s\n",input);
printf("%s\n",output);
}
但是,虽然这个程序可以运行,却得不到我想要的结果。于是,经过查找我发现了问题所在为n的数值,所以我将之改成(最终成功的程序):、
#include<string.h>
#include<ctype.h>
void my_sort(char input[],char output[])
{
int i,n,m,k,j;
c语言字符串排序。(利用字符串函数)

文章内容:c语言字符串排序(利用字符串函数)随着计算机科学的发展和应用,C语言作为一种功能丰富、灵活性强的程序设计语言,一直以来都备受程序员的喜爱。
在C语言中,对字符串的排序是一个基本且常见的操作。
本文将从简到繁,由浅入深地讨论如何利用C语言中的字符串函数进行字符串排序,以便读者能更加深入地理解这一过程。
1. 字符串排序的基本概念在进行字符串排序时,我们需要首先理解什么是字符串。
字符串是由一系列字符组成的,而字符又是按照ASCII码或Unicode编码进行排序的。
当我们排序字符串时,实际上是对字符串中的字符进行排序。
C 语言中,我们可以利用字符串函数来实现这一操作。
2. 利用C语言字符串函数进行排序在C语言中,有许多内置的字符串函数可以帮助我们对字符串进行排序。
其中比较常用的包括strlen()、strcpy()和strcmp()等函数。
通过这些函数,我们可以轻松地对字符串进行长度、拷贝和比较操作。
下面,让我们逐一介绍如何利用这些函数进行字符串排序。
2.1 使用strlen()函数获取字符串长度我们可以利用strlen()函数获取字符串的长度。
这样,我们就可以知道每个字符串的长度,从而为后续的排序操作做好准备。
我们可以编写如下代码来获取字符串的长度:```cint len = strlen(str);```其中,str为待排序的字符串。
2.2 使用strcpy()函数进行字符串拷贝我们可以利用strcpy()函数实现字符串的拷贝。
这样,我们就可以在排序过程中保留原始数据,以便在排序结束后进行对比。
下面是一个使用strcpy()函数的示例:```cchar temp[100];strcpy(temp, str[i]);```其中,temp为用于存储拷贝后字符串的数组,str[i]为待排序的字符串。
2.3 使用strcmp()函数进行字符串比较我们可以利用strcmp()函数对字符串进行比较。
这样,我们就可以按照一定的规则将字符串进行排序。
string排序方法

string排序方法
字符串排序是对一组字符串按照一定的顺序进行排列的过程。
在计算机编程中,常见的字符串排序方法有以下几种:
1. 字典序排序,字典序排序是最常见的字符串排序方法,也称
为按照ASCII码值排序。
按照字母表顺序对字符串进行排序,比较
字符串中每个字符的ASCII码值来确定顺序。
在大多数编程语言中,可以使用内置的排序函数或方法来实现字典序排序。
2. 长度排序,有时候需要按照字符串的长度进行排序,可以先
计算字符串的长度,然后按照长度进行排序。
可以使用自定义的比
较函数来实现长度排序。
3. 自定义排序,除了以上两种方法,还可以根据特定的需求自
定义排序方法。
例如,可以根据字符串中某个字符出现的次数、特
定的子串等进行排序。
在实际编程中,可以根据具体的需求选择合适的排序方法。
在
使用内置的排序函数或方法时,需要注意不同编程语言的实现方式
和函数调用方法。
另外,对于较大规模的字符串排序,还需要考虑
排序算法的效率和性能。
总之,字符串排序是编程中常见的操作,根据具体情况选择合适的排序方法可以提高程序的效率和性能。
希望以上信息能够帮助你更好地理解字符串排序方法。
字符串算法—字符串排序(下篇)

字符串算法—字符串排序(下篇) 本⽂将介绍3区基数快速排序、后缀排序法。
1. 前⽂回顾 在中,我们介绍了键索引计数法、LSD基数排序、MSD基数排序。
但LSD基数排序要求需排序字符串的长度⼀致;MSD基数排序虽然对字符串的长度没要求,但其递归循环⾥的每次循环都需要进⾏很多操作,且需要额外的空间。
本⽂将介绍⼀种更⾼效的字符串排序⽅法:结合MSD基数排序和。
如果对这两种算法不熟悉的,建议先去了解⼀下。
2. 3区基数快速排序(3-way radix quicksort) 从例⼦⼊⼿:与MSD基数排序⼀样,我们设定每个字符串的最后⼀位字符的下⼀个位置的空字符的键索为-1。
a[]是拥有⼀堆字符串的字符串数组。
与MSD基数排序⼀样,每个字符配⼀个正数键索,⽤于⽐较字符间的⼤⼩。
⾸先,对a[0](she)的第⼀个字符(s)进⾏3区快速排序: 3区快速排序会把整个数组分为3个区: 第⼀个区⾥的所有字符串的第⼀个字符都⽐(she)的第⼀个字符(s)⼩,它含有a[0]、a[1]; 第⼆个区⾥的所有字符串的第⼀个字符都与(she)的第⼀个字符(s)相同,它含有a[2]~a[11]; 第三个区⾥的所有字符串的第⼀个字符都⽐(she)的第⼀个字符(s)⼤,它含有a[12]、a[13]。
然后从上往下的,先看第⼀个区,此区含有多个字符串,对此区的第⼀个字符串(by)的第⼀个字符(b)进⾏3区快速排序:(为了⽅便观察,待排序的字符串⽤⿊⾊表⽰) 3区快速排序会把整个区分为3个区: 第⼀个区⾥的所有字符串的第⼀个字符都⽐(by)的第⼀个字符(b)⼩,它含有a[0]; 第⼆个区⾥的所有字符串的第⼀个字符都与(by)的第⼀个字符(b)相同,它含有a[1]; 第三个区⾥的所有字符串的第⼀个字符都⽐(by)的第⼀个字符(b)⼤,它没有元素; 看第⼆个区,它只有⼀个字符串,此区排序完毕; 看第三个区,它没有字符串,此区排序完毕; (为了⽅便观察,已排序完毕的字符串⽤绿⾊表⽰) 然后看下⼀个区,此区含有多个字符串,对此区的第⼀个字符串(seashells)的第⼆个字符(e)进⾏3区快速排序: 3区快速排序会把整个区分为3个区: 第⼀个区⾥的所有字符串的第⼆个字符都⽐(seashells)的第⼆个字符(e)⼩,它没有元素; 第⼆个区⾥的所有字符串的第⼆个字符都与(seashells)的第⼆个字符(e)相同,它含有a[2]~a[6]; 第三个区⾥的所有字符串的第⼆个字符都⽐(seashells)的第⼆个字符(e)⼤,它含有a[7]~a[11]; 看第⼆个区,它有多个字符串,对此区的第⼀个字符串(seashells)的第三个字符(a)进⾏3区快速排序: 3区快速排序会把整个区分为3个区: 第⼀个区⾥的所有字符串的第三个字符都⽐(seashells)的第三个字符(a)⼩,它没有元素; 第⼆个区⾥的所有字符串的第三个字符都与(seashells)的第三个字符(a)相同,它含有a[2]~a[4]; 第三个区⾥的所有字符串的第三个字符都⽐(seashells)的第三个字符(a)⼤,它含有a[5]~a[6]; 然后从上往下的,先看第⼀个区,它没有字符串,此区排序完毕; 看第⼆个区,它有多个字符串,对此区的第⼀个字符串(seashells)的第四个字符(s)进⾏3区快速排序: 3区快速排序会把整个区分为3个区: 第⼀个区⾥的所有字符串的第四个字符都⽐(seashells)的第四个字符(s)⼩,它含有a[2]; 第⼆个区⾥的所有字符串的第四个字符都与(seashells)的第四个字符(s)相同,它含有a[3]~a[4]; 第三个区⾥的所有字符串的第四个字符都⽐(seashells)的第四个字符(s)⼤,它没有元素; 然后从上往下的,先看第⼀个区,它只有⼀个字符串,此区排序完毕; 看第⼆个区,它有多个字符串,对此区的第⼀个字符串(seashells)的第五个字符(h)进⾏3区快速排序: 3区快速排序会把整个区分为3个区: 第⼀个区⾥的所有字符串的第五个字符都⽐(seashells)的第五个字符(h)⼩,它没有元素; 第⼆个区⾥的所有字符串的第五个字符都与(seashells)的第五个字符(h)相同,它含有a[3]~a[4]; 第三个区⾥的所有字符串的第五个字符都⽐(seashells)的第五个字符(h)⼤,它没有元素; 然后从上往下的,先看第⼀个区,它没有字符串,此区排序完毕; 看第⼆个区,它有多个字符串,对此区的第⼀个字符串(seashells)的第六、七、⼋、九、⼗个字符(h)进⾏3区快速排序:(由于这两个字符串是⼀样的,排序结果不变,这⾥省略中间过程,直接到第⼗个字符的排序) 3区快速排序会把整个区分为3个区: 第⼀个区⾥的所有字符串的第五个字符都⽐(seashells)的第五个字符(h)⼩,它没有元素; 第⼆个区⾥的所有字符串的第五个字符都与(seashells)的第五个字符(h)相同,它含有a[3]~a[4]; 第三个区⾥的所有字符串的第五个字符都⽐(seashells)的第五个字符(h)⼤,它没有元素; 然后从上往下的,先看第⼀个区,它没有字符串,此区排序完毕; 看第⼆个区,它有多个字符串,但此区的第⼀个字符串(seashells)没有第⼗⼀个字符,故此区排序结束; 看第三个区,它没有字符串,此区排序完毕; 看下⼀个区,它有多个字符串,对此区的第⼀个字符串(sells)的第四个字符(l)进⾏3区快速排序: 3区快速排序会把整个区分为3个区: 第⼀个区⾥的所有字符串的第四个字符都⽐(sells)的第四个字符(l)⼩,它没有元素; 第⼆个区⾥的所有字符串的第四个字符都与(sells)的第四个字符(hl)相同,它含有a[5]~a[6]; 第三个区⾥的所有字符串的第四个字符都⽐(sells)的第四个字符(l)⼤,它没有元素; 然后从上往下的,先看第⼀个区,它没有字符串,此区排序完毕; 看第⼆个区,它有多个字符串,对此区的第⼀个字符串(sells)的第五、六个字符(h)进⾏3区快速排序:(由于这两个字符串是⼀样的,排序结果不变,这⾥省略中间过程,直接到第六个字符的排序) 3区快速排序会把整个区分为3个区: 第⼀个区⾥的所有字符串的第六个字符都⽐(sells)的第六个字符⼩,它没有元素; 第⼆个区⾥的所有字符串的第六个字符都与(sells)的第六个字符相同,它含有a[5]~a[6]; 第三个区⾥的所有字符串的第六个字符都⽐(sells)的第六个字符⼤,它没有元素; 然后从上往下的,先看第⼀个区,它没有字符串,此区排序完毕; 看第⼆个区,它有多个字符串,但此区的第⼀个字符串(sells)没有第七个字符,故此区排序结束; 看第三个区,它没有字符串,此区排序完毕; 看下⼀个区,它有多个字符串,对此区的第⼀个字符串(shells)的第三个字符(e)进⾏3区快速排序: 如此类推,直到所有区排序完毕。
字符串从小到大排序算法

字符串从小到大排序算法
有很多种方法可以将字符串从小到大进行排序,以下是几种常见的排序算法:
1. 冒泡排序(Bubble Sort):通过反复交换相邻的两个元素,
每一轮将最大的元素沉到最后面,直到所有元素都有序。
时间复杂度为 O(n^2)。
2. 选择排序(Selection Sort):每一轮选择未排序部分的最小
元素,将其依次放在已排序部分的末尾,直到所有元素都有序。
时间复杂度为 O(n^2)。
3. 插入排序(Insertion Sort):每次将一个未排序元素插入到
已排序的合适位置上,直到所有元素都有序。
时间复杂度为
O(n^2)。
4. 快速排序(Quick Sort):通过一趟排序将待排序序列分割
成独立的两部分,其中一部分的所有元素都比另一部分的所有元素小,然后再递归地对这两部分进行排序。
时间复杂度为
O(nlogn)。
5. 归并排序(Merge Sort):将待排序序列不断二分,直到每
个子序列只有一个元素,然后将相邻的子序列合并在一起,最终得到有序序列。
时间复杂度为 O(nlogn)。
根据具体的需求和数据规模,选择合适的排序算法。
c语言字符串中字符排序代码

c语言字符串中字符排序代码1.引言【1.1 概述】字符串是程序设计中常见且重要的数据类型之一,而字符串的排序又是字符串处理中的常见问题之一。
在C语言中,字符串是以字符数组的形式表示的,每个字符都有对应的ASCII码值,这使得我们能够通过比较字符的ASCII码大小来进行字符串的排序操作。
本文旨在介绍C语言中对字符串中字符进行排序的代码实现。
通过学习和理解该部分代码,读者将能够掌握基本的字符串排序算法,并在实际编程中灵活应用。
在接下来的内容中,我们将首先介绍字符串排序的重要性,为何在实际开发中需要对字符串中的字符进行排序。
然后,我们将深入讨论C语言中字符串的表示方式,以及如何利用字符数组和字符指针进行字符串排序。
通过这些内容的学习,读者将能够对C语言中字符串排序的相关概念和技巧有一定的了解和认识。
最后,在结论部分,我们将对本文内容进行简要的总结,并对C语言字符串排序的思考进行一些探讨。
通过阅读本文,读者将能够对C语言字符串排序有更深入的理解,并能够应用于自己的实际开发中,提高程序的效率和可读性。
接下来,我们将介绍字符串排序的重要性,为了更好地理解字符串排序的意义和价值。
1.2文章结构文章结构部分应该详细介绍本篇长文的整体结构,包括各个章节的标题和内容概述。
下面是一个可能的编写示例:"1.2 文章结构"本篇长文主要分为三个部分:引言、正文和结论。
在引言部分,首先给出了整篇文章的概述,包括对C语言字符串中字符排序代码的介绍和重要性的说明。
接着,明确了文章的目的,即通过介绍C语言字符串排序的重要性,并提供代码实现,使读者能够更好地理解和应用这一知识。
正文部分主要分为两个小节。
第一个小节探讨了字符串排序的重要性,强调了字符串在编程中的重要性以及为何需要对字符串进行排序。
通过具体的例子和应用场景,展示了字符串排序对于提高程序效率和功能实现的重要作用。
第二个小节重点介绍了C语言中字符串的表示方法。
汇编课程设计报告字符排序

汇编课程设计报告字符排序一、课程目标知识目标:1. 让学生掌握字符排序的基本概念,理解其在汇编语言编程中的应用;2. 使学生学会使用汇编语言编写简单的字符排序程序;3. 引导学生了解字符排序算法的优化方法。
技能目标:1. 培养学生运用汇编语言进行字符排序编程的能力;2. 培养学生分析、解决字符排序问题的逻辑思维能力;3. 提高学生运用所学知识解决实际问题的能力。
情感态度价值观目标:1. 培养学生对汇编语言的兴趣,激发学生学习编程的热情;2. 培养学生团队合作精神,学会共同探讨、分析问题;3. 增强学生的自信心,让学生体会到编程带来的成就感。
课程性质:本课程为信息技术学科,针对有一定汇编语言基础的学生,以实践操作为主,理论讲解为辅。
学生特点:学生具备一定的汇编语言知识,对编程有一定兴趣,但可能缺乏实际编程经验。
教学要求:结合学生特点,注重实践操作,引导学生通过动手实践掌握字符排序编程方法,并在实践中提高编程能力。
同时,关注学生的情感态度,激发学生的学习兴趣,培养团队合作精神。
在教学过程中,将课程目标分解为具体的学习成果,以便进行有效的教学设计和评估。
二、教学内容1. 理论知识:- 汇编语言字符排序的基本概念;- 字符排序算法的原理和分类;- 汇编语言中的字符串处理指令。
2. 实践操作:- 编写简单的字符排序程序;- 分析字符排序算法的性能和优化;- 实际案例:对一串字符进行排序并输出结果。
3. 教学大纲:- 第一阶段:汇编语言字符排序基本概念和算法原理学习;- 第二阶段:字符串处理指令的掌握及简单排序程序的编写;- 第三阶段:分析优化字符排序算法,提高程序性能;- 第四阶段:综合运用所学知识,完成实际案例。
4. 教学内容安排与进度:- 理论知识:共计4课时,每课时讲解一个知识点;- 实践操作:共计4课时,每课时完成一个阶段的实践任务;- 案例分析与讨论:共计2课时,对案例进行讨论、分析、优化。
5. 教材章节关联:- 本教学内容与教材中关于汇编语言字符串处理和排序算法的章节相关;- 教材中的相关案例和练习题可用于辅助教学,巩固所学知识。
字符串按规则排序算法

字符串按规则排序算法/blog/1723707写这个东西源自于公司组织的一次编程道场,最后的总结就是,尽量使用既有的库,将问题转化为既有库算法能解决的问题,可读性第一,效率第二。
老大们说的话总是让人觉得醍醐灌顶,不要自己实现一个功能为了去榨取那么一点点性能,最终还不一定能榨出来!不知道有没有什么特别的原因,最后几位老大展示出的代码竟然一模一样,虽然语言不同,那就像直接的翻译一般,难道编程有其道,而老大们均掌握了“道”?我也想出了那种“标准的做法”,只是我根本不会用什么库,也根本不了解库,虽然有了伪代码,然而在将其转化为C代码的时候,遇到了无法突破的障碍,因为我根本不知道map或者vector之类的,更别提STL了,我除了知道点C++的一点语法之外,其它的什么都不知道…有时候,我认为我根本不是一个程序员,而是一个网管。
我没有什么技巧可炫,也没有库使用的知识可以利用,只好从零开始用标准C来实现了,虽然效率不一定很高,可读性方面也可能只有我自己能看懂,然而不管怎么说,实现了,而且所有的时间复杂度是可控的,因为整个代码没有掉进任何的库实现的算法黑洞,比如如果你不知道你所使用的sort是怎么实现的,那么它的时间复杂度就是不可控的。
问题是这样的:按照下列规则排序字符串数组1.F一定出现在最前面;2.L一定出现在最后面;3.B一定要在A前面;4.所有相同的字符串必须放在一起。
实际上再抽象一点就是,输入字符串是无序的,但是要确保输出是有序的。
正常的思路就是将字符串的规则键转化为一个数字,然后进行数字排序,然而要处理字符串和索引的关系,这个如果不使用库里面的ADT还真麻烦,于是换一种思路,在扫描字符串的过程中就将其各归其位,各归其位的含义就是根据规则的优先级顺序找到自己的位置,那么二叉树是一个理想的选择。
现在最关键的就是写一个getprio函数以及一个compare函数,而这个是很好办的。
getprio函数的逻辑决定了最终的排序结果,这个函数可以做的很复杂,也可以很简单,比如为了能实现不感兴趣的字符串按照自然顺序输出,并且相同的排在一起这样的需求,可以为getprio函数保存一个容器,保存所有已经匹配到的不感兴趣的字符串的prio值。
c语言字符串排序。(利用字符串函数)

c语言字符串排序。
(利用字符串函数)(最新版)目录1.介绍 C 语言字符串排序的背景和需求2.详述如何使用字符串函数进行排序3.举例说明字符串排序的具体操作4.总结 C 语言字符串排序的优点和不足正文C 语言字符串排序是一种常见的数据处理方式,对于处理大量的文本数据具有重要意义。
在 C 语言中,我们可以通过字符串函数来实现字符串的排序,从而更好地管理和分析数据。
下面,我们将详细介绍如何利用字符串函数进行排序,并举例说明其具体操作。
首先,我们需要了解字符串函数。
在 C 语言中,常用的字符串函数有 strcpy、strcat、strlen 等。
通过这些函数,我们可以实现字符串的复制、连接和长度计算等功能。
而在字符串排序中,我们主要需要用到strcmp 函数,该函数可以比较两个字符串的大小。
strcmp 函数的用法如下:```c#include <string.h>int strcmp(const char *str1, const char *str2);```该函数比较两个字符串 str1 和 str2,返回值如下:- 如果 str1 < str2,则返回一个负数;- 如果 str1 > str2,则返回一个正数;- 如果 str1 == str2,则返回 0。
有了 strcmp 函数,我们就可以实现字符串排序了。
以下是一个简单的例子:```c#include <stdio.h>#include <string.h>int main() {char str1[] = "C 语言";char str2[] = "排序";char str3[] = "教程";// 使用 strcmp 函数进行排序if (strcmp(str1, str2) < 0) {strcpy(str1, str2);strcpy(str2, str1);}if (strcmp(str2, str3) < 0) {strcpy(str2, str3);strcpy(str3, str2);}printf("排序后的字符串:");printf("str1: %s", str1);printf("str2: %s", str2);printf("str3: %s", str3);return 0;}```在这个例子中,我们首先定义了三个字符串 str1、str2 和 str3。
汇编 字符插入字符串排序与删除

1.输入一个字符串2.字符串中的字符排序3.想字符串中插入一个字符4.删除字符串中给定位置处的字符5.删除字符串中的一个字符由于时间有限,本程序未完全调试,功能基本实现,单人存在一定缺陷源程序:DATAS SEGMENTstring DB 170 ;定义一个字符串用于字符串的输入存储,串第一个字节为串的最大长度DB?;第二个字节为串的实际长度DB 170 DUP('$')strtmp DB 170 ;辅助字符串string的操作DB?DB 170 DUP('$')menu DB0AH, 0DH, '-----------------------------------------' DB0AH, 0DH, 'Please choice action:', 0AH, 0DHDB0AH, 0DH, '1.Input a string'DB0AH, 0DH, '2.Sort the string'DB0AH, 0DH, '3.Input a char and inset to the string'DB0AH, 0DH, '4.Delete a char which the place geiven'DB0AH, 0DH, '5.Delete a char in the string'DB0AH, 0DH, '6.Exit'DB0AH, 0DH, '-----------------------------------------', 0AH, 0DH,'$'STR1 DB0AH, 0DH, 'Please input a string, Enter to confirm', 0AH,0DH,'$'STR31 DB0AH, 0DH, 'Please input a char', 0AH, 0DH, '$'STR32 DB0AH, 0DH, 'Please input the postion', 0AH, 0DH, '$'STR4 DB0AH, 0DH, 'Please input the char postion', 0AH, 0DH, '$' STR5 DB0AH, 0DH, 'Please the char', 0AH, 0DH, '$'tip DB0AH, 0DH, 'The string present is:', 0AH, 0DH, '$'DATAS ENDSCODES SEGMENTASSUME CS: CODES, DS: DATAS;宏定义字符输入charin MACRO ;宏定义无参数的字符输入功能MOV AH, 01H ;系统调用输入一个字符用于功能选择INT 21H ;字符默认输入到AL中ENDM;宏定义字符串输入strin MACRO STRINGIN ;将字符串输入到字符串STRINGIN中LEA DX, STRINGIN ;将STRINGIN的偏移地址送到DX寄存器MOV AH, 0AH ;0AH字符串输入功能INT 21H ;调用系统中断ENDM;宏定义字符串输出strout MACRO STRINGOUT ;将字符串STRINGOUT输出LEA DX, STRINGOUT ;将STRIN的偏移地址送到DX寄存器MOV AH, 9 ;09H字符串输出功能INT 21H ;调用系统中断ENDM;宏定义换行endl MACRO ;宏定义换行MOV DL, 0AH ;先输出垂直Tab键MOV AH, 2INT 21H ;调用系统中断实现输出MOV DL, 0DH ;再将输出输出调至段首INT 21H ;调用系统中断ENDMSTART:MOV AX, DATAS ;将数据段地址送到AX中MOV DS, AX ;由AX转送到送到DSP0: strout menu ;字符串输出宏调用输出menu的提示菜单charin ;宏调用字符输入选择相应功能CMP AL, '1'JE P1CMP AL, '2'JE P2CMP AL, '3'JE P3CMP AL, '4'JE P4CMP AL, '5'JE P5CMP AL, '6'JE P6JMP P0P1: strout STR1strin stringendlstrout tipstrout string+2 ;输出字符串stringJMP P0P2: MOV BX, 1 ;以BX指向前面的字符并逐位后移,相当于第一个for循环P2S: INC BXMOV SI, BXP2B: INC SI ;以SI指向后面的字符,相当于内部for循环MOV AL, string[BX]CMP AL, '$'JE P2E ;当BX指向字符串结束符'$'时,结束排序MOV AH, string[SI]CMP AH, '$'JE P2S ;当SI指向字符串结束符时BX后移,SI指向BXCMP AL, AH ;BX和SI均均未到达结束符时,当string[BX] > string[SI]时JA switch ;将两字符交换JMP P2B ;否则跳转switch: MOV string[BX], AH ;交换字符string[BX]和string[SI]MOV string[SI], ALJMP P2BP2E: endlstrout tipstrout string+2JMP P0P3: strout STR31charin ;输入要插入的字符MOV CH, AL ;将输入的字符保存到CH中strout STR32charin ;输入要插入的位置SUB AL, 30H ;将输入的字符转化成数值INC AL ;转化成字符要插入位置的下标MOV BX, 1MOV SI, 1P3B: INC BXINC SICMP BL, AL ;当字符下标到达AL时,将字符AH插入字符串strtmp中JE insetP3CL: MOV CL, string[BX] ;将字符读取到CL中CMP CL, '$'JE P3Copy ;当读到字符的结束符时,将字符串从strtmp中复制回字符串string中MOV strtmp[SI], CL ;为读到结束符时,将字符复制到strtmp 中JMP P3Binset: MOV strtmp[SI], CH ;将字符CH插入字符串strtmp中INC SI ;指针位置后移JMP P3CL ;跳转进行下一个字符的复制P3Copy: MOV BX, 1P3C: MOV CL, strtmp[BX] ;将字符读取到CL中CMP CL, '$'JE P3E ;当读到结束符时跳转MOV string[BX], CL ;将字符写回到string中INC BX ;否则指向下一个字符继续进行下一个字符的复制JMP P3CP3E: endlstrout tipstrout string+2JMP P0P4: strout STR4charin ;输入要删除的字符位置SUB AL, 30H ;将输入的字符转化成数值INC AL ;转化成字符要删除位置的下标MOV BX, 1MOV SI, 1P4B: INC BXINC SICMP BL, AL ;当字符下标到达AL时,跳过该字符的复制JE skipP4CL: MOV CL, string[BX] ;将字符读取到CL中CMP CL, '$'JE P4Copy ;当读到字符的结束符时,将字符串从strtmp中复制回字符串string中MOV strtmp[SI], CL ;为读到结束符时,将字符复制到strtmp 中JMP P4Bskip: INC BX ;指针位置后移JMP P4CL ;跳转进行下一个字符的复制P4Copy: MOV BX, 1P4C: MOV CL, strtmp[BX] ;将字符读取到CL中CMP CL, '$'JE P4E ;当读到结束符时跳转MOV string[BX], CL ;将字符写回到string中INC BX ;否则指向下一个字符继续进行下一个字符的复制JMP P4CP4E: INC BXMOV string[BX], '$';为字符串string加上结尾符endlstrout tipstrout string+2JMP P0P5: strout STR5charin ;输入要删除的字符MOV BX, 1MOV SI, 1P5B: INC BXINC SIP5CL: MOV CL, string[BX] ;将字符读取到CL中CMP CL, '$'JE P5Copy ;当读到字符的结束符时,将字符串从strtmp中复制回字符串string中CMP CL, AL ;当读到字符CL时,跳过该字符的复制JE skip2MOV strtmp[SI], CL ;未读到结束符且未读到字符CL时,将字符复制到strtmp中JMP P5Bskip2: INC BX ;指针位置后移JMP P5CL ;跳转进行下一个字符的复制P5Copy: MOV BX, 1P5C: MOV CL, strtmp[BX] ;将字符读取到CL中CMP CL, '$'JE P5E ;当读到结束符时跳转MOV string[BX], CL ;将字符写回到string中INC BX ;否则指向下一个字符继续进行下一个字符的复制JMP P5CP5E: INC BXMOV string[BX], '$';为字符串string加上结尾符endlstrout tipstrout string+2JMP P0P6: MOV AH, 4CH ;调用系统结束INT 21HCODES ENDSEND START。
字符串的全排列(字典序排列)

字符串的全排列(字典序排列)题⽬描述输⼊⼀个字符串,打印出该字符串中字符的所有排列。
例如输⼊字符串abc,则输出由字符a、b、c 所能排列出来的所有字符串abc, acb, bac, bca, cab, cba。
题⽬分析穷举与递归⼜是⼀个经典问题,最容易想到的解决⽅法仍然是穷举(我实在是太爱穷举法了,每当被问到算法问题不知道如何解决的时候,总可以祭出穷举⼤旗,从⽽多争取3分钟的思考时间)。
穷举虽好,但它⼤多数情况下都不是被需要的那个答案,是因为看起来代码太Low不够⾼⼤上吗?在这种情况下,穷举法裹着貂⽪⼤⾐的亲戚——递归就出现了。
虽然空间复杂度和时间复杂度没有任何改进,⽽且还增加了系统开销(关于递归法的系统开销不在这⾥讨论,之后再找专门的时间阐述),但是就是因为长得好看(代码看起来精炼),递归的B格⼉就⾼了很多。
递归法对于这个题⽬同样⾮常适⽤,基本思路就是固定⼀个字符,然后对剩余的字符做全排列……不赘述,请⾃⼰想。
如果你也跟我⼀样永远想不明⽩递归,那就画画图,写写代码,debug⼀下,每天花3-4个⼩时,静下⼼来仔细捉摸,总(ye)会(bu)想(hui)明⽩的。
贴⼀段July和他伙伴们在《程序员编程艺术:⾯试和算法⼼得》中的代码实现,供做噩梦时使⽤。
p.s. 我已加了注释/** Permute full array of input string by general recusion* @ char* perm [in/out] The string need to do permutation* @ int from [in] The start position of the string* @ int to [in] The end position of the string*/void CalcAllPermutation(char* perm, int from, int to){if (to <= 1){return;}if (from == to){//all characters has been permutedfor (int i = 0; i <= to; i++)cout << perm[i];cout << endl;}else{// always select one character, then full array the left ones.for (int j = from; j <= to; j++){swap(perm[j], perm[from]); //swap the selected character to the beginning of stringCalcAllPermutation(perm, from + 1, to); // Permute left characters in full array.swap(perm[j], perm[from]); //recovery the string to original one (swap the selected character back to its position.)}}}字典序这是⼀个⽐递归更有趣的答案,不知道算不算经典解法,起码开拓了思路,跟每⼀次接触新鲜的算法⼀样,仍然想了半天的时间,因此照例把思考过程更细致的记录下来(虽然July和他伙伴们在《程序员编程艺术:⾯试和算法⼼得》中已经说了很多),再加上⼀些⼩修改。
字符串的排列

字符串的排列⼀、字符串的排列⽤C++写⼀个函数, 如 Foo(const char *str), 打印出 str 的全排列, 如 abc 的全排列: abc, acb, bca, dac, cab, cba⼀、全排列的递归实现为⽅便起见,⽤123来⽰例下。
123的全排列有123、132、213、231、312、321这六种。
⾸先考虑213和321这⼆个数是如何得出的。
显然这⼆个都是123中的1与后⾯两数交换得到的。
然后可以将123的第⼆个数和每三个数交换得到132。
同理可以根据213和321来得231和312。
因此可以知道——全排列就是从第⼀个数字起每个数分别与它后⾯的数字交换。
找到这个规律后,递归的代码就很容易写出来了:#include<iostream>#include<cstring>#include<assert.h>using namespace std;void foo(char *str,char *begin){assert(str&&begin);if(*begin=='\0'){cout<<str<<endl;}else{for(char *pch=begin;*pch!='\0';pch++){swap(*pch,*begin);foo(str,begin+1);swap(*pch,*begin);}}}int main(){char str[]="abc";foo(str,str);return0;}⼆、去掉重复的全排列的递归实现由于全排列就是从第⼀个数字起每个数分别与它后⾯的数字交换。
我们先尝试加个这样的判断——如果⼀个数与后⾯的数字相同那么这⼆个数就不交换了。
如122,第⼀个数与后⾯交换得212、221。
然后122中第⼆数就不⽤与第三个数交换了,但对212,它第⼆个数与第三个数是不相同的,交换之后得到221。
微机原理实验报告——字符串排序
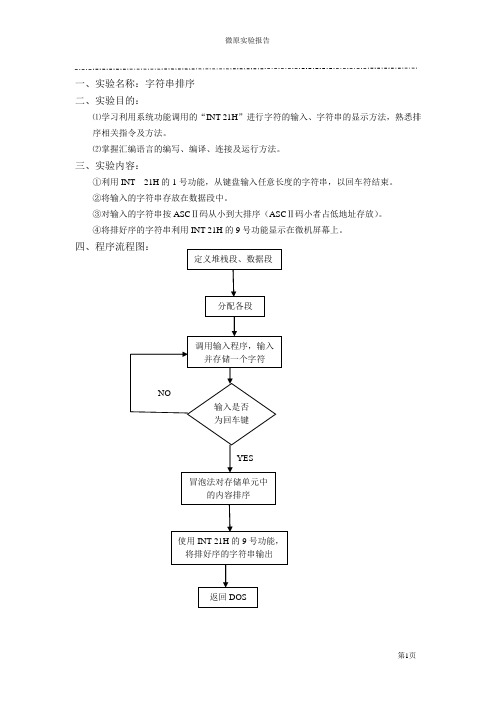
一、实验名称:字符串排序二、实验目的:⑴学习利用系统功能调用的“INT 21H”进行字符的输入、字符串的显示方法,熟悉排序相关指令及方法。
⑵掌握汇编语言的编写、编译、连接及运行方法。
三、实验内容:①利用INT 21H的1号功能,从键盘输入任意长度的字符串,以回车符结束。
②将输入的字符串存放在数据段中。
③对输入的字符串按ASCⅡ码从小到大排序(ASCⅡ码小者占低地址存放)。
④将排好序的字符串利用INT 21H的9号功能显示在微机屏幕上。
四、程序流程图:定义堆栈段、数据段分配各段调用输入程序,输入并存储一个字符NO输入是否为回车键YES冒泡法对存储单元中的内容排序使用INT 21H的9号功能,将排好序的字符串输出返回DOS五、结论:程序运行时,从键盘上输入包含数字、大、小写字母的字符串,回车后,屏幕上显示字符ASCⅡ码从小到大排列的结果。
六、实验心得:通过实验,首先,我进一步理解学习了冒泡法排序的具体过程:冒泡法的外层循环次数等于其排序总数减一,每层内循环次数等于外循环总数减去已执行的次数。
第二,在编写程序时,如若程序太长,最好将一段反复使用的程序段编成子程序,在主程序中反复调用即可。
第三,在使用INT 21H的各种功能时,要注意将功能号值付给AH,并需正确使用入口、出口参数。
最后,堆栈段、数据段使用时要特别注意,堆栈段必须重新定义,程序中使用数据段时也要对数据段进行重新定义,否则程序将产生错误。
附:程序清单STACK SEGMENT STACKDB 100 DUP(?)STACK ENDSDA TA SEGMENTX DB 100 DUP(?)DA TA ENDSCODE SEGMENTASSUME CS:CODE,DS:DA TA,SS:STACKMAIN PROCMOV AX,DATAMOV DS,AXMOV SI,OFFSET XCALL INPUTSUB SI,2MOV BX,SINEXT3:MOV CX,BXMOV SI,OFFSET XNEXT2:MOV AL,[SI]CMP AL,[SI+1]JBE NEXT1XCHG AL,[SI+1]MOV [SI],ALNEXT1:INC SILOOP NEXT2DEC BXJNZ NEXT3MOV DX,OFFSET XMOV AH,9INT 21HMOV AH,4CHINT 21HMAIN ENDPINPUT PROCSTART:MOV AH,1INT 21HMOV [SI],ALINC SICMP AL,0DHJNZ STARTMOV BYTE PTR [SI-1],'$'RETINPUT ENDPCODE ENDSEND MAIN。
字符串的排列

字符串的排列题⽬描述输⼊⼀个字符串,按字典序打印出该字符串中字符的所有排列。
例如输⼊字符串abc,则打印出由字符a,b,c所能排列出来的所有字符串abc,acb,bac,bca,cab和cba。
输⼊描述:输⼊⼀个字符串,长度不超过9(可能有字符重复),字符只包括⼤⼩写字母。
解题思路:以ABC字符串为例,我们⾸先固定位置0,交换A与A,A与B,A与C,然后对于交换后的字符串dfs,固定位置1,交换位置1与位置1+1、交换位置1与位置1+2 ... 同时使⽤set集合过滤重复的字符串,最后将vector中字符串进⾏排序。
class Solution {public:set<string> filter;vector<string>res;void mydfs(string str, int idx){if(idx == str.size()){return;}for(int i = idx; i < str.length(); i++){string nstr = myswap(str, idx, i);if(filter.find(nstr) == filter.end()){res.push_back(nstr);filter.insert(nstr);}mydfs(nstr, idx+1);}}vector<string> Permutation(string str) {mydfs(str, 0);sort(res.begin(), res.end());return res;}string myswap(string str, int idx1, int idx2){string newstr = str;swap(newstr[idx1], newstr[idx2]);return newstr;}};。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计算机原理实验室实验报告
课程名称:计算机语言与汇编原理
姓名学号班级成绩
设备名称及软件环境
实验名称汇编语言实现字符串排序(冒泡排序)实验日期
一.实验内容
利用汇编语言实现字符串排序,输出,查找等功能
二.理论分析或算法分析
在汇编语言中,需要调用外部模块(子程来/函数)来完成部分功能,调用printf函数将字符串显示在屏幕上。
printf函数属于C语言的库函数。
它的执行代码放在一个动态链接库(dynamic load library,DLL)中,这个动态库的名字叫msvcrt.dll。
一个DLL文件对应一个导入库,如msvcrt.dll的导入库是msvcrt.lib;kernel32.dll的导入库是kernel32.lib;user32.dll的导入库是user32.lib等。
导入库文件在Visual C++的库文件目录中,在链接生成可执行文件时使用。
可执行文件执行时,只需要DLL文件,不需要导入库。
printf PROTO C :dword,:vararg
在汇编语言中,可以调用printf 函数。
在程序中要指明printf的调用规则以及它的参数类型:
Printf PROTO: dword,:vararg
printf使用C调用规则(参数自右至左入栈,由主程序平衡堆栈)。
第1个参数是一个双字(:dword),即字符串的地址。
vararg表示后面的其他参数个数可变,可以一个没有,也可以跟多个参数
三.实现方法(含实现思路、程序流程图、实验电路图和源程序列表等)
做一个缓冲区,串口接收数据往缓冲区里写!在串口接收完(可以是判断字符串长度,或者判断结束标识,如0D 0A就可以用来做判断)后,置标志,主程序查询标志,如果有效,从缓冲区头开始,与指定字符串进行比较,直到找到相应字符串,然后进行个字大小的排序,并最终输出排列的顺序表。
四.实验结果分析(含执行结果验证、输出显示信息、图形、调试过程中所遇的问题及处理方法等)
Start: push cs
pop ds
push cs
pop es ;使数据段、附加段与代码段同段
Input_Str: Output Prompt_Str ;提示输入字符串
lea dx,Buffer ;字符串缓冲区地址
mov ah,0ah
int 21h
lea si,Buffer[1] ;实际输入的字符数地址
cld
lodsb
test al,0ffh
jz Input_Str ;若直接回车,没有输入任何字符,则请重新输入
mov cl,al
xor ch,ch
xor bx,bx ;计数器清零,bh=元音字母计数器,bl=辅音字母计数器
Vowel_conso:lodsb
or al,20h ;转换成小写
cmp al,'a'
jb Next_One ;小于'a',不是字母,不计数
cmp al,'z'
ja Next_One ;大于'z',不是字母,不计数
push cx
lea di,Vowel ;元音字符串地址
mov cx,5 ;元音字母个数
repnz scasb ;扫描当前字母是否是元音字母
jcxz $+6
inc bh ;元音字母计数
jmp short $+4
inc bl ;辅音字母计数
pop cx
Next_One: loop Vowel_conso
Output Vowel_Prom ;提示显示元音字母个数
mov al,bh
xor ah,ah
call Dec_ASCII ;显示元音字母个数
Output Conso_Prom ;提示显示辅音字母个数
mov al,bl
xor ah,ah
call Dec_ASCII ;显示辅音字母个数
mov ah,7 ;不带回显的键盘输入,即等待按键(暂停),结束程序int 21h
Exit_Proc: mov ah,4ch ;结束程序
int 21h
Buffer db 255,0 ;字符串缓冲区
Code ENDS
END Start
实验输出图形
调试过程中出现的问题及其解决方法
1.出现不能识别的字符串输出
2.不能对现现有字符串进行排序
3.原始字符串的书写输出出现混乱
解决方法1.对原有需要比较的字符串检查其输入的完整性,和正确性。
2.检查原有代码,看是否有遗漏输入,防止出现程序的顺序性错误,导致程序不能正常运行。
3.数字符串的过程中在相同条件下进行此输入,或者同类型的字符在同一环境下输入。
五.结论
对原有的排序方式进行改进比如:
假设需用冒泡排序将4、5、7、1、2、3这6个数排序。
在该列中,第三趟排序结束后,数组已排好序,但计算机此时并不知道,因此还需要进行一趟比较。
如果这一趟比较中未发生任何数据交换,则计算机知道已排序好,可以不再进行比较了。
因而第四趟比较需要进行,但第五趟比较则是不必要的。
为此,我们可以考虑程序的优化。
为了标志是否需要继续比较,声明一个布尔量flag,在进行每趟比较前将flag 置true。
如果在比较中发生了数据交换,则将flag置为false,在一趟比较结束后,再判断flag,如果它仍为true(表明在该趟比较中未发生一次数据交换)则结束排序,否则进行下一趟比较。
结论:汇编语言可以对现有输入的字符串进行排序并且正确的输出。
报告提交日期。