USENIX Association Proceedings of the
2001 USENIX Annual

USENIX AssociationProceedings of the2001 USENIX AnnualTechnical ConferenceBoston, Massachusetts, USAJune 25–30, 2001THE ADVANCED COMPUTING SYSTEMS ASSOCIATION© 2001 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649FAX: 1 510 548 5738Email: office@ WWW: Rights to individual papers remain with the author or the author's employer.Permission is granted for noncommercial reproduction of the work for educational or research purposes.This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein.A toolkit for user-levelfile systemsDavid Mazi`e res Department of Computer Science,NYUdm@AbstractThis paper describes a C++toolkit for easily extending the Unixfile system.The toolkit exposes the NFS in-terface,allowing newfile systems to be implemented portably at user level.A number of programs have im-plemented portable,user-levelfile systems.However, they have been plagued by low-performance,deadlock, restrictions onfile system structure,and the need to re-boot after software errors.The toolkit makes it easy to avoid the vast majority of these problems.Moreover,the toolkit also supports user-level access to existingfile sys-tems through the NFS interface—a heretofore rarely em-ployed technique.NFS gives software an asynchronous, low-level interface to thefile system that can greatly ben-efit the performance,security,and scalability of certain applications.The toolkit uses a new asynchronous I/O library that makes it tractable to build large,event-driven programs that never block.1IntroductionMany applications could reap a number of benefits from a richer,more portablefile system interface than that of Unix.This paper describes a toolkit for portably ex-tending the Unixfile system—both facilitating the cre-ation of newfile systems and granting access to existing ones through a more powerful interface.The toolkit ex-ploits both the client and server sides of the ubiquitous Sun Network File System[15].It lets thefile system developer build a newfile system by emulating an NFS server.It also lets application writers replacefile system calls with networking calls,permitting lower-level ma-nipulation offiles and working around such limitations as the maximum number of openfiles and the synchrony of many operations.We used the toolkit to build the SFS distributedfile system[13],and thus refer to it as the SFSfile system development toolkit.SFS is relied upon for daily use by several people,and thus shows by example that one can build production-quality NFS loopback servers.In addition,other users have picked up the toolkit and built functioning Unixfile systems in a matter of a week.We have even used the toolkit for class projects,allowing students to build real,functioning Unixfile systems. Developing new Unixfile systems has long been a dif-ficult task.The internal kernel API forfile systems varies significantly between versions of the operating system, making portability nearly impossible.The locking disci-pline onfile system data structures is hair-raising for the non-expert.Moreover,developing in-kernelfile systems has all the complications of writing kernel code.Bugs can trigger a lengthy crash and reboot cycle,while ker-nel debugging facilities are generally less powerful than those for ordinary user code.At the same time,many applications could benefit from an interface to existingfile systems other than POSIX.For example,non-blocking network I/O per-mits highly efficient software in many situations,but any synchronous disk I/O blocks such software,reducing its throughput.Some operating systems offer asynchronous file I/O through the POSIX aio routines,but aio is only for reading and writingfiles—it doesn’t allowfiles to be opened and created asynchronously,or directories to be read.Another shortcoming of the Unixfile system inter-face is that it foments a class of security holes known as time of check to time of use,or TOCTTOU,bugs[2]. Many conceptually simple tasks are actually quite diffi-cult to implement correctly in privileged software—for instance,removing afile without traversing a symbolic link,or opening afile on condition that it be accessible to a less privileged user.As a result,programmers often leave race conditions that attackers can exploit to gain greater privilege.The next section summarizes related work.Section3 describes the issues involved in building an NFS loop-back server.Section4explains how the SFS toolkit fa-cilitates the construction of loopback servers.Section5 discusses loopback clients.Section6describes applica-tions of the toolkit and discusses performance.Finally, Section7concludes.2Related workA number offile system projects have been implemented as NFS loopback servers.Perhaps thefirst example is the Sun automount daemon[5]—a daemon that mounts re-mote NFSfile systems on-demand when their pathnames are referenced.Neither automount nor a later,more ad-vanced automounter,amd[14],were able to mountfile systems in place to turn a pathname referenced by a user into a mount point on-the-fly.Instead,they took the ap-proach of creating mount points outside of the directory served by the loopback server,and redirectingfile ac-cesses using symbolic links.Thus,for example,amd might be a loopback server for directory/home.When it sees an access to the path/home/am2,it will mount the correspondingfile system somewhere else,say on/a/ amsterdam/u2,then produce a symbolic link,/home/ am2→/a/amsterdam/u2.This symbolic link scheme complicates life for users.For this and other reasons, Solaris and Linux pushed part of the automounter back into the kernel.The SFS toolkit shows they needn’t have done so for mounting in place,one can in fact implement a proper automounter as a loopback server.Another problem with previous loopback automoun-ters is that one unavailable server can impede access to other,functioning servers.In the example from the previ-ous paragraph,suppose the user accesses/home/am2but the corresponding server is unavailable.It may take amd tens of seconds to realize the server is unavailable.Dur-ing this time,amd delays responding to an NFS request forfile am2in/home.While the the lookup is pending, the kernel’s NFS client will lock the/home directory, preventing access to all other names in the directory as well.Loopback servers have been used for purposes other than automounting.CFS[3]is a cryptographicfile sys-tem implemented as an NFS loopback server.Unfortu-nately,CFS suffers from deadlock.It predicates the com-pletion of loopback NFS write calls on writes through the file system interface,which,as discussed later,leads to deadlock.The Alex ftpfile system[7]is implemented using NFS.However Alex is read-only,which avoids any deadlock problems.Numerous otherfile systems are constructed as NFS loopback servers,including the se-manticfile system[9]and the Byzantine fault-tolerant file system[6].The SFS toolkit makes it considerably easier to build such loopback servers than before.It also helps avoid many of the problems previous loop-back servers have had.Finally,it supports NFS loopback clients,which have advantages discussed later on.Newfile systems can also be implemented by replac-ing system shared libraries or even intercepting all of a process’s system calls,as the UFO system does[1].Both methods are appealing because they can be implemented by a completely unprivileged user.Unfortunately,it is hard to implement completefile system semantics us-ing these methods(for instance,you can’t hand off a file descriptor using sendmsg()).Both methods also fail in some cases.Shared libraries don’t work with stat-ically linked applications,and neither approach works with setuid utilities such as lpr.Moreover,having dif-ferent namespaces for different processes can cause con-fusion,at least on operating systems that don’t normally support this.FiST[19]is a language for generating stackablefile systems,in the spirit of Ficus[11].FiST can output code for three operating systems—Solaris,Linux,and FreeBSD—giving the user some amount of portability. FiST outputs kernel code,giving it the advantages and disadvantages of being in the operating system.FiST’s biggest contributions are really the programming lan-guage and the stackability,which allow simple and el-egant code to do powerful things.That is somewhat or-thogonal to the SFS toolkit’s goals of allowingfile sys-tems at user level(though FiST is somewhat tied to the VFS layer—it couldn’t unfortunately be ported to the SFS toolkit very easily).Aside from its elegant language, the big trade-off between FiST and the SFS toolkit is per-formance vs.portability and ease of debugging.Loop-back servers will run on virtually any operating system, while FiSTfile systems will likely offer better perfor-mance.Finally,several kernel device drivers allow user-level programs to implementfile systems using an interface other than NFS.The now defunct UserFS[8]exports an interface similar to the kernel’s VFS layer to user-level erFS was very general,but only ran on Linux.Arla[17],an AFS client implementation,con-tains a device,xfs,that lets user-level programs imple-ment afile system by sending messages through/dev/ xfs0.Arla’s protocol is well-suited to networkfile sys-tems that perform wholefile caching,but not as general-purpose as UserFS.Arla runs on six operating systems, making xfs-basedfile systems portable.However,users mustfirst install xfs.Similarly,the Codafile system[12] uses a device driver/dev/cfs0.3NFS loopback server issuesNFS loopback servers allow one to implement a newfile system portably,at user-level,through the NFS proto-col rather than some operating-system-specific kernel-internal API(e.g.,the VFS layer).Figure1shows the architecture of an NFS loopback server.An application accessesfiles using system calls.The operating system’s NFS client implements the calls by sending NFS requestsFigure1:A user-level NFS loopback serverto the user-level server.The server,though treated by the kernel’s NFS code as if it were on a separate machine, actually runs on the same machine as the applications.It responds to NFS requests and implements afile system using only standard,portable networking calls.3.1Complications of NFS loopbackserversMaking an NFS loopback server perform well poses a few challenges.First,because it operates at user-level, a loopback server inevitably imposes additional context switches on applications.There is no direct remedy for the situation.Instead,the loopbackfile system imple-menter must compensate by designing the rest of the sys-tem for high performance.Fortunately for loopback servers,people are willing to usefile systems that do not perform optimally(NFS it-self being one example).Thus,afile system offering new functionality can be useful as long as its performance is not unacceptably slow.Moreover,loopback servers can exploit ideas from thefile system literature.SFS, for instance,manages to maintain performance compet-itive with NFS by using leases[10]for more aggressive attribute and permission caching.An in-kernel imple-mentation could have delivered far better performance, but the current SFS is a useful system because of its en-hanced security.Another performance challenge is that loopback servers must handle multiple requests in parallel.Oth-erwise,if,for instance,a server waits for a request of its own over the network or waits for a disk read,multiple requests will not overlap their latencies and the overall throughput of the system will suffer.Worse yet,any blocking operation performed by an NFS loopback server has the potential for deadlock.This is because of typical kernel buffer allocation strategy.On many BSD-derived Unixes,when the kernel runs out of buffers,the buffer allocation function can pick some dirty buffer to recycle and block until that particular buffer has been cleaned.If cleaning that buffer requires calling into the loopback server and the loopback server is waiting for the blocked kernel thread,then deadlock will ensue. To avoid deadlock,an NFS loopback server must never block under any circumstances.Anyfile I/O within a loopback server is obviously strictly prohibited.How-ever,the server must avoid page faults,too.Even on op-erating systems that rigidly partitionfile cache and pro-gram memory,a page fault needs a struct buf to pass to the disk driver.Allocating the structure may in turn require that somefile buffer be cleaned.In the end,a mere debugging printf can deadlock a system;it may fill the queue of a pseudo-terminal handled by a remote login daemon that has suffered a page fault(an occur-rence observed by the author).A large piece of soft-ware that never blocks requires fundamentally different abstractions from most other software.Simply using an in-kernel threads package to handle concurrent NFS re-quests at user level isn’t good enough,as the thread that blocks may be the one cleaning the buffer everyone is waiting for.NFS loopback servers are further complicated by the kernel NFS client’s internal locking.When an NFS re-quest takes too long to complete,the client retransmits it.After some number of retransmissions,the client con-cludes that the server or network has gone down.To avoidflooding the server with retransmissions,the client locks the mount point,blocking any further requests, and periodically retransmitting only the original,slow re-quest.This means that a single“slow”file on an NFS loopback server can block access to otherfiles from the same server.Another issue faced by loopback servers is that a lot of software(e.g.,Unix implementations of the ANSI C getcwd()function)requires everyfile on a system to have a unique(st_dev,st_ino)pair.st_dev and st_ino arefields returned by the POSIX stat()function.Histori-cally,st_dev was a number designating a device or disk partition,while st_ino corresponded to afile within that disk partition.Even though the NFS protocol has afield equivalent to st_dev,thatfield is ignored by Unix NFS clients.Instead,allfiles under a given NFS mount point are assigned a single st_dev value,made up by the ker-nel.Thus,when stitching togetherfiles from various sources,a loopback server must ensure that all st_ino fields are unique for a given mount point.A loopback server can avoid some of the problems of slowfiles and st_ino uniqueness by using multi-ple mount points—effectively emulating several NFS servers.One often would like to create these mount points on-the-fly—for instance to“automount”remote servers as the user references them.Doing so is non-trivial because of vnode locking onfile name lookups.While the NFS client is looking up afile name,one can-not in parallel access the same name to create a new mount point.This drove previous NFS loopback auto-mounters to create mount points outside of the loopback file system and serve only symbolic links through the loopback mount.As user-level software,NFS loopback servers are eas-ier to debug than kernel software.However,a buggy loopback server can still hang a machine and require a reboot.When a loopback server crashes,any reference to the loopbackfile system will block.Hung processes pile up,keeping thefile system in use and on many operating systems preventing unmounting.Even the unmount com-mand itself sometimes does things that require an NFS RPC,making it impossible to clean up the mess without a reboot.If a loopbackfile system uses multiple mount points,the situation is even worse,as there is no way to traverse higher level directories to unmount the lower-level mount points.In summary,while NFS loopback servers offer a promising approach to portablefile system development, a number of obstacles must be overcome to build them successfully.The goal of the SFSfile system develop-ment toolkit is to tackle these problems and make it easy for people to develop newfile systems.4NFS loopback server toolkitThis section describes how the SFS toolkit supports building robust user-level loopback servers.The toolkit has several components,illustrated in Figure2.nfs-mounter is a daemon that creates and deletes mount points.It is the only part of the SFS client that needs to run as root,and the only part of the system that must function properly to prevent a machine from get-ting wedged.The SFS automounter daemon creates mount points dynamically as users access them.Fi-nally,a collection of libraries and a novel RPC compiler simplify the task of implementing entirely non-blocking NFS loopback servers.4.1Basic APIThe basic API of the toolkit is effectively the NFS3 protocol[4].The server allocates an nfsserv object, which might,for example,be bound to a UDP socket. The server hands this object a dispatch function.The ob-ject then calls the dispatch function with NFS3RPCs. The dispatch function is asynchronous.It receives an ar-gument of type pointer to nfscall,and it returns noth-ing.To reply to an NFS RPC,the server calls the reply method of the nfscall object.This needn’t happen be-fore the dispatch routine returns,however.The nfscall can be stored away until some other asynchronous event completes.4.2The nfsmounter daemonThe purpose of nfsmounter is to clean up the mess when other parts of the system fail.This saves the loopback file system developer from having to reboot the machine, even if something goes horribly wrong with his loopback server.nfsmounter runs as root and calls the mount and unmount(or umount)system calls at the request of other processes.However,it aggressively distrusts these pro-cesses.Its interface is carefully crafted to ensure that nf-smounter can take over and assume control of a loopback mount whenever necessary.nfsmounter communicates with other daemons through Unix domain sockets.To create a new NFS mount point,a daemonfirst creates a UDP socket over which to speak the NFS protocol.The daemon then passes this socket and the desired pathname for the mount point to nfsmounter(using Unix domain socket facilities for passingfile descriptors across processes). nfsmounter,acting as an NFS client to existing loopback mounts,then probes the structure of any loopbackfile systems traversed down to the requested mount point. Finally,nfsmounter performs the actual mount system call and returns the result to the invoking daemon. After performing a mount,nfsmounter holds onto the UDP socket of the NFS loopback server.It also remem-bers enough structure of traversedfile systems to recre-ate any directories used as mount points.If a loopback server crashes,nfsmounter immediately detects this by receiving an end-of-file on the Unix domain socket con-nected to the server.nfsmounter then takes over any UDP sockets used by the crashed server,and begins serving the skeletal portions of thefile system required to clean up underlying mount points.Requests to other parts of thefile system return stalefile handle errors,helping en-sure most programs accessing the crashedfile system exit quickly with an error,rather than hanging on afile access and therefore preventing thefile system from being un-mounted.nfsmounter was built early in the development of SFS. After that point,we were able to continue development of SFS without any dedicated“crash boxes.”No mat-ter what bugs cropped up in the rest of SFS,we rarely needed a reboot.This mirrors the experience of students, who have used the toolkit for class projects without ever knowing the pain that loopback server development used to cause.On occasion,of course,we have turned up bugs in ker-nel NFS implementations.We have suffered many kernel panics trying to understand these problems,but,strictlyFigure2:Architecture of the user-levelfile system toolkitspeaking,that part of the work qualifies as kernel devel-opment,not user-level server development.4.3Automounting in placeThe SFS automounter shows that loopback automounters can mountfile systems in place,even though no previ-ous loopback automounter has managed to do so.SFS consists of a top level directory,/sfs,served by an auto-mounter process,and a number of subdirectories of/sfs served by separate loopback servers.Subdirectories of /sfs are created on-demand when users access the direc-tory names.Since subdirectories of/sfs are handled by separate loopback servers,they must be separate mount points.The kernel’s vnode locking strategy complicates the task of creating mount points on-demand.More specif-ically,when a user references the name of an as-yet-unknown mount point in/sfs,the kernel generates an NFS LOOKUP RPC.The automounter cannot immedi-ately reply to this RPC,because it mustfirst create a mount point.On the other hand,creating a mount point requires a mount system call during which the kernel again looks up the same pathname.The client NFS im-plementation will already have locked the/sfs directory during thefirst LOOKUP RPC.Thus the lookup within the mount call will hang.Worse yet,the SFS automounter cannot always im-mediately create a requested mount point.It must val-idate the name of the directory,which involves a DNS lookup and various other network I/O.Validating a di-rectory name can take a long time,particularly if a DNS server is down.The time can be sufficient to drive the NFS client into retransmission and have it lock the mount point,blocking all requests to/sfs.Thus,the auto-mounter cannot sit on any LOOKUP request for a name in/sfs.It must reply immediately.The SFS automounter employs two tricks to achieve what previous loopback automounters could not.First, it tags nfsmounter,the process that actually makes the mount system calls,with a reserved group ID(an idea first introduced by HLFSD[18]).By examining the credentials on NFS RPCs,then,the automounter can differentiate NFS calls made on behalf of nfsmounter from those issued for other processes.Second,the au-tomounter creates a number of special“.mnt”mount points on directories with names of the form/sfs/ .mnt/0/,/sfs/.mnt/1/,....The automounter never delays a response to a LOOKUP RPC in the/sfs directory. Instead,it returns a symbolic link redirecting the user to another symbolic link in one of the.mnt mount points. There it delays the result of a READLINK RPC.Because the delayed readlink takes place under a dedicated mount point,however,no otherfile accesses are affected. Meanwhile,as the user’s process awaits a READLINK reply under/sfs/.mnt/n,the automounter actually mounts the remotefile system under/sfs.Because nfs-mounter’s NFS RPCs are tagged with a reserved group ID,the automounter responds differently to them—giving nfsmounter a different view of thefile system from the user’s.While users referencing the pathname in /sfs see a symbolic link to/sfs/.mnt/...,nfsmounter sees an ordinary directory on which it can mount the re-motefile system.Once the mount succeeds,the auto-mounter lets the user see the directory,and responds to the pending READLINK RPC redirecting the user to the original pathname in/sfs which has now become a di-rectory.Afinal problem faced by automounters is that the commonly used getcwd()library function performs an lstat system call on every entry of a directory containing mount points,such as/sfs.Thus,if any of the loopback servers mounted on immediate subdirectories of/sfs become unresponsive,getcwd()might hang,even when run from within a workingfile system.Since loopback servers may depend on networked resources that become transiently unavailable,a loopback server may well need to become unavailable.When this happens,the loopback server notifies the automounter,and the automounter re-turns temporary errors to any process attempting to ac-cess the problematic mount point(or rather,to any pro-cess except nfsmounter,so that unavailablefile systems can still be unmounted).4.4Asynchronous I/O libraryTraditional I/O abstractions and interfaces are ill-suited to completely non-blocking programming of the sort re-quired for NFS loopback servers.Thus,the SFSfile system development toolkit contains a new C++non-blocking I/O library,libasync,to help write programs that avoid any potentially blocking operations.When a function cannot complete immediately,it registers a call-back with libasync,to be invoked when a particular asyn-chronous event occurs.At its core,libasync supports callbacks whenfile descriptors become ready for I/O, when child processes exit,when a process receives sig-nals,and when the clock passes a particular time.A cen-tral dispatch loop polls for such events to occur through the system call select—the only blocking system call a loopback server ever makes.Two complications arise from this style of event-driven programming in a language like C or C++.First, in languages that do not support closures,it can be in-convenient to bundle up the necessary state one must preserve tofinish an operation in a callback.Second, when an asynchronous library function takes a callback and buffer as input and allocates memory for its results, the function’s type signature does not make clear which code is responsible for freeing what memory when.Both complications easily lead to programming errors,as we learned bitterly in thefirst implementation of SFS which we entirely scrapped.libasync makes asynchronous library interfaces less error-prone through aggressive use of C++templates.A heavily overloaded template function,wrap,produces callback objects through a technique much like func-tion currying:wrap bundles up a function pointer and some initial arguments to pass the function,and it re-turns a function object taking the function’s remaining arguments.In other words,given a function:res_t function(a1_t,a2_t,a3_t);a call to wrap(function,a1,a2)produces a func-tion object with type signature:res_t callback(a3_t);This wrap mechanism permits convenient bundling of code and data into callback objects in a type-safe way. Though the example shows the wrapping of a simple function,wrap can also bundle an object and method pointer with arguments.wrap handles functions and ar-guments of any type,with no need to declare the combi-nation of types ahead of time.The maximum number ofclass foo:public bar{/*...*/};voidfunction(){ref<foo>f=new refcounted<foo>(/*constructor arguments*/);ptr<bar>b=f;f=new refcounted<foo>(/*constructor arguments*/);b=NULL;}Figure3:Example usage of reference-counted pointers arguments is determined by a parameter in a perl script that actually generates the code for wrap.To avoid the programming burden of tracking which of a caller and callee is responsible for freeing dynamically allocated memory,libasync also supports reference-counted garbage collection.Two template types offer reference-counted pointers to objects of type T—ptr<T> and ref<T>.ptr and ref behave identically and can be assigned to each other,except that a ref cannot be NULL.One can allocate a reference-counted version of any type with the template type refcounted<T>,which takes the same constructor arguments as type T.Figure3 shows an example use of reference-counted garbage col-lection.Because reference-counted garbage collection deletes objects as soon as they are no longer needed,one can also rely on destructors of reference-counted objects to release resources more precious than memory,such as openfile descriptors.libasync contains a number of support routines built on top of the core callbacks.It has asynchronousfile handles for input and formatted output,an asynchronous DNS resolver,and asynchronous TCP connection es-tablishment.All were implemented from scratch to use libasync’s event dispatcher,callbacks,and reference counting.libasync also supplies helpful building blocks for objects that accumulate data and must deal with short writes(when no buffer space is available in the kernel). Finally,it supports asynchronous logging of messages to the terminal or system log.4.5Asynchronous RPC library and com-pilerThe SFS toolkit also supplies an asynchronous RPC li-brary,libarpc,built on top of libasync,and a new RPC。
清华会议分级

2
(2)rank1.5 不在 rank1 中的会议,如果符合下面的条件,其 RANK 为 1.5 *IF >= 1.2,且领域不是非常窄 *IF >=0.9,且领域不是非常窄,且在作为参考的 3 所大学(MIT, UCLA, NTU) 的列表中不只被列做 RANK2 *IF >= 0.6,且在至少一个参考列表中列为 RANK1
列表的生成采用量化标准+定性分析的方法 量化指标包括:Citeseer 给出的排序结果、清华大学计算机系计算的排 序结果(按照 SCI 引用因子的计算方式计算的 IF 排序,计算方法见附 录)、三所大学(MIT、UCLA、NUS)的排序结果。各个列表中的数据统 计见下表。 定性分析由计算机系组织各所代表进行讨论,主要进行了三次讨论,参加 讨论的人员包括:孙茂松、陈文光、冯建华、唐杰、王建勇、徐明伟、 任丰原、刘永进、张敏、崔勇和白晓颖。 部分会议的引用因子满足进入 rank2 的条件,但参与前期讨论的老师都不 熟悉该会议,暂时列为待确认 rank2 会议。 最后 rank1, rank1.5, rank2 将最多只保留 300 个会议。 Rank1 MIT UCLA NUS Citeseer 覆盖的会 议 THU(清华大学) 覆盖的会议 具体评估指标: (1)rank1 *IF 3.5 以上,且其领域不是非常窄 *IF >= 1.5, 且该领域没有其它明显强于此会议的其他会议 *0.8<=IF<1.5,且在作为参考的 3 所大学(MIT, UCLA, NTU)的列表中都列为 RANK1 的会议 38 91 59 965 1202 Rank2 0 93 96
5
3. 一流会议列表(Rank1.5)
会议缩写 会议全称 每年篇数 影响因子 5.79
IEEE会议排名

Rank 1:SIGCOMM:ACM Conf on Comm Architectures,Protocols &Apps INFOCOM: Annual Joint Conf IEEE Comp &Comm SocSPAA: Symp on Parallel Algms and ArchitecturePODC:ACM Symp on Principles of Distributed ComputingPPoPP:Principles and Practice of Parallel ProgrammingRTSS:Real Time Systems SympSOSP: ACM SIGOPS Symp on OS PrinciplesSOSDI: Usenix Symp on OS Design and ImplementationCCS: ACM Conf on Comp and Communications SecurityIEEE Symposium on Security and PrivacyMOBICOM: ACM Intl Conf on Mobile Computing and NetworkingUSENIX Conf on Internet Tech and SysICNP:Intl Conf on Network ProtocolsPACT:Intl Conf on Parallel Arch and Compil TechRTAS: IEEE Real-Time and Embedded Technology and Applications Symposium ICDCS:IEEE Intl Conf on Distributed Comp SystemsRank 2:CC: Compiler ConstructionIPDPS: Intl Parallel and Dist Processing SympIC3N: Intl Conf on Comp Comm and NetworksICPP: Intl Conf on Parallel ProcessingSRDS: Symp on Reliable Distributed SystemsMPPOI:Massively Par Proc Using Opt InterconnsASAP: Intl Conf on Apps for Specific Array ProcessorsEuro—Par:European Conf。
RDP-code

USENIX AssociationProceedings of the Third USENIX Conference on File and Storage TechnologiesSan Francisco, CA, USAMarch 31–April 2, 2004© 2004 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649FAX: 1 510 548 5738Email: office@ WWW: Rights to individual papers remain with the author or the author's employer.Permission is granted for noncommercial reproduction of the work for educational or research purposes.This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein.Row-Diagonal Parity for Double Disk Failure Correction Peter Corbett,Bob English,Atul Goel,Tomislav Grcanac,Steven Kleiman,James Leong,and Sunitha SankarNetwork Appliance,Inc.AbstractRow-Diagonal Parity(RDP)is a new algo-rithm for protecting against double disk fail-ures.It stores all data unencoded,and uses only exclusive-or operations to compute par-ity.RDP is provably optimal in computa-tional complexity,both during construction and reconstruction.Like other algorithms, it is optimal in the amount of redundant in-formation stored and accessed.RDP works within a single stripe of blocks of sizes nor-mally used byfile systems,databases and disk arrays.It can be utilized in afixed(RAID-4) or rotated(RAID-5)parity placement style. It is possible to extend the algorithm to en-compass multiple RAID-4or RAID-5disk ar-rays in a single RDP disk array.It is possi-ble to add disks to an existing RDP array without recalculating parity or moving data. Implementation results show that RDP per-formance can be made nearly equal to single parity RAID-4and RAID-5performance.1IntroductionDisk striping techniques[1,2]have been used for more than two decades to reduce data loss due to disk failure,while improv-ing performance.The commonly used RAID techniques,RAID-4and RAID-5,protect against only a single disk failure.Among the standard RAID techniques,only mirrored stripes(RAID-10,RAID-01)provide protec-tion against multiple failures.However,they do not protect against double disk failures of opposing disks in the mirror.Mirrored RAID-4and RAID-5protect against higher order failures[4].However,the efficiency of the array as measured by its data capacity divided by its total disk space is reduced.In-creasing the redundancy by small increments per stripe is more cost effective than adding redundancy by replicating the entire array[3]. The dramatic increase in disk sizes,the rel-atively slower growth in disk bandwidth,the construction of disk arrays containing larger numbers of disks,and the use of less reliable and less performant varieties of disk such as ATA combines to increase the rate of double disk failures,as will be discussed in Section3. This requires the use of algorithms that can protect against double disk failures to en-sure adequate data integrity.Algorithms that meet information theory’s Singleton bound [6]protect against two disk failures by adding only two disks of redundancy to the num-ber of disks required to store the unprotected data.Good algorithms meet this bound,and also store the data unencoded,so that it can be read directly offdisk.A multiple orders of magnitude improve-ment in the reliability of the storage system can simplify the design of other parts of the system for robustness,while improving over-all system reliability.This motivates the use of a data protection algorithm that protects against double disk failures.At the same time,it is desirable to maintain the simplic-ity and performance of RAID-4and RAID-5 single parity protection.This paper describes a new algorithm, called Row-Diagonal Parity,or RDP,for pro-tection against double failures.RDP applies to any multiple device storage system,or even to communication systems.In this paper,we focus on the application of RDP to disk array storage systems(RAID).RDP is optimal both in computation and in I/O.It stores user data in the clear,andrequires exactly two parity disks.It uti-lizes only exclusive-or operations during par-ity construction as well as during reconstruc-tion after one or two failures.Therefore,it can be implemented easily either in dedicated hardware,or on standard microprocessors.It is also simple to implement compared to pre-vious algorithms.While it is difficult to mea-sure the benefit of this,we were able to im-plement the algorithm and integrate it into an existing RAID framework within a short product development cycle.In this paper,we make the case that the need for double disk failure protection is in-creasing.We then describe the RDP algo-rithm,proving its correctness and analysing its performance.We present some simple ex-tensions to the algorithm,showing how to add disks to an existing array,and how to protect multiple RAID-4or RAID-5arrays against double failures with a single extra parity disk.Finally,we present some observa-tions from our experience implementing RDP, and give some performance results for that implementation.2Related WorkThere are several known algorithms that protect data against two or more disk fail-ures in an array of disks.Among these are EVENODD[5],Reed Solomon(P+Q)era-sure codes[6],DATUM[7]and RM2[8]. RDP is most similar to EVENODD.RM2dis-tributes parity among the disks in a single stripe,or equivalently,adds stripes of parity data that are interspersed among the data stripes.EVENODD,DATUM,and Reed-Solomon P+Q all share the property that the redundant information can be stored sepa-rately from the data in each stripe.This al-lows implementations that have dedicated re-dundant disks,leaving the other disks to hold only data.This is analogous to RAID-4,al-though we have two parity disks,not one.We will call this RAID-4style parity placement. Alternatively,the placement of the redun-dant information can be rotated from stripe to stripe,improving both read and write per-formance.We will call this RAID-5style par-ity placement.Both EVENODD and Reed-Solomon P+Q encoding compute normal row parity for one parity disk.However,they employ different techniques for encoding the second disk of re-dundant data.Both use exclusive-or oper-ations,but Reed-Solomon encoding is much more computationally intensive than EVEN-ODD[5].DATUM uses encodings that gen-erate any number of redundant information blocks.It allows higher order failure toler-ance,and is similar to Reed-Solomon P+Q encoding in the case of protection against two disk failures.RDP shares many of the properties of EVENODD,DATUM,and Reed-Solomon en-coding,in that it stores its redundant data (parity)separately on just two disks,and that data is stored in the clear on the other disks.Among the previously reported algo-rithms,EVENODD has the lowest compu-tational cost for protection against two disk failures.RDP improves upon EVENODD by further reducing the computational com-plexity.The complexity of RDP is prov-ably optimal,both during construction and reconstruction.Optimality of construction is important as it is the normal,failure free operational mode.However,the optimality of reconstruction is just as important,as it maximizes the array’s performance under de-graded failure conditions[9].3Double Disk Failure Modes and AnalysisDouble disk failures result from any com-bination of two different types of single disk failure.Individual disks can fail by whole-disk failure,whereby all the data on the disk becomes temporarily or permanently inacces-sible,or by media failure,whereby a small portion of the data on a disk becomes tem-porarily or permanently inaccessible.Whole-disk failures may result from a problem in the disk itself,or in the channel or network connecting the disk to its containing system. While the mode and duration of the failures may vary,the class of failures that make thedata on a disk unaccessible can be catego-rized as one failure type for the purposes of re-covery.Whole-disk failures require the com-plete reconstruction of a lost disk,or at least those portions of it that contain wanted data. This stresses the I/O system of the controller, while adding to its CPU load.(We will refer to the unit that performs construction of par-ity and reconstruction of data and parity as the controller.)To maintain uninterrupted service,the con-troller has to serve requests to the lost disk by reconstructing the requested data on de-mand.At the same time,it will reconstruct the other lost data.It is desirable during reconstruction to have a low response time for the on-demand reconstruction of individ-ual blocks that are required to service reads, while at the same time exhibiting a high throughput on the total disk reconstruction. Whole-disk failure rates are measured as an arrival rate,regardless of the usage pattern of the disk.The assumption is that the disk can go bad at any time,and that once it does, the failure will be noticed.Whole disk fail-ure rates are the reciprocal of the Mean Time To Failure numbers quoted by the manufac-turers.These are typically in the range of 500,000hours.Media failures are qualitatively and quan-titatively different from whole-disk failures. Media failures are encountered during disk reads and writes.Media failures on write are handled immediately,either by the disk or by the controller,by relocating the bad block to a good area on disk.Media failures on read can result in data loss.While a media failure only affects a small amount of data,the loss of a single sector of critical data can compromise an entire system.Handling media failures on read requires a short duration recovery of a small amount of missing data.The emphasis in the recovery phase is on response time,but reconstruction throughput is generally not an issue.Disks protect against media errors by relo-cating bad blocks,and by undergoing elabo-rate retry sequences to try to extract data from a sector that is difficult to read[10]. Despite these precautions,the typical media error rate in disks is specified by the man-ufacturers as one bit error per1014to1015 bits read,which corresponds approximately to one uncorrectable error per10TBytes to 100TBytes transferred.The actual rate de-pends on the disk construction.There is both a static and a dynamic aspect to this rate. It represents the rate at which unreadable sectors might be encountered during normal read activity.Sectors degrade over time,from a writable and readable state to an unread-able state.A second failure can occur during recon-struction from a single whole-disk failure.At this point,the array is in a degraded mode, where reads of blocks on the failed disk must be satisfied by reconstructing data from the surviving disks,and commonly,where the contents of the failed disk are being recon-structed to spare space on one or more other disks.If we only protect against one disk fail-ure,a second complete disk failure will make reconstruction of a portion of both lost disks impossible,corresponding to the portion of thefirst failed disk that has not yet been re-constructed.A media failure during recon-struction will make reconstruction of the two missing sectors or blocks in that stripe im-possible.Unfortunately,the process of recon-struction requires that all surviving disks are read in their entirety.This stresses the array by exposing all latent media failures in the surviving disks.The three double disk failure combina-tions are:whole-disk/whole-disk,whole-disk/media,and media/media.A properly implemented double failure protection algo-rithm protects against all three categories of double failures.In our analysis of failure rates,we discount media/media failures as being rare relative to the other two double failure modes.Whole-disk/whole-disk and whole-disk/media failures will normally be encountered during reconstruction from an already identified whole-disk failure.RAID systems can protect against dou-ble failures due to media failures by period-ically“scrubbing”their disks,trying to read each sector,and reconstructing and relocat-ing data on any sector that is unreadable.Do-ing this before a single whole-disk failure oc-curs can preempt potential whole-disk/media failures by cleansing the disks of accumulated media errors before a whole-disk failure oc-curs.Such preventive techniques are a nec-essary precaution in arrays of current large capacity disks.The media and whole-disk failure rates as-sume uniform failure arrivals over the lifetime of the disk,and uniform failure arrival rates over the population of similar disks.Actual whole-disk failure rates conform to a bathtub curve as a function of the disk’s service time: A higher failure rate is encountered during the beginning-of-life burn-in and end-of-life wear-out periods.Both of these higher rate periods affect the double disk failure rate,as the disks in an array will typically be the same age,and will be subject to the same us-age pattern.This tends to increase the corre-lation of whole-disk failures among the disks in an array.Disks in the array may be from the same manufacturing batch,and therefore may be subject to the same variations in manufac-turing that can increase the likelihood of an individual disk failing.Disks in an array are all subject to the same temperature,humidity and mechanical vibration conditions.They may all have been subjected to the same me-chanical shocks during transport.This can result in a clustering of failures that increases the double failure rate beyond what would be expected if individual disk failures were un-correlated.Once a single disk fails,the period of vul-nerability to a second whole-disk failure is de-termined by the reconstruction time.In con-trast,vulnerability to a media failure isfixed once thefirst disk fails.Reconstruction will require a complete read of all the surviving disks,and the probability of encountering a media failure in those scans is largely inde-pendent of the time taken by reconstruction. If the failures are independent,and wide sense stationary[12],then it is possible to derive the rate of occurance of two whole-disk failures as[2]:λ2≈λ21t r c n(n−1)2(1)where t r is the reconstruction time of a faileddisk,n is the total number of disks in the ar-ray,λ1is the whole-disk failure rate of onedisk,and c is a term reflecting the correla-tion of the disk failures.If whole-disk fail-ures are correlated,then the correction factorc>1.We know from experience that whole-disk failures are not stationary,i.e.,they de-pend on the service time of the disk,and alsothat they are positively correlated.These fac-tors will increase the rateλ2.The other consideration is that the recon-struction time t r is a function of the totaldata that must be processed during recon-struction.t r is linearly related to the disksize,but also can be related to the numberof disks,since the total data to be processedis the product dn,where d is the size of thedisks.For small n,the I/O bandwidths of theindividual disks will dominate reconstructiontime.However,for large enough n,the ag-gregate bandwidth of the disks becomes greatenough to saturate either the I/O or process-ing capacity of the controller performing re-construction.Therefore,we assert that:t r=d/b r if n<mdn/b s n≥m(2)m=b sb rwhere b r is the maximum rate of reconstruc-tion of a failed disk,governed by the disk’swrite bandwidth and b s is the maximum rateof reconstruction per disk array.The result for disk arrays larger than m is:λ2≈λ21dc2b sn2(n−1)(3)The whole-disk/whole-disk failure rate has acubic dependency on the number of disks inthe array,and a linear dependency on the sizeof the disks.The double failure rate is re-lated to the square of the whole-disk failurerate.If we employ disks that have higher fail-ure rates,such as ATA drives,we can expectthat the double failure rate will increase pro-portionally to the square of the increase insingle disk failure rate.As an example,if the primary failure rateis one in500,000hours,the correlation fac-tor is1,the reconstruction rate is100MB/s,in a ten disk array of240GByte disks,the whole-disk/whole-disk failure rate will be ap-proximately1.2×10−9failures per hour.Both the size of disks and their I/O band-width have been increasing,but the trend over many years has been that disk size is increasing much faster than the disk media rate.The time it takes to read or write an entire disk is the lower bound on disk recov-ery.As a result,the recovery time per disk has been increasing,further aggravating the double disk failure rate.The rate of whole-disk/media failures is also related to disk size and to the number of disks in the array.Essentially,it is the rate of single whole-disk failures,multiplied by the probability that any of those failures will re-sult in a double failure due to the inability to read all sectors from all surviving disks.The single whole-disk failure rate is proportional to the number of disks in the array.The me-dia failure rate is roughly proportional to the total number of bits in the surviving disks of the array.The probability of all bits being readable is(1−p)s where p is the probability of an individual bit being unreadable,and s is the number of bits being read.This gives the a priori rate of whole-disk/media double failures:f2=λ1n(1−(1−p)(n−1)b)(4) where b is the size of each disk measured in bits.For our example of a primary failure rate of1in500,000hours,a10disk array,240 GB disks,and a bit error rate of1per1014 gives a whole-disk/media double failure rate of3.2×10−6failures per hour.In our example,using typical numbers,the rate of whole-disk/media failures dominates the rate of whole-disk/whole-disk failures. The incidence of media failures per whole-disk failure is uncomfortably high.Scrubbing the disks can help reduce this rate,but it re-mains a significant source of double disk fail-ures.The combination of the two double fail-ure rates gives a Mean Time To Data Loss (MTTDL)of3.1×105hours.For our exam-ple,this converts to an annual rate of0.028 data loss events per disk array per year due to double failures of any type.To compare,the dominant triple failure mode will be media failures discovered dur-ing recovery from double whole-disk failures. This rate can be approximated by the analog to Equation4:f3=λ2(1−(1−p)(n−2)b)(5) Substitutingλ2from Equation1gives:f3≈λ21dc2b sn2(n−1)(1−(1−p)(n−2)b)(6)For our example,the dominant component of the tertiary failure rate will be approxi-mately1.7×10−10failures per hour,which is a reduction of over four orders of magnitude compared to the overall double failure rate. The use of less expensive disks,such as ATA disks,in arrays where high data in-tegrity is required has been increasing.The disks are known to be less performant and less reliable than SCSI and FCP disks[10].This increases the reconstruction time and the in-dividual disk failure rates,in turn increasing the double failure rate for arrays of the same size.4Row-Diagonal Parity Algo-rithmThe RDP algorithm is based on a simple parity encoding scheme using only exclusive-or operations.Each data block belongs to one row parity set and to one diagonal par-ity set.In the normal configuration,there is one row parity block and one diagonal parity block per stripe.It is possible to build either RAID-4or RAID-5style arrays using RDP, by either locating all the parity blocks on two disks,or by rotating parity from disk to disk in different stripes.An RDP array is defined by a controlling parameter p,which must be a prime number greater than2.In the simplest construction of an RDP array,there are p+1disks.WeData Data Data Data Row Diag. Disk Disk Disk Disk Parity Parity 0123012340123401234012340123 Figure1:Diagonal Parity Set Assignments in a6Disk RDP Array,p=5define stripes across the array to consist of one block from each disk.In each stripe,one block holds diagonal parity,one block holds row parity,and p−1blocks hold data.The bulk of the remainder of this paper describes one grouping of p−1stripes that includes a complete set of row and diagonal parity sets.Multiple of these stripe groupings can be concatenated to form either a RAID-4 style or RAID-5style array.An extension to multiple row parity sets is discussed in Sec-tion7.Figure1shows the four stripes in a6disk RDP array(p=5).The number in each block indicates the diagonal parity set the block belongs to.Each row parity block con-tains the even parity of the data blocks in that row,not including the diagonal parity block. Each diagonal parity block contains the even parity of the data and row parity blocks in the same diagonal.Note that there are p=5 diagonals,but that we only store the parity of p−1=4of the diagonals.The selection of which diagonals to store parity for is com-pletely arbitrary.We refer to the diagonal for which we do not store parity as the“missing”diagonal.In this paper,we always select di-agonal p−1as the missing diagonal.Since we do not store the parity of the missing di-agonal,we do not compute it either.The operation of the algorithm can be seen by example.Assume that data disks1and3 have failed in the array of Figure1.It is nec-essary to reconstruct from the remaining data and parity disks.Clearly,row parity is use-less in thefirst step,since we have lost two members of each row parity set.However, since each diagonal misses one disk,and all diagonals miss a different disk,then there are two diagonal parity sets that are only missing one block.At least one of these two diago-nal parity sets has a stored parity block.In our example,we are missing only one block from each of the diagonal parity sets0and 2.This allows us to reconstruct those two missing blocks.Having reconstructed those blocks,we can now use row parity to reconstruct two more missing blocks in the two rows where we reconstructed the two diagonal blocks:the block in diagonal4in data disk3and the block in diagonal3in data disk1.Those blocks in turn are on two other diagonals:di-agonals4and3.We cannot use diagonal4 for reconstruction,since we did not compute or store parity for diagonal4.However,us-ing diagonal3,we can reconstruct the block in diagonal3in data disk3.The next step is to reconstruct the block in diagonal1in data disk1using row parity,then the block in diagonal1in data disk3,thenfinally the block in diagonal4in data disk1,using row parity.The important observation is that even though we did not compute parity for diago-nal4,we did not require the parity of diag-onal4to complete the reconstruction of all the missing blocks.This turns out to be true for all pairs of failed disks:we never need to use the parity of the missing diagonal to complete reconstruction.Therefore,we can safely ignore one diagonal during parity con-struction.5Proof of CorrectnessLet us formalize the construction of the ar-ray.We construct an array of p+1disks divided into blocks,where p is a prime num-ber greater than2.We group the blocks at the same position in each device into a stripe. We then take groups of p−1stripes and, within that group of stripes,assign the blocks to diagonal parity sets such that with disks numbered i=0...p and blocks numbered k=0...p−2on each disk,disk block(i,k) belongs to diagonal parity set(i+k)mod p.Disk p is a special diagonal parity disk.We construct row parity sets across disks0to p−1without involving disk p,so that any one lost block of thefirst p disks can be re-constructed from row parity.The normal way to ensure this is to store a single row par-ity block in one of the blocks in each stripe. Without loss of generality,let disk p−1store row parity.The key observation is that the diagonal parity disk can store diagonal parity for all but one of the p diagonals.Since the array only has p−1rows,we can only store p−1of the p possible diagonal parity blocks in each group of p−1stripes.We could select any of the diagonal parity blocks to leave out,but without loss of generality,we choose to not store parity for diagonal parity set p−1,to conform to our numbering scheme.The roles of all the disks other than the di-agonal parity disk are mathematically iden-tical,since they all contribute symmetrically to the diagonal parity disk,and they all con-tribute to make the row parity sums zero.So, in any stripe any one or more of the non-diagonal parity disks could contain row par-ity.We only require that we be able to re-construct any one lost block in a stripe other than the diagonal parity block from row par-ity without reference to the diagonal parity block.We start the proof of the correctness of the RDP algorithm with a necessary Lemma.Lemma1In the sequence of numbers{(p−1+kj)mod p,k=0...p},with p prime and 0<j<p,the endpoints are both equal to p−1,and all numbers0...p−2occur exactly once in the sequence.Proof:Thefirst number in the sequence is p−1by definition.The last number in the sequence is p−1,since(p−1+pj)mod p= p−1+(pj mod p)=p−1.Thus the lemma is true for the two endpoints.Now consider the subsequence of p−1numbers that be-gins with p−1.All these numbers must have values0≤x≤p−1after the modulus oper-ation.If there were a repeating number x in the sequence,then it would have to be true that(x+kj)mod p=x for some k<p. Therefore,kj mod p=0which means that kj is divisible by p.But since p is prime,no multiple of k or j or any of their factors can equal p.Therefore,thefirst p−1numbers in the sequence beginning with p−1are unique, and all numbers from0...p−1are repre-sented exactly once.The next number in the sequence is p−1.We now complete the proof of the correct-ness of RDP.Theorem1An array constructed according to the formal description of RDP can be re-constructed after the loss of any two of its disks.Proof:There are two classes of double fail-ures,those that include the diagonal parity disk,and those that do not.Those failures that include the diagonal parity disk have only one disk that has failed in the row parity section of the array.This disk can be reconstructed from row parity, since the row parity sets do not involve the diagonal parity disk.Upon completion of the reconstruction of one of the failed disks from row parity,the diagonal parity disk can be re-constructed according to the definition of the diagonal parity sets.This leaves all failures of any two disks that are not the diagonal parity disk.From the construction of the array,each disk d intersects all diagonals except diagonal (d+p−1)mod p=(d−1)mod p.Therefore, each disk misses a different diagonal.For any combination of two failed disks d1,d2with d2=d1+j,the two diagonals that are not intersected by both disks are g1=(d1+p−1)mod pg2=(d1+j+p−1)mod p Substituting g1givesg2=(g1+j)mod pSince each of these diagonals is only missing one member,if we have stored diagonal par-ity for the diagonal we can reconstruct themissing element along that diagonal.Since at most one of the diagonals is diagonal p−1, then we can reconstruct at least one block on one of the missing disks from diagonal parity as thefirst step of reconstruction.For the failed disks d1,d2,if we can recon-struct a block from diagonal parity in diago-nal parity set x on disk d1,then we can recon-struct a block on disk d2in diagonal parity set(x+j)mod p,using row parity.Simi-larly,if we can reconstruct a block x from diagonal parity on disk d2,then we can recon-struct a block on disk d1in diagonal parity set(x−j)mod p using row parity. Consider the pair of diagonals g1,g2that are potentially reconstructable after the fail-ure of disks d1,d2.If g1is reconstructable, then we can reconstruct all blocks on each di-agonal(g1−j)mod p,(g1−2j)mod p,...,p−1using alternating row parity and diagonal parity reconstructions.Similarly,if g2is re-constructable,then we can reconstruct all blocks on each diagonal(g2+j)mod p,(g2+ 2j)mod p,...,p−1using alternating row parity and diagonal parity reconstructions. Since g1and g2are adjacent points on the sequence for j generated by Lemma1,then we reach all diagonals0...p−1during recon-struction.If either g1=p−1or g2=p−1,then we are only missing one block from the di-agonal parity set p−1,and that block is re-constructed from row parity at the end of the reconstruction chain beginning with g2or g1 respectively.If both g1=p−1and g2=p−1, then the reconstruction proceeds from both g1and g2,reaching the two missing blocks on diagonal p−1at the end of each chain.These two blocks are each reconstructed from row parity.Therefore,all diagonals are reached during reconstruction,and all missing blocks on each diagonal are reconstructed.We do not need to store or generate the parity of diagonal p−1to complete recon-struction.6Performance Analysis Performance of disk arrays is a function of disk I/O as well as the CPU and memory bandwidth required to construct parity dur-ing normal operation and to reconstruct lost data and parity after failures.In this section, we analyse RDP in terms of both its I/O ef-ficiency and its compute efficiency.Since RDP stores data in the clear,read performance is unaffected by the algorithm, except to the extent that the disk reads and writes associated with data writes interfere with data read traffic.We consider write I/Os for the case where p−1RDP stripes are con-tained within a single stripe of disk blocks,as described in Section7.This implementation optimizes write I/O,and preserves the prop-erty that any stripe of disk blocks can be writ-ten independently of all other stripes.Data writes require writing two parity blocks per stripe.Full stripe writes therefore cost one additional disk I/O compared to full stripe writes in single disk parity arrays.Partial stripe writes can be computed by addition, i.e.recomputing parity on the entire stripe, or subtraction,puting the delta to the parity blocks from the change in each of the data blocks written to,depending on the number of blocks to be written in the stripe. Writes using the subtraction method are com-monly referred to as“small writes”.Writing d disk blocks by the subtraction method re-quires d+2reads and d+2writes.The ad-dition method requires n−d−2reads,and d+2writes to write d disk blocks.If reads and writes are the same cost,then the addi-tion method requires n I/Os,where n is the number of disks in the array,and the subtrac-tion method requires2d+4I/Os.The break-point between the addition and subtraction method is at d=(n−4)/2.The number of disk I/Os for RDP is minimal for a dou-ble failure protection algorithm;writing any one data block requires updating both parity blocks,since each data block must contribute to both parity blocks.We next determine the computational cost of RDP as the total number of exclusive or (xor)operations needed to construct parity. Each data block contributes to one row par-。
USENIX Association

WWW:
Rights to individual papers remain with the author or the author's employer.
Permission is granted for noncommercial reproduction of the work for educational or research purposes.
The implementation uses The Linux Thread Library which is included with glibc package. This library provides very simple view of shared memory because each thread has the same memory space (data and stack). Note that The Linux Thread Library does not use real threads but traditional Linux processes sharing their memory space so in the following we will use the 2 words thread/process with the same meaning.
© 2000 by The USENIX Association
All Rights Reserved
For more information about the USENIX Association:
Phone: 1 510 528 8649
FAX: 1 510 548 5738
Email: office@
(论文)运用java处理web信息流webtrafficprocessinginjava

1前言Web流可以是不同类型的数据传输(比特流,数据包,会话等),不同类型的资源利用情况(输入/输出和网络带宽、CPU、内存、硬盘容量等),不同类型的用户请求序列(浏览器请求,在线交易等)。
人们已经注意到了Web流的复杂性[1][2][3],但他们的研究集中在探索Web流量在一段时间内(例如峰值期间)的随机特性上。
很少同时考虑Web流量在每日、每周呈现出的周期性变化和长期变化趋势[4]。
因此,对Web流的这种既有确定性又有随机性的特性的研究分析,人们需要用新的描述和分析方法来解决相关的问题。
这将给网络建模、流量预报、网络的短期和长期容量设计等基于Web的应用提供新的方法和手段。
Heiierstein等人从流量预报的非稳定特性和依赖于连续时间的稳定性两个方面对Web服务器的流量的变化进行了建模[3][6]。
他们利用这个模型计算超越给定阈值的概率,即,用于阐述:在未来某一个时刻的流量是多大?流量的增长在什么时候会超出限定值?在一周中的哪一天和哪一时刻出现这种情况?等等。
对于非稳定特性,文[7]利用ad hoc模型来估算每周的情况。
文[8]则运用了更常用的时间序列方法和输入输出相关函数来预测系统的变化。
通过加州大学伯克利分校IP服务器收集到的大量客户端数据,Gribbie等人显示了用户端活动具有很强的、可预报的周期性以及在小时间尺度上用户请求的突发性。
Boiot[10]证明了利用经验数据,例如一个服务器处理的Web 请求数,或一个服务器上每小时存取的数据量,可以建立时间序列的实际模型,并利用这些模型实现对用户端请求特性(请求次数和请求文件的大小)的中期预报。
从Web代理服务器的工作负载特性的细节上,Ariitt[11]证明了它的工作负载受到了用户日常活动的影响。
Ariitt在文献[12]中进一步从6组不同的数据中找到了某些变量,利用这些变量可以对Web服务器进行改进。
与所有这些已有的研究工作相比较,笔者结合了FFT和运用JAVA处理Web信息流李宁(中山大学电子与通信工程学,广州510275)E-maii:**************.cn摘要Web信息流量的变化,反映了Web用户对Web服务器的访问,具有长期的、周的、日的、时的和瞬间的随机变化特性。
图计算体系结构和系统软件关键技术综述

图计算体系结构和系统软件关键技术综述1. 引言图计算是指对大规模图数据进行分析和处理的计算过程。
由于图数据的复杂性和规模巨大,传统的计算方法已无法满足对图数据的高效处理需求。
因此,图计算体系结构和系统软件的研究和发展成为了当前计算领域的热点之一。
本文将对图计算体系结构和系统软件的关键技术进行综述。
2. 图计算体系结构2.1 分布式图计算体系结构分布式图计算体系结构是指将大规模图数据分布式地存储和计算的结构。
它由图计算引擎、分布式存储和通信框架等组件构成。
图计算引擎负责图算法的实现和优化,分布式存储用于存储分布式图数据,通信框架用于不同计算节点之间的通信。
常见的分布式图计算体系结构有Google的Pregel和PowerGraph、Apache的Giraph等。
2.2 多核图计算体系结构多核图计算体系结构是指利用多核CPU或GPU来并行处理图数据的结构。
它通过将图数据分割成多份,并在不同核心或处理器上并行计算,从而提高图计算的速度和效率。
为了充分利用多核计算资源,多核图计算体系结构需要考虑数据划分、任务调度和数据同步等关键技术。
目前,多核图计算的研究主要集中在GPU上,如NVIDIA的CUDASWEP和GunRock等。
3. 系统软件关键技术3.1 图计算编程模型图计算编程模型是指用于描述和处理图数据的编程模型。
常见的图计算编程模型有Pregel模型和GraphLab模型。
Pregel模型将图计算过程分为多轮迭代的超步,通过消息传递进行通信和计算。
GraphLab模型则采用顶点中心的计算模式,通过定点更新和边的消息传递进行计算。
这些图计算编程模型在不同的应用场景中有不同的优势。
3.2 图计算优化策略图计算优化策略是指为了提高图计算性能,采取的一系列优化手段和技术。
常见的图计算优化策略有数据压缩、负载均衡和任务划分等。
数据压缩通过压缩图数据的表示方式,减少存储和传输开销。
负载均衡策略通过合理分配计算节点的负载,使得整个计算过程更加均衡和高效。
国内外各领域顶级学术会议大全
网络通信领域
下一代互联网研究中心
rank1
5
IEEE ITC: International Test Conference
偏重于建模和测量的重要国际会议,内容覆盖系统和网络,录用率为10%左右。
网络通信领域
下一代互联网研究中心
rank1
9
MOBIHOC: ACM?International?Symposium?onMobile?Ad?Hoc?Networking?and?Computing
无线网络领域新兴的重要国际会议,内容侧重于adhoc网络。
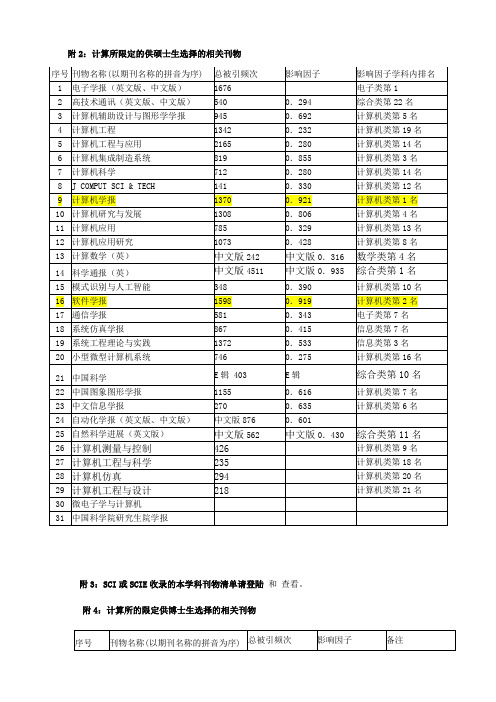
附2:计算所限定的供硕士生选择的相关刊物
序号
刊物名称(以期刊名称的拼音为序)
总被引频次
影响因子
影响因子学科内排名
1
电子学报(英文版、中文版)
1676
电子类第1
2
高技术通讯(英文版、中文版)
540
0.294
综合类第22名
3
计算机辅助设计与图形学学报
945
0.692
计算机类第5名
4
计算机工程
1342
0.232
29
计算机工程与设计
218
计算机类第21名
30
微电子学与计算机
31
中国科学院研究生院学报
附3:SCI或SCIE收录的本学科刊物清单请登陆和 查看。
附4:计算所的限定供博士生选择的相关刊物
序号
刊物名称(以期刊名称的拼音为序)
总被引频次
Improving DES Coprocessor Throughput for Short Operations

USENIX AssociationProceedings of the10th USENIX SecuritySymposiumWashington, D.C., USAAugust 13–17, 2001THE ADVANCED COMPUTING SYSTEMS ASSOCIATION© 2001 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649FAX: 1 510 548 5738Email: office@ WWW: Rights to individual papers remain with the author or the author's employer.Permission is granted for noncommercial reproduction of the work for educational or research purposes.This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein.Improving DES Coprocessor Throughput for Short OperationsMark LindemannIBM T.J.Watson Research CenterYorktown Heights,NY10598-0704mjl@Sean W.Smith∗Dept.of CS/Institute for Security and Technology StudiesDartmouth CollegeHanover,NH03755sws@,/˜sws/AbstractOver the last several years,our research team built a commercially-offered secure coprocessor that,be-sides other features,offers high-speed DES:over20 megabytes/second.However,it obtains these speeds only on operations with large data lengths.For DES operations on short data(e.g.,8-80bytes),our com-mercial offering was benchmarked at less than2kilo-bytes/second.The programmability of our device en-abled us to investigate this issue,identify and address a series of bottlenecks that were not initially apparent, and ultimately bring our short-DES performance close to3megabytes/second.This paper reports the results of this real-world systems exercise in hardware crypto-graphic acceleration—and demonstrates the importance of,when designing specialty hardware,not overlooking the software aspects governing how a device can be used. 1IntroductionWhat is“fast DES?”The challenge of meaningfully quantifying cryptographic performance has been a long-standing issue.Over the past several years,our team has worked on pro-ducing,as a commercial offering,a cryptographic em-bedded system:a high-performance,programmable se-cure coprocessor platform[9],which could take on dif-∗This work was supported in part by the U.S.Department of Justice,contract2000-DT-CX-K001.ferent personalities depending on the application pro-gram installed.This device featured hardware crypto support for modular math and DES in the original ver-sion,with outer-CBC TDES and SHA-1added in the Model2.Our initial commercial target was an applica-tion program[1]that turned the platform into a secure cryptographic accelerator.Besides the physical and logical security of the de-vice,our team prided itself on the fast DES(and,in the Model2,outer-CBC TDES)that our device pro-vided.Measured from an application program on the host(in order to give a more accuratefigure),our initial device performed DES at about20megabytes/second; the follow-on does outer-CBC TDES at close to this rate.We note,however,that we were focused on se-cure coprocessing,and wanted fast DES in contexts where the keys and decisions were under the control of the trusted third party inside the box,not the less se-cure host.Two potential examples of such scenarios include re-encryption of a hardware-protected Kerberos database[3],and information servers that ensure privacy even against root[8].However,thesefigures were for bulk performance:op-erations consisting of CBC encryption or decryption of input data that is itself megabytes long.For operations on short data,our device was several orders of magni-tude slower.When an external colleague—who required large numbers of DES operations on inputs each8-80 bytes—benchmarked our commercial offering,he only measured about1.5kilobytes/second.[5]The programmability of our device enabled us to in-vestigate this issue,and we assumed that our intimate knowledge of the internals would enable us to immedi-ately identify and rectify the bottleneck.This assump-tion turned out to be incorrect.In this paper,we report the lengthy sequence of experiments that followed.We finally improved short-DES performance by three or-ders of magnitude over the initial benchmark,but have been continually surprised at where the bottlenecks re-ally were.We offer this contribution as a real-world systems exercise in cryptographic acceleration.It demon-strates the value of programmability in a cryptographic accelerator—because without thisflexibility,we would not have achieved the three orders of magnitude speed-up.More importantly,it demonstrates the importance of considering how a system will actually be used,and how the control data will be routed,when designing specialty cryptographic hardware.Far too often,the hardware design process leaves these issues for post-facto software experimenters(like ourselves)to dis-cover.Consequently,our work also offers some poten-tial lessons for future design of hardware intended to ac-celerate high-latency operations on small data lengths, as well as for the future design process.2System BackgroundOur device is a multi-chip embedded module,packaged in a PCI card.In addition to cryptographic hardware, and circuitry for tamper detection and response,we have a general-purpose computing environment:a486-class CPU,executing software loaded from internal ROM and FLASH.Two generations of the device exist commer-cially;the older Model1and the newer Model2.We did our experiments on the Model2(since that is all we had);discussions of principles that apply to both models do not specify a model number.2.1SoftwareThe multiple-layer software architecture consists of foundational security control(Layer0and Layer1), supervisor-level system software(Layer2),and user-level application software(Layer3).(See Figure1.) Our Layer2component[2]was designed to support ap-plication development.Within Layer2,a kernel pro-vides standard OS abstractions of multiple tasks and multiple address spaces;these abstractions support in-dependent managers:components within Layer2whichHost IBM4758Figure1The software architecture of thecoprocessor.The host software on the left runson the host system;the card software on theright runs on the486inside the coprocessor. handle cryptographic hardware and other I/O on the bot-tom,and provide higher-level APIs to the Layer3appli-cation on top.Typically,this Layer3application provides the abstrac-tion of its own API to host-side application.Figure2 through Figure4shows the interaction of software com-ponents during applications such as standard DES accel-eration:(Figure2)When it wants to use a service provided by the card-side application,the host-side application issues a call to the host-side device driver.The device driver then opens an sccRequest to the Layer2system software on the yer2then informs the Layer3ap-plication resident on the device of the existence of this request,and some of the parameters the host sent along with it.(Figure3)The Layer3application then handles the host application’s request for service;in this example,it di-rects Layer2to transfer data and perform the necessary crypto operations.(Figure4)The Layer3application then directs Layer2 to close out the sccRequest and send the results back to the host.2.2HardwareOne of the many goals of our device was fast cryptogra-phy.As part of this goal,we included a FIFO/state ma-chine structure that can transport data quickly into and out of an algorithm engine.Figure5shows how this pro-Host IBM4758 Figure2The host application opens an sccRequest to the application layer in thecard.Host IBM4758 Figure3For standard external-external DES,the application layer asks Layer2to perform the operation;Layer2then directs thethe datatransfer.Host IBM4758 Figure4The application layer closes out the sccRequest,and sends the output back tothe host application.prietary FIFO structure works with the DES/TDES en-gine.(In our Model2hardware,this FIFO structure also supports fast SHA-1;in principle,this structure could be applied to any algorithm engine.)For both input and output,we have two pairs of FIFOs—a PCI FIFO and an internal FIFO,for fast external and internal data transfer,respectively.We also have a DMA controller,for CPU-free transfer into and out of inter-nal DRAM.These components enable the device CPU to arrange to do fast data transfer through the various on-board devices,without the active involvement of the CPU after the initial configuration.For example,to sup-port fast bulk DES when the source and destination are both outside the device,the internal CPU can config-ure these components to support an external-to-external data path(PCI Input FIFO to Internal Input FIFO to DES,then back through the output FIFOs),load the rel-evant operational parameters(e.g.,key,IV,mode)into the DES engine,and then let the the hardware move data through on its own.Besides external-to-external DES,other common con-figuration paths include internal-to-internal bulk DES (Output DMA to Internal Input FIFO to DES,then back),and DMA transfer(e.g.,PCI Input FIFO to Internal Input FIFO to Input DMA and vice versa). (Additionally,the DES hardware can be configured in bypass mode,but the commercial Layer2software does not use it.)As an artifact of the hardware design,we have one prin-cipal constraint:both internal FIFO-DES paths must be selected(bulk mode),or neither must be selected(non-bulk mode).However,changing between these modes resets the Internal FIFOs,and during non-bulk mode,the CPU has no way to restrain the Internal Input FIFO fromfilling to capacity.Examples Figure6through Figure10show some ex-amples of how the FIFO hardware supports card appli-cations.•(Figure6)When the host application opens up an sccRequest to the card application,the card typ-ically brings the input data into a DRAM buffer via DMA.(security boundary)Figure 5The FIFO structure supporting DES/TDES,within thecoprocessor.Figure 6The bold arrows show how the internal CPU can configure the FIFOs to bringdata into the card via DMA.•(Figure 7)For a DES request,the card may then transfer the operational parameters from DRAM into the DES chip.•(Figure 8)If the DES request is for external-external DES,the card will then configure the FIFOs to bring the data in from the host,through the DES chip (operating with the parameters we just loaded),then back to the host.•(Figure 9)If the DES request is for internal-internal DES (but is too short to justify DMA),the card may just manually push the bytes through.•(Figure 10)When the sccRequest is complete,the card may send the results back out to the host viaDMA.Figure 7The bold arrows show how the internal CPU can load operational parametersinto the DES chip fromDRAM.Figure 8The bold arrows show how the internal CPU can configure the FIFOs to stream data from the host,through the DESchip,then back out to the host.Figure9The bold arrows show how theinternal CPU can also drive data from DRAMthrough DES via programmedI/O.Figure10The bold arrows show how theinternal CPU can configure the FIFOs to senddata from DRAM back the host via DMA.3The Experiment SequenceThis unfunded“skunkworks”project had several goals: to try to see why the huge gap existed between what a colleague(using slower Model1hardware)measured for short-DES and what we measured for longer bulk DES;to try to improve the performance,if possible; and to explore migration of these changes(if the perfor-mance improves significantly)back into our commercial Layer2software(e.g.,via some new“short-DES”API it provides to Layer3).But as a side-effect,we had a constraint:due to funding limitations(that is,zero funding)and the long-term goal of product improvement,we had to minimize the num-ber of components we modified.For example,modify-ing the host device driver,even just to enable accurate latency measurements,was not feasible;and any solu-tion we considered needed to be a small enough delta that a reasonable chance existed of moving it into the real product.Since the colleague’s database application(as well as the general nature of the problems to which we apply our secure coprocessing technology)required no exposure of key material,we did not measure host-only DES.3.1The Gauntlet is ThrownOur colleague prompted this work when he demon-strated just how poorly our device performed for his ap-plication.Thus,to start our investigation,we needed to nail down the nature of the“DES”performance that he benchmarked at approximately1.5kilobytes/second. Thisfigure was measured from the host-side application program(recall Figure1),using commercial Model1 hardware with the IBM Common Cryptographic Architecture(CCA)application in Layer3.(CCA also inserts a middle layer between the host application and the host device driver).The DES operations were CBC-encrypt and CBC-decrypt,with data sizes distributed uniformly at random between8and80bytes.The IVs and keys changed with each operation;the keys were TDES-encrypted with a master key stored inside the device.Encrypted keys, IVs,and other operational parameters were sent in with each operation,but were not counted as part of the data throughput.Although the keys may change with each operation,the total number of keys(in our colleague’s application,and in others we surveyed)was still fairly small,relative to the number of requests.Experiment1:Establishing a BaselineIdea.Wefirst needed to establish a baseline imple-mentation that reproduced our colleague’s set-up,but in a setting that we could instrument and modify.Our col-league used commercial Model1hardware and CCA;in our lab,we had neither,but we did have Model2pro-totypes.So,we did our best to simulate our colleague’s configuration.Experiment.We built a host application that gener-ated sequences of short-DES requests(cipherkey,IV, data);we built a card-side application that:caught each request;unpacked the key;sent the data,key,and IV down to the DES engine;then sent the results back to the host.Figure11shows this operation.Results.With this faster hardware(and lighter-weight software)than our colleague’s set-up,we measured9-12 kilobytes/second(with the speed decreasing,oddly,as the number of operations increased).We chose keys randomly over a small set of cipherkeys. However,caching keys inside the card(to reduce the ex-tra TDES key-decryption step)did not make a significant performance improvement in this test.Experiment2:Reducing Host-Card Interaction Idea.Within our group,well-established folklore taught that each host-card interaction took a huge amount of time.Consequently,wefirst hypothesized that the reason short DES was so much slower than longer DES was because of the much greater number of host-card interactions(one set per each44bytes of data,on average)that our short-DES implementation re-quired.Experiment.We re-wrote the host-side application to batch a large sequence of short-DES requests into one sccRequest,and then re-wrote the card-side applica-tion to:receive this sequence in one step;process each request;and send the concatenated output back to the host in one step.Figure12shows this operation. Results.We tried a several data formats here.Speeds ranged from18to23kilobytes/second(and now up to 40kilobytes/second with key caching).This approach was an improvement,but still far below the apparent potential—host-card interaction was not the killer bot-tleneck.Experiment3:Batching into One Chip OperationIdea.Another piece of well-established folklore taught that resetting the DES chip(to begin an opera-tion)was expensive,but the operation itself was cheap. Until now,we had been resetting the chip for each oper-ation(again,once per44bytes,on average).Our next step was to see how fast things would go if we eliminated these resets.Experiment.For purposes of this experiment,we gen-erated a sequence of short-DES operation requests that all used one key,one direction(“decrypt”or“encrypt”), and IVs of zero(although the IVs could have been arbi-trary).Our card-side application now received the oper-ation sequence and sent it all down to the Layer2soft-ware.In Layer2,we rewrote the DES Manager(the component controlling the DES hardware)to set up the chip with the key and an IV of zero,and to start pumping the data through the chip.However,at the end of each operation,our modified Manager did the proper XOR to break the chaining.(E.g.,for encryption,the software manually XOR’d the last block of ciphertext from the previous operation with thefirst block of plaintext for the next operation,in order to cancel out the XOR that the chip would do.)Results.Much to our surprise,we now measured as high as360kilobytes/second.Was DES-chip reset the killer bottleneck?Distrusting folklore,we modified the experiment to reset the DES chip forh each operation anyway,and the top-end speed dropped slightly,to320kilobytes/second.So, it wasn’t the elimination of chip resets that was saving time here.Experiment4:Batching into Multiple Chip OperationsIdea.How many Layer3-Layer-2context switches are necessary to handle the host’s batched operation re-quest?Besides reducing the number of chip resets,the one-reset experiment of Experiment3also reduced the context switches from O(n)to O(1)(where n is the number of operations in the batch).The good performance of the multi-reset variant suggested that perhaps these context switches were a significant bottleneck. Experiment.We went back to the multi-key,non-zero-IV set-up of Experiment2,except now the card-side application sends the batched requests down to a modified DES manager,which then processes each one (with a chip reset and new key and IV each time). Figure13shows this operation.Figure11Experiment1:the application handles each operation as a separate sccRequest,with PIO DES.Results.Speeds ranged from30-290kilo-bytes/second.However,something was still amiss.Each short DES operation requires a minimum number of I/O operations: to set up the DES chip,to get and set up the IV,to get and set up the keys,and then to either drive the data through the chip,or let the FIFO state machine pump it through. Extrapolating from this back-of-the-envelope sketch to an estimated speed is tricky,due to the complex nature of contemporary CPUs.However,the sketch suggested that multi-megabyte speeds should be possible.Experiment5:Reducing Data TransfersIdea.From our above analysis of what’s“minimally necessary”for short-DES,we realized that we were wasting a lot of time with parameter and data transport. In practice,each byte of cipherkey,IV,and data was be-ing handled many times.The bytes came in via FIFOs and DMA into DRAM with the initial sccRequest buffer transfer;the CPU was then taking the bytes out of DRAM and putting them into the DES chip;the CPU then took the data out of the DES chip and put it back into DRAM;the CPU then sent the data back to the host through the FIFOs.However,in theory,each parameter(key,IV,and direc-tion)should require only one transfer:the CPU reads it from the FIFO,then acts.If we let the FIFO state ma-chine pump the data bytes through DES in bulk mode, then the CPU never need handle the data bytes at all. Experiment.Our next sequence of experiments fo-cused on trying to reduce the number of transfers down to this minimal level.To simplify things(and since we were starting to try to converge to a“fast short-DES”API),we decided to eliminate key unpacking as a built-in part of the API—since each application has their own way of doing un-packing anyway,and the cost impact was small(for operation sequences distributed over a small number of keys,as we had assumed).Instead,we assumed that,within each application,some“initialization”step would conclude with a plaintext key-table resident in de-vice DRAM.We also decided to standardize operationFigure12Exp2:we reduced host-card interaction by batching all the operations into a single sccRequest.lengths to40bytes(which,in theory,should mean that the speeds our colleague would see will be10%higher than our measurements).We rewrote our host application to generate sequences of requests that each include an index into the internal key-table,instead of a cipherkey.Our card-side application now calls the modified DES Manager(and makes the key table available to it),rather than immediately bring-ing the request sequence from the PCI Input FIFO into DRAM.For each operation,the modified DES Manager then:resets the DES chip;reads the IV and loads it into the chip;reads(and sanity checks)the key index,looks up the key,and loads it into the chip;reads the data length for this operation;then sets up the state machine to crank that number of bytes through the input FIFOs into the DES chip then back out the output FIFOs. Figure14shows this operation.Results.Speeds now ranged up to1400kilo-bytes/second.Experiment6:Using Memory Mapped I/OThe approach of Experiment5showed a major improve-ment,but performance was still lagging behind what we projected as possible.Idea.Upon further investigation,we discovered that, in our device,I/O operation speed is not limited by the CPU speed but by the internal ISA bus(effective transfer speed of8megabytes/second)When we calculated the number of fetch-and-store transfers necessary for each operation(irrespective of the data length),the slow ISA speed was the bottleneck.Consequent discussions with the hardware engineers re-vealed that every I/O register we needed to access—except for the PCI FIFOs—was available from a location that was also memory-mapped—and memory-mapped I/O operations should not be subject to the ISA speed limitations.Figure13Exp4:We reduced internal context switches by batching all the operations into a single call toa modified DES Manager in Layer2.Figure14Experiment5,Experiment6:We reduce unnecessary data transfers by having the modified DES Manager,for each operation,read in the parameters and configure the FIFOs to do DES directly fromand back to the host.Figure15Experiment7,Experiment8:We reduce slow ISA I/Os by batching the parameters for all the operations into one block,and bringing them via PIO DMA.Experiment.First,we proved the ISA-bottleneck hy-pothesis by doubling the number of ISA I/O instructions and observing an appropriate halving of the throughput. Then,we re-worked the modified DES manager of Experiment5to use memory-mapped I/O instead of ISA I/O wherever possible.As an unexpected conse-quence,we discovered a hardware bug—certain state machine polling intermittently caused spurious FIFO reads.(Again,Figure14shows this operation.)Results.Modifying our software again to work around this bug,we measured speeds up to2500kilo-bytes/second.Experiment7:Batching Operation Parameters Idea.The approach of Experiment6still requires reading the the per-operation parameters via slow ISA I/O from the PCI Input FIFO.(Reading them via memory-mapped I/O from the Internal Input FIFO is not possible,since we would loseflow control in non-bulk mode.)However,if we batched the parameters together,we could read them via memory-mapped operations,then change the FIFO configuration,and process the data. Experiment.In our most recent experiment,we rewrote the host application to batch all the per-operation parameters into one group,prepended to the input data.The modified DES manager then:sets up the Internal FIFOs and the state-machine to read the batched parameters,by-passing the DES chip;reads the batched parameters via memory-mapped operations from the Internal Output FIFO into DRAM;reconfig-ures the FIFOs;using the buffered parameters,sets up the state-machine and the DES chip to pump each op-eration’s data from the input FIFOs,through DES,then back out the output FIFOs.Figure15shows this opera-tion.Results.With thisfinal approach,we measured speeds approaching5000kilobytes/second.(As a control,we tried this batched-parameters approach using DMA and a separate request buffer,but obtained speeds slightly slower than Experiment6.)Experiment8:Checking the ResultsIdea.The results of Experiment7pleased us. However,colleagues disrupted this pleasure by pointing out that a recent errata sheet for our DES chip noted that using memory-mapped access for the IV and data length registers may cause incorrect results.We were tempted to dismiss this news,since the exter-nal colleague had merely asked for fast cryptography; he said nothing about correctness.But we investigated nonetheless.Experiment.First,we did a known-answer DES test on the implementation of Experiment7—and it failed. So,we revised that implementation to ensure that the IV and data length registers were access via the slower ISA method.(Again,Figure15shows this operation.) Results.With thisfinal approach,we measured speeds approaching3000kilobytes/second.100kB/s104kB/s100op/batch105ops/batchSec3.1Exp1Exp2Exp4Exp5Exp6Exp7Exp8Figure16Summary of our short-DESexperiments(preliminaryfigures,on an NTplatform)4Analysis4.1PerformanceFigure16summarizes the results of our experiment se-quence.On a coarse level,the short-DES speed can be modelled by:C1·Bats+C2·Bats·Ops+C3·Bats·Ops·DLenBats·Ops·DLenwhere Bats is the number of host-card batches,Ops is the number of operations per batch,DLen is the average data length per operation,and C1,C2,C3are unknown constants,representing the per-batch,per-operation,and per-byte overhead(respectively).4.1.1Improving Per-Batch OverheadThe curve of the top traces in Figure16suggests that, for fewer than1000operations,our speed is still being dominated by the per-batch overhead C1.To reduce this cost,we are planning another round of hand-tuning the code.In theory,we could eliminate the per-batch overhead C1 entirely by modifying the host device driver-Layer2in-teraction to enable indefinite sccRequest s,with some additional polling or signalling to indicate when more data is ready for transfer.However,our experiments were constrained by the limited resources of our own time,and the constraint that(should the results prove commercially viable)it would be possible to migrate our changes into the commercial offering with a minimum number of component changes.Both of these constraints have prevented us from exploring changes to the device driver protocol at this time.4.1.2Improving Per-Operation OverheadThe limitation of short DES puts an upper bound on DLen,which suggests a minimum C2/DLen component that we can never overcome.API Approaches.For future work,we have been con-sidering various ways to reduce the per-operation over-head C2by minimizing the number of per-operation pa-rameter transfers.For example:•The host application might,within a batch of op-erations,interleave“parameter blocks”that assert things like“the next N operations all use this key.”This eliminates bringing in(and reading)the key index each time.•The host application itself might process the IVs before or after transmitting the data to the card,as appropriate.(This is not a security issue if the host application already is trusted to provide the IVs.) This eliminates bringing in the IVs,and(since theDES chip has a default IV of zeros after reset)elim-inates loading the IVs as well.However,these approaches have two significant draw-backs.One is the fact that the“short-DES API”(that might eventually emerge in production code)would look less and less like standard DES.Another is that these variations make it much more complicated to benchmark performance meaningfully.How much work should the host application be expected to do?(Remember that the host CPU is probably capable of much greater compu-tational power than the coprocessor CPU.)How do we quantify the“typical request sequences”for which these approaches are tuned,in a manner that enables a poten-tial end user to make meaningful performance predic-tions?Hardware Approaches.Another avenue(albeit a long-term one)for reducing per-operation overhead would be to re-design the FIFOs and the state machine. In hindsight,we can now see that the current hard-ware has the potential for a fundamental improvement. Currently,the acceleration hardware provides a way to move the data very quickly through the engine,but not the operational parameters.If the DES engine(or what-ever other algorithm engine is being driven this way)ex-pected its data-input to include parameters(e.g.,“do the next40bytes with key#7and this IV”)interleaved with data,then the per-operation overhead C2could approach the per-byte overhead C3.The state machine(or whatever system is driving the data through the engine)would need to handle the fact that the number of output bytes may be less than the number of input bytes(since those include the param-eters).We also need a way for the CPU to control or restrict the class of engine operations over which the parameters,possibly chosen externally,are allowed to range.For example:•The external entity may be allowed only to choose certain types of encryption operations(restriction on type).•The CPU may wish to insert indirection on the pa-rameters the external entity chooses and the param-eters the engine sees(e.g.,the external entity pro-vides an index into an internal table,as we did with keys in the experiments).The issues of Section4.2also apply here.。
计算机领域EI和SCI收录期刊及影响因子

计算机相关专业EI及SCI国际会议及期刊汇总1:EI收录的计算机领域国内相关刊物请登陆查看。
2:供硕士生选择的相关刊物序号刊物名称(以期刊名称的拼音为序) 总被引频次影响因子影响因子学科内排名1 电子学报(英文版、中文版)1676 0.450 电子类第12 高技术通讯(英文版、中文版)540 0.294 综合类第22名3 计算机辅助设计与图形学学报945 0.692 计算机类第5名4 计算机工程1342 0.232 计算机类第19名5 计算机工程与应用2165 0.280 计算机类第14名6 计算机集成制造系统819 0.855 计算机类第3名7 计算机科学712 0.280 计算机类第14名8 J COMPUT SCI & TECH 141 0.330 计算机类第12名9 计算机学报1370 0.921 计算机类第1名10 计算机研究与发展1308 0.806 计算机类第4名11 计算机应用785 0.329 计算机类第13名12 计算机应用研究1073 0.428 计算机类第8名13 计算数学(英)中文版242 中文版0.316 数学类第4名中文版4511 中文版0.935 综合类第1名14 科学通报(英)15 模式识别与人工智能348 0.390 计算机类第10名16 软件学报1598 0.919 计算机类第2名17 通信学报581 0.343 电子类第7名18 系统仿真学报867 0.415 信息类第7名19 系统工程理论与实践1372 0.533 信息类第3名20 小型微型计算机系统746 0.275 计算机类第16名E辑 403 E辑 0.444 综合类第10名21 中国科学22 中国图象图形学报1155 0.616 计算机类第7名23 中文信息学报270 0.635 计算机类第6名24 自动化学报(英文版、中文版)中文版876 0.60125 自然科学进展(英文版)中文版562 中文版0.430 综合类第11名26 计算机测量与控制426 0.406 计算机类第9名27 计算机工程与科学235 0.234 计算机类第18名28 计算机仿真294 0.206 计算机类第20名29 计算机工程与设计218 0.203 计算机类第21名30 微电子学与计算机31 中国科学院研究生院学报13:SCI或SCIE收录的计算机学科刊物清单和查看。
基于行人航位推算的室内定位技术综述

基于行人航位推算的室内定位技术综述蔡敏敏【摘要】行人航位推算系统( PDR )因其无需部署信标节点、成本低廉的特点被广泛应用于室内定位中。
围绕基于行人航位推算的室内定位问题,对行人航位推算中步态检测、步长推算以及方向推算的研究现状进行了系统的梳理和述评,综述了基于行人航位推算的室内定位的发展及该领域的一些主要研究成果,指出了该领域现有研究存在的问题,提出了相应建议和深入研究的方向。
%Pedestrian Dead Reckoning (PDR) systems are widely applied in indoor localization for its no requirement of beacon nodes and low cost. This paper reviewed and commented systematically for step detection , step length estimation and heading estimation in Pedestrian Dead Reckoning (PDR) systems. And it reviewed the development and main results of the current research, discussed the limitation of the existing research and finally put forward some further research ideas.【期刊名称】《微型机与应用》【年(卷),期】2015(000)013【总页数】4页(P9-11,16)【关键词】行人航位推算;惯性传感器;智能手机;室内定位【作者】蔡敏敏【作者单位】南京邮电大学通信与信息工程学院,江苏南京 210000【正文语种】中文【中图分类】TN92;TN96;TP3近年来室内定位系统相当流行,基于室内定位的应用有很多,例如,监测病人在医院里的位置、消防员在失事建筑物内的位置等。
CCF推荐国际学术会议

CCF推荐国际学术会议类别如下计算机系统与⾼性能计算,计算机⽹络,⽹络与信息安全,软件⼯程,系统软件与程序设计语⾔,数据库、数据挖掘与内容检索,计算机科学理论,计算机图形学与多媒体,⼈⼯智能与模式识别,⼈机交互与普适计算,前沿、交叉与综合中国计算机学会推荐国际学术会议 (计算机系统与⾼性能计算)⼀、A类序号会议简称会议全称出版社⽹址1ASPLOS Architectural Support for Programming Languages and Operating SystemsACM2FAST Conference on File and StorageTechnologiesUSENIX3HPCA High-Performance Computer Architecture IEEE4ISCA International Symposium on ComputerArchitectureACM/IEEE5MICRO MICRO IEEE/ACM⼆、B类序号会议简称会议全称出版社⽹址1HOT CHIPS A Symposium on High PerformanceChipsIEEE2SPAA ACM Symposium on Parallelism inAlgorithms and ArchitecturesACM3PODC ACM Symposium on Principles ofDistributed ComputingACM4CGO Code Generation and Optimization IEEE/ACM 5DAC Design Automation Conference ACM6DATE Design, Automation & Test in EuropeConferenceIEEE/ACM7EuroSys EuroSys ACM8HPDC High-Performance DistributedComputingIEEE9SC International Conference for High Performance Computing, Networking, Storage, and AnalysisIEEE10ICCD International Conference on ComputerDesignIEEE11ICCAD International Conference on Computer-Aided DesignIEEE/ACM12ICDCS International Conference on Distributed Computing SystemsIEEE13HiPEAC International Conference on High Performance and EmbeddedArchitectures and CompilersACM14SIGMETRICS International Conference onMeasurement and Modeling ofComputer SystemsACM15ICPP International Conference on Parallel ProcessingIEEE16ICS International Conference onSupercomputingACM17IPDPS International Parallel & DistributedProcessing SymposiumIEEE18FPGA ACM/SIGDA International Symposiumon Field-Programmable Gate ArraysACM19Performance International Symposium on Computer Performance, Modeling, Measurementsand EvaluationACM20LISA Large Installation systemAdministration ConferenceUSENIX21MSST Mass Storage Systems andTechnologiesIEEE21MSSTTechnologiesIEEE22PACT Parallel Architectures and Compilation TechniquesIEEE/ACM23PPoPP Principles and Practice of Parallel ProgrammingACM24RTAS Real-Time and Embedded Technologyand Applications SymposiumIEEE25USENIX ATC USENIX Annul Technical Conference USENIX26VEE Virtual Execution Environments ACM三、C类序号会议简称会议全称出版社⽹址1CF ACM International Conference on ComputingFrontiersACM2NOCS ACM/IEEE International Symposium on Networks-on-ChipACM/IEEE3ASP-DAC Asia and South Pacific Design AutomationConferenceACM/IEEE4ASAP Application-Specific Systems, Architectures, and ProcessorsIEEE5CLUSTER Cluster Computing IEEE 6CCGRID Cluster Computing and the Grid IEEE7Euro-Par European Conference on Parallel and Distributed ComputingSpringer8ETS European Test Symposium IEEE9FPL Field Programmable Logic and Applications IEEE 10FCCM Field-Programmable Custom Computing Machines IEEE 11GLSVLSI Great Lakes Symposium on VLSI Systems ACM/IEEE12HPCC IEEE International Conference on HighPerformance Computing and CommunicationsIEEE13MASCOTS IEEE International Symposium on Modeling,Analysis, and Simulation of Computer and Telecommunication SystemsIEEE14NPC IFIP International Conference on Network andParallel ComputingSpringer15ICA3PP International Conference on Algorithms and Architectures for Parallel ProcessingIEEE16CASES International Conference on Compilers, Architectures, and Synthesis for EmbeddedSystemsACM17FPT International Conference on Field-Programmable TechnologyIEEE18CODES+ISSSInternational Conference on Hardware/SoftwareCodesign & System SynthesisACM/ IEEE19HiPC International Conference on High PerformanceComputingIEEE/ ACM20ICPADS International Conference on Parallel andDistributed SystemsIEEE21ISCAS International Symposium on Circuits and Systems IEEE22ISLPED International Symposium on Low PowerElectronics and DesignACM/IEEE23ISPD International Symposium on Physical Design ACM 24ITC International Test Conference IEEE25HotInterconnectsSymposium on High-Performance Interconnects IEEE26VTS VLSI Test Symposium IEEE中国计算机学会推荐国际学术会议 (计算机⽹络)⼀、A类序号会议简称会议全称出版社⽹址1MOBICOM ACM International Conference on MobileACM1MOBICOM ACM International Conference on Mobile Computing and NetworkingACM2SIGCOMM ACM International Conference on the applications, technologies, architectures,and protocols for computer communicationACM3INFOCOM IEEE International Conference onComputer CommunicationsIEEE⼆、B类序号会议简称会议全称出版社⽹址2CoNEXT ACM International Conference onemerging Networking EXperiments and TechnologiesACM3SECON IEEE Communications SocietyConference on Sensor and Ad Hoc Communications and NetworksIEEE4IPSN International Conference on InformationProcessing in Sensor NetworksIEEE/ACM5ICNP International Conference on NetworkProtocolsIEEE6MobiHoc International Symposium on Mobile AdHoc Networking and ComputingACM/IEEE7MobiSys International Conference on MobileSystems, Applications, and ServicesACM8IWQoS International Workshop on Quality ofServiceIEEE9IMC Internet Measurement Conference ACM/USENIX10NOSSDAV Network and Operating System Supportfor Digital Audio and VideoACM11NSDI Symposium on Network System Designand ImplementationUSENIX三、C类序号会议简称会议全称出版社⽹址1ANCS Architectures for Networking andCommunications SystemsACM/IEEE2FORTE Formal Techniques for Networked andDistributed SystemsSpringer3LCN IEEE Conference on Local ComputerNetworksIEEE4Globecom IEEE Global CommunicationsConference, incorporating the GlobalInternet SymposiumIEEE5ICC IEEE International Conference on CommunicationsIEEE6ICCCN IEEE International Conference onComputer Communications and NetworksIEEE7MASS IEEE International Conference on MobileAd hoc and Sensor SystemsIEEE8P2P IEEE International Conference on P2P ComputingIEEE9IPCCC IEEE International PerformanceComputing and CommunicationsConferenceIEEE10WoWMoM IEEE International Symposium on a Worldof Wireless Mobile and MultimediaNetworksIEEE11ISCC IEEE Symposium on Computers and CommunicationsIEEE12WCNC IEEE Wireless Communications &Networking ConferenceIEEE13Networking IFIP International Conferences onNetworkingIFIP14IM IFIP/IEEE International Symposium onIntegrated Network ManagementIFIP/IEEEIntegrated Network Management15MSWiM Analysis and Simulation of Wireless andMobile SystemsACM16NOMS Asia-Pacific Network Operations andManagement SymposiumIFIP/IEEE17HotNets The Workshop on Hot Topics in Networks ACM中国计算机学会推荐国际学术会议 (⽹络与信息安全)⼀、A类序号会议简称会议全称出版社⽹址1CCS ACMConferenceonComputerand CommunicationsSecurityACM2CRYPTO International Cryptology Conference Springer 3EUROCRYPT European Cryptology Conference Springer 4S&P IEEESymposiumonSecurityandPrivacy IEEE5USENIXSecurityUsenix Security SymposiumUSENIXAssociation⼆、B类序号会议简称会议全称出版社⽹址1ACSAC Annual Computer Security Applications ConferenceIEEE2ASIACRYPT Annual International Conference on theTheory and Application of Cryptologyand Information SecuritySpringer3ESORICS EuropeanSymposiumonResearchin ComputerSecuritySpringer4FSE Fast Software Encryption Springer5NDSS ISOC Network and Distributed SystemSecurity SymposiumISOC6CSFW IEEE Computer Security Foundations Workshop 7RAID International Symposium on RecentAdvancesin Intrusion DetectionSpringer8PKC International Workshop on Practice andTheory in Public Key CryptographySpringer9DSN The International Conference onDependableSystems and NetworksIEEE/IFIP10TCC Theory of Cryptography Conference Springer11SRDS IEEE International Symposium onReliable Distributed SystemsIEEE12CHES Workshop on Cryptographic Hardwareand Embedded SystemsSpringer三、C类序号会议简称会议全称出版社⽹址1WiSec ACM Conference on Security and Privacy inWireless and Mobile NetworksACM2ACMMM&SECACM Multimedia and Security Workshop ACM3SACMAT ACM Symposium on Access ControlModelsand TechnologiesACM4ASIACCS ACM Symposium on Information,Computerand Communications SecurityACM5DRM ACM Workshop on Digital RightsManagementACMManagement6ACNS Applied Cryptography and NetworkSecuritySpringer7ACISP AustralasiaConferenceonInformationSecurityandPrivacySpringer8DFRWS Digital Forensic Research Workshop Elsevier 9FC Financial Cryptography and Data Security Springer10DIMVA Detection of Intrusions and Malware &Vulnerability AssessmentSIDAR、GI、Springer11SEC IFIP International Information SecurityConferenceSpringer12IFIP WG11.9IFIP WG 11.9 International Conferenceon Digital ForensicsSpringer13ISC Information Security Conference Springer14SecureCommInternational Conference on Security andPrivacy in Communication NetworksACM15NSPW New Security Paradigms Workshop ACM 16CT-RSA RSA Conference, Cryptographers' Track Springer17SOUPS Symposium On Usable Privacy andSecurityACM18HotSec USENIX Workshop on Hot Topics inSecurityUSENIX20TrustCom IEEE International Conference on Trust,Securityand Privacy in ComputingandCommunicationsIEEE中国计算机学会推荐国际学术会议 (软件⼯程、系统软件与程序设计语⾔)⼀、A类序号会议简称会议全称出版社⽹址1FSE/ESEC ACM SIGSOFT Symposium on the Foundation of Software Engineering/ European Software EngineeringConferenceACM2OOPSLA Conference on Object-Oriented Programming Systems, Languages,and ApplicationsACM3ICSE International Conference on Software EngineeringACM/IEEE4OSDI USENIX Symposium on OperatingSystemsDesign and ImplementationsUSENIX5PLDI ACM SIGPLAN Symposium on Programming Language Design & ImplementationACM6POPL ACM SIGPLAN-SIGACT Symposiumon Principles of ProgrammingLanguagesACM7SOSP ACM Symposium on OperatingSystems PrinciplesACM⼆、B类序号会议简称会议全称出版社⽹址1ECOOP European Conference on Object-Oriented ProgrammingAITO2ETAPS European Joint Conferences on Theoryand Practice of SoftwareSpringer3FM Formal Methods, World Congress FME4ICPC IEEE International Conference onProgram ComprehensionIEEE5RE IEEE International RequirementIEEE5RE IEEE International RequirementEngineering ConferenceIEEE6CAiSE International Conference on Advanced Information Systems EngineeringSpringer7ASE International Conference on AutomatedSoftware EngineeringIEEE/ACM8ICFP International Conf on FunctionProgrammingACM9LCTES International Conference on Languages, Compilers, Tools and Theory forEmbedded SystemsACM10MoDELS International Conference on ModelDriven Engineering Languages andSystemsACM,IEEE11CP International Conference on Principlesand Practice of Constraint ProgrammingSpringer12ICSOC International Conference on ServiceOriented ComputingSpringer13ICSM International. Conference on Software MaintenanceIEEE14VMCAI International Conference on Verification,Model Checking, and AbstractInterpretationSpringer15ICWS International Conference on WebServices(Research Track)IEEE16SAS International Static Analysis Symposium Springer17ISSRE International Symposium on Software Reliability EngineeringIEEE18ISSTA International Symposium on SoftwareTesting and AnalysisACMSIGSOFT19Middleware ACM/IFIP/USENIX20WCRE IEEE21HotOS USENIX三、C类序号会议简称会议全称出版社⽹址1PASTE ACMSIGPLAN-SIGSOFTWorkshoponProgram AnalysisforSoftwareToolsandEngineeringACM2APLAS Asian Symposium on ProgrammingLanguages and SystemsSpringer3APSEC Asia-Pacific Software EngineeringConferenceIEEE4COMPSAC International Computer Software and Applications ConferenceIEEE5ICECCS IEEE International Conference onEngineeringof Complex Computer SystemsIEEE6SCAM IEEE International Working Conferenceon Source Code Analysis and ManipulationIEEE7ICFEM International Conference on FormalEngineering MethodsSpringer8TOOLS International Conference on Objects,Models,Components, PatternsSpringer9PEPM ACM SIGPLAN Symposium on PartialEvaluation and Semantics BasedProgramming ManipulationACM10QSIC International Conference on QualitySoftwareIEEE11SEKE International Conference on SoftwareKSI11SEKE International Conference on Software Engineering and Knowledge EngineeringKSI12ICSR International Conference on SoftwareReuseSpringer13ICWE International Conference on WebEngineeringSpringer14SPIN International SPIN Workshop on ModelChecking of SoftwareSpringer15LOPSTRProgram Synthesis and TransformationSpringer16TASE International Symposium on TheoreticalAspects of Software EngineeringIEEE17ICST The IEEE International Conference onSoftware Testing, Verification andValidationIEEE18ATVATechnology for Verification and Analysis19ESEM International Symposium on EmpiricalSoftware Engineering and MeasurementACM/IEEE20ISPASS IEEE International Symposium onPerformance Analysis of Systems andSoftwareIEEE21SCCComputingIEEE22ICSSPSystem ProcessISPA中国计算机学会推荐国际学术会议 (数据库,数据挖掘与内容检索)⼀、A类序号会议简称会议全称出版社⽹址1SIGMOD ACM Conference on Management ofDataACM2SIGKDD ACM Knowledge Discovery and DataMiningACM3SIGIR International Conference on ResearchanDevelopment in Information RetrievalACM4VLDB International Conference on Very LargeData BasesMorganKaufmann/ACM5ICDE IEEE International Conference on Data EngineeringIEEE⼆、B类序号会议简称会议全称出版社⽹址1CIKM ACM International Conference onInformationand Knowledge ManagementACM2PODS ACM SIGMOD Conference onPrinciples of DB SystemsACM3DASFAA Database Systems for AdvancedApplicationsSpringer4ECML-PKDDEuropean Conference on PrinciplesandPractice of Knowledge Discovery inDatabasesSpringer5ISWC IEEE International Semantic WebConferenceIEEE6ICDM IEEE International Conference on DataMiningIEEE7ICDT International Conference on DatabaseTheorySpringer8EDBT International Conference on ExtendingDBSpringer8EDBT TechnologySpringer 9CIDR International Conference on Innovation Database ResearchOnline Proceeding 10WWW ConferencesSpringer 11SDMSIAM International Conference on Data MiningSIAM三、C 类序号会议简称会议全称出版社⽹址1WSDM ACM International Conference on Web Search and Data MiningACM 2DEXA Database and Expert System ApplicationsSpringer 3ECIR European Conference on IR Research Springer 4WebDB International ACM Workshop on Web and DatabasesACM 5ER International Conference on Conceptual ModelingSpringer 6MDM International Conference on Mobile Data ManagementIEEE 7SSDBM International Conference on Scientific and Statistical DB ManagementIEEE 8WAIM International Conference on Web Age Information ManagementSpringer 9SSTD International Symposium on Spatial and Temporal DatabasesSpringer 10PAKDD Pacific-Asia Conference on Knowledge Discovery and Data MiningSpringer 11APWeb The Asia Pacific Web ConferenceSpringer 12WISE Web Information Systems Engineering Springer 13ESWCExtended Semantic Web ConferenceElsevier中国计算机学会推荐国际学术会议(计算机科学理论)⼀、A 类序号会议简称会议全称出版社⽹址1STOC ACM Symposium on Theory of ComputingACM 2FOCSIEEE Symposium on Foundations ofComputer ScienceIEEE3LICS IEEE Symposium on Logic in Computer ScienceIEEE⼆、B 类序号会议简称会议全称出版社⽹址1SoCG ACM Symposium onComputationalGeometryACM2SODA ACM-SIAM Symposium onDiscreteAlgorithmsSIAM 3CAV Computer Aided VerificationSpringer4CADE/IJCAR Conference on Automated Deduction/The International JointConference onAutomated Reasoning Springer5CCCIEEE Conference onComputational ComplexityIEEE 6ICALPInternational Colloquium onSpringer6ICALP International Colloquium onAutomata,Languages and ProgrammingSpringer7CONCUR International Conference onConcurrency TheorySpringer三、C类序号会议简称会议全称出版社⽹址1CSL Computer Science Logic Springer2ESA European Symposium onAlgorithmsSpringer3FSTTCS Foundations of SoftwareTechnologyand Theoretical Computer ScienceIndianAssociationfor Researchin ComputingScience4IPCO International Conference onIntegerProgramming and Combinatorial OptimizationSpringer5RTA International Conference onRewritingTechniques and ApplicationsSpringer6ISAAC International Symposium onAlgorithms and ComputationSpringer7MFCS Mathematical Foundations ofComputer ScienceSpringer8STACS Symposium on TheoreticalAspectsof Computer ScienceSpringer9FMCAD Formal Method in Computer-AidedDesignACM10SAT Theory and Applications ofSatisfiability TestingSpringer中国计算机学会推荐国际学术会议(计算机图形学与多媒体)⼀、A类序号会议简称会议全称出版社⽹址1ACM MM ACM International Conference on MultimediaACM2SIGGRAPH ACM SIGGRAPH AnnualConferenceACM3IEEE VIS IEEE Visualization Conference IEEE⼆、B类序号会议简称会议全称出版社⽹址1ICMR ACM SIGMM International Conferenceon Multimedia RetrievalACM2i3D ACM Symposium on Interactive 3DGraphicsACM3SCA ACM/Eurographics Symposium onComputer AnimationACM4DCC Data Compression Conference IEEE5EG EurographicsWiley/ Blackwell6EuroVis Eurographics Conference onVisualizationACM7SGP Eurographics Symposium on Geometry ProcessingWiley/Blackwell8EGSR Eurographics Symposium onRenderingWiley/Blackwell IEEE International Conference on9ICME IEEE International Conference on Multimedia &ExpoIEEE10PG Pacific Graphics: The PacificConference on Computer Graphics and ApplicationsWiley/Blackwell11SPM Symposium on Solid and PhysicalModelingSMA/Elsevier三、C类序号会议简称会议全称出版社⽹址1CASA Computer Animation and SocialAgentsWiley2CGI Computer Graphics International Springer3ISMAR International Symposium on Mixedand Augmented RealityIEEE/ACM4PacificVis IEEE Pacific VisualizationSymposiumIEEE5ICASSP IEEE International Conference on Acoustics, Speech and SPIEEE6ICIP International Conference on Image ProcessingIEEE7MMM International Conference onMultimedia ModelingSpringer8GMP Geometric Modeling and Processing Elsevier9PCM Pacific-Rim Conference onMultimediaSpringer10SMI Shape Modeling International IEEE中国计算机学会推荐国际学术会议(⼈⼯智能与模式识别)⼀、A类序号会议简称会议全称出版社⽹址1AAAI AAAI Conference on ArtificialIntelligenceAAAI2CVPR IEEE Conference on Computer VisionandPattern RecognitionIEEE3ICCV International Conference on ComputerVisionIEEE4ICML International Conference on Machine LearningACM5IJCAI International Joint Conference onArtificialIntelligenceMorganKaufmann⼆、B类序号会议简称会议全称出版社⽹址1COLT Annual Conference on ComputationalLearning TheorySpringer2NIPS Annual Conference on NeuralInformationProcessing SystemsMIT Press3ACL Annual Meeting of the Association for Computational LinguisticsACL4EMNLP Conference on Empirical Methods inNaturalLanguage ProcessingACL5ECAI European Conference on ArtificialIntelligenceIOS Press6ECCV European Conference on ComputerVisionSpringer IEEE International Conference on7ICRA IEEE International Conference onRoboticsand AutomationIEEE8ICAPS International Conference onAutomatedPlanning and SchedulingAAAI9ICCBR International Conference on Case-BasedReasoningSpringer10COLING International Conference onComputationalLinguisticsACM11KR International Conference on PrinciplesofKnowledge Representation andReasoningMorganKaufmann12UAI International Conference onUncertaintyin Artificial IntelligenceAUAI13AAMAS on Autonomous Agents and Multi-agentSystemsSpringer三、C类序号会议简称会议全称出版社⽹址1ACCV Asian Conference on Computer Vision Springer2CoNLL Conference on Natural LanguageLearningCoNLL3GECCO Genetic and Evolutionary Computation ConferenceACM4ICTAI IEEE International Conference onTools withArtificial IntelligenceIEEE5ALT International Conference onAlgorithmicLearning TheorySpringer6ICANN International Conference on ArtificialNeuralNetworksSpringer7FGR International Conference on AutomaticFaceand Gesture RecognitionIEEE8ICDAR International Conference on Document Analysis and RecognitionIEEE9ILP International Conference on InductiveLogicProgrammingSpringer10KSEM International conference on Knowledge Science,Engineering and ManagementSpringer11ICONIP International Conference on NeuralInformation ProcessingSpringer12ICPR International Conference on Pattern RecognitionIEEE13ICB International Joint Conference onBiometricsIEEE14IJCNN International Joint Conference onNeuralNetworksIEEE15PRICAI Pacific Rim International ConferenceonArtificial IntelligenceSpringer16NAACL The Annual Conference of the NorthAmerican Chapter of the Associationfor Computational LinguisticsNAACL17BMVC British Machine Vision Conference British MachineVision Association中国计算机学会推荐国际学术会议(⼈机交互与普适计算)⼀、A类序号会议简称会议全称出版社⽹址1CHI ACM Conference on Human Factors in Computing SystemsACM2UbiComp ACM International Conference onUbiquitous ComputingACM⼆、B类序号会议简称会议全称出版社⽹址1CSCW ACM Conference on ComputerSupported Cooperative Work and Social ComputingACM2IUI ACM International Conference onIntelligent User InterfacesACM3ITS ACM International Conference onInteractive Tabletops and SurfacesACM4UIST ACM Symposium on User InterfaceSoftware and TechnologyACM5ECSCW European Computer SupportedCooperative WorkSpringer6MobileHCI International Conference on HumanComputer Interaction with MobileDevices and ServicesACM三、C类序号会议简称会议全称出版社⽹址1GROUP ACM Conference on Supporting Group Work ACM2ASSETS ACM Conference on Supporting Group Work ACM3DIS ACM Conference on Designing InteractiveSystemsACM4GI Graphics Interface conference ACM5MobiQuitous International Conference on Mobile and Ubiquitous Systems: Computing, Networking and ServicesSpringer6PERCOM IEEE International Conference onPervasive Computing and CommunicationsIEEE7INTERACT IFIP TC13 Conference on Human-ComputerInteractionIFIP8CoopIS International Conference on CooperativeInformation SystemsSpringer9ICMI ACM International Conference on MultimodalInteractionACM10IDC Interaction Design and Children ACM11AVI International Working Conference on AdvancedUser InterfacesACM12UIC IEEE International Conference on Ubiquitous Intelligence and ComputingIEEE中国计算机学会推荐国际学术会议(前沿、交叉与综合)⼀、A类序号会议简称会议全称出版社⽹址1RTSS Real-Time Systems Symposium IEEE⼆、B类序号会议简称会议全称出版社⽹址1EMSOFT International Conference onEmbedded SoftwareACM/IEEE/IFIP2ISMB International conference onIntelligent Systems for MolecularBiologyOxford Journals3CogSci Cognitive Science Society AnnualConferencePsychology Press4RECOMB International Conference onResearch in ComputationalMolecular BiologySpringer5BIBM IEEE International Conference on Bioinformatics and BiomedicineIEEE三、C类序号会议简称会议全称出版社⽹址1AMIA American Medical InformaticsAssociation Annual SymposiumAMIA2APBC Asia Pacific BioinformaticsConferenceBioMed Central3COSIT International Conference onSpatial Information TheoryACM。
Research Interests

Mihai ChristodorescuDepartment of Computer Sciences University of Wisconsin,Madison 1210W.Dayton St.Madison,WI53706,USAVoice:+1608-695-6271Fax:+1608-262-9777/~mihaimihai@ Curriculum VitæResearch InterestsI am interested in all aspects of computer security,with particular emphasis on software security.My current research tackles computer security problems using formal methods that combine pro-gram verification and program analysis to provide quantifiable security guarantees.My dissertation introduces techniques for the detection of malicious behavior inside obfuscated binary code. Education2003–present Ph.D.in Computer Sciences,expected May2007.University of Wisconsin,Madison,WI,USA.Dissertation:Behavior-based Malware Detection.Adviser:Prof.Somesh Jha.1999–2000,2001–2002M.S.in Computer Sciences,Dec.2002.University of Wisconsin,Madison,WI,USA.Adviser:Prof.Somesh Jha.1996–1999 B.S.(High Honors)in Computer Science,May1999.University of California,Santa Barbara,CA,USA.Research Experience2001–present Research Assistant,Wisconsin Safety Analyzer(WiSA)project.University of Wisconsin,Madison,WI,USA.The WiSA project focuses on the use of static analysis to detect vulnerabilitiesin commercial off-the-shelf components(COTS).My research work involves newapproaches to the detection of malicious behavior in obfuscated binary code,usingstatic program analysis and formal methods.2000Research Assistant,Paradyn project.University of Wisconsin,Madison,WI,USA.The Paradyn project develops technology that aids tool and application developersin their pursuit of high-performance,scalable,parallel and distributed software.My research work produced thefirst reentrant binary instrumentation of runningprocesses using the DynInst API.PublicationsDigital copies can be downloaded from /~mihai/publications/.Books1.M.Christodorescu,S.Jha,D.Maughan,D.Song,and C.Wang,editors.Malware Detection,volume27of Advances in Information Security.Springer-Verlag,Oct.2006.Conference Publications2.M. D.Preda,M.Christodorescu,S.Jha,and S.Debray.A semantics-based approach tomalware detection.In Proceedings of the34th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages(POPL’07),Nice,France,Jan.17–19,2007.POPL’07acceptance rate:18.18%(36/198). 3.J.Giffin,M.Christodorescu,and L.Kruger.Strengthening software self-checksumming viaself-modifying code.In Proceedings of the21st Annual Computer Security Applications Confer-ence(ACSAC’05),pages18–27,Tucson,AZ,USA,Dec.5–9,2005.Applied Computer Asso-ciates,IEEE Computer Society.ACSAC’05acceptance rate:22.8%(45/197).4.S.Rubin,M.Christodorescu,V.Ganapathy,J.T.Giffin,L.Kruger,H.Wang,and N.Kidd.Anauctioning reputation system based on anomaly detection.In Proceedings of the12th ACM Conference on Computer and Communications Security(CCS’05),pages270–279,New York,NY, USA,2005.ACM Press.CCS’05acceptance rate:15.2%(38/250).5.M.Christodorescu,N.Kidd,and W.-H.Goh.String analysis for x86binaries.In Proceed-ings of the6th ACM SIGPLAN-SIGSOFT Workshop on Program Analysis for Software Tools and Engineering(P ASTE’05),Lisbon,Portugal,Sept.5–6,2005.ACM Press.PASTE’05acceptance rate:44.7%(17/38).6.M.Christodorescu,S.Jha,S.A.Seshia,D.Song,and R.E.Bryant.Semantics-aware malwaredetection.In Proceedings of the IEEE Symposium on Security and Privacy(S&P’05),pages32–46, Oakland,CA,USA,May8–11,2005.IEEE Computer Society.S&P’05acceptance rate:8.9%(17/192).7.M.Christodorescu and S.Jha.Testing malware detectors.In Proceedings of the ACM SIGSOFTInternational Symposium on Software Testing and Analysis(ISSTA’04),pages34–44,Boston,MA, USA,July11–14,2004.ACM SIGSOFT,ACM Press.ISSTA’04acceptance rate:27.9%(26/93).8.M.Christodorescu and S.Jha.Static analysis of executables to detect malicious patterns.InProceedings of the12th USENIX Security Symposium(Security’03),pages169–186,Washington, DC,USA,Aug.4–8,ENIX Association.Security’03acceptance rate:16.4%(21/128).Journal Publications9. ler,M.Christodorescu,R.Iverson,T.Kosar,A.Mirgorodskii,and F.Popovici.Play-ing inside the black box:Using dynamic instrumentation to create security holes.Parallel Processing Letters,11(2/3):267–280,June/Sept.2001.Invited Publications10.M.Christodorescu and S.Rubin.Can cooperative intrusion detectors challenge the base-ratefallacy?In Malware Detection,volume27of Advances in Information Security,pages193–209, Aug.2005.This edited volume represents the proceedings of the2005ARO-DHS Special Workshop on Malware Detection,Aug.10–11,2005,Arlington,VA,USA.Technical Reports11.M.Christodorescu,J.Kinder,S.Jha,S.Katzenbeisser,and H.Veith.Malware normalization.Technical Report1539,University of Wisconsin,Madison,WI,USA,Nov.2005.12.J.T.Giffin,M.Christodorescu,and L.Kruger.Strengthening software self-checksummingvia self-modifying code.Technical Report1531,University of Wisconsin,Madison,WI,USA,Sept.2005.13.T.Kosar,M.Christodorescu,and R.Iverson.Opening pandora’s box:Using binary coderewrite to bypass license checks.Technical Report1479,University of Wisconsin,Madison,WI,USA,Apr.2003.14.M.Christodorescu and S.Jha.SAFE:Static analysis for executables.Technical Report1467,University of Wisconsin,Madison,WI,USA,Feb.2003.Patents15.M.Christodorescu,S.Jha,J.Kinder,S.Katzenbeisser,and H.Veith.Malware normalization.Patent application in progress,2006.16.M.Christodorescu and S.Jha.Method and apparatus to detect malicious software.UnitedStates patent application20050028002,July29,2003.In Submission17.M.Christodorescu,C.Kruegel,and S.Jha.On inferring specifications of malicious behavior.In submission,Sept.2005.Selected Awards and Achievements2004Distinguished ACM SIGSOFT paper award atInternational Symposium on Software Testing and Analysis(ISSTA’04),2004,Boston,MA,USA.(See publication7.)1996–1999Dean’s honor list at University of California,Santa Barbara.Selected PresentationsConference TalksMay2005“Semantics-Aware Malware Detection”Presented at the IEEE Symposium on Security and Privacy,Oakland,CA,USA,2005.July2005“Testing Malware Detectors”Presented at the International Symposium on Software Testing and Analysis(ISSTA),Boston,MA,USA,2004.Aug.2003“Static Analysis of Executables to Detect Malicious Patterns”Presented at the12th USENIX Security Symposium,Washington,DC,USA,2003.Invited TalksFeb.2006“Testing Malware Detectors/Semantics-Aware Malware Detection”Presented at TrendMicro’s“Meeting of the Minds,”Las Vegas,NV,USA,2006.Sept.2005“Directions in Malware Detection Research”Presented at the3rd workshop of the ARDA Malware Roadmap series,Salt LakeCity,UT,USA,2005.Aug.2005“Improved Defenses through Cooperation of Network-based and Host-based Mal-ware Detectors”Presented at the ARO–DHS Special Workshop on Malware Detection,Arlington,VA,USA,2005.Selected Presentations(continued)Nov.2003“Static Analysis of Executables to Detect Malicious Patterns”Presented at the Software Protection Compilation Workshop,Washington,DC,USA,2003.Teaching Experience2006Teaching Assistant for“Introduction to Information Security.”Graduate and senior-undergraduate level course.Instructor:Somesh Jha.(Universityof Wisconsin,Madison,Computer Sciences course642,Spring2006)Workshop on“The Act of Teaching:Theatrical Tips for Teachers.”Presented by Nancy Houfek,head of voice and speech at Harvard’s Institute forAdvanced Theatre anized by the UW Delta Research Teaching andLearning Community.(Sept.2006)2003–2006Invited Lecturer on malicious code and attack methods.Mentor for several course projects.Course:“Introduction to Information Security.”Instructor:Somesh Jha.(Universityof Wisconsin,Madison,Computer Sciences course642,Spring semester) 2004Workshop on“Creating a Teaching and Learning Philosophy.”Organized by the UW Delta Research Teaching and Learning Community.(Nov.2004)2001Mentor for two course projects.Course:“Analysis of Software Artifacts.”Instructor:Somesh Jha.(University ofWisconsin,Madison,Computer Sciences course706,Fall2001)1999Teaching Assistant for“Java for C++programmers”and“C++for Java program-mers.”Junior-undergraduate level.Instructor:Susan Horwitz.(University of Wisconsin,Madison,Computer Sciences course368,Fall1999)Professional ActivitiesExternal reviewerJournals:ACM Transactions on Internet Technology(TOIT):2004.Communications of the ACM(CACM):2005issue on spyware.Journal of Computer Security(JCS):2006.Conferences:Foundations of Computer Security Workshop(FCS):2001.Symposium on Requirements Engineering for Info.Security(SREIS):2002.USENIX Technical:2004.Network and Distributed System Security Symposium(NDSS):2005,2007.International World Wide Web Conference(WWW):2005.USENIX Security:2005,2006.International Conference on Computer Aided Verification(CAV):2005.Software Engineering for Secure Systems(SESS):2005.Recent Advances in Intrusion Detection(RAID):2005.ACM Conference on Computer and Comm.Security(CCS):2005,2006.Workshop on Rapid Malcode(WORM):2005.LCI International Conference on Clusters:2006.Annual Computer Security Applications Conference(ACSAC):2006.Professional Activities(continued)Research community involvement•Workgroup on Future Malware Threats,3rd workshop of the ARDA Malware Roadmap series, Sept.20–22,2005,Salt Lake City,UT,USA.•Workgroup on Malware Detection,ARO–DHS Special Workshop on Malware Detection,Aug.10–11,2005,Arlington,VA,USA.•ONR CIP/SW MURI Project Review for Dr.James Whittaker(FIT),“Runtime Neutralization of Malicious Mobile Code,”Feb.2005.•Software Protection Compilation Workshop,Nov.12–13,2003,Washington,DC,USA.•Student volunteer for the11th USENIX Security Symposium(Security’02),Aug.5–9,2002,San Francisco,CA,USA.Academic activities•Member of the Graduate Admissions Committee at the Department of Computer Sciences,Uni-versity of Wisconsin,Madison,2002.•Organizer of the computer security seminar at the Department of Computer Sciences,University of Wisconsin,Madison,2001–2006.•Coordinator of the computer security reading group at the Department of Computer Sciences, University of Wisconsin,Madison,2001–2006.Collaboration with industry2006–present Co-founder of Securitas Technologies,Inc.,a Madison,WI,provider of behavior-based malware-detection products.2005–present Transfer of technology for“Effective Malware Detection Through Static Analysis”to Grammatech,Inc.,Ithaca,NY.(ONR STTR Phases I and II) 2006Attended TrendMicro’s“Meeting of the Minds,”Feb.13,2006,Las Vegas,NV, USA.Industrial Employment2006–present Principal Scientist,Securitas Technologies,Inc.,Madison,WI,USA.Spearheaded the transition of the semantics-aware malware detector from re-search prototype to software product.2000–2001Senior Software Engineer,Yodlee,Inc.,Redwood City,CA,USA.Optimized performance offinancial-data aggregation platform.Created bill-payment prototype integrated intofinancial website.Apr.–June1999Embedded Systems Developer,Green Hills Software,Santa Barbara,CA,USA.Ported a cross-platform linker to new targets.Evaluated existing commonalitiesamong embedded CPUs to simplify linker code and speed link time.TranslatedC-based linker modules to new C++architecture.Feb.–Apr.1999Application Software Developer,ZBE,Goleta,CA.Redesigning and implementing new printer control and spooling utilities forhigh-performance and high-quality specialized printers.Studied old code forreusability capabilities.Industrial Employment(continued)June–Sep.1998SNA Server Developer/Summer Intern,Microsoft,Redmond,WA,USA.Completely redesigned the single sign-on user management system,improvingthe response time as well as the recoverability of the Host Security product.Learned new technologies in a short amount of time(such as COM,DCOM,OLE,and OLEDB).Analyzed and proofed the code against threading issues,resource contention,and timing issues.1997–1998NT Systems Developer,Pontis Reseach Inc.,Camarillo,CA,USA.Specialized in distributed security in heterogeneous environments,with em-phasis on NT security and integration of security systems.Tested CTOS-to-NTsecurity interface.Developed and tested NT NetWare Single Sign-on product.Developed a transaction based unified NT security API with rollback capabili-ties.1996–1997Web Designer,Student Computing Facilities,School of Environmental Science and Management,University of California at Santa Barbara,CA,USA.Managed the departmental network of Windows NT,Windows95,and Pow-erPC computers.Designed web pages for internal use(help pages),as well as aprototype for a database with web interface.1995–1996Computer-based Test Technician,Advanced Motion Controls Camarillo,CA,USA.Tested the products on computer,using DAQ in-house developed software.Im-proved the testing technology with regard to speed and accuracy.Full timeemployment.Personal Information•Born in Romania and naturalized citizen of the US.•Language proficiency:English,Romanian,French(written).ReferencesReferences available upon request.。
信息安全四大顶会

信息安全四⼤顶会最近才了解到国际上安全领域的顶级会议【羞愧、⾃省.......安全界有四⼤著名顶级会议,简称:S&P、CCS、Security、NDSS。
⼀、USENIX Security⼆、S&P:IEEE Symposium on Security and Privacy三、CCS:ACM Conference on Computer and Communications Security四、NDSS: Network and Distributed System Security Symposium其他顶级会议期刊:IEEE TRANSACTIONS ON COMPUTERSComputer VisionConf.:Best: ICCV, Inter. Conf. on Computer VisionCVPR, Inter. Conf. on Computer Vision and Pattern RecognitionGood: ECCV, Euro. Conf. on Comp. VisionICIP, Inter. Conf. on Image ProcessingICPR, Inter. Conf. on Pattern RecognitionACCV, Asia Conf. on Comp. VisionJour.:Best: PAMI, IEEE Trans. on Patt. Analysis and Machine IntelligenceIJCV, Inter. Jour. on Comp. VisionGood:CVIU, Computer Vision and Image UnderstandingPR, Pattern Reco.NetworkConf.:ACM/SigCOMM ACM Special Interest Group of Communication..ACM/SigMetric 这个系统⽅⾯也有不少的Info Com ⼏百⼈的⼤会,不如ACM/SIG的精。
Abstract Design and Implementation of Semi-preemptible IO

is thus undesirable. Making disk IOs preemptible would reduce blocking and improve the schedulability of realtime disk IOs. Another domain where preemptible disk access is essential is that of interactive multimedia such as video, audio, and interactive virtual reality. Because of the large amount of memory required by these media data, they are stored on disks and are retrieved into main memory only when needed. For interactive multimedia applications that require short response time, a disk IO request must be serviced promptly. For example, in an immersive virtual world, the latency tolerance between a head movement and the rendering of the next scene (which may involve a disk IO to retrieve relevant media data) is around 15 milliseconds [2]. Such interactive IOs can be modeled as higher-priority IO requests. However, due to the typically large IO size and the non-preemptible nature of ongoing disk commands, even such higherpriority IO requests can be kept waiting for tens, if not hundreds, of milliseconds before being serviced by the disk. To reduce the response time for a higher-priority request, its waiting time must be reduced. The waiting time for an IO request is the amount of time it must wait, due to the non-preemptibility of the ongoing IO request, before being serviced by the disk. The response time for the higher-priority request is then the sum of its waiting time and service time. The service time is the sum of the seek time, rotational delay, and data transfer time for an IO request. (The service time can be reduced by intelligent data placement [27] and scheduling policies [26]. However, our focus is on reducing the waiting time by increasing the preemptibility of disk access.) In this study, we explore Semi-preemptible IO (previously called Virtual IO [5]), an abstraction for disk IO, which provides highly preemptible disk access (average preemptibility of the order of one millisecond) with little loss in disk throughput. Semi-preemptible IO breaks the components of an IO job into fine-grained physical diskcommands and enables IO preemption between them. It
hadoop实验报告

hadoop实验报告1. 引言随着互联网的快速发展和大数据时代的到来,传统的数据处理方法已经无法满足海量数据的处理需求。
在这个背景下,分布式存储和计算框架Hadoop应运而生。
本篇文章将从搭建集群环境、数据导入、任务执行和性能评估等方面进行Hadoop实验的报告。
2. 搭建集群环境在实验开始之前,我们需要搭建一个Hadoop集群环境。
首先,我们需要准备一台主节点和若干台从节点。
主节点将负责整个集群的协调工作,从节点将执行具体的任务。
通过配置和启动Hadoop的各个组件,我们可以实现数据的并行计算和故障容错。
为了确保集群的高可用性和性能,我们还可以使用Hadoop的分布式文件系统HDFS来存储数据。
3. 数据导入数据的导入是Hadoop实验的第一步。
在本次实验中,我们选择了一份包含大量文本数据的文件作为输入。
通过Hadoop提供的命令行工具,我们可以将数据导入到HDFS中进行后续的处理。
不同的数据导入方式可以根据实际需求选择,一般包括本地文件上传、网络数据传输等。
4. 任务执行在集群环境搭建完成并将数据导入到HDFS之后,我们可以开始执行具体的计算任务。
Hadoop支持两种模型:MapReduce和Spark。
MapReduce是Hadoop最早的计算模型,其核心思想是将大规模的数据集划分成许多小的数据块,由多个Mapper和Reducer并行地执行计算任务。
而Spark则是一种更加灵活和高效的计算模型,它将数据集以弹性分布式数据集(RDD)的形式存储在内存中,通过多次迭代快速进行计算。
5. 性能评估对于一个分布式计算框架来说,性能评估是非常重要的。
通过对Hadoop实验中的任务执行时间、计算效率和数据处理能力等指标的测量,我们可以评估集群的性能瓶颈并寻找优化的方法。
常见的性能评估指标包括吞吐量、数据处理速度和并发处理能力等。
6. 结果与讨论在本次实验中,我们成功搭建了一个Hadoop集群环境,并将大量的文本数据导入到HDFS中。
机器人自动寻址设计

参考文献 : 1.M. David, S. Colleen, J. B. Douglas, et al, Inferring Internet denial- of- service activity[J], 2006, ACM Press, 115- 139. 2.U. Tariq, M. Hong and K.- s. Lhee, A Comprehensive Categorization of DDoS Attack and DDoS Defense Techniques [J], 2006, Advanced Data Mining and Applications, 1025- 1036. 3.L. Feinstein, D. Schnackenberg, R . Balupari, et al, Statistical approaches to DDoS attack detection and response [C], 2003, DAR PA Information Survivability Conference and Exposition, 303- 314. 4.J. Shuyuan and D. S. Yeung, A covariance analysis model for DDoS at- tack detection [C],2004, Communications, IEEE International Conference, 1882- 1886. 5.M. G. Thomer and P. Massimiliano, MULTOPS: a data - structure for bandwidth attack detection[C], 2001, Washington, D.C.: USENIX Associa- tion, Proceedings of the 10th conference on USENIX Security Symposium. 6. 程光 , 龚俭 , 丁伟 , 基于抽样测量的高速网 络 实 时 异 常 检 测 模 型 [J], 软 件学报 , 2003, 14(03): 594- 599. 7. 程光 , 龚俭 , 丁伟 , 基于统计分析的高速网络分布式抽样测量模型 [J], 计算机学报 , 2003, 10: 1266- 1273. 8.M. Jelena and R . Peter, A taxonomy of DDoS attack and DDoS defense mechanisms[J], 2004, ACM Press, 39- 53.
EarnCache:一种增量式大数据缓存策略

EarnCache:一种增量式大数据缓存策略郭俊石;罗轶凤【摘要】在共享的大数据集群中,租户竞争可能导致内存资源分配不公平以及利用效率低下.为了提高缓存利用效率和公平性,针对大数据应用的特性,提出一种增量式缓存策略称为EarnCache,即文件被访问得越多,获得的缓存资源就越多.利用文件被访问频率的历史信息,将缓存分配与替换问题抽象成优化问题,给出解决方案.并在分布式存储系统中实现了EamCache及MAX-MIN等不同算法,进行性能分析.实验表明,EarnCache可以提高大数据缓存效率和总体资源利用率.%In shared big data clusters,there exists intense competition for memory resources,which may lead to unfairness and low efficiency in cache utilization.In view of this and based on the characteristics of big data applications,we propose an incremental caching strategy called EarnCache.The basic idea is that the more frequently a file is assessed,the more cache resource it gains.We utilize file accessing irfformation,and further formulize and solve cache allocation and replacement problem as an optimizationproblem.EarnCache and other cache replacement algorithms like MAX-MIN are implemented on a distributed file system and analyzed in detail.The experimental evaluation demonstrates that EarnCache could enhance the cache efficiency for shared big data clusters with improved resource utilization.【期刊名称】《计算机应用与软件》【年(卷),期】2017(034)011【总页数】5页(P44-47,102)【关键词】大数据;缓存分配;增量式【作者】郭俊石;罗轶凤【作者单位】复旦大学计算机科学技术学院上海市智能信息处理重点实验室上海200433;复旦大学计算机科学技术学院上海市智能信息处理重点实验室上海200433【正文语种】中文【中图分类】TP3随着大数据应用对实时运算需求的提升和内存价格的下降,使用内存来缓存数据、加速运算逐渐成为一种趋势。
计算机投稿期刊&&会议等级划分

Reference:国际会议及期刊星级说明(学术影响力):引自李晓明,2007-3-4, "做全面发展的研究生" 一文0级:国内会议,国内核心刊物,如SEWM,《计算机应用》,《计算机工程与应用》,《计算机工程与设计》1级:国内发起并主办的国际学术会议(例如Intl Conf. on Computer Networks and Mobile Computing,GCC)2级:国内一级学术期刊,如《计算机学报》,《计算机研究与发展》,《软件学报》等,重要的地区性国际会议(例如PAKDD,ICADL,APWEB,WAIM,ICCIT, ISPA,ICWL等)2.5级:国际专业知名会议(例如ICWE,DASFAA),影响因子在1.0以下的知名国际专业刊物(例如Intl Journal of Information Technology,Journal of Information Science,Journal of Computer Science and Technology, Journal of Web Engineering,等),《中国科学》,《科学通报》等3级:国际专业品牌会议(例如EDBT,ICDCS),影响因子在1.0-2.0之间的国际专业刊物(例如IEEE Transactions on Computer, Sigmod Record, Journal of Computer Networks,Journal of Software and Systems)4级:国际专业顶级会议(例如SIGMOD,VLDB,CIKM,IC DE,SIGIR,SIGKDD,WWW)与国际著名刊物(例如ACM Computing Surveys, VLDB Journal, ACM Transaction on Information Systems等,以及IEEE Transactions系列中影响因子在2.0以上的)5级:国际著名综合品牌刊物(例如PNAS,Nature,Science等)以下是除5级以外的会议及期刊星级分类:4.0 国际专业顶级会议(A类或引用因子>0.9)ACM Special Interest Group on Data Communication(SIGCOMM)ACM Special Interest Group on Mobility of Sys-tems, Users, Data and Computing (MOBICOM)ACM Special Interest Group on Measurement and Evaluation (SIGMETRICS)ACM/IEEE Intl Symposium on Mobile Ad Hoc Networking and Computing (MOBIHOC)ACM/IEEE World Wide Web Conf. (WWW)Knowledge Discovery and Data Mining (SIGKDD)IEEE Intl Conf. on Data Engineering (ICDE)Intl Conf. on Very Large DataBase (VLDB)Special Interest Group on Information Retrieval (SIGIR)ACM SIGMOD Conf. on Management of Data/Principles of DB SystemsExtending DB Technology (EDBT)Usenix Symp on OS Design and Implementation (OSDI)ACM SIGOPS Symp on OS Principles (SOSP:)Intl Conf. on Machine Learning (ICML)Intl. Conf on Information and Knowledge Management (CIKM)Annual Meeting of the ACL (Association of Computational Linguistics) (ACL)Intl Conf on Extending DB Technology (EDBT)Database and Expert System Applications (DEXA)Symposium on High-Perf Comp Architecture (HPCA )3.5 国际专业品牌会议(B类或0.8<引用因子<0.9)ACM Intl Conf. on Embedded Networked Sensor Systems(SenSys)ACM/SIGAPP Symposium on Applied Computing(SAC)ACM Symp on Principles of Distributed Computing (PODC)IEEE Intl Conf. on Network Protocols (ICNP)IEEE Conf. on Computer Communications (INFOCOM)IEEE Intl Conf. on Distributed Computing Systems (ICDCS)IEEE Intl Conf. on Pervasive Computing and Communications (PerCom)IEEE Conf. on Local Computer Networks (LCN)IEEE Wireless Communications and Networking Conf. (WCNC)IEEE Intl Conf on Networking Topology in Computer Science Conf.(ICN)IEEE Intl Conf. on Mobile Ad-hoc and Sensor Systems(MASS)USENIX USENIX Annual Technical Conf.USENIX Network and Distributed System Security Symposium (NDSS)Intl conf. on Wireless Networks (ICWN)USENIX Conf on Internet Tech and SysIntl Conf on Parallel Arch and Compil Tech (PACT)Symposium on Parallel Algms and Architecture (SPAA )Intl Database Engineering and Application Symposium (IDEAS)3.0 国际专业品牌会议(C类或0.7<引用因子ACM/USENIX Intl Conf. on Mobile Systems, Applications, and Services (MobiSys)ACM/IEEE Annual Intl Conf. on Mobile and Ubiquitous Systems: Computing, Networking and Services (MOBIQUITOUS)ACM Intl Workshop on Mobility in the Evolving Internet Architecture (MobiArch)ACM/IEEE Intl Conf. on Information Processing in Sensor Networks (IPSN)ACM Intl Conf. on Web Search and Data Mining (WSDM)ACM/IEEE Joint Conf. on Digital Libraries (JCDL)IEEE Intl Workshop on Quality of Service (IWQoS)IEEE Intl Parallel and Dist Processing Symp (IPDPS)IEEE/ACM Conf. on High Performance Computing Networking and Storage (Supercomputing)IEEE/ACM Intl Conf. on Information Processing in Sensor Networks (IPSN)IEEE Intl Conf. on Data Mining (ICDM)IEEE Global Communications Conf., incorporating the Global Internet Symposium (Globecom)IEEE Intl Phoenix Conf on Comp & Communications(IPCCC)USENIX Conf. on File and Storage Technologies(FAST)USENIX Symp on Networked Systems Design & Implementation (NSDI)USENIX Intl Workshop on Peer-to-Peer Systems (IPTPS)Intl conf. on Computer Communication (ICCC)IFIP Intl Conf.s on Networking (Networking)Workshop on Data Engineering for Wireless and Mobile Acc (MobiDE)European Conf. on Machine Learning (ECML)European Conf. on Information Retrieval (ECIR)Database Systems for Advanced Applications (DASFAA)2.5 地区专业品牌会议(0.6<引用因子<0.7)ACM Intl Symposium on Modeling, Analysis and Simulation of Wireless and Mobile Systems (MSWiM) IEEE Conf on P2P Computing(P2P)IEEE Communications Society Conf on Sensor and Ad Hoc Communications and Networks(SECON) IEEE Intl Conf on Comp Comm and Networks (ICCCN)IEEE SYMPOSIUM ON COMPUTERS AND COMMUNICATIONS (ISCC)IEEE Semiannual Vehicular Technology Conf (VTC)IEEE/IFIP Network Operations and Management Symposium (MONS)IEEE/IFIP Intl Symposium on Integrated Network Management (IM)IEEE Intl Symposium on Reliable Distributed Systems(SRDS)FORTE Formal Techniques for Networked and Distributed SystemsThe Pacific-Asia Conf on Knowledge Discovery and Data Mining(PAKDD)Asia Pacific Web Conf / Intl Conf. on Web Age Information Management (APWeb / WAIM)Text REtrieval Conf(TREC)Human Language Technology Conf(HLT)Conf of the Intl. Committee on Computational Linguistics (COLLING)Intl Semantic Web Conf(ISWC)European Semantic Web Conf(ECWC)Intl Conf. on Asian Digital Libraries (ICADL)European Conf. on Digital Libraries (ECDL)2.0 地区专业品牌会议(0.5<引用因子<0.6)Intl Conf. on Parallel and Distributed Systems (ICPADS)ACM Workshop on Wireless Mobile Multimedia (WOWMOM)IEEE Intl Conf. on Communications (ICC)Intl Symposium on Parallel and Distributed Processing and Applications (ISPA)Intl Conf on Pervasive Systems and Computing (PSC)Asia Information Retrieval Symp (AIRS)Asia Pacific Web Conf. (APWEB)Intl Conf. on Web-based Learning (ICWL)1.0 国内发起并主办的国际会议Grid Computing Conf. (GCC)Semantic Knowledge Grid (SKG)Intl Conf. on Natural Computation / Intl Conf. on Fuzzy Systems and Knowledge Discovery (ICNC/FSKD) mobiCHINA0.0 国内会议SEWM: Sympo of Search Engine and Web MiningCNCC:中国计算机大会。
国际学术会议影响因子

Estimated impact of publication venues in Computer Science (higher is better) - May 2003 (CiteSeer)Generated from documents in the CiteSeer database. This analysis does not include citations where one or more authors of the citing and cited articles match. This list is automatically generated and may contain errors. Only venues with at least 25 articles are shown.Impact is estimated using the average citation rate, where citations are normalized using the average citation rate for all articles in a given year, and transformed using ln (n+1) where n is the number of citations.Publication details obtained from DBLP by Michael Ley. Only venues contained in DBLP are included.1. OSDI: 3.31 (top 0.08%)2. USENIX Symposium on Internet Technologies and Systems:3.23 (top 0.16%)3. PLDI: 2.89 (top 0.24%)4. SIGCOMM: 2.79 (top 0.32%)5. MOBICOM: 2.76 (top 0.40%)6. ASPLOS: 2.70 (top 0.49%)7. USENIX Annual Technical Conference: 2.64 (top 0.57%)8. TOCS: 2.56 (top 0.65%)9. SIGGRAPH: 2.53 (top 0.73%)10. JAIR: 2.45 (top 0.81%)11. SOSP: 2.41 (top 0.90%)12. MICRO: 2.31 (top 0.98%)13. POPL: 2.26 (top 1.06%)14. PPOPP: 2.22 (top 1.14%)15. Machine Learning: 2.20 (top 1.22%)16. 25 Years ISCA: Retrospectives and Reprints: 2.19 (top 1.31%)17. WWW8 / Computer Networks: 2.17 (top 1.39%)18. Computational Linguistics: 2.16 (top 1.47%)19. JSSPP: 2.15 (top 1.55%)20. VVS: 2.14 (top 1.63%)21. FPCA: 2.12 (top 1.71%)22. LISP and Functional Programming: 2.12 (top 1.80%)23. ICML: 2.12 (top 1.88%)24. Data Mining and Knowledge Discovery: 2.08 (top 1.96%)25. SI3D: 2.06 (top 2.04%)26. ICSE - Future of SE Track: 2.05 (top 2.12%)27. IEEE/ACM Transactions on Networking: 2.05 (top 2.21%)28. OOPSLA/ECOOP: 2.05 (top 2.29%)29. WWW9 / Computer Networks: 2.02 (top 2.37%)30. Workshop on Workstation Operating Systems: 2.01 (top 2.45%)31. Journal of Computer Security: 2.00 (top 2.53%)32. TOSEM: 1.99 (top 2.62%)33. Workshop on Parallel and Distributed Debugging: 1.99 (top 2.70%)34. Workshop on Hot Topics in Operating Systems: 1.99 (top 2.78%)35. WebDB (Informal Proceedings): 1.99 (top 2.86%)36. WWW5 / Computer Networks: 1.97 (top 2.94%)37. Journal of Cryptology: 1.97 (top 3.03%)38. CSFW: 1.96 (top 3.11%)39. ECOOP: 1.95 (top 3.19%)40. Evolutionary Computation: 1.94 (top 3.27%)41. TOPLAS: 1.92 (top 3.35%)42. SIGSOFT FSE: 1.88 (top 3.43%)43. CA V: 1.88 (top 3.52%)44. AAAI/IAAI, Vol. 1: 1.87 (top 3.60%)45. PODS: 1.86 (top 3.68%)46. Artificial Intelligence: 1.85 (top 3.76%)47. NOSSDA V: 1.85 (top 3.84%)48. OOPSLA: 1.84 (top 3.93%)49. ACM Conference on Computer and Communications Security: 1.82 (top 4.01%)50. IJCAI (1): 1.82 (top 4.09%)51. VLDB Journal: 1.81 (top 4.17%)52. TODS: 1.81 (top 4.25%)53. USENIX Winter: 1.80 (top 4.34%)54. HPCA: 1.79 (top 4.42%)55. LICS: 1.79 (top 4.50%)56. JLP: 1.78 (top 4.58%)57. WWW6 / Computer Networks: 1.78 (top 4.66%)58. ICCV: 1.78 (top 4.75%)59. IEEE Real-Time Systems Symposium: 1.78 (top 4.83%)60. AES Candidate Conference: 1.77 (top 4.91%)61. KR: 1.76 (top 4.99%)62. TISSEC: 1.76 (top 5.07%)63. ACM Conference on Electronic Commerce: 1.75 (top 5.15%)64. TOIS: 1.75 (top 5.24%)65. PEPM: 1.74 (top 5.32%)66. SIGMOD Conference: 1.74 (top 5.40%)67. Formal Methods in System Design: 1.74 (top 5.48%)68. Mobile Agents: 1.73 (top 5.56%)69. REX Workshop: 1.73 (top 5.65%)70. NMR: 1.73 (top 5.73%)71. Computing Systems: 1.72 (top 5.81%)72. LOPLAS: 1.72 (top 5.89%)73. STOC: 1.69 (top 5.97%)74. Distributed Computing: 1.69 (top 6.06%)75. KDD: 1.68 (top 6.14%)76. Symposium on Testing, Analysis, and Verification: 1.65 (top 6.22%)77. Software Development Environments (SDE): 1.64 (top 6.30%)78. SIAM J. Comput.: 1.64 (top 6.38%)79. CRYPTO: 1.63 (top 6.47%)80. Multimedia Systems: 1.62 (top 6.55%)81. ICFP: 1.62 (top 6.63%)82. Lisp and Symbolic Computation: 1.61 (top 6.71%)83. ECP: 1.61 (top 6.79%)84. CHI: 1.61 (top 6.87%)85. ISLP: 1.60 (top 6.96%)86. ACM Symposium on User Interface Software and Technology: 1.59 (top 7.04%)87. ESOP: 1.58 (top 7.12%)88. ECCV: 1.58 (top 7.20%)89. ACM Transactions on Graphics: 1.57 (top 7.28%)90. CSCW: 1.57 (top 7.37%)91. AOSE: 1.57 (top 7.45%)92. ICCL: 1.57 (top 7.53%)93. Journal of Functional Programming: 1.57 (top 7.61%)94. RTSS: 1.57 (top 7.69%)95. ECSCW: 1.56 (top 7.78%)96. TOCHI: 1.56 (top 7.86%)97. ISCA: 1.56 (top 7.94%)98. SIGMETRICS/Performance: 1.56 (top 8.02%)99. IWMM: 1.55 (top 8.10%)100. JICSLP: 1.54 (top 8.19%)101. Automatic Verification Methods for Finite State Systems: 1.54 (top 8.27%) 102. WWW: 1.54 (top 8.35%)103. IEEE Transactions on Pattern Analysis and Machine Intelligence: 1.54 (top 8.43%) 104. AIPS: 1.53 (top 8.51%)105. IEEE Transactions on Visualization and Computer Graphics: 1.53 (top 8.59%) 106. VLDB: 1.52 (top 8.68%)107. Symposium on Computational Geometry: 1.51 (top 8.76%)108. FOCS: 1.51 (top 8.84%)109. A TAL: 1.51 (top 8.92%)110. SODA: 1.51 (top 9.00%)111. PPCP: 1.50 (top 9.09%)112. AAAI: 1.49 (top 9.17%)113. COLT: 1.49 (top 9.25%)114. USENIX Summer: 1.49 (top 9.33%)115. Information and Computation: 1.48 (top 9.41%)116. Java Grande: 1.47 (top 9.50%)117. ISMM: 1.47 (top 9.58%)118. ICLP/SLP: 1.47 (top 9.66%)119. SLP: 1.45 (top 9.74%)120. Structure in Complexity Theory Conference: 1.45 (top 9.82%)121. IEEE Transactions on Multimedia: 1.45 (top 9.90%)122. Rules in Database Systems: 1.44 (top 9.99%)123. ACL: 1.44 (top 10.07%)124. CONCUR: 1.44 (top 10.15%)125. SPAA: 1.44 (top 10.23%)126. J. Algorithms: 1.42 (top 10.31%)127. DOOD: 1.42 (top 10.40%)128. ESEC / SIGSOFT FSE: 1.41 (top 10.48%)129. ICDT: 1.41 (top 10.56%)130. Advances in Petri Nets: 1.41 (top 10.64%)131. ICNP: 1.40 (top 10.72%)132. SSD: 1.39 (top 10.81%)133. INFOCOM: 1.39 (top 10.89%)134. IEEE Symposium on Security and Privacy: 1.39 (top 10.97%)135. Cognitive Science: 1.38 (top 11.05%)136. TSE: 1.38 (top 11.13%)137. Storage and Retrieval for Image and Video Databases (SPIE): 1.38 (top 11.22%) 138. NACLP: 1.38 (top 11.30%)139. SIGMETRICS: 1.38 (top 11.38%)140. JACM: 1.37 (top 11.46%)141. PODC: 1.37 (top 11.54%)142. International Conference on Supercomputing: 1.36 (top 11.62%)143. Fast Software Encryption: 1.35 (top 11.71%)144. IEEE Visualization: 1.35 (top 11.79%)145. SAS: 1.35 (top 11.87%)146. TACS: 1.35 (top 11.95%)147. International Journal of Computer Vision: 1.33 (top 12.03%)148. JCSS: 1.32 (top 12.12%)149. Algorithmica: 1.31 (top 12.20%)150. TOCL: 1.30 (top 12.28%)151. Information Hiding: 1.30 (top 12.36%)152. Journal of Automated Reasoning: 1.30 (top 12.44%)153. ECCV (1): 1.29 (top 12.53%)154. PCRCW: 1.29 (top 12.61%)155. Journal of Logic and Computation: 1.29 (top 12.69%)156. KDD Workshop: 1.28 (top 12.77%)157. ML: 1.28 (top 12.85%)158. ISSTA: 1.28 (top 12.94%)159. EUROCRYPT: 1.27 (top 13.02%)160. PDIS: 1.27 (top 13.10%)161. Hypertext: 1.27 (top 13.18%)162. IWDOM: 1.27 (top 13.26%)163. PARLE (2): 1.26 (top 13.34%)164. Hybrid Systems: 1.26 (top 13.43%)165. American Journal of Computational Linguistics: 1.26 (top 13.51%)166. SPIN: 1.25 (top 13.59%)167. ICDE: 1.25 (top 13.67%)168. FMCAD: 1.25 (top 13.75%)169. SC: 1.25 (top 13.84%)170. EDBT: 1.25 (top 13.92%)171. Computational Complexity: 1.25 (top 14.00%)172. International Journal of Computatinal Geometry and Applications: 1.25 (top 14.08%) 173. ESORICS: 1.25 (top 14.16%)174. IJCAI (2): 1.24 (top 14.25%)175. TACAS: 1.24 (top 14.33%)176. Ubicomp: 1.24 (top 14.41%)177. MPC: 1.24 (top 14.49%)178. AWOC: 1.24 (top 14.57%)179. TLCA: 1.23 (top 14.66%)180. Emergent Neural Computational Architectures Based on Neuroscience: 1.23 (top 14.74%) 181. CADE: 1.22 (top 14.82%)182. PROCOMET: 1.22 (top 14.90%)183. ACM Multimedia: 1.22 (top 14.98%)184. IEEE Journal on Selected Areas in Communications: 1.22 (top 15.06%)185. Science of Computer Programming: 1.22 (top 15.15%)186. LCPC: 1.22 (top 15.23%)187. CT-RSA: 1.22 (top 15.31%)188. ICLP: 1.21 (top 15.39%)189. Financial Cryptography: 1.21 (top 15.47%)190. DBPL: 1.21 (top 15.56%)191. AAAI/IAAI: 1.20 (top 15.64%)192. Artificial Life: 1.20 (top 15.72%)193. Higher-Order and Symbolic Computation: 1.19 (top 15.80%)194. TKDE: 1.19 (top 15.88%)195. ACM Computing Surveys: 1.19 (top 15.97%)196. Computational Geometry: 1.18 (top 16.05%)197. Autonomous Agents and Multi-Agent Systems: 1.18 (top 16.13%)198. EWSL: 1.18 (top 16.21%)199. Learning for Natural Language Processing: 1.18 (top 16.29%)200. TAPOS: 1.17 (top 16.38%)201. : 1.17 (top 16.46%)202. International Journal of Computational Geometry and Applications: 1.17 (top 16.54%)203. TAPSOFT: 1.17 (top 16.62%)204. IEEE Transactions on Parallel and Distributed Systems: 1.17 (top 16.70%) 205. Heterogeneous Computing Workshop: 1.16 (top 16.78%)206. Distributed and Parallel Databases: 1.16 (top 16.87%)207. DAC: 1.16 (top 16.95%)208. ICTL: 1.16 (top 17.03%)209. Performance/SIGMETRICS Tutorials: 1.16 (top 17.11%)210. IEEE Computer: 1.15 (top 17.19%)211. IEEE Real Time Technology and Applications Symposium: 1.15 (top 17.28%) 212. : 1.15 (top 17.36%)213. ACM Workshop on Role-Based Access Control: 1.15 (top 17.44%)214. WCRE: 1.14 (top 17.52%)215. Applications and Theory of Petri Nets: 1.14 (top 17.60%)216. ACM SIGOPS European Workshop: 1.14 (top 17.69%)217. ICDCS: 1.14 (top 17.77%)218. Mathematical Structures in Computer Science: 1.14 (top 17.85%)219. Workshop on the Management of Replicated Data: 1.13 (top 17.93%)220. ECCV (2): 1.13 (top 18.01%)221. PPSN: 1.13 (top 18.09%)222. Middleware: 1.13 (top 18.18%)223. OODBS: 1.12 (top 18.26%)224. Electronic Colloquium on Computational Complexity (ECCC): 1.12 (top 18.34%) 225. UML: 1.12 (top 18.42%)226. Real-Time Systems: 1.12 (top 18.50%)227. FME: 1.12 (top 18.59%)228. Evolutionary Computing, AISB Workshop: 1.11 (top 18.67%)229. IEEE Conference on Computational Complexity: 1.11 (top 18.75%)230. IOPADS: 1.11 (top 18.83%)231. IJCAI: 1.10 (top 18.91%)232. ISWC: 1.10 (top 19.00%)233. SIGIR: 1.10 (top 19.08%)234. Symposium on LISP and Functional Programming: 1.10 (top 19.16%)235. PASTE: 1.10 (top 19.24%)236. HPDC: 1.10 (top 19.32%)237. Application and Theory of Petri Nets: 1.09 (top 19.41%)238. ICCAD: 1.09 (top 19.49%)239. Category Theory and Computer Science: 1.08 (top 19.57%)240. Recent Advances in Intrusion Detection: 1.08 (top 19.65%)241. JIIS: 1.08 (top 19.73%)242. TODAES: 1.08 (top 19.81%)243. Neural Computation: 1.08 (top 19.90%)244. CCL: 1.08 (top 19.98%)245. SIGPLAN Workshop: 1.08 (top 20.06%)246. DPDS: 1.07 (top 20.14%)247. ACM Multimedia (1): 1.07 (top 20.22%)248. MAAMAW: 1.07 (top 20.31%)249. Computer Graphics Forum: 1.07 (top 20.39%)250. HUG: 1.06 (top 20.47%)251. Hybrid Neural Systems: 1.06 (top 20.55%)252. SRDS: 1.06 (top 20.63%)253. TPCD: 1.06 (top 20.72%)254. ILP: 1.06 (top 20.80%)255. ARTDB: 1.06 (top 20.88%)256. NIPS: 1.06 (top 20.96%)257. Formal Aspects of Computing: 1.06 (top 21.04%)258. ECHT: 1.06 (top 21.13%)259. ICMCS: 1.06 (top 21.21%)260. Wireless Networks: 1.05 (top 21.29%)261. Advances in Data Base Theory: 1.05 (top 21.37%)262. WDAG: 1.05 (top 21.45%)263. ALP: 1.05 (top 21.53%)264. TARK: 1.05 (top 21.62%)265. PATAT: 1.05 (top 21.70%)266. ISTCS: 1.04 (top 21.78%)267. Concurrency - Practice and Experience: 1.04 (top 21.86%)268. CP: 1.04 (top 21.94%)269. Computer Vision, Graphics, and Image Processing: 1.04 (top 22.03%) 270. FTCS: 1.04 (top 22.11%)271. RTA: 1.04 (top 22.19%)272. COORDINATION: 1.03 (top 22.27%)273. CHDL: 1.03 (top 22.35%)274. Theory of Computing Systems: 1.02 (top 22.44%)275. CTRS: 1.02 (top 22.52%)276. COMPASS/ADT: 1.02 (top 22.60%)277. TOMACS: 1.02 (top 22.68%)278. IEEE Micro: 1.02 (top 22.76%)279. IEEE PACT: 1.02 (top 22.85%)280. ASIACRYPT: 1.01 (top 22.93%)281. MONET: 1.01 (top 23.01%)282. WWW7 / Computer Networks: 1.01 (top 23.09%)283. HUC: 1.01 (top 23.17%)284. Expert Database Conf.: 1.00 (top 23.25%)285. Agents: 1.00 (top 23.34%)286. CPM: 1.00 (top 23.42%)287. SIGPLAN Symposium on Compiler Construction: 1.00 (top 23.50%) 288. International Conference on Evolutionary Computation: 1.00 (top 23.58%) 289. TAGT: 1.00 (top 23.66%)290. Workshop on Parallel and Distributed Simulation: 1.00 (top 23.75%)292. TPHOLs: 1.00 (top 23.91%)293. Intelligent User Interfaces: 0.99 (top 23.99%)294. Journal of Functional and Logic Programming: 0.99 (top 24.07%)295. Cluster Computing: 0.99 (top 24.16%)296. ESA: 0.99 (top 24.24%)297. PLILP: 0.99 (top 24.32%)298. COLING-ACL: 0.98 (top 24.40%)299. META: 0.97 (top 24.48%)300. IEEE MultiMedia: 0.97 (top 24.57%)301. ICALP: 0.97 (top 24.65%)302. IATA: 0.97 (top 24.73%)303. FPGA: 0.97 (top 24.81%)304. EuroCOLT: 0.97 (top 24.89%)305. New Generation Computing: 0.97 (top 24.97%)306. Automated Software Engineering: 0.97 (top 25.06%)307. GRID: 0.97 (top 25.14%)308. ISOTAS: 0.96 (top 25.22%)309. LPNMR: 0.96 (top 25.30%)310. PLILP/ALP: 0.96 (top 25.38%)311. UIST: 0.96 (top 25.47%)312. IPCO: 0.95 (top 25.55%)313. ICPP, Vol. 1: 0.95 (top 25.63%)314. PNPM: 0.95 (top 25.71%)315. HSCC: 0.95 (top 25.79%)316. ILPS: 0.95 (top 25.88%)317. RIDE-IMS: 0.95 (top 25.96%)318. Int. J. on Digital Libraries: 0.95 (top 26.04%)319. STTT: 0.94 (top 26.12%)320. MFPS: 0.94 (top 26.20%)321. Graph-Grammars and Their Application to Computer Science: 0.93 (top 26.28%) 322. Graph Drawing: 0.93 (top 26.37%)323. VRML: 0.93 (top 26.45%)324. VDM Europe: 0.93 (top 26.53%)325. AAAI/IAAI, Vol. 2: 0.93 (top 26.61%)326. Z User Workshop: 0.93 (top 26.69%)327. Constraints: 0.93 (top 26.78%)328. SCM: 0.93 (top 26.86%)329. IEEE Software: 0.92 (top 26.94%)330. World Wide Web: 0.92 (top 27.02%)331. HOA: 0.92 (top 27.10%)332. Symposium on Reliable Distributed Systems: 0.92 (top 27.19%)333. SIAM Journal on Discrete Mathematics: 0.92 (top 27.27%)334. SMILE: 0.91 (top 27.35%)336. ICPP, Vol. 3: 0.91 (top 27.51%)337. FASE: 0.91 (top 27.60%)338. TCS: 0.91 (top 27.68%)339. IEEE Transactions on Information Theory: 0.91 (top 27.76%) 340. C++ Conference: 0.91 (top 27.84%)341. ICSE: 0.90 (top 27.92%)342. ARTS: 0.90 (top 28.00%)343. Journal of Computational Biology: 0.90 (top 28.09%)344. SIGART Bulletin: 0.90 (top 28.17%)345. TREC: 0.89 (top 28.25%)346. Implementation of Functional Languages: 0.89 (top 28.33%) 347. Acta Informatica: 0.88 (top 28.41%)348. SAIG: 0.88 (top 28.50%)349. CANPC: 0.88 (top 28.58%)350. CACM: 0.87 (top 28.66%)351. PADL: 0.87 (top 28.74%)352. Networked Group Communication: 0.87 (top 28.82%)353. RECOMB: 0.87 (top 28.91%)354. ACM DL: 0.87 (top 28.99%)355. Computer Performance Evaluation: 0.87 (top 29.07%)356. Journal of Parallel and Distributed Computing: 0.86 (top 29.15%) 357. PARLE (1): 0.86 (top 29.23%)358. DISC: 0.85 (top 29.32%)359. FGCS: 0.85 (top 29.40%)360. ELP: 0.85 (top 29.48%)361. IEEE Transactions on Computers: 0.85 (top 29.56%)362. JSC: 0.85 (top 29.64%)363. LOPSTR: 0.85 (top 29.72%)364. FoSSaCS: 0.85 (top 29.81%)365. World Congress on Formal Methods: 0.85 (top 29.89%)366. CHARME: 0.84 (top 29.97%)367. RIDE: 0.84 (top 30.05%)368. APPROX: 0.84 (top 30.13%)369. EWCBR: 0.84 (top 30.22%)370. CC: 0.83 (top 30.30%)371. Public Key Cryptography: 0.83 (top 30.38%)372. CA: 0.83 (top 30.46%)373. CHES: 0.83 (top 30.54%)374. ECML: 0.83 (top 30.63%)375. LCTES/OM: 0.83 (top 30.71%)376. Information Systems: 0.83 (top 30.79%)377. IJCIS: 0.83 (top 30.87%)378. Journal of Visual Languages and Computing: 0.82 (top 30.95%)380. Random Structures and Algorithms: 0.81 (top 31.12%)381. ICS: 0.81 (top 31.20%)382. Data Engineering Bulletin: 0.81 (top 31.28%)383. VDM Europe (1): 0.81 (top 31.36%)384. SW AT: 0.80 (top 31.44%)385. Nordic Journal of Computing: 0.80 (top 31.53%)386. Mathematical Foundations of Programming Semantics: 0.80 (top 31.61%)387. Architectures and Compilation Techniques for Fine and Medium Grain Parallelism: 0.80 (top 31.69%)388. KBSE: 0.80 (top 31.77%)389. STACS: 0.80 (top 31.85%)390. EMSOFT: 0.80 (top 31.94%)391. IEEE Data Engineering Bulletin: 0.80 (top 32.02%)392. Annals of Mathematics and Artificial Intelligence: 0.79 (top 32.10%)393. WOSP: 0.79 (top 32.18%)394. VBC: 0.79 (top 32.26%)395. RTDB: 0.79 (top 32.35%)396. CoopIS: 0.79 (top 32.43%)397. Combinatorica: 0.79 (top 32.51%)398. International Journal of Geographical Information Systems: 0.78 (top 32.59%)399. Autonomous Robots: 0.78 (top 32.67%)400. IW-MMDBMS: 0.78 (top 32.76%)401. ESEC: 0.78 (top 32.84%)402. W ADT: 0.78 (top 32.92%)403. CAAP: 0.78 (top 33.00%)404. LCTES: 0.78 (top 33.08%)405. ZUM: 0.77 (top 33.16%)406. TYPES: 0.77 (top 33.25%)407. Symposium on Reliability in Distributed Software and Database Systems: 0.77 (top 33.33%) 408. TABLEAUX: 0.77 (top 33.41%)409. International Journal of Parallel Programming: 0.77 (top 33.49%)410. COST 237 Workshop: 0.77 (top 33.57%)411. Data Types and Persistence (Appin), Informal Proceedings: 0.77 (top 33.66%)412. Evolutionary Programming: 0.77 (top 33.74%)413. Reflection: 0.76 (top 33.82%)414. SIGMOD Record: 0.76 (top 33.90%)415. Security Protocols Workshop: 0.76 (top 33.98%)416. XP1 Workshop on Database Theory: 0.76 (top 34.07%)417. EDMCC: 0.76 (top 34.15%)418. DL: 0.76 (top 34.23%)419. EDAC-ETC-EUROASIC: 0.76 (top 34.31%)420. Protocols for High-Speed Networks: 0.76 (top 34.39%)421. PPDP: 0.75 (top 34.47%)422. IFIP PACT: 0.75 (top 34.56%)423. LNCS: 0.75 (top 34.64%)424. IWQoS: 0.75 (top 34.72%)425. UK Hypertext: 0.75 (top 34.80%)426. Selected Areas in Cryptography: 0.75 (top 34.88%)427. ICA TPN: 0.74 (top 34.97%)428. Workshop on Computational Geometry: 0.74 (top 35.05%)429. Integrated Network Management: 0.74 (top 35.13%)430. ICGI: 0.74 (top 35.21%)431. ICPP (2): 0.74 (top 35.29%)432. SSR: 0.74 (top 35.38%)433. ADB: 0.74 (top 35.46%)434. Object Representation in Computer Vision: 0.74 (top 35.54%)435. PSTV: 0.74 (top 35.62%)436. CAiSE: 0.74 (top 35.70%)437. On Knowledge Base Management Systems (Islamorada): 0.74 (top 35.79%) 438. CIKM: 0.73 (top 35.87%)439. WSA: 0.73 (top 35.95%)440. RANDOM: 0.73 (top 36.03%)441. KRDB: 0.73 (top 36.11%)442. ISSS: 0.73 (top 36.19%)443. SIGAL International Symposium on Algorithms: 0.73 (top 36.28%)444. INFORMS Journal on Computing: 0.73 (top 36.36%)445. Computer Supported Cooperative Work: 0.73 (top 36.44%)446. CSL: 0.72 (top 36.52%)447. Computational Intelligence: 0.72 (top 36.60%)448. ICCBR: 0.72 (top 36.69%)449. ICES: 0.72 (top 36.77%)450. AI Magazine: 0.72 (top 36.85%)451. JELIA: 0.72 (top 36.93%)452. VR: 0.71 (top 37.01%)453. ICPP (1): 0.71 (top 37.10%)454. RIDE-TQP: 0.71 (top 37.18%)455. ISA: 0.71 (top 37.26%)456. Data Compression Conference: 0.71 (top 37.34%)457. CIA: 0.71 (top 37.42%)458. COSIT: 0.71 (top 37.51%)459. IJCSLP: 0.71 (top 37.59%)460. DISCO: 0.71 (top 37.67%)461. DKE: 0.71 (top 37.75%)462. IWAN: 0.71 (top 37.83%)463. Operating Systems Review: 0.70 (top 37.91%)464. IEEE Internet Computing: 0.70 (top 38.00%)465. LISP Conference: 0.70 (top 38.08%)466. C++ Workshop: 0.70 (top 38.16%)467. SPDP: 0.70 (top 38.24%)468. Fuji International Symposium on Functional and Logic Programming: 0.69 (top 38.32%) 469. LPAR: 0.69 (top 38.41%)470. ECAI: 0.69 (top 38.49%)471. Hypermedia: 0.69 (top 38.57%)472. Artificial Intelligence in Medicine: 0.69 (top 38.65%)473. AADEBUG: 0.69 (top 38.73%)474. VL: 0.69 (top 38.82%)475. FSTTCS: 0.69 (top 38.90%)476. AMAST: 0.68 (top 38.98%)477. Artificial Intelligence Review: 0.68 (top 39.06%)478. HPN: 0.68 (top 39.14%)479. POS: 0.68 (top 39.23%)480. Research Directions in High-Level Parallel Programming Languages: 0.68 (top 39.31%) 481. Performance Evaluation: 0.68 (top 39.39%)482. ASE: 0.68 (top 39.47%)483. LFCS: 0.67 (top 39.55%)484. ISCOPE: 0.67 (top 39.63%)485. Workshop on Software and Performance: 0.67 (top 39.72%)486. European Workshop on Applications and Theory in Petri Nets: 0.67 (top 39.80%) 487. ICPP: 0.67 (top 39.88%)488. INFOVIS: 0.67 (top 39.96%)489. Description Logics: 0.67 (top 40.04%)490. JCDKB: 0.67 (top 40.13%)491. Euro-Par, Vol. I: 0.67 (top 40.21%)492. RoboCup: 0.67 (top 40.29%)493. Symposium on Solid Modeling and Applications: 0.66 (top 40.37%)494. TPLP: 0.66 (top 40.45%)495. CVRMed: 0.66 (top 40.54%)496. POS/PJW: 0.66 (top 40.62%)497. FORTE: 0.66 (top 40.70%)498. IPMI: 0.66 (top 40.78%)499. ADL: 0.66 (top 40.86%)500. ICCS: 0.66 (top 40.95%)501. ISSAC: 0.66 (top 41.03%)502. Advanced Programming Environments: 0.66 (top 41.11%)503. COMPCON: 0.66 (top 41.19%)504. LCR: 0.65 (top 41.27%)505. Digital Libraries: 0.65 (top 41.35%)506. ALENEX: 0.65 (top 41.44%)507. AH: 0.65 (top 41.52%)508. CoBuild: 0.65 (top 41.60%)509. DS-6: 0.65 (top 41.68%)511. Computer Networks and ISDN Systems: 0.64 (top 41.85%)512. IWACA: 0.64 (top 41.93%)513. MobiDE: 0.64 (top 42.01%)514. WOWMOM: 0.64 (top 42.09%)515. IEEE Expert: 0.64 (top 42.17%)516. IRREGULAR: 0.64 (top 42.26%)517. TOMS: 0.63 (top 42.34%)518. Multiple Classifier Systems: 0.63 (top 42.42%)519. Parallel Computing: 0.63 (top 42.50%)520. ANTS: 0.63 (top 42.58%)521. ACSAC: 0.63 (top 42.66%)522. RCLP: 0.63 (top 42.75%)523. Multimedia Tools and Applications: 0.63 (top 42.83%)524. ALT: 0.63 (top 42.91%)525. ICCD: 0.63 (top 42.99%)526. ICVS: 0.62 (top 43.07%)527. Workshop on Web Information and Data Management: 0.62 (top 43.16%)528. Software - Concepts and Tools: 0.62 (top 43.24%)529. ICSM: 0.62 (top 43.32%)530. The Visual Computer: 0.62 (top 43.40%)531. SARA: 0.62 (top 43.48%)532. IS: 0.61 (top 43.57%)533. Information Retrieval: 0.61 (top 43.65%)534. CARDIS: 0.61 (top 43.73%)535. DOA: 0.61 (top 43.81%)536. Cryptography: Policy and Algorithms: 0.60 (top 43.89%)537. Electronic Publishing: 0.60 (top 43.98%)538. SSTD: 0.60 (top 44.06%)539. Algebraic Methods: 0.60 (top 44.14%)540. AGTIVE: 0.59 (top 44.22%)541. Computational Logic: 0.59 (top 44.30%)542. Computer Communications: 0.59 (top 44.38%)543. QofIS: 0.59 (top 44.47%)544. Journal of Logic, Language and Information: 0.59 (top 44.55%)545. Expert Database Workshop: 0.59 (top 44.63%)546. IFL: 0.58 (top 44.71%)547. Nonmonotonic and Inductive Logic: 0.58 (top 44.79%)548. Algorithmic Number Theory: 0.58 (top 44.88%)549. Graph-Grammars and Their Application to Computer Science and Biology: 0.58 (top 44.96%) 550. Structured Programming: 0.58 (top 45.04%)551. Information Processing Letters: 0.58 (top 45.12%)552. SIGKDD Explorations: 0.58 (top 45.20%)553. Parallel Symbolic Computing: 0.58 (top 45.29%)555. MIT-JSME Workshop: 0.57 (top 45.45%)556. Knowledge and Information Systems: 0.57 (top 45.53%)557. International Journal of Man-Machine Studies: 0.57 (top 45.61%)558. Software - Practice and Experience: 0.57 (top 45.70%)559. Scale-Space: 0.57 (top 45.78%)560. AI Communications: 0.57 (top 45.86%)561. Kurt Gödel Colloquium: 0.56 (top 45.94%)562. DBSec: 0.56 (top 46.02%)563. ER: 0.56 (top 46.10%)564. IBM Journal of Research and Development: 0.56 (top 46.19%)565. QCQC: 0.56 (top 46.27%)566. Gesture Workshop: 0.56 (top 46.35%)567. CIAC: 0.56 (top 46.43%)568. Artificial Evolution: 0.55 (top 46.51%)569. RANDOM-APPROX: 0.55 (top 46.60%)570. Information Processing and Management: 0.55 (top 46.68%)571. EKAW: 0.55 (top 46.76%)572. Operating Systems of the 90s and Beyond: 0.55 (top 46.84%)573. International Zurich Seminar on Digital Communications: 0.55 (top 46.92%) 574. Annals of Software Engineering: 0.55 (top 47.01%)575. AII: 0.55 (top 47.09%)576. DOLAP: 0.55 (top 47.17%)577. Fundamenta Informaticae: 0.55 (top 47.25%)578. PARLE: 0.55 (top 47.33%)579. Advanced Course: Distributed Systems: 0.54 (top 47.42%)580. BCEC: 0.54 (top 47.50%)581. Digital Technical Journal: 0.54 (top 47.58%)582. IJCAR: 0.54 (top 47.66%)583. Formal Methods in Programming and Their Applications: 0.54 (top 47.74%) 584. IPPS: 0.54 (top 47.82%)585. Knowledge Based Systems: 0.53 (top 47.91%)586. PDK: 0.53 (top 47.99%)587. East/West Database Workshop: 0.53 (top 48.07%)588. International ACM Conference on Assistive Technologies: 0.53 (top 48.15%) 589. Mathematical Systems Theory: 0.53 (top 48.23%)590. ICFEM: 0.53 (top 48.32%)591. DMDW: 0.53 (top 48.40%)592. International Journal of Foundations of Computer Science: 0.52 (top 48.48%) 593. LACL: 0.52 (top 48.56%)594. Advances in Computers: 0.52 (top 48.64%)595. Workshop on Conceptual Graphs: 0.52 (top 48.73%)596. FM-Trends: 0.52 (top 48.81%)597. GREC: 0.52 (top 48.89%)598. Advanced Visual Interfaces: 0.52 (top 48.97%)599. Agents Workshop on Infrastructure for Multi-Agent Systems: 0.52 (top 49.05%) 600. Euro-Par, Vol. II: 0.52 (top 49.14%)601. ICPP (3): 0.52 (top 49.22%)602. Telecommunication Systems: 0.52 (top 49.30%)603. AISMC: 0.52 (top 49.38%)604. ISAAC: 0.51 (top 49.46%)605. ICIP (2): 0.51 (top 49.54%)606. IEEE Symposium on Mass Storage Systems: 0.51 (top 49.63%)607. FAPR: 0.51 (top 49.71%)608. EHCI: 0.51 (top 49.79%)609. CHI Conference Companion: 0.51 (top 49.87%)610. Open Distributed Processing: 0.51 (top 49.95%)611. AUSCRYPT: 0.51 (top 50.04%)612. WWCA: 0.50 (top 50.12%)613. ICIP: 0.50 (top 50.20%)614. ICIP (1): 0.50 (top 50.28%)615. Annals of Pure and Applied Logic: 0.50 (top 50.36%)616. CISMOD: 0.50 (top 50.45%)617. Algorithm Engineering: 0.50 (top 50.53%)618. CASES: 0.50 (top 50.61%)619. EWSPT: 0.50 (top 50.69%)620. ICMCS, Vol. 1: 0.50 (top 50.77%)621. BIT: 0.50 (top 50.85%)622. Computer Performance Evaluation (Tools): 0.50 (top 50.94%)623. Information and Control: 0.50 (top 51.02%)624. Machine Vision and Applications: 0.50 (top 51.10%)625. Discrete Applied Mathematics: 0.50 (top 51.18%)626. PKDD: 0.50 (top 51.26%)627. ESCQARU: 0.49 (top 51.35%)628. IDS: 0.49 (top 51.43%)629. ACISP: 0.49 (top 51.51%)630. Computer Languages: 0.49 (top 51.59%)631. MFDBS: 0.49 (top 51.67%)632. QL: 0.49 (top 51.76%)633. Requirements Engineering: 0.49 (top 51.84%)634. International Journal of Human Computer Studies: 0.48 (top 51.92%)635. IBM Systems Journal: 0.48 (top 52.00%)636. Aegean Workshop on Computing: 0.48 (top 52.08%)637. Spatial Cognition: 0.48 (top 52.17%)638. MFCS: 0.48 (top 52.25%)639. Discrete & Computational Geometry: 0.48 (top 52.33%)640. ITC: 0.47 (top 52.41%)641. A TL: 0.47 (top 52.49%)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
USENIX AssociationProceedings of theFREENIX Track:2002 USENIX Annual TechnicalConferenceMonterey, California, USAJune 10-15, 2002THE ADVANCED COMPUTING SYSTEMS ASSOCIATION© 2002 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649FAX: 1 510 548 5738Email: office@ WWW: Rights to individual papers remain with the author or the author's employer.Permission is granted for noncommercial reproduction of the work for educational or research purposes.This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein.Planned Extensions to the Linux Ext2/Ext3FilesystemTheodore Y.Ts’oInternational Business Machines Corporationtheotso@,/tytsoStephen TweedieRed Hatsct@AbstractThe ext2filesystem was designed with the goal of ex-pandability while maintaining compatibility.This paper describes ways in which advancedfilesystem features can be added to the ext2filesystem while retaining for-wards and backwards compatibility as much as possible. Some of thefilesystem extensions that are discussed in-clude directory indexing,online resizing,an expanded inode,extended attributes and access control lists sup-port,extensible inode tables,extent maps,and prealloca-tion.1IntroductionLinux’s second extendedfilesystem[1](also known as ext2)wasfirst introduced into the Linux kernel in Jan-uary,1993.At the time,it was a significant improvement over the previousfilesystems used in the0.97and earlier kernels,the Minix and the“Extended”or(ext)filesys-tem.Fundamentally,the design of the ext2filesystem is very similar to that of the BSD Fast Filesystem[2].The ext2filesystem is divided into block groups which are essentially identical to the FFS’s cylinder group;each block group contains a copy of the superblock,alloca-tion bitmaps,part of afixed,statically allocated inode table,and data blocks which can be allocated for direc-tories orfiles.Like most classic Unixfilesystems,ext2/3 uses direct,indirect,double indirect,and triple indirec-tion blocks to map logical block numbers to physical block numbers.Ext2’s directory format is also essen-tially identical to traditional Unixfilesystems in that a simple linked list data structure is used to store directory entries.Over the years,various improvements have been added to the ext2filesystem.This has been facilitated by a number of superblockfields that were added to the ext2filesystem just before Linux2.0was released.The most important of thesefields,the compatibility bitmaps, enable new features to be added to thefilesystem safely. There are three such compatibility bitmaps:read-write, read-only,and incompat.A kernel will mount afilesys-tem that has a bit in the read-write compatibility bitmask that it doesn’t understand.However,an unknown bit in the read-only compatibility bitmap cause the kernel to only be willing to mount thefilesystem read-only,and the kernel will refuse to mount in any way afilesystem with an unknown bit in the incompat bitmask.These bitmaps have allowed the ext2filesystem to evolve in very clean fashion.Today,more developers than ever have expressed in-terest in working on the ext2/3filesystem,and have wanted to add or integrate various new exciting features. Some of these features include:preallocation,journal-ing,extended attributes and access control lists,on-line resizing,tail-merging,and compression.Some of these features have yet to be merged into the mainline ext2 code base,or are only available in prototype form.In the case of the journaling support,althoughfilesystems with journaling support are fully backwards compatible with non-journalled ext2filesystems,the implementation required enough changes that the resultingfilesystem has been named ext3.The goal of this paper is to discuss how these features might be added to thefilesystem in a coordinated fash-ion.Many of these new features are expected of modern filesystems;the challenge is to add them while maintain-ing ext2/3’s advantages of a relatively small and simple code base,robustness in the face of I/O errors,and high levels of forwards and backwards compatibility.2Proposed enhancements to the ext2filesystem formatWe will discuss a number of extensions to the ext2/3filesystem which will likely be implemented in the near future.For the most part,these extensions are indepen-dent of each other,and can be implemented in any order, although some extensions have synergistic effects.For example,two new features that will be described below, extent maps and persistent preallocation,are far more ef-fective when used in combination with each other.2.1Directory indexingDaniel Phillips has implemented a directory indexing scheme using afixed-depth tree with hashed keys[3]. This replaces the linear directory search algorithm cur-rently in use with traditional ext2filesystems,and signif-icantly improves performance for very large directories (thousands offiles in a single directory).The interior,or index,nodes in the tree are formatted to look like deleted directory entries,and the leaf nodes use the same format as existing ext2directory blocks.As a result,read-only backwards compatibility is trivially achieved.Furthermore,starting in the Linux2.2kernel, whenever a directory is modified,the EXT2BTREE FL (since renamed EXT2INDEX FL)is cleared.This al-lows us to guarantee read/write compatibility with Linux 2.2kernels,since thefilesystem can detect that the in-ternal indexing nodes are probably no longer consis-tent,and thus should be ignored until they can be recon-structed(via the e2fsck program).Daniel Phillip’s directory indexing code is currently available as a set of patches versus the2.4ext2code base. As of this writing,the patches still need to be merged with the ext3journaling code base.In addition,there are plans to select a better hash function that has better distri-bution characteristics forfilenames commonly found in workloads such as mail queue directories.There are also plans to add hinting information in the interior nodes of the tree to indicate that a particular leaf node is nearly empty and that its contents could be merged with an ad-jacent leaf node.2.2On-linefilesystem resizingAndreas Dilger has implemented patches to the ext2filesystem that support dynamically increasing the size of thefilesystem while thefilesystem is on-line.Be-fore logical volume managers(LVMs)became available for Linux,off-line resizing tools such as resize2fs, which required that thefilesystem be unmounted and checked using e2fsckfirst,were sufficient for most users’needs.However,with the advent of LVM sys-tems that allow block devices to be dynamically grown, it is much more importantfilesystems to be able to grow and take advantage of new storage space which has been made available by the LVM subsystem without need-ing to unmount thefilesystemfirst.Indeed,adminis-trators of enterprise-class systems take such capabilities for granted.(Dynamically shrinking mountedfilesys-tems is a much more difficult task,and mostfilesystems do not offer this functionality.For ext2/3filesystems,filesystems can be shrunk using the off-line resizing tool resize2fs.)A disadvantage of the current ext2resizing patches is that they require that thefilesystem be prepared be-fore thefilesystem can be resized on-line.This prepa-ration process,which must be done with thefilesystem unmounted,finds the inodes using the blocks immedi-ately following the block group descriptors,and relocates these blocks so they can be reserved for the resizing pro-cess.These blocks must be reserved since the current layout of the ext2superblock and block group descrip-tors require an additional block group descriptor block for each256MB,2GB,or16GB of disk space forfilesys-tems with1KB,2KB,and4KB blocksizes,respectively. Although the requirement for an off-line preparation step is quite inconvenient,this scheme does have the advan-tage that thefilesystem format remains unmodified,so it is fully compatible with kernels that do not support on-line resizing.Still,if the system administrator knows in advance how much afilesystem may need to be grown, reserving blocks for use by the block group descriptors may be a workable solution.Requiring advance preparation of thefilesystem can be obviated if we are willing to let thefilesystem be-come incompatible with older kernels after it has been extended.Given that many2.0and2.2kernels do not support LVM devices(and so would be unable to read a filesystem stored on an LVM anyway),this may be ac-ceptable.The change in thefilesystem format replaces the current scheme where the superblock is followed by a variable-length set of block group descriptors.Instead, the superblock and a single block group descriptor block is placed at the beginning of thefirst,second,and last block groups in a meta-block group.A meta-block group is a collection of block groups which can be described by a single block group descriptor block.Since the size of the block group descriptor structure is32bytes,ameta-block group contains32block groups forfilesys-tems with a1KB block size,and128block groups for filesystems with a4KB blocksize.Filesystems can either be created using this new block group descriptor layout, or existingfilesystems can be resized on-line,and a new field in the superblock will indicate thefirst block group using this new layout.This new scheme is much more efficient,while re-taining enough redundancy in case of hardware failures. Most importantly,it allows new block groups to be added to thefilesystem without needing to change block group descriptors in the earlier parts of the disk.Hence,it should be very simple to write an ext2/3filesystem ex-tension using this design that provides on-line resizing capabilities.2.3An expanded inodeThe size of the on-disk inode in the ext2/3filesystem has been128bytes long during its entire lifetime.Al-though we have been very careful about packing as much information as possible into the inode,we arefinally get-ting to the point where there simply is not enough room for all of the extensions that people would like to add to the ext2/3filesystem.Fortunately,just before the release of Linux2.0,most of the work to allow for an expanded inode was added. As part of the changes to version1of the ext2su-perblock,the size of the inode in thefilesystem was added as a parameter in the superblock.The only re-striction on the size of inode is that it must evenly divide thefilesystem blocksize.Unfortunately,some safety-checking code which aborted thefilesystem from being mounted if the inode size was not128bytes was never removed from the kernel.Hence,in order to support larger inodes,a small patch will have to made to the2.0, 2.2,and2.4kernels.Fortunately the change is simple enough that it should be relatively easy to get the change accepted into production kernels.One of the most important features that requires ad-ditional space in the inode is the addition of sub-second resolution timestamps.This is needed because given to-day’s very fast computers,storingfile modification times with only second granularity is not sufficient for pro-grams like make.(For example,if make can compile all of the objectfiles for a library and create the library within a second,a subsequent make command will not be able to determine whether or not the library needs to be updated.)Another limitation imposed by the current inodefield sizes is the use of a16bits for i links count,which limits the number of subdirectories that can be created in a sin-gle directory.The actual limit of32,000is smaller than what is possible with an unsigned16-bitfield,but even if the kernel were changed to allow65,535subdirectories, this would be too small for some users or applications. In addition,extra inode space can also enable sup-port64-bit block numbers.Currently,using4KB blocks, the largestfilesystem that ext2can support is16TB.Al-though this is larger than any commonly available indi-vidual disks,there certainly are RAID systems that ex-port block devices which are larger than this size.Yet another future application that may require addi-tional storage inside the inode is support for mandatory access control[4](MAC)or audit labels.The NSA SE (Security-Enhanced)Linux[5]implementation requires a single32-bitfield for both purposes;other schemes may require two separate32-bitfields to encode MAC and audit label.In order to maximize backwards compatibility,the in-ode will be expanded without changing the layout of the first128bytes.This allows for full backwards compati-bility if the the new features in use are themselves back-wards compatible—for example,sub-second resolution timestamps.Doubling the inode size from128bytes to256bytes gives us room for32additional32-bitfields,which is a lot of extraflexibility for new features.However,the32 newfields can be very quickly consumed by designers proposingfilesystem extensions.For example,adding support for64-bit block pointers will consume almost half of the newfields.Hence,allocation of these new inodefields will have to be very carefully done.New filesystem features which do not have general applicabil-ity,or which require a large amount of space,will likely not receive space in the inode;instead they will likely have to use Extend Attribute storage instead.2.4Extended attributes,access control lists,and tail mergingOne of the more important new features found in modernfilesystems is the ability to associate small amounts of custom metadata(commonly referred to as Extended Attributes)withfiles or directories.Some of the applications of Extended Attributes(EA)include Ac-cess Control Lists[6],MAC Security Labels[6],POSIXCapabilities[6],DMAPI/XDSM[7](which is important for implementing Hierarchical Storage Management sys-tems),and others.Andreas Gruenbacher has implemented ext2exten-sions which add support for Extended Attributes and Ac-cess Control Lists to ext2.These patches,sometimes re-ferred to as the Bestbits patches,since they are available at web site http://www.bestbits.at,have been relatively widely deployed,although they have not yet been merged into the main-line ext2/3code base.The Bestbits implementation uses a full disk block to store each set of extended attributes data.If two or more inodes have an identical set of extended at-tributes,then they can share a single extended attribute block.This characteristic makes the Bestbits imple-mentation extremely efficient for Access Control Lists (ACLs),since very often a large number of inodes will use the same ACL.For example,it is likely that inodes in a directory will share the same ACL.The Bestbits im-plementation allows inodes with the same ACL to share a common data structure on disk.This allows for a very efficient storage of ACLs,as well as providing an im-portant performance boost,since caching shared ACLs is an effective way of speeding up access control checks, a commonfilesystem operation.Unfortunately,the Bestbits design is not very well suited for generic Extended Attributes,since the EA block can only be shared if all of the extended attributes are identical.So if every inode has some inode-unique EA(for example,a digital signature),then each inode will need to have its own EA block,and the overhead for using EAs may be unacceptably high.For this reason,it is likely that the mechanism for supporting ACLs may be different from the mechanisms used to support generic EAs.The performance require-ments and storage efficiencies of ACL sharing justify se-riously considering this option,even if it would be more aesthetically pleasing,and simpler,to use a single EA storage mechanism for both ACLs and generic EAs. There may be a few otherfilesystem extensions which require very fast access by the kernel;for example, mandatory access control(MAC)and audit labels,which need to be referenced every time an inode is manipulated or accessed.In these cases,however,as mentioned in the previous section,the simplest solution is to reserve an extrafield or two in the expanded ext2inode for these applications.One of more promising tactics for solving the EA stor-age problem is to combine it with Daniel Phillips’s pro-posal of adding tail merging to the ext2filesystem.Tail merging is the practice of storing the data contained in partiallyfilled blocks at the end offiles(called tails)in a single shared block.This shared block could also be used as a location of storing Extended Attributes.In fact, tail-merging can be generalized so that a tail is simply a special Extended Attribute.The topic of extended attributes is still a somewhat controversial area amongst the ext2developers,for a number of reasons.First,there are many different ways in which EAs could be stored.Second,how EAs will be used is still somewhat unclear.Realistically,they are not used very often today,primarily because of portabil-ity concerns;EAs are not specified by any of the com-mon Unix specifications:POSIX.1[8],SUS[9],etc.,are not supported byfile archiving tools such as tar and zip,and they cannot be exported over NFS(though the new NFSv4standard[10]does include EA support.)Still, the best alternatives which seem to have been explored to date will probably keep the Bestbits approach exclu-sively for ACLs,and an approach where multiple inodes can utilize a singlefilesystem block to store tails and ex-tended attributes.However,progress is being made:the linux-2.5kernel now includes a standard API for accessing ACLs,and the popular Sambafile-serving application can already use that API,if it is present.2.5Extensible inode tableWith the increase in size of the on-disk inode data structure,the overhead of the inode table naturally will be larger.This is compounded by the general practice of significantly over-provisioning the number of inodes in most Unixfilesystems,since in general the number of inodes cannot be increased after thefilesystem is created. While experienced system administrators may change the number of inodes when creatingfilesystems,the vast majority offilesystems generally use the defaults pro-vided by mke2fs.If thefilesystem can allocate new inodes dynamically,the overhead of the inode table can be reduced since there will no longer be a need to over-allocate inodes.Expanding the inode table might seem to be a simple and straightforward operation,but there are a number of constraints that complicate things.We cannot simply in-crease the parameter indicating the number of inodes per block group,since that would require renumbering all ofthe inodes in thefilesystem,which in turn would require scanning and modifying all of the directory entries in the filesystem.Also complicating matters is the fact that the inode number is currently used as part of the block and in-ode allocation algorithms.An inode’s number,when di-vided by thefilesystem’s inodes per block group parameter,results in the block group where the inode is stored.This is used as a hint when allocating blocks for that inode for better locality.Simply numbering new in-odes just beyond the last used inode number will destroy this property.This presents problems especially if the filesystem may be dynamically resized,since growing thefilesystem also grows the inode table,and the inode numbers used for the extensible inode table must not con-flict with the inode numbers used when thefilesystem is grown.One potential solution would be to extend the inode number to be64bits,and then encode the block group information explicitly into the high bits of the inode number.This would necessarily involve an incompati-ble change to the directory entry format.However,if we expand the block pointers to64bits to support petabyte-sizedfilesystems,we ultimately may wish to support more than232inodes in afilesystem anyway.Unfor-tunately,there are two major implementation problems with expanding the inode number which make pursuit of this approach unlikely.First,the size of the inode number in struct stat is32bits on32-bit platforms;hence, user space programs which depend on different inodes having unique inode numbers may have this assumption violated.Secondly,the current ext2/3implementation relies on internal kernel routines which assume a32-bit inode number.In order to use a64-bit inode number, these routines would have to be duplicated and modified to support64-bit inode numbers.Another potential solution to this problem is to utilize inode numbers starting from the end of the inode space (i.e.,starting from232−1and working downwards)for dynamically-allocated inodes,and using an inode to al-locate space for these extended inodes.For the purposes of the block allocation algorithm,the extended inode’s block group affiliation can be stored in afield in the in-ode.However,the location of the extended inode in this scheme could no longer be determined by examining its inode number,so the location of the inode on disk would no longer be close to the data blocks of the inode.This would result in a performance penalty for using extended inodes(since the location of the inode and the location of its data blocks would no longer necessarily be close to-gether),but hopefully the penalty would not be too great.Some initial experiments which grouped the inode tables of meta-block groups together showed a very small per-formance penalty,although some additional benchmark-ing is necessary.(A simple experiment would be to mod-ify the block allocation algorithms to deliberately allo-cate blocks in a different block group from the inode, and to measure the performance degradation this change would cause.)2.6Extent mapsThe ext2filesystem uses direct,indirect,double indi-rect,and triple indirection blocks to mapfile offsets to on-disk blocks,like most classical Unixfilesystems.Un-fortunately,the direct/indirect block scheme is inefficient for largefiles.This can be easily demonstrated by delet-ing a very largefile,and noting how long that operation can take.Fortunately,ext2block allocation algorithms tend to be very successful at avoiding fragmentation and in allocating contiguous data blocks forfiles.For most Linuxfilesystems in production use today,the percentage of non-contiguousfiles reported by e2fsck is generally less than10%.This means that in general,over90%of thefiles on an ext2filesystem only require a single extent map to describe all of their data blocks.The extent map would be encoded in a structure like this:struct ext2_extent{__u64logical_block;__u64physical_block;__u32count;};Using such a structure,it becomes possible to ef-ficiently encode the information,“Logical block1024 (and following3000blocks)can be found starting at physical block6536.”The vast majority offiles in a typical Linux system will only need a few extents to de-scribe all of their logical to physical block mapping,and so most of the time,these extent maps could be stored in the inode’s direct blocks.However,extent maps do not work well in certain pathalogical cases,such as sparsefiles with random al-location patterns.There are two ways that we can deal with these sorts of cases.The traditional method is to store the extent maps in a B-tree or related data struc-ture,indexed by the logical block number.If we pursue this option,it will not be necessary to use the full balanc-ing requirements of B-trees;we can use similar design choices to those made by the directory indexing designto significantly simplify a B-tree implementation:using afixed depth tree,not rotating nodes during inserts,and not worrying about rebalancing the tree after operations (such as truncate)which remove objects from the tree. There is however an even simpler way of implement-ing extents,which is to ignore the pathological case al-together.Today,very fewfiles are sparse;even most DBM/DB implementations avoid using sparsefiles.In this simplification,files with one or two extents can store the extent information in the inode,using thefields that were previously reserved for the direct blocks in the in-ode.Forfiles with more extents than that,the inode will contain a pointer to a single extent-map block.(The sin-gle extent-map block can look like a single leaf belong-ing to an extent-map tree,so this approach could be later extended to support a full extent-map tree if this proves necessary.)If thefile contains more extent maps than can fit in the single extent-map block,then indirect,double-indirect,and triple-indirect blocks could be used to store the remainder of the block pointers.This solution is appealing,since for the vast major-ity offiles,a single extent map is more than sufficient, and there is no need to adding a lot of complexity for what is normally a very rare case.The one potential problem with this simplified solution is that for very largefiles(over25gigabytes on afilesystem using a 4KB blocksize),a single extent map may not be enough space iffilesystem metadata located at the beginning of each block group is separating contiguous chunks of disk space.Furthermore,if thefilesystem is badly frag-mented,then the extent map mayfill even more quickly, necessitating a fall back to the old direct/double indi-rect block allocation scheme.So if this simplification is adopted,preallocation becomes much more important to ensure that these large block allocations happen con-tiguously,not just for performance reasons,but to avoid overflowing the space in a single extent map block.We can solve thefirst problem of metadata(inode tables,block and inode bitmaps)located at the beginning of each block group breaking up contiguous allocations by solved by moving all the metadata out of the way. We have tried implementing this scheme by moving the inode tables and allocation bitmaps to the beginning of a meta-block group.The performance penalty of moving the inode table slightly farther away from the data blocks related to it was negligible.Indeed,for some workloads, performance was actually slightly improved by grouping the metadata together.Making this change does not require a format change to thefilesystem,but merely a change in the allocation algorithms used by the mke2fs program.However,the kernel does have some sanity-checking code that needs to be removed so that the kernel would not reject the mount.A very simple patch to weaken the checks in ext3check descriptors()was written for the2.4kernel.Patches to disable this sanity check,as well as the inode size limitation,will be available for all commonly used Linux kernel branches at /ext2.html.2.7Preallocation for contiguousfilesFor multimediafiles,where performance is important,it is very useful to be able to ask the system to allocate the blocks in advance,preferably contiguously if possible. When the blocks are allocated,it is desirable if they donot need to be zeroed in advanced,since for a4GBfile(to hold a DVD image,for example),zeroing4GB worthof pre-allocated blocks would take a long time.Ext2had support for a limited amount of preallocation (usually only a handful of blocks,and the preallocated blocks were released when thefile was closed).Ext3 currently has no preallocation support at all;the featurewas removed in order to make adding journaling support simpler.However,it is clear that in the future,we willneed to add a more significant amount of preallocation support to the ext2/ext3filesystem.In order to notify thefilesystem that space shouldbe preallocated,there are two interfaces that could be used.The POSIX specification leaves explicitly unde-fined the behavior of ftruncate()when the argu-ment passed to ftruncate is larger than thefile’s current size.However,the X/Open System Interface developed by the Austin Group[11]states if the size passed to ftruncate()is larger than the currentfile size,thefile should be extended to the requested size.The ext2/ext3can use ftruncate as a hint that space should be preallocated for the requested size.In addition to multimediafiles,there are also certain types offiles whose growth characteristics require per-sistent preallocation beyond the close of the inode.Ex-amples of such slow-growthfiles include logfiles andUnix mailfiles,which are appended to slowly,by differ-ent processes.For these types offiles,the ext2behaviorof discarding preallocated blocks when the lastfile de-scriptor for an inode is closed is not sufficient.On theother hand,retaining preallocated blocks for all inodes isalso not desirable,as it increases fragmentation and cantie up a large number of blocks that will never be used.One proposal would be to allow certain directories and。