面板数据分析 - 中国人民大学--汉青经济与金融研究院
人大汉青研究院金融专硕项目介绍

汉青夏令营介绍
汉青经济与金融高级研究院每年举办“全国经济学与金融学优秀大学生夏令营”, 在全 国范围内选拔优秀学生前来就读。夏令营活动包括学术讲座、机构参观及现场教学、文体活 动和选拔程序等几部分。形式灵活多样,内容丰富多彩,重点考察学生的综合素质,并有汉 青最优秀的学生担任辅导员全程陪同,给予学生学术学习、生活工作的全方位指导。汉青通 过夏令营从全国选拔最优秀的人才,在国内高校中有着广泛的影响和良好的口碑,每年都吸 引上千名优秀学子前来报名。
投资与基金管理方向:为满足中国金融界对高质量金融人才的需求, 汉青研究院还增设 了投资与基金管理方向专业硕士,该方向导师由院内资深教授、兼职教授、投资总监、基金 经理组成,旨在打造未来中国基金业和证券业管理者的摇篮,为基金、证券公司等金融行业 输送高层次应用型人才。
投资与基金管理方向在培养模式上打破常规,实施产学研联合培养模式,从招生、授课 到实习等各个环节都与基金公司和证券公司等金融机构紧密结合。在培养目标上要求学位获 得者具有扎实的经济学理论基础,具备系统的金融学专业知识,熟悉证券和金融产品的理论 与实务,毕业后能胜任基金、证券等金融行业的投资管理工作,同时也具备在社会保险基金 管理中心、保险公司和信托投资公司资产管理部门、商业银行个人理财管理中心、慈善机构 等单位进行投资管理工作的能力。
申请资格: 1.大学本科三年级学生,专业不限 量化金融方向:优先考虑数学、物理、计算机等理工科专业学生 投资与基金管理方向:优先考虑经济金融等专业学生 2.本科前 5 学期平均学分绩排名应为本专业前 10%(所在学校或院系优秀生源集中的
全要素生产率对中国经济增长的影响——基于面板数据分析

全要素生产率对中国经济增长的影响——基于面板数据分析中国是全球最大的经济体之一,几十年来经济增长引人注目。
作为一个出口导向型的国家,中国经济体系中的第一批市场化体制改革造就了一个大规模的制造业,但是为了持续的增长,中国需要转变经济增长模式,从制造业转向服务业和高附加值的产业,同时减少对外部需求的依赖。
全要素生产率(TFP)是经济学中的一个重要概念,用来衡量所有的生产要素,包括生产资本、劳动力和技术等几个方面对产出的贡献。
TFP 对于经济增长至关重要,特别是在资源有限的情况下,如在中国这样的国家,必须考虑和利用每一个生产要素。
基于面板数据的研究表明,在高增长时期,在制造业中,生产资本和劳动力成本的提高引起了生产效率的下降。
去产能和工业结构调整导致传统行业的产能过剩,而技术创新和企业结构调整则对整体生产率的提高更加有益。
在新周期下,转型升级势在必行。
因此,在中国经济转型升级所需的生产要素中,技术进步和企业组织创新对于提高TFP是至关重要的。
然而,中国在技术进步和企业组织创新方面仍然存在许多问题。
中国需要更好地利用现代化的科技以及更加灵活的企业组织结构,以满足市场需求和实现更加高效的生产方式。
尤其是在中国面临生产资本价格上升和失业率增加的情况下,更加重要的是提高生产效率,以保持经济增长的稳定性。
在近年来的研究中,一些学者正着眼于在中国企业中实现组织创新。
这种创新可以帮助企业更好地组织劳动力、资本和其他生产要素,以改善生产效率和质量。
企业组织创新旨在减少企业的生产成本、提高效率、提高质量,以及为中国的经济增长提供更加适合的发展模式。
特别是在新冠病毒疫情影响下,中国企业陷入了前所未有的困境。
病毒爆发带来的防疫措施和供应链中断对其造成了巨大的冲击。
然而,一些中国企业在这种情况下依然实现了可持续发展,其中一些企业通过组织创新提高了生产效率,应对了疫情给企业造成的影响。
总之,TFP对于中国经济的发展至关重要。
通过加强技术创新和企业组织创新,中国可以确保在经济结构调整中实现可持续发展。
面板分位数回归模型

面板分位数回归模型面板分位数回归模型是一种用于分析什么因素会影响某个特定变量的统计模型。
它主要应用于面板数据分析中,旨在解释某个因变量在所研究个体之间的差异,以及这种差异如何随着独立变量的变化而改变。
本文将详细介绍面板分位数回归模型的相关概念、假设、解释和应用,帮助读者了解并运用这一模型。
什么是面板数据?面板数据(panel data)顾名思义,就是由多个时间点和多个个体组成的数据。
每个时间点,我们会针对同一组个体(如公司、城市、家庭等)观测它们的某些属性(如收入、投资、人口等)。
这就像一组交叉的时间序列数据,以时间为独立变量、以不同个体为分组变量。
面板数据有很多优点,比如可以避免交叉截面数据的选择偏差,同时可以对个体和时间进行深入分析,从多个角度突出数据中的趋势和变化。
什么是分位数回归?分位数回归是针对因变量分布的不对称性问题,采用分位数的思想进行统计分析的方法。
它在传统回归的基础上,拓展了解释变量和因变量之间的关系,不仅关注均值,还能反映其它分位数点的差异。
这点对于非线性关系、异方差的回归模型而言,具有更广泛的适用性。
例如:如果我们用年收入来预测房价,直接拟合一个经典的线性回归模型可能效果并不好,因为一部分收入较低的人很难买得起较贵的房子,也存在一些高收入者低房价的情况。
如果我们使用分位数回归模型,我们可以更好地理解收入与房价之间的关系,因为我们能够在不同收入分位数下,看到收入与房价之间的具体关系。
面板分位数回归模型(Panel Quantile Regression, PQR)结合了面板数据和分位数回归两者的优点。
它是一种同时考虑时间和空间对一组个体差异进行分析的方法。
通过对每个个体在不同分位数下的条件分布函数建立模型,可以刻画出因变量随着独立变量的不同取值范围的变化规律。
像传统的面板数据模型一样,PQR模型也需要考虑固定效应和随机效应。
固定效应意味着个体之间差异和时间的差异是不同的,这些固定属性与模型中的控制变量一起被引入回归模型中。
面板数据分析

第十四章 面板数据模型在第五章,当我们分析城镇居民的消费特征时,我们使用的是城镇居民消费和收入的时间序列数据,也就是说,我们的观测对象是城镇居民。
当我们分析农村居民的消费特征时,我们可以使用农村居民的时间序列数据,此时,我们的观测对象是农村居民。
但是,如果我们想要分析全体中国居民的消费特征呢?我们有两种选择:一是使用中国居民的时间序列数据进行分析,二是把城镇居民和农村居民这两个观测对象的时间序列数据合并为一个样本。
第二种选择中所使用的是由多个观测对象的时间序列数据所组成的样本数据,通常被称为面板数据(Panel Data )。
或者被称为综列数据,意即综合了多个时间序列的数据。
当然,面板数据也可以看成多个横截面数据的综合。
在面板数据中,每一个观测对象,被称为一个个体(Individual )。
例如城镇居民是一个观测个体,其消费记为1tC ,农村居民是另一个观测个体,其消费记为2tC,这样,itC (i=1,2)就组成了一个面板数据。
同理,收入itY (i=1,2)也是一个面板数据。
如果面板数据中各观测个体的观测区间和采样频率是相同的,我们就称其为平衡的面板数据,反之,则为非平衡的面板数据。
例如,表5.3.1中城镇居民和农村居民的样本数据具有相同的采样区间和频率,所以,它是一个平衡的面板数据。
基于面板数据所建立的计量经济学模型则被称为面板数据模型。
§14.1 面板数据模型一、两个例子1. 居民消费行为的面板数据分析让我们重新回到居民消费的例子。
在表5.1.1中,如果我们将城镇居民和农村居民的时间序列数据组成面板数据,以分析中国居民的消费特征。
那么,此时模型(5.1.1)的凯恩斯消费函数就可以表述为:itititY C10(14.1.1)ittiitu (14.1.2)其中:itC 和itY 分别表示第i个观测个体在第t 期的消费和收入。
i =1、2分别表示城镇居民和农村居民两个观测个体,t =1980、…、2008表示不同年度。
面板数据和多层次数据的经济统计分析

面板数据和多层次数据的经济统计分析在经济学领域,数据分析是非常重要的一环。
为了更好地理解和解释经济现象,经济学家们需要运用统计工具对数据进行分析。
面板数据和多层次数据是两种常见的数据类型,它们在经济统计分析中发挥着重要的作用。
面板数据是指在一定时间跨度内,对同一组体(如个人、家庭、企业等)进行多次观测所得到的数据。
这种数据类型具有时间序列和截面的特点,可以提供更多的信息,有助于研究者更准确地分析经济现象。
面板数据在经济学研究中的应用广泛,例如用于研究个体消费行为、企业投资决策、劳动力市场等。
面板数据的分析方法有很多种,其中最常用的是固定效应模型和随机效应模型。
固定效应模型假设个体之间的差异是固定的,而随机效应模型则假设个体之间的差异是随机的。
这两种模型都可以通过回归分析来实现,通过控制其他变量的影响,研究者可以更准确地估计出变量之间的关系。
与面板数据不同,多层次数据是指在研究对象内部存在多个层次的数据。
例如,在研究教育系统的效果时,可以将学生作为第一层次,学校作为第二层次,地区作为第三层次。
多层次数据的分析方法可以更好地考虑到层次结构的影响,避免了忽略层次结构带来的偏误。
多层次数据的分析方法主要包括多层次线性模型和多层次逻辑回归模型。
多层次线性模型可以用于分析连续型因变量,而多层次逻辑回归模型则适用于分析二元型因变量。
这些模型可以帮助研究者更好地理解层次结构对变量之间关系的影响,并提供更准确的分析结果。
面板数据和多层次数据的经济统计分析在实际应用中都有广泛的应用。
例如,在教育经济学中,研究者可以利用面板数据和多层次数据分析学校教育质量对学生学业成绩的影响。
在医疗经济学中,可以利用面板数据和多层次数据分析医疗资源配置对健康状况的影响。
在金融经济学中,可以利用面板数据和多层次数据分析金融市场的波动对企业投资决策的影响。
总之,面板数据和多层次数据的经济统计分析为经济学研究提供了更多的工具和方法。
通过运用这些方法,研究者可以更准确地分析经济现象,为政策制定提供科学依据。
计量经济学:面板数据

Panel Data 分析的基本框架
线性模型 非线性模型
Panel Data 分析的基本框架:线性模 型
线性模型: (1)单变量模型 (2)联立方程模型 (3)带测量误差模型 (4)伪Panel Data
Panel Data 分析的基本框架:线性
模型之单变量模型
(1) 固定效应和固定系数模型(Fixed Effect Models and Fixed Coefficient Models):通常采用OLS估计。固 定效应包括时间效应以及时间和个体效应,并可以进一 步放宽条件,允许在有异方差、自相关性和等相关矩阵 块情况下,用GLS估计。 (2)误差成分模型(Error Components Models):最 常用的Panel Data模型。针对不同情况,通常可以用OLS 估计、GLS估计、内部估计(Within Estimator)和FGLS 估计,并检验误差成分中的个体效应以及个体和时间效 应,同时将自相关和异方差情况也纳入该模型框架中。
平行数据的含义
所谓平行数据,是指在时间序列上取多个 截面,在这些截面上同时选取样本观测值 所构成的样本数据。 面板数据是同时在时间和截面空间上取得 的二维数据。从横截面上看,是由若干个 体在某一时刻构成的截面观测值,从纵剖 面上看是一个时间序列。
平行数据研究的应用和发展
最早是Mundlak(1961)、Balestra和 Nerlove (1966)把Panel Data引入到经济计量中。从此 以后,大量关于Panel Data的分析方法、研究文 章如雨后春笋般出现在经济学、管理学、社会 学、心理学等领域。从1990年到目前为止,已 有近1000篇有关 Panel Data理论性和应用性的文 章发表,Panel Data 研究成为近十年来经济计量 学的一个热点。
面板数据的计量经济分析

面板数据的计量经济分析1. 引言面板数据是研究中常用的一种数据形式,它包含多个个体在多个时间点上的观测值。
由于其具有横截面和时间序列的特点,面板数据通常可以提供比纯横截面数据或纯时间序列数据更大的信息量。
计量经济学的面板数据分析方法能够更准确地评估变量之间的关系,并对经济政策的效果进行研究。
本文将介绍面板数据的基本特征、主要的面板数据模型和计量经济学中常用的面板数据分析方法。
2. 面板数据的基本特征面板数据可以分为两种类型:平衡面板数据和非平衡面板数据。
平衡面板数据是指每个时间点上都有完整数据的面板,而非平衡面板数据则是至少有一个时间点上缺失了一些观测值的面板。
面板数据的分析需要考虑两个维度的异质性:个体异质性和时间异质性。
个体异质性是指不同个体之间的特征和行为存在差异,时间异质性是指同一时间点上不同个体之间的特征和行为存在差异。
3. 面板数据模型在计量经济分析中,有几种常用的面板数据分析模型。
3.1 固定效应模型固定效应模型假设每个个体的截距项是固定的,不随个体特征变化而变化。
通过固定效应模型,可以分离掉个体之间的异质性,使得我们更关注变量之间的关系。
固定效应模型的基本形式为:$$ y_{it} = \\alpha + \\beta X_{it} + \\gamma D_i + \\epsilon_{it}$$其中,y it是个体i在时间t的因变量观测值,X it是自变量观测值,D i是个体固定效应,$\\epsilon_{it}$是误差项。
3.2 随机效应模型随机效应模型假设个体截距项是随机的,并且与个体特征无关。
通过随机效应模型,可以同时考虑个体之间的异质性和变量之间的关系。
随机效应模型的基本形式为:$$ y_{it} = \\beta X_{it} + \\gamma D_i + \\alpha_i + \\epsilon_{it}$$其中,$\\alpha_i$是个体随机效应,$\\epsilon_{it}$是误差项。
中国省级面板数据

“中国省级面板数据”资料合集目录一、数字金融能驱动经济高质量发展吗——基于中国省级面板数据的实证分析二、新型城镇化推动产业结构升级了吗——基于中国省级面板数据的空间计量研究三、城市化、社会保障支出与城乡收入差距——来自中国省级面板数据的经验证据四、数字经济发展与高技术产业创新效率提升——基于中国省级面板数据的实证检验五、目标考核、官员晋升激励与安全生产治理效果——基于中国省级面板数据的实证检验六、环境规制、产业结构调整与绿色经济增长——基于中国省级面板数据的实证检验七、财政分权与地方政府行政管理支出——基于中国省级面板数据的实证研究八、地方政府投资行为、地区性行政垄断与经济增长——基于转型期中国省级面板数据的分析九、中国地方政府间支出竞争研究——基于中国省级面板数据的经验证据数字金融能驱动经济高质量发展吗——基于中国省级面板数据的实证分析数字金融能驱动经济高质量发展吗?基于中国省级面板数据的实证分析引言随着科技的不断进步,数字金融逐渐成为全球经济发展的重要引擎。
数字金融通过创新的服务模式和高效的运营方式,为经济高质量发展提供了新的动力。
本文将探讨数字金融与经济高质量发展之间的关系,并利用中国省级面板数据对此进行实证分析。
文献综述自2以来,数字金融的发展历程已经引发了广泛。
大量研究表明,数字金融对经济发展具有积极影响。
然而,现有研究主要集中在宏观层面,较少涉及数字金融对经济高质量发展的影响。
因此,本文旨在弥补这一研究不足,探讨数字金融如何驱动经济高质量发展。
研究方法本文采用固定效应模型,利用2010-2020年中国30个省份的面板数据进行实证分析。
数字金融的发展水平由移动支付、互联网理财、P2P 网贷等指标构成。
同时,我们还控制了其他影响经济发展的因素,如地区产业结构、科技创新能力、基础设施建设等。
结果与讨论数字金融对经济高质量发展具有显著的正向影响。
在数字金融发展水平较高的地区,经济增长质量也相对较高。
第7章面板数据模型分析

第7章面板数据模型分析面板数据模型(Panel Data Model)是一种多变量时间序列数据模型,常用于经济学、金融学和社会科学等领域的研究。
该模型可以同时考虑个体差异、时间效应以及个体和时间的交互作用,具有较高的灵活性和效率。
面板数据可以分为平衡面板数据(Balanced Panel Data)和非平衡面板数据(Unbalanced Panel Data)。
平衡面板数据指各个时间点上个体数目稳定、缺失数据较少的数据集,而非平衡面板数据则相反。
根据数据的特征和研究问题的需要,可以选择适合的模型进行分析。
面板数据模型通常可以分为固定效应模型(Fixed Effects Model)和随机效应模型(Random Effects Model)两类。
固定效应模型假设个体异质性对因变量的影响恒定不变,主要通过个体间的差异来解释变量的变化;而随机效应模型则将个体异质性视为随机变量,并通过估计随机误差项的协方差矩阵来解释因变量的变化。
在面板数据模型分析中,常用的方法包括固定效应模型的最小二乘法(Least Squares Dummy Variable Estimation)和随机效应模型的广义最小二乘法(Generalized Least Squares)。
此外,基于面板数据的研究还可以通过引入仪器变量(Instrumental Variables)来处理内生性问题,或者利用面板数据的特点进行因果推断。
面板数据模型的分析结果可以提供更准确和全面的推断,相比于传统的截面数据或时间序列数据分析方法,更能反映出个体和时间的异质性和相关性。
此外,面板数据模型还可以帮助解决共线性等常见问题,提高模型的解释能力和预测精度。
然而,面板数据模型也存在一些限制和挑战。
首先,面板数据的收集和整理相对复杂,需要耗费较多的时间和精力。
其次,面板数据模型假设个体和时间上的相关性,但在实际研究中,个体和时间的交互作用可能没有那么显著。
金融计量经济第四讲面板数据(PanelData)模型

• 因为是面板数据,涉及截面与时间,与一般的单方 程模型有所不同。模型(4. 1)实际上代表几种情形。 常用的有如下三种情形: • 情形1: i j , i j , • 情形2: i j , i j , • 情形3: i j , i j , • 理论上讲,根据截距或斜率是否可变,排列组合有 四种情形,上面三种未列出截距相同斜率不同的情 形。这三种是代表性的。 • 由截距和斜率的统计关系,情形2又可分为确定效 应模型与随机效应模型。
二、面板数据模型的检验
• 面板数据模型的检验主要是考虑截距项和斜率项在 不同截面不同时间下是否一致,所以检验的第一个 假设为: • H2: yit X it u, it 即斜率截距相同。 • 如果H2不能成立,则检验H1:yit i X it uit • 如果上面二个假设都不成立,则是斜率和截距都不 相同(情形3)的模型: yit i X it i uit • 一般不考虑截距相同而斜率不同的情况,实际应用 中这种情况没有意义。 • 面板数据模型的检验
• 平行数据或面板数据(panel data),我们也称这 些数据为联合利用时间序列/截面数据(Pooled time series,cross section)指在时间序列上取 多个截面,在这些截面上同时选取样本观测值所 构成的样本数据。面板数据计量经济学模型是近 20年来计量经济学理论方法的重要发展之一,具 有很好的应用价值。 • 适用问题如:生产分析中技术进步与规模影响; 开放式基金赎回影响;上市公司股权结构影响; 投资收益基本面影响等。
(二)截距斜率固定模型
• • • • • • • • • • • • • • • • • • • • • • • • • • • • • •
面板数据分位数回归及其经济应用

面板数据分位数回归及其经济应用面板数据分位数回归是一种多变量回归方法,在经济学中具有广泛的应用。
它通过使用面板数据集,考虑个体和时间的异质性,可以更准确地估计经济变量在不同分位数的变化。
面板数据是指对同一组个体(例如家庭、企业或国家)进行多个时间观察的数据集。
与传统的横截面数据或时间序列数据相比,面板数据具有更多的信息,可以提供更准确的估计结果。
面板数据分位数回归将这些数据应用到经济学研究中,以分析变量在不同分位数下的影响和变化。
面板数据分位数回归的基本思想是将依变量和解释变量的关系扩展到不同的分位数。
传统的回归模型通常使用一个条件的均值作为衡量标准,而忽略了分布的其他信息。
而面板数据分位数回归通过分析不同分位数下的条件均值,可以确定变量对于不同个体和时间的异质性的影响。
面板数据分位数回归在经济学中有许多重要的应用。
首先,它可以用于研究不同收入群体的收入差距。
通过将个体收入与其他解释变量的关系扩展到不同收入分位数,可以更好地理解收入分配的变化和影响因素。
这对于制定公共政策和减少贫困具有重要意义。
其次,面板数据分位数回归可以用于研究教育、健康和劳动力市场等领域的不平等问题。
通过分析不同分位数下的教育水平、健康状况和工资收入等变量,可以揭示不同个体和时间的异质性,并提供政策建议。
此外,面板数据分位数回归还可以用于分析企业和产业的效率和生产力的变化。
通过将生产率和利润等变量与其他解释变量在不同分位数下的关系进行比较,可以对企业和产业的差异进行深入研究,为企业管理和政策制定提供参考。
总之,面板数据分位数回归是一种重要的经济学方法,它能够更准确地分析经济变量在不同分位数下的变化。
它在研究收入差距、教育和健康不平等、企业效率等方面具有广泛的应用前景。
通过利用面板数据的丰富信息,我们可以更好地理解经济现象,为公共政策和管理决策提供科学依据。
经济学实证研究中的面板数据分析方法比较

经济学实证研究中的面板数据分析方法比较面板数据(Panel Data),也称为长期数据或混合数据,是指在一定时间内对多个个体或企业进行观测的数据。
面板数据分析方法是经济学实证研究中常用的一种分析工具。
本文旨在比较不同的面板数据分析方法,探讨它们的优劣与适用情况。
一、面板数据的特点面板数据有以下几个显著特点:1. 包含个体特征和时间维度。
即数据中观测个体之间存在差异,而且可以根据时间轴进行观测。
2. 具备更多的信息。
相对于横截面数据或时间序列数据,面板数据可以提供更为全面和详尽的信息,有助于更准确地进行经济学实证研究。
3. 更好地解决内生性问题。
面板数据可以通过个体固定效应或时段固定效应来控制个体异质性和时间变化的影响,从而更好地解决内生性问题。
基于以上特点,面板数据分析方法成为经济学实证研究中重要且有效的分析工具。
二、面板数据分析方法在面板数据分析中,常用的方法主要包括以下几种:1. 固定效应模型固定效应模型假设不同个体之间存在固定的差异,而这些个体差异会对变量的影响造成一定程度的固定效应。
该模型将这些固定效应当作个体的特征进行分析,用于探究个体特征对经济现象的影响。
2. 随机效应模型随机效应模型认为不同个体之间的差异是随机的,并不具备固定效应。
该模型通过引入个体随机效应、错误项相关性等,对面板数据进行分析,得出影响因素对个体和时间的影响。
3. 差异化面板数据模型差异化面板数据模型将固定效应模型和随机效应模型综合起来,将随机效应和固定效应作为影响因素的一部分进行分析。
该模型能够更好地反映个体之间的差异以及个体随时间变化的影响。
4. 两阶段最小二乘法(2SLS)2SLS方法采用两个步骤来估计模型参数。
首先,通过工具变量法或广义矩估计法获取外生变量的估计值;然后,将估计值代入原回归方程中进行估计。
该方法主要用于解决内生性问题。
不同的面板数据分析方法适用于不同的研究问题和数据特点。
研究者需要根据具体情况选择适合的方法,以确保研究结果的准确性和可信度。
【国家自然科学基金】_面板分析_基金支持热词逐年推荐_【万方软件创新助手】_20140803
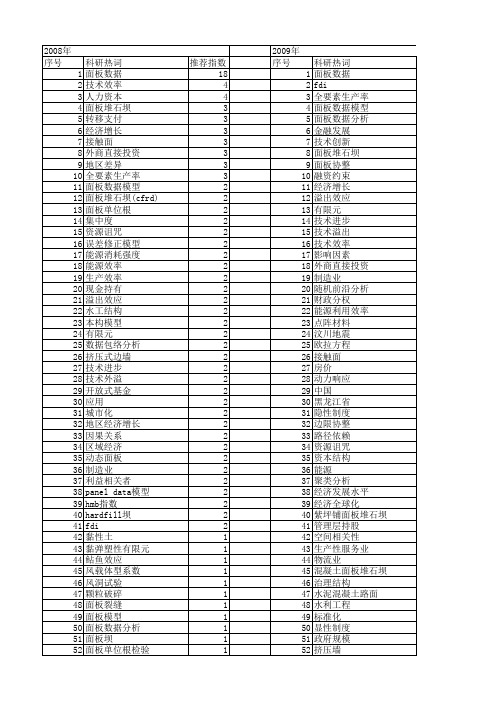
挤出效应 居民消费 就业弹性 夹芯梁 外国直接投资 城乡收入不均等 地理加权回归 商业银行 医疗保险 动力有限元 制度 创新绩效 分权 冲击碾压 农村公路供给 公司绩效 公司价值 全球价值链 产业内贸易 个人账户 r&d pcse稳健估计 hmb指数 gmm估计 gmm dea 高精度反射器 高校科技支出 高新技术企业 高新技术产业 高新技术 高技术产业 高坝结构安全 高土石坝 饲u型 食品需求 风险偏好 预测 预期 面板脱空 面板模型 面板应力 面板因果关系 面板周边缝 面板单位根检验 面板分析 面板 非线性本构关系 非平稳面板计量 非平稳面板数据分析方法 非均衡增长 非参数环境生产前沿 非参数局部线性估计 非农就业
推荐指数 18 4 4 3 3 3 3 3 3 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
能源开发 股权集中 股权属性 股权制衡 股份制银行 耦合协调度 耕地非农化 群体差异 网络协作 统计性质 结构突变 结构特性 经营风险 经济损失 经济一体化 终极股东 组合墙体 级配 紧缩场 等效材料参数 等代拉杆法 竞争性行业 竞争力水平 空间计量模型 空间相关场 科技投入 硐室爆破 知识生产函数 知识溢出 相关性 监管预警 监测信息管理 盈利性 盈余管理 电信综合价格指数 用电需求 生猪 生产要素拥挤 生产能力扩张 生产技术效率 现金流权偏离度 现代物流业 环境污染 环境库茨涅茨曲线 环境变化 环境不公 玉米 独立董事 特殊函数 特有风险 煤炭行业 温度场 渗透比降 渗流场
基于面板数据的营运资本管理行业差异及其影响因素分析

一、问题的提出
关于营运资本管理的影响因素的研究,综观国外的研究成果,Kenneth Nunn 是较早地对营运资本的 战略性影响因素进行实证研究的学者。但是,他的研究仅仅关注于生产领域,只涉及到了“永久性营运资 本”,在数据的范围上也只包括应收账款和存货两部分内容。在后来的研究中,影响营运资本管理的因素 逐渐超出生产领域,研究范围不断扩大。但这些研究成果更多的是关于单个因素对营运资本管理的影响的 研究(比如Rajan和Peterson(1997),忽略了各个单个因素对营运资本总的影响,而这方面却是企业关心的 焦点问题。在财务学术界后来的研究中,对此也缺乏一定的经验研究予以证明。此外,关于营运资本管理 影响因素的研究文献往往使用流动比率,速动比率和净营运资本等作为衡量营运资本管理效率的指标。 Shulman and Cox (1985)在文章中指出流动比率、速动比率是在没有考虑企业是否是持续经营的前提下, 从流动性角度来评价企业的偿债能力的。因此,在预测一个企业是否面临财务危机时,Shulman and Cox (1985)把净营运资本分为营运资本需求(WCR)和净流动差额(NLB)来分别评价营运资本管理和企业 面临财务危机的可能性。他们的研究发现NLB这个指标比传统的指标在预测财务危机和企业流动性方面 更好。Hawawini, Viallet, and Vora (1986)也认为建立在NLB和WCR基础上的评价指标要明显优于传统的指 标。综上文献,可以看出国外学者对于营运资本管理与其影响因素是否显著相关尚处于讨论阶段,还没 有达成统一的共识。基于国外的研究经验,本篇文章使用WCR这一指标作为衡量营运资本管理水平的指 标。其计算公式为: WCR=(应收账款+应收票据+部分其他应收款+预付账款+应收补贴款+存货+待 摊费用)-(应付票据+应付账款+预收账款+应付工资+应付福利费+应交税金+其他应交款+部分其他应付 款+预提费用)
面板数据的常见处理

面板数据的常见处理面板数据是一种特殊的数据结构,通常用于描述在不同时间和不同实体(例如公司、个人等)上的观察结果。
在处理面板数据时,需要采取一些特殊的方法和技术。
本文将介绍面板数据的常见处理方法,帮助读者更好地理解和分析这种数据结构。
一、面板数据的概述1.1 面板数据的定义:面板数据是一种包含多个实体和多个时间点观察结果的数据结构,通常以二维表格的形式呈现。
1.2 面板数据的特点:面板数据具有时间序列和截面数据的特点,能够捕捉实体间的变化和时间上的趋势。
1.3 面板数据的应用:面板数据在经济学、金融学、社会学等领域广泛应用,用于分析实体间的关系和趋势。
二、面板数据的清洗和准备2.1 缺失值处理:面板数据中常常存在缺失值,需要采取合适的方法填充或删除缺失值。
2.2 异常值处理:对于异常值,需要进行识别和处理,以保证数据的准确性和可靠性。
2.3 数据格式转换:将面板数据转换成适合分析的格式,例如长格式或宽格式,以便进行后续的数据分析和建模。
三、面板数据的描述性统计分析3.1 平均值和标准差:计算面板数据的平均值和标准差,了解数据的中心趋势和离散程度。
3.2 相关系数和协方差:计算面板数据的相关系数和协方差,分析不同实体间的关系和趋势。
3.3 可视化分析:利用图表和图形展示面板数据的分布和趋势,帮助更直观地理解数据的特征和规律。
四、面板数据的面板回归分析4.1 固定效应模型:利用固定效应模型分析面板数据中实体间的固定效应,探讨不同实体对因变量的影响。
4.2 随机效应模型:利用随机效应模型分析面板数据中实体间的随机效应,探讨不同实体对因变量的随机影响。
4.3 混合效应模型:结合固定效应和随机效应模型,分析面板数据中实体间的混合效应,更全面地理解实体间的影响。
五、面板数据的时间序列分析5.1 时间序列趋势分析:分析面板数据中时间序列的趋势和周期性,了解时间上的变化和规律。
5.2 季节性分析:分析面板数据中季节性的影响,探讨不同季节对因变量的影响。
我国碳金融市场中碳交易价格的影响因素分析——基于面板分位数模型

我国碳金融市场中碳交易价格的影响因素分析——基于面板分位数模型我国碳金融市场中碳交易价格的影响因素分析——基于面板分位数模型摘要:碳交易作为实现低碳经济转型的重要手段之一,其交易价格的波动对于我国碳金融市场发展和碳减排的有效实施具有重要影响。
本文针对我国碳金融市场中碳交易价格的影响因素展开研究,采用面板分位数模型对影响因素进行分析并给出结果,为进一步完善碳金融市场体系和提高碳交易价格稳定性提供参考。
关键词:碳交易价格;碳金融市场;影响因素;面板分位数模型一、引言随着全球气候变化问题的日益严重,低碳经济已经成为全球各国共同关注和努力的目标。
而在实现低碳经济转型的过程中,碳交易作为一种市场化手段正在逐渐被引入并发展起来,而碳交易价格的波动对于碳金融市场的稳定运行和碳减排的有效实施具有重要的影响。
二、碳交易价格的基本特征碳交易价格是碳金融市场中最具影响力的指标之一,它的波动程度和趋势可以直接反映市场参与者对碳减排的期望和改变。
本节首先对碳交易价格的基本特征进行介绍。
1. 碳交易价格的波动性碳交易价格具有较高的波动性,这是由于碳交易市场的特殊性和碳减排政策的调整频率较高所致。
碳减排政策的变化和市场预期都会对碳交易价格产生重要影响,因此碳交易价格的波动也是合理的。
2. 碳交易价格的季节性变化碳交易价格在不同季节会出现不同程度的变化。
一方面,季节性能源需求的变化会导致碳交易价格在不同季节呈现出不同的走势。
另一方面,碳减排政策的执行和监管也会随着季节的变化而有所差异,从而对碳交易价格产生影响。
三、碳交易价格的影响因素碳交易价格的波动和变化受到诸多因素的影响。
本节主要分析了一些重要的影响因素,并通过面板分位数模型进行量化和分析。
1. 宏观经济因素宏观经济因素对碳交易价格具有重要的影响作用。
经济增长水平、人均收入水平、产业结构等因素都会对碳交易价格产生影响。
通过分析宏观经济变量与碳交易价格的相关性,可以更好地理解宏观经济对碳交易价格的影响。
面板数据门限分位数回归模型及应用

足括号内的条件时,I (×) = 1 ,否则 I (×) = 0 。
1.2 参数估计
PTQR 模型的参数估计可通过优化式(2)得到:
( ) θ̂1(τ)θ̂ 2(τ)θ̂ 3(τ)γ̂ 1(τ)γ̂ 2(τ)
( ) =
arg
θ1
min
θ2 θ3 γ1
γ2
S
(θ1
τ
θ2
åå ( ( | )) N T
(
τ
)
θ
3(
τ
)
γ1(
τ
)
γ
2(
τ
))
=
arg
θ1
min
θ2 θ3 γ1
γ2
i
=
1
t
=
1
ρ
τ
yit - Qyit
τ
xit
(2)
其 中 ,S(θ1(τ)、θ2(τ)、θ3(τ)、γ1(τ)、γ2(τ)) 为 目 标 函
数;ρτ(u) 为非对称损失函数,满足:
{ ρτ(u) =
τu, u ³ 0
(1 - τ)u, u < 0
二个门限值 γ̂ 2(τ) 是基于第一个门限值 γ̂ 1(τ) 确定存在的
条件下获得的,具有一致性;但估计的第一个门限值是基
于假定无门限的条件下,利用加权的绝对偏差和最小获得
的,不具有一致性。因此,需对第一个门限值 γ̂ 1(τ) 进行重 新估计。选取集合 Γ1 中小于第二个门限估计值 γ̂ 2(τ) 的
(1)
( | ) 其中,τ(0 < τ < 1) 为分位点;Qyit τ xit 表示给定 xit 条
件下 yit 的第 τ 条件分位数;γ1(τ) 和 γ2(τ) 为门限值,α(τ)
面板数据模型(8)课案

第8章 面板数据(panel data )模型§8.1 面板数据模型及其检验一、面板数据例例,失业状况分析。
第1种情况假设现有2007年辽宁14个市产业结构与失业状况的数据,则采用回归分析模型 可分析产业结构与失业状况关系。
市 失业率 产业结构 1 2┆ i y 12,,...,k i i i x x xN=14假设现有辽宁沈阳市产业结构与失业状况的1990—2007年数据,则采用 时序分析模型可分析沈阳市的产业结构与失业状况关系。
年 失业率 产业结构 1 2┆ t y 12,,...,k t t t x x x T=18如果有辽宁14个市产业结构与失业状况的1990—2007年面板数据,则须采用panel data 模型,同时,既可分析产业结构与失业状况关系,也可分析产业政策与失业的关系。
按年1990 市 失业率 产业结构 1 2┆ 1i y 12111,,...,k i i i x x x N=14┆第t 年 it y 12,,...,k it it it x x x ┆2007 市 失业率 产业结构1 2┆ 18i y 12181818,,...,k i i i x x x N=14或者按市1 年 失业率 产业结构1 212kT=18┆第i 市 it y 12,,...,k it it it x x x ┆N 年 失业率 产业结构1 2┆ Nt y 12,,...,k Nt Nt Nt x x x T=18第一种情况是,只有N 个样本的截面数据,采用回归分析模型的分析;第二种情况是,只有某一样本的T 时间长度的纵向(时间序列)数据,采用时间序列模型的分析;而第三种情况是,同时有N 个样本的T 时间长度的数据,即面板数据(平行数据、纵向数据、综列数据)。
二、面板数据模型及其类型设被解释变量为y 与k 个解释变量12,,...,k x x x 有线性相关关系1212...k it i i it i it ik it it y x x x u αβββ=+++++ (8.1.1)1,2,...,;1,2,...,i N t T ==若记 (it x =12',,...,)k it it it x x x ,12(,,...,)i i i ik ββββ'=,则上式可写成it i iti it y x u αβ'=++ (8.1.2) 1,2,...,;1,2,...,i N t T ==通常模型满足基本假设条件为2~(0,)it u iid σ,即相互独立、服从以0为期望、2σ为方差的相同分布。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2008年 夏季班
中国人民大学 汉青研究院
课程目标
微观计量经济学是计量经济学的现代分支,用于发展出恰当的经济计量工具用于分析个体(企业、个人等)数据。得益于面板数据的可能性和微观计量经济方法的发展,面板数据分析在微观计量经济学中的作用和重要性日益明显。本课程是在线性回归的框架内处理面板数据分析,线性回归框架包括多种推断方法,如最小二乘法、工具变量法、最大似然估计、广义矩估计(GMM)。然后讨论(线性)面板数据方法,特别是如何控制不可观测的个体效应的问题。本课程会详细讨论随机效应模型和固定效应模型。也会介绍最新发展的动态面板模型。希望通过本课程使学生学会微观计量经济学的基本概念和问题,并将本课程学得的分析工具用于面板数据的实证研究,为今后学习非线性面板数据模型打下基础。 2. 线性回归(续)
非球形扰动项的广义回归模型;异方差;系列相关
3. 回归方程组
看似不相关回归模型;奇异方程组
4. 面板数据
不可观测效应;固定效应v.s. 随机效应; 一阶差分法;面板数据模型的推断;动态面板
教材
J. M. Wooldridge, Econometric Analysis of Cross Section and Panel Data, MIT
Press, 2002.
课程大纲
1. 基本多元线性回归:估计、检验和预测
古典多元线性回归;最小二乘估计量的有限和大样本性质;工具变量估计量;推断和预测;函数形式;设定分析和建模。