NOIP 2007 普及组解题报告
NOIP2007年信息学奥赛普及组复赛参考答案

2007普及组复赛C语言答案;1.奖学金;(scholar.pas/c/cpp);【问题描述】;某小学最近得到了一笔赞助,打算拿出其中一部分为学;任务:先根据输入的3门课的成绩计算总分,然后按上;7279;5279;这两行数据的含义是:总分最高的两个同学的学号依次;7279;则按输出错误处理,不能得分;【输入】;输入文件scholar.in包含行n+1行:;2007普及组复赛C语言答案1.奖学金(scholar.pas/c/cpp)【问题描述】某小学最近得到了一笔赞助,打算拿出其中一部分为学习成绩优秀的前5名学生发奖学金。
期末,每个学生都有3门课的成绩:语文、数学、英语。
先按总分从高到低排序,如果两个同学总分相同,再按语文成绩从高到低排序,如果两个同学总分和语文成绩都相同,那么规定学号小的同学排在前面,这样,每个学生的排序是唯一确定的。
任务:先根据输入的3门课的成绩计算总分,然后按上述规则排序,最后按排名顺序输出前5名学生的学号和总分。
注意,在前5名同学中,每个人的奖学金都不相同,因此,你必须严格按上述规则排序。
例如,在某个正确答案中,如果前两行的输出数据(每行输出两个数:学号、总分)是:7 2795 279这两行数据的含义是:总分最高的两个同学的学号依次是7号、5号。
这两名同学的总分都是279(总分等于输入的语文、数学、英语三科成绩之和),但学号为7的学生语文成绩更高一些。
如果你的前两名的输出数据是: 5 2797 279则按输出错误处理,不能得分。
【输入】输入文件scholar.in包含行n+1行:第l行为一个正整数n,表示该校参加评选的学生人数。
第2到年n+l行,每行有3个用空格隔开的数字,每个数字都在0到100之间。
第j行的3个数字依次表示学号为j-1的学生的语文、数学、英语的成绩。
每个学生的学号按照输入顺序编号为1~n(恰好是输入数据的行号减1)。
所给的数据都是正确的,不必检验。
【输出】输出文件scholar.out共有5行,每行是两个用空格隔开的正整数,依次表示前5名学生的学号和总分。
NOIP2007普及组解题报告

NOIP 2007普及组解题报告1、奖学金 (scholar.pas/c/cpp)【问题描述】某小学最近得到了一笔赞助,打算拿出其中一部分为学习成绩优秀的前5名学生发奖学金。
期末,每个学生都有3门课的成绩:语文、数学、英语。
先按总分从高到低排序,如果两个同学总分相同,再按语文成绩从高到低排序,如果两个同学总分和语文成绩都相同,那么规定学号小的同学排在前面,这样,每个学生的排序是唯一确定的。
任务:先根据输入的3门课的成绩计算总分,然后按上述规则排序,最后按排名顺序输出前5名学生的学号和总分。
注意,在前5名同学中,每个人的奖学金都不相同,因此,你必须严格按上述规则排序。
例如,在某个正确答案中,如果前两行的输出数据(每行输出两个数:学号、总分)是:7 2795 279这两行数据的含义是:总分最高的两个同学的学号依次是7号、5号。
这两名同学的总分都是279(总分等于输入的语文、数学、英语三科成绩之和),但学号为7的学生语文成绩更高一些。
如果你的前两名的输出数据是:5 2797 279则按输出错误处理,不能得分。
【输入】输入文件scholar.in包含行n+1行:第l行为一个正整数n,表示该校参加评选的学生人数。
第2到年n+l行,每行有3个用空格隔开的数字,每个数字都在0到100之间。
第j行的3个数字依次表示学号为j-1的学生的语文、数学、英语的成绩。
每个学生的学号按照输入顺序编号为1~n(恰好是输入数据的行号减1)。
所给的数据都是正确的,不必检验。
【输出】输出文件scholar.out共有5行,每行是两个用空格隔开的正整数,依次表示前5名学生的学号和总分。
【输入输出样例l】scholar.in690 67 8087 66 9178 89 9188 99 7767 89 6478 89 98scholar.out6 2654 2643 2582 2441 237【输入输出样例2】scholar.in880 89 8988 98 7890 67 8087 66 9178 89 9188 99 7767 89 6478 89 98scholar.out8 2652 2646 2641 2585 258【限制】50%的数据满足:各学生的总成绩各不相同100%的数据满足:6<=n<=300【试题分析】简单的排序。
NOIP普及组历届试题分析

对于100%的数据,3 ≤ n ≤ 100 测验题给出的正整数大小不超过10,000。
试题分析
题意大意:给你n个数,在这n个数中,找 到满足A+B=C的C的个数,注意不是这个 等式的个数。
样例中,1,2,3,4有1+2=3,1+3=4两个。
由于本题数据规模n<=100,我们可以直接
枚举C, A, B,三层循环解决问题。
扫雷游戏 (noip2015普及组第二题)
输入样例 1 33 *?? ??? ?*? 输入样例 2 23 ?*? *??
输出样例 1 mine.out *10 221 1*1 输出样例 2 mine.out 2*1 *21
对于 100%的数据,1≤n≤100,1≤m≤100
问题分析:
本题也是简单的枚举类试题。 我们从雷区的第一行第一列(1,1)开始,判断它周围 有多少个地雷。 由于本题读入的是字符,读入时需要注意: readln(n,m); for i=1 to n do begin for j=1 to m do read(a[i][j]); readln; end;
比例简化 (noip2014普及组第二题)
在社交媒体上,经常会看到针对某一个观点同意与 否的民意调查以及结果。例如,对某 一观点表示 支持的有 1498 人,反对的有 902 人,那么赞同与 反对的比例可以简单的记为1498:902。 不过,如果把调查结果就以这种方式呈现出来,大 多数人肯定不会满意。因为这个比例的数值太大, 难以一眼看出它们的关系。对于上面这个例子,如 果把比例记为 5:3,虽然与 真实结果有一定的误差, 但依然能够较为准确地反映调查结果,同时也显得 比较直观。 现给出支持人数 A,反对人数 B,以及一个上限 L, 请你将 A 比 B 化简为 A’比 B’,要求在 A’和 B’均 不大于 L 且 A’和 B’互质(两个整数的最大公约数 是 1)的前提下,A’/B’ ≥ A/B 且 A’/B’ - A/B 的值 尽可能小。
Noip2007、2009普及组复赛答案

Noip2007普及组复赛答案1——奖学金typeaa=recordy,s,w:integer;end;bb=recordf,h:integer;end;var a:array[1..300]of aa;b:array[1..5]of bb;n,i,j,k,t:integer;f:boolean;beginreadln(n);for i:=1 to 5 dowith b[i] do beginf:=0;h:=0;end;for i:=1 to n do beginwith a[i] do read(y,s,w);j:=1;f:=true;t:=a[i].y+a[i].s+a[i].w;while (j<=5)and f do beginif (t>b[j].f)or((t=b[j].f)and(a[i].y>a[b[j].h].y)) then begin for k:=5 downto j+1 do beginb[k].f:=b[k-1].f;b[k].h:=b[k-1].h;end;b[j].f:=t;b[j].h:=i;f:=false;end else if (t=b[j].f)and(a[i].y=a[b[j].h].y) then beginfor k:=5 downto j+2 do beginb[k].f:=b[k-1].f;b[k].h:=b[k-1].h;end;b[j+1].h:=i;b[j+1].f:=t;f:=false;end;j:=j+1;end;for i:=1 to 5 dowith b[i] do writeln(h,' ',f);end.Noip2007普及组复赛答案2——纪念品var a:array[1..30000]of byte;b:array[1..30000]of boolean;w,n,i,zu,k,ma,t:integer;beginreadln(w);readln(n);for i:=1 to 30000 do b[i]:=true;for i:=1 to n do read(a[i]);zu:=0;for i:=1 to n do beginma:=0;t:=0;if b[i] then for k:=i+1 to n doif (a[i]+a[k]<=w)and(a[i]+a[k]>ma)and b[i] and b[k] then begin ma:=a[i]+a[k];t:=k;end;if t<>0 then beginb[i]:=false;b[t]:=false;zu:=zu+1;end;end;for i:=1 to n do if b[i] then zu:=zu+1;writeln(zu);end.Noip2007普及组复赛答案3——守望者的逃离var maxs,mintime,t,m,s,t1,m1,s1:longint;procedure aa(m1,s1,t1:integer);beginif (s1>0)and(t1>0) then begins1:=s1-m1 div 10*60;t1:=t1-m1 div 10;m1:=m1 mod 10;m1:=m1+4;t1:=t1-1;aa(m1,s1,t1);m1:=m1-4;aa(m1,s1,t1);end else beginif maxs<s-s1 then maxs:=s-s1;if (t1>=0)and(mintime>t-t1) then mintime:=t-t1;end;end;beginreadln(m,s,t);maxs:=0;mintime:=2000000;t1:=t;m1:=m;s1:=s;aa(m1,s1,t1);if maxs<s then beginwriteln('No');writeln(maxs);end else beginwriteln('Yes');writeln(mintime);end;end.(pascal语言)Noip2007普及组复赛答案4——Hanoi双塔问题2007年11月21日星期三18:40var a:array[1..62]of integer;i,j,n:integer;f:boolean;beginreadln(n);for i:=2 to 62 do a[i]:=0;a[1]:=2;for i:=2 to n do beginfor j:=1 to 62 doa[j]:=a[j]*2;a[1]:=a[1]+2;for j:=1 to 62 doif a[j]>9 thenbegina[j+1]:=a[j+1]+1;a[j]:=a[j] mod10;end;end;f:=false;for i:=62 downto 1 dobeginif a[i]<>0 thenf:=true;if f then write(a[i]);end;writeln;end.(pascal语言)Noip2007普及组复赛答案4——Hanoi双塔问题2007年11月21日星期三18:40var a:array[1..62]of integer;i,j,n:integer;f:boolean;beginreadln(n);for i:=2 to 62 do a[i]:=0;a[1]:=2;for i:=2 to n do beginfor j:=1 to 62 doa[j]:=a[j]*2;a[1]:=a[1]+2;for j:=1 to 62 doif a[j]>9 thenbegina[j+1]:=a[j+1]+1;a[j]:=a[j] mod10;end;end;f:=false;for i:=62 downto 1 dobeginif a[i]<>0 thenf:=true;if f then write(a[i]);end;writeln;end.问题转述:给出一个一元多项式各项的次数和系数,按照规定的格式要求输出该多项式。
NOIP 2007 普及组 解题报告

NOIP 2007 普及组解题报告By 江苏省赣榆县实验中学初二参赛选手夏雨( 阿洛.c ) 我仅仅想用本文启发一下NOIP2007普及组的同学们,我也不是什么牛,仅仅是意见交流,另:本文供各位路过的牛们鄙视下。
第一题:奖学金【题目描述】:【解题思路】:这一题有很多种做法,包括排序、模拟等等。
现在,介绍一种最优算法,(其实最烂算法也可以全过,数据规模毕竟很小,呵呵)插排(时间复杂度:平均O(N),最坏O(N2),空间复杂度:O(1)。
)思路:1.开一个结构类型(Pascal里是record,C/C++是struct.),包含了学号信息,总分成绩,语文成绩。
或者也可以开三个以下标为关联的一维数组,一次表示上述三个参数。
2.读入。
每当读入一行信息,调用过程insert,从前向后依次寻找,直到寻找到某一记录的总分比当前读入总分小,或其总分和当前读入总分相等且语文成绩比当前总分小,则在当前位置插入所读入的数据。
(这个插入可以是将后面的数据依次向后移动一位,也可以是通过链表的方法实现。
)3.输出,从1至5,输出学号和总分即可。
还有一点要注意的是,当总分相等,且语文成绩也相等的时候,就要将学号小的排在前面。
【解题感想】:对于这种送分题,千万不要辜负出卷人的期望,能拿到的分数就一定要拿到。
否则既对不起老师,也对不起出卷人,更对不起自己。
读题目的时候千万要仔细,我同学就是因为这一题的语文处理有点问题而白白掉了3个点。
第二题奖品分组【题目描述】:【解题思路】:这一题乍一看起来,像是动态规划,很多选手被问题的“最”字迷惑了,拿到题目就开始乐呵呵的DP.殊不知,此题如用动归来做,确实是可以实现的,但编程复杂度很高。
下面介绍一种简单易行的方法:简单哈希表+贪心=哈贪(时间复杂度:平均O(N),最坏O(N2),空间复杂度O(1).)思路:1.开一个a[1..200]的数组作为桶,至于类型Integer足够用了,因为即使最坏情况——所有的数据都在一个桶里,也不过是30000个。
NOIP2007复赛普及组试题
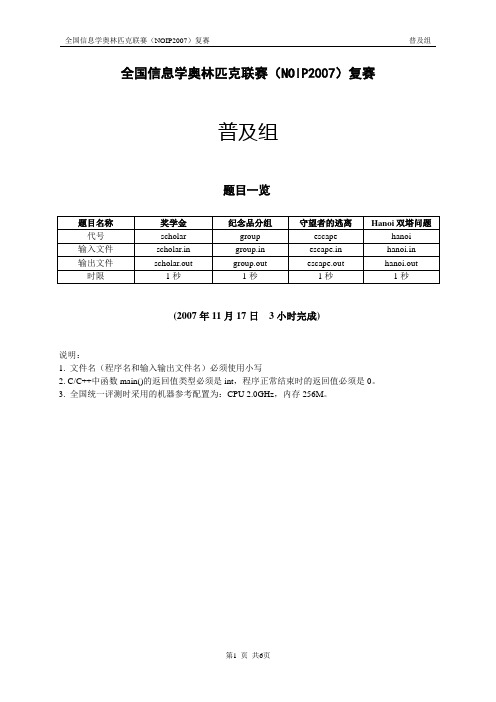
全国信息学奥林匹克联赛(NOIP2007)复赛普及组题目一览(2007年11月17日3小时完成)说明:1. 文件名(程序名和输入输出文件名)必须使用小写2. C/C++中函数main()的返回值类型必须是int,程序正常结束时的返回值必须是0。
3. 全国统一评测时采用的机器参考配置为:CPU 2.0GHz,内存256M。
1.奖学金(scholar.pas/c/cpp)【问题描述】某小学最近得到了一笔赞助,打算拿出其中一部分为学习成绩优秀的前5名学生发奖学金。
期末,每个学生都有3门课的成绩:语文、数学、英语。
先按总分从高到低排序,如果两个同学总分相同,再按语文成绩从高到低排序,如果两个同学总分和语文成绩都相同,那么规定学号小的同学排在前面,这样,每个学生的排序是唯一确定的。
任务:先根据输入的3门课的成绩计算总分,然后按上述规则排序,最后按排名顺序输出前5名学生的学号和总分。
注意,在前5名同学中,每个人的奖学金都不相同,因此,你必须严格按上述规则排序。
例如,在某个正确答案中,如果前两行的输出数据(每行输出两个数:学号、总分)是:7 2795 279这两行数据的含义是:总分最高的两个同学的学号依次是7号、5号。
这两名同学的总分都是279(总分等于输入的语文、数学、英语三科成绩之和),但学号为7的学生语文成绩更高一些。
如果你的前两名的输出数据是:5 2797 279则按输出错误处理,不能得分。
【输入】输入文件scholar.in包含n+1行:第1行为一个正整数n,表示该校参加评选的学生人数。
第2到n+1行,每行有3个用空格隔开的数字,每个数字都在0到100之间。
第j行的3个数字依次表示学号为j-1的学生的语文、数学、英语的成绩。
每个学生的学号按照输入顺序编号为1~n (恰好是输入数据的行号减1)。
所给的数据都是正确的,不必检验。
【输出】输出文件scholar.out共有5行,每行是两个用空格隔开的正整数, 依次表示前5名学生的学号和总分。
NOIP2007试题+答案+解析(学生版)

第十三届全国青少年信息学奥林匹克联赛初赛试题(普及组Pascal 语言二小时完成)●●全部试题答案均要求写在答卷纸上,写在试卷纸上一律无效●●一、单项选择题(共20题,每题1.5分,共计30分。
每题有且仅有一个正确答案。
)1.在以下各项中,()不是CPU的组成部分。
A.控制器B.运算器C.寄存器D.主板2.在关系数据库中,存放在数据库中的数据的逻辑结构以()为主。
A.二叉树B.多叉树C.哈希表D.二维表3.在下列各项中,只有()不是计算机存储容量的常用单位。
A.Byte B.KB C.UB D.TB4.ASCII码的含义是()。
A.二→十进制转换码 B.美国信息交换标准代码C.数字的二进制编码D.计算机可处理字符的唯一编码5.一个完整的计算机系统应包括()。
A.系统硬件和系统软件B.硬件系统和软件系统C.主机和外部设备D.主机、键盘、显示器和辅助存储器6.IT的含义是()。
A.通信技术B.信息技术C.网络技术D.信息学7.LAN的含义是()。
A.因特网B.局域网C.广域网D.城域网8.冗余数据是指可以由其它数据导出的数据。
例如,数据库中已存放了学生的数学、语文和英语的三科成绩,如果还存放三科成绩的总分,则总分就可以看作冗余数据。
冗余数据往往会造成数据的不一致。
例如,上面4个数据如果都是输入的,由于操作错误使总分不等于三科成绩之和,就会产生矛盾。
下面关于冗余数据的说法中,正确的是()。
A.应该在数据库中消除一切冗余数据B.用高级语言编写的数据处理系统,通常比用关系数据库编写的系统更容易消除冗余数据C.为了提高查询效率,在数据库中可以保留一些冗余数据,但更新时要做相容性检验D.做相容性检验会降低效率,可以不理睬数据库中的冗余数据9.在下列各软件,不属于NOIP竞赛(复赛)推荐使用的语言环境有()。
A.gcc B.g++ C.Turbo C D.Free Pascal10.以下断电后仍能保存数据的有()。
2007年NOIP提高组第二题解题报告字符串的展开

2.字符串的展开(expand.pas/c/cpp)【问题描述】在初赛普及组的“阅读程序写结果”的问题中,我们曾给出一个字符串展开的例子:如果在输入的字符串中,含有类似于“d-h”或“4-8”的子串,我们就把它当作一种简写,输出时,用连续递增的字母或数字串替代其中的减号,即,将上面两个子串分别输出为“defgh”和“45678” 。
在本题中,我们通过增加一些参数的设置,使字符串的展开更为灵活。
具体约定如下:(1)遇到下面的情况需要做字符串的展开:在输入的字符串中,出现了减号“-” ,减号两侧同为小写字母或同为数字,且按照ASCII 码的顺序,减号右边的字符严格大于左边的字符。
(2)参数p1:展开方式。
p1=1 时,对于字母子串,填充小写字母;p1=2 时,对于字母子串,填充大写字母。
这两种情况下数字子串的填充方式相同。
p1=3 时,不论是字母子串还是数字子串,都用与要填充的字母个数相同的星号“*”来填充。
(3)参数p2:填充字符的重复个数。
p2=k 表示同一个字符要连续填充k 个。
例如,当p2=3 时,子串“d-h”应扩展为“deeefffgggh” 。
减号两侧的字符不变。
(4)参数p3:是否改为逆序:p3=1 表示维持原有顺序,p3=2 表示采用逆序输出,注意这时仍然不包括减号两端的字符。
例如当p1=1、p2=2、p3=2 时,子串“d-h”应扩展为“dggffeeh” 。
(5)如果减号右边的字符恰好是左边字符的后继,只删除中间的减号,例如:“d-e”应输出为“de” ,“3-4”应输出为“34” 。
如果减号右边的字符按照ASCII 码的顺序小于或等于左边字符,输出时,要保留中间的减号,例如:“d-d”应输出为“d-d” ,“3-1”应输出为“3-1”。
【输入】输入文件expand.in 包括两行:第 1 行为用空格隔开的 3 个正整数,依次表示参数p1,p2,p3。
第 2 行为一行字符串,仅由数字、小写字母和减号“-”组成。
NOIP2007试题+答案+解析(学生版)

第十三届全国青少年信息学奥林匹克联赛初赛试题(普及组Pascal 语言二小时完成)●●全部试题答案均要求写在答卷纸上,写在试卷纸上一律无效●●一、单项选择题(共20题,每题1.5分,共计30分。
每题有且仅有一个正确答案。
)1.在以下各项中,()不是CPU的组成部分。
A.控制器B.运算器C.寄存器D.主板2.在关系数据库中,存放在数据库中的数据的逻辑结构以()为主。
A.二叉树B.多叉树C.哈希表D.二维表3.在下列各项中,只有()不是计算机存储容量的常用单位。
A.Byte B.KB C.UB D.TB4.ASCII码的含义是()。
A.二→十进制转换码 B.美国信息交换标准代码C.数字的二进制编码D.计算机可处理字符的唯一编码5.一个完整的计算机系统应包括()。
A.系统硬件和系统软件B.硬件系统和软件系统C.主机和外部设备D.主机、键盘、显示器和辅助存储器6.IT的含义是()。
A.通信技术B.信息技术C.网络技术D.信息学7.LAN的含义是()。
A.因特网B.局域网C.广域网D.城域网8.冗余数据是指可以由其它数据导出的数据。
例如,数据库中已存放了学生的数学、语文和英语的三科成绩,如果还存放三科成绩的总分,则总分就可以看作冗余数据。
冗余数据往往会造成数据的不一致。
例如,上面4个数据如果都是输入的,由于操作错误使总分不等于三科成绩之和,就会产生矛盾。
下面关于冗余数据的说法中,正确的是()。
A.应该在数据库中消除一切冗余数据B.用高级语言编写的数据处理系统,通常比用关系数据库编写的系统更容易消除冗余数据C.为了提高查询效率,在数据库中可以保留一些冗余数据,但更新时要做相容性检验D.做相容性检验会降低效率,可以不理睬数据库中的冗余数据9.在下列各软件,不属于NOIP竞赛(复赛)推荐使用的语言环境有()。
A.gcc B.g++ C.Turbo C D.Free Pascal10.以下断电后仍能保存数据的有()。
NOIP2007提高组复赛试题解题报告

NOIP2007提高组复赛试题解题报告我小菜也来发题解了,不过现在都已经过去那么长时间再来发题解未免太迟,但是写题解可以让自己对题目始终抱有需要深刻理解的态度,所以我还是坚持写题解。
NOIP2007的题目并不十分难,我们浙江省有1个满分,不知道2008年题目会怎么样。
首先我这里题目就省略了,因为这年头题目网上满天飞,所以直接开始写题解。
一、统计数字。
这题其实是道送分题,而且还十分弱智,不知道是考排序还是数据结构,这题解法有很多,可以快排,BST,HASH。
这些方法都很容易AC,而且据说写裸BST(不严格平衡的BST)都能满分,可见这题简单的程度。
记得当时我是用先读入数据,然后一趟快排,最后去重输出,简单吧,这题我就不费话,直接帖上程序:[参考程序]program count(input,output);constmaxn=200000;maxn1=10000;typearr=array[1..maxn] of longint;nums=recordnumb,time:longint;end;varnum:arr;ans:array[1..maxn1] of nums;i,j,k,n:longint;f1,f2:text;procedure ranqsort(var num:arr; low,high:longint);vari,j,k,tmp,x:longint;beginwhile low<high do begini:=low-1;k:=random(high-low+1)+low;tmp:=num[k]; num[k]:=num[high]; num[high]:=tmp;x:=num[high];for j:=low to high-1 do if num[j]<=x thenbegininc(i);tmp:=num[i]; num[i]:=num[j]; num[j]:=tmp;end;tmp:=num[i+1]; num[i+1]:=num[high]; num[high]:=tmp; ranqsort(num,low,i);low:=i+2;end;end;beginfillchar(num,sizeof(num),0);fillchar(ans,sizeof(ans),0);assign(f1,'count.in'); reset(f1);assign(f2,'count.out'); rewrite(f2);readln(f1,n);for i:=1 to n do readln(f1,num[i]);close(f1);randomize;ranqsort(num,1,n);j:=1; ans[1].numb:=num[1]; ans[1].time:=1;for i:=2 to n do if num[i]=ans[j].numb then inc(ans[j].time) else begin inc(j); ans[j].numb:=num[i]; ans[j].time:=1; end; for i:=1 to j do writeln(f2,ans[i].numb,' ',ans[i].time);close(f2);end.二、字符串的展开这道题是全卷思路最简单的一道题,简单模拟即可,但是这一点恰恰是这道题目的难点,因为字符串处理的题目对编程熟练程度要求比较高,而且这题还要考虑好多种因素,比如说有可能字符串开头出现了“-”号,结果不少人当时就因此有一个点WA的WA,崩溃的崩溃。
Noip2007解题报告

Noip2007解题报告第一题:scholar这个题没什么特别的,主要考察大家对编程的熟练程度。
可用二维数组a的a[1,i]记录下语文成绩,再用a[1,i]、a[3,i]记录总分、编号。
因为数据最多就300个,所以排序可以用冒泡。
在排序时可以将序号也排序,方便控制下标。
我的程序如下:program scholar(input,output);varn,x,y,z,i,j:integer;a:array[1..300,1..3] of integer;procedure swap(var a,b:integer);vars:integer;begins:=a;a:=b;b:=s;end;beginassign(input,'scholar.in');assign(output,'scholar.out');reset(input);rewrite(output);readln(n);for i:=1 to n dobeginreadln(x,y,z);a[i,1]:=i;a[i,2]:=x;a[i,3]:=x+y+z;end;for i:=1 to n-1 dofor j:=i+1 to n doif (a[i,3]a[j,1]) and (a[i,3]=a[j,3]) and (a[i,2]=a[j,2])) thenbeginswap(a[i,1],a[j,1]);swap(a[i,2],a[j,2]);swap(a[i,3],a[j,3]);end;for i:=1 to 5 dowriteln(a[i,1],' ',a[i,3]);close(input);close(output);end.第二题:group这题也不难,有许多人把它想成了DP,其实就是简单的模拟。
先排序(也可用冒泡),然后用2个指针控制下标,每次把第一个(头指针对应数据)和最后一个(尾指针对应数据)相加。
NOIP2007试题+答案+解析(学生版)

第十三届全国青少年信息学奥林匹克联赛初赛试题(普及组Pascal 语言二小时完成)●●全部试题答案均要求写在答卷纸上,写在试卷纸上一律无效●●一、单项选择题(共20题,每题1.5分,共计30分。
每题有且仅有一个正确答案。
)1.在以下各项中,()不是CPU的组成部分。
A.控制器B.运算器C.寄存器D.主板2.在关系数据库中,存放在数据库中的数据的逻辑结构以()为主。
A.二叉树B.多叉树C.哈希表D.二维表3.在下列各项中,只有()不是计算机存储容量的常用单位。
A.Byte B.KB C.UB D.TB4.ASCII码的含义是()。
A.二→十进制转换码 B.美国信息交换标准代码C.数字的二进制编码D.计算机可处理字符的唯一编码5.一个完整的计算机系统应包括()。
A.系统硬件和系统软件B.硬件系统和软件系统C.主机和外部设备D.主机、键盘、显示器和辅助存储器6.IT的含义是()。
A.通信技术B.信息技术C.网络技术D.信息学7.LAN的含义是()。
A.因特网B.局域网C.广域网D.城域网8.冗余数据是指可以由其它数据导出的数据。
例如,数据库中已存放了学生的数学、语文和英语的三科成绩,如果还存放三科成绩的总分,则总分就可以看作冗余数据。
冗余数据往往会造成数据的不一致。
例如,上面4个数据如果都是输入的,由于操作错误使总分不等于三科成绩之和,就会产生矛盾。
下面关于冗余数据的说法中,正确的是()。
A.应该在数据库中消除一切冗余数据B.用高级语言编写的数据处理系统,通常比用关系数据库编写的系统更容易消除冗余数据C.为了提高查询效率,在数据库中可以保留一些冗余数据,但更新时要做相容性检验D.做相容性检验会降低效率,可以不理睬数据库中的冗余数据9.在下列各软件,不属于NOIP竞赛(复赛)推荐使用的语言环境有()。
A.gcc B.g++ C.Turbo C D.Free Pascal10.以下断电后仍能保存数据的有()。
2007年NOIP普及组初赛试题及参考答案

二、问题解答
1、(子集划分)将 n 个数{1,2,…,n}划分成 r 个子集。每个数都恰好属于 一个子集,任何两个不同的子集没有共同的数,也没有空集。将不同划分方法 的总数记为 S(n,r)。例如,S(4,2)=7,这 7 种不同的划分方法依次 为{(1),(234)}, {(2),(134)}, {(3),(124)}, {(4),(123)}, {(12),(34)}, {(13),(24)}, {(14),(23)}。当 n=6,r=3 时,S(6,3)=_________ 。 (提示:先固定一个数,对于其余的 5 个数考虑 S(5,3)与 S(5,2),再分这两种 情况对原固定的数进行分析)。
一、选择题
11. 在下列关于计算机语言的说法中,正确的有( )。 A. 高级语言比汇编语言更高级,是因为它的程序的运行效率更高 B. 随着 Pascal、C 等高级语言的出现,机器语言和汇编语言已经退 出了历史舞台 C. 高级语言程序比汇编语言程序更容易从一种计算机移植到另一种 计算机上
D. C 是一种面向对象的高级计算机语言
│8
一、选择题
8. 冗余数据是指可以由其他数据导出的数据,例如,数据库中已存放了学生的数学、语文和 英语的三科成绩,如果还存放三科成绩的总分,则总分就可以看作冗余数据。冗余数据往往 会造成数据的不一致,例如,上面 4 个数据如果都是输入的,由于操作错误使总分不等于三 科成绩之和,就会产生矛盾。下面关于冗余数据的说法中,正确的是( )。 A. 应该在数据库中消除一切冗余数据 B. 用高级语言编写的数据处理系统,通常比用关系数据库编写的系统更容易消除冗余数据 C. 为了提高查询效率,在数据库中可以适当保留一些冗余数据,但更新时要做相容性检验 D. 做相容性检验会降低效率,可以不理睬数据库中的冗余数据
2007年NOIP提高组第一题解题报告统计数字

1.统计数字(count.pas/c/cpp)【问题描述】某次科研调查时得到了n 个自然数,每个数均不超过1500000000(1.5*109)。
已知不相同的数不超过10000 个,现在需要统计这些自然数各自出现的次数,并按照自然数从小到大的顺序输出统计结果。
【输入】输入文件count.in 包含n+1 行:第 1 行是整数n,表示自然数的个数。
第2~n+1 行每行一个自然数。
【输出】输出文件count.out 包含m 行(m 为n 个自然数中不相同数的个数),按照自然数从小到大的顺序输出。
每行输出两个整数,分别是自然数和该数出现的次数,其间用一个空格隔开。
【输入输出样例】【限制】40%的数据满足:1<=n<=100080%的数据满足:1<=n<=50000100%的数据满足:1<=n<=200000,每个数均不超过1 500 000 000(1.5*109)【主要算法】1、一道去重排序,本来用基数排序已经足够。
但数据范围过大导致超空间,所以可以用快排先对数列进行排序,形成压缩的作用。
【参考程序】varn,i,q,p,k:longint;a:array[1..200000] of longint;num,s:array[1..10000] of longint;procedure qsort(left,right:longint);vari,j,x,m:longint;begini:=left;j:=right;m:=a[(left+right)div 2];repeatwhile m>a[i] do inc(i);while m<a[j] do dec(j);if j>=i thenbeginx:=a[i];a[i]:=a[j];a[j]:=x;inc(i);dec(j);end;until i>j;if j>left then qsort(left,j);if i<right then qsort(i,right);end;beginassign(input,'count.in');reset(input);assign(output,'count.out');rewrite(output);readln(n);for i:=1 to n do readln(a[i]);qsort(1,n);// for i:=1 to n do write(a[i],' ');p:=1;q:=2;num[1]:=a[1];k:=1;for i:=1 to 10000 do s[i]:=1;while q<=n dobeginif a[p]<>a[q] then begin p:=q;q:=q+1;k:=k+1;num[k]:=a[p];end; while a[p]=a[q] dobegins[k]:=s[k]+1;q:=q+1;end;// write(s[k],' ');end;for i:=1 to k do writeln(num[i],' ',s[i]);close(input);close(output);end.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
NOIP 2007 普及组解题报告1.奖学金(scholar.pas/c/cpp)【问题描述】某小学最近得到了一笔赞助,打算拿出其中一部分为学习成绩优秀的前5名学生发奖学金。
期末,每个学生都有3门课的成绩:语文、数学、英语。
先按总分从高到低排序,如果两个同学总分相同,再按语文成绩从高到低排序,如果两个同学总分和语文成绩都相同,那么规定学号小的同学排在前面,这样,每个学生的排序是唯一确定的。
任务:先根据输入的3门课的成绩计算总分,然后按上述规则排序,最后按排名顺序输出前5名学生的学号和总分。
注意,在前5名同学中,每个人的奖学金都不相同,因此,你必须严格按上述规则排序。
例如,在某个正确答案中,如果前两行的输出数据(每行输出两个数:学号、总分)是:7 2795 279这两行数据的含义是:总分最高的两个同学的学号依次是7号、5号。
这两名同学的总分都是279(总分等于输入的语文、数学、英语三科成绩之和),但学号为7的学生语文成绩更高一些。
如果你的前两名的输出数据是:5 2797 279则按输出错误处理,不能得分。
【输入】输入文件scholar.in包含行n+1行:第l行为一个正整数n,表示该校参加评选的学生人数。
第2到年n+l行,每行有3个用空格隔开的数字,每个数字都在0到100之间。
第j行的3个数字依次表示学号为j-1的学生的语文、数学、英语的成绩。
每个学生的学号按照输入顺序编号为1~n(恰好是输入数据的行号减1)。
所给的数据都是正确的,不必检验。
【输出】输出文件scholar.out共有5行,每行是两个用空格隔开的正整数,依次表示前5名学生的学号和总分。
【输入输出样例l】scholar.in scholar.out690 67 8087 66 9178 89 9188 99 7767 89 6478 89 986 2654 2643 2582 2441 237【输入输出样例2】scholar.in scholar.out880 89 8988 98 7890 67 8087 66 9178 89 9188 99 7767 89 6478 89 988 2656 2641 2585 258【限制】50%的数据满足:各学生的总成绩各不相同100%的数据满足:6<=n<=300【试题分析】简单的排序。
因为n<=300,所以选择排序不会超时。
存储方面只需存储三个数:学号、语文成绩和总分。
【参考程序】program a1(input,output);varn,x,y,z,i,j:integer;a:array[1..300,1..3] of integer;procedure swap(var a,b:integer); {交换过程} vars:integer;begins:=a;a:=b;end;beginassign(input,'scholar.in');assign(output,'scholar.out');reset(input);rewrite(output);readln(n);for i:=1 to n dobeginreadln(x,y,z);a[i,1]:=i;a[i,2]:=x;a[i,3]:=x+y+z;end;for i:=1 to n-1 do {选择排序}for j:=i+1 to n doif (a[i,3]<a[j,3]) or ((a[i,3]=a[j,3]) and (a[i,2]<a[j,2])) or ((a[i,1]>a[j,1]) and (a[i,3]= a[j,3]) and (a[i,2]=a[j,2])) thenbeginswap(a[i,1],a[j,1]);swap(a[i,2],a[j,2]);swap(a[i,3],a[j,3]);end;for i:=1 to 5 dowriteln(a[i,1],' ',a[i,3]);close(input); {文件不要忘记关闭}close(output);end.2.纪念品分组(group.pas/c/cpp)【题目描述】元旦快到了,校学生会让乐乐负责新年晚会的纪念品发放工作。
为使得参加晚会的同学所获得的纪念品价值相对均衡,他要把购来的纪念品根据价格进行分组,但每组最多只能包括两件纪念品,并且每组纪念品的价格之和不能超过一个给定的整数。
为了保证在尽量短的时间内发完所有纪念品,乐乐希望分组的数目最少。
你的任务是写一个程序,找出所有分组方案中分组数最少的一种,输出最少的分组数目。
【输入】输入文件group.in包含n+2行:第1行包括一个整数w,为每组纪念品价格之和的上限。
第2行为一个整数n,表示购来的纪念品的总件数。
第3~n+2行每行包含一个正整数pi(5<=pi<=w),表示所对应纪念品的价格。
【输出】输出文件group.out仅一行,包含一个整数,即最少的分组数目。
【输入输出样例】group.in group.out1009902020305060708090 6【限制】50%的数据满足:l<=n<=15100%的数据满足:1<=n<=30000,80<=w<=200【试题分析】贪心法,先排序,然后按以下贪心策略:设s为所需的组数。
i,j为两个指针,开始时指向头和尾。
1.如果a[i]+a[j]<=w,s=:s+1,i:=i+1,j:=j-1。
2.如果a[i]+a[j]>w,s:=s+1,j:=j-1。
因为n<=300000,所以用选择排序可能会超时,最好用快速排序。
【参考程序1】program a2_1(input,output);vara:array[1..30000] of integer;w,n,i,j,s:integer;procedure qsort(h,t:integer);varp,i,j:integer;begini:=h;j:=t;p:=a[i];repeatwhile (a[j]>p) and (j>i) do j:=j-1;if j>i thenbegina[i]:=a[j];i:=i+1;while (a[i]<p) and (i<j) do i:=i+1;if i<j thenbegina[j]:=a[i];j:=j-1;end;end;until i=j;a[i]:=p;i:=i+1;j:=j-1;if i<t then qsort(i,t);if j>h then qsort(h,j);end;beginassign(input,'group.in');assign(output,'group.out');reset(input);rewrite(output);readln(w);readln(n);for i:=1 to n do readln(a[i]);qsort(1,n); {快速排序}i:=1;j:=n;s:=0;while i<=j do {贪心法}beginif i=j thenbegins:=s+1;break;end;if a[i]+a[j]<=w thenbegini:=i+1;j:=j-1;s:=s+1;end;if a[i]+a[j]>w thenbegins:=s+1;j:=j-1;end;end;writeln(s);close(input);close(output);end.【深入思考】快速排序的程序比较难编,是否能有一种比较好编得排序方法呢?答案是肯定的。
设p数组的下标为5至200,每读入一个数字x,就将p[x]加1,这样数字全部读入后就是有序的了,效率甚至比快速排序还高。
这样的话贪心部分也要有所改变。
【参考程序2】program a2_2(input,output);varp:array[5..200] of integer;x,i,w,n,j,s:integer;assign(input,'group.in');assign(output,'group.out');reset(input);rewrite(output);readln(w);readln(n);for i:=5 to 200 do p[i]:=0; {数组清0}for i:=1 to n do {读入数据}beginreadln(x);p[x]:=p[x]+1;end;i:=5;j:=200;s:=0;while i<=j do {贪心法}beginwhile p[i]=0 do i:=i+1; {找到不为空的数据} while p[j]=0 do j:=j-1;if i>j then break;if i=j then {处理i=j的情况}if i*2<=w thenbeginwhile p[i]>=2 dobeginp[i]:=p[i]-2;s:=s+1;end;s:=s+p[i];endelses:=s+p[i];if i+j<=w then {处理i+j<=w的情况}if p[i]>p[j] thenbegins:=s+p[j];p[i]:=p[i]-p[j];p[j]:=0;endelsebegins:=s+p[i];p[j]:=p[j]-p[i];end;if i+j>w then {处理i+j>w的情况}begins:=s+p[j];p[j]:=0;end;end;writeln(s);close(input);close(output);end.3、守望者的逃离(escape.pas/c/cpp)【问题描述】恶魔猎手尤迪安野心勃勃,他背叛了暗夜精灵,率领深藏在海底的娜迦族企图叛变。
守望者在与尤迪安的交锋中遭遇了围杀,被困在一个荒芜的大岛上。
为了杀死守望者,尤迪安开始对这个荒岛施咒,这座岛很快就会沉下去。
到那时,岛上的所有人都会遇难。
守望者的跑步速度为17m/s,以这样的速度是无法逃离荒岛的。
庆幸的是守望者拥有闪烁法术,可在1s内移动60m,不过每次使用闪烁法术都会消耗魔法值10点。
守望者的魔法值恢复的速度为4点/s,只有处在原地休息状态时才能恢复。
现在已知守望者的魔法初值M,他所在的初始位置与岛的出口之间的距离S,岛沉没的时间T。
你的任务写写一个程序帮助守望者计算如何在最短的时间内逃离荒岛,若不能逃出,则输出守望者在剩下的时间能走的最远距离。
注意:守望者跑步、闪烁或休息活动均以秒(s)为单位,且每次活动的持续时间为整数秒。