BQL to SQL Driver配置补充内容(NxDatabaseNetwork)
LoadRunner连接数据库

LoadRunner连接数据库1.连接SqlServer新建参数--data wizard--选择第二项--创建一个ODBC的数据源---选择驱动(因为我们用sqlserver数据库所以我们选择sqlserver的驱动--输入数据源名称(自取)和数据库服务器的名称--用户权限验证(一般默认)--更改默认的数据库为(选择刚才创建的数据源要连接的数据库)--测试数据源--确定后回到SQL语句输入2.连接Orical新建参数--data wizard--选择第二项--创建一个ODBC的数据源---选择驱动(因为我们用Orical 数据库所以我们选择Orical的驱动)--填写Orical数据源驱动的配置信息(数据源名称(自取),TNS service name (LIUDEBAO),userid(使用这个数据库的用户名))--test connection (需要输入用户密码)--确定后再次连接--输入查询语句如果链接不成功,首先检查Orical是否运行正常,然后在检查数据串连接串等设置3.连接mysql(需网上下载mysql驱动安装,因为windows没有自带odbc数据源的mysql驱动)新建参数--data wizard--选择第二项--创建一个ODBC的数据源---选择驱动(因为我们用Mysql 数据库所以我们选择MYsql的驱动(自己已经安装))--)--填写mysql数据源驱动的配置信息(数据源名称(自取),server(Mysql服务器地址,可写IP,若本机可写localhost),用户名,密码,所用的数据库)--此页第二个选项卡(链接选项)写入端口号(Mysql的默认端口号是3306),其他保持默认--点击test测试--回到输入查询语句a.这里需要强调需要额外自己安装mysql驱动b.总是说找不到记录或查询出错,可能是记录之间有空格或逗号。
PLSQLDeveloper连接Oracle数据库详细配置方法

PLSQLDeveloper连接Oracle数据库详细配置⽅法 近段时间很多⽹友提出监听配置相关问题,客户终端(Client)⽆法连接服务器端(Server)。
本⽂现对监听配置作⼀简单介绍,给出PL/SQL Developer 连接Oracle数据库详细配置⽅法,并提出⼀些客户终端⽆法连接服务器端的解决思路,愿对⼴⼤⽹友与读者有⼀些帮助。
⼀、监听器(LISTENER)监听器是Oracle基于服务器端的⼀种⽹络服务,主要⽤于监听客户端向数据库服务器端提出的连接请求。
既然是基于服务器端的服务,那么它也只存在于数据库服务器端,进⾏监听器的设置也是在数据库服务器端完成的。
⼆、本地服务名(Tnsname)Oracle客户端与服务器端的连接是通过客户端发出连接请求,由服务器端监听器对客户端连接请求进⾏合法检查,如果连接请求有效,则进⾏连接,否则拒绝该连接。
本地服务名是Oracle客户端⽹络配置的⼀种,另外还有Oracle名字服务器(Oracle Names Server)等。
Oracle常⽤的客户端配置就是采⽤的本地服务名,本⽂中介绍的也主要是基于本地服务名的配置。
三、Oracle⽹络连接配置⽅法配置Oracle服务器端与客户端都可以在其⾃带的图形化Oracle⽹络管理器(Oracle Net Manager)⾥完成(强烈建议在这个图形化的⼯具下完成Oracle服务端或客户端的配置)。
Windows下启动Net Manager图形窗⼝如下图⽰:1、 Oracle监听器配置(LISTENER)如上图⽰,选中树形⽬录中监听程序项,再点击左上侧“+”按钮添加监听程序,点击监听程序⽬录,默认新加的监听器名称是LISTENER(该名称也可以由任意合法字符命名)。
选中该名称,选中窗⼝右侧栏下拉选项中的“监听位置”,点击添加地址按钮。
在出现的⽹络地址栏的协议下拉选项中选中“TCP/IP”,主机⽂本框中输⼊主机名称或IP地址(如果主机即⽤作服务端也作为客户端,输⼊两项之⼀均有效;如果主机作为服务端并需要通过⽹络连接,建议输⼊IP地址),端⼝⽂本框中输⼊数字端⼝,默认是1521,也可以⾃定义任意有效数字端⼝。
plsql developer 连接数据库 database 写法 -回复

plsql developer 连接数据库database 写法-回复PL/SQL开发者如何连接数据库-写法和步骤作为PL/SQL开发者,连接数据库是我们常常需要处理的任务之一。
数据库是存储和管理数据的重要组成部分,让我们了解一下如何使用PL/SQL 开发者连接数据库的写法和步骤。
在开始连接数据库之前,首先确保你已经安装了适当的数据库管理系统(DBMS),如Oracle、MySQL或Microsoft SQL Server等。
以下是连接数据库的步骤和相应的写法:步骤1:导入必要的包在PL/SQL中,我们需要导入适当的包来访问数据库连接的功能。
这些包通常是特定DBMS的客户端库提供的。
下面是连接Oracle数据库的示例代码:plsql导入包SET SERVEROUTPUT ON;使用Oracle的客户端库executeDBMS_JAVA.SET_NLS_PROPERTY('java.nls.charset.AL32UTF8') create or replace and compile java source named "ConnectionUtil" asimport java.sql.*;import oracle.jdbc.driver.*;public class ConnectionUtil {public static Connection getConnection(String username, String password, String database) throws SQLException {DriverManager.registerDriver(new OracleDriver());Connection conn = null;conn = DriverManager.getConnection("jdbc:oracle:thin:" + database, username, password);return conn;}}/从PL/SQL中调用Java方法CREATE OR REPLACE PROCEDURE ConnectToOracle(username INVARCHAR2, password IN VARCHAR2, database IN VARCHAR2) IS connectionObj ConnectionUtil.Connection;BEGINconnectionObj := ConnectionUtil.getConnection(username, password, database);其他处理DBMS_OUTPUT.PUT_LINE('已成功连接到Oracle数据库'); END;/步骤2:建立连接在这一步骤中,我们使用之前导入的包来建立与数据库的连接。
oracle 数据库database link sql写法

oracle 数据库database link sql写法在Oracle 数据库中,Database Link 是一种连接到其他数据库的机制,允许在一个数据库中访问另一个数据库的对象。
以下是创建和使用Oracle Database Link 的SQL 写法:创建Database Link:```sqlCREATE DATABASE LINK link_nameCONNECT TO usernameIDENTIFIED BY passwordUSING 'connection_string';```- `link_name`:指定Database Link 的名称。
- `username`:连接到目标数据库的用户名。
- `password`:连接到目标数据库的密码。
-`connection_string`:目标数据库的连接字符串。
这可以是TNS(Transparent Network Substrate)服务名或连接描述符。
使用Database Link 进行查询:```sql--使用@ 符号引用Database LinkSELECT * FROM remote_table@link_name;--使用在FROM 子句中指定Database LinkSELECT * FROM remote_table LINK link_name;```- `remote_table`:目标数据库中的表名。
示例:假设有两个数据库:本地数据库(LocalDB)和远程数据库(RemoteDB)。
我们可以按照以下步骤创建Database Link 并进行查询:1. 在本地数据库(LocalDB)中创建Database Link:```sqlCREATE DATABASE LINK remote_linkCONNECT TO remote_userIDENTIFIED BY remote_passwordUSING 'RemoteDB';```2. 在本地数据库(LocalDB)中使用Database Link 查询远程数据库(RemoteDB)中的表:```sql--使用@ 符号引用Database LinkSELECT * FROM employees@remote_link;--或者使用在FROM 子句中指定Database LinkSELECT * FROM employees LINK remote_link;```上述SQL 语句中的`employees` 是远程数据库中的表名。
kettle的dynamic sql执行模板

kettle的dynamic sql执行模板题目:kettle的dynamic sql执行模板提纲:I. 介绍kettle和动态SQLA. 简要介绍kettleB. 动态SQL的概念和用途II. kettle的动态SQL执行模板A. 安装和配置kettleB. 创建Kettle的转换和任务C. 使用动态SQL执行功能1. 添加“Execute SQL Script”步骤2. 配置数据库连接3. 构建动态SQL4. 执行动态SQLD. 使用参数化输入1. 创建参数输入步骤2. 在动态SQL中使用参数3. 执行动态SQLIII. 最佳实践和注意事项A. 安全性考虑B. 控制SQL的执行顺序和依赖关系C. 避免过度复杂化IV. 举例说明A. 示例一:动态表名B. 示例二:动态条件C. 示例三:循环执行D. 示例四:动态建表V. 结论I. 介绍kettle和动态SQLA. Kettle是一种开源的ETL(抽取、转换和加载)工具,可用于数据集成和数据转换。
B. 动态SQL是一种可以根据不同的参数或条件生成和执行SQL语句的技术,它在处理复杂的业务需求和动态环境下非常有用。
II. kettle的动态SQL执行模板A. 安装和配置kettle在官方网站上下载并安装kettle,然后根据需要配置相关的数据库连接和其他参数。
B. 创建Kettle的转换和任务使用kettle的可视化界面创建一个转换或任务,该转换或任务将包含动态SQL执行的步骤。
C. 使用动态SQL执行功能1. 添加“Execute SQL Script”步骤在转换中添加一个“Execute SQL Script”步骤,该步骤用于执行动态SQL。
2. 配置数据库连接在步骤配置中,设置适当的数据库连接信息,以便可以与数据库建立连接。
3. 构建动态SQL在SQL脚本输入框中编写动态SQL。
动态SQL可以包含变量、函数、条件语句等,并可以根据需要生成不同的SQL语句。
在idea yml 中jdbc 连接sqlserver数据库的写法

在idea yml 中jdbc 连接sqlserver数据库的写法首先,您需要在项目的resources文件夹中创建一个名为`jdbc.properties`的文件,并添加以下内容:```makefilejdbc.driver=com.microsoft.sqlserver.jdbc.SQLServerDriverjdbc.url=jdbc:sqlserver://localhost:1433;databaseName=your_databaseername=your_usernamejdbc.password=your_password```其中,`jdbc.driver`是驱动类的全名,`jdbc.url`是连接URL,`ername`和`jdbc.password`分别是您的用户名和密码。
接下来,您需要在idea的`idea.yml`文件中添加以下内容:```yamlservices:database:url: classpath:jdbc/your_database_config.properties```这样,数据库的配置文件`jdbc.properties`就会作为配置源加载。
具体来说,上述代码加载的是resources文件夹下的`jdbc/your_database_config.properties`文件。
在`your_database_config.properties`文件中配置以下内容:```makefilespring.datasource.url=jdbc:mysql://localhost:3306/your_database?useSSL=false&serverTimezone=UTCername=your_usernamespring.datasource.password=your_passwordspring.datasource.driver-class-name=com.microsoft.sqlserver.jdbc.SQLServerDriver```在这里,我们设置了MySQL数据库的连接URL、用户名和密码,以及驱动类的全名。
nifi的sql语法

nifi的sql语法
NiFi的SQL语法主要应用于查询数据库,使用户可以从数据库中获取特定
的信息。
在NiFi中,查询SQL的操作主要涉及以下几个步骤:
1. 创建数据库连接服务:在Processor中,配置PROPERTIES,创建一个
数据库连接服务。
2. 设置SQL select query:在Processor中,设置SQL select query语句,例如“Select id,name From user”。
3. 创建记录服务:在Processor中,创建一个记录服务,例如添加JsonRecordSetWriter,并编辑JsonRecordSetWriter以添加AvroSchemaRegistry。
4. 关联Processor:将ExecuteSQLRecord与PutFile关联起来,从ExecuteSQLRecord中心点击,拖拉到PutFile上。
5. 启用Processor:启用两个Processor后,可以看到输出文件夹中新生成了文件,文件内容即数据库中查出来的数据,是json形式的。
此外,还有一些其他的Processor可以使用,如PutSQL、PutKafka、PutMongo等,它们分别可以将FlowFile的内容作为SQL DDL语句(INSERT、UPDATE或DELETE)执行、将FlowFile的内容作为消息发送
到Apache Kafka、将FlowFile的内容作为INSERT或UPDATE发送到Mongo等。
以上信息仅供参考,如需了解更多信息,建议查阅NiFi的官方文档或咨询专业人士。
PLSQL连接oracle数据库配置

PLSQL连接oracle数据库配置方法一:1)点击Net Configuration Assistant2) 在弹出的对话框中选择本地Net服务名配置,点下一步3)在服务名配置对话框中选择添加,点下一步4)在如下对话框中填写要访问的oralce数据库的服务名,该服务名可以通过oralce登录用户名进入环境,在.cshrc中,环境变量ORACLE_SID对应的值便是这个服务名,也可以在oracle用户环境下执行grep | env ORACLE_SID查找。
点击下一步5)选择TCP协议,点下一步6)主机名中填写要访问的oracle数据库服务器,使用标准端口号1521,点下一步7)选中“是,进行测试”,点下一步8) 点更改登录,填写要访问的数据库用户名和密码,确保其正确。
此处主要是验证前面配置是否正确,如正确这里的测试就可以成功。
如果不正确请检查服务名、ip地址、用户名、密码中是否有写错,并改之,就可以成功了。
测试成功后点下一步9)在下图中填写网络服务名,此处的网络服务名可以随意取名,点下一步,后面配置数据源的时候用的就是这个网络服务名方法一用起来有点小复杂,不过可以了解数据库的配置步骤,方法二相对来说简单很多找到本机oracle数据库安装的如下路径,如:F:\app\Administrator\product\11.1.0\client_1\network\admin,在该路径下有个文件tnsnames.ora,打开文件会发现里面有很多连接配置,直接拷贝一个修改如下红色字SYSDB_102 = //对应的就是上面方法一提到的网络服务名(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 10.41.24.102)(PORT = 1521)) //访问数据库的ip)(CONNECT_DATA =(SERVICE_NAME = sysdb) //数据库服务名))当配置好后,就可以用PLSQL访问数据库了PLSQL连接oracle数据库配置方法一:1)点击Net Configuration Assistant2) 在弹出的对话框中选择本地Net服务名配置,点下一步3)在服务名配置对话框中选择添加,点下一步4)在如下对话框中填写要访问的oralce数据库的服务名,该服务名可以通过oralce登录用户名进入环境,在.cshrc中,环境变量ORACLE_SID对应的值便是这个服务名,也可以在oracle用户环境下执行grep | env ORACLE_SID查找。
Oracle导入SQL脚本执行和常用命令大全-同创IT问答

Oracle导入SQL脚本执行和常用命令大全-同创IT问答Oracle导入SQL脚本执行和常用命令大全Oracle导入SQL脚本执行和常用命令大全show和set命令是两条用于维护SQL*Plus系统变量地命令SQL> show all --查看一切68个系统变量值SQL> show user --显现当前连接用户SQL> show error --显现错误SQL> set heading off --禁止输出列标题,默许值为ON SQL> set feedback off --禁止显现最后一行地计数反馈信息,默许值为"对6个或更多地记录,回送ON"SQL> set timing on --默许为OFF,设置查询耗时,可用来估量SQL语句地执行时间,测试性能SQL> set sqlprompt "SQL> " --设置默许提示符,默许值就是"SQL> "SQL> set linesize 1000 --设置屏幕显现行宽,默许100 SQL> set autocommit ON --设置能否自动提交,默许为OFF SQL> set pause on --默许为OFF,设置暂停,会使屏幕显现停止,等候按下ENTER键,再显现下一页SQL> set arraysize 1 --默许为15SQL> set long 1000 --默许为80说明:long值默许为80,设置1000是为啦显现更多地内容,因为很多数据字典视图中用到啦long数据类型,如:SQL> desc user_views列名可空值否类型------------------------------- -------- ----VIEW_NAME NOT NULL VARCHAR2(30)TEXT_LENGTH NUMBERTEXT LONGSQL> define a = ,,,20000101 12:01:01,,,--定义部分变量,假如想用一个类似在各种显现中所包含地回车那样地常量,--能够用define命令来设置SQL> select &a from dual;原值1: select &a from dual新值1: select ,20000101 12:01:01,from dual,2000010112:01:01-----------------20000101 12:01:01情况提出:1、用户需要对数据库用户下地每一张表都执行一个相同地SQL操作,这时,一遍、一遍地键入SQL语句是很费事地完成方法:SQL> set heading off --禁止输出列标题SQL> set feedback off --禁止显现最后一行地计数反馈信息列出当前用户下一切同义词地定义,可用来测试同义词地真实存在性select ,desc ,||tname from tab where tabtype=,SYNONYM,;查询当前用户下一切表地记录数select ,select ,,,||tname||,,,,count(*) from ,||tname||,;,from tab where tabtype=,TABLE,;把一切符合条件地表地select权限授予为publicselect ,grant select on ,||table_name||,to public;,from user_tables where 《条件》;删除用户下各种对象select ,drop ,||tabtype||,,||tname from tab;删除符合条件用户select ,drop user ,||username||,cascade;,fromall_users where user_id>25;快速编译一切视图----当在把数据库倒入到新地服务器上后(数据库重建),需要将视图重新编译一遍,----因为该表空间视图到其它表空间地表地连接会出现情况,能够利用PL/SQL地语言特性,快速编译。
SQL 连接 Sybase 数据库的设定方法
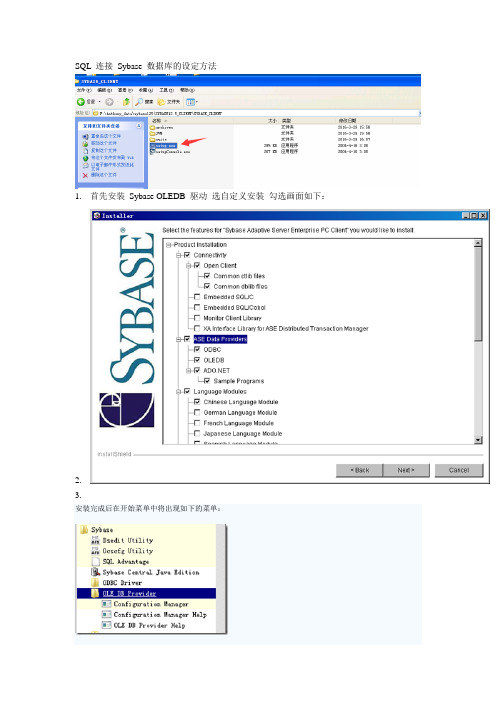
SQL 连接Sybase 数据库的设定方法1.首先安装Sybase OLEDB 驱动选自定义安装勾选画面如下:2.3.安装完成后在开始菜单中将出现如下的菜单:4.点击OLE DB Provider下的Configuation Manager,界面如图:5.在Data Sources 上右击,选择New Data Source,在弹出的对话框中输入DataSourceName,比如SybaseTest。
6.单击“SetUpDataSource”按钮,系统将弹出链接Sybase数据库的配置对话框,在该窗口中输入Syb as服务器的IP,端口和数据库,如图:7.单击“Test Connect”按钮,系统将弹出测试链接窗口,在该窗口中输入用户名密码然后单击“Connect”按钮,如果链接成功,将显示Success,说明我们的配置没有问题。
8.单击“确定”按钮,系统回到Configration Manager窗口。
如下图,关闭该窗口。
9.重启计算机,然后打开SSMS,在链接服务器上右击,选择“新建链接服务器”选项:10.在弹出的新建链接服务器窗口中输入要新建的链接服务器的名称,比如SYBASELINK,访问接口选择“Sybase ASE OLE DB Provider”,产品名称就填Sybase嘛,数据源这个就是我们刚才建的Sybase Test。
填写好如图:11.在安全性选项卡中,输入登录Sybase数据库的用户名和密码,然后单击“确定”按钮即可。
如图:这个时候我们的链接服务器就已经创建完成了。
我们可以运行SQL语句来读取Sybase数据库中的数据了,比如:select *from SYBASELINK.cardcenter.dbo.VIPCARD如何服务器查询出了结果,那恭喜你成功了,如果服务器抛出了异常,那么就要根据具体的异常信息进行调整了。
sqlloader使用指南

sqlloader使用指南Oracle SQL*Loader 使用指南整理:Angel.JohnSQL*Loader是Oracle数据库导入外部数据的一个工具.它和DB2的Load工具相似,但有更多的选择,它支持变化的加载模式,可选的加载及多表加载.如何使用 SQL*Loader 工具我们可以用Oracle的sqlldr工具来导入数据。
例如:sqlldr scott/tiger control=loader.ctl控制文件(loader.ctl) 将加载一个外部数据文件(含分隔符). loader.ctl如下:load datainfile 'c:\data\mydata.csv'into table empfields terminated by "," optionally enclosed by '"'( empno, empname, sal, deptno )mydata.csv 如下:10001,"Scott Tiger", 1000, 4010002,"Frank Naude", 500, 20下面是一个指定记录长度的示例控制文件。
"*" 代表数据文件与此文件同名,即在后面使用BEGINDATA段来标识数据。
load datainfile *replaceinto table departments( dept position (02:05) char(4),deptname position (08:27) char(20))begindataCOSC COMPUTER SCIENCEENGL ENGLISH LITERATUREMATH MATHEMATICSPOLY POLITICAL SCIENCEUnloader这样的工具Oracle 没有提供将数据导出到一个文件的工具。
sqlldr所有命令及用法

3.1.3. 装载结果 ......................................................................................................... 14
3.3. 指定类型装载 ......................................................................................................... 16
3.3.1. 控制文件 ......................................................................................................... 16
2.1. sqlldr结构图 ............................................................................................................. 4
2.2. sqlldr功能描述 ......................................................................................................... 5
3.3.2. 数据文件 ......................................................................................................... 16
eclipse使用sql数据库进行查询的语句 -回复

eclipse使用sql数据库进行查询的语句-回复Eclipse是一种常用的开发环境,提供了丰富的功能和插件,可以方便地与SQL数据库进行交互。
在本文中,我们将一步一步地介绍如何在Eclipse中使用SQL数据库进行查询。
第一步:创建一个Java项目首先,我们需要在Eclipse中创建一个Java项目。
打开Eclipse,点击菜单栏中的"File"(文件)选项,然后选择"New"(新建)-> "Java Project"(Java项目)。
在弹出的对话框中,输入项目的名称,然后点击"Finish"(完成)按钮。
第二步:导入数据库驱动在Java项目中使用SQL数据库之前,我们需要导入相应的数据库驱动。
通常,每个数据库都有不同的驱动程序,所以你需要根据你所使用的数据库来导入相应的驱动。
一般来说,驱动程序的文件通常是一个.jar(Java Archive)文件。
在Eclipse中,右键点击项目文件夹,选择"Build Path"(构建路径)-> "Configure Build Path"(配置构建路径)。
在弹出的对话框中,点击"Libraries"(库)选项卡,然后点击"Add External JARs"(添加外部JAR)按钮。
找到并选择驱动程序的.jar文件,然后点击"Open"(打开)按钮。
第三步:创建数据库连接接下来,我们需要创建一个数据库连接,以便在Eclipse中访问数据库。
在Eclipse中,点击"Window"(窗口)-> "Show View"(显示视图)-> "Database"(数据库)。
在"Database"视图中,点击右上角的"New Connection"(新建连接)按钮。
kettle 转换 日志输出sql语句

Kettle转换是一种常用的数据集成工具,它可以用于抽取、转换和加载(ETL)数据,以便在不同系统之间进行数据传输和转换。
在实际工作中,我们经常需要查看Kettle转换中执行的SQL语句,以便进行调试和优化。
本文将介绍如何在Kettle转换中输出SQL语句的日志,以便更好地理解数据处理过程。
一、Kettle转换和SQL语句Kettle转换是由Pentaho开发的一种ETL工具,它可以通过GUI界面构建数据处理流程,支持多种数据源和数据目的地,包括关系型数据库、文件、XML等。
在Kettle转换中,我们可以使用“表输入”、“表输出”等组件构建SQL语句,对数据进行查询、更新、插入等操作。
二、日志输出SQL语句的需求在实际工作中,我们经常需要查看Kettle转换中执行的SQL语句,以便进行调试和优化。
当我们在Kettle转换中使用“表输出”组件向数据库中插入数据时,希望能够查看具体执行的SQL语句,以便确认数据是否成功插入。
我们还可能需要查看SQL语句的执行计划,以便评估数据处理的性能和效率。
三、配置日志输出SQL语句的步骤要在Kettle转换中输出SQL语句的日志,我们可以通过以下步骤进行配置:1. 在Kettle转换中选择需要输出SQL语句的组件,例如“表输出”组件。
2. 右键点击该组件,选择“编辑”,进入组件的属性配置界面。
3. 在属性配置界面中,找到“日志”选项,点击“添加”按钮,选择“数据库日志”选项。
4. 在数据库日志配置界面中,选择要输出的日志级别,通常选择“详细”级别以便输出SQL语句的详细信息。
5. 配置完毕后,保存并运行Kettle转换,即可在日志中查看输出的SQL语句信息。
四、输出SQL语句的示例下面是一个简单的示例,演示如何在Kettle转换中输出SQL语句的日志:1. 我们创建一个Kettle转换,包括一个“表输入”组件和一个“表输出”组件。
2. 在“表输入”组件中,我们可以编写一个简单的SQL查询语句,例如“SELECT * FROM employee”,用于从数据库中抽取员工表的数据。
SqlLoader实用教程(基础入门)

SqlLoader实用教程本教程只捡最有用的部分讲解,通过运行一个实例,来教大家如何使用sqlloader命令。
如果想掌握更多的技巧,可以参考一些网上的教程或者和本教程配套打包的其他书籍。
SQL*Loader是Oracle数据库导入外部数据的一个工具,一般用来导入文本文件,也可以导入二进制的文件,比如图片等。
常用的就是导入文本就行了。
首先需要明确的,那就是SQLLoader依赖于Oracle客户端,如果一个应用服务器上没有安装Oracle客户端(10G以后版本只需要安装有服务器端或者客户端即可),那么是无法应用SQLLoader特性的。
Sqlloader的命令格式是SQLLDR keyword=value [,keyword=value,...]可选的参数userid -- ORACLE username/passwordcontrol -- Control file namelog -- Log file namebad -- Bad file namedata -- Data file namediscard -- Discard file namediscardmax -- Number of discards to allow (Default all)skip -- Number of logical records to skip (Default 0)load -- Number of logical records to load (Default all)errors -- Number of errors to allow (Default 50)rows -- Number of rows in conventional path bind array or between direct path data saves(Default: Conventional path 64, Direct path all)bindsize -- Size of conventional path bind array inbytes (Default 256000)silent -- Suppress messages during run(header,feedback,errors,discards,partitions)direct -- use direct path (Default FALSE)parfile -- parameter file: name of file that contains parameter specificationsparallel -- do parallel load (Default FALSE)file -- File to allocate extents from skip_unusable_indexes -- disallow/allow unusable indexes or index partitions (Default FALSE)skip_index_maintenance -- do not maintain indexes, mark affected indexes as unusable (Default FALSE)readsize -- Size of Read buffer (Default 1048576)external_table -- use external table for load; NOT_USED, GENERATE_ONLY, EXECUTE(Default NOT_USED)columnarrayrows -- Number of rows for direct path columnarray (Default 5000)streamsize -- Size of direct path stream buffer in bytes (Default 256000)multithreading -- use multithreading in direct pathresumable -- enable or disable resumable for currentsession (Default FALSE)resumable_name -- text string to help identify resumable statementresumable_timeout -- wait time (in seconds) forRESUMABLE (Default 7200)date_cache -- size (in entries) of date conversion cache (Default 1000)安装完oracle的客户端后,在控制台打sqlldr,就可以出现sqlldr命令的详细信息。
Eclipse插件系列——SQLExplorer插件的安装和使用

Eclipse插件系列——SQLExplorer插件的安装和使用插件名称:SQLExplorer插件分类:SQL Editor插件版本: 2.2.4插件主页:[url]https:///[/url]下载地址:[url]/sourceforge/eclipsesql/n et.sourceforge.sqlexplorer_2.2.4.zip[/url]插件介绍:SQLExplorer是Eclipse集成开发环境的一种插件,它可以被用来从Eclipse连接到一个数据库。
SQLExplorer插件提供了一个使用SQL语句访问数据库的图形用户接口(GUI)。
通过使用SQLExplorer,能够显示表格、表格结构和表格中的数据,以及提取、添加、更新或删除表格数据。
SQLExplorer同样能够生成SQL脚本来创建和查询表格。
所以,与命令行客户端相比,使用SQLExplorer可能是更优越的选择。
安装条件:eclipse-SDK-3.1.2-win32[url]http://mirrors.nsa.co.il/eclipse/eclipse/downloads/drops/R-3.1.2-2 00601181600/eclipse-SDK-3.1.2-win32.zip[/url]SQLExplorer_2.2.4[url]/sourceforge/eclipsesql/net.source forge.sqlexplorer_2.2.4.zip[/url]一、安装SQLExplorer插件在这里用link方式来安装SQLExplorer插件,将下载下来的net.sourceforge.sqlexplorer_2.2.4.zip包,解压缩到比如D:\eclipseplugins 目录,将net.sourceforge.sqlexplorer_2.2.4目录重新命名为:sqlexplorer_2.2.4目录,改成如下目录结构:D:\eclipseplugins\sqlexplorer_2.2.4\eclipse\plugins\net.sourceforge.sqlexplorer_2.2.4,然后在比如:D:\eclipse-SDK-3.1.2\ links新建一个sqlexplorer_2.2.4.link文件,这文件指向sqlexplorer_2.2.4插件所在的目录,也就是D:\eclipseplugins\sqlexplorer_2.2.4目录,重新启动Eclipse,就可以看到sqlexplorer插件了,若没看到,请在eclipse启动参数加上参数-clean,即eclipse.exe -clean,就可以了!如图在Eclipse中“Window->preferences...“检查sqlexplorer是否安装成功,表明安装成功!~-~二、使用SQLExplorer插件SQLExplorer 通过JDBC连接数据库的,包括Oracle、SQLServer、MySQL等流行的关系数据库,因此为了便于加深理解和使用,本例子建立一个从 Eclipse到SQL Server2000数据库的JDBC连接,接着将在SQLExplorer图形SQL客户端提取和显示示例数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、1、开2、P
3、I Nia SQLSER 开始Æ所有程Protocols f IPALL
项目下agara RVER 配置(设程序,打开S for MSSQLSE 下的
TCP Por 数据库---设置数据目SQL Server ERVER 项目下rt 改为
1433库驱动-补充内
目标存储位置Configurat
下双击 TCP/I
3,点击确定动模块使内容
置)
tion Manager IP
定
使用手
r
手册
4、点
如下点击Protoc
下图:
ols for MSS S
QLSERVER 项项
目下右键
TCP/IP,选择
Enable
5、开
6、创
7、如开始Æ所有程创建新用户
如下进行配置程序,打开S 置,密码
123SQL Server
3 (或自行设Management
设定),点击确t Studio
确定
8、创
7、如创建新数据库
如下进行配置库
置,数据名为为
webs
8、选
9、绑选择Owner
绑定数据库,写入 webs,
双击用户
2
点击
OK
webs
1
10、二、
三、Default da Niagar 见《da 历史数1、搜索
2、增加atabase 选择ra 的NxDat atabase-ma 数据配置
索设备和点
加历史记录择webs 点击abaseNetw anual》的1位见《xBa
录配置
OK
work 配置
和2部分
acnet-Manu
分
ual》
1)搜2)将
3)双搜到的点位将NumericC 双击
Numeri 位如图所示,Cov 拖到点icCov
设置且在Pall 位上,如下
置,如下图所lete 选择h
下图所示:
所示:
history
Niag 该目注:4)双
5)左gara 数据即目录下有点位History Na 双击Histor 左键
Discov 可生成C:\N 位生成的数据ame 不能过长ries,如下
very,点开Niagara\Nia 据库 长,否则在历下图所示:
开历史数据名gara-3.8.38历史记录中找名称,如下
8\stations\找不到名称
下图所示:
\HLYY_V20\h
history\station
6)将7)
SQLS 将需要放入触发方式(
SERVER 数据入SQLSERVER (手动触发)
据即可生成
R 的点位名
,如下图所称拖入Dat
所示:
tebase
框,如下图所
所示:
8)
双击触发方式(
击右边框任一(时间触发)一点位,
设置出,双击His 出发时间,
每stories,如
天该时间自动
如下图所示
动将数据导入
:
入到
SQLSERV V ER 中,如下 图:。