srilm ngram数据结构
n-gram计算例子

n-gram计算例子English Answer:N-grams.N-grams are sequences of n words from a text or speech. They are used in natural language processing (NLP) for various tasks such as language modeling, machine translation, and text classification.Examples of N-grams.1-grams (unigrams): Single words, such as "the", "dog", and "runs".2-grams (bigrams): Pairs of words, such as "the dog", "dog runs", and "runs fast".3-grams (trigrams): Triples of words, such as "the dog runs", "runs fast", and "fast and".N-gram Calculation Example.Given the sentence "The dog runs fast and barks loudly", we can calculate the n-grams as follows:1-grams: the, dog, runs, fast, and, barks, loudly.2-grams: the dog, dog runs, runs fast, fast and, and barks, barks loudly.3-grams: the dog runs, dog runs fast, runs fast and, fast and barks, and barks loudly.Applications of N-grams.N-grams are widely used in NLP tasks:Language modeling: N-grams can be used to predict the next word in a sequence, which is essential for text generation and machine translation.Machine translation: N-grams can capture word and phrase-level dependencies, improving translation accuracy.Text classification: N-grams can be used to identify patterns and extract features for text classification tasks.Additional Notes.The order of words in n-grams is important.N-grams with higher values of n (e.g., 4-grams, 5-grams) can capture longer-range dependencies but may also suffer from data sparsity.N-grams are typically smoothed using techniques suchas Witten-Bell smoothing or Good-Turing smoothing to handle unseen n-grams.中文回答:N-Gram.N-Gram 是从文本或语音中提取的 n 个单词序列。
数据结构普里姆算法

数据结构普里姆算法普里姆算法(Prim's algorithm)是一种贪心算法,用于在加权无向图中找到最小生成树。
该算法在每一步选择当前生成树到最远未连接点的最小边,直到所有的点都被连接起来。
以下是普里姆算法的基本步骤:1.随机选择图中的一点作为起始点,将其加入生成树集合中。
2.在所有连接已选择点和未选择点的边中,选择权重最小的边。
将这条边以及其对应的未选择点加入到生成树集合中。
3.重复步骤2,直到所有的点都被加入到生成树集合中。
下面是使用Python实现的普里姆算法示例:```pythonimport heapqdef prim(graph,start):mst={}#最小生成树的键值对,键为节点,值为该节点所在的最小权重边visited=set([start])#已访问的节点集合edges=[#用于存储最小权重边的优先队列,键为权重,值为边的信息(weight,start,to)for to,weight in graph[start].items()]heapq.heapify(edges)while edges:weight,frm,to=heapq.heappop(edges)if to not in visited:visited.add(to)mst[to]=(frm,weight)#将边加入最小生成树中for to_next,weight2in graph[to].items():if to_next not in visited:heapq.heappush(edges, (weight2,to,to_next))#将相邻未访问节点加入优先队列中return mst```其中,`graph`是一个字典,表示无向图的邻接表形式。
字典的键表示节点,值是另一个字典,表示与该节点相邻的节点及其对应的权重。
`start`是算法的起始点。
函数返回一个字典,表示最小生成树,其中键是节点,值是该节点所在的最小权重边。
n-gram 分词 原理

n-gram 分词原理一、什么是n-gram分词n-gram分词是一种基于统计的文本处理方法,它将文本按照一定的规则进行切割,形成不同长度的词组。
其中n代表词组的长度,可以是1、2、3等。
二、n-gram分词的原理1. 数据预处理在进行n-gram分词之前,需要对原始文本进行预处理。
这包括去除特殊字符、停用词等。
预处理后的文本更加干净,有助于提高分词的准确性。
2. 构建n-gram模型n-gram模型是基于马尔可夫链的一种文本生成模型。
它将文本看作是一个由词组组成的序列,通过统计词组出现的频率来预测下一个词组的概率。
3. 分词在n-gram模型中,分词的过程就是根据给定的n值,将文本切割成一定长度的词组。
例如,当n=1时,就是将文本切割成单个词语;当n=2时,就是将文本切割成两个词语的组合,依此类推。
4. 评估分词结果对于分词结果,我们可以通过一些指标来评估其准确性。
常见的指标包括精确率、召回率和F1值等。
通过这些指标,我们可以了解到n-gram分词的效果如何,并对其进行优化。
三、n-gram分词的应用1. 机器翻译n-gram分词在机器翻译中有着广泛的应用。
通过将源语言和目标语言的文本切割成一定长度的词组,可以更好地进行翻译。
2. 文本分类在文本分类任务中,n-gram分词可以将文本切割成词组,并将每个词组表示为特征向量。
这样可以更好地表示文本的语义信息,提高分类的准确性。
3. 信息检索n-gram分词可以用于信息检索中的查询扩展。
通过将查询文本切割成词组,并扩展查询词,可以提高检索的准确性和召回率。
四、n-gram分词的优缺点1. 优点n-gram分词简单易懂,容易实现。
同时,它能够捕捉到词组的上下文信息,提高分词的准确性。
2. 缺点n-gram分词忽略了词与词之间的顺序关系,可能会导致分词结果的歧义。
另外,n-gram模型对于未出现的词组无法进行处理。
五、总结n-gram分词是一种基于统计的文本处理方法,通过将文本切割成一定长度的词组,可以捕捉到词组的上下文信息,提高分词的准确性。
Ngram折扣平滑算法

Ngram折扣平滑算法本文档翻译自srilm手册ngram-discount.7.htmlNAMEngram-discount – 这里主要说明srilm中实现的平滑算法NOTATIONa_z代表以a为起始词,以z为结束词的ngram,其中_代表0个或多个词p(a_z) 前n-1个词为a_的情况下,第n个词为z的条件概率a_ n元a_z的前n-1个词构成的前缀_z n元a_z的后n-1个词构成的后缀c(a_z) n元a_z在训练语料中出现的次数n(*_z) 符合*_z这一模式的独立n元数目,“*_z”中‘*’代表通配符n1,n[1] 出现次数为1的ngram数目DESCRIPTIONNgram语言模型主要用于估计前n-1词为a_的情况下,第n个词为z的概率,即概率Pr(z|a_),为简单起见,一般使用P(a_z)表示。
估算概率最直接的方式就是分别在训练集中统计c(a_z)和c(a_),然后求如下公式,即得到相关概率运算结果:(1)p(a_z) = c(a_z)/c(a_)如上的概率估算方法又称为最大似然估计方法。
该方法比较直观易懂,但存在一个不足点就是对于语料中不存在的n元,其概率估算结果将为0。
为了避免该情况的发生,可以通过将观察到的ngram一部分概率分布出去,并将这部分概率值分配到未观察到的ngram上。
这种概率重新分配方式即为通常所说的平滑(smoothing)或折扣(discounting)。
大部分平滑算法都可以使用如下公式来表示(2)p(a_z) = (c(a_z) > 0) ? f(a_z) : bow(a_) p(_z)若ngram a_z在训练集中发生了,则直接使用概率f(a_z),该概率值一般都小于最大似然估计概率值结果,这样留下的一部分概率值可用于训练语料中未覆盖到的n元a_*。
不同的平滑算法区别主要在于采用何种折扣方法对最大似然估计结果进行折扣。
应用公式(2)计算概率p(a_z)时,若ngram a_z在训练语料中没有出现,则直接使用低阶概率分布p(_z),若历史a_在训练语料中没有出现,即c(a_) = 0,这时可以直接使用p(_z)作为当前ngram的概率值,即bow(a_) = 1;否则需要将bow(a_)乘到p(_z)上,以保证概率分布的归一性,即:Sum_z p(a_z) = 1假设Z为词典中所有词构成的集合,Z0为词典中所有满足条件c(a_z) = 0的词构成的集合,Z1为词典中所有满足条件c(a_z) > 0的词构成的集合。
n-gram 句子概率

n-gram 句子概率n-gram是一种基于统计语言模型的方法,它可以用来计算一个句子的概率。
在n-gram模型中,一个句子的概率被分解成一个个单词的条件概率的乘积。
具体来说,n-gram模型假设一个单词出现的概率只与它前面的n-1个单词有关,而与其他单词无关。
因此,一个句子的概率可以表示为:P(w1,w2,w3,...,wn) = P(w1) * P(w2|w1) * P(w3|w1,w2) * ... * P(wn|wn-n+1,...,w2,w1)其中,P(w1)表示第一个单词出现的概率,P(w2|w1)表示在w1出现的情况下,w2出现的概率,以此类推。
n-gram模型中的n值可以根据实际情况进行选择。
通常情况下,n取2或3比较常见。
当n=1时,称为unigram模型;当n=2时,称为bigram模型;当n=3时,称为trigram模型。
在计算句子概率时,需要对语料库进行统计,得到每个单词出现的频率以及每个n-gram出现的频率。
然后,可以使用最大似然估计或平滑技术来计算条件概率。
最大似然估计是一种常用的方法,它假设每个n-gram出现的概率等于它在语料库中出现的频率除以前面n-1个单词出现的频率的乘积。
平滑技术可以避免出现未在语料库中出现的n-gram的概率为0的情况,常见的平滑技术包括拉普拉斯平滑、Good-Turing平滑等。
计算句子概率的过程可以通过递归实现。
具体来说,可以先计算第一个单词出现的概率,然后递归计算后面每个单词在前面n-1个单词出现的情况下的概率,最后将它们的乘积作为整个句子的概率。
总之,n-gram模型是一种基于统计的语言模型,它可以用来计算一个句子的概率。
在实际应用中,可以根据实际情况选择n值,并使用最大似然估计或平滑技术来计算条件概率。
算法:N-gram语法

算法:N-gram语法⼀、N-gram介绍 n元语法(英语:N-gram)指⽂本中连续出现的n个语词。
n元语法模型是基于(n - 1)阶马尔可夫链的⼀种概率语⾔模型,通过n个语词出现的概率来推断语句的结构。
这⼀模型被⼴泛应⽤于概率论、通信理论、计算语⾔学(如基于统计的⾃然语⾔处理NLP)、计算⽣物学(如序列分析)、数据压缩等领域。
N-gram⽂本⼴泛⽤于⽂本挖掘和⾃然语⾔处理任务。
它们基本上是给定窗⼝内的⼀组同时出现的单词,在计算n元语法时,通常会将⼀个单词向前移动(尽管在更⾼级的场景中可以使X个单词向前移动)。
例如,对于句⼦"The cow jumps over the moon" ,N = 2(称为⼆元组),则 ngram 为:the cowcow jumpsjumps overover thethe moon 因此,在这种情况下,有 5 个 n-gram。
再来看看 N = 3,ngram 将为:the cow jumpscow jumps overjumps over theover the moon 因此,在这种情况下,有 4 个 n-gram。
所以,在⼀个句⼦中 N-grams 的数量有: Ngrams(K) = X - (N - 1) 其中,X 为给定句⼦K中的单词数,N 为 N-gram 的N,指的是连续出现的 N 个单词。
N-gram⽤于各种不同的任务。
例如,在开发语⾔模型时,N-grams不仅⽤于开发unigram模型,⽽且还⽤于开发bigram和trigram模型。
⾕歌和微软已经开发了⽹络规模的 n-gram模型,可⽤于多种任务,例如拼写校正、分词和⽂本摘要。
N-gram的另⼀个⽤途是为受监督的机器学习模型(例如SVM,MaxEnt模型,朴素贝叶斯等)开发功能。
其想法是在特征空间中使⽤标记(例如双字母组),⽽不是仅使⽤字母组合。
下⾯简单介绍⼀下如何⽤ Java ⽣成 n-gram。
ngram函数用法

ngram函数用法Ngram函数用法详解Ngram函数是一种文本分析工具,它可以将文本数据转换为n元组(n-gram)序列,从而实现文本的分析和处理。
在自然语言处理、信息检索、文本挖掘等领域中,Ngram函数被广泛应用。
Ngram函数的基本用法是将文本数据转换为n元组序列。
其中,n 表示元组的长度,通常取2、3、4等。
例如,对于一段文本“我爱中国”,当n=2时,Ngram函数将其转换为“我爱”、“爱中国”两个二元组;当n=3时,Ngram函数将其转换为“我爱中国”一个三元组。
通过这种方式,Ngram函数可以将文本数据转换为一系列有序的元组序列,从而方便后续的分析和处理。
Ngram函数的应用非常广泛。
在自然语言处理领域中,Ngram函数可以用于文本分类、情感分析、语言模型等任务。
例如,在文本分类任务中,可以使用Ngram函数将文本数据转换为n元组序列,然后使用机器学习算法对其进行分类。
在情感分析任务中,可以使用Ngram函数将文本数据转换为n元组序列,然后使用情感词典等方法对其进行情感分析。
在语言模型任务中,可以使用Ngram函数将文本数据转换为n元组序列,然后使用统计方法对其进行建模,从而实现自然语言生成和识别等功能。
除了自然语言处理领域,Ngram函数还可以应用于信息检索、文本挖掘等领域。
例如,在信息检索任务中,可以使用Ngram函数将查询语句和文本数据转换为n元组序列,然后使用相似度计算等方法对其进行匹配。
在文本挖掘任务中,可以使用Ngram函数将文本数据转换为n元组序列,然后使用聚类、分类等方法对其进行挖掘和分析。
Ngram函数是一种非常实用的文本分析工具,它可以将文本数据转换为n元组序列,从而方便后续的分析和处理。
在自然语言处理、信息检索、文本挖掘等领域中,Ngram函数被广泛应用,为相关任务的实现提供了有力的支持。
ngram算法原理

ngram算法原理ngram算法是一种基于统计的自然语言处理方法,用于分析文本中的语言模式。
它通过将文本分割成连续的n个字母或单词序列,并计算它们在文本中的出现频率,从而揭示出文本中的潜在规律和关联性。
ngram算法的基本思想是,通过统计文本中连续出现的n个字母或单词的频率,来推断文本的特征和结构。
其中,n被称为ngram的大小,可以是1、2、3等任意正整数。
当n为1时,即为unigram;当n为2时,即为bigram;当n为3时,即为trigram,以此类推。
ngram算法的应用非常广泛,常见的应用包括文本分类、机器翻译、语音识别、信息检索等领域。
在文本分类中,ngram算法可以用于提取文本特征,将文本转化为向量表示,从而实现文本分类任务。
在机器翻译中,ngram算法可以用于建模源语言和目标语言之间的语言模式,从而提高翻译质量。
在语音识别中,ngram算法可以用于建模语音信号的概率分布,从而提高识别准确率。
在信息检索中,ngram算法可以用于计算查询词和文档之间的相似度,从而实现精准的信息检索。
ngram算法的实现步骤主要包括以下几个部分:1. 数据预处理:将文本进行分词或分字处理,得到一系列的单词或字母序列。
2. 统计ngram频率:对于每个ngram(n个连续的字母或单词),统计其在文本中的出现频率。
可以使用哈希表等数据结构来实现高效的频率统计。
3. 特征提取:根据ngram的频率,将文本转化为向量表示。
可以用每个ngram在文本中的频率作为特征值,构成一个特征向量。
4. 模型训练和预测:使用训练数据来训练一个分类器或回归模型,然后使用该模型来预测新的文本。
5. 模型评估:使用测试数据来评估模型的性能,常用的评估指标包括准确率、召回率、F1值等。
ngram算法的优点在于简单易用,能够捕捉文本中的局部信息和上下文关系,适用于各种自然语言处理任务。
然而,ngram算法也存在一些问题,比如数据稀疏性和维度灾难等。
语言模型srilm基本用法

语⾔模型srilm基本⽤法⽬录:⼀、基本训练#功能读取分词后的text⽂件或者count⽂件,然后⽤来输出最后汇总的count⽂件或者语⾔模型#参数输⼊⽂本:-read 读取count⽂件-text 读取分词后的⽂本⽂件词典⽂件:-vocab 限制text和count⽂件的单词,没有出现在词典的单词替换为<unk>;如果没有,所有的单词将会被⾃动加⼊词典-limit-vocab 只限制count⽂件的单词(对text⽂件⽆效),没有出现在词典⾥⾯的count将会被丢弃-write-vocab 输出词典语⾔模型:-lm 输出语⾔模型-write-binary-lm 输出⼆进制的语⾔模型-sort输出语⾔模型gram排序有两种训练⽅法,分别如下:#choice1: text->count->lm#ngram-count -text $text -vocab ${vocab} -order 2 -sort -tolower -lm ${arpa}#choice2: text->count count->lm#ngram-count -text ${text} -order 2 -sort -tolower -write ${count}cat data/corpus/* | tools/SRILM/ngram-count -vocab dict/aicar.v9.wlist -text - -order 3 -debug 1 -interpolate -kndiscount -gt3min 1 -lm lm/aicar_music.v7.13.tg.lm &⼆、语⾔模型打分#功能⽤于评估语⾔模型的好坏,或者是计算特定句⼦的得分,⽤于语⾳识别的识别结果分析。
#参数计算得分:-order 模型阶数,默认使⽤3阶-lm 使⽤的语⾔模型-use-server S 启动语⾔模型服务,S的形式为port@hostname-ppl 后跟需要打分的句⼦(⼀⾏⼀句,已经分词),ppl表⽰所有单词,ppl1表⽰除了</s>以外的单词-debug 0只输出整体情况-debug 1具体到句⼦-debug 2具体每个词的概率产⽣句⼦:-gen 产⽣句⼦的个数-seed 产⽣句⼦⽤到的random seedngram -lm ${lm} -order 2 -ppl ${file} -debug 1 > ${ppl}例:./tools/SRILM/ngram -debug 2 -order 4 -lm lm/final/$name.pru1e-13.fg.lm -ppl $fie.wseg > ppltest/ppl/$p.aicar0.35.pru1e-13.fg.ppl三、语⾔模型剪枝#功能⽤于减⼩语⾔模型的⼤⼩,剪枝原理参考(/xmdxcsj/article/details/50321613)#参数模型裁剪:-prune threshold 删除⼀些ngram,满⾜删除以后模型的ppl增加值⼩于threshold,越⼤剪枝剪得越狠-write-lm 新的语⾔模型ngram -lm ${oldlm} -order 2 -prune ${thres} -write-lm ${newlm}例:./tools/SRILM/ngram -debug 1 -order 4 -lm lm/final/$name.fg.lm -prune 0.0000000000001 -write-lm lm/final/$name.pru1e-13.fg.lm &四、语⾔模型合并#功能⽤于多个语⾔模型之间插值合并,以期望改善模型的效果#参数模型插值:-mix-lm ⽤于插值的第⼆个ngram模型,-lm是第⼀个ngram模型-lambda 主模型(-lm对应模型)的插值⽐例,0~1,默认是0.5-mix-lm2 ⽤于插值的第三个模型-mix-lambda2 ⽤于插值的第⼆个模型(-mix-lm对应的模型)的⽐例,那么第⼆个模型的⽐例为1-lambda-mix-lambda2-vocab 当两个模型的词典不⼀样的时候,使⽤该参数限制词典列表,没有效果-limit-vocab 当两个模型的词典不⼀样的时候,使⽤该参数限制词典列表,没有效果ngram -lm ${mainlm} -order 2 -mix-lm ${mixlm} -lambda 0.8 -write-lm ${mergelm}在合并语⾔模型之前,可以使⽤脚本计算出最好的⽐例,参考srilm的compute-best-mix脚本 #这个后⾯算下,如何求得最好的⽐例五、语⾔模型使⽤词典限制有两种⽅法可以根据给定的词典对模型加以限制⼀种是在训练的时候使⽤-vocab限制另外⼀种是在训练完成以后,使⽤srilm的脚本,如下:#功能对已有的语⾔模型,使⽤新的字典进⾏约束,产⽣新的语⾔模型1.n-grams的概率保持不变2.回退概率重新计算3.增加新的⼀元回退概率#参数模型裁剪:-vocab 词典单词的列表,不包括发⾳-write-lm 新的语⾔模型change-lm-vocab -vocab ${vocab} -lm ${oldlm} -write-lm ${newlm} -order 2这个⼀般都是在训练的时候加词典,很少在训练之后加.。
基于SRILM的ARPA的n-gram语言模型格式

基于SRILM的ARPA的n-gram语⾔模型格式\data\ngram 1=10ngram 2=20ngram 3=30\1-grams:-2.522091 啊 -0.4599362-3.616682 阿 -0.2710813-5.888154 阿坝-5.483542 阿布 -0.02341532-5.513821 阿迪达斯 -0.08972257-5.357502 阿哥-5.619849 阿胶-5.003489 阿拉 -0.0459251-5.11305 阿拉伯 -0.1348525-5.11305 阿拉伯数字 -0.153861\2-grams:-2.841684 阿楠-1.279527 阿布贾-0.7184195 阿迪达斯 </s>-1.628645 阿拉阿拉-1.628414 阿拉蕾-1.272437 阿拉善-1.37447 阿拉伯贵族-1.122427 阿拉伯⼈-1.373596 阿拉伯数-0.9671616 阿拉伯语\3-grams:-0.7579774 啊啊 </s>-0.3643477 啊啊啊-1.625012 啊啊对-1.826232 啊啊⾏-0.1952119 爱啊 </s>-0.1937787 安排啊 </s>-0.2185729 安全啊 </s>-0.1328749 安装啊 </s>-0.3589647 吧啊 </s>-1.99777 吧啊拜拜*上⾯的值都是以10为底的对数值(词组前⾯的数字:概率,词组后⾯的数据,回退权值)计算⼀个句⼦在该ARPA中的概率如下(3gram为例):# Make sure the OOVs change to <unk>#P(word3| word1, word2):# if has (word3| word1, word2){# return P(word3| word1, word2);# }else if has (word2| word1){# return backOff(word2| word1) * P(word3| word2);# }else{# return P(word3| word2);# }#P(word2 | word1):# if has (word2| word1){# return P(word2| word1);# }else{# return backOff(word1) * P(word2);# }python 实现def wordsProbs(words, dict):wordArr = words.split(" ")if len(wordArr) == 3:if dict.has_key(words):return dict.get(words).probelif dict.has_key(wordArr[0] + " " + wordArr[1]):return dict.get(wordArr[0] + " " + wordArr[1]).backoff + wordsProbs(wordArr[1] + " " + wordArr[2], dict) else:return wordsProbs(wordArr[1] + " " + wordArr[2], dict)elif len(wordArr) == 2:if dict.has_key(wordArr[0] + " " + wordArr[1]):return dict.get(wordArr[0] + " " + wordArr[1]).probelse:return dict.get(wordArr[0]).backoff + wordsProbs(wordArr[1], dict) #make sure OOV change to <unk>,or error else:return dict.get(wordArr[0]).prob #make sure OOV change to <unk>,or error*通过以上获取的是logP(3gramWords),probs = 10 ^ logP(3gramWords),probs即是3gramWords的最终概率值。
N-gram基本原理

N-gram基本原理N-gram模型是⼀种语⾔模型(Language Model,LM),语⾔模型是⼀个基于概率的判别模型,它的输⼊是⼀句话(单词的顺序序列),输出是这句话的概率,即这些单词的联合概率(joint probability)。
N-gram本⾝也指⼀个由N个单词组成的集合,考虑单词的先后顺序,且不要求单词之间互不相同。
常⽤的有 Bi-gram(N=2N=2N=2) 和 Tri-gram (N=3N=3N=3),⼀般已经够⽤了。
例如在上⾯这句话⾥,我可以分解的 Bi-gram 和 Tri-gram :Bi-gram : {I, love}, {love, deep}, {love, deep}, {deep, learning}Tri-gram : {I, love, deep}, {love, deep, learning}N-gram中的概率计算联合概率的简单推导过程:A,B,C三个有顺序的句⼦。
由于P(C/(A,B))=P(A,B,C)/P(A,B)P(B/A) = P(A,B)/P(B)所以P(C/(A,B))=P(A,B,C)/(P(B/A) *P(B))P(A,B,C) = P(C/(A,B))*P(B/A) *P(B)所以我们可以很容易的得到上⾯的多个单词的联合概率,但是由于存在参数空间过⼤等问题,我们可以仅仅考虑之前的⼀个或者⼏个词的前提条件的联合概率,可以降低时间复杂度,减少计算量。
然后通过极⼤似然函数求解上⾯的概率值是从整个数据库中去计算上述的概率值,⽽不是⼀整句话。
1、可以⽤于词性标注,类似成多分类的情况:例如:我爱中国!判断爱的词性可以通过P(词性i/(名词我出现,爱字出现))=P(名词我出现,爱字不同的词性)/P(名词的我出现,爱字所有出现的次数)2、可以⽤于垃圾短信分类:步骤⼀:给短信的每个句⼦断句。
步骤⼆:⽤N-gram判断每个句⼦是否垃圾短信中的敏感句⼦。
SRILM详解过程

一、Generating the N-gram Count Filengram-count -text train.zh -order 5 -write train.count -unk-text:training corpus name-order:n-gram count-write:output countfile name-unk:mark OOV as<unk>train.count里面的内容:第一列分别为一元,二元,三元,四元,五元;第二列为counts in training corpus 二、Generating the N-gram Language modelngram-count -read train.count -order 5 -lm train.lm -gt1min 3 -gt1max 7 -gt2min 3 -gt2max 7 -gt3min 3 -gt3max 7 -gt4min 3 -gt4max 7 -gt5min 3 -gt5max 7-read:read count file-lm:output LM file name-gr n min:Good-Turing discounting for n-gramtrain.lm里面的内容第一列为log probability (base 10);第三列为log of backoff weight (base )三、Calculate the Test Data Perplexityngram -ppl test.zh -order 5 -lm train.lm-ppl:calculate perplexity for test datappl 和ppl1分别的计算公式:))/(log (^101))/(log (^10OOVs words prob ppl sentences OOVs words prob ppl --=+--= )(1t i i p l prob T∏==其中l T 为句子的个数 从以上的过程可以看出SRILM 的功能:一.Generate the n-gram count file from the corpus二.Train the language model from the n-gram count file三.Calculate the test data perplexity using the trained language model①平滑方法为Good-Turing时的困惑度:ngram-count -read train.count -order 5 -lm train.lm -gt1min 3 -gt1max 7 -gt2min 3 -gt2max 7 -gt3min 3 -gt3max 7 -gt4min 3 -gt4max 7 -gt5min 3 -gt5max 7②平滑方法为Absolute Discounting时的困惑度:ngram-count -read train.count -order 5 -lm train.lm -cdiscount1 0.5 -cdiscount2 0.5 -cdiscount3 0.5 -cdiscount4 0.5 -cdiscount5 0.5③平滑方法为Witten-Bell Discounting时的困惑度:ngram-count -read train.count -order 5 -lm train.lm -wbdiscount1 -wbdiscount2 -wbdiscount3 -wbdiscount4 -wbdiscount5④平滑方法为Modified Knerser-Ney Discounting时的困惑度ngram-count -read train.count -order 5 -lm train.lm -kndiscount1 -kndiscount2 -kndiscount3 -kndiscount4 -kndiscount5。
N-Gram的数据结构.
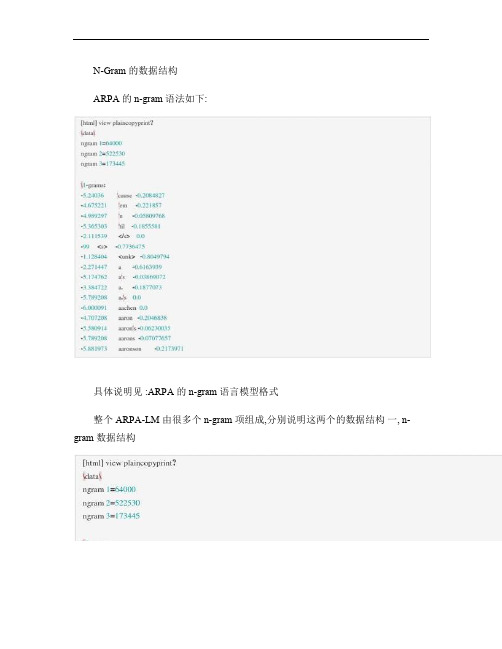
N-Gram 的数据结构ARPA 的 n-gram 语法如下:具体说明见 :ARPA 的 n-gram 语言模型格式整个 ARPA-LM 由很多个 n-gram 项组成,分别说明这两个的数据结构一, n-gram 数据结构words ,表示当前的 n-gram 所涉及的单词,如果是 1-gram ,那就只有一个,如果是2-gram ,那么 words 就包括这两个单词的序号。
log_bo,表示 ngram 的回退概率。
log_prob,表示 ngram 的组合概率。
二, ARPA-LM 数据结构多个项组成的整个 n-gram 语言模型的数据结构如下: [cpp] view plaincopyprint?vocab ,用于构建语言模型的词典指针。
词典定义见:词典内存存储模型 entries,语言模型的所有 ngram 项,是 ARPALMEntry 类型的一个二维数组。
entries[0]存储1-gram , entries[1]存储 2-gram ,依此类推。
n_ngrams,整型数组,依次包含 1-gram,2-gram,3-gram,.... 所包含的 ngram 项个数。
unk_wrd,词典中可以不在语言模型中的词。
unk_id,词典中可以不在语言模型中的词的 ID ,这个 ID 指定为词典的最后一个词序号。
n_unk_words,在读语言模型之后,统计在词典中,但没有用来建立语言模型的词个数,如果没有指定 unk_wrd的话,是不允许的,就表示所有的词典中的词都应该用来建语言模型。
unk_words,存储 6中统计的词序号。
words_in_lm,这个标识词典中的词是否在语言模型中出现。
skipgram原理(一)

skipgram原理(一)Skipgram模型解析引言Skipgram是一种常用的词嵌入模型,它旨在将单词表示为连续向量空间中的点,以便于计算机可以更好地理解和处理自然语言。
本文将深入探讨Skipgram模型的相关原理。
Skipgram模型概述Skipgram模型是一种基于神经网络的词嵌入模型,其目标是通过预测给定词的上下文来学习单词的分布式表示。
该模型通常使用两层神经网络,一层作为输入层,一层作为输出层。
下面是Skipgram模型的主要过程:1.构建训练数据集:根据语料库中的上下文信息,生成训练样本。
这些样本由一个目标词和其周围的上下文词组成。
2.输入层编码:将目标词和上下文词转换为输入层的向量表示。
3.隐藏层计算:通过将输入层的向量表示乘以权重矩阵,得到隐藏层的输出。
4.输出层计算:将隐藏层的输出再次与权重矩阵相乘,得到输出层的向量表示。
5.目标函数计算:使用目标函数(如负对数似然函数)来计算模型的损失。
6.梯度下降优化:通过反向传播算法,更新模型的参数(权重矩阵),以减小损失函数。
7.重复上述步骤,直到模型收敛。
Skipgram模型详解输入层编码在Skipgram模型中,通常使用one-hot编码将词语转换为向量。
one-hot编码是一种将离散特征转换为连续向量的方法,它将特征的每个取值都映射为一个唯一的整数索引,然后使用一个对应取值的向量进行表示,其中只有一个元素为1,其他元素为0。
例如,假设词汇表中有10000个不同的词,我们可以将每个词映射为一个长度为10000的向量,在对应词的索引位置设置为1,其他位置设置为0。
隐藏层计算在Skipgram模型中,隐藏层可以看作是输入层的一个映射,它用于将输入矩阵乘以权重矩阵,得到隐藏层的输出向量。
权重矩阵的维度是隐藏层大小乘以输入层大小。
隐藏层的计算可以看作是对输入层向量的压缩和降维操作,通过学习到的权重矩阵,模型能够提取输入层向量中的重要信息并进行表示。
gram结构域蛋白功能

gram结构域蛋白功能
GRAM结构域是一种常见的蛋白质结构域,它在多种蛋白质中存在,并且具有多种功能。
GRAM结构域通常由50到100个氨基酸组成,在蛋白质结构中形成一个特定的三维结构。
GRAM结构域在细胞信号转导、RNA代谢和膜动力学等生物学过程中发挥重要作用。
以下是一些GRAM结构域的功能:
1. 脂质代谢:GRAM结构域在脂质代谢过程中起关键作用。
它可以与脂质分子相互作用,参与细胞膜的形成和维护,以及脂质信号的传递。
2. RNA结合和修饰:GRAM结构域在RNA结合和修饰中起调控作用。
它能与RNA分子相互作用,参与RNA合成、剪接、降解等过程。
3. 蛋白质互作:GRAM结构域能与其他蛋白质相互作用,参与蛋白质复合物的形成和功能调控。
4. 细胞信号传导:GRAM结构域在细胞信号转导中发挥作用。
它可以与细胞信号分子相互作用,参与细胞内信号转导路径的激活或抑制。
5. 免疫应答:GRAM结构域在免疫应答中发挥作用。
它能够识别并与病原体相关的分子相互作用,参与免疫应答的触发和调节。
GRAM结构域的具体功能可能因蛋白质的特定结构和背景环境而有所不同。
不同的蛋白质可能通过调整GRAM结构域的序列和结构,适应不同的生物学功能和生理过程。
因此,在具体研究中,需要根据具体的蛋白质和研究对象来进一步探索GRAM结构域的功能。
n-gram语言模型回退概率计算

n-gram语言模型回退概率计算n-gram语言模型是一种用于计算文本生成概率的常用方法。
它基于n个词的序列,通过统计语料库中这些序列的出现频率来计算生成某个词的概率。
然而,在实际应用中,由于数据稀疏性和长尾问题,往往需要使用回退概率来改善模型的性能。
在n-gram语言模型中,回退概率用于处理词序列未在语料库中出现的情况。
当模型遇到没有观测到的序列时,回退概率会根据更短的序列进行插值或平滑操作,从而估计该序列的生成概率。
为了更好地理解n-gram语言模型回退概率的计算过程,我们先介绍一下n-gram模型的基本原理。
n-gram语言模型假设每个词的生成仅依赖于前面n-1个词。
这意味着在给定前面n-1个词的情况下,下一个词出现的概率只与这n-1个词有关,与其他词无关。
根据这个假设,我们可以得到生成某个词的条件概率公式:P(wi|wi-1, wi-2, ..., wi-n+1) ≈ P(wi|wi-n+1, wi-n+2, ..., wi-1)其中P(wi|wi-n+1, wi-n+2, ..., wi-1)表示给定前面n-1个词的情况下,下一个词为wi的概率。
在n-gram模型中,通常使用最简单的1-gram(也称为unigram),即假设每个词出现的概率与其他词无关。
此时,生成某个词的概率只与这个词在整个语料库中出现的频率有关,而与其他词无关。
对于大于1的n,我们可以使用n-1个词的频率来计算n-gram概率。
例如,对于2-gram模型,我们可以使用前一个词的频率来计算当前词的生成概率。
具体来说,生成某个词的概率可以通过该词在语料库中出现的次数除以前一个词在语料库中出现的次数得到。
然而,n-gram模型的一个主要问题是数据稀疏性。
在实际应用中,很多n-gram序列在语料库中根本没有出现过,导致模型无法为这些序列提供有效的生成概率。
为了解决这一问题,我们需要使用回退方法来处理未出现的词序列。
回退概率是指在n-gram模型中,当生成某个词的序列未在语料库中观测到时,通过插值或平滑操作运用更短序列的概率来估计该序列的生成概率。
SRILM语言模型格式解读

SRILM语⾔模型格式解读先看⼀下语⾔模型的输出格式\data\ngram 1=64000ngram 2=522530ngram 3=173445\1-grams:-5.24036'cause -0.2084827-4.675221'em -0.221857-4.989297'n -0.05809768-5.365303'til -0.1855581-2.111539 </s> 0.0-99 <s> -0.7736475-1.128404 <unk> -0.8049794-2.271447 a -0.6163939-5.174762 a's -0.03869072-3.384722 a. -0.1877073-5.789208 a.'s 0.0-6.000091 aachen 0.0-4.707208 aaron -0.2046838-5.580914 aaron's -0.06230035-5.789208 aarons -0.07077657-5.881973 aaronson -0.2173971(注:上⾯的值都是以10为底的对数值)ARPA是常⽤的语⾔模型存储格式, 由主要由两部分构成。
模型⽂件头和模型⽂件体构成。
上⾯是⼀个语⾔模型的⼀部分,三元语⾔模型的综合格式如下:\datangram 1=nr # ⼀元语⾔模型ngram 2=nr # ⼆元语⾔模型ngram 3=nr # 三元语⾔模型\1-grams:pro_1 word1 back_pro1\2-grams:pro_2 word1 word2 back_pro2\3-grams:pro_3 word1 word2 word3\end\第⼀项表⽰ngram的条件概率,就是P(wordN | word1,word2,。
,wordN-1)。
第⼆项表⽰ngram的词。
SRILM详解过程
一、Generating the N-gram Count Filengram-count -text train.zh -order 5 -write train.count -unk-text:training corpus name-order:n-gram count-write:output countfile name-unk:mark OOV as<unk>train.count里面的内容:第一列分别为一元,二元,三元,四元,五元;第二列为counts in training corpus 二、Generating the N-gram Language modelngram-count -read train.count -order 5 -lm train.lm -gt1min 3 -gt1max 7 -gt2min 3 -gt2max 7 -gt3min 3 -gt3max 7 -gt4min 3 -gt4max 7 -gt5min 3 -gt5max 7-read:read count file-lm:output LM file name-gr n min:Good-Turing discounting for n-gramtrain.lm里面的内容第一列为log probability (base 10);第三列为log of backoff weight (base )三、Calculate the Test Data Perplexityngram -ppl test.zh -order 5 -lm train.lm-ppl:calculate perplexity for test datappl 和ppl1分别的计算公式:))/(log (^101))/(log (^10OOVs words prob ppl sentences OOVs words prob ppl --=+--= )(1t i i p l prob T∏==其中l T 为句子的个数 从以上的过程可以看出SRILM 的功能:一.Generate the n-gram count file from the corpus二.Train the language model from the n-gram count file三.Calculate the test data perplexity using the trained language model①平滑方法为Good-Turing时的困惑度:ngram-count -read train.count -order 5 -lm train.lm -gt1min 3 -gt1max 7 -gt2min 3 -gt2max 7 -gt3min 3 -gt3max 7 -gt4min 3 -gt4max 7 -gt5min 3 -gt5max 7②平滑方法为Absolute Discounting时的困惑度:ngram-count -read train.count -order 5 -lm train.lm -cdiscount1 0.5 -cdiscount2 0.5 -cdiscount3 0.5 -cdiscount4 0.5 -cdiscount5 0.5③平滑方法为Witten-Bell Discounting时的困惑度:ngram-count -read train.count -order 5 -lm train.lm -wbdiscount1 -wbdiscount2 -wbdiscount3 -wbdiscount4 -wbdiscount5④平滑方法为Modified Knerser-Ney Discounting时的困惑度ngram-count -read train.count -order 5 -lm train.lm -kndiscount1 -kndiscount2 -kndiscount3 -kndiscount4 -kndiscount5。
ngram-count参数

ngram-count参数ngram-count是一个命令行工具,用于统计文本中的n-gram,并生成一个n-gram计数文件。
以下是ngram-count的参数列表和说明,其中参数-n和参数-text为必需参数,其他参数为可选参数。
参数-n:要计算的n-gram的最大n值。
例如,如果参数-n为3,则将计算uni-gram、bi-gram 和tri-gram。
这是必需参数。
要计算n-gram的文本文件的路径。
这是必需参数。
参数-order:参数-addsmooth:应用指定的平滑算法,以避免零计数问题。
默认情况下,ngram-count不应用平滑算法。
支持的平滑算法有:laplace(拉普拉斯平滑)、witten-bell(Witten-Bell插值)和katz(Katz插值)。
指定n-gram计数文件的输出路径。
默认情况下,ngram-count将n-gram计数文件写入标准输出中。
指定未知词汇符号。
默认情况下,未知词汇符号为<unk>。
将文本中的词符映射到其他词符,以便在计算n-gram时将它们视为同一词符。
例如,要将文本中的所有数字映射到<DIGIT>词符,可以使用以下命令行选项:-map-number "<DIGIT>"使用指定的discount smoothing算法。
默认情况下,ngram-count使用Good-Turing 算法进行平滑。
裁剪小计数n-gram,以减少n-gram计数文件的大小。
使用此选项时,可以指定裁剪计数的最小值和最大值:-prune-min 2 -prune-max 10指定裁剪基数的数量,计数文件中的每个n-gram都生成一个裁剪基数:-prune-count n参数-cache:设置n-gram计数缓存的最大大小(以MB为单位)。
默认情况下,n-gram计数缓存为1 GB。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
iv) ngram 逆序
3 Vocab_None
v) ngram 存储 bow 存储 首先存储 bow 值,索引项为逆序后的全部 ngram
Trie 3 Trie: 第 1 层 Trie: 第 2 层 sub data
bow
-0.769151
probs
用于存储 ngram 中的目标元 及其概率值。由于同一个历 史可以衍生出很多 ngram, 因此 probs 是一个映射结构, 即目标元到概率值的映射
sub data
bow
-0.769151
bow
-0.365925
bow
-0.01355691
bow
-0.20034289
probs
probs
probs
probs
5 -1.169282
6 -2.308796
4 -1.210051
初始化 Trie 第 0 层 Trie 1) 写入 Trie 及其子 Trie 构成的 Trie 树的大小 (注:这里非实际大小,而是起到垫位作用) 2) 写入当前 Trie 结点 data 域中 bow 值(-Inf) 3) 写入当前 Trie 结点 data 域中 probs 域保存的映射对数(2) 4) 写入 probs 中每一个映射对,即 wid -> prob; 5) 遍历 sub 中每一个元素,若没有,则执行步骤 7) 6) 写入 wid,Trie subTrie,返回步骤 1) 7) 将文件指针移动到记录当前 Trie 树大小的位置, 即步骤 1) 写入的位置, 写入实际的 Trie 树大小
8) 整个 Trie 树写入完毕,写入过程结束 从上面实际的写入过程可以发现整个写入采用的是一个递归的写入方式, 而且采用了类 似于深度优先的写入方式。 关于 srilm ngram trie 的二进制读取和文本输出方式,如果感兴趣的话可以阅读相关代码,我 相信有了上面的基础后,对这两块的理解应该不成问题。 注:需要注意的是,ngram lm 输出的时候采用了排序输出的方式,采用该方式是十分必要 的,因为这会极大地提高 ngram trie 的加载速度。关于这一点,可以通过相关实验验证。验 证方法:将迭代器中的相关排序函数移除,并输出,同时使用 ngram 对比排序和非排序的 lm 加载速度。
Trie: 第 3 层
sub data
sub data
sub data
sub data
bow
-0.769151
bow
-0.365925
bow
-0.01355691
bow
-0.20034289
probs
probs
probs
probs
5 -1.169282
6 -2.308796
实际过程 5
-1.210051 一定 会 有
sub data
sub data
bow
-0.769151
bow
-0.365925
bow
-0.01355691
probs
probs
probs
prob 存储
Trie 3 4 5 3 Trie: 第 1 层 Trie: 第 2 层
Trie: 第 3 层
sub data
sub data
sub data
bow
下面通过一个实际的例子分析其二进制方式写入过程,这里还是借鉴上面的例子同时 采用上面的构建好的 ngram-trie 结构图来说明 ngram-trie 的二进制写入方式。 Trie sub data
bow
Trie: 第 0 层
每一个 sub 代表一个 Trie 用于存储 ngram 中的目标元
-Inf
-0.769151
bow
-0.365925
bow
-0.01355691
probs 5 -1.169282
probs
probs
实际过程 4
-2.308796 有 希望 -0.200342
i) ngram 读取
-2.308796 有 希望 -0.2003421
ii) 概率值转换
prob = -2.308796
Trie 3 4 Trie: 第 1 层 Trie: 第 2 层
sub data
bow
sub data
bow
-0.365925
-0.769151
probs
probs
prob 存储
Trie sub data
bow
Trie: 第 0 层
用于存储 ngram 中的目标元
-Inf
及其概率值。由于同一个历 史可以衍生出很多 ngram, 因此 probs 是一个映射结构, 即目标元到概率值的映射
Trie: 第 3 层
sub data
sub data
sub data
sub data
bow
-0.769151
bow
-0.365925
bow
-0.01355691
bow
-0.20034289
probs
probs
probs
probs
5 -1.169282
prob 存储
Trie
3
4
5
6 3 4
Trie: 第 1 层 Trie: 第 2 层
及其概率值。由于同一个历 史可以衍生出很多 ngram, 因此 probs 是一个映射结构, 即目标元到概率值的映射
probs 3 -3.464278 4 -2.440158
Trie
3
4
5
6 3 4
Trie: 第 1 层 Trie: 第 2 层
Trie: 第 3 层
sub data
sub data
sub data
i) ngram 读取
-2.440158 有 -0.3659258
ii) 概率值转换
prob = -2.440158 bow = -0.3659258 -2.440158 有 NULL
iii)字符串到索引映射
4 Vocab_None
iv) ngram 逆序
4 Vocab_None
v) ngram 存储 bow 存储 首先存储 bow 值,索引项为逆序后的全部 ngram
因此从以上结构我们可以发现,srilm 结构的存储方式一定要从低元到高元开始存储, 否则会存储过程中会出错。当然该错误稍加处理也是可以避免的。 检索方式 采用该结构后,可以采用如下的检索方式 i) 将待检索的 ngram 反转,并存储在 wid 数组中,设 i = 1; ii) 在 Trie 检索目标元 wid[0],若检索到则获得 prob 值,同时将 bow 值置 0; iii) 检索历史元 wid[i],若检索到则设置 bow 值,并将 Trie 指向 wid[i]对应的子 Trie,同时 执行 i++,否则转到步骤 v; iv)返回步骤 ii v) 检索完毕,返回 prob+bow 值。 因此通过分析上述的检索步骤, 可以发现采用该结构后, 检索 ngram 的时间复杂度几乎为 n, n 为 ngram 的长度。
6 -2.308796
4 -1.210051
存储过程总结归纳 从 srilm 的存储方式,我们可以看出其存储过程为 i) 对于存在 bow 的 ngram,将整个 ngram 作为 Trie 索引 ii) 对于所有的 1 元, 将其存在 Trie 的第 0 层 data 域的 probs 中, 该结构为一个映射 结构 iii)对于大于 1 元的所有 ngram 将其反转后,以历史元为索引检索 Trie,并将目标 元存储在历史元检索到的 data 域的 probs 中,该结构为一个映射结构
一定 -0.7691519 有 -0.3659258
一定 会 -0.01355691 有 希望 -0.200342
一定 会 有
存储步骤 i) ngram 读取 ii) 概率值转换 iii)字符串到索引映射 iv) ngram逆序 v) ngram 存储 实际过程 1
-3.464278 一定 -0.7691519
bow = -0.200342 -1.169282 有 希望 NULL
iii)字符串到索引映射
4 6 Vocab_None
iv) ngram 逆序
6 4 Vocab_None
v) ngram 存储 bow 存储 首先存储 bow 值,索引项为逆序后的全部 ngram
Trie
3
4
5
6 3 4
Trie: 第 1 层 Trie: 第 2 层
ngram trie 二进制写入方式 在介绍 ngram trie 二进制写入方式之前,先让我们大体了解一下 ngram trie 二进制表示 结构。ngram trie 二进制表示结构如下所示: length-of-subtrie back-off-weight number-of-probs word1 prob1 word2 prob2 ... word1 subtrie1 word2 subtrie2 ... 从上述结构可以看出写入每一个 trie 之前,首先书写该 trie 下包含的二进制信息的字节数, 即 length-of-subtrie 值,当然由于 length-of-subtrie 一开始并不知道需要占用多少个字节来表 示,因此可以先写入一个值用来垫位,等完全写完该 trie 的时候,回退到该位置,写入实际 的字节数,若发现一开始为记录 trie 大小分配的字节数不够,则需要重新遍历该 trie,并写 入该 trie 的所有信息。 back-off-weight trie 节点 data 域中 bow 值。 number-of-probs trie 节点 probs 域中存储的 wid->prob 映射对数 写入实际的映射数据 word1 prob1 word2 prob2 ...