用spss求函数参数共17页
spss函数大全解读资料

Spss 算术函数孙中友江苏ABS(numexpr 数值。
返回 numexpr (必须为数值的绝对值。
ARSIN(numexpr 数值。
返回 numexpr 的反正弦(以弧度为单位 ,求出的值必须为 -1 和 +1 之间的数字值。
ARTAN(numexpr 数值。
返回 numexpr 的反正切(以弧度为单位 , numexpr 必须为数字值。
COS(radians 数值。
返回 radians 的余弦(以弧度为单位 , radians 必须为数字值。
EXP(numexpr 数值。
返回 e 的 numexpr 次幂, 其中 e 是自然对数的底数, 而numexpr 是数值。
较大的 numexpr 值可能会产生超过机器性能的结果。
LN(numexpr 数值。
返回以 e 为底数的 numexpr 的对数, numexpr 必须为大于 0 的数值。
LNGAMMA(numexpr 数值。
返回 numexpr 的完全 Gamma 函数的对数, numexpr 必须为大于 0 的数值。
LG10(numexpr 数值。
返回以 10 为底数的 numexpr 的对数, numexpr 必须为大于 0 的数值。
MOD(numexpr,modulus 数值。
返回 numexpr 除以 modulus 所得到的余数。
两个参数都必须为数值,且 modulus 不得为 0。
RND(numexpr 数值。
返回对 numexpr 舍入后产生的整数, numexpr 必须为数值。
刚好以 .5 结尾的数值将舍去 0 以后的数值。
SIN(radians 数值。
返回 radians 的正弦(以弧度为单位 , radians 必须为数字值。
SQRT(numexpr 数值。
返回 numexpr 的正平方根, numexpr 必须为非负数。
TRUNC(numexpr 数值。
返回 numexpr 被截断为整数(向 0 的方向的值。
统计函数后缀 .n 可在所有统计函数中使用以指定有效参数的数目。
spss基础操作及应用PPT课件

4、提供独有的菜单命令向程序文件的转换 功能。几乎每一个对话框都有“Paste”(粘 贴)按钮。可将菜单操作命令直接转换为 程序命令。用户可将命令文件保存或编辑, 也可直接执行该程序文件。因此,编写程 序文件时也不需记忆大量的命令,为高级 用户对数据实现自动分析提供了强有力的 帮助。
8
5、详细的在线帮助(Help)信息。根据不同 层次的用户提供不同的帮助,在使用过程中 用户可以方便地获得相关的帮助信息,也可 直接连接到SPSS Internet主页,查询有关该软 件的最新信息。
可在编辑编辑editedit菜单的选项菜单的选项optionsoptions命令中打开货币命令中打开货币currencycurrency选项卡进行设置其中全部数值选项卡进行设置其中全部数值allallvaluesvalues用于设置首前缀用于设置首前缀prefixprefix尾后缀尾后缀suffixsuffix字符负数字符负数negativevaluenegativevalue栏用于设置负数的首栏用于设置负数的首prefixprefix尾尾suffixsuffix字符系统默认负数的首字符是字符系统默认负数的首字符是小数点分隔符小数点分隔符decimalseparatordecimalseparator栏用于设置小数点的符栏用于设置小数点的符号默认为圆点号默认为圆点periodperiod也可定义为逗号也可定义为逗号commacomma
11
1.2.3 SPSS for Windows的启动
单击“开始”按钮,打开“开始”菜单, 指向“程序”项,选择(单击)“SPSS for Windows\/SPSS for Windows”;或桌面的快 捷方式上双击SPSS for Windows的图标,即 可启动SPSS,SPSS启动成功后出现SPSS的 主画面,进入预备工作状态。
用SPSS作参数估计

0.40 0.35 0.30 0.25 0.20 0.15 0.10 0.05
p的分布
0.32 0.48
0.64
对于 p ,满足下面两个条件时认为样本容量足够大:
—— np 5
—— n(1 p) 5
当样本容量足够大时,p 的抽样分布可用正态近似,即:
p~N P,P1 P
样本容量n=10
抽样(sampling)
样本(sample)
有限总体
31
27
30
29
28
32
41
13
33
26
25
34
38
40
39
36
37
12
14
35
42
23
1
24
2
17
22
15
43
16
44
20
21
91
18
11
45
10
3 4
9
8
7
6
5
自有限总体的重复回 抽样为纯随机抽样。
12
7
3
23
2
23
25
9
36
X
P
样本统计量做为随机变量,具有特定的概率分布。把 握住他们的分布规律就找到了推断总体参数的依据。
0.30 0.25 0.20 0.15 0.10 0.05
x 的分布
1000名公司员工总体,500 个容量为30的简单随机样本 的平均年薪、大学毕业生比 率、年薪标准差的分布直方 图。
50000 51000 52000 53000 54000
从总体中抽取一个样本,构
《SPSS的参数检验》课件
本PPT介绍SPSS的参数检验方法,包括SPSS的基本概念、参数检验的原理, 以及在SPSSatistical Package for the Social Sciences) 是一种常用的统计分析 软件,用于数据处理和数据分析,广泛应用于社会科学和市场调研等领域。
SPSS中的参数检验
参数检验是一种统计方法,用于判断样本数据与总体数据之间的差异是否显著,进而对总体进行推断。
参数检验的概念和原理
参数检验通过计算样本数据的统计量,如均值和标准差,与总体数据的参数 进行比较,以确定样本数据是否代表总体数据。
SPSS中可用的参数检验方法
单样本t检验
用于检验一个样本的均值是否与总体均值存在显 著差异。
非参数检验使用排列、秩次等方法,通过对样本数据的排序和比较,判断总体数据之间是否存在显著差异。
SPSS中可用的非参数检验方法
Wilcoxon符号秩检验
用于比较两个配对样本的中 位数是否存在显著差异。
Mann-Whitney U检验
用于比较两个独立样本的中 位数是否存在显著差异。
Kruskal-Wallis H检验
SPSS的概念和历史
SPSS最初是由斯德哥尔摩大学的研究人员开发的,后来被美国IBM公司收购, 并逐渐发展成为全球最知名的统计分析软件之一。
SPSS的基本功能和应用领域
SPSS具备数据导入、数据清洗、数据可视化、统计模型构建和结果分析等功 能,被广泛应用于市场调研、国民经济指标分析、社会调查等领域。
单样本z检验
用于检验一个样本的比例是否与总体比例存在显 著差异。
独立样本t检验
用于比较两个独立样本的均值是否存在显著差异。
独立样本z检验
spss随机数字函数说明

随机函数:RV.BERNOULLI(prob)。
数值。
返回具有指定概率参数prob 的Bernoulli 分布中的随机值。
RV.BETA(shape1, shape2)。
数值。
返回具有指定形状参数的Beta 分布中的随机值。
RV.BINOM(n, prob)。
数值。
返回具有指定试验次数和概率参数的二项式分布中的随机值。
RV.CAUCHY(loc, scale)。
数值。
返回具有指定位置和刻度参数的Cauchy 分布中的随机值。
RV.CHISQ(df)。
数值。
返回具有指定自由度df 的卡方分布中的随机值。
RV.EXP(scale)。
数值。
返回具有指定刻度参数的指数分布中的随机值。
RV.F(df1, df2)。
数值。
返回具有指定自由度df1 和df2 的F 分布中的随机值。
RV.GAMMA(shape, scale)。
数值。
返回具有指定形状和刻度参数的Gamma 分布中的随机值。
RV.GEOM(prob)。
数值。
以指定的概率参数从几何分布中返回一个随机值。
RV.HALFNRM(mean, stddev)。
数值。
以指定的均值和标准差从半正态分布中返回一个随机值。
RV.HYPER(total, sample, hits)。
数值。
以指定的参数从超几何分布中返回一个随机值。
RV.IGAUSS(loc, scale)。
数值。
以指定的位置和刻度参数从逆高斯分布中返回一个随机值。
PLACE(mean, scale)。
数值。
返回具有指定均值和刻度参数的Laplace 分布中的随机值。
RV.LNORMAL(a, b)。
数值。
返回具有指定参数的对数正态分布中的随机值。
RV.LOGISTIC(mean, scale)。
数值。
返回具有指定均值和刻度参数的logistic 分布中的随机值。
RV.NEGBIN(threshold, prob)。
数值。
返回具有指定阈值和概率参数的负二项式分布中的随机值。
RV.NORMAL(mean, stddev)。
SPSS详细操作广义估计方程

SPSS 详细操作:广义估计方程SPSS 详细操作:广义估计方程2021-03-18 17:40一、问题与数据在临床研究中,经常会比较两种治疗方式对患者结局的影响,并且屡次测量结局。
比方,为了研究两种降压药物对血压的控制收效可否存在差异,研究者会对两个人群服药后在不同样时间点记录血压值,尔后议论降压收效。
也许对两组动物分别施加两种干预,连续记录多个时间点的结局,尔后比较两种干预的收效。
这种设计能够用以下表示图表示:别的,有时研究只需要收集一个时间点的数据,但是一个研究对象会供应多个部位的数据点。
比方,研究者想议论冠芥蒂患者在冠脉搭桥术后应用阿司匹林可否能够有效降低患者血管的再拥堵,议论的方法是术后 1 年做冠脉造影观察血管可否拥堵,但是每个患者可能会在同一次手术中对多条冠状动脉血管进行搭桥,因此有的患者可能会奉献多组数据。
这种设计能够用以下表示图表示:以上两种设计,无论是临床试验还是动物试验都非经常有,它的特点在于数据间非独立,同一个体间数据拥有相关性。
关于这样的设计种类,该如何解析呢?今天我们来介绍别的一种特别好的方法——广义估计方程(GEE 〕。
GEE 既能够办理连续型结局变量也能够办理分种类结局变量,它实质上代表了一种模型种类,即在传统模型的基础上对相关性数据进行了校正,能够拟合 Logistic 回归、泊松回归、 Probit 回归、一般线性回归等广义线性模型。
本文将以阿司匹林预防冠脉搭桥后血管再拥堵为例介绍运用 SPSS 进行 GEE 的操作方法。
以下为数据格式:表 1.数据格式每名患者奉献数据量不等。
如编号为 1 的患者只对一根血管进行了搭桥手术,编号为 2 的患者那么有两根血管进行搭桥手术。
表 2. 变量赋值〔注:本例中数据纯属虚假,解析结果不能够产生任何结论。
性别为待调整变量。
〕二、 SPSS 解析方法1.数据录入 SPSS第一在 SPSS 变量视图〔Variable View 〕中新建上述表 2 中变量,尔后在数据视图〔Data View 〕中录入数据。
用spss求函数参数

04
多元线性回归分析
多元线性回归模型简介
多元线性回归模型是一种统计学方法,用于研究多个自变量与因变量之间 的线性关系。
它通过建立数学模型来描述因变量如何受到多个自变量的影响,并估计每 个自变量的系数。
这些系数反映了自变量对因变量的影响程度和方向。
多元线性回归模型的适用条件
因变量与自变量之间存在 线性关系
SPSS软件简介
历史与发展
SPSS成立于1968年,最初是为社会科学领域的研究者提供统计分析工具。随着计算机技术的不断发展,SPSS的功能 和适用范围也不断扩展,成为全球众多研究者、学生和数据分析师的首选工具。
主要功能
SPSS提供了广泛的统计分析方法,包括描述性统计、回归分析、方差分析、非参数检验等多种功能,能够满足不同 领域的数据分析需求。
点击“确定”开始进行多元线性回归分析。
SPSS将输出回归结果,包括回归系数、标准误、显著 性水平等统计指标,以及模型摘要和方差分析表等。
05
非线性回归分析
非线性回归模型简介
非线性回归模型
非线性回归模型是一种用于描述因变量和自变量之间非线性关 系的统计模型。它扩展了线性回归模型,允许自变量和因变量
02 解读回归系数,了解自变量对因变量的影响程度 和方向。
03 根据需要,进行模型优化和调整,以提高预测精 度。
03
线性回归分析
线性回归模型简介
01
02
03
线性回归模型是一种预 测模型,用于描述因变 量与一个或多个自变量
之间的线性关系。
在线性回归模型中,因 变量是我们要预测的目 标变量,而自变量是我 们用来预测因变量的变
之间的关系是非线性的。
目的
通过非线性回归分析,我们可以探索和描述因变量与一个或多 个自变量之间的复杂关系,并估计这些关系中的参数。
《SPSS参数检验》课件

VS
详细描述
样本量过小可能导致检验效能不足,无法 准确推断总体参数;而样本量过大则可能 增加误差率,影响检验的准确性。因此, 需要根据研究目的和实际情况合理确定样 本量大小。
效应大小问题
总结词
效应大小是指不同组别或处理之间的差异程度。
详细描述
效应大小对参数检验的准确性具有重要影响。如果效应大小较小,即使样本量足够大,也可能无法准 确推断总体参数。因此,在研究设计阶段,需要考虑如何控制或调整效应大小,以提高参数检验的准 确性。
多因素方差分析
总结词
多因素方差分析是一种复杂的方差分析方法,用于比 较两个或多个分类变量对数值型数据的影响。
详细描述
在多因素方差分析中,我们将数值型数据分为若干组 ,每组数据对应两个或多个分类变量的不同水平。通 过比较各组的均值,我们可以了解多个分类变量对数 值型数据的影响。
重复测量方差分析
总结词
参数检验的分类
• 参数检验可以分为单样本检验、独立样本 检验和配对样本检验。单样本检验是对单 个总体参数进行检验,例如检验一个样本 的均值是否等于某个值;独立样本检验是 比较两个独立总体的参数,例如比较两个 不同群体的均值是否相等;配对样本检验 是比较两个相关总体的参数,例如比较同 一对象在不同条件下的观测值是否相等。
一致性卡方检验
01 一致性卡方检验用于检验两个分类变量的一致性 。
02 如果两个分类变量之间存在高度一致性,则实际 观测频数与期望频数之间差异较小。
03
一致性卡方检验的常用公式是:χ² = Σ[(O_i E_i)² / (E_i + 0.5 * (O_i + E_i))]
05
参数检验的注意事项
数据正态性检验
SPSS使用教程

描述样本数据一般的,一组数据拿出来,需要先有一个整体认识。
除了我们平时最常用的集中趋势外,还需要一些离散趋势的数据。
这方面EXCEL就能一次性的给全了数据,但对于SPSS,就需要用多个工具了,感觉上表格方面不如EXCEL好用。
个人感觉,通过描述需要了解整体数据的集中趋势和离散趋势,再借用各种图观察数据的分布形态。
对于SPSS提供的OLAP cubes(在线分析处理表),Case Summary(观察值摘要分析表),Descriptives (描述统计)不太常用,反喜欢用Frequencies(频率分析),Basic Table(基本报表),Crosstabs(列联表)这三个,另外再配合其它图来观察。
这个可以根据个人喜好来选择。
一.使用频率分析(Frequencies)观察数值的分布。
频率分布图与分析数据结合起来,可以更清楚的看到数据分布的整体情况。
以自带文件Trends chapter 13.sav为例,选择Analyze->Descriptive Statistics->Frequencies,把hstarts选入Variables,取消在Display Frequency table前的勾,在Chart里面histogram,在Statistics选项中如图1图1分别选好均数(Mean),中位数(Median),众数(Mode),总数(Sum),标准差(Std. deviation),方差(Variance),范围(range),最小值(Minimum),最大值(Maximum),偏度系数(Skewness),峰度系数(Kutosis),按Continue返回,再按OK,出现结果如图2图2表中,中位数与平均数接近,与众数相差不大,分布良好。
标准差大,即数据间的变化差异还还小。
峰度和偏度都接近0,则数据基本接近于正态分布。
下面图3的频率分布图就更直观的观察到这样的情况图3二.采用各种图直观观察数据分布情况,如采用柱型图观察归类的比例等。
SPSS详细操作:广义估计方程

SPSS详细操作:广义估计方程SPSS详细操作:广义估计方程2017-03-18 17:40一、问题与数据在临床研究中,经常会比较两种治疗方式对患者结局的影响,并且多次测量结局。
例如,为了研究两种降压药物对血压的控制效果是否存在差异,研究者会对两个人群服药后在不同时间点记录血压值,然后评价降压效果。
或者对两组动物分别施加两种干预,连续记录多个时间点的结局,然后比较两种干预的效果。
这种设计可以用如下示意图表示:另外,有时研究只需要收集一个时间点的数据,但是一个研究对象会提供多个部位的数据点。
例如,研究者想评价冠心病患者在冠脉搭桥术后应用阿司匹林是否可以有效降低患者血管的再堵塞,评价的方法是术后1年做冠脉造影观察血管是否堵塞,但是每个患者可能会在同一次手术中对多条冠状动脉血管进行搭桥,因此有的患者可能会贡献多组数据。
这种设计可以用如下示意图表示:以上两种设计,不管是临床试验还是动物试验都非常常见,它的特点在于数据间非独立,同一个体间数据具有相关性。
对于这样的设计类型,该如何分析呢?今天我们来介绍另外一种非常好的方法——广义估计方程(GEE)。
GEE既可以处理连续型结局变量也可以处理分类型结局变量,它实际上代表了一种模型类别,即在传统模型的基础上对相关性数据进行了校正,可以拟合Logistic回归、泊松回归、Probit回归、一般线性回归等广义线性模型。
本文将以阿司匹林预防冠脉搭桥后血管再堵塞为例介绍运用SPSS进行GEE的操作方法。
以下为数据格式:表1. 数据格式每名患者贡献数据量不等。
如编号为1的患者只对一根血管进行了搭桥手术,编号为2的患者则有两根血管进行搭桥手术。
表2. 变量赋值(注:本例中数据纯属虚构,分析结果不能产生任何结论。
性别为待调整变量。
)二、SPSS分析方法1. 数据录入SPSS首先在SPSS变量视图(Variable View)中新建上述表2中变量,然后在数据视图(Data View)中录入数据。
SPSS常用参数设置
SPSS常⽤参数设置SPSS各种通⽤参数,我们可以在编辑-选项卡中进⾏设置,所设参数可⾃动保存,再次启动SPSS时⽆须重新设置。
设置常⽤参数可以让界⾯符合⾃⼰的使⽤习惯,提⾼数据分析的⼯作效率。
由于参数设置内容⽐较多,有些⽐较浅显易懂,下⾯我们就挑重点的给⼤家做个讲解。
常规“⾓⾊”'⾓⾊'选项组为较新版本SPSS软件中的新增内容,其来源于数据挖掘⽅法体系的要求。
为节省时间,提⾼效率,某些对话框允许使⽤预定义⾓⾊,然后⾃动将变量分配到变量列表中。
可⽤⾓⾊如下。
输⼊:变量将⽤作输⼊(如⾃变量、预测变量)。
⽬标:变量将⽤作输出或⽬标(如因变量)。
两者:变量将同时⽤作输⼊和输出。
⽆:变量没有⾓⾊分配,即不被纳⼊分析。
分区:变量将被⽤于将数据划分为单独的训练、检验和验证样本。
拆分:具有此⾓⾊的变量不会在SPSS中被⽤作拆分⽂件变量。
SPSS默认为所有变量分配输⼊⾓⾊,注意⾓⾊分配只影响⽀持⾓⾊分配的对话框。
⼀般情况下,该选项使⽤默认设置即可。
“⽤户界⾯”这⾥设置SPSS的界⾯语⾔形式,设置中⽂或者英⽂等等。
查看器'初始输出状态'该选项组⽤于设置输出结果的初始状态参数。
⾸先在'项'下拉框中选择要设置的输出结果,然后在下⾯设置所选内容的输出参数。
'项'下拉列表中包括⽇志、警告、注释、标题、页⾯标题、枢纽表、表格、⽂本输出、树模型和模型浏览器。
'初始内容'栏可'显⽰'或'隐藏';在'调整'栏中选择对齐⽅式;如勾选'在⽇志中显⽰命令'复选框,SPSS将在⽇志中输出命令语句。
数据'转换与合并选项'选择'⽴即计算值',数据转换、⽂件合并操作将在单击'确定'按钮后⽴即执⾏;如选择'使⽤前计算值'单选按钮,将会延迟转换,只有在遇到命令时,才进⾏转换和合并,数据⽂件较⼤时,⼀般选⽤这种格式。
数据统计分析SPSS教程完整版

安装完成后,双击桌面快捷方式或从 开始菜单启动SPSS。关闭时,点击右 上角的关闭按钮。
数据输入与保存
数据输入
在SPSS中,可以通过直接输入数据或 导入数据(如Excel、CSV等格式)进 行数据输入。
数据保存
数据输入完成后,点击文件菜单选择 保存,选择保存位置和文件名,保存 为SPSS格式(.sav)。
数据统计分析SPSS教程完 整版
contents
目录
• SPSS基础操作 • 描述性统计分析 • 均值比较与T检验 • 方差分析 • 回归分析 • 聚类分析与判别分析 • 主成分分析与因子分析 • SPSS在社会科学中的应用
01
SPSS基础操作
安装与启动
下载和安装
首先需要从SPSS官网或其他可信来 源下载SPSS软件的安装包,按照提 示进行安装。
1. 基本概念:判别分析试图基于 已知分类的训练数据来创建一个 模型,该模型可以将新的未知分 类的数据点正确分类。
3. 注意事项:选择适当的判别函 数和确保训练数据具有代表性是 关键。
07
主成分分析与因子分析
主成分分析
01
主成分分析是一种降维技术,通过线性变换将多个相关变量转化为少 数几个不相关的变量,这些新变量称为主成分。
详细描述
通过频数分析,可以了解数据集中每个变量的分布情况,例如某个分类变量的各个类别的频数、缺失值的频数等 。在SPSS中,可以通过“频率”命令来执行频数分析。
描述性统计量
总结词
描述性统计量用于描述数据集的集中趋势、离散程度和分布形态。
详细描述
描述性统计量包括均值、中位数、众数、标准差、方差等,用于反映数据集的中心趋势和离散程度。 在SPSS中,可以通过“描述统计”命令来计算描述性统计量。
spss讲稿5(1) SPSS参数检验和区间估计(一)

• 应用举例
人均住房面积的平均值是否为20平方米
注意书写步骤
6 - 34
第34页,共71页。
精品教材
统计学
SPSS单样本t检验
(3)option选项:
Missing values: 缺失值的处理(单样本检验时以下选项 没有差别) exclude cases analysis by analysis:当分析时 涉及到有缺失值变量时再剔除相应的个案
标准正态分布
t (df = 13)
t 分布
6
-
33
t
分布与标准正态分布的比较
X
t (df = 5)
不同自由度的t分布
Z
t
第33页,共71页。
精品教材
统计学
SPSS单样本t检验
• 含义:检验某变量的总体均值与指定的检验值之间是否存 在显著差异。例如:人均住房面积的平均值是否为20平方米
• 基本操作步骤 (1)菜单选项:Analyze->compare means->one-samples T test
6 - 26
临界值 H0值 临界值 样本统计量
第26页,共71页。
精品教材
统计学
假设检验的基本问题
/ 2 拒绝
1/2 P 值
/ 2 拒绝
1/2 P 值
临界值 H0值 临界值
Z
计算出的样本统计量
计算出的样本统计量
6 - 27
第27页,共71页。
精品教材
统计学
假设检验的基本问题
• 假设检验的基本步骤:作出统计决策
x
n
当样本容量足够 大时(n 30) , 样本均值的抽样 分布逐渐趋于正 态分布
如何用spss求相关系数

如何用spss求相关系数参见:[1] 衷克定数据统计分析与实践—SPSS for Windows[M].北京:高等教育出版社,2005.4:195—[2] 试验设计与SPSS应用[M].北京,化学工业出版社,王颉著,2006.10:141—多元相关与偏相关如何用SPSS求相关系数1 用列联分析中,计算lamabda相关系数,在分析——描述分析——列联分析2 首先看两个变量是否是正态分布,如果是,则在analyze-correlate-bivariate 中选择pearson相关系数,否则要选spearman相关系数或Kendall相关系数。
如果显著相关,输出结果会有*号显示,只要sig的P值大于0.05就是显著相关。
如果是负值则是负相关。
在SPSS软件相关分析中,pearson(皮尔逊), kendall(肯德尔) 和spearman(斯伯曼/斯皮尔曼)三种相关分析方法有什么异同两个连续变量间呈线性相关时,使用Pearson积差相关系数,不满足积差相关分析的适用条件时,使用Spearman秩相关系数来描述.Spearman相关系数又称秩相关系数,是利用两变量的秩次大小作线性相关分析,对原始变量的分布不作要求,属于非参数统计方法,适用范围要广些。
对于服从Pearson相关系数的数据亦可计算Spearman相关系数,但统计效能要低一些。
Pearson相关系数的计算公式可以完全套用Spearman相关系数计算公式,但公式中的x和y用相应的秩次代替即可。
Kendall's tau-b等级相关系数:用于反映分类变量相关性的指标,适用于两个分类变量均为有序分类的情况。
对相关的有序变量进行非参数相关检验; 取值范围在-1-1之间,此检验适合于正方形表格;计算积距pearson相关系数,连续性变量才可采用;计算Spearman秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据; 计算Kendall秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据。
spss数据处理
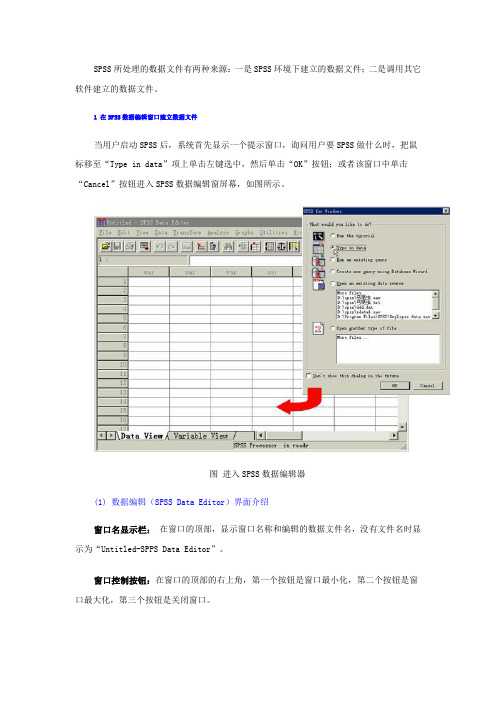
SPSS所处理的数据文件有两种来源:一是SPSS环境下建立的数据文件;二是调用其它软件建立的数据文件。
1 在SPSS数据编辑窗口建立数据文件当用户启动SPSS后,系统首先显示一个提示窗口,询问用户要SPSS做什么时,把鼠标移至“Type in data”项上单击左键选中,然后单击“OK”按钮;或者该窗口中单击“Cancel”按钮进入SPSS数据编辑窗屏幕,如图所示。
图进入SPSS数据编辑器(1) 数据编辑(SPSS Data Editor)界面介绍窗口名显示栏:在窗口的顶部,显示窗口名称和编辑的数据文件名,没有文件名时显示为“Untitled-SPPS Data Editor”。
窗口控制按钮:在窗口的顶部的右上角,第一个按钮是窗口最小化,第二个按钮是窗口最大化,第三个按钮是关闭窗口。
SPSS主菜单:在窗口显示的第二行上,有:File文档,Edit编辑,View显视,Data数据,Transform转换,Analyze分析,Graphs图形,Utilities公用项,Windows视窗。
图 SPSS窗口界面常用工具按钮:在窗口显示的第三行上,有:打开文档,保存文档,打印,对话检索,取消当前操作,重做操作,转到图形窗口,指向记录,指定变量操作,查找,在当前记录的上方插入新的空白记录,在当前变量的左边插入新的空白变量,切分文件,设置权重单元,标记单元,显示价值标签。
数据单元格信息显示栏:在编辑显示区的上方,左边显示单元格和变量名(单元格:变量名),右边显示单元里的内容。
编辑显示区:在窗口的中部,最左边列显示单元序列号,最上边一行显示变量名称,缺省为“Var”。
编辑区选择栏:在编辑显示区下方,Data View 在编辑显示区中显示编辑数据,Variable View在编辑显示区中显示编辑数据变量信息。
状态显示栏:在窗口的底部,左边显示执行的系统命令,右边显示窗口状态。
(2) 数据文件格式数据文件格式以每一行为一个记录,或称观察单位(Cases),每一列为一个变量(Variable)。
如何用SPSS求相关系数

参见:[1]衷克定数据统计分析与实践—SPSSforWindows[M].北京:高等教育出版社,2005.4:195—[2]试验设计与SPSS应用[M].北京,化学工业出版社,王颉著,2006.10:141—多元相关与偏相关如何用SPSS求相关系数1用列联分析中,计算lamabda相关系数,在分析——描述分析——列联分析2首先看两个变量是否是正态分布,如果是,则在analyze-correlate-bivariate中选择pearson相关系数,否则要选spearman相关系数或Kendall相关系数。
如果显著相关,输出结果会有*号显示,只要sig的P值大于0.05就是显著相关。
如果是负值则是负相关。
在SPSS软件相关分析中,pearson(皮尔逊),kendall(肯德尔)和spearman (斯伯曼/斯皮尔曼)三种相关分析方法有什么异同两个连续变量间呈线性相关时,使用Pearson积差相关系数,不满足积差相关分析的适用条件时,使用Spearman秩相关系数来描述.Spearman相关系数又称秩相关系数,是利用两变量的秩次大小作线性相关分析,对原始变量的分布不作要求,属于非参数统计方法,适用范围要广些。
对于服从Pearson相关系数的数据亦可计算Spearman相关系数,但统计效能要低一些。
Pearson相关系数的计算公式可以完全套用Spearman相关系数计算公式,但公式中的x和y用相应的秩次代替即可。
Kendall's tau-b等级相关系数:用于反映分类变量相关性的指标,适用于两个分类变量均为有序分类的情况。
对相关的有序变量进行非参数相关检验;取值范围在-1-1之间,此检验适合于正方形表格;计算积距pearson相关系数,连续性变量才可采用;计算Spearman秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据;计算Kendall秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据。
SPSS常用函数.doc

SPSS常用函数SPSS函数是一个常用程序,并且利用一个或多个自变量(参数)来执行。
每个SPSS函数均有一个关键名称,且绝不能写错。
通常,函数的格式为:函数名称(自变量,自变量,……),某些函数可能只含有一个自变量,而有些函数则可能含有多个自变量,当一个函数含有多个自变量时,各自变量间用逗号(,)隔开,而函数的自变量通常又可分为以下三种:(1)常数,如SQRT(100);(2)变量名称,如MEAN(VAR1,VAR2,VAR3);(3)表达式,如MIN(30,SQRT(100))。
总之,SPSS函数和我们平时EXCEL里面函数格式规则并无差别。
SPSS提供了180多种函数,共可分为十多类(SPSS 17.0中大大小小分了18类)。
和EXCEL一样,我们也不可能记住所有函数,只要知道一些常用函数,至于其他函数要用的时候再去查找也不迟,下面将列举一些常用函数:1.ArithmeticFunctions算术函数算术函数是最常用的函数,可以满足对变量进行的一般运算,算术函数主要有:﹡算术表达式也包括单值与变量名的情况。
2.StatisticalFunctions统计函数统计函数也是统计分析中常用的函数之一,主要反映变量的数据特征,时间序列的滞后期变量等,具体函数有:3.LogicalFunctions逻辑函数l ANY(test,valu,value,…]) 逻辑型函数,自变量为(变量名,x1,x2,…),函数功能是判断变量值是否是x1、x2…中的一个,例如:Any(数学,80,90,70):分别对每条个案判断其数学成绩是否为80或90或70分。
l RANGE(test,lo,hi[,10,hi...] 逻辑型函数变量必须都为数值型或都为字符型,自变量为(变量名,x1,x2),其中:x1≤x2,函数功能是判断某变量值是否在x1至x2之间,例如:RANGE (数学,80,90):分别对每条个案判断其数学成绩是否在80至90分之间4.DateandTimeFunctions日期和时间函数l DATE.DMY (day,month,year)SPSS日期型格式的数值函数,返回与指定的日、月、年相应的日期值。
如何用SPSS求相关系数[宝典]
![如何用SPSS求相关系数[宝典]](https://img.taocdn.com/s3/m/e906f013fab069dc51220154.png)
如何用SPSS求相关系数[宝典]参见:[1] 衷克定数据统计分析与实践—SPSS for Windows[M].北京:高等教育出版社,2005.4:195—[2] 试验设计与SPSS应用[M].北京,化学工业出版社,王颉著,2006.10:141—多元相关与偏相关如何用SPSS求相关系数1 用列联分析中,计算lamabda相关系数,在分析——描述分析——列联分析2 首先看两个变量是否是正态分布,如果是,则在analyze-correlate-bivariate中选择pearson相关系数,否则要选spearman相关系数或Kendall相关系数。
如果显著相关,输出结果会有*号显示,只要sig的P值大于0.05就是显著相关。
如果是负值则是负相关。
在SPSS软件相关分析中,pearson(皮尔逊), kendall(肯德尔) 和spearman(斯伯曼/斯皮尔曼)三种相关分析方法有什么异同两个连续变量间呈线性相关时,使用Pearson积差相关系数,不满足积差相关分析的适用条件时,使用Spearman秩相关系数来描述.Spearman相关系数又称秩相关系数,是利用两变量的秩次大小作线性相关分析,对原始变量的分布不作要求,属于非参数统计方法,适用范围要广些。
对于服从Pearson相关系数的数据亦可计算Spearman相关系数,但统计效能要低一些。
Pearson相关系数的计算公式可以完全套用Spearman相关系数计算公式,但公式中的x和y用相应的秩次代替即可。
Kendall's tau-b等级相关系数:用于反映分类变量相关性的指标,适用于两个分类变量均为有序分类的情况。
对相关的有序变量进行非参数相关检验; 取值范围在-1-1之间,此检验适合于正方形表格;计算积距pearson相关系数,连续性变量才可采用;计算Spearman秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据; 计算Kendall秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
谢谢观赏
WPS Office
Make Presentation much more fun
WPS官方微博 kingsoftwps
Thank you
5.点击约束弹出如下对话框, 选择定义参数约束,并按图 上填写之后点继续。
6.点击选项,进入选项的对话 框,默认值不需要修改,点 击继续。
7.点击确定,得出输 B=2459.396,C=-40.923。
9.函数方程为:lgP=13.7822459.396/(T-40.923)。
解:已知的函数不能用已知 的模型来拟合,所以我们得 输入函数,进而求解。
1.首先启动spss软件。 2.输入数据。(如下图)
3.依次点击:分析、回归、非 线性弹出如下窗口。
4.在因变量中输入“饱和蒸
汽压”,模型表达
式
中输入“EXP(A-B/(T+C))”。
点击“参数”,在名称中
输入“A”,在初始值中 输”0“,然后点击添加。依 次这样输入参数B、C。
用spss求函数参数
在具体的题目中,经常 会给你一组数据,并告诉你 该组数据满足的函数类型, 求函数的参数。
那么该如何求呢?现在 以一个例子说明。
例:正戊烷(C5H12)的饱和蒸
汽数据列于下表,试求饱和 蒸汽压P(KPa)与温度T(K)的 关系。(已知安托尼公式为 lgP=A-B/(T+C),假设该溶液 为理想溶液)