自增字段的SQL语句解决方案
sqlserver中如何实现自增字段?常用操作

sqlserver中如何实现⾃增字段?常⽤操作⽅法如下:例如:create table student(Sno int identity(1,1) primary key,Sname varchar(100))这样我们的Sno字段就可以实现⾃增了,第⼀个参数是标识种⼦(就是开始的值),第⼆个参数是标识增值(每次增加多少)这⾥我们开始为1,每次增加1如果做插⼊的话,则:insert into student values('李四')注意values⾥⾯不要写⾃增字段名的值,因为数据库会⾃动帮你⽣成。
例如第⼀⾏为 1 ⼩明insert into student values('李四')变为 1 ⼩明2 李四扩展资料:SQL Server:修改字段属性总结1:向表中添加字段Alter table [表名] add [列名] 类型2: 删除字段Alter table [表名] drop column [列名]3: 修改表中字段类型 (可以修改列的类型,是否为空)Alter table [表名] alter column [列名] 类型4:添加主键Alter table [表名] add constraint [ 约束名] primary key( [列名])5:添加唯⼀约束Alter table [表名] add constraint [ 约束名] unique([列名])6:添加表中某列的默认值Alter table [表名] add constraint [约束名] default(默认值) for [列名]7:添加约束Alter table [表名] add constraint [约束名] check (内容)8:添加外键约束Alter table [表名] add constraint [约束名] foreign key(列名) referencese 另⼀表名(列名)9:删除约束Alter table [表名] add constraint [约束名]10:重命名表exec sp_rename '[原表名]','[新表名]'11:重命名列名exec sp_rename '[表名].[列名]','[表名].[新列名]'。
SQL语句 自增长

Address varchar(255),
City varchar(255),
PRIMARY KEY ቤተ መጻሕፍቲ ባይዱP_Id)
)
MySQL 使用 AUTO_INCREMENT 关键字来执行 auto-increment 任务。
默认地,AUTO_INCREMENT 的开始值是 1,每条新纪录递增 1。
用于 MySQL 的语法
下列 SQL 语句把 "Persons" 表中的 "P_Id" 列定义为 auto-increment 主键:
CREATE TABLE Persons
(
P_Id int NOT NULL AUTO_INCREMENT,
LastName varchar(255) NOT NULL,
VALUES ('Bill','Gates')
上面的 SQL 语句会在 "Persons" 表中插入一条新纪录。"P_Id" 会被赋予一个唯一的值。"FirstName" 会被设置为 "Bill","LastName" 列会被设置为 "Gates"。
用于 SQL Server 的语法
下列 SQL 语句把 "Persons" 表中的 "P_Id" 列定义为 auto-increment 主键:
INSERT INTO Persons (P_Id,FirstName,LastName)
VALUES (seq_person.nextval,'Lars','Monsen')
SQL自增字段的修改

SQL自增字段的修改SQL⾃增字段的修改SQL2005中⾃增字段默认情况下是没法修改的那么在数据迁移中怎么解决⾃增字段修改的问题呢?在SQL中使⾃ IDENTITY_INSERT 开关允许将显式值插⾃表的标识列中。
IDENTITY_INSERT 开关起到的作⾃是打开⾃增字段标识列,允许插⾃数据例表book 有⾃增字段book_id 和 Book_name 两个字段插⾃数据⾃般是INSERT INTO book (Book_name)VALUES('testIdentity1')如果使⾃INSERT INTO book (book_id,Book_name)VALUES(1000,'testIdentity1')就会出错使⾃IDENTITY_INSERT 开关--打开IDENTITY_INSERTSET IDENTITY_INSERT testIdentity ON--"⾃增字段"已经可以插⾃⾃定义的编号了INSERT INTO book (book_id,Book_name)VALUES(1000,'testIdentity1')--关闭IDENTITY_INSERTSET IDENTITY_INSERT testIdentity OFF打开后⾃定要关闭,不然INSERT INTO book (Book_name)VALUES('testIdentity1')语句会出错上⾃只是插⾃,打开后是不能执⾃Update 的语句的,那么怎么修改呢?我采⾃的⾃法是先删除要修改的那条记录,然后插⾃--删除要修改的记录delete FROM book where book_id=10000--打开SET IDENTITY_INSERT dbo.book_info ON--查⾃⾃定义记录INSERT INTO book(book_id, book_name) VALUES(100,'testIdentity4')--关闭SET IDENTITY_INSERT dbo.book_info OFF。
sqlserver autoincrement -回复

sqlserver autoincrement -回复SQL Server是一种常用的关系型数据库管理系统,它提供了用于处理和存储数据的各种功能和工具。
在SQL Server中,自增字段(Auto Increment)是一种常用的特性,它可以为表中的每一行记录生成一个唯一的、递增的数字值。
在本文中,我们将深入探讨SQL Server中的自增字段,并详细讲解它的使用方法和注意事项。
# 第一部分:什么是自增字段?在关系型数据库中,每一个表都有一个主键(Primary Key)用于唯一标识每一条记录。
自增字段就是主键的一种实现方式,它可以自动为表中的每一行记录生成一个唯一的数字值,而不需要手动为每条记录指定一个值。
自增字段通常是一个整数类型的列,其值会在每次插入新记录时自动递增。
# 第二部分:SQL Server中的自增字段在SQL Server中,实现自增字段的最常用的方式是使用标识列(Identity Column)。
标识列是一种特殊类型的列,其值会自动递增,并且在每个表中只能有一个标识列。
使用标识列可以确保每一行记录都有一个唯一的标识,这对于确保数据完整性和查询性能都非常重要。
要在SQL Server中创建一个带有自增字段的表,可以使用以下的SQL语句:sqlCREATE TABLE 表名(列名数据类型IDENTITY(初始值, 增量) PRIMARY KEY)在上面的SQL语句中,`IDENTITY`关键字表示该列是一个标识列,括号中的参数`初始值`表示标识列开始时的值,`增量`表示每次递增的值。
`PRIMARY KEY`关键字是为了将该列设置为主键。
# 第三部分:自增字段的使用方法一旦在表中创建了自增字段,我们可以通过以下几种方式来使用它:1. 插入数据时不指定自增字段的值当我们向带有自增字段的表中插入新记录时,可以不指定自增字段的值。
SQL Server会自动为每一条记录生成一个唯一的、递增的值。
sqlserver autoincrement -回复

sqlserver autoincrement -回复SQL Server中的自动递增字段(autoincrement)是一个非常强大的功能,它可以自动为每一条新记录分配一个唯一的标识符。
这篇文章将一步一步地介绍如何使用SQL Server中的自动递增字段。
第一步:创建数据库表要使用自动递增字段,首先需要创建一个数据库表。
可以使用SQL Server Management Studio(SSMS)或者其他SQL Server管理工具来执行下面的SQL语句来创建表:CREATE TABLE Employees(EmployeeID INT PRIMARY KEY IDENTITY(1,1),FirstName NVARCHAR(50),LastName NVARCHAR(50),Email NVARCHAR(100))上面的SQL语句创建了一个名为Employees的表,其中包含了四个列:EmployeeID、FirstName、LastName和Email。
EmployeeID列是我们将使用自动递增字段的列。
第二步:插入记录一旦表创建完成,我们可以开始向表中插入记录。
通常情况下,我们不需要手动为EmployeeID列指定值,因为它将自动递增。
执行以下SQL语句来插入一条新的记录:INSERT INTO Employees (FirstName, LastName, Email) VALUES ('John', 'Doe', 'john.doeemail')上述语句插入了一条记录,其中FirstName列的值为'John',LastName 列的值为'Doe',Email列的值为'john.doeemail'。
EmployeeID列的值会自动递增。
第三步:查询记录查询记录时,我们可以看到自动递增字段已经按照指定的规则递增了。
sqlserver autoincrement -回复

sqlserver autoincrement -回复Sql Server中的自增字段(Auto Increment)是一种非常常见和有用的功能,它在数据库中自动分配唯一值给每条记录的特定字段。
本文将以"[Sql Server Auto Increment]"为主题,一步一步回答有关自增字段的相关问题。
首先,让我们从自增字段的概念开始。
自增字段是数据库中一列的属性,该属性允许自动分配唯一的、递增的整数值给每条记录。
这意味着当插入新记录时,数据库引擎会自动为这个字段生成一个唯一的值,无需用户手动输入。
在Sql Server中,创建自增字段有多种方法。
我们将逐一讨论这些方法,以加深对它们的理解。
第一种方法是使用"IDENTITY"属性。
IDENTITY属性可与整数类型的列一起使用,如INT、BIGINT等。
它的语法如下:sqlCREATE TABLE table_name(column_name data_type PRIMARY KEY IDENTITY);在上述语法中,"column_name"表示你想要设为自增的列的名称,"data_type"表示列的数据类型,"table_name"表示你希望创建的表的名称。
通过将IDENTITY属性与PRIMARY KEY属性一起使用,我们能够让自增字段成为表的主键。
第二种方法是使用"SEQUENCE"对象。
SEQUENCE对象允许我们创建一个序列,它可以生成一连串的唯一整数值。
创建SEQUENCE对象的语法如下:sqlCREATE SEQUENCE sequence_nameAS data_typeSTART WITH start_valueINCREMENT BY increment_value[ MINVALUE { value NO MINVALUE } ][ MAXVALUE { value NO MAXVALUE } ][ CYCLE NO CYCLE ];在上述语法中,"sequence_name"表示你希望创建的序列的名称,"data_type"表示序列的数据类型,"start_value"表示序列的起始值,"increment_value"表示序列的增量值。
sql自增号

sql⾃增号1: ⾃增列类型为:int identity(1,1) 当然也可以是bigint,smallinteg: create table tbName(id int identity(1,1),description varchar(20))或在⽤企业管理器设计表字段时,将字段设为int,将标识设为是,其它⽤默认即可2: 查询时加序号:a:没有主键的情形:Select identity(int,1,1) as iid,* into #tmp from TableNameSelect * from #tmpDrop table #tmpb:有主键的情形:Select (Select sum(1) from TableName where KeyField <= a.KeyField) as iid,* from TableName a3:⽣成⾃增序列号的表eg: ⽣成⼀列0-30的数Select top 30 (select sum(1) from sysobjects where name<= )-1 as id from sysobjects a 当然,可能sysobjects 中没有这么多条记录,⽐如只有100条,我需⽣成1-800的序列号如下处理:Select (Select sum(1) from (Select top 800 as name1, as name2 from sysobjects a ,sysobjects b) cc where name1<= 1 and name2 <= 2 ) from(Select top 800 as name1, as name2 from sysobjects a ,sysobjects b) dd应⽤举例eg1:create table t(⽇期 char(8),请假⼈数 int)insert t select '20031001',3Union all select '20031003',2Union all select '20031004',1Union all select '30031031',5要列出2003年10⽉每⼀天的请假⼈数,若没有,以0表⽰。
mysql 数据库自增id 的总结

mysql 数据库自增id 的总结有一个表StuInfo,里面只有两列StuID,StuName其中StuID是int型,主键,自增列。
现在我要插入数据,让他自动的向上增长,insert into StuInfo(StuID,StuName) values(????) 如何写?INSERT INTO StuInfo(StuID,StuName) V ALUES (NULL, `字符`)或者INSERT INTO StuInfo(StuName) V ALUES (`字符`)INSERT和REPLACE语句的功能都是向表中插入新的数据。
这两条语句的语法类似。
它们的主要区别是如何处理重复的数据。
1INSERT的一般用法MySQL中的INSERT语句和标准的INSERT不太一样,在标准的SQL语句中,一次插入一条记录的INSERT语句只有一种形式。
INSERT INTO tablename(列名…) V ALUES(列值);而在MySQL中还有另外一种形式。
INSERT INTO tablename SET column_name1 = value1, column_name2 = value2,…;第一种方法将列名和列值分开了,在使用时,列名必须和列值的数一致。
如下面的语句向users表中插入了一条记录:INSERT INTO users(id, name, age) V ALUES(123, '姚明', 25);第二种方法允许列名和列值成对出现和使用,如下面的语句将产生中样的效果。
INSERT INTO users SET id = 123, name = '姚明', age = 25;如果使用了SET方式,必须至少为一列赋值。
如果某一个字段使用了省缺值(如默认或自增值),这两种方法都可以省略这些字段。
如id字段上使用了自增值,上面两条语句可以写成如下形式:INSERT INTO users (name, age) V ALUES('姚明',25);INSERT INTO uses SET name = '姚明', age = 25;MySQL在V ALUES上也做了些变化。
Sql 主键自增

Sql 主键自增环境:SQL Server 2008 问题:设置主键和把它设为自增。
环境:SQL Server 2008问题:设置主键和把它设为自增。
解决:点击table->选中表->design->选中需要设置主键的字段,单击右键"设置主键"即可。
若要设置主键自增,在列属性中找到标识规范,单击左边的"+"号,把否改为是,其他默认即可。
create table tableName(id int identity(1,1) primary key,data varchar(50))/*identity(1,1)就是自动增加,第一个参数是种子值,第二个是增量值;primary key是主键*/Insert into tableName values('aaaaa');就会自动在数据表中自增添加主键值。
注意:如果主键没有设置为自增那么这条语句将无法执行,会提示:服务器: 消息213,级别16,状态4,行 1插入错误: 列名或所提供值的数目与表定义不匹配。
当然,这样写插入语句是一个很不好的习惯,因为一旦有一天主键自增因为临时原因被取消掉,则插入语句将同时跟着失效。
正确的写法应该是:INSERT INTO tableName (data) VALUES('somedata');另外如果tableName 已经开启了主键自增,那么下面的语句将执行不了:INSERT INTO tableName (id ,data) VALUES(1,'TETS');服务器: 消息544,级别16,状态1,行 1当IDENTITY_INSERT 设置为OFF 时,不能向表'withoutIdentity' 中的标识列插入显式值。
如果需要向自增主键写入数据,可以先将自增约束取消,然后写入数据,再将自增约束加上。
sql语句中添加自定义字段的方法

sql语句中添加自定义字段的方法### SQL语句中添加自定义字段的方法在SQL(Structured Query Language)的使用过程中,我们有时需要动态地向查询结果中添加自定义字段,以便于处理复杂的报表或者满足特定的数据处理需求。
自定义字段通常用于存储计算结果或者创建新的数据组合。
以下是几种在SQL语句中添加自定义字段的方法。
#### 1.`AS`关键字最常见的方式是使用`AS`关键字为查询结果中的某个字段或表达式指定一个别名。
```sqlSELECTcolumn1,column2,column1 + column2 AS custom_fieldFROMyour_table;```在这个例子中,`custom_field`是一个自定义字段,它包含了`column1`和`column2`的和。
#### 2.使用`CASE`语句`CASE`语句允许根据条件逻辑为字段赋予不同的值。
```sqlSELECTcolumn1,CASEWHEN condition THEN "value1"ELSE "value2"END AS custom_fieldFROMyour_table;```在这个例子中,根据`condition`的满足与否,`custom_field`字段会有不同的值。
#### 3.字符串拼接如果你需要创建一个新的字符串字段,可以使用字符串拼接。
```sqlSELECTcolumn1,CONCAT(column2, " ", column3) AS custom_fieldFROMyour_table;````CONCAT`函数将`column2`和`column3`的值拼接起来,并在它们之间插入一个空格。
#### 4.计算字段可以使用各种数学函数来创建计算字段。
```sqlSELECTcolumn1,AVG(column2) AS average_valueFROMyour_tableGROUP BYcolumn1;```在这个例子中,`average_value`是一个自定义字段,它计算了`column1`分组下`column2`的平均值。
解决postgresql自增id作为key重复的问题
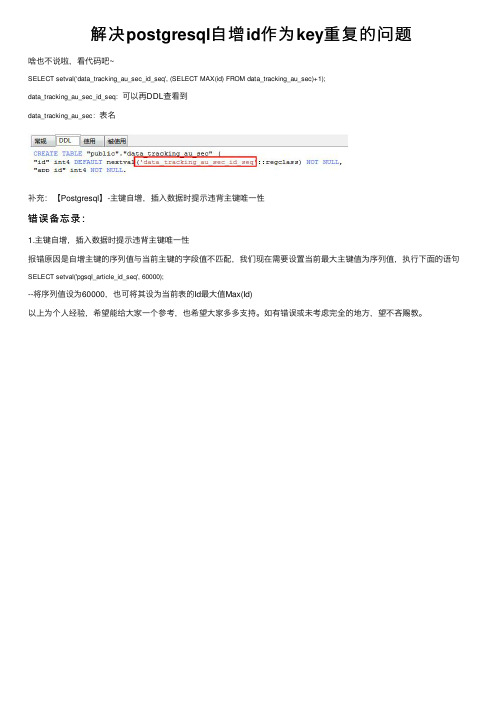
解决 postgresql自增 id作为 key重复的问题
啥也不说啦,看代码吧~
SELECT setval(‘data_tracking_au_sec_id_seq', (SELECT MAX(id) FROM data_tracking_au_sec)+1);
SELECT setval('pgsql_article_id_seq', 000);
--将序列值设为60000,也可将其设为当前表的Id最大值Max(Id) 以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。
data_tracking_au_sec_id_seq:可以再DDL查看到 data_tracking_au_sec:表名
补充:【Postgresql】-主键自增,插入数据时提示违背主键唯一性
错误备忘录:
1.主键自增,插入数据时提示违背主键唯一性 报错原因是自增主键的序列值与当前主键的字段值不匹配,我们现在需要设置当前最大主键值为序列值,执行下面的语句
SQLinsertinto语句写法讲解

SQLinsertinto语句写法讲解⽅式1、 INSERT INTO t1(field1,field2) VALUE(v001,v002);明确只插⼊⼀条Value⽅式2、 INSERT INTO t1(field1,field2) VALUES(v101,v102),(v201,v202),(v301,v302),(v401,v402);在插⼊批量数据时⽅式2 优于⽅式1.【特注】当 id 为⾃增,即 id INT PRIMARY KEY AUTO_INCREMENT 时,执⾏ insert into 语句,需要将除 id 外的所有 field 列举出来(有没有感觉,好不⽅便,期待 mysql 提供⼀个简便⽅法来标记这种情况,因为在早测试数据的时候,普遍会使⽤,⽽列举出除 id 外所有字段,真有⿇烦感)。
⽅式3.1、 INSERT INTO t2(field1,field2) SELECT colm1,colm2 FROM t1 WHERE ……这⾥简单说⼀下,由于可以指定插⼊到 talbe2 中的列,以及可以通过相对较复杂的查询语句进⾏数据源获取,可能使⽤起来会更加的灵活⼀些,但我们也必须注意,我们在指定⽬标表的列时,⼀定要将所有⾮空列都填上,否则将⽆法进⾏数据插⼊,还有⼀点⽐较容易出错的地⽅就是,当我们写成如下简写格式:⽅式3.2、 INSERT INTO t2 SELECT colm1,colm2,…… FROM t1此时,我们如果略掉了⽬标表的列的话,则默认会对⽬标表的全部列进⾏数据插⼊,且 SELECT 后⾯的列的顺序必须和⽬标表中的列的定义顺序完全⼀致才能完成正确的数据插⼊,这是⼀个很容易被忽略的地⽅,值得注意。
【特注】由于插⼊操作只粗略地对表 t1、t2 按顺序对所有字段进⾏ [数据类型] 检查,不对 [字段名] 核对。
这是把双刃剑,既提供便利,⼜存在可能因粗⼼造成风险。
在使⽤中,需确认顺序,使⽤中建议使⽤ [⽅式3.1] 或 [⽅式4].⽅式4、INSERT INTO 表名 SET 列名1 = 列值1,列名2=列值2,...;不过⽤INSERT INTO SET这种⽅式,不能批量增加数据。
SQL SERVER 如何处理带字母的自增列

--需求说明: /* id col
---------- ---------AB00001 AB00002 a b
--当再插入数据的时候让 id 自动变成 AB00003 */
10. --1.求最大值法(高并发时不适用,只是介绍个思路) 11. --测试数据 12. 13. if object_id('[macotb]') is not null 14. drop table [macotb] 15. create table [macotb] (id varchar(7),col varchar(1)) 16. insert into [macotb] 17. select 'AB00001','a' union all 18. select 'AB00002','b' 19. 20. declare @max varchar(7) 21. select @max='AB'+right('00000'+ltrim(max(replace(id,'AB','')+1)),5) from [macotb] 22. insert into [macotb] select @max,'c' 23. 24. select * from [macotb] 25. /* 26. id col
71. ------------ ---72. AB00001 73. AB00002 74. */ 75. 76. insert into [macotb](col) select 'c' union all select 'd' 77. select id,col from [macotb] 78. /* 79. id col a b
SQLServer设置主键自增长列(使用sql语句实现)

create table tb(id int identity(1,1),constrainb(id int identity(1,1) primary key )
主键自增长列在进行数据插入的时候很有用的如可以获取返回的自增id值接下来将介绍sqlserver如何设置主键自增长列感兴趣的朋友可以了解下希望本文对你有所帮助
SQLServer设置主键自增长列(使用 sql语句实现)
1.新建一数据表,里面有字段id,将id设为为主键 复制代码 代码如下:
create table tb(id int,constraint pkid primary key (id)) create table tb(id int primary key )
3.已经建好一数据表,里面有字段id,将id设为主键 复制代码 代码如下:
alter table tb alter column id int not null alter table tb add constraint pkid primary key (id)
4.删除主键 复制代码 代码如下:
Declare @Pk varChar(100); Select @Pk=Name from sysobjects where Parent_Obj=OBJECT_ID('tb') and xtype='PK'; if @Pk is not null exec('Alter table tb Drop '+ @Pk)
pythonmysql自增字段AUTO_INCREMENT值的修改方式
pythonmysql⾃增字段AUTO_INCREMENT值的修改⽅式在之前得⽂章中我们说过,如果使⽤delete对数据库中得表进⾏删除,那么只是把记录删除掉,并且id的值还会保持上次的状态。
即删除之前如果有四条数据,删除之后,再添加新的数据,id怎会从5开始。
但是我们显⽰想让id从2开始,应该怎么做呢?这个时候我们就要学习去修改数据表的⼀些属性值了,⽽这个属性值就是AUTO_INCREMENT。
⾸先我们要知道怎么查看这个属性的值。
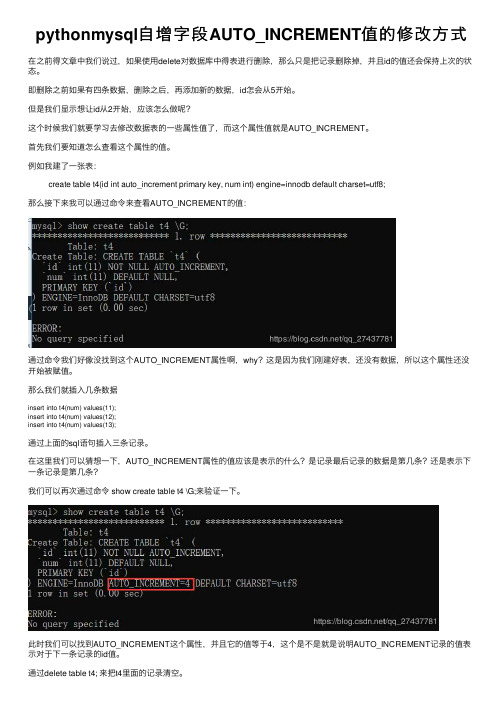
例如我建了⼀张表:create table t4(id int auto_increment primary key, num int) engine=innodb default charset=utf8;那么接下来我可以通过命令来查看AUTO_INCREMENT的值:通过命令我们好像没找到这个AUTO_INCREMENT属性啊,why?这是因为我们刚建好表,还没有数据,所以这个属性还没开始被赋值。
那么我们就插⼊⼏条数据insert into t4(num) values(11);insert into t4(num) values(12);insert into t4(num) values(13);通过上⾯的sql语句插⼊三条记录。
在这⾥我们可以猜想⼀下,AUTO_INCREMENT属性的值应该是表⽰的什么?是记录最后记录的数据是第⼏条?还是表⽰下⼀条记录是第⼏条?我们可以再次通过命令 show create table t4 \G;来验证⼀下。
此时我们可以找到AUTO_INCREMENT这个属性,并且它的值等于4,这个是不是就是说明AUTO_INCREMENT记录的值表⽰对于下⼀条记录的id值。
通过delete table t4; 来把t4⾥⾯的记录清空。
然后再调⽤show create table t4 \G;命令可以发现表的信息并没有因为表⾥的信息被删除⽽改变,这样的话,我们要是想让添加的数据id从2开始不就会不⾏了吗?but,我们可以修改表的信息。
自增字段的SQL语句解决方案

自增字段的SQL语句解决方案.txt不要放弃自己! -------(妈妈曾经这样对我说,转身出门的一刹那,我泪流满面,却不想让任何人看见!)看到这一句小编也心有感触,想起当初离家前往几千里外的地方的时候,妈妈也说过类似的话,但是身为男儿,必须创出一片天,才能报答父母的养育之恩!!create table [表名] ([自动编号字段] int IDENTITY (1,1) PRIMARY KEY ,[字段1] nVarChar(50) default '默认值' null ,[字段2] ntext null ,[字段3] datetime,[字段4] money null ,[字段5] int default 0,[字段6] Decimal (12,4) default 0,[字段7] image null ,)删除表:Drop table [表名]插入数据:INSERT INTO [表名] (字段1,字段2) VALUES (100,'')删除数据:DELETE FROM [表名] WHERE [字段名]>100更新数据:UPDATE [表名] SET [字段1] = 200,[字段2] = '' WHERE [字段三] = 'HAIWA' 新增字段:ALTER TABLE [表名] ADD [字段名] NVARCHAR (50) NULL删除字段:ALTER TABLE [表名] DROP COLUMN [字段名]修改字段:ALTER TABLE [表名] ALTER COLUMN [字段名] NVARCHAR (50) NULL重命名表:(Access 重命名表,请参考文章:在Access数据库中重命名表)sp_rename '表名', '新表名', 'OBJECT'新建约束:ALTER TABLE [表名] ADD CONSTRAINT 约束名 CHECK ([约束字段] <= '2000-1-1')删除约束:ALTER TABLE [表名] DROP CONSTRAINT 约束名新建默认值ALTER TABLE [表名] ADD CONSTRAINT 默认值名 DEFAULT '' FOR [字段名] 删除默认值ALTER TABLE [表名] DROP CONSTRAINT 默认值名删除Sql Server 中的日志,减小数据库文件大小dump transaction 数据库名 with no_logbackup log 数据库名 with no_logdbcc shrinkdatabase(数据库名)exec sp_dboption '数据库名', 'autoshrink', 'true'自增列不能直接修改,必须将原有ID列删除,然后重新添加一列具有identity属性的ID 字段,语句如下alter table 表名drop column IDalter table 表名add ID int identity(1,1)修改日期字段为Datatime类型,首先要保证表中无数据,或现有数据可以直接转换为datetime类型,否则修改字段类型就会失败。
数据库自增字段解决方案

Oracle序列:是Oracle提供的用于产生一系列唯一数字的数据库对象。
其作用在于:1、自动提供唯一的数值;2、共享对象;3、主要用于提供主键值在Oracle数据库中创建序列需要一定的权限create sequence 或create any sequence创建语法:序列在下列情况下会出现裂缝:1、回滚;2、系统异常修改序列:语法与创建一致,将CREATE更换为ALTER修改序列的注意事项:1、必须是序列的拥有者或者对序列具有ALTER权限才能进行修改2、只有将来的序列值会被改变,对已有的序列值不会影响3、改变序列的初始值只能通过删除序列之后重建序列的方法实现删除序列:使用DROP SEQUENCE语句删除在hibernate中可以使用seqhilo和sequence两种形式实现使用序列生成ID,需要先在数据库中创建sequence才行。
MySQLMySQL自增列使用auto_increment标识字段达到自增,在创建表时将某一列定义为auto_increment,则该列为自增列。
PS:指定了auto_increment的列必须要建立索引AUTO_INCREMENT说明:1、如果把一个NULL插入到一个AUTO_INCREMENT数据列里去,MySQL将自动生成下一个序列编号。
编号从1开始,并1为基数递增。
2、把0插入AUTO_INCREMENT数据列的效果与插入NULL值一样。
但不建议这样做。
3、当插入记录时,没有为AUTO_INCREMENT明确指定值,则等同插入NULL值。
4、当插入记录时,如果为AUTO_INCREMENT数据列明确指定了一个数值,则会出现两种情况,情况一,如果插入的值与已有的编号重复,则会出现出错信息,因为AUTO_INCREMENT 数据列的值必须是唯一的;情况二,如果插入的值大于已编号的值,则会把该插入到数据列中,并使在下一个编号将从这个新值开始递增。
也就是说,可以跳过一些编号。
SQL Server设置主键自增

3.已经建好一数据表,里面有字段id,将id设为主键
alter table tb alter column id int not null
alter table tb add constraint pkid primary key (id)
SQL Server设置主键自增长列(使用sql语句实现)
主键自增长列在进行数据插入的时候,很有用的,如可以获取返回的自增ID值,接下来将介绍SQL Server如何设置主键自增长列,感兴趣的朋友可以了解下,希 代码如下
4.删除主键
Declare @Pk varChar(100);
Select @Pk=Name from sysobjects where Parent_Obj=OBJECT_ID('tb') and xtype='PK';
if @Pk is not null
exec('Alter table tb Drop '+ @Pk)
create table tb(id int,constraint pkid primary key (id))
create table tb(id int primary key )
2.新建一数据表,里面有字段id,将id设为主键且自动编号
create table tb(id int identity(1,1),constraint pkid primary key (id))
使用sql语句创建修改SQLServer标识列(即自动增长列)

使⽤sql语句创建修改SQLServer标识列(即⾃动增长列)⼀、标识列的定义以及特点SQL Server中的标识列⼜称标识符列,习惯上⼜叫⾃增列。
该种列具有以下三种特点:1、列的数据类型为不带⼩数的数值类型2、在进⾏插⼊(Insert)操作时,该列的值是由系统按⼀定规律⽣成,不允许空值3、列值不重复,具有标识表中每⼀⾏的作⽤,每个表只能有⼀个标识列。
由于以上特点,使得标识列在数据库的设计中得到⼴泛的使⽤。
⼆、标识列的组成创建⼀个标识列,通常要指定三个内容:1、类型(type)在SQL Server 2000中,标识列类型必须是数值类型,如下:decimal、int、numeric、smallint、bigint 、tinyint其中要注意的是,当选择decimal和numeric时,⼩数位数必须为零另外还要注意每种数据类型所有表⽰的数值范围2、种⼦(seed)是指派给表中第⼀⾏的值,默认为13、递增量(increment)相邻两个标识值之间的增量,默认为1。
三、标识列的创建与修改标识列的创建与修改,通常在企业管理器和⽤Transact-SQL语句都可实现,使⽤企业管理管理器⽐较简单,请参考SQL Server的联机帮助,这⾥只讨论使⽤Transact-SQL的⽅法1、创建表时指定标识列标识列可⽤ IDENTITY 属性建⽴,因此在SQL Server中,⼜称标识列为具有IDENTITY属性的列或IDENTITY列。
下⾯的例⼦创建⼀个包含名为ID,类型为int,种⼦为1,递增量为1的标识列CREATE TABLE T_test(ID int IDENTITY(1,1),Name varchar(50))2、在现有表中添加标识列下⾯的例⼦向表T_test中添加⼀个名为ID,类型为int,种⼦为1,递增量为1的标识列--创建表CREATE TABLE T_test(Name varchar(50))--插⼊数据INSERT T_test(Name) VALUES('张三')--增加标识列ALTER TABLE T_testADD ID int IDENTITY(1,1)3、判段⼀个表是否具有标识列可以使⽤ OBJECTPROPERTY 函数确定⼀个表是否具有 IDENTITY(标识)列,⽤法:Select OBJECTPROPERTY(OBJECT_ID('表名'),'TableHasIdentity')如果有,则返回1,否则返回04、判断某列是否是标识列可使⽤ COLUMNPROPERTY 函数确定某列是否具有IDENTITY 属性,⽤法SELECT COLUMNPROPERTY( OBJECT_ID('表名'),'列名','IsIdentity')如果该列为标识列,则返回1,否则返回04、查询某表标识列的列名SQL Server中没有现成的函数实现此功能,实现的SQL语句如下SELECT COLUMN_NAME FROM INFORMATION_SCHEMA.columnsWHERE TABLE_NAME='表名' AND COLUMNPROPERTY(OBJECT_ID('表名'),COLUMN_NAME,'IsIdentity')=15、标识列的引⽤如果在SQL语句中引⽤标识列,可⽤关键字IDENTITYCOL代替例如,若要查询上例中ID等于1的⾏,以下两条查询语句是等价的SELECT * FROM T_test WHERE IDENTITYCOL=1SELECT * FROM T_test WHERE ID=16、获取标识列的种⼦值可使⽤函数IDENT_SEED,⽤法:SELECT IDENT_SEED ('表名')7、获取标识列的递增量可使⽤函数IDENT_INCR ,⽤法:SELECT IDENT_INCR('表名')8、获取指定表中最后⽣成的标识值可使⽤函数IDENT_CURRENT,⽤法:SELECT IDENT_CURRENT('表名')注意事项:当包含标识列的表刚刚创建,为经过任何插⼊操作时,使⽤IDENT_CURRENT函数得到的值为标识列的种⼦值,这⼀点在开发数据库应⽤程序的时候尤其应该注意。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
37,一个日期格式转换的例子,一般可以用convert,cast等函数转换,但是这个例子没有:
declare @a varchar(50)
declare @b varchar(50)
declare @c int
declare @d varchar(50)
declare @e varchar(50)
11,可以通过多次安装sqlserver为其创建多个实例
12,用系统过程 sp_reZGXX_XM 重新命名表和列:
sp_reZGXX_XM 原表名,新表名
sp_reZGXX_XM "表名.原列名",新列名
13,如果想显示的在identity列中插入值,则需要先设置:set identity_insert 表名 on
新建约束:
ALTER TABLE [表名] ADD CONSTRAINT 约束名 CHECK ([约束字段] <= '2000-1-1')
删除约束:
ALTER TABLE [表名] DROP CONSTRAINT 约束名
新建默认值
ALTER TABLE [表名] ADD CONSTRAINT 默认值名 DEFAULT '' FOR [字段名]
36,创建一个返回一张表的函数:
create function fn_Tree(@Id int)
returns table @tb (id int ,fid int)
as
begin
insert @tb select id,fid from tablename where fid=@id
exec sp_dboption '数据库名', 'autoshrink', 'true'
自增列不能直接修改,必须将原有ID列删除,然后重新添加一列具有identity属性的ID字段,语句如下
alter table 表名
drop column ID
alter table 表名
add ID int identity(1,1)
删除字段:
ALTER TABLE [表名] DROP COLUMN [字段名]
修改字段:
ALTER TABLE [表名] ALTER COLUMN [字段名] NVARCHAR (50) NULL
重命名表:(Access 重命名表,请参考文章:在Access数据库中重命名表)
sp_rename '表名', '新表名', 'OBJECT'
35,为变量赋值方法:set @xxx=??? ,如果变量的值取自一个查询的话,需要用select, 如:select @xxx=??? from ??? where ????
如果要返回一个记录集,但是不是从一个表格,而是全部是系统变量或自定义变量组成。则不必写from子句:select ??,??,??
24,如果group by 子句中用了all,即 group by all xxx ,则不符合检索条件的记录也显示,但不参与统计。
25,having 中,只能包含 group by子句中 指定的列,也可以包含统计函数。where中可指定任何列,但是不能用统计函数
26, having 子句从最终结果中将不满足该条件的分组去掉
插入完毕后最好设置:set identity_insert 表名 off
14, 利用writetext往text 或 image列中写入值:
declare @var varbinary(16)
select @var=textptr(c) from test where a=10
writetext test.c @var 'zhongguo '
删除数据:
DELETE FROM [表名] WHERE [字段名]>100
更新数据:
UPDATE [表名] SET [字段1] = 200,[字段2] = '' WHERE [字段三] = 'HAIWA'
新增字段:
ALTER TABLE [表名] ADD [字段名] NVARCHAR (50) NULL
删除默认值
ALTER TABLE [表名] DROP CONSTRAINT 默认值名
删除Sql Server 中的日志,减小数据库文件大小
dump transaction 数据库名 with no_log
backup log 数据库名 with no_log
dbcc shrinkdatabase(数据库名)
注意:使用Writetext,一般需要首先这样设置:sp_dboption 数据库名,'SELECT into/bulkcopy',true
15, truncate table 表名 删除表格的所有数据,速度很快。
16,统计函数中除了count(*) 之外,都忽略空值(null).
17, 由于text和image类型数据很长,在查询之前可以通过设置全局变量textsize来指定返回数据的长度,set textsize 50
29,在进行union运算时,自动删除结果中的重复行,如果使用all选项 ,则可以将所有行显示在结果中:union all
30, 在union时,合并结果集中的列名有第一个查询给出,所以后面进行排旬时一定要注意order by 子句中的字段名
31,可以通过 select fieldslist into 新表名 from 表名,来创建一个新表,并将当前表中的数据全部插入到新
create table [表名]
(
[自动编号字段] int IDENTITY (1,1) PRIMARY KEY ,
[字段1] nVarChar(50) default '默认值' null ,
[字段2] ntext null ,
[字段3] datetime,
[字段4] money null ,
3, object_id('对象名') 返回该对象名对应的Id,该id存储在sysobjects表中。
4, 建表时自动建立主键约束:create table a(b char(4),c int,constraint 主键名 primary key(c))
或者:create table a(a char(4) cint primary key) 或者:create table a(a char(4) cint constraint 主键名 primary key)
and id not in (select id from @tb)
return
end
表的字段为id,fid
insert @tb select 语句,将查询结果插入到当前的表格(@tb)中
调用:
select * from dbo.fn_Tree(0)
go
select * from dbo.fn_Tree(1
8, 局部临时表 #xxx ,只能被当前会话访问,在该会话结束后自动消失。
9, 全局临时表 ##xx , 可以供多个用户使用,在该会话结束后自动消失。
10,为表 添加/修改/删除列 :alter table 表名 add 列名 type/alter column 列名 newtype/drop 列名
如果想查阅全局变量textsize的值:select @@textsize
18, 通过reaDtext 读取text的数据:
declare @var varbinary(16)
select @var=textptr(c) from test where a=10
readtext test.c @var 4 3
27,不带group by子句时也可以使用having子句,并将整个查询结果作为一个组,但是,由于出现在选择列表中的列
和出现在having子句中的列必须是group by 子句中的列,所以,当不带group by子句时,不能在having子句和
选择列表中直接使用列名,只能使用统计函数。
28,当在group by子句后指定order by子句时,只能在order by子句中指定group by子句中的列或者统计函数
修改日期字段为Datatime类型,首先要保证表中无数据,或现有数据可以直接转换为datetime类型,否则修改字段类型就会失败。
alter table 表名
alter column 日期字段名 datetime
1, 使用一个数据库之前要引用他:use 数据库名
2, exists()判断子查询的结果#39;1/20/03 10:06:41:59'
33,创建唯一约束:create table a(b int not nul constraint 约束名 unique,c char(10) null)
或者:create table a(b int,c char(10),constraint 约束名 unique(b))
34,在sql server表格选定一个单元格,ctrl+0即可将单元格的值置为null
use 数据库a名
checkpoint /*使设置结果生效*/
如果要将统计结果或者计算结果插入到新表中,必须以标题的形式给出列名,如:
select a,b=avg(c) into mm from nn group by a
32, 随即取出N条记录的方法:select top N * from 表名 order by newid()