Understanding MS-SQL Xml Capabilities By Example
mysql分析(二)mysql语法分析

/* Symbols are broken into separated arrays to allow field names with same name as functions. These are kept sorted for human lookup (the symbols are hashed).
| verb_clause { Lex_input_stream *lip = YYLIP;
if ((YYTHD->client_capabilities & CLIENT_MULTI_QUERIES) && lip->multi_statements && ! lip->eof())
{ /* We found a well formed query, and multi queries are allowed: - force the parser to stop after the ';'
lex->many_values.push_back(lex->insert_list)) MYSQL_YYABORT; } ident_eq_list ;
fields: fields ',' insert_ident { Lex->field_list.push_back($3); }
| insert_ident { Lex->field_list.push_back($1); } ;
四、查询指令开始
query: END_OF_INPUT { THD *thd= YYTHD; if (!thd->bootstrap && (!(thd->lex->select_lex.options & OPTION_FOUND_COMMENT))) { my_message(ER_EMPTY_QUERY, ER(ER_EMPTY_QUERY), MYF(0)); MYSQL_YYABORT; } thd->lex->sql_command= SQLCOM_EMPTY_QUERY; YYLIP->found_semicolon= NULL; }
ogc wmts xml写法

OGC WMTS(Open Geospatial Consortium Web Map Tile Service)是一种用于发布地图瓦片的开放标准,并且它采用XML语法来描述地图服务的元数据。
在使用WMTS服务时,了解其XML写法是非常重要的,本文将介绍OGC WMTS XML的写法,并且按照以下内容进行详细说明:一、WMTS Capabilities文档的XML写法WMTS Capabilities文档是WMTS服务的元数据描述文档,它用于描述WMTS服务的基本信息、地图瓦片的URL模板、地图瓦片的坐标系、瓦片集合等重要信息。
以下是WMTS Capabilities文档的XML 写法示例:```xml<WMT_MS_Capabilities><!-- 标识WMTS服务的语言 --><Language>zh-CN</Language><!-- 描述WMTS服务的元数据信息 --><Service><Title>WMTS服务演示</Title><Abstract>这是一个WMTS服务的演示文档</Abstract><OnlineResource xlink:type="simple"xlink:href="xxx"/><!-- 描述WMTS服务支持的地图瓦片集合信息 --><Contents><Layer><Title>地图瓦片集合1</Title><Identifier>TileSet1</Identifier><Abstract>这是地图瓦片集合1的描述信息</Abstract> <WGS84BoundingBox>...</WGS84BoundingBox> <Style><Title>默认样式</Title><Identifier>default</Identifier><LegendURL>...</LegendURL></Style><TileMatrixSetLink><TileMatrixSet>EPSG:4326</TileMatrixSet></TileMatrixSetLink></Layer>...</Contents><!-- 描述WMTS服务支持的地图瓦片样式信息 --><Contents><Title>默认样式</Title><Identifier>default</Identifier><LegendURL>...</LegendURL></Style>...</Contents></WMT_MS_Capabilities>```以上是WMTS Capabilities文档的XML写法示例,其中包括了WMTS服务的基本信息、地图瓦片集合信息、地图瓦片样式信息等关键内容,可以帮助用户了解WMTS服务的基本情况。
Oracle Enterprise Manager 13c Microsoft SQL Server

Oracle Enterprise Manager 13c Microsoft SQL Server Plug-in version 12.1.0.6April, 2016Heterogeneous Datacenter Management Oracle’s Philosophy•Productize our deep understanding of the Oracle stack to provide integrated management•Provide generic Oracle solutions for managing non- Oracle technology–User Experience Management, Middleware Management, BusinessTransaction Management, Testing & T est Data Management , …•Incent and promote others to provide optimized management for non-Oracle technology•Provide product extensibility wherever possible(today’s focus: Plug-In for SQL Server)Third Party Plug-insOracle Plug-insEvent and Service Desk ConnectorsEnterprise Manager 13c Heterogeneous ManagementMaking The Complex Simple In 3 Steps1. Use or create plug-ins using Enterprise Ready Extensible Framework2.Leverage common functions through plug-ins•Performance & Availability Monitoring •Configuration Management •Compliance Management •Job System•Alerting & Notifications •Custom UI •Reporting3. Manage like any other targetMicrosoft SQL Server Plug-in Revamped for Better Analysis and Management New! features•Indexes Page•“Backup all Databases” and“DifferentialBackup” Jobs•Migrated Information Publisher Reports toBusiness Intelligence Publisher Reports•Added Chargeback Functionality•Enabled more Metric Thresholds•Out of the Box, SQL Server ComplianceStandard Template•“Mirroring Statistics” Metricsand more!Plug-in s: Where do you get them? Self Update: Oracle Provided Content▪Self Update▪Download MS SQL Server plug-in directly from Self Update▪Delivers new features andupdates▪Single console to search,download and manage targetplug-ins▪Proactive notification for Oraclesupplied updates if running inconnected mode▪Supports Online & OfflinemodesPlug-In ManagerSingle window Solution for all (Un)Deployment▪Integrated with Self Update▪Plug-ins must bedeployed to OMSbefore agents▪Download, Deploy andUpgrade Plug-Insacross OMS and agentMicrosoft SQL Server Plug-in Features•MS SQL Server as EM Managed Target •Comprehensive collection of monitoring Metrics (~ 400)–Buffer Statistics, Memory Statistics, CacheStatistics–Locks, Processes, Space Usage–Users and Roles–Cluster and AlwaysOn performance and status •Out-of-box thresholds on key metrics•12 Out of the box Reports summarize key configuration and performance data •Comprehensive configuration management –Server Configuration, Database Settings,Registry and Security Settings–Ability to View, Search and Compareconfigurations•Ability to schedule Jobs•Ability to Start/Stop/Pause/Resume SQL Server Instances•Jobs to create, schedule, delete, and restore database backups•Versions supported:–SQL Server 2005, 2008, 2012, and 2014New Intuitive Dashboards •Revamped for Better Analysis and Management•Includes intuitive interface for creating and managing databasebackups•Exposes even more keyperformance indicators, down tothe individual database level•Adds additional Indexes page with advanced investigative andmanagement capabilitiesSQL Server Focused Dashboard Views •View Database server as well asindividual database instancehealth and availability•Individual database status andstatistics with linking to additionaldetails and management•Key health, performance, andavailability views•Cluster and AlwaysOn availabilityand healthInstance-level Database Monitoring Monitor MS SQL databases at theinstance level•Database status and storagemeasurements•In-depth performance metricsDrill into SQL Server Session and Query Statistics •View session statistics by memoryutilization and CPU time•Break down query statistics byexecution count, CPU time, &blocked timeIdentify TOP SQL activity •Identify “Top” SQL queries•View by CPU Time or MemoryUtilization•Limit to last Day, Week or MonthManaging MS-SQL Session •Identify “Top” consumers byCPU or memory utilization•Kill runaway session fromwithin the UIManage Database Backups •Name and create unique backups for anyof your Microsoft SQL Server Databases •Schedule jobs to create new backups •Restore a selected backup•Delete old or unwanted backups from the listView Historical Key Performance Indicators •Process andConnection KPIs•Memory KPIs•SQL Execution KPIs•View the performancehistory by Day, Week,or MonthMetrics100s of performance and configuration metrics available for incident thresholds, reports, analysis and comparison.Drill down into individual MS-SQL statistics •Drill into hundreds of MS-SQLmetrics•Compare multiple MS-SQLserver instances to one-another for a specific metric•View associated alerts forparticular metrics•Choose to view the metric inreal-time or customizedhistorical viewsComprehensive MS-SQL ThresholdsIncident Manager for MS SQL ServerMetric Extensions▪Missing a metric your team depends on?▪Want to integrate custom scripts?▪Use Oracle Enterprise M anager’s Metric Extension capabilities to easily expand and customize the MS SQLsolution with a convenient UI-baseddevelopment workflow.Chargeback Functionality •Monitor and control ITcosts by gathering dataon resource use, and allocating charges accordingly.Latest Configuration of SQL Server•SQL Server version and patch level•Platform and OS details•Relevant Windows registry settings•Individual database details•Microsoft SQL AlwaysOn (HADR)Availability Group detailsCompare SQL Server ConfigurationsMicrosoft SQL Server Compliance Standard•Compliance managementstandard that tracks and reportsconformanceof managed targets to industry,Oracle, or internal standards.•Track and manage the adherenceof managed targets.BI Publisher Reports Comprehensive out-of-the-box reports Includes 12 MS SQL Server reports including reports focused on:•Performance Monitoring•Configuration•StorageReports - Sample Performance•In-depth performance reports•View the SQL query statements consuming the most resources or taking the longest toexecuteReportsTheme: Configuration•In-depth configuration reports •Reports for database and system configuration•At-a-glance comparison of key database configuration valuesReports - SampleTheme: Storage •Schedule a report toidentify databasesstorage utilization •Identify file growth and locationInventory and Usage Details•Drill down multiple levels of inventorydetails•View different trends in inventory countschartedHeterogeneous System TopologyEnterprise Manager helps you meetthe challenges of managing theheterogeneous enterprise–Comprehensive, top-downvisibility into your infrastructure–Rapid, accurate diagnosis &resolution of complex problemsFor More Information… Copyright © 2014 Oracle and/or its affiliates. All rights reserved. | •The Microsoft SQL Server Plug-in is listed in the Oracle Technology Global Price List under: System Monitoring Plug-in for Non Oracle Databases •The Oracle Global Price List can be found at: /us/corporate/pricing/technolo gy-price-list-070617.pdf •Latest Microsoft SQL Server Plug-in documentation : /cd/E63000_01/SQLPG/overvie w.htm#SQLPG110 •Comprehensive Metrics Reference Manual: /cd/E63000_01/EMMDA/dat abase_sql.htm#EMMDA116•Watch the capabilities:https://youtu.be/gz8JS43SS9E。
microsoft sql server 2012英文标准版

microsoft sql server 2012英文标准版Introduction:Microsoft SQL Server 2012 English Standard Edition is a widely used database management system that offers a range of features and functionalities. In this article, we will explore the key aspects of this edition, including its capabilities, performance, security, scalability, and support. By understanding these aspects, users can make informed decisions about utilizing this version of SQL Server for their business needs.Body:1. Capabilities:1.1 Data Storage and Retrieval: Microsoft SQL Server 2012 Standard Edition provides efficient storage and retrieval of data, allowing users to manage large volumes of information effectively.1.2 Query Optimization: The edition offers advanced query optimization techniques, enabling users to retrieve data quickly and efficiently.1.3 Data Analysis: SQL Server 2012 Standard Edition includes robust data analysis tools, such as SQL Server Analysis Services, which allow users to gain valuable insights from their data.2. Performance:2.1 Enhanced Performance Tuning: The 2012 edition introduces various performance tuning enhancements, such as the ability to create columnstore indexes, which significantly improve query performance.2.2 In-Memory OLTP: SQL Server 2012 Standard Edition introduces In-Memory OLTP, a feature that allows users to store and process data in memory, resulting in faster transaction processing and improved overall performance.2.3 Resource Governor: This edition includes the Resource Governor feature, which enables users to allocate system resources, such as CPU and memory, to different workloads, ensuring optimal performance for critical tasks.3. Security:3.1 Transparent Data Encryption: SQL Server 2012 Standard Edition offers Transparent Data Encryption (TDE), which helps protect sensitive data at rest by encrypting the database files.3.2 Auditing and Compliance: The edition includes comprehensive auditing capabilities, allowing users to track and monitor database activities for compliance purposes.3.3 Role-Based Security: SQL Server 2012 Standard Edition supports role-based security, enabling users to define and manage user roles and permissions, ensuring appropriate access to data.4. Scalability:4.1 AlwaysOn Availability Groups: This edition introduces AlwaysOn Availability Groups, a high-availability and disaster recovery solution that allows users to create multiple replicas of a database, providing automatic failover and increased scalability.4.2 Partitioning: SQL Server 2012 Standard Edition supports table partitioning, which improves query performance and simplifies data management for large tables.4.3 Resource Governor: As mentioned earlier, the Resource Governor feature helps manage system resources effectively, enabling scalability by allocating resources based on workload priorities.5. Support:5.1 Community Support: Microsoft SQL Server has a vast community of users and experts who actively participate in forums, blogs, and online communities, providing support and sharing knowledge.5.2 Microsoft Support: Users of SQL Server 2012 Standard Edition can rely on Microsoft's official support channels, which offer comprehensive assistance, including documentation, knowledge base articles, and direct support from Microsoft's technical team.5.3 Upgrades and Updates: Microsoft regularly releases updates, bug fixes, and security patches for SQL Server 2012 Standard Edition, ensuring ongoing support and maintenance for users.Conclusion:Microsoft SQL Server 2012 English Standard Edition is a powerful database management system that offers a wide range of capabilities, enhanced performance, robust security features, scalability options, and reliable support. By leveraging these features, organizations can effectively manage their data, improve performance, protect sensitive information, handle growing workloads, and receive the necessary assistance for smooth operations. Consider adopting SQL Server 2012 Standard Edition for your business needs to unlock its full potential.。
sql server 2014 enterprise evaluation 密钥 -回复

sql server 2014 enterprise evaluation 密钥-回复SQL Server 2014 Enterprise Evaluation is a software product from Microsoft that offers a comprehensive platform for managing and analyzing data. This article will provide a step-by-step guide on how to obtain and use a product key for SQL Server 2014 Enterprise Evaluation.Step 1: Understanding SQL Server 2014 Enterprise Evaluation SQL Server 2014 Enterprise Evaluation is a version of SQL Server designed for trial and evaluation purposes. It provides all the features of the Enterprise edition but has a limited validity period. You can download SQL Server 2014 Enterprise Evaluation from the Microsoft website and evaluate its features before making a purchasing decision.Step 2: Downloading SQL Server 2014 Enterprise EvaluationTo begin, go to the Microsoft website and search for SQL Server 2014 Enterprise Evaluation. Look for a reliable download source and click on the appropriate link to start the download. Make sure to choose the correct version (e.g., 32-bit or 64-bit) based on your system requirements.Step 3: Installing SQL Server 2014 Enterprise EvaluationAfter the download is complete, locate the setup file and run it.Follow the installation wizard's instructions to install SQL Server 2014 Enterprise Evaluation on your system. Ensure that you meet the minimum system requirements specified by Microsoft.Step 4: Launching SQL Server 2014 Enterprise EvaluationOnce the installation is complete, you can launch SQL Server 2014 Enterprise Evaluation from the Start Menu or by searching for it. Open the SQL Server Management Studio (SSMS) and connect to the SQL Server instance where you want to apply the product key.Step 5: Obtaining the Product KeyTo obtain the product key for SQL Server 2014 Enterprise Evaluation, you need to visit the Microsoft Volume Licensing Service Center (VLSC) website. If you do not have an account, create one by following the registration process. Once logged in, navigate to the Product Keys section and search for SQL Server 2014 Enterprise Evaluation.Step 6: Accessing the Product KeyOnce you have found the SQL Server 2014 Enterprise Evaluation product key, click on the corresponding link to view the key. Make a note of the product key as you will need it in the next step.Step 7: Applying the Product KeyGo back to the SQL Server Management Studio and click on the "Help" menu option. From the dropdown menu, select "Enter Product Key." In the dialog box that appears, enter the previously obtained product key and click "Upgrade."Step 8: Verifying the Product KeyTo verify that the product key has been successfully applied, click on the "Help" menu option again and select "About." A new window will open that displays information about your SQL Server installation. Look for the "Product" section and make sure it indicates "Enterprise Edition."Step 9: Evaluating SQL Server 2014 Enterprise EditionAt this step, you have successfully applied the product key for SQL Server 2014 Enterprise Evaluation. You can now explore and evaluate the full range of features and capabilities offered by this edition. Perform tasks such as creating databases, managing users and permissions, executing queries, and analyzing performance.Step 10: Product Activation and LicensingIt is important to note that SQL Server 2014 Enterprise Evaluation has a limited validity period, usually 180 days. To continue using SQL Server after the evaluation period, you will need to purchase a licensed version and apply the corresponding product key. Without proper activation and licensing, you may facelimitations or restrictions in terms of usage and support.In conclusion, SQL Server 2014 Enterprise Evaluation provides a comprehensive platform for data management and analysis. By following the steps outlined above, you can easily obtain and apply a product key to maximize the features and capabilities of this edition. Remember to manage your evaluation period effectively and consider purchasing a licensed version for long-term usage.。
戴尔产品组12TB Microsoft SQL Server 2012快速跟踪数据仓库参考配置说明书

Database Solutions Engineering Dell Product Group Mayura Deshmukh April 2013This document is for informational purposes only and may contain typographical errors and technical inaccuracies. The content is provided as is, without express or implied warranties of any kind.© 2013 Dell Inc. All rights reserved. Dell and its affiliates cannot be responsible for errors or omissions in typography or photography. Dell, the Dell logo, and PowerEdge are trademarks of Dell Inc. Intel and Xeon are registered trademarks of Intel Corporation in the U.S. and other countries. Microsoft, Windows, and Windows Server are either trademarks or registered trademarks of Microsoft Corporation in the United States and/or other countries. Other trademarks and trade names may be used in this document to refer to either the entities claiming the marks and names or their products. Dell disclaims proprietary interest in the marks and names of others.February 2013 | Rev 1.0ContentsExecutive Summary (4)FTDW Reference Architectures Using PowerEdge R720xd Server (4)12TB Dell R720XD FTDW Reference Architecture (5)Hardware Components (5)Internal Storage Controller (PERC H710P Mini) Settings (7)Application Configuration (9)Capacity Details (10)Performance Benchmarking (11)Conclusion (13)References (14)TablesTable 1: Dell Fast Track Reference Architectures for PowerEdge R720xd Server (4)Table 2: Tested Dell FTDW Reference Architecture Components (5)Table 3: Mount Point Naming and Storage Enclosure Mapping (9)Table 4: Capacity Metrics (10)Table 5: Performance Metrics (11)FiguresFigure 1: Proposed Dell Fast Track Reference Architecture (5)Figure 2: Memory Slot Locations (7)Figure 3: Virtual Disk Settings (7)Figure 4: Internal Storage Controller Settings (8)Figure 5: RAID Configuration (8)Figure 6: Storage System Components (9)Figure 7: SQLIO Line Rate Test from Cache (Small 5MB File) (12)Figure 8: SQLIO Real Rate Test from Disk (Large 25GB File) (12)Executive SummaryThe performance and stability of any data warehouse solution is based on the integration between solution design and hardware platform. Choosing the correct solution architecture requires balancing the application’s intended purpose and expected use with the hardware platform’s components. Poor planning, bad design, and misconfigured or improperly sized hardware often lead to increased costs, increased risks and, even worse, unsuccessful projects.This white paper provides guidelines to achieve a compact, balanced, optimized 12TB Microsoft® SQL Server® 2012 data warehouse configuration for Dell™PowerEdge™ R720 and R720xd servers using Microsoft Fast Track Data Warehouse (FTDW) principles. Benefits of implementing this reference architecture include:∙Achieve a balanced and optimized system at all levels of the stack by following hardware and software best practices.∙Avoid over-provisioning hardware resources to reduce costs.∙Implement a tested and validated configuration with proven methodologies and performance behaviors to help avoid the pitfalls of improperly designed and configured systems.∙Easily migrate from a small- to medium-sized data warehouse configuration (5TB) to a large data warehouse configuration (12TB).Data center space comes at a premium. This configuration provides a compact, high-performance solution for large data warehouses with 12TB of data or more.FTDW Reference Architectures Using PowerEdge R720xd Server The Microsoft FTDW reference architecture achieves an efficient resource balance between SQL Server data processing capability and realized component hardware throughput to take advantage of improved out-of-the-box performance.As most data warehouse queries scan large volumes of data, FTDW system design and configuration are optimized for sequential reads and are based on concurrent query workloads. Understanding performance and maintaining a balanced configuration helps reduce costs by avoiding over provisioning of components.Dell provides various Fast Track reference architectures for SQL 2012 built using the Dell PowerEdge12th Generation servers. These solutions are differentiated depending on the data warehouse capacity and scan rate requirements. Table 1 summarizes FTDW configurations with Dell R720XD server.Table 1: Dell Fast Track Reference Architectures for PowerEdge R720xd ServerThe 12TB R720XD configuration described in this white paper is also available as a rapid deployment, with hardware, software, and services included in the Dell™ Quickstart Data Warehouse Appliance 2000 (QSDW 2000). This configuration provides a low-cost and easier migration path for customers who wantto go from a 5TB to 12TB solution. For more information on Dell QSDW 2000, see Dell Quickstart Data Warehouse Appliance.12TB Dell R720XD FTDW Reference ArchitectureThe following sections of this paper describe the hardware, software, capacity, and performance characteristics of a 12TB Microsoft SQL Server 2012 FTDW solution with scan rates of about 2GBps using PowerEdge R720XD servers.Hardware ComponentsRedundant and robust tests have been conducted on PowerEdge servers to determine best practices and guidelines for building a balanced FTDW system. Table 2 provides the detailed hardware configuration of the reference architecture.Figure 1: Proposed Dell Fast Track Reference ArchitectureTested Dell Fast Track Reference Architecture Component DetailsTable 2: Tested Dell FTDW Reference Architecture ComponentsPowerEdge R720xd ServerThe PowerEdge R720xd server is a two-socket, 2U high-capacity, multi-purpose rack server offering an excellent balance of internal storage, redundancy, and value in a compact chassis. For technical specifications of the R720xd server, see the Power Edge R720xd Technical Guide.ProcessorsThe Fast Track Data Warehouse Reference Guide for SQL Server 2012 describes how to achieve a balance between components such as storage, memory, and processors. To balance available internal storage and memory for the PowerEdge R720xd, the architecture uses two Intel Xeon E5-2643 four-core processors operating at 3.3GHz.MemoryFor SQL Server 2012 reference architectures, Microsoft recommends using 128GB to 256GB of memory for dual-socket configuration. Selection of memory DIMMS will also play a critical role in the performance of the entire stack.This configuration was tested with various memory sizes running at different speeds—for example,192GB running at 1333MHz, 192GB running at 1600MHz, 112GB running at 1600MHz, and so on. Using DIMMs with memory rate of 1600MHz showed significant performance improvement (about 400MBs/s) over DIMMS with memory rate of 1333MHz. In the test configuration, the database server is configured with 128GB of RAM running at 1600 MHz to which create a well-balanced configuration.To achieve 128GB of RAM on the PowerEdge R720xd server, place eight 16GB RDIMMS in slots A1-A4 and B1-B4 (white connectors). See Figure 2: Memory Slot LocationsFigure 2 for memory slot locations.Figure 2: Memory Slot LocationsInternal Storage Controller (PERC H710P Mini) SettingsThe Dell PERC H710P Mini is an enterprise-level RAID controller that provides disk management capabilities, high availability, and security features in addition to improved performance of up to6GB/s throughput. Figure 3 shows the management console accessible through the BIOS utility.Figure 3: Virtual Disk SettingsStripe element sizeBy default, the PERC H710P Mini creates virtual disks with a segment size of 64KB. For most workloads, the 64KB default size provides an adequate stripe element size.Read policyThe default setting for the read policy on the PERC H710P Mini is “adaptive read ahead.” This configuration was tested with “adaptive read ahead,” “No read ahead,”and “Read Ahead” settings.During testing, it was observed that the default setting of “adaptive read ahead” gave the best performance.Figure 4: Internal Storage Controller SettingsRAID configurationWhen deploying a new storage solution, selecting the appropriate RAID level is a critical decision that impacts application performance. The FTDW configuration proposed in this paper uses RAID 1 disk groups for database data files and database log files, nine RAID 1 data disk groups, and one RAID 1 log disk group, each created with a single virtual disk. Additionally, two drives in RAID 0 are assigned as a staging area. Figure 5 shows the proposed RAID configuration.Figure 5: RAID ConfigurationRAID 1 Data 5RAID 1Data 6RAID 1Data 7RAID 0StageRAID 1LogsRear Bay DrivesDrive slot configuration:∙Slots 0-17: Nine RAID 1 disk groups were created, each configured with a single virtual disk dedicated for the primary user data∙Slots 18-19: One RAID 1 disk group created from two disks and a single virtual disk dedicated tohost the database log files∙Slots 20-21: RAID 0 disk group created from two disks dedicated for staging∙Slots 22-23: Remaining two disks assigned as global hot spares∙Slots 24-25 (rear bay drives): One RAID 1 disk group for operating systemFor FTDW architectures, it is recommended to use mount-point rather than drive letters for storage access. It is also important to assign the appropriate virtual disk and mount-point names to theconfiguration to simplify troubleshooting and performance analysis. Mount-point names should be assigned in such a way that the logical file system reflects the underlying physical storage enclosure mapping. Table 3 shows the virtual disk and mount-point names used for the specific reference configuration and the appropriate storage layer mapping. All of the logical volumes are mounted to the C:\FT folder.Table 3: Mount Point Naming and Storage Enclosure MappingFigure 6 represents the storage system configuration for the proposed FTDW reference architecture.Figure 6: Storage System ComponentsThe production, staging, and system temp databases are deployed per the recommendations provided in the Fast Track Data Warehouse Reference Guide for SQL Server 2012.Application ConfigurationThe following sections explain the settings applied to operating system and database layers.Windows Server 2008 R2 SP1Enable Lock Pages In Memory to prevent the system from paging memory to disk. For more information, see How to: Enable the Lock Pages in Memory Option.SQL Server ConfigurationThe following startup options were added to the SQL Server Startup options:∙-E: This parameter increases the number of contiguous extends that are allocated to a database table in each file as it grows to improve sequential access.∙-T1117: This trace flag ensures the even growth of all files in a file group when auto growth is enabled. It should be noted that the FTDW reference guidelines recommend pre-allocating the data file space rather than allowing auto-grow.SQL Server Maximum Memory: FTDW for SQL Server 2012 guidelines suggest allocating no more than 92% of total server RAM to SQL Server. If additional applications will share the server, then adjust the amount of RAM left available to the operating system accordingly. For this reference architecture, the maximum server memory was set at 119808 MB (117GB).Resource Governor:For SQL Server 2012, Resource Governor provides a maximum of 25% of SQL Server memory resources to each session. The Resource Governor setting can be used to reduce the maximum memory consumed per query. While it can be beneficial for many data warehouse workloads to limit the amount of system resources available to an individual session, this is best measured through analysis of concurrent query workloads. This configuration was tested with both 25% and 19% memory grant, and the 25% setting was found to be optimal for the proposed configuration. For more information, see Using the Resource Governor.Max Degree of Parallelism: The SQL Server configuration option Max degree of parallelism controls the number of processors used for the parallel execution of a query. For the configuration, settings of 12 and 0 were tested. The default setting of 0 provided maximum performance benefits. For more information, see Maximum degree of parallelism configuration option.Capacity DetailsTable 4Table 4 shows the capacity metrics reported for the recommended reference configuration.Table 4: Capacity MetricsPerformance BenchmarkingMicrosoft FTDW guidelines help to achieve optimized database architecture with balanced CPU and storage bandwidth. Table 5 shows the performance numbers reported for the recommended reference configuration.Table 5: Performance MetricsThe following sections describe the detailed performance characterization activities carried out for the validated Dell Microsoft FTDW reference architecture.Baseline Hardware Characterization Using Synthetic I/OThe goal of hardware validation is to determine actual baseline performance characteristics of key hardware components in the database stack to ensure that system performance is not bottlenecked in intermediate layers.The disk characterization tool, SQLIO, was used to validate the configuration. The results in Figure 7 show the maximum baseline that the system can achieve from a cache (called Line Rate). A small file is placed on the storage, and large sequential reads are issued against it with SQLIO. This test verifies the maximum bandwidth available in the system to ensure no bottlenecks are within the data path.Figure 7: SQLIO Line Rate Test from Cache (Small 5MB File)PERC H710P Mini ControllerSynthetic I/O rate: 2674 MB/sThe second synthetic I/O test with SQLIO was performed with a large file to ensure reads are serviced from the storage system hard drives instead of from cache. Figure 8 shows the maximum real rate that the system is able to provide with sequential reads.Figure 8: SQLIO Real Rate Test from Disk (Large 25GB File)PERC H710P Mini ControllerSynthetic I/O rate: 2616 MB/sFTDW Database ValidationThe performance of a FTDW database configuration is measured using two core metrics: Maximum CPU Consumption Rate (MCR) and Benchmark Consumption Rate (BCR).MCR - MCR indicates the per-core I/O throughput in MB or GB per second. This is measured by executing a pre-defined query against the data in the buffer cache, and then measuring thetime taken to execute the query against the amount of data processed in MB or GB. For thevalidated configuration with two Intel E5-2643 four-core processors, the system aggregate MCR was 2488 MB/s. The realized MCR value per core was 311 MB/s.BCR - BCR is calculated in terms of total read bandwidth from the storage hard drives—not from the buffered cache as in the MCR calculation. This is measured by running a set ofstandard queries specific to the data warehouse workload. The queries range from I/Ointensive to CPU and memory intensive, and provide a reference to compare variousconfigurations. For the validated FTDW configuration, the aggregate BCR was 1909 MB/s.During the evaluation cycle, the system configuration was analyzed for multiple query variants (simple, average, and complex) with multiple sessions and different degrees of parallelism(MAXDOP) options to arrive at the optimal configuration. The evaluation results at each stepwere validated and verified jointly by Dell and Microsoft.FTDW Database Validation with Column Store Index (CSI)SQL Server 2012 implements CSI technology as a nonclustered indexing option for pre-existing tables. Significant performance gains are often achieved when CSI query plans are active, and this performance can be viewed as incremental to the basic system design.After the test configuration was validated, CSI was added. Then, the same set of I/O and CPU-intensive queries were executed to compare throughput achieved using CSI. Throughput rating of 4337.5 MB/s was achieved for CSI-enhanced benchmarks. These numbers can be used to approximate the positive impact to query performance expected under a concurrent query workload.ConclusionThe Dell Microsoft FTDW architecture provides a uniquely well-balanced data warehouse solution. By following best practices at all stack layers, a balanced data warehouse environment can be achieved with a greater performance benefits than traditional data warehouse systems.ReferencesDell SQL Server Solutions\sqlDell Services\servicesDell Support\supportMicrosoft Fast Track Data Warehouse and Configuration Guide Information /fasttrackAn Introduction to Fast Track Data Warehouse Architectures/en-us/library/dd459146.aspxHow to: Enable the Lock Pages in Memory Option/fwlink/?LinkId=141863SQL Server Performance Tuning & Trace Flags/kb/920093Using the Resource Governor/en-us/library/ee151608.aspxMaximum degree of parallelism configuration option/kb/2023536Power Edge R720xd Technical Guide/support/edocs/systems/per720/en/index.htm。
sqlalchemy faseapi案例

sqlalchemy faseapi案例(中英文版)Title: SQLAlchemy and Flask-RESTful API CaseIntroduction:In this case study, we will explore how SQLAlchemy, a popular SQL toolkit and Object-Relational Mapping (ORM) library, can be integrated with Flask-RESTful, a lightweight framework for creating REST APIs, to build a robust and efficient web application.1.Understanding SQLAlchemy:SQLAlchemy is an open-source SQL toolkit and Object-Relational Mapping (ORM) library for Python.It provides a high-level interface for working with databases and allows developers to interact with SQL databases using Python objects.SQLAlchemy is known for its powerful and flexible features, making it a preferred choice for many developers when it comes to database integration in Python applications.1.Introduction to Flask-RESTful:Flask-RESTful is an extension for the Flask web framework that simplifies the process of creating REST APIs.It provides a simple and easy-to-use interface for defining and handling HTTP requests and responses.Flask-RESTful allows developers to focus on the core functionality of their application without worrying about the intricacies of HTTP protocol and request handling.2.Creating a Sample Application:To demonstrate the integration of SQLAlchemy and Flask-RESTful, let"s create a simple sample application that manages user information.We will define a User model with attributes like id, name, and email, and create endpoints for creating, retrieving, updating, and deleting user records.3.Setting up the Database:Before we start coding, we need to set up the database connection.We will use SQLite as our database for this example.T o establish a connection to the SQLite database, we will create a file-based database using the SQLAlchemy engine_from_config() function and set up the necessary tables using the declarative_base() and Column() functions.4.Defining the User Model:ext, we will define the User model using SQLAlchemy"s ORM capabilities.We will create a User class that inherits from the declarative base class, and define its attributes as SQLAlchemy columns.The primary key of the User table will be an auto-incrementing integer, and the other attributes will be of string type.5.Creating Flask-RESTful Resources:ow, let"s create Flask-RESTful resources for managing user records.We will define a UserResource class that inherits from Flask-RESTful"s Resource class.We will implement methods for getting a list of all users, getting a specific user by id, creating a new user, updating an existing user, and deleting a user.6.Associating Resources with URLs:To make the RESTful API accessible via the web, we need to associate the resources with specific URLs.We will use Flask-RESTful"s Api class to create an instance of the API, and use the add_resource() method to associate the UserResource with the appropriate URL pattern.7.Running the Application:Finally, we will run the Flask application and test the REST API endpoints.We will use a web browser or a tool like `curl` to send HTTP requests to the application and receive responses.This will allow us to verify that the application is working as expected and that the SQLAlchemy and Flask-RESTful integration is successful.Conclusion:In this case study, we explored how SQLAlchemy and Flask-RESTful can be used together to build a powerful and efficient web application.By integrating SQLAlchemy"s ORM capabilities with Flask-RESTful"s simple and easy-to-use interface, developers can create REST APIs that interact with SQL databases effortlessly.The sample application we created demonstrates the process of defining a user model, creating Flask-RESTful resources, associating resources with URLs, and running theapplication to test the REST API endpoints.。
SQL Server 2008 R2 版本比较
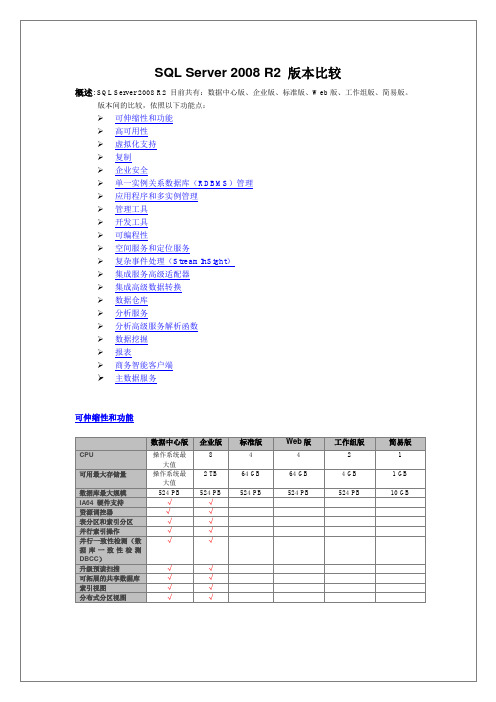
SQL Server Standard, SQL Server Enterprise and SQL Server Datacenter
SQL Server Web
√
√
√
√
√
√
智能感知(Transact-SQL和MDX)
√
√
√
√
√
商务智能开发工具集Assistant1
√
√
√
√
√
SQL查询、编辑和设计工具
√
√
√
√
版本控制支持
√
√
√
√
MDX编辑、调试和设计工具
√
√
√
可编程性
数据中心版
企业版
标准版
Web版
工作组版
简易版
Entity Framework support
√
√
基于策略的资源利用评估
√
√
管理工具
数据中心版
企业版
标准版
Web版
工作组版
简易版
SQL Server Configuration Manager
√
√
√
√
√
√
SQL CMD (command prompt tool)
√
√
√
√
√
√
SQL Server Migration Assistant1
√
√
√
√
√
√
√
√
√
√
√
Sysprep support1
Symantec安全管理解决方案SSIM9600介绍

Measure and Report on Effectiveness
The SIM Wave
SSIM 4.5 is a Leader in the Forrester Wave Report Quotes SSIM is much improved this year with 4.5 SSIM is easier to deploy and configure Improved data management capabilities make it easier to perform historical analysis
+
+
SSIM 后台安全知识库 – 赛门铁克全球智能监控网络
事件收集-集中保存事件信息
集中保存原始日志数据… 用于事后取证 达到合规要求 支持长期日志保存需求 归档文件同时被压缩保存,压缩比率为50%-80% 灵活的存贮选择 (内置存贮或 SAN/NAS/DAS) 不再需要DBA 数据归档和备份更为方便,备份时间和复杂程序较数据库备份都有所减少 归档文件可以用于在线恢复,规则测试和搜索 不再需要数据库的日常维护
Driver: Compliance Compliance teams require proof of a incident response process with a focus on user & access control incident management Needed a mechanism to tie together a broad solution of several Symantec products Solution: Global SSIM Deployment 9 Appliance in 6 Locations across US, EMEA and JPAC SSIM turns millions of events into a handful of incidents daily, processing 7000+ EPS Professional Services delivered a tuned solution Result Limited Security Analyst team addresses top concerns Incident Response Process is fully documented and reports to auditors demonstrate due care
全球国家地区数据库 sql 英文版

全球国家地区数据库 SQL 英文版I. IntroductionIn today's interconnected world, having access to a reliable andprehensive database of global countries and regions is essential for many businesses and organizations. An SQL database that provides information on countries, regions, and their related data is an invaluable resource for a wide range of applications, from emerce and logistics to international relations and academic research. In this article, we will explore the benefits of having a global country and region database in English, the key features and functionalities of such a database, and how it can be implemented and utilized.II. The Importance of a Global Country and Region Database 1. Facilitates International Business: Forpanies engaged in international trade, having access to accurate and up-to-date information on countries and regions is crucial for market research, supply ch本人n management, andpliance with import/export regulations.2. Supports Geographic Analysis: Geographic information is integral to many fields, including urban planning, environmental science, and public health. A country and region databaseprovides a solid foundation for spatial analysis and visualization.3. Enables Cross-Cultural Communication: With the growing popularity of globalmunication platforms, having a reliable database of countries and regions allows for the localization of content, addressing cultural sensitivities, and providing accurate geotargeting.III. Key Features and Functionalities of a Global Country and Region Database in SQL1. Comprehensive Data Structure: A well-designed SQL database should include a wide range of attributes for each country and region, such as name, ISO code, population, capital, currency, language, time zone, and geographical coordinates.2. Standardized Data Format: The database should adhere to international standards for data representation, such as ISO 3166 for country codes and ISO 3166-2 for region codes, to ensurepatibility and interoperability with other systems.3. Data Integrity and Accuracy: Robust data validation and update mechanisms are essential to m本人nt本人n the accuracy and consistency of the database, especially in the context of geopolitical changes and administrative boundaries.IV. Implementation and Utilization of a Global Country andRegion Database in SQL1. Database Design and Schema: The database should be designed with a clear relational schema that organizes data into logical entities (e.g., countries, regions) and establishes relationships between them. This allows for efficient querying and retrieval of relevant information.2. API Integration: To make the database accessible to a wide range of applications, an API can be developed to provide programmatic access to the data, enabling developers to incorporate country and region information into their software systems.3. Geospatial Analysis: Leveraging the spatial capabilities of SQL databases, geographic data can be queried and analyzed to support various use cases, such as proximity searches, boundary delineation, and spatial joins with other datasets.V. ConclusionIn conclusion, a global country and region database in SQL, av 本人lable in English, serves as a foundational resource for diverse industries and disciplines, enabling informed decision-making, cross-border collaboration, and cultural understanding. By embracing the power of data-driven insights, organizations can leverage this database to navigate theplexities of the globallandscape and unlock new opportunities for growth and innovation.。
sql xml解析

sql xml解析XML(可扩展标记语言)是一种用于存储和交换数据的语言。
SQL (结构化查询语言)是一种用于管理关系数据库管理系统(RDBMS)的编程语言。
在关系数据库管理系统中,可以将XML文档存储为文本列,并可以使用SQL查询语句来解析XML数据。
本文将介绍如何使用SQL解析XML数据以及一些有用的XML解析函数。
1. SQL中的XML数据类型在SQL Server中,可以使用XML作为数据类型来存储XML数据。
XML数据类型被定义为用于存储XML文档的数据类型。
当使用XML数据类型存储XML值时,可以使用XML文档中的关系数据来查询整个文档或基于元素的查询。
下面是SQL Server中的XML数据类型的定义:XML [ (n) ]其中,n是可选参数,用于指定XML数据类型的最大大小(以字节为单位)。
2.使用OPENXML解析XML数据OPENXML是SQL Server中的一个内置函数,用于解析XML数据。
使用OPENXML可以将XML文档转换为关系表,并使用SQL查询语言访问数据。
下面是使用OPENXML解析XML数据的一般步骤:步骤1:创建XML文档的表结构。
在创建XML文档之前,需要定义一个表来存储XML文档中的数据。
该表应包含与XML文档元素和属性相对应的列。
步骤2:使用OPENXML将XML数据转换为关系表。
使用OPENXML可以将XML文档转换为关系表。
OPENXML函数需要三个参数:XML文档的标识符,表示文档中节点的XPath表达式,以及一个指示节点的ID的列名。
步骤3:使用T-SQL查询解析XML文档。
一旦将XML文档转换为关系表,就可以使用SQL查询语言来访问数据。
可以使用SELECT语句选择特定的列并应用任何必要的过滤条件。
下面是使用OPENXML解析XML文档的示例:DECLARE @xml XMLSET @xml = N'<employees><employee id="1" fullname="John Smith"><department>Accounting</department><hiredate>2000-01-01</hiredate><salary>50000</salary></employee><employee id="2" fullname="Jane Doe"><department>Human Resources</department><hiredate>2001-01-01</hiredate><salary>60000</salary></employee></employees>'-- Define table structure to store XML data CREATE TABLE #Employees(ID INT IDENTITY(1, 1),EmployeeID INT,FullName VARCHAR(100),Department VARCHAR(50),HireDate DATE,Salary DECIMAL(10, 2))-- Convert XML to relational tableINSERT INTO #Employees (EmployeeID, FullName, Department, HireDate, Salary)SELECTx.value('@id', 'int'), -- Get value of 'id' attributex.value('@fullname', 'varchar(100)'), -- Get value of'fullname' attributex.value('department[1]', 'varchar(50)'), -- Get value of'department' elementx.value('hiredate[1]', 'date'), -- Get value of'hiredate' elementx.value('salary[1]', 'decimal(10,2)') -- Get value of'salary' element**************('/employees/employee')ASt(x)-- Query the XML dataSELECT * FROM #Employees WHERE Salary > 55000-- Clean upDROP TABLE #Employees此示例将XML文档转换为关系表,然后使用T-SQL查询检索数据。
intersystems cache数据库 sql语句 -回复

intersystems cache数据库sql语句-回复什么是Intersystems Cache数据库?Intersystems Cache数据库是一款高性能的多模型数据库管理系统,广泛应用于各个行业的信息管理与系统集成领域。
它以其独特的NoSQL和SQL并存的能力而闻名,具备快速、可靠、可伸缩性强的特点,为用户提供了高效的数据管理和应用开发平台。
Intersystems Cache是基于MUMPS编程语言和技术的产品,MUMPS 是一种高级结构化、面向对象的编程语言,也是Intersystems公司独特的技术基础。
通过内置的数据库引擎和细粒度的数据模型,Cache数据库能够支持多种数据类型,包括关系型数据、多值数据、面向对象数据以及XML数据。
如何使用Intersystems Cache数据库进行SQL查询?Intersystems Cache数据库提供了丰富的SQL查询功能,可以通过标准的SQL语句来操作和查询数据库。
下面将介绍一些常见的SQL操作和查询语句。
1. 创建数据库表:使用CREATE TABLE语句可以创建一个新的数据库表,定义表的字段、数据类型和约束等。
示例:CREATE TABLE Employees (EmployeeID INTEGER PRIMARY KEY,FirstName VARCHAR(50),LastName VARCHAR(50),HireDate DATE);2. 插入数据:使用INSERT INTO语句可以向数据库表中插入新的数据。
示例:INSERT INTO Employees (EmployeeID, FirstName, LastName, HireDate)VALUES (1, 'John', 'Doe', '2020-01-01');3. 更新数据:使用UPDATE语句可以更新数据库表中的数据。
sql server 注册程序集方法

sql server 注册程序集方法I understand that registering a program assembly in SQL Server can sometimes be a complex and daunting task for many developers. The process involves adding a reference to an external .NET assembly in SQL Server, which allows you to call .NET functions from within T-SQL code. This can be extremely powerful and allow for greater flexibility in developing solutions for database applications. However, it can also pose challenges and require a good understanding of both SQL Server and .NET programming.我理解在 SQL Server 中注册程序集有时候对许多开发人员来说可能是一个复杂而艰巨的任务。
这个过程包括在 SQL Server 中添加对外部 .NET 程序集的引用,这样你就可以在 T-SQL 代码中调用 .NET 函数。
这样可以非常强大,为数据库应用程序的开发提供更大的灵活性。
然而,这也可能带来挑战,并需要对 SQL Server 和 .NET 编程有很好的理解。
One important aspect to consider when registering a program assembly in SQL Server is security. It is crucial to ensure that the external assembly being registered is safe and does not pose a security risk to the server. SQL Server provides the ability to setpermissions for assemblies, which can help in controlling access and preventing unauthorized code execution. By carefully managing permissions and auditing the use of registered assemblies, you can improve the overall security of your SQL Server environment.在注册 SQL Server 中的程序集时需要考虑的一个重要方面是安全性。
sql 2003标准文档 -回复

sql 2003标准文档-回复SQL 2003标准文档的内容是关于SQL(Structured Query Language)的规范,它是一种用于管理和操作关系数据库系统的语言。
SQL 2003是最新版本的SQL标准,提供了一套通用的语法和功能,用于实现跨不同数据库管理系统的一致性。
在本文中,我们将一步一步地回答有关SQL 2003标准文档的问题,深入了解其主要内容和重要特性。
第一步:了解SQL 2003标准的背景和目的SQL 2003标准最初由ANSI(美国国家标准学会)和ISO(国际标准化组织)联合制定,旨在定义数据库查询与管理的通用规范。
它的目的是提供一种标准化的语言和功能,使开发人员能够在不同的数据库管理系统中进行兼容和迁移。
第二步:探索SQL 2003标准的主要组成部分SQL 2003标准文档由多个部分组成,其中包括核心语法、基本数据类型、查询语言、事务处理、安全性和扩展功能等。
核心语法:SQL 2003标准定义了SQL的基本语法结构,包括数据操作、数据定义、数据查询和数据控制等方面。
它支持大部分常用的操作,如SELECT、INSERT、UPDATE和DELETE等。
基本数据类型:SQL 2003标准提供了一套标准的基本数据类型,包括数字、字符、日期和时间等类型。
这些数据类型的定义和用法在不同的数据库管理系统中具有一致性。
查询语言:SQL 2003标准定义了强大的查询语言,可以对数据库进行复杂的查询、排序、过滤和聚合等操作。
它还支持多表连接、子查询和视图等高级特性。
事务处理:SQL 2003标准支持事务处理功能,以确保数据库的一致性和完整性。
开发人员可以使用事务来对一系列操作进行分组,并在发生错误时进行回滚。
安全性:SQL 2003标准引入了安全性功能,允许开发人员对数据库对象进行权限管理和访问控制。
这包括定义用户角色、分配权限和实施数据库级别的安全策略等。
扩展功能:SQL 2003标准还定义了一些扩展功能,如XML支持、嵌入式SQL和存储过程等。
MS SQL Server2014标准版、企业版、易捷版对比
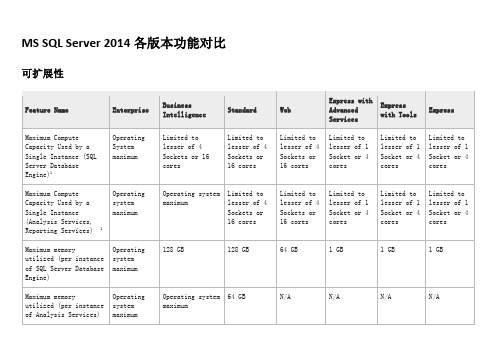
MS SQL Server 2014各版本功能对比可扩展性There are no limits under the Core-based Server Licensing model. For more information, see Compute Capacity Limits by Edition of SQL Server. Top高可用性For more information on installing SQL Server 2014 on Server Core, see Install SQL Server 2014 on Server Core. 2This feature is only available for 64-bit SQL Server.Top容量和性能Top安全性Top 复制Top管理工具2 SQL Server Web, SQL Server Express, SQL Server Express with Tools, and SQL Server Express with Advanced Services can be profiled using SQL Server Standard and SQL Server Enterprise editions.3 Tuning enabled only on Standard edition features.Top可管理性For more information, see Considerations for Installing SQL Server Using SysPrep.2 This feature is only available for 64-bit SQL Server.Top开发工具Top编程性能Top集成服务Top集成服务- 高级适配器Top集成服务- 高级转换功能Top元数据服务NoteTop数据仓库Top分析服务TopBI 语义模型(多维的)AverageOfChildren, and ByAccount, are not. Additive measures, such as Sum, Count, Min, Max, and non-additive measures (DistinctCount) are supported on all editions. TopBI 语义模型(扁平的)TopPowerPivot for SharePointTop数据挖掘Top报表服务报表服务功能For more information on the supported datasources in SQL Server 2014 Reporting Services (SSRS), see Data Sources Supported by Reporting Services (SSRS).2Requires Reporting Services in SharePoint mode. For more information, see Reporting Services SharePoint Mode Installation (SharePoint 2010 and SharePoint 2013).Top报表服务器数据库版本需求When creating a report server database, not all editions of SQL Server can be used to host the database. The following table shows you which editions of the Database Engine商业智能客户端The following software client applications are available on the Microsoft Downloads center and are provided to assist you with creating business intelligence documents that run on a SQL Server instance. When you host these documents in a server environment, use an edition of SQL Server that is supported for that document type. The following NoteTop空间性和位置性服务Top其他数据库服务Top其他组件Top。
mybatis association select用法及搭配

mybatis association select用法及搭配MyBatis Association Select Usage and CombinationMyBatis is a popular Java-based persistence framework that simplifies the process of working with SQL databases. It provides a powerful feature called "Association Select" that allows developers to retrieve and map complex relational data easily. In this article, we will explore the usage of MyBatis Association Select and discuss how it can be effectively combined with other features.1. Introduction to Association SelectAssociation Select in MyBatis allows developers to retrieve and map related entities in a single SQL query. This feature is particularly useful when dealing with complex data models that involve multiple tables and relationships. It eliminates the need for writing separate queries or joining tables manually, resulting in improved performance and reduced complexity.2. Configuring Association SelectTo use Association Select in MyBatis, you need to define the appropriate mappings in the XML configuration file or using Java annotations. Start by defining the parent entity and its properties. Then, specify the association between the parent entity and the child entity using the appropriate mapping tags or annotations.3. Using Association Select in SQL Mapper XMLIn the SQL Mapper XML file, you can leverage Association Select using the `<association>` tag. It allows you to specify the mapping between theparent and child entities based on a common property or column. For example:```xml<resultMap id="parentMap" type="ParentEntity"><id column="id" property="id" /><result column="name" property="name" /><association property="child" javaType="ChildEntity"><id column="child_id" property="id" /><result column="child_name" property="name" /></association></resultMap>```In the above example, we define a resultMap for the ParentEntity that includes an association with the ChildEntity. The association tag specifies the mapping between the parent and child entities based on their respective columns.4. Using Association Select in Java AnnotationsIf you prefer to use Java annotations, you can leverage the`@Association` annotation to configure the association between parent and child entities. For example:```javapublic class ParentEntity {@Idprivate Long id;private String name;@Association(property = "child", joinColumn = "child_id")private ChildEntity child;// Getters and setters omitted for brevity}```In this Java code snippet, we define a ParentEntity class with a child property annotated with `@Association`. The annotation specifies the property name of the child entity and the join column used for the association.5. Benefits of Association SelectUsing Association Select in MyBatis offers several benefits, including:- Simplified Mapping: Association Select eliminates the need for manual mapping of related entities, reducing the amount of code required.- Improved Performance: By retrieving related entities in a single query, MyBatis reduces the number of database round-trips, resulting in improved performance.- Reduced Complexity: Association Select simplifies complex data retrieval scenarios by automatically handling the associations between entities.6. Combining Association Select with other MyBatis FeaturesAssociation Select can be effectively combined with other MyBatis features to further enhance data retrieval and mapping capabilities. Some of the features that work well with Association Select include:- Result Map Inheritance: MyBatis allows the inheritance of result maps, enabling you to reuse mappings across different entities and queries.- Collection Select: MyBatis Collection Select feature is useful when dealing with one-to-many or many-to-many relationships, retrieving and mapping collections of related entities in a single query.7. ConclusionIn conclusion, MyBatis Association Select is a powerful feature that simplifies the retrieval and mapping of related entities in a SQL database. Its usage, in combination with other features like Result Map Inheritance and Collection Select, provides a comprehensive solution for handling complex data models. By leveraging these capabilities, developers can improve the performance and maintainability of their MyBatis applications.。
mybatis物理删除语句 -回复

mybatis物理删除语句-回复MyBatis is a popular Java-based framework that efficiently handles SQL database access. One of its key features is providing a flexible and straightforward way to perform various database operations, including insert, update, select, and delete. In this article, we will focus on the topic of physical deletion statements in MyBatis and explore the step-by-step process to perform them effectively.Physical deletion, also known as hard deletion, is the process of permanently removing data from a database. Unlike logical deletion, where the data is marked as deleted but still preserved in the database, physical deletion eliminates the data completely. MyBatis provides a simple and efficient way to execute physical deletion statements through its powerful XML-based configuration and SQL mapping capabilities.Step 1: Setting Up MyBatis ConfigurationTo perform physical deletion in MyBatis, we need to start by setting up the MyBatis configuration file. This file, typically named`mybatis-config.xml`, contains various configuration settings for MyBatis, including database connection details, type aliases, plugins, and mappers.Within the configuration file, we first specify the database connection details by configuring the `<environments>` element. This element contains one or more `<environment>` sub-elements, where we define the necessary details such as the data source type, transaction management, and the database connection properties.Step 2: Creating SQL MappingsOnce the MyBatis configuration is set up, we need to define the SQL mappings for the physical deletion operation. SQL mappings act as a bridge between the Java code and the database. They provide a logical representation of SQL statements that MyBatis can use to execute database operations.To create SQL mappings for physical deletion, we typically define a `<delete>` element within a `<mapper>` element. The `<delete>` element contains the SQL statement for physical deletion. For example, consider the following SQL mapping:xml<mapper namespace="erMapper"> <delete id="deleteUserById"parameterType="ng.Long">DELETE FROM users WHERE id = #{id}</delete></mapper>In this example, the `<delete>` element specifies the SQL statement for deleting a user from the `users` table based on their ID. The SQL statement uses a parameter `#{id}` to represent the user ID to be deleted.Step 3: Invoking the SQL MappingNow that we have defined the SQL mapping for physical deletion, we can invoke it from our Java code to perform the actual database operation. To do this, we need to create an instance of `SqlSession`, MyBatis's primary interface for executing SQL statements and managing database connections.First, we obtain an instance of `SqlSession` by using the`SqlSessionFactory` class, which is responsible for creating`SqlSession` instances. We can configure the `SqlSessionFactory` by loading the MyBatis configuration XML file that we created in Step1.Once we have the `SqlSession` instance, we can use it to execute the physical deletion SQL statement defined in the SQL mapping. For example, consider the following Java code snippet:javaSqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);try (SqlSession sqlSession = sqlSessionFactory.openSession()) { UserMapper userMapper =sqlSession.getMapper(UserMapper.class);userMapper.deleteUserById(123);sqlSessionmit();} catch (Exception e) {sqlSession.rollback();}In this code snippet, we first create an instance of`SqlSessionFactory` by using the `SqlSessionFactoryBuilder` class.We then open an `SqlSession` from the factory and obtain an instance of the `UserMapper` interface using the `getMapper()` method.Finally, we invoke the `deleteUserById()` method on the`UserMapper` instance, passing the user ID as the argument. After that, we explicitly commit the transaction using the `commit()` method to persist the changes in the database. If any exception occurs during the execution, we roll back the transaction using the `rollback()` method to maintain data consistency.Step 4: Testing and DebuggingAfter implementing the physical deletion functionality, it is essential to thoroughly test and debug the code to ensure its correctness and accuracy. You can create unit tests using frameworks like JUnit to validate the functionality and verify that the data is being correctly deleted from the database.During testing and debugging, pay attention to potential issues such as SQL syntax errors, incorrect or missing SQL mappings, insufficient database privileges, and incorrect parameter values. Debugging tools and logging frameworks can help identify andresolve these issues effectively.ConclusionIn this article, we explored the step-by-step process to perform physical deletion statements in MyBatis. Starting from setting up the MyBatis configuration and creating SQL mappings to invoking the SQL mapping and testing the functionality, we have covered the essential aspects of executing physical deletion operations effectively.MyBatis's flexibility and simplicity make it an excellent choice for performing database operations, including physical deletion. By following the steps outlined in this article and leveraging MyBatis's powerful features, you can confidently implement physical deletion functionality in your Java applications.。
having sum在sql中的用法 -回复

having sum在sql中的用法-回复Title: Understanding the Usage of SUM in SQLIntroduction:SQL (Structured Query Language) is a powerful tool for managing and manipulating data in relational databases. One of the essential functions in SQL is the aggregation function SUM, which calculates the sum of a specific column's values in a table. In this article, we will explore the usage and syntax of the SUM function in SQL, along with various examples, to provide a comprehensive understanding of its capabilities.I. Syntax and Basic Usage:The syntax of the SUM function is straightforward, as shown below:SELECT SUM(column_name) FROM table_name;Here, column_name refers to the specific column whose values we want to sum, and table_name represents the table where the column resides.II. Applying SUM with a Single Column:Let's consider a simple table called "Orders" with columns like "OrderID," "CustomerID," and "OrderAmount." Suppose we want to find the total order amount for all the orders in the table.SELECT SUM(OrderAmount) FROM Orders;By executing the above query, we will obtain the sum of all the values in the "OrderAmount" column, providing the total order amount.III. Utilizing SUM with WHERE Clause:To get more specific results, we can utilize the SUM function with the WHERE clause to filter data before calculating the sum. For instance, we can find the total order amount for a particular customer using the following query:SELECT SUM(OrderAmount) FROM Orders WHERE CustomerID = 'C001';This query filters the orders based on the "CustomerID" column, specifically 'C001', and provides the sum of the order amounts for that particular customer.IV. Grouping Data with SUM:In some cases, we may want to calculate the sum of a column for each distinct value in another column. This can be achieved by combining the SUM function with the GROUP BY clause. Consider a scenario where we wish to calculate the sum of the order amounts for each customer in the "Orders" table.SELECT CustomerID, SUM(OrderAmount) FROM Orders GROUP BY CustomerID;By executing the above query, we will obtain the sum of the "OrderAmount" column for each unique "CustomerID" value. The result will include pairs of "CustomerID" and the corresponding sum.V. Handling NULL Values:When using the SUM function, it is important to note that it ignores NULL values. Therefore, if the column being summed contains NULL values, they will not be included in the calculation. However, if you want to treat NULL values as zero and consider them in the sum calculation, you can use the COALESCE function.The COALESCE function replaces NULL values with a specified value before executing the SUM function.SELECT SUM(COALESCE(OrderAmount, 0)) FROM Orders;In the above query, if any NULL values exist in the "OrderAmount" column, they will be replaced with zero for the sum calculation.Conclusion:The SUM function is a powerful tool in SQL for aggregating data based on a specific column. By understanding its syntax and various use cases, you can effectively perform calculations such as finding the total sum of values in a column, filtering data with WHERE clause, grouping data based on distinct values, and handling NULL values. By incorporating the SUM function into your SQL queries, you can efficiently perform data analysis and generate useful insights from your databases.。
icp-ms

ICP-MS(电感耦合等离子体质谱)技术介绍与应用IntroductionICP-MS (Inductively Coupled Plasma Mass Spectrometry) is an analytical technique used to determine the concentration and composition of elements in a sample. It combines the capabilities of both ICP (Inductively Coupled Plasma) and MS (Mass Spectrometry). This document aims to provide an overview of the ICP-MS technology and its applications.Principle of operationICP-MS operates on the principle of ionization, separation, and detection of ions. The sample is first introduced into an ICP, where it is converted into a plasma state by the application of an RF (Radio Frequency) electromagnetic field. The high temperature generated in the plasma causes the atoms in the sample to ionize. These ions are then extracted and focused into a mass spectrometer.The mass spectrometer consists of three main components: an ion lens, a mass filter, and a detector. The ion lens focuses the ions into a thin beam, which is then passed through the mass filter. The mass filter separates the ions based on their mass-to-charge ratio (m/z), allowing only a specific mass range to reach the detector. The detector records the number of ions detected at each m/z value, generating a mass spectrum.Advantages of ICP-MSICP-MS offers several advantages over other analytical techniques, making it widely used in various fields:1.High sensitivity: ICP-MS is capable of detectingelements at trace levels, down to parts per trillion (ppt) or even lower concentrations.2.Wide dynamic range: The dynamic range of ICP-MSis very large, typically spanning over six orders ofmagnitude. This allows for the analysis of both ultratrace and high-concentration samples without the need fordilution.3.Multi-element analysis: ICP-MS can simultaneouslyanalyze multiple elements in a single sample, providingcomprehensive elemental profiling.4.Isotopic analysis: The mass spectrometer in ICP-MScan measure isotopic ratios, allowing for isotopic analysis and identification of elements.Applications of ICP-MSICP-MS has numerous applications in different fields, including:Environmental analysisICP-MS is extensively used in environmental monitoring and analysis. It enables the detection and quantification oftrace elements in soil, water, and air samples. This information is crucial in assessing environmental contamination, studying geochemical processes, and monitoring the effectiveness of remediation efforts.Pharmaceutical and biomedical researchIn the pharmaceutical and biomedical fields, ICP-MS is employed for analyzing drug formulations, studying metal interactions with biomolecules, and monitoring metal concentrations in biological samples. It aids in understanding drug metabolism, investigating metal-induced toxicities, and ensuring product safety.Geological and mining researchICP-MS is an essential tool in geological and mining research. It provides quantitative analysis of major, minor, and trace elements in rocks, minerals, and ores. This data helps in exploration and evaluation of mineral resources, understanding geological processes, and identifying trace elements associated with specific geological formations.Food and agricultureICP-MS is used in food and agriculture research to determine the elemental composition of food products and assess nutritional quality. It helps in analyzing trace elements, heavy metals, and other contaminants in crops, livestock feed, and food additives. This information is valuable in ensuring food safety, nutritional labeling, and quality control.Forensic analysisICP-MS plays a vital role in forensic analysis, particularly in trace metal detection. It assists in identifying and analyzing gunshot residues, detecting and quantifying toxic elements in biological samples from crime scenes, and linking suspects to specific locations based on elemental compositions.ConclusionICP-MS is a powerful analytical technique with a wide range of applications in diverse fields. Its ability to provide high sensitivity, multi-element analysis, and isotopic measurements makes it an indispensable tool for scientific research and industrial analysis. The continued advancements in ICP-MS technology will further enhance its capabilities and contribute to new discoveries in various domains.Remember to include appropriate references and further reading at the end of your document.。
sql timestamp用法(一)

sql timestamp用法(一)SQL TimestampThe SQL timestamp data type is used to store date andtime values. It represents a point in time and is often usedto track the creation or modification time of a record in a database. In this article, we will explore the different aspects of the SQL timestamp and how it can be used invarious scenarios.1. Definition and SyntaxThe SQL timestamp data type is typically defined as follows: TIMESTAMP. It can store values ranging from ’00:00:01’ UTC to ’ 03:14:07’ UTC. The timestamp value is represented as a string in the format ‘YYYY-MM-DD HH:MI:SS’. However, the actual storage format may vary depending on the database system being used.2. Creating a Timestamp ColumnTo create a timestamp column in a database table, you can use the following SQL statement:CREATE TABLE TableName (...timestampColumnName TIMESTAMP,...);This creates a new column called timestampColumnName of the timestamp data type in the table TableName.3. Inserting Timestamp ValuesWhen inserting values into a timestamp column, you can use the current timestamp value using the CURRENT_TIMESTAMP function. For example:INSERT INTO TableName (timestampColumnName)VALUES (CURRENT_TIMESTAMP);This will insert the current timestamp value into the timestampColumnName column.4. Updating Timestamp ValuesTo update a timestamp column with a new value, you can use the CURRENT_TIMESTAMP function in an update statement. For example:UPDATE TableNameSET timestampColumnName = CURRENT_TIMESTAMPWHERE condition;This will update the timestampColumnName column with the current timestamp value for the rows that satisfy the specified condition.5. Retrieving Timestamp ValuesTo retrieve timestamp values from a database table, you can use the SELECT statement. For example:SELECT timestampColumnNameFROM TableNameWHERE condition;This will retrieve the timestamp values from the timestampColumnName column for the rows that satisfy the specified condition.6. Comparing Timestamp ValuesYou can compare timestamp values using comparison operators such as <, >, <=, >=, =, and <>. This can be useful when querying for specific time ranges or finding the latest or earliest timestamp. For example:SELECT *FROM TableNameWHERE timestampColumnName >= ' 00:00:00';This will retrieve all rows from the TableName table where the timestampColumnName is greater than or equal to ’ 00:00:00’.7. Formatting Timestamp ValuesIn addition to the default format, you can format timestamp values using functions specific to the database system. These functions allow you to customize the output to display only the date or time component, or to format the timestamp in a specific way. The available functions may vary depending on the database system being used.ConclusionThe SQL timestamp data type provides a reliable and consistent way to store date and time values in a database.It can be used to track the creation or modification time of records and allows for easy querying and manipulation of timestamp values. By understanding the various aspects of the SQL timestamp, you can effectively use it in your database applications.8. Working with Time ZonesThe SQL timestamp data type is typically stored in Coordinated Universal Time (UTC). However, depending on thedatabase system, you may have the option to store timestampsin a specific time zone.When working with timestamps in different time zones,it’s important to consider how the values will beinterpreted and displayed. Some database systems provide functions to convert timestamps from one time zone to another. This can be useful when working with data from different regions or when displaying timestamps to users in their local time zone.9. Date Arithmetic and TimestampsYou can perform arithmetic operations on timestamp values, such as adding or subtracting a certain number of days or hours. This allows you to manipulate and calculate dates and times in your queries. The specific functions and syntax for performing date arithmetic may vary depending on the database system being used.For example, to add 7 days to a timestamp value, you can use the following syntax:SELECT timestampColumnName + INTERVAL 7 DAYFROM TableName;This will add 7 days to each timestamp value in the timestampColumnName column.10. Converting Timestamps to Other Data TypesIn some cases, you may need to convert a timestamp value to another data type, such as a string or a numeric value. This can be done using the appropriate conversion functions provided by the database system.For example, to convert a timestamp value to a string in a specific format, you can use the following syntax:SELECT TO_CHAR(timestampColumnName, 'YYYY-MM-DD HH2 4:MI:SS')FROM TableName;This will convert each timestamp value in the timestampColumnName column to a string in the specified format.11. Timestamp ConstraintsTimestamp columns can also be used with constraints to enforce certain rules or conditions. For example, you can use the DEFAULT constraint to set a default value for a timestamp column if no value is specified during an insert operation. You can also use the NOT NULL constraint to ensure that a timestamp value must be provided for the column.Additionally, you can use the CHECK constraint to define specific conditions that the timestamp values must satisfy.This can be useful for validating the range of valid timestamp values or ensuring that timestamps are within a certain time frame.ConclusionThe SQL timestamp data type offers a versatile way to store and manipulate date and time values in a database. By understanding its syntax, usage, and various capabilities, you can effectively utilize the timestamp data type in your SQL queries and database applications. The ability to track and work with timestamp values can greatly enhance the functionality and usefulness of your database systems.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Understanding MS-SQL Xml CapabilitiesBy ExamplePrepared and Presented by Eduardo Sobrino, Open KnowledgeLast Update October 29, 20061.0 AbstractMS-SQL 2005 does further support Xml trough various components, interfaces and features through the Native Client, T-SQL and the .Net CLR. Xml is a first class citizen in this MS-SQL 2005 release. This presentation will go through each of the interfaces available to access the Xml features and tools. Various demonstrations will be provided to show how to manage definition schemas, create valid Xml document instances, and query and manipulate those through XPath, XQuery and XSLT.2.0 Learning StrategyA lot has been written about Xml, for starters you will find tons of documentation just for the standard specifications (see XML in “References/Web Site” section) in top of that there is a lot more describing how it is supported in MS-SQL 2005 (S2k5). Since there is enough to learn to get “proficient” in Xml and in its implementation in S2k5 I propose to use the following learning work agenda:XML 101 Basic Training•Understand Xml Schemas Definition (XSD)•Learn XPath 2.0 Expression Language•Learn XQuery 1.0 Query Language•Learn XSLT 2.0 Style Sheet TransformationXML 102 MS-SQL 2005 Basic Training•MS-SQL 2005 Xml Features Overview•Accessing XML: Client Side• Working with ImagesIf you already understand some of the above just jump into those that you need to review, still I hope that you find interesting material in all. This document doesn’t pretend to be an “In-Depth” knowledge of each topic but to get you started.3.0 Preparing Xml SchemasThe purpose of this section is to review a few details that will help you to read and understand a definition schema and get the basics so you write your own. If you open a new “Xml Schema” (xsd) file in VS 2005 you will get something as follows:<?xml version="1.0" encoding="utf-8" ?><xs:schema targetNamespace="/XMLSchema.xsd"elementFormDefault="qualified"xmlns="/XMLSchema.xsd"xmlns:mstns="/XMLSchema.xsd"xmlns:xs="/2001/XMLSchema"></xs:schema>Sample 3.0.1. Schema root element as auto defined in VS 2005 for a new xsd document.Since it is not clear what you need to do to complete a schema definition let me suggest the following:1. Declare the root “<xs:schema>” element with its related and needed URI’s, related aliasesand namespaces (see Sample 3.0.1). Most of the tools that help you writing “xsd” files output similar “<?xml >” and root schema elements as show in Sample 3.0.1. (see the root schema element discussion in 3.0.1 that follows)2. Declare required “<xs:import>” elements that will be used to reference types, attributesand elements on other xsd’s.3. Define all needed “Types” by using the “<xs:complexType>” or “<simpleType>”elements.4. Define needed attributes and elements with the “<xs:attributeGroup>”,“<xs:attribute>” and “<xs:element>” elements.3.1 Defining root “<xs:schema>”.The first line defines the version and encoding and is followed by the “<xs:schema>” root element with the following attributes:Attribute DescriptiontargetNamespace Specify the namespace for the schema constructs such as elementdeclarations, attribute declaration and type definitions contained inthis file.For additional discussion and alternatives while working with defaultnamespaces read /DefaultNamespace.pdf. elementFormDefault Indicates whether or not locally declared elements must be qualifiedby the target namespace in an instance document. If the value ofthis attribute is 'unqualified', then locally declared elements shouldnot be qualified by the target namespace. If the value of thisattribute is 'qualified', then locally declared elements must bequalified by the target namespace.For a discussion on when to hide or expose namespaces read/HideVersusExpose.html.xmlns=Specify the default namespace. (see the “targetNamespace”attribute)xmlns:mstns=Define the “mstns” alias for the“/XMLSchema.xsd” namespace.xmlns:xs=Define the “xs” alias for the“/2001/XMLSchema” namespace.3.1.1 TODO: declare a URI that identify your definitions.The “/XMLSchema.xsd” is not a URL (a resource Locator) but a (temporary) URI (a resource Identifier). As a URI it does not need to point to any Web resource since its objective is to identify your self. Therefore replace it to a URI of your own.In Sample 3.0.1 schema the “targetNamespace”, namespace (“xmlns:mstns="…"”) declarations and related alias (“mstns”) are used to identify the document. Therefore the use of the “mstns” alias will refer to types and elements defined in this document.3.2 “<xs:import >” needed definitions.You can organize your definitions in different files. To help you understand lets assume that you need that valid values are always used to define a customer (or any other entity) kind. In Sample 3.2.1 schema the “KindType” is used to declare the accepted valid values. This means that any other value will invalidate this restriction and therefore will render submitted xml file as invalid.<?xml version="1.0"?><xsd:schema xmlns:xsd="/2001/XMLSchema"targetNamespace="http://openk/EntityCodesSchema"> <xsd:simpleType name="KindType"><xsd:restriction base="xsd:token"><xsd:enumeration value="Corporate"/><xsd:enumeration value="Person"/><xsd:enumeration value="Institution"/></xsd:restriction></xsd:simpleType></xsd:schema>Sample 3.2.1.Schema defining valid (entity) kinds.To reference the “KindType” from another file you will use the “import” element as shown in Sample 3.2.2.<?xml version="1.0"?><xsd:schema xmlns:xsd="/2001/XMLSchema"xmlns:sql="urn:schemas-microsoft-com:mapping-schema"xmlns:opkc="http://openk/EntityCodesSchema"xmlns:opk="http://openk/EntitySchema"targetNamespace="http://openk/EntitySchema"> <xsd:import namespace=http://openk/EntityCodesSchemaschemaLocation="SampleCodes1.xsd" /></xsd:schema>Sample 3.2.2.Referencing the “KindType” using the “import” element.3.3 Define your types.Reviewing the Sample 3.2.1 you see the use of the “simpleType” element, in Sample 3.3 you see the use of the “complexType”. You will use both tags to define all your types.<?xml version="1.0"?><xsd:schema xmlns:xsd="/2001/XMLSchema"xmlns:sql="urn:schemas-microsoft-com:mapping-schema"xmlns:opkc="http://openk/EntityCodesSchema"xmlns:opk="http://openk/EntitySchema"targetNamespace="http://openk/EntitySchema"> <xsd:import namespace=http://openk/EntityCodesSchemaschemaLocation="SampleCodes1.xsd" /><xsd:complexType name="EntityType"><xsd:sequence><xsd:element name="EntityNo" type="xsd:integer" /><xsd:element name="AlternateId" type="xsd:string" /><xsd:element name="Name" type="xsd:string" /></xsd:sequence><xsd:attribute name="Kind" type="opkc:KindType" /> </xsd:complexType><xsd:element name="Entity" type="opk:EntityType" /></xsd:schema>Sample 3.3.1. Define the “EntityType” type.3.4 Define your supported attributes and elements.Define your needed element definitions as shown in Sample 3.3.1 with the “Entity” declaration based on the “opk:EntityType” type.4.0 Understanding XPath v2.0 Expression LanguageThe good news about XPath is that it is easily learned and simple to use. Let’s say you have an Xml document as shown in Sample 4.0.1. XPath samples that will follow will use this Xml document to demonstrate the possible expressions.<?xml version="1.0"?><entities xmlns:xsi="/2001/XMLSchema-instance"> <entity kindno="2"><entityno>0</entityno><alternateid>0001</alternateid><name>Rivera Rivera, Maria</name><phone>787 764-1942</phone></entity><entity kindno="2"><entityno>1</entityno><alternateid>0002</alternateid><name>Rivera Martinez, Carlos</name></entity><entity kindno="2"><entityno>2</entityno><alternateid>0003</alternateid><name>Rivera Sanchez, Coral</name></entity><entity kindno="2"><entityno>3</entityno><alternateid>0004</alternateid><name>Rivera Roman, Raul</name></entity><entity kindno="1"><entityno>4</entityno><alternateid>C001</alternateid><name>Juancho's Inc.</name></entity><entity kindno="1"><entityno>5</entityno><alternateid>C002</alternateid><name>Carros y Algo Mas</name></entity></entities>Sample 4.0.1. Xml document that defines a list of “entities”.4.1 Basic XPath Expressions.A common XPath expression to access Xml nodes is similar to accessing a node in a file system by using a file path. For example the following expression:/entities/entity/nameThe expected output is:name: Rivera Rivera, Marianame: Rivera Martinez, Carlosname: Rivera Sanchez, Coralname: Rivera Roman, Raulname: Juancho's Inc.name: Carros y Algo Mas(6 row(s) affected)You could also submit the expression as “//entity/name” since the “//” references the “root” (in this case the “entities”) element.To get the above output I submit the following request to MS-SQL 2005:declare @xmldoc as nvarchar(max)set @xmldoc ='<...>'declare @h intexec sp_xml_preparedocument @h output, @xmldocselect'name: '+cast([text] as varchar)from openxml(@h,'//entity/name') x where [text] is not null Note that “<...>” represents the Xml as show in Sample 4.0.1 and was not displayed here to conserve space.You could get the values of an attribute as follows://entity/@kindnoIn the previous case you could use a wild card as “//entity/@*” producing the same result since there is only one attribute. When using the wild card as show and if there were more than one attribute in the “entity” element then all of those will have been outputted.By submitting an expression like “//entity” you will get a list of “entity” elements with all their associated attributes and elements.4.2 XPath Filtering Queries.There are various ways to filter the results as follows:Expression Description//entity [phone] Returns all nodes that contain the “phone”element./entities/entity [@kindno="2"] Returns all nodes where the “@kindno” attributevalue is 2.//entity [@kindno >="1"] Returns all nodes whose “@kindno” attribute valueare greater than or equal too 1.4.3 XPath Functions.XPath provide a useful collection of functions including:Expression Description//entity [substring(name,1,3) ="Riv"] Returns all nodes that begin the “//entity/name”begin with “Riv”.//entity [string-length(name) = 14] This will return just one node where the length ofthe name is equal to 14.Although only few samples were given there are quite few more functions available.5.0 Understanding XQuery v1.0 LanguageXQuery is used for querying data from Xml documents. Within XQuery you can write XPath expressions and it also used to transform Xml documents therefore competing with XSLT.To startup let’s submit the following XQuery through MS-SQL 2005 that without too much thought you will understand:declare @xdoc xmlset @xdoc =''select @xdoc.query('(2+2)') -- add too numbersselect @xdoc.query('"que pasa"') -- output a literalselect @xdoc.query('concat(xs:string(2+2),".")')select @xdoc.query('for $a in (1,2,3)return $a') -- output numbersselect @xdoc.query('for $a in ("manzana","calabaza")return $a') -- output wordsset @xdoc='<root><data>test</data></root>'select @xdoc.query('for $a in (xs:string( "hola"), xs:double( "10.123" ),data(/root/data ))return $a') -- output some more stuffdeclare @price moneyset @price=10.123select @xdoc.query('<value>{sql:variable("@price") }</value>')set @xdoc ='<root><a>1</a><a attr="1">2</a></root>'select @xdoc.query('/root/a[./@attr]')-- bad query will result in an empty sequenceset @xdoc='<a>i-am-not-a-number</a>'select @xdoc.query('xs:double(/a[1])')-- OUTPUT (the result of all the above will be)4que pasa4.1 2 3manzana calabazahola 10.123 test<value>10.123</value><a attr="1">2</a>5.1 The FLWOR Expressions.The bread and butter of XQuery are the FLWOR expressions that are sort of the SQL SELECT statement of this language named after five clauses for, let, where, order by, return. By using a sample file “SampleEntity1.xml” Xml file whose content can be seen in 4.0.1 lets write a FLWOR expression:let $doc := doc("./SampleEntity1.xml")for $v in $doc//entity/namewhere ends-with($v, 'Coral')return $v(: outputs "<name>Rivera Sanchez, Coral</name>" :)Another example:let $doc := doc("./SampleEntity1.xml")for $v in $doc//entity/namewhere substring($v, 1,1) ="R"order by $vreturn $v(: outputs:<name>Rivera Martinez, Carlos</name><name>Rivera Rivera, Maria</name><name>Rivera Roman, Raul</name><name>Rivera Sanchez, Coral</name>:)At the same time we filter data we can also transform the file into something else as follows:<customers>{let $doc := doc("./SampleEntity1.xml")for $v in $doc//entitywhere $v [@kindno="2"]order by $v/namereturn<customer id="{$v/alternateid}">{$v/name}</customer>}</customers>(: outputs: (all kind-no = 2 are customers)<customers><customer id="0002"><name>Rivera Martinez, Carlos</name></customer><customer id="0001"><name>Rivera Rivera, Maria</name></customer><customer id="0004"><name>Rivera Roman, Raul</name></customer><customer id="0003"><name>Rivera Sanchez, Coral</name></customer></customers>:)<?xml version="1.0"?><sales><order orderid="0001"><orderdate>1/1/2006</orderdate><customerid>0001</customerid><items><item><sku>TOY-0001</sku><description>Big Doll</description><unit-cost>10.01</unit-cost><quantity>1</quantity><extended-amount>10.01</extended-amount></item><item><sku>FOOD-0002</sku><description>Rice</description><unit-cost>3.52</unit-cost><quantity>2</quantity><extended-amount>7.04</extended-amount></item></items></order><order orderid="0002"><orderdate>1/1/2006</orderdate><customerid>0002</customerid><items><item><sku>TOY-0001</sku><description>Big Doll</description><unit-cost>10.01</unit-cost><quantity>2</quantity><extended-amount>20.02</extended-amount></item></items></order></sales>Document 5.1.0. Sales Data File.Assuming we do have sales information in an Xml file as shown in Document 5.1.0 and submitting the FLWOR expression that follows we will get the sales details by customer:<sales>{let $doc := doc("./SampleEntity1.xml"),$sal := doc("./SampleSales1.xml")for $s in $sal//order,$v in $doc//entitywhere $s [customerid=$v/alternateid]order by $sal/customeridreturn<customer id="{$s/customerid}">{$v/name}<items>{$s/items/item}</items></customer>}</sales>(: outputs:<sales><customer id="0001"><name>Rivera Rivera, Maria</name><items><item><sku>TOY-0001</sku><description>Big Doll</description><unit-cost>10.01</unit-cost><quantity>1</quantity><extended-amount>10.01</extended-amount></item><item><sku>FOOD-0002</sku><description>Rice</description><unit-cost>3.52</unit-cost><quantity>2</quantity><extended-amount>7.04</extended-amount></item></items></customer><customer id="0002"><name>Rivera Martinez, Carlos</name><items><item><sku>TOY-0001</sku><description>Big Doll</description><unit-cost>10.01</unit-cost><quantity>2</quantity><extended-amount>20.02</extended-amount></item></items></customer></sales>:)Another FLWOR expression (that follows) will also get the sales details by customer: for $v in doc("./SampleEntity1.xml")//entityreturn<customer id="{$v/alternateid}">{$v/name}{ for $a in doc("./SampleSales1.xml")//order [customerid=$v/alternateid]return<purchases>{$a/items/item}</purchases>}</customer>(: outputs:<customer id="0001"><name>Rivera Rivera, Maria</name><purchases><item><sku>TOY-0001</sku><description>Big Doll</description><unit-cost>10.01</unit-cost><quantity>1</quantity><extended-amount>10.01</extended-amount></item><item><sku>FOOD-0002</sku><description>Rice</description><unit-cost>3.52</unit-cost><quantity>2</quantity><extended-amount>7.04</extended-amount></item></purchases></customer><customer id="0002"><name>Rivera Martinez, Carlos</name><purchases><item><sku>TOY-0001</sku><description>Big Doll</description><unit-cost>10.01</unit-cost><quantity>2</quantity><extended-amount>20.02</extended-amount></item></purchases></customer><customer id="0003"><name>Rivera Sanchez, Coral</name></customer> <customer id="0004"><name>Rivera Roman, Raul</name></customer><customer id="C001"><name>Juancho's Inc.</name></customer><customer id="C002"><name>Carros y Algo Mas</name></customer> :)You could calculate the total sales as follows:let $subtotals :=for $s in doc("SampleSales1.xml")//order/items/item return $s/quantity * $s/unit-costreturn<total-sales>{ sum( $subtotals ) }</total-sales>(:<total-sales>37.07</total-sales>:)5.2 Working with User-Defined Functions.You can create your own UDF (“User Define Functions”) and use them as follows: declare function local:extended($q as xs:decimal, $u as xs:decimal) as xs:decimal{let $r := $q * $ureturn ($r)};for $a in doc("./SampleSales1.xml")//order/items/itemreturn<Price sku="{$a/sku}"quant="{$a/quantity}"ucost="{$a/unit-cost}"> {local:extended($a/quantity,$a/unit-cost)}</Price>(:<Price quant="1" sku="TOY-0001" ucost="10.01">10.01</Price><Price quant="2" sku="FOOD-0002" ucost="3.52">7.04</Price><Price quant="2" sku="TOY-0001" ucost="10.01">20.02</Price>:)Let’s list the sale items:declare function local:SoldItems($order as element())as element()*{for $i in $order/items/itemreturn<sale sku="{$i/sku}"description="{$i/description}" />};<sales>{for $s in doc("SampleSales1.xml")//orderreturn local:SoldItems($s)}</sales>(:<sales><sale description="Big Doll" sku="TOY-0001"/><sale description="Rice" sku="FOOD-0002"/><sale description="Big Doll" sku="TOY-0001"/></sales>:)We can get the orders total sale as follows:declare function local:OrderTotals($o as xs:string, $i as element()) as element()*{let $subtotals :=for $s in $i/itemreturn $s/quantity * $s/unit-costreturn<total-sale orderid="{$o}">{ sum( $subtotals ) }</total-sale>};<sales>{for $o in doc("SampleSales1.xml")//orderreturnlocal:OrderTotals($o/@orderid,$o/items)}</sales>(:<sales><total-sale orderid="0001">17.05</total-sale><total-sale orderid="0002">20.02</total-sale></sales>:)Calculate total sales as:declare function local:TotalSales($i as element()) as xs:double{let $subtotals :=for $s in $i/order/items/itemreturn $s/quantity * $s/unit-costreturnsum( $subtotals )};let $o := doc("SampleSales1.xml")/salesreturn<total-sales>{xs:string(local:TotalSales($o))}</total-sales>(:<total-sales>37.07</total-sales>:)5.3 Using the “collection” function for Database Access.Various XQuery processors use the “collection” function to access the database. Although I have seen differences in various products the general idea is that you provide the database the schema and particular table resources as follows:collection("KIFv1.Applications.Sessions")/Sessions [StatusNo=0]As you guess, “KIFv1” is the database, “Applications” the schema and “Sessions” the table. The previous query return all the sessions who’s “StatusNo” is 0.Understand that the XQuery implementation in MS-SQL 2005 does not implement all the language functionality. This implementation does not implements the “fn:doc()” and “fn:collection()” functions.6.0 Understanding XSLTXSLT (or “eXtensible Stylesheet Language: Transfomations”) is a language designed for transforming one Xml document into another. As you will soon see with XSLT you can transform an Xml document into another Xml document, HTML and any other “text-based” formats. Working with XSLT is “relatively simple” you can do a lot just concentrating on how you will like to manage (transform) each of the elements of your document. For example, let’s use the previous Document 5.1.0 sales data and write an XSLT file to create an HTML file that display sales information as shown in Figure 6.0.1.Figure 6.0.1. Sales Data HTML document preview.Most of the work done in the 6.0.1 transformation was done by “matching” each Xml document elements as follows:<?xml version = "1.0"?><xsl:stylesheetxmlns:xsl="/1999/XSL/Transform"version="1.0"><xsl:output method="html"/><xsl:template match="/"> …<xsl:template match="order"> …<xsl:template match="items"> …<xsl:template match="item"> …</xsl:stylesheet>Note that in the previous listing the “...” represent the “template” details that I will show a bit later but is hidden here to clearly reveal each template based on matching an element of the Sales document.Now let’s see each matching element details starting with the document “root” (/):<xsl:template match="/"><html><head><title>Stylesheet Example</title></head><body><table align="center" cellpadding="2" cellspacing="0" border="1px"style="border-color:black; width:500px"><tr style="background-color:#eeeeee"><td><xsl:apply-templates select="sales/order" /></td></tr><tr><td align="right"><span><xsl:value-of select="count(sales/order)"/> Orders for a Total of<xsl:value-of select="sum(sales/order/items/item/extended-amount)"/>(USD) Sales.</span></td></tr></table></body></html></xsl:template>The previous template do output the HTML document and transfer the output of the “sales/order” details as defined in another template as follows:<xsl:template match="order"><span>Order#: <xsl:value-of select="attribute::orderid"/>Customer#: <xsl:value-of select="customerid"/>Date: <xsl:value-of select="orderdate"/></span><xsl:apply-templates select="items"><xsl:sort select="orderdate"/></xsl:apply-templates><hr /></xsl:template>The previous template do output some of the “order” details and transfer the output of the order “items” details to another template as follows:<xsl:template match="items"><table align="center" cellpadding="2" cellspacing="0" border="1px"style="border-color:black" width="100%"><tr style="background-color:lightskyblue"><th style="width:90px">Sku</th><th style="width:160px">Description</th><th style="width:70px">Unit-Cost</th><th style="width:60px">Quantity</th><th style="width:60px">Extended</th></tr><xsl:apply-templates select="item"><xsl:sort select="sku"/></xsl:apply-templates><tr><td colspan="4"></td><td align="right" style="background-color:white"><xsl:value-of select="sum(item/extended-amount)"/></td> </tr>。