语义分析代码(模仿语法制导翻译)
编译原理中的词法分析与语法分析原理解析

编译原理中的词法分析与语法分析原理解析编译原理中的词法分析和语法分析是编译器中两个基本阶段的解析过程。
词法分析(Lexical Analysis)是将源代码按照语法规则拆解成一个个的词法单元(Token)的过程。
词法单元是代码中的最小语义单位,如标识符、关键字、运算符、常数等。
词法分析器会从源代码中读取字符流,将字符流转换为具有词法单元类型和属性值的Token序列输出。
词法分析过程中可能会遇到不合法的字符序列,此时会产生词法错误。
语法分析(Syntax Analysis)是对词法单元序列进行语法分析的过程。
语法分析器会根据语法规则,将词法单元序列转换为对应的抽象语法树(Abstract Syntax Tree,AST)。
语法规则用于描述代码的结构和组织方式,如变量声明、函数定义、控制流结构等。
语法分析的过程中,语法分析器会检查代码中的语法错误,例如语法不匹配、缺失分号等。
词法分析和语法分析是编译器的前端部分,也是编译器的基础。
词法分析和语法分析的正确性对于后续的优化和代码生成阶段至关重要。
拓展部分:除了词法分析和语法分析,编译原理中还有其他重要的解析过程,例如语义分析、语法制导翻译、中间代码生成等。
语义分析(Semantic Analysis)是对代码进行语义检查的过程。
语义分析器会根据语言的语义规则检查代码中的语义错误,例如类型不匹配、变量声明未使用等。
语义分析还会进行符号表的构建,维护变量和函数的属性信息。
语法制导翻译(Syntax-Directed Translation)是在语法分析的过程中进行语义处理的一种技术。
通过在语法规则中嵌入语义动作(Semantic Action),语法制导翻译可在语法分析的同时进行语义处理,例如求解表达式的值、生成目标代码等。
中间代码生成(Intermediate Code Generation)是将高级语言源代码转换为中间表示形式的过程。
中间代码是一种抽象的表示形式,可以是三地址码、四元式等形式。
编译原理语法分析报告+代码
语法分析一、实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二、实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
2.1 待分析的简单语言的语法用扩充的BNF表示如下:⑴<程序>::=begin<语句串>end⑵<语句串>::=<语句>{;<语句>}⑶<语句>::=<赋值语句>⑷<赋值语句>::=ID:=<表达式>⑸<表达式>::=<项>{+<项> | -<项>}⑹<项>::=<因子>{*<因子> | /<因子>⑺<因子>::=ID | NUM | (<表达式>)2.2 实验要求说明输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
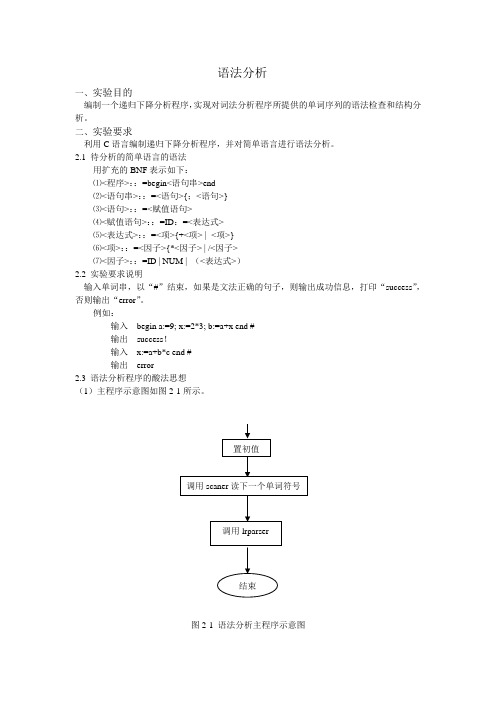
例如:输入begin a:=9; x:=2*3; b:=a+x end #输出success!输入x:=a+b*c end #输出error2.3 语法分析程序的酸法思想(1)主程序示意图如图2-1所示。
图2-1 语法分析主程序示意图(2)递归下降分析程序示意图如图2-2所示。
(3)语句串分析过程示意图如图2-3所示。
图2-3 语句串分析示意图图2-2 递归下降分析程序示意图(4)statement语句分析程序流程如图2-4、2-5、2-6、2-7所示。
图2-4 statement语句分析函数示意图图2-5 expression表达式分析函数示意图图2-7 factor分析过程示意图三、语法分析程序的C语言程序源代码:#include "stdio.h"#include "string.h"char prog[100],token[8],ch;char *rwtab[6]={"begin","if","then","while","do","end"};int syn,p,m,n,sum;int kk;factor();expression();yucu();term();statement();lrparser();scaner();main(){p=kk=0;printf("\nplease input a string (end with '#'): \n");do{ scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;scaner();lrparser();getch();}lrparser(){if(syn==1){scaner(); /*读下一个单词符号*/yucu(); /*调用yucu()函数;*/if (syn==6){ scaner();if ((syn==0)&&(kk==0))printf("success!\n");}else { if(kk!=1) printf("the string haven't got a 'end'!\n");kk=1;}}else { printf("haven't got a 'begin'!\n");kk=1;}return;}yucu(){statement(); /*调用函数statement();*/while(syn==26){scaner(); /*读下一个单词符号*/if(syn!=6)statement(); /*调用函数statement();*/}return;}statement(){ if(syn==10){scaner(); /*读下一个单词符号*/if(syn==18){ scaner(); /*读下一个单词符号*/ expression(); /*调用函数statement();*/ }else { printf("the sing ':=' is wrong!\n");kk=1;}}else { printf("wrong sentence!\n");kk=1;}return;}expression(){ term();while((syn==13)||(syn==14)){ scaner(); /*读下一个单词符号*/ term(); /*调用函数term();*/}return;}term(){ factor();while((syn==15)||(syn==16)){ scaner(); /*读下一个单词符号*/ factor(); /*调用函数factor(); */ }return;}factor(){ if((syn==10)||(syn==11)) scaner();else if(syn==27){ scaner(); /*读下一个单词符号*/expression(); /*调用函数statement();*/ if(syn==28)scaner(); /*读下一个单词符号*/else { printf("the error on '('\n");kk=1;}}else { printf("the expression error!\n");kk=1;}return;}scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;m=0;ch=prog[p++];while(ch==' ')ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;token[m++]='\0';for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}}else if((ch>='0')&&(ch<='9')){ while((ch>='0')&&(ch<='9')){ sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':m=0;ch=prog[p++];if(ch=='>'){ syn=21;}else if(ch=='='){ syn=22;}else{ syn=20;p--;}break;case '>':m=0;ch=prog[p++];if(ch=='='){ syn=24;}else{ syn=23;p--;}break;case ':':m=0;ch=prog[p++];if(ch=='='){ syn=18;}else{ syn=17;p--;}break;case '+': syn=13; break;case '-': syn=14; break;case '*': syn=15;break;case '/': syn=16;break;case '(': syn=27;break;case ')': syn=28;break;case '=': syn=25;break;case ';': syn=26;break;case '#': syn=0;break;default: syn=-1;break;}}四、结果分析:输入begin a:=9; x:=2*3; b:=a+x end # 后输出success!如图4-1所示:图4-1输入x:=a+b*c end # 后输出error 如图4-2所示:图4-2五、总结:通过本次试验,了解了语法分析的运行过程,主程序大致流程为:“置初值”→调用scaner 函数读下一个单词符号→调用IrParse→结束。
语法制导翻译

或1,3,5,2,4,6,7,8,9
编译原理
20
循环依赖Circular dependency
产生式 AB
语义规则 A.s := B.i B.i := A.s + 1
A A.s
B B.i
编译原理
21Biblioteka 属性计算次序构造输入的分析树, 构造属性依赖图, 对结点进行拓扑排序, 按拓扑排序的次序计算属性。
介绍语法制导翻译的实现方法。
编译原理
3
语法制导翻译的一般过程
输入符号串 分析树 依赖图 语义规则的计算顺序
一个句子的翻译过程可以与语法分析过程并行。
编译原理
4
5.1 语法制导定义
语法制导定义是对CFG的推广,每个文法符号都有 一个相关的属性集。
属性:语义信息。一个文法符号通常用一个或若干 个属性来描述它的语义信息。典型例子: ▪ 变量的数据类型 ▪ 表达式的值 ▪ 变量的存储位置 ▪ 程序的目标代码
F.val := digit.lexval
编译原理
13
图5-4
T.val = 15
F.val = 3
T′.inh = 3
.syn =15
digit.lexval =3
*
T1′.inh = 15
F.val = 5
.syn =15
digit.lexval = 5
编译原理
14
继承属性
一个结点的继承属性值由该结点的父结点和(或) 兄弟结点的属性决定。
分析树各结点属性的计算可以自底向上地完成。
编译原理
11
8+5*2 n的注释分析树 (annotated parse tree)
编译原理 第5章语法制导的翻译

属性和文法符号相关联 规则和产生式相关联
根据需要,将文法符号和某些属性相关联, 并通过语义规则来描述如何计算属性的值
E→E1+T E.code=E1.code || T.code || ‘+’ code表示了我们关心的表达式的逆波兰表示,规则说明 加法表达式的逆波兰表示由两个分量的逆波兰表示并置, 然后加上‘+’得到。
digitlexval=3
18
适用于自顶向下分析的SDD
前面的表达式文法存在直接左递归,因 此无法直接用自顶向下方法处理。 消除左递归之后,无法直接使用属性val 进行处理:
比如规则:T→FT’ T’→*FT’ T对应的项中,第一个因子对应于F, 而运算符在T’中。
19
相同表达式的不同文法的比较
38
例5.15 分析栈实现的例子
假设语法分析栈存放在一个被称为stack 的记录数组中,下标top指向栈顶;
stack[top]指向这个栈的栈顶;stack[top-1] 指向栈顶下一个位置; 如果不同的文法符号有不同的属性集合,我 们可以使用union来保存这些属性值。(归 约时,我们知道栈顶向下的各个符号分别是 什么)
语义翻译的流程
输 入 符 号 串 分 析 树 依 赖 图
语
义
规
则
的 计
实际上,编译中语义翻译的实现并不是 按图中的流程处理的;而是随语法分析 的进展,识别出一个语法结构,就对它 的语义进行分析和翻译。
算
9
5.1 语法制导定义
4.什么是语法制导定义(SDD) 上下文无关文法和属性/规则的结合;
语法制导翻译

2
4.1 语法制导翻译简介
语法与语义
1. 语法与语义的关系 语法是指语言的结构、即语言的“样子”;语义是指附着于语
言结构上的实际含意 ,即语言的“意义”。 ① 语义不能离开语法独立存在; ② 语义远比语法复杂; ③ 同一语言结构可包含多种含意,不同语言结构可表示相
② 若b是α中某文法符号Xi的属性,c1, c2, ..., ck是A的属性, 或者是α中其它文法符号的属性,则称b是Xi的继承属性。
③ 称(4.1)中属性b依赖于属性c1, c2, ..., ck。
④ 若语义规则的形式如下述(4.2),则可将其想像为产生式左 部文法符号A的一个虚拟属性。属性之间的依赖关系,在 虚拟属性上依然存在。
k := k+1;
9
4.1 语法制导翻译简介
产生式
语法制导定义
翻译方案
L→E
print(E.post)
print_post(post);
E → E1 + E2 E → num
E.post := E1.post || post(k) := '+'; E2.post || '+'; k := k+1;
1. 编译器各阶段的完整输出,均可以被认为是源程序的某种 中间表示。
2. 本章讨论的是中间代码生成器输出的中间表示,称之为中 间代码。
3. 中间代码实际上应起一个编译器前端与后端分水岭的作用。 4. 要求中间代码具有如下特性,以便于编译器的开发移植和
代码的优化: ① 便于语法制导翻译; ② 既与机器指令的结构相近,又与具体机器无关。 5. 中间代码的主要形式:树、后缀式、三地址码等。
语义分析和语法制导翻译-编译原理-06-(二)

E.place:= E1.place; E.code:= E1.code
E.place:= id.place; E.code:= ' ' E.place:= num.val;E.code:= ' '
注释: || 表示代码序列的连接
T.type := „real‟ L1.in := L.in addtype( id.entry, L.in )
L → id
entry addtype
addtype( id.entry, L.in ) 单词 id 的属性(符号表入口)
在符号表中为变量填加类型信息
属性文法的作用
抽象描述语义处理的要求
习题
1. 下列文法是一个二进制数的文法。试根据 该文法,编写一个语法制导定义,描述由 S 生成的二进制数的数值计算。 S -> L . L L -> L B | B B -> 0 | 1 2. 参照下列表达式文法编写语法制导定义, 描述表达式的类型计算。要求在不同精度的 数的计算中,结果取精度高的类型。 E -> E + T | T T -> n.n | n
分析树和属性计算
S-属性定义:
仅包括综合属性
对于所有A
→ X1 X2 …Xn, 的属性
A的属性计算仅用X1…Xn
如:算术表达式求值的属性文法
L-属性定义:
其属性可用深度优先的顺序从左
至右计算
对于所有 Xi
A→X1 X2 … Xn
属性计算仅使用A X1 X2 … Xi-1 的属性
语法制导翻译方案

语法制导翻译方案1. 简介语法制导翻译是一种通过编译器根据源语言的语法结构来生成目标语言代码的方法。
它使用语法规则和语义动作来将源代码翻译为目标语言,并在翻译过程中进行语义分析和语法分析。
在这篇文档中,我们将介绍语法制导翻译的基本原理和实现方法,并给出一个具体的实例来说明如何使用语法制导翻译方案进行代码翻译。
2. 基本原理语法制导翻译的基本原理是通过使用语法规则和语义动作来将源语言的语句转换为目标语言的等价语句。
它结合了语义分析和语法分析的过程,并通过语法规则和语义动作建立源语言和目标语言之间的映射关系。
在语法分析的过程中,编译器会根据语法规则来判断源语言的语句是否合法,并进行相应的语法转换。
在语义分析的过程中,编译器会根据语义动作来处理源语言的语句,并生成目标语言的等价语句。
3. 实现方法3.1 语法规则语法规则是语法制导翻译的核心部分,它定义了源语言和目标语言之间的转换规则。
语法规则通常由产生式表示,它描述了源语言的各种语句的组合方式和语义含义。
在编译器的实现过程中,需要根据语法规则来判断源语言的语句是否符合规范,并进行相应的转换。
3.2 语义动作语义动作是语法制导翻译中的一种处理方式,它在语法分析的过程中根据语法规则进行相应的处理。
语义动作通常由一段代码表示,它用于实现特定的语义操作,例如变量声明、函数调用等。
在编译器的实现过程中,需要根据语义动作来处理源语言的语句,并生成目标语言的等价语句。
3.3 语法制导翻译的流程语法制导翻译的流程通常包括以下几个步骤:1.词法分析:将源代码分割为一个个的词法单元,并进行词法分析,生成词法分析结果。
2.语法分析:根据语法规则对词法分析结果进行语法分析,生成语法分析树。
3.语义分析:根据语义动作对语法分析树进行语义分析,生成目标语言的等价语句。
4.代码生成:根据目标语言的语法规则将目标语言的等价语句转化为目标语言的代码。
3.4 代码示例以下是一个简单的示例,演示了如何使用语法制导翻译方案将一个简单的算术表达式翻译为目标语言的等价表达式。
语法制导翻译与生成中间代码(附代码)

"<<arg1<<endl; else cout<<address++<<":"<<" "<<result<<" = "<<arg1<<"
"<<op_1<<" "<<arg2<<endl; return result;
} return ""; }
/*****处理表达式*****/ string expression() {
六、附录代码 #include <iostream> #include <algorithm> #include<conio.h> using namespace std;
int address=100; //每条分析语句的地址
int LID=0;
//表示过程执行到相应位置的地址符号
int tID=0;
源程序翻译为四元式输出,若有错误将错误信息输出。
三、设计思路 1. 分析过程 主函数,读取文件,存入字符串数组,调用语义分析,判断
第8讲 语法制导翻译_1

3*5+4n
副作用(Side effect)
语义规则
E.val=15 + T.val=4
print(E.val)
E.val = E1 .val + T.val E.val = T.val
T.val = T1val × F.val
T.val = F.val
T.val=15
F.val=4
T.val=3 * F.val=5 digit.lexval=4
如果一个SDD是S属性的,可以按照语法分析树节点的任何 自底向上顺序来计算它的各个属性值
S-属性定义可以在自底向上的语法分析过程中实现
L- 属 性 定 义
L-属性定义( 也称为L属性的SDD或L-SDD) 的 直观含义:在一个产生式所关联的各属性之间, 依赖图的边可以从左到右,但不能从右到左 ( 个SDD是L-属性定义,当且仅当它的每个属性要 么是一个综合属性,要么是满足如下条件的继承属 性:假设存在一个产生式A→X1X2…Xn,其右部符 号Xi (1 i n)的继承属性仅依赖于下列属性:
A的继承属性 产生式中Xi左边的符号 X1, X2, … , Xi-1 的属性 Xi本身的属性,但Xi 的全部属性不能在依赖图中形成环路
将每个产生式和一组语义规则相关联,用来计算 该产生式中各文法符号的属性值
文法符号的属性
综合属性 ( synthesized attribute) 继承属性 ( inherited attribute)
综 合 属 性 ( synthesized attribute)
在分析树结点 N上的非终结符A的综合属性只能通 过 N的子结点或 N本身的属性值来定义
两个概念
将语义规则同语法规则(产生式)联系起来要 涉及两个概念
Python技术实现自然语言处理中的语义分析

Python技术实现自然语言处理中的语义分析自然语言处理(Natural Language Processing,简称NLP)是一门研究如何使计算机能够理解和处理自然语言的学科。
在NLP的应用中,语义分析是一个关键的环节。
语义分析的目的是从文本中提取出语义信息,帮助计算机理解句子的真正含义。
Python作为一种简单易学且功能强大的编程语言,被广泛应用于自然语言处理任务中。
Python的优势在于它具备丰富的第三方库,其中一些库专门针对NLP任务进行开发。
本文将介绍如何使用Python实现自然语言处理中的语义分析。
在Python中,有几个重要的工具包可以帮助我们进行语义分析。
其中最受欢迎的就是Natural Language Toolkit(NLTK)和spaCy。
这两个工具包都提供了丰富的功能,包括分词、词性标注、句法分析和语义角色标注等。
首先,让我们来看一下Python如何进行分词和词性标注。
分词是将连续的文本分割成单个的词语的过程,而词性标注则是为每个词语标注其相应的词性。
NLTK和spaCy都提供了方便的函数来执行这些任务。
下面是一个使用NLTK进行分词和词性标注的示例:```import nltkfrom nltk.tokenize import word_tokenizefrom nltk import pos_tagdef tokenize_and_tag(text):tokens = word_tokenize(text)tagged_tokens = pos_tag(tokens)return tagged_tokenstext = "I love playing soccer"tagged_text = tokenize_and_tag(text)print(tagged_text)```上述代码使用NLTK的`word_tokenize`函数将输入文本分割成词语,并使用`pos_tag`函数为每个词语标注词性。
编译原理名词解释

编译原理名词解释1. 词法分析器(Lexer):也称为扫描器(Scanner),用于将源代码分割成一个个单词(Token)。
2. 语法分析器(Parser):将词法分析器生成的单词序列转换成语法树(Parse Tree)或抽象语法树(Abstract Syntax Tree)。
3. 语法树(Parse Tree):表示源代码的语法结构的树状结构,它由语法分析器根据语法规则生成。
4. 抽象语法树(Abstract Syntax Tree):比语法树更加简化和抽象的树状结构,用于表示源代码的语义结构。
5. 语义分析器(Semantic Analyzer):对抽象语法树进行语义检查,并生成中间代码或目标代码。
6. 中间代码(Intermediate code):一种介于源代码和目标代码之间的中间表示形式,可以被不同的优化器和代码生成器使用。
7. 目标代码生成器(Code Generator):将中间代码转换成特定目标平台的机器代码。
8. 优化器(Optimizer):用于对中间代码进行优化,以提高代码的执行效率和资源利用率。
9. 符号表(Symbol Table):用于存储程序中的标识符(变量、函数等)的信息,包括名称、类型等。
10. 语言文法(Grammar):定义了一种语言的语法规则,常用的形式包括上下文无关文法和正则文法。
11. 上下文无关文法(Context-free Grammar):一种形式化的语法表示方法,由产生式和非终结符组成,描述一种语言的句子结构。
12. 语言解释器(Interpreter):将源代码逐行解释执行的程序,不需要生成目标代码。
13. 回溯法(Backtracking):一种递归式的算法,用于在语法分析过程中根据产生式进行选择。
14. 正则表达式(Regular Expression):用于描述一类字符串的表达式,可以用于词法分析中的模式匹配。
15. 自顶向下分析(Top-down Parsing):从文法的起始符号开始,按照语法规则逐步构建语法树的过程。
编译原理词法分析和语法分析报告+代码(C语言版)

词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符: = + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图:主程序示意图如图3-1所示。
其中初始包括以下两个方面:⑴关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。
如能查到匹配的单词,则该单词为关键字,否则为一般标识符。
关键字表为一个字符串数组,其描述如下:Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,};图3-1(2)程序中需要用到的主要变量为syn,token和sum3.2 扫描子程序的算法思想:首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。
语法制导翻译与生成中间代码(附代码)
/*****处理表达式*****/ string expression_1(string &op) {
if(shuru[ip]=="*"||shuru[ip]=="/")
{ op=shuru[ip]; ip++; string arg1=element(); string op_1="",result=link("t",tID++); string arg2=expression_1(op_1); if(op_1=="")op_1="="; if(arg2=="") cout<<address++<<":"<<" "<<result<<" =
//while 的语义子程序
condition(L2,next); } else {
puts("Lack(");return; } if(shuru[ip]==")") ip++; else {
语法制导的翻译方案

语法制导的翻译方案1. 引言语法制导翻译是一种基于文法规则的翻译技术,它可以将源语言文本转化为目标语言文本。
在本文档中,我们将介绍语法制导的翻译方案,包括其基本原理、常用方法以及在实际应用中的一些注意事项。
2. 基本原理语法制导的翻译方案基于上下文无关文法(Context-Free Grammar,CFG)和语义动作,它通过在文法规则中插入动作,实现从源语言到目标语言的翻译过程。
在每个文法规则中,我们可以定义一个或多个动作,这些动作在分析过程中被触发,并产生对应的目标语言文本。
3. 常用方法3.1 自顶向下翻译自顶向下翻译是一种从文法的起始符号开始,逐步扩展语法树的过程。
它可以按照语法规则的顺序依次进行翻译,对于每个文法规则,我们可以定义相应的语义动作来生成目标语言文本。
自顶向下翻译的优点是简单直观,但在处理左递归时可能会出现无限递归的情况。
3.2 自底向上翻译自底向上翻译是一种从文法的终结符开始,逐步构建语法树的过程。
它通过将终结符逐步合并为非终结符,最终构建出完整的语法树。
自底向上翻译的优点是可以有效处理左递归,并且可以在翻译过程中处理语法上的歧义。
3.3 语法推导翻译语法推导翻译是一种基于文法推导的翻译方法。
它通过将源语言文本转化为一个推导序列,然后通过逐步应用文法规则,将推导序列转化为目标语言文本。
语法推导翻译的优点是可以明确表示翻译过程中的每一步,并且可以通过扩展文法规则来处理文法上的不完备性。
4. 实际应用中的注意事项在实际应用中,语法制导的翻译方案需要考虑以下几点注意事项:•文法设计:文法的设计需要充分考虑源语言和目标语言之间的语法结构和语义关系。
合理地定义文法规则和语义动作,可以提高翻译的准确性和效率。
•优化翻译过程:在翻译过程中,我们可以通过优化技术来提高翻译的效率。
例如,可以使用语法分析器生成的语法树作为翻译的输入,避免重复的语法分析过程。
•处理语义歧义:在翻译过程中,可能会遇到多义词或歧义句子的情况。
sdt编译原理

sdt编译原理SDT(Syntax Directed Translation)编译原理编译原理是计算机科学中一门重要的学科,它研究的是将高级语言代码转化为可执行的机器代码的过程。
而在编译原理中,SDT (Syntax Directed Translation)是一种用于描述语法制导翻译(Syntax-Directed Translation)的方法。
语法制导翻译是指在语法分析的基础上,通过对语法树的遍历来为每个语法树节点添加翻译动作,从而实现将源程序转化为目标代码的过程。
SDT是一种基于语法制导翻译的具体实现方法,它通过添加语义规则来描述翻译过程中的语义动作。
在SDT编译原理中,一个重要的概念是属性文法(Attribute Grammar)。
属性文法是一种形式化的表示方法,用于描述语法制导翻译中属性的计算和传递规则。
属性文法由三个部分组成:文法规则、属性定义和属性计算规则。
文法规则定义了语法结构,属性定义指定了每个语法结构的属性,属性计算规则定义了属性之间的依赖关系和计算规则。
在SDT编译原理中,属性文法的定义是基于语法规则的。
每个语法规则都可以附加一个或多个属性,这些属性可以是终结符、非终结符或其他用户定义的属性。
通过属性文法的定义,可以实现在语法分析过程中对属性的计算和传递。
SDT编译原理的核心是属性计算规则。
属性计算规则定义了属性之间的依赖关系和计算规则,它描述了如何根据已知的属性值计算未知的属性值。
属性计算规则可以根据语法规则和属性定义来定义,通过对属性计算规则的定义和应用,可以实现语义动作的计算和传递。
在SDT编译原理中,属性计算规则的应用可以分为两个阶段:自上而下的属性计算和自下而上的属性计算。
自上而下的属性计算是从根节点开始,通过对属性计算规则的应用,逐步计算出各个节点的属性值。
自下而上的属性计算是从叶节点开始,通过对属性计算规则的应用,逐步计算出根节点的属性值。
总结起来,SDT编译原理是一种基于语法制导翻译的方法,通过添加语义规则和属性文法的定义,实现了将源程序转化为目标代码的过程。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
#include<iostream>#include<stack>#include<ctype.h>using namespace std;stack<int> state;stack<char> symbol;stack<int> val;char sen[50];char sym[12][6]={//符号表{'s','e','e','s','e','e'},{'e','s','e','e','e','a'},{'r','r','s','r','r','r'},{'r','r','r','r','r','r'},{'s','e','e','s','e','e'},{'r','r','r','r','r','r'},{'s','e','e','s','e','e'},{'s','e','e','s','e','e'},{'e','s','e','e','s','e'},{'r','r','s','r','r','r'},{'r','r','r','r','r','r'},{'r','r','r','r','r','r'}};char snum[12][6]={//数字表{5,1,1,4,2,1},{3,6,5,3,2,0},{2,2,7,2,2,2},{4,4,4,4,4,4},{5,1,1,4,2,1},{6,6,6,6,6,6},{5,1,1,4,2,1},{5,1,1,4,2,1},{3,6,5,3,11,4},{1,1,7,1,1,1},{3,3,3,3,3,3},{5,5,5,5,5,5}};int go2[12][3]={//goto表{1,2,3},{0,0,0},{0,0,0},{0,0,0},{8,2,3},{0,0,0},{0,9,3},{0,0,10},{0,0,0},{0,0,0},{0,0,0},{0,0,0}};void action(int i,char *&a,char &how,int &num,char &A,int &b)//action函数[i,a] {int j,r;switch(*a){case 'i'://case 'd':j=0;break;case '+':j=1;break;case '*':j=2;break;case '(':j=3;break;case ')':j=4;break;case '#':j=5;break;default:j=-1;break;}if(j!=-1){how=sym[i][j];num=snum[i][j];if(how=='r'){switch(num){case 1:A='E',b=3;cout<<"按E->E1+T规约\tE.val=E1.val+T.val\t"<<val.top();r=val.top(); val.pop(); val.pop(); r=r+val.top(); val.pop(); val.push(r);cout<<"\t\t"<<val.top()<<endl;break;case 2:A='E',b=1;cout<<"按E->T规约\tE.val=T.val\t\t"<<val.top()<<"\t\t"<<val.top()<<endl;break;case 3:A='T',b=3;cout<<"按T->T1*F规约\tT.val=T1.val*F.val\t"<<val.top();r=val.top(); val.pop(); val.pop(); r=r*val.top(); val.pop(); val.push(r);cout<<"\t\t"<<val.top()<<endl;break;case 4:A='T',b=1;cout<<"按T->F规约\tT.val=F.val\t\t"<<val.top()<<"\t\t"<<val.top()<<endl;break;case 5:A='F',b=3;cout<<"按F->(E)规约\tF.val=E.val\t\t"<<val.top();val.pop(); r=val.top(); val.pop(); val.pop(); val.push(r);cout<<"\t\t"<<val.top()<<endl;break;case 6:A='F',b=1;cout<<"按F->digit规约\tF.val=digit.lexval\t"<<val.top()<<"\t\t"<<val.top()<<endl;break;default:break;}}}}int go(int t,char A)//goto[t,A]{switch(A){case 'E':return go2[t][0];break;case 'T':return go2[t][1];break;case 'F':return go2[t][2];break;}}void error(int i,int j,char *&a)//error显示函数{cout<<"error"<<endl;switch(j){case 1://期望输入id或左括号,但是碰到+,*,或$,就假设已经输入id了,转到状态5 //state.push(5);//symbol.push('i');//必须有这个,如果假设输入id的话,符号栈里必须有....cout<<"缺少运算对象digit"<<endl;break;case 2://从输入中删除右括号//a++;cout<<"不配对的右括号"<<endl;break;case 3://期望碰到+,但是输入id或左括号,假设已经输入算符+,转到状态6//state.push(6);//symbol.push('+');cout<<"缺少运算符"<<endl;break;case 4://缺少右括号,假设已经输入右括号,转到状态11//state.push(11);//symbol.push(')');cout<<"缺少右括号"<<endl;break;case 5://a++;cout<<"*号无效,应该输入+号!"<<endl;//case 6:// a++;}}int main(){int s;char *a;char how;int num;int b;char A;int sum=-1;while(1){cin>>sen;a=sen;state.push(0);//先输入0状态cout<<"动作\t\t语义规则\t\t规约前val栈顶\t规约后val栈顶"<<endl; while(*a!='\0'){b=0;num=0;how='\0';A='\0';s=state.top();if(isdigit(*a)){sum=0;do{sum=sum*10+(*a-48);a++;}while(isdigit(*a));a--;*a='i';}action(s,a,how,num,A,b);if(how=='s')//移进{cout<<"移进"<<endl;symbol.push(*a);state.push(num);val.push(sum);sum=-1;a++;}else if(how=='r')//规约{for(int i=0;i<b;i++){if(!state.empty())state.pop();if(!symbol.empty())symbol.pop();}int t=state.top();symbol.push(A);state.push(go(t,A));}else if(how=='a')//接受{val.push(-1);cout<<"按L->En规约\tprint(E.val)\t\t"<<val.top();val.pop();cout<<"\t\t"<<val.top()<<endl;cout<<"成功接受"<<endl;cout<<"最终结果:"<<val.top()<<endl;break;}else{error(s,num,a);//错误显示cout<<"输入有误,重新输入!"<<endl;break;}}}return 0;}。