倒排索引的mapreduce代码
Lucene源码分析之倒排索引(一)

Lucene源码分析之倒排索引(⼀)倒排索引是 Lucene 的核⼼数据结构,该系列⽂章将从源码层⾯(源码版本:)分析。
该系列⽂章将以如下的思路展开。
1. 什么是倒排索引?2. 如何定位 Lucene 中的倒排索引?3. 倒排索引是如何搜索的?4. 倒排索引是如何增删改的?本⽂将介绍什么是倒排索引。
了解什么是倒排索引,其实是去了解为什么要有倒排索引。
考虑这样⼀种场景,给你很多篇⽂档,现在要求找出包含指定单词的⽂档。
第⼀种解决⽅案,遍历所有⽂档,⾃然能得到结果。
第⼆种解决⽅案,遍历所有⽂档,得到结果后记录下来,下次再有这种请求时直接读取结果。
如果把所有单词的结果都记录下来,之后的任何请求都能直接从结果中读取,这个结果的集合就叫做倒排索引。
以两个⽂档为例:1.hello world!2.hello china!如何找出包含 china 的⽂档?⼀眼扫过去就知道是第 2 个⽂档(但在⽂档数量很多内容很⼤的情况下,可能需要很多眼)。
但如果将所有结果(即倒排索引)提前记录如下。
单词⽂档hello1,2world1china2让你找出包含 china 的⽂档。
不需要再去扫⽂档,根据倒排索引可知是第 2 个⽂档(在⽂档数量很多内容很⼤的情况下,能极⼤地提升效率)。
有些同学会问,两种解决⽅案都要去遍历⽂档,为什么采⽤第⼆种解决⽅案?因为后者只需要遍历⼀次,以后每次查询的时候直接查询倒排索引即可。
有些同学会问,如果采⽤第⼆种解决⽅案,当增删改⽂档的时候,倒排索引⽂件就不对了,那还是得重新遍历⼀次?不需要,将增删改⽂档转换为增删改倒排索引即可。
有些同学会问,增删改倒排索引的性能会不会很差?这个答案会在后⾯的⽂章中给出。
⽽这也成为 Lucene 不断优化的⽬标之⼀。
elasticsearch倒排索引原理一句话

Elasticsearch倒排索引原理一句话摘要本文介绍了E la st ic s ea rc h倒排索引的原理和作用。
倒排索引是E l as ti cs ea rc h中最重要的数据结构之一,它通过将文档中的每个词与出现该词的文档相关联,提供了高效的全文搜索和检索功能。
1.引言E l as ti cs ea rc h是一个开源的分布式搜索和分析引擎,被广泛应用于各种场景,包括企业搜索、日志分析、数据挖掘等。
在El as ti c se ar ch 中,倒排索引扮演了重要角色,它是实现快速搜索和高效存储的关键技术之一。
2.倒排索引的基本概念倒排索引(I nv er ted I nd ex)是El as tic s ea rc h用于实现全文搜索的核心数据结构。
它由两个基本部分组成:词项列表和倒排列表。
词项列表是将文档中出现的所有词建立一个索引,并进行排序。
倒排列表则是将每个词与出现该词的文档进行关联。
3.倒排索引的构建过程倒排索引的构建过程可以分为三个阶段:分词、建立倒排记录和排序。
首先,将待索引的文档进行分词,将文档拆分成独立的词项。
然后,对每个词项建立倒排记录,记录该词项在哪些文档中出现。
最后,对倒排记录进行排序,以便能够快速地进行搜索和检索。
4.倒排索引的搜索过程倒排索引的搜索过程包括两个关键步骤:词项匹配和文档排序。
首先,将用户查询进行分词,并在倒排索引中查找包含这些词的文档。
然后,根据一定的规则对匹配到的文档进行排序,以便将最相关的文档排在前面。
5.倒排索引的优势与应用倒排索引作为一种高效的全文搜索技术,在各种应用场景中具有广泛的应用。
它可以快速地定位到包含查询词的文档,并根据相关性进行排序,提供精准的搜索结果。
在El as ti cs ea rch中,倒排索引的应用不仅限于文本搜索,还可以用于地理位置搜索、时间序列分析等领域。
6.结论通过本文的介绍,我们了解了El as ti cse a rc h倒排索引的原理和应用。
实操18-MapReduce操作实例-倒排索引

private static Text keyinfo = new Text(); private static final Text valueinfo = new Text("1"); @Override /**
//获取单词 key.set(key.toString().substring(0, indexOf));
//写入上下文中 context.write(key, info);
}
} 3. 创建 Reducer 类 package com.itcast.mr.InvertedIndex;
import java.io.IOException;
//设置 job 对象 job.setJarByClass(InvertedIndexDriver.class); job.setMapperClass(InvertedIndexMapper.class);
job.setCombinerClass(InvertedIndexCombiner.class); job.setReducerClass(InvertedIndexReducer.class);
public class InvertedIndexDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//获取 job 对象 Configuration conf = new Configuration(); Job job = Job.getInstance(conf);
《大数据技术原理与操作应用》第4章习题答案

第4章课后习题答案一、单选题1.在 MapReduce 程序中,map() 函数接收的数据格式是(A. 字符串B. 整型C. LongD. 键值对参考答案:D2.每个 Map 任务都有一个内存缓冲区,默认大小是( ) 。
A. 128 MBB. 64 MBC. 100 MBD. 32 MB参考答案:C3.在 MapTask 的 Combine 阶段,当处理完所有数据时,MapTask 会对所有的临时文件进行一次() 。
A. 分片操作B. 合并操作C. 格式化操作D. 溢写操作参考答案:B4.下列选项中,主要用于决定整个 MapReduce 程序性能高低的阶段是( ) 。
A. MapTaskB. ReduceTaskC. 分片、格式化数据源D. Shuffle参考答案:D二、判断题1. MapReduce 编程模型借鉴了面向过程的编程语言的设计思想。
( )参考答案:错2.在MapReduce 程序进行格式化数据源操作时, 是将划分好的分片格式化为键值对“ < key,value > ” 形式的数据。
( )参考答案:对3.带有倒排索引的文件称为“倒排索引文件”,简称“ 倒排文件” 。
( )参考答案:对4.reduce() 函数会将 map( ) 函数输出的键值对作为输入,将相同 key 值的 value 进行汇总,输出新的键值对。
( )参考答案:对5.MapReduce 通过 TextOutputFormat 组件输出到结果文件中。
( )参考答案:对biner 组件可以让 Map 对 key 进行分区,从而可以根据不同的 key 分发到不同的Reduce 中去处理。
( )参考答案:错7.对于 MapReduce 任务来说,一定需要 Reduce 过程。
( )参考答案:错8.在 MapReduce 程序中,只有 Map 阶段涉及 Shuffle 机制。
( )参考答案:错9.MapReduce 的数据流模型可能只有 Map 过程,由 Map 产生的数据直接被写入 HDFS中。
elasticsearch 倒排索引的数据结构

Elasticsearch 是一个开源的分布式搜索引擎,它支持实时的搜索和分析功能。
倒排索引是 Elasticsearch 的核心数据结构之一,它是实现搜索和分析功能的关键。
本文将详细介绍 Elasticsearch 倒排索引的数据结构,帮助读者深入理解 Elasticsearch 的工作原理和内部机制。
一、倒排索引简介倒排索引(Inverted Index)是一种常见的索引数据结构,它将文档中的词条与之出现的文档进行映射,以便快速定位包含特定词条的文档。
在 Elasticsearch 中,倒排索引是以词条为单位进行构建和存储的,每个词条都记录了包含该词条的文档列表以及在文档中的位置信息。
这种数据结构的设计使得 Elasticsearch 能够高效地进行搜索、聚合和分析操作。
二、倒排索引的数据结构1. 词条字典(Terms Dictionary):词条字典是倒排索引的核心部分,它维护了所有出现过的词条及其对应的词频、文档频率等信息。
词条字典通常采用有序数组或者基于前缀树的数据结构进行存储,以便快速进行词条的查找、插入和删除操作。
2. 倒排列表(Inverted List):倒排列表是词条字典中每个词条对应的存储结构,它记录了包含该词条的文档列表以及在文档中的位置信息。
倒排列表通常采用压缩编码和位图索引等技术进行存储,以节省存储空间和提高访问效率。
3. 文档词频和位置信息(Term Frequency and Position):除了记录文档列表外,倒排列表还需要记录每个文档中词条的词频和位置信息,以便进行相关性评分和短语查询等操作。
文档词频和位置信息通常存储在倒排列表的条目中,用于支持相关性评分和位置查询等功能。
4. 索引段(Index Segment):为了支持分布式和持久化存储,Elasticsearch 将倒排索引划分为若干个索引段进行管理。
每个索引段都包含了倒排列表以及相关的元数据信息,以便支持快速的搜索和更新操作。
21_尚硅谷大数据之MapReduce扩展案例
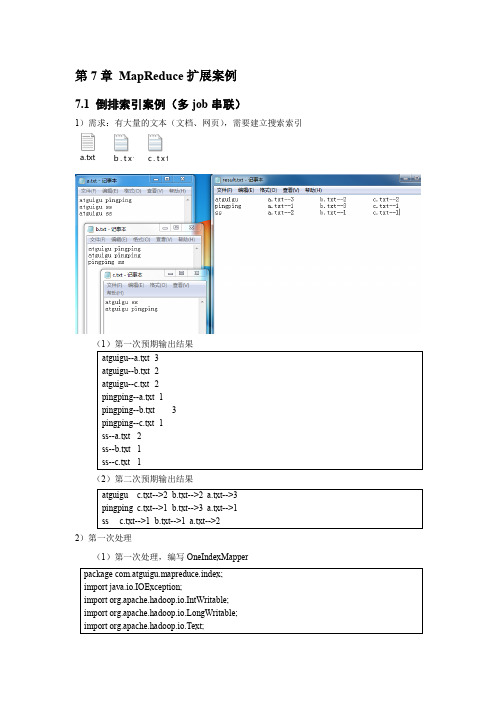
第7章 MapReduce 扩展案例7.1 倒排索引案例(多job 串联)1)需求:有大量的文本(文档、网页),需要建立搜索索引a.txt b .t x t c.t x t(2)第二次预期输出结果2)第一次处理(1)第一次处理,编写OneIndexMapper(2)第一次处理,编写OneIndexReducer(3)第一次处理,编写OneIndexDriver(4)查看第一次输出结果3)第二次处理(1)第二次处理,编写TwoIndexMapper(2)第二次处理,编写TwoIndexReducer(3)第二次处理,编写TwoIndexDriver(4)第二次查看最终结果7.2 找博客共同好友案例1)需求:以下是博客的好友列表数据,冒号前是一个用户,冒号后是该用户的所有好友(数据中的好友关系是单向的)friends.txt求出哪些人两两之间有共同好友,及他俩的共同好友都有谁?2)需求分析:先求出A、B、C、….等是谁的好友第一次输出结果第二次输出结果3)代码实现:(1)第一次Mapper(2)第一次Reducer(3)第一次Driver(4)第二次Mapper(5)第二次Reducer(6)第二次Driver7.3 Top10案例1)需求:对需求2.4输出结果进行加工,输出流量使用量在前10的用户信息2)实现代码(1)编写JavaBean类package com.atguigu.mr;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;import org.apache.hadoop.io.WritableComparable;public class FlowBean implements WritableComparable<FlowBean> {private Long sumFlow; // 总流量private String phoneNum; // 手机号// 空参构造public FlowBean() {super();}public Long getSumFlow() {return sumFlow;}public void setSumFlow(Long sumFlow) {this.sumFlow = sumFlow;}public String getPhoneNum() {return phoneNum;}public void setPhoneNum(String phoneNum) {this.phoneNum = phoneNum;}@Overridepublic String toString() {return sumFlow + "\t" + phoneNum;}@Overridepublic void write(DataOutput out) throws IOException { // 序列化out.writeLong(sumFlow);out.writeUTF(phoneNum);}@Overridepublic void readFields(DataInput in) throws IOException { // 反序列化this.sumFlow = in.readLong();this.phoneNum = in.readUTF();}@Overridepublic int compareTo(FlowBean o) {int result;result = pareTo(o.sumFlow);if (result == 0) {result = pareTo(o.phoneNum);}return result;}}(2)编写TopTenMapper类(3)编写TopTenReducer类(4)编写驱动类。
详解MapReduce的模式、算法和用例 - Hadoop - TechTarget商务智能
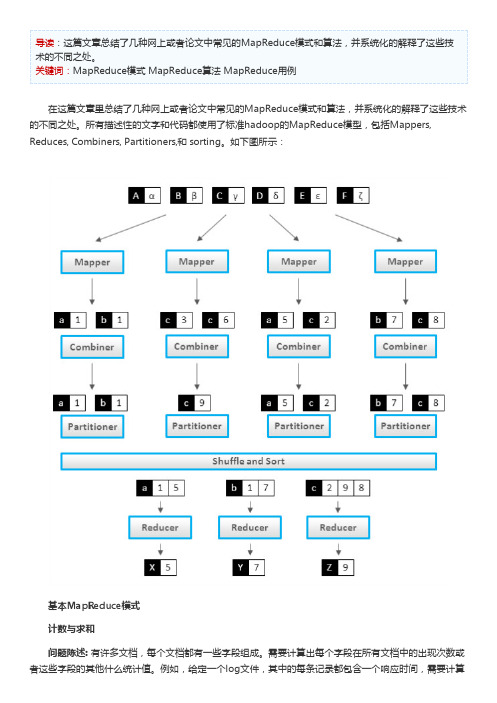
Emit(id m, message getMessage(N))
class Reducer
method Reduce(id m, [s1, s2,...])
如果要累计计数的的不只是单个文档中的内容,还包括了一个Mapper节点处理的所有文档,那就要用 到Combiner了:
class Mapper method Map(docid id, doc d) for all term t in doc d do Emit(term t, count 1)
class N State in {True = 2, False = 1, null = 0}, initialized 1 or 2 for end-of-line categories, 0 otherwise method getMessage(object N) return N.State method calculateState(state s, data [d1, d2,...]) return max( [d1, d2,...] )
class Mapper method Map(docid id, doc d) for all term t in doc d do Emit(term t, count 1)
class Reducer method Reduce(term t, counts [c1, c2,...]) sum = 0
sum =பைடு நூலகம்sum + c Emit(term t, count sum)
大数据Hadoop入门第十九讲 案例:倒排索引

倒排索引概述
一般正常的索引是根据记录来确定属性值的方式,但是在实际的应用中,常 常有需要根据属性值确定记录的情况,这种情况下,一般普通的索引方式无法 进行,这个时候就需要引入倒排索引(inverted index)。直白来讲倒排索引就 是根据值查询记录的索引方式。
倒排索引--图
案例
使用MR任务构建一个根据文档中的单词映射文档uri地址的倒排索引,创建 要求如下所示:
1. 各个文件需要根据指定的关键词创建倒排索引 2. 去掉文件中特殊字符(!,.)和黑名单字符(其他文件指定)(涉及到 ChainMapper和map side join) 3. 计算关键词在文档中出现次数,最终结果按照次数从高到低进行排序;格 式为keyword -> file1,file2,file3(依赖关系组合MR任务解决该要求)
基于mapreduce的倒排索引设计与实现

基于mapreduce的倒排索引设计与实现倒排索引是搜索引擎中非常常用的数据结构,用于快速地根据关键词查找相关的文档。
MapReduce是一种分布式计算框架,可以很好地支持倒排索引的设计与实现。
下面将介绍一种基于MapReduce的倒排索引设计与实现。
首先,需要明确倒排索引的基本原理。
倒排索引是通过将文档中的关键词与对应的文档ID建立映射关系,以实现关键词的快速查找。
基于MapReduce的倒排索引设计可以分为以下几个步骤:1. 数据预处理:将要建立倒排索引的文档集合划分为多个小块,每个小块作为一个输入数据块。
可以使用分布式文件系统(比如Hadoop的HDFS)将文档集合存储在不同的节点上。
2. Map阶段:在每个数据块内部,对于每个文档,将文档ID与关键词进行映射,输出键值对(关键词,文档ID)。
对于每个键值对,Map函数会将其输出为(关键词,文档ID)对应的频率。
频率可以用于后续的相关度计算。
3. Reduce阶段:将Map阶段输出的键值对进行合并,以关键词为键,将对应的文档ID和频率进行归并。
每个Reduce函数对应一个关键词,将其对应的文档ID列表和频率列表合并为一个项,形成倒排索引项。
最后,将倒排索引项输出为(关键词,文档列表)的形式,存储在分布式文件系统中供后续查询使用。
设计倒排索引时,还可以考虑一些优化策略:1. 压缩倒排索引:为了减少存储空间的占用,可以使用一些压缩算法对倒排索引进行压缩,如VByte编码等。
2. 增量更新:对于文档集合中的新增文档,可以设计增量更新的机制,只更新相应的倒排索引,而无需重新建立整个倒排索引。
3. 查询优化:对于查询请求,可以根据查询的关键词进行部分倒排索引的联合,并根据相关度进行排序,以提高查询的效率。
通过以上步骤,就可以基于MapReduce实现一个高效的倒排索引。
这种设计可以充分发挥MapReduce的分布式计算能力,提高索引的构建速度和查询的效率。
倒排索引的使用方法

倒排索引的使用方法
首先,索引构建阶段需要将文档集合进行分词处理,然后对每
个单词构建倒排索引。
这个过程包括以下步骤:
1. 分词处理,将文档中的内容进行分词,将文档拆分成单词或
短语。
2. 构建倒排索引,对于每个单词,记录包含该单词的文档列表。
通常会记录文档ID或者位置信息,以便后续的查询。
在索引构建完成后,就可以进行查询操作了。
查询的过程通常
包括以下步骤:
1. 分词处理,将查询语句进行分词,得到查询的单词列表。
2. 查询倒排索引,根据查询的单词列表,找到包含这些单词的
文档列表。
3. 结合查询结果,将包含所有查询单词的文档进行交集或并集
操作,得到最终的查询结果。
除了基本的构建和查询操作,倒排索引还可以进行一些优化,比如压缩倒排索引以节省空间、使用倒排索引加速短语查询等。
另外,倒排索引也可以应用在各种领域,比如搜索引擎、信息检索、文本挖掘等方面。
总的来说,倒排索引的使用方法涉及到索引构建和查询两个方面,需要对文档进行适当的处理和分析,以便构建出高效的倒排索引并进行快速准确的查询。
希望我的回答能够帮助到你。
倒排索引的一些扩展探讨

从源码可知,ToolRunner.run()将会调用GenericOptionsParser解析命令行参数,并传递给Too.run()。GenericOptionsParser类中将根据传 递的参数给Configuration对象设置值。
public class InvertedIndex extends Configured implements Tool { static class InvertedIndexMapper extends Mapper<LongWritable, Text, Text, IntWritable> { .... } static class InvertedIndexCombiner extends Reducer<Text, IntWritable, Text, IntWritable> { .... } static class InvertedIndexPartitioner extends HashPartitioner<Text, IntWritable> { .... } static class InvertedIndexReducer extends Reducer<Text, IntWritable, Text, Text> { .... } public int run(String[] var1) throws Exception { .... } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); ToolRunner.run(conf, new InvertedIndex(), args); }
项目4 MapReduce分布式计算框架-任务4.5 MapReduce经典案例—倒排索引

章节概要
MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、 框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。
本章通过对MapReduce原理、编程模型及案例进行深入讲 解。
CONTENTS
PART 01
案例分析
PART 02
案例实现
is
file1.txt:1;file2.txt:2
simple
file1.txt:1;file2.txt:1
powerful file2.txt:1
bye
file3.txt:1
Hello
file3.txt:1
Title Works About Help
案例分析
2. 案例需求及分析
首先,使用默认的TextInputFormat类对每个输入文件进行处理,得到文本 中每行的偏移量及其内容。Map过程首先分析输入的<key,value>键值对,经 过处理可以得到倒排索引中需要的三个信息:单词、文档名称和词频。
BITC
项目4 MapReduce分布式计算框架
任务4.5 NE
理解MapReduce的 核心思想
学习目标
THREE
了解MapReduce的 优化策略
TWO
掌握MapReduce的编程 模型和工作原理
FOUR
掌握MapReduce常见 编程组件的使用
Title Works About Help
Title Works About Help
案例实现
3. Reduce阶段实现
根据Combine阶段的输出结果形式,同样在cn.itcast.mr.InvertedIndex 包 下 , 自 定 义 Reducer 类 InvertedIndexMapper , 主 要 用 于 接 收 Combine 阶 段输出的数据,并最终案例倒排索引文件需求的样式,将单词作为key,多个
Mapreduce实例——倒排索引

Mapreduce实例——倒排索引实验⽬的1.了解倒排索引的使⽤场景2.准确理解倒排索引的设计原理3.熟练掌握MapReduce倒排索引程序代码编写实验原理"倒排索引"是⽂档检索系统中最常⽤的数据结构,被⼴泛地应⽤于全⽂搜索引擎。
它主要是⽤来存储某个单词(或词组)在⼀个⽂档或⼀组⽂档中的存储位置的映射,即提供了⼀种根据内容来查找⽂档的⽅式。
由于不是根据⽂档来确定⽂档所包含的内容,⽽是进⾏相反的操作,因⽽称为倒排索引(Inverted Index)。
实现"倒排索引"主要关注的信息为:单词、⽂档URL及词频。
下⾯以本实验goods3、goods_visit3、order_items3三张表的数据为例,根据MapReduce的处理过程给出倒排索引的设计思路:(1)Map过程⾸先使⽤默认的TextInputFormat类对输⼊⽂件进⾏处理,得到⽂本中每⾏的偏移量及其内容。
显然,Map过程⾸先必须分析输⼊的<key,value>对,得到倒排索引中需要的三个信息:单词、⽂档URL和词频,接着我们对读⼊的数据利⽤Map操作进⾏预处理,如下图所⽰:这⾥存在两个问题:第⼀,<key,value>对只能有两个值,在不使⽤Hadoop⾃定义数据类型的情况下,需要根据情况将其中两个值合并成⼀个值,作为key或value值。
第⼆,通过⼀个Reduce过程⽆法同时完成词频统计和⽣成⽂档列表,所以必须增加⼀个Combine过程完成词频统计。
这⾥将商品ID和URL组成key值(如"1024600:goods3"),将词频(商品ID出现次数)作为value,这样做的好处是可以利⽤MapReduce 框架⾃带的Map端排序,将同⼀⽂档的相同单词的词频组成列表,传递给Combine过程,实现类似于WordCount的功能。
(2)Combine过程经过map⽅法处理后,Combine过程将key值相同的value值累加,得到⼀个单词在⽂档中的词频,如下图所⽰。
【大数据实验】使用hadoop实现倒排索引

【⼤数据实验】使⽤hadoop实现倒排索引零碎记事 ⾃上次写博客,已经过了半年了。
这半年时间⾥,我退出了ACM,转⼊了计算机视觉的研究中,ACM的价值观与⾃⼰的价值观还是有所不符,感觉⾃⼰并不是那么适合⼀条路⾛到⿊的竞赛,被束缚住了,还是诗与歌的⽣活更适合⾃⼰,能⼒低点⼜何妨,还是⽣活重要,所以转向压⼒稍低点(?)的科研项⽬⾥。
退出ACM后,也停⽌了刷OJ题,以写题解为主的博客,理所当然地失去了写作源泉,⼀停,就是半年。
说起来,当初转⼊计算机视觉研究的时候,还想着以后博客更新与这个领域相关的东西呢,可惜⾄今为⽌并没学到多少东西,仍然属于半吊⼦状态,实在是没内容拿得出⼿。
那,为什么现在⼜更博客了呢?看标题,还是⼤数据领域的。
这要跟本⼈⽬前就读的⼤数据专业说起,这个专业是学校新开的,⽽我们⼜是其第⼀届学⽣,学校对课程难度拿捏不太准,于是⾃开学后,发⽣了⼀系列离谱的事情,这⾥不吐不快。
开学后,第⼀件事是考上学期遗留下来必须得线下考的试,我们专业在这场考试中,挂掉了60%以上的⼈。
这只是个开端,之后学校排错了课程。
⼤数据的实验课,需要java和Linux作为前置课程,⽽这两个课程⼜是我们这个学期的⼆选⼀选修课(没错,java跟Linux,本来我们这学期只学其中⼀个,个⼈也很疑惑java为什么会是选修。
),怎么考虑本都是下学期才上的,但是不知怎么的排到了这个学期。
然后教务处还发现java跟Linux是选修,就在第⼆周把这两门课紧急调整成了必修,课表课程喜加⼆(⼤数据实验 + 原本没选的java或Linux两者其⼀),于是这个学期12门课程,加上⼀个数据结构课设,做个游戏出来的那种。
学校也是很厉害,这么多个课,居然也不冲突,可能我们专业就两个班,专业课都是两个班⼀起上,⼀个教室就能装得下,课表哪有空直接把课放哪就⾏了,好排。
冲突是不冲突了,反⼈类的安排⾃然还是有的,就拿Java说事,Java有实验课,上这个实验课我们得跨校区去上,⼀般来讲,如果有两节连上的情况,那应该是放在同⼀个时间段⽐较合适,不⽤跑来跑去嘛。
mapreduce倒排索引算法

Mapreduce程序设计报告姓名:学号:题目:莎士比亚文集倒排索引算法1、实验环境联想pc机虚拟机:VM 10.0操作系统:Centos 6.4Hadoop版本:hadoop 1.2.1Jdk版本:jdk-7u25Eclipse版本:eclipse-SDK-4.2.2-linux-gtk-x86_642、实验设计及源程序2.1实验说明对莎士比亚文集文档数据进行处理,对莎士比亚文集文档数据进行倒排索引处理,结果输出到指定文件2.2实验设计(1)InvertedIndexMapper类这个类实现Mapper 接口中的map 方法,输入参数中的value 是文本文件中的一行,利用正则表达式对数据进行处理,使文本中的非字母和数字符号转换成空格,然后利用StringTokenizer 将这个字符串拆成单词,最后将输出结果,outkey为单词+单词所在的文件名,outvalue为1。
public static class InvertedIndexMapperextends Mapper<Object, Text, Text, IntWritable>{private final static IntWritable one = new IntWritable(1);public void map(Object key, Text value, Context context) throws IOException, InterruptedException {//获取文件名以及预处理F ileSplit filesplit =(FileSplit)context.getInputSplit();S tring filename =filesplit.getPath().getName();String line=value.toString();String s;//利用正则表达式除去非数字和字母的符号Pattern p =pile("[^\\w+]");Matcher m=p.matcher(line);S tring line2=m.replaceAll(" ");S tringTokenizer itr = new StringTokenizer(line2); //按照空格对字符串进行划分while (itr.hasMoreTokens()) {s=itr.nextToken().toLowerCase();if(!ls.contains(s)){Text filename_num=new Text(s+","+filename);//将单词和单词所在的文件名进行合并context.write(filename_num, one);}}}} (2)InvertedIndexPartitioner类这个类是自定义的Partitioner类,通过复写getPartition() 方法来自定义子集的分区key。
hadoop倒排索引实验报告

大数据技术概论实验报告作业三**: ***专业: 工程管理专业学号: 2015E**********目录1.实验要求 (3)2.环境说明 (4)2.1系统硬件 (4)2.2系统软件 (4)2.3集群配置 (4)3.实验设计 (4)3.1第一部分设计 (4)3.2第二部分设计 (6)4.程序代码 (11)4.1第一部分代码 (11)4.2第二部分代码 (17)5.实验输入和结果 (21)实验输入输出结果见压缩包中对应目录 (21)1.实验要求第一部分: 采用辅助排序的设计方法, 对于输入的N个IP网络流量文件, 计算得到文件中的各个源IP地址连接的不同目的IP地址个数, 即对各个源IP地址连接的目的IP地址去重并计数举例如下:第二部分: 输入N个文件, 生成带详细信息的倒排索引举例如下, 有4个输入文件:– d1.txt: cat dog cat fox– d2.txt: cat bear cat cat fox– d3.txt: fox wolf dog– d4.txt: wolf hen rabbit cat sheep要求建立如下格式的倒排索引:– cat —>3: 4: {(d1.txt,2,4),(d2.txt,3,5),(d4.txt,1,5)}–单词—>出现该单词的文件个数:总文件个数: {(出现该单词的文件名, 单词在该文件中的出现次数, 该文件的总单词数),……}2.环境说明2.1系统硬件处理器: Intel Core i3-2350M ×4内存: 2GB磁盘: 60GB2.2系统软件操作系统: Ubuntu 14.04 LTS操作系统类型: 32位Java版本: 1.7.0_85Eclipse版本: 3.8Hadoop插件: hadoop-eclipse-plugin-2.6.0.jarHadoop: 2.6.12.3集群配置集群配置为伪分布模式, 节点数量一个3.实验设计3.1第一部分设计利用两个Map/Reduce过程, 在第一个MR中, 读取记录并去除重复记录, 第二个MR按照辅助排序设计方法, 根据源地址进行分组, 统计目的地址数量。
elasticsearch 倒排索引的数据结构 -回复

elasticsearch 倒排索引的数据结构-回复Elasticsearch是一个广泛用于搜索和分析的开源分布式搜索引擎。
它使用倒排索引作为其核心数据结构,以提供高效的文本搜索和分析功能。
本文将深入探讨Elasticsearch倒排索引的数据结构。
倒排索引,也称为反向索引,在信息检索领域被广泛应用。
与传统的正向索引不同,倒排索引按照词项来组织文档。
它的目的是在给定查询时,快速地确定包含该查询词的文档。
在Elasticsearch中,倒排索引是通过三个基本数据结构来实现的:倒排列表、倒排文档列表和词典。
倒排列表是指将每个词映射到包含该词的所有文档的列表。
它以词项为键,以包含该词项的文档列表为值。
倒排列表是倒排索引的核心,其快速访问包含特定词项的文档非常关键。
倒排列表使用跳表和压缩位图等数据结构进行优化,以实现高效的搜索。
倒排文档列表存储了每个文档中包含的所有词项。
对于每个文档,倒排文档列表保持了一个有序的词项列表。
该列表中的每个词项都指向倒排列表中的一个位置,该位置指示了倒排列表中的文档编号。
词典是一个词项和倒排列表位置之间的映射表。
它充当词项到倒排列表之间的“索引”。
词典使用基于前缀压缩的字典树或者有序数组等数据结构实现,以支持高效的前缀匹配。
通过组合倒排列表、倒排文档列表和词典,Elasticsearch能够快速定位包含特定词项的文档。
当用户执行一个查询时,Elasticsearch将使用词典和倒排列表来确定查询词项的位置。
然后,它将检索倒排文档列表中的文档列表,并按相关度进行排序,以便返回最相关的文档。
除了基本的倒排索引数据结构,Elasticsearch还使用了其他技术来增强搜索和分析的性能。
其中之一是布尔过滤器,它可以根据包含或不包含特定词项来快速过滤掉文档。
另一个重要的技术是倒排索引的分片和分布式存储,它允许Elasticsearch在多台机器上存储和处理数据,以实现高可用性和伸缩性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
is file1.txt:1;file2.txt:2;
powerful file2.txt:1;
simple file2.txt:1;file1.txt:1;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class InvertedIndex {
file2 MapReduce is powerful is simple
file3 Hello MapReduce bye MapReduce
Hello file3.txt:1;
MapReduce file3.txt:2;file1.txt:1;file2.txt:1;
while (itr.hasMoreTokens()) {
// key值由单词和URL组成,如"MapReduce:file1.txt"
// 获取文件的完整路径
// keyInfo.set(itr.nextToken()+":"+split.getPath().toString());
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: Inverted Index <in> <out>");
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
file1 MapReduce is simple
倒排索引:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
}
int splitIndex = key.toString().indexOf(":");
// 重新设置value值由URL和词频组成
info.set(key.toString().substring(splitIndex + 1) + ":" + sum);
public static class Reduce extends Reducer<Text, Text, Text, Text> {
private Text result = new Text();
// 实现reduce函数
result.set(fileList);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
+ split.getPath().toString().substring(splitIndex));
// 词频初始化为1
valueInfo.set("1");
context.write(keyInfo, valueInfo);
String fileList = new String();
for (Text value : values) {
fileList += value.toString() + ";";
}
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// 生成文档列表
}
}
}
public static class Combine extends Reducer<Text, Text, Text, Text> {
private Text info = new Text();
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
private FileSplit split; // 存储Split对象
// 实现map函数
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
public static class Map extends Mapper<Object, Text, Text, Text> {
private Text keyInfo = new Text(); // 存储单词和URL组合
private Text valueInfo = new Text(); // 存储词频
System.exit(2);
}
Job job = new Job(conf, "Inverted Index");
job.setJarByClass(InvertedIndex.class);
// 重新设置key值为单词
key.set(key.toString().substring(0, splitIndex));
context.write(key, info);
}
}
// 设置Map输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 设置Reduce输出类型
// 统计词频
int sum = 0;
for (Text value : values) {
sum += Integer.parseInt(value.toString());
Configuration conf = new Configuration();
// 这句话很关键
//conf.set("mapred.job.tracker", "192.168.1.2:9001");
//String[] ioArgs = new String[] { "index_in", "inde名称。
int splitIndex = split.getPath().toString().indexOf("file");
keyInfo.set(itr.nextToken() + ":"
// 实现reduce函数
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// 获得<key,value>对所属的FileSplit对象
split = (FileSplit) context.getInputSplit();
StringTokenizer itr = new StringTokenizer(value.toString());
// 设置Map、Combine和Reduce处理类
job.setMapperClass(Map.class);
job.setCombinerClass(Combine.class);
job.setReducerClass(Reduce.class);