Single-view relighting with normal map painting
hinton 知识蒸馏 kl散度损失函数

hinton 知识蒸馏 kl散度损失函数知识蒸馏是指将一个大型深度神经网络的知识迁移到一个较小的网络中。
这不仅可以使网络更加轻便,还可以提高推理速度和精度,因为较小的网络学习到了更精华的信息。
Hinton是最早推广知识蒸馏的人之一。
他提出的知识蒸馏方法是基于一种特定的模型蒸馏,其核心思想是使用一个小模型去模仿大模型的预测行为。
本文将围绕Hinton知识蒸馏KL散度损失函数进行讲解。
第一步:问题引入当一个大型的深度神经网络完成训练后,我们可以将这个网络视为“老师”模型,它拥有丰富的知识。
但是,由于其庞大的模型和参数数量,它过于复杂,不适合在嵌入式系统、移动设备和低端硬件上运行和部署。
那么,我们怎样才能让小型网络具备大型网络同样的精度呢?第二步:基本原理知识蒸馏的基本思想是将大型网络的丰富知识蒸馏到一个小型网络中,以达到精度相同甚至更高的效果。
在知识蒸馏中,我们需要使用某些方法将老师网络的知识转移到学生网络中。
将软性目标函数添加到学生网络中,来抓住大型网络的行为,并在学生网络的损失函数中添加额外的项,以帮助学生网络更好地学习。
第三步:KL散度KL散度自然是知识蒸馏损失函数中很重要的一部分。
在知识蒸馏损失函数中,KL散度是一个重要的元素之一,它用于量化大型网络和小型网络之间的差异。
KL散度可描述两个概率分布之间的差异,是两个概率分布之间的非对称度量。
第四步:确定损失函数Hinton提出的知识蒸馏KL散度损失函数的公式如下:$KD(P||Q)=\sum_{x}P(x)\log\frac{P(x)}{Q(x)}$其中,P(x)代表老师网络的输出,Q(x)代表学生网络的输出,x代表输出的标签或类别。
此时,KL散度可以用于计算输出分布的差异。
参数T是一个温度参数,它作为一个类似于softmax函数的称为“软化”的激活函数的分母的标准偏差来控制输出分布的熵。
T越大,输出的分布越“平坦”,T越小,输出的分布越“峰形”。
【吴恩达课后编程作业】第三周作业(附答案、代码)隐藏层神经网络神经网络、深度学习、机器学习
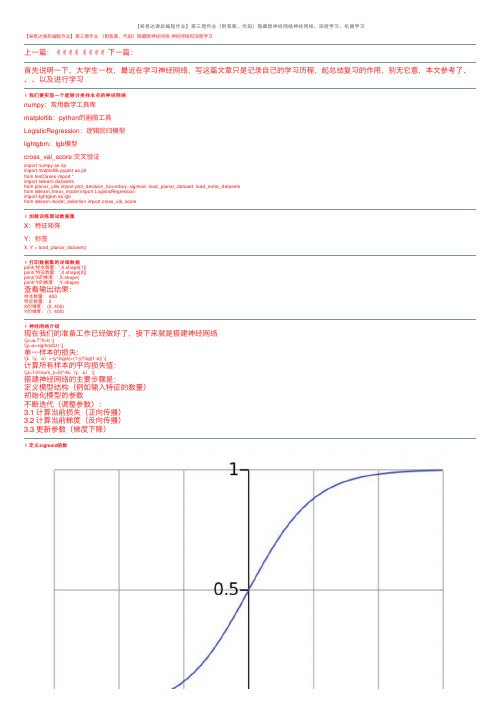
【吴恩达课后编程作业】第三周作业(附答案、代码)隐藏层神经⽹络神经⽹络、深度学习、机器学习【吴恩达课后编程作业】第三周作业(附答案、代码)隐藏层神经⽹络神经⽹络和深度学习上⼀篇:✌✌✌✌✌✌✌✌下⼀篇:⾸先说明⼀下,⼤学⽣⼀枚,最近在学习神经⽹络,写这篇⽂章只是记录⾃⼰的学习历程,起总结复习的作⽤,别⽆它意,本⽂参考了、、、以及进⾏学习✌我们要实现⼀个能够分类样本点的神经⽹络numpy:常⽤数学⼯具库matplotlib:python的画图⼯具LogisticRegression:逻辑回归模型lightgbm:lgb模型cross_val_score:交叉验证import numpy as npimport matplotlib.pyplot as pltfrom testCases import *import sklearn.datasetsfrom planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasetsfrom sklearn.linear_model import LogisticRegressionimport lightgbm as lgbfrom sklearn.model_selection import cross_val_score✌加载训练测试数据集X:特征矩阵Y:标签X, Y = load_planar_dataset()✌打印数据集的详细数据print('样本数量:',X.shape[1])print('特征数量:',X.shape[0])print('X的维度:',X.shape)print('Y的维度:',Y.shape)查看输出结果:样本数量: 400特征数量: 2X的维度: (2, 400)Y的维度: (1, 400)✌神经⽹络介绍现在我们的准备⼯作已经做好了,接下来就是搭建神经⽹络\[z=w.T*X+b \]\[y=a=sigmoid(z) \]单⼀样本的损失:\[L(y,a)=-(y*log(a)+(1-y)*log(1-a)) \]计算所有样本的平均损失值:\[J=1/m\sum_{i=0}^mL(y,a) \]搭建神经⽹络的主要步骤是:定义模型结构(例如输⼊特征的数量)初始化模型的参数不断迭代(调整参数):3.1 计算当前损失(正向传播)3.2 计算当前梯度(反向传播)3.3 更新参数(梯度下降)✌定义sigmoid函数\[a=sigmoid(z) \]\[sigmoid=1/(1+e^-x) \]因为我们要做的是⼆分类问题,所以到最后要将其转化为概率,所以可以利⽤sigmoid函数的性质将其转化为0~1之间def sigmoid(z):"""功能:激活函数,计算sigmoid的值参数:z:任何维度的矩阵返回:s:sigmoid(z)"""s=1/(1+np.exp(-z))return s✌定义各⽹络层的节点数这⾥我们为什么要获取各个层的节点数呢?原因是在初始化w、b等参数时需要确定其维度,以便于后⾯的传播计算def layer_size(X,Y):"""功能:获得各个⽹络层的节点数参数:X:特征矩阵Y:标签返回:in_layer:输出层的节点数hidden_layer:隐藏层的节点数out_layer:输出层的节点数"""# 本数据集为两个特征in_layer=X.shape[0]# ⾃⼰定义隐藏层为4个节点hidden_layer=4# 输出层为1维out_layer=Y.shape[0]return in_layer,hidden_layer,out_layer✌定义初始化w、b的函数在进⾏梯度下降之前,要初始化w和b的值,但是这⾥会有个问题,为了⽅便我们会把w、b的值全部初始化为0,这样做是不正确的,原因是:如果都为0,会导致在传播计算时,模型对称,各个节点的参数不起作⽤,可以⾃⼰推到⼀下所以我们要给w、b进⾏随机取值本⽂参数维度:W1:(4,2)b1:(4,1)W2:(1,4)b2:(1,1)def init_w_b(in_layer,hidden_layer,out_layer):"""功能:初始化w,b的维度和值参数:in_layer:输出层的节点数hidden_layer:隐藏层的节点数out_layer:输出层的节点数返回:init_params:对应各层参数的字典"""# 定义随机种⼦,以便之后每次产⽣随机数唯⼀np.random.seed(2021)# 初始化参数,符合⾼斯分布W1=np.random.randn(hidden_layer,in_layer)*0.01b1=np.random.randn(hidden_layer,1)W2=np.random.randn(out_layer,hidden_layer)*0.01b2=np.random.randn(out_layer,1)init_params={'W1':W1,'b1':b1,'W2':W2,'b2':b2}return init_params✌定义向前传播函数神经⽹络分为正向传播和反向传播正向传播计算求出损失函数,然后反向计算各个梯度然后进⾏梯度下降,更新参数计算公式:\[Z1=W1*X+b1 \]\[A1=tanh(Z1) \]\[Z2=W2*A1+b2 \]\[A2=sigmoid(Z2) \]def forward(W1,b1,W2,b2,X,Y):"""功能:向前传播,计算出各个层的激活值和未激活值(A1,A2,Z1,Z2)参数:W1:隐藏层的权值参数b1:隐藏层的偏置参数W2:输出层的权值参数b2:输出层的偏置参数X:特征矩阵Y:标签返回:forward_params:对应各层数据的字典"""# 计算隐藏层Z1=np.dot(W1,X)+b1Z1=np.dot(W1,X)+b1# 激活A1=np.tanh(Z1)# 计算第⼆层Z2=np.dot(W2,A1)+b2# 激活A2=sigmoid(Z2)forward_params={'Z1':Z1,'A1':A1,'Z2':Z2,'A2':A2,'W1':W1,'b1':b1,'W2':W2,'b2':b2}return forward_params✌定义损失函数损失函数为交叉熵,数值越⼩,表明模型越优秀计算公式:\[J(W1,b1,W2,b2)=1/m\sum_{i=0}^m-(y*log(A2)+(1-y)*log(1-A2)) \]def loss_fn(W1,b1,W2,b2,X,Y):"""功能:构造损失函数,计算损失值参数:W1:隐藏层的权值参数b1:隐藏层的偏置参数W2:输出层的权值参数b2:输出层的偏置参数X:特征矩阵Y:标签返回:loss:模型损失值"""# 样本数m=X.shape[1]# 向前传播,获取激活值A2forward_params=forward(W1,b1,W2,b2,X,Y)A2=forward_params['A2']# 计算损失值loss=np.multiply(Y,np.log(A2))+np.multiply(1-Y,np.log(1-A2))loss=-1/m*np.sum(loss)# 降维,如果不写,可能会有错误loss=np.squeeze(loss)return loss✌定义向后传播函数反向计算各个梯度然后进⾏梯度下降,更新参数计算公式:\[dZ2=A2-Y \]\[dW2=1/m*dZ2*A1.T \]\[db2=1/m*\sum_{i=0}^mdZ2 \]第⼀层的参数同理,这⾥要记住计算各参数梯度,就是⾼数中的链式法则,这也就是为什么叫做向后传播,想要计算前⼀层的参数导数值就要先计算出后⼀层的梯度值\[y=2*x \]\[z=3*y \]\[∂z/∂x=(∂z/∂y )*(dy/dx) \]记住这个⼀切都OKdef backward(W1,b1,W2,b2,X,Y):"""功能:向后传播,计算各个层参数的梯度(偏导)参数:W1:隐藏层的权值参数b1:隐藏层的偏置参数W2:输出层的权值参数b2:输出层的偏置参数X:特征矩阵Y:标签返回:grads:各参数的梯度值"""# 样本数m=X.shape[1]# 进⾏前向传播,获取各参数值forward_params=forward(W1,b1,W2,b2,X,Y)A1=forward_params['A1']A2=forward_params['A2']W1=forward_params['W1']W2=forward_params['W2']# 计算梯度dZ2= A2 - YdW2 = (1 / m) * np.dot(dZ2, A1.T)db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2))dW1 = (1 / m) * np.dot(dZ1, X.T)db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)grads = {"dW1": dW1,"db1": db1,"dW2": dW2,"db2": db2 }return grads✌定义整个传播过程⼀个传播流程包括:向前传播计算损失函数向后传播3.1 计算梯度3.2 更新参数def propagate(W1,b1,W2,b2,X,Y):"""功能:传播运算,向前->损失->向后->参数:W1:隐藏层的权值参数b1:隐藏层的偏置参数W2:输出层的权值参数b2:输出层的偏置参数X:特征矩阵Y:标签Y:标签返回:grads,loss:各参数的梯度,损失值"""# 计算损失loss=loss_fn(W1,b1,W2,b2,X,Y)# 向后传播,计算梯度grads=backward(W1,b1,W2,b2,X,Y)return grads,loss✌定义优化器函数⽬标是通过最⼩化损失函数 J来学习 w 和 b 。
融合注意力和门控空洞卷积的关系识别模型python代码

融合注意力和门控空洞卷积的关系识别模型python代码全文共四篇示例,供读者参考第一篇示例:在深度学习领域,注意力机制和门控卷积是两个被广泛应用的技术。
注意力机制能够帮助模型集中关注于重要的特征,从而提高模型的性能。
而门控卷积则能够有效地捕捉序列数据中的长距离依赖关系。
在本文中,我们将探讨如何将注意力机制和门控卷积结合起来,构建一个用于关系识别的深度学习模型,并使用Python代码实现。
我们需要了解注意力机制和门控卷积的基本原理。
注意力机制是一种用于给予模型不同输入部分不同权重的技术,帮助模型更聚焦于重要的特征。
门控卷积则是一种包含门控单元(如LSTM或GRU)的卷积层,能够在卷积的基础上引入序列建模的能力,捕捉长距离的依赖关系。
接下来,我们将介绍如何将注意力机制和门控卷积结合起来,构建一个关系识别模型。
我们将使用Python编写代码,使用PyTorch作为深度学习框架。
我们需要导入必要的库和模块:```pythonimport torchimport torch.nn as nnimport torch.nn.functional as F```接着,我们定义一个包含注意力机制和门控卷积的关系识别模型:```pythonclass RelationRecognitionModel(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim, num_layers):super(RelationRecognitionModel, self).__init__()self.hidden_dim = hidden_dimself.num_layers = num_layers# 定义门控卷积层self.conv = nn.Conv1d(input_dim, hidden_dim, kernel_size=3, padding=1)# 定义注意力机制self.attention = nn.Linear(hidden_dim, 1)# 定义LSTM层self.lstm = nn.LSTM(hidden_dim, hidden_dim, num_layers, batch_first=True)# 定义输出层self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, x):# 进行卷积操作x = F.relu(self.conv(x))# 计算注意力权重attention_weights = F.softmax(self.attention(x), dim=1)# 将注意力权重应用到卷积结果上x = x * attention_weights# 将数据输入到LSTM层h0 = torch.zeros(self.num_layers, x.size(0),self.hidden_dim).to(x.device)c0 = torch.zeros(self.num_layers, x.size(0),self.hidden_dim).to(x.device)out, _ = self.lstm(x, (h0, c0))# 获取LSTM输出的最后一个时间步的结果,并输入到全连接层out = self.fc(out[:, -1, :])return out```在上面的代码中,我们首先定义了一个包含门控卷积、注意力机制、LSTM和全连接层的关系识别模型。
高光谱图像距离度量与无监督特征学习研究

高光谱图像距离度量与无监督特征学习研究随着遥感技术的不断发展,高光谱图像在土地覆盖分类、环境监测、农业资源管理等领域展示出了巨大的潜力。
然而,高光谱图像的特征维度高、信息冗余度大等问题给图像处理和分析带来了巨大的挑战。
为了应对这些问题,研究人员提出了一种无监督特征学习的方法,以降低高光谱图像的维度并挖掘其潜在信息。
同时,距离度量也成为了高光谱图像处理中一个重要的研究方向,用于度量高维特征空间中样本之间的相似性。
无监督特征学习是一种在没有标签信息的情况下进行特征学习的方法。
在高光谱图像处理中,无监督特征学习可以通过自动学习和发现数据中存在的特征,从而明显降低了数据的维度,并提供了对数据潜在结构的理解。
其中,主成分分析(Principal Component Analysis,PCA)是无监督降维的主要方法之一。
它通过线性变换将高维数据映射到低维空间,其中低维空间保留了大部分的原始数据方差,从而达到降维目的。
此外,独立成分分析(Independent Component Analysis,ICA)也是一种经典的无监督特征学习方法,它通过解决数据的盲源分离问题,得到独立的高维特征表示。
这些无监督特征学习方法为高光谱图像处理提供了有力的工具,可以有效地降低维度、减少冗余信息,并提高后续任务的性能。
距离度量是用于衡量样本之间相似性或距离的方法。
在高光谱图像处理中,距离度量可以用于聚类、分类和检索等任务中。
传统的欧几里得距离在高光谱图像处理中常被用来度量样本之间的相似性,但是欧几里得距离只考虑了样本之间的空间距离,并忽略了样本在高维特征空间中的分布信息。
因此,传统的距离度量方法往往无法准确地刻画高光谱图像中样本之间的差异。
为了解决这个问题,研究人员提出了许多新的距离度量方法。
例如,流形学习方法可以将高维数据映射到低维流形空间,从而有效地保留了数据的局部结构信息。
核函数方法通过在高维特征空间中引入核函数,将样本映射到特征空间中的非线性空间,从而更好地刻画了样本之间的相似性。
图像去雾增强算法的研究-文献综述

福州大学专业英语文献综述题目:图像去雾增强算法的研究姓名:学号:专业:一、引言由于近年来空气污染加重,我国雾霾天气越来越频繁地出现,例如:2012底到2013年初,几次连续七日以上的雾霾天气笼罩了大半个中国,给海陆空交通,人民生活及生命安全造成了巨大的影响。
因此,除降低空气污染之外,提高雾霾图像、视频的清晰度是亟待解决的重要问题。
图像去雾实质上就是图像增强的一种现实的应用。
一般情况下,在各类图像系统的传送和转换(如显示、复制、成像、扫描以及传输等)总会在某种程度上造成图像质量的下降。
例如摄像时,由于雾天的原因使图像模糊;再如传输过程中,噪声污染图像,使人观察起来不满意;或者是计算机从中提取的信息减少造成错误,因此,必须对降质图像进行改善处理,主要目的是使图像更适合于人的视觉特性或计算机识别系统。
从图像质量评价观点来看,图像增强技术主要目的是提高图像可辨识度。
通过设法有选择地突出便于人或机器分析的某些感兴趣的信息,抑制一些无用信息,以提高图像的使用价值,即图像增强处理只是增强了对某些信息的辨别能力[1].二、背景及意义近几年空气质量退化严重,雾霾等恶劣天气出现频繁,PM2。
5[2]值越来越引起人们的广泛关注。
在有雾天气下拍摄的图像,由于大气中混浊的媒介对光的吸收和散射影响严重,使“透过光"强度衰减,从而使得光学传感器接收到的光强发生了改变,直接导致图像对比度降低,动态范围缩小,模糊不清,清晰度不够,图像细节信息不明显,许多特征被覆盖或模糊,信息的可辨识度大大降低。
同时,色彩保真度下降,出现严重的颜色偏移和失真,达不到满意的视觉效果[3—6]。
上述视觉效果不佳的图像部分信息缺失,给判定目标带来了一定的困难,直接限制和影响了室外目标识别和跟踪、智能导航、公路视觉监视、卫星遥感监测、军事航空侦察等系统效用的发挥,给生产与生活等各方面都造成了极大的影响[7—9].以公路监控为例,由于大雾弥漫,道路的能见度大大降低,司机通过视觉获得的路况信息往往不准确,进一步影响对环境的判读,很容易发生交通事故,此时高速封闭或者公路限行,给人们的出行带来了极大的不便[10]。
基于单目图像的深度估计关键技术

本研究旨在提出一种基于单目图像的深度估计方法,解决现有方法面临的挑战。具体研究内容包括:1)研究 适用于单目图像的深度特征提取方法;2)研究深度特征与深度信息之间的映射关系;3)研究如何提高深度估 计的准确性、鲁棒性和泛化能力;4)研究不同应用场景下的实验结果和分析。
研究方法
本研究采用机器学习的方法进行单目图像的深度估计。首先,利用卷积神经网络(CNN)提取图像中的深度 特征;然后,利用回归模型将深度特征映射到深度信息;最后,通过实验验证方法的可行性和优越性。此外, 本研究还将对不同应用场景下的实验结果进行分析,以验证方法的泛化能力和实用性。
基于单目图像的深 度估பைடு நூலகம்关键技术
2023-11-04
目 录
• 引言 • 单目深度估计基础 • 基于卷积神经网络的深度估计方法 • 基于光流法的深度估计方法 • 基于立体视觉的深度估计方法 • 基于单目图像的深度估计实验与分析 • 结论与展望
01
引言
研究背景与意义
背景
随着计算机视觉技术的不断发展,深度估计已成为许多应用领域的重要研究方向 。在单目图像中,由于缺乏立体视觉信息,深度估计变得更加困难。因此,基于 单目图像的深度估计技术对于实现智能视觉分析和应用具有重要意义。
改进的卷积神经网络模型
残差网络(ResNet)
通过引入残差思想,解决深度神经网络训练过程中的梯度消失问题,提高模型的深度和性 能。
稠密网络(DenseNet)
通过引入稠密连接,减少网络中的参数数量,提高模型的表达能力和计算效率。
轻量级网络
针对移动端和嵌入式设备,设计轻量级的卷积神经网络模型,如MobileNet、ShuffleNet 等,提高模型的计算效率和性能。
纹理物体缺陷的视觉检测算法研究--优秀毕业论文

摘 要
在竞争激烈的工业自动化生产过程中,机器视觉对产品质量的把关起着举足 轻重的作用,机器视觉在缺陷检测技术方面的应用也逐渐普遍起来。与常规的检 测技术相比,自动化的视觉检测系统更加经济、快捷、高效与 安全。纹理物体在 工业生产中广泛存在,像用于半导体装配和封装底板和发光二极管,现代 化电子 系统中的印制电路板,以及纺织行业中的布匹和织物等都可认为是含有纹理特征 的物体。本论文主要致力于纹理物体的缺陷检测技术研究,为纹理物体的自动化 检测提供高效而可靠的检测算法。 纹理是描述图像内容的重要特征,纹理分析也已经被成功的应用与纹理分割 和纹理分类当中。本研究提出了一种基于纹理分析技术和参考比较方式的缺陷检 测算法。这种算法能容忍物体变形引起的图像配准误差,对纹理的影响也具有鲁 棒性。本算法旨在为检测出的缺陷区域提供丰富而重要的物理意义,如缺陷区域 的大小、形状、亮度对比度及空间分布等。同时,在参考图像可行的情况下,本 算法可用于同质纹理物体和非同质纹理物体的检测,对非纹理物体 的检测也可取 得不错的效果。 在整个检测过程中,我们采用了可调控金字塔的纹理分析和重构技术。与传 统的小波纹理分析技术不同,我们在小波域中加入处理物体变形和纹理影响的容 忍度控制算法,来实现容忍物体变形和对纹理影响鲁棒的目的。最后可调控金字 塔的重构保证了缺陷区域物理意义恢复的准确性。实验阶段,我们检测了一系列 具有实际应用价值的图像。实验结果表明 本文提出的纹理物体缺陷检测算法具有 高效性和易于实现性。 关键字: 缺陷检测;纹理;物体变形;可调控金字塔;重构
Keywords: defect detection, texture, object distortion, steerable pyramid, reconstruction
II
flownet 结构

flownet 结构FlowNet是一种用于光流估计的深度学习网络结构。
光流估计是计算机视觉领域中的一个重要任务,它可以根据图像序列中的像素位移来推断运动信息。
FlowNet的设计灵感来自于人类的视觉系统,它模拟了人眼对于运动的感知和理解。
FlowNet由两个并行的卷积神经网络组成,分别为FlowNetS和FlowNetC。
FlowNetS是一个较小的网络,用于学习像素级的光流估计。
FlowNetC是一个较大的网络,用于学习较高层次的语义信息。
这两个网络通过共享权重来提高效率。
FlowNet的输入是两幅图像,输出是一个光流图,其中每个像素的值表示对应位置的位移向量。
为了减少计算量,FlowNet采用了金字塔结构,将图像分解为多个不同尺度的金字塔层级。
这样可以在不同尺度上进行光流估计,从而提高估计的准确性。
在训练过程中,FlowNet使用了一个损失函数来衡量估计的光流与真实光流之间的差异。
这个损失函数主要包括了光度差异损失和平滑性损失。
光度差异损失用于衡量估计的光流与真实光流在像素级上的差异,而平滑性损失用于保持光流的连续性和平滑性。
FlowNet的应用非常广泛。
例如,在视频压缩中,光流估计可以用于运动补偿和运动补偿预测,从而提高视频压缩的效率。
在自动驾驶中,光流估计可以用于车辆或行人的运动预测和路径规划。
在虚拟现实中,光流估计可以用于头部追踪和手势识别等交互操作。
总的来说,FlowNet是一种高效而准确的光流估计网络结构,它利用深度学习的方法模拟了人类的视觉系统。
通过学习图像序列中的运动信息,FlowNet可以在各种计算机视觉任务中发挥重要作用,为人类提供更好的视觉体验和交互方式。
无监督单目深度估计研究综述

无监督单目深度估计研究综述深度估计是计算机视觉领域的一个重要任务,它可以用来获取场景中物体的距离信息。
过去的研究主要依赖于有监督学习方法,即使用带有深度标签的数据进行训练。
然而,这种方法需要手动标记大量的数据,非常耗时费力。
为了克服这个问题,无监督单目深度估计应运而生。
本文将对该领域的研究进行综述,介绍其原理、方法和应用。
1. 研究背景深度估计在机器人导航、三维重建、增强现实等领域具有广泛的应用前景。
然而,传统的深度学习方法需要大量的标注数据,成本高昂且不易获取。
无监督单目深度估计旨在通过仅利用单目图像的信息来预测场景的深度,从而解决标注数据不足的问题。
2. 方法概述无监督单目深度估计的方法可以分为几个主要的类别:基于深度自编码器的方法、基于视差图的方法、基于单视图的方法等。
基于深度自编码器的方法利用自编码器结构对深度图进行重建,通过最小化输入图像与重建图像之间的差异来学习深度特征。
基于视差图的方法则假设场景中的物体是静态的,通过匹配图像中不同像素点的视差来估计深度。
而基于单视图的方法则根据图像中的纹理、遮挡等特征来推断深度信息。
3. 优势与挑战与有监督学习相比,无监督单目深度估计具有以下优势:(1)无需标注数据,降低了数据采集和标记的成本。
(2)能够利用未标记的大规模数据进行训练,提高了模型的泛化能力。
(3)有助于探索场景中的自监督信号,促进了对场景理解的进一步研究。
然而,无监督单目深度估计仍然存在一些挑战,如模型训练的不稳定性、深度误差的积累以及对纹理缺失的敏感性等问题。
4. 应用与展望无监督单目深度估计的研究已经取得了一些重要的进展,并在一些特定的应用场景中取得了较好的效果。
例如,在自动驾驶领域,深度估计可以帮助车辆判断前方道路的障碍物距离,提高驾驶安全性。
在增强现实领域,深度估计可以用于实时的虚拟物体插入和场景重建。
未来,我们可以进一步改进无监督单目深度估计的性能,并将其应用于更多的实际场景中,推动计算机视觉技术的发展。
retinaface原理

retinaface原理RetinaFace是一种检测人脸的深度学习算法,能够精确地检测出多个人脸并对其位置、大小和姿态进行准确估计。
RetinaFace最初由中国香港城市大学傅仁辉教授领导的团队开发,在2019年通过CVPR论文《RetinaFace: Single-stage Dense Face Localisation in the Wild》首次公布于众。
RetinaFace的原理基于SSD(Single Shot Multibox Detector)和DenseBox两种方法的结合。
SSD是一种基于深度学习的目标检测算法,能够在不使用候选框的情况下,精确地检测目标。
而DenseBox则是一种密集的候选框生成方法,能够在不牺牲精度的情况下提高检测速度。
通过将这两种方法结合,RetinaFace能够在不牺牲精度的情况下提高检测速度。
更具体地说,RetinaFace首先使用一系列锚框(anchor)对图像进行划分,然后对每个锚框进行分类和回归。
其中,分类是指判断锚框是否包含人脸,回归则是指根据锚框的位置、大小和姿态等信息,对人脸的位置、大小和姿态进行精确估计。
为了提高检测效果,RetinaFace使用了多尺度归一化(multi-scale normalization)和特征金字塔(feature pyramid)等技术,使得算法能够适应不同大小和姿态的人脸。
总的来说,RetinaFace是一种非常高效和精确的人脸检测算法,能够广泛应用于实际场景中的人脸识别、人脸对齐、人脸特征提取等任务。
尤其是在进行大规模人群检测时,RetinaFace具有非常大的优势,能够大幅提高检测速度和准确度。
未来,随着深度学习技术的不断发展,相信RetinaFace会在更多应用场景中得到广泛应用。
机器学习工程师招聘笔试题及解答(某大型集团公司)2024年

2024年招聘机器学习工程师笔试题及解答(某大型集团公司)(答案在后面)一、单项选择题(本大题有10小题,每小题2分,共20分)1、在以下哪种情况下,决策树模型通常比支持向量机(SVM)更适合作为分类器?A、数据量很大,特征维度较高B、数据量较小,特征维度较低C、数据集中包含大量噪声D、需要处理非线性关系的数据2、以下哪项不是深度学习中的常见损失函数?A、均方误差(MSE)B、交叉熵损失(Cross-Entropy Loss)C、Hinge损失(Hinge Loss)D、Kullback-Leibler散度(KL Divergence)3、题干:在机器学习中,以下哪项不是监督学习算法?A、决策树B、支持向量机C、随机森林D、K均值聚类4、题干:在深度学习中,以下哪项不是常见的卷积神经网络(CNN)结构?A、卷积层B、池化层C、全连接层D、LSTM层5、题干:以下哪项不是机器学习中的监督学习算法?A. 决策树B. 支持向量机C. 神经网络D. 随机森林6、题干:在机器学习中,以下哪个指标通常用于评估分类模型的性能?A. 精确率(Precision)B. 召回率(Recall)C. F1 分数(F1 Score)D. 以上都是7、在机器学习领域,以下哪个算法属于监督学习算法?A. 决策树B. 随机森林C. K-means聚类D. 主成分分析8、以下哪个指标通常用于评估分类模型的性能?A. 均方误差B. 精确率C. 平均绝对误差D. 相关系数9、在机器学习中,以下哪项技术不属于监督学习算法?A. 决策树B. 支持向量机C. 神经网络D. 聚类算法 10、以下哪种优化算法在深度学习中应用广泛,尤其适合于大规模稀疏数据集?A. 梯度下降法B. 随机梯度下降法(SGD)C. Adam优化器D. 共轭梯度法二、多项选择题(本大题有10小题,每小题4分,共40分)1、以下哪些技术或方法是机器学习工程师在项目中可能会使用到的?()A、神经网络B、决策树C、关联规则学习D、强化学习E、支持向量机2、以下哪些说法关于机器学习中的监督学习和无监督学习是正确的?()A、监督学习需要明确的标签数据B、无监督学习不需要标签数据C、监督学习的目标是预测或分类D、无监督学习的目标是发现数据中的模式E、监督学习比无监督学习更难实现3、以下哪些技术或方法是机器学习领域中常用的特征工程技术?()A、特征选择B、特征提取C、特征缩放D、特征编码E、特征交互4、在深度学习中,以下哪些是常用的损失函数?()A、均方误差(MSE)B、交叉熵损失(Cross-Entropy Loss)C、对数损失(Log Loss)D、Hinge损失(Hinge Loss)E、Softmax损失5、以下哪些是机器学习中的监督学习算法?()A. 决策树B. K-均值聚类C. 线性回归D. 支持向量机6、在处理大规模数据集时,以下哪些方法可以提高模型的训练效率?()A. 使用批量梯度下降而不是随机梯度下降B. 使用分布式计算框架如SparkC. 使用模型简化技术,如特征选择和维度约减D. 使用数据增强技术7、关于机器学习中的监督学习,以下哪些说法是正确的?A. 监督学习需要大量的标注数据B. 监督学习算法的性能依赖于特征工程的质量C. 监督学习分为回归和分类两种主要类型D. 监督学习可以用于无监督数据的分析8、在深度学习中,以下哪些技术可以提高模型的泛化能力?A. 数据增强B. 正则化(如L1、L2正则化)C. 使用更深的网络结构D. 交叉验证9、以下哪些是机器学习中的监督学习算法?()A. 决策树B. 随机森林C. 神经网络D. K最近邻(KNN)E. 聚类算法 10、在以下机器学习概念中,哪些属于特征工程的内容?()A. 特征选择B. 特征提取C. 特征编码D. 特征降维E. 模型训练三、判断题(本大题有10小题,每小题2分,共20分)1、深度学习模型在训练过程中,随着迭代次数的增加,其准确率一定会不断提高。
人工智能岗位招聘笔试题与参考答案(某大型集团公司)

招聘人工智能岗位笔试题与参考答案(某大型集团公司)(答案在后面)一、单项选择题(本大题有10小题,每小题2分,共20分)1、以下哪个算法不属于监督学习算法?A、决策树B、支持向量机C、K最近邻D、朴素贝叶斯2、在深度学习中,以下哪个概念指的是通过调整网络中的权重和偏置来最小化损失函数的过程?A、过拟合B、欠拟合C、反向传播D、正则化3、以下哪个技术不属于深度学习中的卷积神经网络(CNN)组件?A. 卷积层B. 激活函数C. 池化层D. 反向传播算法4、在自然语言处理(NLP)中,以下哪种模型通常用于文本分类任务?A. 决策树B. 朴素贝叶斯C. 支持向量机D. 长短期记忆网络(LSTM)5、题干:以下哪项不属于人工智能的核心技术?A. 机器学习B. 深度学习C. 数据挖掘D. 计算机视觉6、题干:以下哪个算法在处理大规模数据集时,通常比其他算法更具有效率?A. K最近邻(K-Nearest Neighbors, KNN)B. 支持向量机(Support Vector Machines, SVM)C. 决策树(Decision Tree)D. 随机森林(Random Forest)7、以下哪个技术不属于深度学习领域?A. 卷积神经网络(CNN)B. 支持向量机(SVM)C. 递归神经网络(RNN)D. 随机梯度下降(SGD)8、以下哪个算法不是用于无监督学习的?A. K-均值聚类(K-means)B. 决策树(Decision Tree)C. 主成分分析(PCA)D. 聚类层次法(Hierarchical Clustering)9、以下哪个技术不属于深度学习中的神经网络层?A. 卷积层(Convolutional Layer)B. 循环层(Recurrent Layer)C. 线性层(Linear Layer)D. 随机梯度下降法(Stochastic Gradient Descent)二、多项选择题(本大题有10小题,每小题4分,共40分)1、以下哪些技术或方法通常用于提升机器学习模型的性能?()A、特征工程B、数据增强C、集成学习D、正则化E、迁移学习2、以下关于深度学习的描述,哪些是正确的?()A、深度学习是一种特殊的机器学习方法,它通过多层神经网络来提取特征。
泊松表面重建.

泊松表面重建摘要:我们展示了对有向点集的表面重建可以转化为一个空间泊松问题。
这种泊松公式化表达的方法同时考虑了所有的点,而不借助于启发式的空间分割或合并,于是对数据的噪声有很大的抵抗性。
不像径向基函数的方案,我们的泊松方法允许对局部基函数划分层次结构,从而使问题的解缩减为一个良态的稀疏线性系统。
我们描述了一个空间自适应的多尺度算法,其时间和空间复杂度正比于重建模型的大小。
使用公共提供的扫描数据进行实验,在重建的表面,我们的方法比先前的方法显示出更详细的细节。
1、 引言:由点样本重建三维表面在计算机图形学中是一个热门研究问题。
它允许对扫描数据的拟合,对表面空洞的填充,和对现有模型的重新构网。
我们提出了一种重要的方法,把表面重建问题表示为泊松方程的解。
跟许多先前的工作一样(参见第2部分),我们使用隐式函数框架来处理表面重建问题。
特别地,像[K a z 05]我们计算了一个三维指示函数 (在模型内部的点定义为1,外部的点定义为0),然后可以通过提取合适的等值面获得重建的表面。
我们的核心观点是从模型表面采样的有向点集和模型的指示函数之间有一个内在关系。
特别地,指示函数的梯度是一个几乎在任何地方都是零的向量场(由于指示函数在几乎任何地方都是恒定不变的),除了模型表面附近的点,在这些地方指示函数的梯度等于模型表面的内法线。
这样,有向点样本可视为模型的指示函数梯度的样本(如图1)。
图1 二维泊松重建的直观图例计算指示函数的问题因此简化为梯度算子的反算,即找到标量函数~χ,使其梯度最佳逼近样本定义的向量场V u r ,即,,如果我们使用散度算子,那么这个变化的问题转化为标准的泊松问题:计算标量函数~χ,它的拉普拉斯算子(梯度的散度)等于向量场V u r的散度,在第3、4部分我们将会对上式作精确的定义。
把表面重建问题表达成泊松问题拥有许多优点。
很多对隐式表面进行拟合的方法把数据分割到不同区域以进行局部拟合,然后使用合成函数进一步合并这些局部拟合结果。
单目深度估计技术进展综述

单目深度估计技术进展综述一、概述单目深度估计技术是计算机视觉领域中的重要研究方向之一,其目标是通过从单张图像中估计场景中每个像素点的深度信息。
深度估计技术在自动驾驶、虚拟现实、机器人导航等领域具有广泛的应用前景。
本文将全面、详细、完整地探讨单目深度估计技术的进展。
二、基于传统计算机视觉方法的单目深度估计技术2.1 结构光法2.2 缺陷光流法2.3 聚焦法三、深度学习在单目深度估计中的应用3.1 卷积神经网络的应用1.使用卷积神经网络进行深度估计的基本原理2.基于卷积神经网络的深度估计方法综述3.2 递归神经网络的应用1.递归神经网络在单目深度估计中的优势2.基于递归神经网络的深度估计方法研究进展3.3 生成对抗网络的应用1.生成对抗网络在单目深度估计中的作用2.基于生成对抗网络的深度估计方法发展现状3.4 多尺度深度估计方法1.多尺度深度估计的原理与优势2.多尺度深度估计方法的研究进展四、单目深度估计技术的评价指标与数据集4.1 评价指标1.视差与深度之间的关系2.常用的深度估计评价指标4.2 数据集1.NYU Depth V2数据集2.KITTI Vision Benchmark Suite数据集3.Make3D数据集五、应用与展望5.1 自动驾驶领域中的应用5.2 虚拟现实领域中的应用5.3 机器人导航领域中的应用5.4 单目深度估计技术的未来发展趋势六、总结本文从传统计算机视觉方法到深度学习方法,全面分析了单目深度估计技术的进展和应用。
通过评价指标与数据集的介绍,读者可以更好地了解该领域的研究情况。
最后,我们对单目深度估计技术的未来进行了展望,并指出了该领域需要解决的挑战和发展方向。
参考文献1.Mayer, N., Ilg, E., Hausser, P., Fischer, P., Cremers, D.,Dosovitskiy, A., & Brox, T. (2016). A Large Dataset to TrainConvolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation. In Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition.2.Eigen, D., Puhrsch, C., & Fergus, R. (2014). Depth Map Predictionfrom a Single Image using a Multi-Scale Deep Network. In Advances in Neural Information Processing Systems.3.Eigen, D., Fergus, R., & others. (2015). Predicting Depth, SurfaceNormals and Semantic Labels with a Common Multi-ScaleConvolutional Architecture. In Proceedings of the IEEEInternational Conference on Computer Vision.4.Fu, H., Gong, M., Wang, C., Batmanghelich, K., & Tao, D. (2018).Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.5.Khosroshahi, P., & Kalantar-Zadeh, K. (2019). Generativeadversarial networks for depth map estimation from singlemonocular images. IEEE Transactions on Image Processing.。
无监督损失函数

无监督损失函数
无监督学习是一类不需要人工标注的数据,能够自动从数据中发现模式的机器学习方法。
在无监督学习中,我们通常使用无监督损失函数(unsupervised loss function)来衡量模型的性能。
无监督损失函数的目标是最小化模型对训练数据的重建误差。
通常,我们使用自编码器(autoencoder)构建无监督损失函数。
自编码器是一种神经网络,它将输入数据压缩到一个低维表示,然后再将其重构回原始空间,使得重构误差尽可能小。
常见的无监督损失函数有以下几种:
1. 均方误差损失函数(mean squared error loss):计算重构数据和原始数据之间的平均平方误差。
该损失函数对异常值敏感,适用于数据分布比较均匀的情况。
2. 交叉熵损失函数(cross-entropy loss):用于计算分类问题中的损失,也可以用作无监督损失函数。
它可以有效地惩罚模型对不常见的数据样本进行错误的重构。
3. KL 散度损失函数(KL divergence loss):用于衡量两个分布之间的距离。
在自编码器中,KL 散度被用于衡量潜在变量的分布与先验分布之间的距离,以此
约束潜在变量的分布。
4. 对比损失函数(contrastive loss):用于学习样本之间的相似性,可以有效地对抗背景噪声和类别之间的梯度爆炸问题。
该损失函数通常结合对比学习使用。
无监督损失函数的选择取决于具体的任务和数据特性。
在使用无监督损失函数时,我们需要通过调参和模型选择来找到最佳的损失函数。
单目深度估计 商用案例

单目深度估计商用案例
单目深度估计(Monocular depth estimation)是一种从单个图像中推断
深度信息的技术。
由于其具有成本低、设备简单等优势,单目深度估计在许多商用场景中都有广泛的应用。
以下是一些单目深度估计的商用案例:
1. 自动驾驶:自动驾驶汽车需要精确的深度信息来理解周围环境并做出决策。
单目深度估计可以为自动驾驶系统提供实时、低成本的深度信息,帮助车辆识别障碍物、道路标记和交通信号等。
2. 机器人导航:在工厂、仓库和家庭等环境中,机器人需要精确的深度信息来识别障碍物并进行避障。
单目深度估计可以为机器人提供实时的深度感知能力,提高其导航和操作的准确性。
3. 增强现实:增强现实技术可以将虚拟内容与现实世界相结合,为用户提供更加丰富的交互体验。
单目深度估计可以为增强现实应用提供精确的深度信息,使得虚拟内容能够更加自然地融入现实场景。
4. 安全监控:在安全监控领域,单目深度估计可以帮助监控系统识别出运动物体的距离和速度,提高监控的准确性和实时性。
5. 虚拟现实和游戏:在虚拟现实和游戏中,单目深度估计可以为用户提供更加真实的沉浸式体验。
通过精确的深度信息,游戏和虚拟现实场景中的物体可以呈现出更加逼真的透视效果。
以上案例只是单目深度估计在商用领域的一部分应用,随着技术的不断发展和成本的降低,相信未来会有更多的商业场景会应用到单目深度估计技术。
计算机论文:基于相似度学习的图聚类方法计算机研究

计算机论文:基于相似度学习的图聚类方法计算机研究算法首先在潜在的判别表示上动态地学习图,以降低噪声和异常值的影响。
此外,为了学习具有适当邻居分配的理想图结构,通过施加秩约束来有效地支持后续的聚类过程。
为了求解目标函数,将目标公式转换为可以更容易求解的等价问题,并给出了一种有效的优化解决方案,同时保证了优化算法的收敛性。
实验结果表明,与最新的聚类技术相比,该方法具有更好的性能。
第一章绪论1.1 课题研究背景及意义1.1.1 研究背景随着计算机技术与互联网的飞速发展,高维数据不断涌现,大规模数据的分析与处理成为一种现实的需求与必然趋势,这给相关技术研究带来了巨大的挑战。
现实社会中每天都会产生大量的数据,这些数据往往是没有标注信息的,而信息的标注工作又是非常耗时耗力的。
因此,无监督的数据处理问题引起了广泛的关注。
数据聚类是无监督学习中研究最多、应用最广的一类任务,也是数据挖掘中最基本的主题之一。
数据聚类是将未知标签的数据分为由类似的对象组成的多个不相交的组(每一组称为一个“簇”)的过程。
由聚类所生成的簇是一组数据对象的集合,同一簇中的对象彼此相似,不同簇的对象则相异。
到目前为止,聚类分析已经有很长的研究历史,它具有能够与其他研究方向相互促进的交叉特性。
在过去的几十年里,许多学者提出了多种聚类算法并广泛应用于各个领域,包括数据挖掘、统计学、机器学习、空间数据库技术、生物学以及市场营销等[1]。
面对大规模的复杂数据,传统的聚类方法难以得到令人满意的结果。
由于数据聚类是一个无监督的分类问题,没有任何先验知识可用,在进行数据聚类前并不确定将数据分为多少个簇,也不知道该依据何种空间区分规则来定义簇。
因此,有效地捕获数据中的复杂结构对于数据准确聚类是至关重要的。
研究表明,图论能够有效挖掘潜在的数据结构,因此,将图论与数据聚类任务相结合能够获得更佳的结果。
......................1.2 国内外研究现状1.2.1 单视图数据聚类数据聚类作为一种无监督学习任务,已广泛应用于机器学习、数据挖掘以及计算机视觉等研究领域。
sgdm手册

sgdm手册一、概述SGDM(Stochastic Gradient Descent with Momentum)是一种常用的梯度下降优化算法,用于训练神经网络模型。
本手册将详细介绍SGDM算法的原理、使用方法以及优化技巧。
二、原理SGDM算法是基于梯度下降的优化算法,通过迭代更新模型参数来最小化损失函数。
与传统的梯度下降算法相比,SGDM引入了动量项,可以加速模型收敛速度并且减少震荡。
三、算法步骤1. 初始化参数:设置学习率(learning rate)、动量因子(momentum)、迭代次数等超参数;2. 随机初始化模型参数;3. 迭代更新参数:- 计算当前批次的梯度;- 更新模型参数:使用动量因子调整本次梯度更新的大小,并加权累积之前梯度更新的方向;- 更新动量:根据当前梯度对动量进行更新;- 更新模型参数:根据调整后的梯度和动量更新模型参数;- 计算损失函数:根据更新后的模型参数计算当前损失函数的值;- 记录损失函数值和参数更新情况;4. 重复第3步,直到达到设定的迭代次数。
四、SGDM的优点1. 收敛速度快:SGDM通过动量的引入,加速了模型的收敛速度,并且避免了陷入局部最优解的问题;2. 减少震荡:动量可以减少参数更新的方差,使得参数更新更加平稳,减少了震荡现象;3. 参数调优:学习率和动量因子是SGDM的两个重要超参数,可以通过调节它们的值来优化模型性能。
五、使用SGDM的注意事项1. 学习率的选择:较小的学习率可以使得模型收敛更稳定,但可能会导致训练速度过慢;较大的学习率可以加快训练速度,但可能会导致模型无法收敛。
通常可以尝试不同的学习率,选取在训练集上表现最好的值;2. 动量因子的选择:动量因子决定了参数更新时的权重,较大的动量因子可以加速模型收敛,但可能会导致在局部最优解附近震荡。
通常可以尝试不同的动量因子,选取在验证集上表现最好的值;3. 批次大小的选择:批次大小决定了每次参数更新时使用的样本数量,较小的批次大小会增加参数更新的方差,而较大的批次大小会降低模型的学习速度。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Single-View Relighting with Normal Map Painting Makoto Okabe1Gang Zeng2Yasuyuki Matsushita3Takeo Igarashi14Long Quan2Heung-Yeung Shum31The University of Tokyo,Tokyo,Japan2HKUST,Hong-Kong,China makoto21,takeo@ui.is.s.u-tokyo.ac.jp zenggang,quan@t.hk 3Microsoft Research Asia,Beijing,China4PRESTO,JST yasumat,hshum@AbstractThis paper presents an interactive technique for chang-ing the illumination of objects in a real photograph.1Be-cause lighting effects are very sensitive to surface normal perturbations but hard to automatically analyze,we rely on a pen-based interface to quickly draw an approximate nor-mal map over a photo.The photo and the approximate nor-mal map are then given as input to a novel algorithm that refines the map and assigns reflectance to every pixel.We present relighting results for a variety of scenes,and use our technique to match the illumination of multiple pho-tographs.1.IntroductionIllumination has often been used by painters and pho-tographers as a tool for eliciting striking visual impressions. While physical control of illumination is sometimes possi-ble,changing the illumination of a photo after it has been taken can prove a challenging task.One possible solution is to photograph the same scene under many different illumi-nation conditions and then combine these photos to create new images of the same scenes[16,14,13,6].Unfortu-nately,these types of datasets are hard to obtain because they require a large number of photos,usually under con-trolled illumination conditions.The other approach is to obtain a three-dimensional(3D)model of the scene using a range scanner and apply inverse rendering techniques[15]. However,such data is not always available,especially it is difficult for the scenario of using existing photographs. When just a single photo of a scene is available,with no prior information about its shape or illumination,the re-lighting problem becomes especially difficult.1This work was done while thefirst and second authors were visiting Microsoft ResearchAsia.Figure1.A photograph(left)is relit as a novelimage(right)by a user specified lighting con-dition.The colors and intensities within a photo are created from the interaction of light with surfaces in the scene.This interaction depends on the reflectance properties of the sur-faces,as well as their shape.As a result,accurate relighting can be done only by analyzing how surface reflectance,sur-face shape,and the light source position(s)affect a given photo.This is a highly under-constrained problem because every pixel in the image is a function of incident light-ing,surface orientation and reflectance,none of which are known.Our approach is to efficiently extract a representation that is specifically designed for re-lighting applications. Since we use a single photograph as input,our work is closely related to prior work on single-view modeling[17, 19,1,4,3,9].These methods emphasized the detailedacquisition of full3D scene models using a variety of in-teractive tools.Unlike these approaches,we rely on a re-duced scene representation that is based on surface nor-mals and is much easier to interactively specify.We pro-pose a novel user interface(UI)to assign surface normals to a photograph based on the fact that a human is capable of perceiving surface orientation more precisely than depth of the scene[10].The surface normal representation has been used in the scenario of illumination control for cel animation[8].In our scenario of relighting a single pho-tograph,this representation is also useful in manipulating photographs where the dominant pixel intensity variations are caused by local lighting effects.We show that our tech-nique works well on photographs of many complex scenes.Our work is inspired by a simple and efficient UI of photo-editing applications[17]that allows a user to alter the appearance of an image through simple painting operations, such as brushing andflood-fill.We adopt a pen-tablet input device because it allows a quick and intuitive input method as used in the context of free surface modeling by[7].We take the advantage of the feature of a detectable pen an-gle in recent products,e.g.,Wacom’s Intuos2.Pen angle is directly associated with the surface normal of a scene to achieve an intuitive input of surface normals.We provide a set of input methods to efficiently assign surface normals to the scene.The assigned surface normal is then used to estimate its surface reflectance and a more precise surface normal.Once the scene is represented by our data structure where each pixel encodes surface reflectance and surface normal,the scene can be re-rendered under different illumi-nation conditions(Figure1).2.Our Approach2.1.OverviewOur method consists of two steps:Interactive sur-face normal assignment and simultaneous estimation of re-flectance and detailed surface normal.In thefirst step,a surface normal is assigned via a set of input methods designed for this purpose.Three different types of brushes and aflood-fill tool are provided to facil-itate the assignment process.Once the surface normal is assigned by a user,the second step uses the normal map for automatically and simultaneously estimating the surface reflectance property and afiner surface normal map.Two techniques are proposed to achieve single-view relighting. One is a smoothflood-fill tool for surface normal assign-ment,and the other is an automatic refinement of surface normals and reflectance.Our contributions are as follows.We provide a set of tools to assign surface normals to a single image.The pen angle obtained from a pen-input device is used for intu-itive assignment of surface normals.The system provides three types of brushes to allow users to intuitively paintsur-Figure2.An input image isfirst segmented with our interactive segmentation method.Left:Original image,middle and right:seg-mentation with differentthresholds.Figure3.Important boundaries can be explic-itly specified with a user input stroke.(From left to right)Left:User-defined rough strokes,Middle:segmentation result without strokes,and Right:segmentation result with strokes.Important boundaries are well preserved in the right image.face normals.To facilitate surface normal assignment,a flood-fill tool is developed thatfills in the specified area by smoothly propagating surface normals.We have also developed an algorithm to simultaneously estimate surface reflectance and afiner surface normal from a coarse hand-drawn surface normal.Our system permits relighting of a single photograph under different illumination conditions.2.2.Interactive Normal EditingLabeling Multiple Photo-object Our method begins with labeling photo-objects that are of interest for relight-ing.Once the labels are assigned to photo-objects,the boundaries are used for the following surface normal edit-ing process.To achieve multi-object interactive segmentation,we have added an interactive control to the segmentation method used in[20].The input image isfirst smoothed while preserving edges by a variant of the anisotropic dif-fusion and bilateralfiltering algorithms.After smoothing, each pixel is assigned its own segment label.These labels are merged interactively given a user defined threshold de-fined by a RGB Euclidean distance between average colors of the segments.A user can interactively merge/split the segments by changing the threshold.Once a desired seg-ment is obtained at a certain threshold,a user can mark the edge as an object boundary and continue the labeling process by changing the threshold.In this way,a user canFigure 4.Pen angle is directly associated with the surface normal to allow intuitive nor-mal painting.The cursor in the right image shows the angle of surface normal input.efficiently label photo-objects with changing the segment boundaries(Figure2).We have also developed a tool to explicitly specify im-portant boundaries by stroking.Given a stroke,the system automatically creates an area by dilating the stroke and cal-culating graphcut in the area using the method proposed by[12].In the case the color gradient in the area is rea-sonably small,the algorithm tries to set a boundary along the user input stroke.In this way,important boundaries can be explicitly specified.Figure3illustrates the usefulness of boundary stroke.Surface normal modeling Three different types of brushes and aflood-fill tool are designed for the interactive surface normal assignment.The basis of our UI is a paint-ing UI as used in[17]for depth assignment.Our painting UI has three different brushes to facilitate the task of sur-face normal assignment.Thefirst one is a normal brush with which a user can directly input a surface normal.As a key feature of the normal brush,we use a pen-tablet input device taking advantage of the ability of commercial pen-tablets providing information about angle of pen-input.Pen angle is directly associated with the surface normal in the image(Figure4).This allows a user to intuitively assign surface normals in an image.The second brush is a copy brush that allows copying a surface normal of the specified point and paints areas with the copied surface normal re-gardless of the pen angle.The copy brush is useful when the same surface orientation exists at different locations,as often is the case with architecture.A user can also blur the assigned normal using a blur brush,which is useful to cre-ate smooth variations of the surface normal.The blur brush works as a Gaussian diffusion over the specified area of the normal map.For all brushes,the brush size can be interac-tively varied.The three brushes provide an intuitive and efficient normal-input mechanism,however,it is still a time-consuming task whenfilling-in a large image area.To ac-celerate normal assignment,our system provides a smoothflood-fill tool that canfill up the selected image area by propagating sparse user input.Smooth Flood-fill Tool To facilitate the surface normalassignment process,we developed aflood-fill tool that prop-agates sparse surface normal input to smoothlyfill in the specified image area.We use intensity similarity measureto propagate the coarsely specified surface normal N N x N y N z N1as Levin et ed in the context of color propagation[11].The propagation is bounded bythe pre-defined label and user-specified area where inten-sity change is due to the variation in surface orientation.It is achieved by minimizing the energy functional J:J U∑rU r∑s A rw r s U s2(1)where r and s denote pixel labels,and A r represents a set of adjacent pixels of r.The weighting factor w r s,which sums up to one,represents the similarity between r and s, which is defined in[11]byw r s∝1σ2r Y rµr Y sµr(2)where Y r is the intensity at pixel r,µr andσ2r are the mean and variance of the intensities respectively in N r.Equa-tion(1)is evaluated twice for U N x N z and U N y N z, and the surface normal is re-normalized after computation.The actual computation is performed by solving a sparse system of linear equations which is derived by taking par-tial derivative of Equation(1)by U.For propagating sur-face normal smoothly,w r s can be adjusted according to the image condition.For example,when w r s is proportional to 10,all the intensity information on the image are ignored and painted normal values are simply interpolated on the image coordinate.This mode is useful for a surface with a complex texture whose intensity variations are not directly related to normal variations.Figure5shows the results of ourflood-fill method with and without intensity similarity measure.As shown in thefigure,the assigned surface nor-mal is smoothly propagated.2.3.Refining Reflectance and NormalsOnce the hand-drawn surface normal map is obtained, an automatic method for simultaneously estimating surface reflectance and afine surface normal map is applied.The method takes an input image I r and the user-assigned nor-mal map N r as input.We assume that the scene is gov-erned by a local lighting effect,more precisely,illumination can be approximated by a dominant directional lighting that is represented with a directional vector l and magnitude I p,a small ambient lighting term I a that approximates interreflec-tions,and shadowed area is not dominant in the image.(a)Grayscale (b)Sparse normal (c)Smoothflood-fill(d)Grayscale (e)Sparse normal (f)Smooth flood-fillFigure 5.(a,b,c)shows smooth flood-fill on Greek Building.(a)Grayscale image,(b)Coarse surface normal specified by a user,(c)result of smooth flood-fill using intensity similarity.(d,e,f)shows smooth flood-fill on Flower.(d)Grayscale image,(e)Coarse surface normal specified by a user,(f)result of smooth flood-fill when w r s is proportional to 1.0.The proposed interpolation method is used on petals.In (c,f),XYZ component of surface normal is represented by RGB channel respectively.We use the following local illumination model in thismethod:I rI a k aI p S p k d l nk s H p(3)where k a ,k d and k s are coefficients to describe albedo ofambient,diffuse and specular reflection respectively,n isunit vectors of normal directions,S p r01represents a shadowing term,and H p r is a term that governs intensity of specular highlight.Throughout this paper,we only consider gray images to describe our idea.For color images,the same process is applied for each red,green,and blue components.Light source estimation Our second step begins with es-timating the dominant lighting direction l in the originalscene.Traditionally,techniques from shape from shad-ing [2]have been used to estimate the direction of the light source.Assuming a Lambertian image formation model [5],most of these techniques try to simultaneously recover bothshape and the direction of the light source.In our case,the problem can be more constrained by the user-defined sur-face normal information and pre-defined label map which represents the regions of objects.Assuming that the area which shows diffuse reflection is dominant in each label i ,lighting direction l can be estimated by first minimizing E l :E l∑i∑rIrA iD i l N r2(4)where A i I a k i is a constant ambient,D i I p k i is the dif-fuse component.k i is a constant albedo in label i .E l can be minimized by solving a linear system of equations which is derived by its first derivatives about A i and D i .Once A i and D i are determined,l is then estimated by searching for the minimum energy E l as l argmin E l .In this way,lighting direction l is estimated.At the same time,A i and D i are assigned to each label.(a)Input image(b)Shadow S p(c)Highlight I p k s H pFigure6.Result of shadow detection and highlightdetection.(a)Coarse surface normal(b)Refined surface normalFigure7.Result of surface normal refine-ment.Detailed surface normal is estimated with the proposed method.Determining shadow and highlight Using the estimates A i,D i and l,our method detects the shadowed and specu-lar highlight areas by evaluating deviation from the diffuse reflection model as follows:S p r 1i f I r k i I a t s I p A i t s D i I r A it s D ielse i f I r k i I a A i0otherwise(5)I p k s H p r I r A i D i i f I r A i1t h D iI r A i1t h D i24t h D ielse i f I r A i1t h D i 0otherwise(6)where t s and t h are small positive thresholds that control the smoothness of the shadow and highlight.Figure6shows the result of shadow and highlight detection.Refinement of Reflectance and Normals The hand-drawn surface normal is limited to representing rather coarse surface normals because it is still hard for a user to assignfine geometric details,e.g.,bumps on a piece of fruit,such as an orange’s surface.This methodestimatesFigure9.Close-up view of highlight in relight-ing result.The top-left image shows the orig-inal image,and the rest show relit results. more precise surface normals and reflectance using an input image I and the hand-drawn coarse surface normal map N.Assuming that l is known and constant albedos k i are obtained for labelled region i,we show that the surface re-flectance and normal can be refined by the proposed refine-ment method.Due to the inaccuracy of the coarse surface normal N and constant albedo k i in each label i,Eq.(3)be-comese k i N I r I a k i I p S p k i l N k s H p(7) where e is the residue caused by the error in surface normal and surface reflectance.We use the residue e to refine both surface albedo k i and normal N.To determine the sourceFigure8.Result of single-view relighting.Top row shows original images,and the bottom row shows corresponding relighting results.The second and third row show the refined surface normal map and reflectance images respectively.of the error,i.e.,surface normal or reflectance,we proposeto use a chromaticity similarity measure in the original im-age.In our method,the chromaticity similarityαbetweena pixel r and adjacent pixels s A r is evaluated in thespecified image area as follows:αr1n∑s N rSimilarity C r C s(8)where C R G B03R06G01B representschromaticity and n represents the number of adjacent pix-els s.The function Similarity measures the distancebetween two chromaticities.In our case,we use the innerproduct of normalized vectors to measure the chromaticitysimilarity as Similarity a b a b a b.The residue e is then distributed to surface normal Nand reflectance k i weighed byαfor each pixel by plug-ging e k N1αe k i N and e k i nαe k i N intoEquation(7)and solving respectively for each k and n.Toobtain the refined surface normal n from e k i n with Equa-tion(7),the coarse normal N is rotated on the plane spannedby l and N.There are two solutions of n,and the solutionof n which has a smaller deviation from N is taken by eval-uating n argmin n N.In this way,fine reflectance andnormal map which are necessary for relighting are obtained.Figure7shows the result of surface normal refinement.De-tailed surface normal of bumps of the orange is estimatedwith the proposed method.3.ResultsTo evaluate the performance of the proposed method,we have conducted extensive experiments on various pho-Figure10.Adjustment of photometric consistency in superimposition application.The foreground (the girl in the top-left image)is superimposed on the different background(bottom and right image).The illumination condition of foreground(girl)is aligned to that of the background with our relighting method.(Sunset image courtesy Philip Greenspun,).tographs.We have developed a complete system to achievethe goal and all the relighting results are rendered withoutany other photo-editing tools.Figure8displays the resultof proposed relighting method.The images in the top rowshow the original input images,the second row shows thenormal maps used for relighting,the third row shows theestimated reflectance images,and the relighting results areshown in the bottom row.To produce the relighting result,Equation(3)is used for rendering.For surface normal assignment,like existing3D mod-ellers and image-based modeling methods that allow a userto assign depth values,in practice,our method is limitedto rather simple scenes where image segmentation is fea-sible.As mentioned in[17],image segmentation usuallytakes many hours.The editing time of our results is alsoroughly a few hours on average.Ignoring the image seg-mentation process,we found that the normal assignment ismuch easier than existing methods that assign full3D ordepth by3D modellers and depth painting method.At the boundaries of objects where surface normals arenot smooth,sometimes small artifacts due to the inaccu-racy of the surface normal boundary are observed.To han-dle this problem,pixels that have a significant differencein chromaticity between themselves and the adjacent pixelscompared to that in the original image are replaced with thesmooth interpolation of adjacent pixel values weighed bythe chromaticity similarity in the original image.To renderhighlights,we used a simple Phong model in the experi-ment:I p k s H s r I p k s v m r n i,where v and m are unitvectors of viewing and mirror reflection directions.n i is auser-defined shininess factor.In this way,H s is computedfor each pixel under a new lighting condition.Figure9shows the close-up view of the orange surface in the fruitscene.As we can see clearly in the image,highlight andsmall bumps on the orange surface are naturally rendered.Since the scene structure is represented by surface nor-mals in our method,it is inherently difficult to generate castshadows that are not local lighting effects.However,whenthe scene surface is smooth,we can compute cast shadowby taking the integral of surface normals.We have adopteda method proposed by Robertson et al.[18]to achieve castshadow rendering.The relighting results with cast shadowis shown on the bottom row of Figure8.Our method is useful for illumination alignment for photo-object superimposition(Figure10).With our relight-ing method,photometric consistency between foreground and background is adjusted and visible in the illustration. In this example,we superimposed the foreground onto the background image with adjusting the illumination condition of the foreground.4.Conclusion and Future WorkThis paper presents a new approach to single-view re-lighting.We provide a set of input methods for interac-tive assignment of surface normal.An automatic method for estimating surface reflectance and detailed surface nor-mal from the coarse surface normal input is also proposed. The proposed method uses surface normals to represent the scene geometry in an image,which is sufficient for re-lighting where local illumination effect is dominant.Two key techniques are developed;(1)Smoothflood-fill tool which propagates sparse normal input to smoothlyfill-in the specified image area,and(2)Algorithm to refine sur-face reflectance and normal with the input image and the hand-drawn coarse surface normal.The applicability of the method is evaluated by relighting a variety of photographs and the application of illumination adjustment in photo su-perimposition.There are many promising directions for future research. One is to investigate more efficient tools for surface normal assignment.Our current system provides normal modeling tools based on detectable pen angle of a pen-tablet device. It may be also possible to develop UIs to assign surface normals in a copy-and-paste manner by referencing well-known shapes such as cube,sphere,etc.We are also inter-ested in other interactive tools such like Teddy system[7].To simplify the problem,we limit our method to apply to scenes which are governed by a dominant directional light-ing with an ambient lighting and are composed of surface materials that can be approximated by the Phong’s model. Extending the method to work with more complex lighting models and BRDF models is the other direction of future research,which also makes the refinement algorithm of re-flectance and normal maps more complex but may produce more physically correct relighting results. References[1]S.Boivin and A.Gagalowicz.Image-based rendering of dif-fuse,specular and glossy surfaces from a single image.In SIGGRAPH’01,pages107–116.ACM Press,2001.[2]M.J.Brooks and B.K.P.Horn.Shape and source fromshading.In Int.Joint Conf.Aritficial Intell.,pages932–936, 1985.[3] A.Criminisi,I.D.Reid,and A.Zisserman.Single viewmetrology.Int’l J.of Computer Vision,40(2):123–148, 2000.[4]P.E.Debevec,C.J.Taylor,and J.Malik.Modeling and ren-dering architecture from photographs:A hybrid geometry-and image-based puter Graphics,30(Annual Conf.Series):11–20,1996.[5]J.D.Foley,A.V.Dam,S.K.Feiner,and -puter Graphics:Principles and Practice.Addison-Wesley, 1990.[6]M.Fuchs,V.Blanz,and H.-P.Seidel.Bayesian relighting.In Rendering Techniques2005:Eurographics Symposium on Rendering,pages157–164,2005.[7]T.Igarashi,S.Matsuoka,and H.Tanaka.Teddy:asketching interface for3d freeform design.In SIGGRAPH ’99,pages409–416.ACM Press/Addison-Wesley Publish-ing Co.,1999.[8]S.F.Johnston.Lumo:illumination for cel animation.InNPAR’02:Proceedings of the2nd international symposium on Non-photorealistic animation and rendering,pages45–ff,New York,NY,USA,2002.ACM Press.[9]S.B.Kang.Depth painting for image-based rendering ap-plications.Tech.report,CRL,Compaq Cambridge Research Lab,1998,1998.[10]J.J.Koenderink.Pictorial relief.Phil.Trans.ofthe Roy.Soc.:Math.,Phys,and Engineering Sciences, 356(1740):1071–1086,1998.[11] A.Levin,D.Lischinski,and Y.Weiss.Colorization usingoptimization.ACM Trans.Graph.,23(3):689–694,2004. [12]Y.Li,J.Sun,C.-K.Tang,and zy snapping.ACM Trans.Graph.,23(3):303–308,2004.[13]Z.Lin,T.-T.Wong,and H.-Y.Shum.Relighting with the re-flected irradiancefield:Representation,sampling and puter Vision,49(2-3):229–246,2002.[14]T.Malzbender,D.Gelb,and H.Wolters.Polynomial tex-ture maps.In SIGGRAPH’01:Proceedings of the28th an-nual conference on Computer graphics and interactive tech-niques,pages519–528.ACM Press,2001.[15]S.R.Marschner and D.P.Greenberg.Inverse lighting forphotography.In Proceedings of the Fifth Color Imaging Conference,Society for Imaging Science and Technology, Nov.1997.[16]V.Masselus,P.Peers,P.Dutr´e,and Y.D.Willems.Re-lighting with4d incident lightfields.ACM Trans.Graph., 22(3):613–620,2003.[17] B.M.Oh,M.Chen,J.Dorsey,and F.Durand.Image-basedmodeling and photo editing.In SIGGRAPH’01,pages433–442.ACM Press,2001.[18]P.K.Robertson.Spatial transformations for rapid scan-linesurface shadowing.IEEE Computer Graph.Appl.,9(2):30–38,1989.[19]L.Zhang,G.Dugas-Phocion,J.-S.Samson,and S.M.Seitz.Single view modeling of free-form scenes.In IEEE Conf.on Computer Vision and Pattern Recognition,pages990–997.IEEE Computer Society,2001.[20] C.L.Zitnick,S.B.Kang,M.Uyttendaele,S.Winder,andR.Szeliski.High-quality video view interpolation using a layered representation.ACM Trans.Graph.,23(3):600–608, 2004.。