C语言链表(能看得懂的)共92页
C语言链表ppt课件

2. calloc 函数
函数原形:void *calloc(unsigned n,unsigned size); 作用:在内存动态区中分配 n个 长度为size的
连续空间。 函数返回值:指向分配域起始地址的指针 执行失败:返回null 主要用途:为一维数组开辟动态存储空间。n 为
数组元素个数,每个元素长度为size
{ struct student *p1, *p2;
if(head==NULL) {printf("\nlist null!\n"); goto end; } p1=head;
while(num!=p1->num&&p1->next!==NULL)
{ p2=p1; p1=p1->next; }
if(num==p1->num) 找到了 { if(p1==head) head=p1->next;
27
图11.19
A B CD E (a)
A B CD E (B)
28
图11.20
p1 head
99101
99103
head
(a) p1
99101
99103
p2 (b)
99107
NULL
99107
NULL
原链表
P1指向 头结点
P2指向p1 指向的结 点。P1指 向下移一 个结点。
29
图11.20
10
11.7.3 处理动态链表所需的函数
C 语言使用系统函数动态开辟和释放存储单元 1.malloc 函数
函数原形:void *malloc(unsigned int size); 作用:在内存的动态存储区中分配 一个 长度为size 的连续空间。 返回值:是一个指向分配域起始地址的指针(基本 类型void)。 执行失败:返回NULL
《C语言链表》课件

详细描述
删除链表中的节点需要找到要删除的节点,修改其前一个节点的指针,使其指向要删除节点的下一个 节点,然后将要删除节点的指针置为NULL。如果要删除的是头节点或尾节点,还需要对头指针或尾 指针进行相应的修改。
遍历链表
总结词
了解如何遍历链表中的所有节点
VS
详细描述
遍历链表需要从头节点开始,依次访问每 个节点,直到达到链表的尾部。在遍历过 程中,可以使用一个指针变量来指向当前 节点,每次循环将指针向后移动一个节点 ,即修改指针的next指针。
链表和循环链表的主要区别在于它们的最后一个节点指向的方向。在链表中,最后一个节点指向NULL; 而在循环链表中,最后一个节点指向第一个节点。循环链表具有更好的性能,但实现起来相对复杂一些 。
05
总结与展望
总结链表的重要性和应用场景
总结1
链表作为C语言中一种基本的数据结构,在计算机科学中 有着广泛的应用。通过学习链表,可以更好地理解数据 结构的基本概念,提高编程能力和解决实际问题的能力 。
详细描述
合并两个有序链表可以通过比较两个链表的 节点值来实现。从头节点开始比较,将较小 的节点添加到结果链表中,并将指针向后移 动。重复此过程直到其中一个链表为空。如 果还有剩余的节点,将其添加到结果链表的 末尾。这种方法的时间复杂度为O(n),其中
n为两个链表中节点的总数。
04
常见错误与注意事项
内存泄漏问题
内存泄漏定义
在C语言中,内存泄漏是指在使用动 态内存分配函数(如malloc、calloc 、realloc等)分配内存后,未能正确 释放这些内存,导致程序运行过程中 不断占用越来越多的内存,最终可能 导致程序崩溃或性能下降。
C语言类的双向链表详解

C语⾔类的双向链表详解⽬录前⾔双向链表的定义双向链表的创建节点的创建双向链表节点查找双向链表的插⼊双向链表的节点删除双向链表的删除总结前⾔链表(linked list)是⼀种这样的数据结构,其中的各对象按线性排列。
数组的线性顺序是由数组下标决定的,然⽽于数组不同的是,链表的各顺序是由链表中的指针决定的。
双向链表也叫双链表,是链表的⼀种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。
所以,从双向链表中的任意⼀个结点开始,都可以很⽅便地访问它的前驱结点和后继结点。
⼀般我们都构造双向循环链表。
双向链表的定义双链表(doubly linked list)的每⼀个元素都是⼀个对象,每⼀个对象都有⼀个数据域和两个指针front和tail。
对象中还可以包含其他辅助数据。
设L为链表的⼀个元素,L.front指向他在链表中的后继元素,L.tail指向他的前继元素。
我们可以定义⼀个结构体封装这些数据typedef struct Node{int data;struct Node* front;struct Node* tail;}NODE, * LPNODE;双向链表的创建在C++中,我们以类的形式封装了双向链表。
在类中,我们定义了两个指针,⼀个是指向链表的头部 frontNode,⼀个是指向了链表的尾部 tailNode,另外我们还加⼊了 curSize属性,记录节点的个数。
在对象创建的过程就是链表创建的过程,我们只需要在类的构造函数中初始化参数即可。
class duplexHead {public:duplexHead() {frontNode = NULL;tailNode = NULL;curSize = 0;}LPNODE createNode(int data);LPNODE seachNode(int data);void push_front(int data);void push_back(int data);void push_appoin(int posData, int data);void pop_front();void pop_back();void pop_appoin(int posData);void printByFront();void printByTail();protected:LPNODE frontNode;LPNODE tailNode;int curSize;};节点的创建在上⾯,我们已经知道双向链表的单体长啥样了,我们只需要给他的单体分配空间然后初始化他的参数即可。
C语言课件 链表

3.处理动态链表所需的函数
上例是比较简单的,所有结点都是在程序中定义 的,不是临时开辟的,也不能用完后释放,这种链表 称为“静态链表”。 前面讲过,链表结构是动态生地分配存储的,即 在需要时才开辟一个结点的存储单元 以便插入或追 加节点,删除节点后需要释放节点占用的内存单元。 C 语言提供了相应的函数。
⑴ void *malloc(unsigned int size) :在内存的动态存储区中分 配一个长度为size的连续空间。成功,则返回一个void型的空指针, 否则,返回NULL. 分配内存的字节数。
使用方法: ptr=malloc(size);
返回空类型的指针。 成功:返回内存的地址。 失败:返回NULL。 ⑵void free(ptr) 作用: 释放ptr指向的内存空间。 (3)void *calloc(unsigned n,unsigned size) 在内存的动态区 存储中分配n个长度为size的连续空间。函数返回分配域的起始 地址;如果分配不成功,返回0。
删除结点的函数: struct student *del (struct student *head,int num) {struct student *p1,*p2; if (head==NULL) {printf ("\nlist is null\n");} p1=head; while (p1->num!=num && p1->next!=NULL) {p2=p1;p1=p1->next;} if (p1->num==num) {if (p1==head) head=p1->next; else p2->next=p1->next; printf ("delete:%d\n",num); } else printf ("%ld not been found!",num); return(head); }
C语言_链表ppt课件

特殊的节点,称为头节点,它的data字段不含信息或根据问题的需要 存放特殊信息。
2、链表的遍历(显示链表)
一个非递归算法
以下函数disp()用于显示头节点为*h的链表的所有节点 数据域。
void disp(struct Node *h) { struct Node *p=h; printf("输出链表:"); if(p==NULL) printf("空表\n"); else { while (p->next!=NULL) { printf("%4d",p->data); p=p->next; } printf("%4d\n",p->data); }
在链表结尾出插入一个元素
p
data
首先要用一个循环语句找到q
q
q=h;
h
...
NULL
while(q->next!=NULL)
q=q->next;
p
然后执行插入语句:
data
p->next=NULL;
q
q->next=p;
h
...
NULL
p
data
q
h
...
NULL
在链表中间插入一个元素
p
data
}
单链表的插入
.
3、链表的插入(头指针的情况下)
对于插入有以下几种情况 在一个空链表上插入一个元素。 (即要插入位置前方和后方均无元素) 从链表表头处插入一个元素 (即要插入的位置前方无元素,后方有元素) 从链表结尾处处插入一个元素 (即要插入的位置后方五元素,前方有元素) 从链表的中间插入 (即要插入的位置前方和后方均有元素) 其中第三种情况可以按照第四种情况处理,但有一定特殊性所以将 其分开 注意:产生新的节点必须用malloc或者calloc开辟空间
c语言链表定义

c语言链表定义链表是一种非常基础的数据结构,它的定义可以用多种编程语言来实现,其中最为常见的就是C语言。
本文将着重介绍C语言的链表定义。
第一步:首先,我们需要定义一个链表节点的结构体,用来存储链表中每个节点的数据信息以及指向下一个节点的指针。
具体代码如下所示:```struct ListNode {int val;struct ListNode *next;};```在这个结构体中,我们定义了两个成员变量,一个是表示节点值的val,一个是表示指向下一个节点的指针next。
其中,节点值可以是任意类型的数据,而指针next则是一个指向结构体类型的指针。
第二步:我们需要定义链表的头节点,通常会将头节点的指针定义为一个全局变量,方便在程序的不同部分中都能够访问。
这个头节点的作用是指向链表的第一个节点,同时也充当了哨兵节点的作用,使得链表的操作更加方便。
具体代码如下所示:```struct ListNode *list_head = NULL;```在这个全局变量中,我们定义了一个指向链表头节点的指针list_head,并将它初始化为NULL,表示目前链表为空。
第三步:链表的基本操作主要包括创建、插入、删除和遍历等。
我们将逐一介绍它们的定义方法。
1. 创建链表创建链表时,我们需要动态地分配内存,以保证每个节点的空间都是连续的而不会被覆盖。
具体代码如下所示:```struct ListNode *create_list(int arr[], int n) {struct ListNode *head = NULL, *tail = NULL;for (int i = 0; i < n; i++) {struct ListNode *node = (struct ListNode*)malloc(sizeof(struct ListNode));node->val = arr[i];node->next = NULL;if (head == NULL) {head = node;tail = node;} else {tail->next = node;tail = node;}}return head;}```在这个代码中,我们首先定义了链表的头节点head和尾节点tail,并将它们初始化为空。
C语言链表详解PPT课件

26
链表中结点删除
需要由两个临时指针: P1: 判断指向的结点是不是要删除的结点 (用于寻找); P2: 始终指向P1的前面一个结点;
27
图 11.19
4
结点里的指针是存放下一个结点的地址
Head
1249
1249
A 1356
1356
B 1475
1475
C 1021
1021
D Null
1、链表中的元素称为“结点”,每个结点包括两 个域:数据域和指针域;
2、单向链表通常由一个头指针(head),用于指 向链表头;
3、单向链表有一个尾结点,该结点的指针部分指
7
(4)删除操作是指,删除结点ki,使线性表的长度 减1,且ki-1、ki和ki+1之间的逻辑关系发生如下变 化:
删除前,ki是ki+1的前驱、ki-1的后继;删除后,ki-1 成为ki+1的前驱,ki+1成为ki-1的后继.
(5)打印输出
8
一个指针类型的成员既可指向其它类型的结构体数 据,也可以指向自己所在的结构体类型的数据
(x7,y7)
为了表示这种既有数据又有指针的情况, 引入结构这种数据类型。
3
11.7 用指针处理链表
链表是程序设计中一种重要的动态数据结构, 它是动态地进行存储分配的一种结构。
动态性体现为: 链表中的元素个数可以根据需要增加和减少,不 像数组,在声明之后就固定不变;
元素的位置可以变化,即可以从某个位置删除, 然后再插入到一个新的地方;
数据结构之链表篇(单链表,循环链表,双向链表)C语言版

数据结构之链表篇(单链表,循环链表,双向链表)C语⾔版1.链表 链表是线性表的⼀种,由⼀系列节点(结点)组成,每个节点包含⼀个数据域和⼀个指向下⼀个节点的指针域。
链表结构可以克服数组需要预先知道数据⼤⼩的缺点,⽽且插⼊和删除元素很⽅便,但是失去数组随机读取的优点。
链表有很多种不同类型:单向链表,双向链表和循环链表。
在链表中第⼀个节点叫头节点(如果有头节点)头节点不存放有效信息,是为了⽅便链表的删除和插⼊操作,第⼀个有效节点叫⾸节点,最后⼀个节点叫尾节点。
2.单链表的操作 链表的操作⼀般有创建链表,插⼊节点,删除节点,遍历链表。
插⼊节点的⽅法有头插法和尾插法,头插法是在头部插⼊,尾插法是在尾部插⼊。
下⾯以⼀个带头节点,采⽤尾插法的链表说明链表的各种操作。
1 #include<stdio.h>2 #include<stdlib.h>3//单链表456//节点结构体7 typedef struct node8 {9int value;//数据域10struct node*next;//指针域11 }Node;1213 Node*createList();//创建链表并且返回头节点指针14void deleteNode(Node*head);//删除节点15void insertNode(Node*head);//插⼊节点16void travelList(Node*head);//遍历链表1718int main()19 {20 Node*head=createList();21 travelList(head);22 insertNode(head);23 travelList(head);24 deleteNode(head);25 travelList(head);26return0;27 }28//创建链表,返回头节点指针29 Node*createList()30 {31//采⽤尾插法32 Node*head;//头节点33 Node*tail;//尾节点34 Node*temp=NULL;35int i,value,size;36 head=(Node*)malloc(sizeof(Node));//头节点37 head->value=0;38 head->next=NULL;39 tail=head;40 printf("输⼊节点个数: ");41 scanf("%d",&size);42 printf("输⼊各个节点的值: ");4344for(i=0;i<size;i++)45 {46 scanf("%d",&value);47 temp=(Node*)malloc(sizeof(Node));48 temp->value=value;49 tail->next=temp;//让尾节点的指针域指向新创建的节点50 tail=temp;//尾节点改为新创建的节点51 tail->next=NULL;//让尾节点的指针域为空52 }53return head;54 }55//遍历链表56void travelList(Node*head)57 {58while(head->next!=NULL)59 {60 printf("%d\n",head->next->value);61 head=head->next;62 }63 }64//插⼊节点65void insertNode(Node*head)66 {67int value;68int position;69int pos=0;70 Node*pre=NULL;//⽤来保存要插⼊节点的前⼀个节点71 Node*newNode;72 printf("输⼊要插⼊节点的值: ");73 scanf("%d",&value);74 printf("要插⼊的位置: ");75 scanf("%d",&position);76while(head!=NULL)77 {78 pos++;79 pre=head;80 head=head->next;81if(pos==position)82 {83 newNode=(Node*)malloc(sizeof(Node));84 newNode->value=value;85 newNode->next=pre->next;86 pre->next=newNode;87 }88 }89 }90//删除节点91void deleteNode(Node*head)92 {93int value;94 Node*pre=head;95 Node*current=head->next;96 printf("输⼊要删除节点的值: ");97 scanf("%d",&value);98while(current!=NULL)99 {100if(current->value==value)101 {102 pre->next=current->next;103free(current);//释放空间104break;105 }106 pre=current;107 current=current->next;108 }109 }3.循环链表 循环链表就是让尾节点的指针域不再是NULL,⽽是指向头节点从⽽形成⼀个环。
【数据结构】之链表(C语言描述)

【数据结构】之链表(C语⾔描述) 链表是线性表的⼀种,是⼀种物理存储单元上⾮连续的存储结构,链表中的数据元素之间是通过指针链接实现的。
链表由⼀系列节点组成,节点可以在运⾏时动态的⽣成。
链表中国的每个节点分为两部分:⼀部分是存储数据的数据域,另⼀部分是存储下⼀个节点的地址的指针域。
如果要在链表中查找某个位置的元素,需要从第⼀个元素开始,循着指针链⼀个节点⼀个节点的找,不像顺序表那样可以直接通过下标获取对应的元素,因此,链表不适合查询操作频繁的场景。
如果要在链表中添加或删除某个元素,只需要通过指针操作,将要操作的节点链⼊指针链或从指针链中移除即可,不必像顺序表那样需要移动之后的所有节点,因此,链表更适合增删操作频繁的场景。
使⽤链表不需要像顺序表那样,处处考虑要不要给表扩容,链表中的元素都是在运⾏时动态⽣成的,因此可以充分利⽤计算机的内存空间;但是,由于链表中的每个元素都需要包括数据域和指针域两块区域,因此空间开销也是⽐较⼤的。
下⾯是⽤ C语⾔描述的链表的代码: 链表数据结构的头⽂件LinkedList.h中的代码:/*** 线性表(链式存储)* 注意:线性表的第⼀个节点不存储任何数据,只起到表头的作⽤*/#include <stdio.h>#include <stdlib.h>// 类型定义typedef int Status; // ⽅法的返回值typedef int LinkedElemType; // LinkedList数据结构中节点中存储的数据的类型// LinkedList中的节点的结构体typedef struct LinkedNode {LinkedElemType value;struct LinkedNode* nextNode;} LinkedNode;// LinkedList数据结构typedef struct LinkedList {LinkedNode* data;int length;} LinkedList;// 1.创建带头结点的空链表void initLinkedList(LinkedList* L) {L->data = (LinkedNode*)malloc(sizeof(LinkedNode));if(L->data != NULL) {L->data->nextNode = NULL;L->length = 0;printf("创建链表成功!\n");}}// 2.销毁链表void destroyLinkedList(LinkedList* L) {LinkedNode* node = NULL;if(L->data == NULL) {printf("链表不存在!\n");exit(1);}while(L->data != NULL) {node = L->data;L->data = L->data->nextNode;free(node);}printf("销毁链表成功!\n");}// 3.清空链表(使链表只剩下表头)void clearLinkedList(LinkedList* L) {LinkedNode* node = NULL;if(L->data == NULL) {printf("链表不存在!\n");exit(1);}}L->length = 0;printf("清空链表成功!\n");}// 4.返回链表的长度int getLinkedListSize(LinkedList* L) {return L->length;}// 5.判断链表中是否存储着数据Status isLinkedListEmpty(LinkedList* L) {return L->data->nextNode == NULL;}// 6.返回链表中第i个数据元素的值LinkedElemType getLinkedElemAtPos(LinkedList* L, int i) {LinkedNode* node = NULL;int index = -1;if(L->data == NULL) {printf("链表不存在!\n");exit(1);}if(i < 1 || i > L->length) {printf("下标⽆效!\n");exit(1);}node = L->data;for(index = 1; index <= i; index++) {node = node->nextNode;}return node->value;}// 7.在链表L中检索值为e的数据元素(第⼀个元素)LinkedNode* getLinkedElem(LinkedList* L, LinkedElemType e) {LinkedNode* node = L->data;if(L->data == NULL) {printf("链表不存在!\n");return NULL;}while(node->nextNode != NULL) {node = node->nextNode;if(e == node->value) {return node;}}return NULL;}// 8.在链表L中第i个数据元素之前插⼊数据元素evoid insertLinkedElemBefore(LinkedList* L, int i, LinkedElemType e) { LinkedNode* priorNode = L->data;LinkedNode* nextNode = NULL;LinkedNode* newNode = NULL;int index = -1;if(L->data == NULL) {printf("链表不存在!\n");exit(1);}if(i < 1 || i >= L->length) {printf("下标⽆效!\n");exit(1);}newNode = (LinkedNode*)malloc(sizeof(LinkedNode));newNode->value = e;for(index = 1; index < i; index++) {priorNode = priorNode->nextNode;nextNode = priorNode->nextNode;}priorNode->nextNode = newNode;newNode->nextNode = nextNode;L->length++;printf("在第%d个位置插⼊%d成功!\n", i, e);}// 9.在表尾添加元素evoid insertElemAtEnd(LinkedList* L, LinkedElemType e) {LinkedNode* currNode = NULL;LinkedNode* newNode = NULL;currNode = L->data;while(currNode->nextNode != NULL) {currNode = currNode->nextNode;}newNode = (LinkedNode*)malloc(sizeof(LinkedNode));newNode->value = e;newNode->nextNode = NULL;currNode->nextNode = newNode;L->length++;printf("成功在表尾添加元素%d\n", e);}// 10.删除链表中第i个位置上的元素void deleteLinkedElemAtPos(LinkedList* L, int i) {LinkedNode* priorNode = L->data;LinkedNode* nextNode = NULL;LinkedNode* oldNode = NULL;int index = -1;if(L->data == NULL) {printf("链表不存在!\n");exit(1);}if(i < 1 || i > L->length) {printf("下标⽆效!\n");exit(1);}for(index = 1; index < i; index++) {priorNode = priorNode->nextNode;nextNode = priorNode->nextNode;}oldNode = nextNode;priorNode->nextNode = nextNode->nextNode;L->length--;printf("成功删除第%d个位置上的元素%d!\n", i, oldNode->value); free(oldNode);}// 11.返回给定元素的前驱节点LinkedNode* getPriorLinkedElem(LinkedList* L, LinkedNode* e) {LinkedNode* priorNode = NULL;LinkedNode* currNode = NULL;if(L->data == NULL) {printf("链表不存在!");return NULL;}if(e == L->data->nextNode) {return L->data->nextNode;}priorNode = L->data;currNode = priorNode->nextNode;while(currNode->nextNode != NULL) {if(currNode == e) {return priorNode;}priorNode = currNode;currNode = priorNode->nextNode;}return NULL;}// 12.返回给定元素的后继节点LinkedNode* getNextLinkedElem(LinkedList* L, LinkedNode* e) {LinkedNode* currNode = NULL;if(L->data == NULL) {printf("链表不存在!\n");return NULL;}currNode = L->data;while(currNode->nextNode != NULL) {if(currNode == e) {return currNode->nextNode;}currNode = currNode->nextNode;}return NULL;}// 13.遍历链表void traverseLinkedList(LinkedList* L) {LinkedNode* currNode = NULL;currNode = L->data->nextNode;while(currNode != NULL) {printf("%-4d", currNode->value);currNode = currNode->nextNode;}printf("\n");}testLinkedList() {// 声明链表对象LinkedList list;// 测试节点LinkedNode* testNode;// 初始化链表initLinkedList(&list);// 销毁链表// destroyLinkedList(&list);// 清空链表clearLinkedList(&list);// 获取链表长度printf("当前链表长度:%d\n", getLinkedListSize(&list));// 判断链表中是否存储着数据printf("链表中是否存储着数据:%s\n", isLinkedListEmpty(&list) ? "否" : "是");// 在表尾添加元素insertElemAtEnd(&list, 1);insertElemAtEnd(&list, 2);insertElemAtEnd(&list, 4);insertElemAtEnd(&list, 5);insertElemAtEnd(&list, 6);// 遍历链表中的元素traverseLinkedList(&list);// 获取某个位置的元素值printf("当前链表中第2个元素的值是:%d\n", getLinkedElemAtPos(&list, 2));// 在某元素前插⼊新元素insertLinkedElemBefore(&list, 3, 3);insertLinkedElemBefore(&list, 3, 3);// 遍历链表中的元素traverseLinkedList(&list);// 删除某位置的元素deleteLinkedElemAtPos(&list, 4);// 遍历链表中的元素traverseLinkedList(&list);// 获取对应值的第⼀个元素testNode = getLinkedElem(&list, 3);// 返回某节点的前驱节点printf("测试节点的前驱节点的值是:%d\n", getPriorLinkedElem(&list, testNode)->value); // 返回某节点的后继节点printf("测试节点的后继节点的值是:%d\n", getNextLinkedElem(&list, testNode)->value); } 主函数所在的⽂件main.c中的代码:#include <LinkedList.h>//主函数int main() {testLinkedList(); // 线性表(链式存储)结构的测试return0;} 运⾏结果如下:创建链表成功!清空链表成功!当前链表长度:0链表中是否存储着数据:否成功在表尾添加元素1成功在表尾添加元素2成功在表尾添加元素4成功在表尾添加元素5成功在表尾添加元素61 2 4 5 6当前链表中第2个元素的值是:2在第3个位置插⼊3成功!在第3个位置插⼊3成功!1 2 3 3 4 5 6成功删除第4个位置上的元素3!1 2 3 4 5 6测试节点的前驱节点的值是:2 链表分为好⼏种,上⾯介绍的这种链表叫做线性链表,它的特点是:线性存储,只能通过前⼀个节点找到后⼀个节点,不能通过后⼀个节点找到前⼀个节点; 链表还有其他的⼏种,下⾯来简单介绍:1、循环链表: 链表的头尾节点相连,形成⼀个环。
C语言链表详解及代码分析
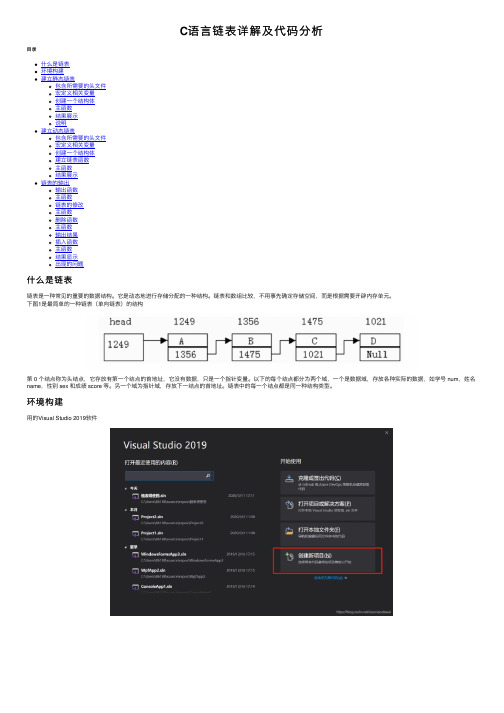
C语⾔链表详解及代码分析⽬录什么是链表环境构建建⽴静态链表包含所需要的头⽂件宏定义相关变量创建⼀个结构体主函数结果展⽰说明建⽴动态链表包含所需要的头⽂件宏定义相关变量创建⼀个结构体建⽴链表函数主函数结果展⽰链表的输出输出函数主函数链表的修改主函数删除函数主函数输出结果插⼊函数主函数结果显⽰出现的问题什么是链表链表是⼀种常见的重要的数据结构。
它是动态地进⾏存储分配的⼀种结构。
链表和数组⽐较,不⽤事先确定存储空间,⽽是根据需要开辟内存单元。
下图1是最简单的⼀种链表(单向链表)的结构第 0 个结点称为头结点,它存放有第⼀个结点的⾸地址,它没有数据,只是⼀个指针变量。
以下的每个结点都分为两个域,⼀个是数据域,存放各种实际的数据,如学号 num,姓名name,性别 sex 和成绩 score 等。
另⼀个域为指针域,存放下⼀结点的⾸地址。
链表中的每⼀个结点都是同⼀种结构类型。
环境构建⽤的Visual Studio 2019软件在源⽂件中添加C⽂件建⽴静态链表包含所需要的头⽂件#include<stdio.h> //标准输⼊输出头⽂件#include<stdlib.h>//包含了C、C++语⾔的最常⽤的系统函数宏定义相关变量#define LEN sizeof(struct Student)//宏定义节点长度得命名#define TYPE struct Student//宏定义结构体变量命名创建⼀个结构体struct Student//定义⼀个学⽣类型结构体,包括学号,分数{long num;float score;struct Student* next;//next是指针变量,指向结构体变量};//指向结构体对象得指针变量既可以指向结构体变量,也可以指向结构体数组中得元素主函数int main(){TYPE* head,*p;//定义头指针struct Student a,b,c;//定义三个结构体变量a.num = 101; a.score = 20;//分别对三个结点赋值b.num = 102; b.score = 20;c.num = 103; c.score = 20;/*1、A.B则A为对象或者结构体2、A->B则A为指针,->是成员提取,A->B是提取A中的成员B,A只能是指向类、结构、联合的指针;*/head = &a;a.next = &b;b.next = &c;c.next = NULL;p = head;//把⾸地址给变量do{printf("%ld %5.1f\n",p->num,p->score);//输出每个结点信息p = p->next;//使P指向下⼀个结点} while (p != NULL);//直到指针域指向空值return 0;}结果展⽰说明将第⼀个结点的起始地址赋值给头指针head,将第⼆个结点的起始地址赋值给第⼀个结点的next成员,将第⼆个结点的起始地址赋给第⼀个结点的next…第三个结点的next赋值为NULL,这就形成了简单的链表。
C语言链表详解ppt课件

换名话说:next存放下一个结点的地址
最新版整理ppt
9
11.7.2 简单链表
例11.7
#define NULL 0
struct student
{ long num; float score;
建
struct student *next; };
立
main()
和
{ struct student a, b, c, *head, *p;
(5)打印输出
最新版整理ppt
8
一个指针类型的成员既可指向其它类型的结构体 数据,也可以指向自己所在的结构体类型的数据
num Score next
99101 89.5
99103 90
99107 85
next是struct student类型中的一个成员, 它又指向struct student类型的数据。
对链表的基本操作有:
(1)创建链表是指,从无到有地建立起一个链表, 即往空链表中依次插入若干结点,并保持结点 之间的前驱和后继关系。
(2)检索操作是指,按给定的结点索引号或检索 条件,查找某个结点。如果找到指定的结点, 则称为检索成功;否则,称为检索失败。
(新3)的插结入点操k作’,是使指线,性在表结的点长k度i-1增与1k,i之且间k插i-1入与一ki个的 逻辑关系发生如下变化:
(x1,y1) (x2,y2)
(x6,y6)
(x7,y7)
为了表示这种既有数据又有指针的情况, 引入结构这种数据类型。
最新版整理ppt
3
11.7 用指针处理链表
链表是程序设计中一种重要的动态数据结构, 它是动态地进行存储分配的一种结构。
动态性体现为:
链表中的元素个数可以根据需要增加和减少,不 像数组,在声明之后就固定不变;
C语言——基础链表详解

C语⾔——基础链表详解敢于向⿊暗宣战的⼈,⼼⾥必须充满光明。
⼀、链表的构成1.构成链表是由⼀连串的结构(称为结点)组成的。
(1)结点的构成:数据(要储存的数据)+指针(指向下⼀个结点的指针)(2)关于⼏个定义头结点:链表⾸结点前的⼀个结点(不是必须的,但是如果有就可以在解决某些问题时候⽅便⼀些,通常可以⽤来储存链表的长度等信息)⾸结点:链表的第⼀个数据元素头指针:必须要有的(⽽头结点可以没有,注意两者⼀个是指针⼀个是结点,⼀个必须有⼀个可以没有),指向头结点/⾸节点的指针(永远指向链表的第⼀个结点)2.结点类型声明、创建结点struct node{int value;struct node *next;//创建了⼀个指向⼀个node类型的指针,⽤于指向下⼀个结点};//⾄此声明了⼀个结点类型//头指针:struct node *first = NULL;//结点创建:struct node *new_node;new_node = (struct node *)malloc(sizeof(struct node));//给结点分配内存单元。
注意:malloc返回的是void类型的指针,所以可以强制类型转换⼀下new_node -> value = 10;//把数据存储到结点中⼆、在链表开始处插⼊结点struct node * first = NULL;struct node *new_node;new_node =(struct node *)malloc(sizeof(struct node));new_node ->value = 10;//将new_node结点插⼊链表开始处new_node->next = first;//new_node指向的node类型的next值为NULL,NULL可作为链表结尾(空指针)first = new_node;//让first 指向 new_node指向的结点(其实就是刚才malloc出来的结点)//ok⾄此,现在就已经有了⼀个链表,它有⼀个结点,结点中储存的值是10new_node = (struct node*)malloc(sizeof(struct node));new_node ->value = 2;new_node->next = first;//⼜新创建了个结点并让next指向第⼀次创建的结点(因为first是指向第⼀次创建的结点的)first = new_node;//可以理解为把头指针重置到头部我们把它封装成函数对于这样的函数我们传⼊⼀个链表list,和⼀个希望存⼊链表的数值nstruct node* add_to_list(struct node *list,int n){sturct noed *new_node;new_node = (struct node*)malloc(sizeof(struct node));if(new_node == NULL){printf("malloc error\n");exit(0);}new_node->value = n;new_node->next = list;//把新结点接到链表中return new_node;}first = add_to_list(first,10);first = add_to_list(first,20);//需要注意的是add_to_list函数是没有办法修改指针的(因为这个相当于复制了⼀个指针传进去,能修改它指向的东西,但是没有办法对他本⾝进赋值存储)//所以我们返回⼀个指向新结点的指针,让他作为返回值赋值储存给first需要注意的是add_to_list函数是没有办法修改指针的(因为这个相当于复制了⼀个指针传进去,能修改它指向的东西,但是没有办法对他本⾝进赋值存储),所以我们返回⼀个指向新结点的指针,让他作为返回值赋值储存给first三、搜索链表while循环可以⽤,但是我们都知道for循环是很灵活的。