磁盘阵列(存储)常见报警信息解答及处理方法下.pdf
[磁盘阵列磁盘红灯故障]磁盘阵列RAID10详解
![[磁盘阵列磁盘红灯故障]磁盘阵列RAID10详解](https://img.taocdn.com/s3/m/bbf0e0c532d4b14e852458fb770bf78a65293ade.png)
[磁盘阵列磁盘红灯故障]磁盘阵列RAID10详解篇一: 磁盘阵列RAID10详解磁盘阵列RAID10优势全面详解当前影响计算机运算速度的不是CPU,也不是内存而是硬盘。
,校验数据平均分布在每块硬盘上。
以n块硬盘构建的RAID 5阵列可以有n-1块硬盘的容量,存储空间利用率非常高。
任何一块硬盘上的数据丢失,均可以通过校验数据推算出来。
RAID5提供了冗余性,磁盘空间利用率较高,读写速度较快。
由于奇偶校验块是平均分布在每个磁盘上的,因此存在着数据条带的顺序和校验块的位置方向的问题,不同的厂家或系统在设计RAID5时有不同的组织方式。
RAID5的关键参数有:◇盘序――每块硬盘的组织顺序,在拆卸前应做好标记。
◇块大小――分割数据块进行存储时的大小单位,可能为十几KB 到上百KB。
◇组织方式――数据块和奇偶校验块存放的方式。
◇起始位置――第一个奇偶校验块的起始位置。
4.磁盘阵列的常见故障[)与修复方法复杂的RAID 系统有着特定的容错机制保护磁盘数据,但由于误操作和硬件故障引起的数据丢失还是经常发生。
虽然RAID提供了容错功能,如果用户没有认真地作备份,忽视了RAID潜在危险,当RAID 故障时都是一场大的灾难。
磁盘阵列设备,在使用过程中,经常会遇到一些常见故障,很多情况下是超出了阵列的冗余能力,这也使得RAID在给我们带来海量存储空间的应用之外,也带来了很多难以估计的数据风险,这里将重点介绍RAID常见故障及相关处理方式。
以RAID5为例,常见有三种基本工作状态,即容错,临界和重建,这三种状态定义如下:容错即容错阵列状态,所有硬盘处于激活状态,阵列具备冗余性,此时任何一个硬盘的故障均不会影响数据可用性。
临界即无容错阵列状态,阵列中某个硬盘单元已经失效,阵列中剩下的硬盘均处于激活状态,但已无法进行XOR奇偶数据写入。
重建即阵列重建/确认状态,一个空闲硬盘正被合并到阵列中。
当重建完成后,阵列将回复到容错状态。
磁盘阵列常见日志信息及解决方式

简介目录1.控制器事件 (2)1.1 严重警告 (2)1.2 一般警告 (3)1.3 通知 (3)2.磁盘 (4)2.1 严重警告 (4)2. 2 一般警告 (6)3.通道 (6)3.1 严重警告 (6)3.2 通知 (8)4.逻辑盘 (9)4.1 严重警告 (9)4.2 通知 (12)5.常见事件 (14)5.1 严重警告 (14)6.周边设备 (16)6.1 严重警告 (16)7.SES 设备 (17)7.1 严重警告 (17)8.常见外围设备 (19)8.1 严重警告 (19)1.控制器事件1.1 严重警告1 .Controller SDRAM ECC <multi-bits/single-bit> Error Detected发生原因:内存Single-bit/Multi-bits Errors处理方法:检查内存是否故障,重新更新FW,如仍有故障请联系供应商解决出现频率:一般2. Controller SDRAM Parity Error Detected发生原因:内存校验错误处理方法:更新FW,更换内存测试,如故障仍未解决,请联系供应商解决。
出现频率:低3. Controller ALERT: Power Supply Unstable or NVRAM Failed发生原因:电源电压输出过低,或者NVRAM内部错误.处理方法:请与供应商联系,如必要可更换新电源出现频率:低4. Controller ALERT: Redundant Controller Failure Detected发生原因:双控制器其中之一发生故障,另一控制器接管处理方法:检查双控制器在硬件、FW及其他设置上是否一致,如确认为硬件故障所致,请联系供应商解决。
出现频率:低5. CHL:_ FA TAL ERROR (_)发现原因:其中一个通道发生故障处理方法:请检查连接线路,双控的模式下,让另一控制器将接替故障控制器的工作,并联系供应商解决.6. Controller BBU Absent or Failed!发生原因:BBU(电池)被移走或故障处理方法:检查BBU是否安装正常出现频率:一般7. BBU Failure Detected发生原因:BBU发生故障处理方法:请联系供应商解决.8. Controller PCI Bus Parity Error Detected发生原因:可能由于控制器内部的温度过高造成部件发生故障处理方法:请联系供应商解决.9. Force Controller Write-Through on Triggered Cause发生原因:控制器切换写入方式为Write-Through处理方法:恢复原来的工作状态,如未解决,请联系供应商解决.1.2 一般警告10. Controller BBU Not Fully Charged!发生原因:BBU充电不足,并且不建议将cach的模式由write-throung改为write-back处理方法:如果电池不能满足长时间的电量负荷,请联系供应商更换电池.11. Controller BBU Thermal Shutdown/Enter Sleep-Mode!发生原因:BBU温度过高(>=45),或是充电完成超过7小时造成控制器BBU突然关闭或者休眠.处理方法:检查环境通风是否良好,电池是否安装正确,出现此日志一般不需要进行特别操作12. Memory Not Sufficient to Fully Support Current Config.发生原因:使用的内存与当前的型号或配置不符处理方法:检查内存是否正常,更换内存测试1.3 通知1. CONTROLLER notice: NVRAM Factory Defaults Restored发生原因:Firmware已经恢复到出厂设置处理方法:请按ESC清掉该信息即可.2. Controller Initialization Completed发生原因:控制器初始化完成.处理方法:系统正常启动.3. Controller NOTICE: Redundant Controller Firmware Updated发生原因:冗余控制器的Firmare已经更新处理方法:按ESC清掉该信息即可.4. Memory is Now Sufficient to Fully Support Current Config.发生原因:添加内存或更换新内存已完成处理方法:按ESC清掉该信息即可.5. NVRAM Restore from Disk is Completed发生原因:已从disk保存的配置恢复到当前运行的配置处理方法:按ESC清掉该信息即可.6. NVRAM Restore from File is Completed发生原因:已从先前保存的一个配置文件恢复到当前运行的配置处理方法:按ESC清掉该信息即可.7. NOTICE: Controller BBU Back On-Line!发生原因:之前报错故障的BBU恢复工作处理方法:按ESC清掉该信息即可.8. NOTICE: Controller BBU Fully Charged!发生原因:控制器BBU充电完成处理方法:按ESC清掉该信息即可.9. NOTICE: Controller BBU Present!发生原因:曾丢失BBU,现已恢复.处理方法:按ESC清掉该信息即可.10. NOTICE: Controller FAN On-Line(_RPM)发生原因:之前报错故障的控制器风扇恢复工作处理方法:按ESC清掉该信息即可.2.磁盘2.1 严重警告1. CHL:_ ID:_ SCSI Target ALERT: Unexpected Select Timeout发生原因:硬盘响应超时,硬盘或与主机的连接线被移走均会导致此问题发生处理方法:检查硬盘是否安装到位,连接线是否可靠2. CHL:_ ID:_ SCSI Target ALERT: Gross Phase/Signal Error Detected发生原因:此通道信号异常处理方法:请联系供应商解决3. CHL:_ ID:_ SCSI Target ALERT: Unexpected Disconnect Encountered发生原因:驱动器通道意外中断处理方法:请检查连接线路,如未解决,请联系供应商.4. CHL:_ ID:_ SCSI Drive ALERT: Negotiation Error Detected发生原因:磁盘通道异常处理方法:请联系供应商解决.5. CHL:_ ID:_ SCSI Target ALERT: Timeout Waiting for I/O to Complete发生原因:可能由于硬盘故障或是线路问题造成硬盘I/O读写超时处理方法:请检查连接线路和硬盘,如未解决,联系供应商解决.6. CHL:_ ID:_ SCSI Target ALERT: SCSI Parity/CRC Error Detected发生原因:磁盘通道发生校验错误处理方法:请检查磁盘连接线路和硬盘, 如未解决,联系供应商解决.7. CHL:_ ID:_ SCSI Target ALERT: Data Overrun/Underrun Detected发生原因:此位置硬盘数据溢出错误处理方法:重新插入此硬盘或更换新硬盘测试,重新更新FW,如故障仍未解决请联系供应商.出现频率:极低8. CHL:_ ID:_ SCSI Target ALERT: Invalid Status/Sense Data Received (Sense_key Sense_code)发生原因:磁盘不能接收到客户端的数据处理方法:请检查磁盘连接线路和硬盘.9. CHL:_ ID:_ SCSI Drive ALERT: Drive HW Error (Sense_key Sense_code) 发生原因:磁盘驱动器不能获得硬件的错误报表.处理方法:插拔故障磁盘,让热备盘进行数据的重建.10. CHL:_ ID:_ SCSI Drive ALERT: Bad Block Encountered - Block_number (Sense_key Sense_code)发生原因:磁盘不能获得介质的错误报表,控制器请求磁盘重试.处理方法:按ESC清掉该信息即可11. CHL:_ ID:_ SCSI Drive ALERT: CHL:_ ID:_ Clone Failed发生原因:磁盘初始化无响应处理方法:请检查磁盘连接线路和硬盘,如未解决,请联系供应商.12. Slot _ _ Drive ALERT: Bad Block Encountered - * * * * * * * * *发生原因:在一个RAID 1/3/5的阵列中,通过介质扫描或是在数据重建的过程中,可能出现发现坏块的事情,但如果显示是“Bad Block Encountered”,说明这不是当前的事情,已经由控制器将坏块所在的数据通过数据重建已经转移到了其他好的块道上了.处理方法:按ESC以清掉该错误信息即可.13. CHL:_ ID:_ SCSI Drive ALERT: Block Reassignment Failed - Block_number (Sense_key Sense_code)发生原因:磁盘块分配失败,磁盘可能被认为已经发生故障.处理方法:重新插拔故障硬盘,如未解决,请联系供应商更换新硬盘.14. CHL:_ ID:_ SCSI Drive ALERT: Aborted Command (Sense_key Sense_code)发生原因:SCSI磁盘失败命令报告处理方法:按ESC已清掉该错误信息.15. CHL:_ ID:_ ALERT: Media Scan Bad Block Unrecoverable-0x0发生原因:介质扫描不能修复该磁盘的坏块.处理方法:更换新硬盘.以防止数据的丢失.2.2 一般警告1. SMART-CH:_ ID:_ Predictable Failure Detected (TEST)发生原因:当开启模拟SMART的功能测试时提示该信息,说明该磁盘能支持此功能.处理方法:按ESC以清掉该信息即可.2. SMART-CH:_ ID:_ Predictable Failure Detected发生原因:SMART提示该磁盘可能会发生故障,这个信息的提示只会在开启了SMART功能之后才会出现.处理方法:为防止数据的丢失,请联系供应商以更换新硬盘.3. SMART-CH:_ ID:_ Predictable Failure Detected-Starting Clone发生原因:SMART发现该位置的磁盘出现故障,并且备用盘已经在尽行数据的重建.处理方法:请联系供应商以更换新硬盘.4. SMART-CH:_ ID:_ Predictable Failure Detected-Clone Failed发生原因:SMART提示此位置的磁盘已经失效,备用盘接替了该磁盘的数据,并自动关掉该磁盘的电力供应.处理方法:请联系供应商以更换新硬盘.5. CHL:_ ID:_ SCSI Drive ALERT: Block Successfully Reassigned –Block_number (Sense_key Sense_code)发生原因:磁盘坏块被重新成功分配.处理方法:按ESC以清掉该信息即可.6. CHL:_ ID:_ SCSI Drive NOTICE: Scan SCSI Drive Successful发生原因:介质扫描新磁盘成功处理方法:按ESC以清掉该信息即可.3.通道3.1 严重警告1.CHL:_ ALERT: Redundant Loop Connection Error Detected on ID:_发生原因:双环连接情况下,其中一个环路故障或断开处理方法:检查连线是否正常,通道有无故障2.CHL:_ Host Channel ALERT: Channel Failure发生原因:主机通道连接失效处理方法:请检查线路连接,光纤连接或是交换机连接,如果仍未解决问题,请联系供应商.3. CHL:_ Drive Channel ALERT: Channel Failure发生原因:磁盘通道失效.处理方法:请检查线路连接,光纤连接或是交换机连接,如果仍未解决问题,请联系供应商.4. CHL:_ ALERT: Fibre Channel Loop Failure Detected发生原因:光纤通道失效处理方法:请检查线路连接,光纤连接或是交换机连接,如果仍未解决问题,请联系供应商.5. CHL:_ ALERT: Redundant loop for Chl:_ Failure Detected发生原因:其中一个冗余的通道已失效处理方法:请检查线路连接,光纤连接或是交换机连接,如果仍未解决问题,请联系供应商.6. CHL:_ ALERT: Redundant Path for Chl:_ ID:_ Expected but Not Found 发生原因:预先设置的通道CHL:_冗余环路连接无效.处理方法:请检查线路连接,光纤连接或是交换机连接,如果仍未解决问题,请联系供应商.7. CHL:_ ID:_ ALERT: Redundant Path for Chl:_ ID:_ Failure Detected发生原因:通道CHL:_冗余环路连接失效处理方法:请检查线路连接,光纤连接或是交换机连接,如果仍未解决问题,请联系供应商.8. CHL:_ Host Channel ALERT: Bus Reset Issued发生原因:通道CHL:_总线重置处理方法:请联系供应商解决.9. CHL:_ Drive Channel ALERT: Data Overrun/Underrun Detected发生原因:CHL:_ ID:_此位置硬盘数据溢出错误处理方法:重新插入此硬盘或更换新硬盘测试,重新更新FW,如故障仍未解决请联系供应商出现频率:极低10. CHL:_ FA TAL ERROR (_)发生原因:通道发生严重错误处理方法:请联系供应商解决.11. CHL:_ RCC Channel ALERT: Data Overrun/Underrun Detected发生原因:RCC通道发生数据溢出错误处理方法:请联系供应商解决.12. CHL:_ Host Channel ALERT: Parity/CRC Error Detected发生原因:主机通道发生奇偶校验错误处理方法:请联系供应商解决.13. CHL:_ Drive Channel ALERT: Gross Phase/Signal Error Detected发生原因:此通道信号异常处理方法:请联系供应商解决出现频率:低14. CHL:_ Drive Channel ALERT: Timeout Waiting for I/O to Complete发生原因:由于线路问题或是磁盘故障造成磁盘I/O读写超时处理方法:请联系供应商解决.15. CHL:_ Drive Channel ALERT: Unexpected Disconnect Encountered发生原因:磁盘通道意外中断请联系供应商解决.16. CHL:_ Drive Channel ALERT: Unexpected Select Timeout发生原因:CH响应超时,与主机的连接线被移走会导致此问题发生处理方法:检查连接线是否可靠出现频率:低17. CHL:_ RCC Channel ALERT: Gross Phase/Signal Error Detected发生原因:RCC通道信号异常处理方法:重新更新FW会解决此问题,如故障仍未解决请与供应商联系出现频率:一般18. CHL:_ RCC Channel ALERT: Parity/CRC Error Detected发生原因:RCC通道奇偶校验错误.处理方法:重新更新FW会解决此问题,如故障仍未解决请与供应商联系出现频率:一般19. CHL:_ RCC Channel ALERT: Timeout Waiting for I/O to Complete发生原因:RCC通道I/O读写超时,这可能是连接链路的问题,也可能是盘阵背板的故障问题.处理方法:请联系供应商解决20. Message CHL:_ RCC Channel ALERT: Unexpected DisconnectEncountered发生原因:RCC通道意外中断处理方法:请联系供应商解决3.2 通知1. CHL:_ NOTICE: Fibre Channel Loop Connection Restored发生原因:光纤环路通道恢复正常处理方法:按ESC以清掉该信息即可.2. CHL:_ ID:_ NOTICE: Redundant Path for Chl:_ ID:_ Restored发生原因:通道CHL:_冗余环路连接恢复正常处理方法:按ESC以清掉该信息即可.3. CHL:_ SCSI Drive Channel Notification: SCSI Bus Reset Issued发生原因:SCSI磁盘通道CHL:_总线重置处理方法:按ESC以清掉该信息即可.4. CHL:_ Host Channel Notification: SCSI Bus Reset Issued发生原因:主机通道CHL:_总线重置处理方法:按ESC以清掉该信息即可.5. CHL:_ LIP(__) Detected发生原因:光纤环路LIP被重置.处理方法:按ESC以清掉该信息即可.4.逻辑盘4.1 严重警告1. LG: _ ALERT: CHL:_ ID:_ Media Scan Aborted发生原因:介质扫描失败,可能的原因是用户强迫终止或是严重的系统故障.处理方法:重新手动执行介质扫描,如未解决,请联系供应商解决.2. LG:_ Logical Drive ALERT: Logical Drive Block Marked _________发生原因:通过比较和校验,已经确定坏的数据块,此时连接到此坏的数据块的主机将接收到介质错误的信息.处理方法:磁盘阵列自动尝试执行数据的重建.以恢复坏块的数据. 3. LG:_ Logical Drive ALERT: Logical Drive Block Recovered ________发生原因:控制器通过比较和重新校验,已恢复逻辑盘坏块的数据.处理方法:按ESC以清掉该信息即可.4. LG:_ Logical Drive ALERT: Logical Drive Block Marked BAD发生原因:控制器通过比较和重新校验,但无法恢复逻辑盘坏块的数据.此时连接到该坏块的主机将收到介质错误的信息.处理方法:请联系供应商解决.5. LG: Logical Drive ALERT: CHL:_ ID:_ Drive Failure发生原因:对应位置的硬盘已失效处理方法:此故障是硬盘连接问题或硬盘本身故障引起的,请检查硬盘是否插紧,并对此硬盘重新扫描或更换硬盘, 如果盘阵已经设置有备用盘,控制器将自动执行数据的重建.出现频率:一般6. LG: Logical Drive ALERT: CHL:_ ID:_ Drive Missing发生原因:对应位置的硬盘丢失处理方法:此故障是硬盘连接问题或硬盘本身故障引起的,请检查硬盘是否插紧,并对此硬盘重新扫描或更换硬盘。
常见报警的解释

常见报警的解释
第一章常见报警的解释
1.1 368报警(串行数据错误)
上图中368报警以及相关编码器报警的原因有:
(1)电机后面的编码器有问题,如果客户的加工环境很差,有时会有切削液或液压油浸入编码器中导致编码器故障。
(2)编码器的反馈电缆有问题,电缆两侧的插头没有插好。
由于机床在移动过程中,坦克链会带动反馈电缆一起动,这样就会造成反馈电缆被挤压或磨损而损坏,从而导
致系统报警。
尤其是偶然的编码器方面的报警,很大可能是反馈电缆磨损所致。
(3)伺服放大器的控制侧电路板损坏。
解决方案:
(1)把此电机上的编码器跟其他电机上的同型号编码器进行互换,如果互换后故障转移说明编码器本身已经损坏。
(2)把伺服放大器跟其同型号的放大器互换,如果互换后故障转移说明放大器有故障。
(3)更换编码器的反馈电缆,注意有的时候反馈电缆损坏后会造成编码器或放大器烧坏,所以最好先确认反馈电缆是否正常。
1.2 电源模块PSM控制板内风扇故障443,610。
磁牒阵列(RAID)常见故障与技巧

磁牒陣列(RAID)常見故障與技巧磁牒陣列(Disk Array)原理-------------------------------1.為什麼需要磁牒陣列?如何增加磁牒的存取(access)速度,如何防止資料因磁牒的故障而失落及如何有效的利用磁牒空間,一直是電腦專業人員和用戶的困擾;而大容量磁牒的價格非常昂貴,對用戶形成很大的負擔。
磁牒陣列技術的產生一舉解決了這些問題。
過去十幾年來,CPU的處理速度增加了五十倍有多,記憶體(memory)的存取速度亦大幅增加,而資料儲存裝置--主要是磁牒(harddisk)--的存取速度只增加了三、四倍,形成電腦系統的瓶頸,拉低了電腦系統的整體性能(through put),若不能有效的提升磁牒的存取速度,CPU、記憶體及磁牒間的不平衡將使CPU及記憶體的改進形成浪費。
目前改進磁牒存取速度的的方式主要有兩種。
一是磁牒快取控制(disk cache controller),它將從磁牒讀取的資料存在快取記憶體(cache memory)中以減少磁牒存取的次數,資料的讀寫都在快取記憶體中進行,大幅增加存取的速度,如要讀取的資料不在快取記憶體中,或要寫資料到磁牒時,才做磁牒的存取動作。
這種方式在單工環境(single- tasking envioronment)如DOS之下,對大量資料的存取有很好的性能(量小且頻繁的存取則不然),但在多工(multi-tasking)環境之下(因為要不停的作資料交換(swapping) 的動作)或資料庫(database)的存取(因為每一記錄都很小)就不能顯示其性能。
這種方式沒有任何安全保障。
其二是使用磁牒陣列的技術。
磁牒陣列是把多個磁牒組成一個陣列,當作單一磁牒使用,它將資料以分段(striping)的方式儲存在不同的磁牒中,存取資料時,陣列中的相關磁牒一起動作,大幅減低資料的存取時間,同時有更佳的空間利用率。
磁牒陣列所利用的不同的技術,稱為RAID level,不同的level針對不同的系統及應用,以解決資料安全的問題。
超导磁存储技术磁盘阵列故障隔离与恢复

超导磁存储技术磁盘阵列故障隔离与恢复随着科技的进步,超导磁存储技术已经成为了数据存储领域的重要技术之一。
磁盘阵列作为超导磁存储技术的重要组成部分,其故障隔离与恢复能力对于保障数据安全和系统稳定性至关重要。
本文将围绕这一主题展开讨论,并提出一些实用建议。
首先,让我们了解一下磁盘阵列的常见故障及其影响。
硬盘故障是磁盘阵列中最常见的故障之一,可能会导致数据丢失或系统崩溃。
另外,电源故障、连接错误等也是常见的故障原因。
这些故障不仅会影响系统的正常运行,还可能导致数据丢失和业务中断,给企业带来重大损失。
那么,如何进行故障隔离和恢复呢?首先,我们需要建立一套完整的故障检测和隔离机制。
通过实时监测磁盘阵列的状态,我们可以及时发现故障并进行隔离。
对于硬件故障,我们需要及时更换故障部件,确保系统恢复正常运行。
对于软件故障,我们需要进行系统修复和优化,以提高系统的稳定性和可靠性。
其次,我们需要制定有效的数据恢复策略。
在故障发生后,我们需要尽快启动数据恢复流程,尽可能减少数据丢失。
这包括备份数据的恢复、受损数据的修复等。
在实施数据恢复策略时,我们需要充分考虑数据的重要性、数据的类型和存储方式等因素,以确保数据恢复的效率和准确性。
除了以上两点,我们还可以从以下几个方面提高磁盘阵列的可靠性:1. 定期进行系统维护和检查,确保系统硬件和软件的健康状态;2. 采用多路径访问方式,提高系统的容错能力;3. 建立完善的备份策略,确保数据的安全性和可靠性;4. 引入先进的容灾技术,实现数据的高可用性。
总之,超导磁存储技术磁盘阵列故障隔离与恢复是一项重要的技术管理工作。
通过建立完善的故障检测和隔离机制、制定有效的数据恢复策略、加强系统维护和检查、采用多路径访问方式和建立备份策略等措施,我们可以提高磁盘阵列的可靠性和稳定性,保障数据的安全性和业务的连续性。
这些措施不仅有助于企业降低风险、提高效率,还有助于提升企业的竞争力和市场地位。
服务器磁盘阵列常见问题及解决方法

一般问题下表说明您可能遇到的一般问题,以及建议的解决方案。
BIOS 启动错误消息
下表说明有关启动时可能显示的 BIOS 错误消息、其问题以及建议的解决方案。
SCSI 电缆和连接器问题
如果您的 SCSI 电缆或连接器发生问题,请先检查电缆连接。
如果问题仍然存在,请访问 Dell 网站 ,以获得有关合格的小型计算机系统接口 (SCSI) 电缆及连接器的信息,或与您的 Dell 代表联系以获得信息。
系统 CMOS 启动顺序
系统启动顺序是由系统 CMOS 公用程序决定。
请按照下列说明更改启动顺序:
1.系统启动时,按。
2.从 System(系统)菜单左方,选择 Boot Sequence(启动顺序)。
3.突出显示您要更改的设备,并使用 Shift-Up/Down 箭头来更改设备的顺序。
4.按返回窗口左方。
5.务必按以确认启动顺序。
如果您按而非,将不会保存您的更改。
6.按 Save/Exit(保存/退出)。
7.系统将重新启动。
预测性故障报告
自我监控、分析及报告技术 (SMART) 用于检查硬盘驱动器,寻找潜在驱动器故障的早期征兆。
SMART 是硬盘驱动器本身的一项功能,不受 RAID 控制器的控制。
所有传送到驱动程序的 SMART 消息都会传送到操作系统中。
操作系统问题
下表说明您可能遇到的操作系统问题,以及建议的解决方案。
CVR配置手册
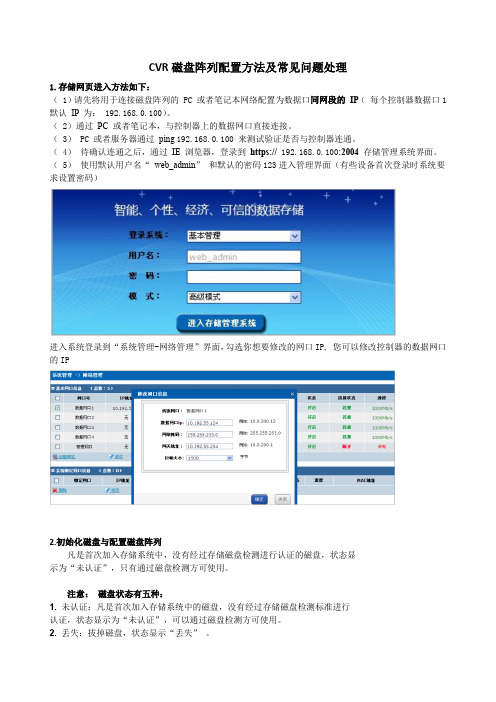
CVR磁盘阵列配置方法及常见问题处理1.存储网页进入方法如下:( 1)请先将用于连接磁盘阵列的 PC 或者笔记本网络配置为数据口同网段的IP(每个控制器数据口1默认IP 为: 192.168.0.100)。
( 2)通过PC 或者笔记本,与控制器上的数据网口直接连接。
( 3) PC 或者服务器通过ping 192.168.0.100来测试验证是否与控制器连通。
( 4)待确认连通之后,通过IE 浏览器,登录到https:// 192.168.0.100:2004 存储管理系统界面。
( 5)使用默认用户名“ web_admin” 和默认的密码123进入管理界面(有些设备首次登录时系统要求设置密码)进入系统登录到“系统管理-网络管理”界面,勾选你想要修改的网口IP, 您可以修改控制器的数据网口的IP2.初始化磁盘与配置磁盘阵列凡是首次加入存储系统中,没有经过存储磁盘检测进行认证的磁盘,状态显示为“未认证”,只有通过磁盘检测方可使用。
注意:磁盘状态有五种:1. 未认证:凡是首次加入存储系统中的磁盘,没有经过存储磁盘检测标准进行认证,状态显示为“未认证”,可以通过磁盘检测方可使用。
2. 丢失:拔掉磁盘,状态显示“丢失” 。
3. 隐患盘:磁盘检测时,发现磁盘存在异常,状态显示为“隐患盘”。
4. 坏盘:磁盘被损坏,同时被阵列踢出,状态显示为“坏盘”,建议对该磁盘进行磁盘检测,按照检测后的状态进行处理。
5. 警告:可以被使用,只要对状态为“警告”的磁盘再进行磁盘检测一次,状态有可能会显示“正常”。
(由于系统有压力的情况下进行磁盘检测,读磁盘的速度小于规定标准10MB/S)。
3.检测磁盘:勾选全部磁盘进行检测,如图3-7 所示。
如果系统中有多块磁盘(大于10块)时,可以点击磁盘信息页面的中的“ Expand”按钮,选中所有磁盘,点击下方的“ 检测” 按钮,进行所有磁盘的检测。
4.配置阵列:点击阵列管理,创建阵列(每11个硬盘创建1个阵列,并添加一个局部热备盘)输入名称并勾选硬盘,接一跳一:选择1号盘后,下一个选择的盘号应该为3号盘。
磁盘阵列故障报告
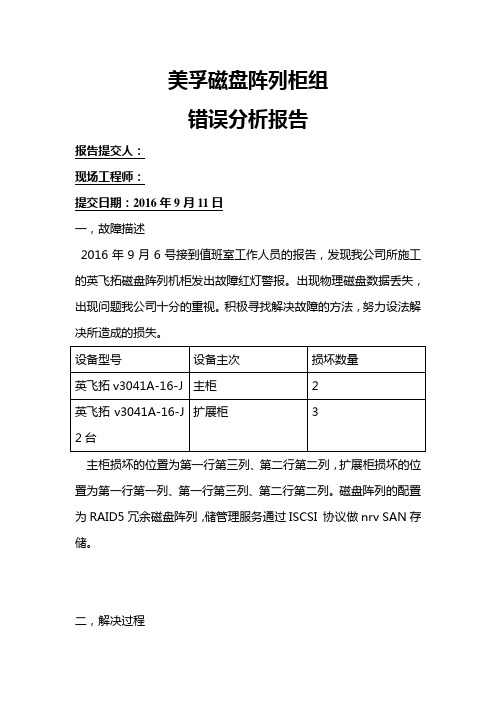
美孚磁盘阵列柜组错误分析报告报告提交人:现场工程师:提交日期:2016年9月11日一,故障描述2016年9月6号接到值班室工作人员的报告,发现我公司所施工的英飞拓磁盘阵列机柜发出故障红灯警报。
出现物理磁盘数据丢失,出现问题我公司十分的重视。
积极寻找解决故障的方法,努力设法解决所造成的损失。
主柜损坏的位置为第一行第三列、第二行第二列,扩展柜损坏的位置为第一行第一列、第一行第三列、第二行第二列。
磁盘阵列的配置为RAID5冗余磁盘阵列,储管理服务通过ISCSI 协议做nrv SAN存储。
二,解决过程2016.09.6 CCTV系统两台DVR工作指示灯经常连续跳跃,怀疑不正常工作,因此安全技术员立即和张工沟通,并联系维修服务商,要求立即到厂紧急查看服务商到厂。
对设备进行检查,发现三套磁盘阵列(A/B/C)中,有五块硬盘指示灯故障报警(磁盘阵列损坏硬盘五块,A损坏两块,BC三块硬盘损坏)。
对系统进行重启,系统重新恢复工作,原DVR连续跳跃指示灯恢复常亮状态。
磁盘故障指示灯亮:查看硬盘状态查到第五块硬盘时发现没有磁盘损坏但是出现了多次的报错。
所以判断磁盘有损坏的征兆,但是不是很明显1-15路摄像机只有0904 06:00左右以后录像,且18:00前呈断续录像状态,16-18路摄像机最早视频为07月07日,19-39路摄像机另一部分摄像机录像数据为04月15日系统调试完成后数据将第3块硬盘克隆到新硬盘整个克隆的过程需要6个小时。
克隆完毕将新的硬盘重新装回磁盘阵列柜中,重新启动磁盘阵列柜。
磁盘阵列柜是根据raid5的冗余校验信息的自动修正盘的错误信息的发现C磁盘阵列所对应的盘符下的所有存储录像存储时间均为0904号,且每一路CCTV每一分钟均有2- 6个不等的300M数据包被保存,而正常情况下,每一路CCTV每半小时至一小时才保存300M数据,然后检查磁盘磁盘阵列,发现磁盘阵列对应的存储路径一切正常。
判断与磁盘阵列无关然后检查硬盘录像机,端口有无异常ip是否存在冲突。
服务器存储故障诊断及排除

2023-11-08CATALOGUE 目录•服务器存储简介•服务器存储故障诊断•服务器存储故障排除•服务器存储故障预防•服务器存储故障案例分析01服务器存储简介服务器存储是指在服务器上进行的存储操作,用于保存和管理数据。
服务器存储通常包括硬盘、固态硬盘(SSD)、存储区域网络(SAN)和网络附加存储(NAS)等。
服务器存储的定义服务器存储能够提供数据备份和恢复功能,保证数据的安全性和完整性。
保证数据安全提高数据可用性优化数据管理通过分布式存储和容灾技术,服务器存储可以提高数据的可用性和访问速度。
服务器存储可以实现数据的分类、整合、迁移和归档,优化数据管理流程。
03服务器存储的重要性0201服务器存储的类型网络附加存储(NAS)将存储设备连接到网络上,实现文件共享和访问,适用于小型网络和办公环境。
存储区域网络(SAN)通过专用网络将多个服务器和存储设备连接起来,实现高速数据传输和共享,适用于大型企业和数据中心。
直接附加存储(DAS)将硬盘或SSD直接连接到服务器上,适用于小型网络和单个服务器。
02服务器存储故障诊断故障诊断的步骤观察服务器的工作状态,检查指示灯、风扇、电源等是否正常工作。
初步检查启动诊断硬件诊断软件诊断通过启动服务器,检查是否能够正常启动,并检查BIOS/UEFI自检过程中是否存在错误提示。
检查内存、硬盘、CPU等硬件设备是否正常工作,如有需要可以进行替换测试。
检查操作系统、驱动程序、应用程序等是否存在问题,尝试进行修复或重新安装。
检查内存条是否存在接触不良、兼容性问题或损坏,如有需要可以替换测试。
内存故障检查硬盘是否存在物理损坏、坏扇区或文件系统错误,可以使用工具软件进行扫描和修复。
硬盘故障检查CPU是否存在过热、过电压或损坏等问题,可以尝试更换风扇或调整电压。
CPU故障硬件故障诊断1软件故障诊断23检查操作系统是否存在病毒、恶意软件、系统文件损坏等问题,可以进行安全扫描、系统恢复或重新安装。
硬盘的常见错误提示及解决方法

硬盘的常见错误提示及解决方法一、显示:“c:drive failure run setup utility,press(f1)to resume” 此类故障是硬盘参数设置不正确所以从软盘引导硬盘可用,只要重新设置硬盘参数即可。
二、显示:“no rom basic,system halted”病因分析:造成该故障的原因一般是引导程序损坏或被病毒感染,或是分区表中无自举标志,或是结束标志55aah被改写。
治疗方法:从软盘启动,执行命令“fdisk/mbr"即可。
fdisk中包含有主引导程序代码和结束标志55aah,用上述命令可使fdisk中正确的主引导程序和结束标志覆盖硬盘上的主引导程序,这一招对于修复主引导程序和结束标志55aah损坏既快又灵。
对于分区表中无自举标志的故障,可用ndd迅速恢复。
三、显示“error loading operating system”或“missing operating system”病因分析:造成该故障的原因一般是dos引导记录出现错误。
dos 引导记录位于逻辑0扇区,是由高级格式化命令format生成的。
主引导程序在检查分区表正确之后,根据分区表中指出的dos分区的起始地址,读dos引导记录,若连续读五次都失败,则给出“error loading opearting system”的错误提示,若能正确读出dos引导记录,主引导程序则会将dos引导记录送入内存0:7c00h处,然后检查dos引导记录的最后两个字节是否为55aah,若不是这两个字节,则给出“missing operation system”的提示。
治疗方法:一般情况下用ndd修复即可。
若不成功,只好用format c:/s命令重写dos引导记录,也许你会认为格式化后c盘数据将丢失,其实不必担心,数据仍然保存在硬盘上,格式化c盘后可用nu8.0中的unformat恢复。
如果曾经用dos命令中的mirror或nu8.0中的image程序给硬盘建立过image镜像文件,硬盘可完全恢复,否则硬盘根目录下的文件全部丢失,根目录下的第一级子目录名被更名为dir0、dir1、dir2……,但一级子目录下的文件及其下级子目录完好无损,至于根目录下丢失的文件,你可用nu8.0中的unerase再去恢复即可。
硬盘故障处理大全

硬盘故障处理大全1、分区表错误的处理故障现象:开机后,屏幕上显示:“Invalid partition table” 硬盘不能启动,可从软盘启动。
故障分析与处理:造成该故障的原因一般是硬盘主引导记录中的分区表有错误,当指定了多个自举分区(只能有一个自举分区)或病毒占用了分区表时将有上述提示。
主引导记录(MBR)位于0磁头0柱面1扇区,由FDISK.EXE对硬盘分区时生成。
MBR包括主引导程序、分区表和结束标志55AAH 3部分,共占一个扇区。
主引导程序中含有检查硬盘分区表的程序代码和出错信息、出错处理等内容。
当硬盘启动时,主引导程序将检查分区表中的自举标志。
若某个分区为自举分区,则有分区标志80H,否则为00H,系统规定只能有一个分区为自举分区,若分区表中含有多个自举标志时,主引导程序会给出“Invalid partion table”的错误提示。
最简单的解决方法是用NDD 修复,它将检查分区表中的错误,若发现错误,将会询问您是否愿意修改,您只要不断地回答“Yes”即可修正错误,或者用备份过的分区表覆盖它也行。
如果是病毒感染了分区表,格式化是解决不了问题的,可先用杀毒软件杀毒,再用NDD进行修复。
如果上述方法都不能解决,就先用FDISK重新分区,但分区大小必须和原来的分区一样,这一点尤为重要,分区后不要进行高级格式化,然后用NDD进行修复。
修复后的硬盘不仅能启动,而且硬盘上的信息也不会丢失。
其实用FDISK 分区,相当于用正确的分区表覆盖原来的分区表。
尤其当用软盘启动后不认硬盘时,可用此方法。
2、硬盘不能工作的故障原因和处理故障现象:微机无法用硬盘启动,检查CMOS参数没有问题。
用软盘启动后可转入C:u25552提示符,但是不能对硬盘进行任何操作。
故障分析与处理:用软盘启动后可转入C:u25552提示符,说明系统是可以识别硬盘驱动器的。
硬盘不仅不能引导系统,而且也不能进行其他操作,说明故障原因可能是硬盘的主引导区或分区表遭到破坏,弄得硬盘不能正常工作。
磁盘阵列故障修复方法

磁盘阵列故障修复方法探析[摘要] 磁盘阵列是由多个稳定性较高的磁盘,组合成一个大型的磁盘组,磁盘阵列具有扩充性及容错机制两大功能,不同的raid 级别数据容错及读写速度不一样,误操作和硬件故障同样会引起的阵列数据丢失,本文探讨了在磁盘阵列各种故障情况下修复方法。
[关键词] 磁盘阵列容错机制故障修复方法1.引言raid是将n台硬盘通过raid 卡(或是软件)组合成虚拟的单台大容量的硬盘使用,其功能是让n台硬盘同时读取,加快数据存取速度及提供容错性, raid是最重要用途是数据存储和备份。
磁盘阵列是由多个稳定性较高的磁盘,组合成一个大型的磁盘组,在储存数据时,将数据切割成许多区段,分别存放在各个硬盘上,磁盘阵列还能利用同位检查,在阵列中任一个硬盘故障时,可重构数据,在数据重构时,将故障硬盘内的数据,经计算后重新置入新硬盘中,磁盘阵列在停机情况下可处理以下动作:◇自动检测故障硬盘。
◇重建硬盘坏道的资料。
◇支持不须停机的硬盘热备空间(hot spare)。
◇支持不须停机的硬盘热备盘自动替换(hot swap)。
◇在线扩充硬盘容量。
2.磁盘阵列的工作原理利用raid技术不仅可以增大存储容量,提高数据传输速率,同时采取冗余信息的方式提供了容错机制,提高了数据存储的可靠性。
实现raid可用两种方法,一种是硬件raid,用专门的控制器raid 卡来完成;另一种是软raid,用软件的方法来实现。
磁盘阵列主要用到以下几种技术:(1)条带化存储raid通过条带化存储和奇偶校验两个措施来实现其冗余和容错的目标。
条带化存储可以以一次写入一个数据块的方式将文件写入多个磁盘。
条带化存储技术将数据分开写入多个驱动器,从而提高数据传输速率并缩短磁盘处理总时间。
(2)奇偶校验奇偶校验通过对所有数据进行冗余校验实现确保数据的有效性。
利用奇偶校验,当raid系统的一个磁盘发生故障时,其它磁盘能够重建该故障磁盘。
(3)磁盘镜像镜像是将数据同时写入两个驱动器的技术,如果一个磁盘发生故障,镜像磁盘将接替它进行运行。
常用业务盘的各种告警

MCU盘维护首先要注意本盘的各种告警,下表中列出了MCU板的告警信息及分析
在实际维护中,ZY-MSAP155还有两项特别重要的监控项目涉及MCU板-----那就是通过网管台查看MCU光口的B1、B2、B3、REI记数,以及指针调整记数。
BI、B2、B3、REI记数反映的是MCU光口与对端SDH设备之间光线路的好坏。
B1、B2、B3指的是接收方向,如B1、B2、B3出现记数,反映的是对方发到本端相应光口收之间有故障。
REI指的是发送方向,如REI出现记数,反映的是本端相应光口发到对方收之间有故障。
指针调整反映的是本设备时钟同步情况,本设备要一直同步于骨干网来的线路时钟。
指针调整发生记数,说明本设备系统时钟相对线路时钟有相位跳变,如记数多说明本设备时钟工作不好,有可能影响设备的正常工作。
TUOP4盘维护要注意各种告警信息,下表列出了TUOP4板的告警信息及分析
TUOFE盘维护要注意各种告警信息,下表列出了TUOFE板的告警信息及分析
TUOFE插盘告警列表
TUOS2盘维护首先要注意本盘的各种告警,表2-5列出了TUOS2板的告警信息及分析
TU16盘维护首先要注意本盘的各种告警,表2-5列出了TUOS2板的告警信息及分析
表2-7 TU16插盘告警信息列表。
磁盘阵列常见故障与技巧

磁盘阵列常见故障与技巧:在选择IDE磁盘阵列卡(IDE RAID卡)来确保数据安全的人越来越多,如何正确使用IDE RAID卡也是个学问。
下面我们就以采用HPT370A/372控制芯片的Rocket100 RAID卡为例来给大家做些讲解常见故障与技巧。
安装需知先找一个空闲的PCI插槽将该卡插进去并将硬盘用硬盘线和该卡安装连接好,安装完适配卡后,在启动计算机的过程中,你会看到该适配卡已成功安装并被系统识别。
而在系统开机时,其控制器的BIOS会显示硬盘状态的信息,按CTRL+H即可进入结构非常清楚的设置菜单,在这里你可以设定磁盘阵列:两个硬盘可以选择条带模式(RAID 0)和镜像模式(RAID 1),有三块硬盘的话只能选跨越扩充或条带模式,而四块就可以选跨越模式、条带模式或条带结合镜像模式(RAID 0+1),而选用RAID 1的话硬盘必须进行同步化。
常见安装故障排除当Rocket100 RAID卡被识别后,板上BIOS开始检测连接设备。
请注意屏幕上出现的设备,如果所连接设备全部正确扫描出,则说明设备已正确连接并被系统识别,再安装好驱动之后你即可使用RAID功能了。
而如果其中有的设备没有被识别出,你可打开机箱,将所连接设备的电源线是否插牢,必要时换一个电源插头试一试;所连接设备的数据线是否正确连接并已插牢,必要时换一根数据线试一试;如果一根数据线上接有两个设备,请确认这两个设备的主从跳线是否设置冲突(一根数据线上的两个设备必须为一主一从)。
硬盘容量的选择考虑到系统的操作性能及磁盘的利用率,我们建议你最好使同样容量的硬盘。
但你如果一定要用不同容量的磁盘,需要注意的是整个阵列的容量要由该阵列中最小容量的硬盘决定,例如在由3个磁盘组成的RAID 0阵列中,总容量等于最小磁盘的容量的3倍。
在RAID 1阵列中,目标盘的容量不能小于源盘的容量。
该阵列的总容量就等于最小磁盘的容量。
但是JBOD是个例外,两个或更多的不同容量的硬盘可以组合起来,形成一个逻辑单盘。
硬盘灯故障说明

解决方案硬盘红灯通常是硬盘故障灯告警的表示(SCSI硬盘红灯可能被管理工具选中或者故障),提示硬盘可能已经出现异常情况或者故障,为了保证数据安全,首先建议尽可能备份重要数据,并且不要轻易插拔硬盘,避免误操作导致数据风险。
如果硬盘出现红灯告警,根据硬盘不同告警状态可以作初始判断和定位。
硬盘指示灯状态定义参考如下图标:SAS 和SATA 硬盘LED 指示灯状态在线/活动LED灯(绿色)故障/UID LED灯(红色/蓝色)解释亮,不亮,或者闪烁交替亮红色和蓝色硬盘故障,或者预告性故障报警;同时被管理工具选中亮,不亮,或者闪烁蓝色硬盘状态正常,同时被管理工具选中亮红色,规律性闪烁(1HZ)预告性故障报警,硬盘需要更换亮不亮硬盘在线,非活动状态规律性闪烁(1HZ)红色,规律性闪烁(1HZ)不要移除硬盘,移除硬盘可能终止当前操作导致数据丢失。
硬盘当前状态为参加阵列容量扩容或者迁移,同时有预告性故障报警。
为使数据丢失风险降低到最低,不要移除硬盘直到扩容或迁移完成规律性闪烁(1HZ)不亮不要移除硬盘,移除硬盘可能终止当前操作导致数据丢失硬盘当前状态为重建,或者参加阵列容量扩容或者迁移不规律性闪烁红色,规律性闪烁(1HZ)硬盘活动状态,同时有预告性故障报警,硬盘需要更换不规律性闪烁不亮硬盘活动状态,当前有正常数据操作不亮红色硬盘故障状态,控制器已将该硬盘置于离线,硬盘需要更换不亮红色,规律性闪烁(1HZ)预告性故障报警,硬盘需要更换不亮不亮硬盘状态为离线,热备盘或者没有配置到阵列中*参考文档:HP ProLiant DL380 G6 Server Maintenance and Service Guide--June 2009 (Fourth Edition) 热插拔SCSI 硬盘LED 指示灯状态活动LED 在线LED 故障LED 解释亮,不亮或者闪烁亮或者不亮闪烁预告性故障报警,硬盘需要更换亮,不亮或者闪烁亮不亮硬盘在线,并且被配置到阵列中。
服务器磁盘阵列常见问题及解决方法

服务器磁盘阵列常见问题及解决方法一般问题下表说明您可能遇到的一般问题,以及建议的解决方案。
问题建议的解决方案系统不从 RAID 控制器启动。
请检查系统的基本输入/输出系统 (BIOS) 配置,查看是否已指定 PCI 中断。
确保已经为 RAID 控制器指定唯一性中断。
在安装操作系统之前,先初始化逻辑驱动器。
阵列中的一个硬盘驱动器发生故障。
•检查 SCSI 电缆。
•如果 SCSI 电缆没有问题,请替换该驱动器。
•重新建立阵列。
特定 SCSI ID 上的一个驱动器重复发生故障。
替换 SCSI 电缆。
于启动时按下并尝试进行新配置时,系统停止响应。
•检查每个通道上的驱动器 ID,确保每个设备有不同的 ID。
•检查以确保内部连接和外部连接未占用相同的通道。
•确定该通道已经过正确的终结处理。
通道尾端的设备必须经过终结处理或电缆上必须已经连接一个终结器。
•检查以确保 RAID 控制器已经正确安置在插槽中。
•替换驱动器电缆。
按并不显示菜单。
必须有彩色显示器才能显示 BIOS 公用程序菜单。
已经安装 RAID 控制器的系统 POST(开机自测)时,BIOS标题显示为乱码或完全不显示。
RAID 控制器高速缓存可能已经损坏或遗失。
无法快闪刷新或更新固件。
联系 Dell 支持人员以寻求协助。
小心:检查一致性或进行后台初始化过程时,请不要执行固件快闪更新,否则可能会失败。
Controller POST command failed (控制器 POST 命令失败)如果内部适配器诊断失败,将显示此消息。
•若要解决问题,请快闪刷新适配器的固件。
• 如果问题仍然存在,请与 Dell 支持人员联系。
<><> 如果适配器的 SEEPROM 读取或写入失败,将显示此消息。
如果是读取失败,将使用一组防止失败的安全默认值。
SEEPROM 损毁或失败可能导致此问题。
• 若要解决问题,请于系统 POST 时按 ,以进入适配器“BIOS Configuration utility”。
硬盘不启动的错误信息及解决方案

硬盘不启动的错误信息及解决方案[日期:2011-05-21] 来源:作者:[字体:大中小]硬盘真是浪得虚名,名为“硬盘”,实际上却非常脆弱。
动不动就跟我们闹别扭,本来应该出现“StartingWin dows98”(如果你是使用Windows2000/XP就不会出现这个英文短语了),这时却给你黑脸看,而且还出现莫名其妙的英文短语。
笔者在这里教你几种方法,专门医治硬盘不能启动的“顽症”。
小知识:硬盘启动过程在BIOS自检确认所有的硬件(包括硬盘)连接正确后,硬盘开始启动,这里以在启动分区安装在Windows98操作系统为例。
第一步:根据CMOS设置的参数,硬盘将磁头定位在物理扇0柱0面1扇上,接着先后读取扇区结束标志55AAH、主引导记录MBR、硬盘分区表HDPT。
第二步:根据硬盘分区表提供的数据,硬盘将磁头定位在活动分区(主DOS引导分区)的引导扇上(一般为物理扇0柱1面1扇),接着先后读取扇区结束标志55AAH、操作系统参数。
第三步:根据操作系统参数,读取文件分配表FAT和两个隐含系统文件Io.sys、Msdos.sys。
第四步:根据Config.sys读取,然后启动到Windows98。
小提示:硬盘不启动的错误信息出现在哪里?如果硬盘能够通过BIOS自检,但是不能启动到操作系统。
一般来说都会在出现“VerifyingDMIPoolDat a..........”过后出现一些英文短句(见图1)。
1.屏幕显示:“DISKBOOTFAILURE,INSERTSYSTEMDISKANDPRESSENTER”含义:磁盘引导区失败,插入系统磁盘并按回车键解决方案:首先要查看一下硬盘的电源线和IDE数据线是否已正确连接,特别是硬盘和光驱接在同一条数据线上,务必要查看一下跳线是否都设成主盘或从盘,如果是的话,应将硬盘跳线设成主盘、光驱跳线设为从盘,然后用下一步骤重新设置硬盘参数。
如果没问题的话,开机后按“Del”键进入CMOS设置。
Infend盘塔RAID介绍及报错说明

服务器硬件设置服务器硬件设置主要涉及到存储子系统的设置,即:RAID5子系统磁盘阵列。
5.1Raid 5的安装过程RAID正常工作界面显示为BVT 4000 Ready1、选择“ENT”键,见界面提示:press 2 seconds for Main menu;2、按“ENT”键2S后进入主菜单:quick logical Drive install;3、按“ENT”键,界面显示:“Set TDRV=5 LG Raid5+Speas或Raid5”;4、选择Raid5+Speas或Raid5,点击“ENT”键确认;5、完成设置,进入设置等待状态:“Init Parity 000%/please wait”。
5.2确认阵列中的坏磁盘如果控制其发出周期性的滴滴报警声,首先确认您的磁盘在阵列中是否有掉线的情况发生,如果有掉线现象,控制其的LCD面板会有以下两种状态的提示;5.2.1状态提示一1、在控制期的LCD面板上会有提示select timeout ;控制器每隔一段时间就会自动监测磁盘的状态,如果没有得到磁盘的响应,就会出现选择超时这个提示:CHL=* ID=* Select Timeout CHL=*表示drives在控制其上面的通道号;ID=*表示该通道上scsi磁盘所获得的ID号;2、如果您按控制器的ESC键后,在控制期的LCD面板上会有提示Drives failure磁盘失败;这时可以通过LCD显示的ID号来定位磁盘:CHL=* ID=* Drives failure CHL=*表示坏磁盘的通道号;ID=*表示坏磁盘的ID号;(在默认的情况下,控制器会按照模组盘位的先后顺序来分配ID号,ID号从0-14即1号盘位应该得到的ID号是0,依次类推就可以根据ID号来识别坏磁盘的位置了。
)3、磁盘在阵列中若有掉线的情况发生,磁盘模组由自动报警功能:到磁盘的状态为off line时,模组由测得的红灯就会亮起。